
Abstract
Diffusion models are critical for spreading influence in social networks, as they contribute in estimating the potential reach of seed nodes, allowing for better evaluation of their goodness and effectiveness. This research aims to develop a diffusion model for weighted social networks, addressing a gap in traditional models that typically only consider the binary state of relationships between nodes. While existing models treat edges as simply existing or not, real-world social networks are inherently weighted, with edge weights reflecting the strength of the link between connecting nodes. To better capture these dynamics, we propose the Link Strength Diffusion (LiSt-D) model, which incorporates the strength of shared relation to determine the probability of diffusion between social actors. The LiSt-D model was tested on three real-world weighted social networks, Bitcoin Alpha, Bitcoin OTC, and Advogato, using seven heuristics to select the initial seed nodes. The findings showed that diffusion spread under LiSt-D covered 90% of the Bitcoin Alpha network, 84% of Bitcoin OTC, and 63% of the Advogato network. LiSt-D model captures the heterogeneity in the link-strength connecting nodes, and demonstrates early peak performance with high stability.
Introduction
Online social networks play a major role in information dissemination and social communications in today's era, transforming the way people connect, interact, and form opinion. Real-world tasks pertaining to social awareness, opinion monitoring, viral marketing, political campaigning, more often than not make use of online social networks for information dissemination and opinion shaping.1–8 Viral marketing leverages the organic spread of information within social networks, capitalizing on word-of-mouth dynamics.9–12 Free samples are given to select individuals deemed influential, with the belief that they would endorse the product to their connections, who in turn pass it on to their networks, and so on. Steered by viral marketing, the phenomenon of influence maximization (IM) has come under research spotlight, thereby making it a favoured domain with works focussing on diffusion of information, innovations and views across social networks. Initially explored in probabilistic contexts9,11 and later transformed into an optimization task, 13 IM addresses the challenge of selecting k initiators (or nodes) that can assist in “maximizing the spread of influence through relationships in the social network. 14 ” However, the goodness (efficacy) of these k initiators, which is the selecting criteria, is always evaluated based on their anticipated influence spread simulated using a diffusion model. Existing works have well established that the core of IM rests heavily on the underlying diffusion model employed, as the influence coverage of the selected k initiators is always considered with respect to a certain diffusion model.2,14–17 Some popular diffusion models often used to study diffusion in social networks are Susceptible-Infected-Recovered (SIR), 18 Independent Cascade (IC), 14 IC-Weighted (IC-W), 14 Linear Threshold (LT), 14 and Trivalency (TV). 19
Majority of the existing works in the addressed subject area focus on unweighted social networks, while overlooking the fact that most social networks in real-world are weighted networks, like friendship networks, rating networks, collaboration networks, trust networks etc.20,21 In a weighted social network, edges have values associated with them, which signify the strength of the link (relationship) connecting a pair of nodes. 22 Edge weight can have different interpretations, like in friendship networks it may represent the strength of the bond shared between friends, while in ratings network it may depict the trust level between connecting users. It has been argued that “a social tie's strength is often a function of its duration, emotional intensity, intimacy, and exchange of services 23 ” and social influence is contingent on factors like relationship strength, user characteristics, network properties, distance between users, and temporal aspects.24–26 Considering relationships regarding their emotional intensity and intimacy has been found to be socially meaningful. 27 In real life, people have various types of relationships or linkages with others, such as acquaintances, business contacts, or best friends, and not all carry the same significance. Diverse interaction patterns can be observed in real-world social networks, based on the intensity of the relation shared by the connecting nodes. Weighting captures this diversity by quantifying the link strength between individuals.28–30 Further, most social relationships are directed, and the intensity of the relation might vary in both directions. Thus, a (directed) weighted network can be considered to aptly represent a real-life social network. In a (directed) weighted social network, the link strength is read in the direction from the sender to the receiver, i.e., relationship strength is assessed from the sender's perspective.
Furthermore, most existing works have focused on developing algorithms for initiator (seed node) identification, while much less emphasis is placed on developing diffusion models. Most existing studies involving weighted social networks have been found to mostly use IC 14 and SIR 18 models as the underlying diffusion mechanism, both of which assume uniform infection (influencing) probabilities for all links in the network, while focussing only on the presence or absence of a link between the connecting nodes, 22 without taking the heterogeneity of their strength into consideration. However, we believe that when working on influence diffusion in weighted social networks, link strength should be incorporated in the underlying diffusion mechanism.
A diffusion model for (directed) weighted social networks, Link Strength Diffusion (LiSt-D), which incorporates relation strength in the computation of diffusion probability between two social actors. The proposed LiSt-D model considers the link strength between social actors which introduces a variation in the influence diffusion probability between the two nodes, which closely resembles the social behaviour of people in real life. Simulation of diffusion using the proposed LiSt-D model is conducted with regards to the total influence spread on 3 real-world weighted social networks. To the best of our knowledge, the presented work is among the preliminary studies focussing on the development of a model for diffusion in (directed) weighted social networks, wherein the likelihood of diffusion from source to target node is based on the strength of the link connecting them.
The rest of this paper is organized as follows: in Section 2, we delve into discussions on research concerning the diffusion of influence in social networks. Section 3 offers a brief overview of fundamental concepts relevant to our study. Our research motivation is outlined in Section 4, followed by the introduction of the LiSt-D model for influence diffusion in (directed) weighted social networks. Section 5 is dedicated to detailing the experimental setup and analysing the obtained results. To end, inferences are drawn in Section 6.
Related work
Numerous research works have tackled the task of increasing the dispersion of information, influence, and perspectives within social networks. The general problem of IM in social networks is about setting apart a tiny set of seed nodes that serve as the first information adopters and aid in the start of a diffusion process. Myriad approaches for IM in social networks have also been worked upon with the utilization of centrality measures, like degree, betweenness, h-index, k-core, etc., that exploit the topological features of the network being widely popular. Centrality measures combined with community detection have also been explored to enhance seed node identification whilst considering both local as well as global characteristics.31,32 HybridRank approach leverages utilises k-shell decomposition centrality to compute coreness of node and combines it with the eigenvector centrality of the node. 33 Liu & Zheng have proposed an approach that assesses nodes’ significance based on the concept of extended degree, that combines a node's degree with degree of its 1-order neighbors. 34 The local and global influence method determines the node's capacity for dissemination depending on its local location, computed by combining node's degree with its clustering coefficient, and global location computed using k -shell decomposition. 35 The Heuristic Independent Path Algorithm uses a vertex cover algorithm which helps minimize computational requirement by discarding irrelevant nodes from the selected domain. 36 The model proposed by Xu et al. first learns influence probabilities, and then transforms the problem to a weighted maximum cut problem which determines seed nodes by analysing the influence flow among nodes. 37 Group of Influential Nodes algorithm spots nodes with higher number of common neighbors and communication links by constructing different sub-graphs so as to expand the search area and reduce the amount of computations. 38 Ge et al. have proposed two models for diffusion that highlight the significance of multi-topic towards seed node selection. 39 Features like users’ spatiotemporal behaviour and community structure characteristics have also been explored for seed selection.40,41 A prediction and replacement approach based on the anticipated outcome for mining seed nodes in a dynamic complex network first predicts the forthcoming network snapshot using information from previous network snapshots, and then uses a quick replacement approach to mine the seed nodes between snapshots. 42 Aspects of a node's temporal behavior, like interaction frequency & self-similarity in interaction pattern, have also been exploited to study their role in quick and widespread spread of information across social networks.43,44
Bellingeri et al. reviewed studies focussing on adopting a weighted network approach towards real-world social networks, emphasizing that edge weights capture interaction heterogeneity, making binary link representations insufficient.
22
WVoteRank,
45
extended the concept of VoteRank
46
by considering edge weights, which are used to determine the seed nodes for unweighted network using voting scheme. WVoteRank computes each node's voting score whilst considering its 1-hop neighbors. Raamakirtinan and Livingston developed a weighted vote ranking approach with a dynamic weight parameter control that incorporates vote, weight, and coreness, to locate influential nodes.
47
Weighted Mixed Degree Decomposition technique for identifying influential nodes considers the underlying relationship strength,
Summary of literature review for weighted social networks.
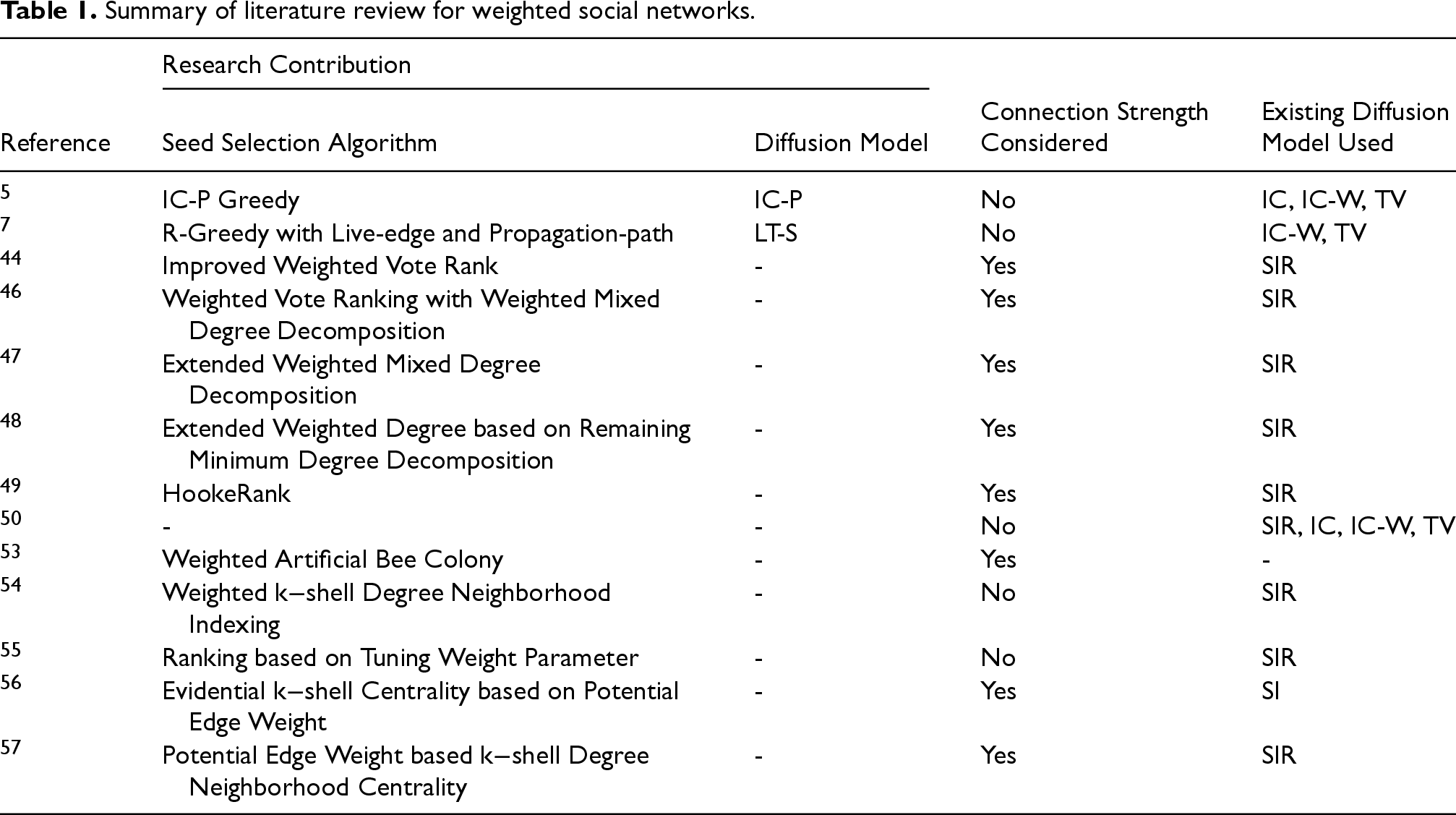
Summary of literature review for weighted social networks.
Review of the existing literature highlights the fact that the studying of influence spread in weighted social networks has been addressed to a limited extent as compared to unweighted social networks. Moreover, most of the work focusses on developing algorithms for identifying better seed nodes. To a much lesser extent does the existing literature concentrate on the study of a diffusion approach that outlines the criteria for node activation. As stated above, the diffusion models widely employed for simulating diffusion in weighted social networks only consider the existence or non-existence of a link. Though it has been established that user interactions are more often than not influenced by the strength of relation shared by the actors, most studies have not taken this aspect into consideration. Motivated by these findings we propose the Link Strength Diffusion (LiSt-D) model for influence diffusion in (directed) weighted social networks, which takes into consideration the impact of the heterogeneity in relations that exists between two users.
This section presents the working of the prevalent models used for studying diffusion in weighted social networks, namely Susceptible-Infected-Recovered (SIR) model, 18 Independent Cascade (IC) model 14 and IC-Weighted (IC-W) model. 14
Network diffusion models
Study of existing literature (Table 1) pertaining to weighted social networks establishes SIR to be the most commonly and widely employed diffusion model. Further, IC and IC-W come a close second. This section presents the working of these three diffusion models.
Susceptible-infected-recovered model
In the SIR model, the nodes are classified into three groups: Susceptible (S), Infected (I), & Recovered (R). It is intended for susceptible nodes to get data from their neighbouring infected nodes. As per the SIR model, hosts become sick, hold onto the infection for a while, and then get recovered. After a host recovers, they no longer remain susceptible to catching the infection. To begin with, all nodes are regarded to be in a susceptible condition, with the exception of seed nodes. The susceptible neighbours of the infected nodes are affected with a likelihood of β after each advancement. Infected nodes move into the recovered stage with γ likelihood, and thereafter they are considered to be immune to further infection and are no longer susceptible.
Independent cascade & independent cascade-weighted models
In both IC and IC-W models, diffusion is contingent upon the likelihood of information propagating between the sender and the recipient. Following are the basic presumptions that guide how these model's function: The underlying network is directed. Nodes signify actors, whilst edges depict relationships between them. Information can only be disseminated by a node to its outgoing neighbours. State of a node can be either active (influenced), indicating adoption of diffused information, or inactive (uninfluenced). Only an activated node can further activate its successors (aka outgoing neighbours). Each activated node gets a single chance in which it can attempt to activate its inactive successors. As the model is progressive, a node that has been activated cannot deactivate, and continues to maintain state until diffusion culminates. Diffusion is carried out in discrete time steps.
The basis of IC and IC-W models is the belief that an uninfluenced node's chances of getting influenced improve as more of its inbound neighbours become active. Diffusion initiates at timestep t with an initial set of active nodes

Real-world social networks are often weighted, wherein a weight is associated with the connecting links such that the weight represents the heterogeneity in the strength of the relation (link) between the connected users. 20 Further, the manner in which information (influence) diffuses from a node to its connections, hugely impacts the spread attained.2,18 Drawing motivation from this notion, our work focuses on developing a diffusion model called Link Strength Diffusion (LiSt-D), for (directed) weighted social networks that incorporates the heterogeneity in the strength of link between social actors when computing the influence diffusion probability. In actuality, link strength generally varies between each pair of social actors, with some being strong, and some weak. Since a higher edge weight signifies more link-strength, the chances of communication and subsequent sharing of information over such an edge is higher, as compared to an edge with lower edge weight. In the proposed LiSt-D model, link strength is read in the direction from the sender to the receiver, i.e., relationship strength is assessed from the sender's perspective. The LiSt-D model is probabilistic, progressive and assumes the social network to be directed.
Algorithm 1 outlines the approach of the proposed LiSt-D model. The model takes a weighted social network 

Table 2 lists the symbols and their meaning as used in Algorithm 1.
List of symbols used in Algorithm 1.
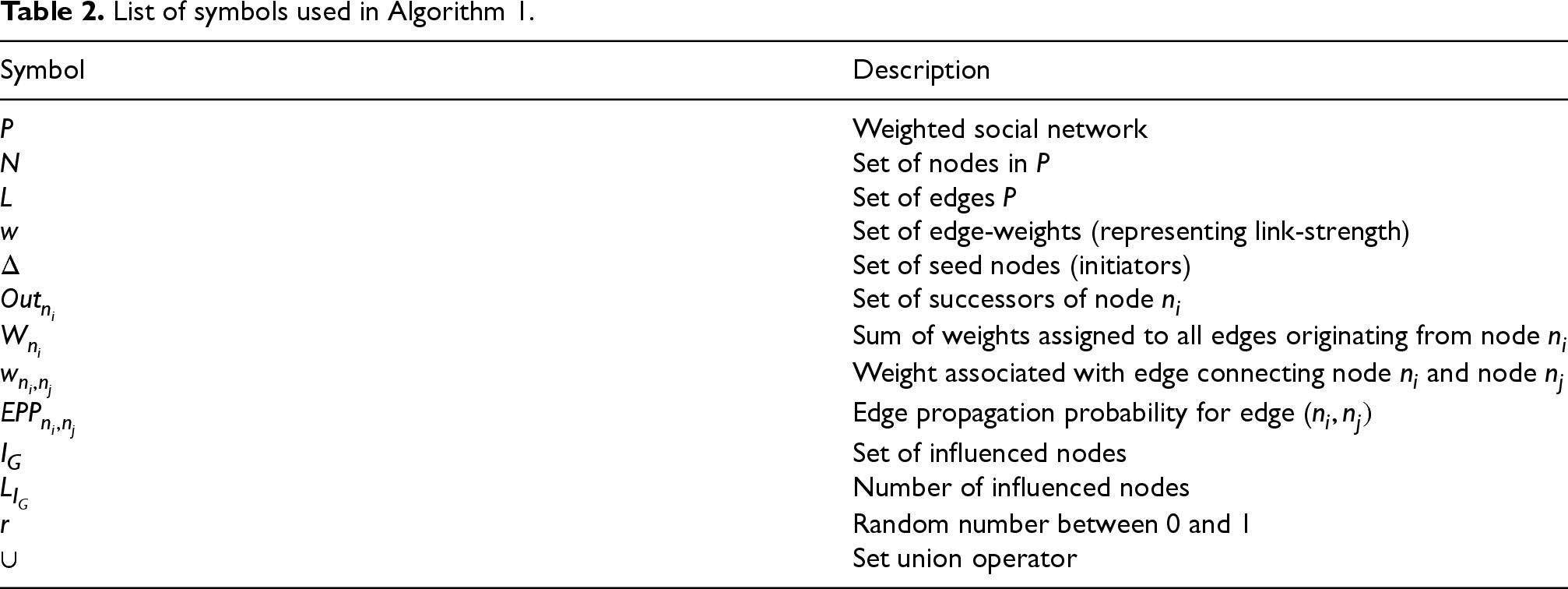
The time complexity of the proposed LiSt-D model comprises two steps: (i) PP assignment for every edge, and (ii) influence spread of each influenced (active) node. In step (i), for each node, weights assigned to the edges between a node and its successor(s) are considered. Assuming a network to be having a total of n nodes and that each node can have up to
Experiments and discussion
Testing of the proposed LiSt-D model was done by employing it to simulate influence diffusion in three real-world weighted social networks, and comparing its performance with other prevalent models. Google Colaboratory (aka Colab) has been used for implementing the experiments using Python programming language.
Dataset description
Three real-world weighted social networks of varying sizes and topological features were used to simulate the diffusion process. All selected networks were directed and follow power-law degree distributions. These datasets were downloaded from http://konect.cc/. Table 3 lists the statistics of the selected networks. In Bitcoin Alpha and Bitcoin OTC networks, edge weights lie in the range [−10, 10], whereas in case of Advogato network all edge weights are positive. As the current study focuses on diffusion in weighted social network, only the magnitude of the edge weight was taken into consideration and not the sign associated with it. To address the concerns associated with negative values, all edge weights were offset by adding a constant value of 10. This transformation preserves the relative differences between data points while ensuring all values are positive. Bitcoin Alpha:58,59 A social network of people who trade Bitcoins on the Bitcoin Alpha platform. Nodes represent members of Bitcoin Alpha platform and an edge between two members denotes that the left member gave a trust rating to the right member. Edge weights represent the ratings given by the member on the left. Bitcoin OTC:58,59 A social network of people who trade Bitcoins on the Bitcoin OTC platform. Nodes represent members of Bitcoin OTC platform and an edge between two members denotes that the left member gave a trust rating to the right member. Edge weights represent the ratings given by the member on the left. Advogato:59,60 A social network representing an online community for developers. Each node denotes a developer and the directed edges represent trust relationships. Edge weights represent the ratings given by the left developer to the right developer.
Statistics of the three real-world social networks.*

Statistics of the three real-world social networks.*
*
Influence spread attained by seed nodes in Bitcoin Alpha Network (
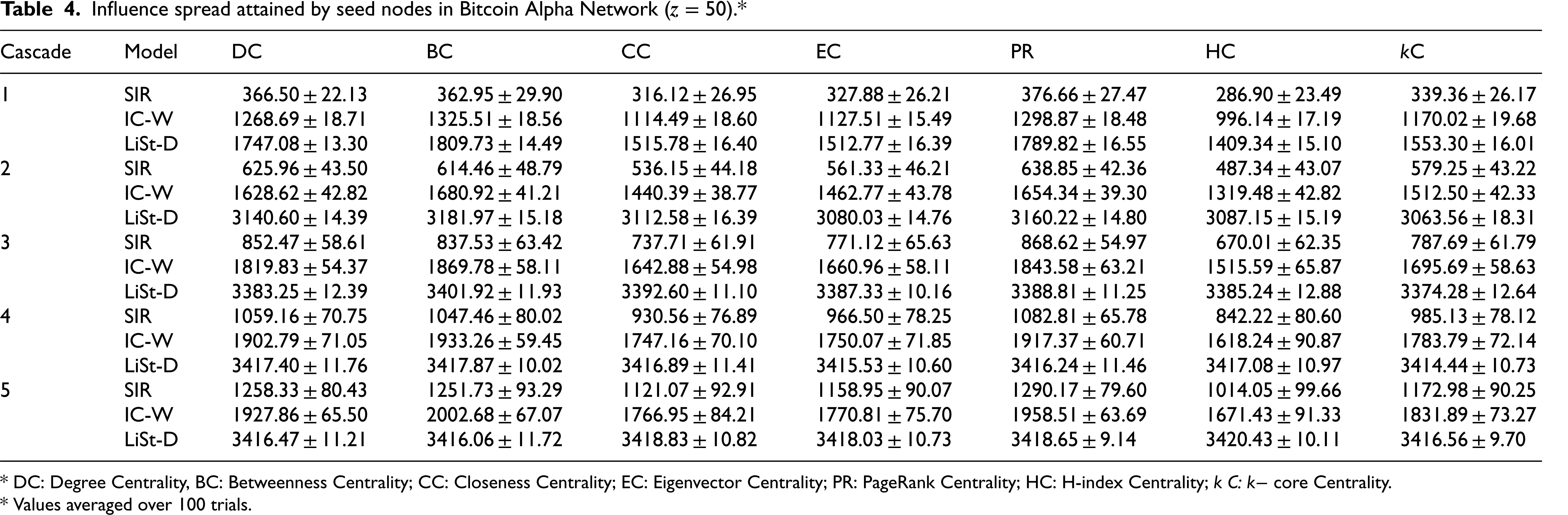
* DC: Degree Centrality, BC: Betweenness Centrality; CC: Closeness Centrality; EC: Eigenvector Centrality; PR: PageRank Centrality; HC: H-index Centrality; k C:
* Values averaged over 100 trials.
Influence spread attained by seed nodes in Bitcoin OTC Network (
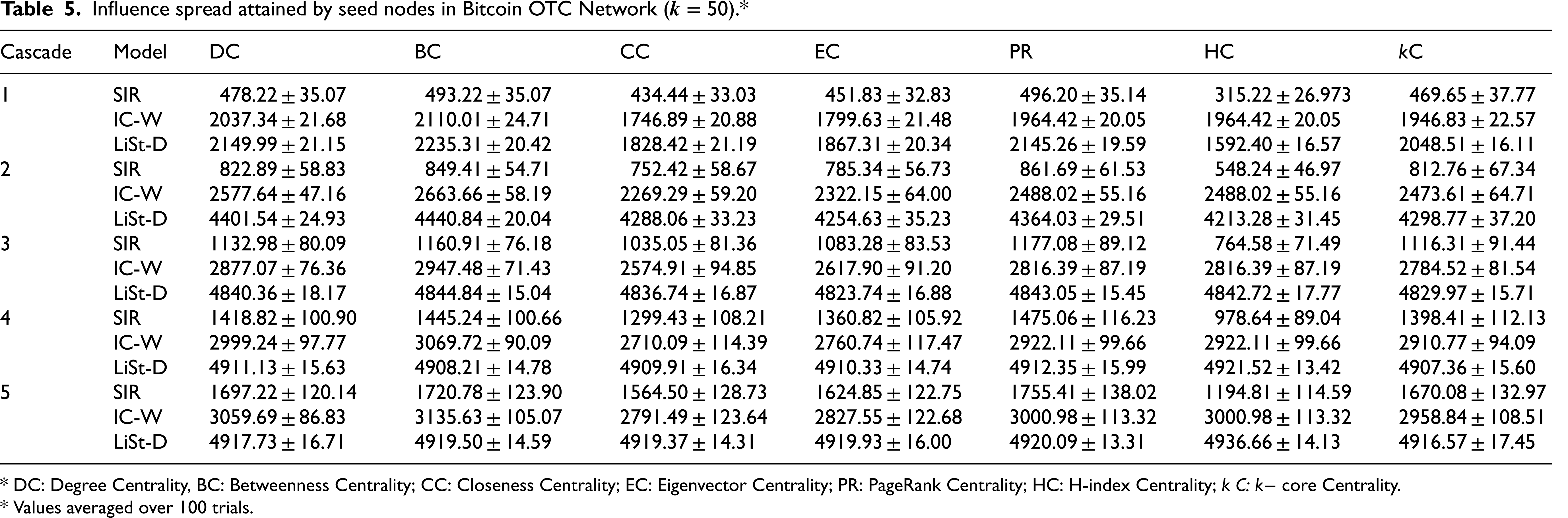
* DC: Degree Centrality, BC: Betweenness Centrality; CC: Closeness Centrality; EC: Eigenvector Centrality; PR: PageRank Centrality; HC: H-index Centrality; k C:
* Values averaged over 100 trials.
Influence spread attained by seed nodes in Advogato Network (
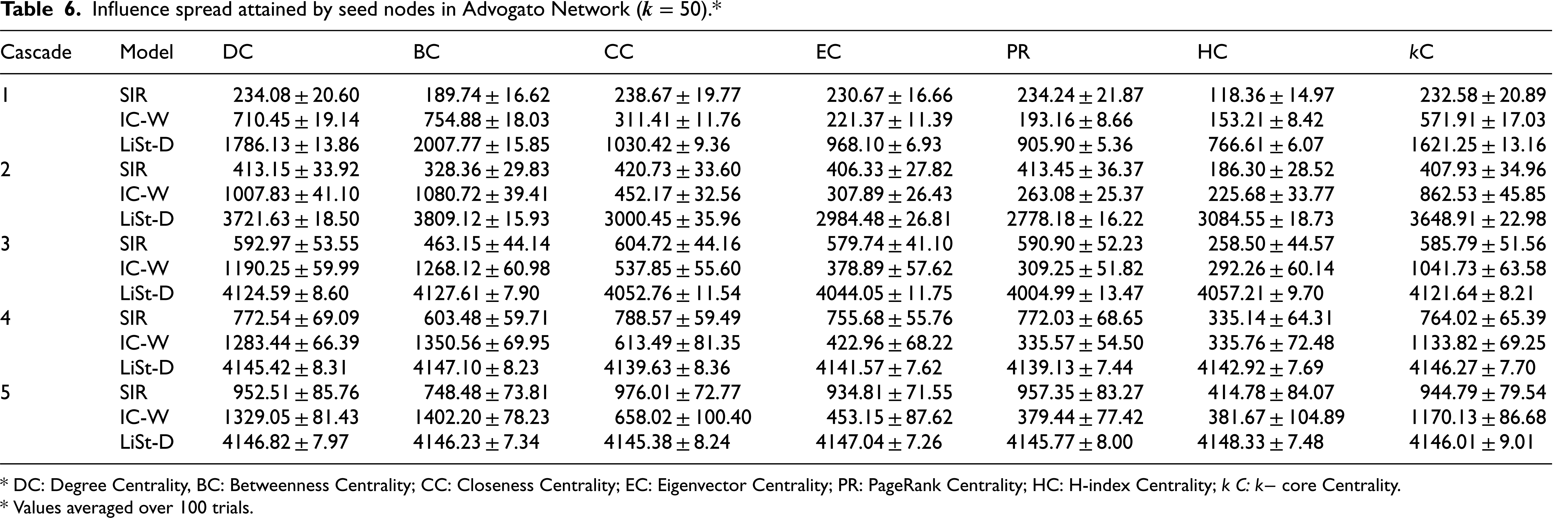
* DC: Degree Centrality, BC: Betweenness Centrality; CC: Closeness Centrality; EC: Eigenvector Centrality; PR: PageRank Centrality; HC: H-index Centrality; k C:
* Values averaged over 100 trials.
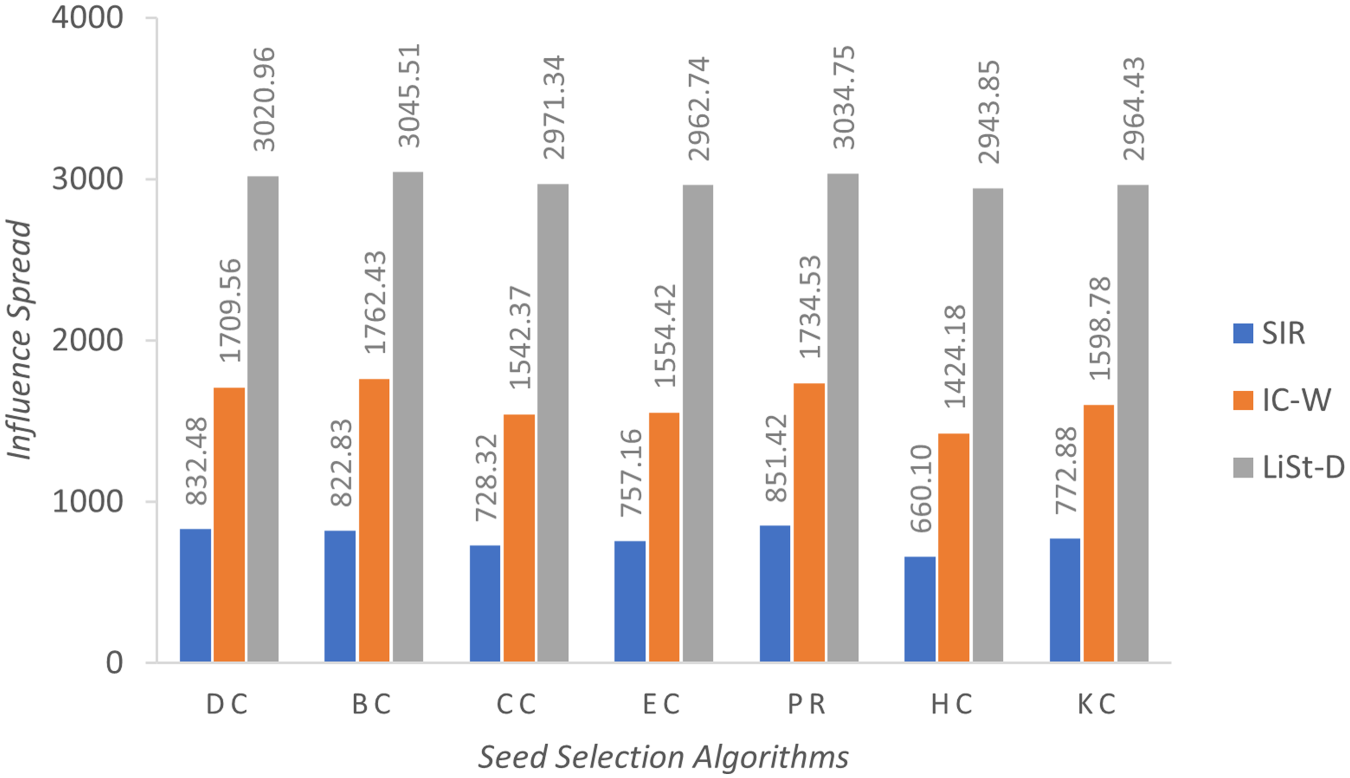
Average influence spread achieved for Bitcoin Alpha network.
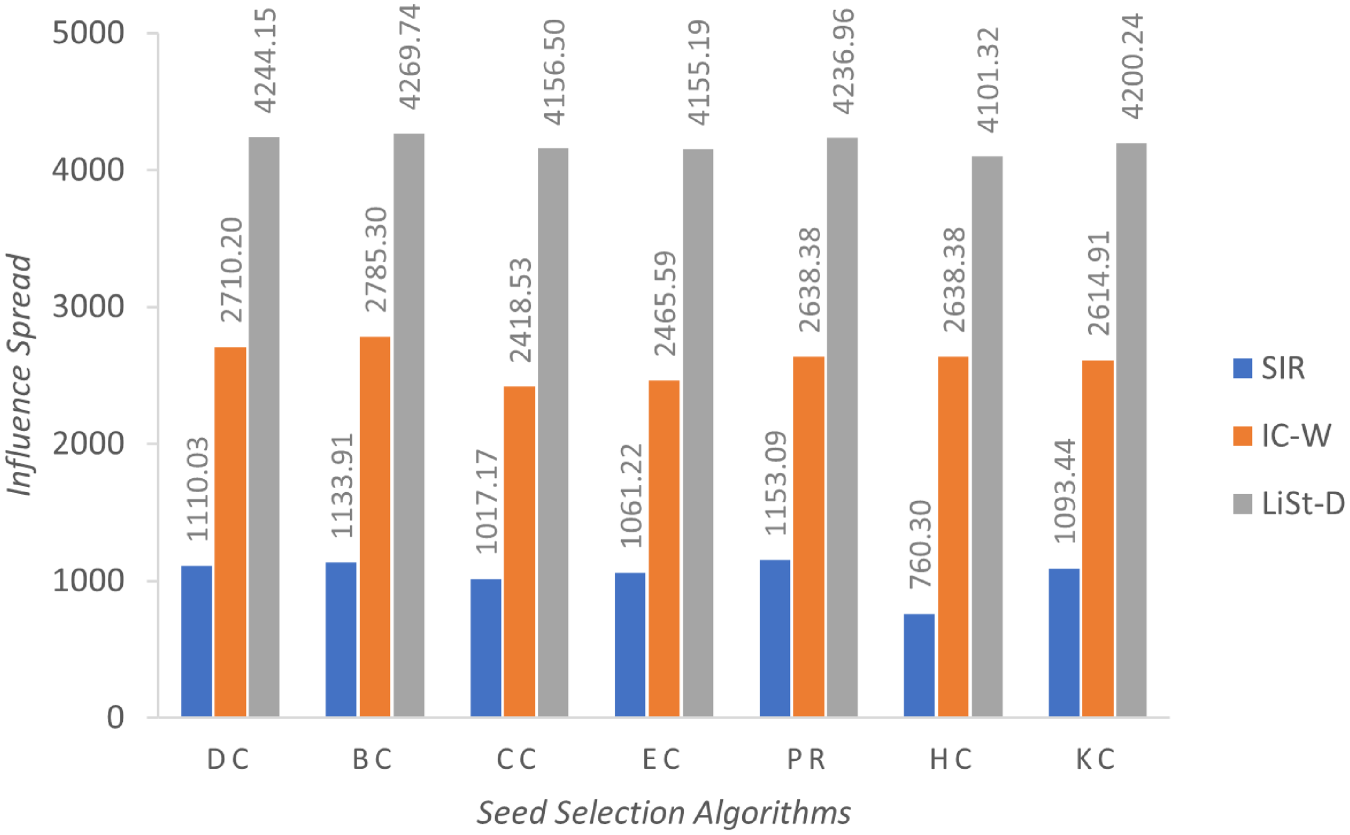
Average influence spread achieved for Bitcoin OTC network.
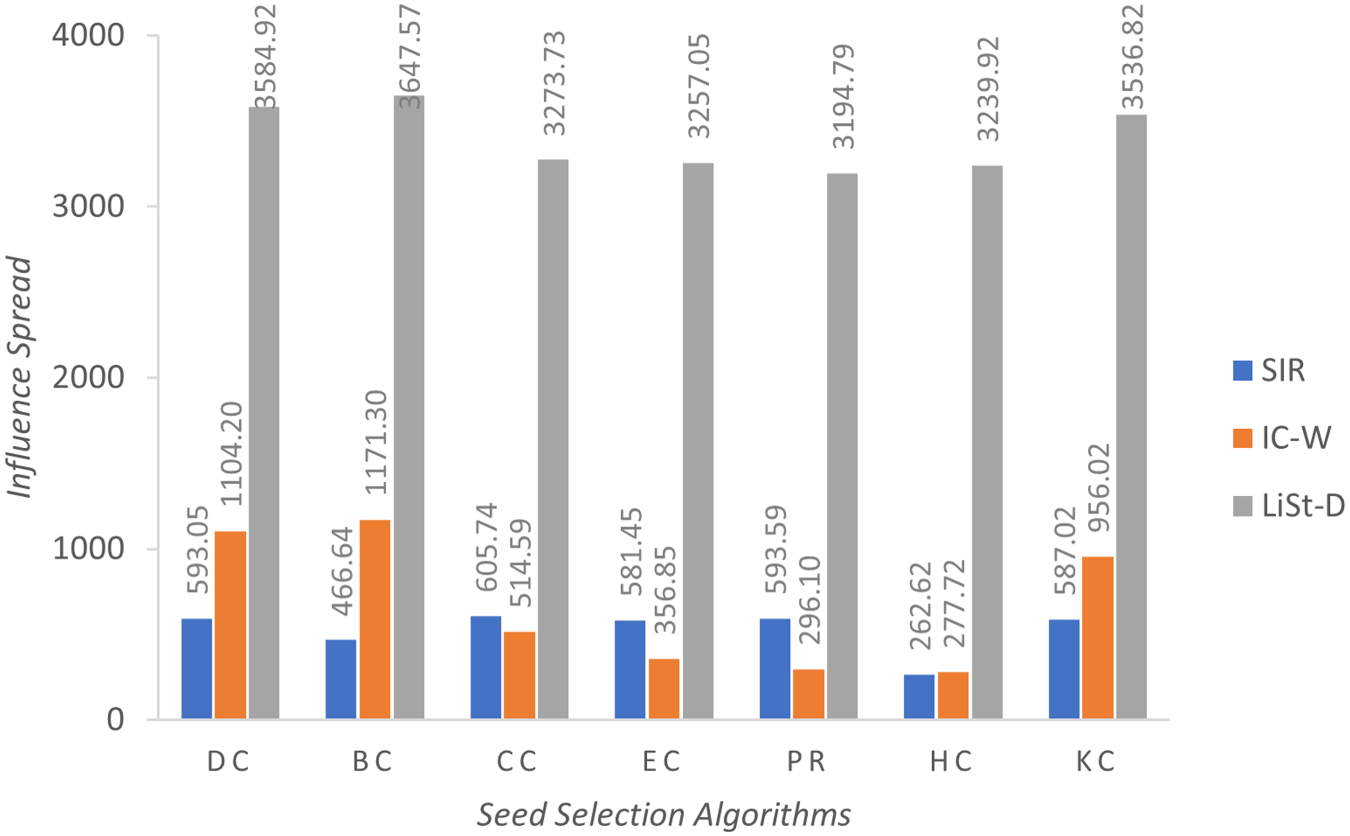
Average influence spread achieved for Advogato network.
Study of existing literature pertaining to weighted social networks also brought forth the fact that most research works have focussed on devising mechanisms for seed node identification, and not on developing diffusion models that accommodate edge weights, resulting in a lack of diffusion models specific for weighted social networks. Hence, in our work, we carry out diffusion in weighted social networks by employing the proposed LiST-D model along with two popular diffusion models, namely SIR and IC-W, and study the findings. We chose SIR as most studies on IM in weighted social networks have been carried out using this model (refer Table 1). IC-W was chosen as its working can be said to include the notion of weighted propagation probability, to some extent. It may be noted that for each model, the parameter settings have been done as per the common practice followed by the research fraternity of the addressed subject area. In SIR model, infection rate (β) is kept as 0.3, and recovery rate (γ) is kept as 0.1. In IC-W model, the value of
In this study, we simulate diffusion under the three models considered, proposed LiSt-D, SIR, and IC-W, and record the experimental findings in terms of a common outcome measure, namely the influence spread achieved by a given seed set. Specifically, if diffusion is initiated with a seed set, the spread is computed as the total number of nodes that become influenced by the end of the process. This provides a consistent basis for comparison across models, even though the underlying mechanisms differ.
It is important to emphasize that the methodological assumptions of the three models define distinct diffusion environments. The LiSt-D and IC-W models both incorporate heterogeneity in infection rates: in IC-W, propagation probability depends on the in-degree of the target node, whereas in LiSt-D, it varies with the link strength between connected nodes. In contrast, the SIR model employs a fixed infection rate, which can slow down diffusion relative to the other two. Further, while both LiSt-D and IC-W treat each node as either uninfluenced or influenced (with the set of influenced nodes monotonically increasing over time), the SIR model allows nodes to transition to a recovered state, thereby stopping their contribution to further spread. This difference naturally results in different growth trajectories of influenced nodes across the three models.
Nevertheless, by consistently measuring the final influence spread achieved for seed sets of equal size and chosen using same centrality measure, we establish a fair basis for reporting results and drawing relative insights. Tables 4–6 present the influence spread attained by the seven seed sets (50 seeds each) across the three real-world social networks studied, with the process simulated for five cascades under each diffusion model. A cascade refers to a discrete time step in the diffusion cycle. Each cascade was executed 100 times, with the intent to alleviate the impact of variation due to randomness, and the average value is reported in the tables. The reported values are in the format of (mean ± standard deviation).
SIR model demonstrates gradual growth and progressive improvement. It shows a steady and consistent increase in spread values across all centrality measures from the subsequent cascades. In cascade1, the model starts with relatively lower spread value, indicating a modest baseline. However, over time, each cascade reveals a marked improvement in performance. By cascade5, the values across all centrality measures have increased significantly compared to the first cascade, indicating that the SIR model becomes more robust or effective over time. IC-W model demonstrates moderate initial performance with consistent gains. It displays a positive growth pattern, though it starts at a higher initial baseline than SIR model. Each successive cascade results in an increase across all centrality measures, although the gains per cascade are generally smaller or more controlled than SIR's jumps.
LiSt-D model demonstrates high initial performance with early plateau. It starts off with substantially higher values across all centrality measures, and these values continue to increase slightly until the third cascade. Thereafter, LiSt-D appears to reach a plateau. The values in cascades 4 and 5 are almost static and near-maximum. This suggests that LiSt-D reaches its optimal performance relatively early, thereby stabilizing its performance. In general, all three models show positive trends over time, indicating that the diffusion process under each model supports iterative improvement, though the magnitude and timing of improvements differ. SIR model is characterized by strong upward growth, IC-W by stable and steady progression, and LiSt-D by early peak performance with high stability. The average influence spread attained by the selected seed sets is presented in Figures 1, 2 and 3 for networks Bitcoin Alpha, Bitcoin OTC and Advogato, respectively. The vertical axis of the figures signifies the influence spread, whilst the horizontal axis signifies the seed selection measures.
Figures 4, 5, and 6 show the diffusion progression trend with respect to the percentage of network influenced, for the three diffusion models, when the diffusion process is initiated using the seed nodes identified through DC. It can be observed from Figures 4, 5 and 6 that cascade 3 onwards, the percentage of network that gets influenced is almost stabilized under the LiSt-D model in all three networks under consideration. For IC-W model stability is visible approximately from cascade 4 onwards. Under the proposed LiSt-D model, 90% of Bitcoin Alpha, 84% of Bitcoin OTC, and 63% Advogato network is getting influenced by the selected seed nodes in five cascades, however under IC-W model, the same seed nodes cover only 51%, 52%, and 20% of Bitcoin Alpha, Bitcoin OTC, and Advogato network, respectively. Similarly, for Bitcoin OTC social network, LiSt-D model is able to cover around 83% of the network, while IC-W and SIR models have covered around 50%, 21%, and 15% of the network, respectively.
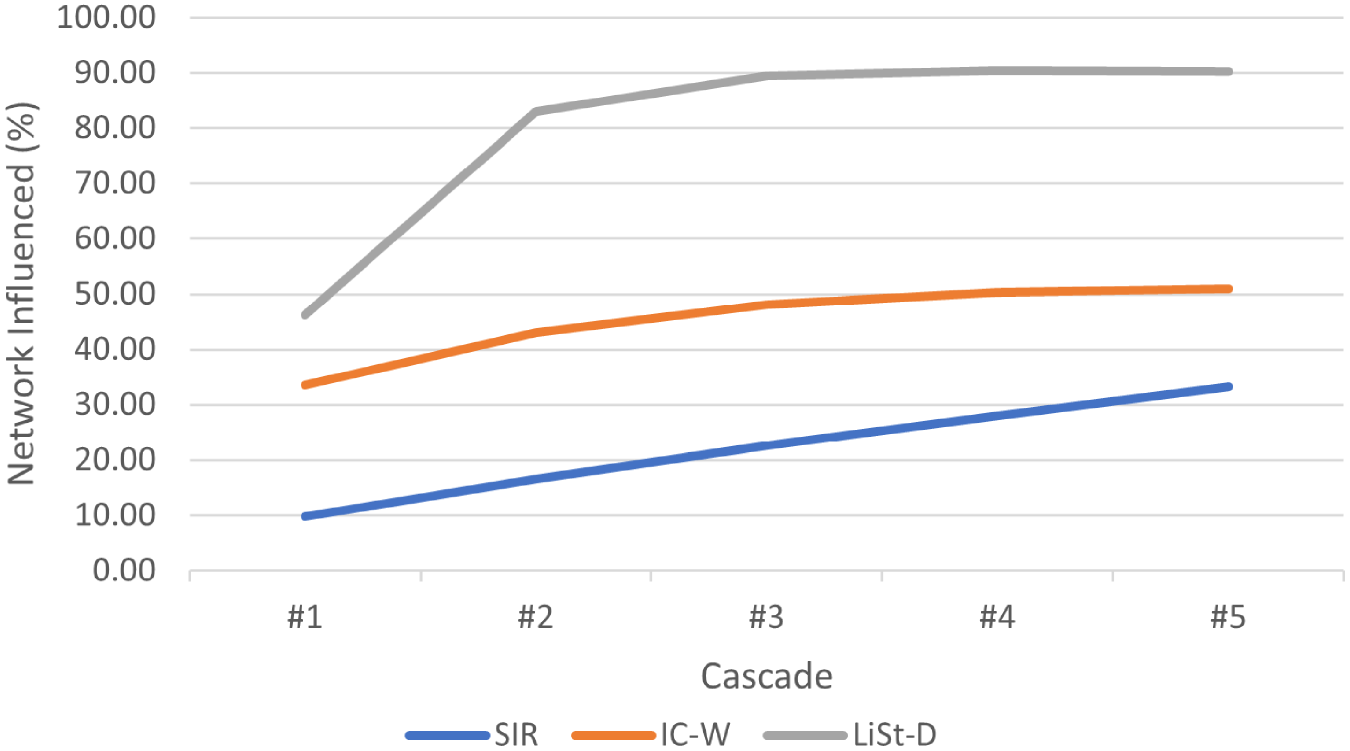
Diffusion trend for Bitcoin Alpha network using DC seed nodes.
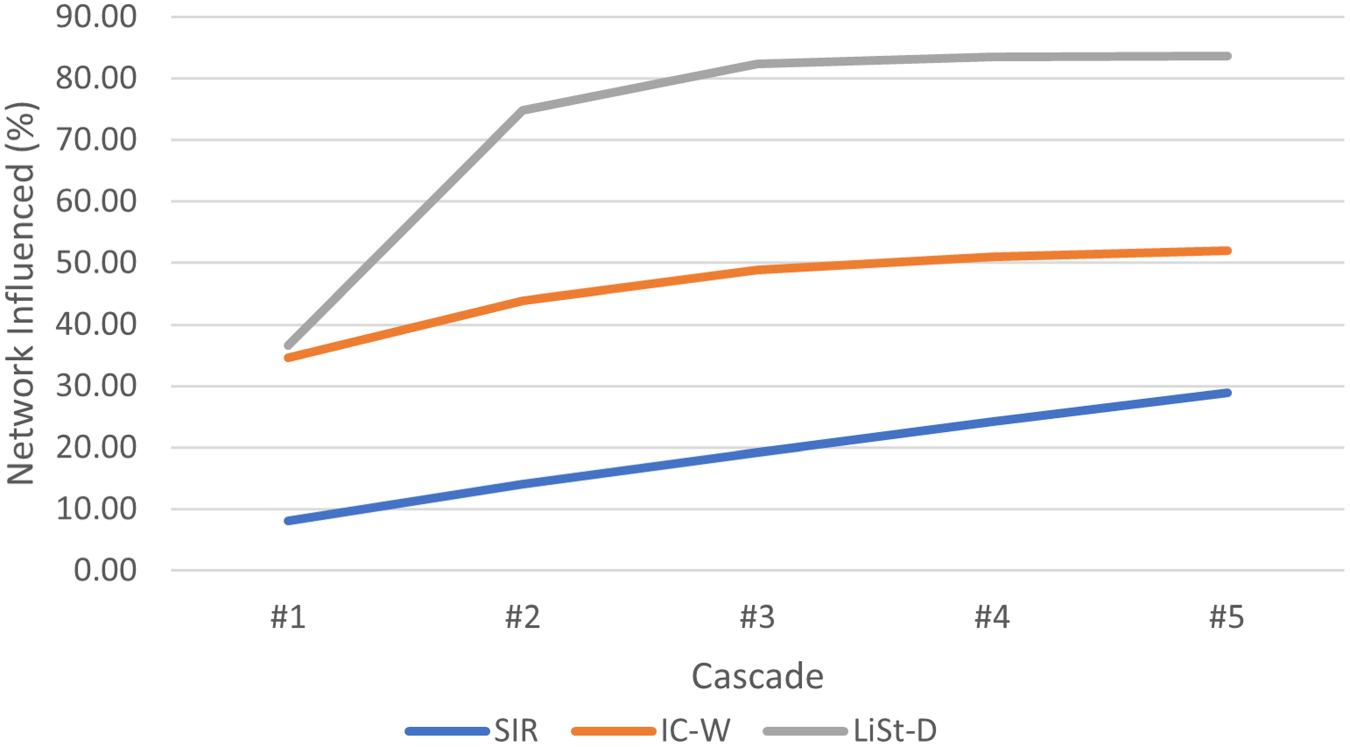
Diffusion trend for Bitcoin OTC network using DC seed nodes.

Diffusion trend for Advogato network using DC seed nodes.
Diffusion models play a crucial role in understanding how influence spreads across a social network by defining the conditions under which influence is transferred from one node to another. Many existing studies tend to focus on a simplified binary view of relationships, i.e., the presence and absence of edges between two actors. Nevertheless, most real-world social networks are weighted, with link strength showing how much one person can influence another. This variation in connection strength is key to understanding how influence spreads and should be considered in diffusion studies Therefore, diffusion models that account for link strength (depicted by edge weights) are necessary to capture the nuances of real-world social influence and offer more realistic predictions of influence dynamics.
In our research, we have proposed the Link Strength Diffusion (LiSt-D) model for influence diffusion in (directed) weighted social networks. The speed of information or influence spread in a network is heavily affected by relationship strength. The proposed model accounts for these variations when calculating diffusion probability between connected users. In this study, simulation of the diffusion process under proposed LiSt-D model is done using three real-world weighted social networks, namely Bitcoin Alpha, Bitcoin OTC and Advogato, wherein edge weights represent the ratings given by the source node to the target node. Seed node selection for initiating the diffusion process is done using seven widespread seed selection algorithms. We conducted experiments to study the diffusion process under three diffusion models, the proposed LiSt-D, SIR, and IC-W. Experimental findings were recorded in terms of the influence spread achieved by the seed nodes. In general, all three models show positive trends over time, indicating that the diffusion process under each model supports iterative improvement, though the magnitude and timing of improvements differ. The proposed LiST-D model is characterized by early peak performance with high stability, SIR model demonstrates strong upward growth, while IC-W shows stable and steady progression. In LiSt-D model, the propagation probability varies with the variation in the link-strength between connecting pair of nodes. There is a heterogeneity in the infection rate for each link, which might result in some propagation probability values being higher, and so spreading of influence might happen at a faster pace, relative to when the propagation probability is constant over all links. The findings showed that diffusion spread under LiSt-D covered 90% of the Bitcoin Alpha network, 84% of Bitcoin OTC, and 63% of the Advogato network.
One of the key limitations of the presented work is that the real-world data being used relies on historical user data (e.g., past interactions) and does not account for the dynamicity in user behaviour. User behaviour can change over time and so the patterns of information spread at one time may not hold in the future. Also, like most work being done in the addressed subject area, the presented work also assumes a fixed and simple network structure, though real-world networks are dynamic and complex, with varying connectivity and changing relationships between individuals over time. Furthermore, social media platforms, which are often used for data collection, may not provide a representative sample of the population, leading to the network data often being incomplete, biased, or difficult to obtain. In addition, privacy concerns also restrict the amount of data that can be gathered. These limitations can be addressed in future work thereby enabling the proposed model to better capture real-world complexities. Future works can further augment the proposed work by incorporating edge weight contribution from the receiving node's perspective. Additionally, multiple objectives such as signed behavior of users, interaction frequency and other activity-based parameters can also be taken into consideration.
Footnotes
Author contributions
Megh Singhal – Methodology, experiment conduction, formal analysis, initial draft writing, review and editing
Bhawna Saxena - Conceptualization, methodology, review and editing, supervision.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interest
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.