
Abstract
Nowadays, there is an increasing trend in movie creation and consumption through video-on-demand platforms like Netflix. It is vital for movie industry companies of this kind to adopt a recommendation-based marketing strategy, as improving customer experience directly contributes to increased profits. In our previous research work, we improved the efficiency of the standard k-NN (K-Nearest Neighbor)-based recommendation system in both accuracy and speed by first clustering customers based on their preferred genres. For the clustering step, we used the K-Means algorithm. In this research work, we expanded our experiments by using other than K-Means clustering algorithms to implement the clustering step of our proposed recommendation system. We used the DBSCAN Clustering algorithm, the Agglomerative Clustering, the Affinity Propagation, the Spectral Clustering, the Mean Shift, the Gaussian Mixture and the K-Means Split Merge algorithms. K-Means clustering is one of the most widely used partitional clustering algorithms in recommender systems due to its simplicity and low computational cost, despite some inherent limitations. Its popularity persists due to its simplicity and its minimal computational requirements. This research aims to improve K-Means-based recommender systems by experimenting with alternative clustering methods.
Introduction
Recent statistics have unveiled a noteworthy pattern concerning video-on-demand films. 1 To be more specific, it appears that there is a noticeable upward trend. The video-on-demand market worldwide is projected to reach a revenue of US$231.50bn by 2027, the number of users is projected to reach 3.4bn and the user penetration rate is expected to increase to 43.2% from 38.3% in 2024. It is obvious that the film industry is a multi-billion-dollar business. Film production and distribution companies could gain a competitive advantage by conducting analysis to better understand their target audience. They can use various sources to conduct their analysis. The internet and social media provide a huge volume of information that could be used for this analysis. This process requires the adoption of machine learning or deep learning techniques to develop opinion mining systems. 2 Hence, it becomes essential for film companies to be well-prepared for acquiring and retaining customers. Their marketing strategies should focus on improving customer experience within their platforms by providing useful and precise suggestions. These procedures are implemented by the Recommendation Systems.
Recommendation Systems (RS) or Recommender Systems (RS) are responsible for filtering the information and providing the most relevant content to the user, improving his/her experience by reducing the information volume that is delivered. 3
Advances in machine learning, data mining, and pattern recognition have provided significant opportunities for improving recommendation systems. A range of algorithms related to data mining and machine learning has been suggested. These include methods such as Matrix Factorization recommender systems, Singular Value Decomposition (SVD) recommender systems, and clustering-based recommender systems, among others (as discussed in4,5). This research focuses on addressing the scalability issue by utilizing clustering techniques.
Collaborative filtering (CF) is a highly effective method within recommender systems, as shown by. 6 In the context of collaborative filtering recommender systems, one common approach is to identify similar users and items by employing similarity metrics like cosine similarity and Pearson Correlation Coefficient (PCC). 4 It has been a successful method for recommending items to users for many years. However, with the substantial increase in the number of users and movies on online platforms like Netflix, especially during and after the Covid period, the scalability issue has become more pressing than ever.
Researchers from 7 noted that recommender systems using clustering-based algorithms to group users and items tend to perform better than those relying only on similarity measures for the entire user and item sets. As the number of users and items increases, computing similarities becomes a highly demanding process. Adapting the recommendation process to smaller subsets of users or items can substantially reduce the computational demands, as suggested by.7,8
Hence, clustering algorithms prove to be a valuable tool for addressing issues of data sparsity and scalability, as noted by.6,7 They help mitigate redundancy and ambiguity, ultimately enhancing the personalization and efficiency of recommender systems.
Thus far, our study analyzes user-specific movie ratings using data mining techniques, including the K-Means clustering algorithm and the k-NN algorithm. Our objective is to accelerate the recommendation process. To achieve this, we break down the problem into smaller components recognizing that solutions for smaller problems are typically faster.
Collaborative filtering involves intensive computations. As the number of users and movies grows, the computational demands increase non-linearly. 9 Moreover, as the number of users and movies increases, collaborative filtering experiences a decline in precision. Most of the computational time is spent on calculating similarity. If U represents the number of users and M denotes the number of movies, the time complexity increases by O(U*M). 10
The conventional recommendation approach, Collaborative Filtering, requires the input of all
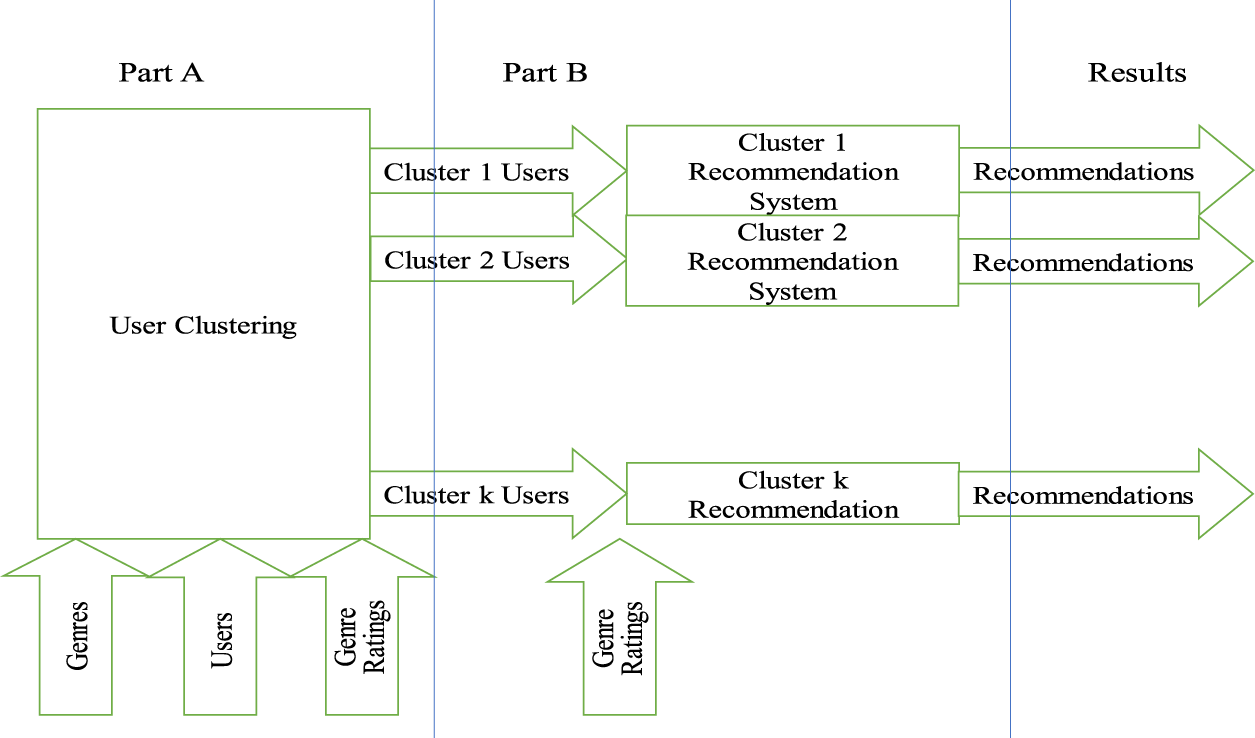
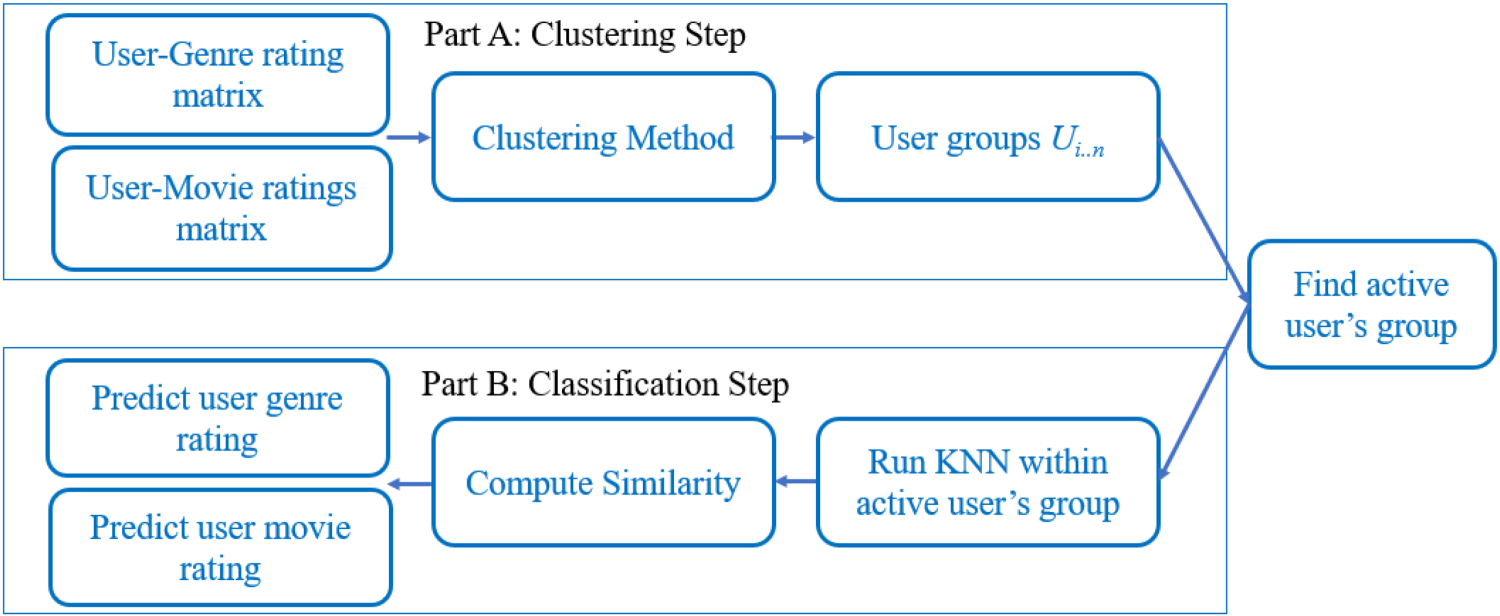
Our proposed method, illustrated in Figure 1, breaks down this process into two steps:
It begins by taking all Subsequently, it may recommend a movie from the movies within the preferred genres.

Recommendation system process.
In part A, a simple approach involves utilizing the k-NN algorithm to compute the similarity between the movie style preferences of the active user (u) and those of all other users. This similarity analysis helps identify the most common movie style preference among users and makes recommendations accordingly. To enhance this process, we implement an initial clustering step (Figure 2).
Finding genres for recommendation.
In this improved approach, we group users into clusters based on their preferred movie genres. By doing this, we can bring together users who share similar tastes and preferences in movie styles. The aim is to efficiently place each user within a cluster where they align with most other users in terms of movie genre preferences. This clustering step streamlines the process of searching for candidate movies to recommend, making it faster and more accurate.
Clustering techniques can be applied to either users or items, resulting in user-based collaborative filtering or item-based collaborative filtering. However, the number of user interactions with items is often limited, as users typically interact with only a small fraction of the total number of listed items on a platform. Moreover, users rarely visit identical items. Consequently, the user-item matrix tends to be sparse, negatively affecting recommender system performance. To reduce sparsity in the user-item matrix, we also cluster users based on genre ratings rather than relying solely on movie ratings. We cluster the users of the system according to the mean rating on genres. Each user is assigned a vector representing their mean rating for each genre. Thus, for a dataset of n users and m genres, we have:
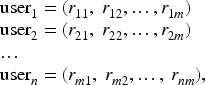
The primary objective of this research was to develop an enhanced movie recommendation framework that delivers improved accuracy and operational efficiency.
We conducted experiments, using different values for the k clusters that K-Means generates and different methods for substituting the unknown genre ratings of the dataset. The results showed a significant improvement in both speed performance and system accuracy. Consequently, the findings could prove advantageous for businesses in their marketing endeavors, enabling them to select high-quality movies and suggest them to users with high interest. As a result, companies stand to gain profits by catering to their customers’ preferences.
The K-Means clustering algorithm that we used in our earlier research is widely utilized in clustering-based recommender systems. 11 K-Means clustering divides data points into K clusters, with each data point assigned to the cluster center that is closest in distance. While K-Means is a straightforward and frequently used partitional clustering method, it faces challenges related to the initial definition of the number of clusters K and the initialization of centroids, as discussed in. 12
Different recommendation datasets may require varying values of K clusters. For instance, a small e-shop dataset with a thousand items might necessitate a different K value than a dataset with a million items. Therefore, specifying a fixed K value at initialization is not a practical approach, especially with the continuous expansion of real-time datasets. Consequently, the primary objective of this research is to address the challenges related to the
Previous research focuses mainly on K-Means for clustering-based Recommender Systems. Our goal is to evaluate other clustering techniques, like Mean Shift, Affinity Propagation, and Spectral Clustering, to determine their effectiveness in improving recommendation accuracy and efficiency. While previous studies have pointed out the gains of clustering in collaborative filtering, our work is a systematic comparison on these techniques in terms of both accuracy and runtime, providing new insights into their practical applicability in large-scale Recommender Systems.
The structure of this paper is as follows: Section Related Work provides a brief introduction to collaborative filtering and the usage of clustering in collaborative filtering recommendations. Section Problem Statement describes the motivation behind our research work. Section Implementation provides a comprehensive overview of the research methodologies employed. Section Experiments and Results elaborates on the experimental setup for clustering algorithms and the user-based collaborative filtering method. Finally, Section Conclusions and Future Work summarizes the study with discussions and final remarks. Additionally, supporting appendices are included, containing figures and referenced links by the paper.
Recommender systems typically rely on one of two methods, or a combination of both: collaborative filtering and content-based filtering. In content-based filtering, recommendations are generated by identifying objects similar to the objects that the user has previously interacted with, using content profiles of those objects. This method employs machine learning classifiers trained on user and item profiles. However, extracting content information can be a challenging task.
On the other hand, collaborative filtering addresses this limitation, as it operates based on past user ratings, eliminating the need for users or items to provide detailed content information. However, content-based filtering is more effective, when it comes to suggesting unrated items to users with unique interests (cold start problem).
Collaborative filtering
Collaborative filtering methods can be broadly categorized into two main types: memory-based and model-based approaches. The memory-based approach can be further categorized into two subtypes: user-based and item-based methods. In the user-based approach, the focus is on identifying similar users, while the item-based approach focuses on finding similar items to make predictions. User-based collaborative filtering operates on the assumption that users with similar preferences tend to rate items in a similar manner. On the other hand, item-based collaborative filtering relies on the idea that users tend to favor items closely related to items that they highly rated in the past.
Memory-based techniques predict ratings by calculating weighted sums of ratings from similar users or items. This similarity-based method computes the distance between users or items based on their ratings, which represents user preferences for items. Therefore, it can suggest items to the current user by utilizing the user-item rating matrix. 13
There are many ways to compare two users or items and find their similarity. The most common methods include the following:
the Mean Squared Difference similarity between all pairs of users (or items), which is the one we use and compute as follows:
the Pearson Correlation coefficient between all pairs of users (or items), which is computed by:
the cosine similarity between all pairs of users (or items), which is computed by:
Then, the prediction

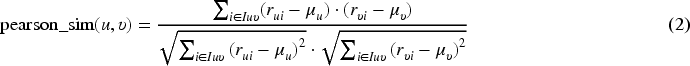
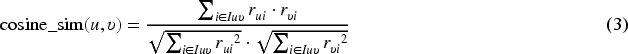

In contrast, model-based techniques leverage machine learning algorithms to create statistical models based on training ratings. These models capture patterns in ratings data, which can be used to make predictions for new data. Model-based methods use user-item ratings, but they do not rely on similarity measures in the database for recommendations. They are applied in collaborative filtering systems using algorithms like Bayesian networks, clustering techniques, neural networks, and singular value decomposition (SVD). 14
Past research has indicated that model-based approaches tend to provide more accurate recommendations. However, memory-based methods offer practical advantages in terms of simplicity, ease of implementation, and lower dimensional requirements. 15
When recommender systems utilize similarity metrics across the entire dataset, they encounter a decrease in accuracy as the data volume grows, which results in issues of data sparsity and limited scalability, as indicated by. 4 In contrast, clustering algorithms offer a solution to overcome these challenges, as demonstrated in the studies.16,17 These algorithms merge elements of both content-based and collaborative filtering approaches to create a hybrid system that enhances overall system performance and computational efficiency.
A clustering-based recommender system involves two key stages: a clustering process, followed by a classification task, as explained in the work by. 18 These attempts try to improve the performance of the system (the Scalability Problem), the recently signed up users or the movies that recently added to the database (the Cold-Start problem) and the movies with very few ratings (the Sparsity Problem). 19
While the clustering mechanism can significantly enhance the performance of the recommender system, it is essential to choose the appropriate clustering method.
K-Means clustering-based collaborative filtering
In 9 it is mentioned that the collaborative filtering is the best and most approved recommender method. However, it is also noted that the method lacks accuracy, and it takes a long time to manage big datasets. They used the K-Means clustering algorithm to overcome these problems. They made use of the Minkowski distance to calculate the distance between the centroids and the rest of the points into the K-Means algorithm to overcome the Scalability challenge. The authors of 20 found out that the appliance of K-Means improved the model performance in terms of Scalability and Sparseness. Also, according to 21 movies with no ratings or users who rarely rate, create issues to the prediction, because they do not provide enough data decreasing the accuracy. Indeed, K-Means provides a better view of the dataset through the clustering of the information. 22 Researchers of 23 developed a movie recommender system using K-Means for the clustering step and data pre-processing, using Principal Component Analysis (PCA). Research work in 24 proposed a movie recommender system that is built using the K-Means Clustering and k-NN algorithms and the results given by the proposed system were better than the existing technique based on the RMSE value. Finally, in our earlier research work, 25 we presented a movie recommendation method based on clustering by genre with better results on both accuracy and speed, compared to the k-NN standard collaborative filtering algorithm.
These studies have used clustering techniques, most notably K-Means, to improve the performance of collaborative filtering-based recommender systems. However, few have explored alternative clustering methods or systematically analyzed their impact on both accuracy and computational efficiency. Our study builds on these previous works by conducting an extensive comparison of multiple clustering algorithms and evaluating their performance in terms of both accuracy (RMSE, MAE) and computational efficiency (runtime). To the best of our knowledge, this is the first study to investigate Mean Shift and Gaussian Mixture models in the context of user-based collaborative filtering.
Problem statement
K-Means clustering is widely employed for identifying neighboring clusters in collaborative filtering recommender systems, because it is easily understandable and has low computational complexity, as demonstrated in.11,26 Although this method performs clustering accurately, it suffers from the challenge of specifying the number of initial clusters and their initialization. 12 Therefore, initial centroid selection and the number of iterations needed for clustering affect the efficiency, which leads to higher computational complexity for large datasets. 27 As mentioned earlier in this paper, different recommendation datasets may require different numbers of K clusters. Specifying a fixed K value at initialization is not a practical approach, especially with the continuous expansion of real-time datasets.
In this research we tried several different clustering algorithms to address the challenges related to the initialization of the K-Means clustering in user-based collaborative filtering and enhance the performance of the recommender system. More specifically, we used the DBSCAN clustering, the Agglomerative Clustering, the Affinity Propagation, the Spectral Clustering, the Mean Shift, the Gaussian Mixture and the K-Means Split Merge algorithms to implement the clustering step (Figure 2, Part A) and we compared the results to our earlier research work that used the K-Means algorithm for clustering the users. In this first step, we group all users according to their preferred genres and according to their preferred movies and we put the most similar users together, before applying the k-NN filtering among the users belonging to the same group. Then, we compare the results in terms of accuracy and runtime efficiency, trying to find a better clustering solution. Our goal is to quickly assign the user to this cluster of users, that he or she shares most common tastes and preferences on the style (=genre) of movies or the movies itself. Then, we can search more easily, quickly and precisely for candidate movies to recommend.
This study goes beyond merely comparing clustering algorithms for recommendation systems; it aims to contribute methodologically through an in-depth analysis of each method's strengths and limitations. Specifically, we provide a structured methodological evaluation that includes both theoretical analysis and empirical investigation, emphasizing the impact of clustering on overall Recommendation System performance and analysis of methodological differences among clustering techniques.
Our research examines how different clustering techniques affect the collaborative filtering process beyond improving computational speed. Our initial hypothesis was that certain clustering algorithms could enhance recommendation quality, which is partially confirmed by the performance of MeanShift. While most related studies focus solely on accuracy or execution time, this work also examines the structural characteristics of algorithms. Specifically, we analyze:
Their ability to handle imbalanced datasets, as examined in the Experiments and Results section, where different clustering techniques were tested on datasets with varying levels of sparsity. Their sensitivity to parameters such as sample size and centroid initialization, as discussed in the Implementation section, where different KMeans initialization strategies were explored. Their behavior when dealing with varying data density and uncertainty levels, analyzed in Experiments and Results, particularly in relation to MeanShift's performance under different conditions and the failure of DBSCAN to generate meaningful clusters due to data sparsity and high-dimensional challenges.
Implementation
Clustering-based user based collaborative filtering
The clustering-based collaborative filtering process involves two distinct tasks: a clustering task, followed by a prediction task. The sequence of actions to be performed is outlined as follows:
Cluster all users, using a clustering algorithm, according to their preferred genres/movies and group the most similar users together. Compute the distance between the active user and the centroid of each cluster. Select the cluster to which the active user is closest. Identify the ‘n’ most similar users from within the chosen cluster for the active user. Predict the user's rating for the active genre/movie based on the ratings provided by these neighboring users.
In Figure 3, we can observe the workflow of the user-based collaborative filtering after clustering. This process consists of a two-step approach, where we first apply distinct clustering methods independently. After this clustering phase, we proceed to the task of predicting genre/movie ratings based on each clustering technique. The subsequent sections will provide a detailed outline of the various clustering methods utilized in this study for user clustering.
Execution steps of clustering-based user based collaborative filtering.
K-Means clustering-based user based collaborative filtering.
This algorithm segments the entire dataset into K distinct clusters or groups. It is known for its rapid convergence toward a locally optimal solution and its ability to handle large datasets. In the initial phase, K data points are selected at random, where ‘K’ signifies the number of clusters that the data points will be divided into. These initial data points serve as the starting cluster centers to initiate the allocation process. Afterward, each data point in the dataset is examined, and it is assigned to the cluster with the closest distance to the cluster center. The mean value of all data points within the cluster is recalculated and designated as the cluster center. The centroid or center of each cluster is updated with the new mean value each time a new data point is added to or removed from the cluster. This iterative process continues until all data points have been assigned to a cluster, and no data point switches its cluster assignment. In our earlier research, K-Means clustering was experimented for different values of cluster sizes Κ, ranging from 1 to 750. One cluster means that there is no clustering and only k-NN is executed. The results showed a significant improvement on both speed performance and accuracy when the data was clustered based on the preferred genres, compared to the simple collaborative filtering method, without the clustering step.
DBSCAN clustering-based user based collaborative filtering.
DBSCAN, short for Density-Based Spatial Clustering of Applications with Noise, is an algorithm designed to group data points into clusters based on their density distribution within a dataset. It perceives clusters as regions where data points are densely packed, separated by areas with lower density. Unlike K-Means, which assumes clusters to be convex, DBSCAN can detect clusters of arbitrary shapes. The algorithm relies on two key parameters: min_samples and eps. min_samples set the threshold for the minimum number of neighboring points within a specified distance (eps) required for a data point to be labeled as a core sample. Core samples represent dense regions within the dataset. Clusters are formed by linking core samples that are near to each other, while non-core samples within the eps distance of a core sample are also included in the cluster. Additionally, DBSCAN can identify outliers, which are data points that do not belong to any cluster. It is particularly effective for datasets with irregular shapes and varying densities. However, performance of DBSCAN is sensitive to the parameter selection, and it may encounter challenges with datasets containing varying densities or high-dimensional data.
While DBSCAN has been successfully applied in various domains, it failed to generate meaningful clusters in our dataset. The key reasons for this failure are outlined below:
High Data Sparsity and Lack of Dense Regions: DBSCAN requires a minimum number of points within a given radius (eps) to form a cluster. In our dataset, user preferences are highly sparse, meaning that there are many isolated points without enough density to form clusters. This sparsity is common in recommendation systems, where user-item interactions are often incomplete, leading to fragmented data distributions. Curse of Dimensionality and Distance Metric Limitations: DBSCAN relies on distance metrics (e.g., Euclidean distance) to define clusters. However, in high-dimensional spaces, such as those in recommendation systems (where each user is represented by a vector of ratings or preferences), the effectiveness of distance-based clustering deteriorates. The difference between near and far points becomes less meaningful due to high dimensionality, a phenomenon known as the curse of dimensionality. Alternative distance metrics (such as cosine similarity) might be more suitable, but DBSCAN is not inherently designed to use them effectively. Handling of Noise and Outliers: DBSCAN classifies points that do not belong to any dense region as noise. In recommendation systems, many users have unique or rare preferences, causing them to be classified as noise rather than being grouped into meaningful clusters. Unlike KMeans, which forces all points into clusters, DBSCAN may leave a significant portion of users unclustered, making it unsuitable for a collaborative filtering framework where every user should belong to a group.
We have tested various parameter values for DBSCAN which resulted in either a single cluster for all users or a separate cluster for each user. No intermediate clustering structure could be achieved.
Agglomerative clustering-based user based collaborative filtering.
Agglomerative clustering is a hierarchical clustering method that operates from the bottom up. Initially, each data point forms its own cluster, and subsequently, the algorithm merges the most similar clusters iteratively until only one cluster remains. Typically, similarity between clusters is calculated using a distance measure such as Euclidean distance or cosine similarity.
The process of agglomerative clustering unfolds as follows:
Every data point starts as an individual cluster. The algorithm identifies the two clusters that are most similar. It merges these two clusters into a single cluster. Steps 2 and 3 are repeated until there is only one cluster left.
The resultant hierarchy of clusters can be visualized using a dendrogram, which illustrates the interrelationships among the clusters in a tree-like structure. Agglomerative clustering is straightforward to implement, but it can be computationally demanding for large datasets. Additionally, it may be susceptible to noise and outliers within the data. The algorithm accepts parameters such as ‘nclusters’, indicating the desired number of clusters, and ‘metric’, which specifies the distance metric used for computing linkage (e.g., Euclidean or Cosine distance).
Using the Agglomerative clustering in our experiments, there was no significant performance improvement towards the KmeansKnn algorithm.
Affinity propagation clustering-based user based collaborative filtering.
Affinity propagation is a clustering technique designed to identify a group of exemplar data points that accurately portray a given dataset. It operates through an iterative process of message passing among data points, adjusting their affinities and selecting exemplars until stable clusters emerge. Initially, all data points are considered as potential exemplars. Subsequently, each data point communicates its representativeness to others via messages. Based on these messages, data points update their affinities and choose the data point with the highest affinity as their exemplar. This cycle continues until a stable set of clusters is achieved, where each data point aligns with a single exemplar. These exemplars effectively serve as the cluster centers. Affinity propagation stands out as a robust clustering algorithm applicable across various datasets. It excels particularly in handling high-dimensional datasets or those with intricate structures.
In our experiments, the Affinity Propagation algorithm produced about 300 clusters based on genre with almost the same performance as the K-Means based filtering.
Spectral propagation clustering-based user based collaborative filtering.
Spectral clustering is an unsupervised method employed for clustering data points based on their similarities. Its approach involves creating a similarity matrix among data points and then utilizing the eigenvectors derived from this matrix to identify clusters. The fundamental concept underlying spectral clustering is that data points that are proximate in the original space should exhibit similar proximities in the spectral space, thereby enabling the use of eigenvectors from the similarity matrix to identify clusters.
The process of spectral clustering entails the following steps:
Creation of a similarity matrix among data points. Computation of the eigenvectors associated with the similarity matrix. Utilization of these eigenvectors to identify clusters of data points.
While spectral clustering presents a relatively straightforward implementation, it can pose computational challenges, especially when dealing with large datasets.
In our experiments, the Spectral Clustering Algorithm performed almost the same as K-Means based filtering, when the missing values were substituted by the average value, but it performed worse when the missing values were substituted by either zero or minus 1.
MeanShift clustering-based user based collaborative filtering.
Meanshift clustering is a centroid-based clustering method that operates without explicit assumptions about the shape or size of clusters. It functions by iteratively adjusting the center of a cluster towards the mean of the points within a defined radius until convergence is reached. This technique is advantageous for identifying clusters of various shapes and sizes and exhibits robustness against noise and outliers. It also demonstrates efficiency, boasting a time complexity of O(nlog n), where n represents the number of data points.
Here's a simplified breakdown of meanshift clustering:
Initialization of cluster centers, which can be achieved randomly or through methods like K-Means clustering. Calculation of the mean of points within a designated radius for each cluster center. Adjustment of the cluster center to match the computed mean. Iteration of steps 2 and 3 until the cluster centers converge.
Upon convergence of the cluster centers, data points can be assigned to the nearest cluster center.
In our experiments there was accuracy performance improvement compared to the K-Means clustering in some cases, but there was no runtime improvement.
Gaussian mixture clustering-based user based collaborative filtering.
Gaussian mixture clustering is an unsupervised learning technique that categorizes data points into clusters based on their resemblance. It operates under the assumption that the data originates from a blend of Gaussian distributions and aims to determine the parameters defining these distributions. The algorithm functions by iteratively assigning data points to clusters and adjusting the parameters of the Gaussian distributions accordingly. This iterative process continues until the clusters stabilize, indicating that data points are appropriately allocated to the clusters most resembling them.
Gaussian mixture clustering is a versatile method extensively applied across diverse domains such as customer segmentation, image segmentation, and anomaly detection. However, the algorithm effectiveness can be influenced by the initial selection of cluster centers, and it may incur significant computational costs when handling large datasets.
In our experiments Gaussian mixture performed worse than K-Means on both accuracy of the predictions and the running time.
K-Means split-merge clustering-based user based collaborative filtering.
The K-Means Split-Merge clustering method is an unsupervised learning technique utilized to divide a given dataset into a predetermined number of clusters. It operates iteratively, alternating between two main steps:
Split Step: Each existing cluster undergoes a division into two smaller clusters by assessing the distance between every data point and the cluster's centroid. Data points closest to the centroid are assigned to one cluster, while those farthest away are allocated to the other. Merge Step: The two clusters exhibiting the highest similarity are combined into a single cluster. This similarity is determined by evaluating the distance between the centroids of the clusters.
These steps repeat until either the desired number of clusters is reached or a predefined stopping criterion is met. It's important to note that the K-Means Split-Merge algorithm demands more computational resources compared to traditional K-Means due to the additional split and merge operations. Nevertheless, it often produces superior clustering outcomes, particularly in scenarios involving intricate data distributions or when the number of clusters isn't known in advance.
In our experiments the K-Means Split-Merge clustering algorithm performed almost the same as the K-Means_avg.
Algorithms
In our earlier research work, we implemented one standard collaborative filtering algorithm that uses the k-NN algorithm to predict the genre rating values and a new proposed algorithm that first applies clustering to the users (we named it KmeansKnn, since we used the K-Means for the clustering step) and then predicts the genre values by using the k-NN for each cluster. We compared them for accuracy in predictions and runtime. The results showed an important improvement on both the speed performance and the accuracy of the system. In this work, we decided to implement new algorithms, that first apply clustering to the users, either by their preferred movie, or by their preferred genres of movies, and to compare their results to our earlier KmeansKnn algorithm results. The algorithms that we implemented are:
1. DBscanKnn 2. AgglomerativeKnn 3. AffinityPropagationKnn 4. SpectralKnn 5. MeanShiftKnn 6. GaussianMixtureKnn 7. KMeansSMKnn
Each algorithm first applies a clustering step on users, and then predicts the genre ratings or the movie ratings by using k-NN for each cluster.
We used the k-NN algorithm from the Surprise Library and all clustering algorithms from the sklearn Library, except for the KMeansSplitMerge that we implemented it by ourselves.
Dataset
For our experiments we used the MovieLens 1 M dataset. This is a stable benchmark dataset that contains ratings from users on movies. The dataset consists of 6000 users, 4000 movies and 1 million ratings and every user has at least 1 rating. The users rated the movies between 1 and 5. The movies are categorized into 19 genres. Each movie may belong to more than one genre. In this case the movie rating counts for all the genres that it belongs to. We split the user-movie rating dataset into 80% of the training set and 20% of the test set. We also used 5-fold cross validation.
Since our experiments are computationally demanding, we ran our tests on a 32 CPU cores system with 128GB ram.
Metrics
We used both Runtime and Accuracy to estimate the results of the implemented methods. Runtime is the fit time in seconds for each split plus the testing time in seconds for each split. Accuracy is estimated by computing the RMSE (Root Mean Squared Error) and the MAE (Mean Absolute Error), between the predicted genre rating and the actual one.


In this section we compare the new clustered collaborative filtering algorithms (DBscanKnn, AgglomerativeKnn, AffinityPropagationKnn, SpectralKnn, MeanShiftKnn, GaussianMixtureKnn, KMeansSMKnn) to the KmeansKnn algorithm that we implemented in our earlier research work. The results are separated into two categories: accuracy results and running time results.
Parameters
The parameters of our experiments are:
The data vectors (points) to be clustered: the users on their preferred genres or the users on their preferred movies. The method to be used in order to handle the unknown values (NaN) in our vectors. This could be:
the zero value the mean value from genre rating the mean value from all user's movie ratings the most frequent value the minus one value kappa: the (max) number of neighbors to take into account for aggregation. nclusters: the number of clusters to be generated. Used for clustering algorithms that demand the number of clusters to be set apriori. The algorithm to be executed in order to perform the clustering step of our procedure.
Results – performance
All algorithms are named like Algorithm_[avg, zero, minus], where Algorithm is one of the DBscan, Agglomerative, the Affinity Propagation, the Spectral, the Mean Shift, the Gaussian Mixture and the K-Means Split Merge clustering algorithms, and _avg stands for the algorithm that substitutes the NaN values of the dataset with the average value of the vector, _zero stands for the algorithm that substitutes the NaN values of the dataset with the zero value and _minus, with the −1 value.
Dbscanknn vs KmeansKnn
DBSCAN failed to generate clusters for our dataset.
Agglomerativeknn vs KmeansKnn
Accuracy Metric:
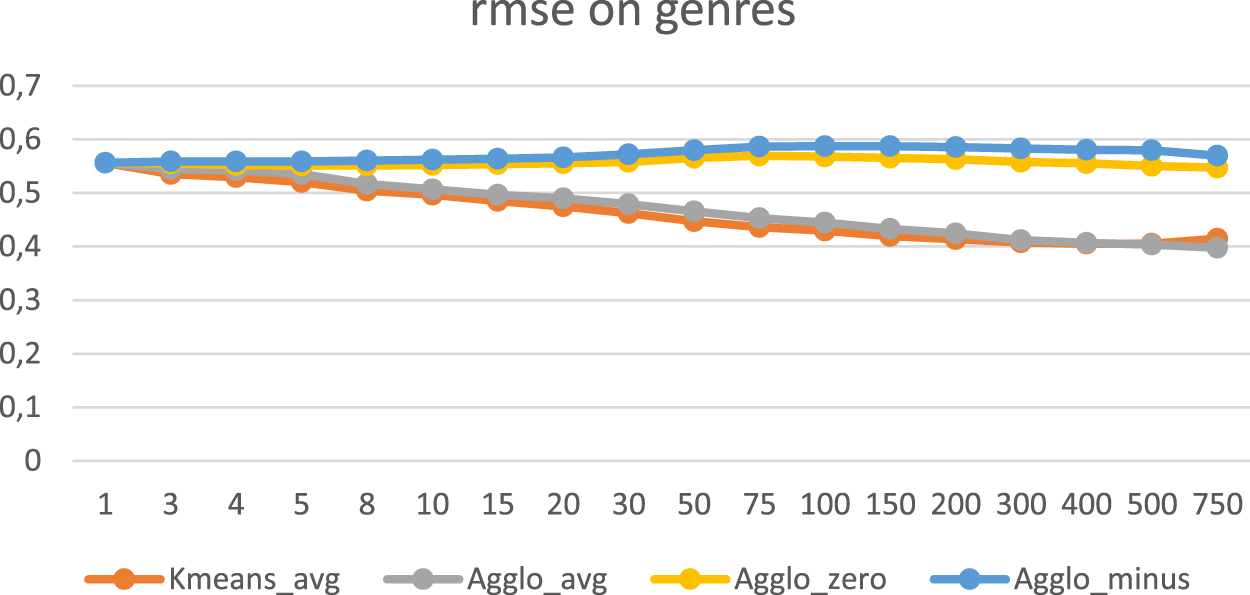
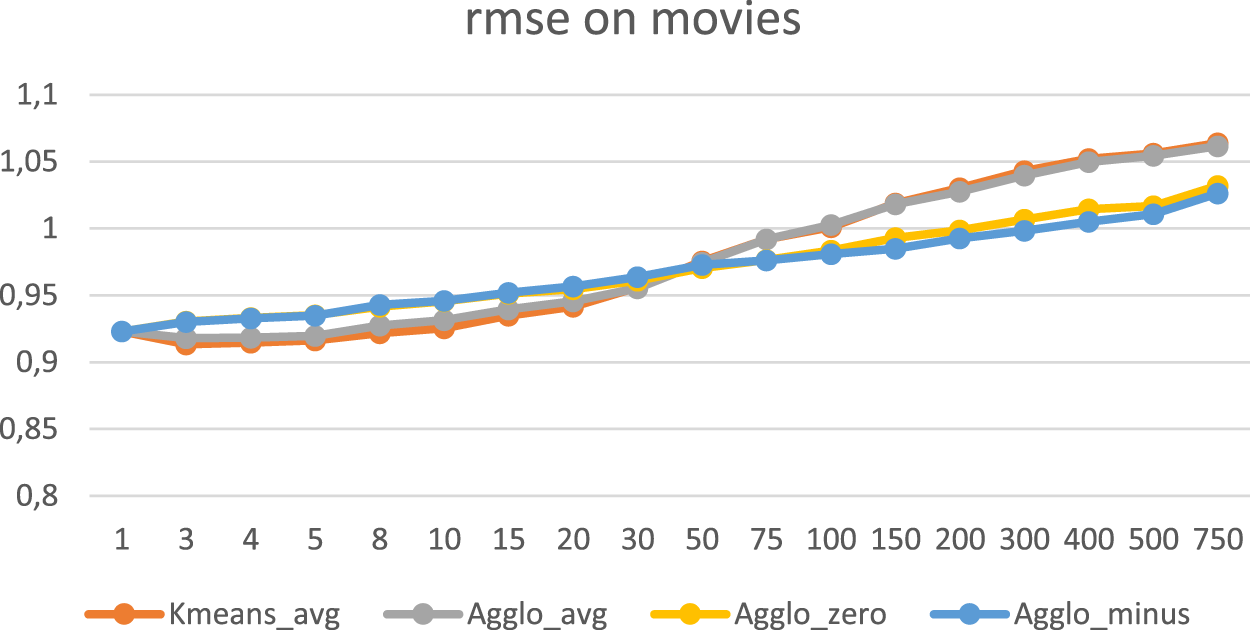
Parameter Setting: [cluster by genre, kappa = 40, nclusters = 1.750], Figure 4. AgglomerativeKnn_avg performed almost the same as KmeansKnn_avg, while AgglomerativeKnn_zero and AgglomerativeKnn_minus performed worse than KΜeansKnn_avg. Parameter Setting: [cluster by movies, kappa = 40, nclusters = 1.750], Figure 5. Using AgglomerativeKnn_zero and AgglomerativeKnn_minus clustering in our experiments, there was an improvement in RMSE and MAE when the number of clusters was bigger than 50, the data vectors (points) to be clustered were the users on their preferred movies and the missing ratings were substituted by zero or minus 1.
RMSE on genre vectors for agglomerative clustering.
RMSE on movies vectors for agglomerative clustering.
Performance Metric:
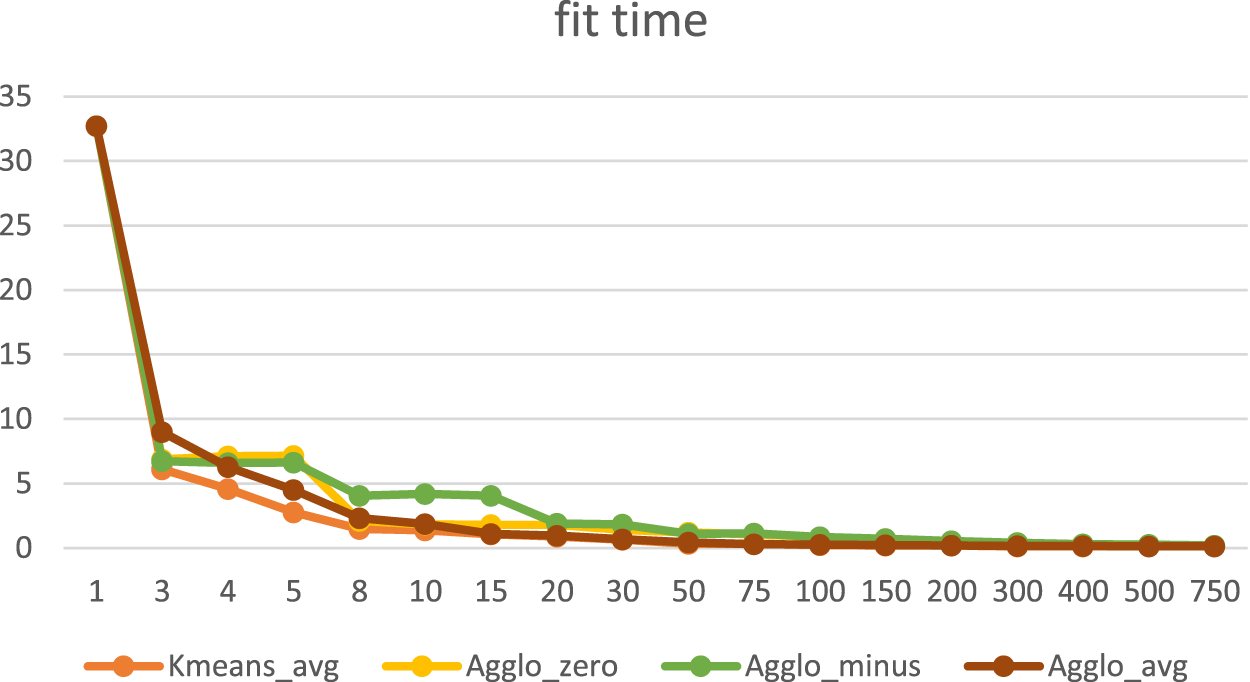
When using the Agglomerative clustering in our experiments, there was no significant performance improvement compared to the KΜeansKnn algorithm in RMSE and MAE, as shown in Figures 4 and 5. There was an improvement only when the number of clusters was greater than 50, the data vectors (points) to be clustered were the users on their preferred movies and the missing ratings were substituted with zero or minus 1. There was no improvement when the missing values were substituted with the average value. Moreover, there was no improvement in running time (Figures 6 and 7).
Performance metric for agglomerative clustering (fit time).

Performance metric for agglomerative clustering (test time).
AffinityPropagation clustering algorithm does not take as an argument the number of clusters to be generated. It iteratively builds clusters until it identifies the groups of exemplar data points that accurately portray a given dataset. In our experiments, Affinity Propagation algorithm produced around 300 clusters. Hence, we compare it to our KmeansKnn algorithm by setting nclusters to 300.
Parameter Setting: [cluster by genre, kappa = 40, nclusters = 300], Figures 8 and 9. As we can observe in Figures 8 and 9, when clustering by genre is applied, only AffinityKnn_avg (which means that the NaN values of the dataset are replaced with the average value of the vector) performs similarly to KmeansKnn_avg. All other versions of the algorithm had lower accuracy than KmeansKnn_avg. Parameter Setting: [cluster by movies, kappa = 40, nclusters = 300], Figures 10 and 11 As we can notice in Figures 10 and 11 there is a significant improvement in the precision of the predicted movies, when the clustering step is performed by the Affinity Propagation algorithm and the missing values of the dataset are replaced with either 0 or −1.
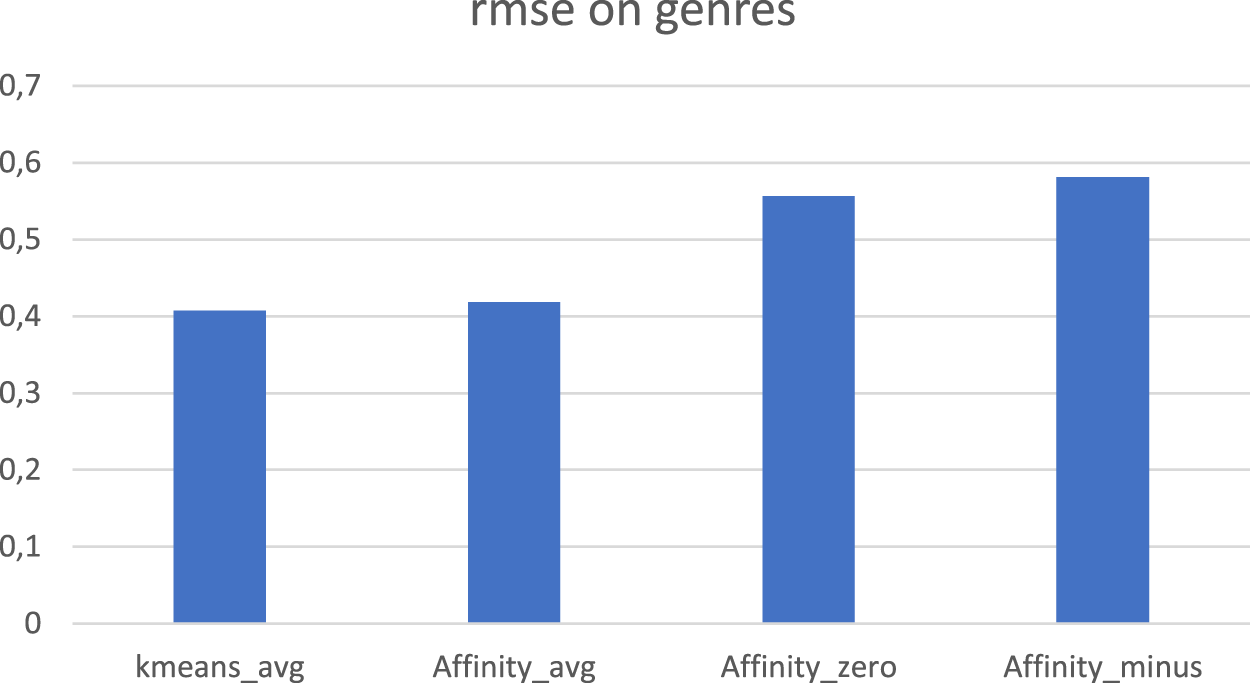
RMSE when affinity propagation clusters data on preferred genres.
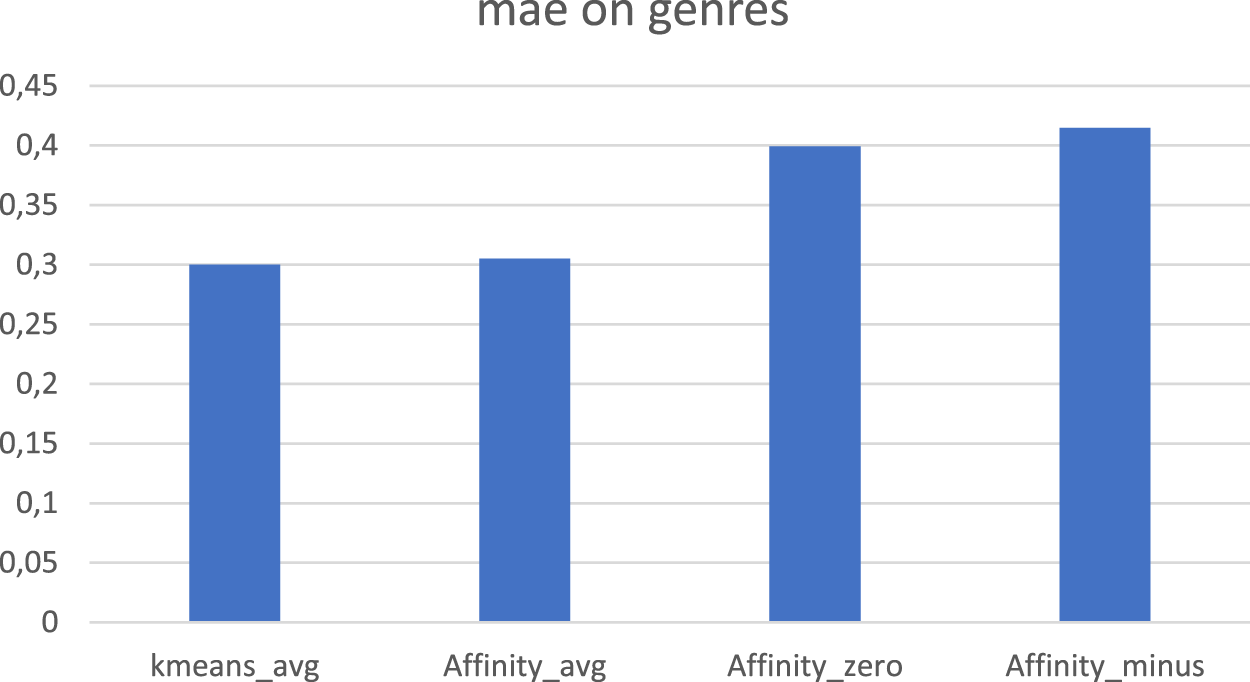
MAE when affinity propagation clusters data on preferred genres.
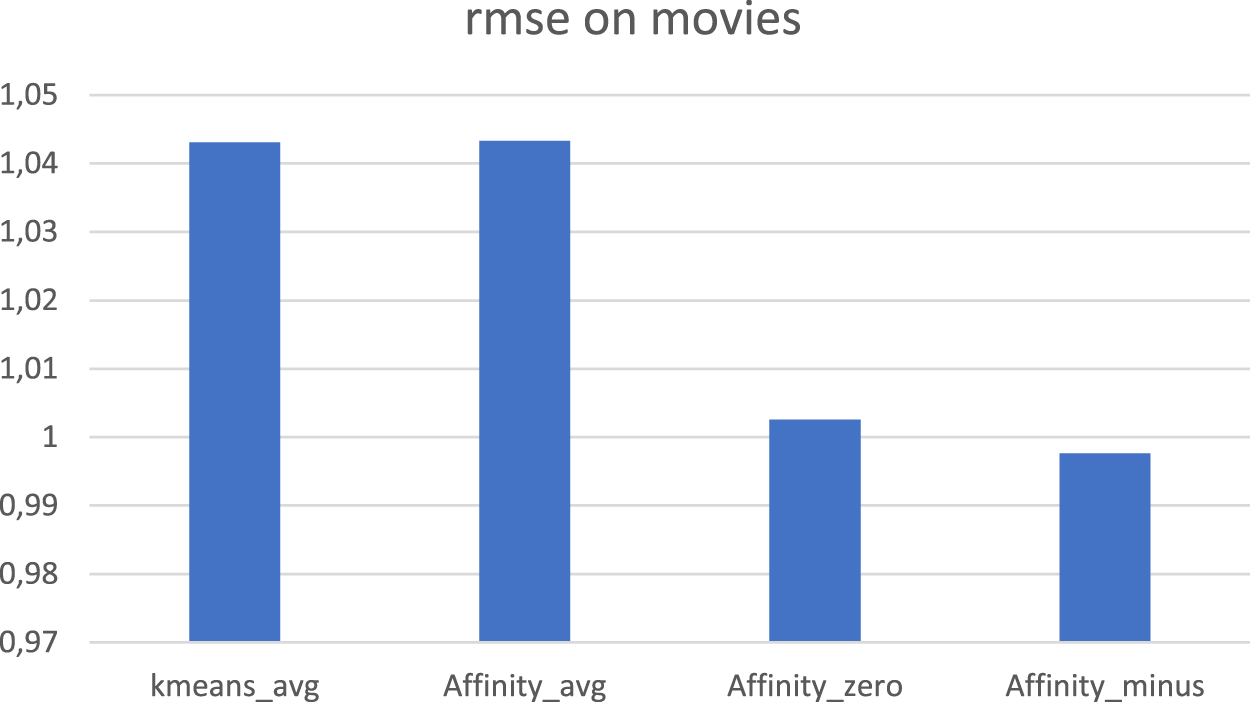
RMSE when affinity propagation clusters data by movie preferences.
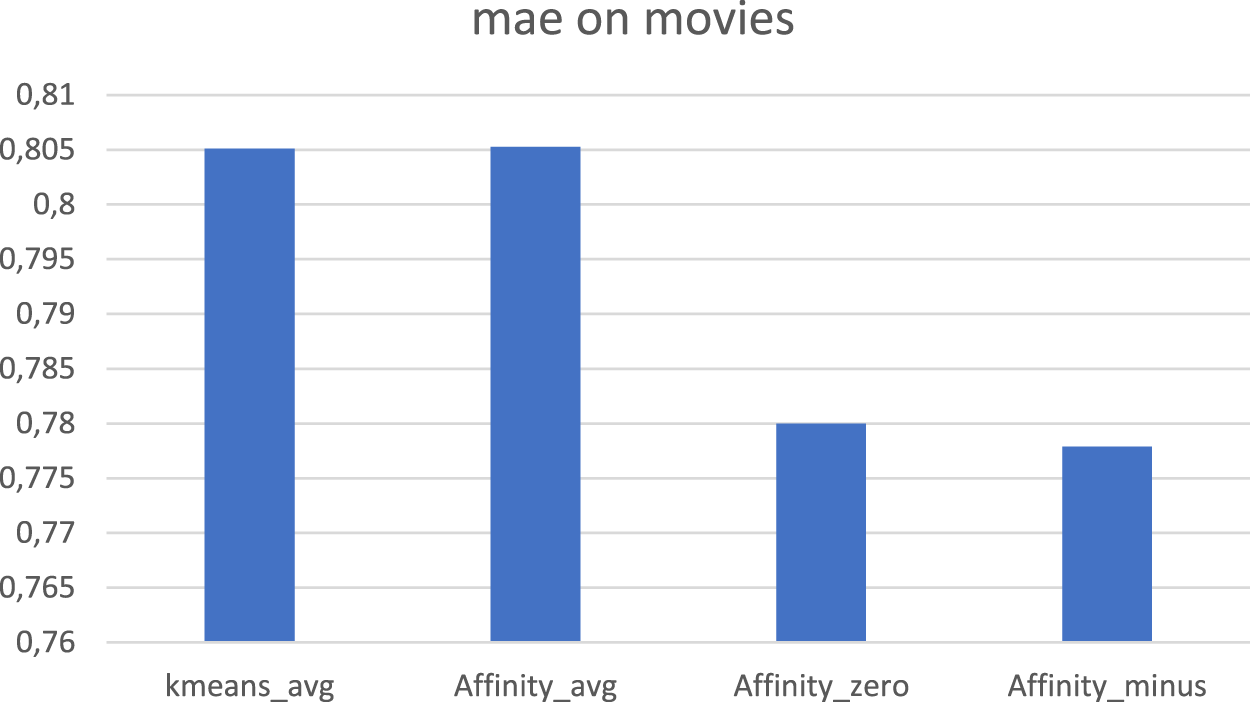
MAE when affinity propagation clusters data by movie preferences.
Parameter Setting: [cluster by genre, kappa = 40, nclusters = 1.750], Figure 12
Parameter Setting: [cluster by movies, kappa = 40, nclusters = 1.750], Figure 13
As we can see in Figures 12 and 13, the Spectral Clustering Algorithm, when it clustered users by the preferred genre performed almost the same as the K-Means based filtering, when the missing values were replaced with the average value, but it performed worse when the missing values were replaced with either 0 or −1. When it was used to cluster users by the preferred movies, it performed almost the same as the K-Μeans algorithm.
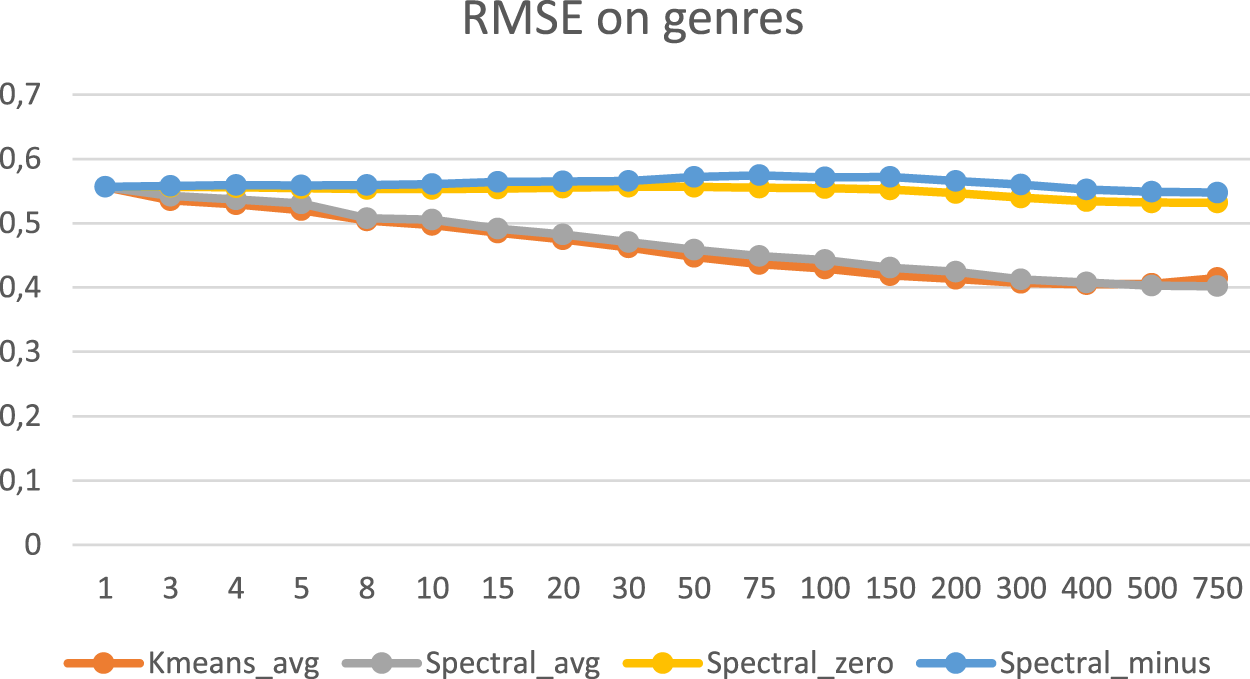
RMSE for spectral when clustering by genre.
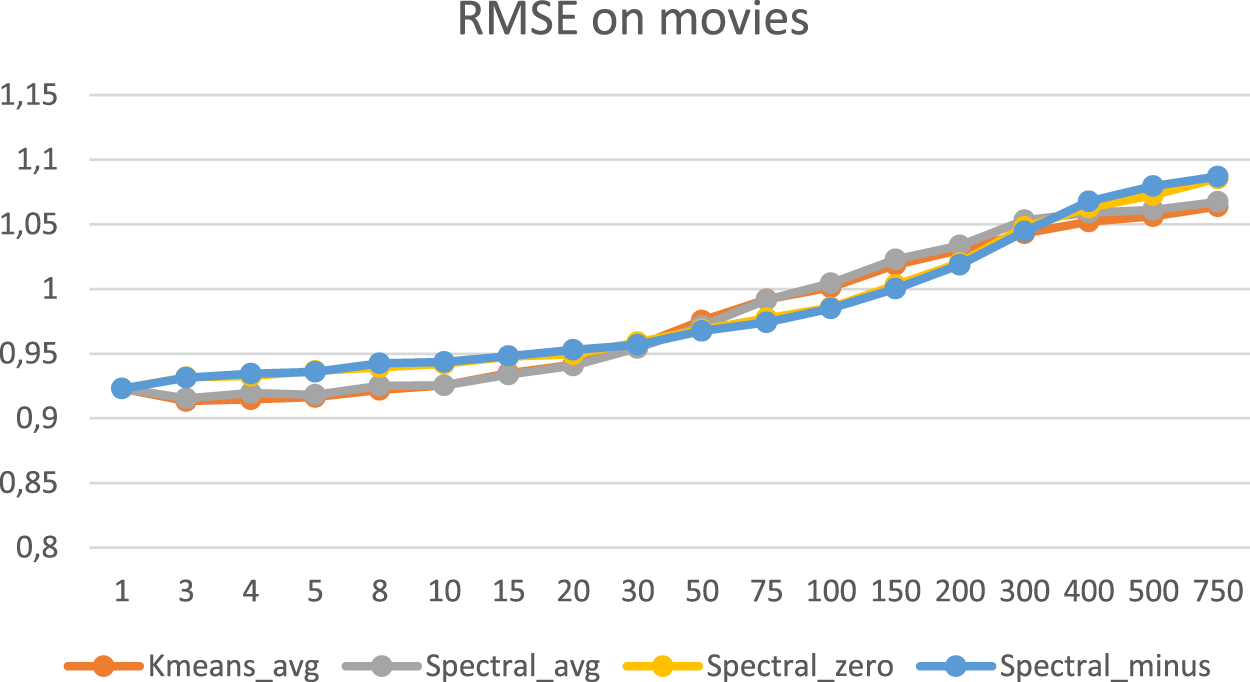
RMSE for spectral when clustering by movies.
a. Parameter Setting: [cluster by genre, kappa = 40, nclusters = 1, 8, 27, 113], Figure 14
b. Parameter Setting: [cluster by movies, kappa = 40, nclusters = 1, 8, 27, 113], Figure 15
In our experiments the MeanShift-Clustering based filtering performed worse in terms of accuracy of the results, when the data were clustered by genre (Figure 14), but it performed much better than K-Means when the data were clustered by the preferred movies (Figure 15). The running time is worse than that of K-Means based filtering (Figures 16 and 17). This is because the MeanShift algorithm from the sklearn library takes as an argument the bandwidth used in the flat kernel. The bandwidth is estimated using estimate_bandwidth, which is significantly less scalable and creates a bottleneck, leading to poor runtime performance.
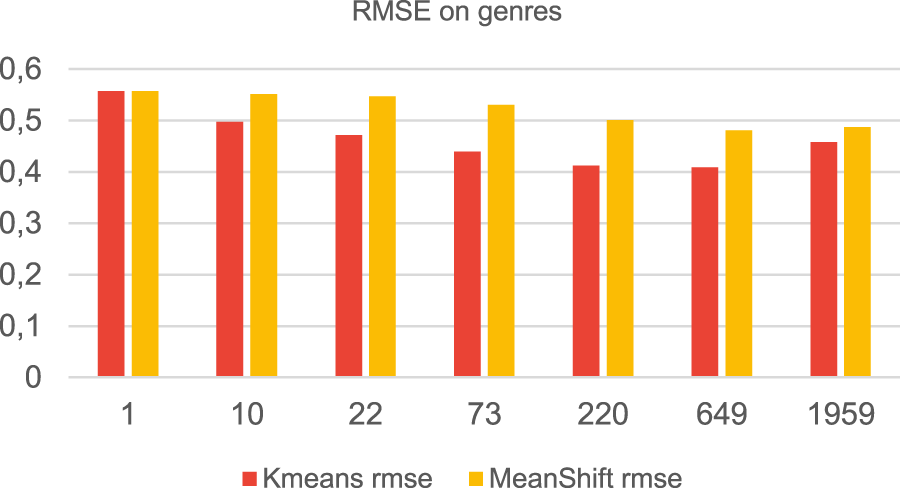
RMSE when clustering by genre.
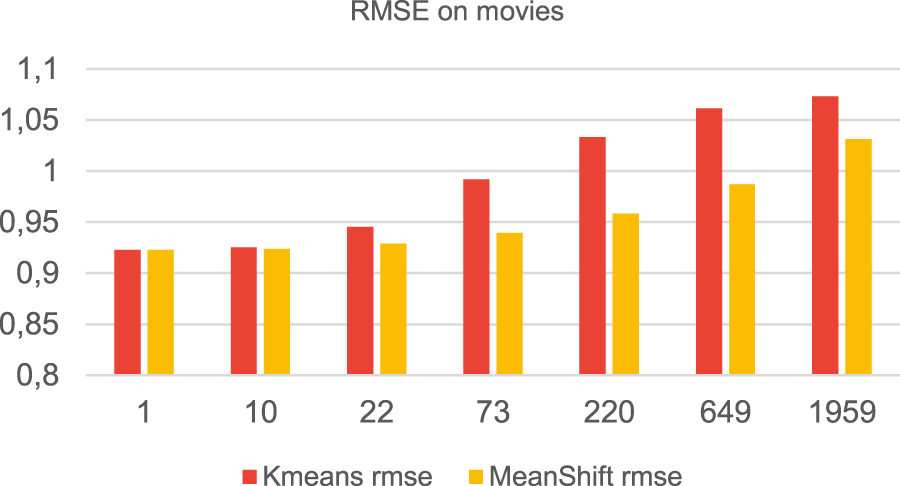
RMSE when clustering by movies.
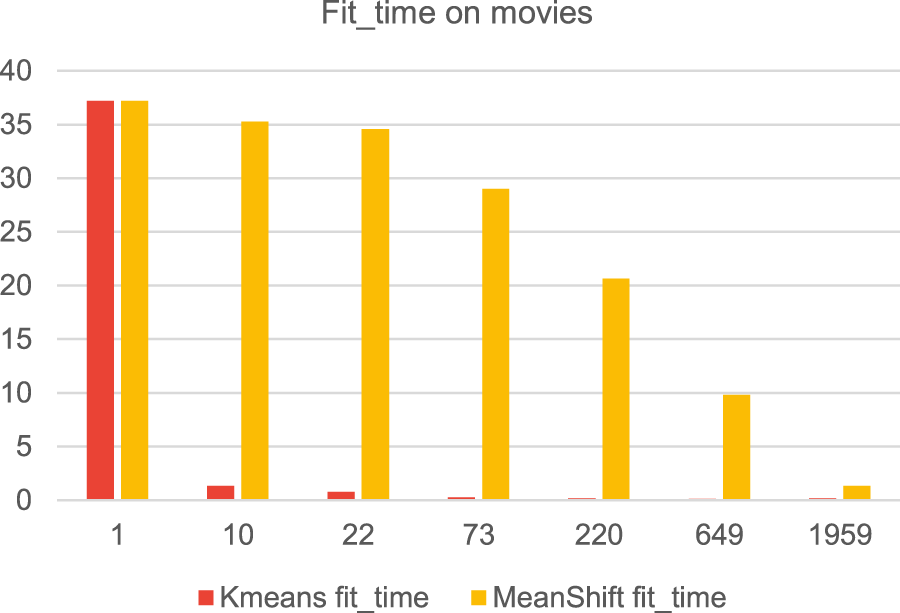
Fit time comparison between MeanShiftKnn_avg and KmeansKnn_avg algorithms.
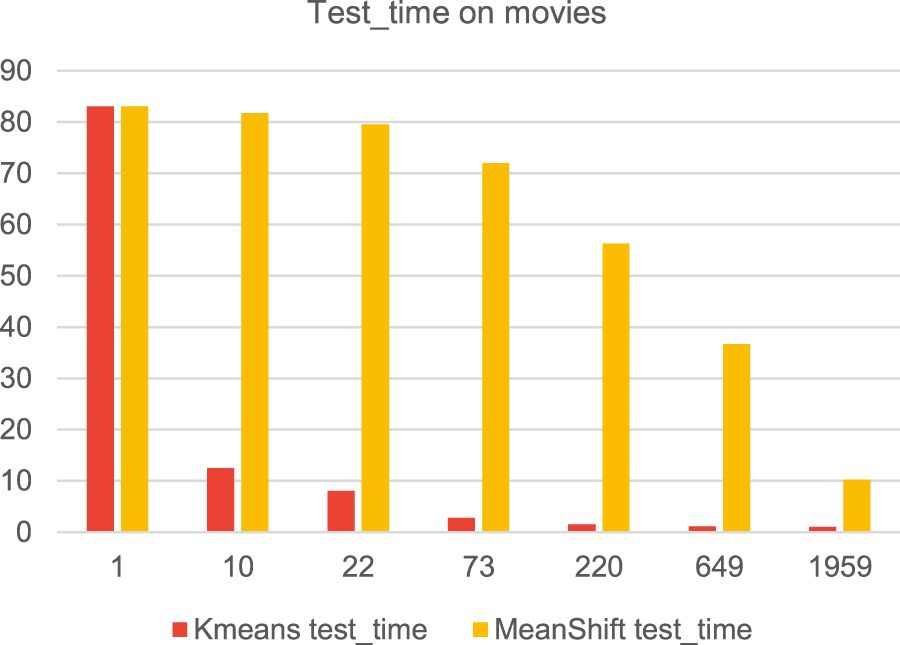
Test time comparison between MeanShiftKnn_avg and KmeansKnn_avg algorithms.
Parameter Setting: [cluster by genre, kappa = 40, nclusters = 1.750], Figure 18.
Parameter Setting: [cluster by movies, kappa = 40, nclusters = 1.750, Figure 19.
In our experiments, GaussianMixture clustering performed worse in terms of accuracy of the results, when the data were clustered by genre (Figure 18), but it performed slightly better, when we clustered data on movies and the number of clusters exceeded 75 (Figure 19). It had worse performance in terms of runtime.
KMeansSMKnn vs KmeansKnn
Parameter Setting: [cluster by genre, kappa = 40, nclusters = 1.750], Figure 20.
Parameter Setting: [cluster by movies, kappa = 40, nclusters = 1.750], Figure 21.
In our experiments, the KΜeans Split-Merge clustering algorithm performed almost the same as the KMeans_avg (where the missing values were replaced by the average value) and the data were clustered by genre or by movie. It performed better when the missing values were replaced by 0 or by −1, the data were clustered by movies and the generated clusters exceeded 50.
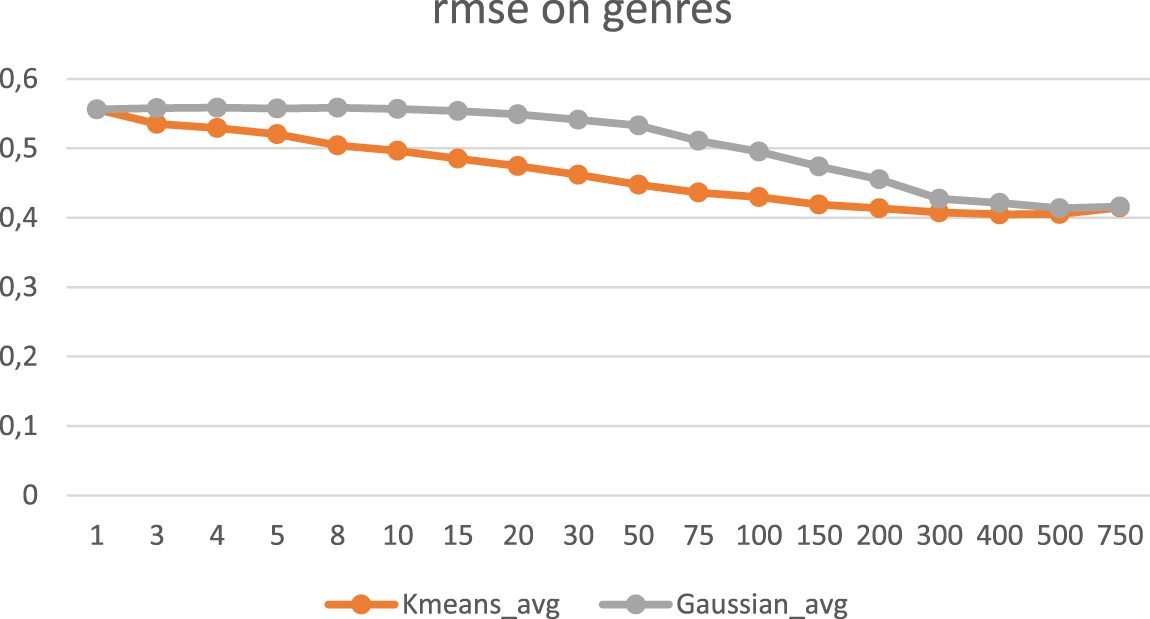
RMSE when clustering by genre.
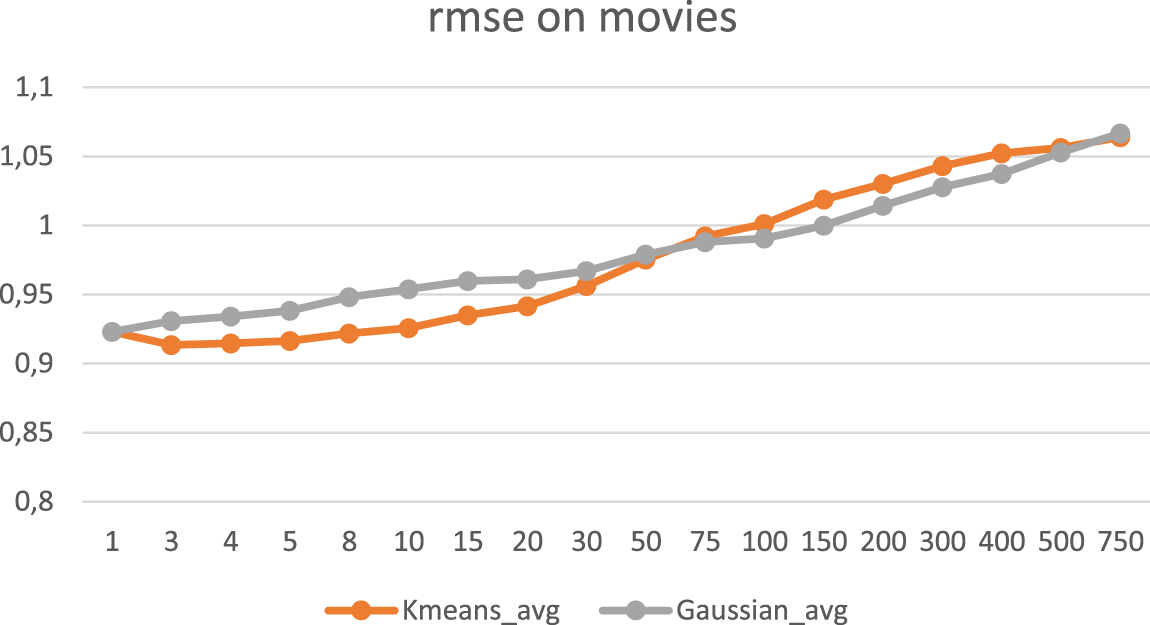
RMSE when clustering by movies.
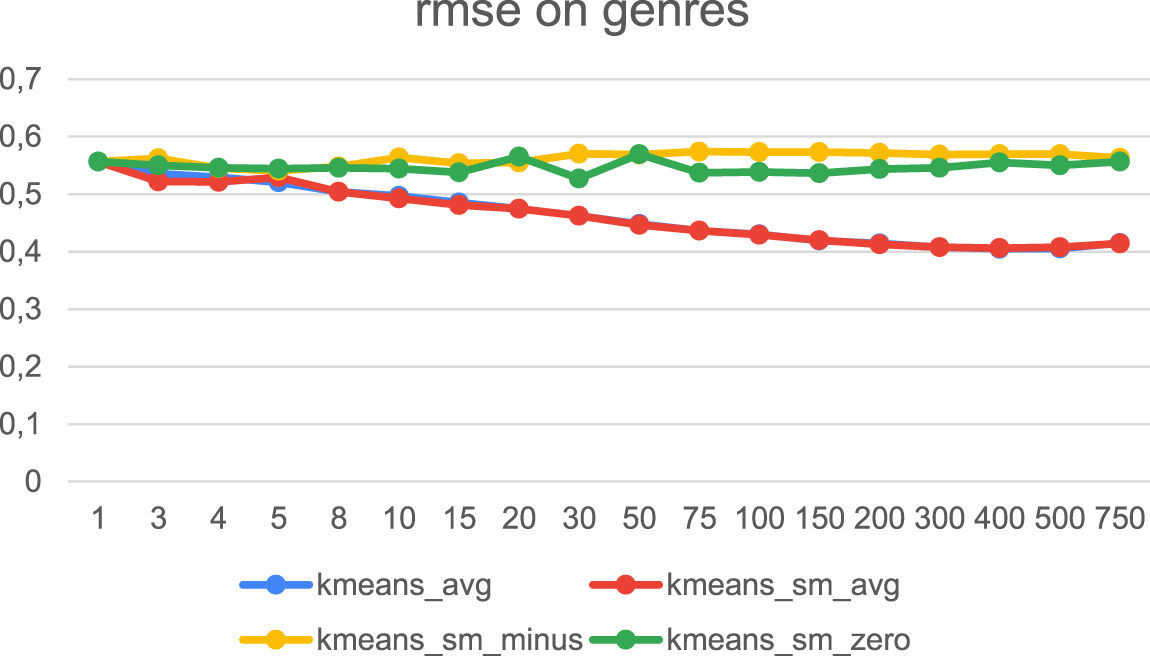
RMSE when clustering by genre.
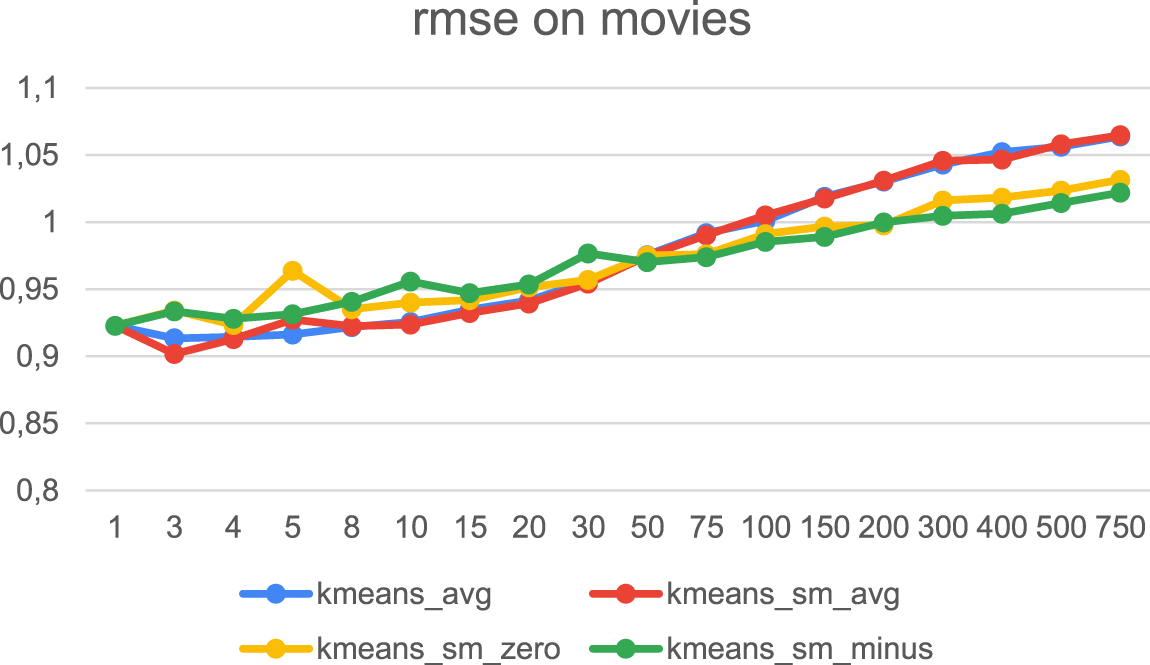
RMSE when clustering by movies.
Although the huge amount of available data simplifies the process of customization and recommendation, it significantly burdens the scalability of methods and their ability to handle sparse data sets. Grouping data before making recommendations to users tends to solve scalability issues. In our previous research work we used K-Μeans on genres to cluster our dataset and there was a significant improvement on both accuracy and runtime performance, compared to the standard k-NN algorithm. The K-Means clustering technique has been a standard choice for clustering in recommendation systems; however, the results of K-Means clustering are very sensitive to the initialization input. In this work we implemented seven algorithms, that all of them, first cluster the dataset either by genre or by movie, and then apply the k-NN algorithm, in order to predict the preferred genre or movie and propose it to the user. Our goal is to examine if there is another clustering technique, other than K-Means, that may give us better results, since it would overcome the K-Means vulnerabilities.
To better understand the trade-offs between accuracy and efficiency, we evaluated the runtime performance of all clustering methods across different dataset sizes. As shown, K-Means remains the most scalable solution, while Mean Shift provides higher accuracy but at a significantly increased computational cost. Affinity Propagation, despite its ability to identify the optimal number of clusters, exhibits unpredictable runtime behavior, making it less suitable for large-scale datasets. Our findings reveal that clustering algorithms exhibit varying scalability behaviors. K-Means, with its linear time complexity O(nki), efficiently scales as dataset size increases. Mean Shift, while offering more accurate clusters, suffers from O(n2) complexity, making it less feasible for large-scale datasets unless implemented in an offline setting. DBSCAN's performance is highly sensitive to parameter tuning (eps, min_samples), leading to cases where it either creates a single cluster or isolates each user into an individual cluster, limiting its scalability. Affinity Propagation, despite being adaptive in selecting the number of clusters, has unpredictable runtime behavior due to the iterative message-passing mechanism. To improve efficiency, future work should explore GPU-accelerated implementations and hybrid models that balance clustering accuracy with computational feasibility.
MeanShift achieves better accuracy in some scenarios, but its high computational complexity poses a challenge, especially for large datasets. The algorithm's inefficiency stems from its reliance on kernel density estimation, requiring multiple iterations over all data points, which increases execution time as dataset size scales. However, since this computational cost primarily affects the training phase and not the real-time recommendation process, MeanShift remains a valuable option for practical applications where clustering can be performed offline. This allows for the benefits of its improved accuracy while mitigating the impact of its runtime limitations.
In conclusion, our work revealed that although K-Means remains an effective and widely used clustering technique, other clustering methods like Mean Shift can, under circumstances, yield in better accuracy but at a computational cost. This is not a suspensive factor though, since the clustering step is performed offline and it does not impact the overall performance. These findings provide valuable insights for researchers and practitioners looking ways to optimize recommendation systems by selecting the most appropriate clustering approach based on their accuracy-performance trade-offs.
As part of future research, we propose the implementation and evaluation of the following two strategies to address identified limitations. First, we may improve K-Means initialization using adaptive centroid selection to reduce result instability. Second, a way to accelerate MeanShift may be to combine it with PCA or dimensionality reduction techniques to lower computational costs while maintaining accuracy.
In this study, we use the K-Nearest Neighbors (KNN) algorithm for making predictions after the clustering step. Although KNN is a popular and effective technique based on similarity, it has certain weaknesses, particularly in terms of computational efficiency and its capability to deal with sparse data. Future studies could explore the integration of alternative classification models with clustering methods to improve both accuracy and performance. A classification model we consider combining with the clustering step is the Support Vector Machine (SVM). SVMs are classification models that can handle high-dimensional data. By first clustering users and then training an SVM model within each cluster, the recommendation system could leverage SVM's ability to handle non-linearly separable data. This approach could be especially beneficial when user preferences follow complex patterns that are not well captured by distance-based methods like KNN.
Future work could also explore hybrid models that combine multiple classification approaches. For instance, such a hybrid model could integrate the outputs of KNN and SVM models to generate a final recommendation score.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.