
Abstract
The Food and Agriculture Organization of the United Nations (FAO) and other agencies of the UN Family of Organizations regularly collect and publish a wealth of official data according to the Open and FAIR data and metadata principles (Findability, Accessibility, Interoperability, Reusability). The role played by statistical classifications in these data activities cannot be overestimated, as they provide the “meaning” of the data collected and disseminated. In this paper we describe Caliper, a methodological and infrastructural framework that enhances the interoperability of statistical classifications, as well as their creation and maintenance. Caliper was launched in 2020, as the FAO platform for the dissemination of statistical classifications. Since 2024, it is a reusable suite of tools supporting the entire life cycle of statistical classifications, including creation, maintenance and publication. Moreover, Caliper is now the infrastructural and methodological basis for a partnership of custodians sharing the vision of an international community of data producers and users devoted to producing better statistics. In this paper we present Caliper as a suite of tools and the Linked Open Data publication style adopted by Caliper. We also discuss the contribution of our endeavor to the achievement of syntactic and semantic interoperability of data. Our work benefits custodians of statistical classifications, data producers, policy makers, researchers, public administration and other agents that are involved in the use, integration and interpretation of data.
Introduction
The Food and Agriculture Organization of the UN (FAO) is committed to the global collection, analysis, interpretation and dissemination of national statistics to support improved policy and investment decisions making in food- and agriculture-related sectors. Moreover, FAO is the custodian of 22 indicators that enable tracking of 8 of the 17 Sustainable Development Goals (SDGs) established by the United Nations in 2015. The large volume of datasets and publications generated through these commitments are routinely made accessible through FAO's website as Open Data under Creative Commons licensing. In support of these activities, FAO devotes an important part of its work to developing standards, tools and methodologies to support and enable effective data collection and dissemination. In this endeavor, a critical role is played by statistical classifications as part of the metadata of statistical datasets.
A statistical classification is a set of predefined categories used to standardize data collection in a domain. Hence, they represent the “meaning” or, in statistical terms, the “dimensions” of data points. In essence, the categories in a statistical classification define the phenomena to observe, which, once measured, become “observations” or “data.” It is relevant here to highlight the difference between a “classification” for statistical data collection (our object of study) and a “classification” in Machine Learning and, in general, in Artificial Intelligence. While the former is a static set of predefined categories, the latter is a process – the process of grouping, clustering or classifying existing data using categories that may be newly created (for example, when applying clustering). Moreover, none of the fundamental features of statistical classifications apply to the process of classification in Machine Learning, such as the requirement for categories to be mutually exclusive and exhaustive.
The importance of classification systems in bringing coherence to data operations across time and space, and in transforming opportunities for data exchange and comparability, has long been recognized by international statistics’ custodians. That recognition has fostered initiatives such as the Neuchatel model 1 and GSIM, the Generic Statistical Information Model, 2 promoted by the United Nations Economic Commission for Europe (UNECE). These initiatives aimed at standardizing the concepts and language to speak about statistical classifications, while remaining “flexible and independent of IT software and platforms”. 2 Such efforts have strengthened the capacity to design database models that accommodate different needs and policies and enabled us to address the challenges of today, i.e., data interoperability and machine-to-machine interaction. In fact, the increase in users’ demand to merge, analyze and interpret disparate data, leads to an increase in the need to share data amongst information systems without loss or corruption of meaning, with limited or no human intervention, i.e., data interoperability. Data interoperability is increasingly required in science, society and administration, and in all those areas where different actors, either individual or institutions, collect data relative to specific phenomena at specific scales, and where complex operations of integration and interpretations are required to provide scientists and decision makers with adequate information. We can distinguish at least two notions of interoperability. On the one hand, syntactic interoperability refers to the formatting (e.g., CSV, JSON) and structure of the data (e.g., the file's organization into fields), to ensure that systems can read and parse each other's data. On the other hand, semantic interoperability goes deeper, as it is about a shared understanding of the entities appearing in the data. Those two notions apply as much to statistical data as to statistical classifications. Together, they make possible a true understanding and interpretation of data. Given the role of statistical classifications in the process of data production and analysis, the interoperability of statistical classifications is a prerequisite for data interoperability.
The work presented in this paper aims at enhancing the interoperability of statistical classifications to the benefit of the global community of data users and data producers. To this end, we have developed Caliper (https://www.fao.org/statistics/caliper), a methodological and infrastructural framework that enhances the interoperability of statistical classifications, as well as their creation and maintenance. Caliper embodies a standard-based approach that enables reuse and combination of off-the-shelf and open-source tools to support all phases of a statistical classification's life cycle. Our work draws from the effort towards conceptual and terminological normalization made by the international community of statistical researchers and practitioners, and leverages web technologies collectively referred to as Linked Data (LD) to propose a solution. We conform to the FAIR (Findable, Accessible, Interoperable and Reusable) data and metadata 3 initiatives, fully embraced by FAO, 4 and we follow our conviction that statistical classifications are public goods. Also, as we embrace the Open Data 5 paradigm (i.e., content is free to for anyone to use, reuse and redistribute, subject only to the requirement of attribution and/or share-alike), we place Caliper in the framework of Linked Open Data (LOD).
The work on Caliper started in 2017, within a 4-year grant from the Bill and Melinda Gates Foundation, and building on experience gained by the authors from prior initiatives undertaken both at FAO6–8 and internationally.9,10 In 2018, the first version of Caliper went online. In 2020, FAO adopted Caliper as its official dissemination service for statistical classifications and presented it to the United Nations Committee of Experts on International Statistical Classifications (UNCEISC). a As of 2024, Caliper is part of the UN Global Platform (UNGP), a cloud-based collaborative ecosystem designed to modernize official statistics through the use of Big Data and data science. The UNGP serves as a digital environment where the global statistical community, including National Statistical Offices (NSOs), international organization, and researchers, can share trusted data and methods (https://unstats.un.org/bigdata/un-global-platform.cshtml). In particular, Caliper is now part of the ARIES for SEEA Sector Hub of UNGP (https://seea.un.org/content/aries-for-seea), and hosted at the Basque Centre for Climate Change (BC3). b
The rest of this paper is organized as follows. Section 2 introduces statistical classifications, highlights the motivation for their modernization, and presents the Linked Open Data framework for publishing data and metadata. Section 3 describes the methodology followed for the creation of Caliper and its content, the functionalities and tools included in the Caliper infrastructure, and the results obtained so far. Section 4 is dedicated to a discussion of the benefits and limitations of Linked Open Data (LOD) with respect to data interoperability, and of the contribution of Caliper to that. Finally, Section 5 presents the conclusions and suggests future development priorities.
Statistical classifications
Statistical classifications and the obstacles to their interoperability
Statistical classifications consist of “sets of discrete categories, which may be assigned to a specific variable registered in a statistical survey or in an administrative file, and used in the production and presentation of statistics”. 12 Statistical classifications and official statistical classifications share the same construction principles, but official classifications typically differ in custodianship (they are created and maintained by authorities with a specific thematic mandate and national, regional or international scope), revision cycle (more formal and structured), mandate and scope (of national or international). Also, differences in documentation policies, revision history and dissemination may apply. In this paper, official and international are used interchangeably.
Classifications are usually presented in handbooks, or manuals, describing all categories in detail, together with some historical notes to illustrate their evolution, and the methodology to adopt for their use when performing data collection, processing or interpretation. Handbooks typically include an appendix dedicated to summarizing the essential information of the classification – for each category, its code and description, organized into a (flat or hierarchical) structure. Classifications’ handbooks are usually disseminated as PDF files, while the precise classifications content is also disseminated as CSV, Excel or DB dump. The availability of APIs for the dissemination for machine use is more an exception than a common practice.
Classifications devised to support data collection at the global level are maintained by international organizations that act as their custodians. International classifications are kept current by means of regular revision cycles that may involve extensive consultations and may last for years. Those international classifications that have been reviewed and approved as guidelines by the United Nations Statistical Commission (UNSC) or other competent intergovernmental bodies (such as the International Standard Industrial Classification of All Economic Activities (ISIC) maintained by the UN Statistical Division (UNSD)), are included in the International Family of Classifications, whose list is maintained by the United Nations Committee of Experts on International Statistical Classifications (UNCEISC). Often, regional bodies or National Statistical Offices develop regional or national versions of international classifications to allow for data collection at regional or national level, as in the case of the Nomenclature of Economic Activities (NACE) that extends ISIC at the European level.
The categories included in a statistical classification, also named items or elements, are endowed with a coding component and a terminological component. 13 Codes, i.e., numeric or alphanumeric strings, offer a compact way of referring to categories in databases and information systems, while the terminological component addresses the human need for names and narrative explanations and definitions (for example in a survey or when interpreting the data), possibly in various languages. From a structural point of view, classifications are often organized into hierarchies, used to represent aggregations of items, and to offer a convenient navigation mechanism within a classification. Items at the same hierarchical level are designed to be mutually exclusive and to provide a complete partition of the universe of discourse, when taken together. Classifications are disseminated together with metadata on various aspects and characteristics such as custodianship, version number, year of publication or validity, structural organization, etc.
Custodians regularly establish correspondences between classifications and official guidelines on their definitions and use are available. 14 We may distinguish different types of correspondences, depending on the types of classifications put in connection. Correspondences may be either stated between different versions of the same classification or between different classifications covering related topics (such as economic activities and the resulting products, as in the case of ISIC and CPC, the Central Product Classifications). Correspondences may also be established between classifications covering the same topic, but a different level of granularity or specialization (for example, between CPC and its European version, CPA, Classification of Products by Activity). Correspondences are usually disseminated as tables. These may be organized at varying levels of complexity, from simple 2-column tables reporting only the codes of the items involved, together with some sort of “flags” to mark partial correspondences, to larger tables that also include descriptions or other pieces of information. In general, correspondence tables are not easily readable by humans or programmatically used by machines.
In the picture we have just sketched, we can recognize several limitations to the interoperability of statistical classifications. Dissemination via PDF is clearly an obstacle to machine readability, but also dissemination via CSV or DB is sub-optimal. In fact, since alternative tabular representations of the hierarchical structure of classifications are possible (e.g., the adjacency list model, the path enumeration model or the nested set model), the structure of the distributed files may vary, representing an immediate obstacle to their programmatic exchange. Data producers will have to download those files and include them in their information systems, with the possible consequent need for re-implementing them according to the data structure required (and replicating the process when new versions are available). Such different file structures add complexity to users, especially those in smaller institutions with limited resources and capacity. Moreover, while codes offer a compact way to refer to the categories in computer databases, they are inherently ambiguous since they are local to the database – the same code may mean different things in different classifications system, or in different versions of the same classification. For example, “0111” is used to designate “Wheat” in CPC 2.1 and “Growing of cereals (except rice), leguminous crops and oil seeds” in ISIC Rev.4.
The creation and maintenance of statistical classifications present challenges too, as discussing, agreeing on and applying new or improved versions of statistical classifications are notoriously time-consuming processes, typically happening in separate tools, the integration of which in final versions further delays the availability of those new versions.
Web technologies and linked open data
The phrase Linked Data15,16 refers to a set of design principles for sharing machine actionable data on the Web. The underlying basic principles of Linked Data are (a) the use of URIs (Uniform Resource Identifiers 17 ) to uniquely name things; (b) the use of the HTTP protocol to look up names; (c) the idea that information is associated with a URIs and (d) the use of links to associate pieces of information.
Arguably, these four principles offer a solution to most of the obstacles relative to the interoperability of statistical classifications that we have mentioned above. Unique URIs address the ambiguity of local codes, the HTTP protocol is the standard protocol for passing data on the web, and links are the natural mechanism to express correspondences. However, the information associated with the URIs must be expressed in a format suitable for web publication (as opposed to local database storage). This format is the Resource Description Framework (RDF). RDF is a data model for Web data interchange, originally developed to describe metadata, i.e., sentences like “ISIC is maintained by UNSD”. From a structural point view, sentences of that type are triplets, or triples, consisting of “subject,” “predicate,” and “object”. In the RDF framework, subjects are assumed to be uniquely identified over the web by means of URIs (when a URI corresponds to an actual web address, it is a Uniform Resource Locator, URL), hence they are “web resources”. Objects can be either web resources or “data objects,” like strings or numbers. Predicates can be defined either locally or in public vocabularies, but the availability and reuse of public and documented vocabularies is critical to ensure the interoperability of data published in this way. Example of these public vocabularies are RDF, SKOS, and XKOS, that we use extensively in our work (methodological information is given in Section 3.1).
Several triples can be stated about the same resource, and a network of such triples form a directed graph, i.e., a mathematical structure made of vertices and edges (similarly to what happens in a relational data model, where each piece of information is a row, and many rows form a table). RDF triples and graphs can be stored in optimized databases for the purpose, i.e., triple stores, and queried using a dedicated query language, SPARQL 18 (just like SQL is the query language for relational databases). Figure 1 shows a fragment of CPC version 2.1 rendered as a graph.
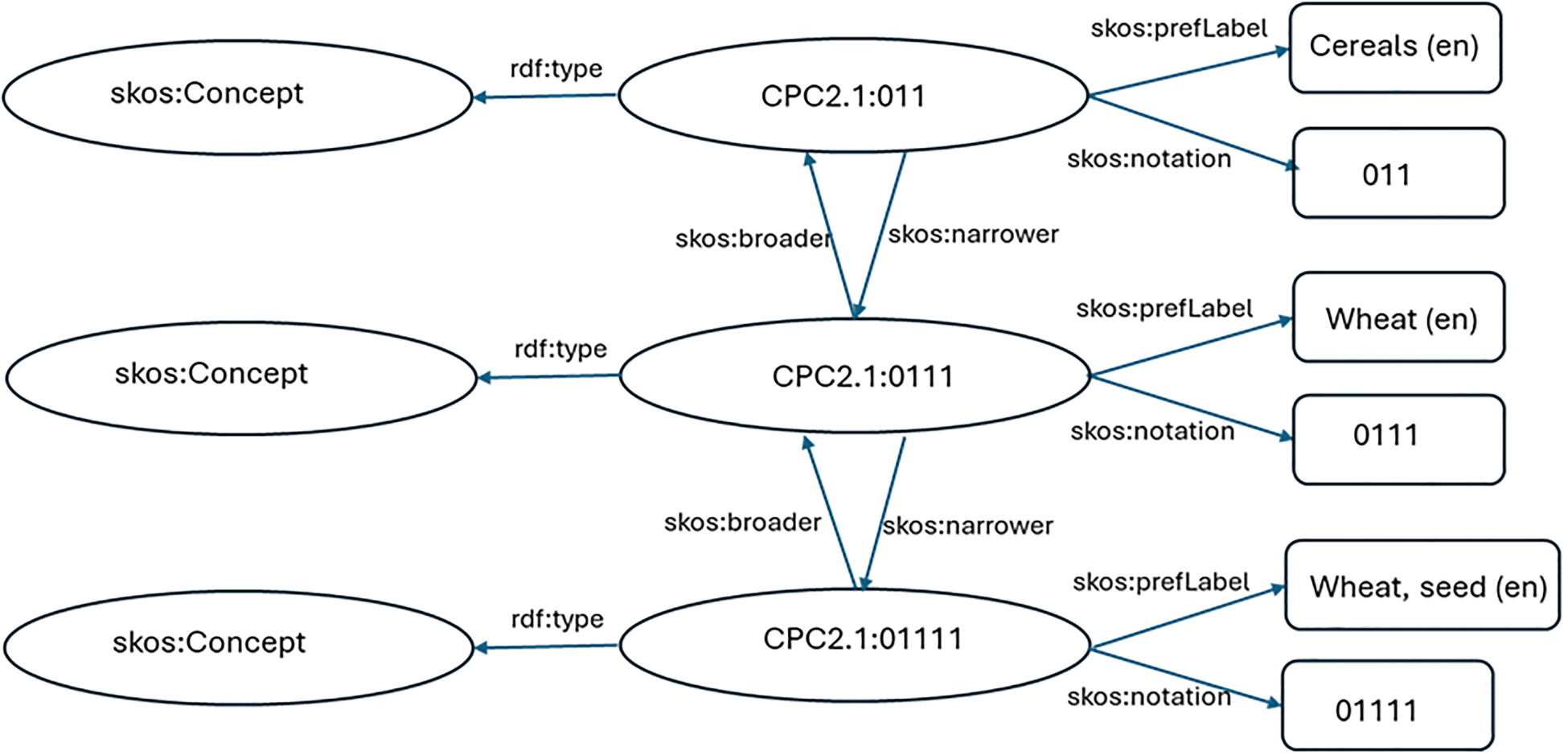
A fragment of CPC version 2.1 rendered as a simplified RDF graph. Each of the three classification’s items is rendered as a skos:Concept, with a code (skos:notation) and an English label (skos:perfLabel). The hierarchical structure of the classification is rendered using the SKOS properties skos:broader and skos:narrower. Each classification item is identified by an URI that, for sake of readability, is represented in a compact way (“CPC2.1:011” is a short for “https://unstats.un.org/classifications/CPC/v2.1/011”).
It is important to notice that the triple structure is the actual data model of RDF. Such abstract data model can be “serialized” using different syntax, such as XML (historically, the first), Turtle (more compact than XML) or JSON-LD (probably, the most popular serialization today). One advantage of using triples and graphs as data model for statistical classifications is that adding new properties to the data corresponds to adding new edges and vertices to the graph, which can be done effortlessly. This is radically different from the relational database world, where adding new properties usually corresponds to performing tasks like checking for duplication of columns’ names or even changing the database scheme. Another advantage is that the actual implementation of a graph in a triple store is transparent to the user, who one can focus on modelling the graph (i.e, selecting the most appropriate RDF vocabulary among the available standards) instead of designing the database scheme. In summary, in the LOD style, a code is no longer an isolated piece of information, but part of a network of information that can be identified and queried by machines with very limited human intervention.
While carrying on our work, we faced different yet interrelated challenges, e.g., define the appropriate model(s) for each classification to include; identify and prioritize the functionalities needed in each phase of the classification life cycle and, consequently, the appropriate tools to support them; arrange the selected tools into an appropriate infrastructure; define a default data flow able to accommodate exceptions when required; implement and test served data into existing information systems; regularly inform users and gather their feedback and input. To address those challenges, we adopted an iterative approach of requirement gathering with different user groups, data modelling and conversion, validation and testing in different tools.
In the rest of this section, we focus on the methodology followed to model and convert statistical classifications as LOD (Section 3.1), the functionalities supported by and the tools included in Caliper (Section 3.2), and the results obtained so far (Section 3.3).
Methodology
In line with current best practices and methodologies,19,20 SKOS and XKOS provide the basic building blocks for modeling all classifications currently included in Caliper. SKOS, the Simple Knowledge Organization System, is a W3C standard [22], originally conceived to publish resources like thesauri, classification schemes, and taxonomies (collectively called Knowledge Organization Systems) on the web. SKOS provides constructs, classes and properties, to express classifications’ items (by means of the class skos:Concept), hierarchies (by means of the properties skos:broader and skos:narrower), and most of the coding and terminological parts of classifications (by means of properties such as skos:notation, skos:prefLabel, skos:definition, skos:scopeNote). An entire statistical classification is rendered by means of the SKOS class skos:ConceptScheme. In addition to SKOS, we also use the vocabulary XKOS 21 (Extended Knowledge Organization System, a former DDI, then W3C standard), that extends SKOS to render pieces of information such as classification levels (xkos:level) and correspondences between classifications (classes xkos:Correspondence and xkos:ConceptAssociation, properties xkos:madeOf, skox:targetConcept, xkos:sourceConcept). To date, the correspondences included in Caliper are only those published by the classifications’ custodians, although automatic or semi-automatic generation of correspondences is possible (for example, via transitive closure or language matching) and actually applied in earlier phases of the project. Correspondences are rendered both as SKOS matches (skos:closeMatch, skos:exactMatch) and as XKOS correspondences. This approach introduces redundancy on purpose, to enable rendering in different tools, even in those not (yet) supporting XKOS. Table 1 below provides a summary of the SKOS constructs used to express the basic part of a statistical classification. The interested reader will find the models adopted explained in full detail at the Caliper website (https://www.fao.org/statistics/caliper/en).
Some of the SKOS constructs used in Caliper and their correspondence to standard terminology for statistical classifications.

Some of the SKOS constructs used in Caliper and their correspondence to standard terminology for statistical classifications.
A few specific decisions were made, especially in the use of SKOS “concept schemes” to render domain specific extensions of classifications (e.g., in the case of CPC v2.1, which “core” classification is maintained by UNSD, and its extension for agriculture, maintained by FAO). As for URIs, they are assumed to reflect the custodianship of the resource (e.g., for FAO, the namespace adopted is “https://stats.fao.org/”) and promote trust among users and partner Organizations (cf. sections 3.3 and 4.2 below). Classifications’ versions are indicated both in the URI of a classification (e.g., https://unstats.un.org/classifications/CPC/v2.1/) and by means of specific metadata elements associated to the concept scheme. In addition to SKOS and XKOS, other standard vocabularies provide the constructs to express information about classifications’ elements. For example, Dublin Core 22 is used to express metadata elements for schemes, and Darwin Core 23 is used to express concepts needed for scientific taxonomies. Moreover, the FAO Geopolitical Ontology 6 is employed to represent geographical entities. 6
The conversion of classifications into LOD was initially made through ad-hoc Python scripts then, increasingly, using the Sheet2RDF tool included in VocBench. Sheet2RDF has proved to be a powerful tool to enable users in the Organization to operate conversions, especially when applying consolidated models. Fitness for purpose of the resulting conversions is ensured by means of iterative cycles of validations with domain experts and application developers.
Caliper infrastructure is designed to support the whole life cycle of statistical classifications – creation, maintenance and use by humans and machines. From the beginning, Caliper was conceived around the idea that the use of web standards would not only improve the level of interoperability of statistical classifications, but it would also allow for the use of off-the-shelf tools to support their entire life cycle, from their creation and maintenance to dissemination. Therefore, the infrastructure of Caliper consists of a set of open-source tools connected organized around a flexible and configurable data flow. Figure 2 below sketches out the functionalities supported by Caliper, the tools that provide them, and their intended users.
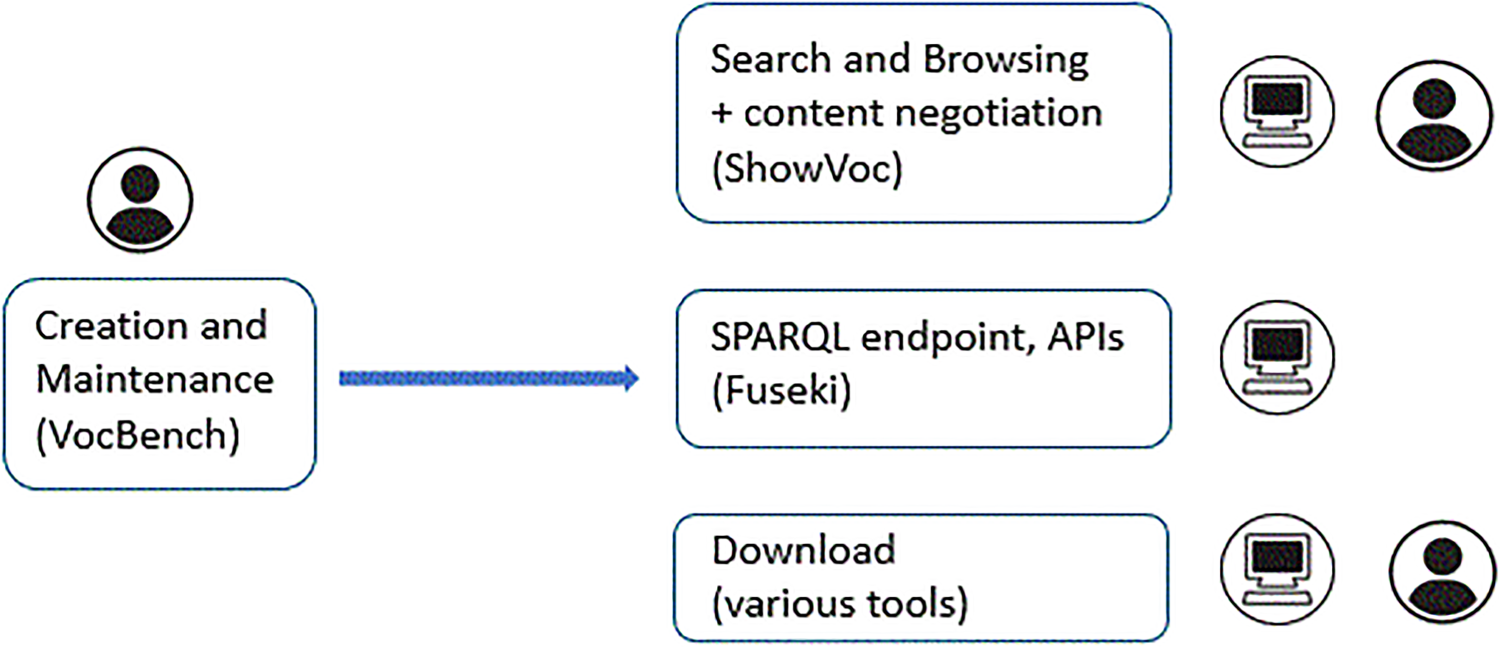
A simplified data flow in caliper. Resources are created and maintained in the editing tool VocBench, then they are published in different ways. ShowVoc makes them available for search and browsing, and it manages the “content negotiation” mechanism to serve the same web resource in different formats according to the client request. Fuseki provides the public endpoint. Various tools are used to produce the exports for download (some exports are produced directly from VocBench). The logos next to the boxes represent the users of specific functionality, i.e., humans or application systems.
During the early phase of Caliper, we experimented with different visualization and browsing approaches, using VocBench together with two more browsing tools, namely Skosmos (https://skosmos.org/) and Drupal (https://new.drupal.org/home). Skosmos is a free and open source and web-based SKOS browser and publishing tool supporting the visualization of lists and hierarchies with multilingual content. Drupal is a free and open-source content management system consisting of a Core, containing basic features common to content-management systems, which can be extended by means of Modules. We used a combination of functionalities from the Core and the Fields module (later replaced by module Imports) to manipulate RDF data a provide a visualization and look-up service for codes, classifications and correspondences that fully addressed the preferences of our colleagues at the FAO Statistics Division. Early versions of Caliper also included Loddy, a tool for content negotiation developed by the University of Tor Vergata, now discontinued and replaced by ShowVoc. Based on our users’ feedback, and on the convenience of having one tool (ShowVoc) to satisfactorily support browsing, searching and content negotiation, we dropped Skosmos, Loddy and Drupal in favor of ShowVoc.
The tools mentioned above are packaged in a Docker to enable smooth deployment of the Caliper infrastructure in different contexts. Originally developed by UNITOV, the Caliper docker is now maintained and regularly upgraded by FAO, in a continuous effort to streamline the efficiency and the usability of Caliper pipelines and APIs. At the time of writing, FAO is taking the necessary steps to make the Docker available to the public.
The Caliper docker allows the smooth deployment of different instances of Caliper, and it triggered an international collaboration dedicated to scaling up the effort of improving the interoperability of statistical classifications. One instance of Caliper is deployed at the ARIES for SEEA Sector Hub of the UN Global Platform. That instance is dedicated to the dissemination of international classifications (replacing the original FAO service), to the revision of existing classifications and to the creation of new ones by the partner custodians. Another instance is deployed at FAO and dedicated to serving classifications and code lists (i.e., sets of classifications items grouped together for specific purposes) and other types of metadata used in FAO internal information systems. Work is ongoing to devise programmatic communication between different instances of Caliper, to enable real-time synchronization of reused resources, collaborative development of new resources, and improved access to distributed resources.
To date, the Caliper instance at the Global Platform exposes classifications in the areas of “Agriculture, Forestry, Fisheries” (Forest products, c ICC, d WCA e ), “Demographic and Social Statistics” (ICATUS f ), “Economic Statistics” (COICOP, g CPC, FCL, h ISIC), and “Geographical Area” (M49 i ). These classifications are maintained either by FAO (ICC, FCL, WCA, Forest products) or by UN (COICOP, ICATUS, M49, ISIC), or both (CPC, starting from version 2.1). Others are under validation or in progress, i.e., COICOP version 2018, CPC version 3.0. Thanks to the collaboration of FAO, UN, and BC3, the list will grow to include more content from the International Family of Statistical Classifications. Moreover, the partnership itself is expected to further grow to include custodians of international, regional or national classifications.
The FAO instance of Caliper, dedicated to serving content to FAO internal information systems, is already operational. Currently, it serves the FAO Statistical Working System (SWS), used for the pre-processing of statistical data that will be later disseminated through FAOSTAT. The connection is implemented as a harvester that queries the Caliper SPARQL endpoint. Its development was straightforward and offered advantages compared to the previous system (based on a relational database), such as coherent look-and-feel between the GUI for editing and for browsing, a global search and browsing facilities and great flexibility in adapting the SPARQL query to the needs of the system. The first code list included in the internal instance of Caliper was the list of aggregates of geographic areas that provide the geographic dimension of data – hence, possibly the most ubiquitous code list for statistical data. Work is ongoing to connect Caliper to FAOSTAT.
Discussion
In this section, we analyze the contribution of the LOD framework to achieving data interoperability and we discuss the contribution of Caliper to that goal.
Interoperability and the LOD framework
The LOD framework represents a step forward to the syntactic interoperability of statistical classifications. It allows for their expression according to standard modelling, using standard vocabularies for RDF. Those models can be exposed with uniform interfaces available for programmatic access via SPARQL endpoints. URIs allow for their unambiguous reference over the web. Hence, thanks to the consistent use of standard data modeling, classifications can be programmatically queried and retrieved through a SPARQL endpoint. SPARQL endpoints offer a flexible way to interact with data, as they allow users to extract virtually any piece of information, in any combination.
The modeling style based on SKOS and XKOS proved to be suitable for any classification that is organized either as a flat list or as a hierarchy, independently of the domain and scope. Also, early work carried out by the authors28,29 with the World Reference Base (WRB) (https://www.isric.org/explore/wrb), the international standard for soil classification system endorsed by the International Union of Soil Science (used by the IPCC to collect and disseminate statistical data about climate change), shows that this approach is flexible enough to accommodate for classifications embodying different organization styles than hierarchical structures (WRB is organized according to the principle of compositionality of basic entities, similar to the approach called post-coordination in library science). More work should be devoted to exploring the possibility of making other types of classifications available in machine-readable and actionable formats. Useful and challenging future extensions to be considered include the Land Cover and Classification System (LLCS).
The expression of correspondences within a statistical classification according SKOS and XKOS is straightforward in the LOD paradigm, but the publication of correspondence tables is less formalized and standardized. The definition of a standard approach to exposing correspondence tables is currently one of the topics under investigation within the LOD CoP led by Eurostat and to which FAO is an active participant.
As a technical limitation of LOD, we need to mention that, by design, links between entities require that entities are represented as web resources. This implies that correspondences may only be established between classifications that are modelled as LOD resources – which is not always the case. The approach adopted in Caliper is to produce a LOD version of the target classification, when not already available as LOD, possibly including only a selected set of information. This approach was experimentally taken at an early stage of Caliper (not included in the current repository), when URIs were assigned to a subset of HS (Harmonized System, https://www.trade.gov/harmonized-system-hs-codes) consisting of only those items that are considered to correspond to CPC. Another approach may consist in defining dedicated properties to be instantiated with the codes from the target classification. We consider this approach as suboptimal, and we have applied it only to some classifications used in the FAO internal instance.
Another possible limitation of LOD applied to statistical classifications concerns the technical skills involved, often very different from the skillsets and backgrounds of statisticians and classifications’ custodians. In fact, although many institutions disseminate statistical datasets as LOD datasets (notably, Eurostat), one may argue that such technology is not yet firmly part of the standard conceptual and technical tools of statisticians.
Finally, it is important to remember that the focus of LOD is syntactic interoperability. Semantic interoperability is out of scope of LOD. Consider for example classifications’ items such as “Italy” or “Rice, broken”, taken from M49 and CPC respectively. They make perfectly legal skos:Concept, but in fact they are just meaningless strings to a computer application - unless some sorts of formal definitions are provided. Depending on the specific contexts of use, such formal definition may need to express information like geographical extension and capital city (for Italy) or the crop of origin and the granularity of the pieces (for broken rice). In other words, stating that a classification item is a skos:Concept does not provide the level of “actionability” of the data that we wish to reach. Popular formal languages to express assertions about entities, properties and relations include OWL (Web Ontology Language), KIF (Knowledge Interchange Format) and F-Logic. They may be used to define semantic layers or “ontologies” that, in addition to classifications, can provide machine applications with the necessary information for their programmatic use without human intervention. Although the definition of such formal layer is outside of the current scope of Caliper, it can contribute to the goal of semantic interoperability (see next section).
Even when considering correspondences, LOD offers a convenient enhancement only at the level of syntactic interoperability. In fact, the comparison and integration of data collected according to different classifications, goal of correspondences, can only be achieved when the classifications involved share the same categorial principles - otherwise the resulting data comparison becomes misleading or impossible. This is very evident in case of a discrete quantitative category such as “Youth”. For statistical purposes, the United Nations defines “Youth” as persons aged between 15–24, while the European Union defines it as people between 15 and 29 years of age. 30 The same difficulty also applies to qualitative categories in virtually all areas of human knowledge.
The contribution of caliper to data interoperability
In our view, Caliper contributes to advancing data interoperability in several ways. It serves existing classifications in formats that are more FAIR, and better suited for machine consumption; it provides the community with a packaged infrastructure, available for reuse, together with all documentation and methodological considerations needed to understand and replicate the effort; it leads an international partnership of classifications custodians and data producers that will further leverage the effort.
At the time of writing, the public instance of Caliper exposes 12 statistical classifications, including metadata and correspondences, maintained either by FAO or by UN. All of them were originally created and disseminated in other tools and formats (typically, Word/Excel for creation, Excel for dissemination) and versioned by their custodians. Resources exposed through Caliper are endowed with stable global identifiers and their content is organized according to standard formats. Together, these features turn statistical classifications into machine-readable resources that can be programmatically queried. Note that, to date, Caliper does not provide semantic harmonization of classification systems, nor any assessment of conceptual equivalence between classifications’ items. In essence – GSIM provides a comprehensive theoretical model for statistical classification, SKOS and XKOS together provide the formal language needed to turn classifications consumable by machines, Caliper provides the full machinery needed to create, search, display, publish and use classifications in electronic environments.
The content exposed is already used by FAO as a reference for its internal statistical activities and for the creation of specific code lists. Its content it is also used within the ARIES for SEEA framework. 31 Within ARIES, a large framework implementing techniques from Artificial Intelligence to achieve interoperability of data and models, for the purpose of composing natural capital accounts, Caliper plays the role of single source of truth for international statistical classifications. The integration of ARIES with Caliper, reached via a SPARQL endpoint, enables ARIES to extract and reuse terms and concepts for machine reasoning and semantic mediation. Future developments could include a stronger collaboration between Caliper and ARIES, where the classifications published in Caliper could be further enriched and semantically disambiguated by means of the domain ontologies within the semantic layer of ARIES. The Caliper infrastructure also directly supports custodians’ work by providing an integrated environment where classifications, metadata and correspondences may be created, discussed upon, validated and published. Another relevant international institutional user of Caliper is Eurostat, that has developed an R-package to facilitate data ingestion by connecting to SPARQL endpoint APIs, including the one of Caliper, to produce correspondence tables.32,33 Within FAO, Caliper serves classifications, and code lists internal statistical systems, through its SPARQL endpoint.
As a packaged infrastructure, Caliper is an ensemble of open-source tools and formalized data flow that can be reused and deployed by interested parties, such as National Statistical Offices or other agencies involved in the creation of reuse of statistical classifications. While most of the Caliper infrastructure and methodologies are readily transferable across institutional context, including the modelling choices (documentation available through the Caliper website), and the tools’ configurations (documentation soon to be published alongside the docker), other aspects are context-specific and require to be defined and configured by the individual organization deploying Caliper (e.g., specific policies for backup and versioning).
Finally, a great contribution of Caliper is the international partnership that is being formed around the UN Global Platform (Section 3.3) - a consortium of custodians of statistical classifications committed to elevating the level of interoperability of their products. The overall goal of the enterprise is twofold: drastically improve the interoperability of international classifications while achieving economy of scale. The consortium will make available as LOD resources an increasing number of international classifications, starting with the International Family of Classifications. Partners will be able to use Caliper as a platform to create and disseminate new content – new classifications’ versions or metadata, standards and any other type of information in support of international, regional or national organization in their data activities. For example, Caliper could be the place to establish and promote semantic correspondences between different classifications, including those operating at different geographic or thematic scope (e.g., between international classifications and their regional and national counterparts). Requirements proposed by partners could be implemented to extend the platform's functionalities for various purposes, ranging from programmatic alert mechanisms to notify updates to third party datasets, integrated search and look-up services for human users, or the assignment of DOIs to classifications and statistical datasets.
The basic principle of the collaboration is that the organizations involved preserve their autonomy in editorial choices, granted that an agreed set of guidelines is respected to ensure consistency in the publication and to keep the requested level of interoperability. The Caliper team will take care of servers, upgrades, creation of working spaces for each organization and provide advice on modeling, tools and functionalities. Custodians will define their unique name space for their URIs, appoint editors and domain experts, and decide on versioning and distributions. Models and functionalities will be proposed, jointly discussed and approved to ensure consistency inside the partnership and with the other communities.
Conclusions and future work
In this paper we have presented Caliper, a fully implemented system for the production and dissemination of statistical classifications that addresses data interoperability at its foundation. The ultimate goal of this endeavor is the production of better, more interoperable, FAIRer official statistics. The theoretical foundations of this work originate from previous work in official statistics and information management. The technological framework is that of web technologies, and particularly the Linked Open Data publication style. In our view, this approach is aligned with the intrinsic nature of statistical classifications as public goods.
The evidence accumulated since the beginning of this work in 2017 indicates that the approach embodied in Caliper is fruitful and versatile. In 2020, Caliper was successfully adopted as the official FAO platform for disseminating statistical classifications (until then, statistical classifications only appeared as metadata of the datasets published in FAOSTAT (https://www.fao.org/faostat/en/)). Then, in 2023 it became the tool to maintain the FAO Names of Countries and Territories (NOCS, https://www.fao.org/nocs). In 2024, Caliper was included in the larger collaborative effort of FAO and UN towards the modernization of official statistics.
Over the years, other institutions have taken a similar approach, most notably Eurostat. 33 The use of standards for modeling and exposing statistical classifications has proven effective in improving the syntactic interoperability of statistical classifications. The use of RDF, in conjunction with SKOS and XKOS, offers a standard interface for the programmatic consumption of statistical classifications by computer applications. Moreover, the consistent use of standards allows us to reuse and combine off-the-shelf tools to fully dissemination (to humans and machines) in the life cycle of statistical classifications. Consequently, what we offer to the international community of statisticians and data users is a fully implemented framework to produce statistical classifications that have been interoperable since the start.
Many user groups can benefit from our work. Custodians have an open-source platform supporting all phases of classifications life cycle, from creation to publication, including APIs and online query. Data users and producers can retrieve machine-readable formats of statistical classifications (either parts or the whole thing) approved by their custodians. Casual users, data journalists, students and researchers can find in Caliper user-friendly and web-based look-up tools to search for definitions and codes as a support to the interpretation of published datasets.
The novelty of our work is twofold. On the one hand, existing technologies and tools have been tested, coordinated and adapted to the context of the global community of official statistics. On the other hand, the fact that interoperability is addressed by the very same classifications’ custodians makes this initiative unique. Caliper is the infrastructural element that allows custodians to maintain and publish classifications with a stamp of officiality, while sharing costs and retaining autonomy in naming, branding and collaboration. In doing so, it is expected to positively impact on the entire international community of statistical data producers and users.
Our future work will follow various lines of development. The content served by Caliper will grow to include the International Family of Classifications, and classifications maintained by other institutions, to extend the partnership around the UN Global Platform to more custodians and data users. This effort will be accompanied by the production of training and documentation material on a regular basis, and the study of solid alignment mechanisms between international and local classifications.
At the technical level, functionalities will be extended to include, among others, an integrated look-up mechanism to retrieve classifications (and items therein) in conjunction with the corresponding handbooks, and REST APIs to expose pre-identified pieces of information to users not familiar with the LOD technology stack. Scenarios of use include the composition and processing of statistical surveys, alignment with NSO's information systems 32 or facilitating more distributed data collection exercise, like in citizen science. Also, there is a plan to build a catalog of all classifications included in Caliper to serve the public with a central repository of classificatory categories for anyone to access, consult, and reuse. The key technical piece underlying the Caliper enterprise is the definition of institutional URIs for statistical classifications as globally unique identifiers. In this respect, future improvements to provide users with versatile identity mechanisms may include the definition of Digital Object Identifiers (DOIs). These could be defined for the double purpose of providing the public with a stable citation mechanism, and providing data producers with an unambiguous, yet compact, way to use codes in information systems. DOI could be assigned to each classification, together with an agreed set of metadata elements, and each classification item would be identified by the combination of the classification DOI and the item's code. This simple, yet powerful mechanism, could also facilitate the alignment between international classifications and their extension in local settings. The use of DOIs would address the need for a stable and reliable repository of identifiers, a global single source of truth for statistical entities.
Footnotes
Acknowledgments
The authors thank the BMGF for the initial funding that led to the development of Caliper. We would also like to thank colleagues at FAO for their contribution during the early phases of this work. Valeria Pesce contributed to the initial prototyping and implementation of the RDF models adopted in Caliper; she also developed and maintained the Drupal interface for browsing and searching data in Caliper. Mukesh Shrivastava strategically boosted Caliper in its initial phases, by shaping its formal arrangement and promoting the use of URIs within the Organization.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.