
Abstract
Objective
Classification of skin lesions plays a crucial role in the early detection and diagnosis of various dermatological conditions. The existing deep learning models are plagued by class imbalance, bad feature extraction, and generalization to unseen data. This study aims to develop a robust hybrid deep learning model for multi-class skin lesion classification.
Methods
We propose a hybrid architecture combining three DenseNet models (DN121, DN169, DN201) and three ResNet models (RN50, RN101, RN152) with attention mechanisms (channel attention, squeeze-and-excitation, soft attention). We concatenated the architectures in a dual way. Finally, the concatenated models are ensembled to enhance performance. The model is trained and evaluated on the HAM10000 dataset, with advanced augmentation strategies applied to address class imbalance and improve generalization on unseen data.
Results
The model achieves an accuracy rate of 91.43% and specificity of 92.04%, bettering existing baseline methods. Attention mechanisms significantly improve feature extraction, dual concatenation provides better feature fusion, and ensemble integration enhances overall model robustness.
Conclusion
Our attention mechanism-based hybrid architecture is a robust and reliable solution for machine-based skin lesion classification. Its strong performance indicates its potential to help dermatologists with timely, precise diagnosis, serving as a foundation for other innovations in medical image analysis.
Keywords
Introduction
Skin lesions denote irregular alterations in the skin’s appearance, while skin ailments encompass a wide array of issues affecting the skin’s well-being, structure, and operation. 1 Skin lesions are frequently the earliest visible indicators of various dermatological disorders. The World Health Organization once said that skin diseases will be the most common disease in human history in the 21st century, with the highest morbidity rate and the highest disability rate. 2 About 30% to 70% of people of different races and ages in the world suffer from skin diseases. 3 Melanoma, the most lethal form of skin cancer, while comparatively rare, accounts for the majority of skin cancer-related fatalities. There are an estimated 76,380 new cases of melanoma and an estimated 6,750 deaths each year in the United States. 4
Early detection of skin lesions is essential to avoid developing serious illnesses. Unfortunately, there are many patients who do not know what their skin condition is due to the high cost and time it takes to get a formal clinical consult. Artificial intelligence (AI) has emerged as a tool with the potential to increase the effectiveness of self-screening for skin cancer. 5 AI, specifically Machine learning (ML) and Deep learning (DL), can detect disease conditions through data analysis, making diagnosis easier and raising awareness about the condition. 6 Despite the considerable volume of research on ML and DL applications for skin lesion detection, several persistent limitations remain. Transfer learning approaches trained on ImageNet data can extract generalizable low-level features; however, they often lack the robustness required for deployment in resource-constrained environments. Furthermore, many such models tend to overfit toward majority classes, leaving minority class distributions inadequately represented due to inherent class imbalance. Finally, Hyperparameters should be selected properly for optimal performance. 7
To address these challenges and establish a robust foundation, we first investigate the following primary research questions. RQ1. How can we use a balance in class distributions to get the best dataset on which to train the models? RQ2. How can data augmentation be employed to achieve better model performance on unseen data, reducing bias and overfitting? RQ3. How would the model be more generalized when many models are combined, as opposed to using only one model?
After conducting our investigation and carefully examining the previously stated questions, we produced the following • • • • •
Literature review
Skin lesion classification has achieved remarkable advancements in recent years with the introduction of deep learning techniques and ensemble learning architectures. Several studies have used well-known datasets such as HAM10000, with the objective being the improvement of classification performance in the face of addressing problems such as class imbalance, feature extraction, and model generalization.
Setiawan and Soewito 8 introduced CRCDKD, a novel approach that incorporates a mean-teacher architecture, categorical relation-preserving contrastive learning, and a decoupled mean teacher knowledge distillation module using DenseNet backbones. Semi-supervised training and distillation of the method at 89.41% accuracy were promising, but the absence of comprehensive testing on weighting schemes and the need for dynamic tuning mean that more can be done to improve model generalization and robustness. Roy et al. 9 proposed a DenseNet-121 backbone fortified with a Symmetry-aware Feature Attention (SaFA) module that uses wavelet-guided gradient-based fusion to take advantage of lesion boundary and symmetry information. The method achieved a competitive accuracy of 90.75%, though the absence of cross-dataset validation and external testing limits the assessment of the model’s generalizability beyond the HAM10000 dataset. Sofana Reka et al. 10 explored quantum machine learning on HAM10000 with quantum CNNs and quantum support vector classifiers. Despite the use of classical pre-trained CNN models such as MobileNet and ResNet50, their approach attained a modest accuracy of 82.86%, hindered by poor generalization between visually similar classes and the high computational demand of quantum approaches by nature. Liu et al. 11 employed an ensemble approach with MobileNetV2, ResNet18, VGG11, and a new fine-tuning stacking model, SkinNet. Despite employing several architectures with weighted meta-learners, this approach achieved 86.78% accuracy, with class imbalance a major limitation. Saha et al. 12 employed YOLOv8 models for real-time skin lesion classification on HAM10000, achieving a maximum accuracy of 86.2% with YOLOv8x-cls. Despite employing data augmentation for over 30 epochs, the study’s limited consideration of newer architectures, such as Vision Transformers or Graph Convolutional Networks, suggests room for improvement. Gururaj et al. 13 proposed DeepSkin, which employed transfer learning using DenseNet169 and ResNet50 with pre-processing methods of oversampling, undersampling, and hair removal via autoencoder-decoder segmentation. This method, with an accuracy of 91.2%, was based on conventional architectures with no significant custom developments or augmentation strategies. Azeem et al. 14 proposed SkinLesNet, a novel four-layer CNN with a bespoke design for smartphone image data and geometric augmentation, trained with Adam optimizer and ReLU activations. The network reported 90% accuracy on HAM10000 but may be prone to overfitting despite dropout layers due to its simple design. Wicaksana et al. 15 employed YOLOv11 alongside VGG19 and ResNet50, with stratified splitting and data augmentation, on HAM10000. YOLOv11 achieved 84.74% accuracy but was outperformed by VGG19 and ResNet50 when classifying lesion classes that are visually similar, highlighting challenges with multi-class complexity. Liu et al. 16 employed an ensemble learning approach with ResNet50, MobileNetV3, GhostNet, and PP-LCNet and an improved Grey Wolf Optimizer for adaptive weighting. The model achieved 88.8% accuracy but encountered high computational complexity caused by repeated model training. Bhowmick et al. 17 proposed Dual Concatenated DenseNet with Attention Fusion (DCDAF) that concatenated multiple DenseNet blocks with attention mechanisms for generalization improvement and achieved 90.24% accuracy. Sole reliance on DenseNet variants can limit feature diversity, with scope to include architectures such as ResNet to provide more representative information. Sönmez et al. 18 employed classic CNNs with transfer learning frameworks such as VGG, ResNet, and MobileNet on balanced subsets of the MNIST and HAM10000 datasets. Although with a total accuracy of 80.79%, the authors opined that this may be insufficient for clinical application, mentioning generalization problems with real samples.
Studies19–27 incorporated augmentation techniques in ISIC2017-2020, HAM10000 and PH2 datasets with transfer learning, but hadn’t tried to explore any ensemble methods.
Furthermore, recent studies by Das et al. have introduced robust ensemble frameworks to address class imbalance in skin lesion classification. In one study, 28 they designed a homogeneous EnsembleSVM model that utilizes SMOTE-TOMEK and target-specific augmentation (including rotation, flipping, and zooming) to balance the dataset. This approach employs a two-stage ensemble of Support Vector Machines, achieving a test accuracy of 98.2% on the HAM10000 dataset. In a subsequent work, 29 Das et al. proposed a hybrid ensemble learning model that combines homogeneous Adaptive Resonance Theory Mapping (ARTMAP) models with a heterogeneous Fuzzy Min–Max (FMM) classifier. By utilizing a rule-based NEFCLASS model for final classification and balancing the data via SMOTE, this method demonstrated a classification accuracy of 98.4%, proving the efficiency of improved ensemble learning strategies in medical image processing.
Dataset description
Overview of the HAM10000 dataset.
The HAM10000 dataset comprises 10,015 dermatoscopic images in JPG format, collected from diverse sources to ensure variability in acquisition settings, subject demographics, and lesion properties. The dataset is subdivided into seven diagnostic classes. • • • • • • •
MEL, BCC, and AK are cancerous lesions, whereas NV, BKL, and DF are non-cancerous lesions; however, VASC lesions can be either cancerous or non-cancerous. The dataset is also plagued by class imbalance, with NV having 6,705 images, while the categories DF (115 pictures) and VASC (142 pictures) are underrepresented (Table 2). An overview of the distribution of classes is shown below (Figure 1). Sample images of different classes: (a) Actinic keratosis, (b) Basal Cell Carcinoma, (c) Benign keratosis, (d) Dermatofibroma, (e) Melanoma, (f) Nevus, (g) Vascular lesions. Detailed distribution of the HAM10000 dataset.

Research methodology
Data preprocessing and augmentation of training sets
This study adopted a structured plan to preprocess and augment the dataset for training and evaluation purposes. The study started with a raw data set that underwent initial preprocessing, which cleaned and standardized it. To fully avoid data leakage and obtain an unbiased evaluation of the data, we first identified and separated all duplicate images in the dataset. Out of the remaining portion of the unique images, an independent test set, 10%, was reserved exclusively as an Independent Test Set
To improve the robustness of the model and its ability to generalize, we employed various data augmentation techniques. Augmentation synthetically increases the dataset size by applying transformations, helping reduce overfitting and improve performance on new data. We tried four different augmentation techniques to find the optimal method: Prior Augmentation (PA), Posterior Augmentation (AP), No Augmentation (NA), and Only Train Set Augmentation (TA). They are diverse based on when and how augmentation is performed, as shown by the following flowcharts (Figure 2). • • • • Four augmentation techniques: (a) prior augmentation, (b) posterior augmentation, (c) No augmentation, (d) only train set augmentation.

We tested these four methods to identify the optimal augmentation strategy, balancing fairness with data enhancement. After scrutinizing the methods, we chose to employ the Only Train Set Augmentation (TA) method. This selection maintains the independent test set completely unseen in order to allow the model’s generalization ability to be evaluated safely and fairly.
Architecture of proposed model
The proposed hybrid architecture (Figure 3) is a multi-level, multi-branch ensemble framework designed to enhance accuracy and robustness in skin lesion classification. The key aspect of this architecture is that it overcomes the limitations of single-model classification by combining the strengths of DenseNet and ResNet, leveraging complementary feature extraction and additional benefits from multiple attention mechanisms. Architecture of our proposed model.
The architecture consists of two parallel, independent primary branches: a DenseNet branch and a ResNet branch. Both are macro-architectures of three base models. The DenseNet branch uses DenseNet-121, DenseNet-169, and DenseNet-201, and the ResNet branch uses ResNet-50, ResNet-101, and ResNet-152. These are chosen for their well-documented image classification performance and for their different architectural components—DenseNet’s dense connectivity and ResNet’s residual connections—that provide an enriched feature set.
To enhance the discriminative capability of each base model, we introduce custom convolutional and attention blocks. As shown in Figure 4, these blocks consist of sequential Conv2D layers with varying kernel sizes followed by batch normalization, allowing the model to capture features at different spatial scales. Specifically, the architecture now comprises eight blocks. • • A detailed view of the custom convolutional and attention block architecture.
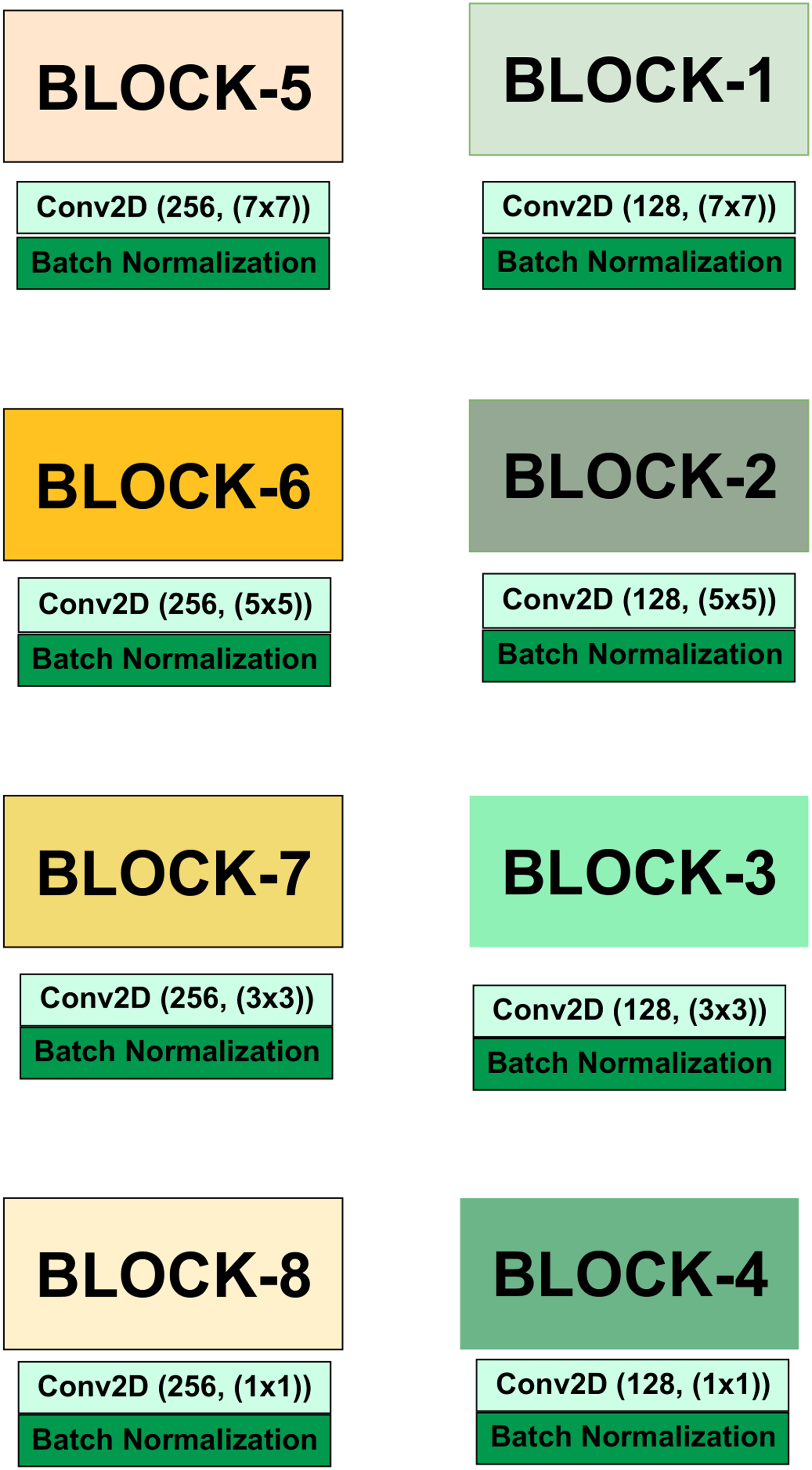
By stacking Blocks 1–4 with lower filter depth and Blocks 5–8 with higher filter depth, the framework ensures that both low-level and high-level features are extracted effectively. These enriched feature representations are subsequently refined using three attention mechanisms—Channel Attention (CA), Squeeze-and-Excitation Attention (SEA), and Soft Attention (SA)—before being passed to the DenseNet and ResNet branches.
In these blocks, we merge three individual attention mechanisms: • •




where • 

After attention-integrated feature extraction, the three DenseNet base model outputs are concatenated and flattened into a common feature vector. Similarly, the same procedure is applied to the three ResNet base models. The dual concatenation strategy is a prominent feature of our approach, as it leverages a broad range of features from the shallow and deep layers of different architectures.
The final step of the framework is an ensemble learning approach. Concatenated DenseNet and ResNet feature vectors are fed into their respective fully connected layers for initial classification. The final prediction is made by averaging the two branch outputs using a weighted ensemble. This multi-branch ensembling technique, which combines features at one level and predictions at the other, yet further boosts the overall strength, generalization capability, and final classification accuracy of the model by minimizing the weakness of any single branch.The weighted ensemble coefficients were determined through a systematic trial-and-error process. First, the individual prediction accuracy of each branch was evaluated independently. Based on these evaluations, higher weights were assigned to branches yielding superior predictive accuracy, while lower weights were assigned to those with comparatively weaker performance. Subsequently, several weight combinations were explored iteratively, and the configuration that produced the highest overall classification performance was selected as the optimal weighting scheme for the final ensemble.
Justification of our proposed architecture
The development of our proposed hybrid framework is driven by the need to address several persistent problems in skin lesion classification, including class imbalance, overfitting, and limitations of transfer learning, as highlighted in the existing literature. The expanded framework, which integrates both DenseNet and ResNet variants, provides a robust and comprehensive solution. The key justifications for our design choices are as follows. • • •
To summarize, this architecture does not rely on a single mode; it explicitly leverages multiple, attention-integrated CNNs in conjunction with an ensembling approach for robust classification. Ultimately, one of our main overall aims is to present a multi-pronged framework that aims to develop a more accurate, robust, generalized solution for skin lesion classification.
Performance evaluation measures
In assessing the reliability and effectiveness of the framework proposed in this study, a number of well-known performance measurement indicators were used. These measurements are extracted from the element of the confusion matrix.
38
The confusion matrix is composed of the following. • • • •
The performance metrics are defined as follows: 1. 2. 3. 4. 5. 6.





The ROC–AUC is computed by plotting the True Positive Rate (TPR) against the False Positive Rate (FPR) across varying thresholds.
40

The ROC–AUC quantifies the model’s discriminative ability; a value closer to 1 indicates better separability between classes. 41
Experimental setup
The architectural model was fully developed on a Kaggle Notebook on an NVIDIA TESLA P100 GPU running at 1327 MHz. After collecting separate images at an input size of (224 × 224 × 3), the dataset was divided into three sets: training set (70%), validation set (15%), and test set (15%).
During the training process, we used a batch size of 16 and the Adam optimizer with a learning rate of 0.001 and an epsilon of 0.1. The loss function used was categorical cross-entropy, along with early stopping to prevent overfitting. To further help with generalization, we augmented the training set to be able to account for rotating, shifting, zooming, and flipping. All input images were resized to 224 × 224 × 3 pixels and normalized before entering the models.
Experimental configuration of models with batch size, attention variant, parameters, and training epochs.

Comprehensive Analysis of Computational Complexity, Memory Footprint, and Inference Speed: Proposed Ensemble vs. Standard Architectures.

Note. Values for standard models are based on the Tensorflow implementation for 224 × 224 (or 299 × 299 for Inception/Xception) input sizes.
This experimental design ensures a balanced evaluation across different model variants and highlights the comparative performance of the proposed ensemble against individual architectures.
To ensure the reliability and reproducibility of the reported metrics, we performed 5 independent training runs using different random seed initializations. The results presented in “Experimental Result Analysis” Section represent the mean values across these iterations. This approach accounts for the stochastic nature of weight initialization and data shuffling, confirming that the ensemble’s performance is consistent.
Experimental Result Analysis
Selection of augmentation strategy
Quantitative comparison of augmentation strategies across different backbones on Internal and Independent Test sets (%).

Table 5 quantitatively demonstrates the superiority of the Only Train Set Augmentation (TA) strategy. The Prior Augmentation (PA) technique assumes. Unusually large training accuracy of most models (e.g., 98.12% for DN201 and 97.85% for DN169), yet this performance is not proportional to the independent test set.
On the other hand, the No Augmentation (NA) approach generally has lower accuracy (e.g., 87.20% training accuracy in DN201), suggesting that the model is not a good generalizer in the absence of the variety that augmentation provides. Posterior Augmentation (AP) yields inconsistent results and significantly reduces training stability (e.g., 80.24% DN169).
Only the Train Set Augmentation (TA) approach is the most balanced and strong. It is not only highly trained (e.g., 90.02% on DN201) but also independent of the artificial inflation typical of PA and performs well on the independent test set (e.g., 92.03% on DN201). TA has the benefit of augmenting only the training data, which in effect enhances intra-class variability and minimizes overfitting without affecting test set integrity.
Thus, TA was implemented as the best augmentation approach for all further experiments in this study.
Comparison with different models
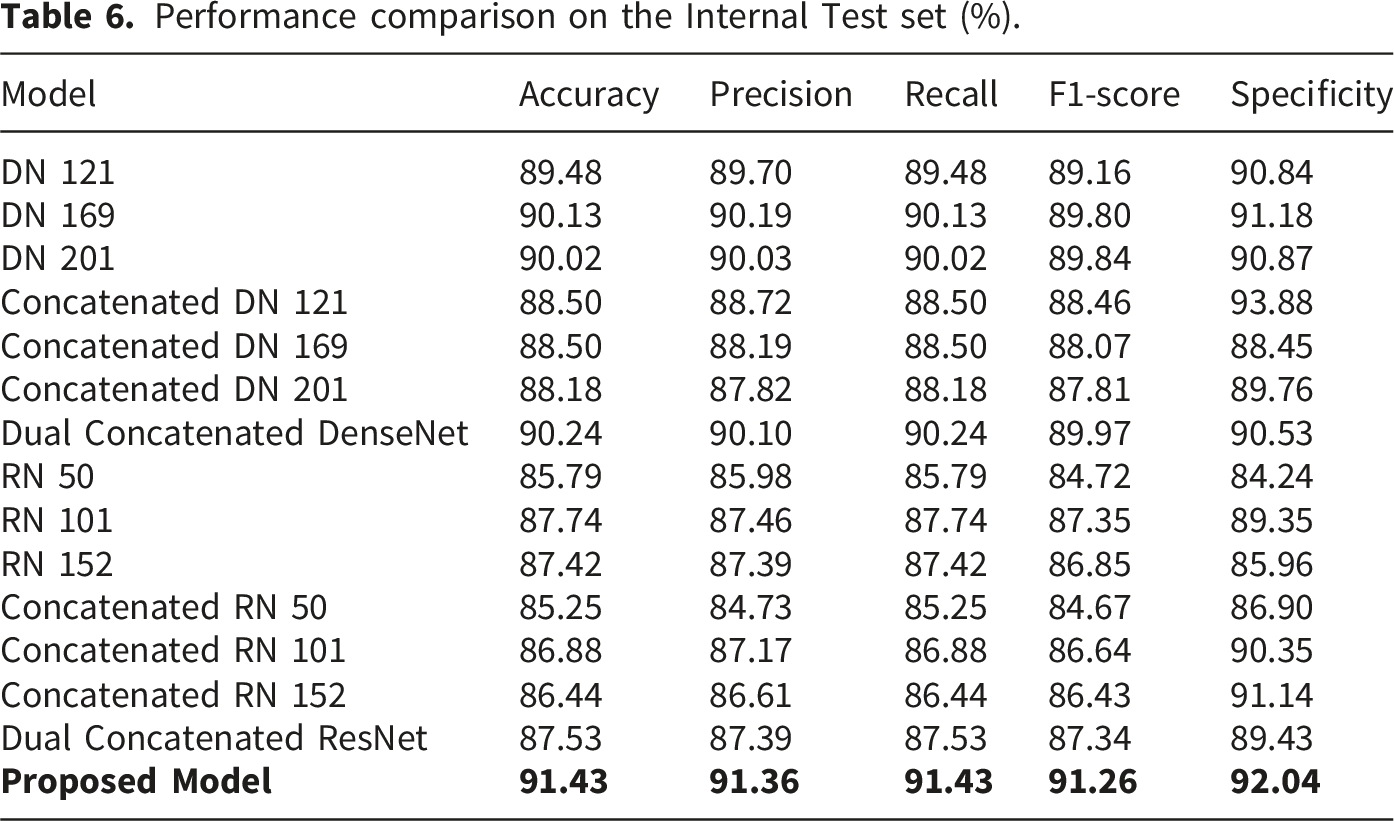
Performance comparison on the Internal Test set (%).
Performance comparison on the Independent Test set (%).

The proposed model outperforms both the individual and concatenated counterparts on all measures for the Test set, achieving a top accuracy of 91.43%. On the Independent Test set, while some individual models like DN 169 and DN 201 are slightly better on accuracy (92.02% and 92.03%, respectively), the proposed model remains at 90.82%
Performance of Dual Concatenated DenseNet
The accuracy and loss curves (Figure 5) indicate stable convergence after approximately 150 epochs, with validation accuracy closely tracking training accuracy, suggesting minimal overfitting. The confusion matrix (Figure 6) reveals high true positive rates for dominant classes like ’nv’ (melanocytic nevi) but some misclassifications in minority classes such as ’df’ (dermatofibroma). The ROC curves (Figure 7) demonstrate excellent discriminative ability, with AUC values ranging from 0.945 to 0.987 across classes. Model accuracy and loss curves for Dual Concatenated DenseNet. Confusion matrix for Dual Concatenated DenseNet. ROC curves for Dual Concatenated DenseNet across lesion classes.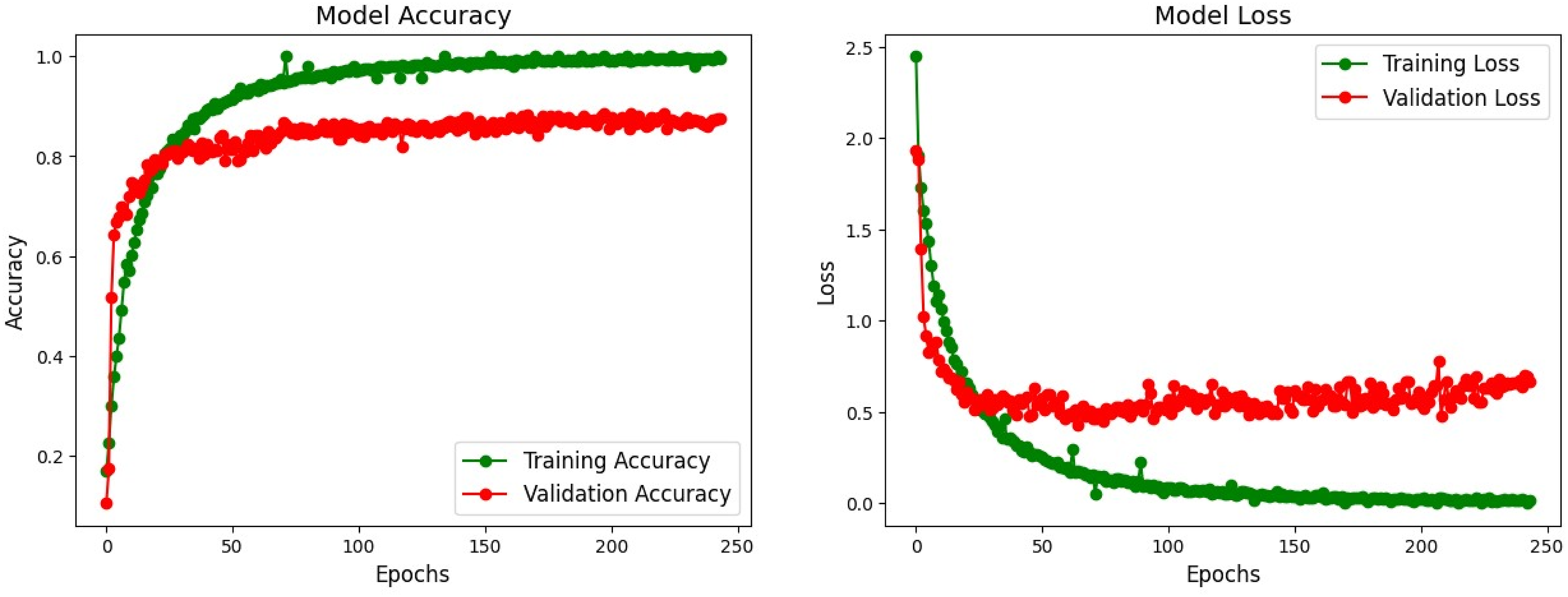
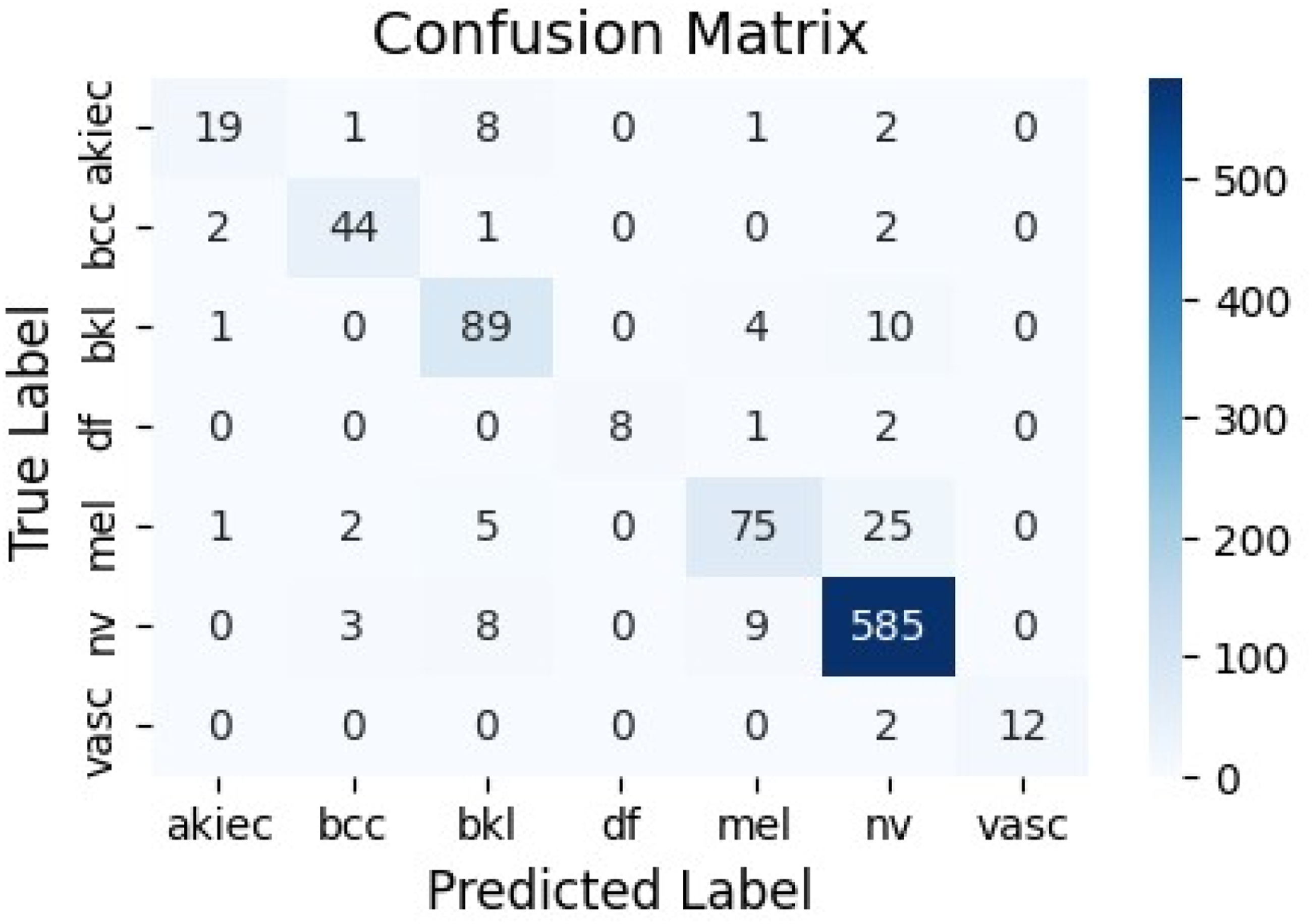
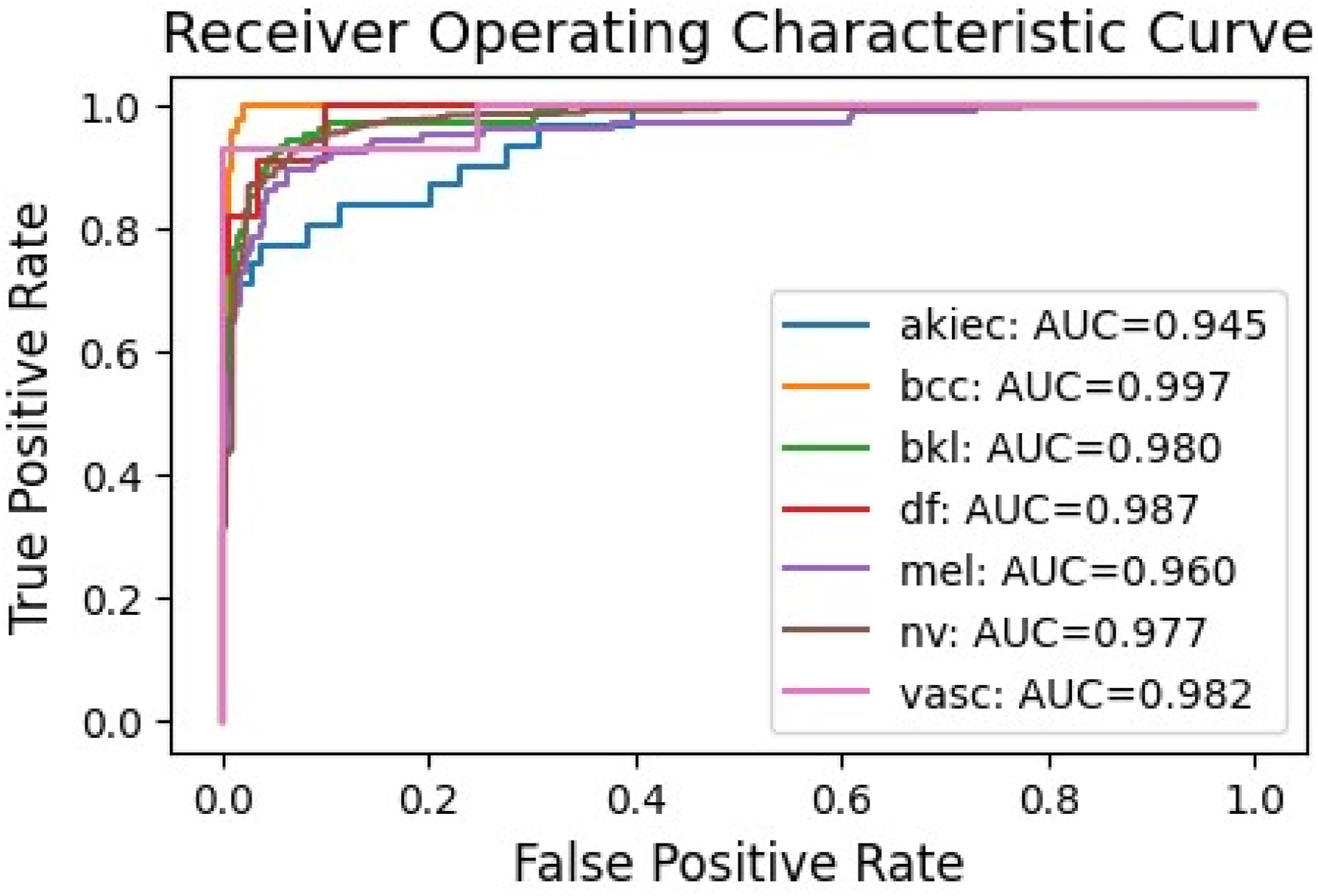
This model shows improved feature extraction compared to individual DenseNet variants, benefiting from the dense connectivity and attention focus on relevant lesion characteristics.
Performance of Dual Concatenated ResNet
The training curves display consistent improvements in accuracy and a decrease in loss, with validation metrics levelling off around the 200th epoch (Figure 8). The confusion matrix (Figure 9) demonstrates adequate classification for classes like ’bkl’ (benign keratosis-like) and ’mel’ (melanoma), though some overlap is observed between ’akiec’ (actinic keratoses) and ’bcc’ (basal cell carcinoma). The ROC–AUC values are robust (Figure 10), averaging above 0.95, indicating dependable binary classifications within a multi-class context. Model accuracy and loss curves for Dual Concatenated ResNet. Confusion matrix for Dual Concatenated ResNet. ROC curves for Dual Concatenated ResNet across lesion classes.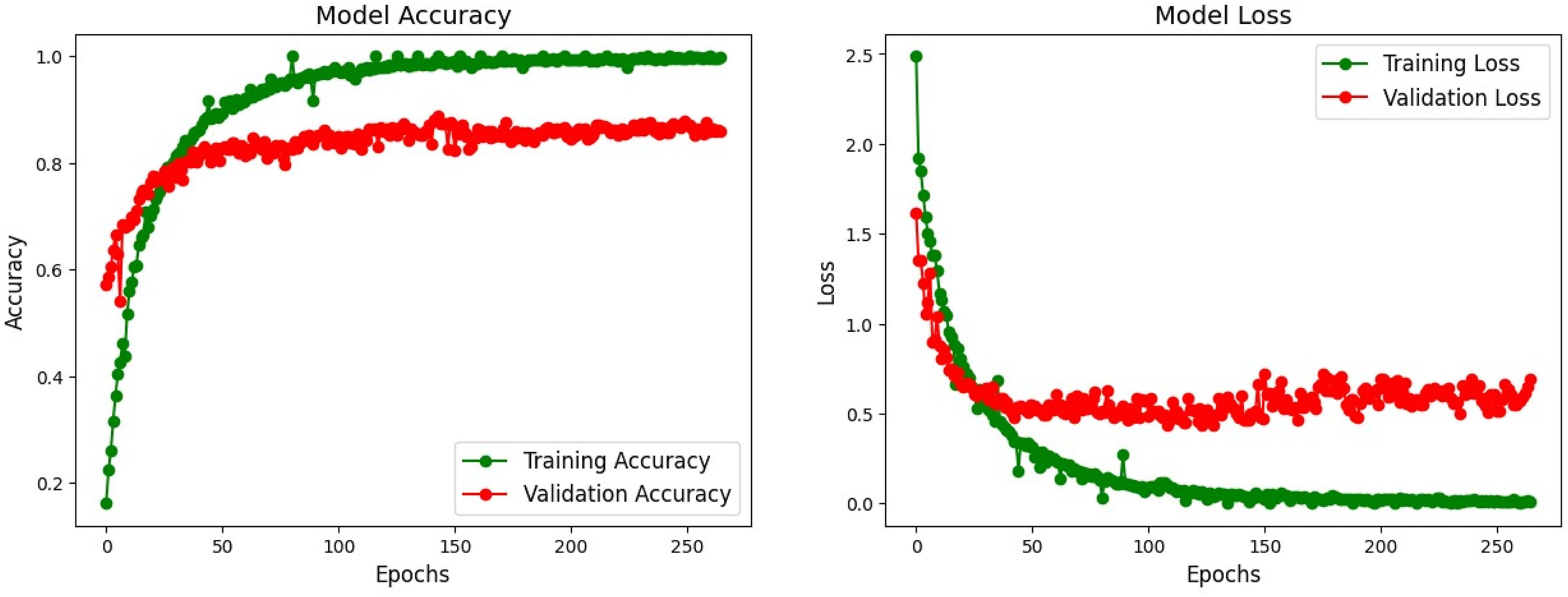
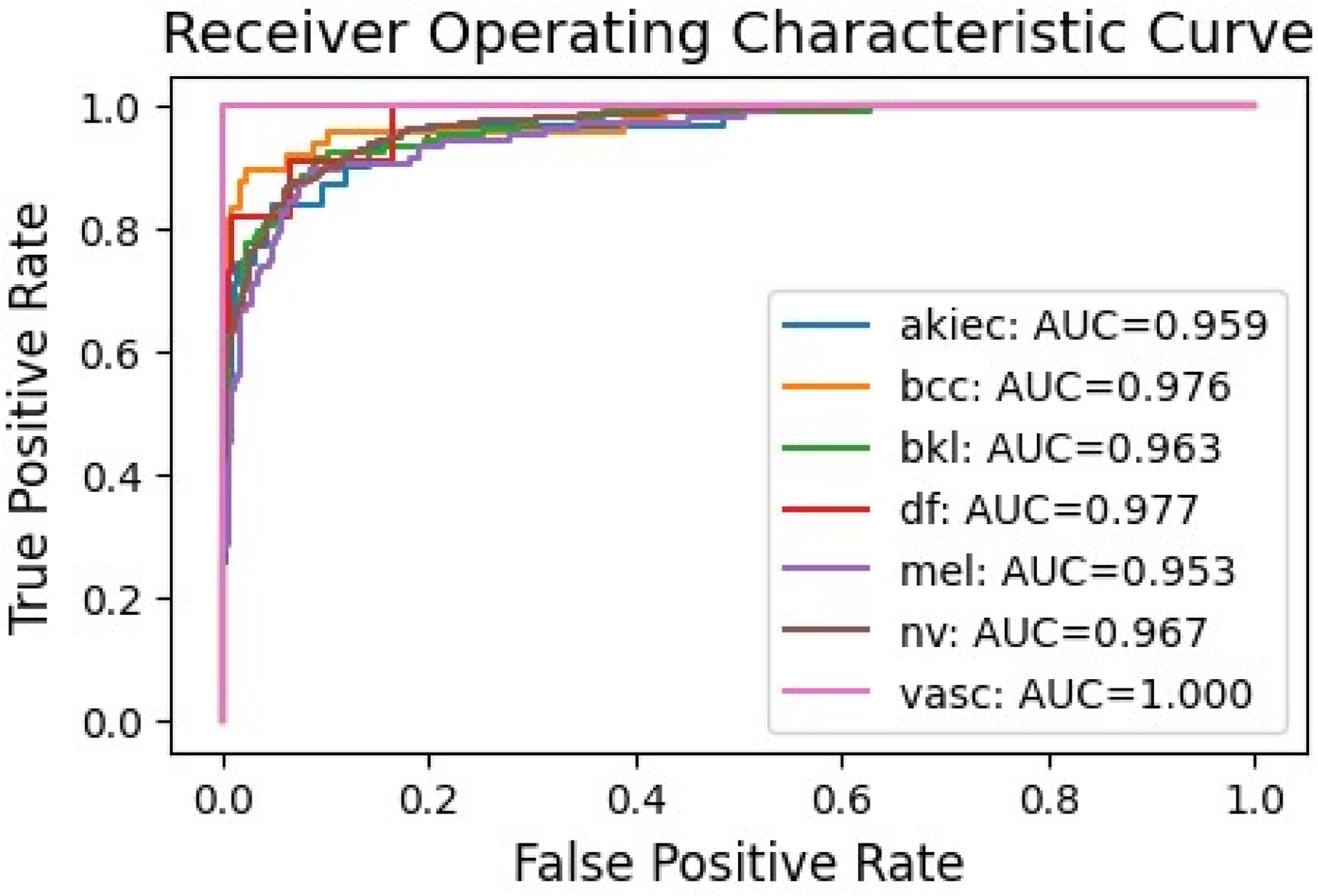
This architecture utilizes residual connections to address the issue of vanishing gradients, leading to improved performance compared to standalone ResNet models, especially in deeper networks.
Performance of proposed model
The proposed hybrid ensemble, integrating Dual Concatenated DenseNet and ResNet with attention mechanisms, achieves the highest performance on the Internal Test set with the following metrics: 91.43% accuracy, 91.36% precision, 91.43% recall, 91.26% F1-score, and 92.04% specificity.
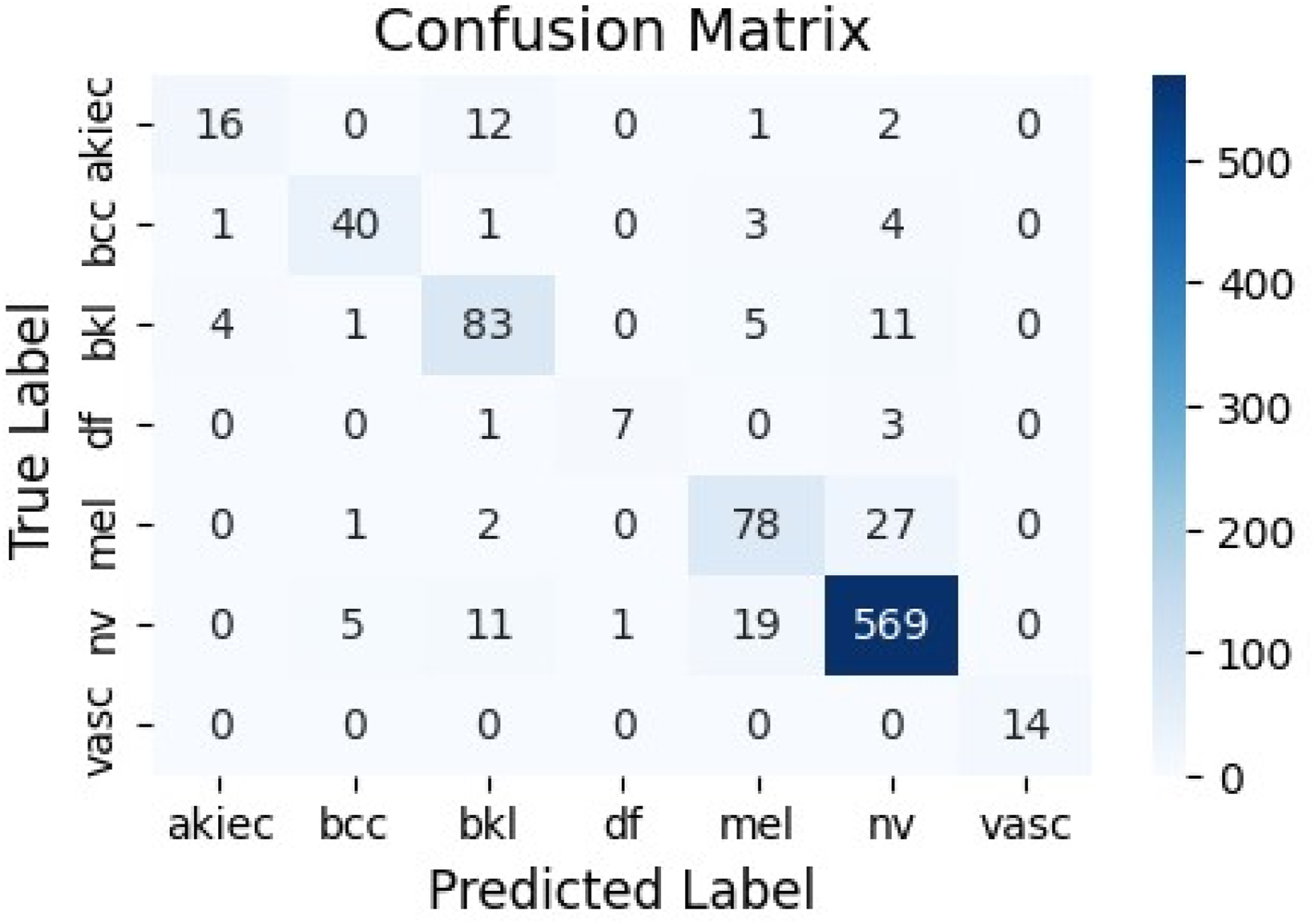
The model’s training demonstrates rapid convergence, with low validation loss indicating strong generalization. The confusion matrix (Figure 11) shows excellent diagonal dominance, with ’nv’ correctly classified in 585 instances and minimal errors in rare classes like ’vasc’ (vascular lesions). ROC curves from component models exhibit near-perfect AUCs (e.g., 0.987 for ’bcc’, 0.982 for ’nv’), underscoring its diagnostic reliability. Confusion matrix for the Proposed Model.
Overall, the ensemble strategy enhances robustness, outperforming component models by fusing complementary features from DenseNet’s dense blocks and ResNet’s residuals.
Class-wise accuracy analysis
To provide a more detailed assessment of the proposed model while accounting for the class imbalance inherent in the HAM10000 dataset, we conducted a class-wise performance analysis based on the confusion matrix (Figure 11). By comparing the number of correctly and incorrectly classified samples for each lesion category, the corresponding class-wise accuracy values were computed. The detailed results are presented as follows. • • • • • • •
This class-wise evaluation indicates that the proposed model achieves high true positive rates for majority classes such as ’nv’ and ’bcc’, while also maintaining strong discriminative performance across more challenging minority classes. These results highlight the effectiveness of the applied training set augmentation and attention-based feature fusion strategies.
Ablation study
To systematically evaluate the contribution of individual components within our proposed framework, we conducted an ablation study. This analysis isolates the performance of the base architectures and the intermediate concatenated modules to quantify the gains achieved through our attention mechanisms and dual concatenation strategy.
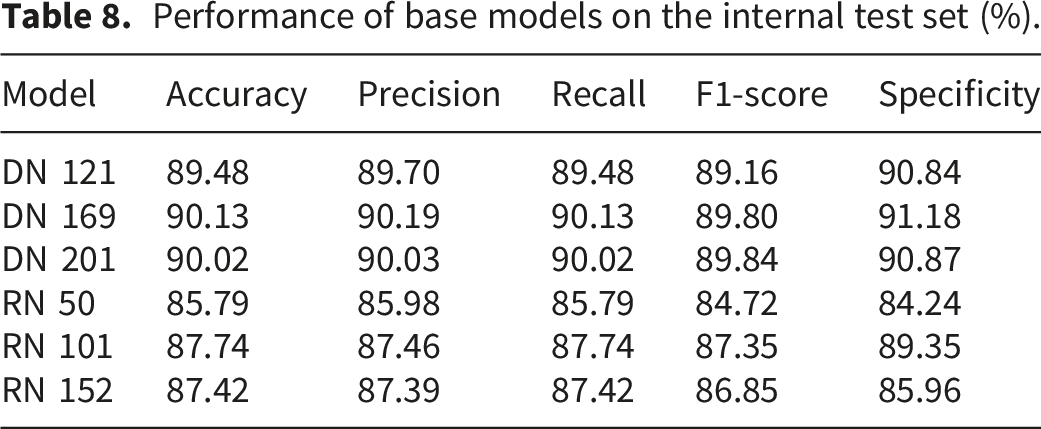
Performance of the base models
Performance of base models on the internal test set (%).
Performance of base models on the independent test set (%).

Performances without dual concatenation
Performance of concatenated variants on the internal test set (%).

Performance of concatenated variants on the independent test set (%).

Comparison of ensemble techniques
Performance comparison with other ensemble techniques on the Internal Test Set (%).

Answers to the research questions
Answer to RQ1
To tackle the big class imbalance in the HAM10000 dataset, we looked into various augmentation methods: Prior Augmentation (PA), Posterior Augmentation (AP), No Augmentation (NA), and Only Train set Augmentation (TA). Our findings showed that just augmenting the training set (TA) gave us the best balance. This approach helped boost the minority classes without messing up the validation or test sets, which meant we avoided any data leakage and got a fair evaluation of how well the model generalizes. As a result, we decided to use TA as our primary approach to addressing class imbalance in this study.
Answer to RQ2
The experimental results indicate that the targeted augmentation of the training set—which includes techniques such as rotation, shifting, zooming, and flipping—significantly enhanced the robustness of the model. This augmentation increased intra-class diversity, enabling the model to identify discriminative patterns, even within underrepresented classes. The performance observed on the test set, which yielded an accuracy of 91.43% and a specificity of 92.04%, demonstrates that the augmented training effectively mitigated overfitting by enabling the model to generalize well to previously unseen images. Additionally, the consistent stability of accuracy and loss curves throughout the epochs further substantiates the efficacy of the augmentation strategy in minimizing bias and variance.
Answer to RQ3
Our experiments confirmed that multi-level ensembling with attention mechanisms strongly enhanced generalization relative to single architectures. Although performance for individual DenseNet (DN121, DN169, DN201) and ResNet (RN50, RN101, RN152) models was strong in isolation, their performance varied across datasets. The hybrid ensemble, which merged Dual Concatenated DenseNet and Dual Concatenated ResNet with integrated attention mechanisms, performed better on the test set than the individual models. The ensemble’s ability to merge the complementary strengths of DenseNet’s dense connections and ResNet’s residual learning improved feature diversity and reduced sensitivity to overfitting. This was clearly demonstrated by the improved balance among performance metrics and near-perfect ROC–AUC scores across classes, showcasing the ensemble’s stability for real-world diagnostic use.
Theoretical justification of novelty claims
To substantiate the contributions listed above, we provide the following theoretical intuitions:
Justification for NC1
Addressing class imbalance via augmentation requires a theoretically sound strategy. No Augmentation fails as the model biases toward the majority class. Prior Augmentation, where the entire dataset is augmented before splitting, inevitably causes data leakage; variations of the same image may appear in both training and testing sets, leading to inflated, unrealistic accuracy. Posterior Augmentation on the test set is invalid because test data must remain pristine to represent unseen real-world samples. Only Train Set Augmentation (TA) is the only method that theoretically ensures the model learns from a balanced distribution while being evaluated on an independent, unadulterated distribution. This guarantees that the reported performance reflects true generalization rather than memorization.
Justification for NC2
Standard Convolutional Neural Networks (CNNs) treat all pixels and channels equally, often leading to noise interference. We integrate three distinct attention mechanisms to mimic human visual focus. Channel Attention theoretically weighs the RGB channels, determining which color spectrum carries the most diagnostic information. Squeeze-and-Excitation (SEA) operates by ”squeezing” (suppressing) less relevant background regions and ”exciting” (amplifying) the weights of infected or informative regions. Soft Attention applies a probabilistic mask to randomly emphasize different feature regions. The integration of these mechanisms ensures the model focuses strictly on lesion morphology rather than skin artifacts.
Justification for NC3 & NC4
A single model architecture imposes a specific inductive bias; for instance, DenseNet emphasizes feature reuse, while ResNet emphasizes residual learning. Relying on a single model creates a risk of overfitting to that specific architectural bias. By hybridizing different architectures (DenseNet and ResNet) and different depths (e.g., DN121, RN50), we create a diverse feature space. Theoretically, this ensemble approach ensures that if one model overfits or fails to capture a pattern, the complementary strengths of the other models compensate. This structural diversity is what leads to the improved generalization and robustness claimed in NC4.
Justification for NC5
In imbalanced datasets like HAM10000, a model can achieve high accuracy simply by predicting the majority class (the ”accuracy paradox”). Therefore, accuracy alone is a theoretically insufficient metric. By validating our model against Precision, Recall, F1-Score, Specificity, and ROC-AUC, we theoretically confirm that the model is learning to distinguish distinct lesion types rather than exploiting class distributions.
Discussion and extended comparison
Performance comparison with existing models from the literature (%).

Our model is the highest in accuracy (91.43%), precision (91.36%), recall (91.43%), and F1-score (91.26%), and also has a good specificity (92.04%). Although there were competitive results in individual metrics in some of the previous works, none of them were uniformly more effective than our framework in all the measures. This shows how strong our hybrid attention-integrated ensemble method is in the classification of skin lesions.
Results with confidence interval
The confidence intervals for the classification metrics were computed using the normal approximation interval method based on the predictions obtained from the independent test set. For a given performance metric p and total number of test samples n, the standard error (SE) is calculated as:
The corresponding 95% confidence interval is then estimated as:
The normal approximation is statistically appropriate in this study because the conditions npgt5 and n1-pgt5 are satisfied for all reported metrics, which fulfills the requirements of the Central Limit Theorem given the large-scale nature of the HAM10000 dataset.
The reported results were obtained from a single finalized training run using the fixed train-validation-test split described in the experimental setup. The confidence intervals therefore quantify the statistical uncertainty associated with the finite test sample size rather than variability across multiple independent training runs.
Performance metrics with 95% confidence intervals.

Comparison with state of the art method
Comparison with state-of-the-art MobileNet variants on the Internal Test Set (%).

Threats to validity
Although the proposed framework performs well, several threats to validity need to be noted. First, it should be noted that this study uses only the HAM10000 dataset. Although it has been accepted as a standard dataset in the field, it should be noted that it only assesses the model’s robustness on a single dataset, namely the ISIC dataset.
Second, due to the high computational complexity of the proposed multi-branch ensemble model, which uses six intensive models, the train, validation, and test splits were fixed rather than using k-fold cross-validation. While bias was reduced through the use of a separate test set and stratified samples, the lack of cross-validation means the performance measures may differ slightly depending on the data split. Future studies should aim to include multiple dataset validations and proper cross-validation techniques.
Third, this study is limited by the absence of cross-dataset evaluation, which prevents a comprehensive analysis of dataset bias and domain shift. Since our model was trained and evaluated exclusively on the HAM10000 dataset, its performance on data with different statistical distributions, such as images acquired using various dermatoscopic equipment, various lighting conditions, or patient demographics, is not established. We acknowledge that domain shift is a critical challenge in medical image analysis, and relying on a single dataset may introduce inherent biases. While conducting a full cross-dataset evaluation is beyond the scope of the current work, validating the model on external, heterogeneous datasets (e.g., ISIC archives or diverse clinical repositories) is a priority for our future research to ensure true clinical generalizability.
Finally, our ensemble method performed very well, but a customized ensemble learning method like28,42–46 for specifically this domain that can determine the optimal weight of the predictions can be a massive improvement for our architecture.
Feasibility in real clinical or mobile health settings
Our proposed framework demonstrates significant potential for deployment in real-world clinical and mobile health environments. First, the model is trained on the HAM10000 dataset, which consists of real clinical dermatoscopic images. It is important to note that the high performance metrics recorded by the model, such as accuracy and specificity, demonstrate that predictions made by the model are highly reliable. However, it is imperative to clarify the intended scope of this tool. We declare that the output is a probabilistic prediction, not a definitive medical diagnosis. If the model predicts a skin lesion as positive for a specific disease, it serves as an early warning system, suggesting that the patient should consult a dermatologist immediately for a formal diagnosis. We explicitly state:
Regarding mobile health settings, deploying this architecture as a mobile application is highly feasible. While the training phase is computationally intensive, the deployment phase utilizes the pre-trained weights. A mobile application would not need to retrain the model; it would simply perform inference using these saved weights. Consequently, the computational burden on the mobile device is minimal, making the application lightweight and compatible with a wide range of mobile hardware. Developing this mobile interface remains a key objective for our future work.
Conclusion and future work
This paper presents a novel hybrid deep learning architecture for robust skin lesion classification. The architecture comprises three DenseNet models, three ResNet models, and three attention mechanisms (channel attention, squeeze-and-excitation attention, and soft attention) to create a more robust model with improved feature extraction. The resulting ensemble model achieved 91.43% accuracy and 92.04% specificity on the HAM10000 dataset, surpassing existing baseline methods. Our research underscores the efficacy of leveraging diverse architectures and attention mechanisms to address challenges such as class imbalance and inadequate generalization, which are prevalent in medical imaging datasets.
Despite the strong performance of the proposed model, a notable limitation is its computational complexity, which may hinder its implementation in resource-constrained environments. Future work will aim to optimize the model architecture to minimize computational demands while preserving performance levels. Furthermore, we intend to validate the model’s effectiveness across additional, more varied skin lesion datasets to confirm its generalizability. Further investigations will also consider advanced methodologies such as knowledge distillation to develop a more lightweight and efficient version of the model tailored for mobile or edge device applications. Moreover, we will try to mitigate our threats to validity.
Footnotes
Acknowledgment
We are grateful that the Computer Science and Engineering Department of the Rajshahi University of Engineering and Technology, Bangladesh, assisted in the study process.
Ethical consideration
This study utilizes the HAM10000 dataset,
30
which was obtained from the
Author contribution
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.