
Abstract
Background
The integration of Large Language Models into medical diagnosis represents an emerging field with the potential to support diagnostic workflows across diverse clinical settings. However, the trends and evolutionary trajectory of LLM-assisted diagnostic research remain insufficiently understood.
Objective
This bibliometric review aims to map the global research landscape, identify key research clusters, and analyze the development trajectory of LLM technologies in medical diagnosis, with an emphasis on descriptive synthesis rather than formal evaluation.
Methods
A bibliometric analysis was conducted on relevant publications retrieved from the Web of Science Core Collection, covering the period from Q1 2023 to Q1 2025. The extracted data were processed and visualized using Excel, ArcGIS, VOSviewer, CiteSpace, and Pajek. The analyses included publication trends, influential authors and institutions, collaboration networks, and research cluster mapping.
Results
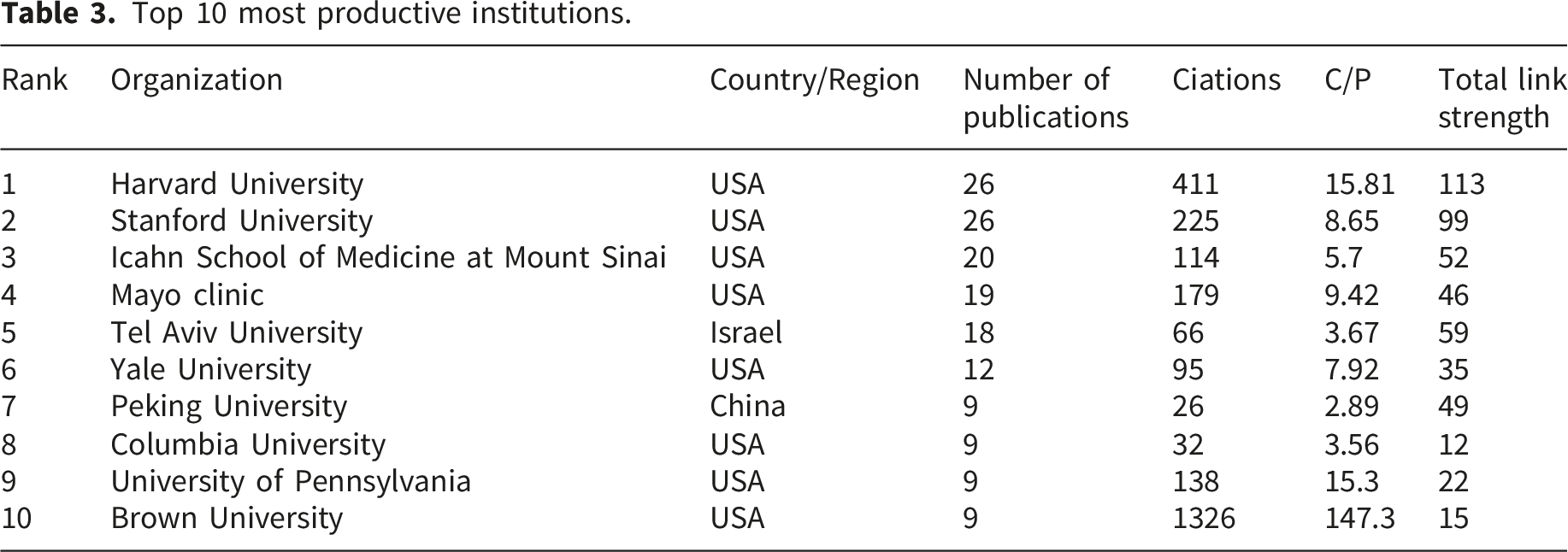
A total of 650 publications were included in the analysis. Research output increased markedly from Q1 2023 onward, rising from 2 publications to 148 by Q1 2025, corresponding to an average quarterly growth rate of 71.25%. The United States (273 publications), China (135 publications), and Germany (65 publications) emerged as the leading contributing countries. The three most productive institutions were all based in the United States: Harvard University (26 publications), Stanford University (26 publications), and the Icahn School of Medicine at Mount Sinai (20 publications). Keyword co-occurrence analysis identified 10 core clusters, with a modularity Q value of 0.8231 and a silhouette S value of 0.9412, indicating a highly coherent clustering structure and strong internal consistency.
Conclusion
The development of LLM technologies has substantially influenced the research landscape of medical diagnostics. As this field continues to evolve, it is crucial to refine model performance, integrate multimodal data, and address ethical considerations. Future research should focus on optimizing LLMs for specific clinical applications and evaluating their implementation in real-world healthcare settings.
Keywords
Introduction
Artificial intelligence (AI) has been extensively applied across diverse scientific and engineering domains.1–4 Within medicine, its potential applications have long attracted sustained scholarly attention and practical exploration. 5 The release of OpenAI’s ChatGPT in late 2022, followed by subsequent large language models (LLMs), has intensified global interest in this domain. LLM-assisted diagnostic research refers to studies that examine large transformer-based language models (e.g., GPT, Gemini, and Llama) primarily as clinician-facing decision-support tools and natural-language interfaces for diagnostic workflows. As decision-support systems, LLMs may assist physicians by generating differential diagnostic suggestions, synthesizing clinical knowledge, and retrieving diagnostically relevant information from heterogeneous medical data sources, with the understanding that final clinical judgment remains under physician oversight. 6 Simultaneously, as language interfaces, LLMs may facilitate interaction with electronic health records, medical literature, imaging reports, and other digital health resources through conversational interfaces. 7 These functions distinguish LLM-assisted diagnosis from general AI paradigms, which encompass broader algorithmic approaches such as convolutional neural networks or rule-based systems, 8 as well as from conventional clinical natural language processing, which has typically relied on smaller, task-specific architectures for narrow natural language processing tasks such as information extraction and text classification. 9 Importantly, this study does not conceptualize LLMs as fully autonomous reasoning agents capable of independently establishing definitive diagnoses without human oversight.
The integration of LLMs into medical diagnosis has emerged as a rapidly expanding area of academic and clinical interest. A recent SWOT-based review examining artificial intelligence in clinical medicine highlighted the potential role of LLMs in supporting diagnostic processes. 10 As a new generation of foundation models, LLMs are characterized by advanced natural language understanding, contextual reasoning, and knowledge synthesis capabilities, enabling them to process heterogeneous medical data such as clinical narratives, electronic health records, imaging reports, and biomedical literature. 11 These capabilities may offer potential avenues to support clinical decision-making, diagnostic reasoning, and knowledge-assisted medical interpretation; however, their clinical utility remains to be established through further empirical investigation.
This growing interest has prompted an expanding body of research investigating the application of LLMs in diagnostic contexts. A notable development in this field occurred in December, 2022, with the publication of “Large Language Models Encode Clinical Knowledge” by Karan Singhal et al. on arXiv. In this study, the authors introduced “MultiMedQA,” a comprehensive benchmarking framework encompassing seven medical question-answering datasets, including MedQA, MedMCQA, and PubMedQA, to evaluate LLM performance across diverse clinical tasks. Using this framework, they assessed the diagnostic capabilities of Flan-PaLM, a medically adapted version of the PaLM model, and suggested the potential applicability of LLMs in diagnostic contexts. This work attracted substantial academic attention and was subsequently published in Nature, contributing to growing scholarly interest in this research domain. 12 Following this influential publication, the literature on LLM-assisted medical diagnosis has expanded across multiple clinical specialties, including gastrointestinal pathology, 13 hepatology, 14 dermatology, 15 epileptology, 16 ophthalmology, 17 orthopedics, 18 oral medicine, 19 pulmonology, 20 cardiology, 21 cognitive neurology, 22 and affective disorders such as depression. 23
Simultaneously, the integration of LLMs into clinical practice has begun to receive increasing attention. A survey conducted by the American Psychiatric Association in late 2023 revealed that more than 70% of psychiatrists reported having used ChatGPT in professional practice, with many respondents reporting its use in diagnostic deliberation. 24 Similarly, a 2024 report by the European Commission documented the implementation of LLM-assisted diagnostic tools in selected European hospitals for breast cancer screening, with preliminary findings suggesting potential clinical utility. 25 Evidence from Japan further suggested that ChatGPT-4 demonstrated diagnostic performance approaching that of board-certified physicians in selected experimental evaluation settings, with the correct diagnosis appearing among the top 10 differential diagnoses in 83% of cases and as the top-ranked diagnosis in 60% of cases. 26 In addition, in February 2025, Peking Union Medical College and the Chinese Academy of Sciences launched Xiehe·Taichu, an LLM designed for rare disease diagnostic support. 27 Complementing these developments, a recent global survey involving approximately 800 psychiatrists found that over half of respondents believed LLMs could assist diagnostic decision-making through the synthesis and interpretation of patient information. 28 Despite these advances, the integration of LLMs into clinical settings has also prompted ongoing discussion regarding ethical, legal, and practical challenges, including concerns regarding data privacy, model reliability, interpretability, and regulatory governance.
In response to the rapidly growing academic and clinical interest in the application of LLMs to diagnostic medicine, a comprehensive synthesis of the existing literature is both timely and essential. To date, no bibliometric analysis has systematically mapped the intellectual landscape or traced the research trajectory of this emerging field. Bibliometric analysis offers a robust, quantitative method for mapping scholarly output, identifying influential contributors, and characterizing dominant research themes.29,30 This study applies bibliometric techniques, integrating descriptive, relational, and evolutionary approaches, to examine the literature on LLMs in diagnostic medicine, with a focus on publication trends, influential authors and institutions, collaborative networks, and research clusters. In addition, to complement the bibliometric findings, a targeted analysis of PubMed-indexed clinical studies was conducted to characterize clinical application domains, methodological features, evidence levels, and emerging translational challenges associated with LLM-assisted diagnosis. It should be emphasized that this study aims to provide high-level, trend-based insights rather than direct guidance for the design or validation of LLM-assisted diagnostic tools. The BIBLIO Checklist for this bibliometric review is provided in Supplemental File 1.
Methods
Literature search
The overall study framework is illustrated in Figure 1. The Web of Science Core Collection (WOSCC), a widely used multidisciplinary citation database that indexes high-impact, peer-reviewed scholarly publications, was systematically searched to retrieve relevant literature from database inception through April 13, 2025. Although LLMs gained widespread academic and public attention primarily after late 2022, the search strategy was intentionally extended to the inception date. This approach was adopted to minimize the likelihood of excluding potentially relevant earlier studies that may have employed precursor language-model architectures or conceptually related terminology within diagnostic contexts. Study framework.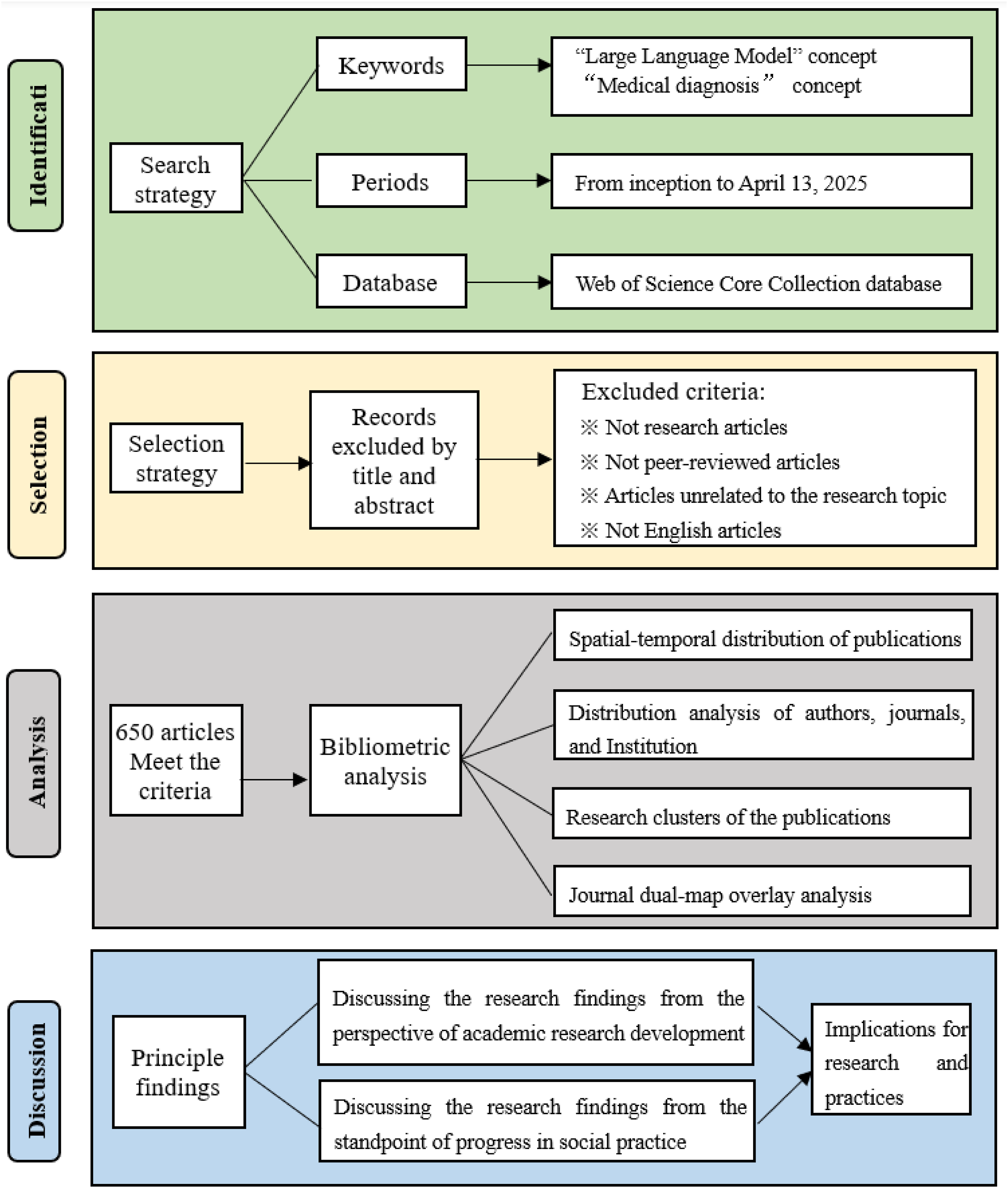
The search strategy was as follows: TS=((“Large Language Model*” OR LLM OR GPT OR Claude* OR Gemini OR Llama* OR LaMDA OR GEMMA) AND (“medical diagnos*” OR “clinical diagnos*” OR “disease diagnos*” OR “patient diagnos*” OR “computer-aided diagnosis” OR “AI-assisted diagnosis” OR “LLM-assisted diagnosis” OR “intelligent diagnosis” OR “automated diagnosis” OR “diagnostic medicine” OR “diagnostic evaluation” OR “diagnostic conversation” OR “diagnostic process” OR “diagnostic support” OR “diagnostic consultation” OR “diagnostic aid” OR “diagnostic assistant” OR “diagnostic chatbot” OR “diagnostic reasoning” OR “diagnosis assistance” OR “diagnosis process” OR “disease identification” OR “disorder identification” OR “health condition identification” OR “health problem identification” OR “disease detection” OR “disorder detection” OR “health condition detection” OR “health problem detection” OR “symptom analysis” OR “clinical assessment” OR “clinical reasoning” OR “clinical decision-making” OR “medical decision-making” OR “diagnostic decision-making” OR “clinical decision support” OR “medical decision support” OR “diagnostic decision support”))
Inclusion/exclusion criteria
In this study, inclusion criteria were defined to ensure the selection of methodologically robust and thematically relevant literature. Specifically, studies were included if they (1) were original research articles, (2) were peer-reviewed publications, (3) were published in English, and (4) focused on the application, evaluation, or methodological development of LLMs in medical diagnostic contexts. Correspondingly, studies were excluded if they (1) were not original research articles, including editorials, letters, commentaries, correspondence, conference abstracts, and errata, (2) were not peer-reviewed publications, such as theses and dissertations, technical reports, preprints, and book chapters, (3) were published in languages other than English, or (4) lacked substantive relevance to LLM-assisted diagnosis.
Literature selection
The literature screening process was independently undertaken by two reviewers (Haokun Wang and Quan Zhang) according to the predefined inclusion and exclusion criteria. Prior to formal screening, a calibration assessment involving a random subset of 100 records was performed to ensure consistent interpretation of the inclusion and exclusion criteria. Inter-reviewer agreement was evaluated using Cohen’s kappa coefficient, yielding a value of 0.796, indicating substantial agreement between reviewers.
31
Disagreements that arose during the screening process were adjudicated by a third researcher (Hongjuan Li), and all discrepancies were resolved through structured deliberation until consensus was achieved.
32
The literature identification and selection workflow (see Figure 2) was conducted in alignment with the PRISMA reporting framework
33
and relevant methodological guidance for bibliometric studies.
34
A total of 826 records were initially identified from the WOSCC database. Following manual deduplication, 3 duplicate records were removed, leaving 823 unique records for subsequent evaluation. The titles and abstracts of all remaining records were then screened, and no studies were excluded due to inaccessible bibliographic information. Full-text eligibility assessment was subsequently conducted according to the predefined inclusion and exclusion criteria. Specifically, non-original research articles (n = 42) were excluded, alongside non-peer-reviewed publications (n = 24), non-English studies (n = 13), and articles lacking substantive thematic relevance to LLM-assisted diagnostic applications (n = 94). Ultimately, 650 articles met the eligibility criteria and were included in the final bibliometric analysis. All eligible records were subsequently imported into the analytical platforms for bibliometric processing and visualization. PRISMA flow diagram.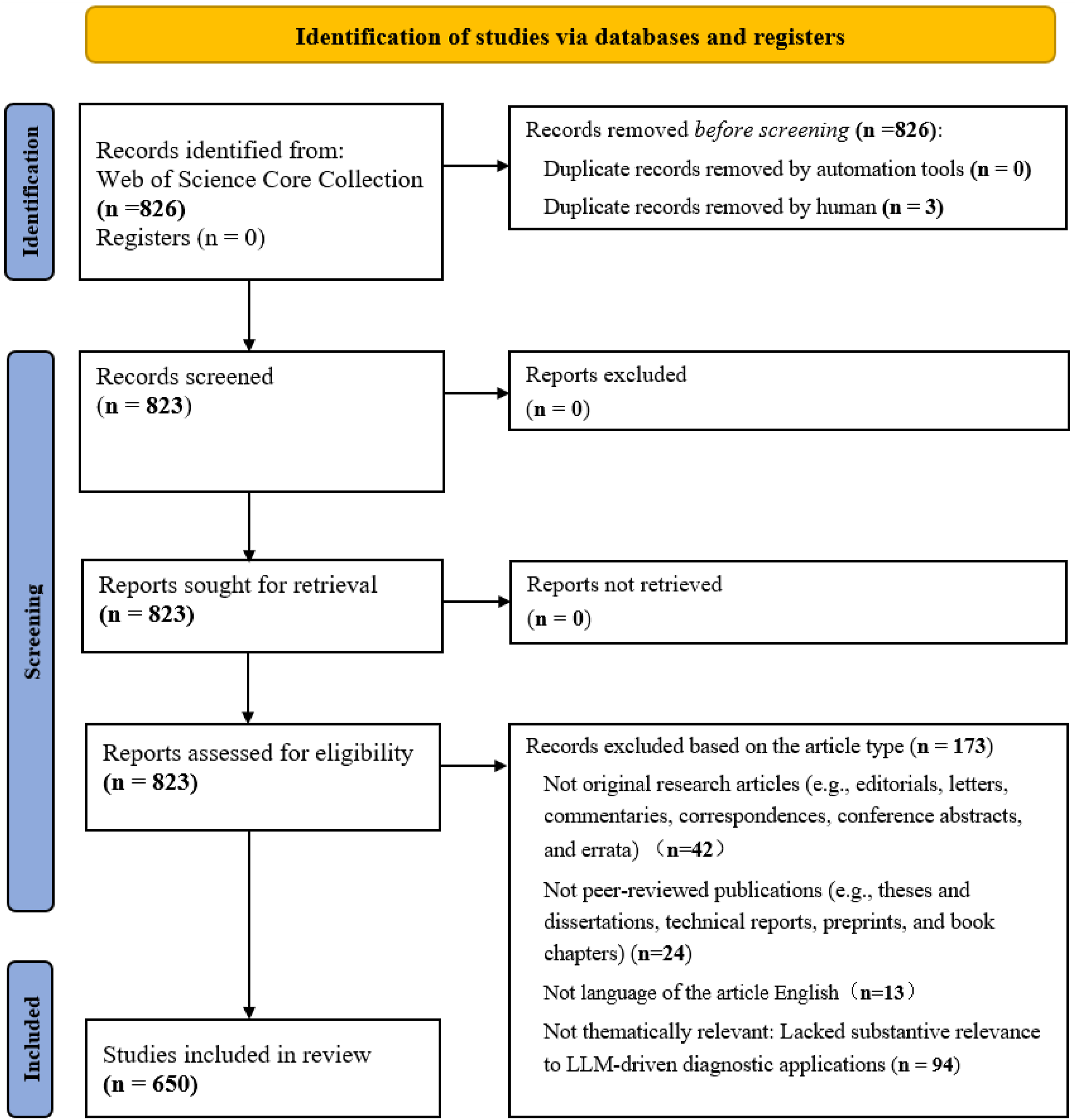
Data analysis
The analytical process integrated multiple software platforms, including Microsoft Excel 2019, ArcGIS, VOSviewer (Version 1.6.20), CiteSpace (Version 6.4.R1), and Pajek, to support bibliometric analysis and visualization. Microsoft Excel 2019 was used to visualize temporal trends in publication output. ArcGIS was utilized to map the geographic distribution of publications across countries and regions. CiteSpace was employed to identify and visualize thematic research clusters within the publication corpus. The analytical parameters were configured as follows. The time-slicing window spanned 2023–2025 with a one-year slice length. Node selection was operationalized using the g-index (k = 25). Network pruning was performed using the Pathfinder, Minimum Spanning Tree, and Pruning the Merged Network algorithms. VOSviewer was applied to quantify publication and citation performance and to construct collaboration and co-citation networks involving countries, authors, journals, and institutions. In country co-authorship analysis, each country was required to contribute at least one publication. In author co-authorship analysis, a minimum threshold of three publications per author was imposed. In journal co-citation analysis, only cited sources receiving at least 40 citations were included. For institutional collaboration networks, a minimum threshold of four publications per institution was enforced. Threshold parameters were selected with reference to established practices in bibliometric visualization and were adjusted to balance information retention, network readability, and interpretability. 35 CiteSpace was further used to generate a dual-map overlay that contextualized disciplinary linkages between citing and cited journals. Detailed analytical procedures and software configurations are provided in Supplemental File 2 to facilitate methodological transparency and reproducibility.
Results
Temporal-spatial distribution of publications
In this emerging field, the first indexed publication appeared in February 2023. Since then, scholarly output has expanded markedly, increasing from 2 articles in Q1 2023 to 148 in Q1 2025. This corresponds to an average quarterly growth rate of 71.25%, calculated using the geometric mean method (Figure 3). By April 13, 2025, the WOSCC database had indexed a total of 650 publications on this topic. This increase in publication volume may reflect growing academic interest in the application of LLM-assisted diagnosis in clinical contexts. Temporal distribution of publications.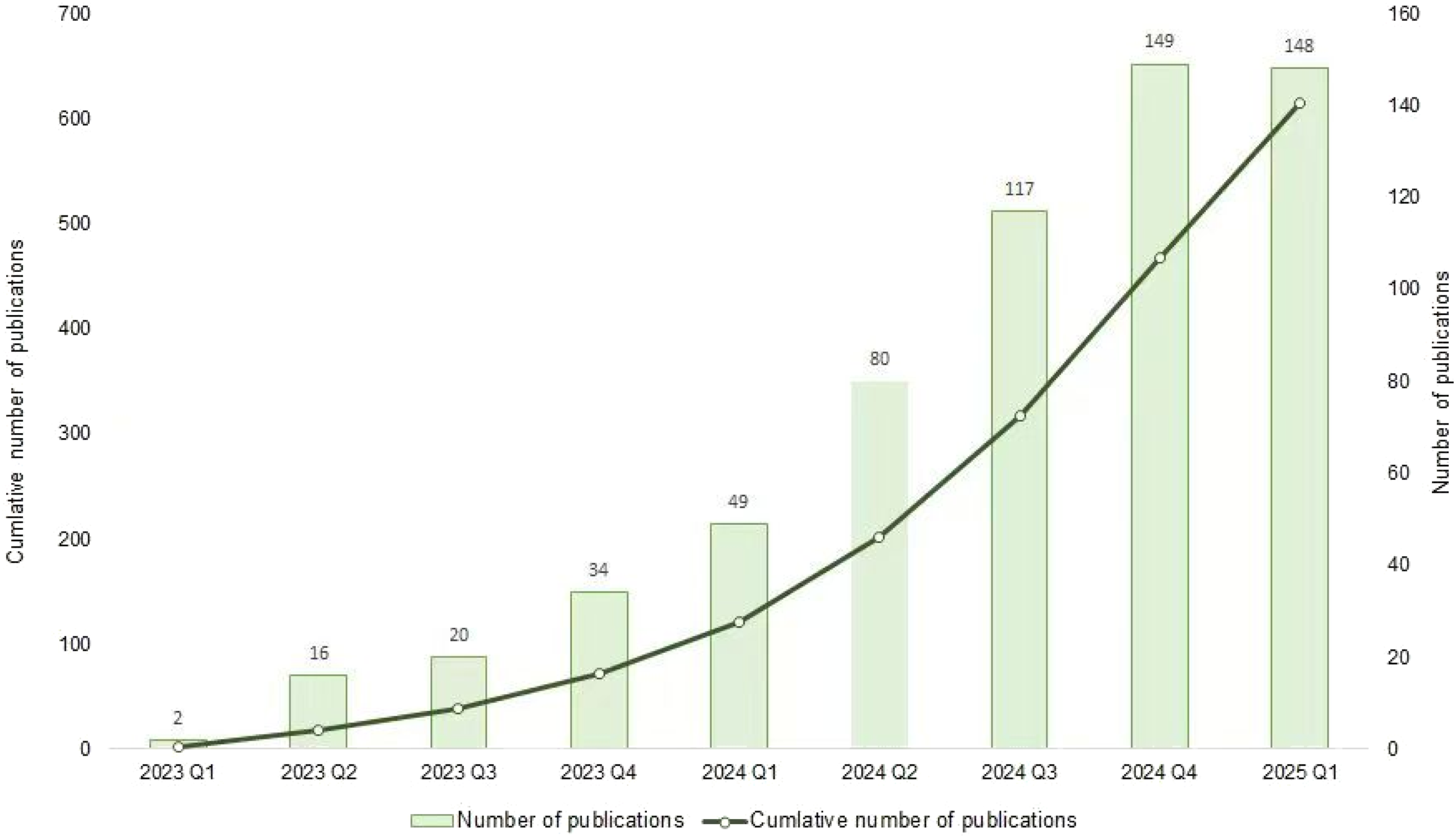
Research on LLM-assisted diagnosis spanned 69 countries, indicating widespread international research activity in this emerging field (Figure 4). The United States led with 273 publications, followed by China (135) and Germany (65), suggesting a geographically uneven distribution of research output. Although bibliometric data are well suited to characterizing geographic patterns, they do not support causal inference regarding the determinants of national research productivity. Accordingly, the interpretations presented below should be regarded as contextual and speculative reflections informed by the broader scientific and policy literature, rather than empirically validated explanations established by the present analysis. The dominance of these countries may reflect differences in research infrastructure, funding capacity, data availability, and technological ecosystems. For instance, the development of advanced LLMs by major technology organizations, together with the presence of leading academic medical centers and robust academic-clinical collaboration ecosystems, may create favorable conditions for research activity. In the United States, the development of frontier LLMs, including GPT-4, Claude, Gemini, and Llama, by U.S.-based organizations, along with contributions from institutions such as the Mayo Clinic, Harvard Medical School, and the University of Pennsylvania, may contribute to a technologically enriched environment for clinical AI research. In addition, access to large-scale biomedical datasets, which are essential resources for this field, may also facilitate scholarly activity. In Germany, the Health Data Use Act has established a legislative framework supporting a centralized digital health infrastructure, which may facilitate researchers’ access to pseudonymized health data across institutions. Moreover, national investments in digital health and strategic policy initiatives may be associated with scholarly output. In China, the National Health Commission issued the Guidelines for Artificial Intelligence Application Scenarios in the Health Sector in November 2024, which outlined priority domains for AI deployment and referenced the potential integration of advanced LLMs into clinical contexts. Such policy initiatives may be viewed as part of the broader institutional and scholarly discourse surrounding emerging AI technologies. Nevertheless, it is important to emphasize that the present study did not examine the causal relationship between policy environments and publication output. Accordingly, these interpretations should be regarded as hypothesis-generating contextual observations and interpreted with appropriate caution. Spatial distribution of publications.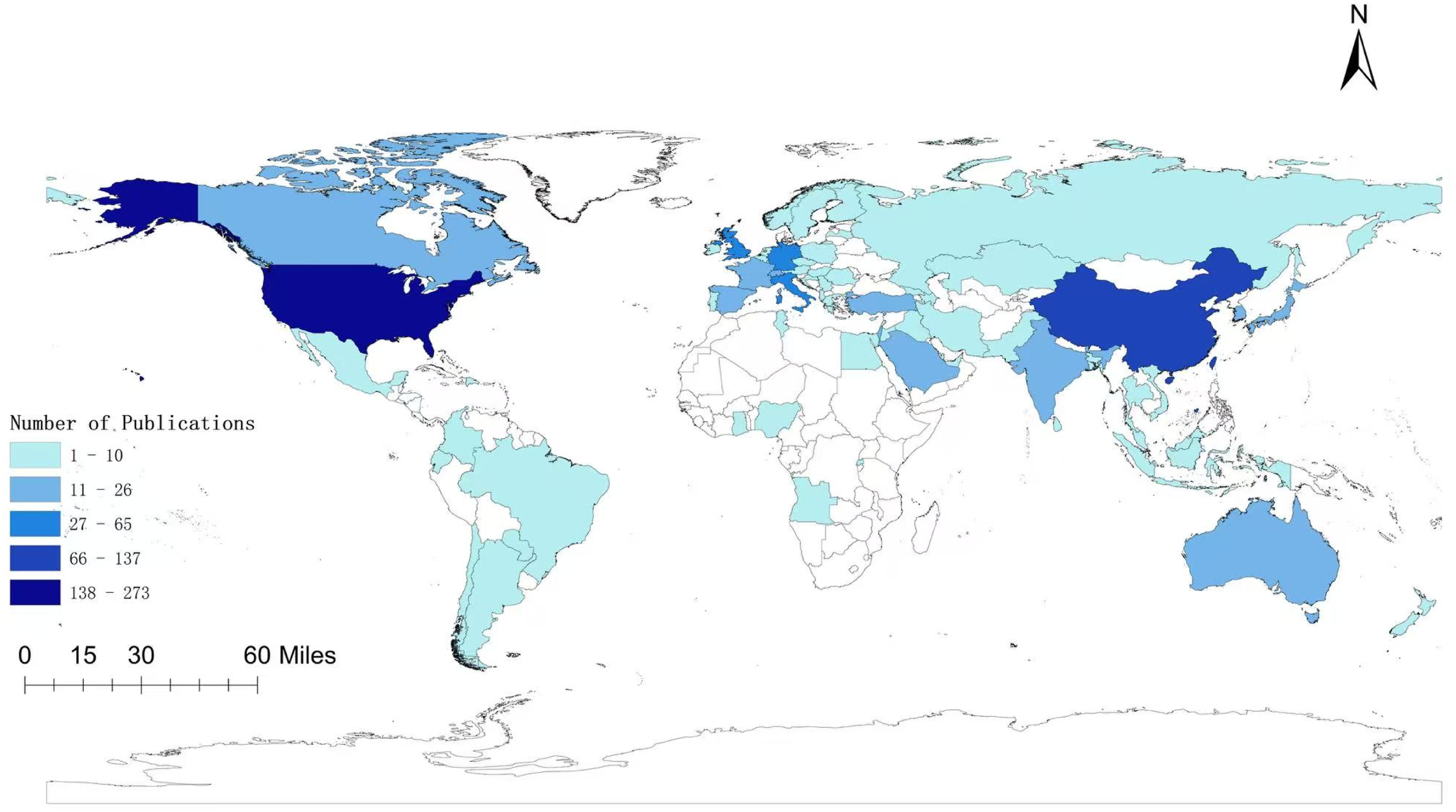
Co-authorship network analysis (Figure 5) demonstrated a progressively interconnected yet markedly asymmetrical global collaboration landscape. The United States occupied the dominant central node in the network, exhibiting the highest degree of connectivity and functioning as a principal bridge linking multiple international research clusters. China, Germany, and the United Kingdom emerged as important secondary hubs, each maintaining robust cross-national collaborative linkages. In contrast, countries such as Japan, South Korea, Turkey, Pakistan, Portugal, Ireland, and Poland contributed to the literature but remained in comparatively peripheral positions within the network. Notably, the analysis indicated limited representation from countries in Africa and South America, with these regions either appearing only at the margins of the network or remaining largely absent. Overall, the collaboration structure was concentrated around a limited number of global centers, suggesting an uneven distribution of collaborative influence across the international research network. Collaborative networks of top 69 countries.
The dominance of high-income countries, particularly the United States, as collaborative hubs may warrant consideration from the perspective of global equity in AI-driven healthcare research. Although bibliometric network analysis cannot directly measure disparities in healthcare access or outcomes, the geographic concentration of scholarly influence may warrant careful consideration. Specifically, this pattern may suggest that the literature surrounding the development and refinement of LLM-based diagnostic technologies is more strongly represented by the clinical contexts, datasets, and priorities of high-income settings. Conversely, the limited participation of many African and South American countries may suggest the possibility of underrepresentation of diverse regional perspectives and healthcare contexts within the research landscape. Such underrepresentation may theoretically raise concerns regarding contextual validity and the potential for algorithmic bias. For instance, models trained primarily on Western clinical data may exhibit uncertain generalizability in low-resource settings characterized by distinct disease burdens, healthcare infrastructures, and clinical practices. This imbalance may also have potential implications for future inequities in the translation and accessibility of AI-assisted diagnostic technologies, particularly in regions where healthcare resources remain limited. Although these interpretations remain speculative and are inferred from collaboration structures rather than direct clinical evidence, they may highlight the potential value of inclusive international partnerships, capacity-building initiatives, and cross-regional data-sharing frameworks to support the equitable advancement of AI-assisted healthcare technologies worldwide.
Distribution and co-authorship analysis of authors
Top 10 most productive authors.

A co-authorship analysis was also conducted using VOSviewer to examine collaboration patterns among authors (Figure 6). The dataset comprised 76 researchers, each with at least three publications. The analysis indicated that several authors, including Klang E, Glicksberg B, Hirosawa T, Shimizu T, and Omar M, exhibited extensive collaborative linkages within the network. Additionally, a well-defined collaborative network was observed among Klang E, Glicksberg B, Omar M, and Nadkarni G. Notably, these leading collaborators were predominantly U.S.-based, with three affiliated with the Icahn School of Medicine at Mount Sinai, suggesting that collaboration within this cluster was largely concentrated within a single national context. Meanwhile, authors such as Cheungpasitporn W, Chen J, Cho S, Craici I, Ferber D, and Fink A occupied positions within several collaborative subnetworks, reflecting their participation in ongoing research collaborations within the field. Collaborative networks of top 76 authors.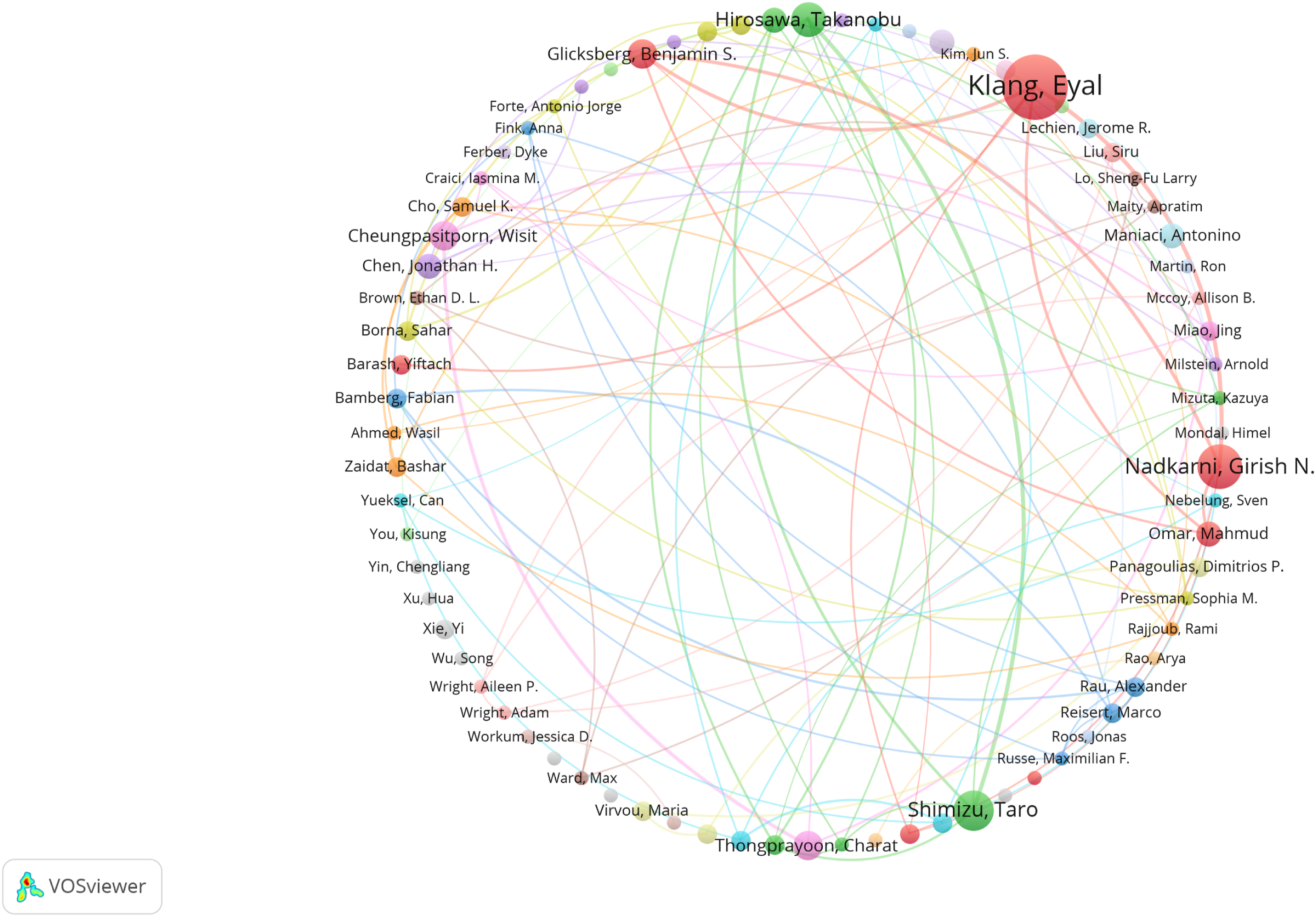
Distribution and co-citation analysis of journals
Top 10 most productive publication sources.
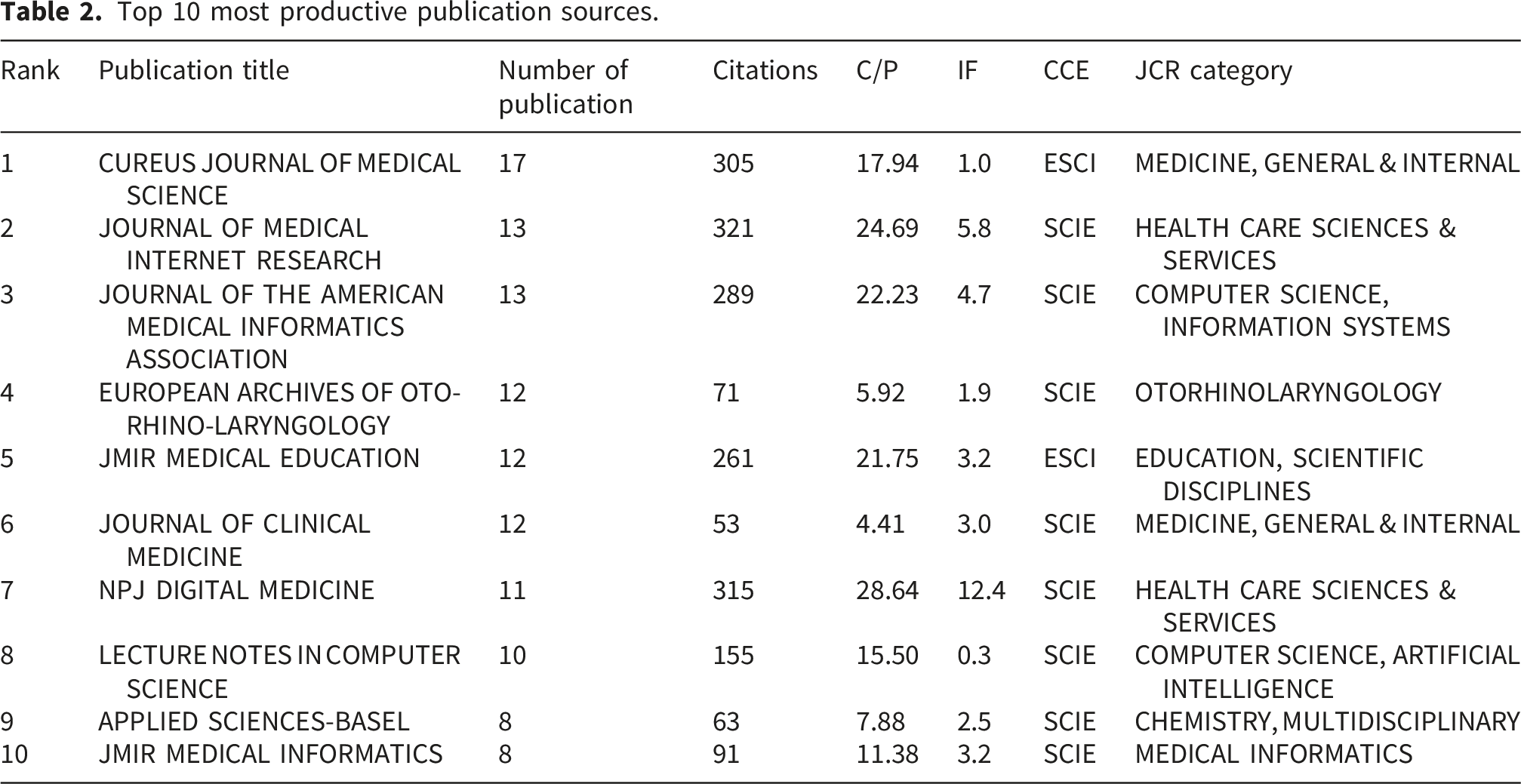
A VOSviewer-based co-citation analysis was subsequently conducted to examine inter-journal citation relationships among peer-reviewed journals, deliberately excluding preprint platforms such as arXiv and medRxiv to avoid potential network distortion (Figure 7). The analysis incorporated 80 journals that satisfied the predefined citation threshold. The findings indicated that Cureus Journal of Medical Science was frequently co-cited with JMIR, JMIR Medical Education, Nature, PLOS Digital Health, and Radiology. Other prominent co-citation links involved Bioinformatics, Lecture Notes in Computer Science, and JAMIA, as well as cross-disciplinary clusters connecting Advances in Neural Information Processing Systems, Journal of Biomedical Informatics, and IEEE Access. Co-citation network of top 80 journals.
A dual-map overlay generated via CiteSpace (Figure 8) further contextualized the disciplinary intersections between publishing and citing journals. On the left side of the map, the dominant domains of the citing journals included “Mathematics, Systems, Mathematical,” “Medicine, Medical, Clinical,” “Ecology, Earth, Marine,” and “Molecular, Biology, Immunology.” On the right side, the principal domains of the cited journals comprised “Systems, Computing, Computer,” “Environmental, Toxicology, Nutrition,” “Chemistry, Materials, Physics,” and “Health, Nursing, Medicine.” Green citation paths indicated that journals categorized within the “Medicine, Medical, Clinical” domain predominantly cited literature originating from the domains of “Health, Nursing, Medicine” as well as “Molecular, Biology, Genetics.” The dual-map overlay of journals of LLMs in medical diagnosis.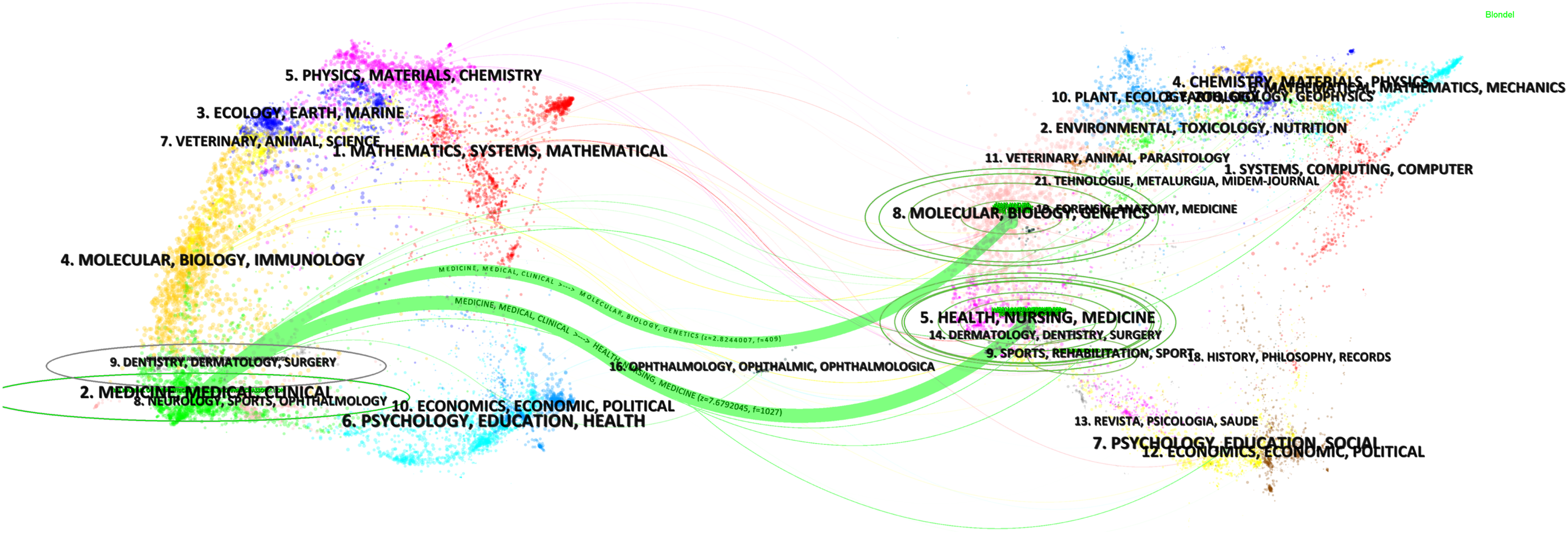
Distribution and co-authorship analysis of institutions
Top 10 most productive institutions.
Institutional collaboration patterns were further examined using a network analysis approach, focusing on the top 89 institutions with at least four publications each (Figure 9). The findings indicated that institutions such as Harvard University, Stanford University, Tel Aviv University, Mayo Clinic, and the Icahn School of Medicine at Mount Sinai maintained particularly high levels of collaborative activity. Notable bilateral partnerships included Harvard University–Mayo Clinic, Icahn School of Medicine at Mount Sinai–Tel Aviv University, and Chaim Sheba Medical Center–Tel Aviv University. Additional strong collaborations were observed between Harvard University and Stanford University, the Zucker School of Medicine and Ohio State University, Ben-Gurion University of the Negev and Tel Aviv University, the Icahn School of Medicine at Mount Sinai and Sheba Medical Center, as well as the VA Palo Alto Health Care System and Stanford University. The network also revealed clusters of collaborating institutions, including a U.S.-centered cluster primarily composed of Harvard University, Stanford University, Mayo Clinic, and the VA Palo Alto Health Care System, as well as an Israeli-centered cluster involving Tel Aviv University, Chaim Sheba Medical Center, the Icahn School of Medicine at Mount Sinai, and Ben-Gurion University of the Negev. Overall, these findings suggested a high degree of domestic collaboration within the United States and relatively dense intra-regional collaboration among Israeli institutions, whereas cross-regional collaboration remained comparatively limited. Collaborative networks of top 89 institutions.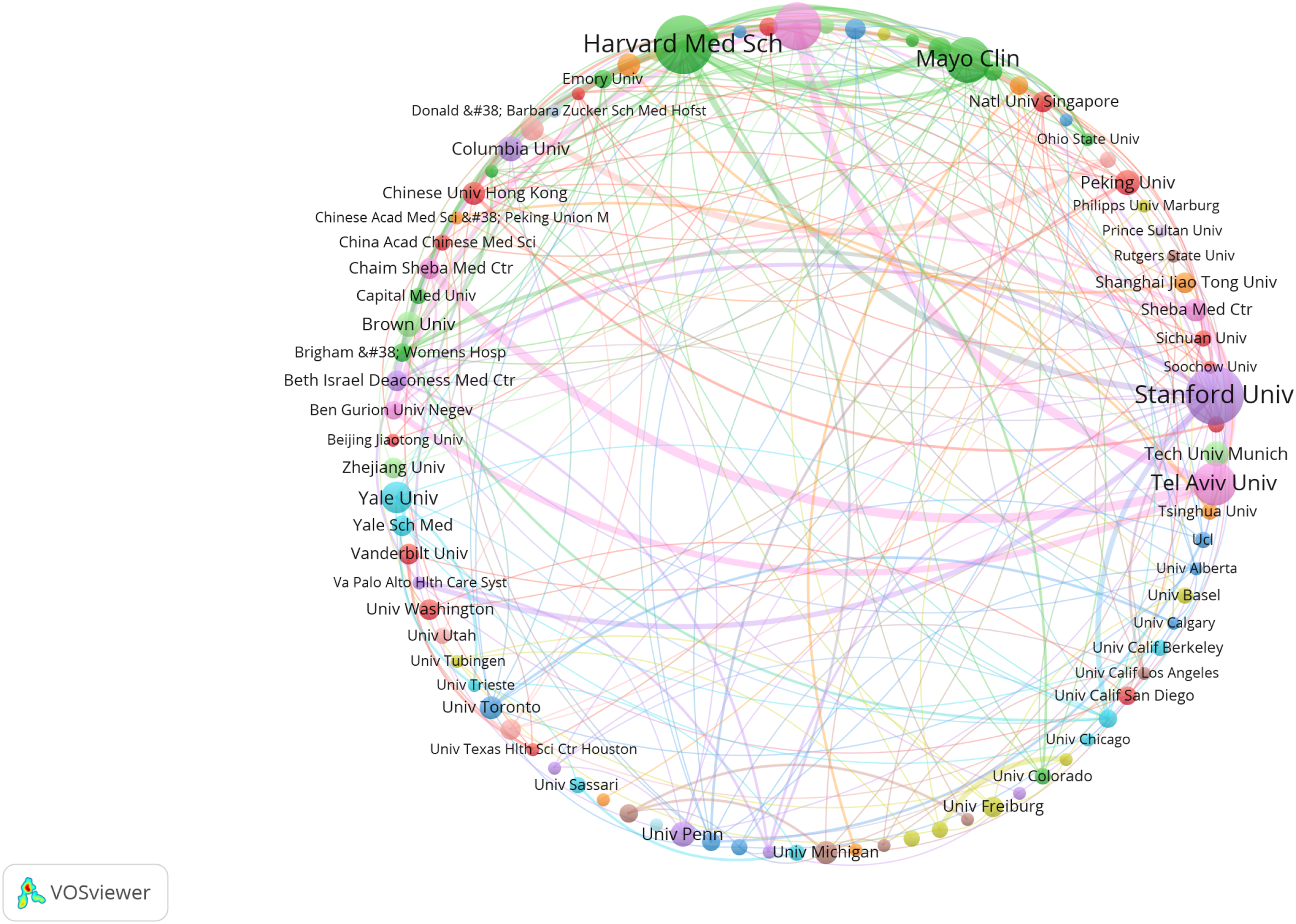
Research clusters of the publications
Research clusters were identified through frequency and link-strength analysis of 259 keywords extracted from the literature database using CiteSpace, thereby characterizing the distribution and interrelationships of the principal thematic domains (Figure 10). Ten clusters were identified and subsequently categorized into five overarching groups. Research clusters network map.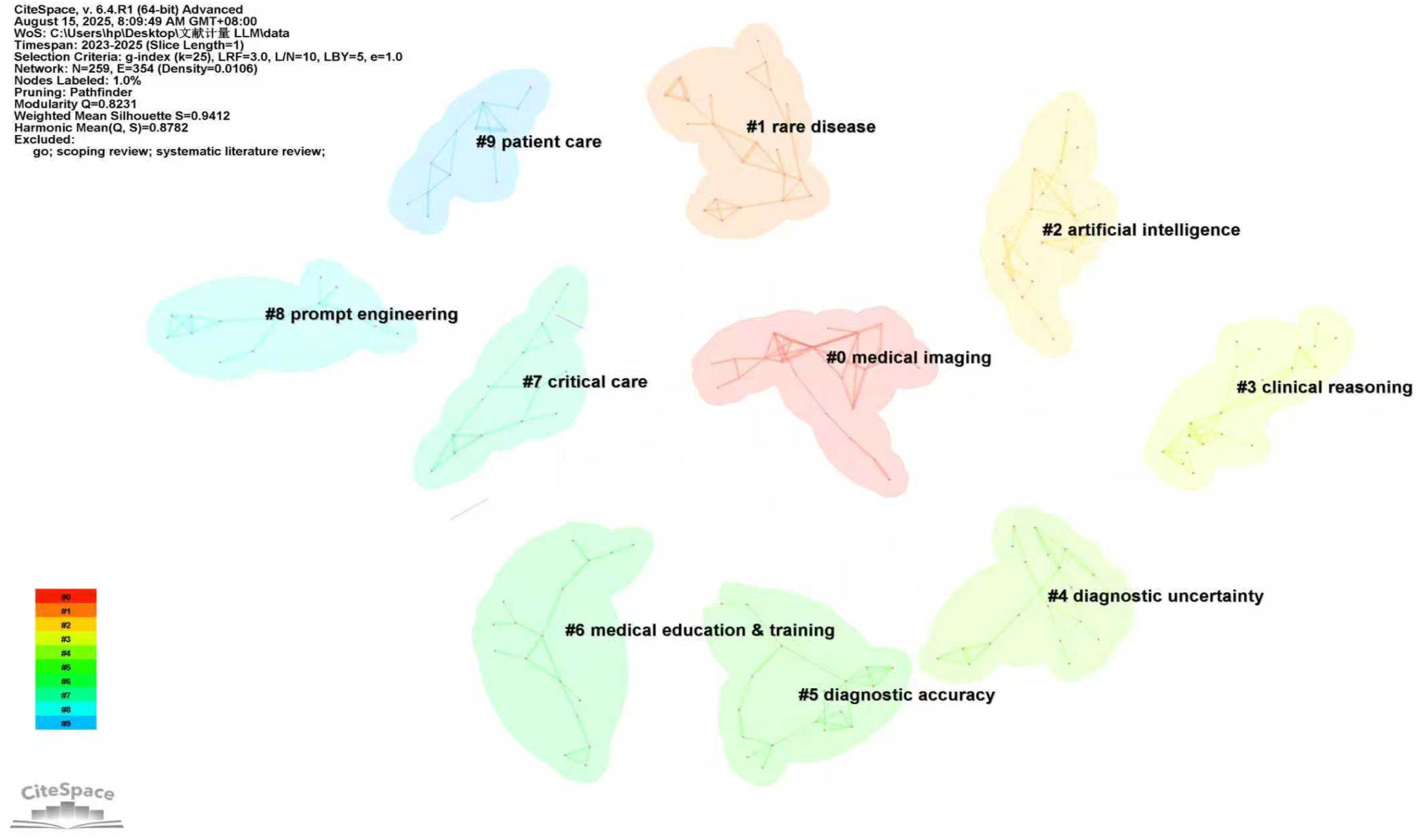
• Cluster 0 (23 keywords, including artificial intelligence, neural networks, machine learning, large language model, multimodal large language models, big data, and AI-powered algorithms) primarily reflected the concentration of research activity on the fundamental computational frameworks and data infrastructures underpinning this field. Specifically, big data was frequently referenced as a foundational component encompassing heterogeneous datasets, including patient records, laboratory findings, diagnostic imaging, and biomedical text corpora.
38
Machine learning, neural networks, and LLMs also emerged as central methodological themes within the cluster.39,40 • Cluster 2 (22 keywords, including medical imaging, identification, CT, diagnosis, image processing, images, knowledge graph, and diabetic retinopathy) highlighted the prominence of imaging-related research within the broader LLM-assisted diagnosis literature.
41
Imaging modalities such as CT, MRI, and retinal imaging were frequently represented as key data domains associated with LLM applications.
42
Similarly, terms such as image processing and knowledge graphs indicated ongoing scholarly interest in enhancing data representation and semantic integration. The presence of disease-specific terms, such as diabetic retinopathy, reflected specific application areas explored within the literature.
43
Together, Clusters 0 and 2 represented two major thematic domains identified through keyword co-occurrence analysis, namely computational methodologies and medical imaging applications. These clusters represented thematic concentrations within the literature rather than evidence of established clinical effectiveness or real-world implementation. The keyword associations within these clusters indicated thematic attention to LLM architectures for medical data processing, 44 multimodal data integration, 45 image analysis techniques, 46 and structured knowledge representation, 47 alongside ethical and legal considerations. 48
• Cluster 4 (20 keywords, including decision making, disease detection, electronic medical records, multimodal data, skin cancer, multiple sclerosis, cervical cancer, and diagnostic uncertainty) was characterized by keyword associations related to diagnostic complexity and uncertainty as represented in the literature. Such uncertainty is commonly associated with complex or rare conditions characterized by overlapping symptoms or incomplete clinical information. The co-occurrence of terms related to multimodal data and electronic medical records suggested thematic attention to the integration of diverse clinical data sources, such as electronic health records, laboratory results, and imaging data, within LLM-related studies. Keyword associations within this cluster indicated multiple thematic areas of investigation, including contextual interpretation of medical information,
56
addressing ambiguity and incomplete information,
57
supporting differential diagnosis and multi-criteria decision-making,
58
and adaptive learning and model refinement.
59
• Cluster 5 (18 keywords, including information, electronic health records, named entity recognition, artificial hallucinations, and diagnostic accuracy) represented a complementary thematic domain focused on the evaluation of the reliability and validity of LLM-generated diagnostic outputs. Keywords such as artificial hallucinations and diagnostic accuracy underscored sustained scholarly attention to the reliability, limitations, and dependability of LLM-generated results. Keyword associations within this cluster indicated thematic attention to probabilistic reasoning and confidence estimation,
60
mitigation of LLM hallucinations,
61
and strategies for bias reduction in LLM-assisted decision-making.
62
• Cluster 6 (17 keywords, including medical education and training, clinical practice guidelines, quality, physicians, clinical practice, errors, accuracy, and best practices) highlighted an additional thematic direction focused on the intersection of LLMs with medical education, professional training, and clinical practice contexts. The co-occurrence of terms such as medical education, clinical practice, and best practices suggested that the literature increasingly explored the intersection of LLMs with educational and professional development environments. Within this body of work, LLMs were frequently discussed within experimental or conceptual contexts—for example, in case-based learning and clinical training scenarios—rather than as validated clinical tools. Accordingly, these discussions remained largely exploratory and should not be interpreted as evidence of established effectiveness. Keyword associations within this cluster indicated thematic attention to simulation-based learning,
63
real-time feedback and instructional support,
64
multimodal scenario integration,
65
and the design of adaptive or personalized educational tools.
66
• Cluster 1 (23 keywords, including cancer, breast cancer, rare disease, thyroid cancer, human phenotype ontology, random forest, differential diagnosis, risk assessment, care, active surveillance, and survival) reflected a substantial concentration of scholarly attention on disease-focused applications, particularly within oncology and rare diseases. The frequent co-occurrence of terms such as risk assessment, survival, and differential diagnosis suggested thematic attention to disease detection, prognostic evaluation, and clinical management applications within the literature. Keyword associations within this cluster indicated several thematic areas, including early detection,
67
active surveillance strategies,
68
robust risk-assessment frameworks,
69
and predictive modeling tailored to disease-specific contexts.
70
• Cluster 7 (15 keywords, including data models, adaptation models, critical care, acute respiratory distress syndrome, critical care nephrology, bias, and diagnostic errors) highlighted a thematic domain centered on critical care and high-acuity clinical settings. The co-occurrence of keywords related to critical illness, diagnostic errors, and adaptation models suggested scholarly attention to the potential use of LLM-assisted systems in complex and time-sensitive environments. Keyword associations within this cluster indicated thematic attention to real-time diagnostic support in acute settings,
71
prediction of patient deterioration and complications,
72
guidance for treatment protocols and pharmacological management,
73
and monitoring of patient safety.
74
• Cluster 9 (13 keywords, including patient care, ai chatbot evaluation, education, artificial intelligence applications, chatbots, and first aid) emphasized an application-oriented thematic domain associated with routine patient care and healthcare delivery contexts. The co-occurrence of terms such as chatbots, patient care, and education suggested thematic attention to clinical communication, patient interaction, and healthcare delivery processes. Keyword associations within this cluster indicated multiple thematic areas of investigation, including preventive care and screening,
75
automation of administrative tasks and documentation,
76
optimization of healthcare workflows,
77
and chronic disease management and monitoring.
78
Analysis of clinical research
A targeted PubMed search retrieved 96 clinical studies meeting the inclusion criteria. The search strategy is detailed in Supplemental File 3, and the inclusion and exclusion criteria are described in the Methods section. These publications spanned a broad spectrum of clinical contexts, thereby providing a fine-grained overview of the clinical domains, study designs, and evaluation settings represented within the emerging literature on LLM-assisted diagnosis. The analysis below is organized according to five key axes.
The 96 included studies demonstrated a highly heterogeneous distribution across clinical specialties, reflecting both the broad range of clinical domains investigated and the concentration of research activity within selected specialties. Gastroenterology and Hepatology represented the largest cluster (27.9%, n = 26), primarily comprising studies involving LLM-assisted colonoscopy for colorectal polyp and adenoma detection, as well as upper gastrointestinal endoscopy applications focusing on esophageal squamous cell carcinoma, Helicobacter pylori infection diagnosis, and bowel preparation quality assessment. Oncology constituted the second largest domain (19.8%, n = 19), encompassing applications such as prostate cancer detection using MRI and biopsy interpretation, sentinel lymph node evaluation in breast cancer, and melanoma detection in dermatology. Internal Medicine and General Practice accounted for 13.5% (n = 13), including diagnostic reasoning support, retrieval-augmented generation–based pre-procedure informed consent chatbots, and health economic evaluations of LLM-assisted diagnostic interventions in nutrition-related settings. Cardiology and Cardiovascular Medicine represented 10.4% (n = 10), covering ECG-based mortality alert systems, cardiomyopathy screening in pregnancy, cardiovascular risk stratification, and heart failure diuretic management. The remaining studies were distributed across Emergency Medicine (6.2%, n = 6), Pulmonology and Respiratory Medicine (5.2%, n = 5), Neurology (4.2%, n = 4), Ophthalmology (4.2%, n = 4), and other specialties.
The methodological characteristics of the included studies were heterogeneous, with randomized controlled trials (RCTs) constituting the largest study design category and accounting for 66.7% (n = 64) of all studies. Among these RCTs, parallel-group superiority designs predominated, whereas non-inferiority and equivalence designs represented a substantial minority. Non-randomized interventional studies—including single-arm cohort studies, paired-reader studies, and observational implementation studies— accounted for 8.3% (n = 8) of the sample. These methodological designs were primarily used to examine real-world implementation and generally provided a lower level of causal inference than randomized study designs. Prospective observational studies comprised 12.5% (n = 12) of the total and generally evaluated LLM-assisted diagnostic systems within routine clinical workflows. Retrospective observational studies and secondary analyses of prior trial data comprised the remaining 12.5% (n = 12), predominantly serving to validate AI algorithms using previously collected imaging or histopathological datasets, or to explore emerging biomarker endpoints within completed trial cohorts.
Classification according to the Oxford Centre for Evidence-Based Medicine (OCEBM) hierarchy revealed the following distribution of evidence levels across the included studies. Approximately 10.4% (n = 10) of studies qualified at OCEBM Level 1, encompassing high-quality RCTs. The majority of studies—64.6% (n = 62) —were classified as OCEBM Level 2, including individual cohort studies or RCTs that did not meet Level 1 criteria. A total of 15.6% (n = 15) of studies were categorized as Level 3, comprising cohort studies and case-control studies lacking strong controls. The remaining 9.4% (n = 9) of studies were classified as Level 4, predominantly consisting of descriptive case reports and low-quality controlled observational studies.
Despite the growing body of evidence, the literature identified several translational challenges that may constrain the integration of LLMs into clinical practice. Several studies highlighted concerns regarding performance variability across heterogeneous clinical environments characterized by differences in data distributions, workflow conditions, and operator-dependent factors. LLMs also raised potential safety concerns, including the risk of model hallucinations, while standardized prospective monitoring frameworks remained insufficiently developed. Heterogeneity in operator expertise was additionally reported as a factor that may influence the consistency of AI-assisted diagnostic performance, as performance gains may disproportionately amplify pre-existing levels of clinical expertise rather than reduce variability in diagnostic performance. In addition, geographic underrepresentation—with research output heavily concentrated in high-income regions—may limit the available evidence regarding the transferability of findings to populations with distinct epidemiological profiles. Furthermore, barriers to workflow integration persisted, including increased consultation time requirements and the lack of structured integration into clinical workflows, rendering technical performance alone insufficient for meaningful adoption.
Discussion
This study analyzed 650 publications indexed between Q1 2023 and Q1 2025, with the aim of providing a comprehensive overview of the development trajectory, research clusters, current research status, and emerging trends in LLM-assisted diagnosis.
Temporal distribution analysis demonstrated sustained and rapid growth in this field since 2023, with an average quarterly growth rate exceeding 70%. While bibliometric analysis does not support causal inference, this growth may be associated with several concurrent developments. From a technological perspective, advances in frontier models such as GPT-4 may have contributed to lowering barriers to experimentation through improvements in natural language understanding, multimodal reasoning, and API accessibility. 83 Clinically, increasing pressures associated with population aging, the escalating burden of chronic disease, workforce shortages, and rising healthcare expenditures may likewise have contributed to growing interest in scalable diagnostic solutions.84,85 In addition, the broader transition toward data-driven medicine may have further stimulated scholarly interest in LLM-assisted diagnostic approaches. 86 These factors should be interpreted as contextual considerations rather than definitive causal explanations.
The United States, China, and Germany emerged as the three leading contributors to research on LLM-assisted diagnosis. Notably, the United States dominated the most productive authors and institutions, underscoring its leading position in this field. In terms of scientific collaboration, a global cooperation network has already formed, connecting the United States, China, Germany, Italy, the United Kingdom, and Israel. The United States functioned as the principal hub, maintaining extensive partnerships with numerous countries. Regionally, a China-centered cluster has developed in Asia, whereas a Germany-centered cluster has emerged in Europe. It is also noteworthy that countries across Africa and South America remained markedly underrepresented. This pattern may be viewed, within the broader literature, as potentially associated with disparities in computational infrastructure, access to large-scale biomedical datasets, and differences in regulatory or governance environments. This geographic imbalance may also be interpreted as potentially influencing the datasets, implementation priorities, and validation contexts underlying future LLM-assisted diagnostic systems, which may further raise theoretical concerns regarding contextual generalizability and algorithmic bias in low-resource settings. Although these interpretations remain speculative and are inferred from collaboration structures rather than direct empirical evidence, they underscore the potential importance of inclusive international collaborations, cross-regional data-sharing frameworks, and sustained investment in digital research infrastructure.
Ten clusters were identified in the field and subsequently grouped into five overarching categories. The keyword co-occurrence analysis indicated that Group 1 was primarily characterized by the intersection of two closely related technical domains: multimodal AI architectures and medical imaging. This group reflected a concentration of research activity centered on computational frameworks and data integration strategies within the literature. From an interpretive perspective, these bibliometric patterns may reflect increasing scholarly attention to multimodal diagnostic frameworks.87,88 The frequent co-occurrence of keywords related to textual, imaging, and other data modalities further supports this interpretation. However, such patterns should be regarded as narrative synthesis rather than evidence of demonstrated improvements in diagnostic performance or clinical effectiveness.89,90 Consistent with these thematic patterns, recent literature has increasingly explored disease-specific applications of multimodal LLMs in domains such as radiology and ophthalmology, including CT-based intracranial assessment and retinal image interpretation for diabetic retinopathy screening. These studies commonly emphasize the integration of radiologic findings, textual interpretation, and knowledge-grounded contextual reasoning, illustrating how multimodal frameworks are being investigated across different diagnostic settings. Nevertheless, current investigations remain predominantly experimental, and future studies may benefit from prospective validation across heterogeneous populations, rigorous benchmarking against clinician performance, and systematic evaluation of generalizability beyond curated datasets. In addition, the presence of terms related to ethical and legal considerations indicated scholarly attention to governance and trustworthiness within this technical domain. Consistent with this observation, the broader literature has increasingly discussed issues such as regulatory readiness, algorithmic fairness, accountability frameworks, data privacy, informed consent, and liability allocation, highlighting the growing prominence of governance considerations in multimodal diagnostic AI research.
Group 2 focused on the translation of LLM technical capabilities into clinically meaningful reasoning processes. The literature frequently discussed the application of LLMs in contexts associated with clinical decision-making. From a narrative synthesis perspective, these themes may reflect growing scholarly interest in how LLMs could be conceptually aligned with selected components of clinical reasoning, particularly information synthesis and hypothesis generation. However, the bibliometric methodology does not permit inferences regarding whether LLMs replicate or approximate human cognitive processes; consequently, such interpretations should remain appropriately qualified. 49 Building on this conceptual and methodological framing, recent research has focused on clinical reasoning and collaborative aspects of LLM-assisted diagnosis, particularly diagnostic accuracy and calibration, human–AI collaboration, clinical decision-making, and uncertainty management, as examined in experimental or simulated settings, with the aim of improving the reliability, interpretability, and clinical relevance of model-supported diagnostic reasoning. In parallel, translational and implementation considerations have also received attention, including clinical validation, robustness and safety assessment, and dataset representativeness, which together shape the methodological and institutional requirements for the responsible deployment of LLM-based diagnostic systems for potential clinical implementation in the future.
Group 3 elucidated a set of application-oriented research themes identified through keyword co-occurrence analysis, particularly those related to diagnostic uncertainty and medical education. The literature frequently engaged with challenges associated with complex clinical data, model reliability, and educational or training contexts. From an interpretive perspective, these bibliometric findings may reflect broader scholarly interest in exploring how LLMs could be applied in contexts characterized by diagnostic uncertainty, particularly those involving ambiguous or incomplete clinical information. Consistent with these thematic patterns, recent studies have increasingly explored strategies for managing diagnostic uncertainty, improving the reliability of LLM-generated outputs, and mitigating risks associated with hallucinations and inaccurate recommendations; integration of multimodal data sources and complementary AI approaches has emerged as a recurring area of investigation.91–94 However, these strategies remain largely exploratory and have not yet been systematically validated in real-world clinical settings. In addition, the literature has increasingly examined the use of LLMs in educational and training environments, with simulation-based learning, feedback generation, and case-based instruction frequently discussed as potential application areas.
Group 4 emphasized application contexts evident in the bibliometric structure, including disease-focused research, critical care settings, and patient-facing healthcare services, thereby indicating coverage across multiple clinical domains and care levels. From a narrative synthesis perspective, these patterns may reflect increasing scholarly attention to the potential integration of LLM-assisted systems into diverse healthcare environments, ranging from high-acuity clinical settings to routine care and patient-facing services.95,96 Consistent with these thematic patterns, recent studies have increasingly examined disease-specific applications, real-world implementation scenarios, and the use of domain-adapted models across heterogeneous clinical settings. At the clinical deployment level, the literature has increasingly emphasized implementation-related considerations, including clinician oversight, workflow integration, consultation-time burden, auditability, and prospective safety monitoring. These recurring themes suggest that successful translational deployment may depend not only on algorithmic performance but also on the broader sociotechnical environments in which LLM-assisted systems are implemented. This highlights the potential value of integrating perspectives from clinical informatics, human factors engineering, and implementation science alongside conventional model-evaluation frameworks.
Group 5 highlighted prompt engineering as a distinct methodological theme emerging from the keyword co-occurrence analysis, indicating growing scholarly attention to interaction design with LLMs. From a bibliometric interpretive perspective, these patterns may reflect increasing interest in how input formulation may influence LLM-generated outputs in medical contexts. Consistent with these thematic patterns, recent studies have increasingly examined structured prompting, domain-specific adaptation, and clinician-AI interaction as approaches for optimizing interactions with foundation models and improving the relevance and reliability of generated outputs.97,98 Emerging literature has also explored adaptive prompting strategies responsive to patient complexity, automated frameworks for prompt evaluation, and the integration of prompting techniques into broader clinical decision-support ecosystems. In parallel, retrieval-augmented prompting, self-reflective reasoning pipelines, and automated prompt-optimization frameworks are increasingly discussed as methodological approaches that may further support the reproducibility, robustness, interpretability, and safety of LLM-assisted diagnostic interactions.
Building on the translational challenges identified in the Results section, the current literature suggests several complementary directions for future investigation. Large-scale multicenter studies may benefit from extending beyond surrogate performance metrics to examine patient-centered outcomes, including disease-specific survival, quality-adjusted life-years (QALYs), and complication rates. The literature has also demonstrated increasing attention to the development of standardized safety evaluation frameworks for LLM-assisted diagnosis, particularly those incorporating prospective assessment of diagnostic errors, inaccuracies, and potential clinical harm. Research on implementation across heterogeneous healthcare systems may further benefit from rigorous evaluation of adoption processes, workflow integration, and cost-effectiveness. In addition, equity-focused research may benefit from the inclusion of underrepresented populations from resource-constrained settings to improve generalizability across diverse epidemiological and healthcare contexts. Human–AI collaboration likewise emerged as a recurring theme, encompassing questions related to variability in clinician expertise, appropriate degrees of algorithmic autonomy, explainability mechanisms, uncertainty communication, and calibration of clinician reliance. Finally, longitudinal investigations may help clarify the potential influence of LLM integration on clinician decision-making, including issues related to automation bias and changes in diagnostic performance over time. Collectively, these directions reflect emerging research priorities identified within the current literature and may inform the responsible, safe, and clinically meaningful integration of LLM systems into clinical practice.
Limitations
This study has several limitations. First, the search strategy was iteratively developed based on commonly used LLM-related terminology, representative model names, and terminology identified through preliminary scoping searches and relevant review literature. Nevertheless, given the rapid evolution of nomenclature within the fields of LLMs and medical informatics, it remains possible that certain relevant publications employing unconventional, emerging, or insufficiently indexed terminology were not captured. Second, the present study primarily relied on the Web of Science Core Collection as the principal source database, potentially resulting in incomplete coverage of studies indexed in other databases and the underrepresentation of emerging research disseminated through preprint repositories and conference proceedings frequently used in artificial intelligence and computational medicine research. Consequently, the findings may partially reflect the indexing structure and publication dynamics of the WOSCC database rather than the full spectrum of ongoing scholarly activity within the field. Accordingly, future studies incorporating multiple databases, preprint repositories, conference proceedings, and domain-specific AI indexing platforms may provide a more comprehensive characterization of the evolving LLM research landscape. Third, the relatively short observation period (2023–2025) may accentuate apparent publication growth trends while limiting the ability to derive stable long-term evolutionary conclusions regarding the field. Accordingly, the observed growth patterns should be interpreted as early indicators of rapid scholarly expansion rather than definitive longitudinal trajectories. Fourth, bibliometric methods inherently capture publication volume, citation patterns, and thematic structures; however, they do not assess technical performance, clinical effectiveness, implementation outcomes, or patient-level impact. Consequently, the findings should be interpreted as reflecting patterns of research activity rather than evidence of clinical utility or effectiveness. Finally, keyword-based clustering analyses are sensitive to author-selected terminology, indexing practices, and database-specific metadata structures, which may introduce thematic overlap, cluster instability, and classification inaccuracies.
Conclusion
This bibliometric review mapped the evolving landscape of LLM-assisted diagnosis, highlighting the growth in scholarly publications, which reflected increasing academic and clinical interest rather than empirically validated technological maturity or demonstrated clinical advancement. The literature was characterized by prominent thematic concentrations related to computational foundations, clinical reasoning, diagnostic uncertainty, clinical applications, and prompt engineering methodologies. Keyword clustering and thematic analyses further identified recurrent areas of scholarly attention, including multimodal data integration, interpretability, clinician–AI interaction, and domain-specific diagnostic applications. Equally critical are recurring ethical and equity considerations—including bias mitigation, data governance and security, and global equity in access and representation—which continue to constitute subjects of ongoing scholarly and policy discourse rather than established safeguards or universally realized outcomes. Collectively, these findings provide a structured overview of the current research landscape and synthesize its major thematic directions, thereby informing future investigation of LLM-assisted diagnostic systems.
Supplemental material
Supplemental material - Application of large language models in medical diagnosis: A bibliometric review
Supplemental material for Application of large language models in medical diagnosis: A bibliometric review by Quan Zhang, Haokun Wang, Hongjuan Li, Fengbo Jiao, Hongchen Zhou, and, Meiyu Li in Digital Health.
Footnotes
Acknowledgments
The authors acknowledge the contributions of researchers whose work has advanced the field of LLMs in medical diagnosis.
Ethical considerations
This study exclusively used publicly available bibliographic data retrieved from the Web of Science Core Collection and PubMed. No human participants, clinical data, or identifiable personal information were involved. Therefore, in accordance with institutional and international research ethics guidelines, ethical approval was not required.
Author contributions
Investigation: HW, ML; Data curation: ML, FJ; Project administration: QZ, HL; Methodology: HW, HL, QZ; Software: HW, HZ; Visualization: HW, HZ; Formal analysis: QZ, ML; Writing—original draft: HW, ML, QZ; Conceptualization: HL, HW; Writing—review & editing: FJ, QZ; Supervision: QZ, HL; Funding acquisition: QZ, HL.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research was supported by the National Social Science Fund of China (25BSH015). The funding body had no role in study design, data collection, data analysis, or manuscript preparation.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets generated and analyzed during this study are available from the corresponding author upon reasonable request.
Guarantor
QZ and HL are the guarantors of this work.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.