
Abstract
This study examines the education return premium in China’s public sector and its role in driving labor allocation. Using China General Social Survey (CGSS) data from 2003 to 2021, we employ propensity score matching (PSM) and Oaxaca-Blinder (OB) decomposition to address selection bias. Results show a significant education return premium (Δβ = .5014) in the public sector despite an overall income discount (ATT = −0.324). Heterogeneity analysis reveals stronger premiums in SOEs versus core public sectors (government/institutions). Macro-temporal analysis confirms a positive correlation between education premium and public employment share. Robustness checks, including Rosenbaum bounds, CIA tests, and placebo tests (fake sector), support the findings. Policy implications suggest optimizing public sector compensation to leverage education premiums and enhancing private sector benefits to attract talent.
Plain Language Summary
Why do many highly educated workers in China choose jobs in the public sector, even though average salaries there can be lower than in private firms? This study finds the answer is not in the base salary, but in the ‘education premium’—the extra income gained from each additional year of schooling. Our analysis of national survey data from 2003 to 2021 shows that the public sector rewards education more highly than the private sector does. This higher return on education, along with benefits like job security, makes public sector careers attractive to educated individuals. This talent flow, however, may impact economic innovation and growth. Therefore, we suggest that policymakers optimize the public sector’s compensation structure to better utilize its human capital, while enhancing the benefits package in the private sector to better compete for talent.
Keywords
Introduction and Literature Review
The National civil service examination, known as “China’s first exam,” has experienced 30 consecutive years of heating up since China established a civil service examination and recruitment system in 1994. According to data from the website of Zhonggong Education, the number of applicants for the National exam in 2024 will be 2,913,800, and the number will be 1.437 million in 2020, more than doubling in just 4 years. Moreover, in addition to the large number of the “army” of public examination, there are even some young people with high degrees, according to the report on the employment quality of graduates of Peking University in 2021, 14.86% of the undergraduates graduating from Peking University in 2021 went to work in the public administration, social security and social organization industries (According to the classification standard of National economic Industries of the People’s Republic of China, public administration, social security and social organization industries mainly include: ① organs of the Communist Party of China; ② State institutions; ③ The CPPCC and the democratic parties; ④ Social security; ⑤ Mass organizations, social organizations and other member organizations; ⑥ Grassroots self-governing organizations, industries and other categories. It is roughly equivalent to the public sector, so hereinafter referred to as the public sector industry), and among master’s graduates, the proportion of employment in the public sector industry is as high as 19.87%, and the proportion of doctoral graduates in the public sector industry is lower, but also 9.19%. According to the report on the quality of employment of graduates from Tsinghua University in 2022, the situation is similar, and among graduates from Tsinghua University in 2022, the proportion of bachelor’s, master’s and doctoral degrees going to the public sector industry is 10%, 17.1%, and 17.1% respectively. Given China’s already limited stock of human capital, the rush of so many bright minds into the public sector is bound to have all sorts of adverse effects on China’s economic development. At present, a large number of studies have analyzed the adverse economic and social consequences of this phenomenon of talent rushing into the public sector in China. These studies specifically encompass adverse impacts on economic growth, innovation, and other areas. On economic growth, for instance, S. Li and Yin (2017), based on empirical analysis of China’s prefecture-level data, demonstrated that the cream of the crop disproportionately flowed into governmental sectors, which deprived the private sector of vital human capital and ultimately hampered economic growth. Additionally, J. Li and Nan (2019) reinforced this thesis, evidencing that excessive allocation of human capital to the public sector is detrimental to sustained economic expansion, particularly by dampening productivity gains in innovation-intensive industries. In contrast, Zhu and Wei (2024) revealed from a policy perspective that corrective measures for human capital misallocation in the public sector would not only elevate the steady-state economic growth rate but also generate substantial welfare improvements across the economy—effectively constituting a Pareto improvement. In terms of innovation, Y. Chen and Xu (2019) demonstrate that excessive talent allocation to government sectors significantly suppresses regional innovation efficiency. This detrimental effect on innovation is further corroborated by Tan and Li (2019), X. Z. Li et al. (2022), and Z. Sun (2023), whose analyses consistently reveal human capital overcrowding in public institutions stifles innovation outputs. Finally, in other aspects, these studies specifically document adverse impacts of human capital misallocation on: Exports (W. Jiang et al., 2019; S. Y. Li, 2022), Income inequality (Y. A. Chen, 2020; Y. A. Chen & Xu, 2019), and Consumption (J. Li & Si, 2020).
A comprehensive review of the extant literature reveals that excessive accumulation of human capital within the public sector could potentially impede broader socio-economic progress through various adverse mechanisms. This raises a pivotal question: How can policymakers effectively guide human capital allocation across sectors? Addressing this challenge requires a comprehensive understanding of the underlying causes of human capital misallocation to formulate targeted solutions. Therefore, identifying the root causes of human capital misallocation between public and private sectors becomes imperative.
Baumol (1990) proposed that the compensation structure embedded in social institutions determines human capital allocation. Specifically, when a wage premium exists in the public sector, the labor force tends to rationally favor public sector employment. Cavalcanti and Santos (2021) further underscore the critical role of public-private sector wage differentials in shaping human capital allocation and economic growth. Their counterfactual simulation using Brazilian data reveals that reducing the public sector wage premium from 19% to 15% would yield a 4.7% increase in long-term output. A critical question arises: Does such a public sector wage premium indeed exist? The empirical literature reveals mixed findings. Most studies in developed economies support its existence. For instance, Smith (1976) conducted the seminal analysis of public-private wage differentials using U.S. Census Public Use Samples from 1960 and 1970. His study found that federal employees earned significantly more than private-sector counterparts, with 65% of the gap attributable to discriminatory factors (e.g., non-merit-based hiring). Similarly, Gunderson (1979) analyzed 1971 Canadian Census data and identified a public sector wage premium, particularly pronounced among women and low-income workers. Krueger (1988) reinforced this consensus through multi-dataset analyses of U.S. federal, state, and local government wages, consistently finding public sector wages exceeding private sector levels. In a recent study, Sławińska (2021) employs the Oaxaca-Blinder decomposition technique to analyze public-private sector wage differentials across 26 EU nations during 2008 to 2013. The findings reveal that public-sector employees secured significantly higher compensation than their private-sector counterparts in most countries, with structural wage gaps persisting amid fiscal consolidation. However, contrasting evidence emerges from Pederson et al. (1990), whose analysis of Danish data (1976–1985) indicates lower public sector wages relative to the private sector.
Research on developing countries yields even more divergent conclusions. For instance, Nielsen and Rosholm (2001) analyzed Zambian cross-sectional data (1991, 1993, 1996) and identified a consistent public sector wage premium across all income quantiles. In contrast, Stelcner et al. (1989) applied a switching regression model to Peru’s 1985–1986 labor market data, revealing significantly lower average wages in the public sector compared to the private sector—a disparity that incentivized public sector workers to engage in part-time private employment. Similarly, Adamchik and Bedi (2000) employed a switching regression framework in Poland and found a private sector wage advantage, particularly pronounced among university-educated workers. Botchway and Asiedu (2020) demonstrate through Oaxaca-Blinder (OB) and Jones-Mendola-Pezzotti (JMP) decompositions that private-sector employees in Ghana command a 23% wage premium relative to state-owned enterprise (SOE) workers, revealing market-driven compensation advantages in the formal private economy. Imbert (2013) documented phased fluctuations in Vietnam’s public-private income gap, suggesting temporal heterogeneity in sectoral wage differentials. In a seminal recent study, El-Haddad and Gadallah (2021) empirically validate the existence of institutional wage premiums within Egypt’s public sector through rigorous application of the RIF-FFL decomposition methodology. Cross-country analyses further complicate the picture: Panizza et al. (2001) examined panel data from 17 Latin American countries (1980–1998), estimating an initial 14% public sector premium that dropped to 4% after excluding informal sector workers. In a comparable vein, Gindling et al. (2020) demonstrate through a cross-national analysis of 68 countries that while the public sector typically pays a wage premium when compared to the private sector including informal segments, this premium dissipates entirely when benchmarked solely against the formal private sector—highlighting how informal labor markets distort conventional sectoral wage comparisons.
Studies on China’s public-private sector income differentials yield inconsistent conclusions, which can be categorized into three groups based on opposing findings.
(a) Studies Identifying a Public Sector Premium
J. W. Zhang and Xue (2008) employed the Heckman two-step method using PSFD (Panel Study of Family Dynamics) data to analyze wage disparities between state-owned and non-state-owned sectors. Their analysis revealed a significant wage premium in state-owned enterprises (SOEs), with average wages twice those of the non-state sector. Notably, over 80% of this gap was attributed to human capital differences. Extending this work, the authors applied the Heckman selection model to 2002 CHIPS (China Household Income Project Survey) data, controlling for labor force participation and sector selection biases. Both OLS and Heckman estimates confirmed a persistent public sector wage premium, with the gap widening and discriminatory factors (e.g., institutional barriers) explaining a higher proportion when selection biases were accounted for. Contrastingly, Zhao (2002) analyzed 1996 urban household survey data and found private sector wages exceeding SOE wages in raw comparisons. However, after incorporating non-wage benefits (e.g., housing subsidies, pensions), total compensation in SOEs surpassed private firms significantly.
(b) Studies Reporting a Public Sector Disadvantage
Liu and Zhang (2020) leveraged CFPS2010 (China Family Panel Studies) data with quantile regression, demonstrating that wages in public institutions, SOEs, and private enterprises consistently exceeded those in the narrow public sector (i.e., government agencies) across all income quantiles. Similarly, Yao et al. (2016) conducted an Oaxaca-Blinder decomposition on CHIP2008 data, revealing higher wage returns in the private sector compared to the public sector. However, when regional disparities were adjusted, the public sector exhibited higher income returns—a paradox suggesting spatial heterogeneity in compensation structures.
(c) Studies Identifying Phased Characteristics in Compensation Structures
Research on China’s public-private sector remuneration differentials reveals distinct temporal patterns. Yin and Gan (2009) analyzed CHNS (China Health and Nutrition Survey) data spanning 1989 to 2009, documenting a structural shift: public sector wages trailed non-public sector wages by 2.9% during 1989 to 1997, but surpassed them by 13.48% in 2000 to 2006. Building on this, Y. B. Zhang (2012) replicated the phased hypothesis with identical methodologies, finding post-2000 heterogeneity across income quantiles—public sector advantages persisted in lower quantiles, while non-public sectors dominated in higher quantiles. X. J. Chen and Yu (2019) employed Recentered Influence Function (RIF) unconditional quantile regression on CHNS microdata to track the state versus non-state sector wage gap. Their decomposition analysis captured an evolutionary trajectory: state sector wages transitioned from a discount (pre-reform) to a premium (post-2000s), with the primary drivers shifting from institutional factors (e.g., SOE monopoly privileges) to human capital determinants (e.g., education returns) in recent decades. This aligns with K. Z. Jiang et al. (2012), whose analysis of 1992 to 2008 data identified a reversal: non-public sector wage superiority during 1992 to 1996 gave way to public sector dominance post-1999. Notably, Zhou and Wang (2013) conducted a longitudinal analysis of CHNS survey data (1989–2009) using unconditional quantile regression, uncovering a V-shaped trajectory in the state sector premium—an initial narrowing followed by post-2000 widening, attributable to labor market liberalization and SOE restructuring policies. Finally, Tian and Shen (2022) leverage CHIP 2013/2018 data and Copula-based empirical methods to reveal a striking temporal shift: public-sector workers enjoyed a statistically significant wage premium in 2013, yet faced a distinct pay penalty by 2018. This reversal challenges conventional assumptions about public-sector compensation persistence. Complementarily, heterogeneity analyses confirm sectoral wage gaps dynamically interact with gender and education. As Wan et al. (2021) demonstrate using endogenous switching models applied to CHIP 2013 urban survey data: Men earn higher wages in the non-public sector than in public institutions, Women conversely achieve income advantages within the public sector—highlighting how institutional pay structures asymmetrically shape gender outcomes in China’s segmented labor market.
Research Gaps and This Study's Contributions
The literature review reveals three critical gaps: (1) inconsistent empirical conclusions requiring rigorous re-examination, (2) narrow conceptualization of compensation limited to wage differentials, and (3) outdated datasets constraining policy relevance. To address these limitations, and while building on the existing literature, our study provides the most comprehensive temporal analysis using CGSS 2003–2021, focuses on returns to education as a novel mechanism, and combines multiple methods to address selection bias and distributional effects. This offers updated insights for China’s post-2013 reform era.
Rather than claiming entirely novel concepts, this study offers substantive incremental contributions by refining, integrating, and updating existing research paradigms in the following ways:
First, regarding the analysis of sectoral income differentials: While prior studies (e.g., Yao et al., 2016; J. W. Zhang & Xue, 2008) have established the foundation, their conclusions are inconsistent and often rely on static or dated snapshots. Our contribution lies not in discovering the gap itself, but in providing a robust, longitudinal re-examination that tracks the evolution of this gap across critical policy periods (post-WTO, post-2008 crisis, post-2013 reforms) using the most recent nationally representative data (CGSS 2003–2021). This allows us to move beyond the question of “if a gap exists” to “how the gap has dynamically changed” in China’s contemporary reform context, offering much-needed updated evidence.
Second, regarding the conceptualization of compensation and the mechanism: We acknowledge that analyzing education returns and broader compensation is not unprecedented. Our incremental contribution is twofold:
Mechanism Integration: We pioneer the direct integration of sectoral income differentials with labor mobility decisions to empirically test how compensation gaps (including education returns) actually distort human capital allocation—a theoretical link often discussed but underexplored empirically in transitional economies like China.
Conceptual Clarification and Measurement Honesty: We explicitly conceptualize “employment value” as encompassing both monetary and non-monetary benefits (welfare, job security, etc.) to better reflect real-world career choices. We acknowledge that due to data limitations, our empirical measurement of total income is currently limited to monetary wages. However, by formally establishing this comprehensive conceptual framework, we provide a clearer blueprint for future research when better data becomes available, and we rigorously analyze the component we can measure (cash income) within this broader theoretical context.
Third, we move beyond the mere existence of a sectoral income gap to probe its underlying drivers, with a particular focus on the returns to education as a pivotal mechanism. While prior literature has documented the average wage differential, our contribution is to empirically test whether and how the premium for educational attainment differs between the public and private sectors, and how this disparity contributes to human capital misallocation. This mechanistic focus is especially relevant for China’s college-educated cohort—a group critical for innovation-led growth—although our analysis encompasses the entire labor market. Decomposing the variations in the education premium between sectors provides novel insights into the root causes of skill-occupation mismatches.
Finally, regarding methodology: Our primary methodological contribution is not in using any single technique in isolation, as OB decomposition or quantile regression have been used before. It is in the deliberate combination of PSM, OB decomposition, and quantile regression within a unified framework to tackle different aspects of the problem. This multi-method approach is specifically designed to address selection bias (via PSM), decompose the gap’s sources (via OB), and unveil its distributional heterogeneity (via Quantile Regression) in a more comprehensive and robust manner than most prior studies that typically employ only one or two of these methods.
Research Objectives and Empirical Strategy
The primary objectives of this paper are threefold: (1) to re-examine the public-private income differentials using the latest CGSS data; (2) to analyze the returns to education as a key mechanism driving sectoral choice; and (3) to address the methodological challenges of selection bias and heterogeneous distributional effects.
Crucially, each objective necessitates a specific econometric technique, and their combined use is central to our research design—not merely for robustness checks. The rationale for this multi-method approach is as follows:
To mitigate selection bias (Objective 3) arising from the non-random sorting of individuals into sectors, we employ Propensity Score Matching (PSM). We selected PSM over alternatives like the Heckman model due to its semi-parametric nature and flexibility in handling non-linear relationships without stringent distributional assumptions (W. Sun et al., 2016). This method allows us to construct a valid counterfactual for a causal interpretation of the income gap.
To deconstruct the matched income gap (Objective 1) and test the mechanism of returns to education (Objective 2), we apply the Oaxaca-Blinder (OB) decomposition. This technique is necessary to quantify what portion of the gap is due to differences in observable characteristics (e.g., a more educated workforce) versus differences in the returns to those characteristics (e.g., a higher premium for the same education).
To fully capture distributional heterogeneity (Objective 3) obscured by mean analysis, we implement Unconditional Quantile Regression (UQR). This method is objectively essential to determine if the income gap and returns to education are consistent across the entire earnings distribution, providing nuanced insights for policy.
We anticipate that this rigorous, multi-pronged empirical strategy will yield robust results showing a significant public sector compensation premium in contemporary China, primarily driven by higher returns to education and non-wage benefits, and that this premium varies substantially across the income distribution.
Paper Structure
The remainder of this paper is structured as follows: Section 2 establishes a theoretical model and proposes research hypotheses. Section 3 details the data sources and variable definitions. Section 4 presents the empirical results conducted through the aforementioned techniques. Section 5 concludes with policy implications.
Theoretical Framework and Research Hypotheses
Theoretical Framework
To elucidate the core mechanism of human capital allocation, we develop a parsimonious model grounded in random utility theory (McFadden, 1974). An individual i chooses to work in the sector that delivers the highest utility. The utility from working in sector j (public or private) is:
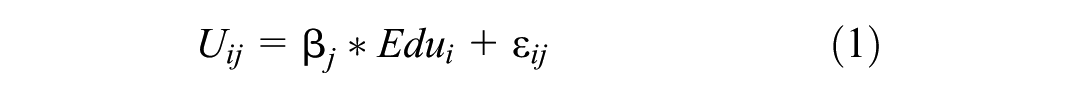
where
The individual selects the public sector if

Let

where
Testable Hypotheses
From Equation 3, we derive our core testable hypotheses at both the micro and macro levels.
This micro-foundation allows for aggregation to the macro level. The share of the workforce employed in the public sector, S_pub, is the expectation of individual choice probabilities:
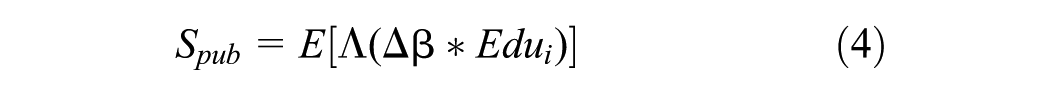
Equation 4 establishes the critical link between a micro parameter and a macro outcome, leading to our second hypothesis.
Empirical Roadmap
To empirically test the hypotheses derived from our theoretical model, our analysis in Section 4 proceeds through the following structured sequence:
Testing
Estimating the Premium: We employ Propensity Score Matching (PSM) to address selection bias, followed by Oaxaca-Blinder (OB) decomposition to quantify the public sector education premium (Δβ) at the mean.
Examining Heterogeneity: We use Unconditional Quantile Regression (UQR) to explore variation across the income distribution and conduct additional analysis using a narrow public sector definition (excluding SOEs) to test for sectoral heterogeneity.
Testing
Robustness Checks: We perform comprehensive tests to validate our findings, including:
Rosenbaum bounds sensitivity analysis for hidden bias in PSM.
CIA tests using pre-treatment variables (e.g., gender, parental education, parental employment sector).
Placebo tests with fake sector definitions.
OB decomposition with alternative benchmarks (e.g., using private-sector coefficients as the reference) to assess sensitivity to baseline choices.
Additional controls for occupation and firm size, with standard errors clustered at the province level.
This multi-method approach ensures each step is tied to our theoretical framework, while robustness checks enhance the credibility of our results.
Data and Sample, Measurement of Variables, and Econometric Framework
Model Design
In studying the income disparity between the public and private sectors, a critical issue that must be addressed is sample selection bias. Specifically, since individuals are not randomly assigned to either sector but actively choose between public and private employment, it is possible that certain unobserved factors simultaneously influence both their sector choice and their income level. This can lead to biased estimates in the analysis.
The primary methodologies in the literature to correct for this sample selection bias include the Heckman sample selection model, the endogenous switching regression model, and propensity score matching (PSM). While all three approaches aim to address selectivity bias, the former two suffer from significant limitations compared to PSM. First, they inherently impose strong parametric assumptions, primarily relying on linear functional forms for the outcome equations. Second, these parametric models may rely on imposing restrictions on non-comparable samples (W. Sun et al., 2016). In contrast, propensity score matching largely overcomes these drawbacks. Consequently, the subsequent empirical analysis in this paper will employ PSM to investigate the income gap between China’s public and private sectors.
Propensity score matching (PSM), initially developed by Rosenbaum and Rubin (1983), is a semi-parametric estimation method. Its approach to estimating the sectoral income differential involves first estimating a propensity score based on observed covariates. This score represents an individual’s probability of being employed in the public sector. Specifically, a logit model is used to estimate this probability:
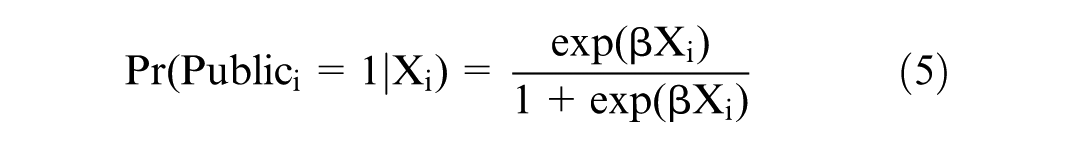
Where:
β is the vector of corresponding coefficients.
Using the estimated propensity scores, the method then matches each individual in the “treatment” group (public sector employees) with one or more individuals in the “control” group (private sector employees) who have a very similar propensity score. By pairing individuals with comparable background characteristics and pre-treatment tendencies, PSM mitigates the influence of confounding factors and allows for a more accurate estimation of the average treatment effect on the treated (ATT), effectively isolating the impact of sector affiliation on income.
Data Sources and Preprocessing
This study utilizes data from the Chinese General Social Survey (CGSS), the earliest nationwide academic survey project in China, initiated by Renmin University of China in 2003. The dataset spans 12 survey years (2003, 2005, 2006, 2008, 2010, 2011, 2012, 2013, 2015, 2017, 2018, and 2021) and contains comprehensive individual-level information, providing robust support for analyzing the differences in education returns between public and private sectors and labor force employment choices.
To ensure the reliability of the findings, the analysis focuses exclusively on working-age individuals: males aged 16 to 60 and females aged 16 to 55. Samples outside these age ranges, individuals currently enrolled in school, those without employment, and cases with missing key variables were excluded. The final dataset comprises 42,091 valid samples, including 15,556 from the public sector and 26,535 from the non-public sector.
Variable Definitions
This section details the variables employed in the regression analysis, including their definitions and measurement.
Dependent Variable
Annual Income Level (logincome): Based on the design of the CGSS questionnaire, this variable utilizes the annual income reported by individual respondents. The nominal income figures are adjusted for inflation using the Consumer Price Index (CPI) to express them in constant 2021 prices. The resulting real income value is then transformed using the natural logarithm. It should be noted that, While CGSS data captures self-reported total annual income, which is intended to reflect comprehensive compensation, the precise inclusion and accurate valuation of all non-wage benefits (e.g., employer-provided housing, health insurance) by respondents may present a measurement challenge.
Treatment Variable
Sector of Employment (public): This binary variable distinguishes between the public sector (public = 1) and the non-public sector (public = 0).
The classification of sectors aligns predominantly with the established practice in the literature: government agencies (dangzheng jiguan) and public institutions (shiye danwei) constitute the public sector, while privately-owned enterprises (siying qiye) are classified as non-public. The main ambiguity lies in the treatment of State-Owned Enterprises (SOEs). Some studies categorize SOEs within the non-public sector, arguing they operate as profit-maximizing entities. Others contend that SOEs in China fulfill unique social responsibilities beyond pure profit maximization and should therefore be classified as part of the public sector.
To address this ambiguity, the baseline regression adopts the latter approach, grouping SOEs with the public sector (public = 1). This classification is justified by the institutional realities in China, where SOEs often operate under quasi-governmental roles, fulfill social and political mandates beyond pure profit maximization, and are subject to direct state oversight and personnel management similar to core public institutions (X. J. Chen & Yu, 2019; Zhou & Wang, 2013). Subsequently, a robustness check reclassifies SOEs as non-public (public = 0) to verify that the core findings are not sensitive to this specific definitional choice.
Control Variables
(1) Gender (gender): Binary variable coded as 1 for Male, 0 for Female.
(2) Household Registration(hukou): Binary variable coded as 1 for Urban Registration (chengzhen hukou), 0 for Rural Registration (nongcun hukou).
(3) Marital Status (marriage): Binary variable coded as 1 for Married, 0 for other statuses (including single, divorced, widowed, etc.).
(4) Educational Attainment (education): Reflecting standard methodology in the literature, this continuous variable represents the total number of years of formal education, assigned as follows: No Formal Education = 0; Primary School = 6; Junior Secondary School = 9; Senior Secondary School/Vocational High School/Technical Secondary School (zhongzhuan) = 12; College Diploma (dazhuan) = 15; Bachelor’s Degree (benke)= 16; Graduate Degree or above (yanjiusheng ji yishang) = 19
(5) Potential Work Experience (experience) & its Square (experience2): Constructed following the conventional formula: Experience = Age-Years of Education (education)−6. To capture potential non-linear effects of experience on income, the squared term (experience^2) is also included.
(6) Political Affiliation (party): Binary variable coded as 1 for members of the Chinese Communist Party (CCP), 0 for non-members or members of other parties.
(7) Parental Employment Sector (fpublic, mpublic): To account for documented patterns of intergenerational transmission within public sector employment (Han et al., 2016), the sector of employment for each parent is included. fpublic indicates the father’s employment sector (1 = Public, 0 = Non-public). mpublic indicates the mother’s employment sector (1 = Public, 0 = Non-public).
Descriptive statistics for all variables are presented in Table 1.
Descriptive Statistics of Each Variable.

Note. The standard deviation is in parentheses.
“***” and “**” respectively represent that the t value is significant at the levels of 1%, and 5%.
Based on the descriptive statistics presented in Table 1, several preliminary conclusions can be drawn:
Sectoral Income Gap: Annual total income (logincome) appears slightly higher in the non-public sector compared to the public sector, though the difference is not substantial.
Marital Status Composition: The proportion of married individuals is significantly higher within the public sector. This may reflect a stronger preference among married individuals for job stability, a characteristic often associated with public sector employment.
Urban Hukou and CCP Membership: Individuals in the public sector exhibit a notably higher prevalence of both urban household registration (hukou) and membership in the Chinese Communist Party (party). This likely stems from a two-way relationship: urban registration and CCP affiliation may facilitate entry into the public sector, while conversely, public sector employment may also increase an individual’s chances of obtaining urban registration and/or party membership.
Human Capital Endowment: Individuals employed in the public sector demonstrate stronger human capital attributes. Both average years of education (education) and work experience (experience) are higher in the public sector compared to the non-public sector. This pattern aligns with the observed “public sector job application surge” (kao gong re) among highly-educated individuals in China in recent years. Furthermore, the lower job turnover in the public sector allows employees greater opportunity to accumulate more extensive experience within a specific role.
Intergenerational Transmission: Evidence of significant intergenerational transmission is present concerning access to public sector positions.
However, it is crucial to emphasize that these findings are preliminary and derived solely from descriptive analysis of the raw data. More precise causal inferences require the subsequent econometric testing presented below.
In addition, the expected influence of the control variables differs between the two primary stages of our analysis: the selection into the public sector (estimated via the logit model for propensity scores) and the determination of income (the outcome equation). Table 2 summarizes the theoretical expectations for each variable’s coefficient in both models, along with the primary rationale. These expectations are derived from standard labor economics theory and the findings of prior studies on the Chinese labor market.
Theoretical Expectations for Variable Coefficients in Sector Choice and Income Determination Models.

Finally, to provide a more intuitive visualization of the income disparity between China’s public and private sectors and its evolution over time, we employ kernel density plots to illustrate the income distributions for each sector across all 12 years covered in the CGSS data. The results are presented in Figure 1.

Kernel density plot of the logarithm of total revenue from 2003 to 2021.
Observations from Figure 1: Over the entire 12-year period, the average level of total income (logincome) for employees in the public sector consistently exceeds that of their counterparts in the private sector. Crucially, the income distribution within the private sector exhibits significantly fatter tails at both the lower and upper ends compared to the public sector. This indicates greater income dispersion (i.e., larger income inequality) among private sector workers. In contrast, the income distribution within the public sector appears more compressed, signifying a narrower range of incomes and consequently, lower income inequality within that sector.
Empirical Results and Related Tests
Empirical Strategy: A Roadmap
To test the hypotheses derived from the theoretical framework (Section 2), we employ a multi-stage empirical strategy designed to address methodological challenges—selection bias, decomposition of income differentials, and distributional heterogeneity—while providing a comprehensive view of the mechanisms. This approach ensures each step aligns with distinct research objectives, and the combination of techniques is necessary for robustness and depth.
Our analysis proceeds in the following sequence:
Model 1: Testing the Micro-Choice Mechanism (
We estimate a Logit model of sectoral choice to examine whether higher education levels increase the probability of selecting into the public sector, conditional on observables (e.g., gender, Hukou, Party membership). This provides a direct test of
Models 2–3: Estimating the Education Return Premium (Δβ) and Addressing Selection Bias
To robustly estimate Δβ (the public sector’s education return premium), we address selection bias via a two-step procedure:
Propensity Score Matching (PSM): We use PSM (one-to-one nearest-neighbor matching) to create a balanced sample where public and private sector workers are comparable based on pre-treatment covariates (e.g., education, experience, demographic factors).
Oaxaca-Blinder (OB) Decomposition: On the matched sample, we apply OB decomposition to decompose the mean income gap into explained (characteristics) and unexplained (coefficients) components, isolating Δβ.
Model 4: Examining Heterogeneity
We employ Unconditional Quantile Regression (UQR) to assess whether Δβ varies across the income distribution (e.g., low, median, high quantiles). Additionally, we test sectoral heterogeneity by re-running analyses with a narrow public sector definition (excluding SOEs) to ensure results are not driven by SOE inclusion.
Model 5: Temporal Analysis for Macro-Implication (
We test
Model 6: Robustness Checks
To ensure validity, we conduct extensive robustness tests:
Rosenbaum Bounds Sensitivity Analysis: To assess hidden bias in PSM estimates.
CIA Tests: Using pre-treatment variables only (e.g., parental education, childhood Hukou) to verify the conditional independence assumption.
Placebo Tests: Employing fake sector definitions to rule out spurious correlations.
OB Decomposition with Alternative Benchmarks: Using private-sector coefficients as the reference to test sensitivity to baseline choices.
Additional Controls: Including occupation and firm size variables in OB decompositions, with standard errors clustered at the province level for conservative inference.
This sequential approach ensures that each empirical model serves a distinct purpose, from micro-level choice to macro-level trends, while robustness checks enhance the credibility of our findings.
Propensity Score Estimation Results
The estimation results of the propensity score using the logit model are shown in the Table 3.
Estimation Results of Propensity Score by Logit Model.

Note. The errors in parentheses are standard errors.
“***” and “*” respectively represent that the t value is significant at the levels of 1%, and 10%.
The results from the logit model, which estimates the propensity for public sector employment, are presented in Table 3. The findings are largely consistent with theoretical expectations and the established literature on China’s labor market, while also revealing one significant and insightful deviation.
As anticipated, educational attainment exhibits a strong, positive, and statistically significant effect on the probability of public sector employment. This result provides direct empirical support for the hypothesis
Urban hukou and CPC membership are paramount positive predictors, reflecting the well-documented institutional barriers and advantages in accessing public sector careers. The significant, positive coefficients for parental public sector employment (fpublic, mpublic) provide strong evidence of intergenerational transmission of occupational access.
The negative coefficient for gender suggests a stronger preference for public sector stability among women compared to men, while the positive sign for marriage indicates that married individuals also favor public sector employment.
However, the results for work experience present a nuanced deviation from the standard assumption of diminishing returns. Contrary to the initial conditional expectation, the coefficient for the squared term of experience (experience2) is positive and significant. This indicates that the marginal effect of additional experience on the probability of public sector employment increases over time. A compelling explanation for this finding lies in the unique seniority-based reward architecture of China’s public sector, where promotions, pension benefits, and job security are explicitly tied to tenure. This creates a powerful accelerating incentive and a “lock-in” effect, making the sector disproportionately more attractive as workers accumulate more experience.
Collectively, these results confirm that selection into China’s public sector is strongly non-random and is systematically driven by human capital, institutional status, and family background. The model’s strong explanatory power (Pseudo R2 of .2149) affirms its appropriateness for generating reliable propensity scores for the subsequent matching analysis.
Premium Situation of Public Sector Revenue
After estimating the propensity score of the individuals, the individuals in the treatment group and the control group are matched based on this score, and the average treatment effect, that is, the income premium of the public sector, is calculated. The specific matching methods of propensity score matching mainly include one-to-one matching, radius matching, kernel matching, etc. In this part, in order to reflect the changes of the income premium of the public sector over time. In addition to calculating the income disparity between the public and private sectors of the entire sample, we also calculated the income disparity between sectors in each year. The matching method used was one-to-one matching. The specific results are shown in the following Table 4. (It should be noted that, due to the small sample size in 2011, it might not be possible to find individuals in the control group with propensity scores similar to those in the treatment group. Therefore, the result reported by stata software is “no observations.” The subsequent table involving the empirical results of 2011 is the same as this)
ATT Values Obtained by the One-to-One Propensity Score Matching Method.

“***” and “**” respectively represent that the t value is significant at the levels of 1%, and 5%.
As shown in the above table, after correcting the sample selection bias using the propensity score matching method, the income of the non-public sector was significantly higher than that of the public sector. The income of the public sector was 32.4% lower than that of the non-public sector. Moreover, in each year, except for 2003 when the income of the public sector was higher but not significant, the income of the public sector was relatively low in the remaining years. Especially since 2017, the revenue of the public sector has consistently been significantly lower than that of the non-public sector.
In order to verify the reliability of the conclusion, a balance test of the matching effect needs to be conducted. The test results are shown in the following Figure 2:

Balance test.
It can be seen from the figure that after matching, the standardized deviations of all variables have decreased, which indicates that the balance test has been passed. Through matching, we have obtained comparable treatment groups and control groups.
Furthermore, to ensure the quality of our matching procedure, we tested the common support assumption. The results of this test are presented in Figure 3.

Test of the common support assumption.
Figure 3 shows that for most of the propensity score distribution, both the treatment and control groups lie within the region of common support. The substantial overlap indicates that the common support assumption is satisfied.
Decomposition of Income Disparity
The following of this article will decompose income differences through the Oaxaca-Blinder decomposition method (referred to as OB decomposition hereinafter) to analyze the sources of income differences between the public and private sectors. The idea of the OB decomposition method is to decompose income differences into coefficient differences and endowment differences by constructing a counterfacutal group. Among them, Endowment differences refer to the income differences caused by the different productivity of the labor force in the two sectors. This part of the difference is called the explainable part. Coefficient differences refer to the differences caused by the different rates of return on homogeneous labor in the two sectors. This part is called the unexplainable part or the discriminatory part.
Specifically, regarding the research topic of this article, we take the public sector as the benchmark group, construct the counterfactual group as “non-public sector labor force regarded as working in the public sector,” and express the income they obtain as
Therefore, the income disparity between the public and private sectors can be expressed as:
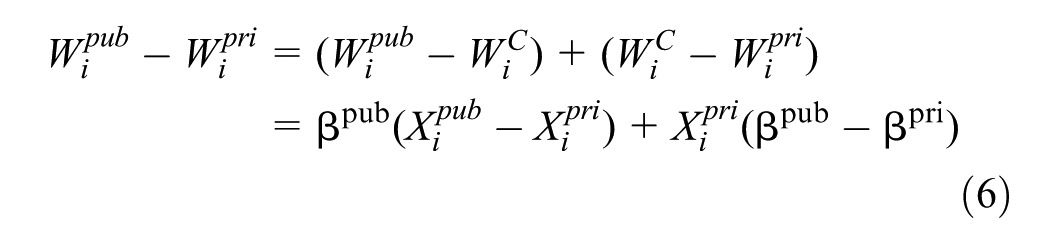
Among them,
The specific regression results are presented in Table 5. The Oaxaca-Blinder decomposition yields insights critical to our theoretical framework. Under our income difference definition (
Decomposition Results of OB.

Note. The errors in parentheses are standard errors.
“***” respectively represent that the t value is significant at the levels of 1%.
Specifically, regarding the returns of educational variables, as shown in the lower panel of Table 5 are significantly higher in the public sector. It is important to note that in our decomposition setup (
Heterogeneity Analysis: Sectoral and Distributional Dimensions
This subsection examines heterogeneity in the education return premium across sectors and income distribution. We first analyze sectoral differences using a narrow public sector definition (excluding SOEs) to isolate the core government effect, followed by distributional analysis using quantile regression on the broad definition.
Sectoral Heterogeneity: Narrow Public Sector Versus Private Sector
We employ OB decomposition on the matched sample from propensity score matching (PSM) to isolate sectoral effects. The OB results (Table 6) reveal that the narrow public sector exhibits an overall income premium (total gap = −0.237, indicating higher income compared to the private sector). Decomposition shows this premium is primarily driven by endowment differences (explained component = −0.311), indicating that public sector workers possess superior observable characteristics (e.g., higher education levels). The coefficient effect (unexplained component = 0.074) is positive but small, suggesting that structural returns to characteristics play a minimal role, with private sector returns slightly higher if characteristics were equal.
The OB Decomposition Results of the Narrow Public Sector.

Note. The errors in parentheses are standard errors.
“***”, “**”, and “*” respectively indicate that the t value is significant at the levels of 1%, 5%, and 10%.
For the education variable specifically, the OB decomposition (Table 6, lower part) shows a negative coefficient effect (−0.416) and a negative endowment effect (−0.236), indicating that both higher educational endowment and higher returns to education in the public sector contribute to the premium, with the endowment effect being larger in magnitude. This implies that the income advantage stems mainly from better educational characteristics of public sector employees, supplemented by slightly higher returns to education.
Distributional Heterogeneity: Income Quantile Analysis
We next use unconditional quantile regression (UQR) with the broad public sector definition to explore income distribution effects. Results (Table 7) show the education premium is positive and significant across quantiles, confirming that the public sector offers higher returns to education regardless of income level.
Quantile Regression Results of the Income Equation of the Public and Private Sectors From 2003 to 2021.

Note. The errors in parentheses are standard errors.
“***”, “**”, “*” represent the t value under the level of 1%, 5%, and 10%.
Macro-Level Implications (H2)
Building on the micro-foundations established earlier—where the public sector offers a higher return to education despite an income discount—this section tests the macro-level hypothesis
To test
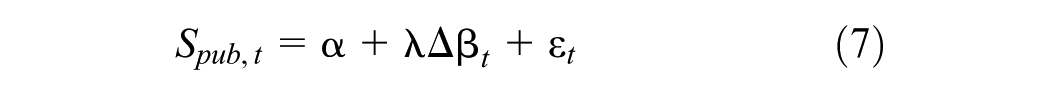
where λ captures the effect of the education premium on employment share.
The scatter plot of these variables (Figure 4) reveal a clear positive correlation, suggesting that years with a higher education premium are associated with a greater proportion of individuals selecting into the public sector.

Scatter plot of education return rate premium and public employment share.
Regression results confirm this relationship: the coefficient on the education premium is positive and statistically significant (γ = 0.048, p < .05), providing strong support for
Regression Results of Equation 7.

Note. Standard error in parentheses.
“***” and “**” indicate statistical significance at the 1% and 5% levels, respectively.
This macro-level evidence completes our argument: the “craze” for public sector jobs among the educated is not merely a sociological phenomenon but is rationalized by persistent economic incentives—specifically, the higher valuation of human capital in the public sector. The findings underscore that policy shifts affecting the education premium could have meaningful impacts on labor market dynamics and human capital distribution.
Robustness Checks
To ensure the robustness of our core finding—a positive education return premium in the public sector—we subject it to a battery of tests. These checks address potential methodological biases, including selection on unobservables, model specification, and clustering issues. The results consistently support the premium’s validity, as summarized below.
Alternative Matching Algorithms and Hidden Bias
We first test the sensitivity of our propensity score matching (PSM) results to different matching techniques. Using kernel and radius matching instead of nearest-neighbor matching, the estimated premium remains stable and significant (Table 9). To assess hidden bias, we apply Rosenbaum bounds sensitivity analysis (Table 10). The premium remains statistically significant at the 1% level even under substantial unobserved confounding (Γ = 2.5), indicating robustness to omitted variables.
ATT Values Obtained by Other Matching Methods.

“***”, “**”, and “*” respectively represent passing the significance test at the 1%, 5%, and 10% levels.
Rosenbaum Bounds Sensitivity Analysis for the Propensity Score Model.

Conditional Independence Assumption (CIA) Test
We test the CIA by using only pre-treatment variables (gender, parental employment sector, parental education) for matching and OB decomposition. The balance test confirms covariate balance after matching (Figure 5). The OB decomposition results (Table 11) show that the education premium remains positive and significant, supporting the CIA. We report only the OB decomposition table for brevity, as the Logit and PSM results are intermediate steps.

The balance test of the CIA test.
OB Decomposition With Pre-treatment Variables.

Note. The errors in parentheses are standard errors.
“***” indicates statistical significance at the 1% levels.
Additional Controls and Clustering Adjustments
We include occupation and firm size controls to account for job characteristics and organizational scale (firm size is measured by the number of employees). This addresses potential omitted variable bias, as these factors may influence both sector choice and income. Standard errors are clustered at the province level due to missing primary sampling unit (PSU) identifiers in some survey years, which could lead to understated errors if clustered at the individual level. Province-level clustering provides a more conservative estimate. The OB decomposition results remain robust (Table 12).
OB Decomposition With Occupation and Firm Size Controls.

Note. The errors in parentheses are standard errors.
“***” indicates statistical significance at the 1% levels.
OB Decomposition With Alternative Benchmarks
The OB decomposition results can be sensitive to the choice of benchmark coefficients. In our baseline, we used the public sector as the reference. To test sensitivity, we re-run the decomposition using the private sector as the benchmark (Tables 13 and 14). The education premium remains significant and qualitatively unchanged, confirming that our results are not driven by benchmark selection.
“OB Decomposition With Private-Sector Benchmark” for Broad Definition.

Note. The errors in parentheses are standard errors.
“***” indicates statistical significance at the 1% levels.
“OB Decomposition With Private-Sector Benchmark” for Narrow Definition.

Note. The errors in parentheses are standard errors.
“***” indicates statistical significance at the 1% levels.
Placebo Test With Fake Sector Definition
To rule out spurious correlations, we conduct a placebo test by randomly assigning 30% of the sample to a fake “public sector” (treatment group) and re-running the PSM and OB decomposition. If our model is valid, the fake treatment should yield an insignificant premium. The results (Table 15) show no significant education premium, supporting the authenticity of our core finding. We report only the OB decomposition table for simplicity.
Placebo Test With Fake Sector Definition.

Note. The errors in parentheses are standard errors.
“***” and “*” indicate statistical significance at the 1% and 10% levels.
Overall, these tests provide strong evidence that the education return premium is a robust and persistent feature of China’s public sector labor market, resilient to alternative specifications, hidden bias, and placebo interventions.
Conclusions and Implications
This study re-examined the public-private sector compensation differential in China, moving beyond the debate on average wages to focus on the returns to education as a pivotal mechanism driving human capital allocation. Using CGSS data from 2003 to 2021 and a robust multi-method empirical strategy, we established a consistent finding: despite an overall income discount, China’s public sector offers a significant and robust education return premium. This premium rationalizes the sectoral choices of highly educated workers and is positively correlated with the public sector’s share of educated employment at the macro level.
Summary of Findings in Relation to Research Objectives
Our findings can be summarized against the three primary objectives of this paper:
Re-examination of Income Differentials: After correcting for selection bias, we find a persistent income discount (ATT = −0.324) for the broad public sector (including SOEs) compared to the private sector over the study period. However, kernel density plots reveal a more compressed income distribution within the public sector, indicating lower inequality.
Analysis of Education Returns as a Key Mechanism: The OB decomposition reveals that the income gap is primarily driven by a large, positive coefficient effect, underscoring structural differences in how sectors reward characteristics. Crucially, the education variable shows a significant negative coefficient difference (−0.5014), unambiguously indicating a higher marginal return to each year of education in the public sector—the central mechanism we hypothesized.
Addressing Methodological Challenges: The findings from PSM, OB decomposition, and Quantile Regression are mutually reinforcing and robust to an extensive battery of checks, including Rosenbaum bounds, CIA tests, placebo tests, and alternative model specifications, ensuring the credibility of our conclusions.
Policy Implications
Our results offer nuanced implications for policymakers:
For Public Sector Reform: Rather than across-the-board wage increases, which may be fiscally challenging, policies should focus on optimizing the existing education premium. This can be achieved by strengthening performance-based advancement systems and explicitly linking promotions and skill-based pay to educational attainment, thereby enhancing the efficiency of human capital utilization within the public sector.
For Private Sector Development: To compete for top talent, private enterprises need to address their relative disadvantage. Strategies should include developing comprehensive compensation packages that enhance social security, pension benefits, and job stability, effectively closing the non-wage benefit gap with the public sector.
Limitations and Future Research
Acknowledging the limitations of our study, particularly the potential measurement error in capturing non-wage benefits through self-reported income data, opens avenues for future research. Subsequent studies could utilize administrative data to more precisely quantify total compensation and explore regional and industrial heterogeneities in the education premium.
Footnotes
Ethical Considerations
This study did not involve human or animal participants, nor did it require ethical review.
Consent to Participate
This study did not involve human participants or personal data requiring informed consent.
Author Contributions
Ping Li: Conceptualization, Writing—Review & Editing; Yanda Hang: Investigation, Software, Formal Analysis, Writing—Original Draft.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.