
Abstract
Background
Acute decompensated heart failure (ADHF) is a state of systemic congestion which frequently requires hospitalization. Early and noninvasive detection of decompensation remains challenging. This study evaluated whether voice characteristics differ between patients hospitalized with ADHF and after recovery to examine the potential of voice as a non-invasive biomarker for ADHF.
Methods
Patients requiring hospital admission for ADHF were prospectively enrolled. Patients with respiratory infection, sepsis, lung or vocal cord disease, acute coronary syndrome, or serum creatinine>3.0mg/dL were excluded. Voice was recorded at two time points: at admission for ADHF and at discharge after recovery. Low-level audio features were extracted, and Mel-spectrograms derived from the voice waveforms were used as the input feature for deep learning-based classification models. Model performance was primarily evaluated at the patient-state level using area under the receiver operating characteristic curve (AUC) with 95% confidence intervals estimated by patient-level bootstrap resampling.
Results
A total of 100 patients were included (mean age 70.5 years; 47% women) and randomly divided into a training group (N=88) and a test group (N=12). In the analysis with low-level audio features, harmonics-to-noise ratio and Shimmer demonstrated discriminative potential between decompensated and recovered states. In patient-state-level analysis, the best-performing model, ConvNeXt-large, achieved a mean AUC of 0.83 (95% CI 0.70-0.95). Segment-level analysis demonstrated higher discriminative performance (AUC up to 0.87), suggesting the presence of discriminative acoustic features.
Conclusions
Voice characteristics differed between admission and discharge states in patients hospitalized for ADHF, and voice analysis using deep learning models was able to distinguish acute decompensated and recovered states in patients with ADHF. Our results suggest that voice analysis may provide a novel and non-invasive approach for detection of ADHF.
Introduction
Heart failure (HF) is a clinical syndrome characterized by impaired heart function leading to inadequate systemic perfusion and congestion. 1 More than 64 million individuals worldwide are affected by HF, 2 and its prevalence exceeds 15% among adults aged 80 years or older.3,4 HF remains the most common cause of hospitalization in adults over 65 years of age 5 and it remains as one of the most costly and disabling diseases causing frequent visits to the emergency room. 6 Acute decompensated heart failure (ADHF), defined by pulmonary and systemic congestion resulting from elevated cardiac filling pressures, 7 requires timely management. Since HF hospitalization is closely associated with an increase of readmission, in-hospital and post-discharge mortalities in short- and long-term,8,9 early identification of acute decompensation is crucial.
Common strategies to monitor pulmonary and systemic congestion for patients with HF include serum biomarkers and imaging modalities. Measurement of serum biomarkers such as N-terminal pro-B-type natriuretic peptide (NT-proBNP) or B-type natriuretic peptide (BNP) is recommended by current guidelines.1,10,11 Soluble suppression of tumorigenicity 2 (sST2), a novel biomarker reflecting inflammation and fibrosis, have demonstrated prognostic value in HF. 12 Imaging techniques such as chest x-ray and computed tomography (CT) provide valuable information on pulmonary congestion, pleural effusion, and cardiomegaly. However, both biomarkers and imaging techniques are difficult to repeat due to cost, discomfort associated with phlebotomy, and the inconvenience of hospital visits to undergo these tests. Imaging techniques such as chest CT could quantify the severity of pulmonary congestion; however, they cannot be repeated frequently due to risks associated with cumulative radiation exposure. Recently, a pulmonary pressure-guided therapy for HF patients was introduced which provided continuous monitoring and early intervention, but it has potential of complications, requires high initial and maintenance costs as well as invasive procedure. 13 Non-invasive tests such as lung ultrasound or wearable monitoring systems either require hospital visits with trained medical professionals or remain insufficiently validated for routine clinical practice. 14 Therefore, a non-invasive, safe, inexpensive, and easily accessible method to detect congestion and decompensation is urgently needed for patients with HF.
Body fluid overload in ADHF can influence voice characteristics through edema of the lungs, larynx, and vocal cords. Although body weight monitoring is recommended to detect congestion, edema-associated weight gain is only detectable after certain amount of time in disease progression, making it unreliable to be an early predictor of ADHF. 15 Moreover, the amount of pulmonary and systemic congestion to cause a change in body weight may be greater than the amount of congestion to cause changes in voice. The phonation threshold pressure, an indicator of the pulmonary drive for phonation, was increased in healthy adults with systemic dehydration caused by administering a single 60-mg dose of furosemide. 16 This raises the possibility that voice could be a more sensitive and useful marker of ADHF reflecting changes associated with congestion earlier than body weight assessment. Voice is a non-invasive and easy-to-obtain biomarker that can be easily monitored, even in telemedicine settings, to detect congestion in patients with HF; however, relevant studies are scarce. A pilot study of 10 patients with ADHF suggested that several voice measures could be early indicators of HF through acoustic speech analysis but limited by its small sample size. 15 An uncontrolled, retrospective and observational study investigated the association between voice signal characteristics and adverse clinical outcomes in patients with HF but it lacked standardized voice analysis protocols. 17 A small, prospective study of 40 ADHF patients found significant differences between baseline and discharge recordings, but was limited by not using clinical-grade detectors. 18
In this prospective study, we evaluated whether voice characteristics differ between the decompensated and recovered states in patients hospitalized for ADHF. We further examined the ability of voice features and deep learning-based models to distinguish between these states to assess the potential of voice as a useful and non-invasive biomarker for detecting ADHF.
Methods
Study design and population
This prospective observational study was conducted at Korea University Guro Hospital, Seoul, Korea. Patients requiring admission for ADHF were eligible for enrollment. Patients were excluded if they had significant concurrent respiratory infection or sepsis; significant lung or vocal cord diseases which could affect voice (including chronic obstructive pulmonary disease or asthma); acute coronary syndrome; inability to speak Korean; or severe renal dysfunction defined as serum creatinine >3.0 mg/dL or receipt of renal replacement therapy. Patients were discharged when their treating physicians determined that recovery from ADHF was sufficient for home discharge, based on an integrated assessment of vital signs, symptoms, echocardiographic findings, laboratory results, and overall clinical status. Patients who left against medical advice or died during hospitalization were dropped out in the final analyses. A total of 112 patients were enrolled between July 1, 2020, and December 31, 2022 (Figure 1). This study was approved by the Institutional Review Board of Korea University Guro Hospital (N: 2020GR0356), and all patients signed a written informed consent. This study was conducted in accordance with the ethical principles of the Declaration of Helsinki. Study schema.
Voice acquisition and clinical data
The voice was recorded twice: at hospital admission for ADHF and at discharge after recovery from ADHF. Voice was recorded in a quiet education room in the cardiology ward using a Sony PCM-A10 recorder located approximately 20cm from patient’s mouth at a sampling frequency of 48 kHz and a scale of 24 bits. Patients were asked to phonate five fundamental Korean vowels (“[a], [e], [i], [ɔ], [u]”) for 3 seconds each and then to repeat the sentence “daehan minkook manse” five times. Serum NT-proBNP, sST2, BUN, creatinine, and body weight were measured at both admission and discharge.
Data preparation
A total of 100 patients were eligible for analysis after excluding 12 patients with incomplete voice recordings. The voice recordings were processed using frequency analysis algorithm with Fourier transform and Praat program to report 4 different low-level speech features-fundamental frequency (F0), harmonics-to-noise ratio (HNR), Jitter, and Shimmer. The study population was randomly assigned to two mutually exclusive groups: training (N=88) and test (N=12).
For deep learning analysis, voice recordings obtained at admission and discharge were converted into Mel-spectrograms for model input. Multiple recordings obtained from each patient at each clinical state were retained as repeated observations for model training.
The primary analysis was conducted at the patient-state level, where the unit of analysis was the patient-state (admission or discharge recording from an individual patient). For each patient-state, predicted probabilities obtained from individual recordings were averaged to derive a single patient-state probability for performance evaluation.
In addition, a secondary segment-level analysis was performed to evaluate the model’s ability to detect discriminative acoustic patterns within short voice segments. For this analysis, a sliding data augmentation strategy was applied, in which audio recordings were segmented into 1-second windows with a sliding step of 0.1 seconds across the signal. Each segment was treated as an individual sample, resulting in 9,442 training samples and 663 test samples. The window length and hop length were 1s and 21ms, respectively.
Low-level audio features
Low-level audio features were analyzed to identify voice characteristics associated with decompensated (‘wet’) and recovered (‘dry’) states. F0 is a fundamental frequency, HNR measures the ratio between periodic and non-periodic components of a speech sound. Jitter refers to consistency of period, and Shimmer reflects consistency of amplitude of voice oscillation. Jitter or Shimmer increases when irregularity of period or amplitude of oscillation increases.
Deep learning models
We trained the models to classify whether a certain voice belonged to the ADHF or recovered state. This was treated as a binary classification task. To train the deep learning-based binary classification models, the input features, model structure, and loss function were selected first. For the input feature, a Mel-Spectrogram, a time-frequency domain feature, was extracted from the voice recordings since it has the advantage of representing frequency domain characteristics of vocalizations. The hyperparameters of the Mel-Spectrogram were as follows: N-FFT = 1,024, hop_length = 256, and mel_bin = 128.
For the model structures, two broad types of the deep learning-based classification models are utilized: convolutional neural networks (CNNs) and Transformer (Supplemental Figure 1). CNN-style classification models, including ResNet50, 19 ConvNeXt, 20 DenseNet201, 21 ResNeXt, 22 and EfficientNet-b7, 23 refine the local features of the Mel-Spectrogram to find the optimal features for ADHF classification during the gradient descent steps. The typical structure of the CNN-style classification model consists of the first convolution layer, CNN stem, and a classification layer. The first convolution layer initially adjusts the channels of the input features. Second, the stem extracts hidden features using CNN layers. For DenseNet201, the stem contains four dense layers and three transition layers. Other CNN-style classification models have different CNN structures in their stems. The hidden features are converted into ADHF classification results, enabling humans to understand them by the classification layer.
Transformer style classification models, such as ViT 24 and PVT, 25 find optimal attention maps between cropped patches of the Mel-Spectrogram. Features were optimized using attention maps to focus on the more important input features and to remove meaningless features. The input features were first cropped into patches and projected onto hidden feature tokens. Each hidden feature token represented a truncated patch. Moreover, a classification token was added to the hidden feature tokens to calculate the attention maps. The hidden feature tokens were refined using attention maps in the multi-head attention layers. Finally, the refined hidden features of the classification token were converted into ADHF classification results by the classifying layer.
We trained the deep learning-based classification models with AdamW optimizer 26 with a learning rate of 0.00001 and cross-entropy loss. Each model was trained five times with different learning rates ranging from 0.00001 to 0.00005, and performance was calculated with the average, maximum and minimum Area Under the Curve (AUC). All experiments for the deep learning models were performed using the PyTorch library of the Python programming language.
Statistical analysis
Continuous variables are presented as mean ± standard deviation or median (interquartile range), as appropriate. Categorical variables are presented as counts and percentages. Baseline clinical characteristics were compared between the training and test groups using the Wilcoxon rank-sum test. Paired comparisons between admission and discharge states were performed using the Wilcoxon signed-rank test. Linear regression analyses were performed to assess associations between selected serum biomarkers (NT-proBNP and sST2) and low-level audio features.
The performance of deep learning-based classification models for distinguishing acute decompensated heart failure (ADHF) from the recovered state was evaluated using receiver operating characteristic (ROC) curves and the area under the ROC curve (AUC) with 95% confidence intervals. Model performance was evaluated at two levels. The primary analysis was conducted at the patient-state level, where predicted probabilities obtained from individual recordings were averaged to generate a single probability per patient-state, reflecting the clinically relevant unit of inference. Confidence intervals were estimated using bootstrap resampling at the patient level within the independent test cohort. Segment-level analyses were performed to assess the model’s ability to detect discriminative acoustic features and were considered secondary.
All statistical analyses were conducted using Scipy and Matplotlib libraries of Python programming language. A two-sided P value <0.05 was considered statistically significant. This study was designed as a prospective exploratory proof-of-concept investigation, and no formal a priori sample size calculation was performed.
Results
Baseline characteristics
Baseline characteristics of patients with ADHF.

Values are expressed as mean±SD or median with interquartile ranges, or number (%), as appropriate. Comparisons between the training and test groups were performed using the Wilcoxon rank-sum test. Paired comparisons between admission and discharge values were performed using Wilcoxon signed-rank test.
LVEF = left ventricular ejection fraction; NT-proBNP = N-terminal pro-B-type natriuretic peptide; sST2 = soluble suppression of tumorigenicity 2; SBP = systolic blood pressure; BUN = blood urea nitrogen.
Low-level audio feature analysis
We analyzed voice characteristics for all patients with low-level audio features. Analysis of low-level audio features for “daehan minkook manse” is presented in Supplemental Figure 2. Results for other pronunciations are shown in Supplemental Figure 3. HNR and Shimmer differed significantly between ‘wet’ and ‘dry’ states across all pronunciations (P <0.05 for all comparisons). Jitter showed a significant difference between ‘wet’ and ‘dry’ states only for “[u]”.
We also conducted a linear regression analysis with absolute values of ‘wet’ and ‘dry’ states by inputting audio features and classic serum biomarkers of HF (NT-proBNP and sST2) for “daehan minkook manse” (Supplemental Figure 4). No clear linear associations were observed between low-level audio features and serum biomarkers. Linear regression plots of other pronunciations are presented in Supplemental Figure 5.
The distributions of selected low-level audio features and deep learning-derived scores are illustrated in Figure 2. Paired comparisons between admission and discharge states are shown for each patient. While HNR and Shimmer demonstrated differences between states (Figure 2(a) and (b)), the separation between admission and discharge states was more pronounced for the deep learning-derived score (Figure 2(c)), indicating a clearer distinction between clinical states compared with individual low-level features. Distribution of low-level audio features and deep learning-derived scores according to patient state.
Deep learning-based classification
We further analyzed voice with Mel-Spectrogram and deep learning models. Model performance was evaluated at both the patient-state level and the segment level. At the patient-state level, ConvNeXt-large demonstrated the highest overall performance, achieving an AUC of 0.83 (95% CI, 0.70-0.95), whereas other models showed AUC values ranging from 0.60 to 0.81 (Figure 3(a) and Table 2). Accuracy ranged from 55.8% to 71.7% across models. Performance of deep learning models for distinguishing acute decompensated heart failure from recovered state. Performance of deep learning models for distinguishing acute decompensated heart failure from recovered state. AUC values are presented with 95% confidence intervals. Accuracy is presented as percentage. AUC = area under receiver operating characteristic curve; ADHF = acute decompensated heart failure; NT-proBNP = N-terminal pro-B-type natriuretic peptide; sST2 = soluble suppression of tumorigenicity 2. Additional HF features are NT-proBNP, sST2, and body weight.
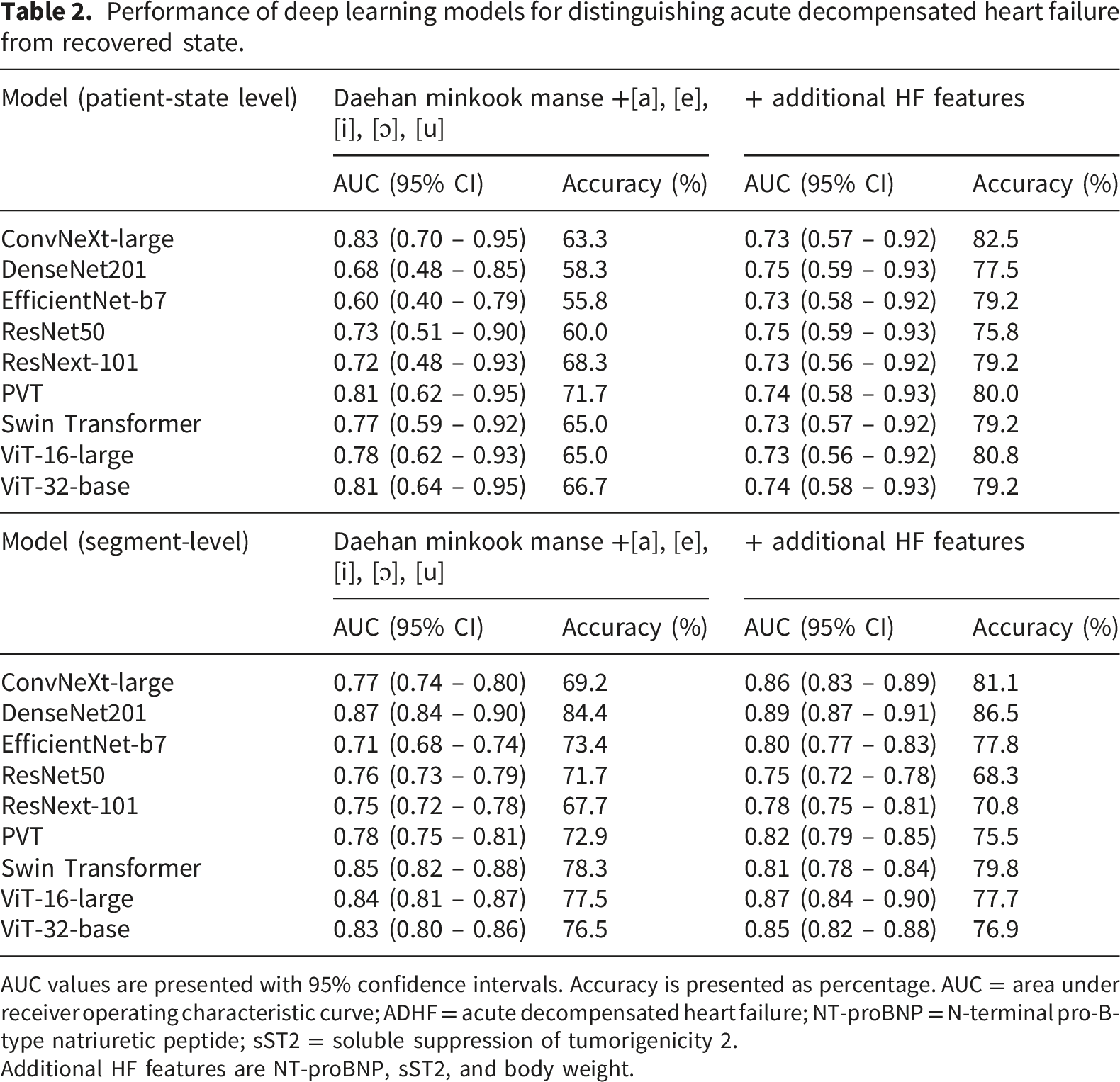
When evaluated at the segment level, models demonstrated higher apparent discriminative performance compared with patient-state-level analysis (Figure 3(b) and Table 2). DenseNet201 achieved the highest segment-level performance, with an AUC of 0.87 (95% CI, 0.84-0.90), while other several other models also showed good discriminative performance.
Performance was higher at the segment level than at the patient-state level, reflecting the non-independence of multiple recordings obtained from the same individual. The patient-state-level analysis therefore provides a more conservative and clinically relevant estimate of model performance. The incorporation of additional clinical HF features (NT-proBNP, sST2, and body weight) did not consistently improve AUC across models. At the patient-state level, modest increases in accuracy were observed in some models, whereas improvements were less consistent at the segment level (Table 2).
Model performance by pronunciation
Performance of deep learning models for distinguishing acute decompensated heart failure from recovered state according to pronunciation.

AUC values are presented with 95% confidence intervals. Accuracy is expressed as percentage.
AUC = area under receiver operating characteristic curve; ADHF = acute decompensated heart failure.
Discussion
In this proof-of-concept study, we evaluated whether voice characteristics could serve as a non-invasive biomarker for detecting ADHF. By analyzing voice recordings obtained at hospital admission and recovered states in patients with ADHF, we demonstrated that specific low-level audio features differed according to volume status and that deep learning-based models were able to distinguish decompensated from recovered states at the patient-state level. These findings suggest that changes in voice during HF exacerbation may reflect volume states and support the potential role of voice as a novel, patient-centered and noninvasive approach to monitor HF status.
Although the long-term aim of our study is to enable telemedicine-based monitoring for early detection of ADHF while minimizing patient burden and hospital visits, the present study focused on voice recordings obtained at hospital admission and at discharge to capture distinct states of decompensation and recovery. To identify specific characteristics that reflect HF exacerbation and to discover deep learning models that can be adapted for telemedicine HF monitoring, patients requiring hospital admission could be an ideal model for testing because voice characteristics may reflect extremes of HF presentation. Voice is produced as a coordinated interaction of the lungs, larynx, and articulators. 27 Patients with ADHF have pulmonary congestion and systemic edema, which can affect the conditions of the articulatory organs. Swelling of articulatory organs, including the vocal cords, tongue, lips, and cheeks, can cause changes in voice and speech production. In line with this, HNR and Shimmer showed significant differences between admission (wet) and discharge (dry). Voice recorded at discharge showed higher HNR and lower Shimmer compared to the admission state, indicating clearer and more stable phonation.
While low-level audio features alone showed limited classification performance, deep learning-based models using Mel-Spectrogram demonstrated meaningful discrimination between decompensated and recovered states in the patient-state-level analysis. Compared with segment-level analyses, performance estimates were more conservative, with the best-performing model (ConvNeXt-large) achieving a mean AUC of 0.83, although confidence intervals remained wide due to the small independent test cohort. Segment-level analysis was not intended to estimate clinical performance, but rather to evaluate whether discriminative acoustic patterns exist within short voice segments. In contrast, patient-state-level analysis reflects the clinically relevant unit of inference, where multiple recordings from the same patient are aggregated. The discrepancy between segment-level and patient-state-level performance highlights the distinction between signal detectability and clinical applicability. The addition of established HF markers, including NT-proBNP, sST2, and body weight, did not consistently improve model discrimination. This suggests that voice-based features may capture information related to congestion that is not fully reflected by conventional biomarkers, although this observation requires validation in larger cohorts. Our findings do not suggest that voice analysis should replace established biomarkers. Rather, voice could serve as a complementary, relatively continuous, and non-invasive monitoring tool, particularly in real-world settings where frequent hospital visits are impractical. Such monitoring may be valuable for detecting gradual physiological changes preceding overt decompensation and prompting timely clinical evaluation when indicated; however, further studies in longitudinal and ambulatory settings are needed to evaluate the potential of voice analysis to detect early or subclinical changes prior to overt clinical deterioration. We also observed heterogeneity in model performance across different pronunciation tasks, suggesting that pronunciation-specific modeling strategies may be required to optimize classification performance. Notably, consistent patterns across both patient-state-level and segment-level analyses suggest that certain phonation tasks may offer more robust discrimination, supporting the importance of task selection in future clinical applications.
A key strength of this study lies in its within-patient paired design, which could reduce inter-individual variability in voice characteristics and allow each patient to serve as their own control. This design choice is particularly relevant in voice-based analyses. Although the overall cohort size was modest, the paired structure and strict separation of patients between training and test datasets were intended to mitigate overfitting and to provide an initial assessment of generalizability.
This study has several limitations. First, only patients who could speak Korean were included in this study. Although we attempted to minimize the effect of pronunciation differences by including both sentence tasks and fundamental vowel phonations, it may be difficult to apply our results to other patient groups who speak different languages. However, analyses of fundamental vowel sounds - shared across many languages – showed consistent classification performance, suggesting applicability potential beyond Korean speakers. Second, because the voice recordings of the specific phrases had to be collected from patients, patients in intensive care units or the emergency room were not able to participate in the study because of intubation, or substantial noise from surrounding machines such as ventilators, continuous renal replacement therapy machines, cardiac monitors, and defibrillators. However, in real-world settings, voice recordings may be obtained under more diverse acoustic conditions and using different recording devices, which could influence signal quality. Further studies in more diverse settings are therefore warranted. Third, exclusion of patients with respiratory infections, lung diseases, and renal dysfunction could limit the complete reflection of the real-world HF patients. Fourth, the study population was restricted to patients hospitalized for ADHF, and chronic stable HF patients were not evaluated. In addition, potential influences of demographic factors such as age and sex on voice characteristics were not specifically examined and warrant further investigation. Fifth, the independent test cohort was relatively small, resulting in wide confidence intervals for performance estimates. Although patient-level evaluation and strict separation between training and test datasets were applied, the small sample size limits the precision of performance estimates and requires validation in larger cohorts. Finally, since the model validation was performed using an internal dataset, further studies may be needed to enhance generalizability.
Conclusions
In this study, specific voice features, including HNR and Shimmer, differed between admission and discharge in patients hospitalized with ADHF. Deep learning models demonstrated the ability to distinguish decompensated from recovered states at the patient-state level. These findings support the feasibility of voice analysis as a complementary, noninvasive approach for monitoring HF status.
Supplemental material
Supplemental material - Voice features and deep learning models for identifying acute decompensated heart failure
Supplemental material for Voice features and deep learning models for identifying acute decompensated heart failure by Jieun Lee, Gwantae Kim, Insung Ham, Kyungdeuk Ko, Soohyung Park, Dong Oh Kang, Jah Yeon Choi, Eun Jin Park, Sunki Lee, Seung Young Roh, Dae-In Lee, Jin Oh Na, Cheol Ung Choi, Jin Won Kim, Seung-Woon Rha, Chang Gyu Park, Jae-Gu Cho, Eugene Yang, Eung Ju Kim, Hanseok Ko by Digital health.
Footnotes
Acknowledgments
The authors thank all patients with ADHF for participating in this study.
Ethical considerations
This study was approved by the Institutional Review Board of Korea University Guro Hospital (N: 2020GR0356), and all patients signed a written informed consent. This study was conducted in accordance with the ethical principles of the Declaration of Helsinki.
Author contributions
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was selected as an interdepartmental collaborative study between the medical and engineering schools at Korea University. This selected interdepartmental study was partially funded by a research grant from Korea University (K2011361).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship.
Data Availability Statement
The dataset generated and/or analyzed during the current study are available from the corresponding author on a reasonable request.
Trial registration
The trial was registered at the Korean Clinical Trials Registry (The Clinical Research Information Service established at the Korea Disease Control and Prevention Agency with support from the Ministry of Health and Welfare) – number KCT0007646. (https://cris.nih.go.kr/cris/search/detailSearch.do?seq=25650&search_page=L).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.