
Abstract
This article investigates the roles that interactive alignment of manual gesture, postural sway, and eye-gaze play in small groups engaged in collaborative remembering. Qualitative analyses of a video corpus demonstrate that the coordination of these behaviors may contribute to joint remembering in various ways, depending upon the cognitive and communicative affordances of these behaviors. The observation that these behaviors are different in their nature and their contributory potential to shared remembering is corroborated by the results of a quantitative analysis, which suggests that co-speech gesture, postural sway, and eye-gaze have different interactional dynamics. This supports the conclusion that in order to understand the role of multimodal alignment in the discourse of shared remembering, co-verbal behavior should not be treated as a homogeneous category. Finally, we discuss the potential of combined qualitative–quantitative approaches to inform the interplay of verbal and bodily coordination during interactive memory construction.
Introduction
Discourses that form practices of remembering always emerge from experience in situated communicative interactions (Bietti, 2010, 2012, 2014; Edwards and Middleton, 1986; Hayashi, 2012; Lynch and Bogen, 2005; Middleton and Brown, 2005; Middleton and Edwards, 1990; Woffit, 2005). Brown et al. (2001) argued that memory “is something that speakers perform, rather than a simple process in the course of routine interaction” (p. 125). In other words, remembering in real-life settings is a situated activity or resource that serves to achieve specific goals, not merely instantiations of a storage device or archive located in people’s brains.
This proposal has given rise to an assembly of studies, in several disciplines, on how practices of memory-making unfold on a social and collective basis. Discursive psychologists and conversation analysts have conducted research on the interactional organization of remembering in terms of sequential organization, co-option, and pragmatics (Middleton and Brown, 2005: 99). The results of such research led some to conclude that remembering and forgetting can be considered as interactional practices grounded in and bounded to the communicative actions produced by the participants engaged in social interaction and dependent on the dynamics of everyday situations (e.g. Hayashi, 2012). These studies are undoubtedly endowed with high ecological validity, not only because they were conducted in real-world settings (Woffit, 2005: 220), but also, and fundamentally, due to the fact that they indicate the everyday function and uses of remembering when people are intending to achieve interactional goals.
In cognitive psychology, research on collective remembering follows rather different practices. A major focus in this research is the way different cognitive, linguistic, and interactive phenomena influence processes of collective memories as they are formed, shared, and consolidated during conversations (Hirst and Echterhoff, 2012). An important underlying presumption in this work is that the unreliability and malleability of human memory (unlike computer memory) “creates the opportunity for speakers to reshape both listeners’ memories and their own” (Hirst and Echterhoff, 2008: 209).
Other experimental research in socially distributed remembering in cognitive psychology (Harris et al., 2011, 2014) supports the view that collaboration between members of dyads may help facilitate recall. These studies have been largely based on research programs in transactive memory in cognitive psychology (Wegner, 1986), philosophical psychology (Theiner, 2013), organizational and communication sciences (e.g. Hollingshead, 1998), as well as the learning sciences (Jackson and Moreland, 2009; for a review see Ren and Argote, 2011). A common tenet of these studies is that the constitution of transactive memory systems relies on interactants’ ability to develop an implicit distribution of cognitive labor, whereby each group member assumes responsibility for learning information within his or her own domain of expertise. Each group member also expects others to learn information about other relevant domains and assume accountability for that. Ethnographic studies in cognitive science (Bietti, 2012; Dahlbäck et al., 2013) and computer science (Wu et al., 2008), conducted in naturalistic settings where people are engaged in situated activities, have further emphasized the importance of situational context in shaping the ways people interactively construct and communicate their memories.
Despite the fact that most of these researchers maintain the view that remembering is an embodied and situated practice, which forms part of real-world activities, the studies mentioned in this section have not accounted for, in detail, the central role that embodied resources (e.g. manual gesture, body posture, and eye-gaze) play in conversational remembering. We believe that this methodological limitation is related to the fact that most of their analyses are based on talk-in-interaction and only use audio data. In other words, apart from a few studies (Goodwin, 1987), investigations on the interactional dynamics of remembering in groups have based their findings merely on the systematic analysis of verbal behavior, leaving the entire multimodal dimension of joint and collaborative remembering aside. A better understanding of the multimodal nature of joint and collaborative remembering activities in natural settings, therefore, is crucial if we agree with Kendon’s (1986) point regarding the key role that gesticulation plays in everyday communication:
I believe gesticulation arises as an integral part of an individual’s communicative effort and that, furthermore, it has a direct role to play in this process. Gesticulation is often an important component of the utterance unit produced, in the sense that the utterance unit cannot be fully comprehended unless its gestural component is taken into consideration. In many instances it can be shown that the gesticulatory component has a complementary relationship to what is encoded in words, so that the full significance of the utterance can only be grasped if both words and gesture are taken into account. (p. 12, emphasis in original)
In accordance with Kendon, we believe that the unimodal (i.e. verbal only) approaches discussed in this section have at least two shortcomings: Not only have co-verbal behaviors such as manual gesture and body posture been shown to be relevant to the retrieval of memories by individuals (e.g. Goldin-Meadow et al., 2001), but the alignment of co-verbal resources among participants has also been shown to be fundamental to various facets of joint action in general (e.g. Richardson et al., 2007). In this article, we address the relation between alignment of multimodal communicative resources and collaborative remembering, aiming to bridge this gap to some degree. After providing a brief literature review on the study of alignment in conversation, we report on qualitative and quantitative analyses of a multimodal data set in order to characterize how interactive alignment of manual gesture, postural sway, and eye-gaze contribute to collaborative remembering.
Multimodal alignment
Individuals engaged in social interactions often align their communicative resources in order to achieve shared goals. That is, they copy each other’s verbal and co-verbal behaviors both simultaneously and sequentially. For example, alignment may be manifested in the repetition of lexical items or syntactic constructions across interlocutors’ utterances (Allen et al., 2011; Du Bois, 2010; Pickering and Garrod, 2004), or in copying of features of other’s spoken signals such as intensity, pitch, and voice quality (e.g. Levitan and Hirschberg, 2011).
Converging evidence, moreover, reveals that patterns of alignment occur in a range of co-verbal behaviors. De Fornel (1992), for instance, observes speakers’ reciprocal use of each other’s iconic manual gestures in particular interactional contexts. Bergman and Kopp (2012) report that speakers in natural dialogue tend to mimic particular form features of each other’s co-speech gestures—a finding that has also been obtained in experimental studies (Kimbara, 2006; Mol et al., 2012). Shockley and colleagues (Schockley et al., 2007), in a similar vein, have demonstrated a direct link between stress patterns of the words spoken by members of dyads and the way they coordinate their postural sway during conversational interactions. A study on gaze (Richardson et al., 2007), additionally, reported tight coupling of eye-gaze during conversational interaction. As their experimental subjects discussed a work of art, their eye-movements became distinctly synchronized in time (note that this is different from the phenomenon of alternating eye-gaze in relation to turn-taking in conversation discussed in Goodwin (1981)). Louwerse and his collaborators (Louwerse et al., 2012) showed that people align different behavioral channels in a synchronized fashion, suggesting that different behavioral resources constitute a holistic web of mutual inter-animations.
Various explanations for these observations have been proposed. Pickering and Garrod’s (2004) “mechanistic theory of dialogue” suggests that interactive alignment smoothens communication by enhancing accessibility of lexical and syntactic resources. Thus, alignment is argued to reinforce the “implicit common ground” between speakers, to facilitate the co-construction of shared situation models (Pickering and Garrod, 2004), and to allow for anticipation of upcoming utterances (Pickering and Garrod, 2009). Situation models (Van Dijk, 2014; Van Dijk and Kintsch, 1983; Zwaan and Madden, 2004; Zwaan and Radvansky, 1998) have a marked semantic nature because they enable us to construct and represent meanings from what is expressed, conveyed, and perceived by sounds (and music), writing, visual images, eye-gaze, hand-pointing, touch, face expressions, and other body movements as part of everyday action and experience. To avoid terminological confusion, “semantic” is used here to refer to the capacity of situation models to construct and represent meaning, not to “semantic memory.” That is, the term semantic here applies to the meaning, reference, and discourse semantics, not to socially shared knowledge organized in semantic memory.
Dale and colleagues claim that alignment is “one way of reducing the cognitive load of interlocutors, thereby condensing the complexity of the interaction” (Dale et al., 2014: 69). In any case, verbal and co-verbal alignment between interlocutors can be thought of as allowing for some level of intersubjectivity in terms of “the sharing of experiential content (e.g. feelings, perceptions, thoughts, and linguistic meanings)” (Zlatev et al., 2008: 1). This perspective has led some researchers to conduct studies on alignment in relation to transactive memory (Tollefsen et al., 2013). However, this new line of inquiry has only explored the potentialities of such new integration and has not provided new findings nor examined how instances of alignment provide the interactional architecture for collaborative remembering in dyads and small groups. In the remainder of this article, we assess some contributions of interactive alignment to the process of joint remembering, particularly focusing on three types of behaviors: co-speech gesture, postural sway, and eye-gaze. We first provide a brief characterization of the way these behaviors differ in their nature and in their affordances in communicative discourse. Then we discuss our qualitative analysis of a video corpus, illustrating how the alignment of each of these three behaviors conceivably facilitates collaborative remembering among small groups. Finally, we present results of a quantitative analysis to examine whether and how the differences in these behaviors’ roles in shared remembering are reflected in the temporal dynamics of the alignment patterns observed in our data.
Behaviors to be examined
Co-verbal behaviors like manual gesture, body posture, and eye-gaze all serve different interactional functions and are linked to speech in different ways. The following are some parameters among which they differ, based on research on Western European languages:
1. Their degree of relevance for memory retrieval by individuals.
Manual gesture while speaking is known to improve performance in simultaneous memorization tasks (Goldin-Meadow et al., 2001; Stevanoni and Salmon, 2005). Research on body posture (Dijkstra et al., 2007; Koch et al., 2014; Riskind, 1983) has found compelling evidence regarding the important role that bodily states play in encoding and retrieving episodic and autobiographical memories. Casasanto and Dijkstra (2010) have shown that the participants of their study remember more positive autobiographical memories as the result of moving marbles upward compared to what occurs when they move them downward. Their analysis has found that as the subjects move the marbles downward they begin to remember more negative experiences (Casasanto and Dijkstra, 2010: 182).
Regarding gaze, several studies (Macrae et al., 2002; Mason et al., 2004) have suggested that a person’s direct gaze (in contrast to averted gaze) toward a target enhances its subsequent memorability—of the object gazed at—and significantly improves the gazer’s recognition of it. Although it has been shown that eye-movements may affect cognitive processes, especially spatial reasoning in problem solving (Thomas and Lleras, 2007), evidence suggests that gaze-direction may not play a functional in retrieving long-term memories (Anderson et al., 2004; Micic et al., 2010).
2. The degree to which they can serve as communicative “signs.”
The extensive research on manual gestures illustrates their potential for symbolic reference, particularly for conventionalized “emblematic” gestures (Efron, 1972 [1941]), whereas the range of information conveyed symbolically by posture and gaze is much more constrained.
3. The degree to which they are obligatory.
Speech-linked gestures (McNeill, 1992) are required with certain deictic and demonstrative expressions (e.g. “I want the one over there”) but variably optional with other types of utterances. Posture and gaze, in contrast, are inherent behaviors of speakers and therefore naturally obligatory.
4. The degree to which they are automatic or controlled.
The use of manual gesture, changes of posture, and movement of eye-gaze all go in and out of speakers’ conscious awareness, but manual gesture, as a behavior taking place in front of the speaker, is one that speakers can more easily pay visual attention to and control, as opposed to the automatic saccades of the eyes, for example.
5. The degree to which they are speaker-bound, that is, whether listeners also perform these behaviors.
Given the obligatory nature of posture and gaze, these are aspects of all participants’ behaviors in interaction, whereas the rate of gesturing by the speaker is much higher than that of those listening (McNeill, 1992).
6. Their role in establishing shared attention.
Eye-gaze clearly plays a role in establishing shared attention (Kleinke, 1986) and when focused on one’s gestures it also puts them in the attentional spotlight (Müller, 2008; Streeck, 2009). Alignment of body posture in conversations has been related to shared engagement in cooperative tasks, and leaning forward, in particular, has been associated with signaling interest (Whittaker and O’Conaill, 1997).
Implications for multimodal shared remembering
Given these differences in their nature and communicative affordances, it can be expected that alignment of the behaviors examined has different roles within the activity of collaborative remembering.
Alignment of co-speech gesture may serve a wide range of functions in this respect. Deictic gesturing (e.g. hand-pointing) allows speakers to establish the focus of visual attention on sources of relevant information (in our data, the pictures; see below), thereby externally grounding their individual and shared memories. Representational gestures, on the other hand, may be deployed for aiding autobiographical memory retrieval, but can also be used communicatively, to evoke a shared conception of a particular feature of an event among interlocutors.
As for the alignment of postural sway among participants, the communicative functions are less obvious. As pointed out above, postural alignment is a largely automatic phenomenon that is more likely to play a role in the establishment of mutual engagement in the joint activity of memory co-construction than to serve a particular symbolic function.
Alignment of eye-gaze, finally, may play out in various ways. Sequential eye-gaze coordination can be deployed to regulate the distribution of interactional turns, for instance, in order to reinforce the accountability of the recipient to respond to a question or to go on with the description of the events being collaboratively recalled. Simultaneous alignment of eye-gaze, in contrast, is typically interpreted as a symptom of shared attention. Looking away from the interactional participants, furthermore, has been associated with individual semantic retrieval, as well as display of uncertainty (Goodwin, 1987).
Based on this initial characterization of the behaviors of interest and the corresponding expectations with respect to their contributions to collaborative remembering, we now report on initial qualitative and quantitative analyses of a video corpus consisting of recordings of small groups engaged in collective remembering. In doing so, we aim to provide insights into how and to what extent the different cognitive and communicative affordances of the behaviors of interest are reflected in the way these behaviors are actually employed and aligned during the interactive discourse of shared remembering.
Data
The video data used for these analyses come from an ongoing project on collaborative remembering in small groups. Two groups of four participants were recruited in Argentina. One consisted of four close friends: Tommy, Augusto, Nacho, and Santi (all male, aged 21 to 23 years). The other group consisted of family members: parents Marta and Diego (aged 63 and 57 years, respectively) and children Diegui and Dolores (32 and 30 years, respectively). Criteria for selecting these participants were that they had gone through a shared event together (e.g. vacations that they spent together as a group) and that they possessed some objects related to the event that they experienced together as groups (e.g. vacation pictures). All participants were native Spanish speakers and were paid (100 ARS (Argentine Peso) = 18 US$) for their participation in the study.
Sessions of collaborative remembering were recorded in the home of one of the members of each group, as this type of atmosphere is in accordance with the setting in which collaborative remembering with intimates naturally takes place. The focus groups were recorded with two digital video cameras placed in different corners of the room. Participants were asked to recollect memories based on the pictures they had brought along. The conversation among family members was about a trip that they had made together from Buenos Aires to Maui, Hawaii, to attend the wedding of the parents’ daughter (the sister of the other family members). The conversation among friends was about a 2-week summer vacation they had spent together at a summer resort on the coast of Argentina.
The interventions of the research assistant were minimal, the only purpose being to re-orient the conversation toward the events depicted in the pictures, for example, by formulating questions of the type “Do you remember what you did after…?” There were no time constraints for the completion of the conversation. The same procedure was applied to both groups. The overall length of the recordings was 14.54 minutes for the family and 22.08 minutes for the friends.
Qualitative analyses
The following three case studies exemplify instances where the alignment of co-speech gesture, posture, and gaze (in combination with other types of alignment) conceivably contribute to the process of shared remembering.
Gesture
In Figure 1(a), Diegui and Marta are trying to locate, in chronological time, one of the photographs that they had brought in. The interactional sequence begins with Diegui’s question and pointing gesture (0–1.5 sec; Figure 1(a)). This occurrence of a pointing gesture operates as a “directing-to action” toward the picture being discussed (i.e. an action in which “speakers try to move the addressees’ attention to the object” (Clark, 2003: 248). Figure 1(b) shows Marta and Diego performing an almost simultaneous pointing gesture at the picture that Diegui had pointed to just before. Marta’s and Diego’s pointing gesture is immediately mirrored by Diegui (3.5–4.0 sec; Figure 1(c)). By simultaneously and sequentially aligning hand-pointing, they externally ground their memories of the location where the photograph was taken, which answers Diegui’s inquiry at the beginning of the sequence (0–1.5 sec; Figure 1(a)). Subsequently (4.5–5.0 sec; Figure 1(d)), Marta flexes her right hand forward at the wrist while suggesting that the events that the particular photograph depicts occurred the third day after arrival, not the second as she had previously claimed (2.5–3.0 sec; Figure 1(d)), thereby representing the passage of time via a gestural movement in space (Calbris, 1985; Cienki, 1998).
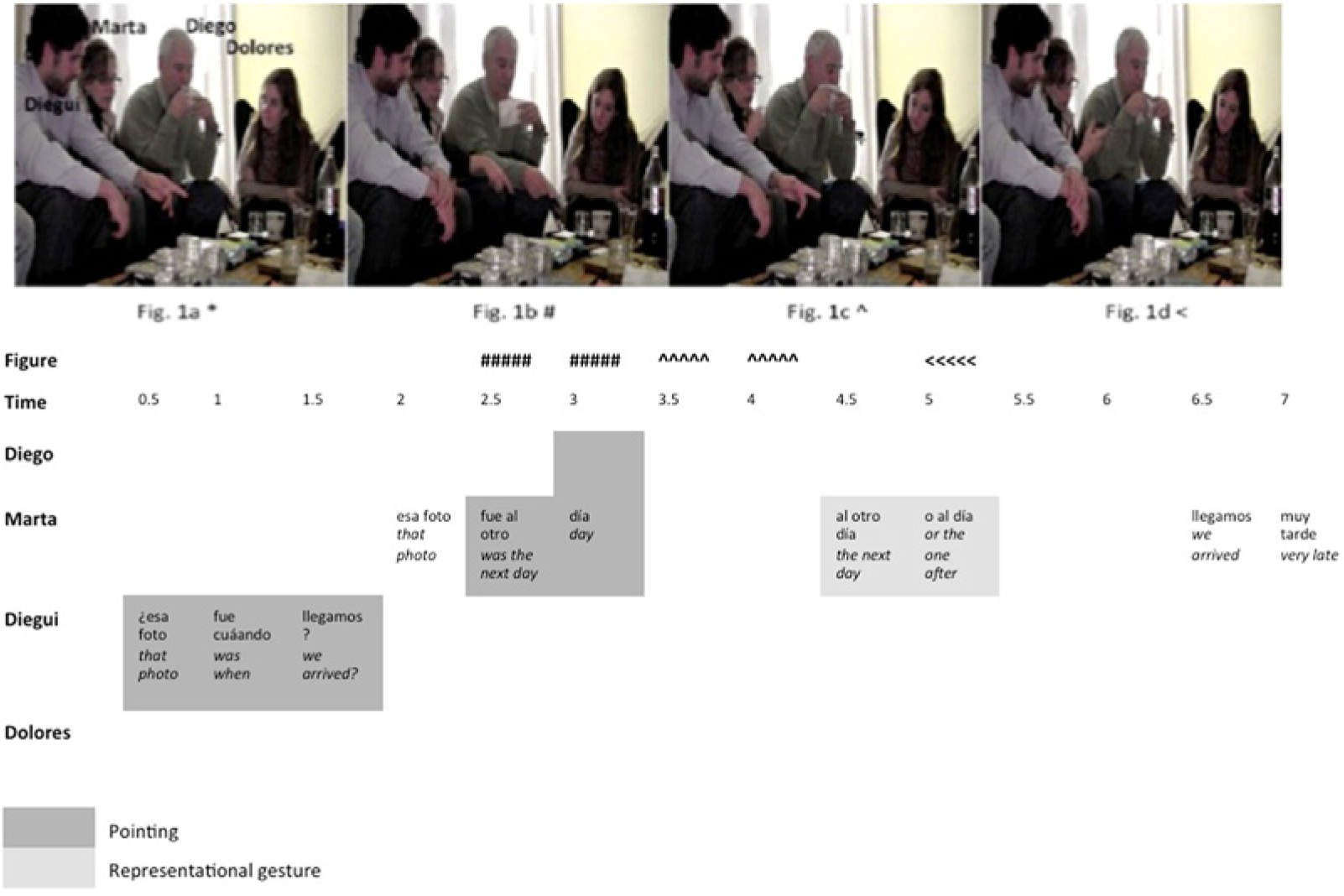
Gesture.
Diegui’s and Marta’s collaborative behavior is also supported by instances of repetition of lexical items: “foto”/picture, “esa foto”/that picture, and “otro día”/another day. As the interactional sequence in Figure 1 shows, there is a clear coordination between these cases of lexical alignment and the gestural alignment described above.
Posture
Augusto’s question at the beginning of the transcript in Figure 2(a) establishes a shared goal. The goal is to recall who was missing in the picture that they are using to remember what they were doing in that specific situation (0–1.0 sec). However, finding out which of the friends was missing in the photograph also entailed jogging their memories as to who the photographer was. Augusto reformulates his initial question in these terms some time afterward (5.0–6.0 sec), thus making clear that his goal is not only to remember who was missing, but also to recall who had taken the picture.

Posture.
Augusto’s questions (0–1.0 sec and 5.0–6.0 sec; Figure 2(c)) do not only provoke the participants to focus their visual attention on the picture but also seem to trigger the formation of similar postural behaviors while all participants try to answer the question (chin rest -lean forward, 5.0–12.0 sec; Figure 2(c)). Subsequently, when Santi answers the question of who took the picture (11.0–11.5 sec), Augusto directs his gaze to Santi (12.5 sec, Figure 2(d)). Shortly after that moment, Augusto, Tommy, and Santi lean back and all laugh simultaneously, the reason being that it was Augusto himself who had actually taken that picture.
Throughout the entire interactional sequence initiated by Augusto’s questions, the alignment of postural behaviors co-occurs with the repetition of syntactic structures and lexical items (e.g. “era de día”/it was daylight; and “quién sacó la foto”/who took the picture).
Gaze
At the beginning of the sequence portrayed in Figure 3(a), Augusto introduces a new character “Mitch” in the reconstruction of the events depicted in the picture they are looking at (1.0 sec; Figure 3(a)). After Nacho’s agreement about the presence of the new character Mitch (1.5 sec; Figure 3(b)), we observe how Augusto and Santi, while trying to recall who else was in their company, repeat lexical items (1.0–2.0 sec; Figure 3(a) and (b)), which operates to linguistically ground remembering. Interestingly, the process of lexical alignment between Augusto and Santi coincides with a change in direction of Santi’s gaze (2.0 sec; Figure 3(b)). Subsequently, Santi continues with the description and introduces a new character in the events while he still gazes at Augusto. It is at this point that Tommy changes gaze-direction toward Santi (2.5 sec). While they are looking at each other (2.5–5.0 sec, and Figure 3(c) and (d)), we can again notice the repetition of lexical items, which linguistically grounds the activity of shared remembering between Santi and Tommy. Figure 3(d) shows Augusto’s changing of gaze-direction toward Santi at the point when they verbally agree on the current description of the events (4.0–4.5 sec).

Gaze.
In each of the cases above, the activity of collaborative remembering is not just a process accomplished through the exchange of verbal utterances, but is accompanied by co-verbal resources as well. The co-verbal behaviors examined in these examples ostensibly carry out different interactional functions. Gestural alignment appeared to evoke shared attention to the relevant elements of the discourse and to enhance agreement on the salient features of the events and objects discussed; postural alignment coincided with verbal expression of mutual engagement and shared thinking about particular questions and referents; and the coordination of gaze and visual focus appeared to be primarily associated with attention consolidation and directing of others’ attention.
Quantitative analysis
Provided that co-speech gesture, postural sway, and gaze make qualitatively differential contributions to collaborative remembering, one could expect these behaviors to be coordinated in different ways among participants. In this section, we examine whether this is the case by means of quantitative analyses of the data. In particular, we explore to what degree each of these behavioral channels is aligned in simultaneous and sequential manners during the course of the interaction.
In preparation of this analysis, we annotated the video recordings by assigning binary values to a range of behavioral channels (19 in total) for every 0.5 sec interval, designating whether each of these behaviors was performed or not at that time by each of the participants. The minimal time unit of 0.5 sec was motivated by the finding that time samples of such order of magnitude are appropriate for detecting and discerning patterns of behavioral entrainment (see, for example, Bietti et al., 2013; Louwerse et al., 2012). The choice of behaviors coded emerged from the data; the researchers did not impose the categories a priori. For the current analysis, these behaviors were clustered into three categories: (1) gestural behaviors, including deictic as well as non-deictic gestures; (2) postural behaviors, including the participants’ leaning direction relative to the pictures and their arm positions relative to their bodies; 1 and (3) gaze behaviors, at the pictures or at one of the co-participants.
For each behavioral variable, we computed two types of alignment rates. Time points where two or more participants concurrently performed a given behavior were counted as instances of simultaneous alignment; time points where a behavior was initiated within 10 seconds after another participant had withdrawn that same behavior were counted as sequential alignment. This 10-second interval is motivated by the finding that behavioral mimicry happens with substantial delay (Bietti et al., 2013; Louwerse et al., 2012) but should at the same time “be characterized by latencies short enough to allow the perceptions involved to contribute to next turns or coordinating actions” (Louwerse et al., 2012: 4). Cases of cross-modal alignment (e.g. manual gesture —body posture) are not accounted for.
For all coded behaviors, we counted up instances of simultaneous and sequential alignment defined as such and compared our observations to a chance baseline. This baseline was computed via a stratified shuffling procedure: for all participants, the order of observed sequences of behaviors was shuffled 1000 times, keeping the sequences themselves preserved, to yield a distribution of virtual data. Figures 4 and 5 compare the mean alignment rates in these distributions to those our actual data accumulated over all participants. Error bars represent confidence intervals: the 95% most probable alignment rates yielded by the chance simulations.
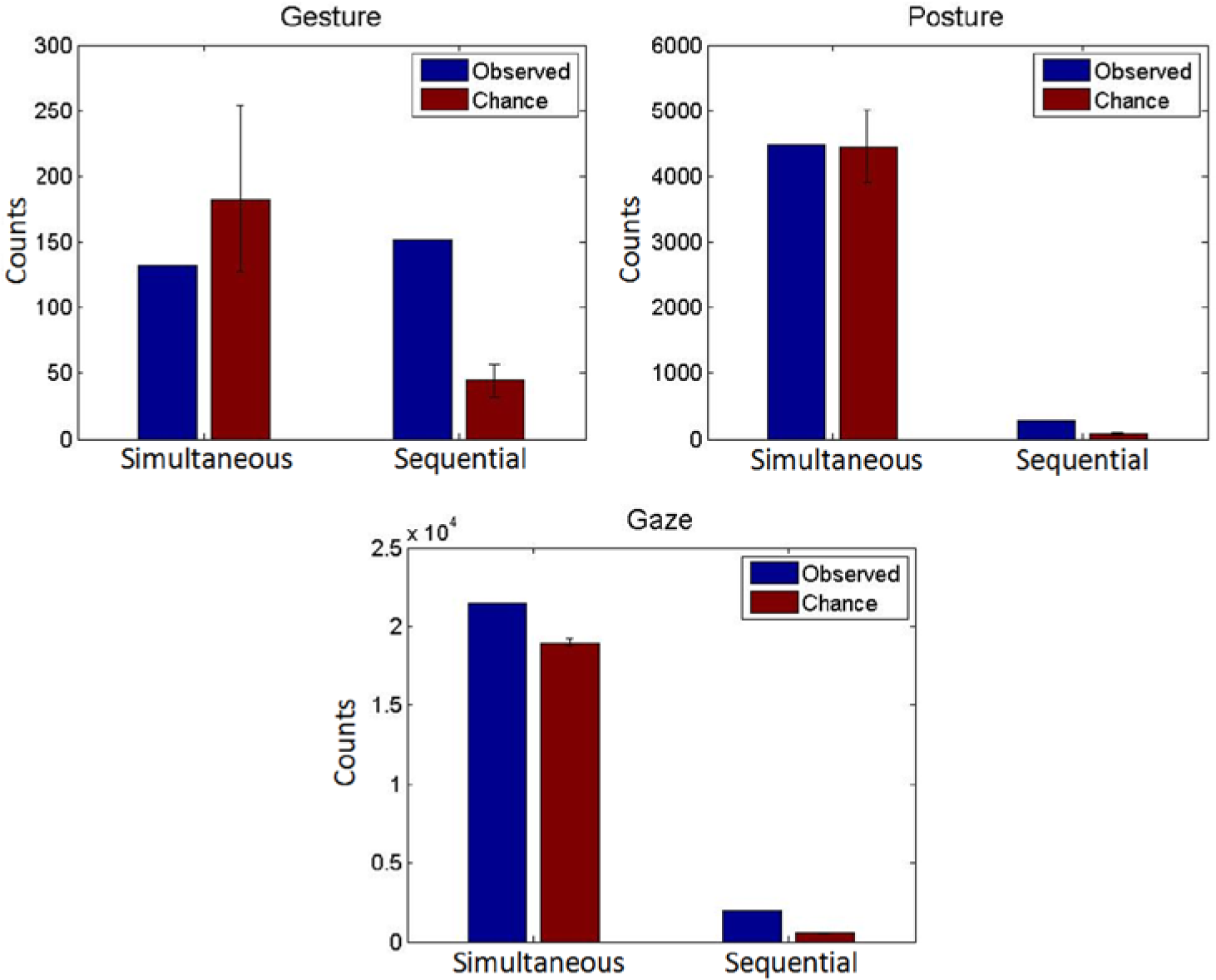
Simultaneous and sequential alignment rates in the friends’ conversation. Blue bars represent single observations (alignment rates during the entire conversation); because we do not aim to estimate population parameters, error bars are not provided here. Error bars on the red bars represent 95% confidence intervals based on 1000 chance simulations.
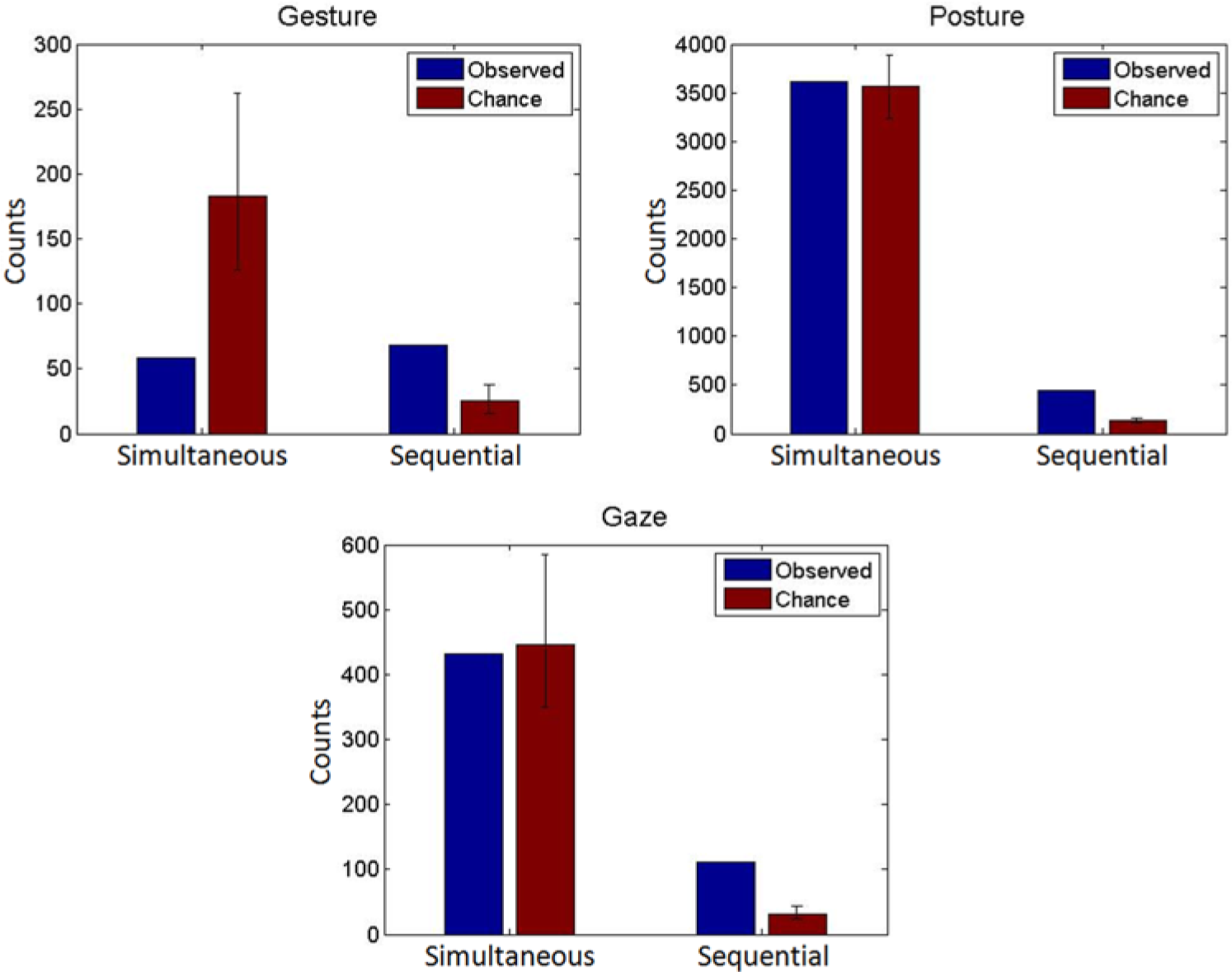
Simultaneous and sequential alignment rates in the family conversation. Blue bars represent single observations (alignment rates during the entire conversation); because we do not aim to estimate population parameters, error bars are not provided here. Error bars on the red bars represent 95% confidence intervals based on 1000 chance simulations.
Sequential alignment rates, as Figures 4 and 5 show, are significantly higher than chance for all three behavioral channels in both data sets. That is, the probability that these rates would have been observed if the behavioral sequences of the participants would have been produced in an entirely random order is very small (p < .05). Simultaneous alignment rates, however, exceed the chance baseline only in one of the two data sets (the friends) and only for one type of behavior (gaze). For gestural behaviors, simultaneous alignment is in fact observed less often than expected by chance, but this is only significant in the family data set.
Although the outcomes of this analysis are not independent of the strategies employed for data coding and the definitions of different types of alignment, we believe that these findings have important implications with respect to the role of behavioral coordination in collaborative remembering. First, these results suggest that in this context, different types of behaviors have different dynamics. This is likely to be a result, at least in part, of the differences in the defining characteristics of these behaviors and the differences in their affordances (see above).
Gestures, for instance, are tightly coupled to speech and may, therefore, be less susceptible to simultaneous alignment than, for instance, gaze. Hence, these observations strongly corroborate the claim that the “multimodal resources” involved in collaborative remembering do not constitute a homogeneous category. Different types of behaviors employed in shared remembering seem to be coordinated in different ways among participants and should, therefore, be taken into account in their own right.
A second possible implication involves being very careful in interpreting concurrent performance of a given behavior by two people as exhibiting instances of interactive coordination. As our data show, moments where two people perform the same behavior at the same time are not more frequent than what is expected on the basis of mere coincidence (except for the case of gaze in one of the two data sets). What may seem like postural mimicry, thus, might often simply be due to the fact that people are naturally obliged to position their body in one way or the other anyway and inadvertently do so in a similar fashion, rather than a result of interactive mechanisms or engagement in joint action. The same note of care in principle applies to sequential alignment, but to a lesser extent: coincidental copying of behaviors in a sequential manner is very unlikely to explain the observed frequency of this phenomenon in our data.
How does this note of care apply to interpreting examples like those presented in the “Qualitative analysis” section? Here, too, the ostensible instances of behavior copying may in theory be coincidental rather than invoked by the participants’ engagement in a joint activity. A number of further analyses can be helpful to confirm the claim that these instances of behavior matching are “real” (i.e. as emerging from the interaction) and relevant to the activity of collaborative remembering. One source of additional evidence, for example, is the consistent co-occurrence of behavior matching with patterns of lexical and syntactic alignment, as discussed in the qualitative analyses above. Further evidence may come from detailed analyses of the specific tasks participants perform while in alignment with one another (e.g. referring to particular events or asking tag questions), as to get a better idea about which aspects of the broader discourse of shared remembering may actually benefit from these means of behavioral coordination. An important next step is to closely examine the interplay of mechanisms of attention and mechanisms of communication, both of which are integral to the co-construction of shared memories but pose differential cognitive and communicative demands. That is, in order to achieve a better understanding of the role that multimodal alignment plays in the activity of collaborative remembering, it is important to tease apart the ways communicative and attentional systems exploit the multimodal resources people have at their disposal.
Conclusion
This article explores the roles that alignment of manual gesture, postural sway, and eye-gaze play in small groups engaged in collaborative remembering. A review of the literature revealed that these types of behaviors have quite different cognitive and communicative affordances. Qualitative analyses of a video corpus, in accord with this fact, demonstrated that the roles of these behaviors in joint remembering are indeed quite diverse. Whereas co-speech gesture can be relevant to a range of facets of the discourse, including symbolic reference, external grounding, and fostering of individual memory retrieval, postural and gaze seem to be involved primarily in display of mutual engagement and establishment of shared attention.
The observation that these behaviors are different in their nature and in their contributory potential to collaborative remembering was corroborated by the results of a quantitative analysis: we found that simultaneous alignment rates for co-speech gestures were below chance, and that in fact only simultaneous gaze alignment significantly exceeded the chance baseline (in one of two data sets). Thus, the three behaviors examined have different interactional dynamics and should not be treated as a homogeneous category. Furthermore, these analyses impose a note of caution on the interpretation of qualitative analyses. We argue that in order to interpret ostensible cases of behavioral mimicry as deriving from interactional mechanisms, additional evidence is needed, for instance, in the form of coinciding lexical alignment.
Based on our preliminary findings, we believe that a substantial part of the joint activity of collective remembering in small groups takes place outside the verbal domain. It is therefore fruitful for future studies on collaborative remembering in small groups to take into consideration the coordination of multimodal resources among interactants and their interplay with elements of linguistic expression. Combined qualitative–quantitative research methods akin to those described in the current article, conducted in relatively naturalistic settings, have the potential to provide more insights into the interactional dynamics of co-verbal behaviors in discourses that form practices of remembering.