
Abstract
Experience sampling methodology (ESM) has provided researchers with a flexible and innovative measurement tool, and the methodology has become increasingly popular in several fields of psychology. Therefore, validity studies on such measures are important. The present study investigated convergent and discriminant validity of ESM measures using peer-ratings as the criteria. We obtained ESM self- and other-ratings of personality states, situation perceptions, and feelings from 344 occasions, from 49 target participants. The results showed that several—but not all—widely used ESM self-ratings have substantial and distinct self-other agreement. We conclude that many ESM self-reports are likely to capture, at least to an extent, target persons’ actual personality states, feelings, and situation perceptions.
Keywords
Experience sampling methods in personality and social psychology have massively increased in popularity during the last 30 years (e.g., Hamaker & Wichers, 2017). Experience sampling methodology (ESM; also referred to as ecological momentary assessment or ambulatory assessment) refers to a data gathering technique in which data are collected from participants repeatedly on many occasions over some—usually relatively short—period of time (Stone & Shiffman, 2002). An example ESM procedure would have participants respond to five brief questionnaires per day for 13 days (e.g., Fleeson, 2001). However, there is plenty of variation in both the length and the frequency of measurement in ESM studies (e.g., Fleeson & Gallagher, 2009; Sun & Vazire, 2019; Wrzus et al., 2015).
Experience sampling methods have given psychologists a novel way to access people’s everyday lives. To name just a couple of examples, ESM studies allow personality researchers to connect personality states to simultaneous feelings and situation perceptions (e.g., Fleeson et al., 2002; Horstmann et al., 2020), motivation researchers to connect everyday life events to goal pursuit (e.g., Ghassemi et al., 2021), and mental health researchers to connect momentary ruminative thoughts to depressive symptoms (Connolly & Alloy, 2017). Furthermore, by sampling individuals’ personality states, feelings, or other psychological constructs repeatedly over time, researchers are able to capture participants’ typical or habitual way of acting or feeling and connect such variables to other person-level characteristics such as personality traits or life satisfaction (e.g., Fleeson, 2001; Grühn et al., 2008; Grzywacz et al., 2004). In sum, ESM offers a plethora of opportunities of gaining new types of psychological data.
Because of the popularity and usefulness of ESM techniques, psychometric validation of such techniques is essential. ESM studies typically collect data via self-reports. In a prototypical ESM questionnaire, participants are asked to describe their behavior, feelings, or other psychological activity during the last hour or last 30 min. Increasingly, physiological measures such as indicators of blood pressure (e.g., Ilies et al., 2010) are included into the ESM protocols, but self-reports remain the main method. Because participants are asked to describe what they are doing at the moment, ESM greatly reduces the memory bias problem of traditional self-reports. However, ESM self-reports are still susceptible to social desirability concerns (e.g., participants may not want to report undesirable behavior) and lack of self-knowledge (e.g., participants may evaluate their own behavior inaccurately). Thus, validating the ESM self-report measures is important.
Several studies have provided evidence of convergent validity for some ESM measures. First, studies using audio recordings of target participants’ everyday lives have shown that observer-ratings of such audio files correlate with time-matched ESM self-ratings of personality states (Sun & Vazire, 2019), quality and quantity of social interaction (Sun et al., 2020a), and positive and negative emotions (Sun et al., 2020b). Fleeson and Law (2015) found correspondence between ESM self-reports and observer-ratings of aggregated extraverted and conscientious behavior in a laboratory setting. Bleidorn and Peters (2011) recruited work colleague dyads and found evidence for self-colleague agreement for PANAS ratings. Abrahams et al. (2021) had student teachers and their supervisors rate student teachers’ personality states and situation perceptions in the same (teaching) situations and found significant (though small) momentary self-other correlations. Finally, Breil et al. (2019, Study 2) found that ESM informant-ratings of sociability correlated with ESM self-ratings of sociability in an event-contingent ESM design.
In sum, previous studies have shown that self-reports of personality states, emotions, situations, and social interactions are related to observer-ratings of the same dimensions. The present study aims to complement this literature in following ways: First, like Abrahams et al. (2021, Table 7, Table S2), we study self-other agreement on personality states and situation characteristics using an informant embedded into the same situation. However, we will use an everyday life ESM design that has the potential to cover a more diverse set of both situations and peer-raters, and, thus, to provide information about self-other agreement across several types of natural life situations. Breil et al.’s (2019, Study 2) procedure was quite similar to ours, but they used event-contingent data collection, only one personality state (sociability) and focused on prediction of sociability in particular classes of situations. Instead, we use a general ESM procedure, a wider range of personality state dimensions, and focus on self-other agreement. Second, the present study complements research using observer-ratings of audio recordings from natural life situations (e.g., Sun & Vazire, 2019): We also sample natural life situations, but use peer-ratings as the criteria, providing a cross-method replication attempt of the results obtained via audio recordings (Sun et al., 2020b; Sun & Vazire, 2019).
Finally, the present study is, to our knowledge, the first to investigate discriminant validity in ESM ratings. Establishing discriminant validity for ESM measures is important because lack of it may result in false conclusions. For instance, a researcher may wish to investigate whether momentary dominance is related to momentary social status; however, if their measure of momentary dominance is confounded with other states (lacking discriminant validity), it is possible that those other states are in fact responsible for the relation between dominance and status. As most of the previous ESM studies studying self-other agreement (Breil et al., 2019; Fleeson & Law, 2015; Sun et al., 2020a, 2020b; Sun & Vazire, 2019b), we focus on rank-order agreement, instead of absolute agreement, as the validity indicator of interest. Finally, we focus on agreement on momentary ratings instead of agreement on average (between-person) ratings.
In choosing the dimensions of interest, the present study draws, first, from the Whole Trait theory (Fleeson & Jayawickreme, 2015). According to this theory, personality traits manifest in everyday life as momentary states related to the underlying traits (e.g., Fleeson, 2001). Personality states derived from the Big Five/Five Factor/HEXACO models are commonly used in ESM research (e.g., Abrahams et al., 2021; Fleeson & Gallagher, 2009; Leikas & Ilmarinen, 2017; Sun & Vazire, 2019). Therefore, self-ratings of such personality states are important targets of validation efforts.
Classifying psychologically relevant features of situations has been notoriously difficult in the history of behavioral, personality, and social sciences (e.g., Rauthmann et al., 2015). This is not surprising, as “situation” is a very broad term and can refer to a plethora of characteristics, such as physical (e.g., location) or social (e.g., dyadic vs. group setting) features of the situation, or to the psychological meaning of the situation. Rauthmann et al. (2015) argued that in psychology, it is most fruitful to investigate situations at the level of their psychological meaning. This is also how situations are defined in the present study.
There are currently two well-founded models of situational perceptions: the DIAMONDS model (Rauthmann et al., 2014) and CAPTION model (Parrigon et al., 2017). However, due to an ongoing effort to build a complementary situational taxonomy using somewhat different starting point than the DIAMONDS and CAPTION models (a top-down approach; e.g., Reis, 2018), the present study took a different approach. In essence, several theories that have produced reliable evidence of situational effects on behavior and mood were reviewed and used to select situational features. The extent to which the situation was approach- and avoidance-related (derived from the approach-avoidance motivation theory, e.g., Elliot, 1999), competitive and cooperative (derived from the social interdependence theory, e.g., Deutsch, 1949, 2011), free and constrained by circumstances (derived from the strong situation theory, e.g., Cooper & Withey, 2009; Mischel, 1977), and pleasant and unpleasant (to cover basic valence differences between situations) were included. These features were selected because they are likely to vary both between persons and between situations and to have consequences to personality states and emotions (e.g., Heller et al., 2007; Impett et al., 2010; Meyer et al., 2010; Stanne et al., 1999).
Finally, momentary mood, stress, and fatigue were measured to investigate self-peer agreement on momentary feeling states.
Method
Transparency and Openness
We report how we determined our sample size, all data exclusions (if any), all manipulations, and all measures in the study, and we follow JARS (Kazak, 2018). All data, analysis code, and research materials are available in the Online Appendix at https://osf.io/gc8jw/?view_only=36078622b03d4f35b1ebb5800b1dc259. This study’s design and its analysis were not preregistered.
Power Calculations
The target effect of interest in the present study was the relation between momentary self-reports and momentary peer-reports, that is, a relation between two Level 1 variables in multilevel data. The planned ESM protocol was 10 days: four questionnaires per day. Our previous experiences suggested that with the resources we had for this study, N = 70 is a reasonable expected sample, and about 70% is a reasonable expected response rate. However, the effective sample size would be determined by the number of participants providing an adequate number of peer-reports, and, without precedent, it was difficult to predict how many peer-reports per participant would be obtained. Furthermore, it was difficult to evaluate the expected effect size. In Breil et al.’s (2019, Study 2) study, the average within-person correlation between self-reported and other-reported momentary sociability was r = .28, suggesting a small-to-moderate effect size. As this variable was identical to one of our variables, we used this correlation to guide our power calculations and conducted power calculations in a simulated data set for an effect size of .28. Random intercept variance was set at 0.60, slope variance at 0.03, and residual variance at 1.0. Random parameters were retrieved from previous ESM studies using comparable variables (e.g., Leikas, 2020; Leikas et al., 2021; Leikas & Ilmarinen, 2017). We used the powerSim function in the simr package (Green & MacLeod, 2016) in R (R Core Team, 2020).
The simulation results suggested that with a sample of 30 and with five observations per participant, the power to detect a Level 1–Level 1 association with an effect size of 0.28 was 0.80 (95% confidence interval [CI] = [0.79, 0.81]). Thus, it seemed likely that assuming the effects of interest were at least small to moderate in size, we would be able to detect the effects even if the number of participants and the number of reports per participants would be considerably lower than in a typical ESM study.
No formal stopping rule for data collection was set because based on our previous experiences in recruiting for similar studies, we anticipated that we would end up with a smaller sample than we would prefer. The data were collected in February and March 2018.
Participants
Participants were recruited via e-mail invitations inviting recipients to participate in a daily life study, with a compensation of two cinema tickets (total value ca. 22 €). Invitations were sent to several student mailing lists of Finnish universities. In total, 57 people responded. These individuals were sent detailed information about the study and a link to an online consent form and a background questionnaire. All 57 individuals completed the consent form and were included in the ESM phase. One participant did not respond to any ESM prompt, and seven participants did not provide any peer-reports, leaving us with a sample of 49 (44 women, five men). Participants’ mean age was 26.1 years (SD = 6.02 years, range = 19–41 years).
Procedure
Participants completed a background questionnaire 1 online and went through a 10-day ESM phase with four prompts per day. The prompts were always sent between 9 and 10 a.m., 12 p.m. and 1 p.m., 4 and 5 p.m., and 8 and 9 p.m. (at random times within these hours). The prompt consisted of a text message containing a link to the online ESM questionnaire (programmed via form software “E-lomake”). Answering was possible for 1 hr after the prompt arrived, after which the questionnaire was locked. Participants were asked to respond to as many questionnaires as possible but informed that neither response rate nor the number of peer-reports provided would affect compensation.
The ESM questionnaire had two parts: self-report part and peer-report part. The self-report part always appeared first. In that part, participants were first asked to rate their current mood, stress, and fatigue. Then, they were asked to rate their personality states during the last 30 min, and then, features of the situation(s) they had encountered during the last 30 min (starting from the moment they started to complete the questionnaire). Next, they were asked whether there was another person present who was willing to respond to questions about the participant. The response alternatives were “Yes,” “No,” “I can’t ask anyone at the moment,” and “I’m alone.” If a participant replied other than “yes,” the questionnaire was saved and closed. Participants were not given detailed instructions regarding what to do if peers refused; they could keep asking others or stop asking at their volition. This omission was meant to lower participant burden by allowing them to decide what level of pressure they were willing to inflict on others in each situation.
If participant responded “yes” to the peer-reporter question, the peer part of the questionnaire appeared, and the participant was instructed to report how long they had been consecutively with the person willing to respond, and then to give their phone to the peer. The peer questionnaire instruction read as follows: Please respond to the questions below regarding the person who asked you to respond. This person will not see your answers (as long as you press “save” at the end of the questionnaire). We are interested in
The peer-report part first asked the peer to report what is their relationship with the participant. Then, they were asked to respond to the mood, stress, fatigue items in peer-report form. Next, they were asked how long they had been in the presence of the participant consecutively, after which they were asked to respond to the personality state and situation questions in the peer-report form. In addition, peers were asked to rate how easy it was to make the personality state and situation ratings.
Measures
Momentary Mood, Stress, and Fatigue
Momentary feelings were measured with single items happy, stressed out, and tired, and all answered with a 5-point scale from 1 (not at all) to 5 (very much). Participants were asked to “Evaluate your state of mind right now. Are you . . .” followed by the three items. Peers were asked to “Evaluate his/her state of mind right now. Is s/he . . .” followed by the three items.
Personality States
Self- and peer-reported personality states were measured with items derived from the Big Five/Five-Factor models. These items were sociable, dominant, energetic, insecure, nervous, friendly, imaginative, productive, and responsible, complemented with socially competent. Participants were asked to “evaluate your behavior during the last 30 minutes. During the last 30 minutes I have been . . .” followed by the personality state items. Peers were asked to “evaluate his/her behavior during the last 30 minutes or during the time you have spent together (if less than 30 minutes). He/she has been . . .” followed by the behavior items. A 5-point response scale from 1 (not at all) to 5 (very much) was used.
Situational Features
Participants were asked to “Evaluate the situation or situations you have been in during the last 30 minutes” with eight items: (1) the situation required cooperation, (2) a desired goal was pursued, (3) the situation was pleasant, (4) there was an attempt to prevent an unwanted outcome from happening, (5) I was free to do what I wanted, (6) there was competition between myself and someone else, (7) circumstances or other people dictated what I had to do, and (8) the situation was unpleasant. Peers were asked to “Evaluate the situation or situations she/he has been during the last 30 minutes or during the time you have spent together (if less than 30 minutes),” followed by the situation items in peer-report form. The items were responded on a scale from 1 (not at all) to 5 (very much).
Additional ESM Rating (Participant)
If participants responded “yes” to the peer question, they were asked how long they had been consecutively with the person willing to provide the peer-ratings. The response options were a few minutes, 5 to 10 min, 10 to 20 min, 20 to 30 min, 30 to 60 min, and over an hour.
Additional ESM Ratings (Peer)
At the beginning of the peer questionnaire, peers were asked what was their relationship with the participant (response options were friend, relationship partner, mother/ father/sister/brother, other relative, work colleague, teacher, child, stranger, none of the above) and how long they had known the participant (with response options I don’t know this person, less than 6 months, 6–12 months, 1–2 years, 3–5 years, 5–10 years, more than 10 years). After the feeling questions, they were asked how long they had been with the participant consecutively, with the same response options as in the participant version of this question. Furthermore, after the personality state and situation ratings, peers were asked how easy it was to make each set of ratings on a scale from 1 (very difficult) to 5 (very easy).
Results
Participants provided a total of 1,542 ESM reports (78.7% of the potential maximum of 1,960). On average, participants provided 31 reports (median = 32, mode = 37, range = 10–38 reports). Out of the 1,542 reports provided, 344 (22.3%) included a peer-report. Participants provided seven peer-reports on average (median = 6, mode = 1, range = 1–23). For more details of the ESM reports, see Online Appendix.
Table 1 presents descriptive statistics for self- and peer-ratings from peer-rating available situations (n = 344), and Table 2 presents variance components for self- and peer-ratings. Table A1 in the Online Appendix presents descriptive statistics for momentary self-reports as a function of the availability of a peer-report, along with multilevel regression results for the differences between the two types of situations (Table A2 in the Online Appendix shows Ms and SDs for all four response options). As shown there, participants seemed to experience peer-report available situations as more enjoyable than no-peer-report situations, reporting, for instance, better mood, lower stress, and higher pleasantness in peer-report available situations. We return to this issue in section “Limitations.”
Descriptive Statistics for Self- and Peer-Ratings (From Situations for Which a Peer-Report Was Available)
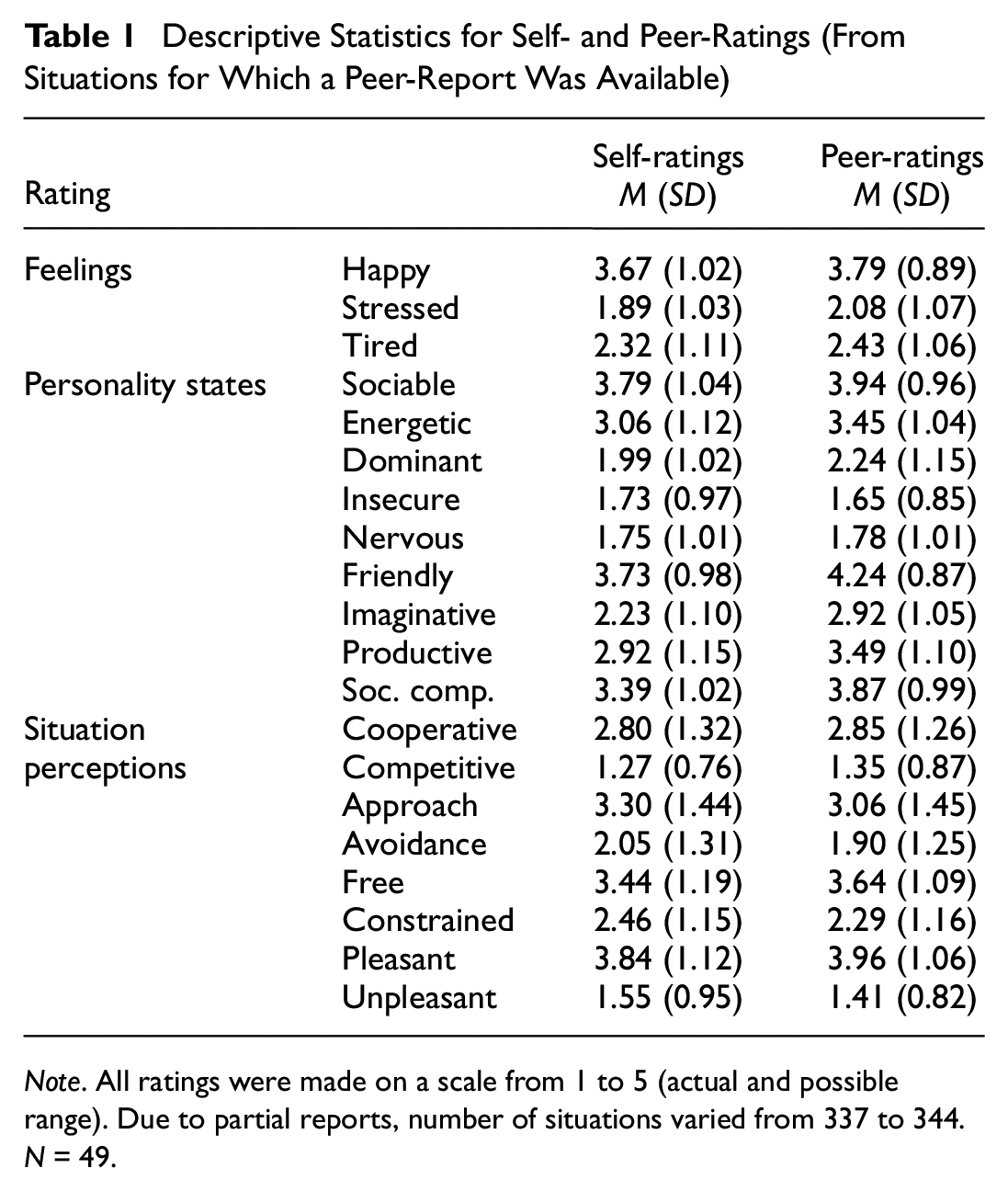
Note. All ratings were made on a scale from 1 to 5 (actual and possible range). Due to partial reports, number of situations varied from 337 to 344. N = 49.
Between- and Within-Person Variance Components of Self- and Peer-Reports (Peer-Report Situations Only, N = 49, n = 344)

Note. Figures represent percentages of total variance, calculated from unconditional (null) multilevel random intercept models by (1) dividing the person variance with total variance and (2) dividing the residual variance with total variance.
Main Analyses
First, we set out to investigate convergent validity. To address the multilevel nature of the data, multilevel regression analyses were used for this purpose. We focused on the situations for which both a self-report and a peer-report was available (N = 49, n = 344); 2 that is, at this point, we dropped the data from situations for which there was no peer-report. Next, self-ratings were person-mean centered (Raudenbush & Bryk, 2002). Then, each peer-report was predicted with the corresponding self-report in a series of multilevel regressions including a random slope. The analyses were conducted in the R environment (v. 4.0.2, R Core Team, 2020) using the lme4 package (Bates et al., 2015). Random slope models for eight dimensions had singular fit, most likely due to a combination of very small slope variance and low N. These models were re-run as random-intercept only models (see Table 3). Standardized betas were calculated via “pseudo” method in the sjstats package (v. 0.18.1; Lüdecke, 2021) in R; this method standardizes the Level 1 coefficients according to within-cluster (here: within-participant) variance, and it is recommended for multilevel models (Hoffman, 2015, p. 342). 3 Because many comparisons (21) were administered to the same data set, Bonferroni correction was used. The corrected p value was 0.05/21 = .002.
Results of Multilevel Regression Models Predicting Each Peer-Report From the Corresponding Person-Mean Centered Self-Report (N = 49, n = 338–344)

Note. R 2s are marginal pseudo-R 2s calculated with the MuMIn package (v. 1.43.17; Bartoń, 2020) in R (Marginal pseudo-R 2s were calculated using the MuMIn package [v. 1.43.17; Bartoń, 2020] and the function r.squaredGLMM, which calculates the statistic based on Nakagawa et al.’s [2017] recommendation. The formula is R_GLMM(m)2 = (σ_f2)/(σ_f2+σ_α2+σ_ε2), where σ_f2 is the variance of the fixed effects, σ_α2 is the variance of the random effect(s), and σ_ε2 is the observation level variance [derived via delta method]). A hyphen in the slope σ2 column indicates that the random slope model failed to converge, and the model was run as random-intercept only model. The variables for which the self-report was a significant predictor per the adjusted p value are in boldface.
The results are presented in Table 3. As shown there, for all dimensions, the 95% confidence intervals excluded zero, and the adjusted p value was significant for 17 out of the 21 dimensions. Agreement was strongest for the personality states sociable, nervous, and productive, for situational cooperativeness, and for stress and fatigue (βs > .36). For the personality states friendly and imaginative, as well as for situational features competitive and free, self-peer agreement was rather weak (βs < .21) and not significant per the adjusted p value. Individual-level slopes for the dimensions for which they were available are presented in Supplemental Figures S1 to S13. Figure 1 presents a forest plot summarizing the convergent validity findings.
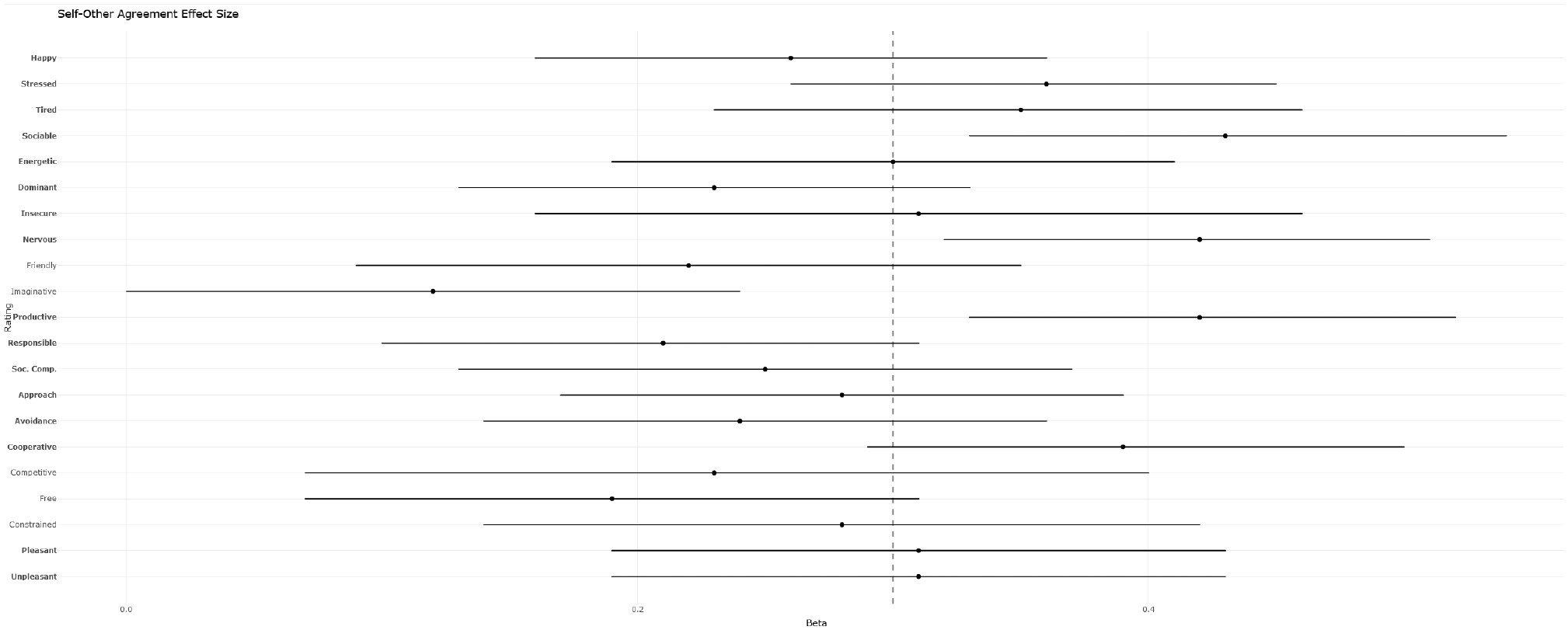
Self-Peer Agreement Effect Sizes (Standardized Betas) With 95% CIs.
Next, discriminant validity of the ESM reports was investigated via creating a multitrait-multimethod matrix (MTMM; Campbell & Fiske, 1959, see supplemental file) by computing repeated measures correlations between all ratings using the rmcorr package (Bakdash & Marusich, 2021) in R. Self-peer convergence correlations are highlighted in red. In addition, self–self correlations (heterotrait-monomethod correlations) higher than the relevant convergence correlation are highlighted in yellow, peer–peer correlations (also heterotrait-monomethod correlations) higher than the relevant convergence correlation are highlighted in pink, and self–peer-non-convergence correlations (heterotrait-heteromethod correlations) equal to or higher than |.30| are highlighted in turquoise.
Convergence correlations for most ratings were higher than the relevant heterotrait-heteromethod correlations, which is the first criterion for discriminant validity (Campbell & Fiske, 1959). The exceptions were happiness, energetic, friendly, responsible, social competence, and situational pleasantness. Several heterotrait-monomethod correlations were higher than all convergence correlations, which violates the second criterion for discriminant validity (Campbell & Fiske, 1959). However, there were strong conceptual overlaps between many of the ratings (e.g., tired and energetic; nervous and insecure). Therefore, we interpret the overall level of discriminant validity through the first criterion only (see Table 4).
Summary of Validity Results

Note. Convergent validity was considered “Good” if the convergent validity beta was ≥.30 and the p value was <.002, “Average” if beta was between .20 and .29 and the p value was ≤.002, and “Poor” if these criteria were not fulfilled. Discriminant validity was considered “Good” if the corresponding convergent correlation in the matrix was higher than all relevant heterotrait-heteromethod (hthm) correlations, and the relevant hthm correlations were <|.30|; “Average” if the convergence correlation was higher than all relevant hthm correlations but there were relevant hthm correlations higher than or equal to |.30|, and “Poor” if the convergence correlation was not higher than all relevant hthm correlations. Incremental validity was considered “Good” if the corresponding rating was the only significant predictor in the multiple multilevel regression, the SEM with the target coefficient free had better fit than the fully constrained SEM, and the target coefficient was larger in the free SEM than in the constricted SEM. Incremental validity was considered “Average” if the corresponding rating predicted the peer-report but was not the only significant predictor, and if the free SEM had better fit than the fully constrained SEM. Incremental validity was considered “Poor” if the corresponding rating did not significantly predict the peer-report and/or if the free SEM did not have better fit than the fully restricted SEM. “Good” validity ratings are in boldfaced and marked with++, “Average” ratings are in regular font and marked with +, and “Poor” ratings are in italics and marked with –.
Finally, we investigated incremental validity via multiple multilevel regression analyses and multilevel structural equation models. Details of these analyses can be found in the Online Appendix.
Discussion
Self-other agreement was found for several experience sampling measures in the present study—for personality states, feelings, and situation perceptions, and in convergent, discriminant and incremental validity analyses. The results suggest that many ESM self-ratings reflect, at least to an extent, actual personality states, feelings, and perceived situation characteristics that are visible to outside observers. This, in turn, indicates that quite a few ESM self-ratings have some level of validity.
The present results are important given that ESM self-ratings are widely used but have not been extensively validated. To our knowledge, the present study is the first to investigate self-other agreement for personality states, situation ratings, and feelings using informants embedded into the situations, and the first to provide evidence of discriminant validity of ESM measures. Thus, it complements previous ESM validity studies that investigated convergent validity of ESM ratings using observer-ratings from laboratory situations (Fleeson & Law, 2015), observer-ratings of audio recordings (e.g., Sun & Vazire, 2019), or other-ratings of personality states in a teaching situation (Abrahams et al., 2021), as the criteria.
Strongest self-other agreement was found for the personality states sociable, nervous, and productive; cooperativeness of the situation; and tiredness and stress. All these dimensions also showed good or moderate discriminant validity. These results are well in line with previous studies on personality judgment; out of all traits, extraversion and conscientiousness are easiest to judge by observers and informants (e.g., Carney et al., 2007; Connelly & Ones, 2010), and here, personality states related to these traits (plus nervousness) showed highest self-other agreement. This increased our confidence that self-other agreement observed was based on target participants’ actual personality states.
The high self-peer agreement for nervousness and stress was somewhat surprising, as trait neuroticism is typically difficult to judge (e.g., Carney et al., 2007). However, it seems plausible that momentary stress and nervousness are somewhat visible, even if dispositional nervousness or stress-proneness is not. In addition, informants may have had information about whether the target person was in a stressful situation. Another surprising finding was the low agreement for friendliness. Intuitively, it would seem easy to judge others’ friendliness. However, we believe that this was due to peers rating targets as very high in friendliness on average (Table 1). Self-reports of friendliness, by contrast, were more normally distributed. Thus, a possible reason for this result is that peer-ratings of momentary friendliness are based on target person’s behavior, typically perceived as very friendly, whereas self-ratings of friendliness may be additionally based on target’s internal feelings and thoughts, which may have been less friendly on occasion.
The results also provided novel information about self-other agreement on situation perceptions. The results suggested at least moderate agreement for cooperativeness and valence of the situation, and weak-to-moderate agreement for the other situation perceptions, except for freedom. All situation ratings except pleasantness showed moderate discriminant validity. Thus, though it might seem plausible that it is easier for outsiders to judge personality states (and, perhaps feelings) than situation perceptions, we found no evidence for that: convergent and discriminant validity was found for both personality states and situations perceptions. Perhaps, the peer-raters often shared the targets’ situational context or perhaps peers can evaluate others’ situation perceptions about as well as they can evaluate personality states. It would be interesting to see self-peer agreement results for more established situation perceptions measures, such as the DIAMONDS (Rauthmann et al., 2014) or CAPTION (Parrigon et al., 2017) measures.
Limitations
The most prominent limitation of the present study was the very small and almost all-female sample. This makes it necessary to view the results as very preliminary. The reliability of the findings is uncertain until replicated in a larger and more representative sample. It is also quite possible that small self-other agreement associations were left undetected due to inadequate power. Furthermore, differences between peer-report and self-report only situations (Tables A1 and A2 in the Online Appendix) may have contributed to limitations of the study. Unsurprisingly, participants reported higher levels of sociability and friendliness in peer-report situations than in no-peer-report situations. Furthermore, situations for which peer-reports were available seemed to be more enjoyable to participants than situations with self-reports only. Thus, our results may not reflect self-peer agreement in less social and less enjoyable situations.
The lack of explicit instructions for participants regarding asking a peer may have affected the results as well. For instance, some participants may have been more persistent in attempting to recruit peer-raters, and some participants’ daily routines may have allowed more opportunities for acquiring peer-raters. Thus, the results may reflect self-other agreement only among certain types of individuals. We ran some control analyses to explore this possibility and found that participants’ age, personality traits, 1 self-reported number of close friends,1 and loneliness1 were unrelated to the number of peer-reports provided (Table A3 in the Online Appendix). Participants who were in a relationship provided significantly more peer-reports on average than single participants (Table A4 in the Online Appendix). However, given the null relations with the other variables (Table A3 in the Online Appendix), we believe this difference reflects access to a peer-rater rather than relevant psychological differences between single and non-single participants.
Using mostly familiar others as peer-reporters is a methodological limitation as socially desirable responding may affect the reports made by familiar others (i.e., they may have a positive overall view of the target person, or they may wish to present the target person in a positive light; e.g., Leising et al., 2010). However, previous research suggests that socially desirable responding does not have a substantial influence on self-other agreement in personality trait ratings (Lönnqvist et al., 2007; Roth & Altmann, 2019). Second, it seems plausible that momentary personality state ratings by peers would be less susceptible to social desirability concerns than peer-ratings of personality traits because a rating of someone’s momentary state does not say anything about the target person’s stable characteristics, whereas a rating of someone’s personality does. Nevertheless, in group situations, our participants could choose their most preferred rater from the group, and they could respond “no” to the peer-rater availability question if they did not want an available peer to respond. Thus, it is possible that the peer-ratings presented here are typically from peers that participants saw as desirable raters; it remains unclear whether there is self-peer agreement between targets and less desirable peer-raters. Finally, using an ad hoc measure of situation perceptions instead of an established measure made it difficult to connect the present results to existing ones.
Conclusion
Self-other agreement is a central topic in personality and social psychology (e.g., Funder, 1995; Funder & West, 1993; Watson et al., 2000), and it has long been considered a well-founded way of validating self-report instruments (e.g., McCrae et al., 2004; Watson & Clark, 1991; Woodruffe, 1985). The present study provided evidence that many commonly used experience sampling self-ratings also show self-other agreement and, thus, some convergent validity. To sum up, to an extent, momentary ESM self-reports seem to capture target participants’ actual personality states, feelings, and situation perceptions.
Footnotes
Handling Editor: Marlone D. Henderson
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the Academy of Finland (grant numbers 266076 and 309537).
Supplemental Material
The supplemental material is available in the online version of the article.