
Abstract
Named entity recognition is a highly relevant research topic in the field of natural language processing owing to its widespread application, which mainly involves three types of nested entities, discontinuous entities and flat named entities. Notably, nested named entities are characterized by one entity containing multiple sub-entities, ambiguous boundary definitions, and flexible structural formats. These features give rise to challenges such as semantic ambiguity, slow decoding efficiency, error propagation, and information loss. Therefore, to effectively address these issues and enhance classification performance, it is critical to integrate information sources such as internal markers, neighbouring word pairs, first and last word pairs, labels, and related spans. This is achieved in the present study via a newly proposed nested named entity recognition model based on triple cross affine attention. The proposed model encodes the input text using the BERT model and Bi-LSTM before extracting relevant features from the input text by applying DCNN. The extracted feature sequences are used as input into the triple cross affine attention module which computes the scores, allowing the model to classify and predict the outputs using the MLP layer. The experimental results demonstrate that the precision, recall, and F1 value metrics of the proposed method outperform other existing benchmark algorithmic models when applied to the ACE2004, ACE2005, and GENIA standard datasets. Additionally, it exhibits superior recognition performance in nested named entity recognition.
Keywords
Introduction
The term “named entities” typically refers to entities in the text that have specific meanings or strong referentiality, such as names of individuals, locations, organizations, dates, times, and proper nouns. As these are common features of textual information, named entity recognition (NER) is a crucial aspect of natural language processing (NLP). As its objective is to extract named entities from unstructured input text, NER plays an increasingly important role in various downstream applications, such as relationship extraction (Li et al., 2021; Wei et al., 2020), entity linking (Feng et al., 2020; Le & Titov, 2018), and question answering systems (M et al., 2016). Traditional named entity recognition approaches mainly focus on flat entities, making them inappropriate for nested entities which are more complex and harder to recognize.
To overcome this issue, a variety of models for named entity recognition have been developed. including those BERT-based deep neural networks (Zheng et al., 2021), based on sequence labeling (Ma & Eduard, 2016; Zheng et al., 2019). Entity categories are labeled for each word in turn, based on the order and interconnectedness of the words in the sentence. Several modelling approaches based on hypergraphs (Lu & Roth, 2015; Wang & Lu, 2018) and based on linguistic segmentation (Kim et al., 2021), these approaches are effective in representing entity spans for triage subtasks. Yan et al. proposed a sequence-to-sequence model (Yan et al., 2021), which focuses on recognizing and labeling entities in the input sequence by converting the input sequence into a vector representation of fixed dimensions, encoding the input sequence, and then decoding the encoding result to generate the output sequence. Luan et al. proposed a method to categorize spanning entity words (Li et al., 2021; Luan et al., 2019) by enumerating named entities one by one. Recently, M et al. proposed a method for classifying word-word relationships based on unified named entity recognition (Jingye et al., 2022; Natawut et al., 2021), This is achieved by adopting a 2D grid to represent the neighbouring words, as well as the first and last associated words. However, these methods tend to produce false structure and structural ambiguity in contextual semantic information reasoning when there are nested entities in the statements, which can lead to unsatisfactory recognition performance and problems such as slow decoding efficiency and false propagation in the recognition of named entities. At the same time, focusing only on the local semantic information of the text and concentrating on the entity boundaries, which performs better in flat named entities, but for nested entities may lose part of the semantic information or generate ambiguity due to the complexity of the entities, which leads to problems such as poor recognition.
As shown in Figure 1, in the sentence “United Nations Secretary General Guterres Has Been Living In New York”, it is easy to recognize “United Nations” as “ORG”, “Secretary General” and “Guterres” as “PER”, “Secretary” as “POS”, and “New York” as “LOC”, because all instances are flat named entities. However, to detect all named entities within the nested named entity “United Nations Secretary General Guterres”, the fields between “United Nations”, “Secretary”, “General”, and “Guterres” need to be extracted. Such proximity semantic relationships are more complex to establish than flat named entity recognition, and thus require more sophisticated approaches. One such strategy denoted as triple cross imitation is proposed in this paper. The resulting model was inspired by word-word relationship classification (Jingye et al., 2022; Natawut et al., 2021), potential lexicalization constituency analysis (Lou et al., 2022) and the fusion of heterogeneous factors and affine mechanisms (Wan et al., 2022; Yuan et al., 2022), and is accordingly named Triple Cross Affine Attention (TCAA) model.

Schematic Representation of Nested Relationships and Span Mapping Relationships for Entity Word Pairs.
The model focuses on predicting the relationship between two types of entity words, adjacent word pairs and span boundary word pairs, and follows the process of span representation learning and categorization. In the span representation learning phase, a triple affine attention mechanism is employed to aggregate label-level span representations by using boundary and label representations as queries and internal tokens as keys and values. Subsequently, label-level span representations are generated based on boundaries and labels with associated spans as queries. Then, the span representation and boundary representation of the label-level categorization are fused with each other through a scoring function to facilitate the interaction between different factors. Also, BERT (Devlin et al., 2019) and BiLSTM (Lample et al., 2016) model are used for word representation.
In the next step, dilated convolution and attention mechanism are used to extract information, effectively capturing the interactive information between nearby word pairs and distant word pairs. At the same time, the extracted semantic information is mapped through a deep affine model (Bob et al., 2019; Yuan et al., 2022). The proposed model is tested by applying it to English datasets ACE2004, ACE2005 and GENIA, and the experimental results confirm that it outperforms the reference benchmark model. Accordingly, the main contributions of this article stem from proposing:
Propose a word pair relationship detection method for label-level classification span representation and boundary representation of nested named entities, which can promote the interaction between different word elements, and The method of dilated convolution + triple cross affine attention, which can effectively extract the relationship between nearby and distant word pairs.
As their name suggests, nested named entities contain multiple named entities of different lengths. For example, “United Nations” in “United Nations Secretary General” is an entity of the type “organization name”, while the whole entity is an entity of the type “person”. Currently available approaches for dealing with nested named entities include Seq2seq (Yan et al., 2021), affine mechanisms (Bob et al., 2019; Yuan et al., 2022) word-pair relation classification (Jingye et al., 2022; Natawut et al., 2021), and span-based representation (Li et al., 2021).
The Seq2seq (Yan et al., 2021) is a model architecture based on a recurrent neural network (RNN) comprising two modules an encoder and a decoder, which are used to map input sequences to output sequences. However, since the encoder encodes the entire input sequence into a fixed-length vector, it may not be able to fully capture the contextual information of long texts. Moreover, due to the vanishing and exploding gradient problems that are inherent in RNNs, long-distance dependencies may not be accurately captured.
The affine mechanism-based method (Bob et al., 2019; Yuan et al., 2022) treats the entity extraction task as a problem of identifying start and stop word indices, which are used for classifying the resulting span. This method relies on a multi-layer neural network to output scores for all spans and ranks candidate spans based on these scores to satisfy constraints.
The objective of methods based on word-pair relation classification (Jingye et al., 2022; Natawut et al., 2021) is to extract each such relationship type from a sentence in order to finalize the corresponding entity type. However, as this strategy is based on the classification of local word pairs, its performance may be degraded in the presence of long-distance dependencies.
In the method based on span representation (Fu et al., 2021; Li et al., 2021; Zhong & Chen, 2021), the start and end points of each text span are enumerated in sequence, resulting in a nested named entity that comprises all words in the demarcated span. This method embeds the span start position, termination position and length information into the vector space (Huang et al., 2022; Liu et al., 2021), and encodes the span information into the model input by splicing together the tokens representing the left and right endpoints of the span. Moreover, by learning the span width embedding, the method can better understand the information conveyed by the span length.
Although the models briefly described above have some shortcomings, they are the most advanced approaches currently available and have exhibited good performance in nested named entity recognition when tested on standard nested datasets such as ACE2004, ACE2005, GENIA and KBP2017.
Problem Statement
Nested Named Entity Recognition Definition
Nested named entity recognition is a special task aimed at recognizing all nested entities in a text with a specific meaning and is a difficult problem in natural language processing. In practice, nested named entity recognition faces greater technical difficulties due to its specificity, given that one named entity may contain multiple named sub-entities, which leads to semantic ambiguity and incomplete information extraction during the recognition process. The key challenges associated with the existing named entity recognition methods are discussed below.
Analysis of Difficulties in Recognizing Nested Named Entities
Compared with flat named entities, the structure and form of nested named entities are more complex, mainly in the following aspects:
Entity spans differ: a word can be one type of entity that, when combined with other words, creates another category of entity. As shown in Figure 1, the sentence “United Nations Secretary General Guterres” and “United Nations Secretary General Guterres” is a person entity “PER”, while “United Nations” is “ORG” and “United Nations Secretary” is “POS” and “United Nations Secretary General” is also “PER”. As all shorter entities are nested in longer entities, this compromises decoding efficiency, which increases the difficulty of recognition.
Entity boundaries are more difficult to determine, given that different boundaries are applied to nested named entities depending on the semantic understanding. For example, in the text segment “United Nations Secretary General Guterres”, “United” is considered the starting boundary, whereby the potential existence of multiple ending boundaries may lead to problems such as mis-propagation of semantic information in model processing.
The form and structure of nested named entities are more flexible, due to which different word pairings may result in different entity types or different spans of the same entity type, which can easily lead to problems such as information loss in model recognition.
In response to the aforementioned problems, as a part of this work, word pair relationships between nested entities are proposed (including adjacent, first and last, and non-entity word pair relationships), and effective feature representations are designed to allow nested entities to be extracted from textual information.
In light of the characteristics of nested named entities and the challenges associated with their identification, the following ideas and methods are implemented in this work:
A triple affine attention mechanism is designed by extracting contextual information of named entities through dilated convolution (DCNN). The triple affine attention mechanism is used to map the nested relationships between named entities, after which multi-layer perceptron (MLP) is used in prediction. Feature representation is designed by developing an effective method for extracting nested named entity information from the provided text.
To assess the performance of the proposed model, it was applied to three commonly used English nested named entity recognition datasets-ACE2004, ACE2005 and GENIA-and the obtained results were compared with those achieved by the existing methods.
The aim of the proposed model, denoted as Triple Cross Affine Attention (TCAA) model, is to improve the local information decoding efficiency, while mitigating the semantic information error propagation and information loss. For this purpose, the seven-component framework shown in Figure 2 was adopted. Each component is described in detail below.
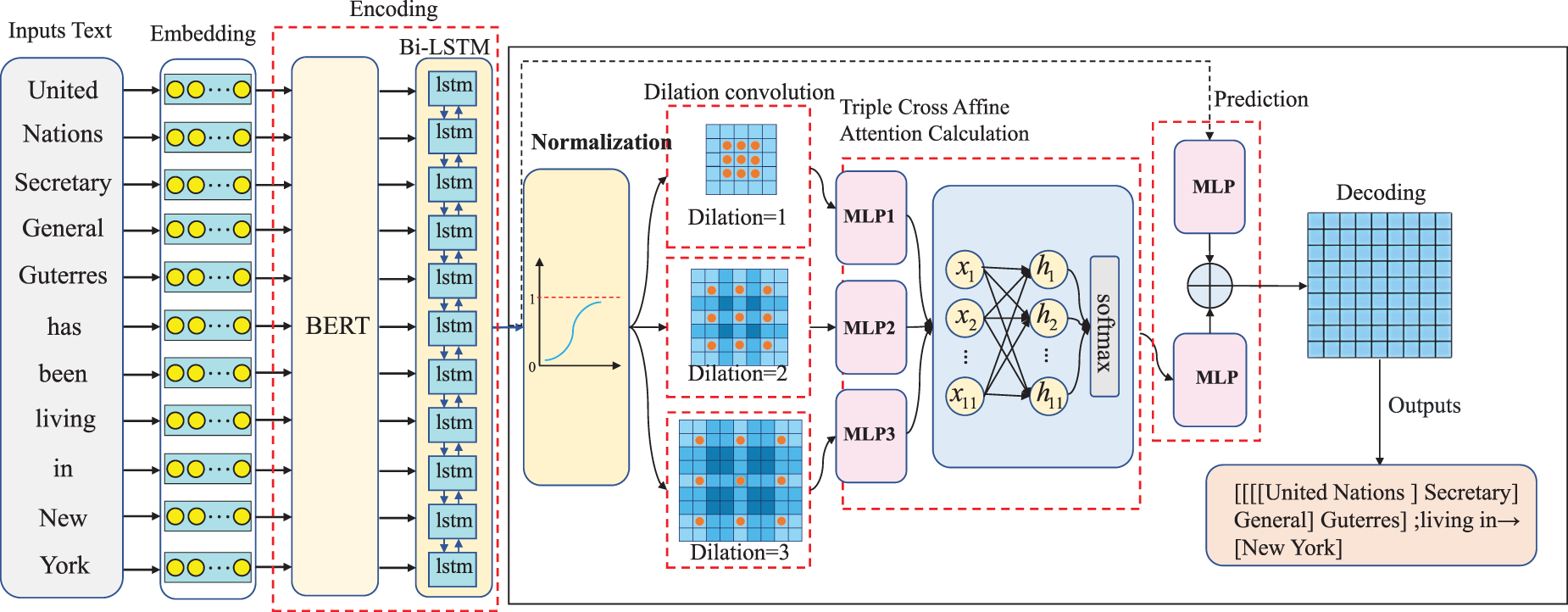
Model Framework.
Ample body of evidence demonstrates that BERT (Devlin et al., 2019) is one of the most advanced models for representation learning in named entity recognition. Accordingly, it is utilized in the proposed method as the encoding input. Given an input sentence

The next stage in the TCAA framework pertains to normalization (Liu et al., 2021), which is required for processing word pair representation, with the aim of reducing the impact of data noise on model performance and improving its generalizability and robustness. Since both neighbouring word pairs and first and last word relationships are unidirectional. Given the

Where
In the TCAA framework, the Dilated Convolutional Neural Network (DCNN) (Yu & Koltun, 2015) serves as a refiner (Jingye et al., 2022) and its main function is to extract the input text features. Specifically, dilated convolutions are employed to capture the interactive information of word-pair relationships between near and distant words. A residual connection (He et al., 2016) is added in the convolution to avoid vanishing and exploding gradient problems. In the convolutional input, it is composed of three parts, namely word embedding, position embedding and segment embedding, which model word, position and sentence information respectively. The tensor
These tensors are connected as convolution input using the following expressions:


Affine Transformation
As affine transformation is the next stage of the TCAA framework, the vector

In order to obtain the neighbouring word pair relationship and the span between the start and the terminating word, a triple cross affine attention mechanism model is developed. As shown in Figure 3, it is used for calculating the relationships between entities, the span representation and the affine score, as shown below:


Affine Score Attention Calculation.
By performing affine operations on the input tensor, different labels, attention weights, and scores can be obtained to achieve interaction with the entity span representation. At the same time, MLP is adopted to perform nonlinear transformation on the input. MLP consists of a combination of multiple linear layers and activation functions that map the input sequence to the hidden dimension and the input to the output dimension. According to MLP, the input is mapped into one of the following three output tensors: head, middle and tail. These output tensors are subsequently multiplied with the tensor

This representation separates the attentional weights and scores of different labels and can interact well with the spanning representation of entities. Moreover, by multiplying the affine attention score with the normalized tensor



The association score between different entities can be calculated using the multiplication of the 3D tensor. By introducing relationships between different types of entities, the model can better capture the contextual information between entities. On the other hand, the attention mechanism calculates the association weights between different positions in the sequence, which can be used to capture the semantic information between entities. Ultimately, by providing these association weights as MLP inputs for linear and nonlinear mapping, the feature representation capability and modelling ability can be improved.
Once affine attention transformation and convolution operations have been performed, and the representations and affine scores of adjacent word pairs have been captured, start–stop word pairs can be obtained. It has been shown (Li et al., 2021) that model performance is enhanced when affine attention and MLP jointly predict relational word pairs. As the input to affine attention is the normalized output




Finally, the word representation prediction value and the affine attention prediction value are added and are passed through the function as the final output.
As previously noted, the model proposed here is tasked with predicting adjacent word pairs and their relationships, whereby the stop word is both premised and depends on the start word. As shown in Figure 4, in the decoding process, the terminating word is utilized to find the path of the starting word. Each path corresponds to an entity word and can be viewed as a directed word graph. The goal of decoding is to find certain paths from one word to another in the graph that correspond to relationships between neighbouring word pairs, whereby each path corresponds to an entity. In addition to the type and boundary identification for named entity recognition, the relationship between start and end words can also be used as auxiliary information for disambiguation to finally identify the corresponding entity type.

Decoding Process, where “ ” Denotes Entity Parsing and “  ” and “
” and “  ” Denote Entity Words.
” Denote Entity Words.
As the cross-entropy loss function is targeted and has better performance in classification tasks and sequence prediction, it is utilized for the backpropagation process in neural network training. When updating the gradient, a mask operation is introduced to deal with padding values with inconsistent sequence lengths. By multiplying the mask tensor with the prediction and the true label tensor, the padding part can be ignored. In calculating the loss for the valid part of the sequence only, model performance can be considerably improved. In sentence
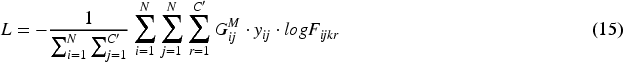
Datasets
In order to verify the feasibility and validity of the proposed model, the corresponding experiments were conducted on three English datasets containing nested named entities–ACE2004, ACE2005, and GENIA–described in detail in Table 1 and outlined below:
ACE2004 is a news domain dataset containing 7, 905 sentences and 27, 781 entities. It was divided into training set, validation set and test set at the ratio of 80:8:12. ACE2005 is also a dataset in the news domain and contains 16, 053 sentences and 56, 042 entities, and was divided into training, validation and test sets at the ratio of 91:5:4. GENIA (Kim et al., 2003) is a dataset in the biomedical domain and contains 18546 sentences and 56042 entities, and was divided into training, validation and test sets at the ratio of 81:9:10.
Experimental Data Distribution.

In order to verify the effectiveness of the model proposed in this article, the following benchmark methods were utilized in the experimental comparative analyses:
Evaluation Indicators
To assess the effectiveness of named entity recognition models, three commonly used evaluation metrics–Precision, Recall and F1 value (F measure)–were adopted. When calculating these indicators, TP (true positive) was considered to represent the number of samples that are actually true when the predicted result is also true, FP (false positive) denoted the number of samples that are actually false when the predicted result is true, and FN (false negative) reflected the number of samples that are actually true when the predicted result is false. These indicators were utilized in the expressions given below.
The precision rate was calculated to measure how much of the sample predicted to be true in the model’s prediction results is true:

Recall was used to measure the proportion of samples that are actually true that the model predicts correctly:

As the 
The Python3.8 language and the Pytorch1.13.0 framework were adopted in all experiments, which were performed on the CentOS7.6.1810 system and A40 graphics card. The parameter settings are shown in Table 2.
Parameter Settings.

Parameter Settings.
As shown in Table 3, the method proposed in this paper exhibits a significant performance improvement over the benchmark model on several different datasets. The evidence of this enhancement can be fully realized from the experimental metrics, and the consistency results between different datasets further validate the effectiveness of the method. These findings are of great significance in the research and practice in this area and provide a solid foundation for further exploration and application of the method.
Experimental Results.

Experimental Results.
As can be seen from Table 3, when applied to the ACE2004 dataset, the Recall rate and F1 value of the TCAA model proposed in this article were better than those obtained for the baseline method. Compared with the W2NER [14] model, the Recall and F1 scores are improved by 0.5% and 0.35%, respectively. However, the precision is slightly lower, which may be because the data sample size is low and there may be noise in the training data set, making it difficult for the model to capture data characteristics and fully learn the data distribution during the learning process. The Precision, Recall and F1 trends are shown in Figure 5.
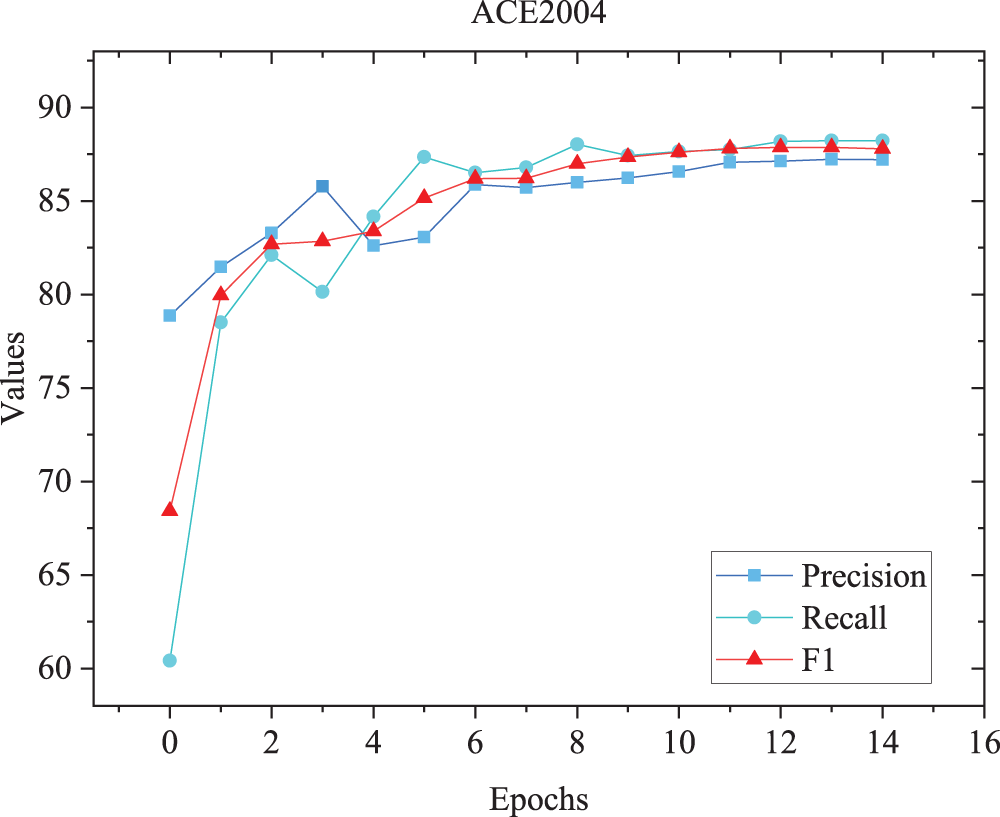
The Precision, Recall, and F1 Trend of ACE2004 on the Test Set.
According to the results reported in Table 3, the Precision, Recall and F1 value of the proposed TCAA model are 86.97%, 89.30% and 87.79%, respectively, when applied to the ACE2005 dataset. Compared with the W2NER [14] model, the TCAA model has improved these metrics by 1.94%, 0.68% and 1% respectively, rendering it superior to the baseline method. The trends of the Precision, Recall and F1 values of the sequences are shown in Figure 6, indicating that they reach a plateau after the 4th iteration.
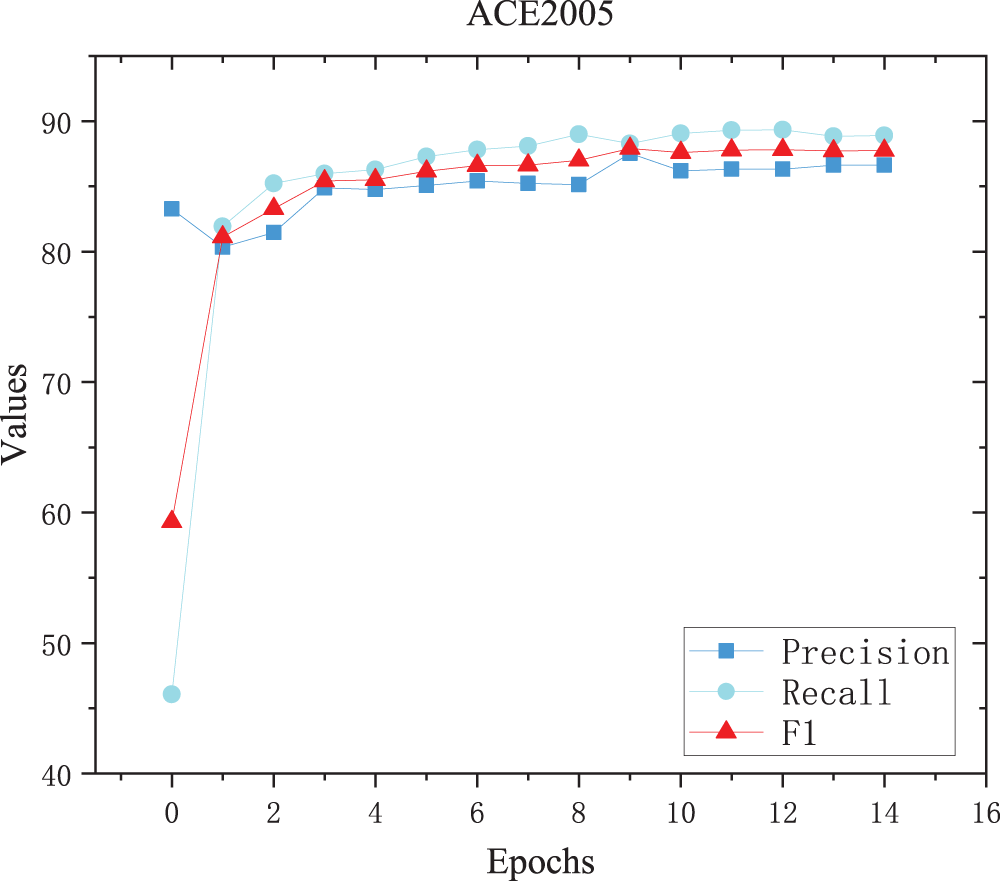
The Precision, Recall, and F1 Trend of ACE2005 when the TCAA Model is Applied to the Test Set.
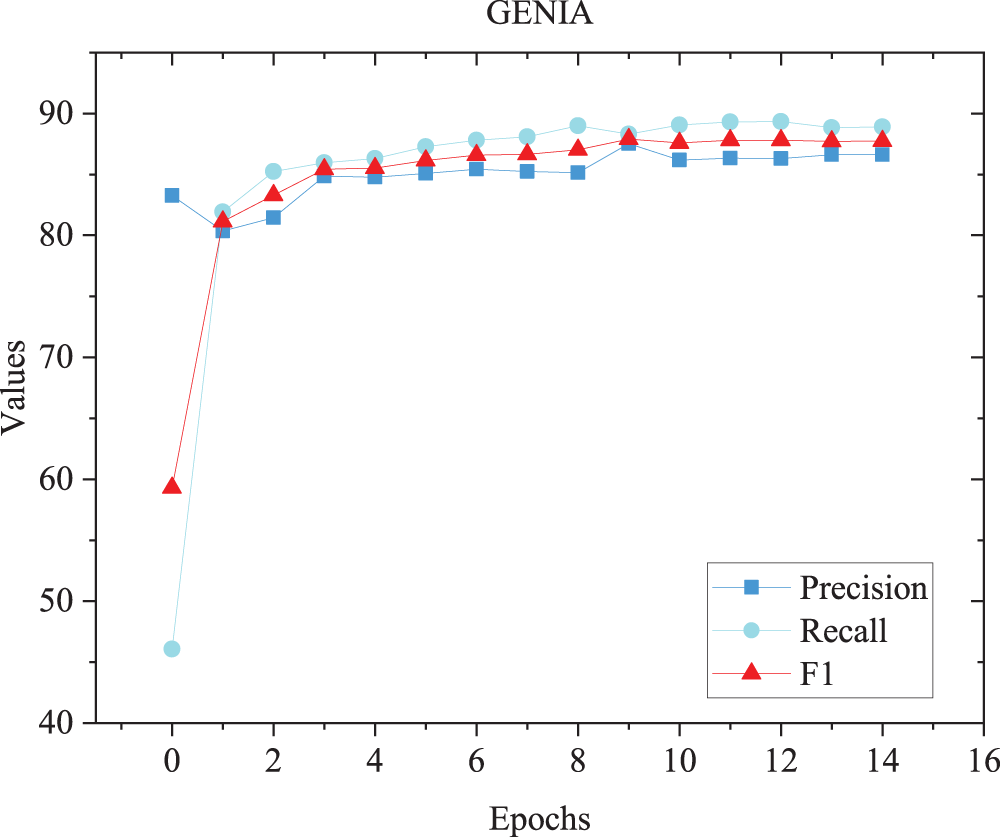
The Precision, Recall, and F1 Trend of GENIA when the TCAA Model is Applied to the Test Set.

Loss Curve.
As can be seen from Table 3, when applied to the GENIA dataset, the TCAA model outperforms the other benchmark methods in terms of all evaluation metrics. Compared with the W2NER [14] model, the Precision, Recall and F1 values are improved by 0.32%, 0.28% and 0.19%, respectively, as shown in Figure 7.
The trend the training loss of the proposed model exhibits when applied to the ACE2004, ACE2005 and GENIA datasets is shown in Figure 8. It is evident that the ACE2005 dataset initially had the fastest convergence while the GENIA dataset exhibited the best convergence. However, after the 4th iteration, the loss of all three datasets leveled off.
As shown in Table 4, we conducted a case study of model predictions on the validation set for both the ACE2004 and GENIA datasets, and the results show that our model performs very well in recognizing nested entities and long entities. For example, in the ACE2004 dataset, entities with a maximum length of 43 or with a three-level nesting structure are accurately predicted. Due to the dynamic label assignment mechanism, each entity can be predicted by multiple instance queries, which ensures a high coverage of entity prediction and indicates that our model has the ability to predict with finer-grained recognition.

However, the model still has shortcomings in its ability to understand special nested sentences. For example, in the case study of the GENIA dataset, “Positive” and “Negative” are misidentified as “Protein”, but they are not actually entity types. In fact, they do not belong to the entity type, but to the sentiment-attitude type words. In addition, there are cases of misclassification in multiple redundant nested clauses that are longer than long clauses, such as the long sentence “The two kidnappers, whom Baghdad confirmed were Saudi Arabians” in dataset ACE2004, which was misclassified as “The two kidnappers, who Baghdad confirmed were Saudi Arabians”. as a “PER” entity.
Meanwhile, in order to demonstrate the effectiveness of our proposed model, we conducted and visualized a comparison of the training time with the current better baseline model under the same conditions, as shown in Figure 9. The baseline training iteration cycle time is about 240 seconds, while ours is about 184 seconds, verifying the excellent performance of our model.
Ablation Study
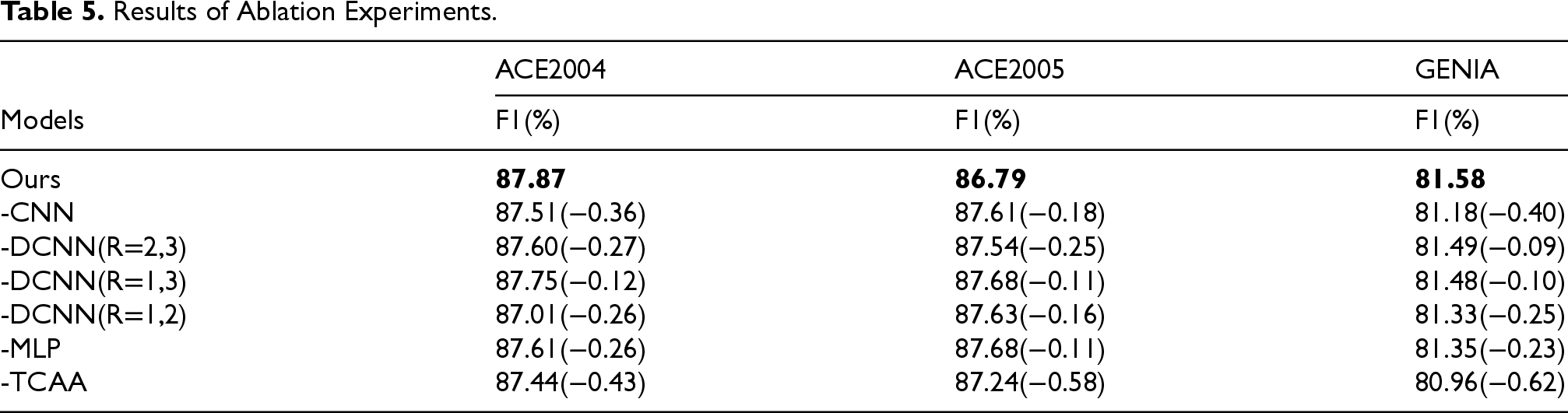
For experimentally testing the model proposed in this paper, different modules were reduced to the three datasets (ACE2004, ACE2005 and GENIA). The specific experimental results for different module overlays are shown in Table 5. The experimental change trend of F1 value on three data sets in different modules is given. Figure 10. Based on the obtained results, it is apparent that, when convolutional neural network (CNN) was reduced to the ACE2004, ACE2005 and GENIA data sets, the F1 value decreases by 0.36%, 0.18% and 0.80%, respectively indicating that the convolutional neural network is increased. Usefulness, when cutting the convolutional network with expansion rates (r=1,2, and 3) respectively, the F1 value decreases in the three data sets, and the degree of decrease is different, indicating that when the expansion rate is different, the convolutional neural network model The contributions on different data sets are different; when the MLP model is reduced, the experimental results all decline to a considerable extent, indicating that mlp plays an important role in the model; when the TCAA module is reduced, in the three The F1 values on the dataset dropped by 0.43%, 0.53% and 0.62%, respectively, indicating that our model plays an indispensable role in showing excellent performance.
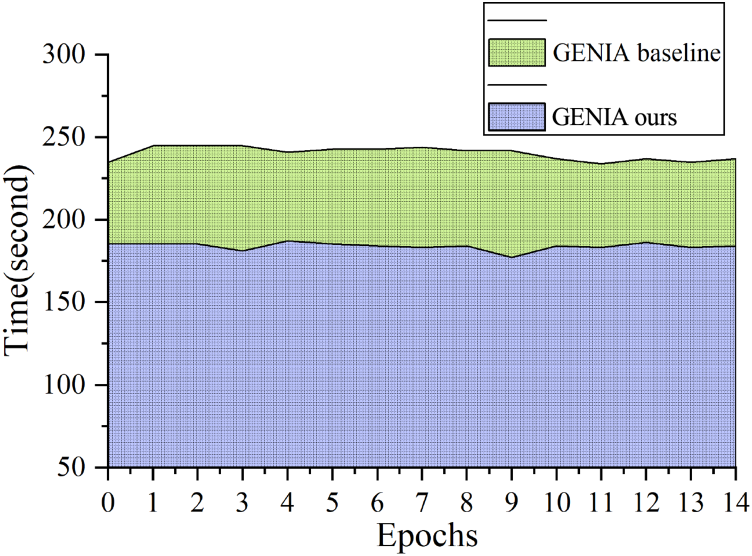
Training Time vs. Baseline on the GENIA Dataset.
Results of Ablation Experiments.
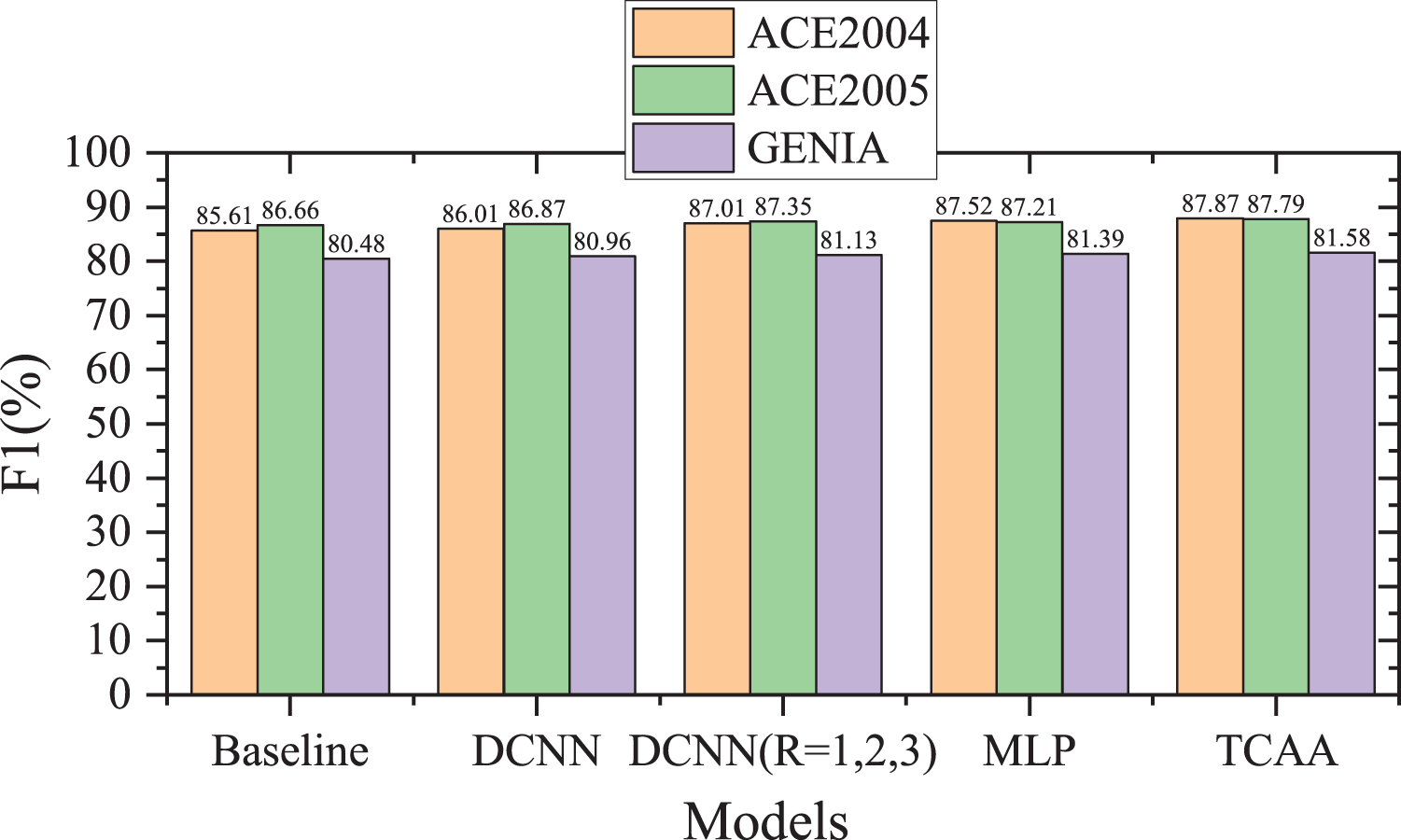
F1 Values in Different Module.
In summary, through ablation experiments, the roles played by different modules in the model were verified, and its usefulness and feasibility were confirmed.
In this paper, a nested named entity recognition method based on triple cross affine attention was presented. This method combines the advantages of various technologies such as BERT pre-training model, Bi-LSTM, DCNN, Attention and MLP. In addition, it can effectively fuse the relationships between internal tags, adjacent word pairs, first and last words, and related spans, etc., thereby significantly improving the precision, recall rate, and F1 score of named entity recognition.
In order to verify the performance of the model proposed in this article, we conducted comparative experiments with eight other currently commonly used benchmark models by applying each on three standard English datasets (ACE2004, ACE2005 and GENIA) that contain nested named entities. Experimental results show that the F1 value of the proposed model reaches 87.87% when applied to the ACE2004 dataset, which is 0.35% higher than the best baseline method. The F1 value reaches 87.79% when applied to the ACE2005 dataset, which is 0.35% higher than the best baseline method. Finally, when applied to the GENIA dataset, the F1 value reached 81.58%, which was an improvement of 0.19% compared to the best baseline method. Based on the experimental results, we can conclude that the model proposed in this article can effectively improve the nested named entity recognition task performance, verifying its effectiveness and feasibility in this context.
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (62341115); the Science and Technology Projects of Guizhou Province (QKHJC[2018]1082); the Guizhou Minzu University of Foundation Research Project (GZMUZK[2023]YB13).
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.