
Abstract
This research paper addresses the pressing problem of financial fraud in the changing context of digital banking by integrating machine learning and explainable AI, specifically exploiting SHapley Additive exPlanations (SHAP). With a focus on enhancing both accuracy and interpretability, this study utilizes a synthetically generated dataset from the PaySim simulator, encompassing 6,362,620 records. The usefulness of an Ensemble Learning Model with a Voting Classifier is shown by its evaluation of different machine learning models, which achieves an excellent accuracy of 99.904%.Emphasizing transparency, accountability, and regulatory compliance, this work employs SHAP analysis to unveil attribute-level interpretability, providing stakeholders with clear insights. The goal of this interdisciplinary endeavor is to provide a safe space for digital finance by bridging the gap between precision and interpretability, which will aid in the creation of open methods.
Keywords
Introduction
In today's digitally-dominated world, the simplicity and efficacy of banking have changed due to the advancement of financial technology, bringing in a new era of previously unimaginable opportunities. Though there are many challenges associated with this increase in digital financial interactions, the growing threat of financial fraud is one of the most critical ones. There is an immediate a need reliable systems that can identify and stop fraudulent actions as they happen, as the Association of Certified Fraud Examiners (ACFE) reports that worldwide fraud losses have reached a concerning 5% of yearly income. 1
The sheer volume of global digital payment transactions, projected to reach US$16.62tn by 2028 (Statista), underlines the growing reliance on digital financial interactions. 2 Nevertheless, with this digital transformation comes an alarming increase in the cost of cybercrime, projected to reach US$10.5 Trillion annually by 2025. 3 The sophistication of modern fraud schemes, leveraging advanced techniques such as machine learning to evade detection, 4 poses not only a severe financial risk but also jeopardizes the trust that underpins the entire financial ecosystem.
Financial institutions face a multifaceted challenge, with an estimated $4.23 loss for every dollar lost to fraud in 2022, 5 considering both the immediate financial impact and the long-term consequences. Regulation compliance, driven by the GDPR and PSD2, necessitates accountability as well as transparency in processing of data and decisions. In response to this evolving landscape, the adoption of machine learning in financial services is growing, with 70% of financial institutions reporting its use for fraud detection as of 2020. 6
Traditional machine learning models frequently function as opaque, or “black-box,” entities, making it challenging for stakeholders to understand the logic underlying the models forecasts. Not only does a lack of transparency undermine trust, but it also creates regulatory problems in sectors where explainability is essential. According to data scientists, machine learning models can not be understood or trusted unless they are interpretable. 7 Combining machine learning with explainable AI is the focus of this study since it offers a solution to the problems of accuracy and interpretability in financial fraud detection systems.
Explainable AI becomes crucial for demystifying machine learning models’ decision-making processes, especially with SHAP (SHapley Additive exPlanations). Explainable AI is essential for fostering trust in financial institutions and guaranteeing accountability in algorithmic decision-making, and its necessity extends beyond compliance. This research combines the power of explainable AI with ensemble machine learning to create financial fraud detection models that perform well in accuracy and offer stakeholders interpretable insights. The ultimate objectives are to strengthen the barrier against financial fraud, promote trust in financial institutions, and create a safe environment for digital finance.
Literature survey
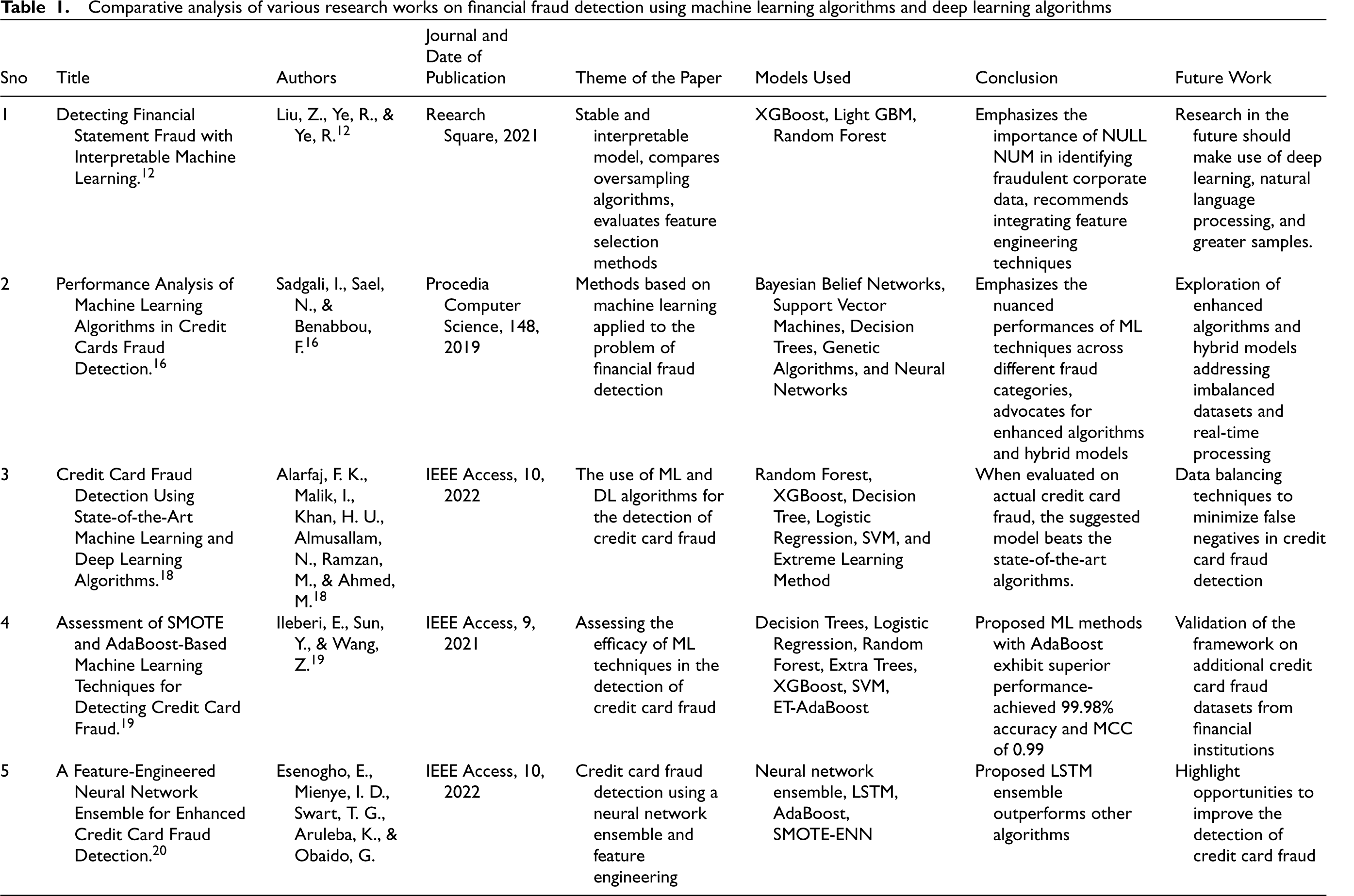
The need for robust systems to detect and prevent fraudulent activities has become paramount, leading to a shift from traditional approaches to more adaptive and intelligent solutions. Ali et al. 8 reviewed ML applications in detecting financial fraud, emphasizing the limitations of traditional methods and highlighting SVM and ANN as key algorithms. It addresses issues and gaps, suggesting exploration of ensemble methods and unsupervised learning like clustering. Enhanced anomaly detection and incorporation of text-mining techniques such as Word2Vec, Doc2Vec, or BERT are recommended for improved ML models in combating financial fraud, providing a comprehensive overview and insights for potential advancements. In their extensive review of 75 publications spanning 2009–2019, Al-Hashedi et al. 9 classified financial fraud as follows: bank fraud, insurance fraud, financial statement fraud, and cryptocurrency fraud. Of the 34 data mining methods that are included, SVM is the most popular, accounting for 23 percent of all uses. Naïve Bayes and Random Forest follow closely behind (15 percent each). The majority of studies (81.33%) focus on bank and insurance fraud, offering valuable insights for academia and industry. The review contributes significant information to the field by expanding the sample and summarizing notable works. Wickramanayake et al. 10 address card payment fraud, a significant challenge in the global digital economy. Using a taxonomy derived from studies conducted between 2009 and 2020, 11 it investigates fraud detection technologies that make use of data mining and machine learning advancements. Reviewing 45 papers, the survey highlights strategies that take into account how fraud affects businesses, use feature engineering to profile cardholders, and adjust to changing fraud trends. The paper concludes with a comparative evaluation of classification algorithms, aiming to provide a comprehensive overview for academia and commercial developers tackling payment fraud detection.
A study conducted by Liu et al. 12 focuses on creating a stable and interpretable model for financial fraud detection, particularly for imbalanced datasets. It identifies Smote as the most effective oversampling algorithm and highlights Adaptive Lasso as the top performer for feature selection. LightGBM outperforms XGBoost and Random Forest in feature importance ranking. The study emphasizes the significance of NULL NUM in identifying fraudulent corporate data and recommends incorporating WoE encoding and IV value testing for improved model performance. In conclusion, the paper suggests future research directions, including larger sample sizes, exploration of deep learning, and integration of natural language processing technologies for enhanced financial statement fraud detection. Anomaly detection methods for financial fraud are reviewed by Hilal et al., 13 with an emphasis on how technologically driven fraud has led to recent advances in unsupervised and semi-supervised learning. Issues with money laundering, insurance fraud, and credit card fraud are addressed, with a focus on the transition from supervised to unsupervised and semi-supervised methods. 11 Generative models like GANs and AEs are highlighted for effective feature extraction, while deep learning architectures like CNNs and LSTMs capture temporal relations. The paper suggests future research directions, advocating for combined models and emphasizing interpretability in fraud detection.
Mittal S. & Tyagi S. 14 examine security concerns in online credit card usage within the evolving e-commerce landscape over the past 25 years. Credit card fraud may be difficult to detect in real time, and skewed datasets are just two of the problems highlighted in this analysis of attack routes and solutions. 15 The review underscores the recent surge in credit card transactions and subsequent fraud, leading to the development of machine learning-based models. Some of the problems that have been identified include a lack of standard algorithms and a lack of understanding of credit card processing. 11 Furthermore, the article stresses the importance of benchmark datasets and investigates the unrealized possibilities of big data analytics and streaming data in relation to future advancements in fraud detection. 15
Sadgali I. et al. 16 evaluate machine learning techniques, emphasizing hybrid methods, for detecting various financial fraud types, including credit card fraud. In order to solve imbalanced datasets and increase accuracy in credit card fraud detection, the conclusion calls for improved algorithms and hybrid models. The findings emphasize the effectiveness of Support Vector Machines (SVMs) in instantaneous transactional fraud detection. 16 In response to the growing problem of financial fraud in online services, Alghofaili Y. et al. 17 provide a fresh strategy based on deep learning's Long Short-Term Memory (LSTM) for better detection. In less than a minute, the LSTM based model achieves 99.95% accuracy on a genuine credit card fraud dataset, outperforming previous techniques and demonstrating its potential to advance fraud detection for huge datasets and real-time processing demands. 17
The study by Alarfaj F. K. et al. 18 addresses credit card fraud detection challenges, proposing enhanced deep learning algorithms. By improving its performance on the European card benchmark dataset, the model outperforms previous techniques, earning a f1-score of 85.71 percent, a precision of 93.1 percent, and an area under the curve (AUC) of 98.0 percent. 18 These findings demonstrate the promise of highly developed algorithms for the accurate identification of credit card fraud in the real world. 18 For the purpose of detecting credit card fraud, Ileberi E. et al. 19 use AdaBoost in conjunction with a number of machine learning methods, such as Decision Trees, Random Forest, Extra Trees, XGBoost, Logistic Regression, and Support Vector Machine.ET-AdaBoost achieves 99.98% accuracy and an MCC of 0.99 in the comparison study conducted on the European fraudulent transactions with credit cards dataset, demonstrating exceptional levels of accuracy. 19 The suggested machine learning techniques utilizing AdaBoost demonstrate exceptional results when tested on a biased artificial credit card fraud dataset. 19 By combining an ensemble classifier with an LSTM base learner in AdaBoost and making use of SMOTE-ENN for hybrid resampling, Esenogho E. et al. 20 presented a successful approach to detecting credit card fraud. The suggested method outperforms other algorithms, achieving high specificity (0.998) and sensitivity (0.996), indicating its potential to improve credit card fraud detection. 20 The increased difficulty of credit card fraud during the COVID-19 pandemic's spike in online purchases was discussed by Alfaiz N. S., & Fati S. M.. 21 The AllKNN-CatBoost model outperformed sixty-six other ML models on a real-world dataset, with an AUC of 97.94%, a recall of 95.91%, and an F1-Score of 87.30%. 21 The results emphasize its potential significance in preventing fraudulent credit card transactions during online activities, outperforming previous approaches.
Awosika T. et al. 22 introduced a novel approach to address fraudulent transactions in the financial sector, combining Explainable AI (XAI) and Federated Learning (FL) to enhance transparency and interpretability in fraud detection systems. The integration of SHAP ensures accurate and understandable predictions, shedding light on influential features and justifying decisions. This emphasis on transparency becomes crucial in sensitive domains, emphasizing that XAI is essential for accountability, user trust, and regulatory compliance in FL-based fraud detection systems. Table 1 shows the comparative analysis of various research works on financial fraud detection using machine learning algorithms and deep learning algorithms.
It is evident from the in-depth review of numerous sources on financial fraud detection that machine learning (ML) approaches are essential for tackling the difficulties associated with financial fraud detection. SVMs, Decision Trees, Random Forest, ANNs, and deep learning models such as LSTM are highly favored for their exceptional accuracy, according to the reviewed literature.23,24 The emphasis on ensemble methods, data resampling techniques, and feature engineering highlights the ongoing pursuit of refining existing models. Additionally, the incorporation of advanced technologies, such as Generative Adversarial Networks (GANs) signals a growing awareness of the need for interpretability and transparency in fraud detection systems. While the field has made substantial progress, the papers collectively advocate for future research directions, including exploration into less-studied algorithms, text-mining techniques, natural language processing, and the integration of novel approaches like federated learning and Explainable AI (XAI). The continuous evolution of financial fraud detection methodologies remains critical to staying ahead of sophisticated fraudulent activities and safeguarding financial systems.
Proposed methodology
When someone “intentionally and knowingly deceives the victim by misrepresenting, concealing, or omitting facts about promised goods, services, or other benefits and consequences that are nonexistent, unnecessary, never intended to be provided, or deliberately distorted for the purpose of monetary gain,” they are committing actions of financial fraud. 25 Financial fraud in mobile money transfers is the focus of this research work. Mobile money refers to monetary services and transactions that may be carried out via a mobile device, such a phone or tablet. 26 Connectivity to a bank account is not always an option for these services. 26
This research focuses on enhancing fraud prevention systems by not only prioritizing model accuracy but also emphasizing explainability through SHAP analysis as illustrated in Figure 1. The study's overarching goal is to provide more open and understandable methodology by deconstructing machine learning models, with a focus on their use in financial fraud scenarios. An ever-changing cybersecurity environment is being tackled by combining machine learning with explainable AI. The goal is to strengthen defences and provide stakeholders with interpretable information to combat financial crime. 27
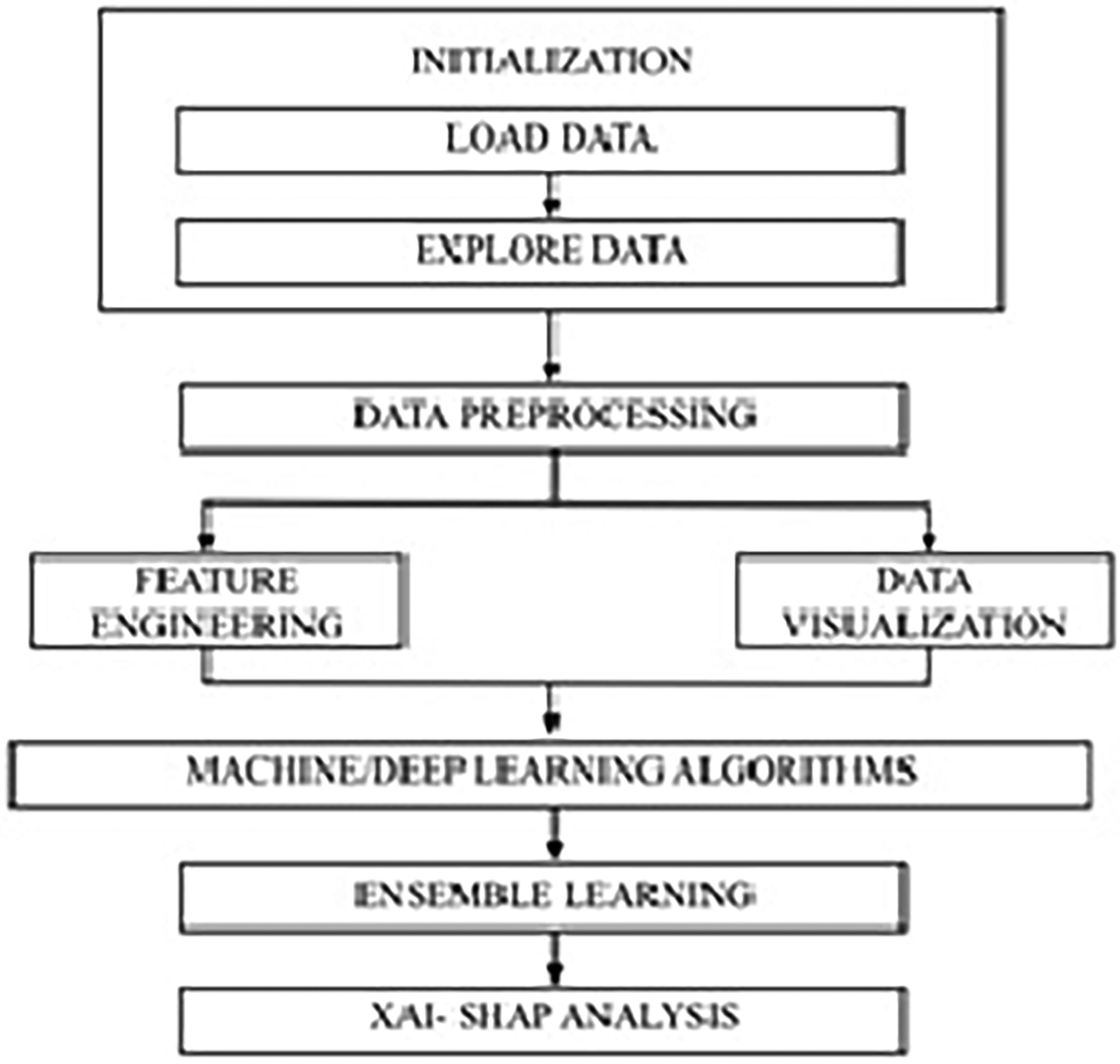
Architecture of the proposed methodology.
With this dataset, we want to address a knowledge vacuum in publicly available financial services datasets, with a focus on mobile money transactions as a relatively young industry. Many real-world datasets are not available to the public because of the sensitive nature of financial transactions. 28 To get around this constraint, the dataset is artificially constructed using a simulator called PaySim. To simulate mobile money transactions, PaySim uses a subset of real transactions extracted from a provider's monthly financial data. A multinational firm is now running the mobile banking service in more than 14 countries across the world, and they are the ones who provided the initial logs.
The Swedish Knowledge Foundation (grant: 20140032) is supporting the study “Scalable resource-efficient solutions for big data analytics,” which includes this dataset. 29 The dataset encompasses a comprehensive 6,362,620 records, of which 6,354,407 are valid transactions, constituting 99.87%, and 8213 are fraudulent transactions, amounting to 0.13%. Among the flagged transactions, totaling 16, all fall under the “TRANSFER” type and are marked as fraudulent. The transaction amounts in this subset range from 353,874.22 to 10,000,000.0.
In this preliminary phase, we commence by importing essential libraries and conducting a comprehensive examination of the dataset. Our initial focus involves scrutinizing for any missing data and delving into the distribution patterns of both valid and fraudulent transactions, establishing a foundational understanding for subsequent preprocessing steps.
In addition, we enhance our exploratory analysis through data visualization techniques, enabling a more insightful understanding of the dataset's characteristics and aiding in the identification of patterns or trends that may influence the subsequent modeling process. Figure 2 presents a pie chart illustrating the distribution of transaction types, revealing that Transfer Transactions constitute 19%, while Cash Out Transactions dominate the majority with an 81% representation.
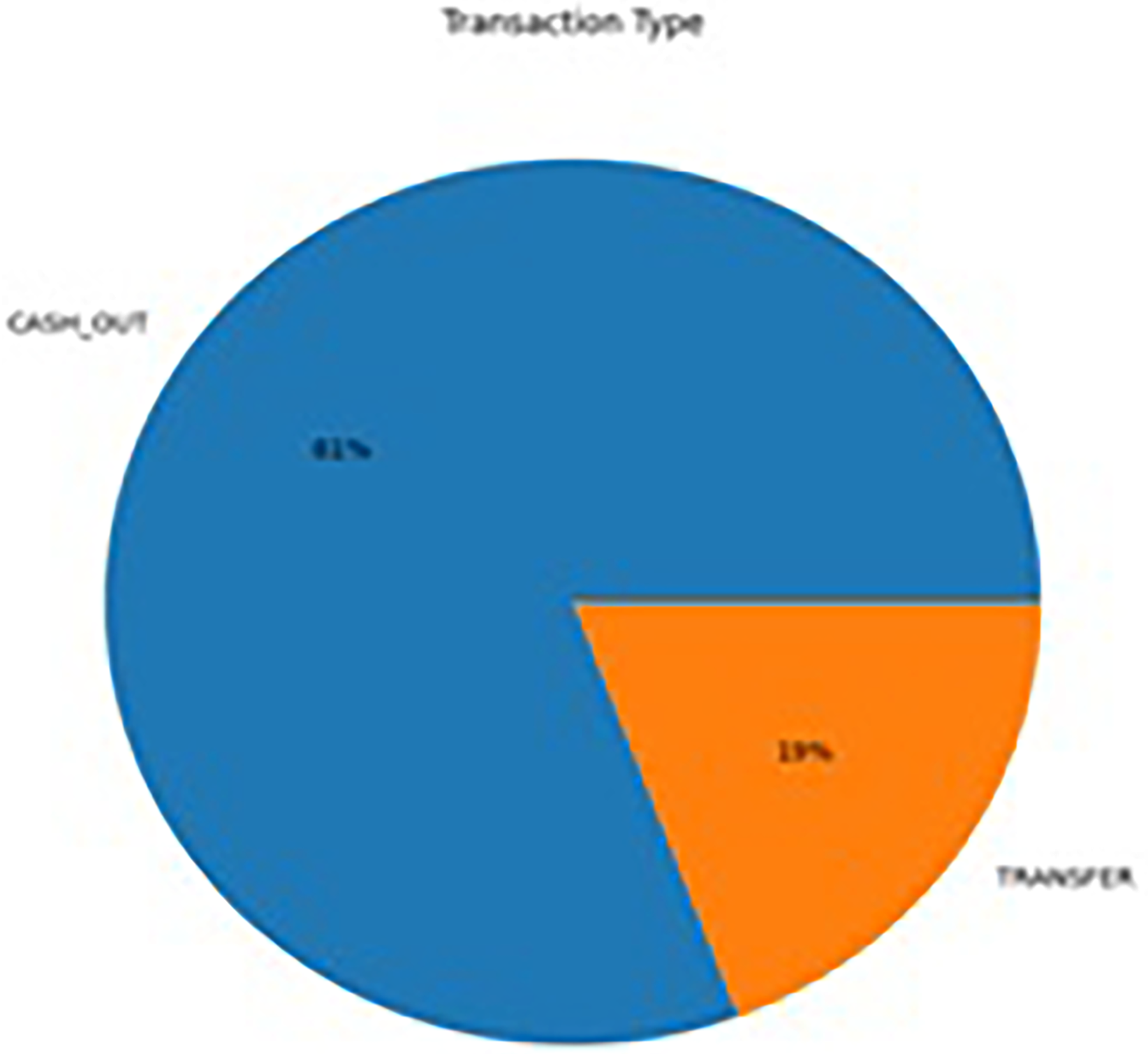
Pie chart of ratio of transaction types.
In Figure 3, a bar graph delineates the total monetary value associated with each transaction type. Cash Out transactions exhibit a substantial total amount of 394,412,995,224, while Transfer transactions surpass with a total amount of 485,291,987,263, offering a comprehensive visual representation of the financial magnitudes associated with each transaction category. In Figure 4, a bar graph meticulously portrays the incidence of fraudulent transactions within each transaction type. Notably, Cash Out transactions account for 223,750 instances, while Transfer transactions reveal a higher frequency with 532,909 cases, providing a nuanced insight into the distribution of fraudulent activities across different transaction categories.

Total amount transacted in each transaction type.
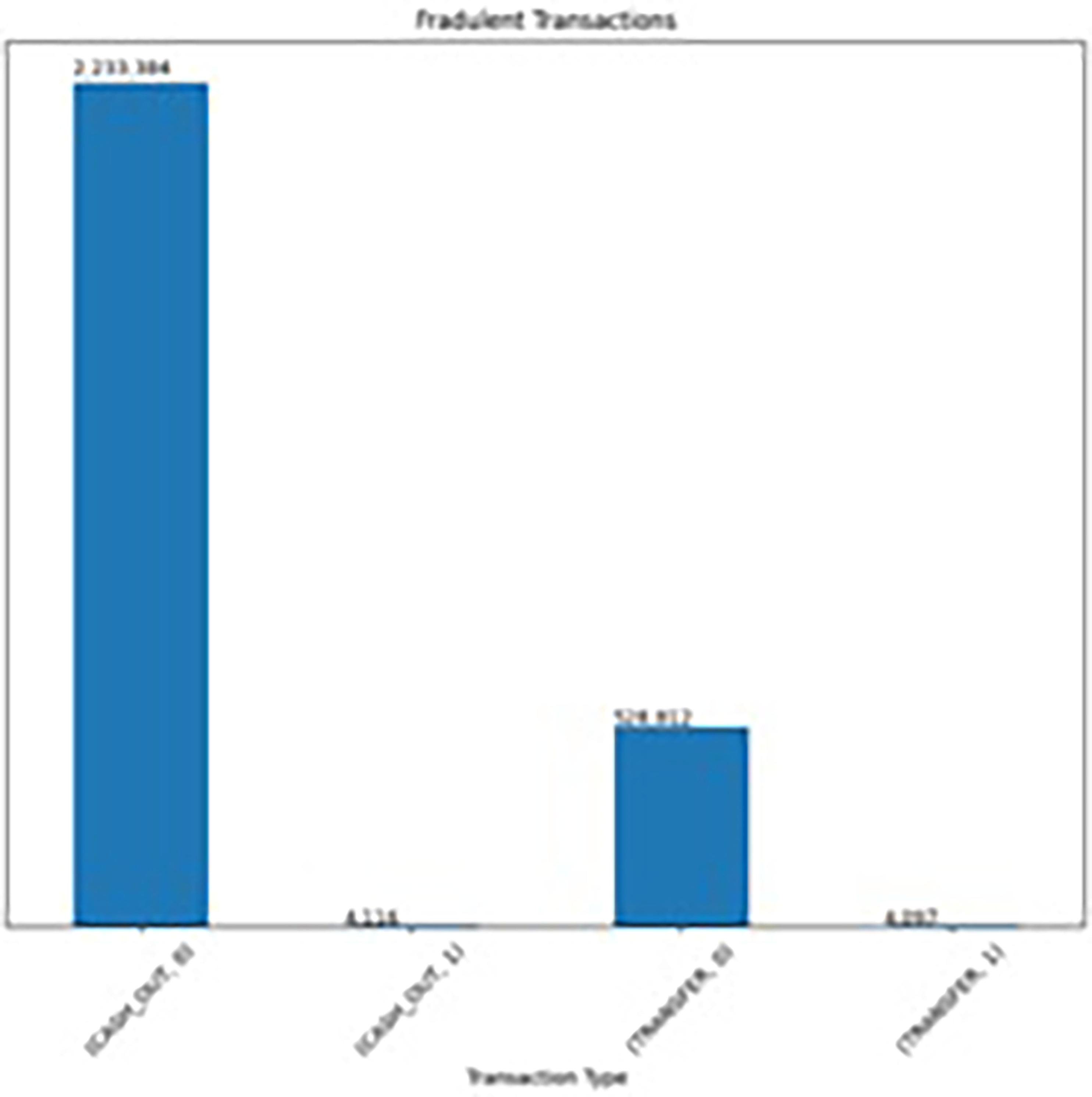
Fraudulent transactions types- cash out and transfer.
To fortify the robustness of our analysis, we diligently address potential imbalances inherent in the dataset. Moreover, we meticulously investigate and rectify disparities in balances at both the origin and destination following transactions. The identification and analysis of transactions with amounts less than or equal to zero offer valuable insights into potential anomalies that may impact the model's performance. Table 2 shows different attributes of the dataset.
Following the initial exploratory phase, we transition to a meticulous feature engineering process to enhance the dataset's suitability for machine learning model training. Begin with the 11 columns that make up the original features: “step,” “type,” “amount,” “nameOrig,” “oldbalanceOrg,” “newbalanceOrig,” “nameDest,” “oldbalanceDest,” “newbalanceDest,” “isFraud,” and “isFlaggedFraud.” Then we go on to the current features. Unwanted features such as “step,” “type,” “nameOrig,” “nameDest,” “error_orig,” “error_dest,” and “isFlaggedFraud” are subsequently removed to streamline the dataset.
To ensure uniformity, continuous values within the columns “amount,” “oldbalanceOrg,” “oldbalanceDest,” “newbalanceOrig,” and “newbalanceDest” are standardized to fall within the 0 to 1 range using the StandardScaler. One of the most important steps in getting data ready to train machine learning models is employing the ‘train test split’ approach to divide the resultant dataset into several sets: training and testing. To make sure the split is acceptable, we look at the size of the training and testing sets.
Additionally, we conduct checks for missing values in the target variable, “isFraud,” and address them by dropping rows with missing values. After cleaning the data, it is divided into two sets: one for testing and one for training. The stratification is kept and the test size is set at 20%. The final dimensions of the split datasets are verified to confirm the successful completion of the preprocessing steps.
Classification models
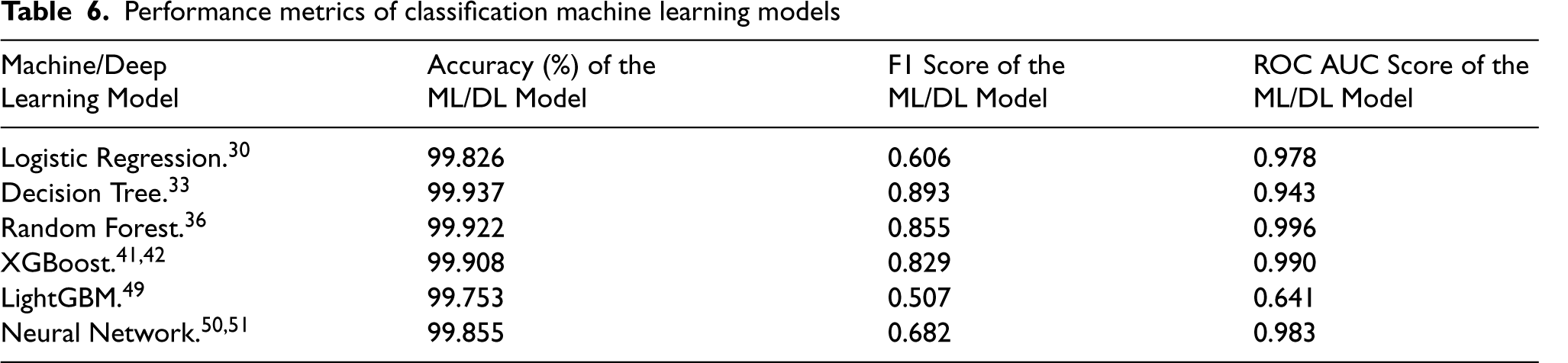
One of the most important uses of machine learning is fraud detection, where choosing the right model may have a huge impact on efficiency. In this study, we dive headfirst into the complex world of fraud detection and analyse six well-known machine learning models: Neural Network, XGBoost, Decision Tree, Random Forest, and Logistic Regression. The research aims to provide a detailed and thorough knowledge of each model's effectiveness and suitability for handling the intricacies of fraud detection by carefully using several performance indicators, such as accuracy, F1 score, confusion matrix, and ROC AUC score.
Logistic regression
David Cox developed the basic technique for creating a logistic model (sometimes called the logit model) in 1958 and named it logistic regression. Due to its connection to logistic data distribution, its primary benefit is that it can be applied to both class probability estimation and classification. It applies a nonlinear sigmoidal function as shown in equation 1 on a linear combination of features.
30

When it comes to supervised learning, decision trees are the way to go. 33 To aid in decision-making, decision trees use a tree structure that mimics human brain processes. 33 Attribute selection as the decision tree's root node is the first step. 33 Additionally, for each single attribute value, it creates a branch and splits the instance into many subgroups. Thirdly, there is a connection to a branch from the root node in each subset. 34 With each branch completed, the algorithm repeatedly continues the process. 35
Random forest
When it comes to categorization, the Random Forest (RF) algorithm is among the top options. RF is capable of properly categorizing massive volumes of data. This method of learning involves training a large number of decision trees, with the goal of having each tree anticipate the modal outputs. 36 According to, 36 RF uses random vector values for each tree as its predictors. The basic premise is that a group of “weak learners” may work together to create a “strong learner."36–40
XGBoost
An implementation of Gradient Boosting that makes use of gradients derived from decision trees is known as Extreme Gradient Boosting (XGBoost). Iteratively, it builds simple, brief decision trees. Because of its extreme bias, every tree is referred to as a “weak learner.” XGBoost starts by constructing the first, most basic tree, which performs poorly. After then, it creates a second tree that is trained to predict actions that the previous tree—a poor learner—was unable to do. The method generates progressively weaker learners, each of them fixing the preceding tree before the stopping condition—for example, the quantity of trees (estimators) that need to be produced—is satisfied. XGBoost offers further benefits: Training is quick and can be split up or divided among multiple clusters.41,42
LightGBM
Comparative analysis of various research works on financial fraud detection using machine learning algorithms and deep learning algorithms
Comparative analysis of various research works on financial fraud detection using machine learning algorithms and deep learning algorithms
Neural networks (NNs) and artificial neural networks (ANNs) are two names for the same kind of AI model that attempts to simulate brain activity. In the 1990s, they were presented as a different approach to address geographic issues, and more recently, they have grown because of developments in computer power, artificial intelligence, and data availability, among other areas. 50 Neural Networks can learn complex nonlinear relationships using training example sets. They work particularly effectively in pattern identification scenarios where complex trends in high-dimensional data need to be identified. 51
A stratified K-Fold cross validation was performed to ensure the reliability and robustness of the experiments. Tables 3, 4 and 5 show the cross validation results of various models on the metrics accuracy, F1 score and ROC AUC scores respectively. We summarize the average performance characteristics of our machine learning models for classification in Table 6, providing a thorough understanding of their efficacy. Accuracy, F1 score, and ROC AUC score are some of the most important metrics that reveal the models’ overall classification accuracy, precision-recall balance, and ability to discern between positive and negative examples.
Detailed information of the dataset attributes

Detailed information of the dataset attributes
Cross validation results on accuracy (%)

Cross validation results on F1 scores

Cross validation results on ROC AUC scores

Performance metrics of classification machine learning models
Nemenyi Post-Hoc Test Results

Additionally, Friedman's statistical test is used to compare the performance of different models. The resulting p-value is 0.000139 which is significantly less than the significance level 0.05 indicating that there are significant differences between the performances of the models. The Nemenyi post-hoc test provides pairwise comparisons between the models. Table 7 shows the p-values for the comparisons.
The results suggest that certain models such as Logistic Regression, Decision Trees, Random Forest, LightGBM have performance differences that are statistically significant.
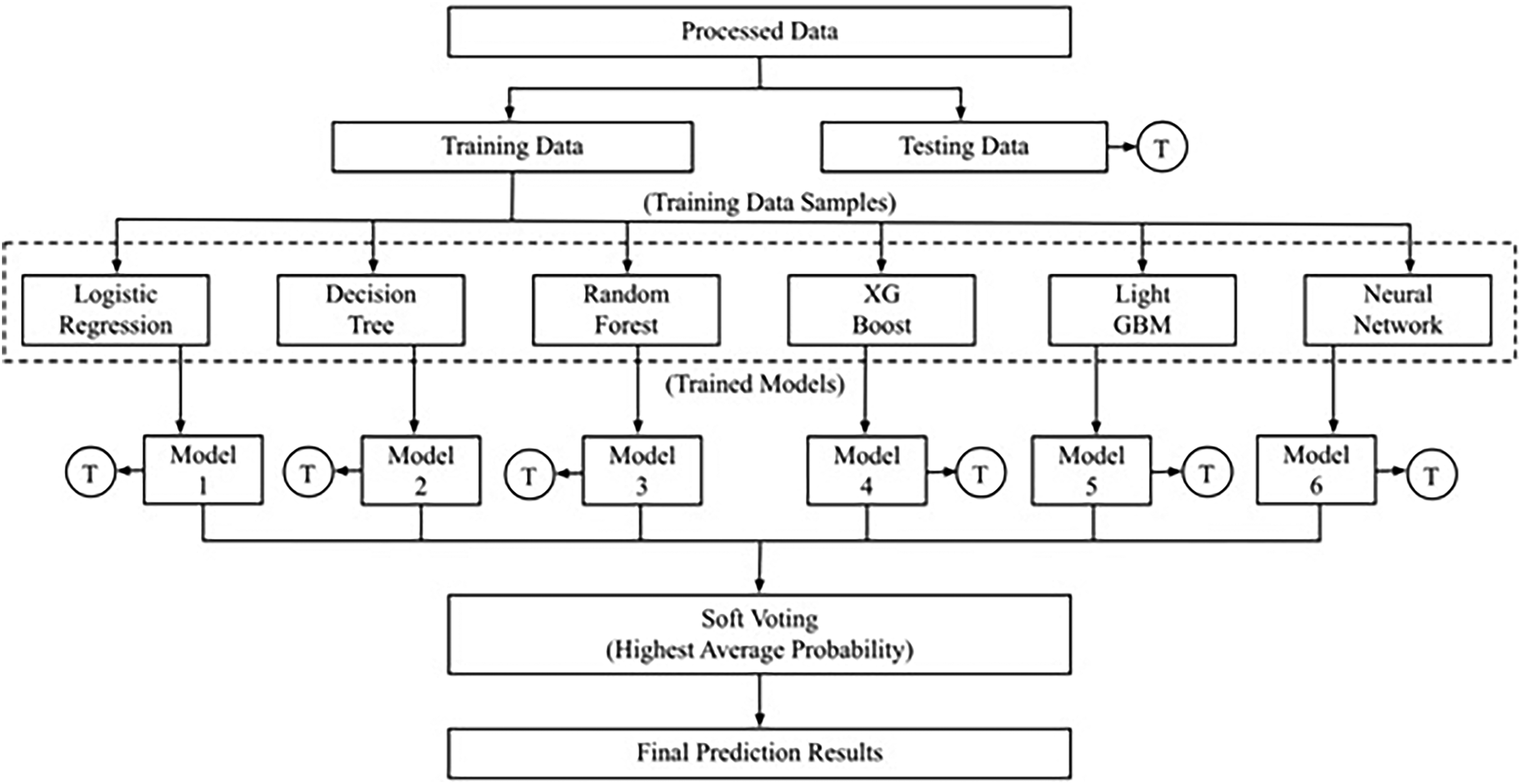
When solving tasks like classification, ensemble learning uses a combination of many learning models that have been deliberately generated. 52 This is based on the notion that two minds are preferable to one. Additionally, we gather information from various sources and rank or combine them in order to make strategic judgments. A supervised learning algorithm is an ensemble in and of itself. Many classifier systems are another name for ensemble learning systems. 32 Using the same data to train several models and then combining their predictions is known as ensemble learning. 53 The goal of ensemble learning is to improve performance above that of a single model by combining many models into a single ensemble. 53 The first step is to determine how to build the ensemble models, and the second is to figure out how to aggregate the forecasts of each member of the ensemble. One way to make predictions more accurate is to use ensemble learning. 54
This instance makes use of a meta classifier, which is able to merge prediction models from different or comparable machine learning datasets by means of a majority vote or soft voting. To choose the most likely class, soft voting averages the base models’ class pseudo-probabilities. 55 The voting classifier outperforms the other baseline models because to its ability to incorporate the predictions of many ML and DL models. 56 Figure 5 illustrates our proposed ensemble model, a culmination of various classifiers aimed at elevating predictive performance through strategic combination. A number of classifiers—including XGBoost, LightBGM, Neural Networks, Decision Tree Classifier, and Random Forest Classifier—are part of this ensemble. Table 8 shows the Stratified K-Fold cross validation results of the ensemble learning model.
Proposed ensemble model.
Cross validation results of ensemble learning classifier

Table 9 provides the average summary of the performance metrics of the ensemble learning model, with a focus on accuracy, F1 score, and ROC AUC score. The collective assessment highlights the model's exceptional accuracy of 99.904%, underscoring its efficacy across diverse classification scenarios.
Performance measure of ensemble learning classifier

Process of explainable AI.
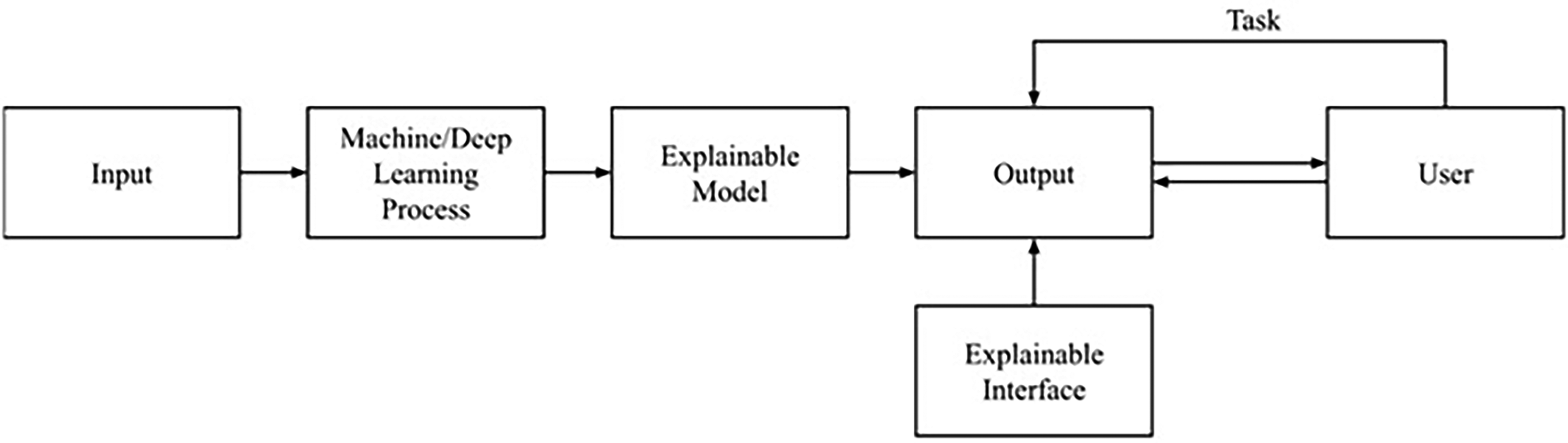
Coined by DARPA in 2016, Explainable AI (XAI) addresses the need for transparency in AI systems, countering the ‘black box’ nature of machine learning. Crucial in delicate fields like healthcare and banking, XAI seeks to ensure that AI systems are transparent and easy to interpret. Using white-box models such as Concept Bottleneck Models, XAI justifies decisions, promoting trust and facilitating user comprehension. Symbolic regression is proposed for supervised machine learning to ensure transparency and auditability. Overall, XAI seeks to demystify AI decisions, enhancing user trust and understanding.57–60
In Figure 6, we can see how the requirements or application domain dictate the input data used to train the models, the prediction approach that is selected, and the XAI methods that are used to explain the models’ inner workings and output via an explanation interface. 57 Because we are aware of Explainable AI's results, we will be more confident in AI models. Users can enhance the model's accuracy and identify its shortcomings by using the output information. The end effect will be that consumers are better able to decide how to enhance the model. 61
In this study, we interpret machine learning model output using SHAP, a common explainability technique utilized in Explainable AI (XAI). Basically, SHAP functions as a “feature attribution method”. 62 Similar to a game theory approach, SHAP enhances the readability of each prediction independently by determining the importance values for each attribute. Three important attributes make up the aggregate degree of feature importance maintained by the SHAP values: “Missingness, accuracy, and consistency”. In terms of interpretation, SHAP is more intuitive and simpler to compute. 63 In addition to being model-agnostic, it provides explanations that are both local and global and is more dependable when dealing with any kind of data. In order to empower players according to their level of participation, we employ Shapley values, which adhere to the four axioms of player engagement: “Efficiency, Symmetry, Dummy, Additive”. 64 Shapley first coined the term SHAP in 1951. It is used to describe a certain output depending on how each input is involved in a prediction.
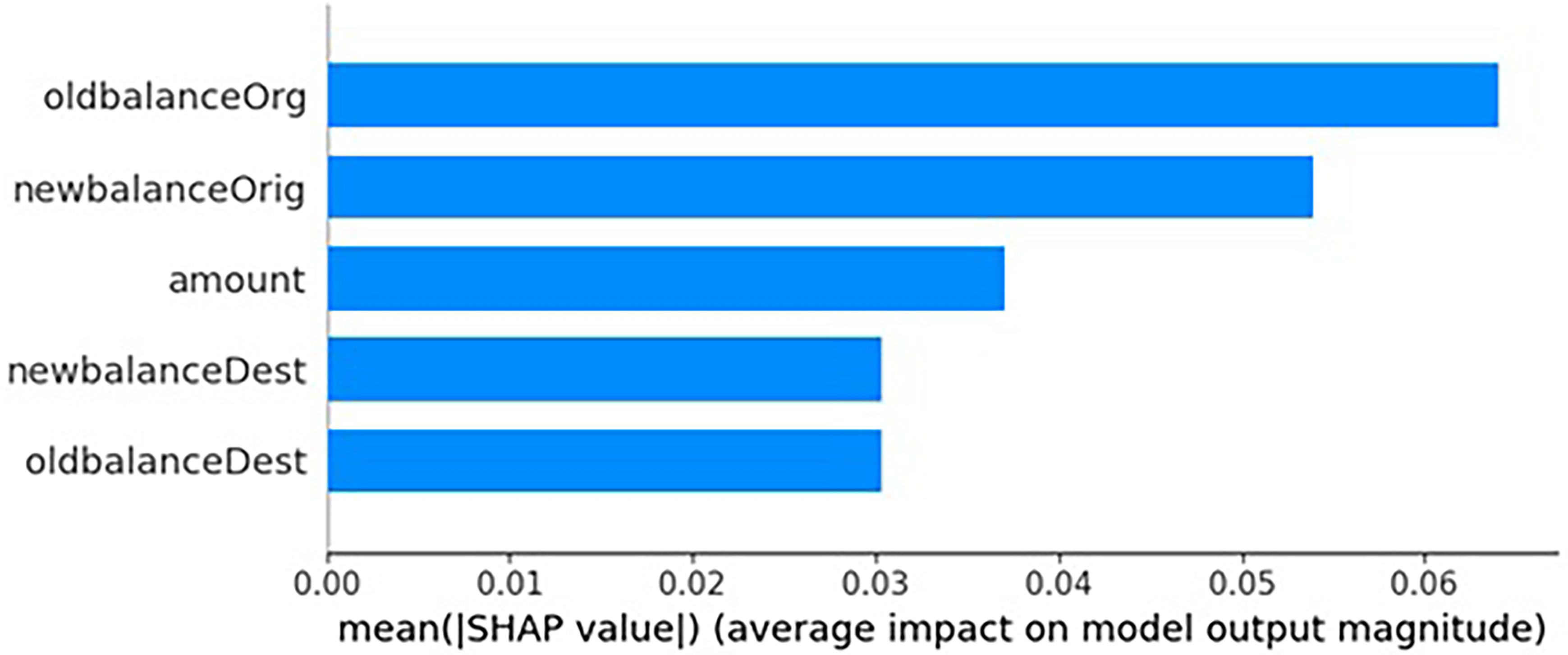
Table 10, along with Figures 7 and 8, unveils the mean SHAP values, shedding light on the pivotal role of selected attributes within the framework of a predictive model. The utilization of SHAP values facilitates a nuanced understanding of each attribute's contribution to the model's output. Remarkably, the OldBalanceOrg attribute takes precedence with the highest mean SHAP value of 0.065, signifying its discernibly stronger impact on the model's predictive outcomes. By giving a quantifiable measure of attribute impact and providing insight into the model's decision-making processes, these values improve the interpretability and understanding of feature significance. 65
Average impact of attributes on model output

Average impact of attributes on model output
Mean SHAP value (average impact of attribute on model output).
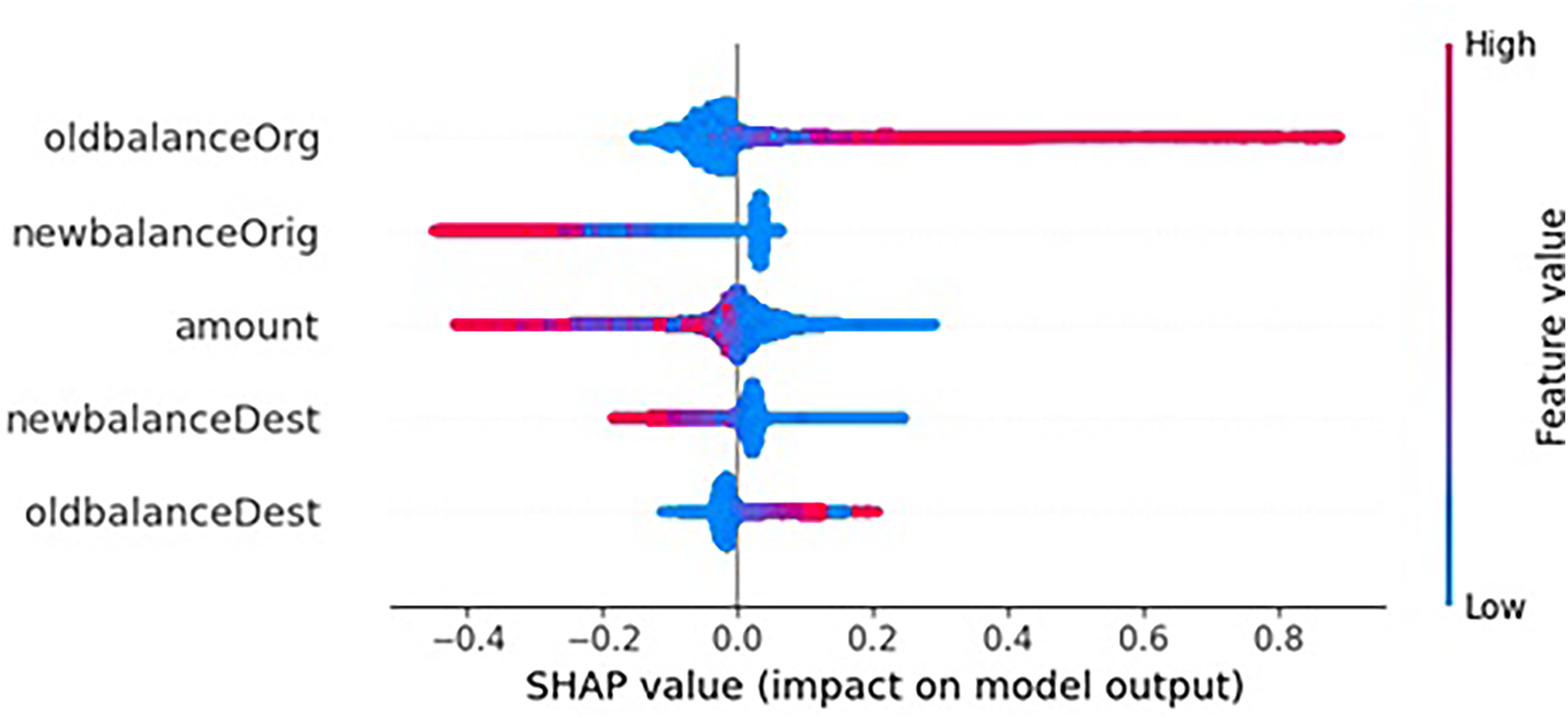
SHAP value and feature value.
The assessment of individual machine learning models underscores their exceptional performance in detecting financial fraud, with the Decision Tree model showcasing remarkable results. An F1 Score of 0.893, a ROC AUC Score of 0.943, and a maximum accuracy of 99.937 percent distinguish the Decision Tree model as the best performer among the models that were evaluated.
With a 99.904% accuracy rate, an F1 Score of 0.814, and a remarkable ROC AUC Score of 0.990, the Ensemble Learning Model—implemented via a Voting Classifier—demonstrates itself as a strong solution. This collective performance underscores the efficacy of amalgamating diverse models for enhanced fraud detection.
To delve into the interpretability of these models, a thorough SHAP analysis was conducted, revealing key attributes and their mean SHAP values. Particularly noteworthy were attributes such as OldBalanceOrg, NewBalanceOrg, Amount, NewBlanceDest, and OldBalanceDest, which exhibited significant impacts on model outputs. These insights provide valuable clarity to stakeholders, fostering a deeper understanding of the models’ decision-making processes and thereby augmenting transparency and interpretability in the realm of financial fraud detection.
Conclusion
In this research, we tackled the growing challenges in financial technology, specifically addressing the rising threat of fraud in mobile money transactions. While digital finance brings convenience, it also exposes institutions to sophisticated fraud. Our study emphasized both high model accuracy and explainability by integrating machine learning with Explainable AI, leveraging SHAP analysis. This work not only advances fraud prevention in digital finance but also sets a precedent for transparent and interpretable machine learning systems. By prioritizing clarity, it empowers stakeholders with effective decision-making tools in the evolving cybersecurity landscape, marking a significant stride against financial fraud in the digital era.
Future work
The future of financial fraud detection and prevention involves integrating cutting-edge technologies to combat sophisticated fraud schemes. Key advancements include the development of real-time analysis and adaptive systems for dynamic threat response, the use of behavioral biometrics for enhanced user recognition, blockchain technology for immutable and transparent ledgers, quantum-resistant encryption methods, collaborative threat intelligence sharing, the examination of non-financial data for contextual insights, regulatory compliance solutions leveraging advanced technologies, and AI-driven user authentication processes. These innovations aim to create more resilient and intelligent systems, crucial for staying ahead in the ever-evolving landscape of digital finance.
Footnotes
Ethical approval
Informed consent
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.