
Abstract
This study investigated if improving a chatbot using user test feedback can enhance the perceived value of a chatbot for a specific biobanking use case. The chatbot was designed to guide participants in a research study around a biobank site to facilitate their data collection experience by conversing with them about what to do and where to go and answering any questions about the measurements, the research, or the biobank. A total of 32 test participants tested the chatbot and provided feedback about their experience, and the answers were analyzed to evaluate perceived value. The first group of users tested the initial version of the chatbot, and the second group tested the improved version of the chatbot. The results demonstrated that by including user feedback to design the chatbot, the perceived value in the second testing increased. Following these early-stage study results, it was determined that the chatbot was ready for deployment in the biobank.
Introduction
While there is increasing evidence that self-measurements for biobank data collection can improve participant empowerment and data quality, 1 there is concern regarding the sufficiency of support during autonomous data collection. A biobank in the Netherlands that collects physical and lifestyle data from a large cohort of volunteers recently implemented a self-measurement for body composition on site, among other measurements. While the aim of introducing this self-measurement was to improve the efficiency of the site and reduce staff burden, in practice, the participants experienced confusion when performing the self-measurement and still relied on staff for guidance. With the rise of large language models, chatbots have demonstrated humanlike performance as assistants in healthcare. 2 Aevai Health B.V., a start-up in the Netherlands, developed a chatbot (Alva) to guide participants during two biobank site visits (one of which includes self-measurements such as weight and height, and the second includes blood tests performed by a doctor’s assistant) and to improve participant experience by answering questions about the biobank, the research, and the measurements. However, the perceived value of such chatbots as assistants largely depends on their ability to meet participant needs and expectations. Aevai Health B.V. leveraged user feedback to improve the chatbot before on-site deployment.
This early-stage case study investigates whether systematically improving the chatbot based on user feedback could enhance its perceived value as a guiding tool for biobank data collection visits.
Materials and Methods
Chatbot
In this case study, a chatbot (Alva) was offered to participants as a web app interface with an instruction video, accessed via a quick response (QR) code. Alva used a structured conversation to guide participants to different stations at the site and to perform measurements. Alva also included the technology “Retrieval Augmented Generation” and used privacy-preserving open-source, large language models—customized with a knowledge base to provide answers accurately about the biobank and the measurements. The first version of Alva and the improved version of Alva were developed and tested during this case study, referred to as V1 and V2, respectively. In Figure 1, the functionalities of Alva are shown via the different web app pages.
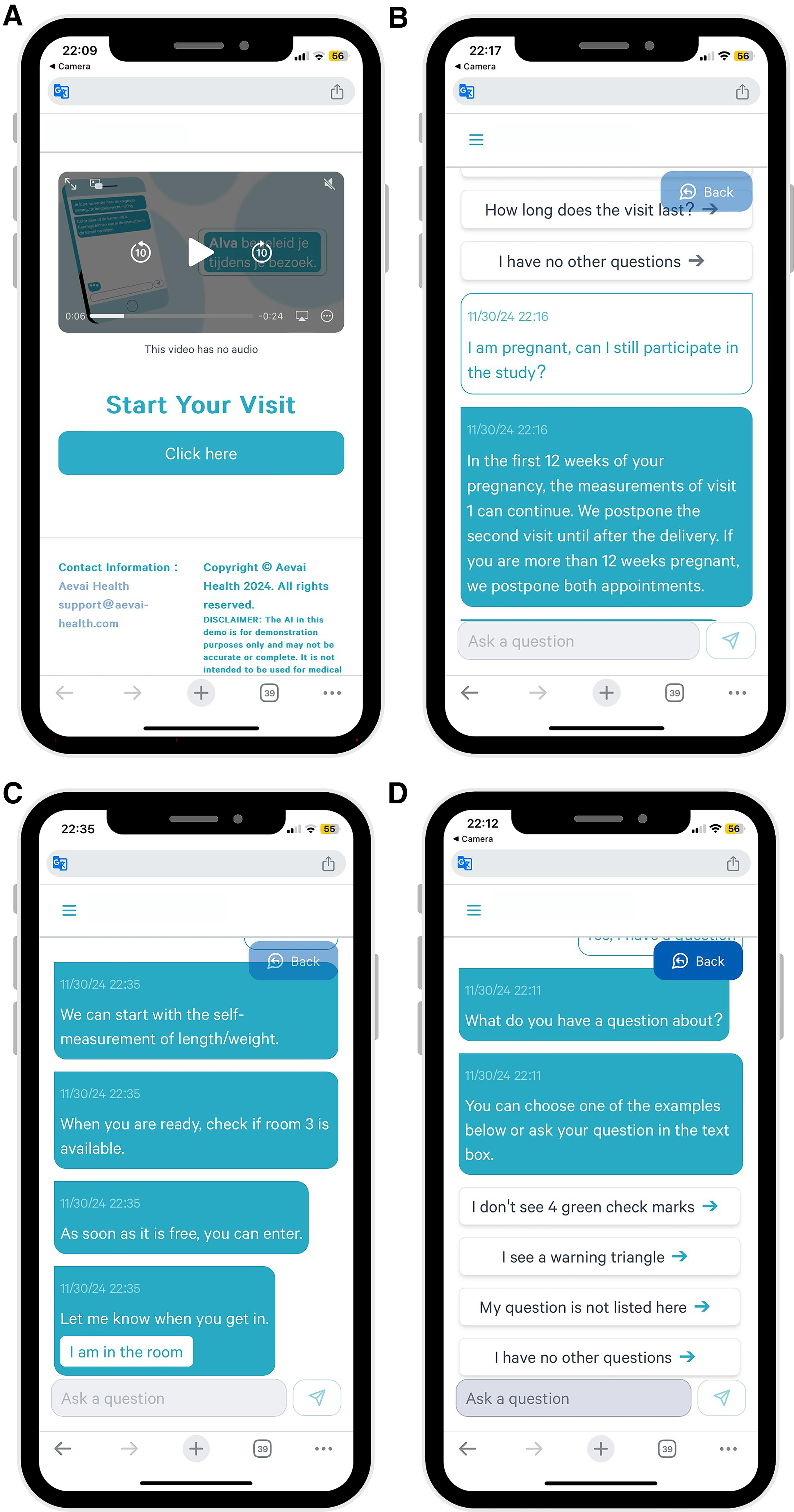
Testing sessions and data collected
Two user testing sessions were conducted prior to the deployment of Alva at the biobank site. Both testing sessions involved an anonymous simple survey of several questions, including open text fields, six of which are included in this analysis. The transcripts of the participants with Alva were collected but were not included in this analysis. Alva can guide the participants through two different visit types, and the tests involved both visits 1 and 2. For the first testing session, Alva V1 was tested by staff from the biobank and external participants, promoting diversity (n = 20). To ensure thorough initial testing of Alva V1, at least two participants were required to watch the instructional video, and at least two participants were asked to follow a specific conversational flow (based on their initial health status). The rest of the pool of participants was free to choose whether they watched the instructional video or what conversational flow they followed. During the second testing session, Alva V2 was tested by new, external participants (n = 12), and no restrictions on conversational flow were implemented. There was no overlap between the participants in the two groups.
Participant population
The participant population chosen for both of the testing rounds included participants with ages between 26 and 65 years old, and it was primarily a Dutch population (which was representative of the actual biobank participant population). For the first and second testing sessions, 36% and 8%, respectively, of the participant population had no prior experience with AI chatbots.
IRB statement
This study was reviewed and deemed ethically acceptable by the biobank and by Aevai Health B.V.; more details can be found in the Supplementary Information.
Data analysis
Median and bootstrapped 95% confidence intervals were calculated to summarize the rating results collected by the surveys and were compared between the two testing sessions. In addition, the distribution of participants that did not experience frustration during chatting with Alva and would use Alva again for guidance at a biobank site was used as a proxy for a perceived value of the chatbot.
Results
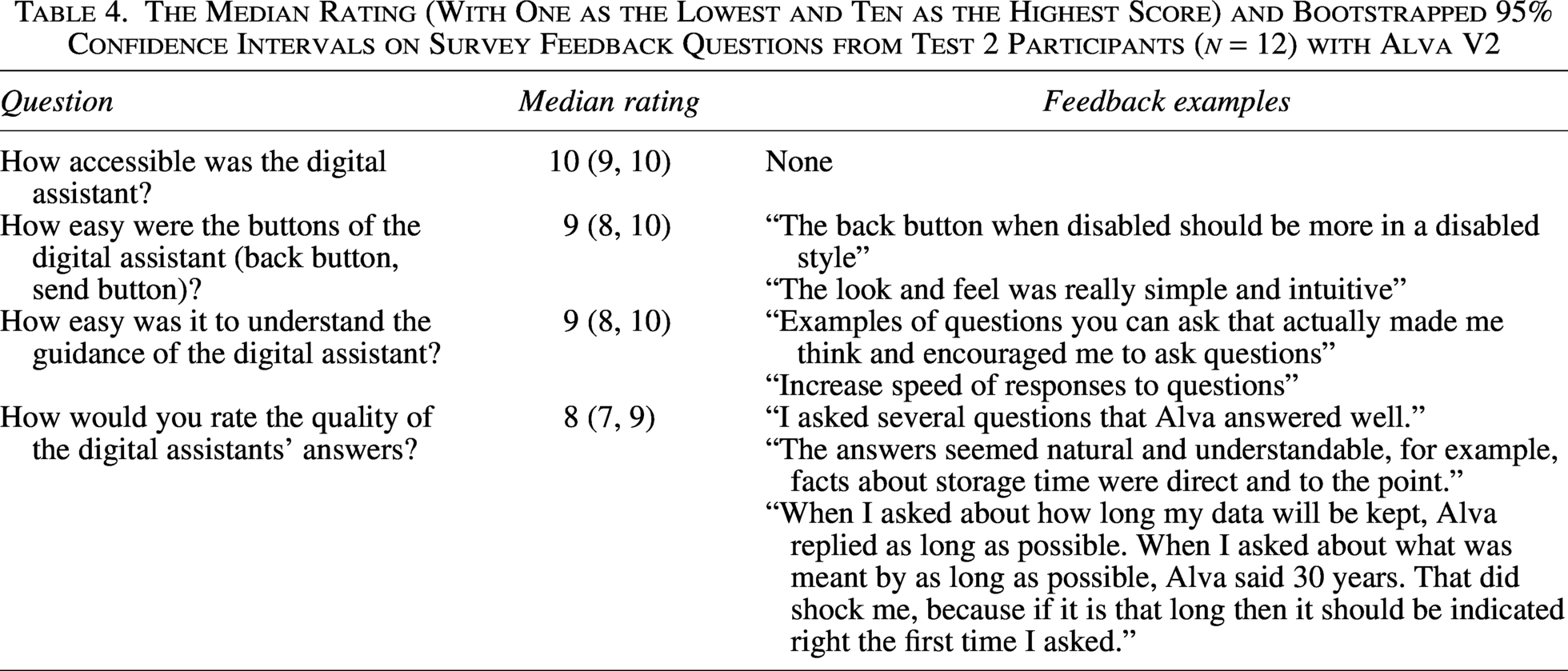
The results from six survey questions selected for this analysis and the changes made between Alva V1 and Alva V2 are shown in the tables as follows. For Alva V1, the median rating for the first four questions and examples of the feedback provided are shown in Table 1, and the distribution of results from the last two questions is shown in Table 2. In Table 3, the changes that were made based on user feedback to improve Alva V1 to become Alva V2 are provided. For Alva V2, the median rating for the first four questions and examples of feedback provided are shown in Table 2, and the distribution of results from the last two questions is shown in Table 4. Additional technical changes were made to reach Alva V2 (see the Supplementary Information Table S1).
The Median Rating (with 1 as the Lowest and 10 as the Highest Score) and Bootstrapped 95% Confidence Intervals on Survey Feedback Questions from Test 1 Participants (n = 20) with Alva V1

The Distribution on Survey Feedback Questions from Test 1 Participants (n = 20) with Alva V1

The User-Driven Points of Improvement That Were Made to Obtain Alva V2 Based on the Group 1 Testing Session

The Median Rating (With One as the Lowest and Ten as the Highest Score) and Bootstrapped 95% Confidence Intervals on Survey Feedback Questions from Test 2 Participants (n = 12) with Alva V2
Discussion
After the first testing session with Alva V1, participants highly rated the accessibility of the chatbot, and provided mixed but relatively high ratings for the ease of use of the interface, the guidance, and the quality of the responses (Table 1). However, the majority of participants did find the interaction frustrating (Table 2). While the majority of participants indicated that they would use Alva again, they perceived greater value from the assistance offered by Alva rather than from the guidance offered by Alva. Based on this, several improvements were made to the conversation flow and the knowledge base of the chatbot (Table 3): the implementation of these changes is described in the Supplementary Information. In the second test, with Alva V2, the participants provided higher ratings for all of the questions (Table 4), and the majority did not find the interaction with Alva frustrating; all of them would use Alva again (Table 5).The main persistent criticism was regarding the quality of the answers, that Alva can initially be vague and will only provide more details when the participant asks specifically for it. Alva was designed to respond concisely with simple terminology for a lay audience. A future improvement would be to include more personalization; that is, Alva matches the language style of the user after a few prompts. In addition, a relatively small knowledge base was used, which can reduce the accuracy and specificity of the answers. In a recent study to explore postoperative care with a chatbot, the authors found that it could only respond adequately independently 31% of the time to the patient, possibly due to a lack of medical vocabulary understood by the chatbot. 3 This emphasizes the importance of the knowledge used by the chatbot to understand and answer user queries.
The Distribution on Survey Feedback Questions from Test 2 Participants (n = 12) with Alva V2

Limitations
We acknowledge several methodological limitations of this study. A small sample size of participants was included; the two groups contained different participants, and their instructions were not identical; and the testing environment represented a simulation of the biobank site (not the site itself). Hence, this testing may not generalize effectively to the real scenario with real participants. Challenges faced in the real setting may include a greater diversity of questions that will be asked to Alva and the possibility that participants may find it complex to use Alva while being tasked to do measurements in a new environment. This could result in a bias regarding the quality of the data collected from the measurements. To investigate this bias when Alva is deployed on the site, it is important that there should be a group of participants that do not use Alva. In this way, the data collected on the measurement between the two groups could be compared for distribution shifts.
Conclusions
This study investigated the effect of optimizing a chatbot for guidance and assistance during biobank data collection on its perceived value. As a result, the Alva V2 chatbot was planned for deployment at two of the biobank’s sites for 5 weeks in each location.
Authors’ Contributions
F.V.D.G. conceived and designed the study, co-developed the study surveys, performed the investigation, conducted data analysis, interpreted the data, drafted the article, critically revised the article, approved the final version, and agreed to be accountable for all aspects of the work. A.M. contributed to study design, codeveloped the study surveys, participated in data analysis and interpretation, critically revised the article for important intellectual content, approved the final version, and agreed to be accountable for all aspects of the work. G.M. developed the chatbot versions evaluated in the study, participated in interpretation of technical and outcome data, critically revised the article, approved the final version, and agreed to be accountable for all aspects of the work.
Footnotes
Acknowledgments
The authors, at Aevai Health B.V., would like to thank the biobank and the external test users for their support during the development of Alva. The authors also thank Naila Loudini for facilitating the initial connection with the journal.
Author Disclosure Statement
The authors disclose their conflict of interest as cofounders of Aevai Health B.V. and regarding the development of the chatbot (Alva) as a commercial product. In addition, F.V.D.G. is employed by Radboud University Medical Centre, A.M. is employed by the University of Groningen, and G.M. is employed by marXact.
Funding Information
This project has been cofunded by the European Union under the Development of EHealth Solutions Improving Resilience in Europe (DESIRE) Open Call under Agreement 2024/080. The rest of the financial contribution is received from Aevai Health B.V. and the biobank.
Supplemental Material
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.