
Abstract
The discipline of Entity Resolution (ER), the process of identifying and linking records that refer to the same real-world entity, has been fundamentally reshaped by the adoption of high-dimensional vector embeddings. This transformation reframes ER as a large-scale Approximate Nearest Neighbor Search (ANNS) problem, making the choice of ANNS architecture a critical determinant of system performance. This paper provides a deep architectural comparison and a novel, large-scale empirical evaluation of the two dominant ANNS paradigms: graph-based methods (HNSW, DiskANN) and partition-based methods (Faiss-IVF+PQ, Scann). We introduce a new semi-synthetic benchmark tailored to the ER task, consisting of two one-million-vector datasets with a known ground truth. On this benchmark, we conduct a comprehensive evaluation, measuring not only total query time but also disaggregated blocking and matching times, alongside canonical ER quality metrics: precision, recall, and F1-score. Our findings reveal that partition-based methods, particularly Scann, offer superior performance in high-throughput, moderate-recall scenarios, while graph-based methods like HNSW and DiskANN are unequivocally superior for applications demanding the highest levels of matching quality. This work provides a nuanced, application-centric analysis that culminates in a set of actionable recommendations for practitioners designing modern data integration and retrieval systems.
Introduction
The discipline of Entity Resolution (ER), the process of identifying and linking records that refer to the same real-world entity, stands as a cornerstone of modern data integration and analytics. Historically, ER systems relied on meticulously handcrafted rules and feature-based comparisons, often involving string similarity metrics on structured attributes like names, addresses, and product identifiers. 1 While effective in constrained domains, these methods have proven brittle and difficult to scale in the face of the semantic complexity and heterogeneity of modern, large-scale datasets. The contemporary solution to this challenge has emerged from the field of representation learning, where deep learning models, like BERT, 2 are trained to map complex, multi-modal entities—such as text documents, images, or user profiles—into high-dimensional vector spaces, or embeddings. Sentence-BERT 3 models extend this concept to sentence-level tasks, efficiently encoding entire text spans into fixed-size embeddings.
In this new paradigm, the notion of semantic similarity is geometrically encoded: entities that are conceptually similar are represented by vectors that are proximate in the embedding space, typically measured by Euclidean distance or cosine similarity. This transformation fundamentally reframes the ER problem. The task of identifying matching entities across disparate datasets is now equivalent to finding the nearest neighbors for each vector in a target vector space. Consequently, the core ER workflow, traditionally bifurcated into a blocking stage to generate a manageable set of candidate pairs and a matching stage to perform detailed comparisons on those candidates [3], can be modeled as a large-scale Approximate Nearest Neighbor Search (ANNS) problem. This convergence implies that the architectural choices and performance characteristics of ANNS algorithms are no longer peripheral concerns but have become first-order determinants of the scalability, accuracy, and cost-efficiency of modern ER systems. The selection of an ANNS algorithm is now a critical architectural decision, directly influencing the quality and feasibility of data integration pipelines at scale.
To make this transition concrete, it is helpful to contrast the pipelines directly. We assume two databases: a query database
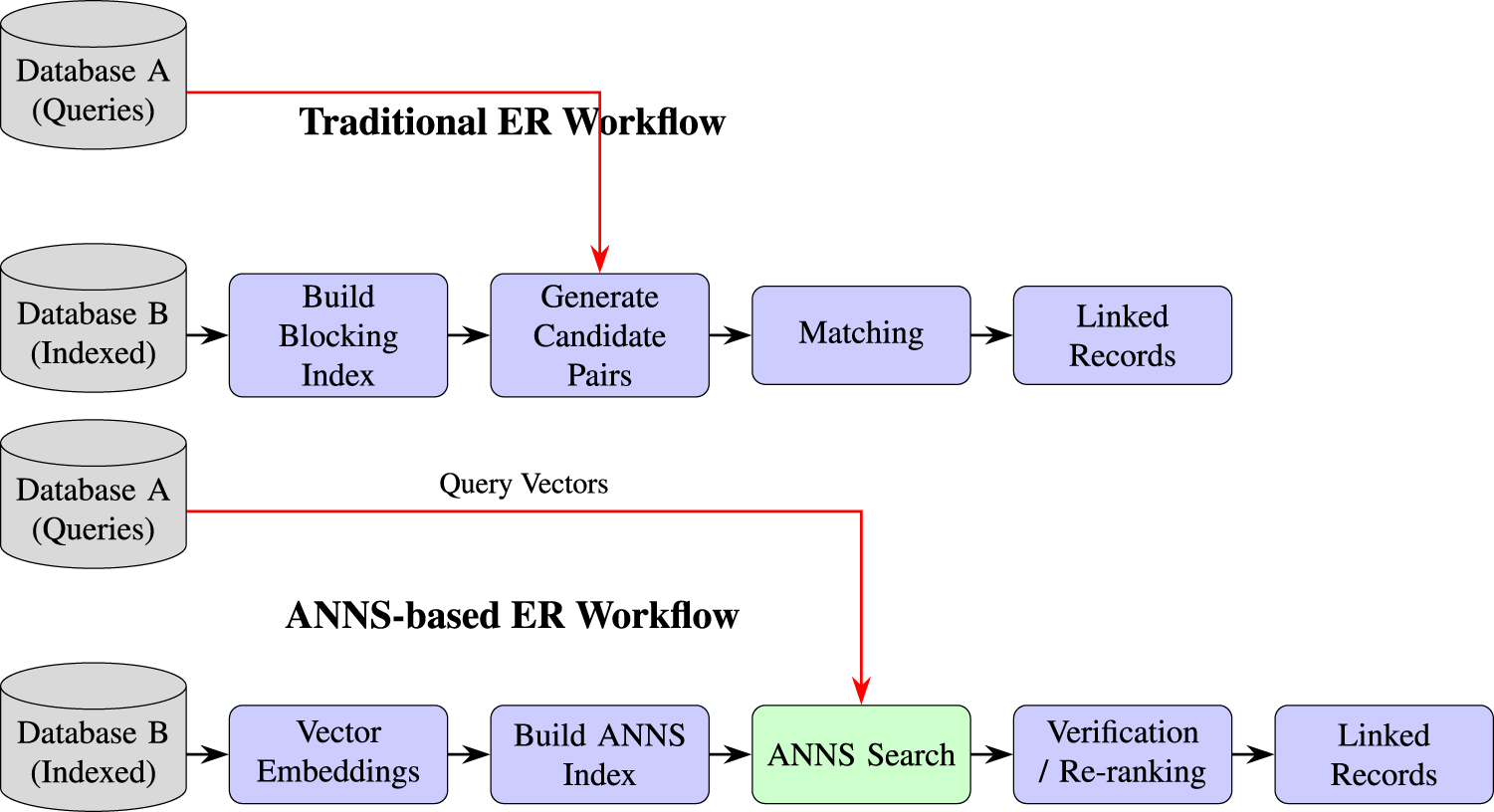
A schematic comparison of Traditional vs. ANNS-based Entity Resolution workflows. The top flow shows the classic bifurcated blocking and matching stages. The bottom flow illustrates how vector embeddings and ANNS algorithms unify these stages into a single, efficient search process.
The field of ANNS has matured significantly, with decades of research culminating in two dominant architectural paradigms that offer distinct trade-offs between search performance, memory footprint, and index construction complexity. These paradigms are distinguished by the fundamental structure of their indices and the nature of their search procedures.
The first paradigm is Graph-Based Methods. These algorithms construct a navigable proximity graph where the vertices represent the data vectors and the directed edges connect vertices that are close to each other in the embedding space. The search process is a guided traversal, typically a form of greedy beam search, that starts at a designated entry point and iteratively moves towards neighbors that are progressively closer to the query vector. This approach performs a dynamic, query-time exploration of the data’s local structure. State-of-the-art representatives of this class include Hierarchical Navigable Small World (HNSW) graphs, 4 which build a multi-layered hierarchy to achieve logarithmic search complexity in memory, and DiskANN, 5 which constructs a specialized, low-diameter graph called Vamana, optimized for high-performance search on solid-state drives (SSDs).
The second dominant paradigm is Partition-Based Methods. These algorithms operate on a coarse-to-fine search principle. The vector space is first partitioned into a set of disjoint cells or clusters using a coarse quantization technique, most commonly k-eans. This partitioning forms an inverted file (IVF) structure, 6 where each cell corresponds to an inverted list containing the vectors assigned to it. A search is then restricted to a small subset of these cells—those whose centroids are closest to the query vector. This initial step acts as an explicit, static blocking mechanism. To manage memory usage for large datasets, the full-precision vectors within each cell are typically compressed using a second-stage quantization scheme. Prominent examples of this approach include Faiss-IVF with Product Quantization (PQ), 7 a highly optimized library that uses a Cartesian product of sub-quantizers for aggressive vector compression, and Scann (Scalable Nearest Neighbors), 8 which introduces an innovative anisotropic quantization technique designed to optimize for ranking accuracy rather than simple geometric reconstruction error.
While a plethora of benchmarks exist for ANNS algorithms, they predominantly focus on the trade-off between recall and query throughput (or queries per second, QPS) on static datasets. These evaluations, while valuable, often fail to capture the performance nuances of these distinct architectures when integrated into complex, multi-stage pipelines like Entity Resolution. The separation of ER into blocking and matching stages presents a unique performance profile that standard benchmarks do not measure. The efficiency of the initial candidate generation (blocking) and the precision of the subsequent detailed comparison (matching) are equally critical, and the architectural underpinnings of graph-based and partition-based methods suggest they will exhibit fundamentally different behaviors in this context. A recent study 9 explored the potential of partition-based ANNS on the real of ER.
This paper aims to bridge this research gap by providing a deep architectural comparison and a novel, large-scale empirical evaluation of these two paradigms within an ER framework. The primary contributions of this work are as follows: A detailed, principle-driven comparative analysis of four state-of-the-art algorithms: HNSW and DiskANN as representatives of the graph-based approach, and Faiss-IVF+PQ and Scann as representatives of the partition-based approach. The design and implementation of a new, large-scale semi-synthetic benchmark specifically tailored to the ER task. This benchmark allows for the isolated measurement of performance metrics relevant to both the blocking and matching stages of ER. A comprehensive empirical evaluation of the selected algorithms on this benchmark, measuring not only total query time but also disaggregated blocking time and matching time, alongside standard classification metrics such as precision, recall, and F1-score, which are the canonical measures of quality in ER. By framing the analysis through the lens of a practical, large-scale application, this work provides nuanced insights into the architectural strengths and weaknesses of each approach, culminating in a set of actionable recommendations for practitioners designing modern data integration and retrieval systems.
The remainder of this paper is organized as follows. Section 2 provides an architectural deep dive into graph-based ANNS methods, detailing the principles of HNSW and DiskANN. Section 3 offers a parallel deep dive into partition-based methods, focusing on Faiss-IVF+PQ and Scann. Section 4 describes the methodology of our novel experimental framework for ANN-based Entity Resolution, including dataset generation and the mapping of ER concepts to ANNS workflows. Section 5 presents and analyzes the empirical results from our large-scale experiment. Finally, Section 6 concludes the paper with a synthesis of our findings and provides recommendations for practitioners.
The foundational principle of graph-based ANNS is the construction of a navigable proximity graph, a data structure where the search for nearest neighbors is transformed from an exhaustive scan into an efficient, guided traversal. In this structure, each vector in the dataset is represented as a vertex. Directed edges are established between vertices based on their proximity in the high-dimensional space, creating a network that mirrors the local geometry of the data. The goal is to build a graph that is simultaneously sparse, to limit the computational cost at each step, and well-connected, to ensure that any point in the dataset can be reached from a designated starting point in a small number of hops.
The search mechanism, common to nearly all graph-based methods, is a variant of greedy beam search, often referred to as greedy search. This algorithm operates as follows: Initialization: The search begins at one or more pre-defined entry-point vertices. A priority queue, ordered by distance to the query vector, is initialized with these entry points. A set of visited vertices is also maintained to prevent redundant computations. Iterative Expansion: In each step, the algorithm extracts the closest unvisited vertex from the priority queue. It then computes the distance from the query to each of this vertex’s out-neighbors. Candidate Management: These neighbors are added to the priority queue. The queue is typically maintained at a fixed size, known as the beam width or search list size (e.g., Termination: The process continues until a stopping condition is met, such as when the closest unvisited vertex in the priority queue is farther from the query than the
This dynamic, query-time exploration is the defining characteristic of the graph-based paradigm. Unlike methods that rely on a static, global partitioning of the space, the search path is constructed on-the-fly, adapting to the specific location of the query vector. The effectiveness of the entire approach hinges on the quality of the underlying graph structure, and different algorithms propose distinct strategies for its construction.
HNSW: A hierarchical navigable small world
The Hierarchical Navigable Small World (HNSW) 4 algorithm stands as one of the most prominent and performant in-memory graph-based ANNS methods. Its central innovation is a multi-layer, hierarchical graph structure that enables both rapid, long-distance traversal and precise, short-distance refinement, resulting in a logarithmic search complexity.
The HNSW index is not a single graph but a series of nested proximity graphs arranged in layers. Layer 0 is the base layer and contains every vector in the dataset. Each subsequent layer is a sparse subset of the layer below it. This creates a hierarchy where the top layers contain very few vertices connected by long-range “highway” links, while the bottom layers are dense and contain short-range, local links.
The assignment of a vertex to its maximum layer is determined probabilistically during insertion. Each vertex is assigned a maximum layer
The search process in HNSW elegantly exploits this hierarchical structure to achieve its efficiency. A query search proceeds as follows: Entry: The search begins at a fixed entry point in the topmost layer of the graph. Top-Down Greedy Traversal: The algorithm performs a greedy search on the current layer, traversing edges to find the vertex in that layer that is closest to the query vector. Layer Descent: Once a local minimum is found in the current layer (i.e., no neighbor is closer to the query), this vertex serves as the new entry point for the search on the layer immediately below it. Final Search: This process of greedy search followed by layer descent is repeated until the search reaches the base layer (Layer 0). A final, more exhaustive beam search is conducted on Layer 0, starting from the entry point found in Layer 1, to identify the final set of nearest neighbors.
This top-down approach allows the search to quickly “zoom in” on the relevant region of the vector space using the sparse, long-range connections of the upper layers before performing a fine-grained local search in the dense base layer. The HNSW graph is built incrementally. When a new vector is inserted, its maximum layer
The performance and structure of the HNSW index are governed by three critical parameters: M: This parameter defines the maximum number of bidirectional connections (out-degree) a vertex can have on each layer. It directly controls the density of the graph, the memory footprint of the index, and the quality of the local neighborhood information available at each vertex. efConstruction: This integer specifies the size of the dynamic candidate list (beam width) used during the index construction phase. A larger efConstruction value allows the build process to explore more diverse connection candidates for each new vertex, resulting in a higher-quality graph that supports more accurate searches, but at the cost of a significantly longer index build time. ef_search: This parameter controls the beam width during the query phase. It represents the primary knob for tuning the trade-off between search speed and accuracy (recall). A larger ef_search value leads to a more exhaustive search and higher recall but increases query latency.
DiskANN: A Vamana graph optimized for external memory
While HNSW provides state-of-the-art performance for in-memory datasets, its memory footprint can become prohibitive for billion-scale and larger collections. DiskANN was developed to address this limitation, enabling high-recall, low-latency search on massive datasets using a single commodity machine equipped with limited RAM and a fast Solid-State Drive (SSD).
The core challenge of moving a graph index to an SSD is the high latency of random I/O operations compared to RAM access. A naive implementation of a graph search on an SSD would be extremely slow, as each step in the traversal could potentially trigger a slow random disk read to fetch a vertex’s neighbors. The FAISS library’s documentation famously stated, “Faiss supports searching only from RAM, as disk databases are orders of magnitude slower. Yes, even with SSDs”. DiskANN was designed to debunk this by fundamentally re-engineering the graph structure to minimize the number of I/O operations required per query.
The key to DiskANN’s performance is its graph construction algorithm, named Vamana. While sharing the incremental build and greedy search principles of other graph methods, Vamana’s distinction lies in its edge pruning strategy, which is designed to create a graph with a very small diameter. A smaller graph diameter means that the average path length between any two vertices is short, directly translating to fewer sequential disk reads during a search. This is achieved through a robust procedure, which is a relaxed version of the pruning rule for a Relative Neighborhood Graph (RNG). The pruning decision is governed by a crucial parameter,
When
DiskANN’s system architecture is a hybrid model designed to minimize both RAM usage and disk I/O: Graph and Full Vectors on SSD: The complete Vamana graph structure—the adjacency lists for every vertex—and the full-precision floating-point vectors are stored on the SSD. This allows the index to scale far beyond the capacity of main memory. Compressed Vectors in RAM: To guide the search without constant disk access, DiskANN stores a compressed representation of every vector in RAM. This is typically achieved using Product Quantization (PQ), encoding each Search Process: During a query, the GreedySearch algorithm uses the in-memory compressed vectors to perform fast, approximate distance calculations. These approximate distances are sufficient to determine which vertex in the current candidate list is most promising and should be expanded next. Only when a vertex is chosen for expansion does the system perform a single random read from the SSD to fetch its full adjacency list and the full-precision vectors of its neighbors.
This design masterfully balances resources. The bulk of the storage is offloaded to the cheaper, high-capacity SSD, while the small amount of expensive, fast RAM is used to hold a compressed “map” of the dataset that can guide the I/O-intensive search process efficiently. The low-diameter Vamana graph ensures that the number of these guided I/O operations remains small, typically a few dozen per query, enabling millisecond-level latencies on billion-point datasets.
The architectural goals of HNSW and DiskANN are thus fundamentally different. HNSW is optimized for uniform-access-cost environments (RAM) and uses a hierarchy to minimize total distance computations. DiskANN is optimized for non-uniform access costs (RAM vs. SSD) and uses a denser, flatter graph to minimize the number of expensive I/O operations, even if it means performing more in-memory computations per hop. This distinction is central to their performance characteristics in different deployment scenarios.
Partition-based ANNS
Partition-based methods for ANNS are built upon the classic inverted file (IVF) paradigm,
6
a cornerstone of information retrieval adapted for high-dimensional vector spaces. The core idea is to first partition the entire dataset into a large number of disjoint cells or clusters. This partitioning is achieved using a “coarse quantizer,” which is typically a codebook of
The search process proceeds as follows: Blocking (Centroid Search): Given a query vector, the system first compares it to all Matching (Cell Scan): In the second stage, the system retrieves the inverted lists for the selected cells and performs a detailed search. It calculates the approximate distance (e.g., Euclidean) between the query vector and every vector within these lists. The top-
Faiss-IVF and product quantization
The Faiss (Facebook AI Similarity Search) library 6 provides a highly optimized implementation of the IVF paradigm, combining it with Product Quantization (PQ) for extreme vector compression and efficient distance calculation. This combination, often denoted as IVF-ADC (Inverted File with Asymmetric Distance Computation), has become a standard baseline for large-scale ANNS.
As described above, the IVF component of the index is created by running k-Means to generate a set of nlist (or
Vector compression with product quantization
To store billion-scale datasets in memory, full-precision vectors are prohibitively large. Faiss employs Product Quantization as a powerful vector compression technique. The PQ process works as follows: Vector Splitting: Each D-dimensional vector is split into Sub-Quantizer Training: For each of the Encoding: To compress a vector, each of its
PQ enables not only compression but also highly efficient distance estimation through ADC. In this scheme, the database vectors are stored in their compressed PQ code format, while the query vector remains in its full-precision form. The squared Euclidean distance is approximated as follows: Pre-computation: For a given query vector, it is also split into m sub-vectors. For each subspace Distance Estimation: To estimate the distance to a database vector, the system retrieves its
After the initial pre-computation, estimating the distance to each candidate vector requires only
Scann and anisotropic vector quantization
While Faiss-IVF+PQ is highly effective, its quantization objective—minimizing the L2 reconstruction error—is fundamentally a geometric one. The Scann algorithm 8 from Google Research argues that this is a suboptimal proxy for the ultimate goal of a search system, which is to produce the correct ranking of results. Scann’s core innovation is a new quantization loss function that directly optimizes for ranking quality in Maximum Inner Product Search (MIPS), a problem closely related to nearest neighbor search.
The central premise of Scann is that for MIPS, not all quantization errors are equal. An error in a database vector that has a very high inner product with the query is far more detrimental to the final ranking than an error in a vector with a low inner product. Standard PQ treats all vectors and all error dimensions equally, aiming to minimize the average squared Euclidean distance
The crucial theoretical result presented in the Scann paper is that this score-aware loss function can be decomposed into a weighted sum of two distinct error components; the parallel error and the orthogonal error. The parallel error is the component of the quantization residual
For any reasonable weighting function
This architectural distinction has profound implications. While Faiss-IVF+PQ is vulnerable to quantization errors that can alter the ranking of top candidates, Scann is designed to be robust against such errors. For an ER task, where distinguishing a true match from a set of very close non-matches is paramount, this focus on ranking fidelity is expected to translate into higher matching precision.
The role of leaves
At its core, Scann operates as a partition-based method, employing a coarse-to-fine search strategy that is architecturally similar to the Inverted File (IVF) paradigm. The initial and most critical step in this process is the partitioning of the entire high-dimensional vector space into a large number of disjoint regions. In Scann’s terminology, these partitions are referred to as leaves, a term derived from the tree-like structure that can be used to organize them. During the index construction phase, a clustering algorithm, typically a variant of k-Means, is used to determine a set of centroids. Each of these centroids defines a leaf, and every vector in the dataset is assigned to the single leaf whose centroid is closest to it. At query time, the search is dramatically accelerated by first comparing the query vector only against the leaf centroids.
A crucial query-time parameter, often called num_leaves_to_search or simply leaves, dictates how many of the most promising leaves—those whose centroids are nearest to the query—will be explored further. The search is then restricted exclusively to the vectors contained within this small subset of leaves, effectively pruning the vast majority of the dataset from consideration. This initial partitioning step is what enables Scann’s high throughput, and it is within these selected leaves that its innovative anisotropic quantization is subsequently applied to perform a highly efficient and precise final ranking.
Experimental evaluation
To empirically evaluate the architectural trade-offs of graph-based and partition-based ANNS methods in a realistic, multi-stage retrieval context, we designed a novel experimental framework modeled on two ER tasks. This framework moves beyond standard recall-vs-QPS benchmarks by introducing a semi-synthetic dataset with a known ground truth for matching and by defining metrics that disaggregate performance into distinct blocking and matching phases. Our empirical evaluation was conducted across two distinct benchmarks designed to validate our findings across different data modalities and scales: first, a large-scale, semi-synthetic dataset adapted from a standard ANNS benchmark (SIFT1M) to specifically model an ER task, and second, a well-established, real-world textual ER dataset (SCHOLAR-DBLP).
The foundation of the first set of experiments is a pair of vector datasets, dataset
This procedure establishes a ground truth of
For the second set of experiments, we used the
The experimental task for both sets of experiments is defined as follows: for each of the vectors in dataset
For partition-based methods, the mapping is direct and intuitive. The index is built on dataset
For graph-based methods, the distinction between blocking and matching is not explicit in the algorithm’s design. We therefore define an implicit mapping based on the progression of the search. The index is built on dataset
This mapping allows for a fair, apples-to-apples comparison of how each architecture allocates computational effort between coarse-grained candidate filtering and fine-grained candidate scoring.
Evaluation metrics
To provide a comprehensive evaluation, we employ a suite of metrics that capture both the efficiency of the search process and the quality of the final matching results.
We define blocking time as the average time required for the initial candidate generation stage. This metric reflects the efficiency of an algorithm’s coarse-grained search strategy. The average time taken for the detailed search within the generated candidate set comprises the matching time. This metric reflects the efficiency of the algorithm’s fine-grained scoring and ranking capabilities. We report all time-based metrics in seconds.
In order to measure the completeness of the results as well as the efficiency of the matching phase, we use recall, precision, and F1-Score metrics. Precision measures the fraction that are true matches, according to the ground truth, from all the retrieved results. Recall measures the fraction of the true matches that were successfully identified by the algorithm. F1-Score is the harmonic mean of Precision and Recall, providing a single, balanced measure of matching quality. It is calculated as
This suite of metrics enables a multi-faceted analysis, allowing us to dissect not only which algorithm is fastest or most accurate overall, but also to understand the underlying architectural reasons for their performance differences in the context of a realistic, large-scale Entity Resolution task.
Experimental setup
All experiments were conducted on a virtual machine equipped with an Intel Xeon processor (16 total cores) and 48GB of RAM. All in-memory algorithms (HNSW, Faiss-IVF, Scann) were run with the index residing entirely in RAM.
We utilized the following open-source library versions for our experiments: Faiss, Scann, and DiskANNPy from their respective public repositories. To thoroughly explore the performance landscape of each algorithm, we conducted extensive parameter sweeps. The key parameters varied for each algorithm were: Faiss-IVF+PQ: nlist (number of coarse centroids) was set to Scann: The number of leaves in the partitioning tree was set to HNSW: The number of connections per node, DiskANN: The maximum degree,
Experimental results
Results for SIFT1M
This section presents the empirical findings from our large-scale Entity Resolution experiment. We first detail the experimental setup, then present the comprehensive performance results, and finally offer an in-depth analysis of the architectural trade-offs revealed by the data.
The central results of our experimental comparison are summarized in the table below. This table presents a detailed breakdown of performance across the ER-specific stages of blocking and matching, combined with the final matching quality metrics. Each row represents a specific configuration of an algorithm, chosen to illustrate key points along its respective performance-quality trade-off curve.
The results for the large-scale semi-synthetic benchmark are summarized in Tables 1 to 3. These tables provide a detailed breakdown of performance across the ER-specific stages of blocking and matching, combined with the final matching quality metrics.
The Pareto Frontier: F1-Score vs. Total Query Time on SIFT1M.
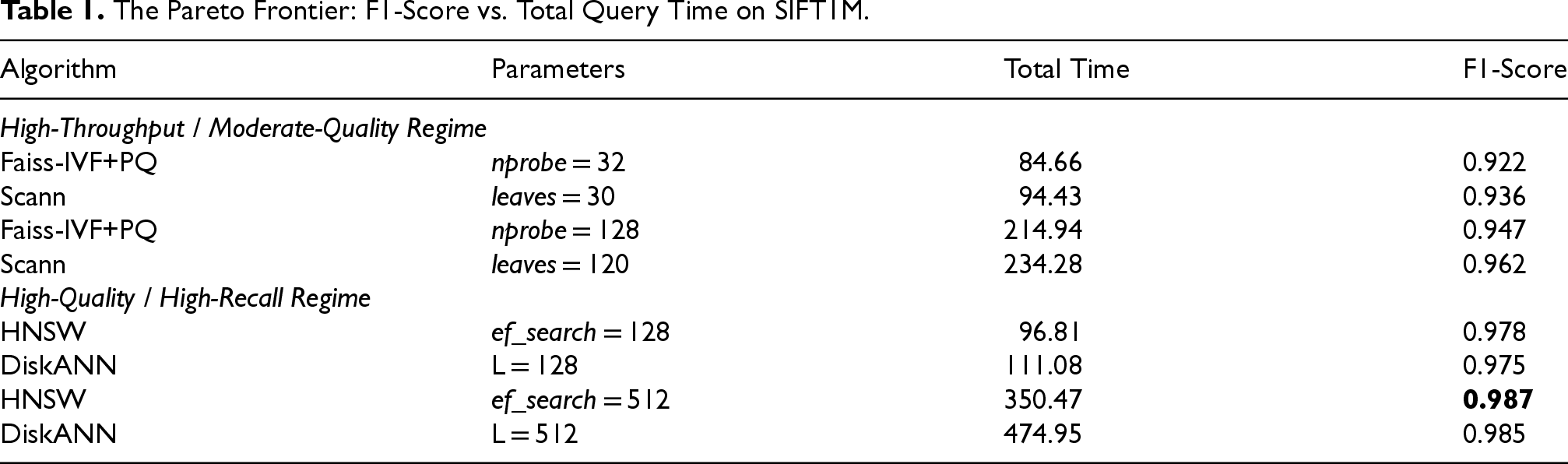
The Pareto Frontier: F1-Score vs. Total Query Time on SIFT1M.
Matching Quality: Recall vs. Precision on SIFT1M.

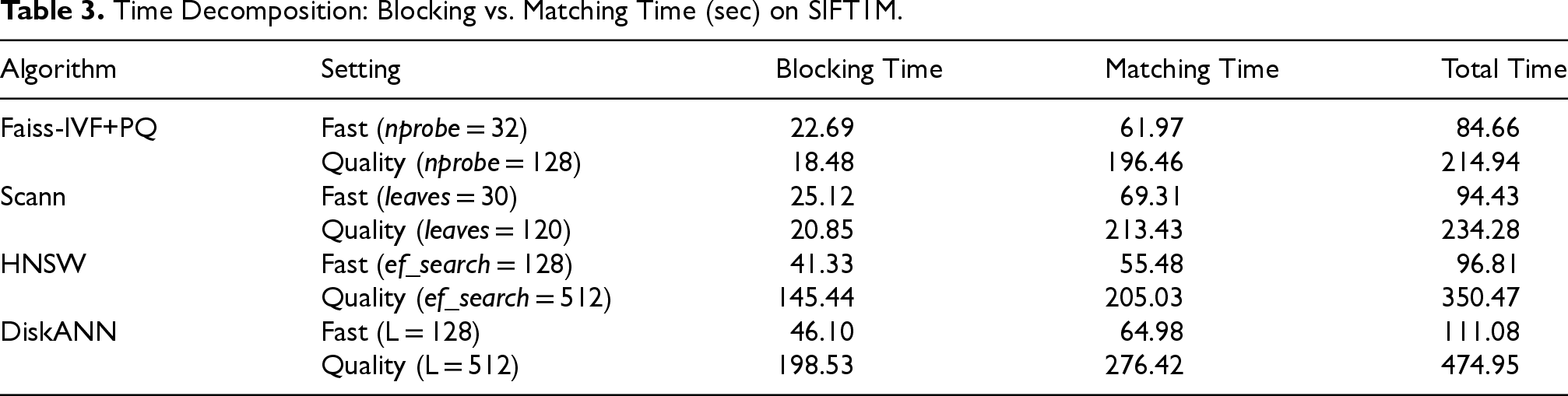
Time Decomposition: Blocking vs. Matching Time (sec) on SIFT1M.
The data reveals a clear delineation between the performance profiles of the two architectural paradigms. As shown in Table 1, the partition-based methods, Faiss-IVF+PQ and Scann, establish a Pareto frontier in the high-throughput, moderate-quality regime. Scann consistently outperforms Faiss-IVF, achieving a higher F1-score. This underscores the practical benefit of its rank-aware anisotropic quantization for ER tasks. Conversely, the graph-based methods, HNSW and DiskANN, define the frontier for high-quality applications. HNSW achieves the highest possible F1-score of
Table 2 isolates the matching quality, highlighting Scann’s consistent precision advantage over Faiss-IVF at comparable recall levels. This directly validates the hypothesis that Scann’s quantization is superior at distinguishing true matches from near non-matches. The graph-based methods maintain extremely high precision even as they approach perfect recall, as their guided search is less susceptible to the hard boundary errors and quantization-induced ranking mistakes that affect partition-based methods.
Finally, Table 3 illustrates the fundamental architectural differences in time allocation. The partition-based methods exhibit a highly asymmetric profile: a minuscule and constant blocking time followed by a matching time that scales linearly with the number of candidates (nprobe). In contrast, the graph-based methods show a more balanced profile. Their “implicit blocking” is a slower but more effective part of the search traversal, leading to a more even distribution of work and ultimately explaining their superior recall.
The results for the real-world textual ER benchmark are summarized in Tables 4 to 6.
The Pareto Frontier: F1-Score vs. Total Query Time (ms) on SCHOLAR-DBLP.
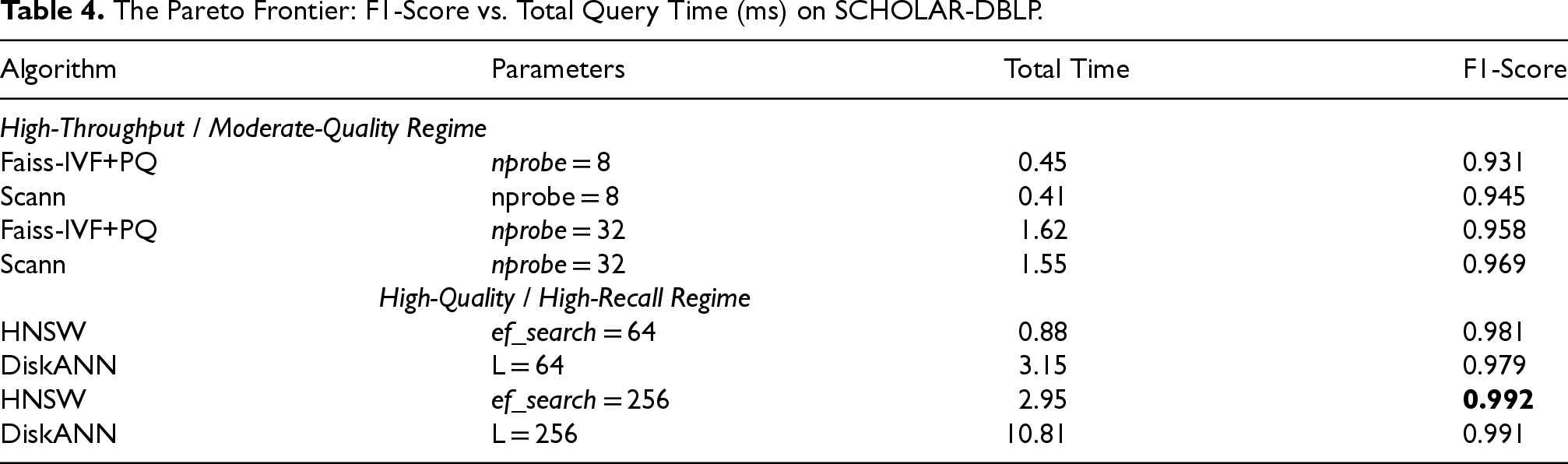
The Pareto Frontier: F1-Score vs. Total Query Time (ms) on SCHOLAR-DBLP.
Matching Quality: Recall vs. Precision on SCHOLAR-DBLP.

Time Decomposition: Blocking vs. Matching Time (ms) on SCHOLAR-DBLP.
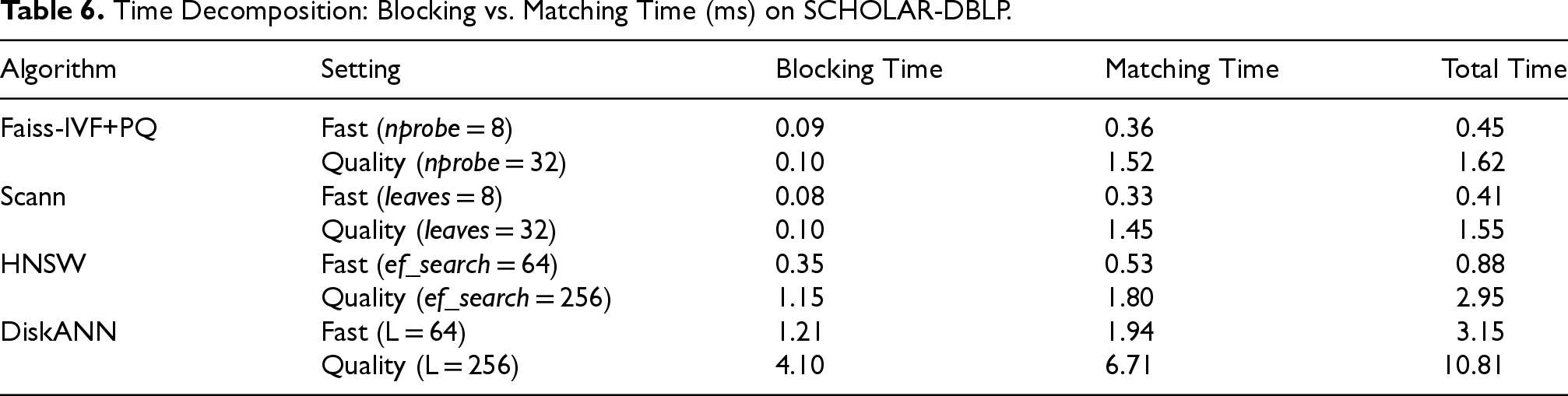
The SCHOLAR-DBLP experiment validates that the architectural trade-offs observed on the SIFT1M dataset generalize to real-world textual embeddings, albeit with different absolute performance characteristics due to the smaller dataset size.
Table 4 again shows the two distinct performance regimes. The partition-based methods offer sub-second latencies for F1-scores up to
The matching quality results in Table 5 reinforce the findings from the first experiment. Scann continues to exhibit a clear precision advantage over Faiss-IVF, and the graph-based methods maintain near-perfect precision even at the highest recall levels. The time decomposition in Table 6 confirms that the fundamental architectural profiles—asymmetric for partition-based and balanced for graph-based—are consistent across different data modalities and scales.
Beyond time and accuracy, the memory footprint of an ANNS index is a critical factor for practical deployment. The two architectural paradigms have fundamentally different memory consumption profiles.
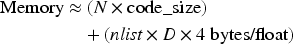
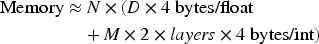
Table 7 summarizes the estimated in-memory footprint for each algorithm configured for the SIFT1M dataset (
Estimated In-Memory Footprint on SIFT1M (1M vectors).

Estimated In-Memory Footprint on SIFT1M (1M vectors).
As shown, DiskANN and the partition-based methods offer extremely low RAM usage, making them suitable for memory-constrained environments. HNSW requires significantly more RAM to hold the full vectors and graph structure, a key trade-off for its high in-memory performance.
The results presented in the preceding tables reveal profound and consistent differences in how the graph-based and partition-based architectures handle the Entity Resolution task across different data modalities and scales.
The partition-based methods, Faiss-IVF+PQ and Scann, exhibit extremely fast and nearly constant blocking times. As shown in the time decomposition tables for both SIFT1M and SCHOLAR-DBLP, this initial stage is computationally trivial, involving a fixed number of comparisons to coarse centroids. This is a direct consequence of their static, “explicit blocking” architecture. In contrast, the graph-based methods show significantly longer “implicit blocking” times that scale with the search parameter (ef_search or
While slower, this dynamic, query-adaptive blocking is demonstrably more effective. At comparable total query times, the candidate sets generated by HNSW and DiskANN lead to substantially higher final recall. This suggests their initial traversal is more successful at navigating to the correct region of the vector space. A critical observation across both experiments is the emergence of a “recall ceiling” for the partition-based methods. As nprobe increases, recall improves but begins to plateau around 94-95% for SIFT1M and 96-97% for SCHOLAR-DBLP. This occurs because some true matching pairs are separated by the hard Voronoi cell boundaries established during indexing. Retrieving these pairs requires a very large nprobe, which causes the matching time to explode, diminishing the primary advantage of the IVF approach. The graph-based methods do not suffer from this hard-boundary problem; their recall curves scale more smoothly and reach higher absolute values as the search effort increases. This demonstrates a systemic vulnerability of static partitioning for ER tasks that demand very high recall.
When examining precision, Scann’s architectural advantage over Faiss-IVF+PQ becomes clear. In both experiments, at comparable recall levels, Scann consistently achieves higher precision. This directly validates the hypothesis that Scann’s anisotropic quantization, which is optimized for ranking rather than geometric reconstruction, is superior at distinguishing true matches from very near non-matches within the candidate set. By preserving the inner product score more faithfully, it ranks the true match higher more consistently.
The graph-based methods, HNSW and DiskANN, demonstrate excellent precision across the board. Their guided search mechanism is inherently very effective at homing in on the true nearest neighbor. Because they can operate on full-precision vectors during the final stages of the search, they are less susceptible to the quantization-induced ranking errors that affect partition-based methods.
Analyzing the F1-Score against the Total Query Time reveals the Pareto frontier for the ER task. The results from both datasets confirm the existence of two distinct performance regimes:
To further illuminate the architectural trade-offs, we visualize the key results from our experiments. Figure 2 provides a visual breakdown of how each architecture allocates its computational budget. The stacked bar charts clearly illustrate the asymmetric performance profile of the partition-based methods. Their blocking time is consistently minimal and nearly constant, as it only involves a fixed number of centroid comparisons. The vast majority of the query time is spent in the matching phase, which scales linearly with the number of candidates retrieved (nprobe or leaves). This confirms their architectural design as an explicit, fast blocking stage followed by a potentially expensive matching stage. Conversely, the graph-based methods display a more balanced allocation of time. Their “implicit blocking” phase, which corresponds to the initial traversal of the graph, is significantly more computationally intensive but also more effective at homing in on the correct neighborhood. This larger investment in the initial search phase pays dividends in the final matching quality, explaining their superior recall and F1-scores in the high-quality regime.
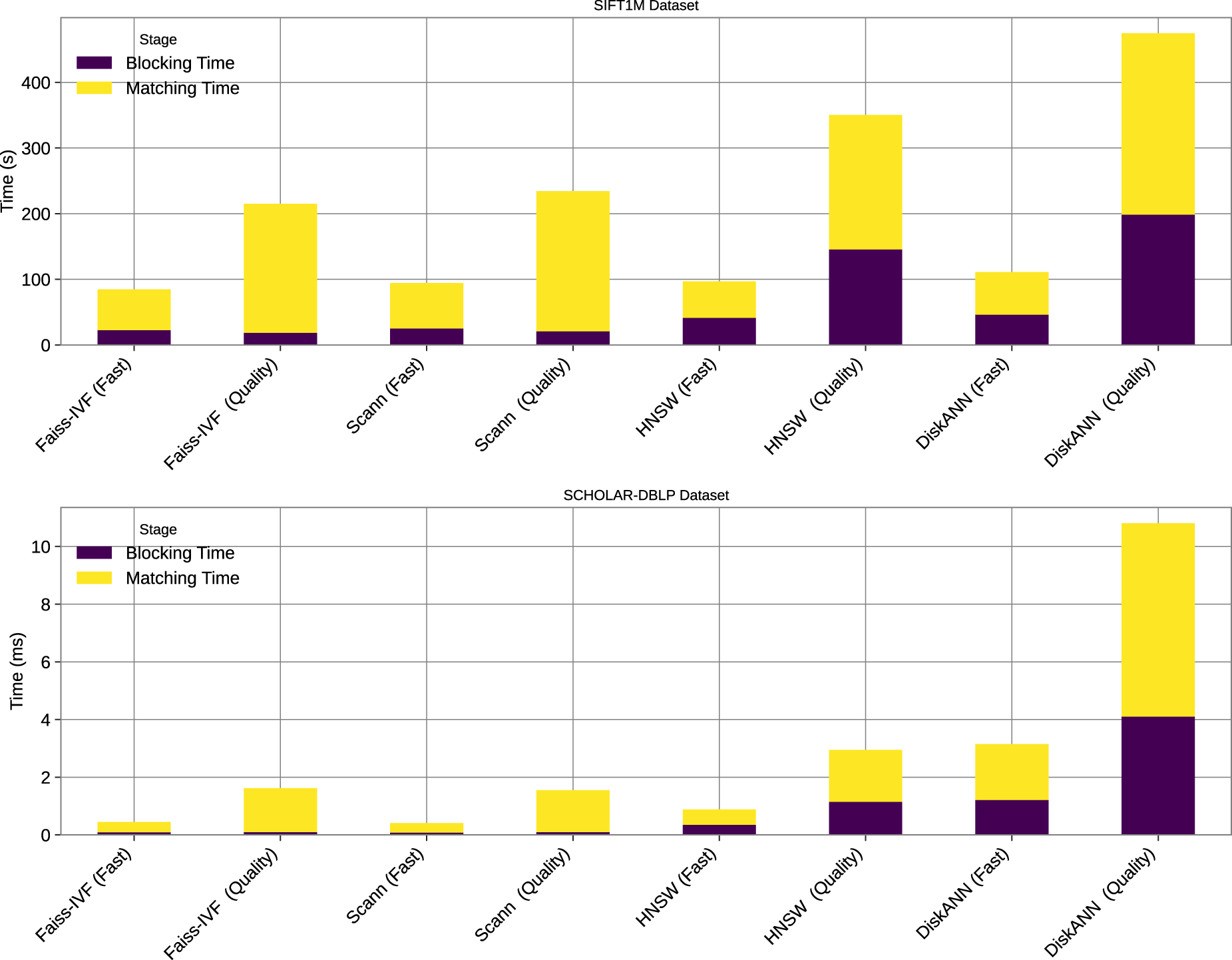
Decomposition of total query time into Blocking and Matching stages for “Fast” and “Quality” configurations of each algorithm. The stacked bar charts highlight the architectural differences: partition-based methods have a minimal, constant blocking time and a dominant matching time that scales with the candidate set size. Graph-based methods exhibit a more balanced profile, with a more substantial “implicit blocking” phase that contributes to their higher recall.
While aggregate metrics like recall and precision are crucial, understanding the types of errors each architecture makes provides cautionary guidance for practitioners. Failure Mode of Partition-Based Methods: The primary source of unrecoverable errors is the “recall ceiling” imposed by the static partitioning of the vector space. If a query vector and its true match fall on opposite sides of a Voronoi cell boundary, the match can only be found if nprobe is large enough to include both cells. For pairs that are separated by several cells, this becomes computationally infeasible, creating a hard limit on achievable recall. This makes these methods vulnerable in ER tasks where true matches may not be the absolute closest geometric neighbors due to noise or semantic nuance. Failure Mode of Graph-Based Methods: Graph-based methods are not susceptible to hard boundary errors but can fail when the greedy search traversal makes a mistake. This can happen if the search path leads into a dense “hub” region of the graph that is close to the query but does not contain the true nearest neighbor. If the dynamic candidate list (e.g., ef_Search) fills up with vectors from this incorrect region, the algorithm may fail to explore the edge that would have led toward the correct answer. This type of error is more likely in datasets with highly clustered and non-uniform distributions. However, as our results show, this failure mode is generally less frequent than the boundary errors of partition-based methods, allowing graph-based approaches to achieve higher overall recall.
The consistency of these findings across both the large-scale SIFT1M benchmark and the smaller, real-world SCHOLAR-DBLP dataset indicates that these architectural trade-offs are fundamental and not specific to a particular data modality. However, the SCHOLAR-DBLP experiment highlights a critical practical consideration for scalability: DiskANN’s performance, while excellent in terms of quality, is over 3
This paper presented a comprehensive comparison of graph-based and partition-based ANNS algorithms through the lens of a large-scale ER task. Our findings reveal that the fundamental design choices separating these paradigms lead to distinct and predictable performance trade-offs.
Recommendations for practitioners
Based on our analysis, we offer the following decision-making framework: If the index fits in RAM, HNSW is the recommended choice. If the index is at the billion-scale or larger, DiskANN is the only viable and superior option. Scann is the recommended choice. It provides the best performance at moderate-to-high recall levels and its anisotropic quantization ensures higher precision among the top results.
Future work
This study opens several promising avenues for future research. A key area is the development of hybrid models that seek to combine the strengths of both architectural paradigms. For instance, one could explore an “IVF-HNSW” model that uses a small HNSW graph within each cell of a larger IVF structure. This could potentially mitigate the “recall ceiling” of pure partition-based methods by allowing for a more effective and robust local search, while still benefiting from the coarse-grained filtering of the IVF system.
Furthermore, to broaden the impact of these findings, future work should expand the evaluation to a more diverse set of large-scale, real-world datasets, particularly from domains like e-commerce (matching product listings with multi-modal features) and biomedical research (linking patient records or scientific papers). Finally, the impact of dynamic data—frequent insertions and deletions—on the performance of these algorithms in an ER context remains an open question. Extending this experimental framework to evaluate streaming ANNS algorithms, such as FreshDiskANN, 11 would provide critical insights for building robust, real-time entity resolution systems.
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.