
Abstract
Objective
This study assesses ChatGPT-4o′s responses to common patient inquiries regarding urinary incontinence (UI), a condition that significantly impacts quality of life but often goes untreated due to low healthcare-seeking behavior. The evaluation focuses on four key metrics: understandability, actionability, reliability, and readability.
Material and Methods
In this non-human subject qualitative study, 13 patient-focused questions—derived from AUA/SUFU and EAU guidelines—were posed to ChatGPT-4o in Turkish. The questions were categorized into four themes: Definition, Diagnosis, Management, and Surgical Considerations. Three blinded experts (an urogynecologist, a urologist, and a pelvic floor physiotherapist) independently evaluated the responses using the
Results
In evaluating ChatGPT-4o’s performance in urinary incontinence education, experts found strong agreement in their assessments, with inter-rater reliability scores were 0.80 (95% CI: 0.70-0.91) for PEMAT and 0.82 (95% CI: 0.70-0.91) for mDISCERN. The AI’s responses were consistently highly understandable, particularly when explaining diagnoses (achieving a peak score of 94.4 %), yet they were significantly less actionable, meaning they often failed to provide clear, practical steps for patients to follow. This gap was most evident in surgical considerations, which were deemed the least actionable at 68.2 %. The overall
Conclusion
While ChatGPT-4o yields comprehensible health information, its limited actionability and high linguistic complexity pose barriers to patients with lower health literacy.
Introduction
Modern healthcare paradigms prioritize patient empowerment through the acquisition of self-management skills. Effective communication is a prerequisite for the health-seeking behaviors necessary to treat conditions like urinary incontinence (UI)1,2
In regions like Türkiye, where UI education is often opportunistic and unstructured, this digital shift is particularly pronounced. Generative AI, specifically Large Language Models (LLMs) like ChatGPT, offers a new frontier for delivering tailored, empathetic health information. However, current online resources, such as YouTube, frequently lack the clarity or actionable guidance required for effective patient use. Given that only approximately one-quarter of women with UI obtain medical advice, evaluating whether AI can bridge this information gap is a clinical necessity.
AI-powered chatbots have been adopted across specialties to provide health guidance, including in chronic disease management, mental health support, telemedicine triage, and perioperative care. 4 ChatGPT, developed by OpenAI and based on the Generative Pre-trained Transformer (GPT) architecture and has evolved significantly since its inception in 2018. 5 With advancements through GPT-2, GPT-3, and GPT-4, the tool now supports real-time, multimodal interaction via GPT-4o, enabling text, voice, and image understanding. 6 These capabilities make ChatGPT a valuable asset in patient-centered healthcare, delivering accessible, tailored, and empathetic information—enhancing trust, reducing anxiety, and improving comprehension.5–7 Previous studies suggest that, when thoughtfully integrated into clinical contexts, ChatGPT can improve health literacy and support shared decision-making.8,9
While some researchers have emphasized the potential application of ChatGPT in the field of urogynecology, such as its comparable accuracy and completeness in counseling for pelvic floor surgery, 10 its practicality remains uncertain. In the context of UI, studies show that online platforms like YouTube often host content that is poorly understandable and lacking actionable guidance—e.g., 87.5% of English-language incontinence videos were deemed not easily understandable or actionable for viewers. 11 Other studies have shown that much of the publicly available online information regarding UI is incomplete, inaccurate, or conveyed at an understandability level too high for the average patient. 12 Consequently, high-quality UI information online is scarce, which may deter women from seeking professional care. Epidemiological data indicate that only around one quarter of women with UI obtain medical advice or treatment. 13 This is a major concern, as UI significantly diminishes quality of life. 14 Beyond physical discomfort, UI can cause psychological distress such as shame and poor self-image, and has even been associated with increased mortality in older adults. 14
Despite the growing interest in digital health resources, there is still a clear research gap regarding the understandability and actionability of educational materials on UI, particularly those generated by AI. Given the rising popularity of ChatGPT, it is essential to evaluate the reliability of AI-generated content in the context of UI diagnosis and management. This study aimed to investigate how ChatGPT-4o counsels and guides women regarding UI, with a specific focus on understandability, actionability, reliability and readability of the information provided for the general Turkish public evaluated by health experts.
Materials and methods
I. Study design and selection process
The present study was deemed exempt from ethical approval by the Bezmialem Vakif University Institutional Review Board, as it involved a non-human subject qualitative design. Initially 25 patient questions regarding urinary incontinence were derived from patient materials available based on American Urological Association/Society of Urodynamics, Female Pelvic Medicine & Urogenital Reconstruction (AUA/SUFU) and the European Association of Urology (EAU).15–18 After excluding 12 queries; a list of prompts comprising 13 UI related questions remained. (Figure 1) (Appendix 1). The prompts were strategically structured into four primary themes: Flowchart of the selection process for patient questions on urinary incontinence.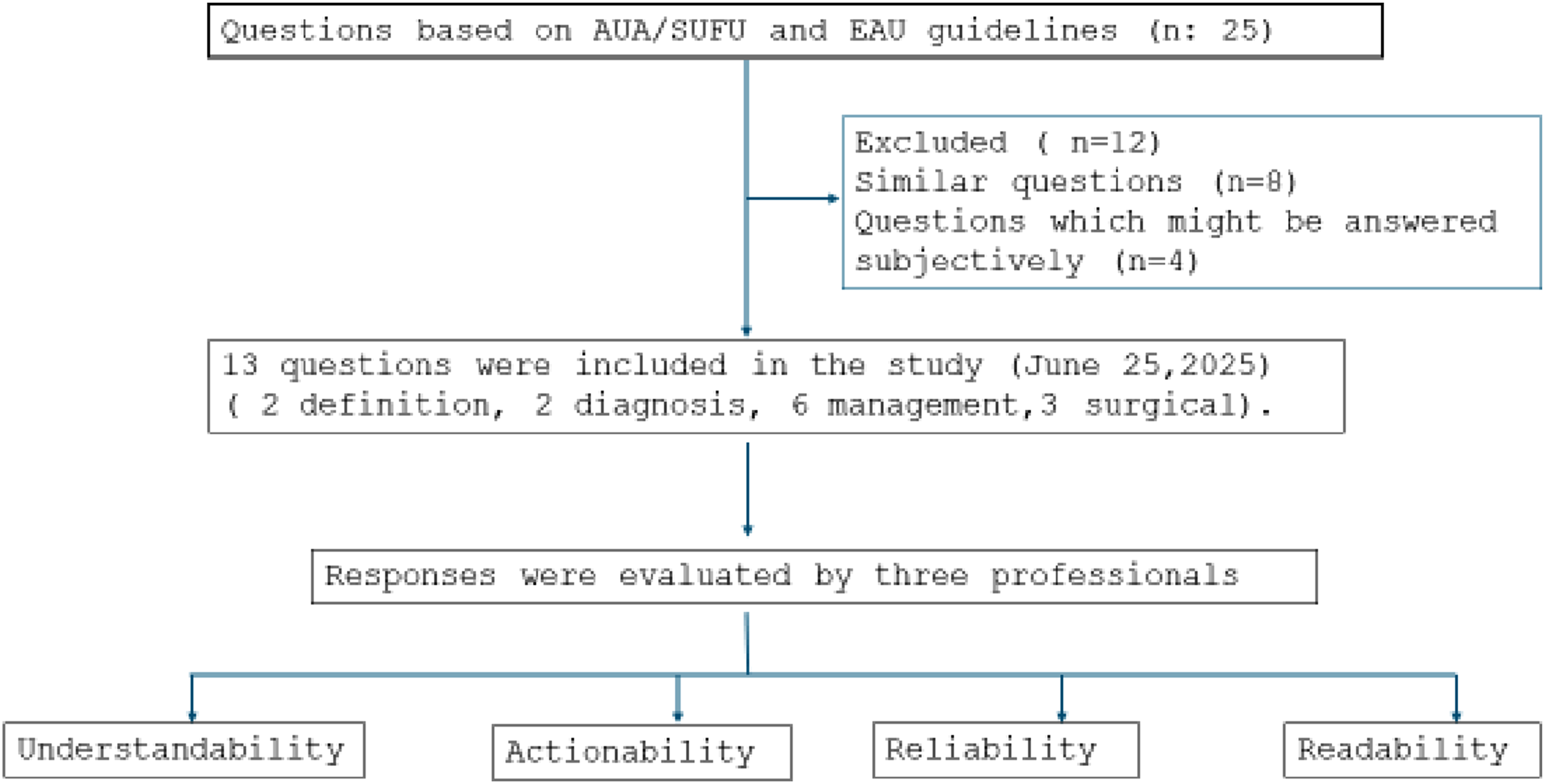
The questions were categorized into four primary themes:
II. Evaluation methodology
On June 25, 2025, all three of the researchers who were blinded to each other accessed ChatGPT-4o and input the prompt, “I am a patient and I want information regarding involuntary leakage of urine”, written in Turkish. The researchers then posed the above mentioned 13 patient questions about UI. Following the ChatGPT-4o interaction, the generated responses were evaluated by three clinical experts: an urogynecologist (A.F.G.K.), a physiotherapist (B.C.), and a urologist (A.I.). All 13 prompts were assessed using the PEMAT and modified DISCERN tools. Validated Turkish versions of both scales were employed. In addition, readability was measured using the Çetinkaya-Uzun readability formula tailored for the Turkish language by the principal researcher.
III. Scale and formulas used for evaluation of content
a. The PEMAT instrument
The
b. Modified DISCERN instrument (mDISCERN)
The DISCERN instrument is a standardized, validated tool designed to assess the quality of written consumer health information and consists of three parts. Developed to guide both healthcare professionals. The first part is used to assess the reliability of the information while the second and third parts determine the overall quality. The modified DISCERN (mDISCERN) tool has previously been utilized to evaluate 19 reliability of responses. mDISCERN tool only includes the first part of the original tool (Appendix 3). Each item was rated on a 5-point Likert scale ranging from 1 (“not at all”) to 5 (“definitely yes”), with an optional “not applicable” (N/A) response that is excluded from scoring. The total mDISCERN score was categorized as follows: poor (8-15 points), fair (16-31 points), and good (32-40 points).
c. Çetinkaya-Uzun readability formula
The
To apply it, one must first count the total number of syllables, words, and sentences in the text. After calculating the averages, these values are entered into the formula to generate a numerical score. According to the scale developed by Çetinkaya and Uzun, a score above 80 indicates the text is very easy to read (suitable for primary school level), a score between 60 and 80 is easy to moderate, 50 to 60 is considered moderately difficult (often suitable for high school readers), and below 50 suggests the text is difficult and may require university-level reading skills.
Statistical analysis
After three researchers evaluated the content generated by ChatGPT 4o, descriptive statistics were utilized to express data. Mean and standard deviations were given for the total instrument scores. Readability score was calculated by the principal investigator using a custom Excel tool. Inter-rater reliability among the evaluators was assessed using the Intraclass Correlation Coefficient (ICC) based on a two-way random-effects model with absolute agreement.
Results
Domain specific PEMAT scores.

Domain Specific mDISCERN Scores.

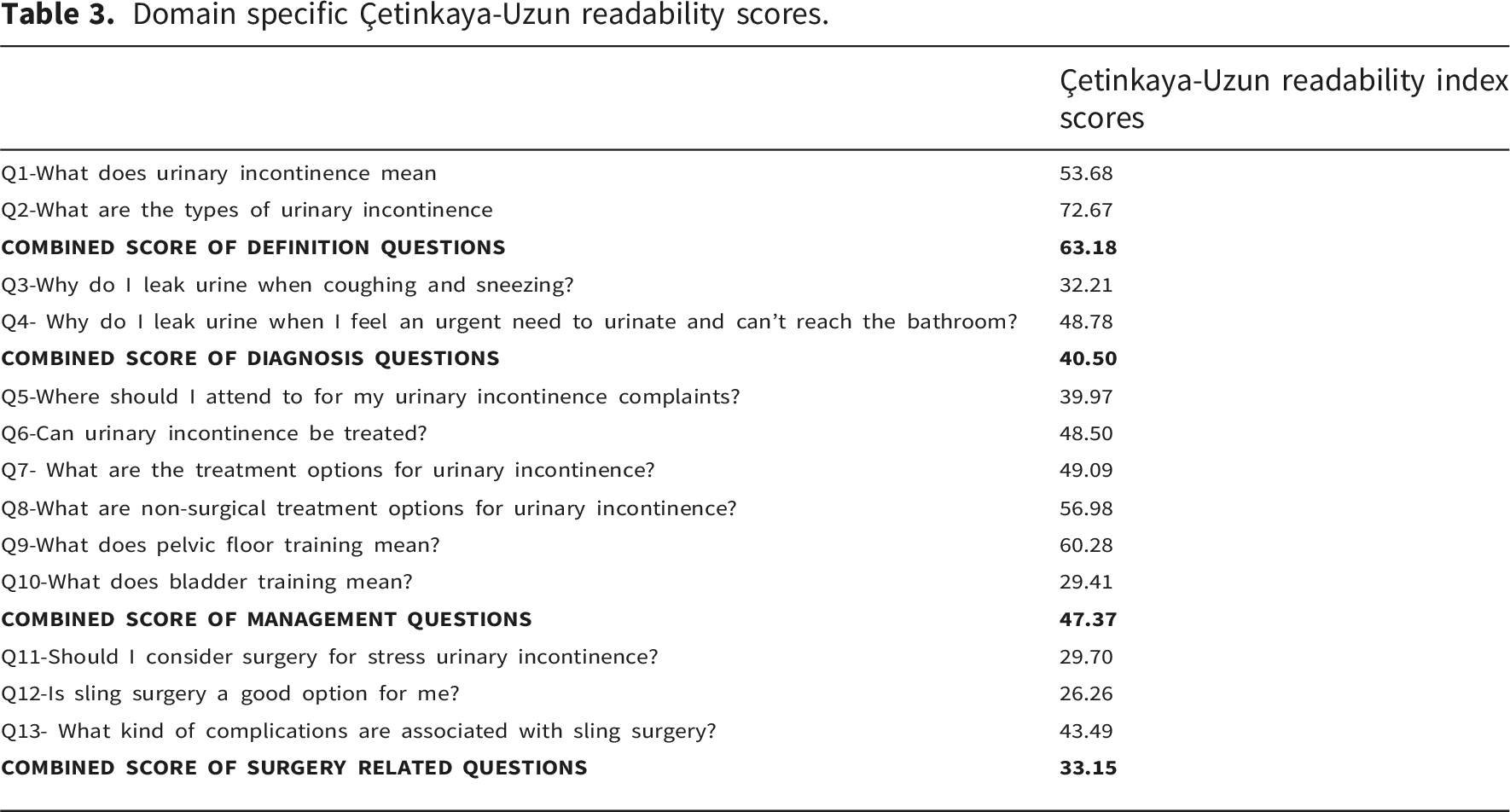
Domain specific Çetinkaya-Uzun readability scores.

Heat map of question domains (dark green indicates higher scores, red indicates lower scores).
Discussion
The principal finding of this study is that ChatGPT-4o demonstrated high understandability addressing common patient inquiries about UI. High understandability/low actionability phenomenon is a cross-linguistic problem. Culture-specific adjustments like using the Çetinkaya-Uzun index and addressing local specialist titles are essential for accurately assessing AI utility. The “diagnosis” domain achieved the highest levels of understandability, particularly for questions explaining leakage during coughing or urgency. The “diagnosis” domain reached 94.4%, effectively explaining symptoms like leakage during coughing. The lowest score was the “definition” domain with 89.9 %. Similarly, Chen et al. previously evaluated ChatGPT-3.5 and reported the following overall understandability scores: 95.2% for definitions, 92.9% for management, 88.1% for diagnosis, and 81.4% for surgery-specific questions. 18 Other literature sources utilized Likert scales rather than PEMAT percentages to measure how well the information was communicated. Rotem et al. approached 37 urogynecologists who rated ChatGPT’s responses. 20 They found a high level of comprehensiveness, with an average score of 4.0 out of 5. Approximately 74% of experts gave favorable ratings (a score of 4 or higher) for how well the information was conveyed. Barbosa-Silva et al. did not use a percentage score but noted that ChatGPT’s ability to engage in human-like conversation significantly simplifies complex medical terminology, making it more accessible and digestible for the average user. 21
Additionally in this present study we demonstrated that ChatGPT-4o′s performance was less favorable in actionability scores, ranging from 60.7% to 100%. While in comparison; Chen et al. reported the most critical findings, with an actionability score of only 18%. 18 This suggests a major failure in motivating readers to take specific medical steps or seek professional help, despite the information being relatively easy to understand.
In terms of reliability our results indicated that ChatGPT-4o showed “fair” reliability. Correspondingly, Rotem et al. also showed positive reliability, where global experts gave ChatGPT an average accuracy score of 3.9 out of 520. Barbosa et al. investigated how reliable ChatGPT was in answering 14 frequently asked questions (FAQs) regarding female urinary incontinence (UI) compared to established scientific guidelines. 21 Most answers (6 out of 14) were classified as “more correct than incorrect”. Only one response—regarding bladder retraining —was rated as completely “correct” by the experts. Ultimately, the investigation highlighted a concern regarding inconsistency in the AI’s accuracy and noted that almost all answers failed to provide the full content expected based on medical guidelines.
In our study, readability assessments using the Çetinkaya–Uzun index indicated that most responses required university-level reading comprehension, reinforcing the need to address health literacy disparities, particularly for underserved populations. The study by Cao et al. specifically used the Simple Measure of Gobbledygook (SMOG) index as one of its primary tools to evaluate and compare the readability of responses from DeepSeek and ChatGPT-4.019. The SMOG index was employed to calculate the years of education required to understand the generated text, finding that ChatGPT-4.o’s responses were primarily at an “undergraduate college” level while DeepSeek’s were closer to a “high school” level. Chen et al. also utilized the SMOG index to evaluate the readability of ChatGPT-3.5’s responses to 11 frequently asked questions regarding female stress urinary incontinence. 18 The question regarding surgical considerations (“Should I think about surgery for SUI?”) received the highest SMOG score of 15.3, indicating it was the most linguistically complex response. Overall, Chen et al. highlighted a significant readability barrier, noting that while the information was often accurate and understandable in structure, the advanced reading level remains a major area for improvement to make AI tools more accessible to the general public.
To make AI tools like ChatGPT more useful for women with urinary incontinence, several improvements are needed. First, responses should be based more closely on established medical guidelines to increase reliability. Second, the language should be simplified to match the reading level of the general public, while still remaining accurate. Third, information should include clear, practical steps that patients can follow, such as how to do pelvic floor exercises or when to see a doctor. Fourth, ChatGPT should provide references and explain its answers more transparently to build trust. Finally, future development should involve input from specialists and patients to make sure the information is accurate, culturally appropriate, and relevant to real-life care. These steps would make AI-generated information more actionable and supportive in guiding women to seek professional help for UI.
A limitation of this study is its reliance on a single ChatGPT query for survey responses. Since the model produces different outputs with each prompt, variability across responses is inevitable. ChatGPT occasionally strayed from the prompt’s intent, offering generic or abbreviated explanations—echoing prior research that underscores its lack of clinical depth and up-to-date evidence citations. Another limitation is the relatively small number of domain experts consulted, which may have introduced subjectivity and limited the generalizability of the findings. Additionally, the use of the Turkish language instead of English can come in the way of translation and generalisation to other populations world wide. Finally AI-generated responses may be misleading and possess potential risks. 22
Conclusion
While ChatGPT demonstrates a degree of informational integrity, many of its outputs in this study contained technical language and complex phrasing. This may limit accessibility for individuals with lower levels of health literacy. To ensure effective patient education—particularly in sensitive areas such as urinary incontinence,23,24further refinement of AI-generated content is necessary. Importantly, the role of healthcare professionals remains critical in interpreting, contextualizing, and validating this information to support informed decision-making and optimal patient outcomes.
Supplemental material
Supplemental material - Assessing the understandability, actionability, reliability, and readability of ChatGPT-4o in providing patient education on urinary incontinence
Supplemental material for Assessing the understandability, actionability, reliability, and readability of ChatGPT-4o in providing patient education on urinary incontinence by Ayse Filiz Gokmen Karasu, Betul Cinar, Melda Kuyucu, Abdullah Ilktac, and Tural Ismayilov in DIGITAL HEALTH.
Supplemental material
Supplemental material - Assessing the understandability, actionability, reliability, and readability of ChatGPT-4o in providing patient education on urinary incontinence
Supplemental material for Assessing the understandability, actionability, reliability, and readability of ChatGPT-4o in providing patient education on urinary incontinence by Ayse Filiz Gokmen Karasu, Betul Cinar, Melda Kuyucu, Abdullah Ilktac, and Tural Ismayilov in DIGITAL HEALTH.
Supplemental material
Supplemental material - Assessing the understandability, actionability, reliability, and readability of ChatGPT-4o in providing patient education on urinary incontinence
Supplemental material for Assessing the understandability, actionability, reliability, and readability of ChatGPT-4o in providing patient education on urinary incontinence by Ayse Filiz Gokmen Karasu, Betul Cinar, Melda Kuyucu, Abdullah Ilktac, and Tural Ismayilov in DIGITAL HEALTH.
Footnotes
Ethical considerations
The present study was deemed exempt from ethical approval by the Bezmialem Vakif University Institutional Review Board, as it involved a non-human subject qualitative design.
Consent to participate
The present study did not involve any patient data therefore patient consent was not sought.
Author contributions
Funding
The authors received no financial support for the research, authorship, and/or publication of this article: This research was self funded by the researchers.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Data is available upon request. Also Chat GPT produces data that is publicly available.
Trial registration
Our present study does not require a clinical trial registration because it involved a non-human subject qualitative design.
Permission to reproduce material from other sources
ChatGPT is a publicly available chatbot. The data is publicly reproducible.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.