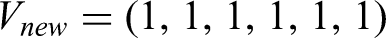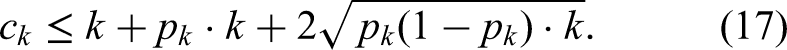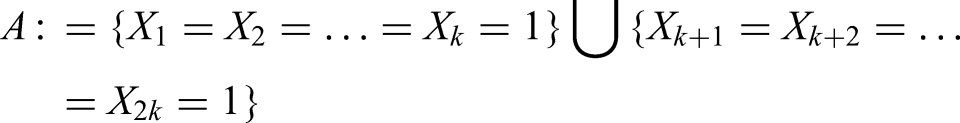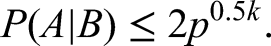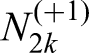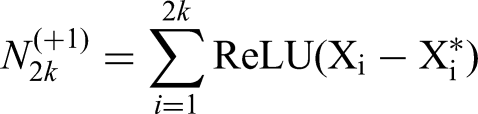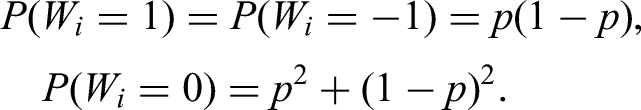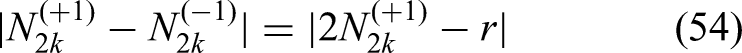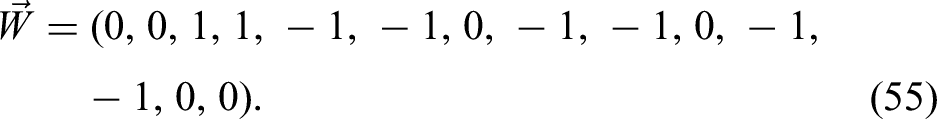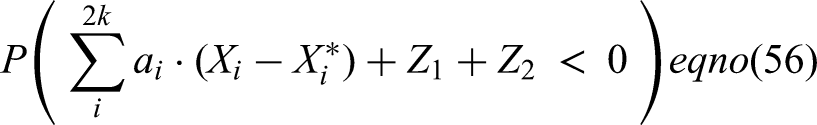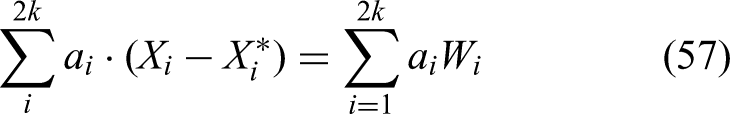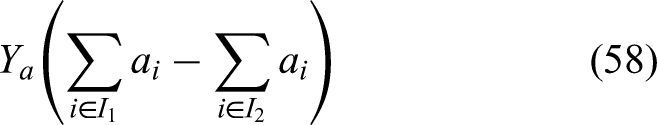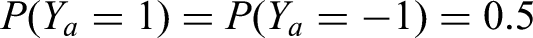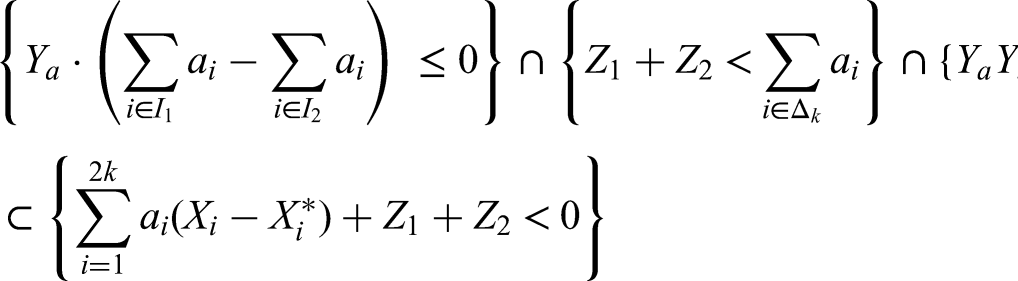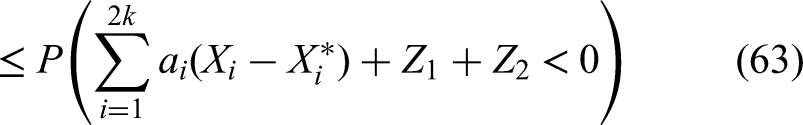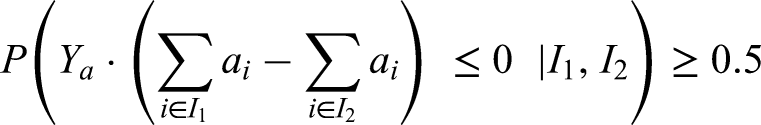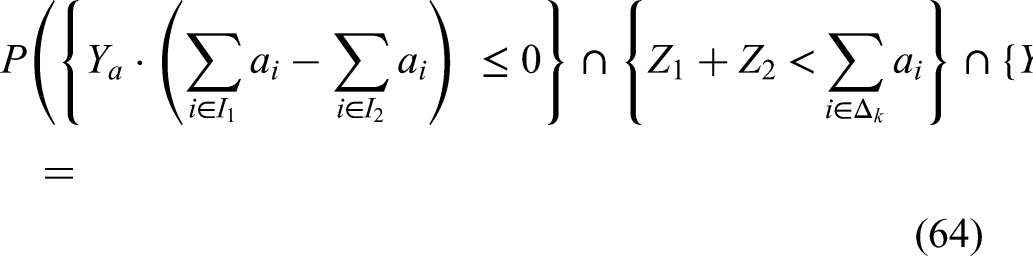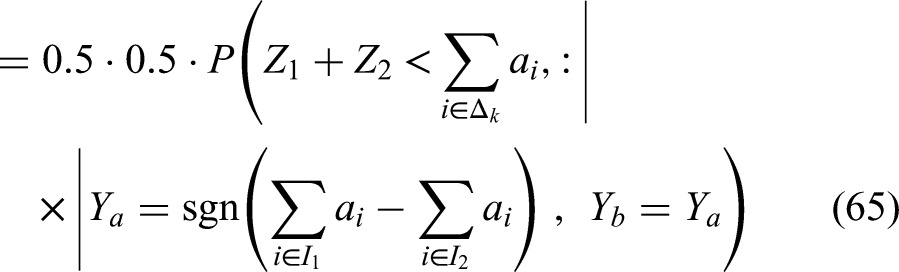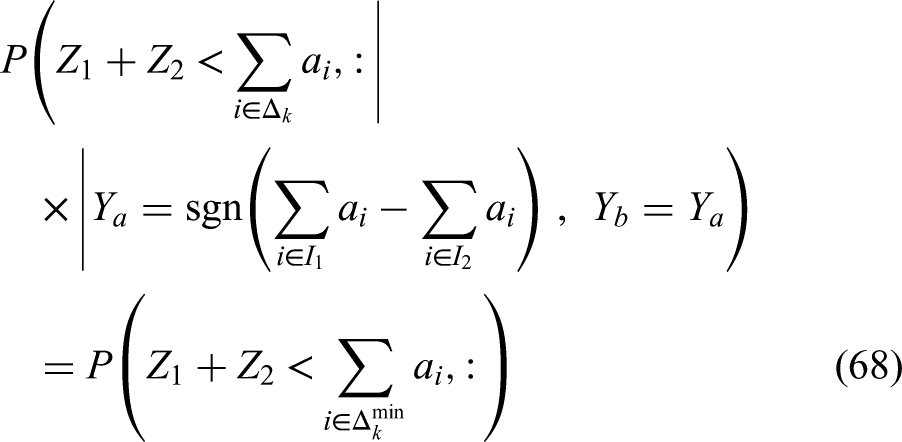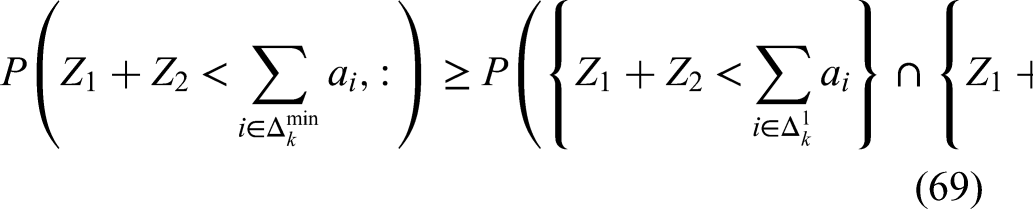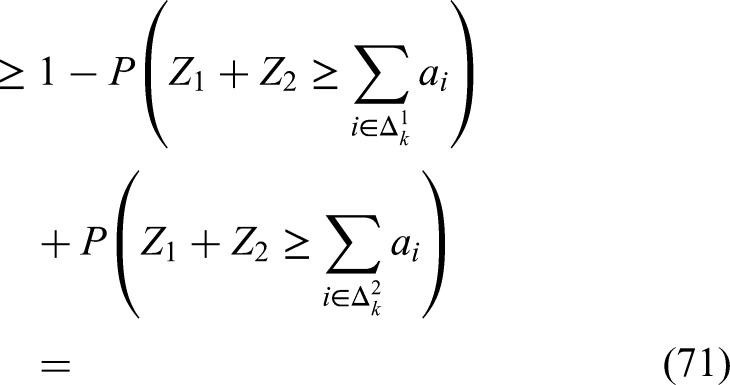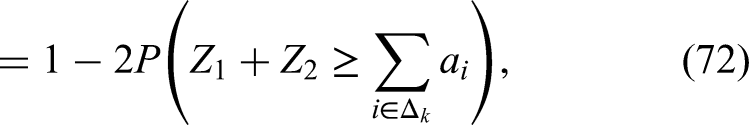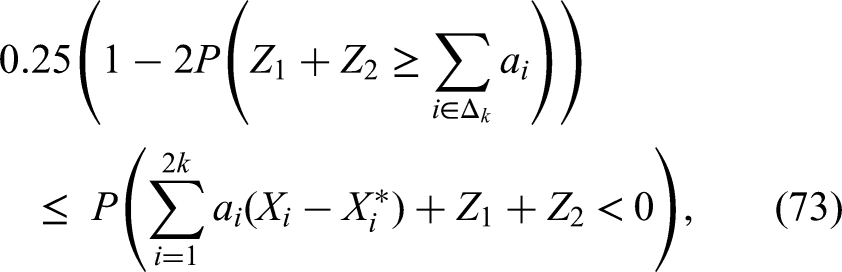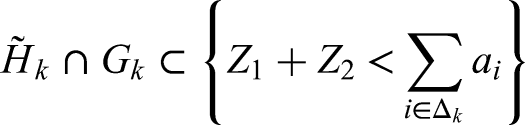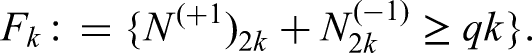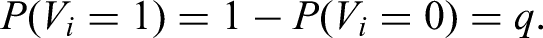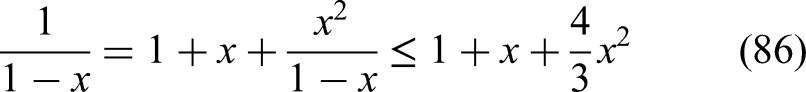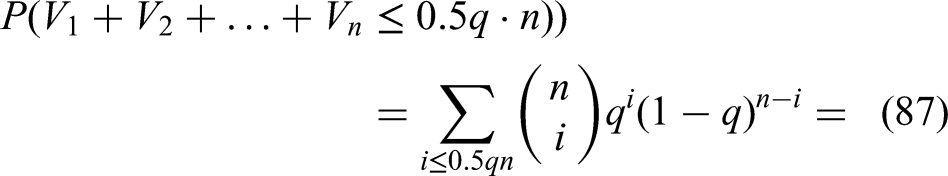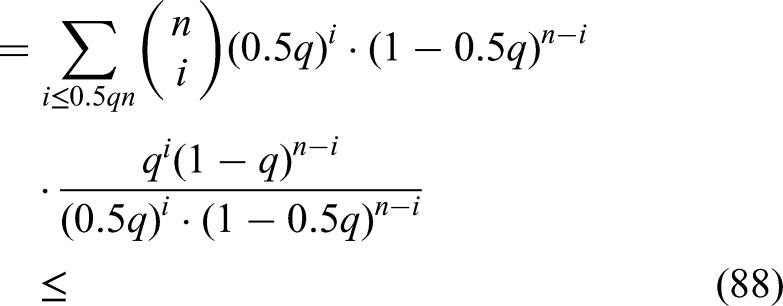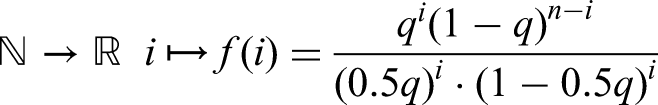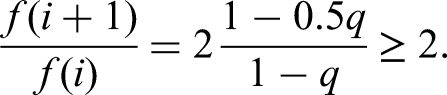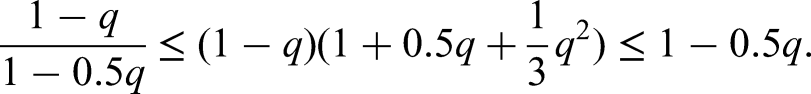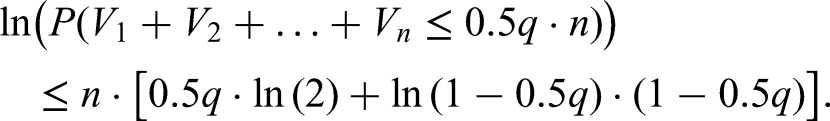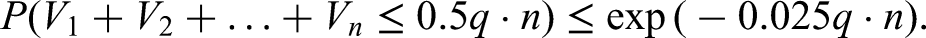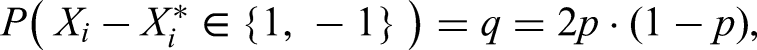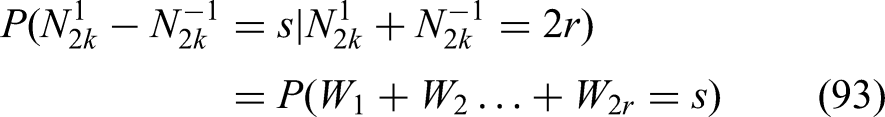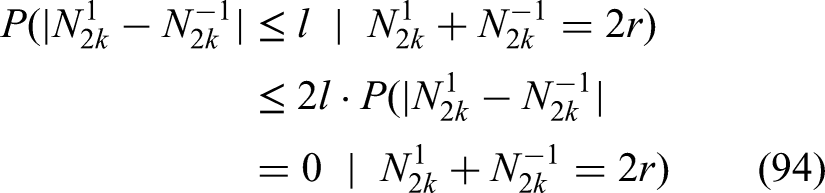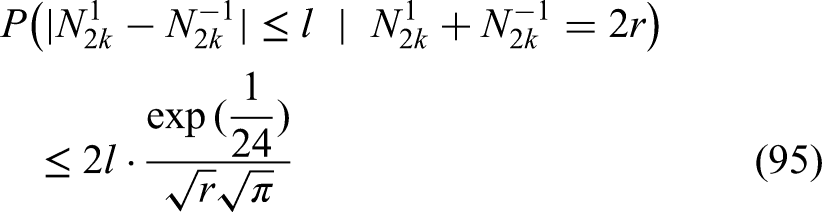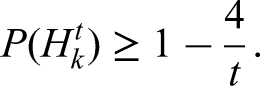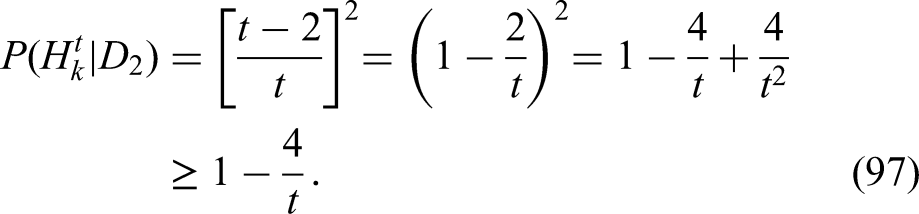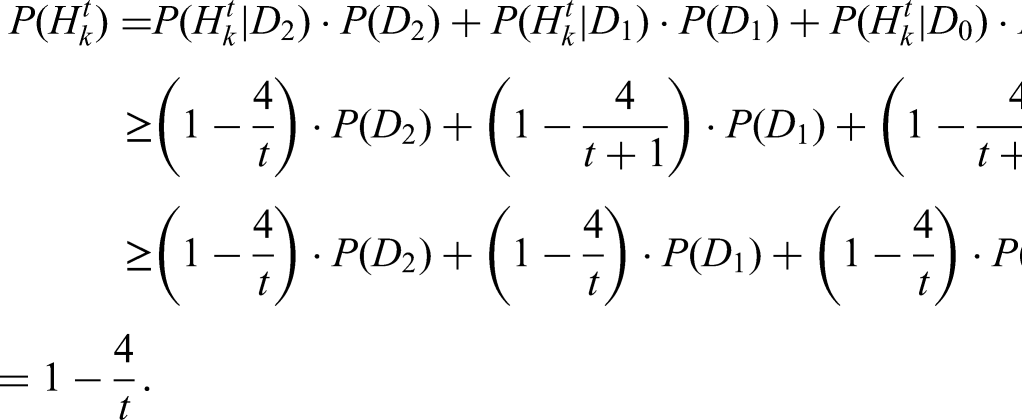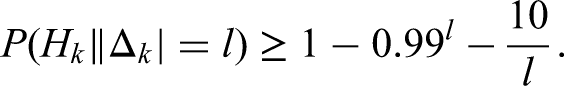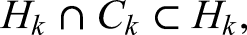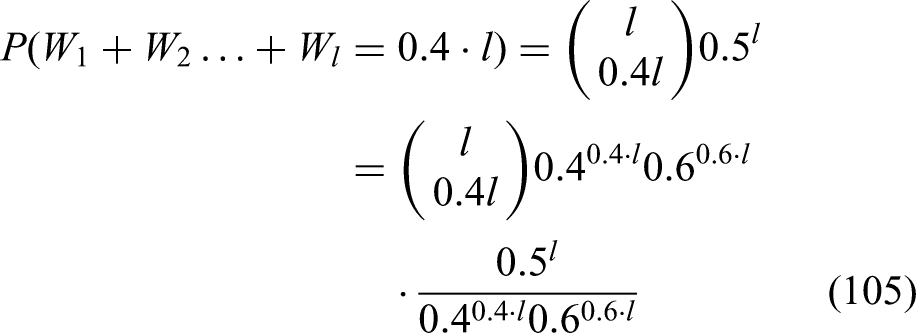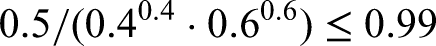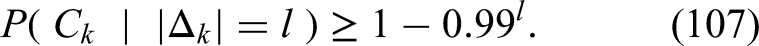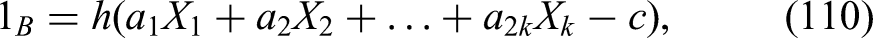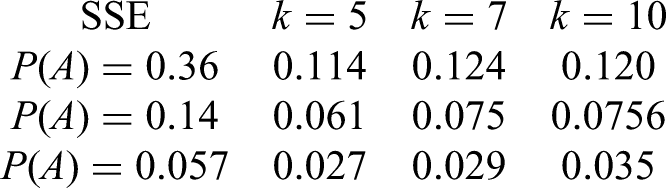We consider the compression of a depth-2 feed-forward layer of Transformer into a single fully connected layer. To model this, we take a binary vector with independent entries as input. We define the event to be that for two disjoint subsets of size of the entries of the vector, all entries of at least one of the subsets are equal to . This represents the information of two layers of a feed-forward layer. We study the approximation of the event by applying a linear functional to the binary vector, followed by a Heaviside (threshold) function. We establish an explicit lower bound on the relative error of any such approximation, valid for all choices of linear functionals. Notably, this lower bound approaches as becomes large. This result provides a theoretical explanation for the well-known heuristic that sparse Transformers, although requiring more parameters, achieve better performance. If it were possible to approximate accurately with a dense representation, one could convert sparse architectures to dense ones without any loss in performance—but our result shows that such a compression necessarily incurs a significant error.
In this article, we prove that a disjunction of two sets of -conjunctions of independent events can not be approximated closely by a single linear functional. This problem corresponds to reducing two lines in a transformer’s fully connected layer into a single line. If this would be possible, then it would be possible to compactify transformers without quality loss. But it is known that in practice this is not the case, since scientists work on producing1–3 cost-efficient sparse transformers. Further down, we explain the connection with transformers. (For general reference.4) But, let us first explain the mathematical setting of our result: In what follows we assume that are i.i.d. Bernoulli variables, with
The main result of this paper, Theorem 1, is an explicit lower bound on the relative error for approximating the event
by a one-dimensional functional followed by a Heaviside function, hence by an event:
where are real numbers. Note that we could always take the event to be
and then . For a good predictor, we would like and both close to , not close to which translates to the condition:
for a small constant . (See Condition (7) below, which in terms implies (8) and (11).)
The explicit bound we prove is asymptotically , when is large enough. In other words, the in (7) can never go much below . This has an extremely important implication for Transformers: compression is not possible without quality loss.
Let us consider the case of . Let be a nine-dimensional column vector, with i.i.d Bernoulli variables as entries except the last one, which is always . We define the event as in (1). Let
and let . Now, consider
where ReLU(.) sets any negative component of a vector to 0 and leaves the positive ones unchanged. Note that the quantity in (3) is greater than or equal to if and only if the event occurs. Meanwhile, an expression of the form , where and are linear maps of appropriate dimensions, corresponds to the feed-forward layer of a Transformer. Here, the input to the feed-forward layer is the vector . In this sense, the event is realized through two fully connected layers encoded in the matrix of a Transformer.
The functional appearing in the definition of event in (2) can be viewed as corresponding to a single row of the matrix in the Transformer’s fully connected layer. We choose to use the Heaviside function instead of ReLU to define event . We could as well use two ReLU activations—which would make the notation more complicated.
Since we have no control of the coefficients , the difficulty is to get our bound irrespective of the choice of the coefficients . These coefficients could be of different orders of magnitude.
So, summarizing one more time: why is this “approximating by a one dimensional functional” important at all? The event represents the logic of two lines in the transformer’s “fully connected” matrix followed by ReLU. On the other hand, the event would correspond to one line in such a fully connected layer of the transformer. Hence, if it would be possible to approximate well by , then one could compress many lines in the transformers into less lines without substantial loss of quality.
The current AI revolution represents a transformation on the scale of the 19th-century Industrial Revolution. This breakthrough is driven almost entirely by Transformers—large language models based on deep neural networks, trained primarily through self-supervised learning.
Transformers contain billions of parameters and require massive datasets—billions of words—for training. At their core, they are deep neural networks with one key innovation: self-attention, introduced in the seminal 2017 paper “Attention Is All You Need,”4 which sparked the subsequent wave of advancements in the field.
However, training such models is computationally expensive, often requiring days of supercomputer time. Interestingly, sparse Transformers—models in which only a subset of parameters is active at any given time—can outperform dense ones in terms of quality. Yet, they typically involve more total parameters, making them more costly to train.
Several approaches have been proposed to mitigate this cost,1–3 such as initializing training with a dense Transformer and transitioning to a sparse model mid-way, thereby reducing computational demands.
Why sparse is higher quality was an open question until our current article. The result of this article shows that one can not compress two lines of the fully connected layer into one without information loss. It is a simple probabilistic result, which, to be understood does not require any knowledge of transformers. But it has deep implications for transformers: since if one could compress lines of the fully connected layer into strictly less lines without information loss, one would then have dense transformers, with equal performance than sparse ones.
It’s worth noting that rigorous theoretical understanding of Transformers remains limited. A few results exist on scaling laws,5,6 but much of their behavior is still empirically understood.
This article is part of an upcoming series in which we aim to rigorously establish key properties of Transformers from multiple perspectives. Next, we present a numerical example to further illustrate the dense-to-sparse paradigm.
In the next little example we are going to present, the event contains disjunctions instead of just , unlike the situation in our main Theorem 1. This is not to confuse the reader, but this setting of the current example is best for getting an understanding of how multiple layers could be approximated into a single layer and how this would lead to dense Transformers.
Hence, here the example: let be two integers. Next, consider more generally than in the rest of the paper, the event to be defined by:
Let be the indicator variable for the event , meaning that if holds, and otherwise. Let be the times matrix, with the th line consisting of ones in the entries number to .
Say and . Then, the matrix would be equal to:
In the current case, the event is given as:
Let . Note that for our binary vector , the event holds if and only if the vector
contains a two somewhere as entry. If we subtract from each entry of that vector, and delete all negative values, then this is equivalent to saying that the sum of the entries (after ReLU with bias ) must be bigger equal to .
From what we said previously, we can now express by the following formula:
where is any function so that for and for , while is a row vector of length containing only ’s. The column vector of length , containing only ’s is denoted by . Now, if we would add to the matrix a last column of ’s and to the vector a last entry equal to , then we can rewrite the equation (4) to obtain
As already mentioned in the earlier example, the part corresponds to the fully connected layer of a transformer. The original Transformer had such layers placed one after the other. The matrix which in our current toy example is times in the Transformers would be times .
Note that in our current toy example, the matrix is sparse: it contains many ’s. On the other hand, it renders the event perfectly through equation (5). Our matrix has three rows. We could try to compress it to one row. For this, we would “guess that the event holds”, when we have:
Here the new matrix , would be
and hence contain only one row. So, it would compress three rows into . But it would no longer be sparse. It would still catch the event when it occurs, but it would make errors as soon as, for example, or . In real life, the dense Transformers do exactly the same then what we show in our current example of dimension reduction. We reduce our matrix to a smaller matrix with less parameters but, which will make errors in predicting the event . In real life, there can be correlations between the inputs. Imagine, in our current toy-example, that would strongly correlate with , and that would strongly correlate with , while would strongly correlate with . Assume there would be no other strong correlations. Then, our one line (6) could still predict the event with high probability. Why? Because, due to the correlation, the errors might be rare. For example, , creates an error, because and are not part of the same index group. The index groups here would be , and . For example, would see inequality (6) satisfied, but the event not holding. Hence, a prediction error if we use (6) to predict the event . However, with the correlations as explained, that error might have a small probability because, if is highly correlated to but not to , then , has much less probability than . Hence, the correlations can reduce the probability of prediction error when compressing the transformer, but they do not eliminate these errors completely!
Main part
If the events and should be close to each other, that means that the probability should be small. However, we will have situations where by itself has polynomial small probability. Then, we need not just to be small, but small in comparison to . Hence, the condition we will impose is
for a small . This then implies
where the very last inequality above was obtained using (7). Using Bayes rule and condition (8), we find
Now, if condition (7) holds, then , which applied to (9) implies:
So, we have that for any , Condition (7) implies (8) and (11). The goal of this article is to provide a lower bound beneath which in (7) can not decrease. In other words, we show that the event can not approximate very closely. This means that a depth-2 feed-forward layer cannot be approximated well by a single layer, without incurring a loss in precision. We start with a simplified example, before our Main Theorem (1). In this simplified example, we consider one specific function, the one where all coefficients are equal to , and show how one cannot approximate well by the event . This example should already give some intuition on what the general case is:
Let be i.i.d. Bernoulli variables with . Consider the event defined as:
for some real number indexed by . Let be the event:
Then, if
and if
we find that
as . Hence, one can not approximate the event well by . (The condition (13) is there to avoid the trivial case, where you have only a “fixed” small amount of zeros in the string )
Let
The idea is simple: as long as there are more than zeros in the string , then to have all those zeros present in only one of the two strings or is highly unlikely. This is the same as the second principle of thermodynamics: for a container filled with gas (and no partition), the probability that all particles are only in one half of the space is highly unlikely. Conditional on the event or , any position of the ’s is equally likely. So, we can find an explicit lower bound for having all ’s in one string and not in the other given their total number . For this, we place a number of ’s equal to in the positions , making sure there are not to ’s in the same spot. When you choose at random a place for the first , any position among at first is equally likely. If you want the event to hold, you need that second to be in same string as the first placed. This is roughly a probability of . Assume, without loss of generality the first two ’s you placed at random are in the string . Then the third placed at random must also be in the string in order for the event to hold. This has roughly a probability of again. The exact probability is since two positions are already occupied by the previously place ’s. As you keep filling the first string with zeros, the probability will decrease. This argument provides the following lower bound:
This is a negative exponential small bound in . As long as we can show that with the event holding, typically the number of zeros defined by:
is not too small, we have that is exponentially small rather than close to , which would prove our theorem. Then by law of total probability and using the bound (14), we find for any that:
Using the bound (2.8), and assuming , (hence , we find:
which together with (2.89) yields:
With the help of the Central Limit Theorem (CLT), we find:
With the help of the CLT, we find
for large enough . Same thing holds for , hence for we find:
If the constant used in the definition of satisfies:
This almost finishes the proof since, when (2.11) holds, we have that
where the right side goes to infinity due to condition (2.7). This implies that under we have more than 0’s, which leads to going to when be- cause of our thermodynamical argument. Let us now see this in a slightly more precise way: Take to be defined:
Now, is a binomial with parameters and , so that the expectation is:
which for large enough k is bigger than (thanks to (2.7)). For a binomial variable, when one moves away from the expected value, the probabilities decrease, hence:
where the last bound on the right side of the equation above goes to as because of (2.7). Together with (2.13), this implies
The last limit above together with (2.10) and the fact that goes to (again due to (2.7)) imply
and finishes this proof.
Next, we aim to prove the same result as stated in the lemma above, but for a general linear functional of the form given in (20). In the earlier lemma, we considered the special case where all coefficients satisfy . We now remove this restriction and allow arbitrary coefficients . This generalization is the content of our main result, Theorem (1), where we show that the event cannot be closely approximated by the event defined in (21). The event is characterized by a linear functional exceeding a given threshold. The quality of this approximation can be measured by the smallest satisfying condition (7). This minimal represents the relative approximation error. Theorem 1 establishes a lower bound on , as stated in (23). Notably, this bound includes a term minus which corresponds to the probability of the event . Therefore, the lower bound in (23) is only meaningful when is sufficiently small—otherwise, the bound could become negative. In the context of our intended Transformer application, this condition is indeed satisfied. With the transformer application we had in mind, the event represents the occurrence of a specific word at a specific position in the text—an event whose probability is typically quite small.
For example:
The most likely guess for the masked word is Happy, so we define the event
In general, the probability of a specific word appearing at a given position in a text is relatively small. Therefore, we can safely assume that
(If we consider intermediate layers of a Transformer rather than the final output layer, the prediction pertains not to a word itself but to a feature of the representation at that stage. However, a similar argument still applies.)
Let . The lower bound given in (23) includes negative terms of order , as well as additional negative contributions captured by the expression in (24). These latter terms tend to zero as increases. Thus, for the bound in (23) to be effective, both and must grow. If or remain small our bound does not work. This implies that the number of zeros in the binary string must also grow. However, this growth can be quite slow and still suffice for our result to hold. For instance, if the expected number of zeros is only , while the rest of the string consists of ones, the bound still yields meaningful results.
In other words, our bound applies across a wide range of scenarios. We may even allow the probability to vary with writing . In particular, it ensures that cannot remain below by more than an infinitesimal amount, while and grow to infinity.
Empirically, this phenomenon already appears for fairly moderate values of . (See the “Simulations” section.)
Assume and let . Let be any real numbers and let
Let be the event:
and let be the event defined:
Let . Then, inequality
implies
where is defined by:
(Note that inequality (22) when is small, shows that approximates closely. We could view as the size of the relative error of approximating by . Hence, inequality (23) yields a lower bound on the approximation error as grows and assuming that also goes to infinity at the same time. This means that we can not approximate the event very closely by using only one functional followed by Heaviside function).
Let be the event
and let be the event
Let be the event that among the first bits, there are exactly equal to , hence
similarly, we define the event :
So, similarly to our previous notation, we put:
and
Now, we want to show that Condition (7) can not hold for small. We do the proof by contradiction. So, let us assume on the contrary that (7) holds for close to . We have shown, that (7) implies (8). But, (8) means that:
So, let us first outline the main idea of the proof: clearly (25) implies that when holds, then also holds with high probability and the same is true when holds. Now, conditional on , we have that is equal to:
Hence,
But, when we go over to conditioning on instead of , then the event is likely to no longer hold. This would imply that should hold with high probability. (Hence suddenly becomes likely smaller than instead of larger.) But going from conditioning on to conditioning on , all we did is turn one bit from the first into . Hence, we subtract a random quantity from the variable (26), where is defined by
So,
Let us calculate the expectation:
and the standard deviation of the variable (26) is:
Now, assume that the CLT applies to the variable (26). (For our proof below, we do not make this assumption. This assumption of CLT holding is only used for our heuristic argument, and we believe it might more or less hold in many cases with real-life data). Then, we get that the variable (26) is approximately a normal with expectation
and standard deviation , given in (30). That would be to say that “approximately “ (27) can be rewritten as:
But, conditioning on , we obtain that
must hold with high probability according to (28) This reversal of likely inequality going from (31) to (32) is not possible if is typically a much smaller order than ! Now, typically (30) is much larger than (29), except in situations where, for example, all the first coefficients are large and the subsequent coefficients are close to . But in that case, we could do the same argument using and instead of and . Let us be more precise. By Jensen’s inequality we have
Hence, the expression is an order larger than the left most side of (33). The two expressions (29) and (30) above are defined each for different sets of indexes. One is for and the other for . So, a priori (33) does not directly apply. However, when instead of , we take the maximum
then, (33) with that replacement holds. Let us now show the formal proof. One of the difficulties will be that we can not assume normal approximation for the variable (26) since the coefficients for may all be of different orders and we don’t want to impose any restriction there. So, again, we assume Condition (7) to hold, which is to say that
Conditional on , we have that is equal to the variable (26), so that (41) implies
Now, recall that is the event
Hence, when holds, then does not hold. Hence
where again . By Condition (7), we have and hence with the help of (43), we find:
and hence
Dividing the last inequality above by , we find:
Here, for the very last equation above, we used that is -times larger than and each. Now, Conditional on , the variable is equal to the variable (26) minus , where is the random variable which can take any of the values with equal probability . Hence, we obtain from (44), that
Where we take to be i.i.d. binary random variable independent of the sequence , but having same probability distribution. Now, we multiply the inequality inside the probability above by and obtain
so that
The last inequality above, together with (42) imply
Now let be a random variable which takes on values from the set with equal probability . Then, a similar argument but using and instead of and leads to an equation similar to equation (45), given as follows:
which typically is much bigger than , hence making the inequality (47) very unlikely to hold. Indeed, if that variable has much bigger standard deviation than the typical order of magnitude of , and since that variable is symmetric around the origin, than we would expect that the probability of (47) to be about and not close to ! (Again, we look at the case where is large and hence is small. So, then if additionally would be small, then the expression on the right side of (47) would be close to . That contradiction is what our proof that can not be too small is based on.) Now, to prove this formally, there is still some work, since a random variable could theoretically have most of its mass close to , and only a very small mass very far away, creating a large standard deviation…. We can not assume CLT to apply to the sum inside the probability on left side or (47). Otherwise, we would be done with our proof for lower bound for . Indeed, if the CLT would hold, then the probability on the left side of (47) would be about , which would then turn (47) into a lower bound for . Sadly enough, however, since the coefficients might be of many different orders, we can not assume the CLT to hold! Now, we have to consider the possibility that among the coefficients , there should be many ’s.
First case: there are more than of the coefficients equal to 0.
Let be the integer subset for which the coefficients are :
Let be the event that either all ’s with are or all coefficient with index contained in . Hence,
For to hold, we have that needs to be satisfied, and hence
leading to
But, since is only involved with the ’s for which , we have that is independent of , and hence:
We assume here that there are at least of coefficients with , for which . That means in each integer interval and there are at least indices for which . Again, is the probability to have a one: . Due to independence, the event that for all in , with , we have , has a probability less than . The same is true for the event to have for all for which . Hence,
Using the very last inequality above together with (11) implies
We are now ready to look at second case:
Second case: here we assume that at least of the coefficients are non-zero. To start with, let us define:
to be the number of indexes in for which . Hence
and let
Note that both and are Binomial variables with parameters and . Let . Again, this is a Binomial variable with parameters and .
So, we are going to “simulate” for which coefficients in , we have and for which we have . This representation will be very useful for our proof. Let us first give an example:
Let . Let us define the random variables as follows: . The variable are i.i.d. and
We consider the string . We are first going to flip a coin to determine which of the ’s are such that . When , this means that either or . In that case, we write , where is the set . The coin is not fair, but has a side with a written on it and the other side with . (Because, when is not in then it is equal to . So, after a simulation, here is what we obtained:
At this stage of the “simulation” of , we have already determined which ’s are equal to . But among those which are not , we have not yet determined which among the ’s in the above string correspond to and which ones correspond to . Note that according to our notation, the total number of ’s is equal to , in the present simulation given in (51), we find . Next, we are going to determine which of the ’s satisfying are such that and for which of those we have . It is easy to see that given (51), the ’s for which , have equal probability to be or independently of each other. This is to say, that conditional on the total number of ’s in being equal to , the number of ’s is binomial:
In other words, we can flip a fair coin to determine which of the are and which are . For large , we will have about which are and which are , this assuming:
Instead of flipping a fair coin independently to determine the and the ’s for every index , we will pick two sets and of same size among the indices for which . In the case of our current numeric example, (51), the set of indices with are . We pick in that set with equal probability among all subsets of size , a subset : We obtained: Then, Now, we flip a coin to determine which of the subsets or will host the ’s and which will have the ’s. (That is, we have a variable so that if , then gets the ’s and if we fill with ’s. ) In our simulation, we obtained , so that we put for the s with indices in and for indices in . This would lead to a simulated :
The above binary vector is only an intermediate “simulation” and not yet the final . To get the final we are going to modify the above one given in (53). The reason is that In (53), we have that same number of as we have ’s, so that . In general, that difference has a small probability to be , so the simulation so far given in (53) does not yet have the same probability distribution as the true . What we will do to get the exact distribution is to simulate the difference given the already simulated . That means we simulate the difference in size between the sets and . Note that, conditional on (52), we have is a binomial variable with parameters and . Note that when condition (52) holds, then and hence . The absolute value of the difference in size of the sets and can be written as:
and hence we can simulate the left side of (54) conditional on (52), by simulating a Binomial variable with parameters and and then taking for the simulated value of (54), the value: . So, in our numeric example (51), we had . We simulated (54) given condition (52) and obtained that the difference in size between the sets and should be . This means that we need to remove two elements from one of the sets or and add it to the other set in order to obtain a difference in size of . We flip first a coin to determine in which of the two sets or we remove the set of two points, and which of these sets the two points get added to. The set of size in our example, will be denoted by . The coin is represented by a Bernoulli variable , which is independent of anything else, and so that . When , we remove two elements from (meaning ) and otherwise from . Assume we flip the coin and get . Then that means that we pick to be a subset of . We pick among all subsets of size two from . In our current numeric simulation, we would found . Hence, from (53), we are going to change the sign of and leading to
After this final step, we get in (55) a binary string with the desired distribution of . If you compare (53) with the final result (55), we see that the only change happened by changing the sign of the ’s with index in . This version of given in (55), is our final version representing the simulation of
Why do we need this representation of our data using the sets , and ? The answer is as follows: we want to lower bound to show that we can not approximate the event very closely by , (check definition of and and in the statement of this current Theorem.) Now, such a lower bound is based on inequality (47) and noticing that when is not very small, typically the standard deviation given in (48)i is a bigger order than . Recall that and are two of the numbers chosen at random. So, if the CLT would apply for the sum inside the probability in (47), then the probability on the left of (47) would be about . (Again assuming that is of smaller order than the standard deviation (48). Hence, you would get a bound close to for the probability in (47), which then translates into a lower bound for . Now the problem is that we can not be sure that the CLT applies. First, because for CLT you can not have a few terms among which are larger than the sum of all the others. But there is no guarantee for that. Second, we want a bound which is true for all sequences and not just one specific, which means we could not use the regular CLT, but would need a uniform one. So instead of CLT, we use our simulation-representation” of . Meaning, it is going to be the fluctuation of , which will be used instead of CLT. So, in other words, in order to lower bound we need a lower bound on the following probability:
So instead of taking right away the sum:
we are first going to take our simulation (53), which is not yet the final version. With this stage of simulation replacing the final in the right side of 112 by (53), we get the expression:
when we then go over to using the “final version” of as given in 55. We have to subtract the term:
This then leads to formula (61) below. Now, by symmetry expression (58), has a probability to be less or equal to of at least . Same thing for expression59. But when both these expressions are strictly negative, we only need (59) to be strictly larger in absolute value than for the inequality inside the probability (56) to hold. In other words, the probability (56) shouldn’t be much less than following this argument. And this in terms, allows to get the lower bound (77) on . Of course, we also need to show that with high probability is strictly less than . For this, we assume without loss of generality that all coefficients are non-negative. Now, has typically a size of order . so, when you pick at random terms from a set of positive numbers to build a some, than that is usually bigger than when you pick only two at random! (Provided .) For the proof, see Lemma (5) below.
Let us give the precise definition of our “simulation” representation of , hence of :
Simulate a Binomial variable with parameters and to get . (That is the number of indexes for which ) Say you obtain the number . (We assume the number to be even to simplify notations).
Choose a random set of the integer interval with size with size . This will be the set of indexes for which .
Select with equal probability a subset of of size among all subsets of that size. Let be the complement in : . One of the subsets will roughly correspond to the indexes with , and the other will correspond to the indexes with . Why do we say roughly? Because both sets and have equal size at this stage of the simulation and at next stage we will correct that to not make them exactly equal.
Next, we flip a fair coin to decide which of the two set or will have the ’s and which will have the ’s. Hence, for which we will have and which will correspond to . So:
and hence we can already approximate the sum:
This is only an approximation because the sets and in our simulation have exactly the same size and this is going to be corrected later on.
Since and have exactly the same size, we need to correct the approximation formula (60) for that. So, we are going to choose a random set in or in in the next for which we will change the sign on that set. This will be done in the next bullet point. But here we first need to decide if we want to reduce or . For this, we flip a fair coin , so that
If , then , while if , then .
At this stage, we simulate the size of the subset with distribution given the sum be . Hence, we draw from the conditional Law:
to obtain the number .
We now choose the random set : if , then we choose with equal probability from all subsets of with size . If, on the contrary, , then we choose from all subsets of of size . This then defines the simulated random set . We can now correct the approximation formula (60), into an exact formula:
We are now ready to show the detail of what we already outlined, that is, the obtaining of our lower bound (77) for :
We can assume that without lack of generality. So, that is what we do from here on. Note that when in the expression on the right of (61), the first sum is less or equal to and the sum strictly exceeds , while , then the expression on the left of (61) plus is strictly below :
which implies
Note that are independent of each other. So, when conditioning on , we find:
Note that , simply means that . So, once is determined, the probability that be equal to is , and hence:
where for and when . Now, the condition
simply means that the random set is chosen from one of the two sets or with index for which the sum
is less. Let and be two random sets of same size equal to the size of that is equal to . We chose both sets independently of each other with equal probability among all subsets of size within their respective . Hence, is in and in , hence:
We also take that one of these two sets equals the set . (In other words, in terms of simulation, we can assume having determined the sets and and the size of first, then picking a random set in each and , namely the two sets and . Then a coin is flipped to obtain a value for which will determine which of the two or becomes ) Let , be among the two random sets and the one for which the sum (67) is smaller. In other words, is under the condition (66). We thus have:
Note that when is less than for both , then the same thing holds for when the sum is taken for ranges over . Hence, we get
Now, for any two events and we have that and hence:
where for the very last equation above we used that there is no difference from the distribution point of view between the sets , , or .
We can combine (62), (63), (64), (65), (68), (69), (70), (71) to obtain:
Now, let be the event that at least three of the coefficients in the set
are bigger or equal to . Let be the event that at least one coefficient of the set (74) is non-zero. Then clearly when and both hold, then is strictly less than so that:
and hence
Now, let and to random coefficients selected with equal probability form the biggest terms in the set (74) independently of each other. Then, is stochastically less than . This implies that
where designates the event that at least three terms from the random set (74) are larger or equal to Hence, we get
The last inequality above combined with (73) implies:
This last inequality above combined with (47), implies
We will assume that is relatively small. So, the last inequality above bounds , away from as soon as we get good bounds on and . Now, is the event that there is at least on non-zero element in the random set . For this event to hold with high probability, the set needs to contain sufficiently many elements. Same thing for the event , which also depends on the set being sufficiently large. Recall that the size of is obtained by flipping a fair coin times, and then counting the difference between the number of heads and the number of tails. So, for to be large enough, we need in the first place to be sufficiently large. This is the content of the next event. For this let . Let
Recall that is a Binomial variable with parameters and . So according to Lemma 2, with taken equal to , we find
Let be the event bounding the number of elements in the random set as follows:
When, holds, then has high probability according to Lemma 3:
Finally, when holds, then the set as at least elements. Recall that here we assumed at least of the coefficients for to be non-zero. So, for them to be all zero at the same time would have a probability of to the power size of the set . This implies that:
According to Lemma 5:
Now, clearly
To bound the right side of (82), we use (78), (79), (80) and (81), which leads to
Note that the bound on the right side of the last inequality above, that is goes to as goes to infinity…. We can now plug the bound (83), into (77), to finally obtain the desired result:
Let . Let be i.i.d. Bernoulli variables so that
Then, for all , we have:
Let be such that
We have leading to
where to obtain the very last inequality above we used (85). We have
where to obtain the very last inequality above we used the fact that the map
is increasing. Indeed,
Hence, on the interval we have that is maximal for . This allowed as to obtain inequality (89), by replacing by in (88). Now, note that
is the probability that a Binomial Variable with parameters and be less than . Hence, being a probability, expression (90) is less or equal to . Hence, in (89), we can replace (90) by and get the following upper bound:
Applying this to the right side of (91) and taking the logarithm, we find
The last inequality above, together with the fact that implies finally:
Now, since we assumed that , we have that which, when applied to (92), finally yields:
Assume that are two natural numbers so that . Then,
Next note that conditional on , we have that is a binomial variable with parameters and and same thing for . To understand why, consider the definition of and : we had is the number of indices for which and similarly is the number of indices for which . We could first determine (simulate), which of the indices are such that are or : that would yield the number . Then every index for which is given, has a probability of to have (conditional probability given ) and the same thing for . Now the probability to have or is
we designate that probability by . So, is the number of indexes for which holds. Conditional on the difference behaves like the position of a symmetric random walk after steps:
where are i.i.d. variable with
The probabilities of decreases as one moves away from (because binomial varialbw probability decreases when moving away from expectation), so that:
We can apply that last inequality above with (93) and (94), to obtain
Noting that the bound on the right side of the very last inequality above decreases in , we find:
which finishes this proof!
For any integer , Assume we chose in the integer interval a subset of size at random, with equal probability among all subsets of that size. Then, we chose independently two additional integer points and from the interval , with equal probability among all the points. (The random variables and are independent of each other and of the set ). Let be the event that there are at least three points of , which are larger or equal to . Then,
For , let be the event that exactly of the two points are the integer set . Given that holds, so both and are in , we have that can be any of the points in . In other words, once we have determined the set , then which of these points is and which is is obtained by choosing at random with equal probability among the points of . So, when holds, for the event to hold, we simply need none of the points and to be equal to the two biggest points of the set . This has a probability: , so that we find
Assume next, that exactly one of the points is in the set , so that the event holds. Then we can consider the set
which has size , when holds. Having determined, that set (98), any two points are equally likely to be the points and . Hence to get to hold, we need the two points not be equal to the two biggest points of that set with size , hence
Finally, when holds, then the set given in (98) has size leading to the inequality
We can now use the Law of Total Probability together with the inequalities (97), (99) and (100),to find:
Hence,
which finishes this proof.
Let be the event that there are at least three points of , which are larger or equal to . Then, we have
Let us divide the integer interval into two subsets and of equal size each. Furthermore, this partition of into and is done to separate the larger coefficients from the smaller ones. More precisely,, we assume that for all if and , then
Recall, that the points and are chosen at random from the set .
Let be the event that among the points of the random sets at least are in the interval . Note that
hence
Now, when holds, then at least of the points of are in . So, when holds, that means that there are at least points of the random set in the interval . In that case, the event happens every time there are least of these points which are larger than . This corresponds to the event with . (Note the event was defined for a random subset of size from , but the same probability must hold when we have the same problem for a random subset from the integer interval and size ] ). Hence, we get the bound:
The event on the right side of the inequality above can be bounded thanks to the previous Lemma, so that
Now, the probability of a random integer points chosen at random in the interval to be within the interval is . So, by large deviation to have only of the random points of in instead of about is exponentially negatively small in the size of . To get a bound, consider:
Let be i.i.d. Bernoulli variable with
Now, we want to bound the probability to get of ’s, instead of :
Now, the expression:
is the probability that a binomial variable with parameters and takes on the value . Hence, it is less than or equal to . Together with equation (105), this implies
Now, the number
so that the right side of (106) is bounded by yielding:
(One should note that we showed the bound 106 for the probability to be exactly equal to rather than less or equal to . However, the same bound also holds for less or equal to , and the proof is very similar using the same technique as in the proof of Lemma (2) So, together inequalities (101), (102), (103) and (104) imply
Simulations
In this article, we investigate how tightly we can bound the probability of the symmetric difference between the events and . Specifically, we aim to determine how small the constant can be in the inequality
The main results of this article is presented in Theorem 1 is a lower bound for such satisfying (109). Note that the expression on the left side of (109) is equal to the expected sum of squared differences between the corresponding indicator functions:
Here, the indicator function is equal to when the event holds, and otherwise. Similarly, when holds, and otherwise. In the context of this paper, the event is given, but for :
we try to determine coefficients so as to approximate as closely as possible. When we try to approximate as closely as possible with , we are dealing with the Perceptron algorithm with one Neuron. The original Perceptron algorithm is only guaranteed to work when the data is linearly separable, which is not the case here. Gradient descent would not work here, since the Heaviside function in
is not continuous at . (Here for and for ). For our simulations, instead of Heaviside, we will use the Sigmoid function:
which takes values between and . Henceforth, instead of approximating by (110), we approximate it by
The closest approximation possible in terms of expected Sum of Squared Error is a lower bound to the expected Sum of Squared error of the approximation with . The reason is that the Heaviside function can be approximated arbitrarily closely by the Sigmoid function:
for all .
The surprising discovery we made in our simulations, is that for relatively small , like and not exceedingly small , we seem to not be able to go much below for the Sum of squared error, rather than our theoretical bound which is asymptotically about . Again, our result is asymptotic, for converging to infinity and assuming . However, in the table below we see that gradient descent can not find a solution much below in most cases, even for values of which are not very small and which is not very large! Also, we had no doubt that the result would hold for large k, since the Central Limit Theorem would apply in that case. But, in applications like a chat-bot, the implications often contain between and arguments. We see in the simulations below that our lower bound already applies with that order of magnitude. This implies that the current result also applies to real-life applications. Let us see our numeric results for Sum of Squared Error for approximating with the Sigmoid given in (111). Hence, the following table contains the value
The table is for different values of and :
When we now calculate the ration from the table above, we get a lower bound for satisfying (109) and depending on and :
Our theoretical bound is , but in the last table above we are mostly close to . This would correspond to our heuristic argument given at the beginning of the proof of Theorem 1, which used as assumption the holding of the CLT, which may not always be the case. Seeing the values in the last table above, we believe that the heuristic argument presented at the beginning of the proof of Theorem 1, which implied a lower bound approximately equal to , seems to apply quite well for practical situations.
Footnotes
ORCID iD
Heinrich Matzinger
Funding
The authors received no financial support for the research, authorship and/or publication of this article.
SharmaUKaplanJ. Scaling laws from the data manifold dimension. J Mach Learn Res2022; 23(1): 343–376.
6.
GordonMADuhKKaplanJ. Data and parameter scaling laws for neural machine translation. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. pp. 5915–5922.