
Abstract
To address the motion blur problem in inspection images of wind power equipment, this paper proposes a fast motion deblurring method based on a Multi-Input Multi-Output (MIMO) framework. First, considering the presence of both linear and nonlinear motion blur in wind power equipment images, we construct a real-world motion-blur dataset for wind turbine inspection. Second, to capture the frequency characteristics of blurred inspection images, a Fourier domain convolution model was designed, enabling the network to better capture global differences between blurred and sharp images. This improves performance while reducing model size. Then, a Half-Batch Normalization (HBN) module is proposed to retain more original feature information during normalization, further improving the algorithm's effectiveness. Additionally, an Efficient Channel Attention (ECA) mechanism is integrated into the network to expand the receptive field of convolution operations and enhance the performance of Fourier convolution, thereby improving deblurring quality. Experimental results demonstrate that the proposed method outperforms existing algorithms in terms of Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index Measure (SSIM) on wind power inspection images. Furthermore, the model size is compressed to 39.5 MB, and the restoration speed is increased to 0.52 s. The code is available at : https://github.com/lingzhiy/Motion.
Introduction
Wind energy is a sustainable energy source with minimal environmental pollution. Wind turbines are the primary devices used to convert natural wind energy into electrical power through the rotation of their blades. Routine inspection of wind turbines primarily relies on identifying surface damage,1,2 such as leading-edge erosion, surface cracks, damaged lightning arresters, and broken vortex generators. Wind turbines are typically constructed on a large scale to ensure sufficient power output. For example, mainstream wind turbine models in China have a capacity of 1500 kW, with rotor diameters of approximately 77 meters and tower heights reaching 70 meters. Due to their large size and height, manual inspection is difficult and often impractical. Therefore, wind turbines are commonly monitored using drone-captured images.3–5
When aerial vehicles capture images of wind power equipment, motion blur often occurs. The presence of blur in the collected images degrades the performance of damage detection, thereby hindering timely maintenance and potentially causing severe equipment damage. Motion blur is caused by relative movement between the camera and the target object. Linear motion produces linear blur, while nonlinear motion results in rotational blur. 6 During flight at varying speeds, influenced by high-altitude airflow or operator errors, the aerial vehicle's speed fluctuates, causing linear motion blur in the captured images. Conversely, during stationary shooting, due to the large rotor diameter of wind turbines and a constant angular velocity, the blades closer to the edge experience greater rotational displacement than those near the center. This results in different degrees of blur across various parts of the blades, constituting nonlinear rotational motion blur.7,8 For wind power equipment, rapid and effective image processing is required, making it crucial to develop methods capable of quickly restoring both linear and nonlinear rotational motion blur.
Current research on motion blur image restoration primarily focuses on two categories: prior knowledge-based algorithms and deep learning-based methods. Prior knowledge-based approaches typically assume a predefined blur kernel. Researchers such as Jia, 9 Levin, 10 Perrone, 11 and Fei Wen 12 have proposed various methods to optimize these priors; however, the restored images often suffer from poor quality, with unclear details and edge information. These methods estimate the blur kernel by imposing multiple constraints while simultaneously solving for the latent sharp image. For instance, Chen et al. 13 proposed a method that heavily relies on regularization terms. Consequently, prior-based restoration algorithms commonly exhibit significant artifacts, fixed multi-scale iteration counts, and unsatisfactory restoration performance, limiting their applicability in practical scenarios.
With the continuous advancement of deep learning technologies, deep learning-based deblurring methods have emerged that do not rely on prior knowledge of blur kernels, directly restoring blurred images through deep networks and thereby overcoming the limitations of prior-based approaches. These algorithms are primarily built upon frameworks such as CNNs, GANs, and Transformers. Nah 14 first proposed a kernel-free end-to-end convolutional neural network (CNN) framework that utilizes an improved residual structure 15 to learn the difference between blurred and sharp images. Subsequently, Kupyn et al.16,17 and Zhang 18 introduced GAN-based methods to further enhance image restoration quality. Following this, Zamir, 19 Suin, 20 Mao, 21 and others incorporated various modules within network architectures to improve learning capacity, though this resulted in larger models and longer training times. Gao et al. 22 applied diffusion models to address wind turbine blade image restoration; however, the introduced diffusion process significantly reduces restoration speed, which adversely affects real-time processing. Li et al. 23 conducted a systematic review of image restoration methods based on diffusion models, and pointed out that diffusion models have already surpassed traditional GAN methods in deblurring tasks, while also noting that frequency domain analysis provides a new perspective for image restoration. Prameeladevi Chillakuru et al. 24 employed an improved version of GoogleNet to conduct restoration experiments on a custom dataset, achieving superior signal-to-noise ratio, structural similarity, and speed compared to traditional methods. Zheng et al. 25 used a multi-scale attention fusion module to dynamically weight cross-layer features with global attention, achieving efficient hierarchical feature aggregation and performing well in image restoration for general dynamic scenes. With the advent of Transformers, Wan, 26 Lin, 27 and Zamir 28 proposed various Transformer-based networks for motion blur restoration. Although Transformers offer strong global context modeling capabilities that mitigate CNN drawbacks such as limited receptive fields and input content adaptability, their computational complexity grows quadratically with spatial resolution, rendering them impractical for motion blur restoration tasks in wind power equipment images. Despite the promising restoration performance of these large-scale models, their long training times and slow inference speeds cannot meet the demands for fast and efficient processing required in wind power inspection scenarios. Jiang et al. 29 reviewed various types of degradation phenomena from the perspective of frequency and proposed the SFHformer framework, integrating the fast Fourier transform mechanism into the Transformer architecture. Through dual-domain hybrid modeling in the spatial and frequency domains, they achieved excellent performance in multiple restoration tasks. This work validates the universal value of frequency-domain information in image restoration. Chen et al.30,31 proposed the HINet and AdaRevD algorithms, while Chu et al. 32 introduced the Test-time Local Converter (TLC) method; These studies have effectively reduced network model sizes, improved restoration speed, and enhanced algorithm practicality. However, since all these methods perform convolution operations in the spatial domain, they still require stacking multiple convolutional layers to enlarge the receptive field. For motion-blurred images in wind turbine inspection, issues of relatively large model size and slow restoration speed persist. In terms of agent-based methods, Jiang et al. 33 proposed the MAIR multi-agent image restoration system, which divides real-world degradation into three categories: scene degradation, image degradation, and compression degradation, improving restoration quality while reducing inference costs. Sun et al. 34 proposed AdaPrompt-IR, which decomposes degradation representation codebooks and captures various types of degradation, combined with degradation semantic mining and prompt learning, achieving unified processing across multiple restoration tasks. This method verified the feasibility of cross-task learning of degradation commonalities.
In addition to the aforementioned deep learning-based motion deblurring methods, another category of related research explores the intrinsic structure of data through weakly supervised or semi-supervised learning methods to reduce reliance on large-scale paired datasets. In the field of unsupervised graph learning, Wang et al. 35 proposed a discrete multi-view graph clustering framework that learns the similarity between samples by directly optimizing discrete clustering indicators. Although such methods are primarily used for clustering tasks, their ability to capture the global distribution and local similarity of data provides a new perspective for handling non-uniform blur distributions in images. In semi-supervised image restoration, Su et al. 36 addressed the image dehazing task by proposing training with both synthetic hazy images and real hazy images: for real hazy images, multiple prior-based dehazed images are used as pseudo-clear images, and a supervision signal is formed through an image quality-guided adaptive weighting scheme; in weakly supervised image restoration, Wang et al. 37 captured lighting information and haze distribution by estimating atmospheric light, scattering coefficients, and scene depth, and designed a discrete wavelet discriminator to enhance the model's generalization ability to real scenes from both spatial and frequency dimensions. The semi-supervised/weakly supervised learning strategies, domain adaptation mechanisms, and physics model-guided ideas adopted in the above studies provide important methodological references for the deblurring task of wind power inspection images in this paper, particularly offering insights into reducing reliance on paired data and improving generalization capability in real-world scenarios.
Research indicates that high-frequency information covers the entire receptive field of an image; In other words, in the frequency domain, there is no need to stack convolutional layers to expand the receptive field. Therefore, this paper proposes a frequency-domain-based motion blur restoration algorithm tailored for wind power equipment images, involving the following steps: first, a convolutional block that exclusively learns high-frequency information is designed, which reduces network depth, compresses model size, and enhances algorithm performance; Second, to address the suboptimal restoration of linear motion blur and poor contour recovery, we introduce a Half-Batch Normalization (HBN) module. This module enables the network to capture more global information and improves restoration quality; Finally, an Efficient Channel Attention (ECA) mechanism 38 is incorporated into the network to strengthen local convolutional feature interaction, thereby enhancing deblurring quality. The proposed algorithm, targeting wind power equipment images, effectively addresses both linear motion blur and nonlinear rotational motion blur problems exhibiting similar characteristics.
Algorithm design
Inspection images of wind power equipment are primarily acquired using aerial vehicles, and the causes of motion blur in these images can be categorized into two main types: First, during high-altitude flights, aerial vehicle body vibrations caused by airflow disturbances lead to camera shake, resulting in motion blur; Since the airflow direction is generally stable, this motion blur is characterized as linear motion blur. Second, when the aerial vehicle hovers during imaging, the normal operation of the wind turbine causes the blades to rotate, generating motion blur in the captured images due to blade movement; this blur manifests as nonlinear rotational motion blur. The proposed algorithm is specifically designed to address and restore these two types of motion blur encountered in wind power equipment inspection images.
Algorithm overall framework
This paper adopts the overall framework of the MIMO 39 algorithm and, considering the specific characteristics of motion-blurred wind power equipment images and the need for rapid and efficient processing, redesigns the encoder part of the U-shaped structure within the MIMO algorithm. The encoder's residual structure consists of conventional 3 × 3 convolutional blocks and FT-Blocks, where the FT-Blocks are constructed using FT-Conv, Efficient Channel Attention (ECA), and Half-Batch Normalization (HBN). FT-Conv directly compensates for the high-frequency information loss caused by motion blur through a global receptive field in the frequency domain, fundamentally addressing the issue of insufficient receptive fields in spatial domain CNNs, while also reducing the number of parameters in the encoder; HBN, through a structured design of ‘half regularization, half identity mapping,’ retains the original feature information while ensuring training stability, providing a stable propagation path for the frequency domain features extracted by FT-Conv; ECA, with an almost negligible increase in parameters, further amplifies the effective channel response based on the well-constructed features by FT-Conv and HBN. This collaborative design enables the model to achieve high-quality restoration of both linear and nonlinear motion blur in wind power inspection images while maintaining lightweight (39.5 MB) and real-time inference (0.52 s per frame), the detailed structure is illustrated in Figure 1.
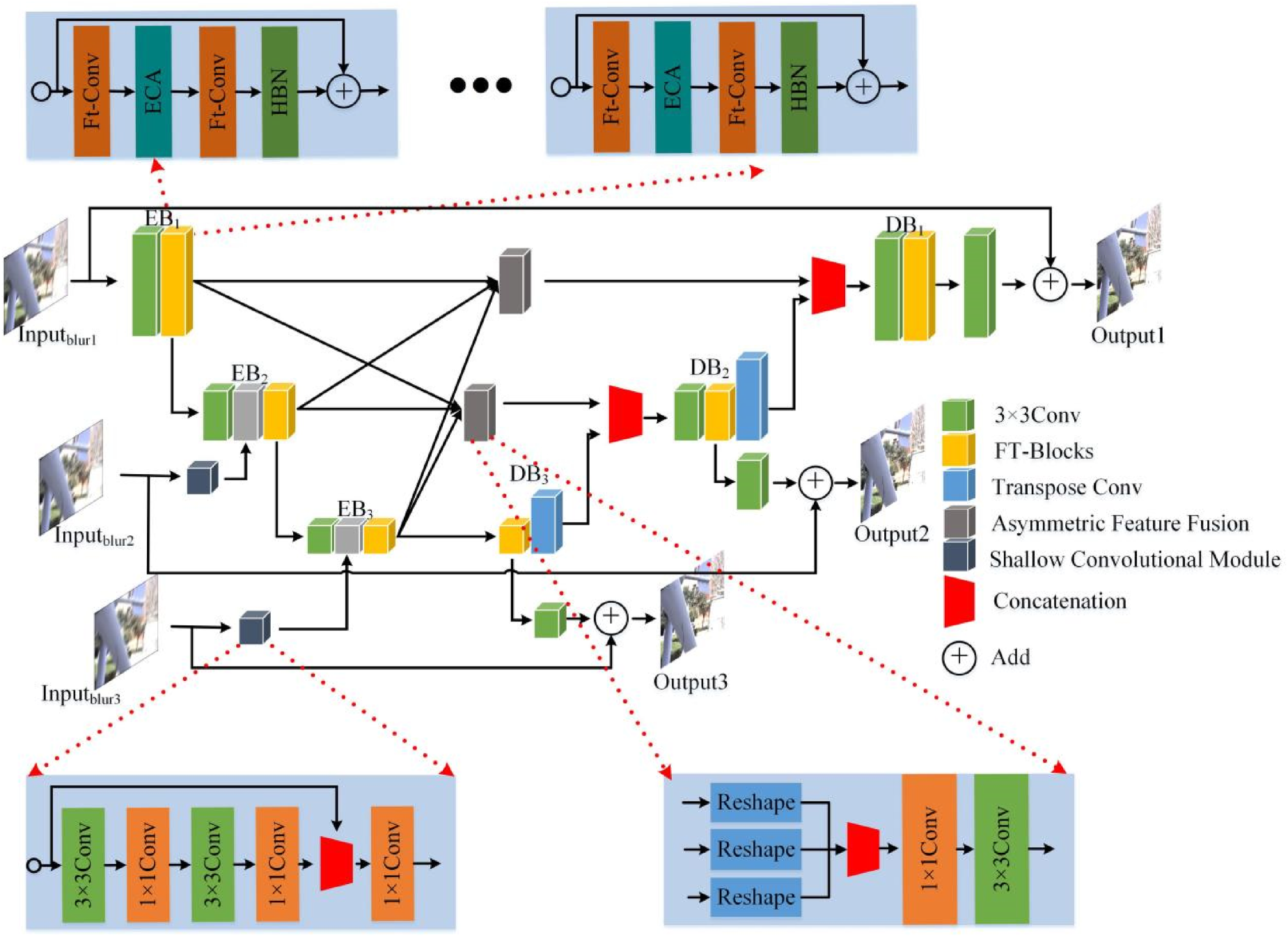
Overall architecture of the algorithm.
In order to better understand how the input image is ultimately transformed into the restored image through each module, Table 1 clearly describes the overall process of the model.
Algorithm flowchart.

Existing deep learning-based motion deblurring methods primarily perform convolution operations in the spatial domain, which corresponds to low-frequency information. To enlarge the receptive field in the spatial domain, these methods require stacking an increasing number of convolutional layers, resulting in larger network models that fail to meet the demands for fast and efficient processing in wind power equipment image applications. Since frequency-domain representations inherently capture global information, the network can achieve a strong receptive field from the early stages. Moreover, a comparison between the frequency spectra of sharp and blurred images (as shown in Figure 2) reveals that blur information is predominantly distributed in the high-frequency regions. Therefore, this study introduces the Fourier transform (FT) into the design of deep learning convolutional blocks, transforming image data from the spatial domain to the frequency domain and performing convolution operations specifically on the high-frequency components.

Frequency Spectra of blurred and sharp images.
The proposed Fourier Convolution (FT-Conv) in this paper applies the Discrete Fourier Transform (DFT) to the spatial domain information of the image, as shown in Equation (1).
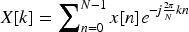
In this equation, 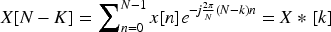
As shown in Equation (2), since the Fourier transform decomposes a signal into its constituent frequency components, Fourier convolution can simultaneously consider all frequency components, thereby capturing global information. Based on this principle, this paper designs the Fourier Convolution (FT-Conv) as follows: first, the spatial feature maps are transformed into the frequency domain using the Discrete Fourier Transform (DFT); Then, conventional convolution is applied in the frequency domain, which avoids the high computational cost associated with direct Fourier-domain convolution, enabling effective learning of high-frequency information. Due to the properties of the FT-Conv, the algorithm captures global image information from the early stages, thereby better capturing the global differences between blurred and sharp image pairs.
The performance advantages of FT-Conv can be analyzed from the perspective of signal processing. According to the convolution theorem, convolution in the spatial domain is equivalent to pointwise multiplication in the frequency domain:
In the feature extraction network of the proposed algorithm, a large amount of feature information is extracted. Applying standard Batch Normalization 40 to these features can easily lead to the loss of original information, resulting in degraded restoration quality of linear motion-blurred images and poor recovery of contour edges in wind turbine images. To address this issue, a novel normalization module called Half-Batch Normalization (HBN) is designed, as illustrated in Figure 3.
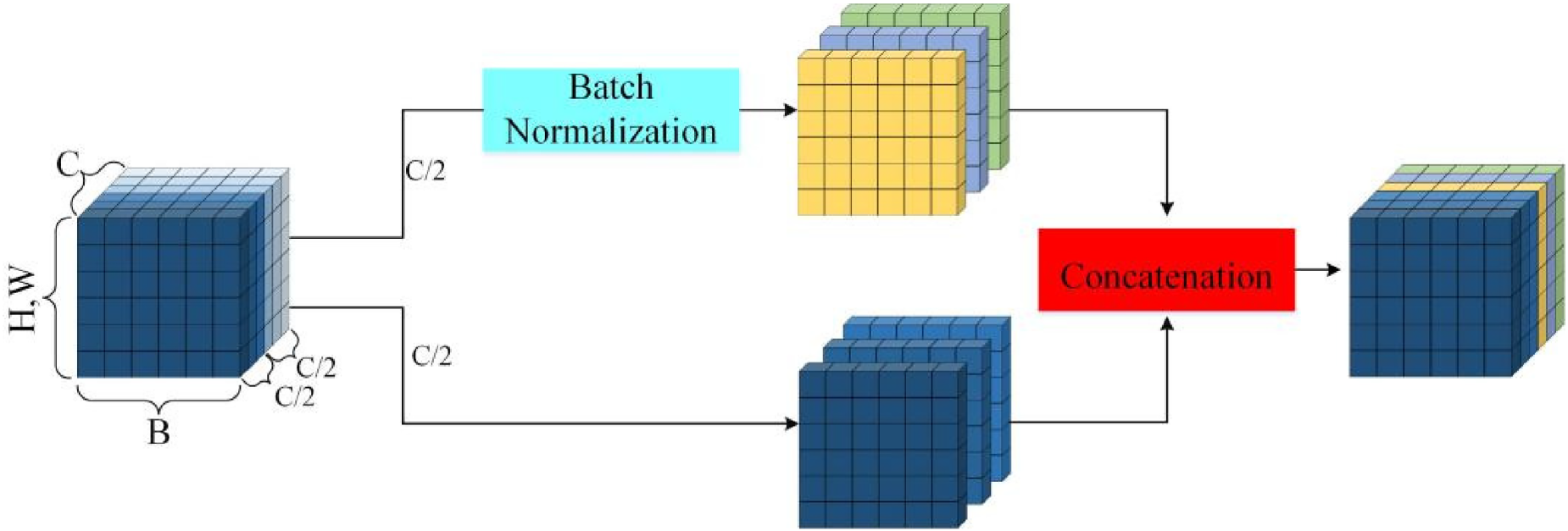
Schematic diagram of the half-batch normalization mechanism.
The core design idea of HBN is to perform selective regularization of features along the channel dimension, with half of the channels undergoing BN to ensure training stability, and the other half maintaining an identity mapping to preserve the original feature information. Specifically, this module first splits the input feature map into two parts along the channel dimension. The data in one half of the channels is processed by standard batch normalization, as shown in equation (3)
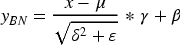
In this equation, x and y denote the input and output data, while
Half of the channel data remains unprocessed, and the original channel information is directly output. The feature information from the processed and unprocessed channels is then combined to produce the final output 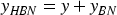
Here, y denotes the output without any processing, and
The output information entropy of standard BN is mainly limited by the estimation accuracy of batch statistics, whereas HBN, by retaining the original distribution of half of the channels, ensures that the lower bound of the overall output entropy is higher than that of standard BN. In other words, HBN can preserve more of the original feature information while performing regularization. Let the information entropy of the original features be H(X); HBN's output information entropy satisfies
Therefore, this module not only retains the features of the original BN module that make the data distribution more stable and improve model performance and generalization ability, but also, by preserving half of the original feature information of the channels, it enhances the fusion of high-level and low-level information in blurry images, allowing the algorithm to acquire more global information, and the
To further enhance the algorithm's performance while minimizing model size and parameters, 41 an Enhanced Channel Attention (ECA) module is incorporated after the convolutional operations. This module dynamically adjusts the weights of different channels based on their inter-channel dependencies, thereby improving the restoration capability of the algorithm. The ECA mechanism effectively enlarges the receptive field of convolutional operations, enabling better capture of contextual information within images, which in turn boosts the performance of the CNN and improves image deblurring quality, as illustrated in Figure 4.
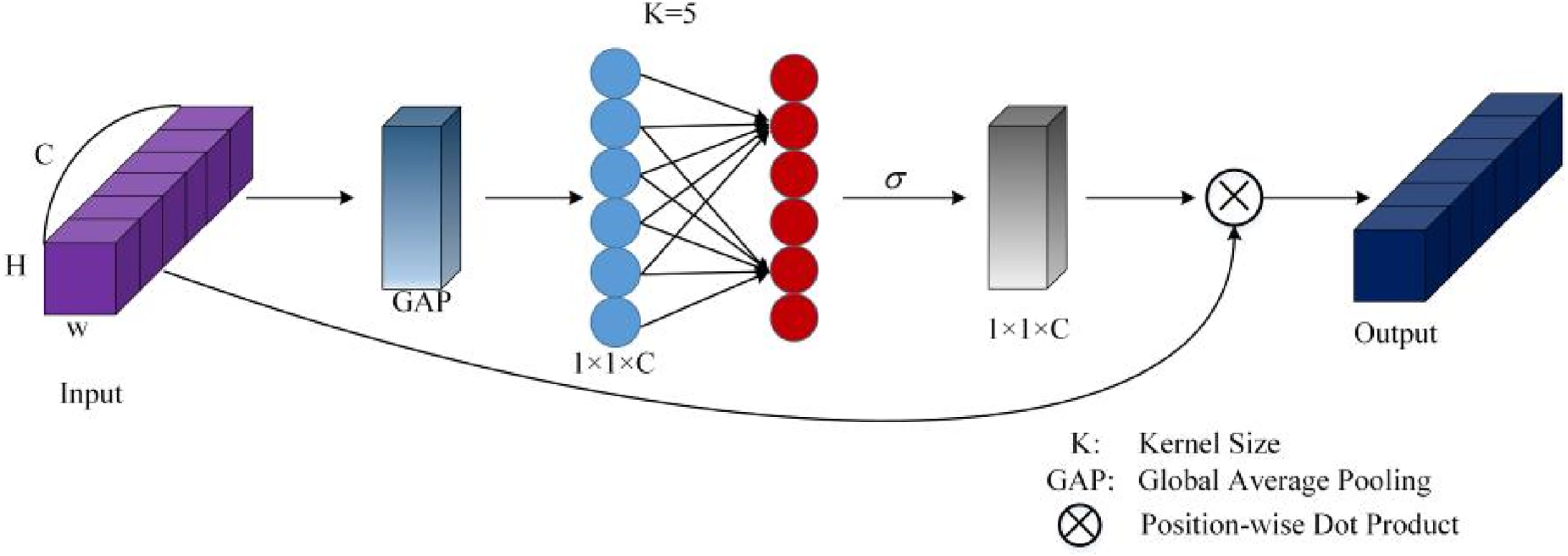
ECA schematic diagram.
This paper uses a composite loss function to train the network, which mainly consists of three parts: MSE Loss, Frequency Loss, and Edge Loss. The total loss function is mathematically defined as equation (5), where 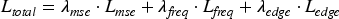
MSE Loss measures the pixel-wise difference between the restored image and the true clear image, ensuring that the restored image is consistent with the real image at the pixel level. Let the predicted image be Y, the true label image be y, the image size be H × W, and each pixel position be (i, j), as in equation (6):
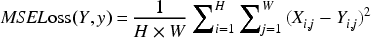
The Frequency Loss constrains the consistency between the restored image and the real image in the frequency domain. First, a discrete Fourier transform is applied to the two images separately, and then the Euclidean distance between their spectra is calculated to guide the network in better restoring high-frequency detail information. Here, let the input image be X, the predicted image be x, 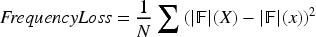
Edge Loss enhances the clarity of edge contours in restored images, which is beneficial for the restoration of the edge contours of wind turbine blades. Here, W is the real image, w is the predicted image, and 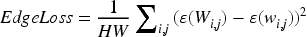
The above composite loss function constrains the network training process from the three dimensions of pixel level, frequency domain, and edges, enabling the model to restore clear high-frequency details and edge information while maintaining overall structural consistency.
Dataset preparation
Since this algorithm is supervised learning-based, it requires paired sharp and blurred images during training.42,43 Aiming to better adapt the algorithm to wind power inspection scenarios, where the images primarily contain linear motion blur and nonlinear rotational motion blur, this study constructs two datasets: Subset A and Subset B.
Subset A is a linear motion blur dataset generated by applying convolution operations using linear blur kernels of varying sizes with the same motion blur intensity, as well as kernels of the same size with varying motion blur intensities, on sharp images to produce blurred counterparts. The dataset comprises 2000 training pairs and 1000 testing pairs. As illustrated in Figure 5, the kernel sizes and motion blur intensities ranging from 0 to 1 effectively simulate a wide variety of linear motion blur scenarios encountered in wind power equipment images. Subset B is a nonlinear rotational motion blur dataset created by capturing wind power equipment videos at 60 frames per second (fps). The videos were frame-extracted and interpolated to 120 fps. Every 7 consecutive frames were averaged to generate blurred images, effectively simulating nonlinear rotational motion blur. As shown in Figure 6, the synthesized images realistically exhibit increasing blur intensity toward the blade edges and pronounced fast motion blur at the outermost tips of the blades. This dataset consists of 2400 training pairs and 600 testing pairs.
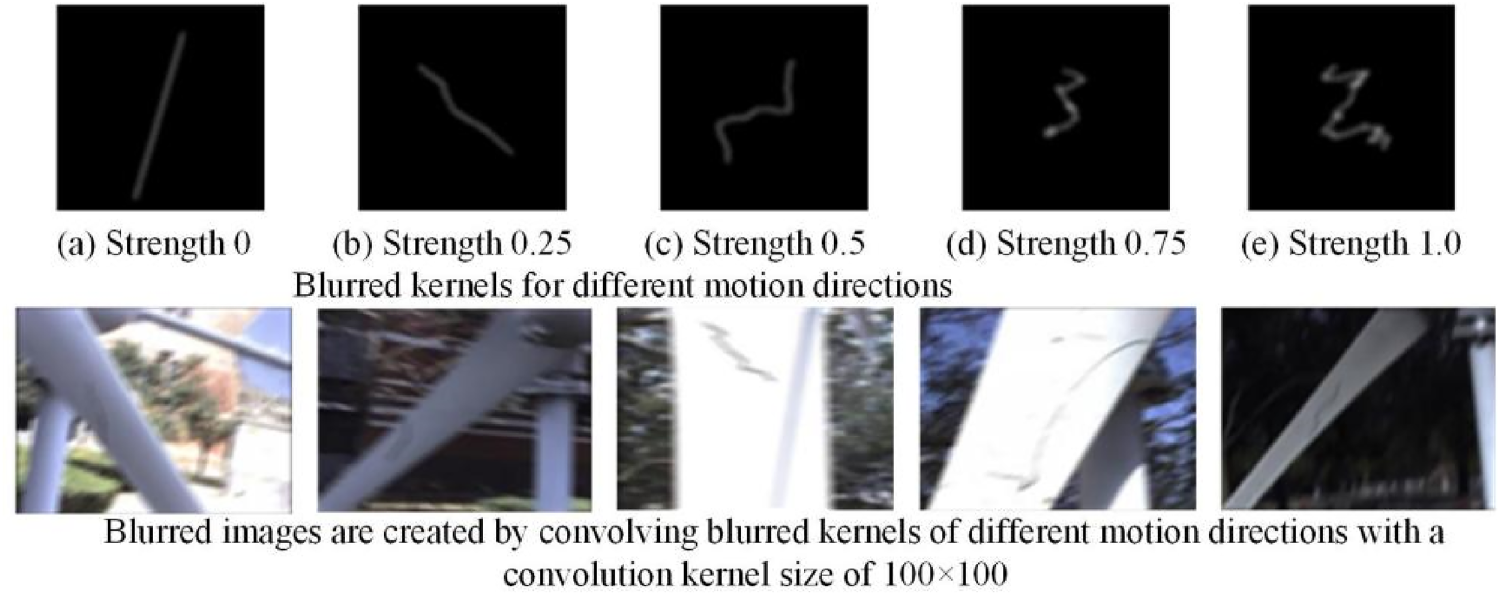
Blurred images of subset A.

Subset B synthetic image.
To enhance the generalization capability of the network, various data augmentation techniques were applied to the training dataset, including horizontal flipping, random affine transformations, transposition, non-rigid deformations, random adjustments to hue, saturation, brightness, and contrast, and random erasing. Experiments were conducted on a system with an Intel i7-10700 CPU and an NVIDIA RTX 3080 GPU, running the Windows 10 operating system, and utilizing the PyTorch deep learning framework. During the training process, the batch size was set to 8, and the initial learning rate was set to 0.001. An adaptive learning rate adjustment strategy was used: when the validation loss did not decrease for 5 consecutive epochs, the learning rate was multiplied by 0.1 to decay. All models were trained until the loss function fully converged, with the total number of training epochs set to 300.
In the evaluation on public datasets (GOPRO, NFS, DVD), this paper uses exactly the same hyperparameter settings, namely batch size = 8, initial learning rate = 0.001, adaptive learning rate decay strategy, and epoch = 300, to ensure a fair comparison between the method in this paper and existing methods.
Experimental results and analysis
To validate the effectiveness of the proposed method, ablation studies and subjective visual comparison experiments were conducted on the wind power equipment test dataset developed in this study. Additionally, objective evaluation metrics were compared on both the proposed wind power inspection test set and publicly available datasets, including GOPRO, NFS, and DVD.
Ablation study
Based on the MIMO network framework, this study introduces a customized design tailored to the characteristics of motion-blurred wind power equipment images. To evaluate the effectiveness of each proposed module, ablation experiments were conducted on Subset A and Subset B. The results in terms of PSNR, SSIM, parameter count, and restoration speed for different configurations are presented in Tables 2 and 3.
Subset A ablation experiments.

Subset A ablation experiments.
Subset B ablation experiments.

The test results of different image restoration algorithms on Subset A and Subset B are presented in Tables 2 and 3. The reported metrics—PSNR, SSIM, model size, and restoration speed—are averaged over all images in the respective test sets. To comprehensively evaluate the independent contribution of each module, we individually added the FT-Conv, HBN, and ECA modules on the MIMO baseline. Adding FT-Conv alone (MIMO FT) increased PSNR by 1.9921 and SSIM by 0.0221 on subset A, and increased PSNR by 0.9134 on subset B, while reducing parameters by 3.6MB and improving restoration speed by 0.02 s. The improvement was the most significant, indicating that the global receptive field in the frequency domain is crucial for motion blur restoration. Adding HBN alone (MIMO HBN) increased PSNR by 0.2104 and SSIM by 0.0163 on subset A, and increased PSNR by 0.16 on subset B. The improvement was relatively limited, suggesting that HBN's advantage of ‘preserving original features’ is hard to fully leverage when used alone. Adding ECA alone (MIMO ECA) increased PSNR by 0.1022 and SSIM by 0.021 on subset A, but decreased PSNR by 0.06 on subset B, with weak or even slightly negative effects, because ECA requires sufficient global context information to effectively allocate attention weights. Adding HBN on top of FT-Conv (MIMO FT HBN), compared with FT-Conv alone, further increased PSNR by about 0.80 and SSIM by 0.0076 on subset A, increased PSNR by about 0.40 on subset B, and improved restoration speed by 0.01 s, validating the complementarity of FT-Conv and HBN—FT-Conv provides global frequency domain features, while HBN preserves these features during the normalization process. Adding ECA on top of FT-Conv and HBN (complete model), compared with MIMO FT HBN, further increased PSNR by about 0.56 and SSIM by 0.01 on subset A, increased PSNR by about 0.40 and SSIM by 0.0049 on subset B, while keeping parameters and restoration speed unchanged. This indicates that the channel attention mechanism of ECA can only be effective when based on the well-constructed features from FT-Conv and HBN.
Images captured by an industrial camera were processed using the proposed method, as well as the AdaRevD, 44 EVSSM, 45 and MIMO algorithms for deblurring. The restored images were then compared by magnifying defect regions and edge contours to evaluate subjective visual quality. To further demonstrate the superiority of the proposed algorithm, images with varying backgrounds and lighting conditions were selected for comparison. Figures 7 and 8 show examples of linear motion-blurred images under different lighting conditions, while Figures 9 and 10 present nonlinear motion-blurred images resulting from wind turbine blades rotating at different speeds.

Linear motion blur images (bright).

Linear motion blur images (dark).

Non-linear motion blur images.

Non-linear motion blur images.
By comparing the experimental results shown in Figures 7 and 8, it can be observed that for linear motion blur, where the degree of blur is relatively severe, both the AdaRevD and EVSSM methods fail to restore the images effectively. The images restored by AdaRevD show limited visual improvement and exhibit noticeable color imbalance. The EVSSM method, on the other hand, produces severe artifacts, including prominent checkerboard patterns. In contrast, both the MIMO method and the proposed approach achieve better restoration quality, with visible cracks on the wind turbine blades. Although the MIMO-restored images appear visually appealing, they suffer from over-smoothing and noticeable deformation along the blade edges. The proposed method demonstrates a higher degree of restoration fidelity, effectively preserving the blade contours while clearly recovering the crack details.
By comparing the experimental results in Figures 9 and 10, where Figure 9 corresponds to a blurred image captured during slow blade rotation and Figure 10 corresponds to one captured during fast rotation, it can be observed that the AdaRevD method continues to exhibit severe color imbalance. While the EVSSM, MIMO, and the proposed method are all capable of restoring the blurred images to some extent, in cases of faster blade rotation, both EVSSM and MIMO struggle to accurately recover the blade edges in regions where the color contrast between the blades and the background is low, resulting in noticeable artifacts and incomplete restoration. In contrast, the proposed method demonstrates superior performance in preserving blade edge contours, even under challenging conditions involving high-speed rotational motion blur.
In order to further verify the effectiveness of the method proposed in this paper in practical engineering environments, we collected on-site detection images from a real wind farm for testing. As shown in Figure 11, the test images cover wind turbine blurry images from different angles and heights. The experimental results show that the model proposed in this paper can still restore images well in these challenging real-world scenarios and outperforms the comparison models in image restoration performance, confirming its good engineering generalization capability.

Restored image of a real blurred fan blade.
The proposed method, along with the AdaRevD, EVSSM, and MIMO algorithms, was evaluated using objective metrics including Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM). In addition, the restoration speed per image and the size of the trained model were recorded for comprehensive performance comparison. This evaluation provides a quantitative assessment of each method's effectiveness in terms of restoration quality, computational efficiency, and model compactness.
On the proposed blurred image test dataset, identical training epochs were conducted on Subsets A and B for all methods. The PSNR, SSIM, parameter count, and restoration speed for each approach are summarized in Table 4. Compared to AdaRevD, EVSSM, MIMO, and WTE-DDPM,
22
the proposed algorithm is significantly more lightweight, the weight model of this article is only 39.5MB, which is 27.6MB less than HINT,
46
and its restoration speed is faster. The PSNR and SSIM achieved by the proposed algorithm show substantial improvements over other methods, attributable to the incorporation of the FT-Conv, HBN, and ECA modules.
Subset A and subset B comparison experiments.
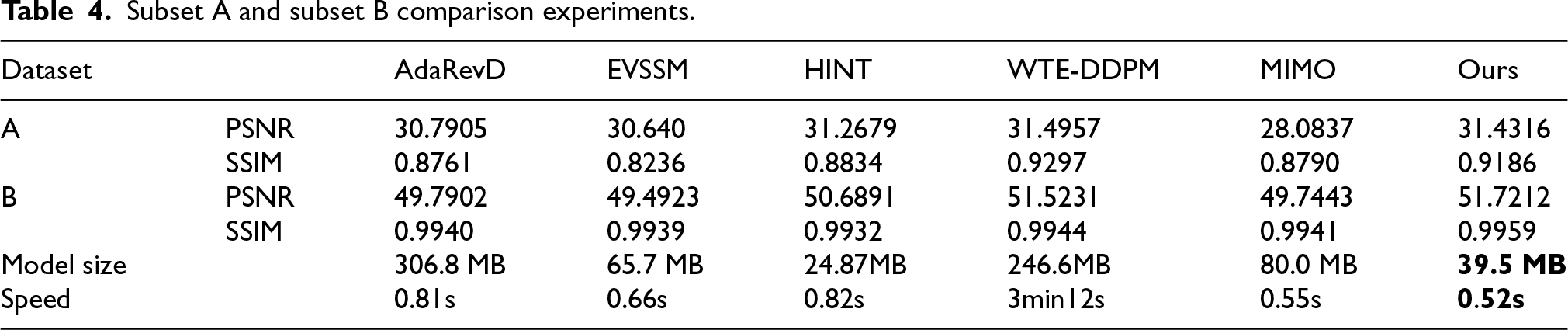
From the inference time shown in Table 4, the average restoration speed of a single image using the method in this paper is 0.52 s, faster than AdaRevD (0.81 s), EVSSM (0.66 s), HINT (0.82 s), WTE-DDPM (192 s), and MIMO (0.55 s). Compared with AdaRevD, which has the largest number of parameters (306.8 MB), the method in this paper reduces the number of parameters by about 87% while increasing inference speed by approximately 36%. Compared with EVSSM and MIMO, which have a similar number of parameters, the method in this paper has obvious advantages in both parameter count and inference speed. It is particularly noteworthy that although WTE-DDPM uses a diffusion model architecture and achieves a higher PSNR on subset B, its inference time is as long as about 3 min and 12 s, and its number of parameters reaches 246.6 MB, making it difficult to meet the demand for fast processing in practical wind power inspection scenarios. HINT, as a lightweight model (24.87 MB), achieves a PSNR of 31.27 dB on subset A, slightly lower than the 31.43 dB of the method in this paper, but its inference speed of 0.82 s is slower than that of this method. The above comparisons indicate that the method in this paper achieves the best balance between restoration quality, inference speed, and model size: compared with the diffusion model WTE-DDPM, the method in this paper trades a minimal PSNR difference for nearly 370 times faster inference; Compared with the lightweight model HINT, the method in this paper achieves higher PSNR while being faster in inference. This result validates that the method in this paper has good computational efficiency and practicality for real-world wind power inspection scenarios. The efficiency advantage of the method in this paper mainly benefits from: 1) The FT-Conv module reduces network depth through a global receptive field in the frequency domain, reducing computational redundancy; 2) The HBN module only needs to learn BN parameters for half of the channels, further compressing computational cost.
To evaluate the capability of the proposed algorithm in handling other types of blurred images, training and testing were conducted on publicly available datasets GOPRO, NFS, and DVD. The PSNR, SSIM, model size, and restoration speed for different methods are summarized in Table 5. On the GOPRO and DVD datasets, the proposed algorithm achieves higher PSNR values compared to AdaRevD, EVSSM, and MIMO, while its SSIM scores are slightly lower than those of the other methods. For the NFS dataset, the proposed method attains PSNR values higher than AdaRevD and MIMO but lower than EVSSM, and its SSIM surpasses all competing algorithms. Notably, the proposed model remains more lightweight and achieves faster restoration speeds across all datasets. The comparative experiments on GOPRO, NFS, and DVD demonstrate that the proposed approach is effective for general blurred image restoration tasks, with performance close to mainstream algorithms, while maintaining a smaller model size and faster inference speed.
GOPRO, DVD, NFS public datasets comparison experiments.
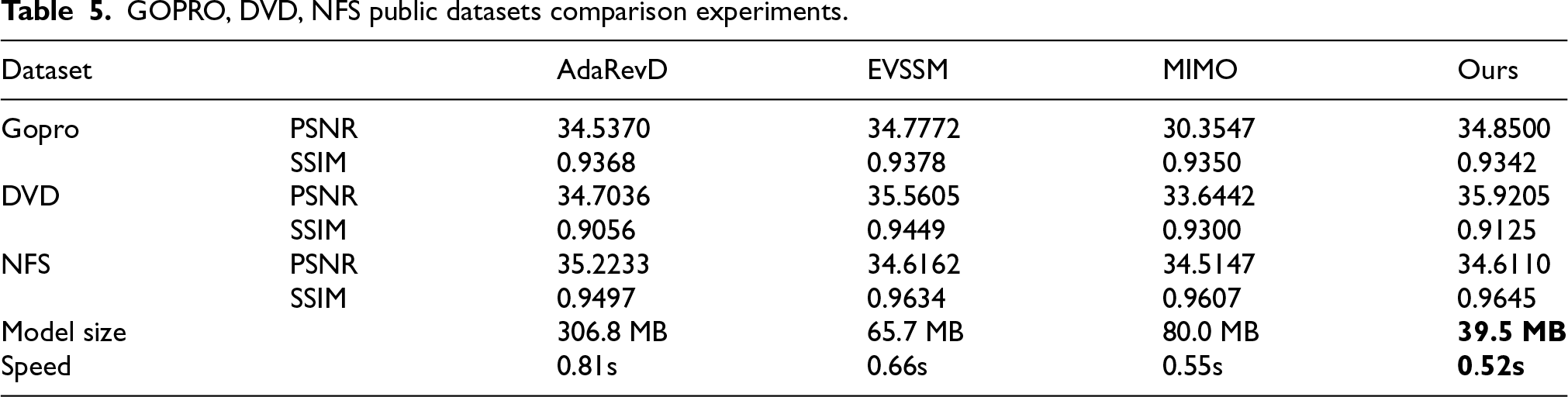
This paper proposes a frequency-domain transformation and HBN-based deblurring algorithm for wind power equipment. It analyzes the causes of motion blur in wind power equipment images and the limitations of existing deblurring methods. Building upon the MIMO network framework, an FT-Conv convolutional approach is designed to enable the algorithm to cover the entire image receptive field from the initial stages, thereby better capturing the global differences between blurred and sharp image pairs. This design reduces network depth, improving restoration speed and quality.
To address the unique characteristics of motion-blurred wind power equipment images, this study constructs two specialized datasets representing linear motion blur and nonlinear rotational motion blur. Additionally, a novel Half-Batch Normalization (HBN) block is introduced to preserve more original feature information during regularization, enhancing the fusion of high-level and low-level features to capture more global context and improve performance. The network also incorporates the Enhanced Channel Attention (ECA) mechanism to expand the convolutional receptive field, thereby boosting the effectiveness of FT-Conv and improving image deblurring quality.
Experimental validation on the proposed datasets demonstrates that the proposed method achieves higher PSNR and SSIM scores compared to other deep learning methods. The network model size is compressed to 39.5 MB, and the restoration speed per image is improved to 0.52 s, enabling fast and effective processing. Further evaluation on public datasets GOPRO, NFS, and DVD shows that the proposed method attains PSNR and SSIM values comparable to state-of-the-art approaches, while significantly reducing model size and hardware requirements. The accelerated restoration speed makes the method well-suited for efficiently handling large volumes of blurred wind power equipment images, meeting the practical demands of wind power equipment inspection.
Although the method proposed in this paper achieves better performance compared to other methods in the task of wind power equipment motion blur image restoration, every method has inherent limitations. This paper discusses, from an objective perspective, the scenarios in which the proposed method may perform poorly. It has limitations in restoring extremely nonlinear motion models, although the method performed well on the subset B of nonlinear motion blur. However, in actual wind farms, extreme situations such as typhoon conditions or severe vibrations of flying devices can cause motion blur that severely weakens or even completely removes high-frequency information, making it difficult to effectively extract global differential information; it is sensitive to low signal-to-noise ratio (SNR) or high-noise environments. In low SNR environments, the presence of significant noise components may cause the model to inadvertently amplify noise during restoration, severely affecting the visual quality of the restored image; it has insufficient adaptability to scenarios without completely matched paired data. The proposed method belongs to a fully supervised learning framework, and the training process relies on a large number of paired blurred-clear images. In some scenarios, it is impossible to obtain clear images from the same perspective and at the same moment, which can lead to a significant decline in restoration performance.
Therefore, while the proposed method shows excellent performance in the task of wind power equipment motion blur image restoration, it has certain limitations in extreme data scenarios and parameter generalization. When the application scenario is close to the experimental conditions of this paper, the proposed method can achieve optimal performance.
Footnotes
Acknowledgments
We sincerely express our gratitude to every author for their contributions during the completion of the article. We also extend our respect to the editors and every reviewer for their efforts. We appreciate your dedication. Additionally, we would like to thank the author who provided the reference code for this article.
Ethical approval and informed consent statements
Consent was sought from each author and the subjects who provided data for the dataset in this paper, and no ethics were involved in the rest of the paper.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
Due to the nature of this research, participants of this study did not agree for their data to be shared publicly, so supporting data is not available.