
Abstract
How should climate policy be framed to maximize public support? We evaluate the effects of five distinct message frames—scientific, religious, moral, and two economic (efficiency and equity)—on support for climate change policy using a randomized experiment with over 2300 U.S. respondents. Moving beyond pairwise frame comparisons, we adopt a policy learning approach that identifies the most effective frame using cross-validated sample splitting, thereby avoiding selective inference. We find that the economic efficiency frame consistently yields the largest gains in policy support, outperforming both the control condition and all alternative frames, on average. While the effects of covariate conditional frame assignment were modest and not significantly different from assigning the best overall frame, we find consistent positive effects of the efficiency frame across partisan subgroups. Our findings offer methodological and substantive contributions: we highlight how policy-learning methods can be applied in experimental framing studies, and we offer specific evidence on the relative efficacy of alternative framing messages on support for several climate policies.
Introduction
Climate change is an urgent global challenge that demands broad public engagement. How climate issues are communicated can shape policy support. Despite widespread scientific consensus on the causes and impacts of climate change, large segments of the public remain skeptical or indifferent to the urgency of the issue (Pasquini et al., 2023). Effective communication strategies are therefore essential, and framing is one important aspect of such strategies. While framing effects on public attitudes toward climate policy have been widely studied (Benjamin et al., 2017; Feldman and Hart, 2021; Rossa-Roccor et al., 2021), most work compares the relative efficacy of a pair of frames (e.g., comparing beliefs about “climate change” as compared to “global warming”; Watts et al., 2015), and questions remain about which types of frames are generally most effective across different demographic and ideological groups.
In this study, we measure support for climate policies following messaging under several alternative frames. We propose our research question as “which of these alternative frames is most effective at advancing support for climate policy, and what is the treatment effect of that most effective frame as compared to a control condition?” While pairwise tests of different framings can provide evidence of the relative direction of framing effects, our research question may not be best answered by tests of separate hypotheses that each intervention improves over a given alternative. Building on an established literature on sample splitting (Cox, 1975) and selective inference (Taylor and Tibshirani, 2015), and recent work on policy learning and heterogeneous treatment effects (Athey and Wager, 2021) we demonstrate experiment design and analytical procedures for answering such questions by identifying interventions that maximize expected outcomes and estimating their effects—while maintaining valid inference.
In addition to reporting average treatment effects and assessing the overall effectiveness of the best-performing frame, we explore the potential for conditional frame assignment—matching individuals with the frame most likely to resonate with their values and beliefs. We employ machine learning techniques to model heterogeneity in treatment effects, enabling us to predict the best frame for each individual based on their demographic and attitudinal profile. While we do not find evidence that different frames are better for different subgroups, this procedure demonstrates approaches to study how different groups respond to different types of messages.
As a basis for this study, we extend the design of Severson and Coleman (2015), which examined the effects of scientific, moral, religious, and economic frames on public support for climate change policies. In addition to adopting alternative analytical techniques, we use a larger and more diverse sample, allowing for better powered statistical analysis and greater generalizability of our findings.
Our research aims to contribute to the broader literature on policy communication and framing. In particular, we seek to inform the development of more effective communication strategies for climate policy advocates, policymakers, and organizations working to build public support for urgent environmental action.
Motivation
Variations in framing can be associated with different responses (Newell and Pitman, 2010). Understanding which framing is effective for different types of people is important in ascertaining the ways people interpret and contextualize information (Foust and Murphy, 2009).
We use five of the six original frames in Severson and Coleman (2015): scientific, secular moral, religious, and economic (efficiency and equity) categories, as well as a pure control condition. 1 We adapted the wording used in the original text, making warnings more specific and adding some modifications on the source of recommendations with the intention of providing strong proposals for each framing type.
While this set of frames is not exhaustive, our objective is to expand on existing research using a larger sample size and testing procedures that provide information on relative performance across arms. Indeed, there are countless conceivable alternative framings that could be used. However, each additional frame that we incorporated would have reduced the number of respondents receiving any given frame in expectation, while increasing the challenge of our best arm identification objective (Paulson, 1964). Consequently, we are only able to report on the best arm identified within this defined treatment set.
Severson and Coleman (2015) examined heterogeneity based on political ideology, pro-sociality, scientific confidence, political trust, and church attendance. However, with as few as 46 observations per condition, power to detect heterogeneity is limited. We also explore heterogeneity and attempt to discover the effects of providing a conditional framing assignment. Further details on the exact procedures are presented in the Design section.
Frames
Science-based framing emphasizes the scientific consequences of climate change and is the “traditional communication approach of climate science and climate policy advocates,” with the negative aspect highlighting “the negative consequences of inaction.”
Moral convictions and relevant emotions play an important role in shaping political attitudes (Emler, 2003; Skitka et al., 2005), sparking increased political engagement (Marietta, 2008), and moral appeals may have the potential to reduce an existing partisan gap in support for climate policy (Feinberg and Willer, 2013).
Religious involvement has been demonstrated to be predictive of measures of environmental concern (Eckberg and Blocker, 1989; Kanagy and Nelsen, 1995). While not deemed one of the most effective framing methods in Severson and Coleman’s paper, religious framing remains an extremely dominant framing in media, specifically framing that targets a Christian audience. As such, we decided to keep this treatment and tailor the framing to align more closely with Christianity instead of being broadly targeted.
Finally, regarding economic framing, Nerlich (2010) asserts that “economic uncertainties over the costs and benefits of greenhouse gas control have played a major role in framing the policy discourse (Spash, 2007).” Additionally, economic frameworks can be presented in various ways, each with varying degrees of effectiveness toward shifting climate change policy support. Ultimately, the effectiveness of economic framings toward shifting policy support appears to vary based on the specific framing used, and it may be useful to test several different economic framings, in this case the efficiency and equity framings, in order to provide a broader overall picture of the usefulness of economic framings as a whole.
Methods
Design
We recruited 2344 respondents through the Cloud Connect Survey platform. Participants were paid $1.50 to take a 5-min survey administered through Qualtrics. Participants previously provided demographic information to Cloud Connect, including age, sex, race, education, occupation, household income, relationship/marital status, political party, and employment status. Upon entering the study, respondents were presented with an informed consent agreement.
We then asked a block of demographic questions. During this block, we also measured pre-test response to our outcome measure, support for several climate policies, along with two pre-treatment attention checks.
Respondents were then randomly assigned one of the five framing conditions or a control condition. Treatment was assigned uniformly at random using simple random assignment so that between 358 and 411 participants were assigned to each frame (15.3 to 17.5% of the sample). All frames follow a similar structure with a claim on climate change, followed by examples of consequences and ending with a call to action. Frames have comparable length and detail with efforts to ensure that any effects observed are due to the frame itself and not the quality of the argument’s wording or execution. We then asked respondents to reflect on the text of the framing in an open-response question to encourage deeper engagement with the message content. Following treatment delivery, we measured post-test response, which included the same four policy questions asked earlier. Survey questions and full framing text are reported in the supplementary material.
Our outcome is measured as the average of post-test response on support for a gas tax, a carbon dioxide tax, a treaty to cut carbon dioxide emissions, and regulation of carbon dioxide, with support for each measure corresponding to various degrees of support: Strongly Oppose (0), Oppose (1), Support (2), and Strongly Support (3). We use an identical measure in our pre-test response.
We limited our survey to respondents in the United States, and we enforced approximate balance on political party, targeting 30% Democrats, 30% Republicans, and 40% independents or other political alignment. Our study sample largely reflects national distributions on party identification. However, respondents did not reflect the U.S. population in other categories, with 75.3% of respondents identifying as White (according to the 2020 Census, 57.8% of the U.S. population identifies as White and non-Hispanic).
Results
All cleaning and analysis code is available at our project GitHub repository: https://github.com/UChicago-pol-methods/climate-framing-replication.
Within-respondent response and treatment effects
Figure 1 illustrates the distribution of pre-test response on the policy index measure by treatment condition, as well as differences from pre- to post-test measures. Each square represents an individual respondent: white colored squares represent individuals who did not change their position from pre- to post-test, cool colored squares decreased their support for the measures, whereas warm colored squares increased their support. The relatively larger share of warm colored squares among the non-control conditions demonstrates that more respondents in these conditions increased rather than decreased their support for climate change measures. Figure 2 illustrates the same trends, showing average pre- and post-test measures by treatment conditions. Stars represent statistical significance of average within-respondent differences; we see that on average, respondents increased their support for climate change measures, with statistically significant differences in all conditions except for the control (p < 0.05 for all treatment conditions, and for most conditions, p < 0.001). Response distributions and pre- to post shifts on the policy index measure. The sample is survey respondents, n = 2344. Each block represents one respondent. The x-axis represents pre-test values of the policy index measure, which ranges in value from 0 to 3. Individual changes from pre-test to post-test response are represented by the color scale. Pre-test and post-test response by treatment condition. The sample is survey respondents, n = 2344. Estimates are simple means of pre-test and post-test response on the policy index measure by treatment condition; error bars represent symmetric 95% confidence intervals. Stars represent statistical significance of differences in means between measures within groups. + p < 0.1, *p < 0.05, **p < 0.01, ***p < 0.001.

Mean response estimates by party identification.

Note. The sample is all respondents, n = 2344. Columns represent averages of policy index questions, pre- and post-delivery of treatment. Standard errors are reported below estimates in parentheses.
Between-respondent treatment effects
Treatment effect estimates and response.
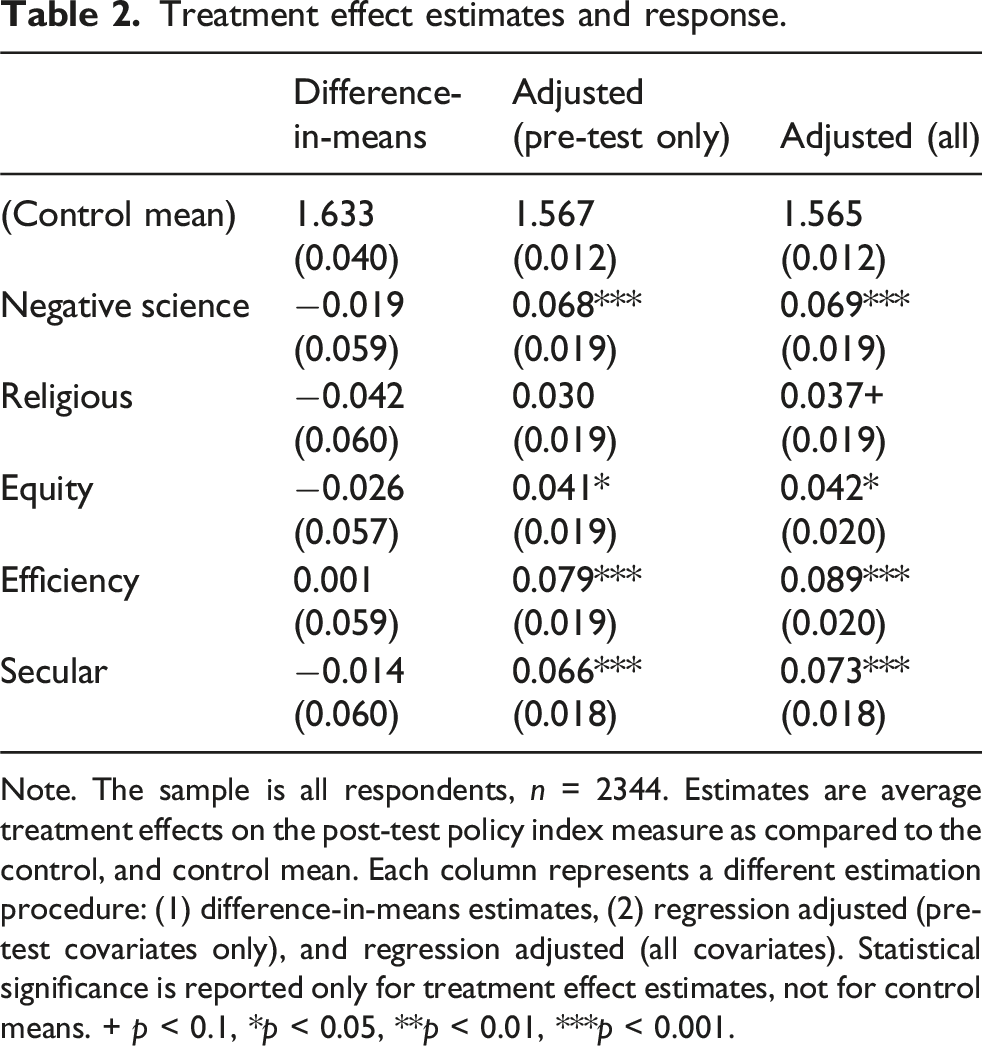
Note. The sample is all respondents, n = 2344. Estimates are average treatment effects on the post-test policy index measure as compared to the control, and control mean. Each column represents a different estimation procedure: (1) difference-in-means estimates, (2) regression adjusted (pre-test covariates only), and regression adjusted (all covariates). Statistical significance is reported only for treatment effect estimates, not for control means. + p < 0.1, *p < 0.05, **p < 0.01, ***p < 0.001.
We also pre-registered reporting regression-adjusted estimates of treatment effects; these estimates target the same estimand as the difference-in-means estimates, average between-respondent treatment effects, but they control for the observed variation in pre-test response. In our regression adjustments, in addition to treatment indicators, we de-mean covariates and interact them with each treatment indicator, following Lin (2013). Specifically, in our regressions, we controlled for both pre-test responses only and then pre-test response along with a suite of other covariates: age, 7-point party identification, 7-point ideology, an indicator for full-time employment status, an indicator for white race, income, an indicator for married or in a civil union/partnership, an indicator for college-education, an indicator for female, pro-sociality measure, scientific confidence scale, religiosity, attendance to a house of worship, reward consequence scale, and an economic reasoning scale. Once variation in pre-test response is accounted for, our regression-adjusted between-respondent estimates reveal similar trends as our within-respondent estimates: for both the pre-test only and full covariate specifications, treatment effects are positively signed, and statistically distinguishable from zero (p < 0.05), with the exception of our religious framing measure.
Which framing works best?
We are not simply interested in rejecting separate null hypotheses that each of the framing messages is an improvement over no message at all, however. Rather, we would like to determine which framing message is most effective, and to produce a valid estimate of treatment effects under that message, avoiding challenges with selective inference (Taylor and Tibshirani, 2015). We would also like to determine if different policies are better for different people.

We approach this task using a k-fold cross-validation procedure, following the steps described in Algorithm 1. This involves splitting our dataset into k separate folds, where each fold acts as a test set while the remaining k − 1 folds serve as the training set—in our case we use five folds. In the first stage, we perform best fixed treatment and best covariate conditional treatment selection. For each fold, we first (1) use the relevant training set to fit a simple linear model of treatment on treatment indicators, pre-test response, and treatment and pre-test response interacted, and predict response for the test data. In the test data, we identify the arm with the highest predicted response on average based on our model as the best fixed arm, and we save this variable. We use a simple model for best fixed arm identification, as we would like to control for unnecessary noise, but we do not need flexible estimates that vary greatly across respondents. Then, (2) on the same training set, we train separate random forest models for each treatment condition, and again predict outcomes on the test data. For these forests, we use the same set of covariates as in our regression-adjusted estimates described in the section on Between-respondent treatment effects. We use this more flexible model to predict for every observation in the test data which of the treatments would be best for that observation’s covariate profile, and save a new variable with the selected treatment values. We repeat this across folds, resulting in two new variables for the entire data set, the best fixed treatment, and best covariate conditional treatment, as selected using only the respective training folds. This procedure was pre-registered and we use the original python code from our replication repository at the time of our pre-registration for this exercise.
Treatment effect estimates for best fixed and best personalized arms.

Note. The sample is all respondents, n = 2344. Estimates are average treatment effects as compared to the control on the post-test policy index measure of (1) the best learned fixed treatment, (2) the best learned personalized treatment, and differences in (3) the best fixed treatment over the best personalized treatment, and (4) the best fixed treatment as compared to all other non-control framings. Estimates are produced as simple difference in means across folds (column 1), and from combining fold-wise causal forest estimates, (column 2). + p < 0.1, *p < 0.05, **p < 0.01, ***p < 0.001.
Our procedure for selecting the best fixed arm allows that across folds, it is possible that different arms could be selected as best. However, we find in every fold, the Efficiency framing was selected as best. Covariate-adjusted average treatment effects under this arm are 0.066 units in our climate support index, equivalent to an additional 25% of the sample assigned to a condition increasing their post-treatment support for one of the policy measures by one level (e.g., from Oppose to Support, or from Support to Strongly Support. See Table 3, row 1 column 2.). We do not find an improvement in conditioning types of framing on covariate profiles—indeed, using our pre-registered approach for learning different framings for different types of people, the average treatment effect for conditional assignment is directionally worse than simply assigning all respondents the framing that works best, on average, although these differences are not statistically distinguishable from zero at conventional significance levels (Table 3, row three). This does not mean that there is no type of allocation of frames that might work better for different types of people, simply that using our data, we do not find evidence that our method for conditional assignment improves over assigning the framing that works best on average. However, we do find that our best framing works: it directionally improves over the average of all of the other framings (Table 3, row four). This difference is relatively small, 0.035 in our outcome measure, equivalent to approximately 15% of the sample assigned to the Efficiency condition increasing their post-treatment support for one of the policy measures by one level, as compared to respondents assigned the other conditions (p = 0.069 when adjusting for covariates).
Treatment effect estimates and response by party identification, controlling for pre-test response.

Note. The sample is all respondents, n = 2344. Estimates are average treatment effects on the post-test policy index measure as compared to the control, and control mean, controlling for pre-test response on each of the policy measures separately. Estimating procedures are discussed further in the text. Statistical significance is reported only for treatment effect estimates, not for control means. + p < 0.1, *p < 0.05, **p < 0.01, ***p < 0.001.

Average treatment effects by party identification. The sample is survey respondents, n = 2344. Estimates are average treatment effects on the post-test policy index measure as compared to the control, controlling for pre-test response on each of the policy measures separately; error bars represent symmetric 95% confidence intervals. Estimating procedures are discussed further in the text.
Accounting for covariates within parties also provides a more accurate interpretation of the data. We can see that every treatment resulted in directionally positive effects across all parties, except for the Religious framing among Democrats.
For Democrats, the Negative Science, Efficiency, and Secular framings are associated with treatment effects that are statistically distinguishable from zero at conventional significance levels; for independents (the smallest group), only the Efficiency framing was associated with effects distinguishable from zero; for Republicans, the Negative Science, Religious, Efficiency, and Secular framings were all effective.
Discussion
Our study contributes to the growing body of research on framing effects in climate change communication by providing new insights into both the relative effectiveness of alternative types of frames and the potential for covariate conditional framing to enhance policy support. Overall, our findings suggest that economic efficiency frames are more effective than other proposed frames in garnering support for climate policies across political and ideological groups. The economic efficiency frame emphasizes the financial consequences of climate inaction, which appear to resonate more broadly than frames that focus on the secular moral, religious, scientific, and equity dimensions of the issue.
There are also limitations to our study that warrant further exploration, particularly regarding scope and generalizability. First, our sample size was large and diverse, but it was not fully representative of the U.S. population in some key demographic areas, particularly race and income. While we do not find evidence of meaningful heterogeneity in which intervention was most effective across the covariate profiles we collected in this study, we do find suggestive evidence that subgroups have different patterns of support for climate change policy at baseline, and that treatment effect magnitudes may be different across these groups. This suggests limitations in straightforward generalization of our effect estimates to alternative populations. Additionally, while we examined the relative impact of several previously proposed framing categories, there are certainly many other potentially impactful frames, such as for example around political objectives, health impacts, or inter-generational obligations, as well as alternative approaches to tailored communication strategies. The emergence of generative language models presents a new opportunity to explore the feasibility and impact of tailored messaging in future research. Finally, our study was conducted in late April of 2024. Given the economic climate and concerns about rising costs of living at the time of the study, it is possible that messages framed around economic efficiency held particular salience at this time. Replicating this experiment in different economic and social contexts across a broader set of proposed framings could provide additional insights into generalizability with respect to alternative treatment sets, target populations, and contexts (Egami and Hartman, 2023).
However, we believe that our proposed procedures represent an important tool for rigorously evaluating alternative interventions: when researchers care about learning and obtaining unbiased estimates of outcomes under the best unique intervention and the best covariate conditional assignment policy, they can use a design like the one proposed here.
Supplemental material
Supplemental Material - Which frame fits? Policy learning with framing for climate change policy attitudes
Supplemental Material for Which frame fits? Policy learning with framing for climate change policy attitudes by Molly Offer-Westort, Will Gruen, Carter Herron, Kaden Hyatt, Max Buford, Kevin Davis, Diego Fonseca, Mushkie Gurevich, Tiffanie Huang, Rocio Jerez, Quinn Liu, Obi Obetta, Miguel Orellana, James Passmore, Jack Qiu, Julian Rapaport, Iñigo Sanchez-Asiain Domenech, Fernando Sandoval, Jose A. Tandoc, and Ravi Yalamanchili in Research & Politics
Footnotes
Acknowledgments
We thank the participants of the 2024 Visions in Methodology workshop for feedback on this project.
Ethical considerations
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by funding from the University of Chicago’s Core Conversations Innovation Grant.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Copyright statement
Copyright ⓒ 0000 SAGE Publications Ltd, 1 Oliver’s Yard, 55 City Road, London, EC1Y 1SP, UK. All rights reserved.
Carnegie Corporation of New York Grant
This publication was made possible (in part) by a grant from the Carnegie Corporation of New York. The statements made and views expressed are solely the responsibility of the author.