
Abstract
The study presents a longitudinal and comparative analysis of Large Language Model (LLM) in mathematics exam creation processes based on the Revised Bloom’s Taxonomy (RBT). The study focuses on three widely used free applications: ChatGPT, Gemini, and Claude. In this study, conducted at the secondary school level, the features expected in mathematics written exam questions (scientific relevance, target relevance, and understandability) were examined in terms of their conformity to the RBT steps. The study was conducted with data obtained from LLMs in 2024 and 2026. The results revealed the changes in LLMs over the 2-year period and the differences in the taxonomy levels and question-writing skills. Within the scope of the questions analysed, it was determined that the advantages and limitations of the LLMs changed over time, and that questions targeting especially the upper levels of the taxonomy showed improvement after the second prompt in both years. The results highlight the potential of LLM as instructional tools, which still require human control, and underscore the need for continuous evaluation and validation as these technologies evolve.
Plain Language Summary
The study presents a longitudinal and comparative analysis of Large Language Model (LLM) in mathematics exam creation processes based on the Revised Bloom’s Taxonomy (RBT). The study focuses on three widely used free applications: ChatGPT, Gemini, and Claude. In this study, conducted at the secondary school level, the features expected in mathematics written exam questions (scientific relevance, target relevance, and understandability) were examined in terms of their conformity to the RBT steps. The study was conducted with data obtained from LLMs in 2024 and 2026. The results revealed the changes in LLMs over the two-year period and the differences in the taxonomy levels and question-writing skills. Within the scope of the questions analyzed, it was determined that the advantages and limitations of the LLMs changed over time, and that questions targeting especially the upper levels of the taxonomy showed improvement after the second prompt in both years. The results highlight the potential of LLM as instructional tools, which still require human control, and underscore the need for continuous evaluation and validation as these technologies evolve.
Introduction
In addition to the many technological applications in education, LLMs have been widely used (Haspekian et al., 2024). The ability of AI systems, also known as chatbots or large language models (LLMs), to adapt to changing situations makes them an important resource for education both in classrooms and online (Long & Magerko, 2020). Accordingly, AI has reshaped learning and teaching processes by penetrating areas such as instruction, assessment and evaluation, and administrative affairs in education (Chen et al., 2020; Opara et al., 2023). These developments indicate that the impact of AI in education will continue to increase.
The use of AI in education has both advantages and disadvantages, and opinions on the subject vary (Adeshola & Adepoju, 2024). AI can guide learning and significantly enhance learning environments (Rane, 2024). Its capacity for personalised learning and constant availability promotes inclusive education practices (Opara et al., 2023). However, AI also has limitations, such as generating erroneous information and misleading users. Given the growing use of AI in education and the generally positive public perception of this technology, it is important to transform its potential risks into pedagogical advantages (Adeshola & Adepoju, 2024). Consequently, studies that critically examine LLMs, adapt them to educational systems, and highlight their limitations will enhance our understanding of the role of AI in education (Chen et al., 2020).
One application of artificial intelligence (AI) in education is assessment and evaluation. Research indicates that AI is used to evaluate student responses and generate assessment questions (Lo, 2023). In the context of mathematics education, the mathematical accuracy of questions used in assessment and evaluation processes is a key factor in evaluating AI-assisted question development applications (Svičević et al., 2025; Wei, 2024). In mathematics education, studies indicating that AI responds adequately to basic-level questions but produces incorrect expressions and misinformation in advanced topics support this view (Urhan et al., 2024; Wardat et al., 2023). The potential of AI to answer questions raises concerns regarding its level of question development competence. In studies evaluating the question development potential of AI across different fields and in mathematics education, it is stated that AI can generate questions; however, it has limitations, such as containing incorrect information and operating at low cognitive levels (Rycroft-Smith et al., 2024; Segal & Klemer, 2025; Urhan et al., 2024). It has also been noted that AI performs differently across various areas of mathematics, demonstrating greater proficiency in number theory than in geometry (Svičević et al., 2025; Wei, 2024). Nevertheless, it has been emphasised that AI demonstrates superhuman abilities in cognitively demanding tasks (Spreitzer et al., 2024; Svičević et al., 2025). Therefore, despite its limitations, it has been suggested that LLMs will reduce the time required for question preparation and that updated versions will yield better results in question development (Ngo, 2024). Therefore, examining the change and potential of LLMs in fulfilling given tasks during the process of developing questions for mathematics exams in 2024 and 2026 using the same prompts can provide valuable insights into the evolving aspects of AI and the support it can offer in assessment and measurement. It is important to reveal the change in LLMs over time by determining the extent to which they are involved in exam design, considering factors such as cognitive level, mathematical accuracy, and question types, and by evaluating their success in this process. This study, therefore, aims to investigate the potential, evolution, and comparison of LLMs for creating mathematics exams in two different learning areas (fractions and angles in triangles) with an interval of approximately 2 years. The exams were structured according to the Revised Bloom’s Taxonomy (RBT), which allows for determining the cognitive level of each question.
Theoretical Framework
The assessment of students’ mathematical competencies is important in mathematics education (Niss, 2003). Attention should be paid to the design of assessment tools used to assess students’ knowledge and skills (Neubrand, 2018). Although many methods can be used in assessment, one of the most preferred methods is written exams (Omar et al., 2012). Different features come to the forefront in studies examining the characteristics that exam questions should possess. The literature (Bilgeç, 2016; Haladyna, 2004; Stein et al., 2009; Sweller, 1998) highlights factors such as question type, alignment with intended objectives, cognitive load, and scientific accuracy as prominent features. Not only is it important what information questions assess, but also the cognitive level at which that information is elicited. Cognitive load theory, proposed by Sweller (1988), is based on the principle that instructional content presented to students should be cognitively balanced. If the cognitive demands of the presented content exceed the learner’s capacity, learning, retention, and transfer are negatively affected (Plass et al., 2003). The expressions used in instructional content should be clear and understandable and should avoid unnecessary complexity. In other words, the instructional content and assessment tools presented to students should use clear and understandable language and maintain a balanced cognitive load. Stein et al. (2009) explain the cognitive nature of mathematical questions and emphasise that the level of cognitive demand in mathematical tasks directly affects students’ thinking processes. They state that mathematically superficial or poorly structured tasks are insufficient to activate higher-order cognitive processes, whereas tasks that make mathematical relationships explicit and require reasoning present higher cognitive demands. Therefore, mathematics questions should be mathematically accurate and scientifically consistent and should include both higher- and lower-level cognitive questions to achieve balance (Stein et al., 2009; Swart, 2010). In this context, Bloom’s Taxonomy (Bloom et al., 1956), which presents cognitive levels in a hierarchical structure, provides a theoretical framework for determining the cognitive levels of mathematics examination questions and ensuring balance among them.
Bloom et al. (1956) developed the Taxonomy of Cognitive Domains, which categorises learning objectives according to cognitive processes. The taxonomy, in which cognitive processes are ordered from simple to complex in a single dimension, was criticised for some of its features due to changing needs in the process and was updated by Anderson and Krathwohl (2001). Thus, the Revised Bloom’s Taxonomy (RBT) emerged. This taxonomy addresses cognitive processes within a hierarchical structure, ranging from simple to complex. However, Anderson and Krathwohl (2001) revised the taxonomy in line with emerging theoretical and pedagogical needs. Thus, the Revised Bloom’s Taxonomy (RBT) was developed. The RBT considers cognitive processes at six levels—remembering, understanding, applying, analysing, evaluating, and creating—while classifying knowledge as factual, conceptual, procedural, and metacognitive (Krathwohl, 2002). Both the original and revised taxonomies acknowledge that lower cognitive levels require less complex processes than higher levels (Bloom et al., 1956; Krathwohl, 2002).
In curriculum development and instructional content design, Bloom’s Taxonomy is the most widely used and accepted framework for determining the cognitive levels of exam questions (Chang & Chung, 2009; Seaman, 2011). Bloom’s Taxonomy is used extensively in the analysis of exam questions, particularly in mathematics education (Akinboboye & Ayanwale, 2021). Since each step in the taxonomy requires a different level of mental activity, it is recommended that exams administered to students reflect each step of Bloom’s Taxonomy and include diverse question types (Afacan & Nuhoğlu, 2008; Linn & Gronlund, 2000).
Another criterion considered in exam design is question type. Open-ended and single-answer question types (e.g., multiple-choice, matching, and true–false questions) used in mathematics education have distinct strengths and weaknesses (Bilgeç, 2016). Open-ended questions, which can provide broader opportunities for student-centred assessment than multiple-choice questions, require greater effort and meticulousness in scoring and in ensuring validity and reliability (Carroll, 1999; O’Neil & Brown, 1998). On the other hand, although multiple-choice questions are easier to score, their preparation process requires meticulous work and can be challenging (Arıcan, 1996). While open-ended questions more effectively measure higher-level cognitive behaviours, multiple-choice questions offer the advantage of being administered to large populations and standardising assessment results (Friborg & Rosenvinge, 2013; O’Neil & Brown, 1998). In addition, matching and fill-in-the-blank questions are traditional assessment tools commonly used in mathematics education (Bilgeç, 2016). Matching questions are particularly effective in identifying connections between concepts, definitions, and mathematical relationships. However, they mostly measure cognitive skills at the recall and comprehension levels (Haladyna et al., 2002). Fill-in-the-blank questions require students to correctly recall and apply specific concepts, symbols, or operations. However, due to the limited context they provide, such questions may be inadequate for measuring higher-order cognitive processes (Haladyna, 2004). While these traditional question types offer advantages such as practicality and rapid feedback in the assessment process, they should be used carefully and sparingly when evaluating higher-order thinking skills, such as mathematical reasoning and problem solving (Haladyna et al., 2002). For this reason, question types such as open-ended or multiple-choice questions should be determined by considering their advantages and disadvantages in line with the purpose being measured (Bilgeç, 2016). Furthermore, to serve their purpose and accurately measure behaviour in mathematics education, questions must be scientifically sound and aligned with the target learning outcomes being assessed (Kilpatrick et al., 2001). Finally, it is important to write questions in clear and concise language so that students can correctly understand them and demonstrate the cognitive skills being measured. Questions containing unclear, linguistically complex, or ambiguous expressions have been shown to negatively affect students’ cognitive performance and weaken the validity of assessment results (Haladyna, 2004). In line with these explanations, mathematics exam questions must be scientifically sound, free from mathematical errors, relevant to the learning outcomes being assessed, and written in clear and understandable language. They should also reflect a balanced distribution of cognitive skills and be structured using appropriate question types.
Mathematics exams are assessment tools designed to measure specific learning outcomes and should be systematically designed in terms of cognitive level and question structure. The literature indicates that teachers most frequently use multiple-choice questions in classroom exams, while open-ended and short-answer questions are used less frequently (Doğan, 2019; Zeren et al., 2023). Furthermore, it has been suggested that exam questions prepared by teachers tend to focus on lower-level cognitive behaviours (Himmah et al., 2019). Similarly, national mathematics exam questions and the mathematics curriculum have been reported to lack a balanced distribution of cognitive levels, with a high concentration at the application and analysis levels (Aydoğdu & Gültekin, 2025). It is also emphasised that mathematics questions in textbooks predominantly assess lower-level cognitive skills (Bal & Yılmaz, 2022; Üredi & Ulum, 2020). In light of these limitations, it is becoming increasingly important to examine the opportunities offered by technology and LLMs for question development and exam preparation in mathematics education. In mathematics education, which naturally and intensively involves technology (Wing, 2006), it is necessary to address the potential contributions of digital tools and AI-based applications to assessment and evaluation processes, as well as the technical and methodological challenges that may arise in these processes (Çelik Görgüt, 2023; Nortvedt & Buchholtz, 2018; Trgalová & Tabach, 2024).
Today’s world is going through a period dominated by uncertainty, volatility, complexity, and ambiguity, where the speed and depth of development in AI technologies challenge the imagination. Educational processes are rapidly evolving from the stage of “AI-Guided Learning,” where students are passive recipients, to “AI-Interactive Learning,” where collaboration with systems occurs, and finally to the most advanced stage, the paradigm of “AI-Driven Personalized Learning,” where the student becomes the leader of their own educational journey (Kyambade et al., 2025; Ouyang & Jiao, 2021). Particularly in mathematics education, while problem posing is recognised as a fundamental process that enhances conceptual understanding and creativity, AI-supported scaffolding strategies have begun to play a critical role in developing this complex skill (Arslan & Güler Selek, 2025; Kim et al., 2026). In this longitudinal process covering the years 2024 to 2026, the immense increase in the mathematical reasoning and problem-generation capacities of LLMs (including the transition process from GPT-3.5 to advanced systems like GPT-4 and o1) has created a “digital ripple” that is changing the nature of education (Fan, 2025; Strielkowski et al., 2025; Walkington, 2025). However, the continued need for expert oversight regarding the accuracy and originality of problems generated by AI (Korkmaz Güler & Yıldız, 2025; Urhan et al., 2024) necessitates that teachers possess a critical perspective, using these tools as a complementary element (Kim et al., 2026; Walkington, 2025). In this context, monitoring the development of mathematical skills within a rapidly changing technological ecosystem is of decisive importance in the transition to intelligent educational systems that place the student at the centre of the process and prioritise human-machine collaboration. Accordingly, the study aims to answer the following research questions:
What are the performances of ChatGPT, Gemini, and Claude in generating mathematics exam questions on fractions and angles in triangles, regarding their strengths and limitations in RBT levels and question criteria (scientific relevance, target appropriateness, and understandability)?
To what extent do the performances of these models differ between their 2024 and 2026 versions across the specified criteria?
In this research, the free versions of the LLMs discussed in the literature were used in 2024 and 2026: ChatGPT-3.5, Gemini, and Claude 3.5 Sonnet in 2024, and ChatGPT, Gemini 3.0, and Claude 4.6 Sonnet in 2026. For the sake of clarity in the text, the LLMs will be referred to in the study using their general names along with the year. ChatGPT is the most widely used LLM, particularly in educational research, and has been studied extensively in areas such as measurement and evaluation, problem-solving, and content creation (Lo, 2023). The Gemini and Claude models have also become established in educational research, with comparative studies examining their performance in reasoning and content creation (Oh et al., 2024; Segal & Klemer, 2025). The growing use of these models in educational contexts has made it necessary to compare how different LLMs perform on similar tasks. In studies comparing LLMs, Lee et al. (2024) compared Gemini Pro with ChatGPT and concluded that Gemini was not very successful in text comprehension; its student evaluation performance was limited and could be improved through simpler expressions and fragmented visuals. Rycroft-Smith and Macey (2024) compared the ability of three different LLMs—Copilot, Claude, and ChatGPT 3.5—to generate questions on the area of a rectangle. While ChatGPT offered more multi-part questions and scoring opportunities, this also increased the probability of the model producing errors. Oh et al. (2024) found that ChatGPT performed best in solving mathematical problems, followed by Claude and Gemini. However, Korkmaz Güler and Yıldız (2025) found that although ChatGPT and Gemini had different strengths in identifying mathematical misconceptions in student answers, both LLMs produced incorrect solutions. Numerous studies emphasise that LLMs can produce incorrect solutions and should therefore be used with caution in mathematics education (Çavuş Erdem, 2025, 2026; Segal & Klemer, 2025; Urhan et al., 2024; Wardat et al., 2023). The performance of LLMs has been found to vary depending on the mathematics subject area, with geometry proving to be more challenging (Svičević et al., 2025; Wei, 2024). Taken together, these studies demonstrate the potential of LLMs for solving and generating questions. However, there are currently no studies longitudinally addressing the performance of LLMs in creating mathematics exams across different subject areas. In this context, longitudinally comparing the ability of ChatGPT, Gemini, and Claude to create mathematics exams on fractions and angles in triangles is expected to contribute to the existing literature.
Method
In order to collect more comprehensive data, the study aimed to develop a mathematics exam covering subjects from two learning areas in 2024 and 2026. The learning areas of numbers and geometry account for the largest proportion of topics in the mathematics curriculum. “Fractions” and “Angles in Triangles” were randomly selected from each learning area. The aim of the study is to answer the following question: What are the capabilities and limitations of the LLMs ChatGPT, Gemini, and Claude in creating mathematics exams on fractions and angles in triangles, aligned with the RBT levels and adhering to the required characteristics of exam questions (scientific relevance, target relevance, and understandability), and how has the change in these tools over time (2024 and 2026) occurred? The data were collected in May–June 2024 and in February 2026, and the LLM steps were followed exactly the same in both years (Figure 1).

Steps followed in the study.
Data Collection
The selected LLMs were asked to create exams at the 6th-grade level (angles in triangles) and the 5th-grade level (fractions) based on the RBT in both years. The prompts provided were the same for all LLMs. When an error was detected in the analysed questions, the appropriate second prompt shown in Table 1 was applied according to the type of error. The number of prompts was limited to two to minimise interference with the LLMs. The first and second prompts given to the LLMs during exam creation are presented in Table 1.
Prompts Used in the Study.
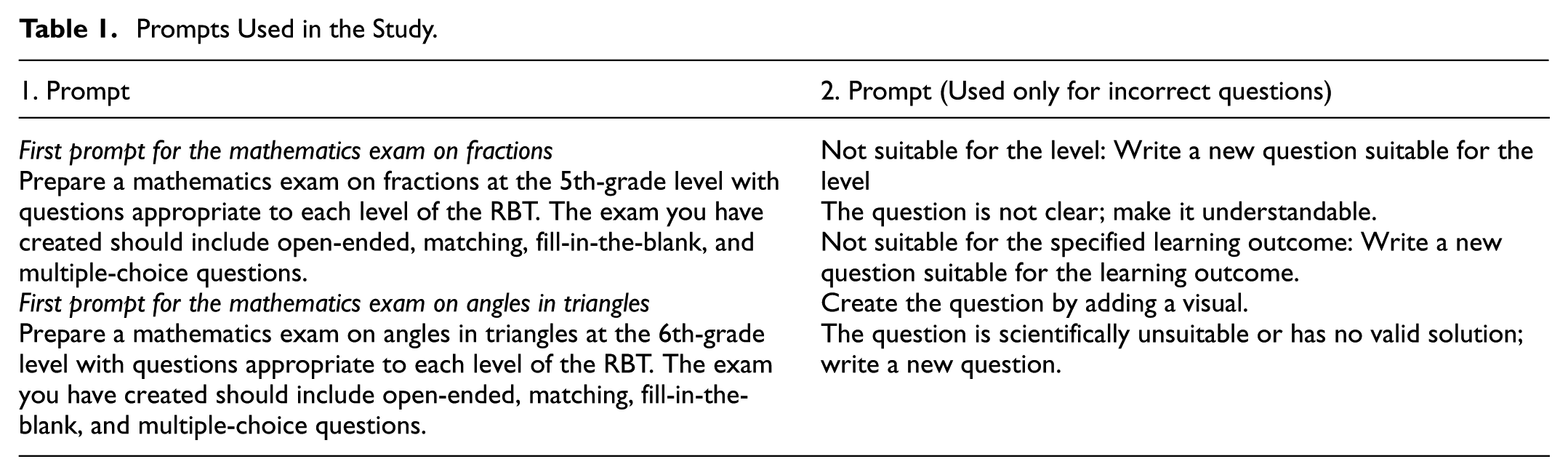
As shown in Table 1, the first prompts were the same, whereas the second prompts varied depending on the questions generated. For example, if a problem was detected in the comprehensibility of a question, the second prompt used was “The question is not clear; make it understandable.”
Data Analysis
Content analysis was used to evaluate the questions generated by the LLMs. The same analysis steps were applied for the 2024 and 2026 data. The questions were evaluated by considering the criteria of scientificity, target relevance, and understandability in accordance with the RBT levels. The steps followed in the study are presented in Figure 1.
The questions at each level in the created exams were analysed individually. For example, ChatGPT generated four questions on the angles in triangles from the remember level in the exam. During the analyses, the total number of questions at the remember level was considered to be four, and each question was analysed individually. In the analyses conducted according to the RBT, the features that questions should measure at each level were tabulated (Table 2). Content analysis was conducted by the researchers. The researchers were experts in the field of mathematics education. Coders were fully blinded to LLM identity. All outputs from the three LLMs were randomised and pooled into an anonymous collection, with each output assigned a neutral identification number. The coding was performed using only these anonymised texts and pre-defined objective criteria. The researchers involved in the coding were unaware of which output belonged to which LLM until the evaluation phase was complete. Both evaluators independently coded all questions based on the criteria of RBT alignment, scientific accuracy, clarity, and alignment with learning outcomes. When coding according to the RBT, if a question possessed characteristics of more than one cognitive level, the highest level to which the question primarily directed the response was selected. This rule was explained to the evaluators prior to coding and reinforced with examples. Following independent coding, the agreement between the analyses was calculated using the formula developed by Miles and Huberman (1994) [Reliability = Agreement / (Agreement + Disagreement)], and the agreement rate between the coders was 92%. For the disagreements comprising the remaining 8%, support was obtained from an expert in mathematics education with experience in RBT and assessment and evaluation. A detailed discussion process was conducted with the participation of both researchers and the expert, resulting in the resolution of coding disagreements and the achievement of a final consensus. All analyses were reported based on these final agreed-upon codes. Sample analyses conducted within the scope of the criteria are presented in Table 3. In the study, the criteria determined by Krathwohl (2002) were considered while checking compliance with the taxonomy level. These criteria constitute the structure of the cognitive process dimension of the RBT and are presented in Table 2.
Exam Question Evaluation Criteria.

Examples of the Question Analysis Process.
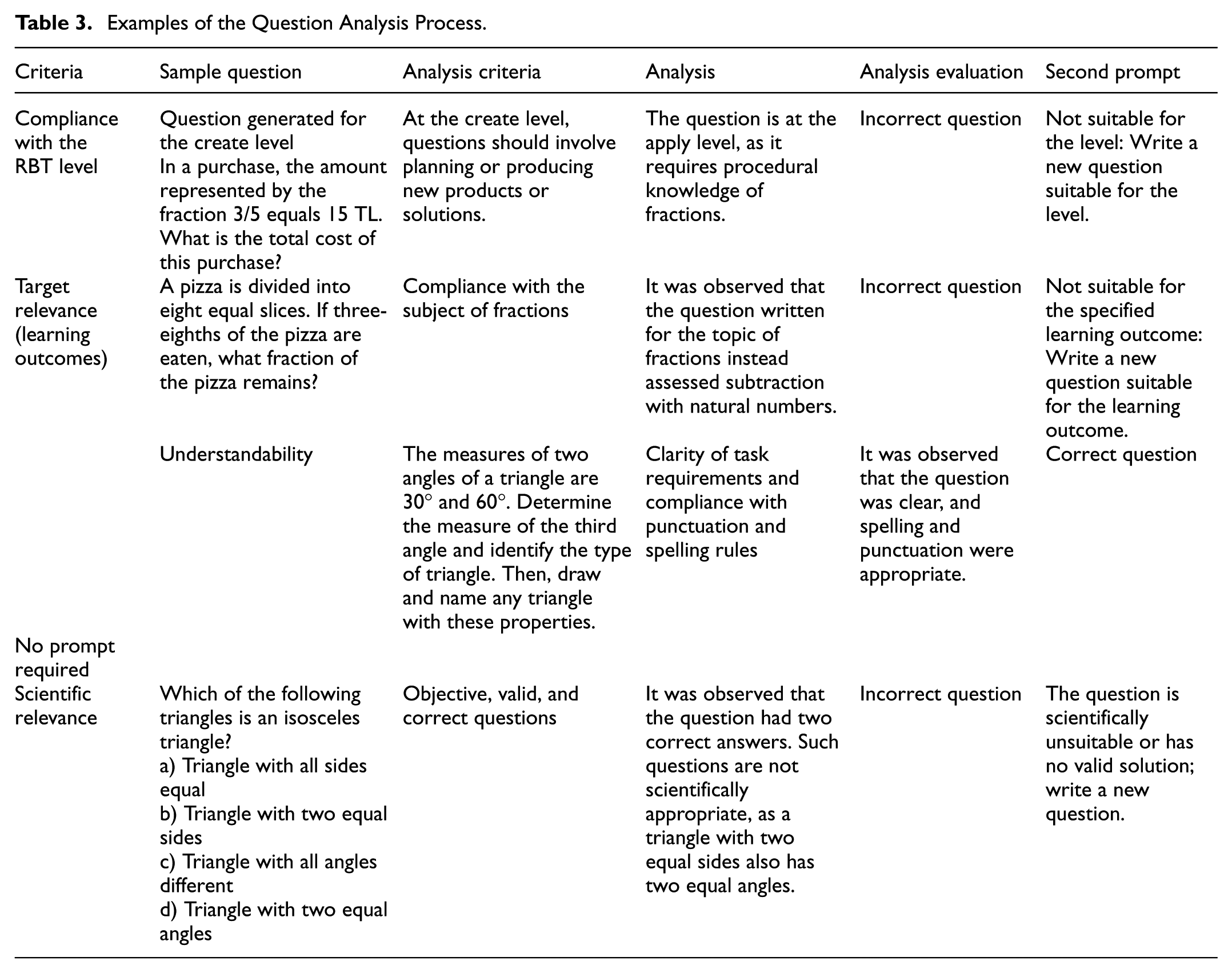
Each question generated by the LLMs was coded as suitable or not suitable according to whether it met the criteria listed above.
As shown in Table 2, the features associated with each level were specified, and the questions were analysed in terms of whether they reflected these features. For example, if a question at the understanding level contains features such as interpretation, exemplification, classification, summarising, inference, comparison, or explanation, it was classified as suitable for that level. In addition to the RBT, criteria related to scientific relevance, target relevance, and understandability were established, and each question was analysed individually by the researchers. Sample analyses illustrating the question analysis process are presented in Table 3.
As shown in Table 3, the questions were analysed in detail according to the specified criteria, and the second prompt was provided only for incorrect questions. In order to check the internal validity of the study, the consistency and language of the data collection tool were checked during the data collection process. To test external validity, the data obtained from the LLMs were coded according to the RBT levels; criteria for scientific relevance, target relevance, and understandability were defined; the data analysis stages were described in detail; the findings were reported; and the results were compared with the literature. The researchers were responsible for data collection, data analysis, detailed reporting of the findings, and objective comparison of the results with the literature.
Results
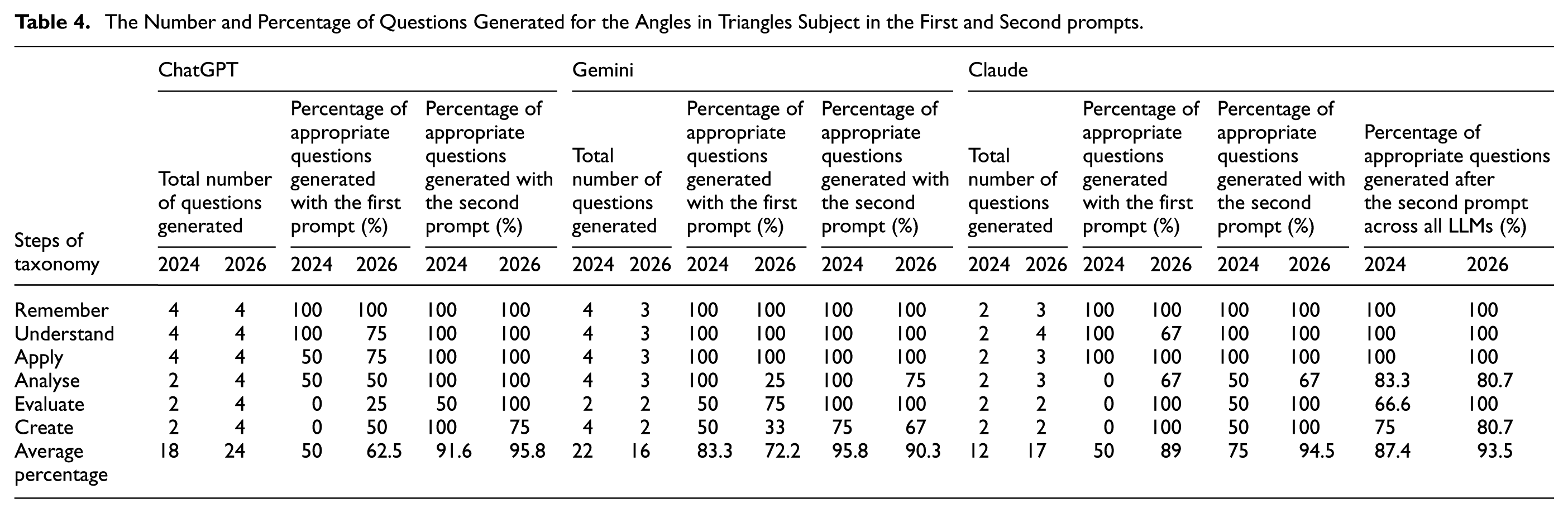
To investigate the capabilities and limitations of ChatGPT, Gemini, and Claude, the questions generated by these LLMs in 2024 and 2026 were analysed using content analysis based on four main criteria: alignment with Revised Bloom’s Taxonomy (RBT) levels, scientificity, target relevance, and understandability. The distribution of questions across cognitive levels was examined to determine how well each tool addressed lower and upper-order thinking skills. Additionally, a longitudinal comparison between the 2024 and 2026 data was conducted to identify changes in the tools’ performance over time. This section presents comparative analyses of math exam questions generated by ChatGPT, Gemini, and Claude. The first section presents data on angles in triangles; the second, on fractions; and the final section presents a comparative analysis of the LLMs’ identified limitations and advantages, supported by examples. In the study design, each LLM was given up to 2 prompts to perform a task. Tables 4 and 5 present the success rates of each LLM after the first and second prompts for the years 2024 and 2026, respectively, and compare them longitudinally. In the subsequent tables, the LLMs’ question-generation performance for the first and second research questions is analysed separately for 2024 (Tables 6 and 7) and 2026 (Tables 8 and 9), using each criterion. Table 10 presents the changes in the strengths and limitations of the LLMs used in the study across the years, within the scope of the research questions. Additionally, the findings are supported by screenshots taken from the LLMs. Thus, the results presented below reveal both the comparative strengths and weaknesses of each LLM and their evolution across the 2-year period. The performance of LMMs in generating questions related to angles in triangles following the first and second prompts is presented in Table 4.
The Number and Percentage of Questions Generated for the Angles in Triangles Subject in the First and Second prompts.
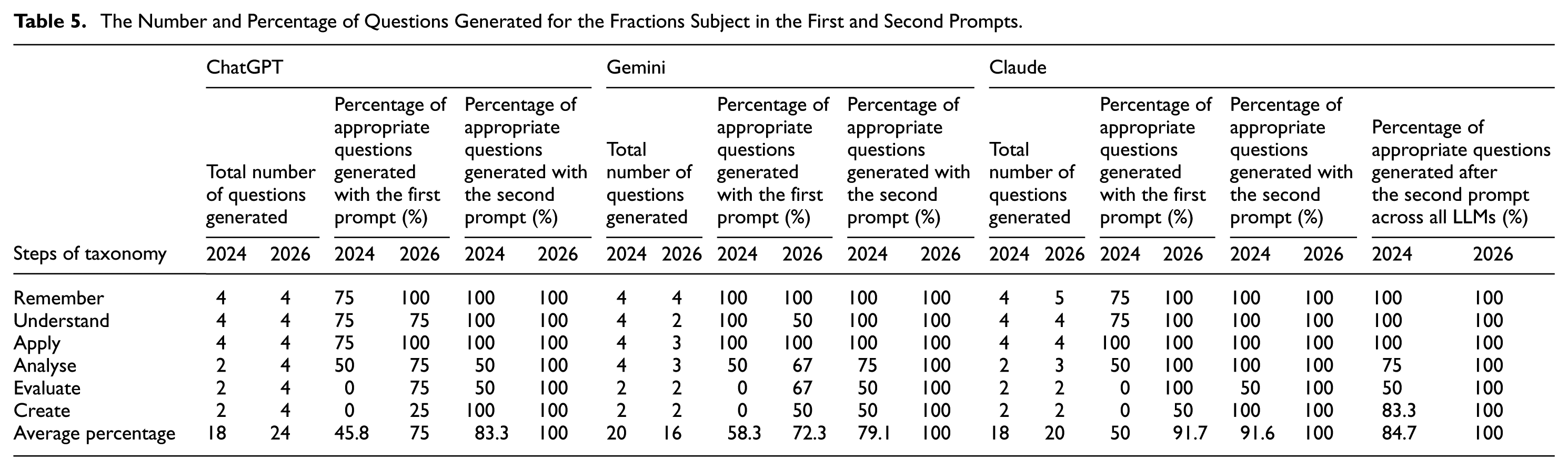
The Number and Percentage of Questions Generated for the Fractions Subject in the First and Second Prompts.
Comparative Analysis of the Questions Generated for the Angles in Triangles Subject According to Taxonomy Levels.
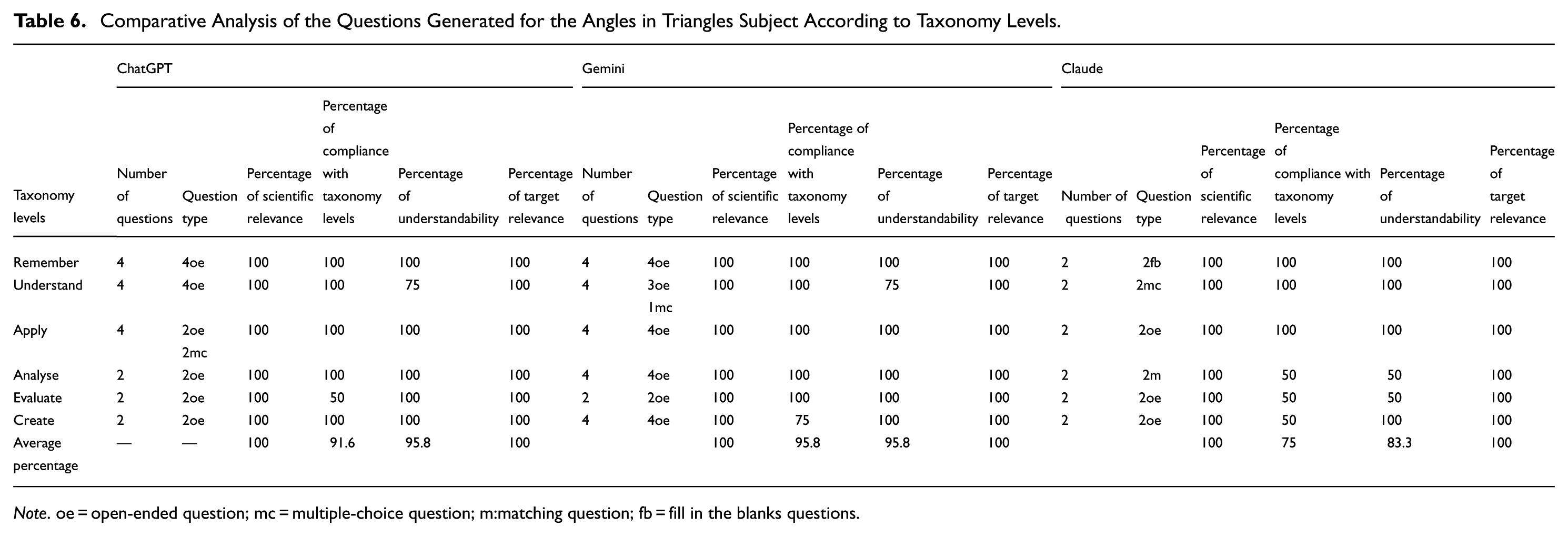
Note. oe = open-ended question; mc = multiple-choice question; m:matching question; fb = fill in the blanks questions.
Comparative Analysis of the Questions Generated for the Fractions Subject According to Taxonomy Levels.
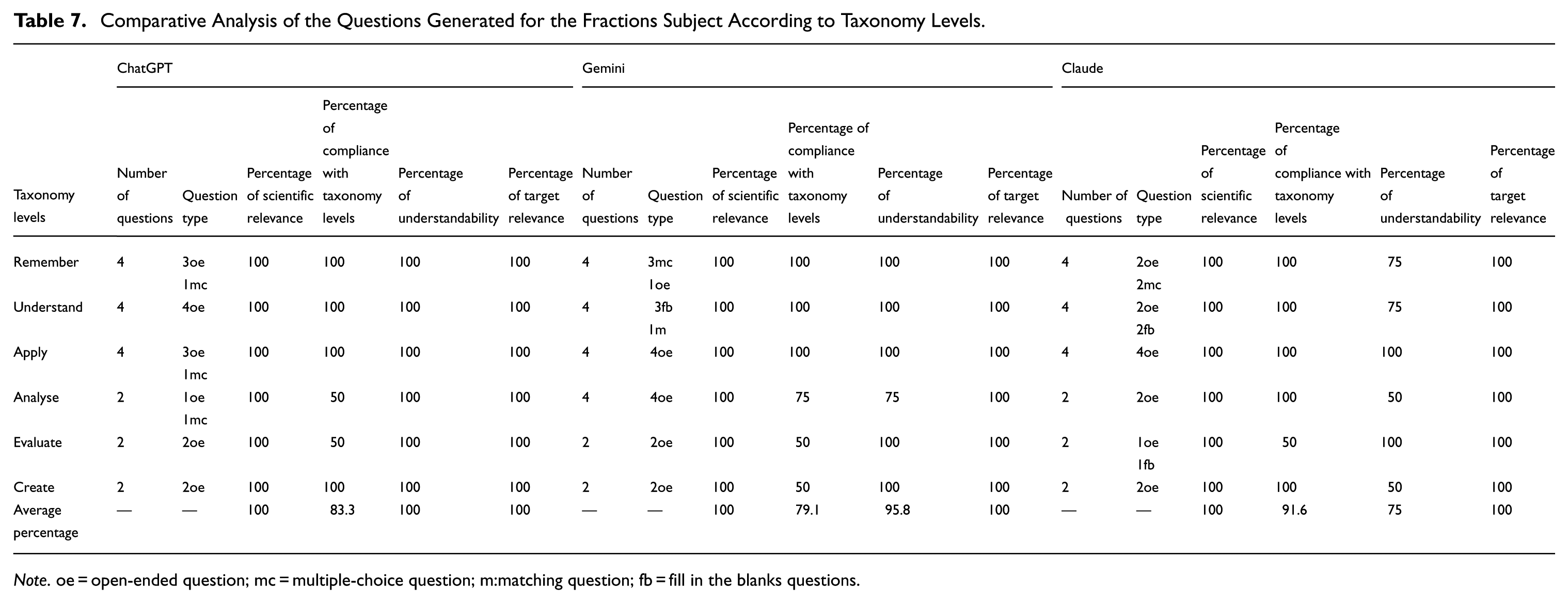
Note. oe = open-ended question; mc = multiple-choice question; m:matching question; fb = fill in the blanks questions.
Comparative Analysis of the Questions Generated for the Angles in Triangles Subject the According to Taxonomy Levels.
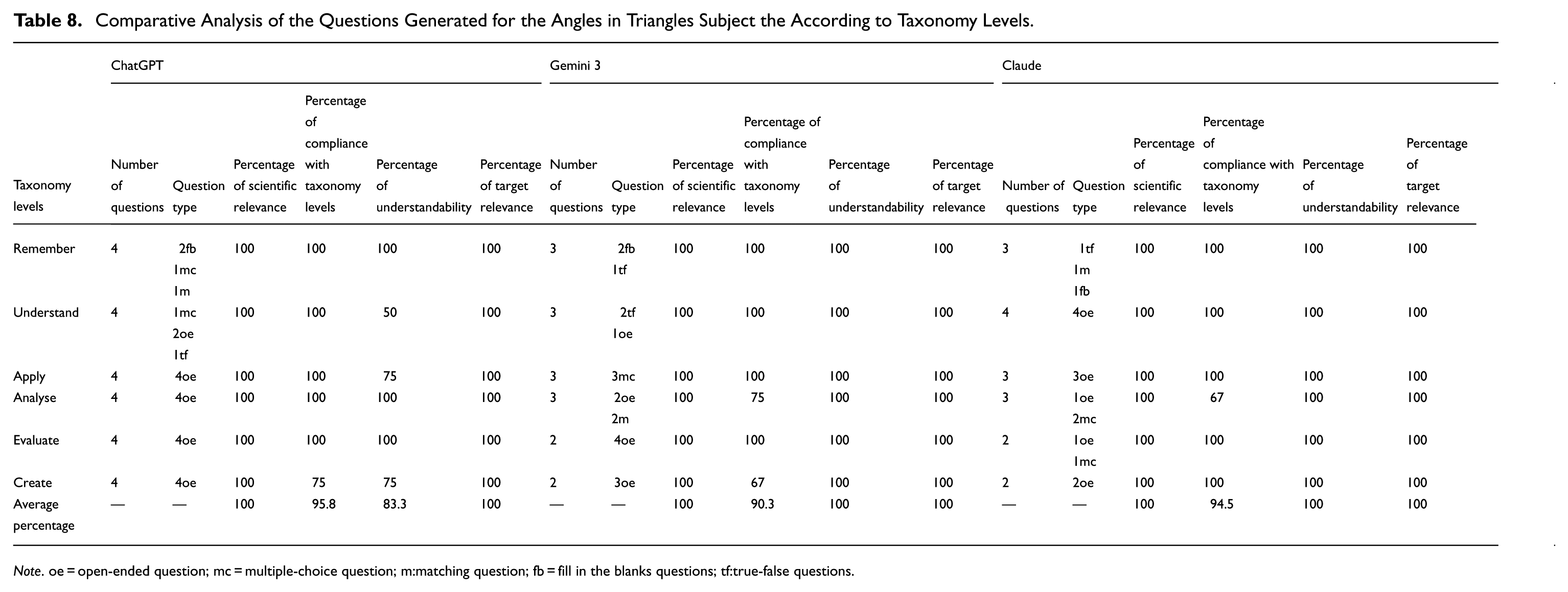
Note. oe = open-ended question; mc = multiple-choice question; m:matching question; fb = fill in the blanks questions; tf:true-false questions.
Comparative Analysis of the Questions Generated for the Fractions Subject the According to Taxonomy Levels.
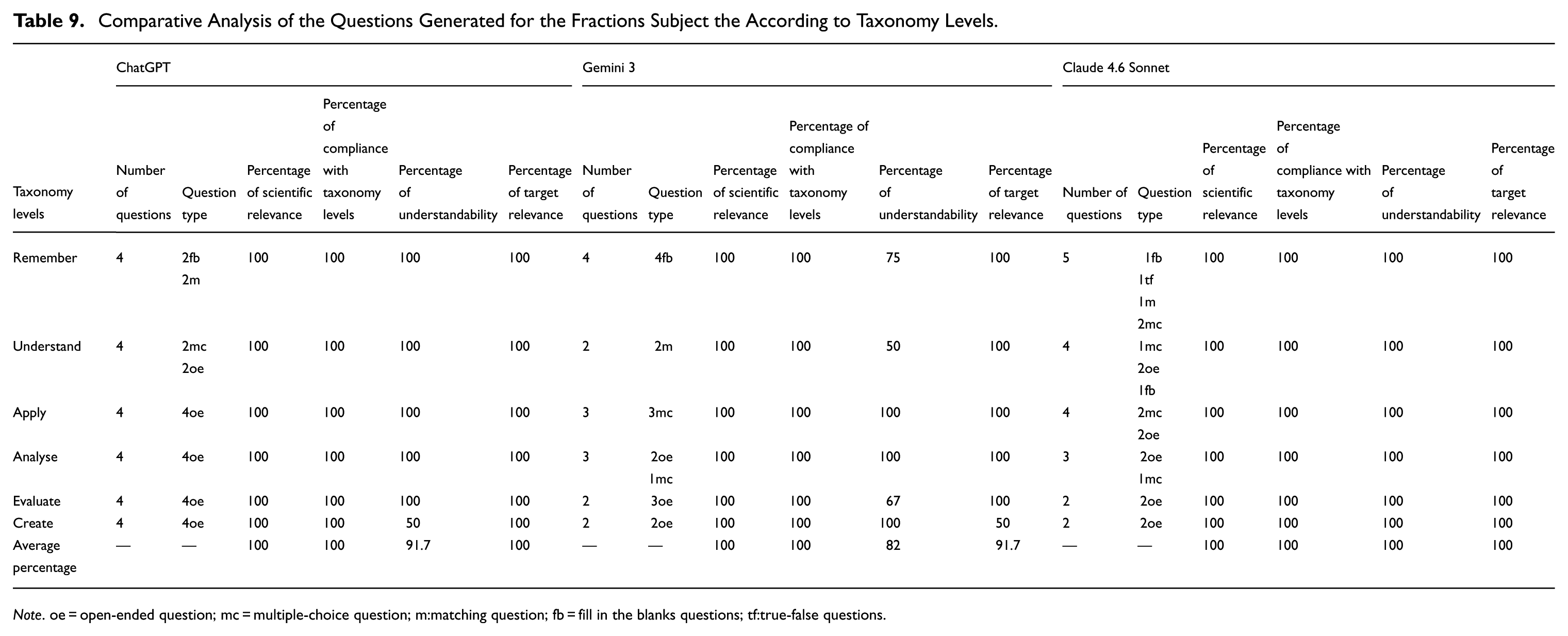
Note. oe = open-ended question; mc = multiple-choice question; m:matching question; fb = fill in the blanks questions; tf:true-false questions.
The Limitations and Advantages of the LLMs Used in the Study.

An examination of Table 4 reveals that in the 2024 version, after the first prompt, the percentage of questions appropriate for lower-order cognitive levels was higher compared to upper-order levels. The increase in success at upper-order levels was generally achieved through corrective prompts such as “write a new question appropriate for the level.” During this period, Gemini had the highest rate of generating questions appropriate for the taxonomy, while Claude had the lowest. In the 2026 version, it is observed that LLMs were more successful at lower-order levels, similar to 2024; however, after corrective prompts (“make it appropriate for the level,”“write it in a more comprehensible way,”“rearrange by adding a visual”), a significant improvement was achieved, especially in the quality of upper-order questions. This development was most prominently observed in the Claude model, with Claude showing the highest success after the first prompt, while ChatGPT showed the highest success after the corrective prompt. The post-correction performance of the LLMs in 2026 is generally similar to each other. Compared to the 2024 versions, the 2026 versions showed a 6.1% increase in overall performance.
The distribution of questions generated by the LLMs after the second prompt according to the criteria will be presented separately for the 2024 and 2026 versions. Table 6 presents the distribution for the 2024 version.
Table 6 shows that there are differences between the 2024 versions of the LLMs. Gemini was found to be the LLMs that met the criteria to the greatest extent. LLMs generally created questions according to taxonomy levels. While Claude was the LLM that generated the greatest variety of questions, all LLMs generally produced open-ended questions. While ChatGPT and Gemini were generally successful in generating questions aligned with taxonomy levels after the second prompt, Claude’s percentage decreased at the higher levels. Similarly, limitations were observed in Claude with respect to the understandability criterion. It was observed that all LLMs were 100% successful in terms of scientific relevance and target relevance. The distribution of questions according to the 2026 versions is presented in Table 8.
Looking at Table 8, it is seen that with the second prompt, the LLMs largely met the criteria determined for the mathematics exam. Overall, Claude was the LLM that best met the criteria. In terms of question diversity, Gemini and ChatGPT showed progress compared to their previous versions; however, for upper-level questions, the LLMs generally generated open-ended questions. Similar to 2024, Claude used different question types. All three LLMs generated questions that were mathematically accurate and aligned with the learning objectives. The LLMs showed progress in creating questions according to taxonomy levels. Regarding the comprehensibility criterion, while ChatGPT’s performance did not show improvement, Gemini and Claude reached 100%.
The percentages of the questions generated for the fractions topic after the first and second prompts are presented in Table 5.
An examination of Table 5 reveals that in the 2024 version, all LLMs demonstrated more successful performance at lower-order levels. In the versions from that period, while questions could not be generated for the evaluation and creation levels with the first prompt, appropriate questions were generated with the second prompt. While Gemini had the highest percentage of appropriate questions with the first prompt, Claude achieved the highest percentage with the second prompt. In the 2026 version, a significant performance increase was observed in all models at both lower-order and upper-order levels. It is seen that after the second prompt, the rates of generating questions appropriate for upper-order cognitive levels reached 100%. This development was more pronounced in the Claude model, indicating that the model achieved a remarkable improvement in its capacity to generate questions appropriate for upper-order levels. The progress achieved in the 2026 versions of the LLMs had a higher percentage in the fractions subject compared to the angles in triangles subject, revealing a significant difference of 15.3%. The distributions of questions according to each criterion for the 2024 versions are presented in Table 7.
Table 7 shows that the highest percentage of questions appropriate for the taxonomy belongs to Claude, while the lowest belongs to Gemini. While open-ended questions were the most frequently used overall, Gemini and Claude generated the widest variety of question types. In Gemini, despite the second prompt, the percentage of questions aligned with taxonomy levels decreased at the higher levels. Some limitations were observed in Claude with respect to the understandability criterion. This issue was infrequent in the other LLMs. No problems were detected in any LLM after the second prompt in terms of scientific relevance and target relevance. The question distribution of the 2026 versions of the LLMs is given in Table 9.
Table 9 shows that all three LLMs achieved complete success in creating questions appropriate for the taxonomy. Claude was the LLM that achieved complete success in every criterion and made significant progress in the comprehensibility criterion. Gemini and ChatGPT have some limitations in producing comprehensible questions. In terms of question diversity, while all three LLMs offered rich content, Claude used more question types. Open-ended questions are prominent at upper-order levels, and the tools developed questions that were scientifically sound and aligned with the learning objectives.
ChatGPT, Gemini, and Claude’s 2024 and 2026 versions had both advantages and limitations. The advantages and limitations identified within the scope of the study are presented in Table 10.
As shown in Table 10, each LLM exhibits distinct advantages and limitations. It is observed that some limitations were resolved in the 2026 versions of the LLMs. The 2026 version of Claude stands out compared to other LLMs with its advantages, such as creating an answer key and preparing exam instructions. Sample cases from the 2024 versions of each LLM are presented. Figure 2 presents an example of a limitation observed in ChatGPT.

Example screenshot illustrating the limitations of ChatGPT.
As shown in Figure 3, after the first prompt, ChatGPT organised questions according to the original Bloom’s Taxonomy rather than the RBT. Accordingly, the final taxonomy levels are treated as analysis, synthesis, and evaluation, and questions are generated following this sequence.

Screenshot illustrating the advantages of the Gemini AI Tool.
An example case of the Gemini LLM is presented in Figure 3.
As shown in Figure 3, Gemini could not draw an obtuse triangle; however, it explained step by step how to draw an obtuse triangle and provided links for additional information.
Finally, a screenshot illustrating incorrect triangle drawings produced by Claude is presented in Figure 4.

Screenshot illustrating the limitations of the Claude.
As shown in the figure, Claude identified the image on the left as a right triangle while generating the question. The generated shape clearly has four sides. Although the shape has four sides, it is described as having three angles (30–60–90), which is inconsistent with the properties of a triangle. The model failed to generate a triangle with three sides corresponding to a 30–60–90 right triangle. An attempted example of an obtuse triangle is also shown on the right. The generated shape is not an obtuse triangle but instead consists of an acute triangle combined with a five-sided polygon. Errors related to triangle drawings constitute one of Claude’s limitations.
In the 2026 versions, all LLMs demonstrated overall success in exam creation. However, the ability to generate questions containing visuals was identified as a significant difference among the LLMs. The initial questions generated by ChatGPT and Gemini did not include visual elements. With the second prompt, ChatGPT added some visual elements that were mathematically accurate, although some were not entirely clear. Despite the second prompt, Gemini did not include visual elements. Claude was able to generate error-free questions containing visuals with the first prompt. The visuals generated by ChatGPT and Claude are presented below (Figure 5).

Screenshot of the visuals generated by Chatgpt and Claude.
Discussion
This study comparatively revealed, using data from 2024 and 2026, the current potential and limitations of existing LLMs in the areas of “fractions” and “angles in triangles” in terms of their suitability for RBT levels and their ability to meet key question characteristics (scientific accuracy, understandability, and alignment with specified learning outcomes). In 2024, all three LLMs demonstrated a high potential to generate appropriate questions at the lower taxonomy levels. However, these percentages decreased at the higher taxonomy levels. A key finding of the study is that LLMs were more successful in preparing questions that measure lower-level cognitive skills (e.g., recall and understanding) but lagged behind in generating questions that assess higher-level cognitive skills (e.g., evaluation and creation). This finding indicates that LLMs still lag behind human expertise in tasks requiring mathematical reasoning, original scenario construction, and multi-step evaluation. It is well established that lower cognitive levels require less complex cognitive processes than higher levels (Bloom et al., 1956; Krathwohl, 2002). Bloom’s lower levels theoretically target pattern-recognition cognitive processes, whereas higher levels target analytical reasoning (Monrad et al., 2021). The findings of the study also showed that this theoretical distinction was directly reflected in LLM performance in 2024. The 2024 data of LLMs were found to be successful in imitating standard question levels and sentence structures frequently encountered in textbooks or online sources. However, they were generally unsuccessful in preparing questions that measure higher-level skills, such as questioning the rationale behind a concept, critiquing a solution, or constructing a new problem scenario. Frieder et al. (2024) observed that ChatGPT was insufficient for writing complex and creative mathematical problems. Within the scope of this study, it was determined that this limitation also applied to Gemini and Claude with the 2024 data. Since each level of the taxonomy requires a different degree of mental activity, it is recommended that exams administered to students reflect all levels of Bloom’s Taxonomy and include diverse question types (Afacan & Nuhoğlu, 2008; Linn & Gronlund, 2000). An examination of the 2026 data revealed significant progress in LLM performances. Similar to the 2024 data, the success in writing questions targeting the lower levels of the taxonomy with the first prompt was high, but decreased when moving to upper levels. However, with the second prompt, it was observed that all questions prepared by all LLMs for the fractions subject were entirely at the desired taxonomy level, and great success was achieved for the angles in triangles subject. The most important factor underlying this leap is thought to be the evolution of the methods and datasets used in training the LLMs. In the period from 2024 to 2026, the models were likely trained not only with more mathematical problems but also with “chain-of-thought” data explaining problem-solving strategies, proof techniques, and multi-step reasoning processes. Consequently, the models have now become capable of modelling not just the answer to a question, but also the logical structure and cognitive steps that constitute that question. In other words, LLMs appear to have moved beyond knowing “what” to ask, learning “how” to design a question that will stimulate thinking. This success observed in 2026 can be considered strong evidence that LLMs are transforming from mere information storage and repetition tools into tools capable of creating pedagogical content and designing cognitive processes. This situation is promising for the future of educational technologies and AI-supported learning platforms. As Kyambade et al. (2025) stated, this rapid development can be seen as a process of AI approaching the “AI-Driven Personalized Learning” paradigm. However, it was observed that despite this success achieved with second prompts, the process of using LLMs as learning environments that generate appropriate questions for each level while preparing mathematics exams on “fractions” and “angles in triangles” still requires teacher supervision and pedagogical filtering. This result has been frequently emphasised in the mathematics education literature (Segal & Klemer, 2025; Urhan et al., 2024). As also frequently emphasised in the literature, LLMs necessitate that teachers have a critical perspective, using these tools as a complementary element (Kim et al., 2026; Walkington, 2025). In other words, LLMs should be seen as a complementary tool rather than a replacement for traditional instruction (Turmuzi et al., 2026). The study results support the literature in this sense.
As individual approaches are important in the question-based categorisation of the RBT (Monrad et al., 2021), the approaches adopted by LLMss are also important. It is an expected result that LLMss, which contain information in raw form, are effective at preparing knowledge-oriented questions without critically examining the information when generating lower-level questions in the first prompt. This situation is also observed in human performance. Studies have shown that teachers’ and educators’ ability to write questions targeting the upper levels of the RBT is lower than their ability to write questions targeting lower levels (Boylu, 2019; Himmah et al., 2019; Özyalçın & Kana, 2020). The results show that although the success of question preparation in the first prompt increased in 2026, LLMs do not surpass human performance in tasks such as preparing questions at the upper levels of the RBT when the first prompt is used. However, controlling AI-generated questions through appropriate prompts was found to have the potential to save time and resources in the creation of mathematics exams. In addition, this approach can provide insight into potential question types by making the time- and experience-intensive question-writing process more efficient. However, because chat-based LLMs operate based on user-provided commands and generate different responses depending on the language and specificity of those commands (Rospigliosi, 2023), the study’s results may vary according to the prompts used. When using a more general instruction—particularly in the first prompt (Prompt 1)—LLMss were more successful in preparing lower-level questions in both data sets. In contrast, when asked in the second prompt to rewrite questions by indicating their shortcomings (alignment with RBT levels, scientific relevance, understandability, and target relevance), the models were more successful in preparing higher-level questions. The most effective second prompts were those related to scientific relevance and target relevance. Limiting the process to a maximum of two prompts was intended to minimise researcher intervention and to identify the natural tendencies and basic capabilities of LLMs. By the end of the study, it was shown that increasing the number of interventions or requesting more specialised prompts led to more successful outcomes in preparing mathematics exams at the desired level. At this stage, AI, whose performance improves with human intervention, can be considered to play a supportive role in the exam creation process by facilitating teachers’ work and saving time. Looking at the 2024 and 2026 data, this limitation may be addressed through more specific prompts, such as: “Prepare a question suitable for the analysis level in which the student learns that dividing by a fraction is equivalent to multiplying by its reciprocal.” Ünal et al. (2025), found that customised prompts performed better in preparing mathematics questions. This finding is consistent with the results of the present study. This highlights the decisive role of prompt engineering in LLM performance. Therefore, it should be noted that more numerous and higher-quality prompts may yield different results and that the present findings are valid within the context of a specific prompt set and a limited number of questions.
The study focused on the middle school–level topics of “fractions” and “angles in triangles.” The nature of these topics may have influenced LLM performance. For example, questions on “angles in triangles” typically require visual representations. It has been reported that LLM performance varies depending on the mathematics subject area, with geometry topics posing greater challenges (Svičević et al., 2025; Wei, 2024). The study findings showed that there were very serious limitations in visual preparation in 2024, but with the 2026 data, this limitation decreased significantly for Claude. In the 2026 version, ChatGPT was able to add correct visual elements, although some were not fully comprehensible. Claude’s success in preparing visual geometry questions was particularly noteworthy. This situation recalls the reality that LLMs are creating a “digital ripple” that is changing the nature of education (Fan, 2025; Strielkowski et al., 2025; Walkington, 2025). However, all three LLMs designed questions without using visual elements for the fractions subject. Additionally, the success in exam preparation for the angles in triangles subject was lower than for the fractions subject in both years. The visual input and output capabilities of current LLMs may have limited the quality and originality of the generated questions. The fact that LLMs generally designed questions without visual elements in their 2026 versions as well supports this idea. In contrast, the topic of “fractions” is more abstract and relies on symbolic operations. This suggests that model performance is not independent of the characteristics of the topics being assessed and the currency of the LLM used. Therefore, the findings of this study cannot be generalised to mathematics topics with different content characteristics (e.g., algebra or probability), and LLM performance in creating exams for such topics may vary.
Within the scope of the study, it was determined that the performance of the three LLMs differed from one another over the years. Within the scope of the 2024 data, Gemini showed the highest performance in the angles in triangles subject, while Claude showed the highest performance in the fractions subject in taxonomy-based question writing. Lee et al. (2024) compared Gemini Pro with ChatGPT and concluded that Gemini was not very successful at understanding texts; its student assessment performance was limited and could be enhanced through the use of simple expressions and fragmented visuals. These results are consistent with the findings of the present study. Looking at the 2026 data, it is clear that Claude performed best in exam preparation for both fractions and angles in triangles. This situation indicates that, as AI advances rapidly, LLMs are developing at different rates. While all three LLMs were successful in terms of relevance to objectives and scientific relevance, the 2026 data yielded the same result. However, while Claude’s performance was lower than the other LLMs on the comprehensibility criterion in the 2024 data, it was observed that by 2026, it had closed this gap and generated completely comprehensible questions. It is well established that questions containing unclear, linguistically complex, or ambiguous expressions negatively affect students’ cognitive performance, thereby weakening the validity of measurement results (Haladyna, 2004). These findings align with previous results indicating that the performance of LLMs varies depending on the task and that AI technologies are rapidly changing and developing (Hochmair et al., 2024). Studies comparing LLMs have identified varying strengths and limitations across models. For example, Rycroft-Smith et al. (2024) compared the ability of three different LLMs—Copilot, Claude, and ChatGPT 3.5—to write questions about the area of a rectangle. They found that ChatGPT offered more opportunities for multi-part questions and scoring; however, this also increased the risk of errors. In this sense, the performance differences between LLMs highlighted in previous research were also identified in this study.
Considering the types of questions designed by LLMs, it was determined that in both the 2024 and 2026 data, Claude offered richer content in terms of question variety compared to the LLMs; however, overall, all three LLMs tended to prefer open-ended questions at upper-order levels. It can be considered that tasks such as ensuring logical distractor selection in multiple-choice questions, managing multidimensional matching processes, or avoiding ambiguous expressions in fill-in-the-blank questions while focusing on critical domain-specific information may pose difficulties for LLMs. For example, it is often argued that applying Bloom’s cognitive domains when creating multiple-choice questions results in items that measure higher-order thinking rather than the recall of factual information (Cecilio-Fernandes et al., 2018; Crowe et al., 2008; Monrad et al., 2021). At the same time, the process of preparing multiple-choice questions requires meticulous effort and is highly complex (Arıcan, 1996). In this sense, LLMs’ preference for open-ended questions may be related to the relative ease of the preparation process. Goodman et al. (2024) stated that ChatGPT is more successful in writing open-ended questions; this finding shows that this is still valid for the questions designed at upper-order levels in this study. ChatGPT extensively used open-ended questions in both of its versions. Although other LLMs included different question types in 2026, they were more inclined to prepare open-ended questions at upper-order levels.
This study determined that LLMs have distinct advantages and limitations relative to one another. For example, considering the 2024 data, Gemini’s ability to enhance comprehensibility by providing appropriate links when content is insufficient, Claude’s relative strength in preparing diverse question types (open-ended, multiple-choice, fill-in-the-blank, and matching), and ChatGPT’s higher level of comprehensibility compared to the other LLMs represent their respective strengths. Examining the 2026 data, it was determined that the limitations of ChatGPT and Gemini were similar, but Claude did not have its existing limitations from 2024 during this intervening period. ChatGPT and Gemini have limitations such as a tendency to produce short-text questions at upper levels and limitations in creating questions containing visuals. It was determined that Claude had no limitations in these respects. Similarly, another feature distinguishing Claude from the other LLMs was observed to be its success in creating questions containing visuals. These advantages and limitations are likely outcomes of differences in the underlying infrastructures used by the LLMs. The change in the data collected over two different years is thought to be due to the evolution of the LLMs’ datasets. In the period from 2024 to 2026, the models were likely trained not only with more mathematical problems but also with “chain-of-thought” data explaining problem-solving strategies, proof techniques, and multi-step reasoning processes. This is thought to have caused their limitations to decrease and their advantages to increase. This change, particularly in Claude, indicates that LLMs are progressing and developing at different rates. Considering that the capabilities of LLMs are improving rapidly (Koubaa, 2023), the results presented in this study should be regarded as reflecting the current state of LLM capabilities. This highlights the need for ongoing evaluation and validation as AI technologies continue to evolve.
Conclusion
The results are critically important for teachers and curriculum developers. Examining the 2024 and 2026 data of LLMs, it was observed that they showed very rapid development and that the limitations they had in 2024 were largely resolved. Significant progress was observed, particularly in Claude and ChatGPT, in terms of creating mathematics questions containing visual elements. This situation provides a hint that LLMs will quickly overcome their other limitations in the coming periods. However, the results have not changed the conclusion that teachers should view LLMs as time-saving assistive tools. Teachers should view LLMs as time-saving aids. LLMs can rapidly generate question pools for assessing lower-level cognitive skills; however, questions intended to measure higher-level cognitive skills must be reviewed, edited, and enriched by teachers to ensure pedagogical appropriateness, progressive difficulty, and the promotion of higher-order thinking. Similarly, curriculum designers can treat questions generated by LLMs as a starting point or a source of ideas rather than relying on them directly. In other words, teachers and curriculum developers can view these technologies as powerful assistants rather than as autonomous decision-makers.
LLMs should be further developed to more effectively measure higher-level mathematical thinking processes with a single prompt. It was observed that the percentage of questions prepared at the desired level increased with the use of second prompts. This finding shows that improved results can be achieved through targeted interventions. This performance can be further improved through the application of prompt engineering techniques.
Limitations and Future Studies
The study results are limited to data obtained from ChatGPT, Gemini, and Claude—free chat-based LLMs—during May–June 2024, and February 2026, using a specific prompt set and a limited number of questions on the middle school–level topics of “fractions” and “angles in triangles.” It should be noted that the study was conducted to capture the current state and development of LLM performance. In this context, future studies may examine the criteria used by AI language models when generating questions aligned with the RBT in newer model versions. In addition, future research may focus on identifying appropriate prompts for developing mathematical questions.
Footnotes
Ethical Considerations
This study did not require institutional ethics committee approval, as it did not involve human or animal participants. However, commercial AI platforms (ChatGPT, Gemini, and Claude) were used in the study. Throughout the research process, all actions were conducted in accordance with the terms of service and data privacy policies of these platforms. Furthermore, all generated content was used solely for academic analysis purposes.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data supporting the conclusions of this paper will be made available by the authors upon reasonable request.