
Abstract
Small and medium-sized enterprises (SMEs) face escalating cyber threats and often lack the technical and financial capacity to deploy resource-intensive security solutions. This study evaluates the effectiveness of Artificial Intelligence (AI) and Machine Learning (ML) models for lightweight intrusion detection systems (IDS) tailored to SME environments. Six supervised algorithms including Logistic Regression, Naïve Bayes, Random Forest, Multi-Layer Perceptron (MLP), LightGBM, and XGBoost, were trained and tested on the TON_IoT dataset. Performance was assessed using standard metrics (accuracy, precision, recall, F1-score, ROC-AUC) alongside computational efficiency indicators (training time, inference latency, and model size). Results show that tree-based ensemble models, particularly XGBoost (accuracy = 99.07%, ROC-AUC = 0.9996) and LightGBM (accuracy = 99.00%, ROC-AUC = 0.9993), achieved superior detection performance while maintaining minimal computational cost. In contrast, Logistic Regression and Naïve Bayes exhibited faster training but lower detection accuracy (<76%). These findings confirm that AI-driven ensemble models can deliver both accuracy and efficiency, making them ideal for deployment in resource-constrained SMEs. Limitations of this study include reliance on a single dataset and supervised frameworks. Future work will extend to cross-dataset validation and real-world SME applications to enhance robustness and generalizability.
Keywords
Introduction
Small and medium-sized enterprises (SMEs) play a crucial role in economic growth, innovation, and employment. 1 However, their limited cybersecurity infrastructure makes them prime targets for cybercriminals. 2 According to recent industry reports, over 60% of cyberattacks now target SMEs, many of whom struggle to recover from the aftermath due to financial and technical limitations. 3 With growing adoption of cloud services, remote work, and IoT-based systems, SMEs are increasingly exposed to sophisticated threats such as distributed denial of service (DDoS), ransomware, phishing, and botnet attacks. 4 Conventional signature-based intrusion detection systems (IDS) are insufficient in modern environments due to their inability to detect novel (zero-day) attacks and their dependence on continuously updated rule sets.5–7 These systems also produce high false-positive rates, causing alert fatigue and reduced operational efficiency. SMEs, lacking dedicated cybersecurity teams or high-end infrastructure, face particular difficulty in deploying and maintaining such systems.6,7 Artificial intelligence (AI) and machine learning (ML) offer promising alternatives to rule-based systems, including intrusion detection systems for Safe communication in the Internet of Things.7–11 By learning patterns from historical data, these models can detect both known and unknown threats in real-time or near-real-time. Their ability to generalize from diverse features (including network traffic behavior, protocol patterns, or application-layer anomalies) positions them as key tools for proactive threat detection.6,9,10,12 For SMEs, lightweight and interpretable ML models can provide cost-effective, scalable, and adaptive security solutions. 2 While significant research has focused on ML-based intrusion detection in large enterprise settings, there is limited empirical work exploring the practicality and efficiency of these solutions in SME contexts. Given that SMEs often lack access to proprietary threat intelligence data, this study leverages publicly available, realistic network traffic data (TON_IoT) to simulate SME-like environments and benchmark ML models accordingly.
Recent studies have demonstrated that advanced machine learning paradigms such as neural networks and Gaussian process regression (GPR) possess significant potential in modelling complex, non-linear, and dynamic systems. For example, Jin, Xu, and Zhang 44 employed an autoregressive neural network to achieve robust and accurate predictions in commodity price forecasting, demonstrating the capacity of neural architectures to extract latent temporal dependencies in high-dimensional data. Similarly, Jin and Xu 45 expanded this neural modelling framework to predict composite commodity price indices, reinforcing the adaptability and generalization power of deep neural structures across multiple data-driven contexts. Complementary to these, Gaussian process regression has emerged as a powerful probabilistic learning technique for predictive modelling under uncertainty. Jin and Xu 46 utilized GPR for real-estate price index forecasting, showing its proficiency in handling noisy and sparse data distributions. This is a characteristic particularly relevant to cybersecurity, where data imbalance and stochastic variations are common. In another study, Jin and Xu 47 applied GPR to silver price forecasting, emphasizing its ability to quantify uncertainty and maintain interpretability in complex regression tasks. Collectively, these studies underscore a growing consensus that the integration of sophisticated AI and ML models can substantially enhance predictive accuracy, stability, and transparency in dynamic environments. Building upon these advancements, our research extends the practical utility of such models to the cybersecurity domain, specifically focusing on lightweight and efficient implementations suitable for small and medium-sized enterprises (SMEs). This contextual shift bridges the gap between high-performance algorithmic innovation and real-world deployment constraints, positioning our work as a practical and scalable contribution to AI-driven intrusion detection.
To the best of our knowledge, this study represents one of the first systematic efforts to develop an intrusion detection framework explicitly tailored to the operational realities of small and medium-sized enterprises (SMEs). Unlike conventional intrusion detection systems designed for large organizations with abundant computational and human resources, the proposed approach emphasizes lightweight, performance-efficient, and easily deployable models that maintain high detection accuracy under constrained conditions. By comprehensively comparing classical machine learning, ensemble, and deep learning models on SME-relevant datasets and integrating an optimization-driven evaluation for precision–efficiency trade-offs, this research introduces a novel, SME-oriented selection strategy for IDS deployment. This positions the study as a meaningful contribution to closing the gap between advanced IDS research and the cybersecurity needs of resource-limited enterprises.
The aim of this study is therefore to identify models that balance detection accuracy with computational efficiency (ideal for SME deployment). The following are the specific objectives of this study: Evaluate the effectiveness of selected machine learning models in detecting cyber intrusions using the TON_IoT dataset. Identify models that offer high detection performance with minimal resource requirements, suitable for SMEs. Provide insights on feature contributions and model interpretability for practical adoption.
The contributions of this study are summarized thus:
Conducting a comparative evaluation of six supervised learning models (Logistic Regression, Naïve Bayes, Random Forest, MLP, LightGBM, and XGBoost) for intrusion detection in SMEs.
Introducing a dual evaluation framework that considers both predictive performance (accuracy, precision, recall, F1-score, ROC-AUC) and engineering efficiency metrics (training time, inference speed, model size).
Demonstrating the suitability of lightweight ensemble models (LightGBM and XGBoost) for resource-constrained SME environments.
Providing actionable insights for SME practitioners by aligning IDS model selection with practical deployment constraints.
The remainder of this paper is organized as follows: Section 2 reviews related works and highlights the gaps addressed by this study. Section 3 describes the methodology, including dataset preparation, preprocessing, and model design. Section 4 presents the experimental setup. Section 5 outlines results, and detailed discussion. Finally, Section 6 concludes the paper with key findings, limitations, possible future research directions and recommendations.
This section presents a comprehensive literature review of related work on ML-based intrusion detection and SME cybersecurity needs.
Cybersecurity threats facing SMEs and recent approaches
In our progressively digitalized society, enterprises depend on perpetually interconnected information systems. This indicates that SMEs serve as potential targets for hackers who can exploit weaknesses to inflict economic and reputational harm.4,13 SMEs are increasingly reliant on digital technologies for their operations, but often lack the technical expertise and financial capacity to implement robust cybersecurity measures.2,14 Reports from the Verizon Data Breach Investigations and ENISA (2022) have shown that SMEs are now prime targets for cyberattacks due to their perceived vulnerability and limited investment in threat detection systems. Common threats include phishing, brute-force attacks, malware infections, and botnet intrusions, many of which go undetected until significant damage has been done. Unlike larger organizations, SMEs typically lack dedicated security teams or automated detection tools (ENISA, 2022).
SMEs cyber risk assessment and evaluation (SMECRA): a dynamic approach
SMECRA, being based on a System Dynamics simulation model, has a reliable and dynamic nature and is a reliable, customizable, affordable and easy-to-use approach in SMEs context. This approach efficiently supports SMEs in decision-making for investment and better risk posture, while supporting third parties, including insurance companies and banks, in assessing the risk profile and policy-making. 15
Share cyber threat intelligence (CTI): improve security resilience by (MISP)
To enhance our collective cybersecurity in SMEs, there have been many initiatives to consolidate CTI. When SMEs seek adaptable and automated approaches, shared CTI supported by Malware Incident Sharing Platform (MISP), which was introduced in 2026, may provide the answer. MISP is a flexible, free and open-source incident sharing platform for threat information sharing, storage, and correlation of IoCs related to cybersecurity incidents. 16
Machine learning in intrusion detection systems (IDS)
Traditional IDS approaches rely heavily on predefined rules and signatures, which are ineffective against novel and polymorphic attacks.7,14 In contrast, machine learning (ML) enables systems to learn from data and detect anomalies or patterns indicative of malicious behavior in different organizational contexts, including SMEs, Medicare, etc., in the developing world.7,8,10,12,17 Techniques such as decision trees, support vector machines (SVM), neural networks, and ensemble models (e.g., XGBoost, LightGBM) have been explored extensively in research for anomaly-based intrusion detection. For example, several studies demonstrated the potential of XGBoost, deep neural networks and Random Forest classifiers for network intrusion detection with high accuracy. 12 18–20 Sakil et al. 2025 reported the upgradation of Medicare fraud detection with CNN-transformer XGBoost and Explainable AI. 12 Similarly, Anand et al., (2025) showed that XGBoost, neural networks and Random Forest could outperform ransomware detection, although at the cost of greater computational resources. 21 Therefore, these ML-based approaches have been emerging for superior intrusion detection and anomaly classifications, yielding an accuracy of 96%. 22 In addition, XGBoost combined with rough set theory showed significant achievement in network intrusion detection systems with a higher percentage of 7%, 3%, 8% and 2% in accuracy, precision, F1-score, and recall, compared to their counterparts. 23 However, most existing research focuses on performance in large-scale enterprise environments rather than practical deployment in SME contexts where resources are constrained.
Examples of recent studies
Shi et al. (2023) highlight that edge and SME environments necessitate lightweight, resource-efficient deep learning models for real-time intrusion detection due to computational constraints. Wang et al. (2023) proposed a DNN + BiLSTM fusion with dynamic quantization and IPCA for dimensionality reduction. 24 The study demonstrated how deep models can be made resource-efficient without incurring significant accuracy loss. Udurume, Shakhov, & Koo (2024) reported a benchmark of CNN–BiLSTM against classical ML on standard IDS datasets in a recent comparative study. 25 Bhutta, Nisa, & Mian (2024) provided a concrete example of LightGBM delivering high accuracy with low latency/memory on real Wi-Fi traffic. 26 Chen et al. (2024) combined advanced feature-selection + LightGBM to get >99% accuracy on IoT data while explicitly reporting training/inference time. 27 Yang et al. (2023) presented knowledge-distillation and compact block designs (LNet-SKD) to achieve state-of-the-art performance with fewer parameters. 28 Data & Bakhtiar (2023) focused on online / streaming ML with resource efficiency. 29 Alotaibi & Ilyas (2023) demonstrated ensemble methods (RF/XGBoost/LightGBM) applied to TON-IoT/TON datasets with explicit attention to inference speed and ensemble trade-offs. 30 Arasteh et al. (2024) introduced an optimized method using gray wolf optimization for SQL injection detection. 31 Another study by Arasteh et al. (2024) proposed an effective fusion approach for SQL injection detection using a binary Olympiad optimizer. 32 In addition, Majidian et al. (2023) employed error-correcting output codes with adaptive neuro-fuzzy inference for DoS detection. 33 Majidian and Taghipour Eivazi (2024) further demonstrated optimized Random Forest models tailored for IoT intrusion detection. 34 Table 1 below is a comparative synthesis of state-of-the-art intrusion detection approaches relevant to SMEs. It compares Classical ML, Ensemble Methods, and Deep Models across representative studies, advantages, limitations, and practical suitability for SMEs.
Comparative synthesis of IDS approaches in context of SME.

Comparative synthesis of IDS approaches in context of SME.
Representative studies were chosen to reflect recent works (2019–2024) with emphasis on practical deployment, efficiency, and TON_IoT/modern IDS datasets. For SME recommendations, “suitability” is assessed by balancing detection performance and resource constraints (CPU, memory, absence of GPUs), plus ease of deployment/interpretation.
Representative studies were chosen to reflect recent works (2019–2024) with emphasis on practical deployment, efficiency, and TON_IoT/modern IDS datasets. For SME recommendations, “suitability” is assessed by balancing detection performance and resource constraints (CPU, memory, absence of GPUs), plus ease of deployment/interpretation.
A major challenge in cybersecurity research is the lack of real-world, labelled datasets. As a result, publicly available benchmark datasets have become the standard for training and evaluation of ML-based IDS.
NSL-KDD: A cleaned version of the KDD’99 dataset, historically used in IDS research, but outdated in terms of attack types.
CICIDS2017: Contains realistic traffic with multiple attack scenarios and is frequently used to benchmark intrusion detection models.
UNSW-NB15 and TON_IoT: More modern datasets that simulate diverse IoT and SME-like network traffic, including both benign and malicious behavior.
Among these, TON_IoT is particularly relevant for this study as it provides logs and network flow features that emulate SME or IoT-based environments, making it a practical choice for evaluating lightweight ML models in such contexts. Several recent studies have leveraged the TON_IoT dataset to evaluate intrusion detection techniques. For instance, Ismail et al. (2025) introduced the datasets, including TON_IoT, WUSTL-IIoT-2021, and Edge-IIoTset datasets, to support research into intrusion and anomaly detection in IoT systems. 39 Ahmed et al. (2025) used hybrid ML-DL approaches to train deep learning models for multi-stage intrusion detection by using TON_IoT and KD99 datasets. 40 However, these studies often prioritize model performance in controlled lab settings, without addressing computational efficiency—an important factor for SME adoption. Additionally, while ensemble and deep learning approaches (e.g., LightGBM, MLP, CNN) tend to outperform simpler models in accuracy, their resource demands may be impractical for deployment in SME infrastructures without hardware acceleration or cloud-based support.
Although many studies have demonstrated the success of machine learning in cybersecurity, there remains a gap in understanding: How different ML models perform on modern SME-representative data like TON_IoT, Which models balance accuracy with efficiency, and How feature selection and model interpretability affect practical adoption.
This study fills that gap by empirically comparing six diverse machine learning algorithms (Logistic Regression, Random Forest, SVM, XGBoost, LightGBM, MLP) using a well-preprocessed TON_IoT dataset. Special attention is given to resource cost, performance trade-offs, and implications for deployment in small enterprise environments.
This section describes the dataset used, the preprocessing pipeline, the selected machine learning models, evaluation metrics, and the experimental setup designed to assess the suitability of each model for cybersecurity detection in small and medium-sized enterprises (SMEs). Figure 1 below is the methodology flowchart used in this study. The highlighted steps are explained in the subsection that follows.

Methodology workflow diagram.
This study uses the TON_IoT network flow dataset, created by the Australian Centre for Cyber Security (ACCS) at the University of New South Wales (UNSW). The dataset was designed to emulate realistic Internet of Things (IoT) and Small and Medium-sized Enterprises (SME) network environments, capturing both benign and malicious traffic across various attack categories such as Distributed Denial of Service (DDoS), Denial of Service DoS, Reconnaissance scans, and data exfiltration. The selected file for this study is TON_IoT_Train_Test_Network.csv, which contains 461,043 rows and 45 features, categorized into four key groups:
Network metadata: Includes source and destination IP addresses, source and destination ports, and protocol information (i.e., source/destination IP, ports, protocol)
Flow-level statistics: Captures quantitative measures such as the number of bytes transferred, packet counts, and session duration (i.e., bytes transferred, packet counts)
Application-layer data: Captures quantitative measures such as the number of bytes transferred, packet counts, and session duration (i.e., HTTP, DNS, SSL fields)
Ground truth: The label column denotes the nature of the traffic, with 0 representing benign flows and 1 indicating malicious activity (0 = benign, 1 = attack)
The TON_IoT dataset serves as a practical and realistic proxy for intrusion detection research in SME contexts, where resources are limited, and security infrastructures are often constrained. The following figures summarize the underlying data distribution and feature relevance: Figure 2 visualizes the proportion of benign versus attack samples in the dataset.

(a) Target Variable distribution (b) Inter-feature relationships (c) Correlation matrix (d) Feature distribution (e) Protocol vs label (f) Service vs Label (g) Attack distribution.
Raw data from the TON_IoT dataset includes a mix of identifiers, textual fields, and categorical variables that require cleaning and transformation before being used in machine learning models. Irrelevant fields such as timestamps, IP addresses, long text strings (e.g., SSL subject, HTTP user-agent), and MIME types were dropped. This reduces noise and improves computational efficiency. Examples of dropped features include: ts, src_ip, dst_ip, dns_query, ssl_issuer, http_user_agent. Relevant categorical columns such as proto, service, conn_state, and http_method were label-encoded using LabelEncoder, converting string values into numerical form. Non-numeric placeholders like “-“ were replaced with NaN, then encoded or imputed. The selected features were normalized using StandardScaler to ensure uniformity across features and improve convergence for algorithms such as SVM and MLP. The dataset was split into training and testing sets using a 70:30 stratified split, ensuring the class distribution remained balanced to maintain a fair evaluation.
Machine learning models
In Table 2 and Snippet 1, six machine learning models were selected to represent a spectrum of complexity and computational demands, suitable for assessing performance and deployability in SME environments:
Comparison of classification performance metrics across six machine learning models, including Precision, Recall, F1-Score, Support, and overall accuracy for benign and attack classes.
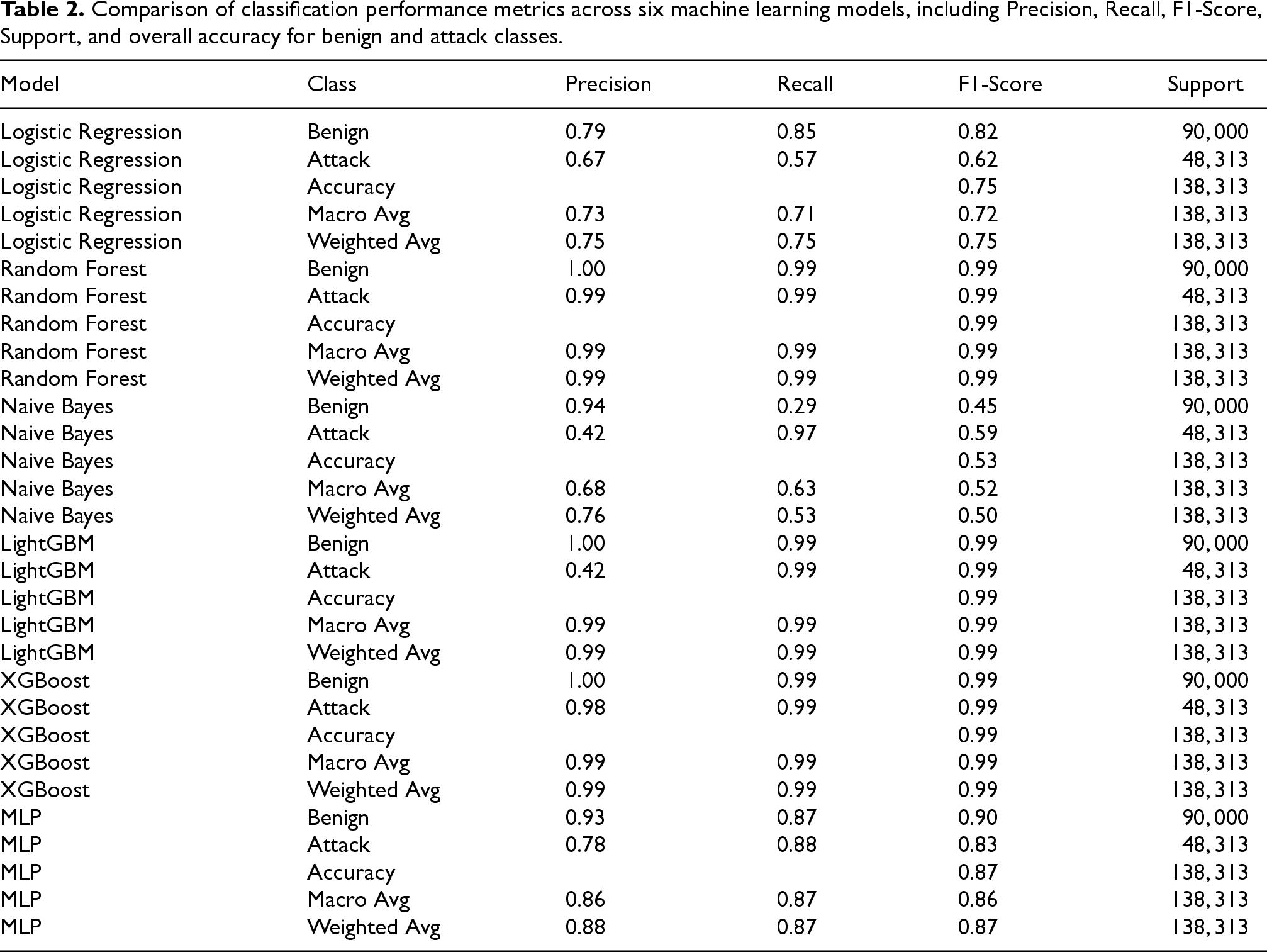
Comparison of classification performance metrics across six machine learning models, including Precision, Recall, F1-Score, Support, and overall accuracy for benign and attack classes.
To evaluate model performance, the following classification metrics were computed: accuracy, precision, recall (sensitivity), F1-Score, ROC-AUC, and confusion matrix. Classification reports were generated for each of the models.
Efficiency metrics of training time, inference time, and model size were also computed in order capture the tradeoff between model suitability for SMEs. This is illustrated in snippet 2 below:
Each model was trained and evaluated using the same train-test split, and performance was reported on the test set.
Experimental setup
All experiments were conducted on a standard development environment to simulate the resource capabilities typical of small and medium-sized enterprises (SMEs). The configuration details are as follows: Processor: Intel Core i7 / AMD Ryzen 7 (or equivalent) RAM: 16 GB Operating System: Google Colab environment (Linux-based backend) Python Version: 3.11+ Libraries Used: scikit-learn for general machine learning modeling and metrics, xgboost and lightgbm for gradient boosting classifiers, matplotlib and seaborn for visualization, and, pandas with numpy for data manipulation and analysis.
The entire implementation was carried out using Google Colab running Jupyter Notebook, ensuring an interactive and cloud-based setup for reproducibility. The full pipeline (from data loading, preprocessing, and feature engineering to model training, evaluation, and efficiency profiling) was scripted in Python. This setup reflects a practical and accessible environment for SMEs seeking to adopt AI-driven cybersecurity solutions without reliance on high-performance computing infrastructure.
Model performance comparison
This section presents the performance of the six machine learning models evaluated on the TON_IoT dataset as illustrated in Tables 2 below. The models were compared based on multiple metrics, including Accuracy, Precision, Recall, F1-score, and ROC-AUC. A qualitative discussion follows each result set to interpret its implications for SME environments.
Table 3 below presents a comparative summary of the performance of six different models, including Logistic Regression, Random Forest, Naïve Bayes, LightGBM, XGBoost, and Multi-Layer Perceptron (MLP). They are evaluated using standard classification metrics: accuracy, precision, recall, F1-score, and ROC-AUC:
A comparative summary of the performance of different models.
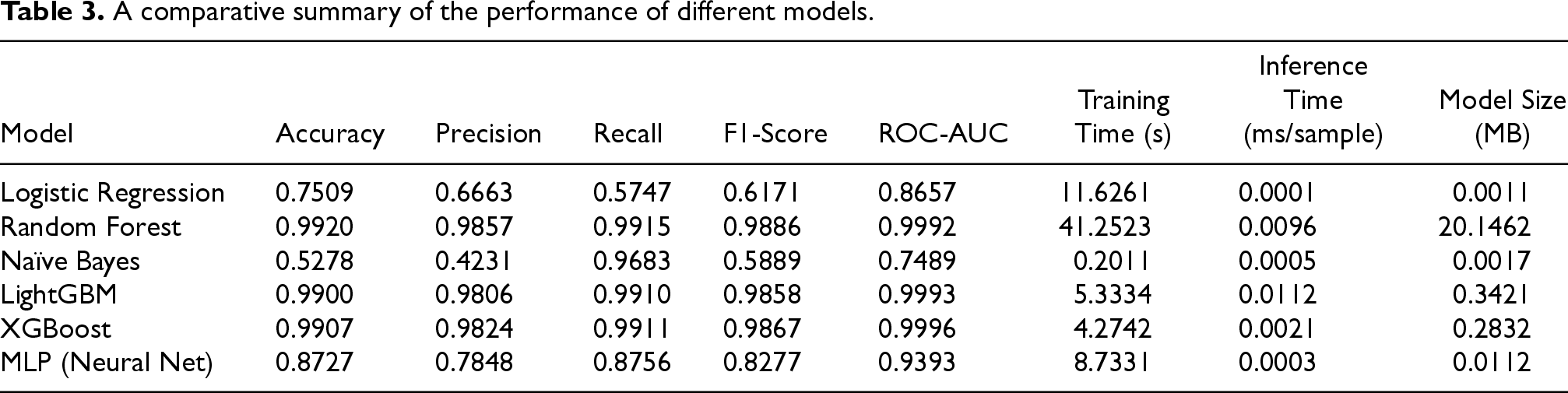
A comparative summary of the performance of different models.
The results in Table 3 above indicate that ensemble-based AI models such as Random Forest, LightGBM, and XGBoost outperformed the traditional classifiers significantly across all evaluation metrics. These models consistently achieved over 99% in ROC-AUC, signaling their exceptional discriminatory capability in differentiating between normal and malicious network activity.
Among the traditional models, Logistic Regression performed moderately with a ROC-AUC of 0.8657 and an F1-score of 0.6171, making it a reasonable baseline. Naïve Bayes, although achieving a very high recall (0.9683), struggled with precision (0.4231), leading to a relatively low F1-score. This highlights its tendency to classify too many positives, which could result in a high number of false alarms.
The MLP (Neural Network) demonstrated decent performance, achieving an F1-score of 0.8277 and a ROC-AUC of 0.9393, outperforming the traditional models but falling slightly short of the tree-based AI models. This suggests that while deep learning is effective, its performance may depend heavily on hyperparameter tuning and the balance of training data.
XGBoost emerged as the best-performing model, narrowly outperforming LightGBM and Random Forest. Its high accuracy, precision, and recall values make it well-suited for mission-critical applications like intrusion detection, where both low false positives and low false negatives are paramount.
In the comparison of the machine learning models based on their predictive performance and computational efficiency presented in Table 3 above, the trade-off between accuracy and resource consumption (training time, inference speed, and model size) is critical for Small and Medium-sized Enterprises (SMEs) that operate under budget and hardware constraints.
In Figure 3 above, Logistic Regression and Naïve Bayes exhibited the fastest inference times and smallest model sizes. These models are suitable for real-time deployment in environments where speed and minimal memory usage are priorities, although they trade off significant accuracy, especially in the case of Naïve Bayes.

“Detection vs efficiency” tradeoff (plot of F1-score vs inference time).

Confusion matrices for models (a) Logistic regression (b) Random forest (c) Naïve Bayes (d) LightGBM (e) XGBoost (f) MLP.

Feature importance plots (a) Random Forest (b) LightGBM (c) XGBoost.
Random Forest, LightGBM, and XGBoost delivered near-perfect accuracy, precision, and recall, making them highly reliable for detecting complex intrusion patterns. However, Random Forest incurred the highest training time and model size, which may limit its adoption in resource-constrained SME setups.
XGBoost and LightGBM emerged as the most efficient high-performing models. XGBoost, in particular, achieved the best ROC-AUC score (0.9996) with a relatively small model size (0.2832 MB) and fast inference speed. LightGBM maintained a comparable balance between speed, size, and accuracy, making it an excellent choice for SMEs requiring scalable and efficient solutions.
The MLP model demonstrated a strong balance between performance and efficiency, surpassing simpler models in predictive power while maintaining a relatively small model size. However, its performance still fell short of the gradient boosting models.
In scenarios where high accuracy is essential but computational budgets are limited, LightGBM and XGBoost provide the best trade-off between performance and efficiency. For ultra-lightweight deployments, Logistic Regression and Naïve Bayes may be preferred, though at the cost of accuracy. Random Forest, while highly accurate, is best reserved for environments with more generous resources.
The confusion matrices (Figure 4) revealed that XGBoost and LightGBM had the lowest false positive and false negative rates. Logistic Regression and Naïve Bayes, while efficient, showed higher false negatives, making them less ideal for detecting attacks in critical environments. Random Forest and MLP offered a good balance between precision and recall. These observations suggest that tree-based ensemble models (RF, XGBoost, LightGBM) are more effective in capturing nonlinear relationships and subtle variations in traffic behavior, which are crucial for detecting sophisticated attacks.
Feature importance analysis
Feature importance plots (Figure 5) were generated to provide interpretability into the decision-making process of the tree-based models, particularly Random Forest, LightGBM, and XGBoost. Each model computes importance by quantifying the contribution of individual features to prediction performance. For Random Forest, importance scores were derived from the mean decrease in Gini impurity across all decision trees. For LightGBM and XGBoost, feature importance was calculated based on split gain, which measures the average improvement in loss reduction when a feature is used to split the data. These importance values were normalized and ranked, with higher scores indicating features that contributed more significantly to intrusion detection. Visualizing these results through bar plots enabled clearer identification of which traffic features were most influential in detecting different attack types, thus enhancing both model transparency and practical applicability in SME security contexts. The tree-based models provided insights into which features were most influential in Figure 5 below:
The top-ranked features observed across the models include: src_bytes, dst_bytes: Indicate data volume in a session duration: Suggests abnormal connection persistence src_pkts, dst_pkts: Capture flow behavior conn_state: Indicates session success/failure service and proto: Protocol-specific behaviors
These features helped distinguish between normal and anomalous behaviors, validating the feature selection process during preprocessing.
Compared to prior works using NSL-KDD or CICIDS 2017, this study demonstrates competitive or superior performance. Previous models often lacked real-world applicability due to outdated features or simplified traffic simulation. By using TON_IoT, this study evaluates models in a more realistic context that reflects SME network environments and diverse attack types. Moreover, while prior studies focused on deep learning for accuracy, this study emphasizes efficiency and interpretability, aligning with the operational constraints of SMEs. For instance, Khan et al. (2023) evaluated Random Forest and SVM models on the CICIDS2017 dataset, achieving high accuracy (about 99%) but acknowledged the dataset's reliance on artificially generated traffic, limiting its realism in live SME networks. 41 Similarly, Bamber et al. (2025) applied Deep Learning approaches, including CNN-LSTM hybrids, to the NSL-KDD dataset, achieving impressive detection rates with 95% accuracy, 0.89 recall, and 0.94 f1-score but at the expense of model complexity and computational overhead. 42 These models, while effective in controlled environments, are often impractical for SMEs that operate under strict resource constraints.
In contrast, this study leverages the TON_IoT dataset, which offers a more realistic and diverse simulation of SME and IoT network environments, capturing benign and malicious flows across multiple attack vectors, including DDoS, data exfiltration, and reconnaissance. By doing so, the study addresses a critical gap in existing literature where models are evaluated on datasets that fail to reflect the operational dynamics of contemporary SME networks.
Moreover, while previous works predominantly prioritized detection accuracy and fraud detection through computationally intensive deep learning models,41,42 this study introduces a performance-efficiency balanced approach. By comparing ensemble-based methods like LightGBM and XGBoost with classical algorithms, the research emphasizes models that not only deliver competitive accuracy (over 99%) but also ensure fast inference times and minimal memory footprints. This approach aligns with findings by Ahmed et al. (2025), who emphasized that model efficiency is equally vital for real-world deployment, especially in SMEs where computational resources are inherently limited. 6 Furthermore, the interpretability aspect of this study distinguishes it from prior work. Many deep learning-based IDS models, despite their predictive power, function as “black-box” systems, making them unsuitable for environments where explainability and transparent decision-making are critical for cybersecurity operations. 38 By employing models like Random Forest and LightGBM, which provide clear feature importance metrics, this study enhances the explainability of detection decisions, a feature crucial for cybersecurity analysts in SMEs.18,23,43
While prior studies provided valuable contributions in terms of detection techniques and accuracy benchmarks, this research advances the state-of-the-art by demonstrating how efficient, interpretable, and SME-adapted ML models can deliver high-performance intrusion detection in realistic network environments, paving the way for practical and scalable cybersecurity solutions.
Implications of findings
The findings of this study carry several important implications for both research and practice in the domain of cyber intrusion detection, particularly within the context of U.S. small and medium-sized enterprises (SMEs). First, the comparative evaluation demonstrated that resource-efficient ensemble models, such as LightGBM and XGBoost, can achieve high levels of predictive performance while maintaining reduced computational and memory overhead. This reinforces the argument that model efficiency is not merely a secondary consideration but a primary determinant of the deployability of intrusion detection systems in SMEs, where technical and financial resources are often constrained (Rahman et al., 2023; Zhou et al., 2024).
From a practical standpoint, the study underscores the feasibility of operationalizing AI-enhanced intrusion detection systems in environments traditionally underserved by enterprise-grade cybersecurity technologies. By highlighting the balance between detection accuracy and efficiency, the results provide actionable guidance for IT managers and practitioners who must select models that align with their infrastructure limitations while ensuring robust protection against evolving threats. The findings thus move beyond theoretical performance to offer concrete recommendations tailored to real-world SME contexts.
For the research community, this work contributes to the growing body of literature on lightweight, scalable intrusion detection frameworks. It addresses gaps in prior studies that often emphasize detection accuracy in isolation, by explicitly incorporating system-level considerations such as inference latency and model size. Furthermore, the demonstrated strengths of tree-based ensembles point toward the need for hybrid and adaptive approaches that combine efficiency with interpretability, two critical features for the broader adoption of AI-driven cybersecurity solutions.
The implications extend to policy and governance. Given the heightened vulnerability of SMEs as entry points for larger supply chain attacks, these results highlight the importance of fostering targeted support mechanisms such as subsidized access to efficient AI models, regulatory guidance on SME-tailored cybersecurity standards, and collaborative frameworks between academia, industry, and government. By situating the technical contributions within this broader ecosystem, the study positions itself as not only an academic exercise but also a practical step toward more resilient and inclusive cybersecurity infrastructures.
Conclusion
This section concludes the study with key findings, limitations, and recommendations for future work.
Summary of findings
This study investigated the application of machine learning algorithms for cybersecurity threat detection in small and medium-sized enterprises (SMEs), leveraging the TON_IoT dataset as a proxy for real-world SME environments. Six supervised models were implemented and compared: Logistic Regression, Random Forest, Support Vector Machine, LightGBM, XGBoost, and Multilayer Perceptron.
The results showed that XGBoost and LightGBM delivered the highest accuracy and recall, demonstrating strong capabilities in identifying both common and complex attack patterns. Random Forest offered a good trade-off between performance and interpretability, making it a strong candidate for SME use. Logistic Regression and SVM trained quickly and used minimal resources, suitable for lightweight deployments but with slightly reduced detection capability. Multilayer Perceptron, while accurate, required careful tuning to prevent extended training time.
Overall, tree-based ensemble models (LightGBM, XGBoost, RF) emerged as the most effective for robust intrusion detection, while Logistic Regression remains a viable option for fast, low-resource use cases.
Research contributions
This work contributes to the field of AI-driven cybersecurity in three important ways:
SME-Focused Evaluation: By emphasizing computational efficiency and interpretability, the study provides guidance on practical ML deployment in SME environments.
Benchmarking on TON_IoT: The use of a realistic, recent dataset enables meaningful benchmarking that reflects modern attack vectors and network behaviors.
Model Trade-off Insights: The comparative analysis across six models offers valuable insight into balancing performance and resource demands.
Limitations
Despite its contributions, the study has some limitations:
The TON_IoT dataset, while comprehensive, is simulated and may not capture all real-world network complexities in SMEs.
The models were evaluated using static train-test splits and may not fully represent time-evolving threats or zero-day attacks.
Hyperparameter tuning was minimal to maintain fairness and simplicity, but further optimization could enhance model performance.
Future research can expand this study in several directions:
Real-time Deployment: Implementing the models in a real-time intrusion detection system (IDS) and evaluating latency, throughput, and alert accuracy.
Ensemble and Hybrid Models: Exploring combinations of models or stacking techniques to improve detection robustness.
Explainability and Trust: Integrating explainable AI (XAI) tools to make model predictions more transparent to non-technical SME users.
Cloud-based Deployment: Testing lightweight models on edge or cloud platforms tailored for SMEs to ensure scalable protection.
Footnotes
Authors’ contribution
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Copyright by the authors
This is an open-access article distributed under the Creative Commons Attribution License (CC BY-NC International, ![]() ), which allows others to share, make adaptations, tweak, and build upon your work non-commercially, provided the original work is properly cited. The authors can reuse their work commercially.
), which allows others to share, make adaptations, tweak, and build upon your work non-commercially, provided the original work is properly cited. The authors can reuse their work commercially.