
Abstract
Research has shown that accounting for moral sentiment in natural language can yield insight into a variety of on- and off-line phenomena such as message diffusion, protest dynamics, and social distancing. However, measuring moral sentiment in natural language is challenging, and the difficulty of this task is exacerbated by the limited availability of annotated data. To address this issue, we introduce the Moral Foundations Twitter Corpus, a collection of 35,108 tweets that have been curated from seven distinct domains of discourse and hand annotated by at least three trained annotators for 10 categories of moral sentiment. To facilitate investigations of annotator response dynamics, we also provide psychological and demographic metadata for each annotator. Finally, we report moral sentiment classification baselines for this corpus using a range of popular methodologies.
In this work, we introduce the Moral Foundations Twitter Corpus (MFTC), a collection of 35,108 tweets that have been hand annotated for 10 categories of moral sentiment. To facilitate the use of this corpus for theoretical and methodological research, we also provide baseline results for a wide range of models trained to detect moral sentiment in tweets. The motivation behind this work is to advance research at the intersection of psychology and natural language processing (NLP), an area that has received increasingly widespread attention in recent years. However, while a large portion of such research has focused on the task of inferring latent person-level traits and states (Iliev, Dehghani, & Sagi, 2014; Kern et al., 2016), such as personality (Azucar, Marengo, & Settanni, 2018; Garcia & Sikström, 2014; Park, Schwartz, & Eichstaedt, 2014), values (Boyd et al., 2015), and depression (Eichstaedt et al., 2018; Resnik, Garron, & Resnik, 2013; Zhou et al., 2015), this work is oriented toward a different task: measuring psychologically relevant constructs at the document level.
This task shares many similarities with standard sentiment classification tasks that focus on determining whether a “text”, such as a tweet, expresses a particular sentiment such as positive or negative affect (for an accessible discussion of text analysis methods in psychology, see Iliev et al., 2014). However, it also introduces notable challenges such as the fact that moral sentiment categories co-occur, moral sentiment is often only implicitly signaled, and ground truth is, by definition, subjective. Despite these difficulties, research suggests that accounting for expressions of moral sentiment can afford insight into important downstream phenomena (Hoover, Dehghani, Johnson, Iliev, & Graham, 2017; Sagi & Dehghani, 2014) such as violent protest (Mooijman, Hoover, Lin, Ji, & Dehghani, 2018), charitable donation (Hoover, Johnson, Boghrati, Graham, & Dehghani, 2018), social avoidance (Dehghani et al., 2016), diffusion (Brady, Wills, Jost, Tucker, & Van Bavel, 2017), and political discourse (Dehghani, Sagae, Sachdeva, & Gratch, 2014; Johnson & Goldwasser, 2018).
However, a major obstacle for both theoretical and methodological research in this domain has been the difficulty of obtaining sufficient data. In our experience, all categories of moral sentiment have low base rates, which complicate assembling a suitable corpus for annotation. Further, compared to sentiment domains like positive and negative valence or the basic emotions, annotating expressions of moral sentiment requires considerable domain expertise and training. Accordingly, conducting either theoretical or methodological research in this area has required substantial initial costs.
To address this issue, we have assembled a collection 35,108 tweets drawn from corpora focused around seven distinct, socially relevant discourse topics: All Lives Matter (ALM), Black Lives Matter (BLM), the Baltimore protests, the 2016 Presidential election, hate speech and offensive language (Davidson, Warmsley, Macy, & Weber, 2017), Hurricane Sandy, and #MeToo. Already, portions of this corpus have facilitated advances in both theoretical and methodological research. For example, Hoover, Johnson, Boghrati, Graham, and Dehghani (2018) relies on the Hurricane Sandy annotations to investigate the relationship between charitable donation and moral framing, and Mooijman, Hoover, Lin, Ji, and Dehghani (2018) use the Baltimore Protest annotations to predict violent protest from online moral rhetoric. These annotation sets have also been used for recent work advancing methods for measuring sentiment in natural language (Garten, Boghrati, Hoover, Johnson, & Dehghani, 2016; Garten et al., 2018; Lin et al., 2018).
While the limited availability of data has been a major obstacle for research in this area, the general absence of measurement baselines has also been a problem. As in any other area of psychological research, understanding the validity and relative performance of different approaches to measurement is essential for conducting reliable research and improving on current methodologies. Accordingly, we also report baseline results for multiple computational approaches to measuring moral sentiment in text. In addition to providing novel information about the relative performance of popular approaches to measuring moral sentiment in text, these baselines can inform future methodological innovation and help calibrate measurements of moral sentiment in other corpora.
Finally, we also provide psychological and demographic metadata for our annotators in order to facilitate investigations into annotator response patterns. In our view, accounting for annotator backgrounds is an important area for future research on sentiment analysis, particularly in domains characterized by high subjectivity such as moral values (Garten, Kennedy, Hoover, Sagae, & Dehghani, 2019; Garten, Kennedy, Sagae, & Dehghani, 2019). While, for example, an annotator’s political ideology might not have a substantial influence on how they annotate “positive” and “negative” sentiment in a corpus of restaurant reviews, it seems likely that their ideology could substantially influence how they annotate expressions of moral values in a politically relevant corpus. We believe that developing a better understanding of these dynamics will be important as this area of research continues to develop. Accordingly, for each annotator, we provide responses to a range of psychological and demographic measures that can be used for investigations of annotator response patterns.
Our hope is that making these resources available for the research community will facilitate both theoretical and methodological advances by lowering the cost of conducting research in this area. Researchers can use these annotated tweets to evaluate new methods and train models for downstream application as well as to work on current problems in NLP, such as domain transfer and multitask learning (for discussion, see Ruder, 2017). To this end, we next provide a detailed description of the corpus, our annotation procedures, and a set of baseline classification results from a range of methods.
Corpus Overview
As noted above, the MFTC consists of 35,108 tweets drawn from seven different discourse domains. These domains were chosen for several reasons. First, we chose discourse domains related to issues that we know a priori are morally relevant in order to maximize the likelihood of selecting tweets that contain moral sentiment. Further, while many domains may seem to satisfy the constraint of being morally relevant, it was also necessary to select domains with sufficient popularity among Twitter users as, otherwise, we would not be able to obtain a sufficiently large sample of tweets.
Given these constraints, we strove to select a set of domains (1) that were relevant to current problems in the social sciences (e.g., prejudice, political polarization, natural disaster dynamics) and (2) that we expected a priori to contain a wide variety of moral concerns. Regarding the latter aim, we sought to accomplish this by selecting domains that were a priori associated with the political Left (e.g., BLM) or Right (ALM), both ideological poles (e.g., the Presidential election), or not aligned with either ideological group (e.g., Hurricane Sandy). Through these considerations, our goal was to maximize the variance in expressions of moral sentiment in the annotation corpus. This is particularly important, as the content of moral sentiment expressions can vary substantially with discourse context. For example, the moral sentiment contained in the BLM corpus is substantively distinct from the moral sentiment expressed in the Hurricane Sandy corpus, as these corpora focus on largely distinct issues. This heterogeneity makes out-of-domain prediction particularly difficult because expressions of moral sentiment in one domain will not necessarily generalize well to data drawn from a different domain. Accordingly, to help address this issue, we provide moral sentiment annotations for tweets drawn from multiple, heterogeneous contexts.
Annotation
Each tweet in the MFTC was labeled by at least three trained annotators (Total N = 13; see Table 1 for the distribution of annotators for each subcorpus) for 10 categories of moral sentiment as outlined in the Moral Foundations Coding Guide (see Appendix).
Number of Tweets Annotated by N Annotators for Each Subdomain.
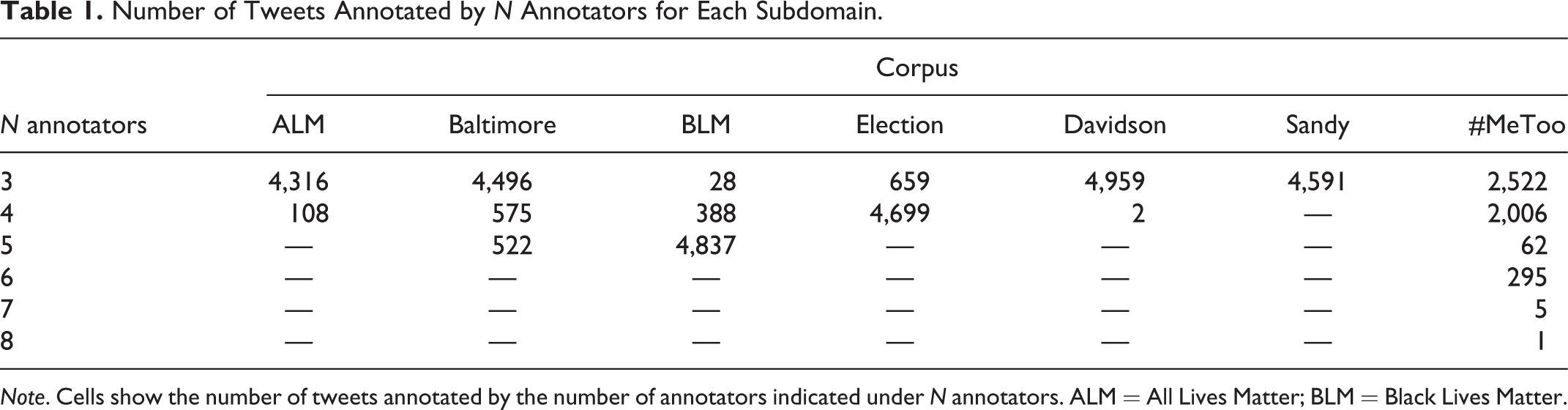
Note. Cells show the number of tweets annotated by the number of annotators indicated under N annotators. ALM = All Lives Matter; BLM = Black Lives Matter.
These categories are drawn from Moral Foundations Theory (Graham et al., 2013; Graham, Haidt, & Nosek, 2009), which proposes a five-factor taxonomy of human morality. In this model, each factor is bipolar, with each pole representing a virtue, or a prescriptive moral concern, and a vice, a prohibitive moral concern. The proposed factors (virtues/vices) are: Care/harm: prescriptive concerns related to caring for others and prohibitive concerns related to not harming others, Fairness/cheating: prescriptive concerns related to fairness and equality and prohibitive concerns related to not cheating or exploiting others, Loyalty/betrayal: prescriptive concerns related to prioritizing one’s in-group and prohibitive concerns related to not betraying or abandoning one’s in-group, Authority/subversion: prescriptive concerns related to submitting to authority and tradition and prohibitive concerns related to not subverting authority or tradition, and Purity/degradation: prescriptive concerns related to maintaining the purity of sacred entities, such as the body or a relic, and prohibitive concerns focused on the contamination of such entities.
While researchers often do not discriminate between the virtues and vices of a given foundation, their expressions in natural language are typically distinct and often independent. For example, an utterance focused on a harm violation (e.g., hurting someone emotionally or physically) is not necessarily also going to express care concerns. Accordingly, to account for the semantic independence between virtues and vices, each tweet in the corpus has been annotated for both.
Annotators, who were all undergraduate research assistants , participated in repeated training sessions during which they developed expert-level familiarity with the Moral Foundations Taxonomy. In early annotation stages, annotator disagreement was also addressed through discussion and, if necessary, subsequent label modification. However, moral sentiment is, in our view, qualitatively different from some other, more conventional, sentiment domains. In many cases, it is difficult to make a final determination of whether or not a document expresses moral sentiment or, for that matter, which moral sentiment it expresses, as such judgments are, ultimately, subjective (See Appendix for discussion).
Accordingly, while uniform annotator training is important, we believe that excessive focus on maximizing annotator agreement risks artificially inflating agreement at the cost of suppressing the natural variability of moral sentiment. Thus, while annotators were instructed to strive for consistency, they were also encouraged to avoid heuristics that might increase agreement with other annotators but would also lead them to neglect their own judgments.
Relying on this training, annotators were independently assigned to label each tweet from a subset of tweets sampled from a corpus associated with one of the seven discourse domains (see Table 2). The annotators used an annotation tool developed by Mooijman et al. (2018; this tool is available at https://github.com/limteng-rpi/moral_annotation_tool). Specifically, each tweet was assigned a label indicating the absence or presence of each virtue and vice or a label indicating that the tweet was nonmoral. This yielded a set of 11 labels for each tweet.
Moral Foundations Twitter Corpus (MFTC) Discourse Domains.
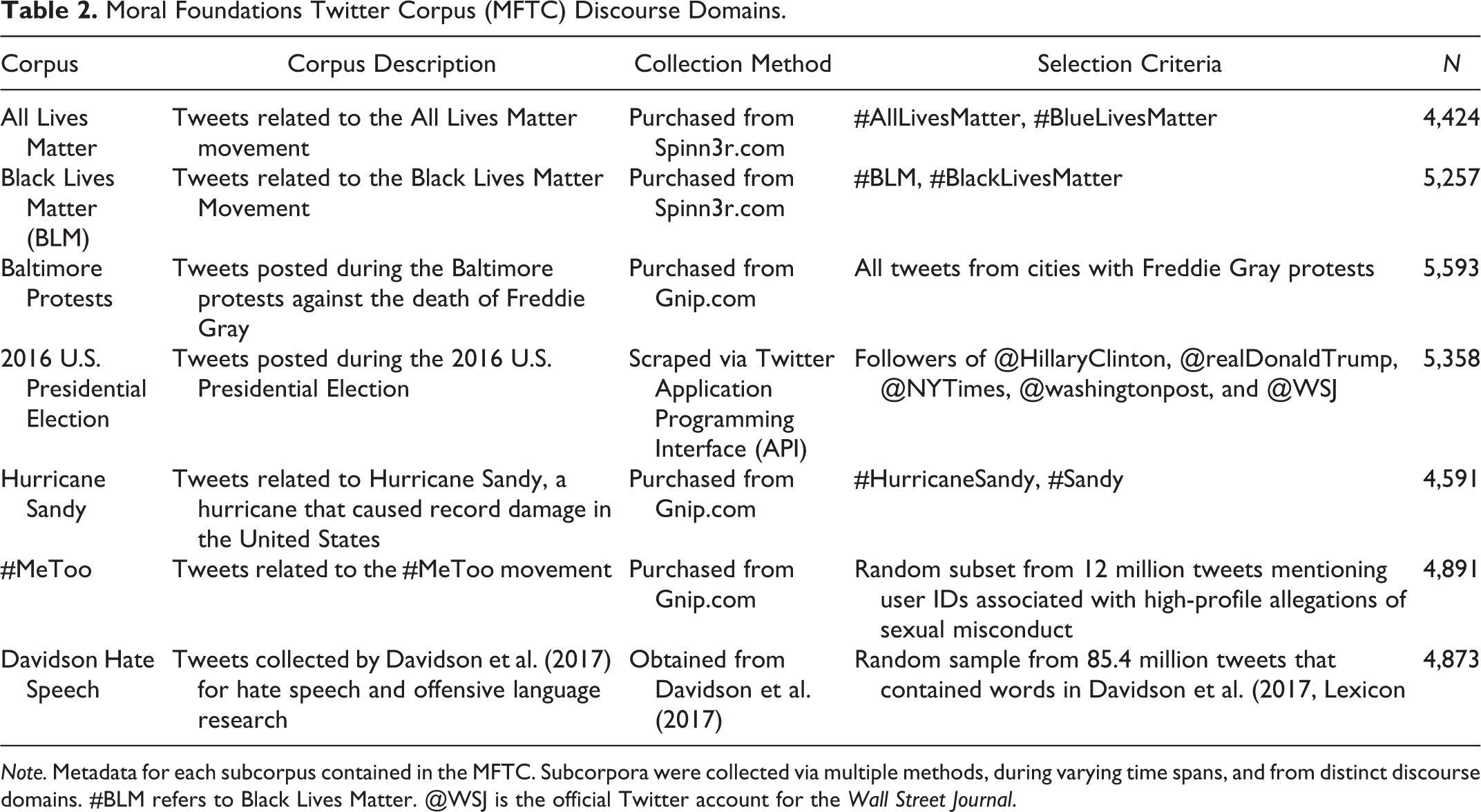
Note. Metadata for each subcorpus contained in the MFTC. Subcorpora were collected via multiple methods, during varying time spans, and from distinct discourse domains. #BLM refers to Black Lives Matter. @WSJ is the official Twitter account for the Wall Street Journal.
Annotator Metadata
For each annotator, we have also collected responses to a range of psychological and demographic measures. We provide measures of annotator’s level of education, academic achievement (e.g., Scholastic Aptitude Test (SAT) score, Grade Point Average (GPA)), political ideology, political affiliation, Moral Foundations Values measured via the Moral Foundations Questionnaire (MFQ; Graham et al., 2009), analytic thinking (Toplak, West, & Stanovich, 2014), and everyday moral values (Hochreiter & Schmidhuber, 1997; Lovett, Jordan, & Wiltermuth, 2012). Annotators' Moral Foundations and political ideology scores were observed to skew liberal (see Table 3), which was expected due to the fact that annotators were drawn from the University of Southern California undergraduate student body.
Annotator Moral Values and Political Ideology.
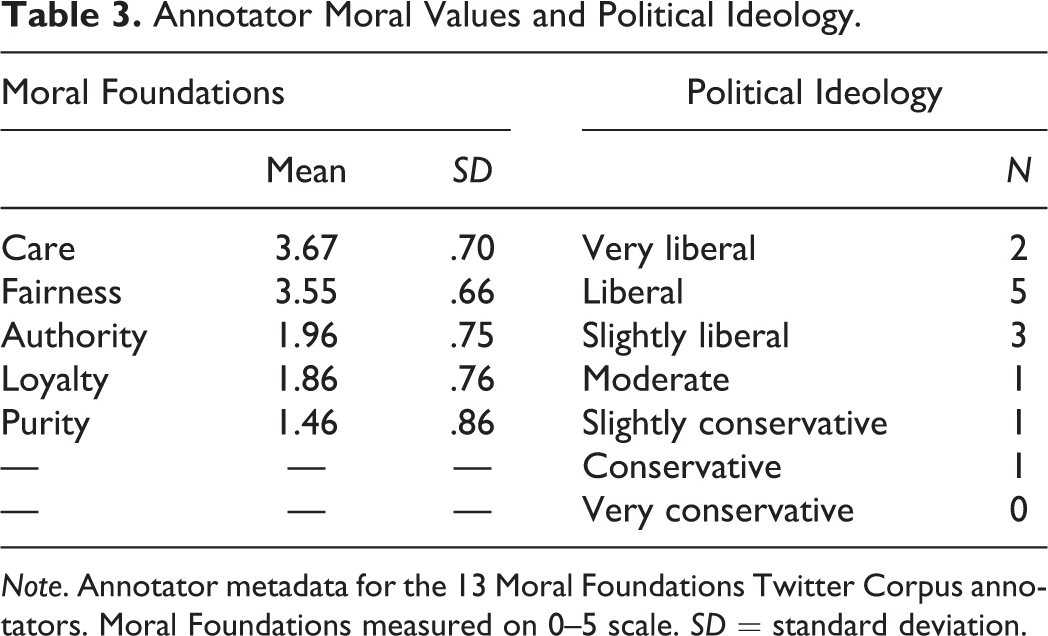
Note. Annotator metadata for the 13 Moral Foundations Twitter Corpus annotators. Moral Foundations measured on 0–5 scale. SD = standard deviation.
These measures were obtained after the annotation process and thus were not used as criteria for selecting annotators. Further, while we have yet to fully incorporate these data into our own work, we suspect that accounting for and better understanding the association between annotators’ individual differences and their annotations will be an important step for research in this domain.
General Sampling Procedure
To assemble the MFTC, we sampled tweets from larger corpora associated with each of the seven discourse domains (see Table 2). While, as noted above, these domains were selected to maximize the base rates of moral sentiment, the proportion of tweets containing moral sentiment within each domain was still too low to use fully randomized sampling. Accordingly, our general sampling procedure relied on a combination of random sampling and semisupervised selection as in Garten et al. (2018) and Hoover et al. (2018).
Specifically, for each discourse domain, we used distributed dictionary representation (DDR; Garten et al., 2018) to calculate moral loadings for each tweet for each of the 10 virtues and vices. Then, for each virtue and vice, the 500 tweets with the highest loadings were selected for annotation. Finally, an additional 500 tweets were sampled from the subset of tweets with loadings that were ± 1 SD from 0.
This procedure yielded approximately 500 × 11 = 5,500 tweets per discourse domain. However, because virtues and vices regularly co-occur, some duplication is expected under this sampling procedure. Accordingly, as duplicates are removed, the final sampled N is less than the upper bound of 5,500.
Annotation Results
Overall, this annotation and sampling procedure yielded 4,000–6,000 annotated tweets for each discourse domain (see Table 4). It should be noted that the frequencies in Table 2 have been calculated based on annotators’ majority vote, which was operationalized as receiving at least 50% agreement on the presence of a moral label. For example, if a particular tweet was annotated as “purity” by two of the four annotators, then that tweet would be marked as a positive case for purity concerns (see Table 5 for the distribution of majority vote moral labels that were decided by tie). It should also be noted that a particular tweet can be annotated for multiple labels based on this procedure.
Frequency of Tweets per Foundation Calculated Based on Annotators’ Majority Vote.
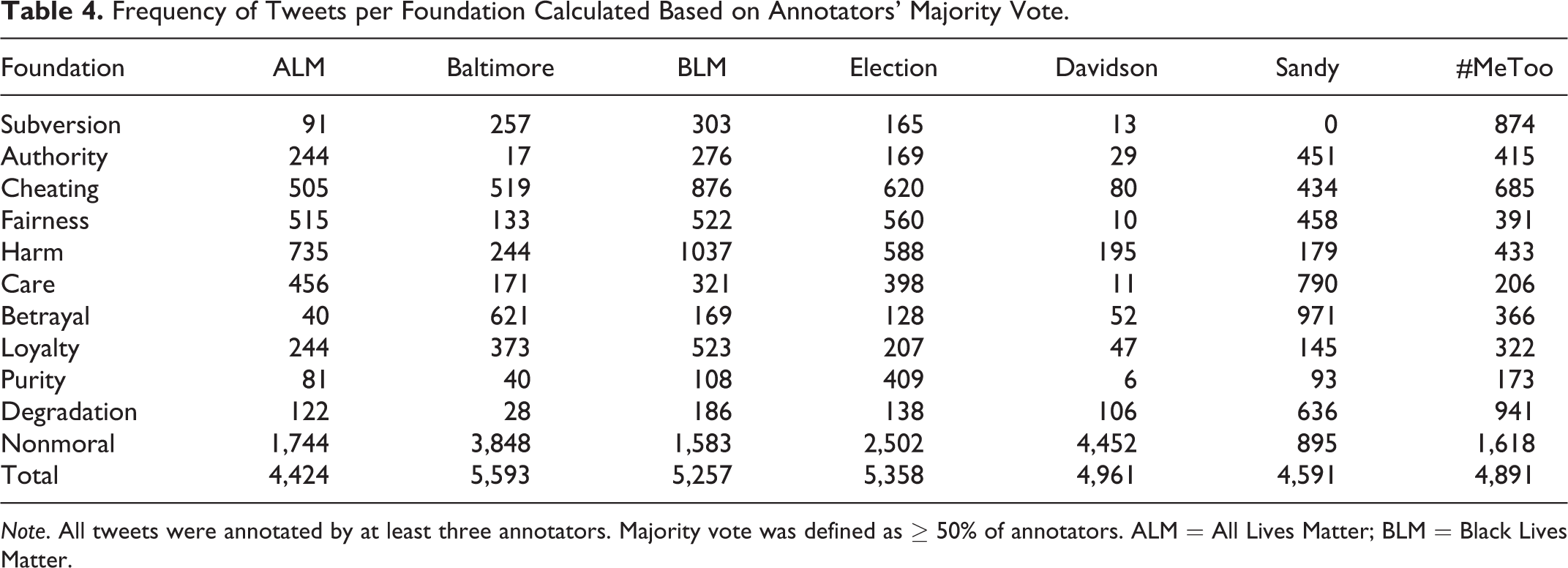
Note. All tweets were annotated by at least three annotators. Majority vote was defined as ≥ 50% of annotators. ALM = All Lives Matter; BLM = Black Lives Matter.
N and % Ties for Majority Vote Moral Labels Assigned by Even Number of Annotators.

Note. Values in the first row indicate the total number of labels assigned by an even number of annotators. Values in the second row indicate the percentage of majority vote moral labels assigned by 50% of an even number of annotators (i.e., that were tied). ALM = All Lives Matter; BLM = Black Lives Matter.
Notably, the rates of each of the virtues and vices varies substantially across domain. For example, only approximately 2% of the ALM data (Total = 4,424) were labeled as degradation; while, in contrast, approximately 14% of the Sandy data (Total = 4,591) were labeled as degradation. These domain-level variations highlight the fact that the relevance of a particular moral concern to a given domain depends on the domain’s content.
To evaluate interannotator agreement, we calculated both Fleiss’s (1971) kappa and prevalence- and bias-adjusted Fleiss’s kappa (PABAK; Sim & Wright, 2005) for multiple annotators (See Table 6). Fleiss’s kappa represents the degree of observed agreement among annotators beyond what is expected by chance. However, it is strongly influenced by the prevalence of positive cases, and it can be difficult to interpret when applied to annotation data with skewed distributions of positive cases such as ours. PABAK adjusts for this (for discussion, see Sim & Wright, 2005) and offers an indication of the degree to which kappa is influenced by issues of prevalence or bias. As expected, due to the b of moral content across all corpora, all kappas were relatively low. However, adjusting for prevalence and bias suggests that interannotator agreement for each virtue and vice is reasonably high across discourse domains.
Interannotator Agreement (PABAK and Kappa) Scores for All Datasets and Foundations.
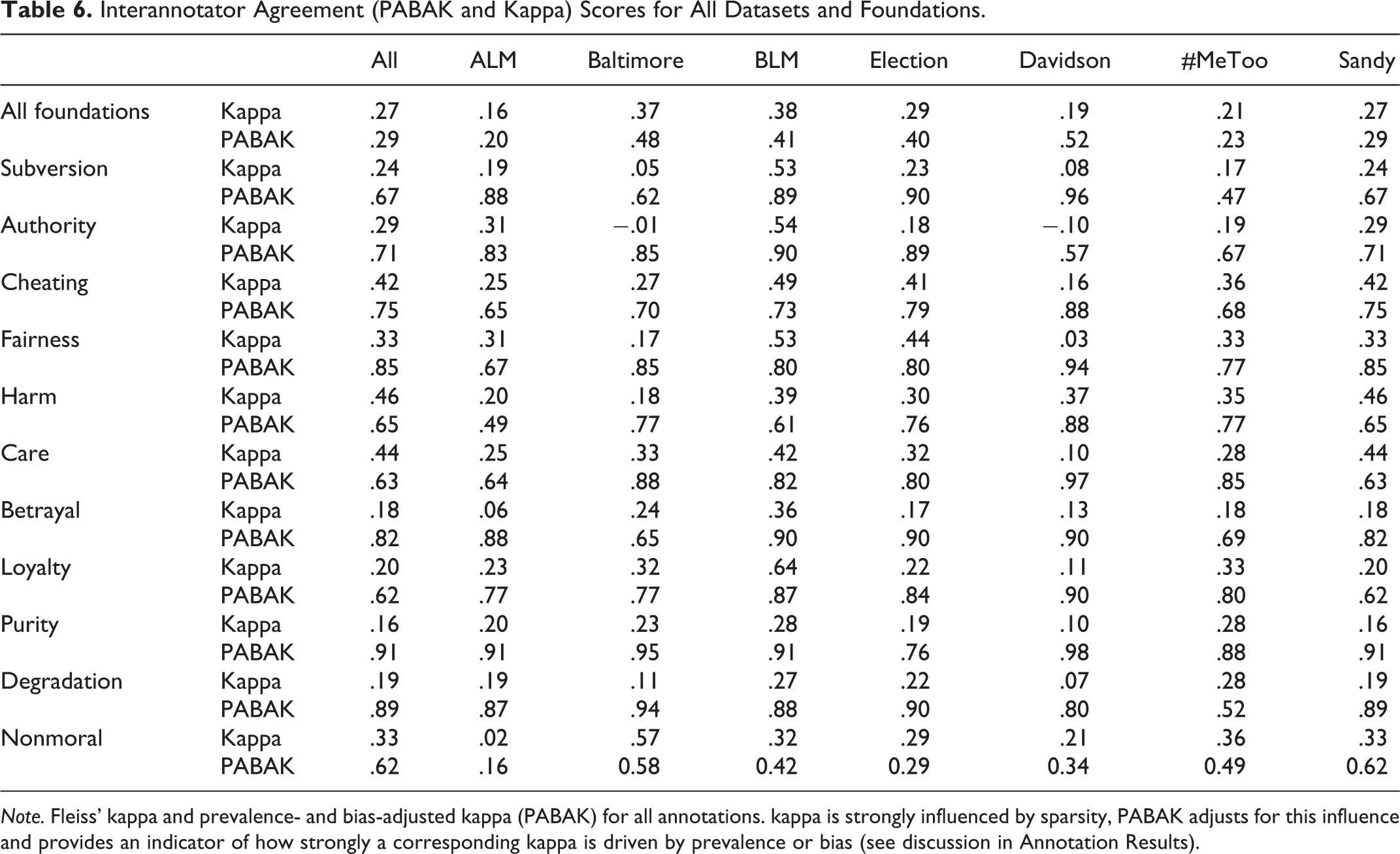
Note. Fleiss’ kappa and prevalence- and bias-adjusted kappa (PABAK) for all annotations. kappa is strongly influenced by sparsity, PABAK adjusts for this influence and provides an indicator of how strongly a corresponding kappa is driven by prevalence or bias (see discussion in Annotation Results).
Baseline Computational Measurements of Moral Sentiment
While human annotation remains the most accurate method for measuring moral sentiment in text, the large sample sizes often used to investigate text-based moral sentiment usually necessitate supplementing human annotations with computational approaches. Such approaches range from word count methods, which rely on tallies of construct-relevant words to measure the presentence of a semantic construct, to machine learning pipelines that rely on state-of-the-art neural network architectures. Although various combinations of these methods have been used to investigate moral sentiment in text, there has been very little systematic investigation of their relative performance—that is, the degree to which they can reliably detect expressions of moral sentiment in natural language.
Accordingly, we next report classification baselines for a range of computational methods that have been used to measure moral sentiment in text. Specifically, we evaluate the degree to which five different approaches to measuring moral sentiment in text are able to identify MFTC messages that express moral sentiment, which we operationalize as messages that received a positive majority vote from human annotators. For each approach, we attempt to predict the document-level presence of moral sentiment for each of the five Moral Foundations both within and across each of the discourse domains represented in the MFTC. The performance baselines obtained through this experiment can serve as benchmarks for researchers investigating moral sentiment in other corpora, goals for researchers working on developing new methodologies for detecting moral sentiment in text, and guidelines for researchers trying to determine which methodological approach to use for a particular use-case.
Method
In order to provide a full-spectrum classification baseline for this corpus, we selected methodologies from a range of widely used approaches to sentiment classification. Specifically, we report results from four approaches. The first three approaches involve two steps: first, extracting “features” (e.g., word frequencies) from each tweet and then, second, using these features to train a classifier to predict whether a given tweet contains moral sentiment as indicated by human annotation majority vote. In this work, we use a support vector machine (SVM; Drucker, Burges, Kaufman, Smola, & Vapnik, 1997; James, Witten, Hastie, & Tibshirani, 2013) classifier for the classification step. In the fourth approach, we rely on a neural network classifier. In contrast to the other approaches, the neural network classifier is applied directly to each tweet, and, through an iterative optimization process, it learns which features predict moral sentiment.
Model Set 1
In the first of approach, we use the Moral Foundations Dictionary (MFD; Graham et al., 2009; available at https://www.moralfoundations.org/othermaterials), a set of a priori selected words associated with each virtue and vice, to obtain message-level frequencies for words associated with each virtue and vice. These word counts were then used to train separate linear SVM (Drucker et al., 1997; James et al., 2013) models with ridge regularization to predict the binary presence of each Moral Foundation according to the majority vote human annotations, collapsing across virtues and vices. Each SVM was trained with C, a regularization parameter, set to 1 (for an introduction to SVM models, see James et al., 2013).
Model Set 2
For the second model set, we replaced the MFD with the MFD2(Frimer, Boghrati, Haidt, Graham, & Dehghani, 2015, available at https://osf.io/ezn37/), an updated lexicon of words associated with each virtue and vice. Using word frequencies based on the MFD2, we generated predictions of moral sentiment using linear SVMs with the same implementation as for Model Set 1.
Model Set 3
For the third model set, we again trained linear SVMs to predict moral sentiment; however, rather than relying on word counts, we used DDR (see Garten et al., 2018) to calculate moral loadings for each message. We used the same seed words for DDR as the ones used in the second study of Garten et al. (2018). These loadings represent the estimated similarity between a given message and latent semantic representations of each foundation. These loadings were then used as features to train a third set of linear SVMs.
Model Set 4
For the fourth model, we implemented and trained a multitask long short-term memory (LSTM; for an informal introduction to LSTMs, see Olah, 2015) neural network (Collobert & Weston, 2008; Luong, Le, Sutskever, Vinyals, & Kaiser, 2015) to predict moral sentiment. LSTMs are particularly effective for document-level classification tasks, as they rely on a recurrent structure that yields latent representations of documents that encode long-term dependencies among words. Here, we use a multitask architecture that involves training a model to predict labels for multiple outcomes. Specifically, for each discourse domain, we trained a multitask model to predict the document-level presence of each Moral Foundation.
To establish performance baselines, we first collapsed tweet annotations by taking the majority vote for each Foundation, where majority was considered ≥ 50%. We use this approach because it is a well-known and straightforward method for aggregating human annotations; however, we also believe that applying more sensitive annotation aggregation methods (e.g., see Passonneau & Carpenter, 2014; Paun et al., 2018) to the MFTC will be a fruitful area for future research. We then trained each model type separately on each discourse domain to predict each Moral Foundation. Then, using the entire corpus, we trained each model type to predict each Moral Foundation (i.e., “All” corpus). Finally, we also collapsed across Moral Foundations and trained each model type—on each discourse domain and the entire corpus—to predict whether documents were moral or not moral. All models were trained with 10-fold cross-validation to mitigate overfitting and approximate out-of-sample performance. To compare model sets, we rely on three performance metrics: precision, recall, and F1. Precision, the number of true positives divided by the number of predicted positives, represents the proportion of predicted positive cases that actually are positive cases. In contrast, recall, the number of true positives divided by the number of true positives and false negatives, represents the proportion of positive cases that the classifier correctly identifies. Finally, F1, the harmonic mean of precision and recall, provides a balanced summary of a classifier’s ability to precisely identify true positives while also maximizing the proportion of true positives that are identified.
Results
As expected, performance varied substantially across methodology, discourse domain, and prediction task. Further, our results suggest that in the context of different domains and prediction tasks, each methodology showed different strengths and weaknesses. For example, while predictions derived from the LSTM models almost always outperformed predictions derived from the other models in terms of F1 and Precision, DDR generally yielded higher recall compared to both the LSTM- and dictionary-based approaches (see Tables 7 –12). Notably, the results from DDR and LSTM models trained to predict only the presence of general moral sentiment, as opposed to a specific foundation, also suggest that poor performance may be a function of sparsity. That is, when all moral sentiment labels are collapsed into a single class, and there are thus more positive training observations, performance improves and stabilizes across discourse domains.
Model F1, Precision, and Recall Scores for Moral Sentiment Classification.
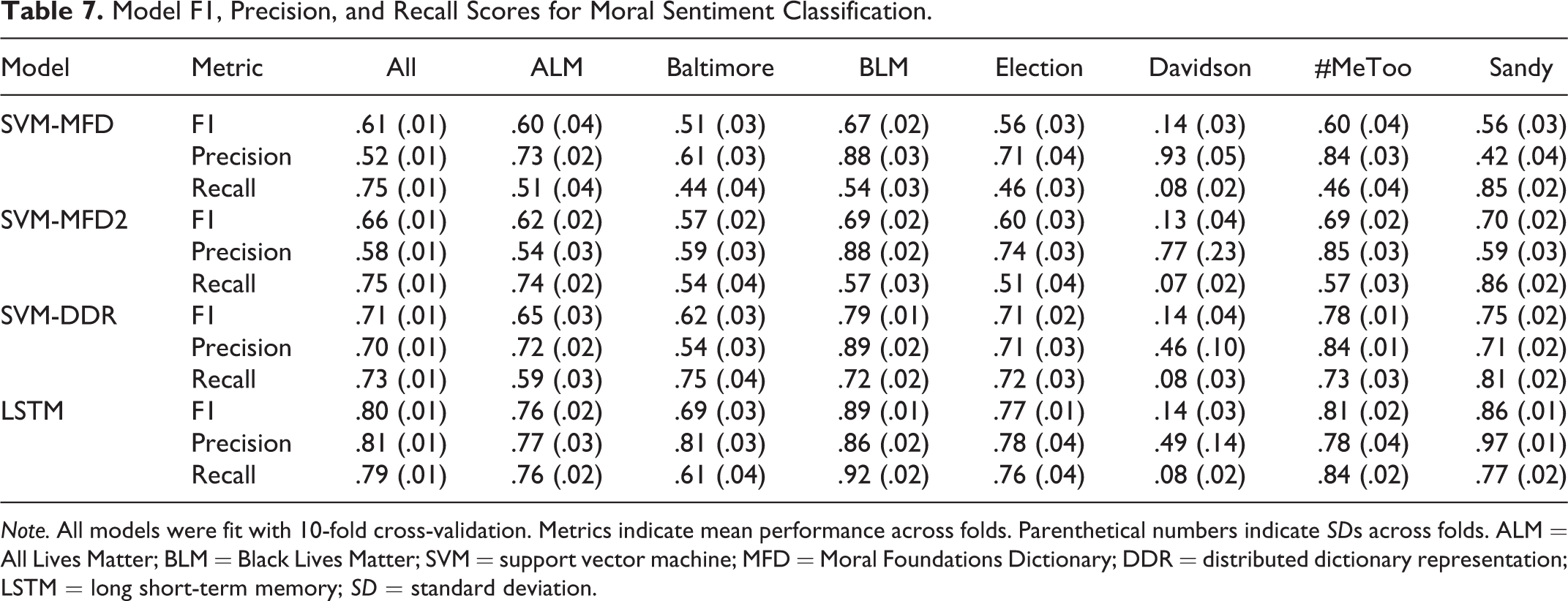
Note. All models were fit with 10-fold cross-validation. Metrics indicate mean performance across folds. Parenthetical numbers indicate SDs across folds. ALM = All Lives Matter; BLM = Black Lives Matter; SVM = support vector machine; MFD = Moral Foundations Dictionary; DDR = distributed dictionary representation; LSTM = long short-term memory; SD = standard deviation.
Model F1, Precision, and Recall Scores for Care.
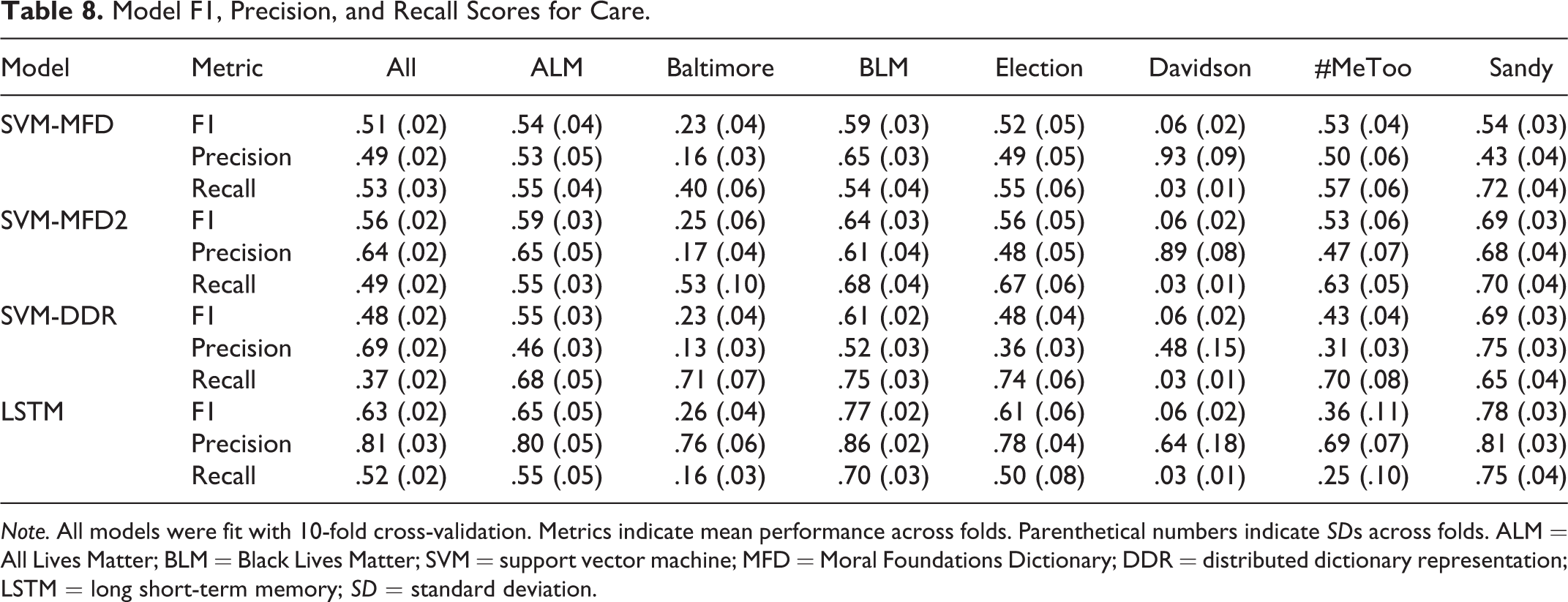
Note. All models were fit with 10-fold cross-validation. Metrics indicate mean performance across folds. Parenthetical numbers indicate SDs across folds. ALM = All Lives Matter; BLM = Black Lives Matter; SVM = support vector machine; MFD = Moral Foundations Dictionary; DDR = distributed dictionary representation; LSTM = long short-term memory; SD = standard deviation.
Model F1, Precision, and Recall Scores for Fairness.
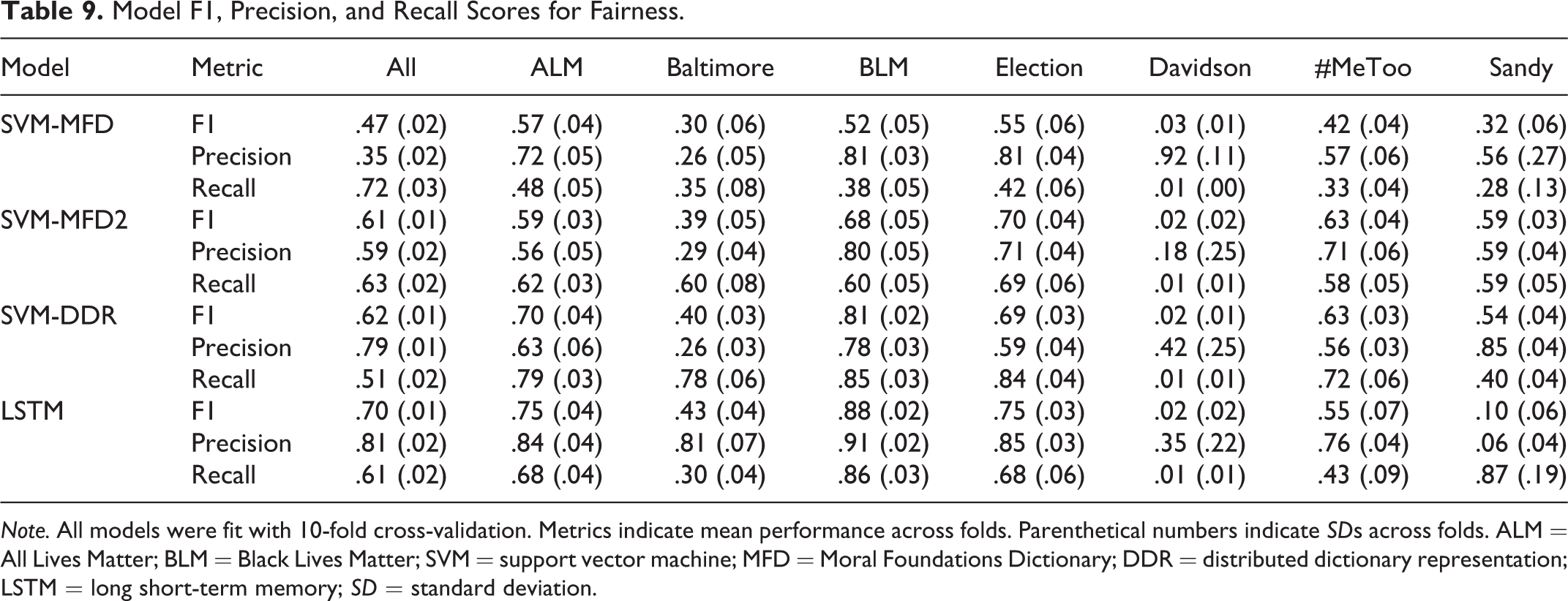
Note. All models were fit with 10-fold cross-validation. Metrics indicate mean performance across folds. Parenthetical numbers indicate SDs across folds. ALM = All Lives Matter; BLM = Black Lives Matter; SVM = support vector machine; MFD = Moral Foundations Dictionary; DDR = distributed dictionary representation; LSTM = long short-term memory; SD = standard deviation.
Model F1, Precision, and Recall Scores for Loyalty.
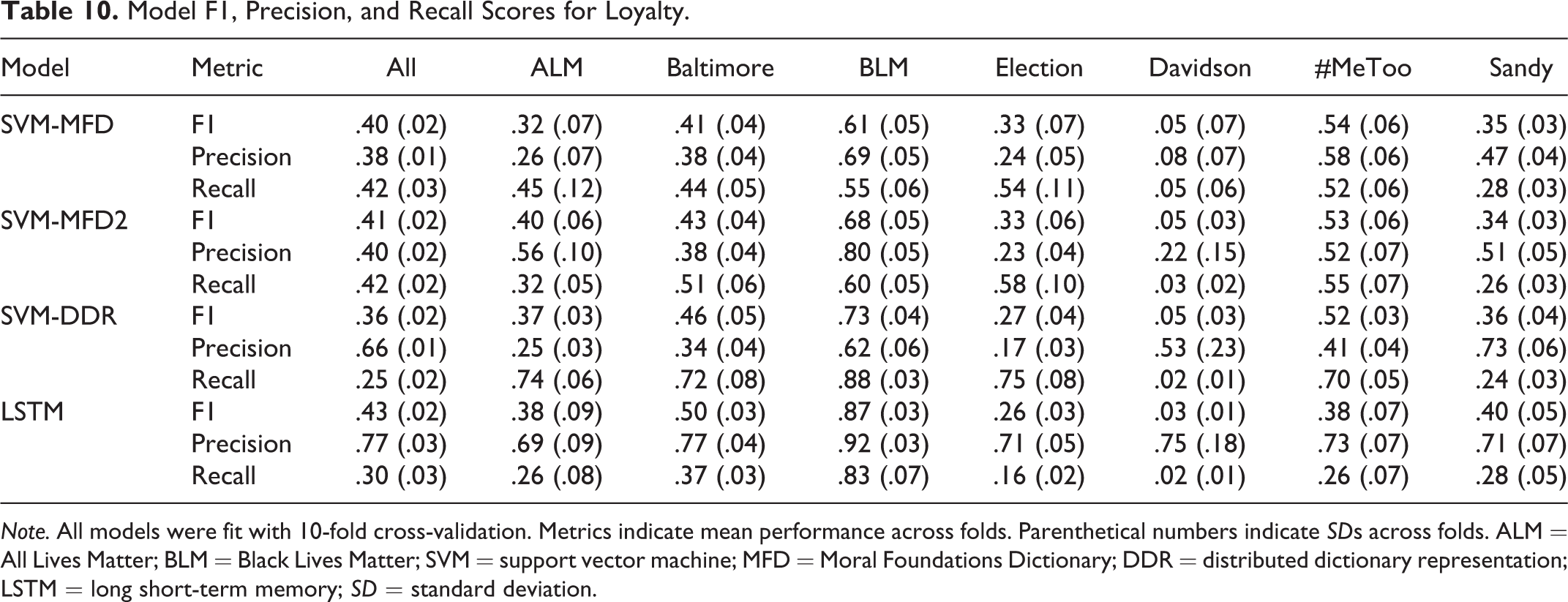
Note. All models were fit with 10-fold cross-validation. Metrics indicate mean performance across folds. Parenthetical numbers indicate SDs across folds. ALM = All Lives Matter; BLM = Black Lives Matter; SVM = support vector machine; MFD = Moral Foundations Dictionary; DDR = distributed dictionary representation; LSTM = long short-term memory; SD = standard deviation.
Model F1, Precision, and Recall Scores for Authority.
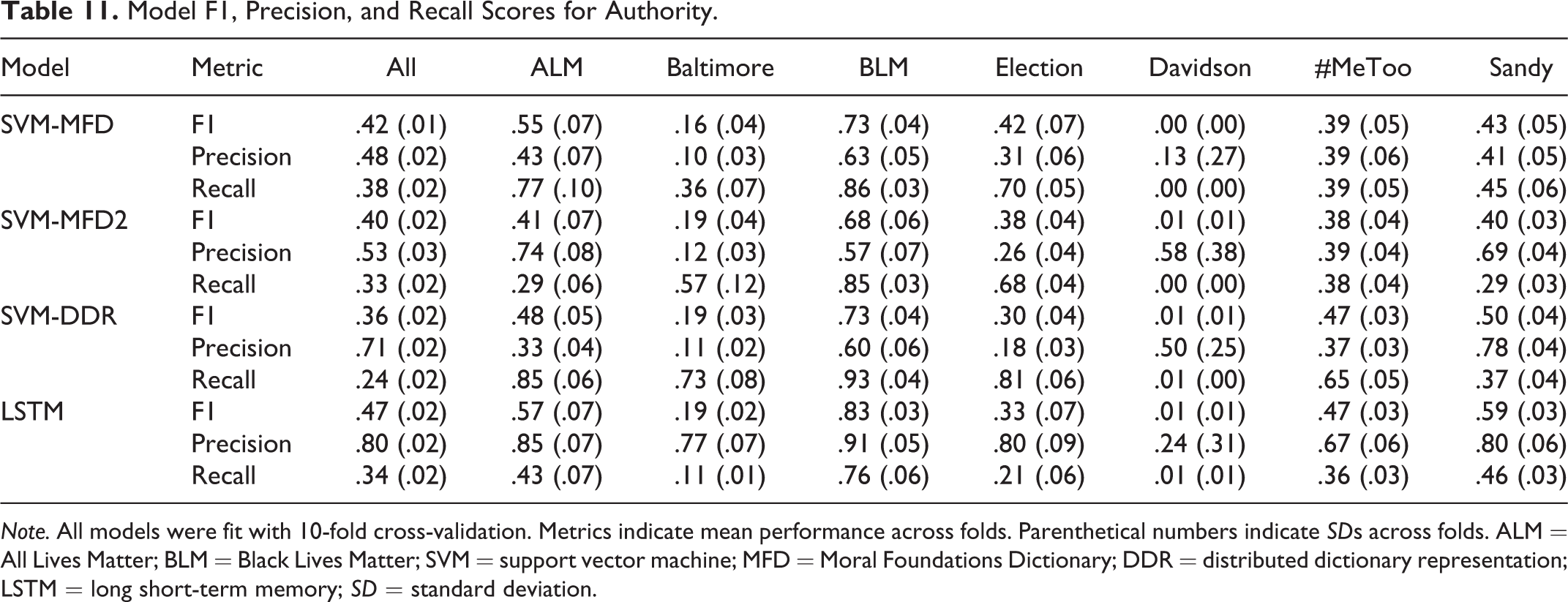
Note. All models were fit with 10-fold cross-validation. Metrics indicate mean performance across folds. Parenthetical numbers indicate SDs across folds. ALM = All Lives Matter; BLM = Black Lives Matter; SVM = support vector machine; MFD = Moral Foundations Dictionary; DDR = distributed dictionary representation; LSTM = long short-term memory; SD = standard deviation.
Model F1, Precision, and Recall Scores for Purity.
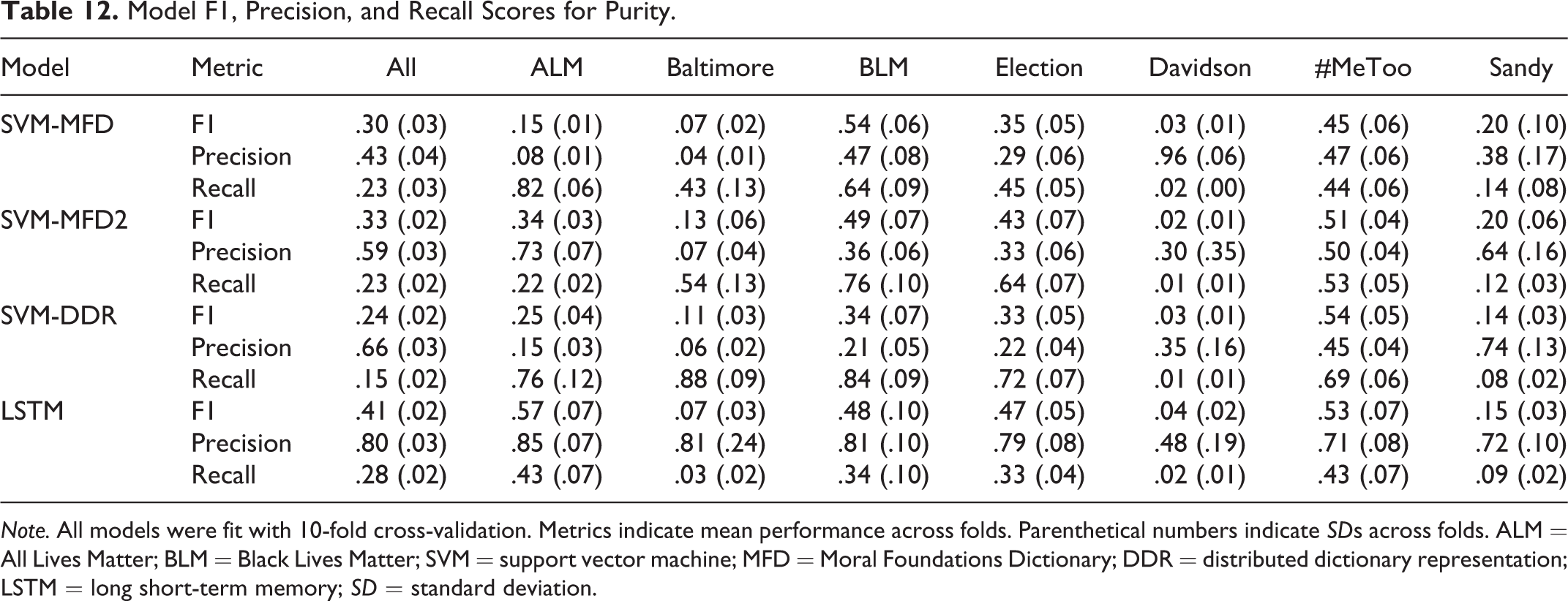
Note. All models were fit with 10-fold cross-validation. Metrics indicate mean performance across folds. Parenthetical numbers indicate SDs across folds. ALM = All Lives Matter; BLM = Black Lives Matter; SVM = support vector machine; MFD = Moral Foundations Dictionary; DDR = distributed dictionary representation; LSTM = long short-term memory; SD = standard deviation.
Finally, in some cases, the dictionary-based approaches also largely outperformed DDR in terms of precision. Finally, our results suggest, while, on average, the MFD and MFD2 dictionaries yield comparable performance in terms of F1, performance differences, again, depend on discourse domain and Foundation. Further, across discourse domains and Foundations, the MFD2 appears to offer higher precision compared to the original MFD. In contrast, the original MFD appears to offer generally better recall compared to the MFD2.
Together, our classification results demonstrate the viability of measuring moral sentiment in natural language using a range of methodologies; however, they also highlight the difficulty of this task. Regardless of methodology, considerable performance variation was observed across both discourse domain and Foundation. In our view, this raises multiple important goals for future research such as working toward a better understanding of the causes of this variation and developing methodological approaches that minimize it.
Discussion
By understanding and measuring the expression of moral sentiment in natural language, researchers can gain insight into a variety of important digital- and real-world phenomena (Hoover, Johnson-Grey, et al., 2017; Sagi & Dehghani, 2014). However, in practice, it can be quite costly to take advantage of these opportunities. In our view, a major driver of this cost has been the difficulty of obtaining annotated data, which is necessary for evaluating method performance and training supervised language models.
To address this issue, we have developed the MFTC, a collection of 35,108 tweets drawn from seven different domains and annotated for 10 types of moral sentiment. Using the MFTC, we also report classification baselines for a range of approaches to measuring moral sentiment in text. Finally, we also report individual difference measures for each annotator, so that researchers can investigate the potential effects of annotator characteristics on the annotation process.
Researchers can use this corpus to train supervised models for predicting moral sentiment in new data. For example, researchers interested in measuring expressions of moral sentiment in a new sample of tweets collected from one of the MFTC domains could train a classifier on the MFTC and then use that classifier to predict moral sentiment in the new sample. Alternatively, researchers could also use a MFTC-trained classifier to predict moral sentiment in a new sample taken from a different domain of discourse. However, for such applications, it is important to note that expressions of moral sentiment are often domain specific. For instance, the moral relevance of “Freddie Gray,” the name of the Black man whose death in police custody triggered the Baltimore Protests, is likely very different in the BLM corpus compared to the ALM corpus. Accordingly, we would encourage researchers interested in measuring moral sentiment in domains not included in the MFTC to use the MFTC to supplement their own annotations. For instance, they could annotate a portion of tweets collected from the new domain and then combine these annotations with the MFTC to train a domain-specific classifier that is also informed by the MFTC annotations. In our view, this may be a particularly useful approach, as it equates to using the MFTC to mitigate the limiting issues of sparsity.
The MFTC can also facilitate new methodological research on computational measurement of moral sentiment. While our baseline results suggest that, in most cases, state-of-the-art approaches such as LSTMs outperform simpler approaches, these performance differences appear to vary substantially across discourse domains. Using the MFTC, researchers can develop a better understanding of what drives these variations, find ways to integrate the strengths of distinct methodological approaches, and, ultimately, develop methods that are able to more directly address the difficulties observed in moral sentiment classification.
Finally, relying on the annotator metadata included with the MFTC, researchers can begin investigating the effects that annotator individual differences may have on annotation outcomes. Developing a better understanding of these dynamics is particularly important for moral sentiment analysis, as moral sentiment is an inherently subjective construct. For instance, future research could focus on integrating approaches to representing “ground truth” that are more sophisticated than “majority vote,” such as approaches based on cultural consensus theory (Romney, Weller, & Batchelder 1986; Weller & Mann, 1997). To directly address issues of annotator characteristics, researchers could also use model-based approaches to measuring ground truth from human annotations (e.g., see Paun et al., 2018), which can be extended to include annotator characteristics. While such investigations likely would require additional annotations, our hope is that researchers will make them public and thus extensions of the MFTC. By adding to the MFTC over time, it could become an even more useful resource for investigating moral sentiment in natural language.
Open data standards regarding annotated text corpora are a key element in the emerging field of computational social science. They afford greater research transparency and can help facilitate scientific progress via the free dissemination of materials that are costly to assemble. Our hope is that, as more researchers use the MFTC, the resources we provide here will be continually expanded. Through the MFTC, our goal is to contribute to this culture of openness and thereby help facilitate both applied and methodological advances in the computational social sciences.
Footnotes
Appendix
Authors’ Note
Gwenyth Portillo-Wightman, Leigh Yeh, Zahra Kamel, Madelyn Mendlen, Gabriela Moreno, Christina Park, Tingyee E. Chang, Jenna Chin, Christian Leong, Jun Yen Leung, Arineh Mirinjian contributed equally to this work.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work has been funded in part by NSF IBSS #1520031, NSF CAREER BCS-1846531, and the Army Research Lab.