
Abstract
Background
Large language models (LLMs) are increasingly used in medical education, but their performance and reliability on mechanistically demanding topics like acid–base interpretation are unclear.
Methods
We conducted a cross-sectional head-to-head evaluation of three LLMs (ChatGPT, DeepSeek, Perplexity) using 75 textbook acid–base cases related to management and drug treatment. One obsolete case was excluded, leaving 74 vignettes (29 metabolic, 10 respiratory, 35 mixed) that generated 510 multiple-choice questions (MCQs). Each MCQ was mapped to case category, one of seven cognitive domains, and one of four distractor-based difficulty bands. All questions were posed via public web interfaces in two independent phases (Phase I and II). Primary outcome was accuracy (proportion correct); consistency outcomes were identical answers across phases and reproducibly correct answers (correct in both phases).
Results
Overall accuracy was 59.8% (305/510) for ChatGPT, 58.8% (300/510) for DeepSeek, and 53.7% (274/510) for Perplexity (Cochran’s Q p = 0.16); ChatGPT and DeepSeek each outperformed Perplexity (p = 0.0086 and p = 0.0374). In metabolic cases (164 items), Perplexity scored 50.6% versus 60.4% and 62.8% for ChatGPT and DeepSeek. Accuracy was highest for compensation/expected response (116 items; 70.7% for ChatGPT and DeepSeek, 62.1% for Perplexity) and lowest for metabolic acidosis subtypes (59 items; 52.5%, 42.4%, 32.2%). Accuracy declined with difficulty, with Perplexity significantly lower than the other models in moderate–hard and hard bands. Identical answers across phases occurred in 81.7% of items for ChatGPT, 81.1% for DeepSeek, and 76.1% for Perplexity, but reproducibly correct answers were 52.1%, 48.8%, and 43.2%.
Conclusions
ChatGPT and DeepSeek showed moderate performance and generally higher accuracy than Perplexity. Stable repeated errors despite only moderate reproducibly correct responses support cautious interpretation of LLM outputs and argue against their use as stand-alone tools for acid–base learning or clinical decision making of management and drug treatment .
Keywords
Introduction
Large language models (LLMs) are increasingly being integrated into healthcare and medical education, where they are promoted as tools that can streamline documentation, augment decision making, and provide interactive tutoring for students and clinicians. 1 Recent work has shown that systems such as ChatGPT can reach or exceed passing thresholds on high-stakes licensing examinations like the United States Medical Licensing Exam (USMLE), reinforcing the perception that these models possess clinically useful knowledge. 2 At the same time, medical LLMs are vulnerable with incorrect statements that pose safety risks when users over-trust their outputs in clinical contexts.
Acid–base disorders represent a particularly important and challenging domain in medical training, and many learners seek assistance from online and other digital resources when studying these problems. 3 These disturbances are common across internal medicine, nephrology, emergency medicine, and critical care, and they often signal life-threatening conditions such as lactic acidosis, toxin ingestions, or complex mixed metabolic–respiratory states.3,4 Correct management demands a systematic, stepwise interpretation of arterial blood gases and serum chemistries, including identification of the primary disorder, assessment of expected compensation, and evaluation for mixed patterns. 5 Educational strategies therefore frequently employ structured clinical vignettes and multiple-choice questions that require learners to work through each interpretive step, yet it remains uncertain how well contemporary LLMs can support this kind of detailed, domain-specific reasoning.6,7
Most published evaluations of LLMs in medicine have taken a broad view, examining performance on large, multi-system examination banks or full licensing exams that mix basic science, organ-based pathophysiology, and clinical management questions. 8 These studies demonstrate impressive overall accuracy but typically summarize results at the exam or discipline level, with limited analysis of specific mechanistic subdomains such as acid–base interpretation. In parallel, model families like DeepSeek have been proposed as high-reasoning systems for medical question answering, with detailed analyses suggesting strong diagnostic accuracy but highlighting ongoing challenges in aligning model reasoning with expert judgment. 9 Perplexity, by contrast, positions itself as a “cited answer engine” that layers retrieval over LLMs to deliver concise, reference-backed responses for research and professional use. 10 Direct head-to-head comparison of these different design philosophies on a single, standardized set of acid–base cases has not yet been reported.
Recent evidence suggests that prompt structure and instruction style can significantly influence the accuracy, relevance, and reliability of LLM outputs in clinical settings. 11
In parallel, recent domain-specific evaluations in digital medicine have shown that LLM performance may vary substantially across specialized medical question sets, highlighting the importance of context-specific benchmarking.12,13 Transparent reporting of prompting procedures is therefore important for the interpretation, reproducibility, and fair comparison of comparative LLM studies.
LLMs in healthcare need to be accurate and also give steady answers over time. If the same or a similar question gets different answers on different days this can confuse learners and may put patients at risk. Because of this recent work looks beyond single test accuracy and measures how consistent the models are and how often they repeat the same answer and how often they hallucinate.14,15 This shows that reliability is more than just getting one question right once. The present study therefore aimed to evaluate the performance of three widely accessible LLM assistants—ChatGPT, DeepSeek, and Perplexity—on a comprehensive collection of 75 acid–base disturbance cases encompassing metabolic, respiratory, and mixed disorders. Across the 510 associated multiple-choice questions, mainly related with clinical management and drug treatment, we compared overall accuracy between models, examined domain-level performance for key interpretive steps (baseline status, primary disturbance, anion gap, metabolic acidosis subtype, compensation, laboratory interpretation, and mixed or other disorders), and explored how performance varied across distractor-defined difficulty levels. In addition, by repeating the full question set in a second independent run for each model, we assessed within-model response consistency and the proportion of answers that were reproducibly correct.
Methodology
Study design and data source
We performed a cross-sectional benchmarking study of three LLM assistants on a fixed set of expert-written acid–base multiple-choice questions. The dataset was drawn from Critical Concept Mastery Series: Acid-Base Disturbance Cases which contains 75 clinical vignettes of acid–base disturbances each followed by several single-best-answer questions. 16 The benchmark was derived from an existing expert-authored educational case resource rather than a newly developed questionnaire or survey instrument. The source was accessed through the Saudi Digital Library via AccessMedicine. All model interactions used the public web interfaces of ChatGPT, DeepSeek, and Perplexity. All model interactions were performed in October 2025 using the unpaid public web interfaces of ChatGPT (GPT-5; fallback GPT-5 mini), DeepSeek (DeepSeek-V3.2-Exp), and Perplexity (default free model). Each question was posed to all three models in two independent phases—an initial run (Phase I) and a re-run (Phase II) to allow assessment of both accuracy and response consistency.
Data availability
The benchmark items were derived from the subscription-access source described above. As the original clinical case vignettes and MCQ texts are third-party copyrighted material, they are not reproduced verbatim in the article or supplementary files without permission from the rights holder. Researchers with lawful access to the source material can reconstruct the benchmark and verify the study procedures and findings.
Case classification
For subgroup analysis, we manually classified each vignette in Critical Concept Mastery Series: Acid–Base Disturbance Cases according to its overall acid–base pattern based on arterial blood gases, serum electrolytes, anion gap (corrected when needed), and clinical context. Cases were placed into three mutually exclusive groups: metabolic acid-base disorder, respiratory acid-base disorder, or mixed acid-base disorder. One vignette (Case 45) was excluded as obsolete, leaving 74 cases for analysis by case type.
Question selection
All multiple-choice questions attached to the acid–base cases were screened for inclusion. We included items that (1) had a clearly specified correct option(s) in the answer key, (2) could be represented fully in text without requiring additional images or external material, and (3) were directly related to interpretation or management of the acid–base disturbance in the vignette. Questions that were duplicated, ambiguous, not clearly linked to a single best answer, or lacking an answer key were excluded. After applying these criteria, 510 unique questions formed the primary dataset for accuracy analyses. For the consistency analyses, we used the full set of 510 questions that were answered by all three models in both Phase I and Phase II. Because the benchmark used existing expert-written items we did not develop a separate questionnaire. Instead we defined content coverage using the inclusion criteria and item mapping by case type and cognitive domain.
Question mapping to domains
Each question was assigned to one primary “mapping category” that reflected the main cognitive step required to reach the answer. The seven categories were: baseline status (overall acidemia or alkalemia and the general acid–base pattern), primary disturbance, anion gap, metabolic acidosis subtype, compensation or expected response, laboratory interpretation and drug treatment (such as electrolytes, osmolal gap, lactate, or ketones), and mixed or other disorders (including identification of mixed patterns or specific diagnoses).
Difficulty grading
To explore performance across levels of item difficulty, we graded each question according to the plausibility of the distractors. Items with clearly implausible alternative options were considered easier, whereas items with several clinically plausible alternatives were considered more difficult. Based on this rubric, questions were grouped into four bands: easy/low–moderate, moderate, moderate–hard, and hard. This process yielded 5 easy/low–moderate, 214 moderate, 213 moderate–hard, and 76 hard questions (508 total with difficulty labels; two items were not assigned a difficulty rating but were retained for the main accuracy analyses). Difficulty grading was performed independently by two authors with subsequent consensus review.
Prompting procedure and data collection
For each item we used a standardized prompt with the case stem, laboratory values, and all options asking the model to choose the single best answer only.
The task given to the models was a forced-choice multiple-choice task rather than an open-ended request to generate a diagnosis, management plan, or free-text clinical analysis. Depending on the item, the required reasoning could involve interpretation of the acid-base disorder, identification of the primary disturbance, anion gap analysis, compensation assessment, laboratory interpretation, or selection of the best option related to diagnosis or management.
Each question was entered into a fresh chat session for each model in both Phase I and Phase II, with identical wording and option order, and no prior question context was carried over between items to minimize memory effects and cross-question interference. After completing all questions once, we repeated the full process after a washout period. Model outputs were recorded as option letters. Free-text responses were mapped to the corresponding multiple-choice option when the selected answer was stated explicitly or could be matched unambiguously to a single option. Responses that selected more than one option, contained conflicting final answers, or could not be mapped unambiguously to a single choice were scored as incorrect. Correctness was assessed independently by two authors against the source answer key, and any discrepancies were resolved by a third author.
Outcomes
The primary outcome was accuracy, defined as the proportion of questions each model answered correctly across the 510-item set, with results also examined by case category (metabolic, respiratory, mixed), mapping category, and difficulty band. For consistency, we compared Phase I and Phase II responses for each model on 510 questions and, for every question–model pair, classified the pattern as both correct, Phase I correct/Phase II wrong, Phase II correct/Phase I wrong, both wrong with the same option, or both wrong with different options. From these patterns we calculated total agreement (the proportion of items with either both correct or the same wrong option) and reproducible correct answers (the proportion of items answered correctly in both phases).
Statistical analysis
Descriptive statistics were used to summarize the number and proportion of correct answers for each model overall and within subgroups. The primary inferential analysis compared overall accuracy across the three models on paired questions using Cochran’s Q test. Prespecified pairwise head-to-head comparisons for the primary outcome were performed using McNemar tests with Holm correction applied across the three pairwise comparisons. For the primary pairwise overall comparisons, effect sizes were reported as absolute differences in accuracy expressed in percentage points
Results
The data source contained 75 case studies. One case study was considered obsolete because it did not meet the inclusion criteria. The remaining 74 case studies were divided into three acid base subtypes i.e., There were 29 metabolic disorder cases and 10 respiratory disorder cases and 35 mixed acid base disorder cases. The 74 vignettes together generated 510 multiple choice questions that met all inclusion criteria. Of these questions 164 were linked to metabolic cases and 48 to respiratory cases and 298 to mixed cases. Questions were not spread evenly across cases. The number of questions per case ranged from 4 to 10 with a mean of about 7 questions.
Overall model accuracy
Accuracy of ChatGPT, DeepSeek, and Perplexity on acid–base MCQs overall and stratified by case category and question domain.
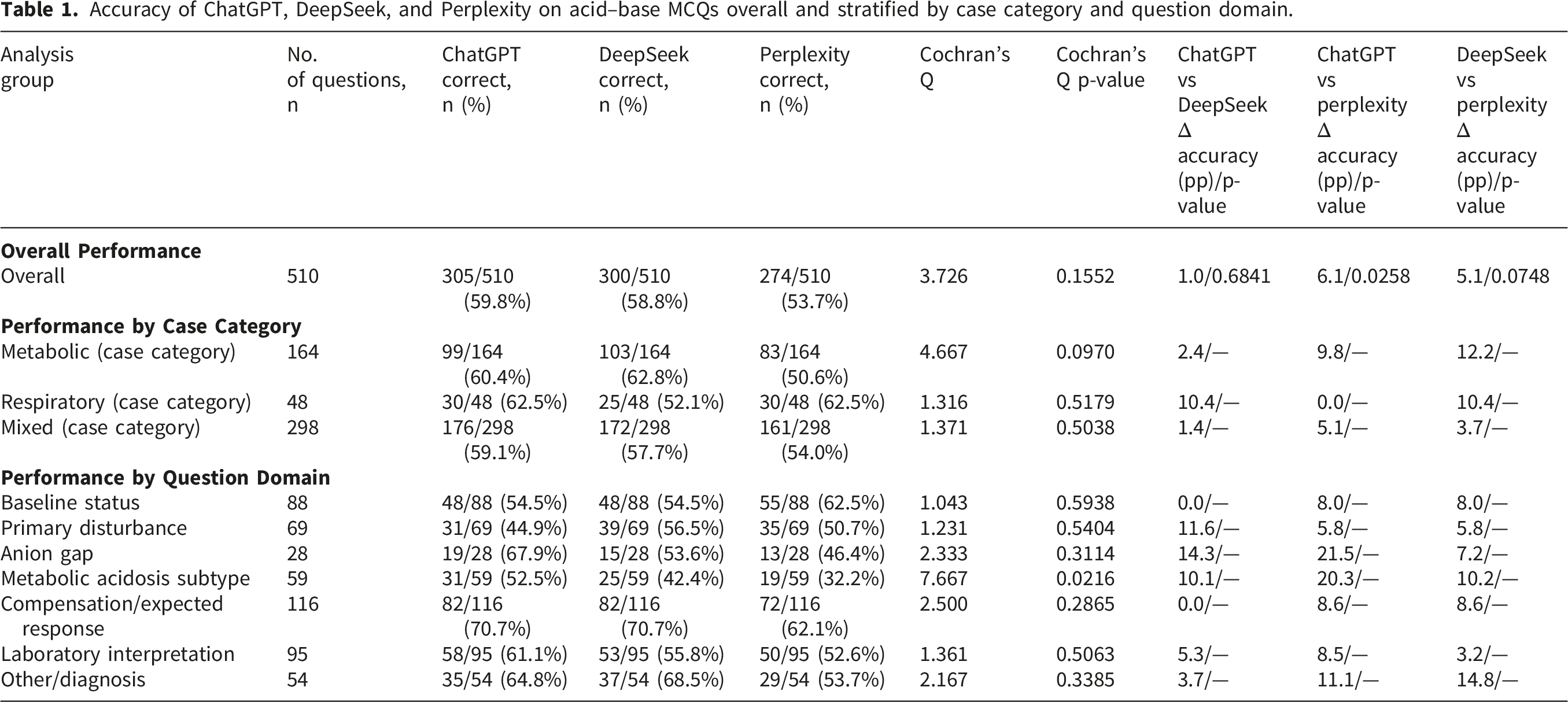
Accuracy by case category
Accuracy of ChatGPT, DeepSeek, and Perplexity across acid–base case categories and MCQ question domains, with pairwise McNemar comparisons.

Accuracy by mapping category
Domain-level accuracy varied across mapping categories as illustrated in Figure 1. For borderline status questions (88 items) accuracy was 54.5% for both ChatGPT and DeepSeek and 62.5% for Perplexity. For primary disturbance questions (69 items) accuracy was 44.9% for ChatGPT 56.5% for DeepSeek and 50.7% for Perplexity. For anion gap questions (28 items) accuracy was 67.9% for ChatGPT 53.6% for DeepSeek and 46.4% for Perplexity. In contrast all three models performed less well on metabolic acidosis subtype questions (59 items) with accuracies of 52.5% for ChatGPT 42.4% for DeepSeek and 32.2% for Perplexity. As these domain-level comparisons involved multiple testing and some small subgroup sizes they were interpreted descriptively rather than as confirmatory findings. Heat map of model accuracy for acid-base MCQs across question domains for ChatGPT, DeepSeek, and Perplexity.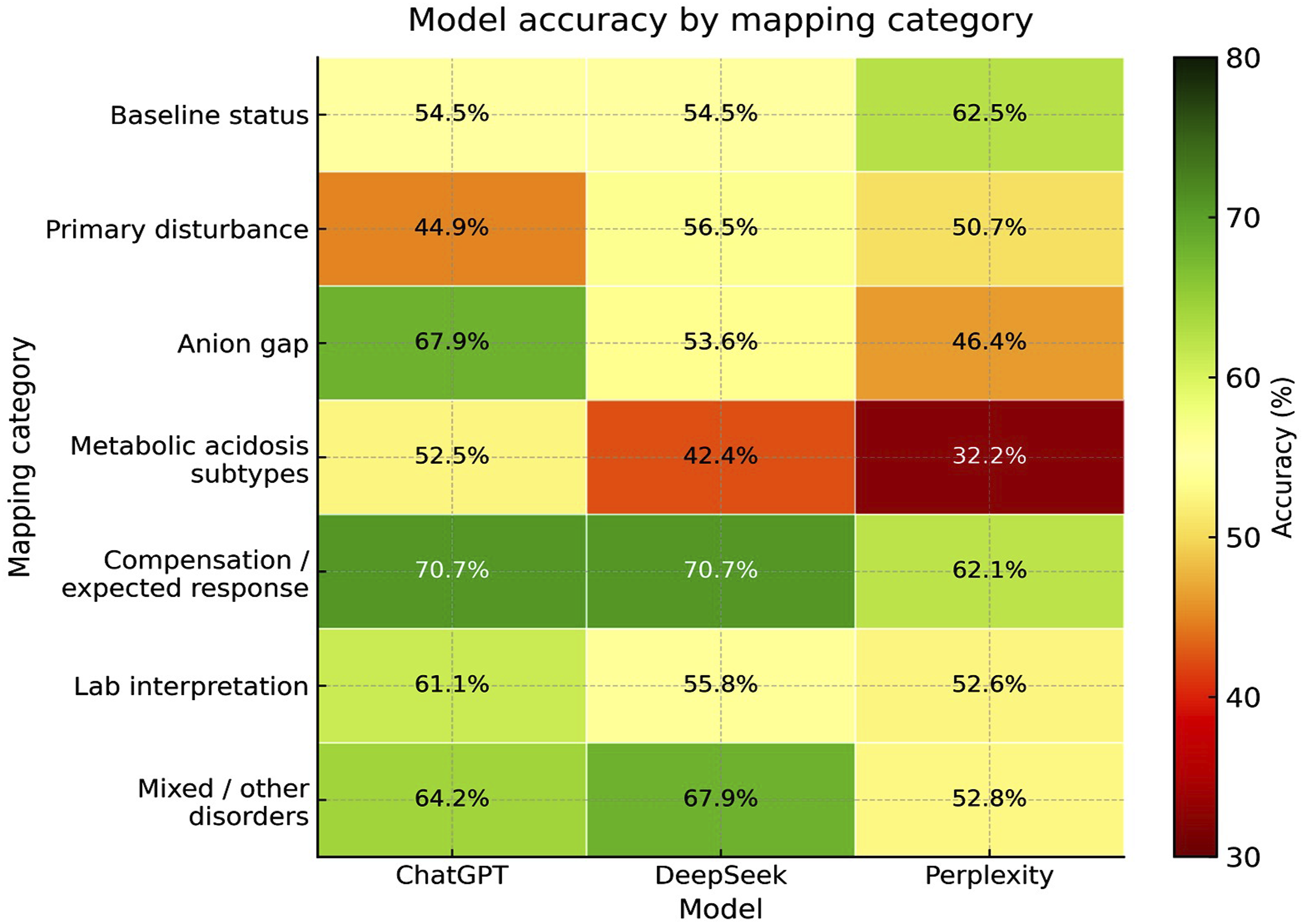
Accuracy was highest for compensation or expected-response questions with 70.7% for both ChatGPT and DeepSeek and 62.1% for Perplexity across 116 items. Accuracy for laboratory interpretation questions was more moderate with 61.1% for ChatGPT 55.8% for DeepSeek and 52.6% for Perplexity across 95 items. For other or diagnosis questions across 54 items ChatGPT and DeepSeek again showed higher numerical accuracy than Perplexity at 64.8% 68.5% and 53.7% respectively. As these domain-level analyses were exploratory these findings are presented descriptively. Additional domain-level values are shown in Table 2.
Accuracy across difficulty levels
Descriptive accuracy of ChatGPT, DeepSeek, and Perplexity across distractor-plausibility difficulty levels by acid–base case category.

Response consistency between phase I and phase II
Consistency analysis included all 510 items answered in both phases and is summarized in Figure 2(a). Response patterns were highly stable between Phase I and Phase II with total agreement rates of 81.7% for ChatGPT 81.1% for DeepSeek and 76.1% for Perplexity. Absolute accuracy changed only modestly between the two runs for each model. This suggests limited variability under the applied prompting conditions. Reproducibly correct answers provided a stricter measure of reliability with correct responses in both phases for 52.1% of questions in ChatGPT 48.8% in DeepSeek and 43.2% in Perplexity as shown in Figure 2(b). The gap between total agreement and reproducibly correct responses indicates that a substantial proportion of stable answers were consistently wrong. Consistency and reproducibility of Phase 1 and 2 (re-run) responses for ChatGPT, DeepSeek, and Perplexity on acid-base imbalance management cases (a) Summary table (b) Radar plot of reproducible correct answers.
Discussion
In this benchmarking study we evaluated three widely accessible LLM assistants on a focused set of expert-written acid–base disturbance cases. Across all 510 questions, ChatGPT and DeepSeek showed similar overall accuracy just under 60%, while Perplexity performed less well at about 54%. This pattern was most pronounced in metabolic cases, where Perplexity trailed ChatGPT and DeepSeek by roughly 10–12 percentage points, whereas performance in respiratory and mixed cases was broadly comparable. Domain-level analyses showed that all three models performed best on compensation or expected response questions and on basic anion gap interpretation, but accuracy dropped for metabolic acidosis subtype classification and some diagnostic items. Accuracy also decreased in a graded manner with increasing distractor plausibility, and the largest gaps between models appeared in the moderate–hard and hard difficulty bands, again with Perplexity lagging behind. Consistency analyses revealed that answer patterns were highly stable between Phase I and Phase II, with identical responses on about four out of five questions for each model. However, only about half of all items were answered correctly in both phases, indicating that many errors were not random but were reproduced consistently.
Our overall accuracy estimates fall in the middle of what has been reported for LLMs in medical question-answering. Meta-analyses and umbrella reviews of ChatGPT in medicine describe pooled accuracies around 50–60% on a variety of clinical and educational tasks, with wide heterogeneity between datasets and question formats.17–19 This range aligns closely with the 53–60% accuracy we observed, especially when considering the challenging nature of mechanistic acid–base reasoning. At the same time, some USMLE-style evaluations have reported much higher scores for GPT-4, including accuracy around 80–90% on large sets of Step 1–type questions and across multiple clinical disciplines.2,20 The discrepancy between those higher figures and our more modest performance likely reflects important differences in task design. In USMLE-focused work, ChatGPT has often been evaluated on broad, mixed-topic question banks where many items test recall of facts or relatively straightforward single-step reasoning. For example, Kung et al. reported that ChatGPT performed at or near the 60% passing threshold across USMLE Step 1, Step 2 CK, and Step 3 sample questions, 2 and Mackey and Weingarten found that ChatGPT-4 answered 86% of 1300 Step 1–style questions correctly with no major variation across systems or disciplines. 20 By contrast, our benchmark concentrates on multi-step interpretation of arterial blood gases, anion gaps, compensation, and mixed metabolic–respiratory patterns. In this setting, even small numerical slips or misclassification of mixed disorders can convert an otherwise plausible explanation into an incorrect multiple-choice answer, which may depress overall accuracy despite apparently reasonable reasoning.
In the current study, the non-significant findings were also informative. The absence of a significant overall three-way difference and the limited separation between ChatGPT and DeepSeek in several analyses suggest similar performance under the standardized prompting and unpaid public-interface conditions used here. Some subgroup analyses also included relatively small numbers of items, which may have limited the ability to detect modest differences. As all three models were evaluated without domain-specific fine-tuning or institutional customization, these findings likely reflect baseline rather than optimized performance.
The pattern by case category suggests that topic and case structure influence LLM performance in clinically relevant ways. In our dataset, the three systems behaved similarly on respiratory and mixed acid–base cases, with accuracies on respiratory questions (n = 48) of 62.5% for ChatGPT, 52.1% for DeepSeek and 62.5% for Perplexity, and on mixed cases (n = 298) of 59.1%, 57.7% and 54.0%, respectively. In metabolic cases (n = 164), however, ChatGPT and DeepSeek achieved 60.4% and 62.8% accuracy while Perplexity dropped to 50.6%, creating a gap of about 10–12 percentage points. This is consistent with evidence from broader USMLE-style evaluations where accuracy varies by topic and difficulty. Penny et al. found ChatGPT-4 reached 71.3% overall on 900 AMBOSS questions yet showed significant variation in accuracy across 18 medical topics and a clear decline with higher difficulty, 21 and Alfertshofer et al. reported overall ChatGPT accuracy of 57.7% across 3000 Step 2 CK questions with performance ranging from 71.7% in male reproductive questions to 46.3% in immune system questions. 22 Disease-specific work in other domains has also shown uneven performance, for example ChatGPT responses on thyroid nodules being at least partly correct in 69.2% of questions but with more frequent gaps than in other otolaryngology content. 23 Together, these findings and our metabolic–respiratory–mixed pattern support the view that LLM performance is strongly topic dependent and that model choice may be especially important for metabolically complex acid–base problems.
The domain-level mapping highlights more specific strengths and weaknesses. In our data, compensation or expected-response questions (n = 116) showed the highest accuracy for all three models, with ChatGPT and DeepSeek each answering 70.7% correctly and Perplexity 62.1%. By contrast, metabolic acidosis subtype questions (n = 59) produced the lowest scores and the largest spread, with accuracies of 52.5% for ChatGPT, 42.4% for DeepSeek and only 32.2% for Perplexity. Compensation tasks mainly require application of well-established quantitative rules, such as Winter’s formula or standard expectations for respiratory and renal adaptation, which are widely taught in stepwise acid–base approaches and case-based reviews.24,25 Subtyping metabolic acidosis is more demanding because it requires integration of anion gap calculations with clinical context, recognition of mixed metabolic patterns and discrimination between several plausible etiologies. Similar patterns have been described in other vignette-based evaluations, where LLMs can produce coherent answer explanations but still make systematic errors on multi-step physiologic problems or complex diagnostic chains.26,27 The uneven domain profile in our study, with relatively strong performance on compensation and anion gap interpretation but weak performance on subtype classification, supports these observations and reinforces the need for domain-specific and task-level evaluation rather than relying only on overall accuracy.
The graded decline in accuracy across difficulty bands provides further insight into how these models handle more challenging items. In our dataset, all three systems performed relatively well on easier questions, with ChatGPT and Perplexity each answering 80.0% of easy or low–moderate items correctly and DeepSeek answering 40.0%, and performance on moderate questions remaining similar at 61.2% for ChatGPT, 56.1% for DeepSeek and 59.8% for Perplexity. As distractors became more clinically plausible in the moderate–hard band, accuracy fell to 58.2% for ChatGPT, 62.0% for DeepSeek and 49.8% for Perplexity, and in the hard band to 57.9%, 59.2% and 44.7%, respectively, with Perplexity showing the steepest decline. Difficulty-related gradients have also been documented in other exam-based evaluations: Penny et al. reported that ChatGPT-4 achieved an overall accuracy of 71.3% on 900 AMBOSS USMLE-style questions, yet its performance decreased significantly as AMBOSS hammer difficulty ratings increased, 21 and Newton et al. found that ChatGPT-4o′s scores on medical science examinations fell markedly on novel and more complex items compared with previously released questions. 28 Likewise, an analysis of 2,377 USMLE Step 1 preparation questions showed that ChatGPT’s accuracy was negatively correlated with question difficulty ratings and was lowest in the highest difficulty tiers. 29 Plausible distractors encode realistic diagnostic or management alternatives rather than obviously incorrect options, so errors in these harder bands are likely to reflect deeper reasoning failures rather than superficial recall mistakes. The widening gap between models in our moderate–hard and hard groups therefore suggests that comparisons based only on overall accuracy may underestimate important differences in performance under more demanding, clinically relevant conditions.
The consistency analysis addresses another dimension of reliability. Each model produced identical answers in about 76–82% of question pairs across the two phases, indicating limited stochastic variation under our prompting protocol and relatively stable “preferences” for specific options, a pattern similar to other clinical evaluations where repeated or slightly rephrased prompts yield high internal stability but only moderate agreement with expert standards [8]. Our metric of reproducibly correct answers was more cautious, with only 52.1% of items for ChatGPT, 48.8% for DeepSeek, and 43.2% for Perplexity answered correctly in both phases, in line with studies showing that, although ChatGPT may be consistent, accuracy still varies across prompts and topics and correct answers are not guaranteed even when wording and context are controlled.18,30,31 These reliability patterns have important implications for education and training: learners often treat concordant answers as a marker of trustworthiness, yet several studies suggest that trainees struggle to detect AI-generated hallucinations or subtle clinical inaccuracies, especially when explanations are confident and fluent, 32 and emerging work on medical hallucinations in foundation models indicates that LLMs may generate factually incorrect or weakly supported statements with high apparent certainty that could influence clinical decisions. 33 Commentaries have therefore urged caution in using ChatGPT for biomedical queries noting that fabricated references and decontextualized claims can be difficult even for experienced clinicians to recognize, 34 and in the context of our findings this means that stable but wrong acid–base answers may be particularly hazardous because internal consistency and plausible reasoning can reinforce incorrect mental models in students and junior clinicians.
Despite these concerns, the pattern of performance observed in our study suggests a possible adjunctive role for LLMs in selected acid–base learning contexts, particularly for structured tasks such as compensation calculations, anion gap interpretation and some laboratory-based questions. However, this interpretation should remain cautious because we did not directly test educational effectiveness or compare model performance with that of human learners. A systematic review of AI-generated medical MCQs shows that such items can approach the quality of human-written questions but still require careful review and editing, 35 and experiments with fictional medical content suggest that LLMs can learn consistent internal rules yet continue to make systematic errors on harder problems. 36 This supports a hybrid model for acid–base education in which rule-based calculators handle core computations while LLMs supply narrative explanations and case-based feedback, rather than serving as stand-alone arbiters of correctness.
This study has several strengths, including the use of a single expert-authored source to build a coherent set of 74 acid–base cases and 510 questions, detailed mapping by case type, domain and difficulty, standardized prompting across three LLMs, and a two-phase design that captured both accuracy and stability, addressing methodological gaps noted in recent reviews. Key limitations are that the dataset was drawn from a single expert-authored source using a purposive sampling approach, some subgroup analyses included small numbers of items, and the study used a cross-sectional design based on model performance at one time point. These factors may limit representativeness and generalizability. There was no human comparison group, models were tested via public interfaces that may change over time, and multiple-choice questions cannot fully represent real clinical reasoning, which may differ in open-ended or image-based tasks. Importantly, this study did not directly evaluate educational outcomes or clinical safety. Therefore, any implications regarding educational usefulness or safe deployment should be interpreted cautiously.
Conclusion
Current general-purpose LLMs showed moderate accuracy and high internal stability on this acid–base benchmark clinical management and treatment, but they often reproduced the same incorrect answer across repeated queries. This indicates that repeated agreement may reflect stable error rather than dependable reasoning. Although these systems may show promise in selected structured tasks, this study did not directly evaluate educational effectiveness or clinical safety. They therefore should not be used as stand-alone tools for acid–base learning or clinical decision making. Future work should compare model performance with that of learners at different training levels and explore strategies to improve reasoning reliability and communicate model uncertainty more effectively.
Footnotes
Ethical considerations
Institutional Review Board Statement: Ethical approval was not required for the study involving humans in accordance with the local legislation and institutional requirements.
Consent to participate
Written informed consent to participate in the study was not required form the participants or the participant’s legal guardians in accordance with the national legislation and the institutional re-quirements.
Author Contributions
Conceptualization: Azfar Athar Ishaqui & Moteb Khobrani.
Data Curation: Salman Ashfaq Ahmad & Azfar Athar Ishaqui.
Formal Analysis: Moteb Khobrani & Asaad Ahmed Asaad Khalil.
Methodology: Azfar Athar Ishaqui.
Project Administration: Azfar Athar Ishaqui.
Software: Salman Ashfaq Ahmad.
Supervision: Moteb Khobrani.
Validation: Asaad Ahmed Asaad Khalil.
Visualization: Asaad Ahmed Asaad Khalil.
Writing – Original Draft: Moteb Khobrani, Asaad Ahmed Asaad Khalil, Salman Ashfaq Ahmad, Azfar Athar Ishaqui.
Writing – Review & Editing: Salman Ashfaq Ahmad & Azfar Athar Ishaqui.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors extend their appreciation to the Deanship of Research and Graduate Studies at King Khalid University for funding this work through large group research under grant number RGP2/120/47.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets generated and/or analyzed during the current study are from the corresponding author on reasonable request.