
Abstract
This teaching case demonstrates the crucial role of cybersecurity incident management in ensuring business continuity and resilience of organizations. Considering the rise of large-scale and sophisticated cyberattacks, this case provides readers with a better understanding of incident management activities and their impact on organizations’ operations. We first introduce incident management and related terms and concepts such as business continuity and resilience. Next, we report how a European company, active in the manufacturing sector, responded to a recent ransomware attack. As such, this case provides readers with insider insights and lessons learned from a real-life incident management case. The paper demonstrates that, often companies have to adjust their cybersecurity incident response procedures on the spot and engage in ad hoc planning to deal with the dynamic nature of incidents. In addition, the case highlights the importance of the social and business dimensions of incident response processes.
Keywords
Cybersecurity incidents
Organizations’ business operations and routine activities can be disrupted by different natural, accidental, or intentional incidents and events. However, with the rapid digitalization of organizations and societies, cybersecurity incidents are increasingly affecting organizations and their operations (Grispos et al., 2015). The National Institute of Standards and Technology (NIST, 2006, page 7) defines a cybersecurity incident as: ‘An occurrence that results in actual or potential jeopardy to the confidentiality, integrity, or availability of an information system or the information the system processes, stores, or transmits or that constitutes a violation or imminent threat of violation of security policies, security procedures, or acceptable use policies’.
A cybersecurity incident is an adverse event that can compromise information security. While an event is any observable action, activity, or transaction within a system or a computing environment, an adverse event has the potential to threaten or compromise an information systems asset and lead to negative consequences and damage. For example, when a user tries to access or change a file within the computing environment, this is simply an event. However, unauthorized access to and modification of a file are adverse events. When potentially adverse events match conditions defined by incident detection systems or mechanisms in place, an alert is generated (see Figure 1). The observed event which has triggered the alert must be further analysed to examine if it is genuinely an incident or just a false alarm. Often hundreds or thousands of events are observed in a system or computing environment. However, only a smaller portion of them are flagged as potential adverse events that require further investigation to identify genuine security incidents. Nevertheless, the sheer volume of alerts or false alarms generated can cause alert fatigue, a situation where security teams start ignoring genuine alerts and incidents. Such ignorance can lead to situations where a cyberattack goes undetected for a long period, similar to the Target data breach (Pigni et al., 2018). Relationship between events, alerts, and incidents.
Cybersecurity incidents, such as ransomware attacks, can compromise a firm’s information systems and digital infrastructure and lead to business disruptions and halt an organization’s operations (Phillips and Tanner, 2019). Ransomware is a type of malicious software or malware that encrypts information systems assets, especially data, making them unavailable or inaccessible for use, except a ransom is paid to the attacker to decrypt the data and make it available or accessible again (Al-Rimy et al., 2018). For example, a ransomware attack can compromise the availability of a database containing customers billing information and disrupt business operations as employees and units (e.g. sales and accounting) cannot access and use the asset and complete their tasks. Such a ransomware attack can halt business operations from hours to days, depending on the assets being compromised and the firm’s cybersecurity incident response (CSIR) capabilities (Weber and Mathews, 2023). Ransomware typically spreads through phishing (e.g. as malicious email attachments) or through drive-by downloads when a user visits a malicious website, without understanding that the malware is being downloaded to their device.
Cybersecurity incidents can lead to operational downtime and impose substantial financial losses (e.g. loss of revenue) and costs (e.g. data recovery and legal fees). In addition, cybersecurity incidents erode stakeholders’ trust and damage a company’s reputation, especially if sensitive data is compromised or when the incident is managed poorly (Tøndel et al., 2014). This in turn can impact the firm’s long-term business relationships (Kaschner, 2024) and its market value. Cybersecurity incidents can also lead to legal repercussions for firms, especially the ones operating in highly regulated domains (Mashinchi et al., 2024).
Cybersecurity incident management
Cybersecurity incident management is a process that aims to identify and address any malicious event or activity that can compromise a system’s or an organization’s information security objectives. During this process, a security incident is to be identified, classified, and responded according to the CSIR plan. However, since the incident management process plays a crucial role in maintaining an organization’s business continuity and resilience, the CSIR plan is often accompanied by a business continuity plan to handle a cyberattack or incident while ensuring the central business continues functioning. Therefore, organizations must have robust incident management and business continuity plans in place (Kaschner, 2024; Ricks, 2024).
Incident management activities are about planning and following proper protocols and steps when a security incident happens (Paul, 2013). In other words, security incident management aims to minimize the damage brought by security intrusions, allow the organization to learn, as well as strengthen incident prevention and detection within and across organizations (Grispos et al., 2017). This is done by following a CSIR plan, which defines the strategy to detect, analyse, and react to security incidents and communicate the incident and the response in a way that minimizes the impact of incidents and supports rapid recovery of business operations (Tøndel et al., 2014). Regardless of the guidelines followed, a cybersecurity incident process consists of a set of common steps and activities.
Incident response process
A CSIR process consists of different stages and activities for identifying, analysing and responding to security incidents in a timely manner, to minimize their impact and to restore operations rapidly. Considering the lifecycle of a cybersecurity incident, a CSIR process can be divided into three main phases: (1) Readiness phase consisting of preparation and detection and analysis stages, (2) response phase consisting of containment and eradication stages, and (3) recovery phase consisting of post-incident response and post-incident analysis (see Figure 2). Overview of a linear incident management process.
Preparation
Preparation is the first step, which deals with implementing controls to reduce the likelihood and number of incidents in a computing environment. As a part of this stage, a formal plan for responding to incidents is developed. Such a cybersecurity incident management plan can be designed based on widely used information security incident management standards and guidelines like the ISO/IEC 27035:2023 Information Security Incident Management (ISO/IEC, 2023) or the NIST Special Publication 800-61 Computer Security Incident Handling Guide (Cichonski et al., 2012). The plan provides a framework and guidance for coordinating CSIR phases and efforts. While a comprehensive and tested plan enables a better response to an incident, in reality, it is often difficult to follow the plan because the response must be flexible and fluid. Therefore, the organizations must be ready to adjust those plans as needed. It is also beneficial to exercise incident management activities to ensure our protocols are effective and employees are prepared for security incidents.
As a part of the preparation stage, a team responsible for implementing the plan is specified, which is often called a Computer Security Incident Response Team or Cybersecurity Incident Response Team. This CSIR team is responsible for reducing the impact of security incidents and helping the business resume operations as soon as possible. Therefore, in addition to an incident response manager and a group of security and threat intelligence analysts, the CSIR team is recommended to include specialists from other units, such as business, human resources, legal, and public relations, that can help navigate the incident and deal with legal issues and communicate with stakeholders.
Detection and analysis
Stage deals with detecting and determining deviations or malicious behaviour in a computing environment. This stage consists of several steps. In the first step (i.e. collection), different types of information and logs are collected from intrusion detection and network monitoring systems or mechanisms about suspicious events and activities to be analysed. In the next step (i.e. normalization), the information is cleaned, redundant data removed, and useful data identified. Next, the logs are analysed to examine a potentially harmful or adverse event to determine whether it is a cybersecurity incident or not and to identify any relationships between these incidents and potential threats or attackers (i.e. correlation). After an incident is identified, it should be visualized and presented to stakeholders in a brief and understandable format (i.e. visualization).
Containment
Starts after a security incident has been detected and validated. The first thing that needs to be done is to contain the incident to limit its damage. For example, this may mean shutting down a compromised server or disconnecting it from the network. Alternatively, a deviant user’s access can be restricted to the computing environment. Containment must be done carefully and strategically to avoid any undesirable consequences. Therefore, different factors must be considered, such as preserving the evidence of the incident, availability of services, time and resources to execute the strategy, and the lifecycle of the selected solution (Paul, 2013).
Post-incident response
Consists of recovery mechanisms to restore the resources into the working state. For example, systems or databases can be restored from legitimate backups, compromised accounts recreated, passwords changed, and new servers or laptops are taken into use (Paul, 2013). Finally, a
Most traditional incident management models and frameworks are linear, similar to Figure 2, which often fail to reflect the concurrent nature of real-world incident management. Due to the complexity of cybersecurity incidents and the dynamic nature of business environments, adhering to linear CSIR plans can slow down the process, make it overly complicated, and render it too rigid to be effective. This is especially the case when dealing with large-scale and sophisticated incidents, where new threats and unpredictable adverse events can emerge during the response process. As a result, the CSIR teams may need to repeat certain steps, complete them simultaneously, or even go back to previous steps. In addition, linear incident management processes prohibit learning and root cause analysis opportunities during the response process, since CSIR teams are mainly occupied with containment, eradication, and recovery activities.
Therefore, it is recommended to adopt an iterative and agile incident management approach, where incidents are addressed iteratively and collaboratively (Grispos et al., 2014; He et al., 2022). This enables organizations to respond more effectively to incidents and to adapt to sudden and unexpected changes during the response process. Such iterative approaches allow CSIR teams to tackle incidents in smaller increments, re-evaluating the situation as it unfolds and addressing threats as they arise. At the same time, CSIR teams can frequently reflect on the process and engage in learning during the process without waiting for the incident to be over to conduct a formal post-incident documentation and learning. The iterative approaches also allow organizations to increase consistency in incident response since the CSIR team can effectively communicate and collaborate with various stakeholders and create a shared understanding of the incident (He et al., 2022). Figure 3 shows an iterative and agile incident management process. An iterative and agile incident management process.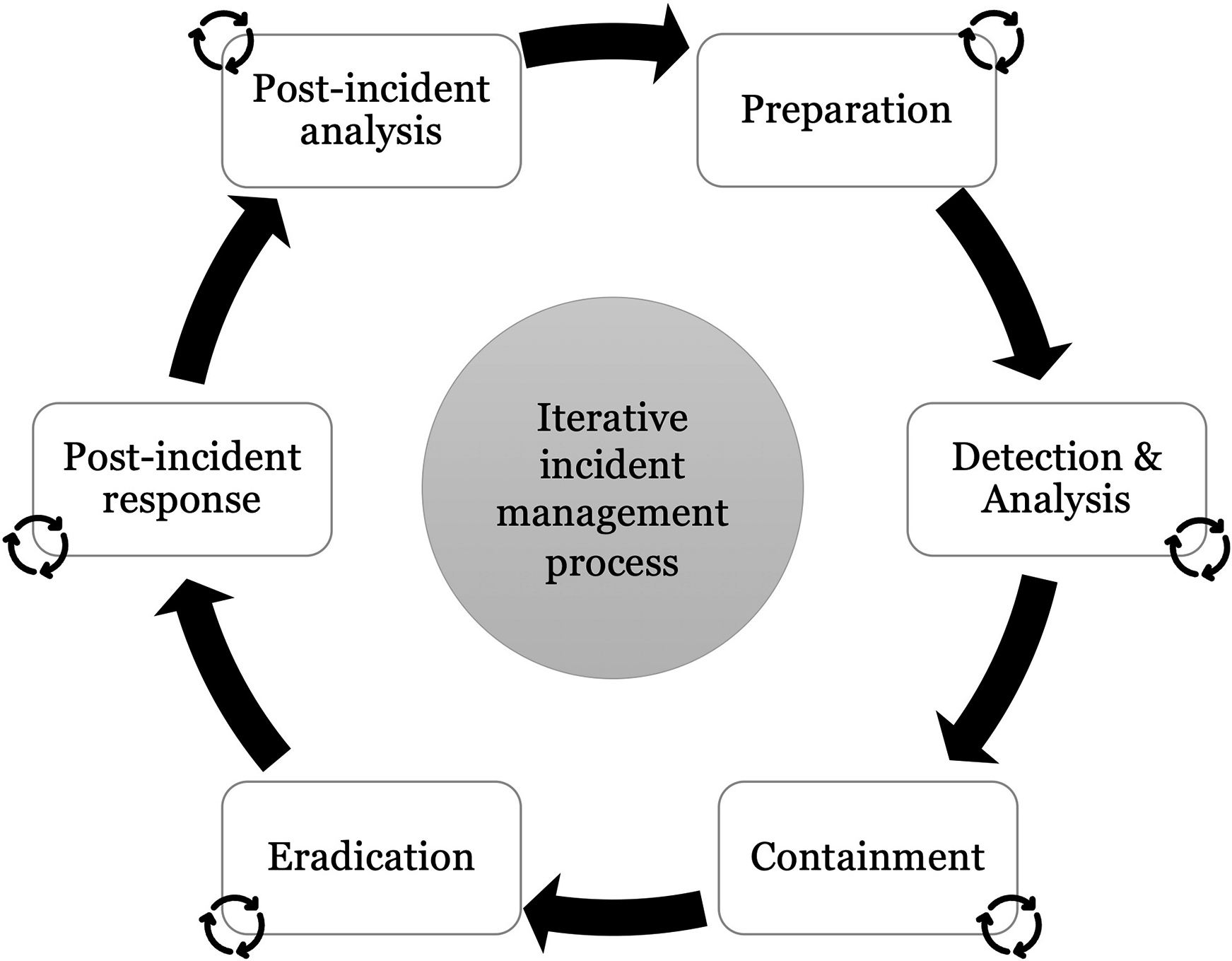
Organizational aspects of incident management
Incident management is a complex socio-technical process which requires close collaboration and coordination between various stakeholders and organizational functions. Information technology (IT) and security operation centres (SOCs) play a crucial role in developing and implementing necessary technical security controls and mechanisms to prepare the organizations for responding to potential security incidents. In addition, CSIR teams play an important role in detecting and handling incidents and monitoring and comprehending evidence about incidents. However, these teams are prone to face technical challenges, such as the accuracy of monitoring tools and emerging threats, as well as organizational challenges, such as lack of skilled and experienced incident handlers, insufficient security awareness among employees, and information gaps between and within departments. Thus, it must be ensured that everyone within the organization is aware of their role and responsibilities in incident management processes and they are able to support the CSIR teams.
The management is mainly involved in the governance of the response efforts. They can ensure that enough resources are invested in establishing a multidisciplinary CSIR team, employees are trained to spot potential vulnerabilities, and more generally create an encouraging environment for sharing information and efficient reporting (Yohannes et al., 2019). In addition, they are responsible for addressing stakeholders’ concerns proactively and getting involved in crisis communication. Management often needs to respond to a high volume of requests from stakeholders (e.g. partners, law enforcement, and board of directors), engage in proactive communication with the public, and determine the legal resourses available to the organization. To that end, risk and compliance experts can support the management and the CSIR team by assessing and considering the compliance and regulatory issues. Public relations and communication experts can contribute to the process by ensuring that the incident and its consequences are communicated to affected stakeholders and public professionally as soon as possible.
Employees’ engagement in incident management process is crucial for organizations to effectively respond to cybersecurity incidents. Employees should report suspicious and adverse events no matter if they themselves have triggered the incident or not (Ballreich et al., 2023). Employees might make unintentional mistakes, experience suspicious activities, or be deceived by attackers, leading to inadvertently leaking sensitive data or damaging IT assets or components of the digital. Reporting such incidents immediately allows security teams to contain these incidents and limit their consequences (Koivunen, 2012).
Evidence suggests that users often fail to report incidents, suspicious emails, or other cybercrimes such as data leaks (Kwak et al., 2020). Various factors can hinder or deter information security incident reporting (Ballreich et al., 2023), including a lack of awareness about what and how to report. Some employees may also fear punishments associated with reporting that they have accidentally triggered an information security incident (Van de Weijer et al., 2020). Additionally, employees may feel bad about making a security mistake and try to avoid embarrassment by not reporting if they believe no one will find out (Ballreich et al., 2023). Lastly, employees may consider the risks associated with an incident or suspicious event minor and not worth reporting. To address these issues, organizations should pay closer attention to SETA initiatives on activities that equip individuals with information security incident detecting and reporting guidance (Grispos et al., 2017). It is crucial to increase employee awareness about the importance of incident reporting, provide clear instructions and easy reporting mechanisms, and ensure reporting is risk-free for employees. For example, SETA programs can improve users’ awareness of the importance of reporting suspicious phishing emails, which is the most common attack vector used by hackers (Kwak et al., 2020).
Cybersecurity incidents, business continuity, and resilience
Depending on their nature and scope, business disruptions can lead to unbearable financial, reputational, and societal consequences for organizations and their stakeholders.
As organizations are increasingly more and more reliant on information systems and as their computing environment and digital infrastructures are becoming larger and more complex, compromising an information systems asset anywhere in the firm’s digital infrastructure can affect other areas of the environment and paralyse decision-making and value generation capabilities. A cybersecurity incident can disrupt an organization’s business operations and cause direct and indirect financial losses for the organization. The amount of costs or damage caused by an incident depends on the compromised information systems assets and business operations being dependent on or otherwise linked to those systems. In some cases, organizations can respond to and recover from an incident efficiently and rapidly, while in other cases responding to an incident and restoring business operations can be too difficult and costly for an organization. For example, the Finnish psychotherapy clinic Vastaamo (Ghanbari and Koskinen, 2024) went bankrupt following a data breach. However, if an organization is well-prepared for potential security incidents and have proper incident management processes in place, it is easier to react to business disruptions more efficiently and control their potential damages. Therefore, organizations must implement adequate safeguards to prevent security incidents and business disruptions in the first place. However, since these incidents are becoming inevitable, it is imperative to detect and contain cybersecurity incidents as soon as possible and maintain business continuity by responding to those incidents and restoring their operations in a timely and effective manner.
This is often referred to as business continuity, which in essence translates to an organization’s ability to rapidly detect and mitigate disruptive events to recover business operations to normal state (Raggad, 2010). To achieve this, organizations have business continuity plans, which determine a sequence of steps that the organization should follow to restore business operations when a disruptive event happens. The plan also defines the necessary requirements for each functional unit and its departments to continue their operations (Raggad, 2010). As such, a business continuity plan concerns the entire organization and therefore it must be approved by business owners or leaders.
To conclude, aligning cybersecurity incident management plan and business continuity plan is essential to ensure a coordinated response to cybersecurity incidents and minimize disruptions caused by them (Mäkká and Kampová, 2024; Phillips and Tanner, 2019). In other words, to ensure business continuity, an organization must maintain the resilience of its computing environment and its components. Resilience is the ability of a system or an organization to withstand or rapidly recover from disruptions or shocks and to minimize the effects of any business disruptions (Boh et al., 2023) caused by incidents and catastrophes and continue to evolve to better respond to such disruptions in the future. To maintain resilience, all departments and units as well as employees must be able to continuously deliver their intended services despite adverse cybersecurity incidents (e.g. an attack) and external shocks (e.g. pandemic). To that end, developing and regularly updating incident management plans, as well as conducting frequent incident response exercises in coordination with the business continuity teams can enhance preparedness and response efficiency (Ricks, 2024; Zeijlemaker et al., 2024).
Case description
In 2022, a large European manufacturing company announced that it had been a target of a ransomware attack that affected all its divisions and operations on a global scale. An attacker had gained access to some of the company’ information assets, which also included personal data, and made those unavailable for the company to use. It appeared that the compromised data had not been made public, at least not at the time of the announcement, as the purpose of the attack was to extort ransom from the company. Nevertheless, the attack halted the company’s operations as the company had to shut down its data centres to contain and assess the damage. This also had an impact to the company’s customers, which were dependent on the company to deliver the ordered products.
The attackers had gained access to a number of the company’s IT systems as one of the employees had fallen prey to a phishing attack and clicked a link in an email, resulting in a malware installation that went undetected by the company’s IT security controls. There were antivirus software and firewalls in place, but the capabilities of the company were not fully on par with the latest developments on system monitoring and intrusion detection. The malware enabled the attackers to identify a computer with administrative access and steal the credentials for that computer. This allowed the attackers to obtain administrative rights to key data assets and encrypt them, making them unavailable for the company and its employees.
In terms of the timeline of the attack, it took three days from the initial intrusion to the actual launching of the attack. The attackers had entered the company’ network on Tuesday afternoon and waited patiently until Friday when they executed their ransomware to start encrypting the company’s information assets. Launching a cybersecurity attack just before weekend is common, or as the company’s director of cybersecurity noted: ‘That’s very typical of them [cybersecurity attackers], they wait until Friday evening, Saturday morning to start the operations because they know that the most companies are at their worst in the defence on Friday night. They then have more time to operate without being unlucky, [as in] interrupted in the process’.
The company became aware of the attack when its cybersecurity director received a call in the early hours of Saturday (European time) from one of the company’s factories in North America, which was still running in full steam when the attack was launched on Friday (North American time). The factory informed the director that something was wrong with the production line, and that there was a message on the screen of one of the computers stating that company data had been encrypted, accompanied by a link to a Tor address for further information. After a brief discussion with managers, the decision was made to shut down all systems to prevent the attack from spreading, and an emergency meeting was called to discuss the situation for early Saturday morning. The company also immediately began looking for additional resources to deal with the attack, in addition to preparing the notifications for relevant actors, including the police and data ombudsman, as required by the European General Data Protection Regulation (GDPR).
A key objective for the company was to first understand what exactly had occurred as well as how to proceed. The company did have a CSIR plan, alongside disaster recovery and business continuity plans. However, due to its scale and impact, the attack called for a more organized response and the involvement of top management, who frankly did not have the time to go through hundreds of pages of existing plans but wanted to focus on tackling the situation at hand. As a result, a more situational, ad hoc planning was required.
Generally, it is widely acknowledged that often the plans are created at least partly for regulatory reasons, and while they can be of use for managing smaller security incidents, their usefulness with more serious incidents is less clear. Among others, as the situation and its implications become more complex and constantly evolve, improvisation is required to manage these larger cybersecurity attacks that threaten the organization on a broader scale: ‘We had an incident response plan and we have all kinds of disaster recovery and business continuity and those kinds of plans. But I don't think those were followed that much because the effect of the incident was so immense in the organisation, [that] the global leadership team, our top management team, and others were involved in doing the crisis management from day-to-day […] So I think that those crisis plans should be more about templates’.
Instead of being able to resort to pre-existing step-by-step frameworks presented in incident management plans, the planning during the incident was in a continuous manner as plans were further developed and updated as information on the situation accrued. Among others, it became quickly known that the company’s own CISR resources were not enough, but more outside expertise was required, and the company moved quickly to hire outside consultants to help with the incident. In addition, as these kinds of incidents do not respect normal working hours, the situation required round the clock operations.
Among the key reasons for hiring external CISR consultants was the possibility to have people with experience on handling similar situations to help with the response. The company also decided to follow a rather innovative approach and provide sufficient resources to form two separate teams to work on the incident independent from each other. While this meant that there was higher chance of conducting same investigative actions twice, it was seen as a worthy move to obtain results faster in identifying the root cause for the incident and to minimize the risk of not noticing something of importance. Finding the root cause was crucial since before that was not clear and fixed, there was no guarantee the incident could not reoccur. At the same time, there was an immense time pressure as many of the company’s employees were sitting idle due to the attack as the two teams were trying to get to the bottom of how the incident had occurred. The interviewee explained: ‘We hired some external expertise to actually do the forensics in two different teams […] so that we could have faster results. And even with the risk of people doing the same thing twice, we wanted to make sure that we find the root cause of incident as fast as possible because it's not possible and it's not feasible to do the recovery work before we know what happened […] we did decide that it's cost effective to actually have two companies, two teams doing the same things at the same time’.
While the two teams were working to enable the technical recovery from the incident, that did not inhibit the business management to begin their work on recovering the business, which in essence meant trying to figure how to maintain business continuity and run their operations without the support of the compromised information assets. To keep up with the latest developments, there were two daily meetings containing both the technical teams and the managers from business side of the company. The latter were particularly keen to know how long it would take to get the IT back up and running.
Initially the technical teams had estimated that recovery would take approximately two weeks. In the end, they managed to do that in 10 days, starting from the incident occurring to the moment when the first truck filled with customers’ orders was able to set off from one of the company factories. From those 10 days, it took about a week for the teams to figure out what exactly had happened, followed by two to three days to recover the compromised systems. To achieve this, the teams working on the incident worked in three shifts round the clock, after which they continued to work in two shifts from seven in the morning till late, seven days a week. IT and the cybersecurity specialists returned to normal working hours three weeks after the incident. Production was restored to its normal levels earlier, approximately one month after the attack. Nevertheless, the attack caused significant costs in terms of overtime work, external consultancy services purchased, and loss of revenue.
The company refused to pay the requested ransom, especially since the company knew that the publication of the data was most likely inevitable as the attackers had to protect their reputation of making good of their threats. This turned out to be also the case later on. Throughout the incident, the company informed and kept in contact with the different countries’ law enforcement, particularly since the compromised data also contained personal information. However, the company had the resources and was better positioned to conduct the incident response by themselves with the help of external CSIR experts they had hired. Naturally companies do not have such remedies at their disposal that the law enforcement has, such as detaining people. However, law enforcement and police were responsible for post-incident investigations of the criminal act itself and not responding to the incident or helping the company restore business operations.
Key takeaways
In the post-incident analysis, it was seen as important as having the right people to lead the process straight from the beginning. The fact that external consultants were onboard also helped with coordinating the response to alleviate possible tensions as they could act as sort of referees, or more objective actors not interested in office politics, simply trying to deal with the situation at hand. In terms of areas that needed improvement, the company realized that the documentation could have been more up to date than it was, as this would have enabled the CSIR team to obtain necessary information quicker than it had been possible in the attack. The incident further emphasized the importance of frequent and early communications in incident management. The whole event also emerged as a possibility to learn. Instead of downplaying the incident, it can be used to make improvements, in terms of strengthening existing systems and processes to avoid similar incidents in the future.
In terms of technical improvements, the company took the incident as an opportunity to accelerate its move from on-premise to cloud-based systems, which was also seen as improving the overall security of the company’s IT systems. Furthermore, the downtime caused by the incident enabled the company to use that time to make other improvements, which would have required similar service interruptions if conducted at some other point in time. Endpoint detection software and enhanced system monitoring capabilities were also implemented, or as the cybersecurity specialist noted: ‘We had traditional antivirus, obviously, and some, like, personal firewalls in the computers, but it doesn't do much, because it doesn't have the capability to actually find those subtle attacks. [Advanced tools] and that kind of stuff before [the incident] was not funded, but after the incident, obviously the first things we got were better tools to actually prevent this from happening again’.
Another interesting realization from the incident was how maintaining the security of certain information system assets that are seen of lesser importance may turn out to be crucial for maintaining business continuity. As the company representative noted, among the most important applications for the business operations was label printing, a key component of automated warehouses utilized by the company. Even though the application was very simple and the process as such trivial, when label printing was shut down due to the attack, this in essence meant that nothing could be shipped, rendering also all the other processes related to shipping of no use.
Finally, vital for handling the incident was not only having sufficient resources in place but also people management, which in practice included aspects such as making sure everyone was able to also rest during the incident. Similarly, talking and sharing experiences with other companies that had faced similar situations was seen as helpful, already to know how those companies had handled similar situations in the past. On the technical side, it was seen of importance to have network monitoring tools as well as teams that can operate quickly if so needed. The incident provided a reminder to get rid of and replace any tool that could be considered as too risky in terms of creating vulnerabilities, while also stressed the point on training the employees to be aware of phishing and other attacks. Even though there are always employees who will not follow the provided cybersecurity guidance or instructions, making that number as small as possible helps to reduce the overall risk of a cybersecurity incident.
Discussion questions
1- Why is a well-defined cybersecurity incident management plan crucial for organizations, and what should it include? 2- What role do employees play in cybersecurity incident management, and why is it important to encourage them to report suspicious activities? 3- What are the benefits of adopting an agile approach to cybersecurity incident management compared to traditional linear models? 4- How did the attack affect the case company’s business operations? 5- Why is the coordination between cybersecurity incident management and business continuity planning essential? 6- Reflecting on the case, what organizational challenges can hinder effective cybersecurity incident management, and how can organizations address them? 7- How should the company communicate with its stakeholders during the attack? 8- How would you characterize the company’s response to the attack? 9- In your view, should have the company paid the ransom? Why? 10- What key lessons were learned from the case regarding incident response, planning, and organizational preparedness?
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of AI use
The authors have used Grammarly to improve the language of the case and teaching notes. However, the authors have reviewed the suggested changes and edited the content as needed and take full responsibility for the content of the publication.