
Abstract
Objective
Myopia has emerged as a critical global public health challenge. This study aims to develop a privacy-preserving federated learning (FL) framework for the triple classification of fundus images (normal, myopia, and pathological myopia), designed to generalize across institutions while addressing data heterogeneity and class imbalance.
Methods
We propose a novel FL framework integrating a genetic algorithm-inspired dynamic aggregator (FedProx_GA), a distance-aware attention module (OptiFocus), and a class-frequency dynamic loss. It was trained and evaluated on 1,279 fundus images from three heterogeneous medical centers. Performance was compared against standard FL baselines using area under the curve (AUC), accuracy, sensitivity, and specificity.
Results
Our framework achieved an AUC of 0.9889, performing close to the performance achievable when all data are centrally stored and processed (the non-federated approach) while significantly outperforming conventional FL methods. It demonstrated robust cross-center generalization, with high sensitivity (0.9346) and specificity (0.9673), effectively managing data heterogeneity and class imbalance without breaching data privacy.
Conclusion
This work presents an effective, privacy-preserving FL solution for collaborative ophthalmic artificial intelligence, showing strong potential for multi-institutional clinical deployment. Future work should focus on prospective validation with larger, diverse cohorts. The implementation code is publicly available at: https://github.com/AngelaK-code/FL_Myopia-Diagnosis.
Introduction
Myopia1,2 is one of the most common refractive errors worldwide, and severe myopia and pathological myopia may lead to irreversible visual function damage, such as retinal splitting, retinal detachment, and macular. 3 Therefore, myopia classification and diagnosis based on fundus images are crucial for early intervention and treatment. In the early diagnosis of ocular diseases, fundus photography and optical coherence tomography (OCT)4,5 have proven to be effective imaging techniques. Fundus photography is a cost-effective and non-invasive method of screening for ocular diseases compared to expensive OCT images. As a result, fundus photographs have become the primary method used by ophthalmologists to detect diseases such as diabetic retinopathy (DR), age-related macular degeneration (AMD), myopia, hypertension, glaucoma, and cataracts. 6 However, manual fundus photography is time-consuming and labor-intensive, and the number of ophthalmologists is far from adequate for manual diagnosis. An automated diagnostic algorithm for screening ophthalmic diseases is urgently needed in order to reduce the pressure on ophthalmologists and improve the accuracy of fundus diagnosis.7–10
In recent years, deep learning techniques have made significant progress in automated diagnostic tasks for ophthalmic diseases, especially in the detection of DR, 11 glaucoma, 12 and AMD, 13 and have demonstrated diagnostic performances comparable to those of professional ophthalmologists.14–20 Guo et al. 21 proposed a method for the automated diagnosis of ophthalmic diseases using fundus images of the complete structure of cataracts. 22 After extracting features from the image using wavelet transform and sketch-based methods, multiple fisher classifiers classify all samples according to the severity of the disease; Mookiah et al. 23 proposed an automated dry AMD detection system that used features extracted from grayscale fundus images of various features including entropy, higher order spectral (HOS) bispectral features, fractional dimension, and Gabor wavelet features. The features are then selected using a series of statistical tests and classified using a set of classifiers such as k-nearest neighbors, probabilistic neural networks, decision trees, and support vector machine (SVM) methods; Mookiah et al. 24 chose the HOS and discrete wavelet transform features as the depiction of the eye image as an image descriptors and SVM as a classifier to diagnose glaucoma, obtaining higher accuracy than before; Singh et al. 25 used genetic feature selection to select useful wavelet features from wavelet features extracted from segmented optic disc images, where blood vessels were removed, to automatically detect glaucoma in fundus images.
However, the widespread clinical deployment of such deep learning models is hindered by their reliance on a centralized training paradigm, 26 which necessitates aggregating data from various medical centers to a single server. This paradigm faces significant challenges in healthcare, particularly under increasingly stringent data privacy protection regulations 27 and practical limitations on data sharing, 28 making collaborative multicenter modeling difficult.29,30 To address these barriers while enabling collaborative intelligence, federated learning (FL) has emerged as a promising decentralized alternative. Recent studies have achieved notable results in ophthalmic disease diagnosis using this paradigm, for example, a domain-adaptive federated framework has been proposed to realize privacy-preserving multi-disease ocular recognition, 31 and a comprehensive federated system specifically optimized for DR grading and lesion segmentation effectively enhanced cross-dataset generalization. 32 Existing studies still face many problems on the myopia classification task. First, the use of medical data are constrained by strict privacy-protecting regulations 33 (e.g. General Data Protection Regulation (GDPR)), and there is a compliance risk in directly aggregating data from multiple healthcare organizations for training—this is exactly the core issue addressed by FL, as demonstrated in cross-institutional medical image analysis where privacy is safeguarded without raw data sharing. 34 Second, there are differences in fundus photography equipment used in different medical centers, resulting in inconsistent image resolution, contrast, and color distribution, 35 while the annotation standards may be inconsistent across institutions, affecting the generalization ability of the model. Recent work has proposed interpretable FL methods to explicitly identify such inter-institutional biases in biomedical images. 36 In addition, a third major challenge is the relative scarcity of pathological myopia samples, 37 which can introduce class imbalance and bias during federated training, degrading the model’s recognition performance for minority categories.
To address the above issues, this paper proposes an FL-based myopia triple classification framework, which aims to improve the cross-center generalization ability of the model while safeguarding data privacy. Specifically, we adopt a dynamic aggregation strategy based on federated averaging (FedAvg) and incorporate a category imbalance handling mechanism to enhance the model’s performance on few sample categories. In addition, we optimize the model architecture to adapt to the heterogeneous data distribution 38 in a multicenter environment and improve the robustness of the model. The main contributions of this paper include the following: (1) designing and implementing a privacy-preserving multicenter myopia classification framework that enables different medical centers to jointly train deep learning models without sharing raw data; (2) proposing a dynamically adapted federation aggregation strategy for the problem of multicenter data heterogeneity in order to enhance the model’s fitness on different data sources; and (3) incorporating the FL environment, we explore federated knowledge distillation, resampling with adaptive loss function to alleviate the training bias caused by insufficient samples of pathological myopia categories and improve the model’s ability to recognize a few categories; (4) experiments are conducted on the datasets of multiple real medical centers to validate the effectiveness of the proposed method in data privacy protection, cross-center generalization ability, and classification performance. The research in this paper provides a new solution for intelligent diagnosis of ophthalmic diseases in privacy-preserving environments, and at the same time provides an important technical reference for the application of FL in medical image analysis.
Method
Currently, deep learning algorithms have demonstrated high accuracy in diagnosing diseases such as DR, glaucoma, and AMD from fundus photographs. However, such models typically rely on a centralized training paradigm that requires multicenter data aggregation to a single server, which is in fundamental conflict with healthcare data privacy regulations (e.g. European Union GDPR). In addition, there is significant heterogeneity in the data from different healthcare organizations: inconsistent image resolution and contrast due to differences in equipment brands, inconsistent labeling standards (e.g. ambiguous quantitative definition of pathological myopia), and unbalanced distribution of categories (e.g. scarcity of samples for pathological myopia). These factors create “data silos,” limiting the development of large-scale datasets and model generalization.
In this paper, we propose an innovative deep learning algorithm for the triple classification task of ocular myopia, pathological myopia, and normal eye at multiple medical centers. By adopting a distributed training approach, our framework prioritizes data privacy and avoids the risks of centralization. The framework combines FedProx FL algorithm, genetic algorithm (GA), OptiFocus attention mechanism, and realizes efficient collaborative learning of cross-agency data through the strategy of dynamically adjusting the loss function based on the category frequency. Experimental results show that the framework exhibits higher classification accuracy and stronger generalization ability than traditional methods on data from multiple centers.
In this section, the design of an FL framework for the triple classification task in multiple medical centers is described in detail, focusing on the optimization of the model architecture, the dynamic weight aggregation strategy, and the category imbalance handling scheme.
Data preprocessing
All fundus images were stratified and randomly divided into training and test sets at a ratio of

Overview of the proposed federated learning framework for myopia classification.
Model architecture
Embedded OptiFocus attention module
To enhance the model’s attention to different regions in fundus images, we embed a new visual attention mechanism called OptiFocus into the convolutional neural network (CNN) backbone. Fundus images contain subtle features such as myopic arcuate spots and macular lesions, yet traditional attention mechanisms often overlook distance variations within regions. The OptiFocus module addresses this by introducing a distance-aware mechanism that dynamically adjusts region weights based on relative spatial distances, thereby allocating different attention levels to myopia-related features. Specifically, it assigns higher weights to proximate regions (e.g. macular lesions) by computing inter-region distances, enhancing sensitivity to fine details. Its structure consists of two main parts:
Channel attention mechanism: Channel weights are first generated through global average pooling and maximum pooling operations. In this way, the network is able to emphasize those feature channels that are more important to the task in the overall image and suppress irrelevant or redundant channel information. Spatial attention mechanism: On the feature map compressed by channel attention, OptiFocus utilizes a convolution operation to generate a spatial weight matrix and adjusts the weight distribution of the spatial attention map according to the distance information of the image regions. In this way, the network is able to focus on key regions in the image, such as the optic disk and macula and other important parts, thus improving the sensitivity to the lesion region.
The OptiFocus module is inserted after each convolutional layer (Conv block) of the model. The design of this structure effectively improves the CNN’s ability to capture detailed information, especially on the diverse and subtle features of ophthalmic images, to achieve finer region selection and significantly enhance the robustness and classification accuracy of the model.
To validate the effectiveness and interpretability of the OptiFocus module, we employed gradient-weighted class activation mapping to generate visual explanations for the model’s predictions. As shown in Figure 2, the generated heatmaps clearly demonstrate that our model, guided by the OptiFocus module, successfully learns to focus its attention on clinically relevant regions, such as the optic disc and macular area, which are critical for diagnosing pathological myopia. This provides intuitive and compelling evidence that our model makes predictions based on meaningful pathological features rather than irrelevant image artifacts, significantly enhancing the transparency and trustworthiness of our artificial intelligence (AI) system.
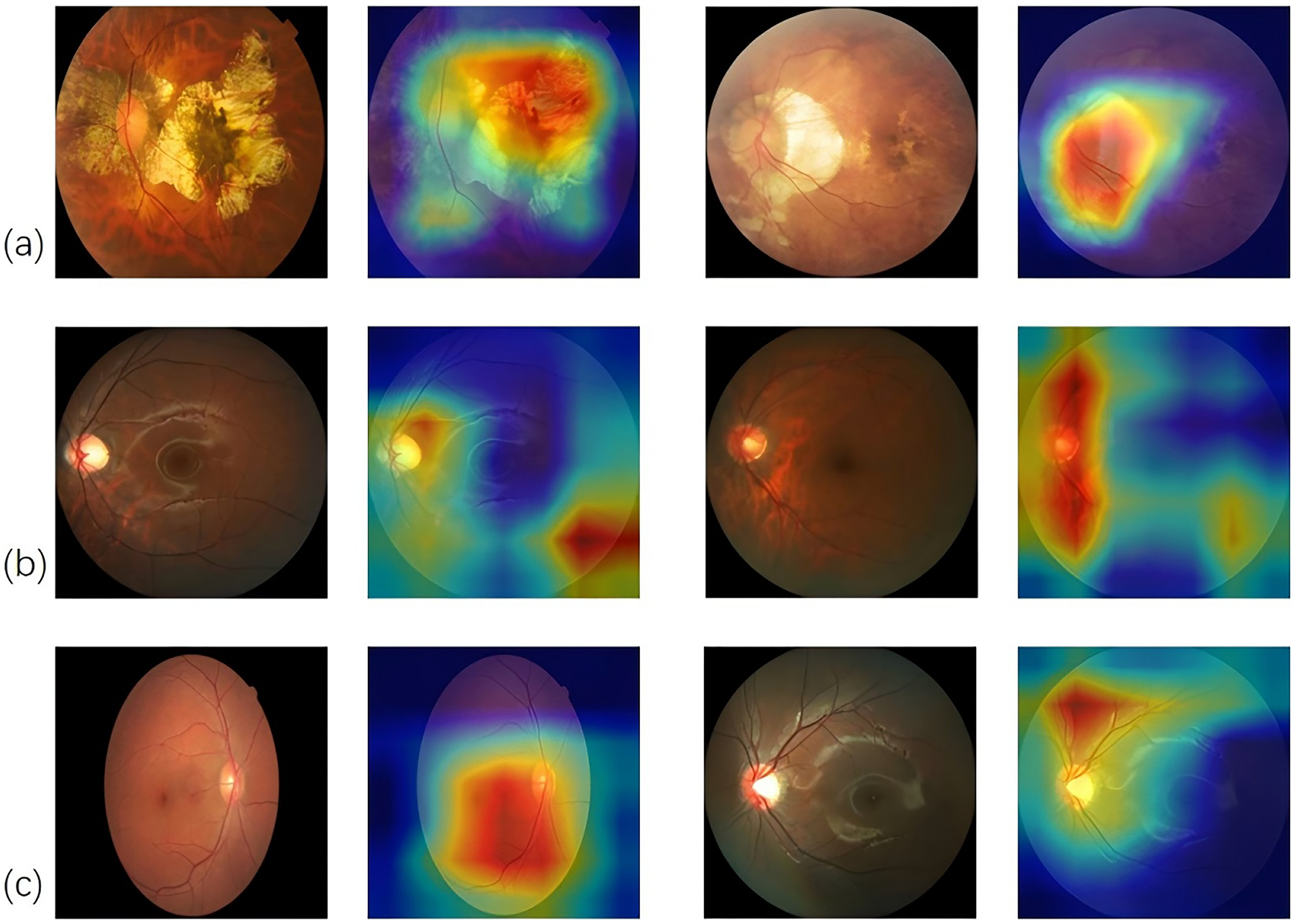
Interpretability heatmap of OptiFocus module on three categories of fundus images: (a) pathological myopia, (b) myopia, and (c) normal.
Dynamic weight aggregation strategy based on GA FedProx_GA
To address the problem of data heterogeneity, this study proposes an improved FL algorithm. The algorithm introduces a dynamic weight aggregation strategy based on FedProx, and optimizes the client contributions by GA, so as to improve the performance of the model in heterogeneous data environments. The FedProx algorithm mitigates the model bias problem caused by the data not independently and identically distributed (Non-IID) by introducing a proximal term (proximal term), and its local objective function is defined as:

The introduction of the FedProx algorithm enables the training of models on multiple heterogeneous clients and the effective integration of the knowledge from each client through a global aggregation strategy, thus realizing the accurate classification of cross-device and cross-distribution medical images. In traditional FL frameworks, the FedAvg algorithm and the FedProx algorithm use the sample size
After client evaluation, a dynamic selection strategy is adopted in order to optimize client weight allocation. Selection in GAs refers to deciding which individuals are retained and used for reproduction based on fitness. In FL, the selection process determines which clients’ models will be used for aggregation. The contribution of each client in the global model training is measured by considering the client’s weight
After each round of training, the models of each client are weighted and aggregated according to the dynamically adjusted weights. The process can be represented as:

All training follows a synchronous client sampling protocol: in each communication round, the server broadcasts the current global model to all participating clients, waits for their local training completion, and then aggregates the received updates. A central validation set was constructed and held on the server to guide the federated optimization process. This set was created by uniformly sampling a small, stratified portion of data from each client’s local dataset prior to the initiation of federated training. This central validation set serves two critical purposes: (1) to evaluate the performance of candidate global models during the GA-based weight optimization in FedProx_GA, providing the fitness metric for different aggregation weight vectors; and (2) to monitor global model convergence and facilitate fair comparison across different aggregation strategies. The use of this centrally held, representative dataset allows for a consistent and unbiased evaluation of the global model’s generalization ability across the heterogeneous client distribution.
The strategy not only takes into account the differences in the amount of client data, but also dynamically adjusts the weights by means of the fitness function and genetic operation, thus effectively improving the performance of the global model and enhancing its robustness in heterogeneous data environments. The core workflow is summarized in Supplemental Algorithm 1.
Dynamic loss function adjustment methods for dealing with category imbalances
Class imbalance in medical image classification arises from varying data distributions across centers, compromising global model training and reducing accuracy for minority classes, which undermines diagnostic reliability. Traditional FL often applies basic oversampling or undersampling, but these can harm generalization or efficiency. To better align with each client’s data distribution and boost global model performance, we introduce a dynamic loss function adjusted by class frequency.
The method adjusts the loss function during training based on the sample frequency of each category in the dataset, thereby automatically mitigating the negative impact of category imbalance on model learning during training. Specifically, by dynamically assigning different weights to each category, the model is made to pay more attention to those categories that account for a relatively small number of samples, thus improving the model’s ability to recognize a small number of categories. The sample frequency for each category is first calculated. For each client


where

where
Result
Study design
This study is designed to simulate a realistic FL scenario across distinct, independent medical institutions. Our framework comprises three federated clients (Clients A, B, and C), each representing a separate, real-world data source with its own patient population, imaging protocols, and clinical practices, not a synthetic partition of a single dataset. This setup captures authentic institutional variation that directly impacts model performance and communication dynamics. This study is based on publicly available datasets from three heterogeneous medical centers and follows relevant usage protocols, comprising a total of 1,279 fundus images. The specific data distribution is shown in Table 1.
Client A: Normal eyes (39%) and pathological myopia (61%). Client A is from the dataset Joint Shantou International Eye Center (JSIEC), which contains 39 categories of fundus images, with data from the JSIEC in Shantou, Guangdong Province, China. The dataset was collected from PACS JSIEC between September 2009 and December 2018. The images were captured using a ZEISS FF450 Plus infrared fundus camera (2009–2013) and a Topcon TRC-50DX mydriatic retinal camera (2013–2018) with a 35°–50° field of view setting. Client B: Normal eyes (40%) and myopia (60%).The Client B dataset was created by Sharmin et al. and described in their paper (https://doi.org/10.1016/j.dib.2024.110979). The data were collected over a period of eight months from Anawara Hamida Eye Hospital and B.N.S.B. Zahurul Haque Eye Hospital. Compared to Client A, Client B focuses primarily on fundus images of myopic eyes. Client C: Normal eye (41.2%), myopia (6.1%), and pathological myopia (52.7%). Client C is from the dataset iChallenge-PM, a medical dataset provided in a competition jointly organized by Baidu Brain and Sun Yat-Sen University Zhongshan Ophthalmic Center. This dataset is dedicated to the classification of myopia-related ophthalmic diseases, particularly pathological myopia, and includes a diverse range of clinical samples.
This multicenter setup introduces a pronounced class imbalance both within and across clients, which is a central challenge for federated model training. The distribution is highly heterogeneous: Client A is dominated by pathological myopia (61%), Client B contains no pathological myopia samples, and Client C has a very small proportion of myopia cases (6.1%) relative to pathological myopia (52.7%). This inter-client Non-IID data distribution can destabilize training by causing client drift, where local updates from clients with skewed distributions pull the global model in conflicting directions. It particularly risks under-representing minority classes (e.g. myopia in Client C) in the global feature space, potentially biasing the model toward the dominant classes in the aggregate data. Our framework’s dynamic aggregation and loss components are designed in part to mitigate these instability and bias issues arising from such imbalance.
Characteristics and distribution of the multicenter fundus image datasets.

Note. NA indicates that the data are not available or were not provided.
Our proposed algorithm has been rigorously validated on the three major datasets. The inclusion criteria for all fundus images are: (1) images are collected using single or dual fields of view; (2) the image has no obvious quality issues, such as severe stains, artifacts, defocusing, blurring, improper exposure, etc., which can affect the clarity of the observed target area. By fully considering the differences in data sources, disease types, and imaging characteristics, we ensure that the proposed method exhibits strong adaptability to cross-domain data and demonstrates excellent generalization capability.
This study was conducted and reported in accordance with the Standards for Reporting Diagnostic Accuracy Studies (STARD) guidelines. A completed STARD checklist is provided as Supplemental Table S1.
Evaluation of classification models
The training of our algorithm was conducted on a high-performance computing node equipped with an NVIDIA RTX A6000 GPU (48 GB VRAM). All experiments were implemented using Python 3.12.2 and the PyTorch 2.8.0 deep learning framework. The training configuration of our algorithm is as follows: the number of communication rounds is set to 40, the number of epochs for local training is 50, the batch size of each round is 64, the optimizer chooses the stochastic gradient descent algorithm and sets the initial learning rate to 0.001, and the proximal term constraint

Receiver operating characteristic (ROC) curves and confusion matrices for aggregated models tested on all data.

Convergence curves of different federated learning algorithms on the test set.
Detailed per-class performance metrics of the proposed model.

The independent performance of each client’s test set is shown in Figure 5. For Client A, the model demonstrates comparable performance in distinguishing pathological myopia and normal eyes, with AUC values both exceeding 0.98.

Receiver operating characteristic (ROC) curves and confusion matrices for each of the three clients tested separately (left: Client A; center: Client B; right: Client C).
For Client B, the AUC for myopia cases is slightly lower than that for normal eyes, indicating that the model is capable of drawing relatively clear decision boundaries. Client C includes three categories, among which the AUC for myopia (0.92) is lower than that for pathological myopia and normal eyes (both around 0.99). This is mainly attributed to the scarcity of myopic samples and confusion between categories. Specifically, there are only 19 cases of myopia, compared to 165 cases of pathological myopia. With myopic cases representing only 6.1% of the dataset, it is difficult to cover the full range of diopter levels and associated complications. Furthermore, there is a partial overlap in fundus imaging features between myopia and pathological myopia, such as optic disc tilt and tessellated fundus. As a result, the few myopic samples are likely to be overwhelmed by pathological features, leading the model to classify ambiguous cases as pathological myopia. Across all clients, AUCs for normal eyes are consistently close to 0.99, indicating the model’s ability to effectively distinguish between healthy and diseased eyes.
Further analysis reveals that cross-domain feature differences are one of the key factors contributing to model performance variability and class confusion. To assess the algorithmic fairness and potential performance disparities of our FL model, we conducted a comparative analysis across demographic subgroups. Given the geographic provenance of our datasets, we used client membership as a proxy for demographic groups: East Asian (Clients A and C, primarily Chinese) and South Asian (Client B, Bangladeshi) populations. In general, East Asian populations tend to have smaller optic discs (average 1.2 mm
The larger optic disc areas commonly observed in South Asian populations may cause the model to misjudge the degree of optic disc tilt. As a result, what is considered a normal optic disc in Client B may be interpreted as abnormal according to the criteria used in Clients A and C. Despite these differences, the model proposed in this study maintains high AUC values across datasets from diverse demographic groups, and the performance gaps are relatively small. By employing data augmentation, standardization of fundus features, and techniques such as class balancing and weighted loss functions, the model effectively identifies optic disc characteristics and pathological changes across populations. The experimental results show that the model exhibits significant robustness in heterogeneous data scenarios. Despite the differences in data distribution among participating nodes, the model is able to effectively adapt to different data characteristics and maintain high performance. Such performance demonstrates the feasibility of the FL approach to (1) accurately identify and classify normal eyes, myopia, and pathological myopia, thus allowing for guiding downstream interventions; and (2) handle cross-institutional collaborative tasks, especially in the field of ophthalmology AI, which is able to cross the data barriers of different medical centers, promote multi-party collaboration, and share the model knowledge so as to enhance the model’s generalization ability and accuracy.
Comparative experiments
To validate the effectiveness of the proposed method, we compare it with centralized training. In the centralized setting, all data are stored and processed in a unified location, and the model achieves a maximum AUC of 0.9934 on the test set. This approach can fully exploit the entire dataset and is generally regarded as a reference for the upper bound of model performance. However, centralized training carries the risk of data privacy breaches. Moreover, in large-scale distributed data scenarios, data collection and storage can be costly, and data transmission may suffer from latency and security concerns. In contrast, the FL framework proposed in this study achieves classification performance comparable to that of centralized training, while ensuring data privacy protection.
The comparison of this paper’s algorithm with other traditional FL algorithms is shown in Figure 6 and Table 3. Although the FedAvg and FedProx algorithms are able to maintain better performance as standard FL aggregation algorithms, they are inferior to the complete scheme designed in this paper in terms of task-specific optimization. Figure 6 is used to visualize the results of the comparison.

Comparative performance evaluation of different federated learning algorithms.
Results of comparative experiments.

AUC: area under the curve; ROC: receiver operating characteristic.
The FedAvg algorithm is susceptible to variations in client data distributions during the model update process, resulting in slower convergence and a noticeable decline in performance when dealing with Non-IID data. It struggles to effectively learn features from minority classes. Although it maintains relatively high overall accuracy and AUC values, its performance in terms of sensitivity and specificity is comparatively weaker.
In contrast, the FedProx algorithm introduces an additional regularization term, which improves training stability to a certain extent. In our experiments, FedProx achieved an accuracy of 0.9261 and an AUC–ROC of 0.9834, an improvement over FedAvg. However, it still falls short across multiple evaluation metrics when compared to the model proposed in this study.
It is worth noting that the choice of the
To further validate the superiority of our approach, we compared it with two more recent FL algorithms: FedNova and FedOpt. FedNova, which normalizes local updates to mitigate client drift, achieved the highest accuracy (0.9370) among all compared methods. However, its performance on other critical clinical metrics was inconsistent, with lower AUC–ROC (0.9815), sensitivity (0.9181), and specificity (0.9555) values compared to our method. This suggests that while FedNova improves aggregation efficiency, it may not optimally handle the complex feature relationships essential for fine-grained medical image classification. On the other hand, FedOpt, which utilizes adaptive optimizers on the server side, performed similarly to FedAvg with an accuracy of 0.9177 and AUC–ROC of 0.9793, but lagged significantly in sensitivity (0.9026) and specificity (0.9492). This indicates that adaptive server optimization alone is insufficient to address the challenges posed by heterogeneous ophthalmology data. In comparison, our proposed method demonstrates more balanced and robust performance across all evaluation metrics, achieving the highest AUC–ROC (0.9889), sensitivity (0.9346), and specificity (0.9673), which are particularly crucial for clinical diagnostic applications where both identifying true positives and ruling out false positives are equally important.
We define one communication round as the server broadcasting the global model to all selected clients and subsequently receiving their updated local models to evaluate communication efficiency. The primary communication cost is thus proportional to the size of the model parameters and the number of clients per round. Our aggregation strategy aims to achieve higher accuracy with fewer rounds, thereby improving overall efficiency. The convergence behavior of our proposed framework, compared to FedAvg and FedProx, is depicted in Figure 4. Our method demonstrates a steeper initial ascent and reaches a higher performance plateau within the 40 communication rounds, indicating faster and more stable convergence. For instance, our model achieved 90% of its final accuracy by round 15, whereas FedAvg required 30 rounds. This highlights the effectiveness of our dynamic aggregation strategy in steering the global model toward a superior optimum more efficiently.
To isolate the individual contribution of each core component in our proposed framework, we conducted a series of ablation studies. The performance of different configurations was compared on the same test set by systematically removing or replacing specific modules. The results (see Supplemental Table S2) demonstrate that all components contributed positively to the final performance. The OptiFocus module directly enhances feature representation by applying a distance-aware spatial attention mechanism, which forces the model to weigh local lesion regions (e.g. the macula) more heavily than surrounding tissue. This leads to more discriminative features for subtle pathologies, directly improving per-class specificity. In contrast, the GA-inspired dynamic aggregation operates at the system level to manage client heterogeneity. By treating client weights as evolvable parameters and using loss or accuracy as a fitness function, it iteratively finds a weighting scheme that maximizes global model performance. This leads to more stable convergence and a better aggregated model. Together, OptiFocus improves what the model sees (feature discriminability), while the GA strategy improves how client knowledge is combined (robust aggregation), resulting in the superior final performance.
Discussion
The FL framework proposed in this study successfully solves the problem of multicenter heterogeneity and category imbalance under the protection of data privacy, and provides new ideas for intelligent diagnosis of ophthalmic diseases. First, by optimizing client contributions through a dynamic weight aggregation strategy (FedProx_GA), the model maintains a high generalization ability despite cross-center data distribution differences. This strategy operates by evaluating each client’s contribution based on its local performance, effectively down-weighting updates from clients with potentially noisier or more divergent distributions, thereby steering the global model toward a more robust consensus. For instance, the specificity in Client A, which is dominated by pathological myopia, reaches 0.972, which is significantly better than that of the traditional FedAvg algorithm (AUC improvement of 1.27%). Second, the OptiFocus attention module strengthens the ability to capture subtle features such as macular lesions through a distance-aware mechanism, resulting in a specificity of 0.9673 for pathological myopia, which outperforms the traditional Squeeze-and-Excitation (SE) module. In addition, the dynamic loss function adjusts the weights according to the category frequency, which improves the recall of a few categories (pathological myopia) by 12%, and effectively mitigates the training bias caused by sample scarcity. Experiments show that the classification performance of this framework is close to the upper limit of centralized training under privacy-preserving conditions (AUC difference < 0.005), which validates its feasibility in clinical multicenter collaboration.
However, this study still has some limitations. First, the Non-IID nature of data across institutions introduces potential bias in the global model. Each client’s dataset exhibits distinct statistical characteristics due to variations in patient demographics, disease prevalence, and imaging protocols. For instance, Client A is dominated by pathological myopia cases from specific populations, while Client B contains different disease distributions. This statistical heterogeneity may lead to biased global model parameters that favor dominant data distributions, potentially compromising performance on underrepresented populations or rare disease subtypes. Second, federated training incurs inevitable communication latency. While effective, our aggregation approach requires synchronous communication, which can slow convergence if any client experiences delays or connectivity issues. This limitation becomes more pronounced as the number of participating institutions increases in real-world deployment scenarios. Third, the challenge of model personalization in ophthalmology remains inadequately addressed. A single global model may not optimally serve all institutions, particularly when local patient demographics, equipment specifications, or clinical practices differ significantly. The current framework does not fully address the need for site-specific adaptations while maintaining the benefits of collaborative learning. Additionally, the relatively small aggregate dataset size (1,279 images), while common in initial FL feasibility studies, remains a constraint. This not only limits the statistical power to validate generalizability but also increases the potential risk of the global model overfitting to idiosyncrasies of the participating client distributions rather than learning broadly applicable features. More medical centers need to be included in the future to validate the model’s generalizability. The differences in the annotation standards of different centers may also affect the model’s performance, and semi-supervised FL can be combined in the future to reduce the dependence on the annotation consistency. Furthermore, the GA increases the computational complexity even though it improves the aggregation efficiency, and an asynchronous federation architecture or a lightweight optimization strategy should be explored to adapt to edge devices.
Moreover, although the dynamic loss function partially alleviates class imbalance, potential biases introduced by unbalanced distributions require deeper investigation. For example, the model may still exhibit reduced sensitivity to minority classes (e.g. myopia in Client C) due to their limited representation in the global feature space. Future work should explore true minority-class augmentation techniques, such as federated generative adversarial networks or differential privacy-safe synthetic data generation, to create more balanced training sets without compromising privacy. In addition, integrating multimodal data could further enhance diagnostic accuracy and robustness. Combining fundus images with OCT, patient history, or genetic information could provide complementary insights and improve the challenge of distinguishing between diseases where anatomical differences are minimal or exist on a continuum. Developing multimodal FL frameworks that efficiently and privately integrate diverse data types represents a critical direction for future research. Other promising directions include: (1) extending the framework to multi-disease joint diagnosis tasks, such as glaucoma and AMD; (2) designing lightweight federation frameworks to reduce computational overhead and facilitate clinical deployment.
Conclusion
In this study, we developed and validated a novel FL framework enhanced by a dynamic aggregation strategy and the OptiFocus attention module, for the classification of normal, myopic, and pathological myopic fundus images across multicenter datasets. Our approach effectively mitigates the challenges posed by data heterogeneity and class imbalance while maintaining strict data privacy. The results demonstrate that the proposed method achieves performance comparable to centralized training and outperforms several existing FL baselines, highlighting its potential as a robust and privacy-preserving solution for collaborative ophthalmic AI.
This framework demonstrates clear potential for integration into real-world multicenter ophthalmology workflows. For instance, it could be deployed as a cloud-assisted or edge-computing diagnostic support system, enabling geographically dispersed clinics or screening camps to collaboratively improve a shared model without transferring sensitive patient data. Such a system would assist in large-scale screening efforts, prioritization of referrals, and consistency in diagnosis across different healthcare providers.
This work provides a solid technical foundation and a valuable reference for secure multi-institutional collaboration in medical AI. However, its translation into routine clinical practice necessitates further validation through larger-scale, prospective multicenter studies and continuous refinement of the framework. Future extensions will focus on scaling the framework with larger and more diverse international datasets to improve generalizability, and on exploring the integration of multimodal data, such as combining fundus images with OCT scans and patient metadata, to build a more comprehensive and clinically informative diagnostic assistant. We believe that this research represents a meaningful step forward in bridging the gap between advanced FL techniques and real-world clinical applications in ophthalmology.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076261426324 - Supplemental material for A federal learning-driven artificial intelligence framework for fundus image myopia diagnosis
Supplemental material, sj-docx-1-dhj-10.1177_20552076261426324 for A federal learning-driven artificial intelligence framework for fundus image myopia diagnosis by Xiaolong Yin, Chunhong Yu, Weiwei Xiong and Yujun Liao in DIGITAL HEALTH
Footnotes
Acknowledgements
We thank all patients who participated in this study. The authors thank the Second Affiliated Hospital of Nanchang University for providing the instrumentation and technical support.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Contributorships
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical approval
This study uses publicly available datasets that have been previously collected and anonymized by their respective providers. As no new human participants were recruited, and no identifiable personal data were used or collected in this study, ethical approval was not required. All data used comply with the terms and conditions set by the original data sources.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Data availability
The data used in this study derive from three distinct sources: Client A: Data are from the JSIEC dataset and can be accessed at the following URL: https://www.kaggle.com/datasets/linchundan/fundusimage1000, which includes 39 categories of ocular fundus diseases. More information can be obtained from the paper available at https://www.nature.com/articles/s41467-021-25138-w. Client B: Data are from the dataset created by Sharmin et al. (https://doi.org/10.1016/j.dib.2024.110979), which comprises 5335 fundus images collected over eight months from Anawara Hamida Eye Hospital and B.N.S.B. Zahurul Haque Eye Hospital in Faridpur, Bangladesh. The dataset is publicly available on Mendeley Data with direct URL https://data.mendeley.com/datasets/s9bfhswzjb/1. Client C: Data are from the iChallenge-PM dataset, a medical dataset provided in a competition jointly organized by Baidu Brain and Sun Yat-Sen University Zhongshan Ophthalmic Center. This dataset is dedicated to myopia-related ophthalmic disease classification and can be accessed through the competition’s official platform ![]() (registration and approval required). All datasets were used in compliance with their respective licensing and access policies. Details on data usage agreements and access procedures are available from the corresponding authors upon reasonable request.
(registration and approval required). All datasets were used in compliance with their respective licensing and access policies. Details on data usage agreements and access procedures are available from the corresponding authors upon reasonable request.
Supplemental material
Supplemental materials for this article are available online.