
Abstract
Artificial intelligence is a disruptive area which transforms cutting-edge healthcare technology to analyze clinical workflows, sharpen diagnostics, and improve precision medicine. The goal of this review is to identify approaches involving a collaborative examination to determine the key features influencing the adoption of artificial intelligence methodologies in advanced cutting-edge solutions for metabolomics and drug design. In clinical and translational settings, a comprehensive investigation of legal and ethical principles will be included to highlight the significance of omics analysis and drug design in the application of artificial intelligence tools with artificial intelligence in healthcare, the real-world uses, and difficulties tied to societal and regulatory issues. The real-world effects of artificial intelligence for researchers and technicians can provide guidance for tailored strategies focused on leveraging potential to improve high-dimensional data analysis on metabolomics and drug design. As artificial intelligence methodologies continue to evolve, efforts must be directed toward structured frameworks that uphold human oversight and engagement to optimize the utility of artificial intelligence algorithms and big data methodologies. The key contributions of this study include a comprehensive overview of cutting-edge artificial intelligence methodologies and software programs in metabolomics and drug design, and critical perspectives which can solidify the future directions in the development of algorithmic approaches to bridge metabolomics and drug design.
Introduction
Precision medicine is a paradigm-shifting approach that processes the vast data of individual variations based on patients’ genetics and lifestyles to detect diseases and manage lifelong health. 1 As foundation tools, artificial intelligence technologies can identify complex biological, chemical, pharmacological associations of features in multi-omics data which represent patients’ individual variations 2 ; features can represent metabolites, biochemical variables or environmental exposures, and interactions of features can indicate co-existing elements, activators or inhibitors. Artificial intelligence and big data methodologies that explain interrelated structures in real-world data should be developed and extended. Artificial intelligence algorithms in the analysis of high dimensional data can illustrate the interactions of metabolites and furthermore metabolic pathways related to the complex mechanisms used to predict targeted outcomes such as absorption, distribution, metabolism, excretion, and toxicity. 3 Analyzing interactions of features in high dimensional data is challenging since big data includes large volume of data with high complexities. 4 Effective analysis and valid statistical inference of high dimensional biomedical data followed by significant interpretation of analysis results should be devised. The application of feature engineering with statistical analysis of high dimensional features to predict outcomes can be significantly considered. Artificial intelligence techniques with statistical analysis can help to analyze unknown or complex interactions of biomedical features in a dimensionality reduction framework. Available artificial intelligence tools have broadly been applied to genomic data,5,6 but rarely to metabolomics for drug design. Precision medicine requires well-organized data collection and processing in metabolomics and drug design. As a fundamental tool with the profiling of small molecules, metabolomics has been used to obtain biomedical information and illustrate the properties of collected and processed metabolomics data. 7
Artificial intelligence algorithms in biomedical applications.

Environmental factors including metal toxicity can occur from environmental exposure to heavy metals such as cadmium or lead causing deleterious effects in the function of the biological system. 39 To examine metabolomics affected by heavy metals, many studies are conducted in biological model systems.40,41 This study proposes the utilization of machine learning algorithms to identify the effect of heavy metals on the metabolites in biological entities. The utilization of algorithms estimates the association of strongly interacting metabolites and classified the exposure to cadmium or lead. 42 The data analysis results can be corroborated for the association of metabolomics from medical literature with the use of artificial intelligence models for high throughput analysis in the biological model system. 43 The interaction of metabolites in high-dimensional metabolomics can occur with the existence of common environmental exposures such as trace elements. 44 The use of high-dimensional metabolomics data in biology is still at a nascent stage. It is strongly expected that big data analytics tools can improve the classification of target health outcome in the field of biology because large-scale data has been cumulated. Big data analytics in metabolomics strengthens the development of classification models which can effectively and efficiently define whether strongly interacting metabolites can estimate a health outcome. 45 Depending on the structures of metabolomics data and classification model, biological mechanisms can be thoroughly investigated. This study explores the network of metabolites related to the effect of environmental exposure such as trace elements and the network is formed to utilize machine learning algorithms with statistical pre-processing of metabolomics data. 46 The advantage of developing and utilizing big data analytics tools is to visualize the associations of interconnected metabolites and classify the existence of environmental exposures in metabolomics. 7 The utilization of big data analytics tools enables biomedical researchers to identify biological pathways, possibly understanding the biological mechanisms of metabolism. 47 Studies on metabolomics have been implemented in order to develop existing artificial intelligence methodologies for application to complex networks of metabolites related to health conditions. 48 Extensively analyzing high-dimensional datasets with complex structures requires computational and statistical methods to investigate the biological pathways of metabolomic data. If there are missing values in the biomedical data, there may be multiple reasons affected by insufficient or unrelated answers to survey inquiries or numerous experiments with inconsistent results from the complex data. 49 While assuming and building a network model of complex but sparse biomedical data, extensive datasets with complex structures can decrease computational efficiency of data analysis in practice. 50 Below, an example is shown regarding the applications of artificial intelligence methodologies including principal component analysis and network analysis based on LASSO for the analysis of zebrafish metabolomics which is possibly affected by environmental exposures such as metal toxicity. This example demonstrates that to analyze large and complex biomedical data (e.g. zebrafish metabolites) and predict a specific outcome (e.g. exposure level), not only a single artificial intelligence method (e.g. PCA) but also additional methods including network analysis can be utilized to obtain an improved classification result. Various software programs which can solve such problems are listed in the later sections.
As shown in Figure 1, detecting exposed zebrafish using principal component analysis only is not clear since the classified groups are tightly clustered. In this case, network analysis which identifies the interactions of metabolites can be suggested as shown in Figure 2. Classification of exposed and not exposed metabolites of zebrafish using principal component analysis. PCA failed to separate exposed vs. non-exposed metabolites, indicating high feature interdependence; network analysis resolved connectivity and exposure patterns. Interactions of metabolites in zebrafish models. LASSO method was applied to build networks of metabolites in an undirected graphical model.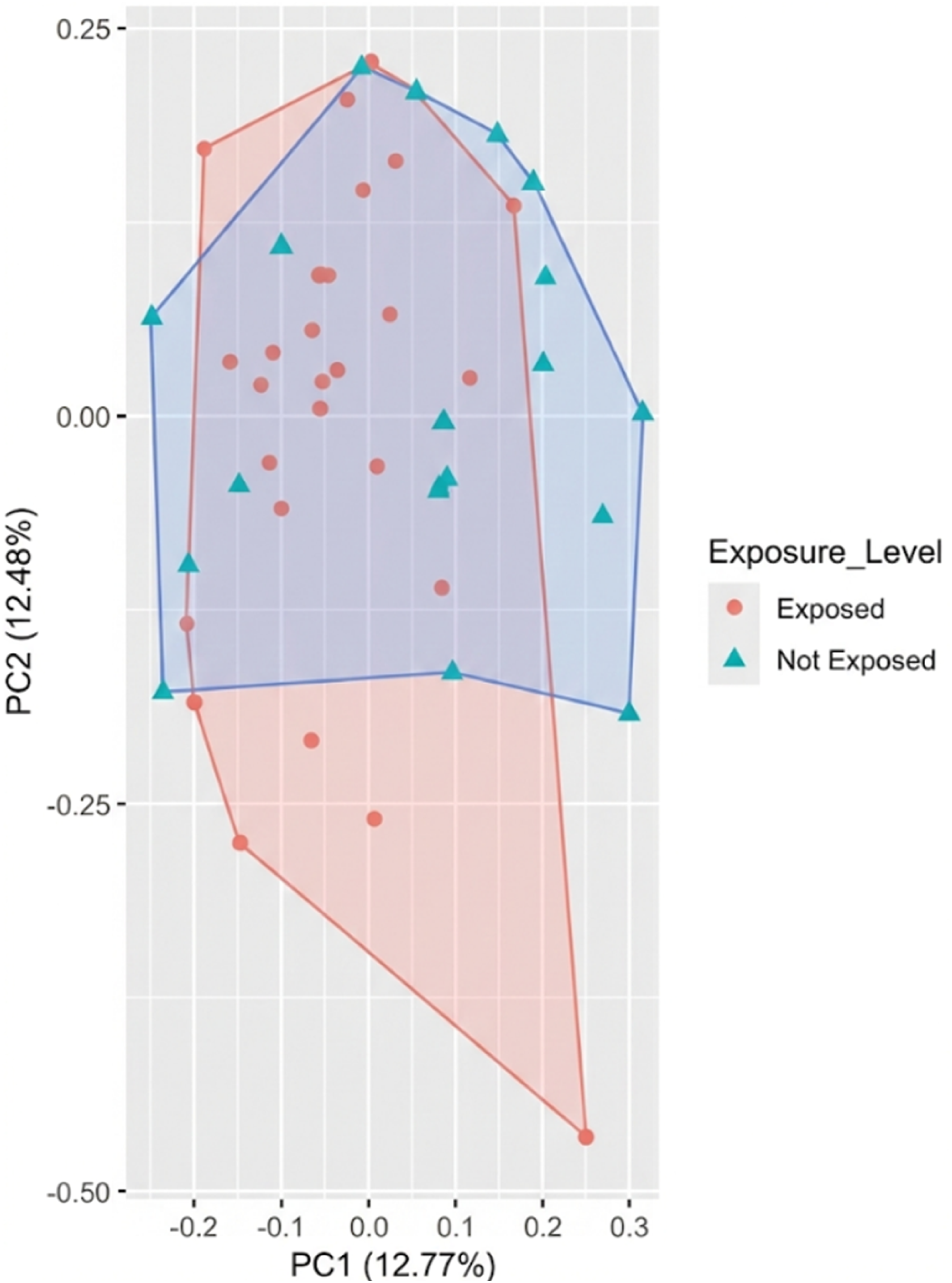

Effectively and efficiently utilizing appropriate artificial intelligence techniques with network analysis and statistical inference is quite significant since big data are huge and include complex interactions of factors. Thus, this review will survey major artificial intelligence methodologies significantly applied in metabolomics studies which can be utilized to biomedical data in drug design with different levels of predictive accuracy or model performance. While the model performance and efficacy of artificial intelligence methods in drug design are considered, major challenges and limitations including data security, legal regulations, or ethical issues will be discussed to optimize the big data analytics in biomedical sciences and healthcare. 51
In drug design with metabolomics studies, alterations in metabolic patterns of biomedical data can reveal mechanisms of absorption, distribution, metabolism, excretion or toxicity.
52
Removing a potentially harmful chemical entity in the development process can be shown in recent studies using metabolomics for identifying environmental toxicity biomarkers. It is demonstrated that environmental exposure to various toxicants including heavy metals can lead to changes in oxidative stress responses, or amino acid and lipid storage processes. The main goal of the research is depicted in Figure 3. How AI integrates with omics data, network analysis, and clinical decision-making.
Search strategies of this review have included a comprehensive literature search of relevant articles from Google Scholar, PubMed, and WEB of Science electronic databases. This limited most of the publication dates to 2010 to 2025. The database search terms included “big data”, “metabolomics”, and “drug design” which are Medical Subject Headings (MeSH) terms included in the keyword search.
The objective of this review is to convey a comprehensive overview of cutting-edge artificial intelligence models and software programs for metabolomics and drug design with perspectives on challenges and future research directions. This review will organize the current literature to offer researchers possibilities in the most recent trends and advancements in application of artificial intelligence in metabolomics and drug design.
Artificial intelligence techniques
In biomedical research, supervised learning covers machine learning techniques that identify approximated functions linking input data to a continuous or categorical output through computational and statistical validation. Labeled training data can be used to evaluate a collection of training observations to derive a generalized prediction function in text or imaging data. Unsupervised learning analyzes biomedical data sets without labels, involving clustering, feature extraction, and dimensionality reduction. 53 Reinforcement learning methods involve rewards or penalties by leveraging big data gathered from the agent’s environment to increase the reward or reduce the risk. A robust tool for training artificial intelligence models can improve automation or the effectiveness of complex systems in biomedical research. Analytics of high-dimensional data in healthcare can be utilized on structured, semi-structured, or unstructured information. 54 Structured data in orderly format is systematically organized and easily accessible by software applications while unstructured data mainly consists of text or imaging elements. Semi-structured data is not stored in a relational database like structured data is, but metadata pertains to information regarding large-scale data which specifies key details about the data. Regarding data preprocessing, this review will address data management in large-scale healthcare analytics by emphasizing the significance of data quality and standardization with data governance frameworks and standardized protocols for data collection and reliability. 55
Supervised learning
The decision tree is a non-parametric supervised learning technique which is applied for both classification and regression, by analyzing the instances by traversing down from the root to leaf nodes. 56 Decision tree can be used to identify drug metabolism and pharmacokinetic mechanisms for new chemicals. Since chemical data including metabolism and pharmacokinetic mechanisms involve complex structures of biological or chemical entities, building the appropriate size of decision tree is crucial to avoid the overfitting of modelling and save processing time for big data analytics. 57 Decision tree can train models to perfectly classify outcomes using metabolomics and drug data, but early stopping in the modeling can be quite significant to obtain the optimized artificial intelligence model. 58
A random forest algorithm implements prediction or classification across various domains of application. 59 The random forest algorithm trains multiple decision trees in parallel on subsamples of the datasets by estimating majority voting or averages to determine the prediction results. Random forest algorithm can be used in the GC-MS analysis using various clinical metabolomic datasets for biomarker selection. Metabolic pathways of glycolysis, microbial-host metabolism, and drug gene expression. 60 Since random forest implements bagging over decision trees, the process of sampling over complex high-dimensional datasets requires efficient computation with proper levels of decision trees. 61
K-Nearest Neighbors is a type of instance-based learning referred to as a lazy learning algorithm. 62 K-nearest neighbors algorithm sets the number of nearest neighbors in the prediction problem with all data points according to similarity metrics based on the majority vote of k closest neighbors for each data value. Since metabolomics datasets contain missing values and nonlinear dependencies among features, data imputation implemented by k-nearest neighbors method can accurately reconstruct and complete metabolomics data with the generalized modeling. 63 K-nearest neighbors method can be used to identify molecular connectivity to filter potentially problematic absorption, distribution, metabolism, or excretion properties. However, as an instance-based method, k-nearest neighbors algorithm should optimize computational time estimated by the size of biomedical data and the number of neighbors, resulting in high computational complexity with biomedical entities. 64
The regression method takes a linear function by establishing a relation between the outcome variable and one or more explanatory variables, producing the optimal straight line. 65 As regression methods, LASSO and Ridge regression effectively construct learning models with high-dimensional features and simplify the model with regularization by considering multicollinearity. 66 The prediction of specific continuous outcomes can be estimated by considering the interactions of metabolites in the network and LASSO by jointly modelling biomedical entities. LASSO can be used to predict absorption, distribution, metabolism, excretion or toxicity properties with explainability which selects significant molecular substructures or chemical properties which affect predictive accuracy. 67 However, in recent studies, in terms of prediction accuracy, random forest or boosting methods outperform LASSO. As one of supervised classification methods, regression can be used to identify pathway features to build metabolic networks in the pathway modeling 26
The architecture of neural network method includes modelling functions and steps in learning examples of biomedical research. 68 Neural network methods can be applied to define characteristic metabolites for the discrimination of the geographical or biological differences between entities and detect biomarkers for prediction of outcomes. 69 In drug design studies, the dependent variables of drug discovery can discrete outcomes like permeability or the continuous outcome of IC50 values with molecular structures. 70 The structure of neural networks consists of nodes and edges, indicating that the complex structure of neural network can cause inefficiencies as in the big data analytics with random forest. As a type of deep neural network, the application of the convolutional neural network model can better interpretability in the analysis of metabolomics by utilizing spectral metabolomics profiles with biomedical research driven by artificial intelligence. 24 The graph neural network can be utilized to analyze molecular structures over bonds and connections among fragments by increasing prediction accuracies of molecular properties. 25
A support vector machine is a non-parametric approach in machine learning for modeling regression and classification tasks with high-dimensional data. 71 The hyperplane preserves the maximum distance from the nearest training data points in any class, as a wider margin is linked to a lower generalization error for the classifier. A support vector machine is used to investigate disease diagnosis with alterations in metabolite concentrations in biofluids or pharmacokinetic studies to classify the variations between two clinical groups. 72 In large biomedical data sets, the utilization of support vector machine may require long training times with high computational cost.
Gradient Boosting is a method of ensemble learning that implements the integration of analytical models. Extreme Gradient Boosting, XGBoost, is a gradient boosting method that provides estimations during the search for the best model. 73 XGBoost with metabolic profiles can be applied to conduct comparative analyses on cases and controls by identifying biomarkers for specific diseases. 74 Boosting methods can be applied for a reliable framework in target identification of drug design. Since boosting is computationally intensive in the analysis of biomedical data with high complexity, flexibility in allocating resources is required. 75
Unsupervised learning
K-means clustering effectively provides reliable results when data points are grouped into a cluster, minimizing the distance between each data value and the centroid. 76 The K-means algorithm randomly assigns the k centroids and subsequently allocates each data point to the closest cluster. K-means clustering can be applied to classify metabolites using a data-driven approach focused on distinct biological profiles and cluster the composition of drugs related to these biological traits. 77 With a random choice of centroids of clusters, the classification outcomes may, however, vary in biomedical data.
Hierarchical clustering can build a hierarchy of clusters represented as a tree structure in an agglomerative or divisive way. 78 Hierarchical clustering can be used to cluster mass spectra for metabolomics data which visualizes the identification of specific biological profiles and data-driven approach for screening of biological drugs. 79 Hierarchical clustering is sensitive to outliers and preprocessing biomedical data to remove extreme data values is critical.
Gaussian Mixture Models assign each data value a probability of being classified to each cluster. 80 Classifying data values using Gaussian Mixture Models reinforces the identification of diseases with various biomedical conditions from the molecular level to human level. Since generating the precise prediction of drug results is a complex and difficult process, the utilization of Gaussian Mixture Models can be expanded to thoroughly monitor patients’ overall symptoms by different time groups. 81 Similarly with K-means clustering, the initialization of Gaussian Mixture Models may cause the failure to converge. If the true biomedical data distribution is non-normal, prediction or classification using Gaussian Mixture Models will underperform. 82
Principal component analysis is used to transform a set of correlated variables into a set of uncorrelated variables known as principal components. 83 Principal component analysis acts as a technique for feature extraction that reduces the dimensionality of datasets by maximizing the variance of projections and minimizing reconstruction errors. Principal component analysis conducts partial classification of metabolites and loadings of principal component analysis can be monitored for the detection of more important metabolites in the analysis. 84 Since the principal components instead of features are used to understand biomedical data, direct selection of interpretation of significant features is not possible.
T-SNE (t-distributed stochastic neighbor embedding) implements a statistical method for visualizing big data by embedding data points into a low-dimensional map and can be utilized to analyze metabolite profiles and metabolic pathways. 85 Due to the complexity of biomedical data, t-SNE not only requires high computational time but also produces non-deterministic results with challenging interpretability. 86
UMAP (Uniform Manifold Approximation and Projection for Dimension Reduction) can be used for visualization with nonlinear dimensionality reduction. 87 UMAP can be applied to low-dimensional metabolites without bias across multi-omics contexts, identifying potential drug leads or improving model generalizability. With complex high-dimensional biomedical data, UMAP may generate non-existent clusters by determining clusters which may not be close to each other. 88
In GANs, the generator generates real samples, and discriminator distinguishes generated samples from real samples, and in VAEs, an encoder embeds data to latent representations, and a decoder reconstructs the data with re-sampled representations, minimizing the reconstruction error during the training process. 89 GANs are used to generate the structures of molecules in drug-target interaction. 34 The improved VAEs can detect the structural interaction of molecules and generate molecules with improved properties more effectively 35
Reinforcement learning
Q-learning is a model-free off-policy reinforcement learning algorithm which can optimize reward based on Markov decision processes and SARSA is an on-policy reinforcement learning algorithm to make agents learn optimal policies with temporal difference. 90 In real-time applications, Reinforcement learning can be applied to analyze electronic health records in health care systems as targeted nodes. 91 Reinforcement learning algorithms are utilized to conduct the generation of new chemical structures by overcoming the complexity of chemical space exploration by avoiding massive computing. 92
Personalized drug design and precision medicine
The aim of precision and personalized medicine with artificial intelligence technologies is to supplement healthcare systems which store and process demographic and biomedical traits of patients. 93 Overall factors related to a single patient include both biomedical and demographic factors related to substantial genotypes and phenotypes to maintain health and handle diseases. With the patients’ lifestyles and specificity in pathology, managing patients’ illness is as crucial as the disease process regarding diagnostic and therapeutic methodologies. 94 Clinical specialists have referred to disease-specific guidelines to standardize healthcare for patient care. Advances in genetic testing for the identification of subtypes of diseases or drug responses have led to a more stable customization of clinical treatment. 95
Personalized drug design processes and utilizes the genetic, environmental and clinical information of patients to expand molecular insights for the detection and analysis of diseases such as HIV with clinical decision support to improve preventive health care strategies and treatment outcomes. 96 Information from the human genome helps biomedical researchers and healthcare providers develop optimized care strategies for phases of a disease, covering the long but effective path from scientific breakthroughs in the lab to the vital application of the innovative medical skills into human biology in clinical and transitional sciences. 97 A patient’s genes, environments and lifestyles for precision medicine allows for the detection of latent risk factors for disease susceptibility, forecasting responses to drug treatments, and evaluating the likelihood of side effects after pharmacological intervention. 98
Precision medicine methodologies have been devised to optimize clinical assessments and treatment outcomes for clinicians and practitioners. 99 Diagnostic tests are arranged to extract the optimal treatments based on molecular or cellular data. Wearable sensors in precision medicine have led to findings related to tailored interventions for older patients dealing with syndromes and morbidities. 100 Collaborative efforts in precision medicine can greatly accelerate progress of personalized drug design with artificial intelligence methods and medical skills including chemotherapies. 101 The analysis of biomedical data with complex structures and high dimensionality on molecular and human levels can be very challenging. The effective and efficient analysis of high-dimensional biomedical data can be implemented with large network analysis. The network analysis can improve the process for suitable medications to match the dosage and timing for delivery or minimize adverse medical effects. 102
Software for network analysis.

Application of artificial intelligence in metabolomics and drug design
AI in metabolite biomarker discovery
Detecting significant biomarkers with metabolomic studies of metabolic alterations and external biomedical factors can give insights into the diagnoses of complex diseases. Input datasets for metabolite biomarker discovery include clinical data such as age, gender, or BMI and the metabolites with metabolite abundance. 108 The databases for biomarker discovery include MarkerDB, a resource for molecular biomarkers with consistency and applicability. 109 Artificial intelligence models can help researchers to classify diagnosed or undiagnosed cases with accurate statistical analysis to identify metabolic patterns. 110 The application of artificial intelligence models can detect biomarkers and targets for successful precision medicine.
AI-based metabolic pathway modeling
Metabolic pathways can be identified with the utilization of artificial intelligence methodologies such as ensemble modeling where multiple modeling algorithms are included to analyze and predict features of metabolic pathways. 111 Input data for the metabolic pathway modeling include molecular fingerprints or concentration values of metabolites. The database KEGG includes pathway maps with information about molecular interaction in functional and systems biology. 112 Large-scale artificial intelligence models simulate the networks of metabolic alterations to analyze metabolic pathways. Analyzing metabolic pathways encourages researchers to discover important biochemical reactions and metabolic mechanisms. 113
AI for drug target identification
Researchers can conduct the identification of drug targets in a data-driven system-level inference by handling biological complexity and limited scalability. 114 The types of data include ligands or proteins stored and curated in databases such as DrugBank or ChEMBL.115,116 The patterns from omics data are used to track specific targets or regulatory networks. 117 The biomedical data analysis can identify binding sites in target proteins with virtual screenings. 118 The identification of drug targets with knowledge about biological activity can lead to pharmacokinetic studies.
AI for ADMET prediction, Pharmacokinetic properties can be specified by processes of absorption, distribution, metabolism, excretion, and toxicity in drug discovery and development. Key target outcomes include human intestinal absorption or Caco-2 permeability for absorption, Blood-Brain Barrier permeability for distribution, Cytochrome P450 interaction or metabolic stability for metabolism, total clearance for excretion, or hERG Channel inhibition or hepatotoxicity for toxicity. 119 Types of input data for ADMET prediction are chemical structures represented by Simplified Molecular Input Line Entry System (SMILES) and chemical descriptors such as molecular weight or hydrogen bond donors or acceptors. 120 The databases of SMILES include PubChem, DrugBank or ChEMBL.115,116,121 Artificial intelligence and big data methodologies can effectively examine high-dimensional biomedical data including SMILES with optimized model performance and generalizability of reproducible artificial intelligence models on standardized datasets.
Integration of metabolomics in drug discovery pipelines
The current drug discovery pipelines include natural product-based drug-discovery pipelines and interdisciplinary fields of research with metabolomics studies.122,123 The Human Metabolome Database (HMDB) is one of the largest and most comprehensive collections of human metabolites and metabolism data. 124 The utilization of artificial intelligence methodologies with statistical analysis enables the efficient curation of complex metabolomics data in HMDB and the integration of metabolomics in drug discovery will lead to crucial findings in biomedical sciences related to drug design and development. 48 As one of open-source pipelines for the integration of metabolomics in drug discovery, NP3 MS Workflow shows an effective approach to extract significant features from complex mixtures for untargeted metabolomics. 125 Investigating metabolic networks at varied molecular levels can provide the improved analysis of selected biomarkers or targets related to drug reactions and diagnoses of diseases in drug discovery.126,127
Challenges of artificial intelligence in healthcare
Data protection regulations.

While artificial intelligence in healthcare can advantageously enhance precision medicine and personalized drug design, the utilization of large-scale biomedical data may face algorithmic bias or data vulnerability. Algorithmic bias can be related to disparities for minority groups, requiring responsible deployment with algorithmic fairness since artificial intelligence applied to the analysis of non-representative data can result in bias or inaccuracy handling racial, gender, or socioeconomic factors in precision medicine. 129 Explainable artificial intelligence platforms in user-friendly interfaces should be introduced for clinicians and policy makers to understand how stable and safe the integration of artificial intelligence with biomedical data analysis can be in healthcare systems. In clinical decision making of healthcare systems, issues related to algorithmics bias in the ethical examination of profiling methods using synthetic data can be mitigated by considering the ethical aspects encompassing algorithmic biases or privacy issues. 130 Maintaining data diversity, handling resource limitations, and controlling algorithmic biases must be considered along with the difficulties of merging AI-driven systems into biomedical workflows. Artificial intelligence technologies can effectively and appropriately function across various groups in society by addressing issues stemming from health professional practices that have traditionally been biased with inaccurate documentation, resulting in imbalanced predictions that unfairly affect certain groups. 131
Healthcare data confidentiality can be validated in ethical, legal and technical aspects within various regulatory systems. International regulations can flexibly reflect local variations regarding cutting-edge technological approaches to strengthen security vulnerabilities. The notable variations in data privacy have stemmed from regions of different times. For example, North America confronts HIPAA enforcement issues or Europe has been tied up with GDPR. 132 With regulations, standardizing demographic traits of human population over healthcare systems has been complicated with the wide range of pharmaceutical products involving the Food and Drug Administration. Nonprofit organizations have developed standardized metrics to assist with the growing regulatory requirements for care units and hospital operations. 133 HIPAA encompasses several provisions which can ensure standardization and privacy over distinct claim forms in circulation, and apart from the well-known component of patient confidentiality. 134 Existing frameworks in healthcare systems often fail to encompass artificial intelligence technologies which implement real-time learning, validation processes in clinical practices. 135 An extensive examination of the relationship between artificial intelligence and regulatory systems can resolve ethical or legal conflicts and obtain equitable and secure medications. 136
Limitations and future directions
Potential research directions and innovative studies have been proposed to build the incorporation of artificial intelligence in pharmacology, clinical trials, and healthcare services. 137 The use of artificial intelligence models in drug discovery can investigate the application of artificial intelligence methods, including machine learning and generative artificial intelligence within the field of drug development. 138 Biomedical researchers may concentrate on virtual screening, de novo molecular design, and forecasting drug-target interactions to speed up the discovery of new therapeutic agents.
Artificial intelligence methodologies applied to clinical research can create a range of algorithms to develop trial designs, simplify patient recruitment, and establish frameworks of interdisciplinary research. 139 Techniques for utilizing real-world evidence can be examined through electronic health records, wearable devices, and mobile health applications with clinical trial processes and high-quality biomedical and clinical data.
Software for metabolomics analysis.

Software for drug design.

Healthcare text mining methods have broadened insights from unstructured clinical data, medical publications, and biomedical information produced by patients. 153 Interactively building natural language processing models for clinical decision support can give coding and documentation efficiency while analyzing population health with refined information retrieval and knowledge discovery in healthcare environments. 154
Conclusion
The future directions regarding the application of artificial intelligence methodologies in precision medicine are crucial with the improved healthcare services. Studies in biomedical sciences focus on achieving more precise and efficient artificial intelligence algorithms, enhancing data quality and accessibility, and resolving ethical and privacy issues. The primary challenge in solidifying artificial intelligence methodologies for clinical environments with medical documentation is to provide effective, efficient, and fair artificial intelligence tools for practitioners and healthcare professionals within the healthcare system. The application of artificial intelligence and statistical methods to convert data into insights will have a great impact on the healthcare industry, replacing a significant portion of the tasks performed by clinicians. Preserving human factors in medicine with algorithmic fairness and transparency can improve the likelihood of inducing suitable treatment decisions. Digital health is transforming the conventional medical hierarchy into an equitable collaboration between patients and healthcare providers. The disruptive artificial intelligence technologies can provide the potential to strengthen healthcare systems with big data analytics. With high volume of texts, signals, images in healthcare systems, the next decade of biomedical research may utilize and control artificial intelligence focusing on multimodal learning with continuously increasing complex data. Researchers in the next generation will effectively and efficiently analyze big data with appropriately established ethics and algorithmic fairness with artificial intelligence tools. By prioritizing data privacy and security related to experiences of patients, researchers should transform biomedical sciences into a lively and evolving environment with healthy artificial intelligence.
Footnotes
ORCID iDs
Ethical considerations
Because this study did not involve humans or animals, and the underlying data were obtained from public databases, ethical approvals and informed consent were not required.
Author contributions
Conceptualization, S.K. and J.W.L.; Writing — original draft preparation, S.K. and J.W.L.; Writing — review and editing, All co-authors; Visualization, S.K. and J.W.L.; Supervision and Funding acquisition, J.W.L.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This article is financially supported by the 2026 College of Public Policy at Korea University. This work was supported by the National Research Foundation of Korea (NRF) grant (BK21 FOUR (Education & Research Center for Leading Talent in Data Science-Based Future Health Society, Korea University, Sejong)) funded by the Korea government (MOE).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.