
Abstract
In response to the increasing demand for information, official statistics often rely on multi-source production processes. Since registers have lower production costs compared to sample surveys, they are frequently integrated to produce the required estimates. This paper proposes a reference reconciliation method for integrating a register of addresses with a register of buildings. The method exploits spatial proximity and property ownership information. It is implemented and evaluated using residential addresses from the Italian region of Tuscany, based on data from the Integrated System of Statistical Registers of the Italian National Institute of Statistics. Results show that the proposed method increases the percentage of matched addresses by 20%. Moderate precision and high recall values are key performance indicators of the approach. The method also allows for various extensions, including parameterization (e.g., urban/rural contexts), application to different statistical units and the use of complex distance measures.
Keywords
Introduction
Over the past decade, the Italian National Institute of Statistics (Istat) has shifted its statistical production paradigm toward an integrated approach, promoting extensive use of registers. 1 The modernization of production processes involves several high-impact initiatives aimed at extending and enhancing an integrated use of multiple data sources. 2 This new production paradigm underpins the Integrated System of Statistical Registers (ISSR), a unified logical data asset resulting from the integration of survey and administrative data.
The ISSR includes four master statistical registers (ISSR also includes other registers.): the Population Register, the Business Register, the Register of Activities, and the Register of Places. These registers describe their entire corresponding populations of statistical units. 3 Within the ISSR, each individual, enterprise or place is assigned a unique and unambiguous identification code.
One of the main objectives of the ISSR is to geo-reference all core statistical units. To reach this aim, extensive integration procedures have been implemented, involving the Statistical Register of Places and other registers. However, an initial integration step is needed within the Statistical Register of Places. Indeed, this register integrates and connects different spatial units, including addresses, buildings and dwellings, census blocks, grid cells, and territorial administrative and statistical areas. 4 Figure 1 illustrates the ISSR components involved in this research: the Register of Addresses (RA), the Register of Buildings (RB), and the Population Register.
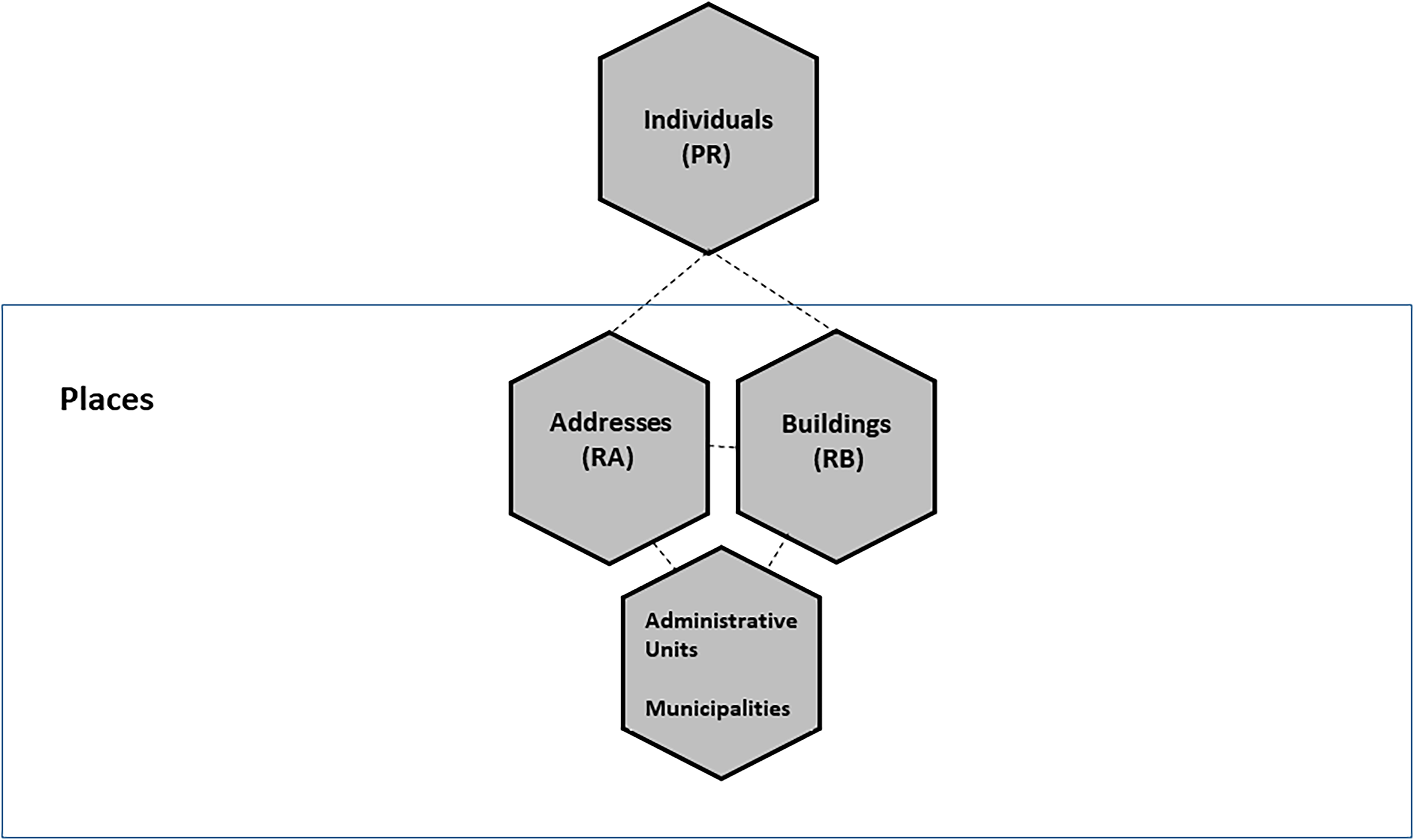
Registers involved in this study: population register and, in the box, components of the statistical register of places.
The complex structure of the Statistical Register of Places is based on the observation that most statistical units rely on addresses. An address is defined as any direct or indirect access from a street to a building unit where activities may occur. It is therefore represented as a spatial point that can be mapped using its latitude and longitude coordinates. In Italy, the main source of address data within the ISSR is the National Archive of Addresses of Urban Streets, although several other administrative archives and data sources also contribute. 4 The Register of Addresses (RA) contains the addresses gathered from all these administrative sources. Each address in the RA is assigned a unique identification code, called ID. Currently, the RA contains data on approximately 30 million IDs; about 88 percent of them have associated geographical coordinates, 44 percent are residential addresses, i.e., at least one person has declared residence at that location. 4
Italian real estate assets constitute the stock information contained in the Register of Buildings (RB). This register primarily relies on cadastral administrative and spatial data, while also integrating information from geographic agencies and open data sources. A unique identifier is assigned to each building, preserving the hierarchical structure of the units (nested building units or dwellings within a building). Currently, the RB includes data on approximately 29 million buildings, of which 14.4 million are residential. 4 Around 80 percent of buildings have valid geographical coordinates (of their building centroid).
An additional ISSR objective is to achieve single cohesive units—such as individuals linked to their dwellings, employees to their workplaces, and students to their schools, etc. Joint information on population and dwellings is of strategic importance, as it enables the production of numerous quality-of-life statistical indicators. In official statistics, common examples include indicators on living conditions, housing quality, home ownership, overcrowding rates, and population statistics related to territories. Istat already disseminates such statistics, but usually they stem from sample surveys, which involve high response burden and high costs. Estimating these indicators through the ISSR would significantly reduce costs for both respondents and producers.
The creation of cohesive statistical units allows for the effective use of microdata from available registers in a manner consistent with official statistics quality standards. 5 From a theoretical perspective, the sole information on addresses would allow the integration of individuals with their dwellings. Specifically, each individual in the Population Register resides at a residential address r, which is included in the RA. Simultaneously, each individual's home is located at a building address, b, which is drawn from the RB. By linking residential and building addresses through an ID-based deterministic record linkage, it becomes possible to integrate information on the population and the territorial characteristics of dwellings.
However, the information provided by addresses alone is insufficient to create a complete set of cohesive units. Specifically, an ID may exist in the Register of Addresses (RA) but not in the Register of Buildings (RB); that is, there may be residential addresses where no building is located. A key assumption in ID-based deterministic record linkage is that an address is registered in both the RA and RB under the same ID. When this assumption does not hold, biased statistics may result. 6 The problem of determining which IDs correspond to the same real-world address is known as reference or identifier reconciliation.7–9 Despite the use of various synonyms (see Table 1 in 11 , for example), scientific literature mentions reference reconciliation as the initial step in any data integration process.10–14
This paper focuses on the reference (ID) reconciliation of addresses between RA and RB, using attributes from both RB and the Population Register. In this context, all addresses are contained within RA, but they originate from different sources.
On the one hand, residential addresses, denoted as r, are those included in administrative records certifying population residence. In Italy, two key regulations govern residential addresses: Chapter VII (Articles 41–44) of Legislative Decree No. 223/1989 and the Prime Minister's Decree (D.P.C.M.) of 12 May 2016 on the Population Census and the national archive of addresses. As in many countries, 15 municipalities are responsible for the registration, deletion, and updating of residential addresses. As a result, the efficiency of this administrative process varies significantly across different municipalities, leading to a level of heterogeneity that cannot be easily accounted for in standardized data processing phases.
On the other hand, building addresses, denoted as b, originate from cadastral administrative data sources, which have distinct data generation, processing, and transmission procedures. It is well known that cadastral administrative data are prone to updating issues, as changes are typically made only in response to specific requests from property owners or following legal, fiscal, or administrative actions. As a result, cadastral information is updated infrequently, while residential addresses are more regularly validated and updated, often due to population migration, for example. Therefore, discrepancies between residential and building addresses may also arise from the temporal misalignment in the updates of these two types of addresses. 16
Addresses may also be incomplete, particularly with regard to street numbers, suffixes, or types (e.g., street vs. road). Additionally, street numbers are more commonly missing in rural areas than in urban areas. In low-density population regions, further complications arise from the use of rural routes or place names (e.g., localities) instead of numerical street addresses.17,18 Finally, while standardization methods routinely applied to addresses help resolve many inconsistencies, they can also introduce uncertainties. This is especially true for ambiguous street names (e.g., “via del Corso” (Avenue Street, an example of using a type of street as a street name)) or combined street names (e.g., names with double adjectives or previously assigned names).
To summarize, differences may exist for the same address when derived from different sources. Figure 2 illustrates an address r in the Register of Addresses (RA), where the textual component is correctly and fully listed, along with its assigned ID. The nearby building with address b, derived from cadastral information, is missing street number details. As a result, b has a different ID, as its content differs from that of r. The ID-based record linkage fails because the missing textual information prevents the correct r-b association, even though they represent the same physical address. To improve the cohesiveness of the ISSR, it is therefore necessary to reconcile the addresses in RA and RB.
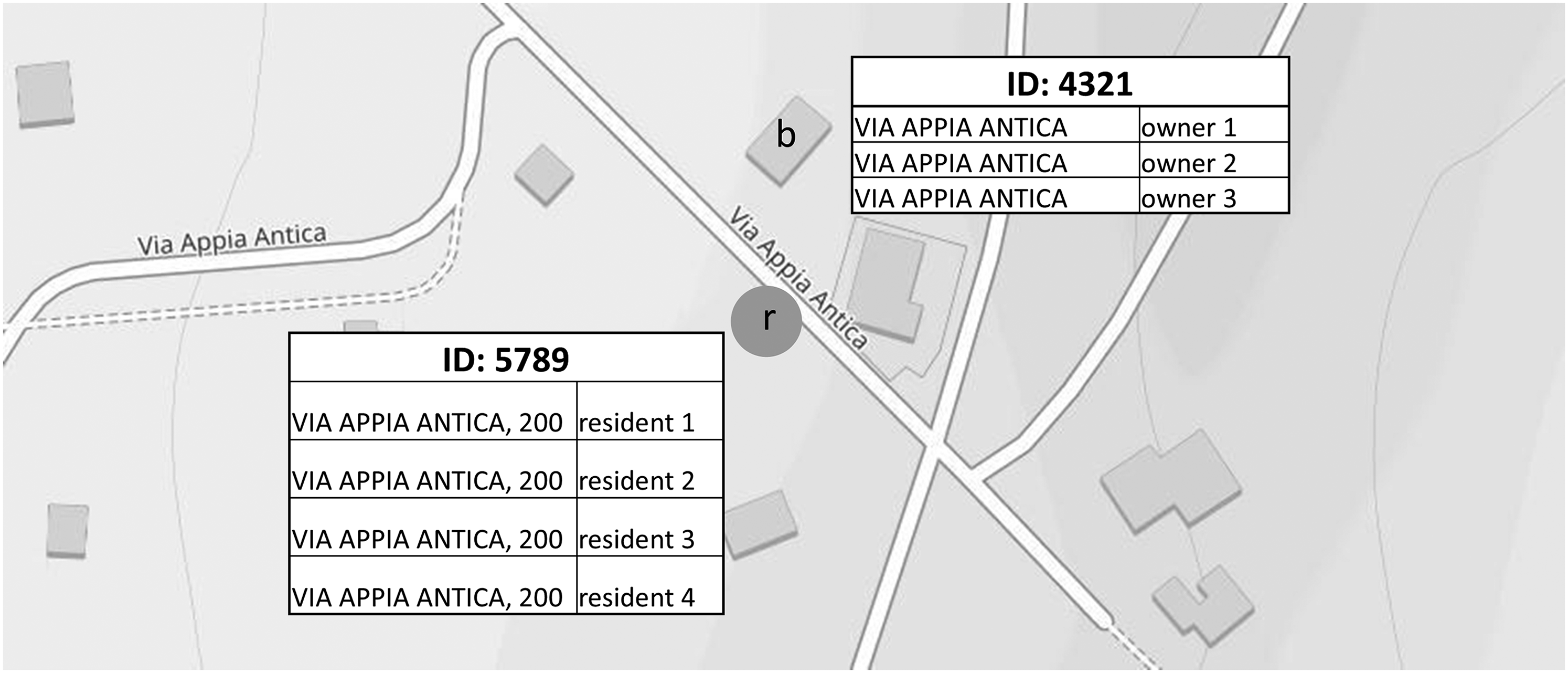
Id address of residence, r, and address of the building, b. They do not allow for an ID-based record linkage between the residents in r and their home in building at the address b due to missing street number in b.
The aim of this paper is to present a spatial reference (ID) reconciliation method applied to address and building registers. The method utilizes additional information from the specific statistical unit to be geo-referenced. In this study, the reference reconciliation focuses on residential addresses, where the population resides.
The paper is structured as follows. Section 2 describes the proposed attribute-driven spatial reference reconciliation method for addresses in the RA and RB registers, with a brief overview of the involved registers. Section 3 presents preliminary findings from the Italian region of Tuscany. Finally, Section 4 concludes the paper and outlines potential directions for future research and improvements.
This section firstly provides a description of the study area, along with an overview of the Register of Addresses (RA) and the Register of Buildings (RB). It then details the proposed spatial reconciliation method.
Study area
The data used in this paper are derived from the Register of Buildings and the Register of Addresses. The study area corresponds to the Nomenclature of Territorial Units for Statistics (NUTS) 19 level two region (NUTS2) of Tuscany, located in central Italy. Tuscany is composed of ten smaller NUTS3 regions and 273 municipalities (see Figure 3). According to the degree of urbanization, 20 over 60 percent of the municipalities are rural, 36 percent are classified as towns, and there are seven cities. The total population is approximately 3.7 million, spread over an area of less than 23 thousands km².
Tuscany region in Italy and its smaller NUTS3 regions.
The Italian Cadastral Information System 21 serves as the primary source of information for the Register of Buildings (RB). The cadastral system is fundamental for the legal identification of real estate, fiscal equity, and the management of land use and zoning, 22 as well as for land planning. 15 Italy employs a system of cadastral and land registry parcels, which includes an urban Cadastre (for buildings). The Land Registry is simply a collection of deeds, 22 while the urban Cadastre identifies each real estate unit. Cadastres based on the concept of a cadastral parcel—defined by the uniformity of soil, topography, ownership, and municipality—assign a single identifier to each parcel.
For the purposes of this paper, the cadastral information in the Register of Buildings (RB) is divided into two core components: the administrative component (derived from the Urban Building Cadastre archive) and its spatial representation within a cartographic system.
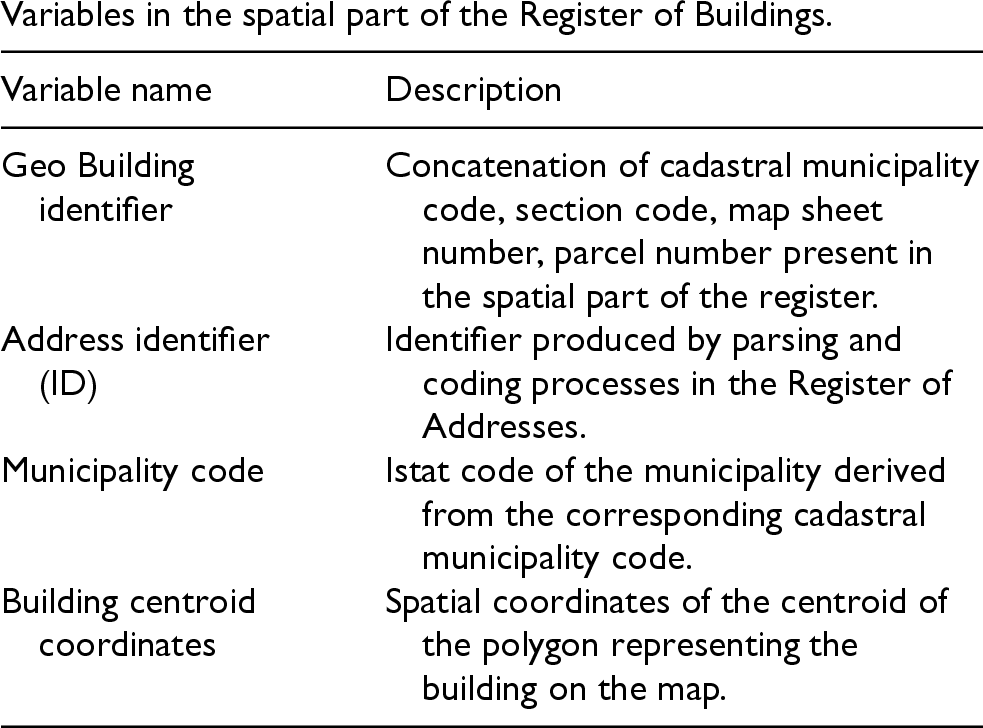
The administrative component of RB includes technical-physical, legal, and economic data for each unit. The main variables utilized in this paper are the cadastral building identifier, address identifier (ID), municipality code, cadastral typology, and personal identifier (see the Appendix). This paper focuses solely on buildings with dwellings, referred to as residential buildings. The spatial information in RB includes the geo-building identifier, address identifier (ID), municipality code, and building centroid coordinates 23 (see the Appendix).
Before the reconciliation process, a record linkage between the administrative and spatial components of the Register of Buildings (RB) is required. Specifically, matching by building identifier (Cadastral Building Identifier and Geo Building Identifier) enables the association of each unit with its corresponding centroid coordinates. This step may result in some buildings having missing coordinates. Inaccuracies such as updating issues, differences in map projections, or errors in reporting outdated cadastral information are common causes of internal mismatches.22,24 In Tuscany, approximately 89 percent of buildings in RB have valid geographical coordinates, specifically those of the building centroids (see the first column in Table 1).
Percentage of buildings and residential addresses with geographical coordinates by NUTS3 regions of Tuscany.
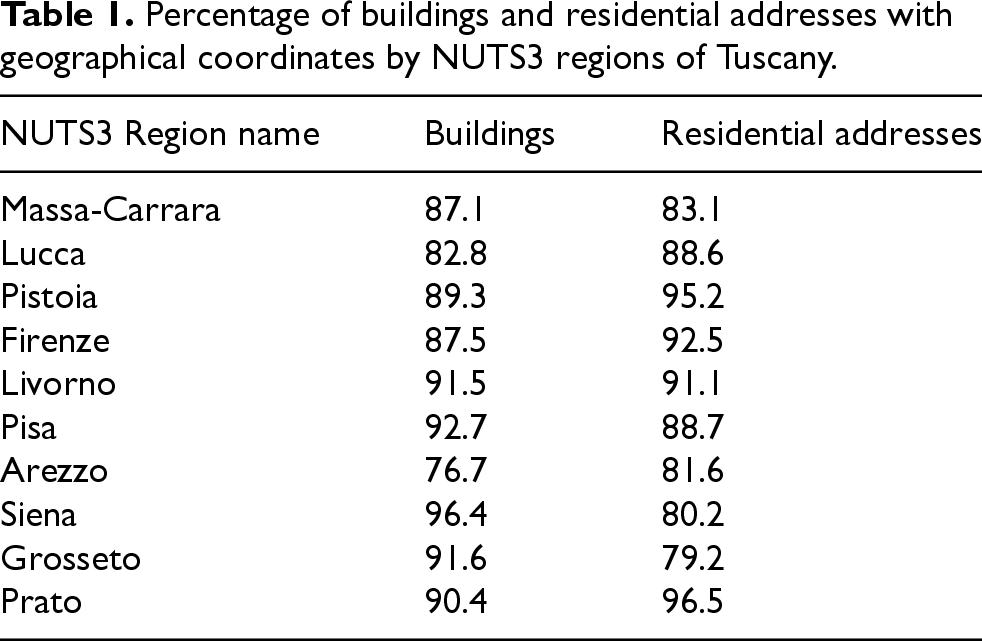
Percentage of buildings and residential addresses with geographical coordinates by NUTS3 regions of Tuscany.
The main variables from the Register of Addresses (RA) used in this research are address identifier (ID), municipality code, address coordinates, and information indicating whether the address is residential (see the Appendix). Several address quality issues can hinder the geo-referencing process. 25 The positional accuracy of addresses has been widely studied, 26 but other issues include missing street numbers, spelling errors in street names, 27 and address types referring to localities, particularly in rural areas. Table 1 presents the distribution of residential addresses with geographical coordinates. The variability observed in Table 1 is due to differences in data collection procedures, as well as the geomorphological and demographic characteristics of the NUTS3 regions. Nevertheless, the percentages suggest a satisfactory level of geospatial coverage.
The ID-based deterministic record linkage between the Register of Addresses (RA) and the Register of Buildings (RB) for Tuscany reveals that these registers share approximately 56 percent of addresses. This suggests that individuals living at the remaining percentage of addresses do not have corresponding dwellings. Table 2 displays the distribution of shared addresses by NUTS3 region. The goal of the spatial reference reconciliation method presented in this paper is to increase these shared percentages.
Percentage distribution of RA and RB shared IDs before the application of the reference reconciliation method, by NUTS3 regions of Tuscany (percentage on total number of residential IDs).

The scientific literature on address reference reconciliation, particularly in the context of matching points of interest, encompasses various methods, ranging from simple rule-based approaches to machine or deep learning techniques.28,29 In the context of ISSR data integration, this paper proposes an optimization-based address reconciliation method that leverages spatial information associated with addresses, building centroids, and property characteristics.
In this case study, the units linked to addresses are individuals. Only non-shared residential addresses with spatial coordinates are selected from the Register of Addresses (RA). From the Register of Buildings (RB), only buildings with single-owners (single-owners are those individuals owning a single dwelling in a municipality or multiple dwellings as long as these belong to the same building) are included in the analysis. Additionally, the method selects only those buildings for which building centroid coordinates are available.
The rationale behind the method relies on the following two assumptions:
Ownership condition: single-owners of a dwelling in the municipality of residence usually live in their own property; Spatial condition: the geographical coordinates of a building's centroid are assumed to lie in close proximity to the point representing its address on the map.
While the second condition is intuitive, the first is based on the fact that approximately 75 percent of Italians live in their own homes (https://ec.europa.eu/eurostat/web/interactive-publications/housing-2023#:∼:text=In%20the%20EU%20in%202022,31%25%20lived%20in%20rented%20housing). The proposed ID reconciliation method operationalizes these two conditions. Figure 4 illustrates the method. In the first step, residents at a given non-shared address
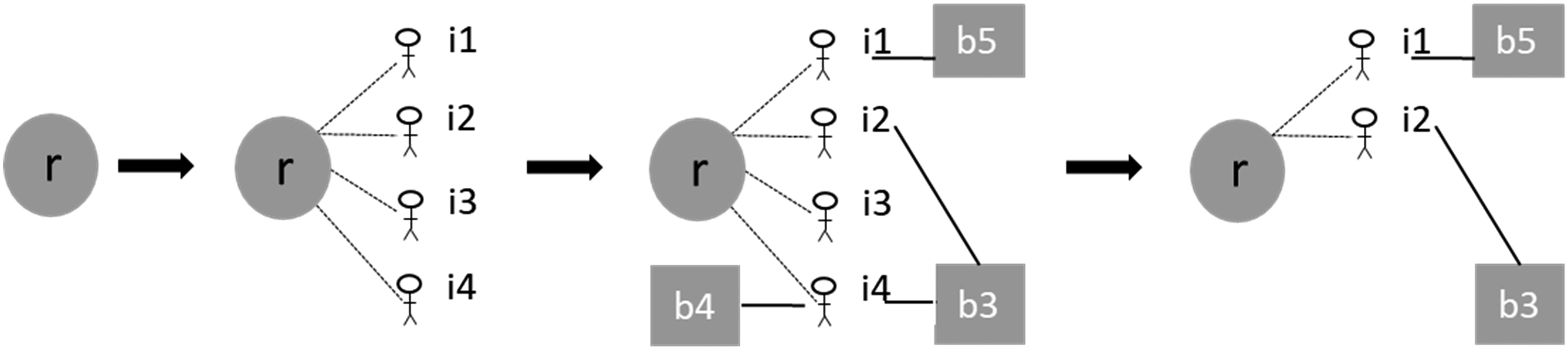
Address matching driven by ownership status; r = residential address, b = building address, symbols labeled i1, i2, i3 and i4 represent individuals, dashed lines indicate residential relationships, full lines indicate ownership relationships.
The spatial matching problem described earlier can be viewed as an optimal assignment problem, where features in the Register of Addresses (RA) are matched to corresponding features in the Register of Buildings (RB). For each 
Further, let 
Then, the reference reconciliation problem may be expressed as a linear optimization problem (LP):

The formulation of address matching problems within an optimization framework offers several advantages. Firstly, LP problems are typically solved using specialized software such as Gurobi (https://www.gurobi.com/) or CPLEX (https://www.ibm.com/it-it/products/ilog-cplex-optimization-studio). Secondly, different cost functions and constraints in equation (3) can reflect various matching settings. For example, the constraints in equation (3) can be straightforwardly modified to establish a one-to-many or many-to-many relationship between RA and RB, thereby addressing different assignment problems. 30
The method does not rely on any a priori distance threshold for identifying r-b links. By being independent of any distance threshold, the method avoids issues related to computational burden or the risk of having empty admissible subsets of the Register of Buildings (RB). 31
However, in practice, some data selection may be beneficial for computational efficiency. A maximum distance could be set, beyond which no candidate pairs are considered admissible. Alternatively, a further refinement can be achieved by using a slightly more complex proximity-based dissimilarity function like
This section presents preliminary results of the spatial reconciliation procedure, focusing on its outcomes, identification rates, precision, and recall.
Using information from addresses, buildings, and population registers in the Tuscany region, the spatial matching procedure identifies approximately 200 thousands new addresses (21 percent) as referring to the same real-world entity. Table 3 illustrates the improvements across Tuscany regions. The Pisa and Pistoia regions show the most significant number of newly matched addresses. Firenze exhibits the smallest increase in newly matched addresses; however, addresses in this region demonstrate the best agreement even without reference reconciliation (see Table 2). In general, the lower the initial matching rate between addresses, the greater the impact of ID reconciliation.
Increase in the percentage distribution of RA and RB shared addresses after the application of the reference reconciliation method by NUTS3 regions of Tuscany.
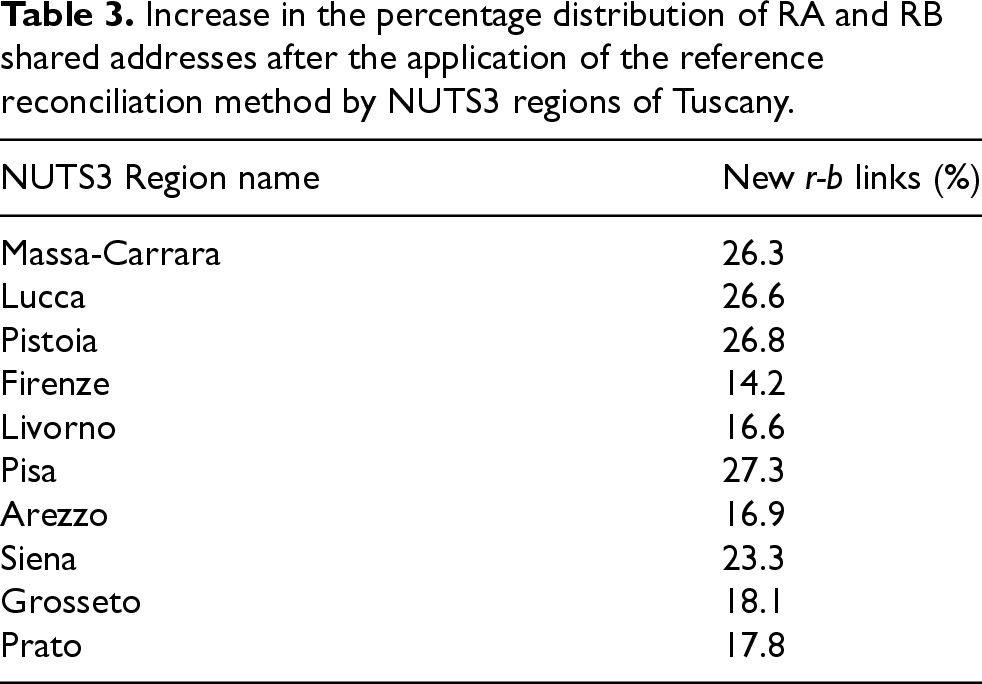
Increase in the percentage distribution of RA and RB shared addresses after the application of the reference reconciliation method by NUTS3 regions of Tuscany.
Investigating the causes of missing original links could help improve administrative data collection processes. Once links between addresses are validated, it becomes possible to identify the factors that hindered their original linkage. In this application, 60 percent of these addresses have a different street number. Approximately 23 percent of building addresses lack a street number altogether, while only 10 percent show a discrepancy in street type or street name.
To evaluate the spatial matching procedure's ability to reconcile candidate r-b pairs, the identification rate is computed. This rate is defined as the number of reconciled r and b addresses divided by the corresponding target number of residential and building addresses. Figure 5 shows these rates, which are evaluated for different admissibility distances between residential addresses and building centroids. In line with scientific literature on address quality, the identification rate is calculated based on the degree of urbanization of Tuscany municipalities. 20

Tuscany identification rates of addresses in RA and RB by degree of urbanization.
Our results confirm that urban and rural areas require distinct processing. For any fixed admissibility distance, significant differences between urban and rural areas are evident in both registers; however, RB exhibits considerably higher dissimilarities than RA. For the RA, the urban-rural divide decreases as the distance increases: the greater the distance, the smaller the difference between urban and rural addresses. In urban areas, a 100 m distance is sufficient to identify about 80 percent of addresses, whereas in rural areas, a distance of 300 m is needed to achieve the same result. Overall, distance does not influence urban-rural differences in RB. This issue may be related to several factors, such as second homes, depopulation, or aging populations in rural areas, and will be the subject of further investigation.
Finally, the last two indicators used to evaluate the outcomes of the spatial matching procedure are precision and recall. Precision is computed as the percentage of correctly matched units among all units, while recall is defined as the percentage of correctly matched units among all units that should be matched. Table 4 presents the values of these two quality measures in Tuscany.
Precision and recall of the spatial matching procedure by NUTS3 regions of Tuscany.
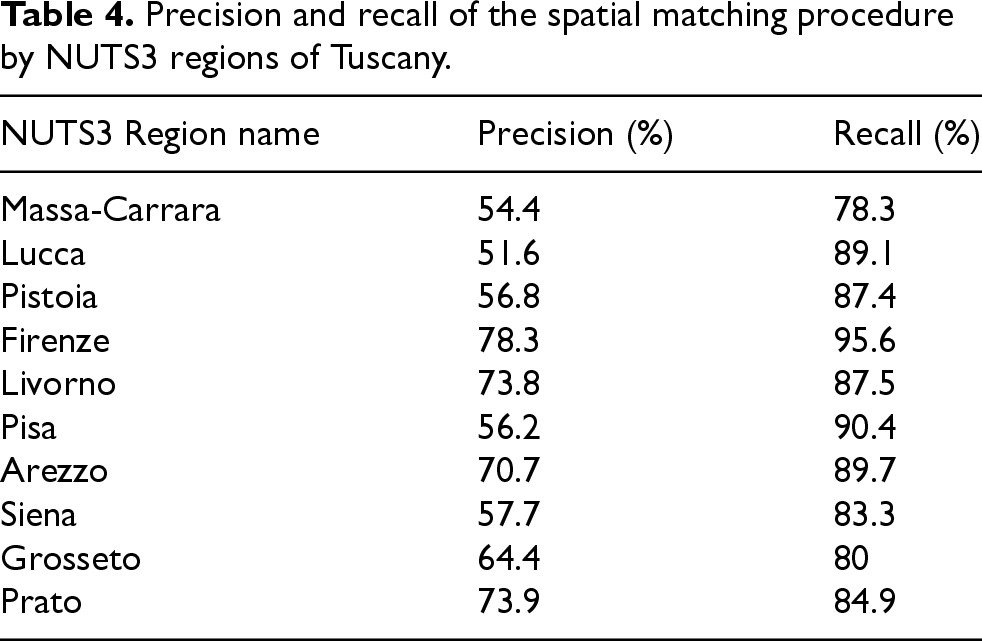
To approximate these statistics, the benchmark is represented by the addresses shared by RA and RB (i.e., the common IDs). In four NUTS3 regions, precision exceeds 70 percent. However, other regions show lower values for this indicator. One way to increase precision is by reducing the number of false positives—i.e., decreasing the number of r-b links established by the spatial matching procedure that are not originally linked. While the proposed spatial matching procedure can be further improved, it is important to note that, in our data reconciliation problem, the benchmark does not fully cover the entire population. As a result, any reference reconciliation method will inevitably yield some false positives.
Table 4 shows high recall values (with an overall mean of about 87 percent), indicating the excellent accuracy of the proposed attribute-driven spatial matching procedure.
In response to the high costs of sampling surveys and to the aim of improving the quality of its products and processes, official statistics have increasingly adopted a multi-source paradigm. In Italy, the Integrated System of Statistical Registers (ISSR), a unified logical data asset, supports the production of official statistics. This paper focuses on implementing a reference reconciliation method for addresses and building registers to enhance integration within the ISSR. Several quality-of-life statistics could benefit from the joint use of these registers.
The method incorporates both spatial and non-spatial conditions. The spatial condition relates to the proximity between the spatial point representing the residential address and the geographical coordinates of a building centroid. The non-spatial condition involves the attribute used to filter and validate matches between residential addresses and buildings, specifically the property ownership status of the resident population. The results from the application to the Tuscany region are highly encouraging.
Based on these results, we assert that ownership-based spatial matching is a valid context-specific reference reconciliation method. While the method has been tested on residential addresses, the same approach can be applied to other statistical units, such as local units of enterprises, thereby enhancing reconciliation for a broader range of data. An additional attractive feature of the method is its independence from training sets, making it a ready-to-use algorithm. Furthermore, the procedure is flexible enough to be adapted to different contexts, such as urban/rural areas, by adjusting the allowed thresholds. Finally, the method can also be applied in other scenarios, such as validating existing linkages between addresses and buildings, deduplication or assessing the quality of cadastral information, thus highlighting municipalities with specific issues.
The method is particularly relevant for National Statistical Institutes that have access to detailed administrative data on property ownership and need to improve the matching of addresses from different sources. A high rate of dwelling ownership can be advantageous for achieving good results, but other information, such as rental data, can also be considered. A key factor in this application is the availability of detailed information on the internal composition of buildings, including the number and configuration of residential units. When multiple owners reside in the same building, the correctness of associations can be verified based on their homogeneity. Conversely, if no prior associations exist, the propagation of links can be extended to all dwellings within the building, thereby increasing the matched population rate. Finally, we note that the method relies on a high degree of completeness in the Register of Addresses. However, this type of register often suffers from over-representativeness. This reference reconciliation method can also help improve and update dictionaries and thesauruses.
In addition to its application across the entire national territory, the ownership-driven spatial data reconciliation method can be extended in several directions. On one hand, it could be applied to other types of holding rights, such as rentals, or to different types of owners, including legal entities or individuals who own multiple properties. The method could also be adapted to focus on households rather than individuals. On the other hand, alternative distance measures could be explored, such as incorporating string similarity, for instance. From a computational perspective, to reduce complexity, clusters of addresses and groups of buildings could be processed simultaneously. In this context, the proposed optimization formulation could be adapted to accommodate more complex scenarios. From a statistical standpoint, evaluation tools could be further developed, such as performing sensitivity analysis, even considering the geometrical shapes of the buildings involved.
The ultimate goal is the development and maintenance of a National Statistical Institute territorial infrastructure that combines spatial and non-spatial information, enhancing the rate of cohesive units, which are essential for accurate geo-coding and multi-source statistics.
Footnotes
Acknowledgements
Istat is not responsible for any views expressed in this paper.
We are deeply grateful to the reviewers for their careful reading of the manuscript and for their insightful comments and detailed suggestions, which significantly contributed to improving the quality of the paper.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Appendix
List of the main variables used in this research from the Register of Buildings (RB) - both administrative and spatial parts - and the Register of Addresses (RA).
Variables in the administrative part of the Register of Buildings. Variables in the spatial part of the Register of Buildings. Variables in the Register of Addresses.
Variable name
Description
Cadastral building identifier
Concatenation of cadastral municipality code, section code, map sheet number, parcel number.
Address identifier (ID)
Identifier produced by parsing and coding processes in the Register of Addresses. This study focusses only on residential addresses.
Municipality code
Istat code of the municipality derived from the corresponding cadastral municipality code.
Cadastral typology
Description of the building unit intended use. For the scope of this research, the focus is on residential buildings/dwellings.
Consistency data
Number of rooms, surface of the unit, etc.
Personal Identifier
Identifier of individuals or legal entities holding rights (ownership, rental, etc.) on the building unit inside the building.
Variable name
Description
Geo Building identifier
Concatenation of cadastral municipality code, section code, map sheet number, parcel number present in the spatial part of the register.
Address identifier (ID)
Identifier produced by parsing and coding processes in the Register of Addresses.
Municipality code
Istat code of the municipality derived from the corresponding cadastral municipality code.
Building centroid coordinates
Spatial coordinates of the centroid of the polygon representing the building on the map.

Variable name
Description
Address identifier
Identifier produced by parsing and coding processes.
Municipality code
Istat code of the municipality to whom the address belongs at a specific date.
Address coordinates
Address spatial coordinates.