
Abstract
Adult listeners rapidly reweight their reliance on acoustic dimensions of their native language during spoken word recognition following exposure to statistical deviations in the covariance between two cues to a contrast. This form of perceptual learning, referred to as dimension-based statistical learning (DBSL), has been shown to be highly context-sensitive for stop voicing cued by voice onset time and F0. The present study probes generalisation of DBSL across place of articulation, when learning conditions from previous studies are enhanced: introducing an additional contrast in training, and removing word frame variability. Experiment 1 serves as a robust conceptual replication of same-place learning, using a between-subjects design and two separate word-frame contexts. Experiment 2 follows the same design, probing if learning generalises across place of articulation. Experiment 3 also examines cross-phoneme generalisation, but using a within-subjects design. We find no evidence of learning across the four generalisation sub-experiments, demonstrating that DBSL for stop voicing is very place-specific. In the between-subjects experiments, we find larger learning effect estimates than in our previous study with variable word frames, and larger estimates for -ALE compared to -ILL frames, providing further evidence of context-sensitivity of DBSL, in the form of lexical/word-frame context.
Keywords
Introduction
The acoustic properties which characterise and distinguish speech sounds are highly variable, so much so that no two realisations of a given speech sound will share identical acoustic statistics (i.e., lack of invariance; Liberman et al., 1967). Nevertheless, listeners are remarkably adept at solving this many-to-one mapping from physical input (speech) onto abstract output (linguistic representation). As part of the solution to the lack of invariance problem, speech perception is a dynamic and adaptive process. One of the most well-evidenced and empirically-testable theories of how robust adaptation to variation in the speech signal is achieved is that of distributional learning (Johnson, 1997; Kleinschmidt & Jaeger, 2015; Schertz & Clare, 2020; Tan & Jaeger, 2025; Xie et al., 2023). Distributional learning theories hypothesise that listeners gradually learn, store and update the distributional statistics of acoustic cues, serving as the bases from which they decode the incoming speech signal. A specific phenomenon in spoken word recognition said to involve distributional learning is called dimension-based statistical learning (DBSL; Idemaru & Holt, 2011; Liu & Holt, 2015; M. Lehet & Holt, 2017). This, in its classic instantiation, involves the downweighting/shifting of a secondary cue for a given contrast based on systematic changes to its covariance with the primary cue. For example in early work on DBSL, Idemaru and Holt (2011) found that, following exposure to a covariance between voice onset time (VOT) and fundamental frequency (F0) for the /b/-/p/ stop voicing contrast that was the inverse of a typical native English speaker (analogous to a non-native accent), native listeners rapidly downweighted their use of the secondary F0 cue. This neutralisation of F0’s informativeness was posited to arise because, against long-term exposure, its distributional statistics now contradicted the information carried by the primary VOT cue.
Fundamental to successful speech perception is not just adaptation, but also generalisation (Kleinschmidt & Jaeger, 2015). As a broad example, generalising from one speaker to another (who may share dialect, gender, etc.) would enable more efficient and accurate learning of their distributional statistics, preventing the listener from having to learn their cue distributions from scratch. However, a coherent understanding of the dichotomy between context-specificity and generalisation, and how this may differ across perceptual learning paradigms is not present in the literature. For example, robust cross-talker (as well as cross-contrast) generalisation has been observed for lexically-guided perceptual retuning (LGPR; Kraljic & Samuel, 2006), whereas more recent studies have identified marked talker-specificity (Luthra et al., 2021; Tamminga et al., 2020). Both talker generalisation and specificity in LGPR can be explained when factoring in the role of acoustic similarity between talkers (Theodore et al., 2020). Nevertheless, these at first conflicting findings in LGPR elucidate the general state of the perceptual learning literature in that we do not yet fully understand the exact nature of the trade-off between generalisation and specificity. Indeed, for the case of DBSL, we are not yet aware of the exact limits of generalisation, nor the true extent to which learning is constrained by the immediate acoustic-phonetic context.
Context-Specificity Versus Generalisation in Dimension-Based Statistical Learning
Robust cross-talker generalisation of DBSL has been evidenced for vowel quality cued by F1 and duration (Liu & Holt, 2015). This suggests that (at least for the vowel contrast in their experiment), DBSL operates over abstract, talker-general representations. However, the authors used a single talker’s voice in their stimuli, which was synthetically modified to produce two distinct voices. To our knowledge, generalisation across two actually different talkers has not yet been examined and may result in less robust or even no generalisation. This would better assess whether DBSL for vowel quality cued by F1 and duration is strictly talker-independent, or if learning in fact operates over representations encoding (some) talker-specific information, with cross-talker generalisation of learning possible, albeit modulated by acoustic similarity between exemplars.
Cross-talker generalisation of DBSL has to our knowledge not been explicitly tested for the case of stop voicing cued by VOT and F0 at vowel onset. However, marked talker-specificity has been attested (Zhang & Holt, 2018). In this experiment, the authors tested if listeners could track coevolving distributional regularities between VOT and F0 for two distinct voice qualities (indicative of a male and female speaker, respectively). Specifically, in one experiment block, a group was exposed to a canonical relationship between VOT and F0 for a male speaker and a reversed one for a female speaker, then in the following block a canonical distribution for the female speaker and a reversed one for the male speaker, with the other participant group experiencing blocks in reverse order. Listeners were able to apply within-block and update across-block different F0 cue weights for the two speakers, evidencing an ability to simultaneously track talker-specific distributional statistics. Moreover, the two distinct talkers were synthesised from the same base file, so one could assume that using two actually different talkers would only enhance the talker-specificity observed here. This differs from the robust talker generalisation observed for vowel quality, and suggests a possible asymmetry in how these two contrasts are abstracted over talkers in DBSL, although an abstract-exemplar hybrid model of speech perception is still compatible with both results (Kleinschmidt & Jaeger, 2015; Pierrehumbert, 2006, 2016).
There appears to be further asymmetry in the generalisability of DBSL between vowel quality cued by F1 and duration and stop voicing cued by VOT and F0. For example, DBSL has been shown to robustly generalise across word frame for vowels (Liu & Holt, 2015). In this study, listeners were exposed to a reversed covariance between spectral quality and vowel duration for the nonwords ‘setch’ and ‘satch’. Following exposure to the reversed distribution, listeners demonstrated a complete neutralisation of the temporal cue for a novel word frame (set-sat). However, these word frames are highly similar, with the vowel embedded in ‘s_t’ in both words, which may have contributed to the attested word frame generalisation. A subsequent study used a less similar target word frame (seppa-sappa; M. Lehet & Holt, 2020). While the learning effect gained from the setch-satch exposure trials only partially generalised to the novel context, the duration cue was nevertheless fully neutralised.
In contrast, DBSL for stop voicing has been shown to only weakly generalise across word frame (Idemaru & Holt, 2020; Murphy et al., 2025; Steffman et al., 2025). Idemaru and Holt (2020) found learning to only partially generalise when varying the context of the following vowel (e..g., from beer-pier to bill-pill). In a prior experiment with variable word frames in training and test trials, we too found only a modest effect size for the interaction between F0 and distributional manipulation (Steffman et al., 2025). Moreover, evidence from a passive exposure paradigm provides yet stronger evidence for word-frame sensitivity, with learning failing to generalise at all (Murphy et al., 2025). In this experiment, participants heard a sequence of training stimuli, with either categorical or reversed VOT-F0 covariance, only overtly tasked with categorising a following test stimulus. While DBSL with no generalisation was robustly replicated in this paradigm (see also A. J. Hodson et al., 2023), no learning effect was shown to generalise across word frame (e.g., from beer-pier to bear-pear). Murphy et al. (2025) suggested that active categorisation of the statistics-bearing exposure stimuli may be necessary for learning to generalise, and indeed, upon restoring active categorisation of training stimuli, learning was shown to weakly generalise across word frame. This has tentatively been linked to attention, goal setting, and participants being able to infer a relationship between training and test stimuli.
Complementing this finding of weakened/no generalisation of DBSL across word frame for stop voicing, there is evidence that listeners are able to track separate changes in VOT and F0 covariance between two lexical contexts, as opposed to aggregating across them (Idemaru & Vaughn, 2020). In the same experiment block, listeners were concurrently exposed to a canonical covariance between VOT and F0 for one lexical context (beer-pier) and a reversed covariance for the other (bear-pear). The authors found that listeners downweighted F0 in categorising [b] and [p] in one context while simultaneously upweighting F0 in categorising [b] and [p] in the other. This finding serves as another indicator of the seemingly highly context-sensitive nature of DBSL for this contrast. The authors note that their results could suggest that the biphone is the linguistic unit over which DBSL operates, although this may be specific to stop voicing cued by these two dimensions, arising from the fact that F0 is a property of the following vowel, thus entangling both consonant and vowel in the learning of stop voicing distributions. In this sense, aggregating or generalising learning across word frames such as beer-pier and bear-pear (as has been used for most studies) would require abstraction over the following vowel quality.
Further context-specificity of DBSL for stop voicing cued by VOT and F0 has been demonstrated for the case of place of articulation (Idemaru & Holt, 2014; Steffman et al., 2025). Idemaru and Holt (2014) found that, between canonical and reversed exposure blocks, listeners did not reweight their use of the F0 dimension for stop voicing categorisation when trained on an alveolar contrast (deer-tear) but tested on a bilabial one (beer-pier), and vice-versa. In Steffman et al. (2025), we sought to jointly examine the role of variability (in the form of more lexical contexts) and increased evidence (in the form of another contrast in training, with a different place of articulation) on generalisation. For example, a listener tested on their weighting of F0 for categorising bilabial stop voicing contrasts (bot-pot, bill-pill and bore-pore) was trained on a canonical/reversed VOT-F0 covariance for alveolar (dot-tot, dill-till and door-tore) as well as velar (got-cot, gill-kill and gore-core) minimal pairs. Here, we also found a distinct lack of evidence that learning can generalise, despite introducing what we deem as increased evidence for a distributional pattern. The results from these two studies therefore suggest that listeners do not generalise across the phonological category of stop voicing, and as such may be capable of tracking separate distributional statistics across phonologically-related speech categories (Idemaru & Holt, 2014). However, given the aforementioned word frame sensitivity of DBSL for stop voicing, the variability in word frame that we introduced into our experiment design may have interacted with listeners’ ability to generalise, possibly preventing them from wholly benefiting from the increased evidence of a distributional pattern in the form of an additional training place of articulation. Reducing or removing this frame-based variability will allow us to better evaluate if generalisation can in fact drawn out.
In summation, previous work on the generalisibility of DBSL points towards the learning of VOT-F0 covariance for stop voicing being heavily constrained by the acoustic-phonetic context, while vowel quality cued by F1 and duration seems more permitting of generalisation. However, perceptual learning for speech has been shown to be modulated by a variety of experimental conditions, such as quantity of evidence (Cummings & Theodore, 2023), explicit feedback (M. I. Lehet et al., 2020) and, specifically for the case of DBSL generalisation, an active versus passive exposure paradigm (Murphy et al., 2025). As such, learning for stop voicing cued by VOT and F0 may in fact be generalisable, for example across place of articulation, if learning conditions are optimised. Optimising conditions in an attempt to induce generalisation will allow us to better comment on the extent of context-sensitivity, limits of generalisation, and representations accessed in DBSL for speech, and if indeed learning asymmetries across sound classes can be found. The present study contributes to this line of research.
The Present Study
The present study is comprised of three perceptual learning experiments in a classic DBSL paradigm, each contributing to our understanding of DBSL and its generalisation, or lack thereof, across place of articulation. All three experiments also provide an opportunity to explore possible asymmetries across contrasts (either across word frame or place of articulation).
The first experiment serves as a conceptual replication of DBSL for stop voicing, without generalisation from training to test stimuli across word frame or place of articulation (Idemaru & Holt, 2011). Experiment 1 also allows for assessment of the influence of word frame variability on the magnitude of learning, when effect sizes are compared to those for the same-place experiment in Steffman et al. (2025). Here, we use an identical between-subject design, with the same size and composition of training and test stimuli, an equal number of participants, and the same F0 perturbation range and duration. If Experiment 1 evidences larger effect sizes compared to our previous study, this would suggest that word frame variability may modulate DBSL for stop voicing cued by VOT and F0.
Experiment 2 also uses a between-subject design, probing if DBSL generalises across place of articulation. As in Steffman et al. (2025), we train listeners on the distributions for two voicing contrasts at different places of articulation, instead of just one as in Idemaru and Holt (2014). The key departure from our previous study is that we have removed word frame variability in an attempt to induce generalisation of learning. Whether reducing this frame-based variability actually produces an environment more conducive to elicit generalisation or not, it nevertheless allows us to better assess if exposure to reversed cue distributions for two places of articulation actually serves as stronger evidence for listeners.
Experiment 3 also investigates if DBSL can generalise across place of articulation but using a within-subject design, as has been used in classic DBSL studies (Idemaru & Holt, 2011; Liu & Holt, 2015). The goal in Experiment 3 was to evaluate this relevant methodological question. We do not necessarily expect our findings to differ between Experiments 2 and 3, as a between-subject paradigm is equally common in the general perceptual learning literature (Bradlow & Bent, 2008; Norris et al., 2003; Samuel, 2020). Nevertheless, a direct comparison of within versus between-subject designs is lacking in the DBSL literature to our knowledge and, if our findings concur between Experiments 2 and 3, it would allow us to more concretely comment on the generalisability of DBSL across place of articulation. Moreover, this would demonstrate that future research in DBSL can benefit from both between- and within-subject design studies.
Methods
All data for the paper, R scripts used to analyse the data and generate figures, and statistical models are included on an open-access repository hosted on the OSF, which can be accessed at https://osf.io/3zk5a.
Materials
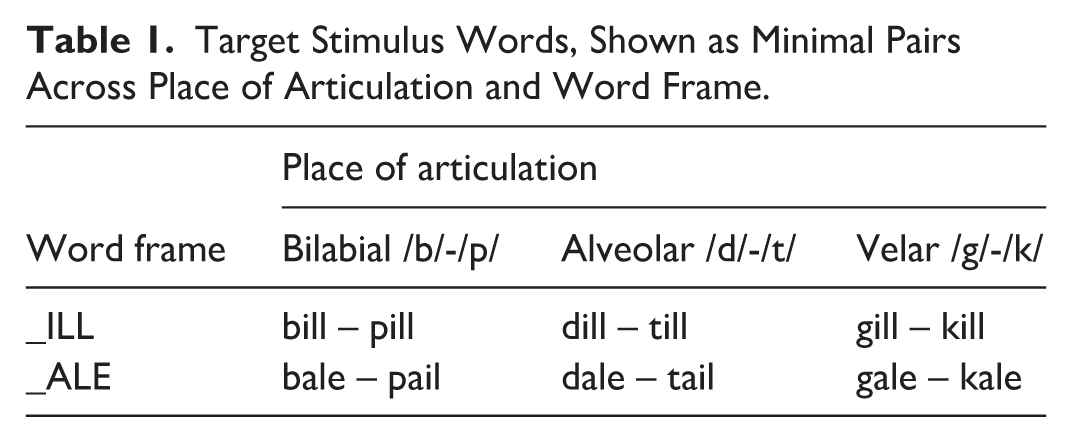
Six minimal pairs were used as base stimuli in this study, contrasting voiced and voiceless onset plosives and spanning three places of articulation across two word frames (Table 1). The base recordings were collected in a sound-attenuated room with an AKG CK 98 unidirectional hyper-cardioid condenser microphone capsule (AKG Acoustics, Vienna, Austria). The stimuli were recorded within a larger session at a sampling rate of 48 kHz and 16-bit depth, by a male speaker of Southern Standard British English.
Target Stimulus Words, Shown as Minimal Pairs Across Place of Articulation and Word Frame.
Stimulus Creation
The structure of the stimulus arrays closely paralleled the methodology employed in earlier DBSL studies. For each minimal pair, the utterances served as the continuum endpoints. VOT and F0 were then manipulated in Praat (Boersma & Weenink, 2025) using Winn (2020) VOT continuum script. The VOT ranges varied by word frame and place of articulation: in the ILL frame, 0 to 40 ms for bilabials, 0 to 70 ms for alveolars, and 0 to 80 ms for velars; in the ALE frame, 0 to 40 ms for bilabials, and 0 to 70 ms for both alveolars and velars. The script began with voiced stop tokens (/b, d, g/) as the base files, to which aspiration noise was added using a cut-back-and-replace method that preserved the overall aspiration + vowel duration. F0 values from the voiced base files provided the starting point for further manipulation, with shifts of −10 to +30 Hz applied. These changes extended over the first 75 ms of the vowel, after which F0 returned to the natural values of the recording. This 75 ms manipulation window reflects both production norms (Hanson, 2009; Winn, 2020) and the speaker’s natural voiceless productions. Crucially, even for cut-back vowels, the F0 contour remained intact and was cut away by the manipulation procedure, instead being transposed to the new vowel onset. The results of this manipulation, as illustrated with the kill-gill pair (velar stops with ILL frame), are shown in Figure 1.
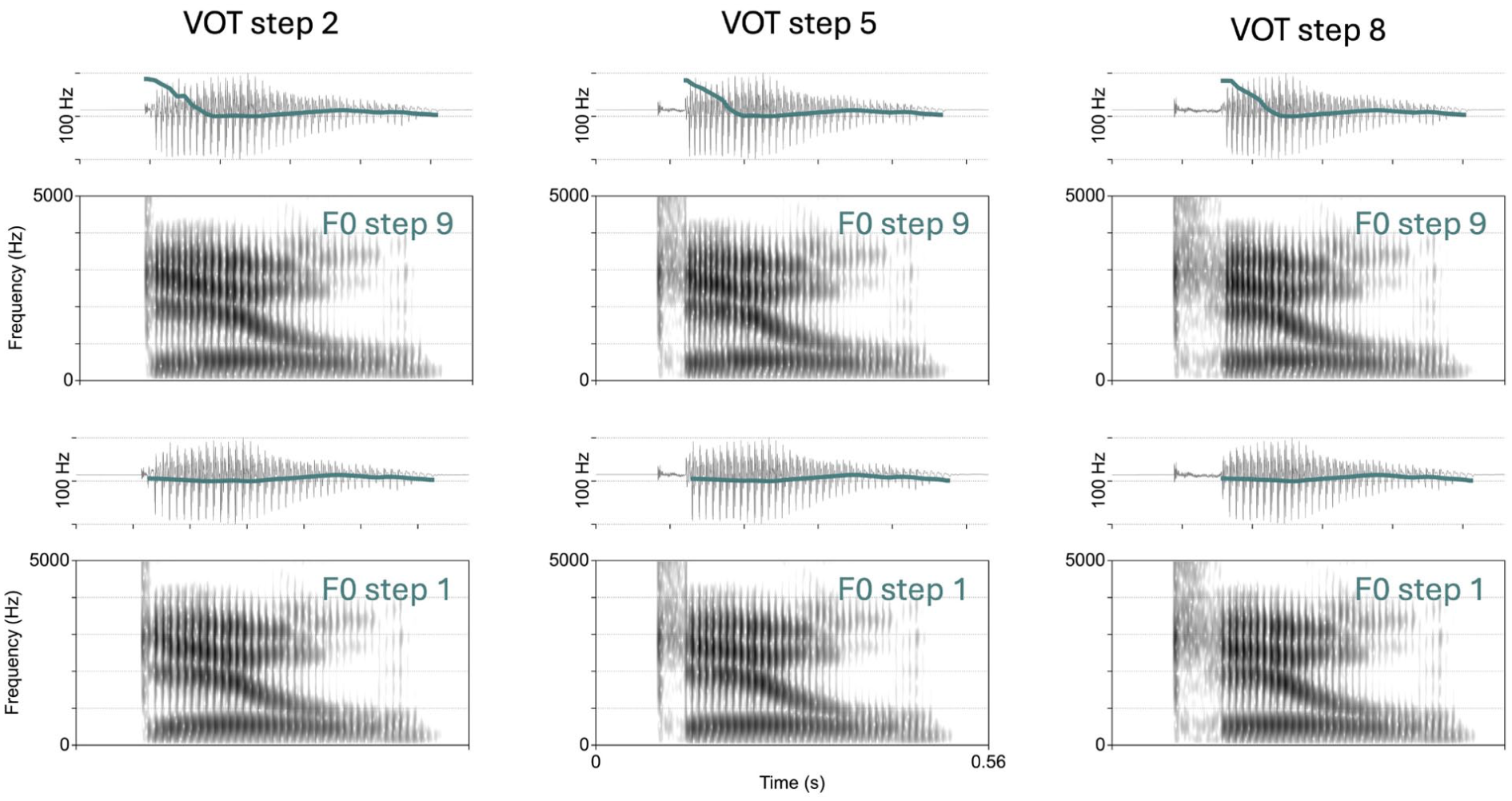
Waveform and spectrogram representations of the stimuli for the kill-gill pair. The waveform is overlaid with an F0 trace. Three VOT steps are shown in the columns, and two F0 steps are shown in the rows.
F0 and VOT were manipulated systematically and orthogonally, yielding a matrix of 81 continuum steps (9 VOT × 9 F0). The perturbation range for F0 was selected to balance naturalness with perceptual salience, based on the authors’ judgements.
Training materials were constructed to expose listeners to canonical versus reversed cue distributions, in the typical manner for DBSL studies (Idemaru & Holt, 2011, 2014, 2020). From the 9 × 9 stimulus grid, 20 items were selected as training stimuli for each minimal pair: 10 in the canonical distribution and 10 in the reversed distribution. In the canonical set, VOT and F0 covaried positively, reflecting the typical English pattern in which voiceless (longer-VOT) stops are associated with higher F0. In the reversed set, by contrast, voiceless stops co-occurred with lower F0, producing negative covariance between the two dimensions. Both conditions relied on steps with perceptually unambiguous VOT values (steps 1–3 voiced, steps 7–9 voiceless). Altogether, this yielded 120 distinct training items (20 per pair × 6 pairs), presented in varying combinations as described below. Figure 2A illustrates how these training points were distributed across the continua.
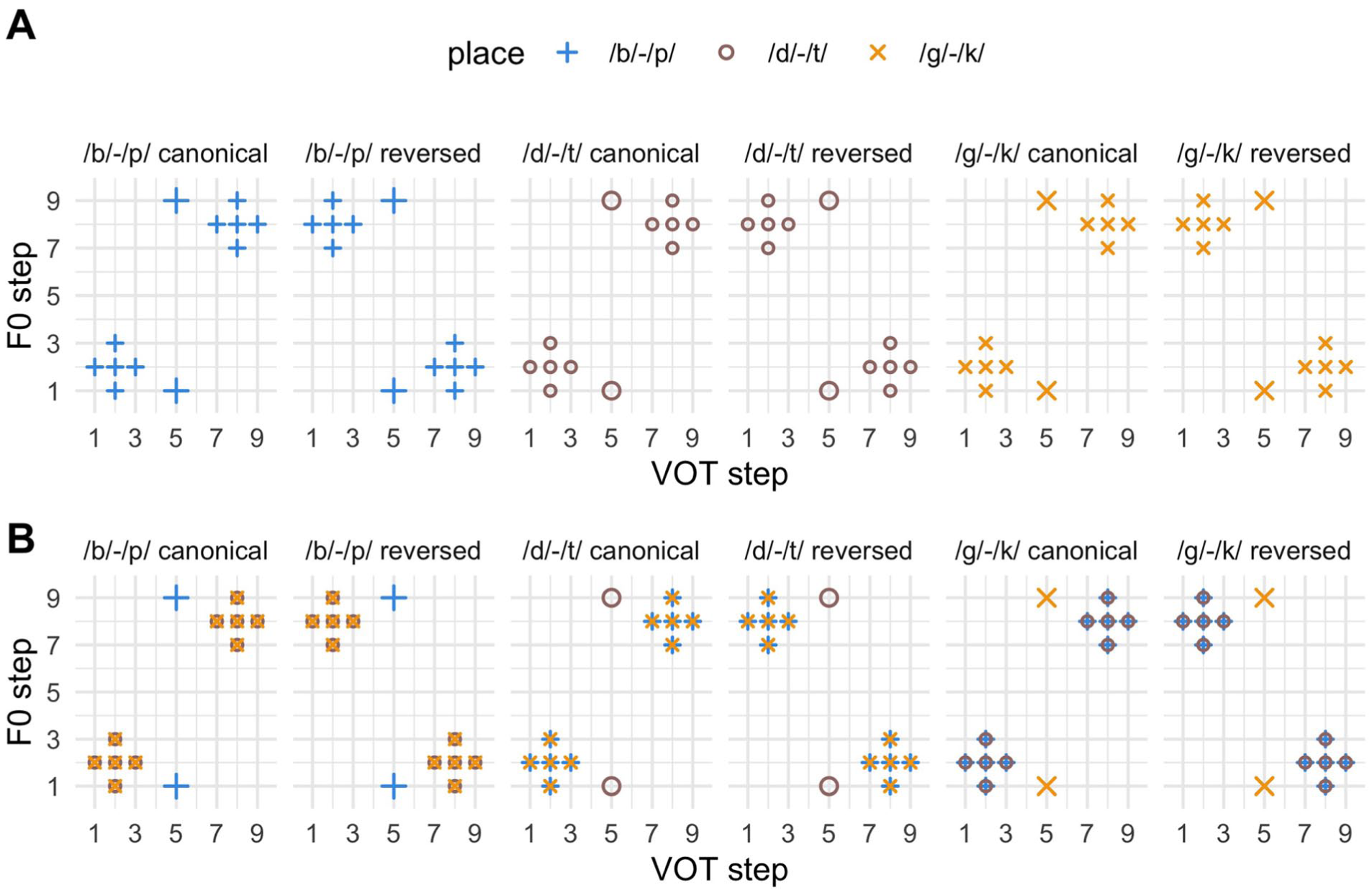
(A) Stimulus arrays for the same-place conditions (Experiment 1). (B) Stimulus arrays for the different place conditions (Experiments 2 and 3).
Test items were designed to probe reliance on F0 when VOT is ambiguous. For each minimal pair, two stimuli were created with VOT fixed at step 5, a midpoint judged by the authors to be perceptually uncertain (shown in Figure 1 and 2). These tokens differed only in F0, which was set to the extreme low and high ends of the manipulation scale (F0 step 1 or 9). Since F0 is known to play a decisive role in voicing judgements when VOT is neutral (Abramson & Lisker, 1985; Idemaru & Holt, 2011, 2014, 2020), responses to these stimuli reveal how exposure to canonical versus reversed distributions shaped perception. Specifically, listeners trained with canonical distributions were expected to categorise low-F0 tokens as voiced and high-F0 tokens as voiceless, while those trained with reversed distributions were predicted to show a reduced reliance on F0. In total, this yielded 12 test items, 2 for each of the 6 minimal pairs (Table 1).
Stimulus Presentation and Conditions
In the between-subjects design, each participant was assigned to either canonical or reversed training stimuli, yielding six groups in total (2 Distributional Conditions × 3 Target Places of Articulation).
In the between-subjects design, each participant categorised 270 trials. One hundred eighty of these were training trials. In Figure 2A, for the same-place of articulation conditions, note that there are 10 total training stimuli for each group (panel) in the array in either the reversed or canonical condition. These 10 stimuli were repeated a total of 18 times resulting in the 180 training trials. The 90 test trials were constituted of 45 repetitions of the 2 test trial tokens in each stimulus array (the larger points at VOT step 5). Importantly, the test stimuli trials were identical across distributional conditions. The test and training stimuli were fully randomised together with the training trials, with no indication to listeners of the difference between them. The structure was highly similar for the switched place Experiment, which is schematised in Figure 2B. The test trial presentation was the same as the same-place experiment: 45 repetitions of each of the 2 test trial tokens for each place of articulation. The difference was the place of articulation of the training trials, as shown in the figure: if the test place was bilabial, training places were alveolar and velar; if the test place was alveolar training places were bilabial and velar, etc. The number of training trials was the same (180), this time constituted of 9 repetitions of each of the 10 training stimuli, for each training place of articulations (2 Places × 10 Stimuli × 9 Repetition). In this way, the amount of training was the same, in terms of number of trials, but differed in whether they came from the same-place as the test trials (same-place Experiment) or two different places (switched place Experiment).
In the within-subjects design, each individual heard both canonical and reversed blocks. Block order was counterbalanced across participants, resulting in six sub-groups crossing the target place of articulation and block order. There were 150 trials in each block, and 300 trials total. There was no indication to participants when the second block started.
Within each block, there were 100 training trials, 10 repetitions of each of the 10 training stimuli (i.e., those represented by the 10 smaller shapes in a given panel in Figure 2B). There were five repetitions for each of the two training places of articulation (2 Places × 10 Stimuli× 5 Repetition). There were 50 test trials (25 repetitions of the test trial stimuli) in each distributional block, again fully randomised with the training trials for that block. Note that a given participant heard only one test target place with the other two places heard as training, as the between-subjects design was applied to the switched place of articulation only.
Participants and Procedure
Each experiment has two sub-experiments, which vary the word frame, as described above). Participants for five of the six sub-experiments were recruited online, from Prolific (https://www.prolific.com), subject to several constraints implemented by Prolific’s filters. These were: being a monolingual speaker of English who was born in the United Kingdom, residing in the United Kingdom at the time of the study, and having self-reported normal hearing. Participants were instructed to take the experiment in a quiet setting with headphones. The ALE frame sub-experiment in Experiment 2 served as the basis of an undergraduate honours dissertation, and so participant recruitment was held to less strict constraints. Participants were recruited by word-of-mouth, and not paid for their participation. The majority of these individuals were monolingual speakers of English, born and based in the United Kingdom, however some were either bilingual or speakers of non-U.K. English. All self-reported normal hearing, and provided information on age, sex, gender and language background.
Recall that there are six conditions in each sub-experiment. In the between-subject designs, there were 20 participants recruited for each of the 6 conditions, totalling 120 for each frame (120 for ILL frames, 120 for ALE frames). For Experiment 2 ALE frames, there were 5 listeners per condition, totalling 30 participants overall. In the within-subject designs, as individual participants are exposed to both canonical and reversed frames, there were 6 groups based on place of articulation (3) and block order (that is, canonical first or reversed first) as there were more trials overall in the within-subjects design, we recruited 18 participants in each of the 6 groups, for 108 total in each sub-experiment.
The procedure was a simple two-alternative forced choice task, in which listeners were presented with an auditory stimulus and provided a response by clicking on one of two response options. The experiment was implemented in Testable (Rezlescu et al., 2020). Listeners were instructed that they would hear a speaker of English produce words and that their task was simply to select the word that they heard. The response options were presented as clickable buttons with orthographic representations from Table 1, which were counterbalanced across trials for which side of the screen they appeared on (each option appearing on the left half of the time and on the right half of the time). A response could not be registered until the audio had played. There was an ITI of 300 ms between the registration of a click response, and the beginning of a subsequent trial. The experiments took 10 to 15 min to complete.
Statistical Analysis
The data were analysed by linear mixed-effects regression models with a logistic link function, and with a Bayesian implementation using brms (Bürkner, 2017). The dependent variable in all models was listeners’ binary categorisation responses, with a voiceless response mapped to 1 and a voiced response mapped to 0. As is typical for analysis of this type of DBSL paradigm, we only analyse the test trials (VOT step 5).
Priors for all models were specified as weakly-informative and normally-distributed with a mean of 0 and an SD of 1.5 for both the intercept and fixed effects. For the intercept, this encodes a prior expectation of a value of 0 (in log-odds space, that is 50% probability of a voiceless response). For the fixed effects, this encodes the prior expectation of no effect. However, in both cases, the wide SD, nearly flat in probability space (McElreath, 2018), allow for a wide range of intercepts above and below zero in log-odds and for both large and small effects of each fixed effect in either a positive or negative direction. 1
In the between-subjects designs, the fixed effects in the model were F0 step (sum coded with step 1 mapped to −0.5, and step 9 mapped to 0.5), distributional condition (sum coded with canonical mapped to −0.5, and reversed mapped to 0.5), and target place of articulation (sum coded using contr.sum(3) in R), as well as the interaction of all these fixed effects. The random effects in the model were intercepts for participant and a random slope for F0 step (the only fixed effect which a given participant saw multiple levels of).
In the within-subjects designs, the fixed effects were the same with the addition of the block order variable (sum coded with canonical first mapped to −0.5, and reversed first mapped to 0.5), which was also interacted with all other fixed effects. Because each participant in this design was also exposed to each distributional condition, this was added as a random slope and interacted with the random slope for F0 step.
In our assessment of the results, for both between and within-subjects designs, we focus our discussion on several aspects. The first is the two-way interaction between F0 step and distributional condition. Given the coding scheme for the variables, the main effect of F0 represents that effect when averaging over the other variables, that is, for the data on aggregate. We expect this value should be positive because F0 step 9 is mapped to 0.5 the model will report the predicted change in log-odds for step 9 relative to step 1 (mapped to −0.5). The two-way interaction indicates if the distributional manipulation induces a credible modulation of this effect. With the reversed condition mapped to 0.5, this means the fixed effect will represent the predicted change in log-odds for the F0 effect in the reversed condition relative to the canonical condition (coded as −0.5 in the model). We thus expect the interaction to be negative in general, if the reversed condition does indeed result in a downsizing (or reversal) of the F0 effect. If the two-way interaction is credibly non-zero, this indicates a reliable change in the F0 effect across distributional conditions. Conversely, if it is not credible, we can conclude there isn’t evidence for a change in the size of the F0 effect based on the distributional manipulation, that is, no evidence for distributional learning. They key question we will ask of each experiment is thus: is there credible evidence for a two-way interaction between F0 step and distributional condition (i.e., a different effect size or directionality for F0 in each distributional condition).
Our secondary interest in this paper is to test for possible differences across place of articulation, which would be evident in two-way interactions between place of articulation and F0 (evidencing different F0 effect sizes for different places), or three-way interactions between place of articulation, F0 and distributional manipulation (evidencing differences in DBSL for different places of articulation).
In interpreting the output from the models, we focus on two indices of an effect’s existence. The first is ‘probability of direction’ (henceforth pd), computed using bayestestR (Makowski et al., 2019). This value reports the percentage of an effect’s posterior distribution sitting either side of zero (i.e., having a positive or negative estimate). A pd of 50% therefore corresponds to a distribution centred precisely on zero, indicative of a parameter having no reliable effect on the outcome variable, with many estimates at or near zero and equally-probably positive or negative effects. Contrastingly, a pd of 100% reports that an effect’s posterior distribution completely excludes zero, providing robust evidence that the effect does indeed exist. The second index for an effect’s existence we use is posterior median and 95% credible intervals (CrIs) for the marginal effect of F0 across conditions, computed with emmeans (Lenth, 2023). Ninety-five percent CrIs report the range within which 95% of the posterior draws (centred around the median) for a model parameter fall. If the 95% CrI excludes zero, this provides credible evidence that the effect size is non-zero, and has a consistent direction. Conversely, a 95% CrI that includes zero provides a lack of evidence for an effect’s existence, as there is substantial variation in its estimated direction. Connecting both indices, a pd greater than 97.5% corresponds to the 95% CrI of an effect excluding zero and so, using our confidence threshold, would serve as credible evidence of an effect’s existence. It is worth noting that our choice of a 95% CrIs is entirely arbitrary, but conventional in the field (analogous to a ‘p < .05’ level of significance in frequentist inference). Importantly, it allows us to decisively comment on an effect’s existence or lack thereof.
Results
Evidence for Overall Same-Place Learning
We first examine the effect of F0 across distributional conditions in Experiment 1, to assess if a conceptual replication of same-place DBSL has been induced with our stimuli. Results (empirical data and model estimates) from Experiment 1 are summarised visually in Figure 3. Figure 3A and D shows the proportion of voiceless responses for canonical and reversed distributions, aggregated across place of articulation, in the -ILL and -ALE frame experiments, respectively. For both sets of empirical data, a downsizing in the saliency between F0 steps can be observed for the reversed distribution, indicative of learning having taken place. However, F0 influence has not been fully neutralised, and its directionality certainly not reversed. Most crucial to our assessment of the existence of a credible learning effect is the probability of direction value for the interaction between F0 and distributional condition. A pd >97.5, demonstrative of the 95% CrI lying entirely either side of zero, would provide credible evidence that the effect of F0 is modulated by distributional condition (i.e., that DBSL has taken place).
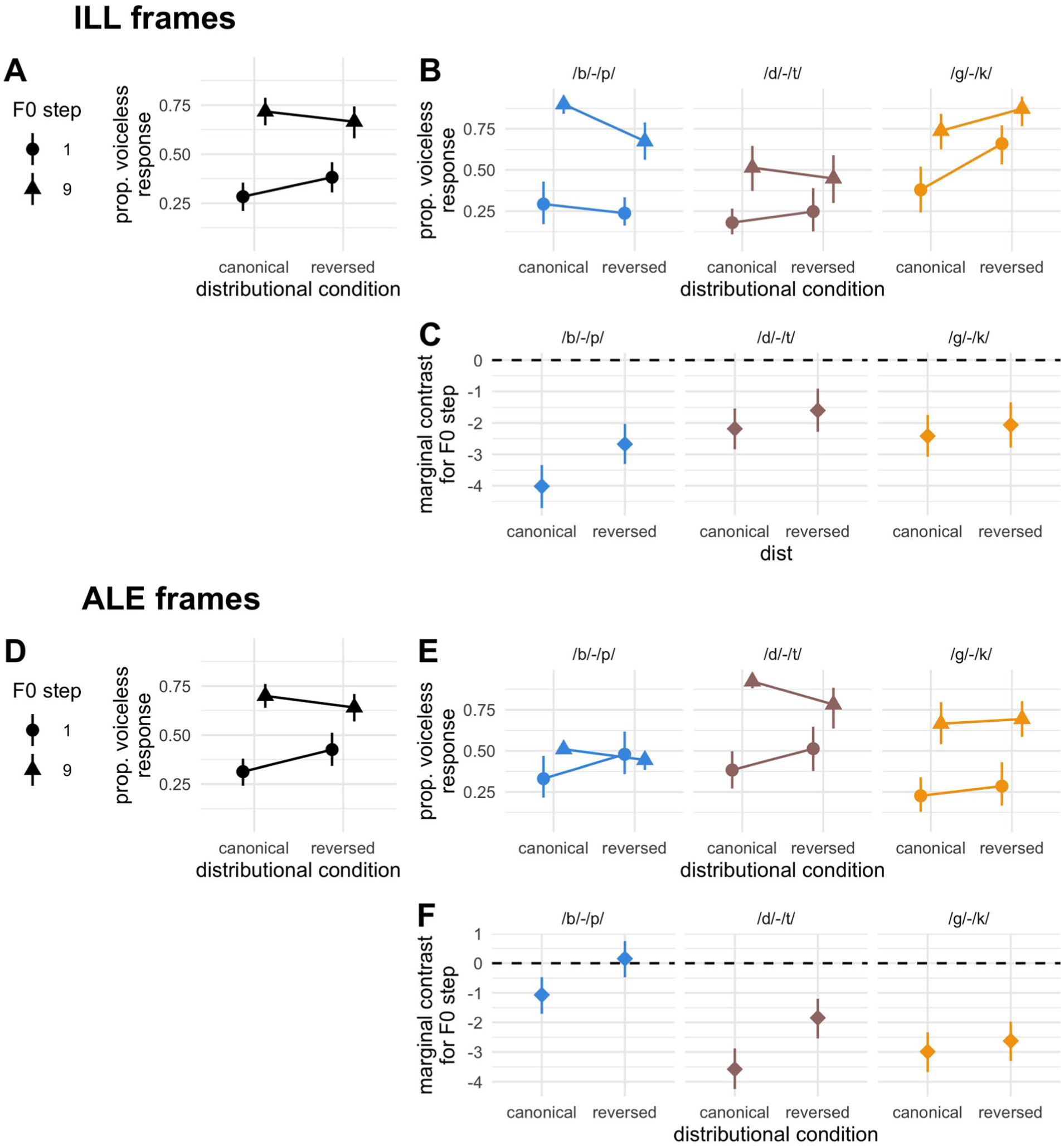
Results from Experiment 1. (A, B and D, E) Empirical data by F0 step and distributional condition, aggregated (A, D) and split (B, E) by place of articulation, for -ill and -ale word frames respectively. (C, F) Estimated marginal effect of F0 by distributional condition, split by place of articulation, for -ill and -ale word frames, respectively.
Focusing on just the same-place estimates (Experiment 1), an overall clearly non-zero positive effect of F0 is present in both models – that is, higher F0 increases the log-odds of a voiceless response (-ILL frames:
Evidence for Overall Generalisation
We now focus on evidence of learning in the switched place experiments. The existence of a credible two-way interaction between F0 and distributional manipulation would signal that DBSL has indeed generalised across place of articulation. Results (empirical data and model estimates) from Experiments 2 and 3 are summarised visually in Figures 4 and 5, respectively. Figures 4A and D, and 5A and D show the proportion of voiceless responses for canonical and reversed distributions, aggregated across the place of articulation, in the -ILL and -ALE frame sub-experiments, with designs between and within-subjects, respectively. The empirical data in all four sub-experiments exhibit a slight reduction in the difference between F0 steps for the reversed condition, but with F0 remaining a reliably robust cue. For three of the four sub-experiments, this reduction is also much less visually acute than what was observed in Experiment 1, but for the between-subject ALE frame experiment, the downsizing of F0 saliency appears more in line with that observed in Experiment 1, suggesting that learning may have transferred across place of articulation. Recall, however, that this sub-experiment contained only 30 participants, with participation not remunerated, and subject to less strict constraints. These empirical data should therefore be interpreted with caution, given the consistent evidence of minimal F0 downweighting in the other three sub-experiments.
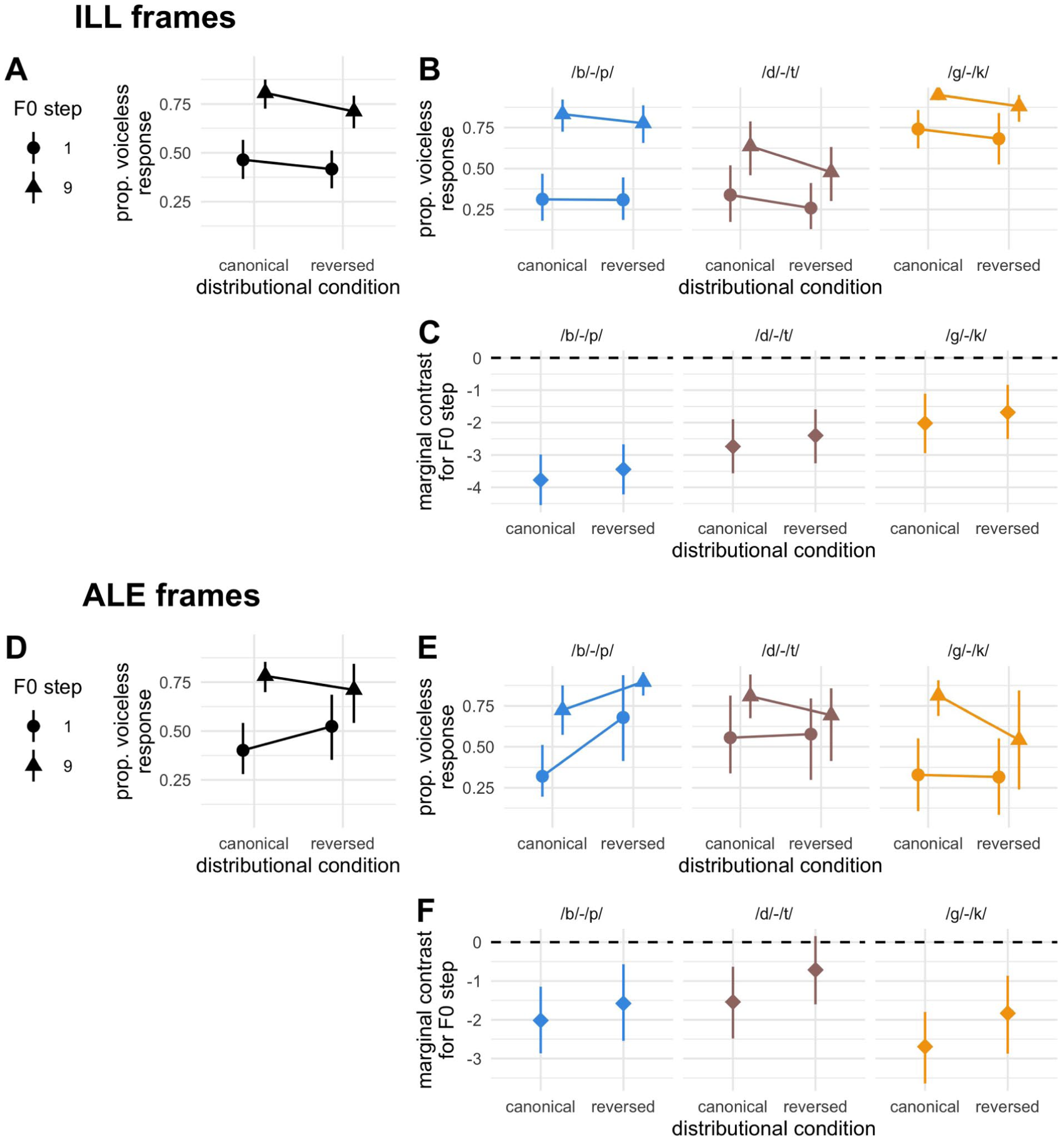
Results from Experiment 2. (A, B and D, E) Empirical data by F0 step and distributional condition, aggregated (A, D) and split (B, E) by place of articulation, for -ill and -ale word frames, respectively. (C, F) Estimated marginal effect of F0 by distributional condition, split by place of articulation, for -ill and -ale word frames, respectively.
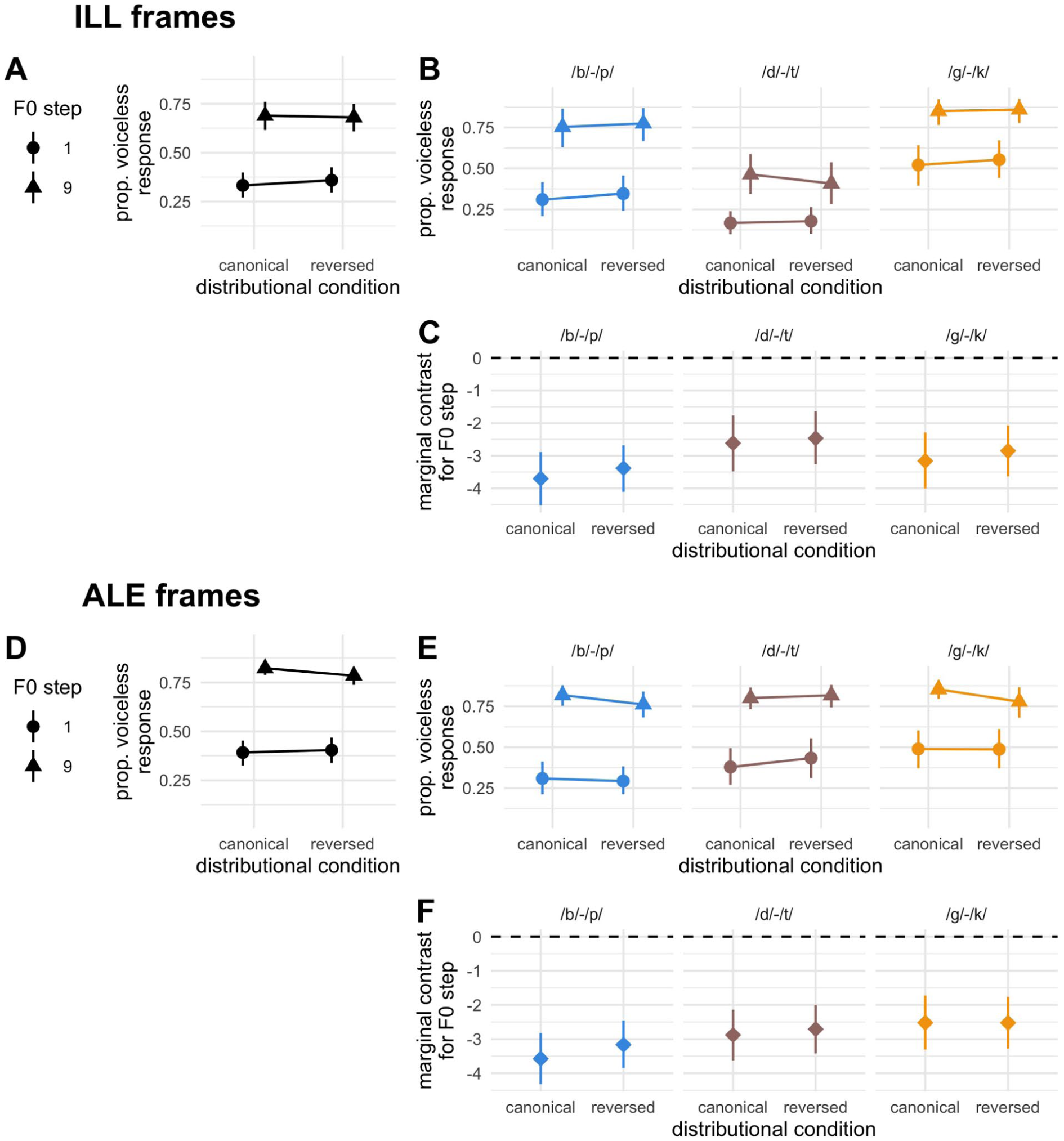
Results from Experiment 3. (A, B and D, E) Empirical data by F0 step and distributional condition, aggregated (A, D) and split (B, E) by place of articulation, for -ill and -ale word frames, respectively. (C, F) Estimated marginal effect of F0 by distributional condition, split by place of articulation, for -ill and -ale word frames, respectively.
Again, we look to the regression model outputs to concretely assess if DBSL has transferred to the test stimuli. Model estimates for the main effect of F0 and also its interaction with distributional condition are summarised in Table 2.
Model Estimates for the Main Effect of F0, As Well As Its Interaction with Distributional Condition, on the Log-Odds of a Voiceless Response, for Experiments 2 and 3.
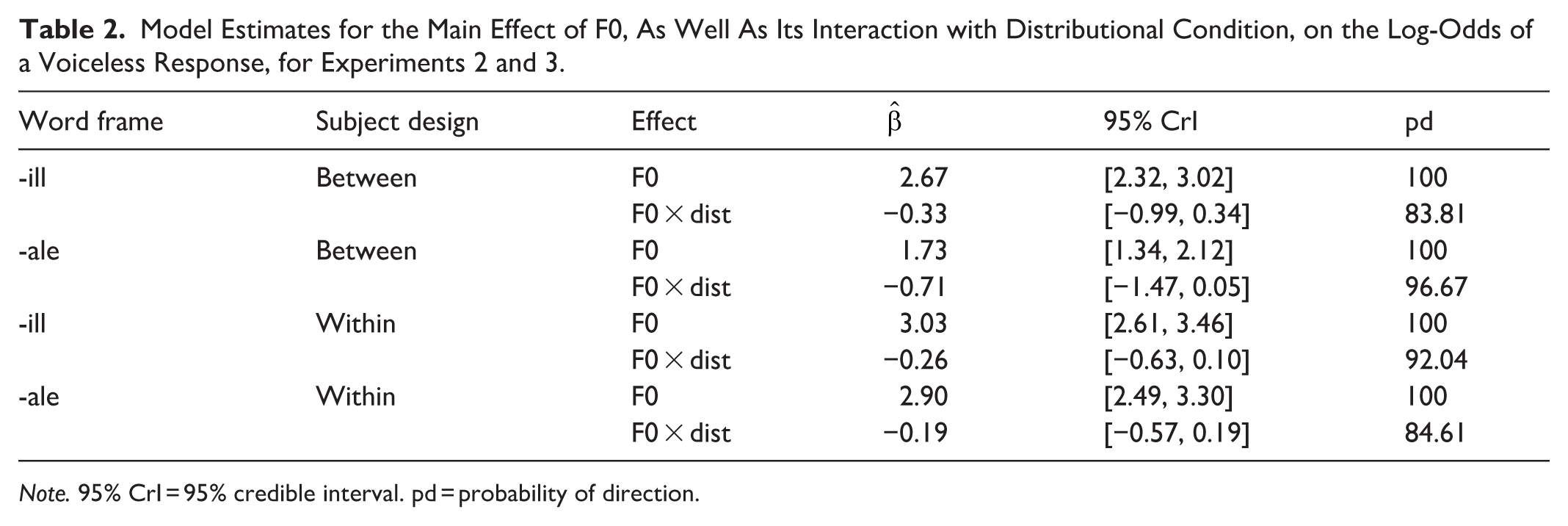
Note. 95% CrI = 95% credible interval. pd = probability of direction.
In all four models, there was a strong main effect of F0 on the log-odds of a voiceless response, demonstrating that in general, when VOT was ambiguous, F0 reliably cued the distinction between voiced and voiceless stops. Crucially, however, the interaction between F0 and distributional condition did not meet our credibility threshold in any of the four models. Therefore, Experiments 2 and 3 provide considerable evidence that DBSL for stop voicing cued by VOT and F0 does not generalise across place of articulation. The estimated marginal effect of F0 also remained credible in the reversed condition across all four experiments, with 95% CrIs overlapping considerably between canonical and reversed distributions in all models (see Appendix Table A1). It is worth noting that the directionality of the interaction effect aligned with what is expected of DBSL, with all four median estimates for the interaction having a negative sign, and a sizeable amount of the posterior distribution lying on the negative side of zero (probability of directions ranging from 83.81 to 96.67. Again comparing results to our previous generalisation study that included word frame variability in both training and test trials, all four models here provide increased (albeit still non-credible) evidence for learning, serving as further indication of word-frame sensitivity in DBSL (Steffman et al., 2025). Nevertheless, the overarching conclusion from Experiments 2 and 3 is that DBSL did not generalise across place of articulation, despite removing word-frame variability and introducing an additional place of articulation in training. With four experiments, using two different word frames, and both between- and within-subject designs, we deem this to be a clear and convincing lack of evidence for generalisation. 2 Moreover, as conclusions and effect sizes align between experiment designs, our findings provide increased validity to the use of between-subject designs in DBSL research.
As a visual summary of the results presented thus far, model estimates for the interaction between F0 and distributional condition across the three experiments and each frame are presented in Figure 6. The figure presents draws from the posterior distribution for model estimates for the critical learning-diagnostic effect in each of the six statistical models. The estimates are shaded according to whether the test place of articulation in training was the same (two leftmost distributions) or switched. The colour indicates whether the experimental design was within- or between-subjects. As described above, a clearly non-zero, credible effect is present for the two same-place analyses, providing clear evidence of learning. The remaining four switched place analyses have 95%, which include the value of zero, taken here as an absence of convincing evidence for an effect. As noted above, it is nevertheless the case that all estimates lean negative, that is, in line with the predicted learning effect.
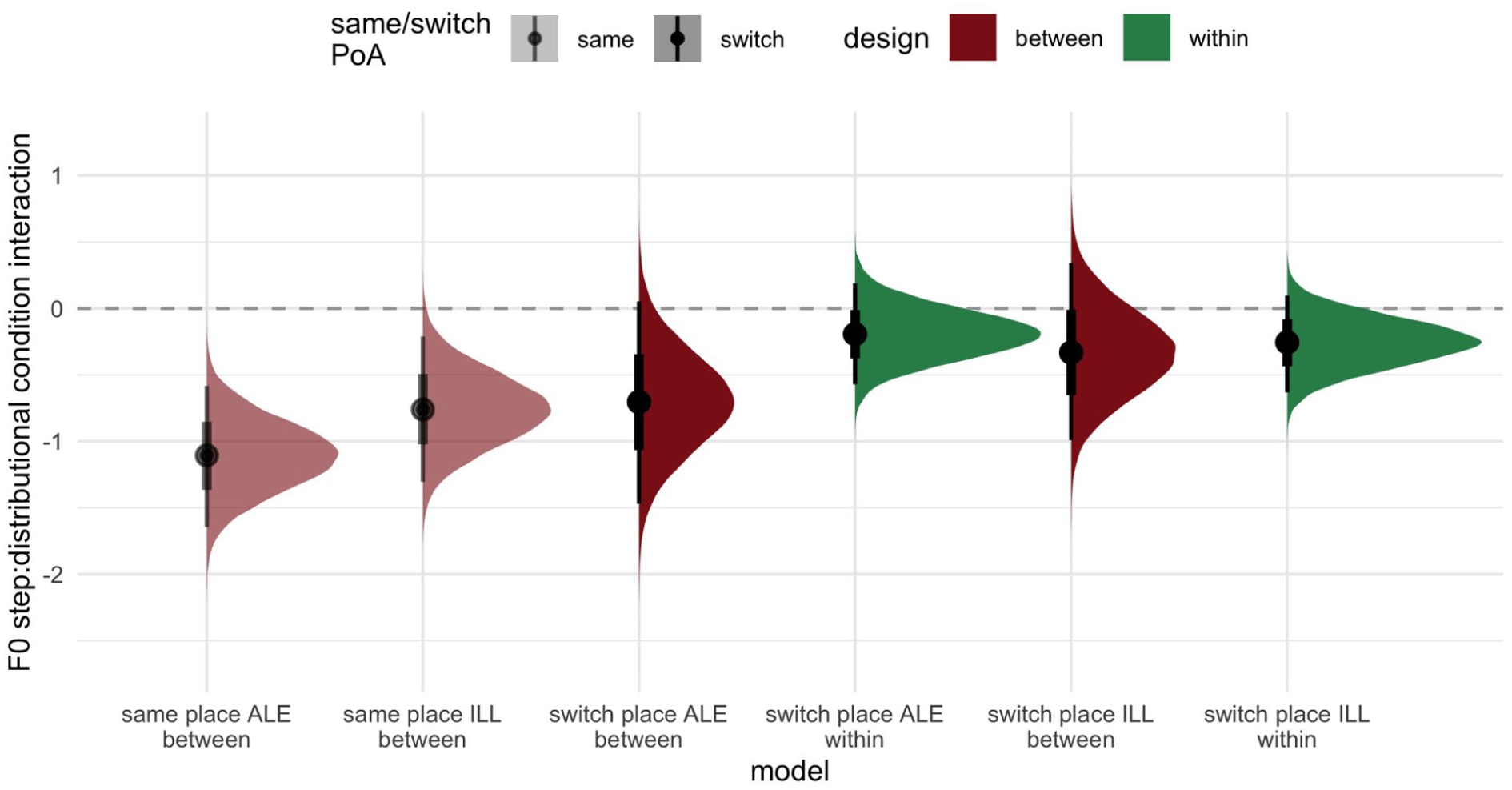
Posterior distribution estimates from the experiments in the paper for the two-way interaction between distributional manipulation and F0 (in log-odds), indexing a difference in F0 cue weighting across distributional conditions. The point is the median, and bars indicate 66% CrI (innermost wider bars) and 95% CrI (outermost thinner bars).
As one additional way to assess overall evidence for a difference between same and switched place learning, we fit a model which combined all of the data across the 6 experiments, collating data from a total of 606 participants (120 from each of the 2 same-place between-subjects experiments and from the switch place between-subjects ILL experiment, 108 from each of the 2 within-subjects experiments, and 30 from the switch place ALE between-subjects experiment). The random effect structure was also the same as before with by-participants slopes for F0, as only the participants in the within-subjects experiments were exposed to both levels of this variable, making the maximal random effect structure which can apply to all 606 participants. One additional variable was added to the fixed effects, which was sum-coded as all other variables. This was same/switch indicating whether a particular trial was from a same or switched place condition block. This referred to the blocks that participants saw in the within-subjects experiment, and to all trials a given participant saw in the between-subjects experiment. This additional variable, when interacted with others in the fixed effects allows us to assess the role of same/switched learning in mediating the size of the critical two-way interaction across experiments. Therefore, the three-way interaction between F0, distributional condition, and same/switch variable in the combined model serves as an overall index of same versus switch place learning asymmetries. This three-way interaction was indeed credibly non-zero (
Exploring Place of Articulation Effects
To identify possible learning asymmetries between places of articulation, we analyse differences in the estimated marginal effect of F0 between canonical and reversed distributions across the three voicing contrasts. 3 Marginal contrasts for F0 step split by place of articulation are visualised in Figures 3C and F to 5C and F, for -ILL and -ALE frames, respectively. With no clear place differences in Experiments 2 and 3, as well as the overall finding that learning did not generalise, we turn our focus to the output from the same-place models in Experiment 1. 4 Table 3 reports the values for the marginal contrast of F0 step split by place of articulation for the same-place experiment.
Estimated Marginal Effect of F0 (Median Estimates and 95% Credible Intervals, Computed with Emmeans Contrasts) on the Log-Odds of a Voiceless Response, Split by Place of Articulation and Distributional Condition, for the -ill and -ale Frame Same-Place Models in Experiment 1.

Note. 95% CrI = 95% credible interval.
Perhaps the most striking place-based difference in F0 downweighting can be observed for the velar place of articulation. Whereas in both word frames, a clear downweighting is evidenced for both bilabial and alveolar stops, the estimated marginal effect of F0 sees only a moderate reduction between canonical and reversed distributions for both -ALE and -ill velar contrasts. While only qualitative, this same pattern was found in our frame-based variability study, which to our knowledge was the first time DBSL for stop voicing was tested at the velar place of articulation (Steffman et al., 2025). The reasons for such asymmetry are unclear and, in the absence of credible model interactions, further evidence is required to concretely comment on the seemingly less-permitting nature of velar contrasts in DBSL. Strong evidence of learning can on the other hand be found in the marginal contrasts for F0 step for both alveolar and bilabial places of articulation. In the -ill frame model, there is a strong downsizing of the F0 effect in the reversed distribution for the bilabial voicing contrast, with 95% CrIs for the estimated marginal effect of F0 not overlapping between canonical and reversed conditions. F0 nevertheless remained canonically informative, with 95% CrIs in the reversed condition not including zero. The alveolar contrast also evidences a downsizing in F0 effect, although this is notably less extreme, with 95% CrIs overlapping between canonical and reversed estimates, contradicting the finding in our previous study of larger downsizing for alveolars (Steffman et al., 2025). The reverse is observed in the -ALE frames, with a larger reduction in F0 effect for the dale-tail contrast, although 95% CrIs did not overlap between canonical and reversed estimates for either contrast, evidencing robust learning at both places of articulation. What is more striking however is the evidence of possible cue shifting (as opposed to just downweighting) of the F0 dimension for the bale-pail contrast, as the estimated effect of F0 changed directionality from negative in the canonical training block to positive in the reversed. This indicates that, following exposure to the reversed distribution, listeners were more likely to provide a voiceless response to low F0, and a voiced response to high F0 – the inverse of canonical English use of the F0 dimension. This is the first time that apparent shifting has been invoked with our stimuli, however, as the 95% CrI overlaps zero, it cannot be explicitly discerned to have taken place. The relatively similar magnitude of F0 downweighting between bilabial and alveolar stops is also illustrated in non-credible three-way interactions in both models between F0 step, distributional condition and place of articulation, demonstrating that learning effects for both places do not credibly deviate from the grand mean. This symmetry is intriguing in the context of credible two-way interactions between F0 step and place. In the -ill frame model, the two-way interaction between F0 step and place of articulation is credible for both bilabial (
Discussion
Adult listeners have demonstrated an ability to rapidly reweight their reliance on acoustic dimensions of their native language during spoken word recognition following exposure to short-term statistical patterns in the covariance between two cues. This form of perceptual learning, known as DBSL, has been shown to robustly occur when listeners are trained and tested on the phonetic contrast for a particular minimal pair (Idemaru & Holt, 2011; Liu & Holt, 2015). Nevertheless, a powerful characteristic of perceptual systems is their ability to generalise learning to novel albeit similar contexts given limited input, although previous research has found that DBSL for the stop voicing contrast appears markedly sensitive to the acoustic-phonetic context, with learning only weakly generalising across word frame (Idemaru & Holt, 2020), and not generalising across place of articulation (Idemaru & Holt, 2014; Steffman et al., 2025). Across six perceptual learning experiments, we have examined the reweighting of F0 as a cue to stop voicing following exposure to a reversed correlation between VOT and F0, testing if listeners are able to generalise learning across stop place of articulation. Experiment 1 served as a conceptual replication of DBSL (with a between-subjects design), demonstrating that listeners credibly downweighted their reliance on the F0 dimension, when trained and tested on a reversed cue distribution for the same contrast (i.e., with no generalisation across word frame or place of articulation). Experiments 2 and 3 served to investigate if more (potential) evidence, in the form of reversed cue distributions for two places of articulation in training (c.f., Idemaru & Holt, 2014), and removal of word frame variability (c.f., Steffman et al., 2025), would induce generalisation of DBSL within the phonetic category of stop voicing, to an unexposed place of articulation. In aggregate, no credible evidence of perceptual learning was found in Experiments 2 and 3, with DBSL not generalising across place of articulation, despite removing word-frame variability and introducing an additional place of articulation in training. With four sub-experiments, using two different word frames, and both between- and within-subject designs, we deem this to be particularly strong evidence that learning of the covariance between VOT and F0 for stop voicing is indeed very place specific. This provides further evidence that DBSL for this contrast is markedly constrained by the immediate acoustic-phonetic environment and, in conjunction with the finding that DBSL may not be modulated by increased demand on cognitive functions – specifically working memory – suggests that DBSL for stop voicing operates at a low level of the linguistic representation (A. Hodson et al., 2022). Further evidence of context-sensitivity was observed when comparing learning effect sizes between the between-subject experiments in the present paper and our previous study, highlighting a modest moderating role of word-frame variability on learning. In an attempt to elicit cross-place generalisation, we removed the frame-based variability present in Steffman et al. (2025), given previously attested word frame sensitivity and specificity in DBSL for stop voicing (Idemaru & Holt, 2014, 2020; Idemaru & Vaughn, 2020; Murphy et al., 2025). Although DBSL was found to not generalise in Experiments 2 and 3, model estimates for the interaction between F0 step and distributional condition for same-place learning were larger in magnitude in the present study, suggesting that DBSL is to some extent sensitive to word-frame variability. A slightly larger estimate for the effect of the reversed distribution on F0 cue weight was also observed for the -ALE compared to -ILL word frames, further suggesting that properties of the following word frame or vowel may influence learning effect magnitudes. Future experiments could therefore expand on this to more concretely assess possible learning asymmetries across word frames. This appears a particularly insightful direction given the finding that listeners are able to simultaneously track distributional changes for different lexical contexts, exhibiting separate cue weights for the same stop voicing contrast per word frame (Idemaru & Vaughn, 2020). The authors therefore suggested that the biphone could be the linguistic unit over which DBSL operates, at least for stop voicing cued by VOT and F0, as F0 is primarily a property of the following vowel. This hypothesis could be put to a more strenuous test, examining both generalisation and specificity of DBSL between lexical contexts with the same word-initial biphone (e.g., bill-pill, bin-pin, and contexts with different word-initial biphones (e.g., bill-pill, ban-pan).
While we have made informed methodological choices in an attempt to induce cross-place generalisation, we acknowledge that the conditions of our experiments are by no means maximally optimal in this sense. This is particularly the case for the F0 manipulations of our stimuli, with less extreme perturbations (both in terms of endpoint ranges and temporal extent) than what has been used in previous studies (c.f., Idemaru & Holt, 2011, 2014, 2020). Our F0 continua were directly informed by speech production research (Hanson, 2009; Hombert, 1975), and therefore should better reflect the magnitude of learning experienced in the wild with more naturalistic speech. However, our stimuli did produce smaller DBSL effects in our same-place experiment than what has been observed in these previous studies with more extreme F0 continua, with F0 remaining a canonically reliable cue to the stop voicing contrast in all but one participant group (same-place -ALE bilabial). Therefore, if cross-place generalisation is at all tied to general learning effect sizes, a study with two training places of articulation and crucially more extreme F0 continua may well elicit credible evidence of learning generalising within the phonological stop voicing category. Nevertheless, the clear learning for the same-place of articulation in Experiment 1 shows that the learning signal is strong enough, when there is no need to generalise across contrasts.
The results for same-place learning across our two studies also identify an apparent resistance to DBSL amongst listeners for contrasts at the velar place of articulation, although the reasons for this are unclear. Future studies could therefore assess if this aversion to learning for velar stop voicing contrasts persists in more optimal learning conditions, for example, using stimuli with larger F0 differences. It is also worth noting that previous studies have, to our knowledge, only tested DBSL for the bilabial and alveolar places of articulation, so the inclusion of velar contrasts in our experiments also may well contribute to the overall smaller learning effects, aggregated across places of articulation, observed here compared to in previous studies.
We also acknowledge recent developments in exposure paradigm design as integral to future research on the extent of context-sensitivity and limits of generalisation in DBSL. For example, a repeat-exposure design, conducted over several sessions spanning several weeks (as in Xie & Kurumada, 2024, 2025) would provide a better examination of the limits of cross-phoneme generalisation for the stop voicing contrast. In such a design, it may be the case that generalisation can be drawn out, but only following several exposure sessions, possibly owing to listeners gradually becoming more aware of the relationship between training and test stimuli. This would align with previous evidence that active, but not passive, exposure to training stimuli induces word-frame generalisation for the stop voicing contrast, strengthening the claim that attention and goal setting may facilitate successful generalisation (Murphy et al., 2025). Or perhaps cross-place generalisation can still not be teased out despite repeated exposure, evidencing a clear inability to access the phonological category of stop voicing in DBSL regardless of the quantity of short-term input. Not only are such novel exposure paradigms better suited to provide more robust conclusions on the context-sensitivity/generalisability of DBSL for different sound classes and contrasts, but they are also strongly informed by the types of cognitive processes hypothesised to bring about adaptive speech perception (see Xie et al., 2023, for further motivations). Another novel design, the incremental exposure-test paradigm, allows for more fine-grained monitoring of the time-course of adaptation by tracking cumulative changes in listener’s categorisation responses, as well as examining the mechanism(s) behind distributional learning by fitting the data to a Bayesian ideal adaptor model (Tan & Jaeger, 2025). This was motivated by the finding that multiple competing theories of adaptive speech perception (namely, (a) low-level pre-linguistic signal normalisation, (b) changes in/selection of linguistic representations, and (c) changes in post-perceptual decision-making) can often account for the same behavioural data, when experiment designs are less informed by the different outcomes hypothesised by these three processes. An interesting finding in their study was that, while a psychometric distributional learning model explained listeners’ perception to a high degree of accuracy, learning was constrained and prematurely converged with diminishing returns, a previously unattested phenomenon. Future extensions of the present results could therefore extend these methods to the learning of two covarying cues – for example, the same mechanism/process behind this observation of premature convergence may also explain the partial/incomplete word-frame generalisation attested in DBSL for stop voicing (Idemaru & Holt, 2020). These novel exposure paradigms have so far to our knowledge only been applied to distributional learning for one cue, or accent adaptation more generally, and so provide plenty of scope for future research in DBSL, particularly we deem in regards to fleshing out possible asymmetries in how DBSL operates and generalises across sound classes, specifically vowels and stop consonants, and how this may relate to variability in their production. Evidence from previous studies suggests that learning for vowel quality cued by F1 and duration may be more robust and more permitting of generalisation than for stop voicing cued by VOT and F0, and a tentative hypothesis for the stronger learning effects observed for vowels is that they exhibit greater within-category variation and their cue distributions tend to overlap significantly more (Hillenbrand et al., 1995; Lisker & Abramson, 1964), so greater plasticity in vowel categorisation is required to account for this variation (Liu & Holt, 2015). A thorough comparison of learning asymmetries across sound classes is lacking in the literature, and these novel exposure designs and computational modelling in their complement provide a means to better explain the link between the phonetic properties of the input (i.e., variation in speech acoustics) and perceptual changes in the output (i.e., changes in categorisation functions). Centring the question on individual differences, the same participants could be tested on DBSL for both stops and vowels, with acoustic dimensions tightly informed by speech production research, to examine what mechanisms, phonetic properties of stimuli and/or prior expectations may explain this apparent asymmetry, and how learning differences may change or persist over time.
Conclusions
In conclusion, the present study details six sub-experiments in which we have tested both same-place and switched place DBSL, for two different word frames, using both between- and within-subject designs, providing further robust evidence that DBSL for stop voicing does not generalise across place of articulation. This is despite introducing more evidence for generalisation in the form of reversed cue distributions for two places of articulation, and removing word-frame variability. Nevertheless, we acknowledge additional methodological choices, particularly newly emerging exposure paradigms informed by theoretical considerations, as a means to yet further test the limits of generalisation in DBSL, as well as fleshing out various asymmetries in the learning and reweighting of covarying acoustic dimensions in spoken word recognition.
Footnotes
Appendix
Estimated Marginal Effect of F0 (Median Estimates and 95% Credible Intervals, Computed with Emmeans Contrasts) on the Log-Odds of a Voiceless Response, for Canonical and Reversed Distributions, from Each of the Six Sub-Experiment Models.
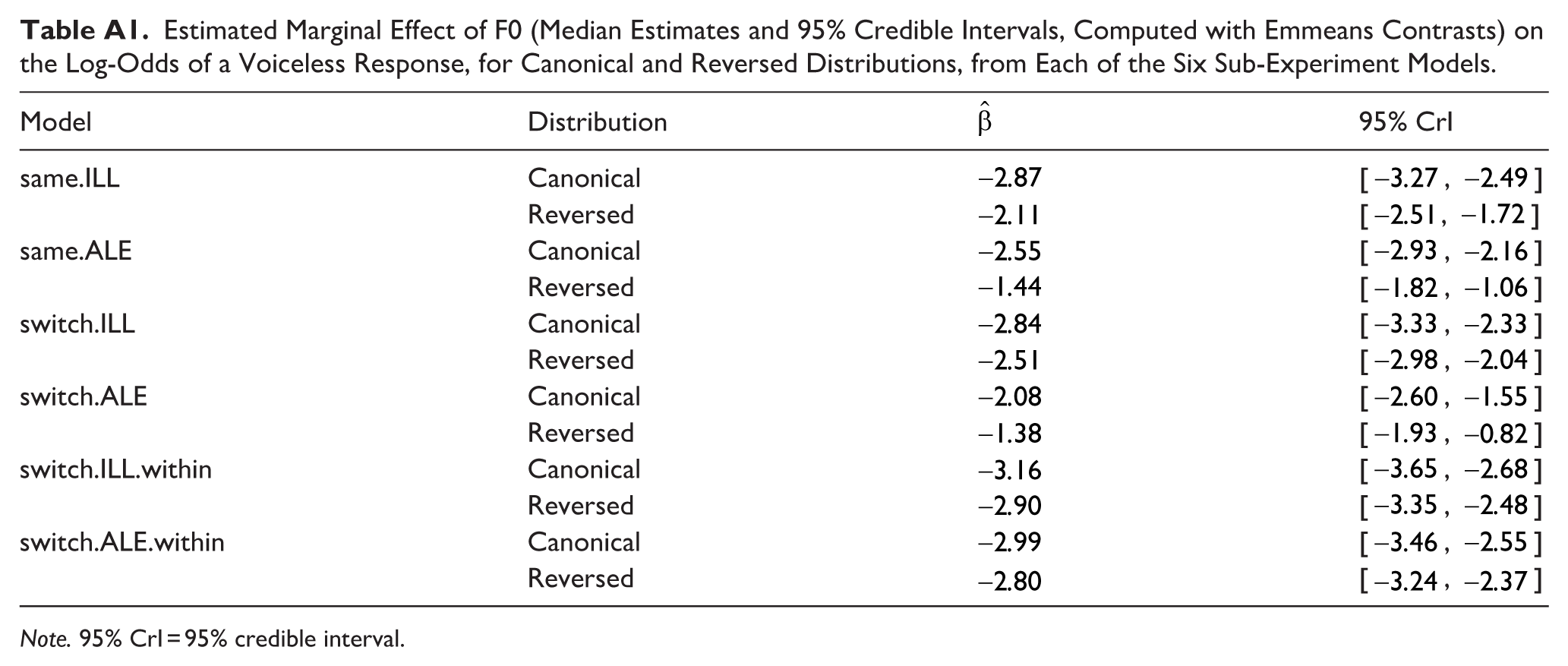
| Model | Distribution |
|
95% CrI |
|---|---|---|---|
| same.ILL | Canonical | −2.87 | [−3.27, −2.49] |
| Reversed | −2.11 | [−2.51, −1.72] | |
| same.ALE | Canonical | −2.55 | [−2.93, −2.16] |
| Reversed | −1.44 | [−1.82, −1.06] | |
| switch.ILL | Canonical | −2.84 | [−3.33, −2.33] |
| Reversed | −2.51 | [−2.98, −2.04] | |
| switch.ALE | Canonical | −2.08 | [−2.60, −1.55] |
| Reversed | −1.38 | [−1.93, −0.82] | |
| switch.ILL.within | Canonical | −3.16 | [−3.65, −2.68] |
| Reversed | −2.90 | [−3.35, −2.48] | |
| switch.ALE.within | Canonical | −2.99 | [−3.46, −2.55] |
| Reversed | −2.80 | [−3.24, −2.37] |
Note. 95% CrI = 95% credible interval.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This grant was supported by BA/Leverhulme Small Research Grant 2425/250068. Additionally, many thanks are due to William Peralta for assistance with recording the speech materials used to make the stimuli.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.