
Abstract
This study aims to enhance the prediction precision of aircraft engine remaining useful life (RUL) by overcoming common challenges in current models, such as ineffective feature extraction and insufficient modeling of long-term temporal dependencies. We propose a novel multilayer hybrid architecture that combines bidirectional long short-term memory (BiLSTM) and gated recurrent unit (GRU) networks, augmented with an attention mechanism to enhance the model’s focus on informative temporal patterns. In this framework, raw time series data are initially processed by the BiLSTM to extract bidirectional features associated with engine health conditions. The GRU network is subsequently used to effectively model long-range dependencies, thereby enriching the temporal representation. An adaptive attention module is included to assign varying importance to different features, allowing the model to focus on key indicators of engine condition. Evaluation results on the FD001 and FD003 datasets show that the model achieves root mean squared error reductions ranging from 8.81% to 30.60% and from 7.48% to 37.96%, validating its performance and robustness in RUL forecasting. In comparison with conventional BiLSTM and GRU models, the proposed BiLSTM-GRU-Attention architecture integrates attention-based feature weighting with a hybrid recurrent framework, thereby offering a concise and effective approach to RUL prediction for aircraft engines.
Keywords
Introduction
As the core propulsion system of aerospace vehicles, the operational status of aircraft engines directly affects equipment reliability and flight safety. Aircraft engine failures can pose significant threats to the stable operation of the entire system. Therefore, maintenance and inspection of aircraft engines must be prioritized in aviation maintenance planning. 1 With the continuous advancement of science and technology, a new form of productive force—characterized by innovation capability, technological advancement, and intelligent applications—has been widely applied in the industrial sector, bringing transformative changes to the maintenance and management of aero-engines. In Prognostics and Health Management, the integration of advanced data analytics, artificial intelligence (AI), and internet of things technologies has become a key enabler for improving the accuracy and reliability of remaining useful life (RUL) estimation.
Accurate prediction of the RUL of aircraft engines not only ensures stable operation but also enables effective condition-based maintenance of the engines, thereby reducing the likelihood of catastrophic failures during operation, but also assists stakeholders in formulating scientifically grounded maintenance strategies. This facilitates a shift from traditional time-based maintenance to condition-based maintenance, significantly enhancing both the safety and economic efficiency of aviation operations. In this process, big data analytics, machine learning, and intelligent decision support tools—key components of emerging productivity paradigms—play a pivotal role in optimizing predictive models, improving prediction accuracy, and enhancing real-time responsiveness. Consequently, these technologies have driven substantial technological advancements and management innovations within the aerospace industry.
Existing methodologies for predicting the RUL of aircraft engines are generally classified into three main categories: physics-based models, data-driven approaches, and hybrid techniques,2–4 with a comparative overview illustrated in Table 1.
Comparison of commonly used remaining useful life prediction methods
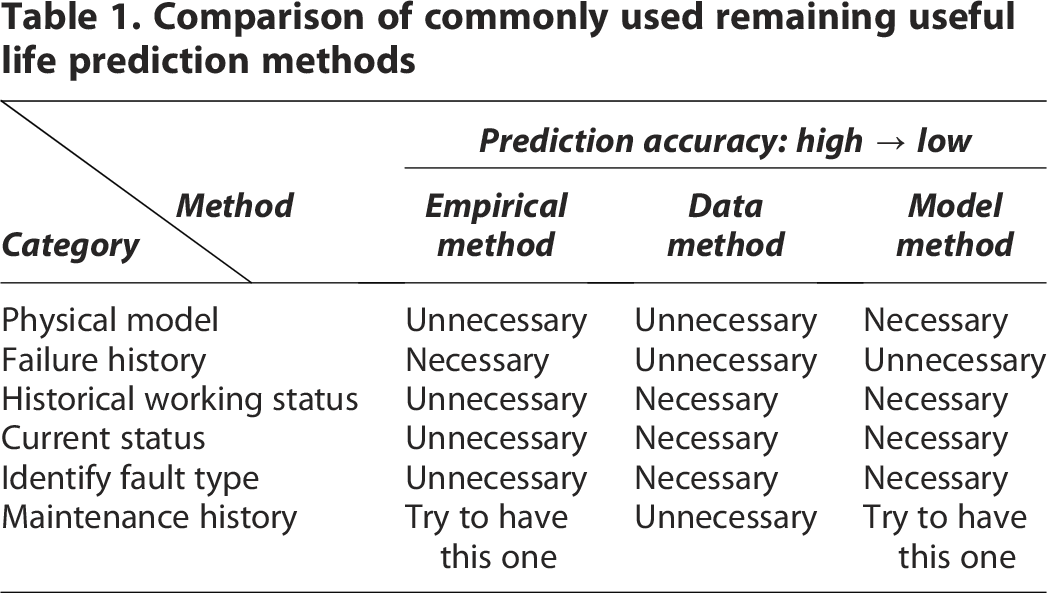
Physics-based approaches estimate the RUL by incorporating observed data into mathematical or physical models that describe the degradation behavior of industrial system components. 5 Li et al. 6 simplified the computation by utilizing the stress ratio to represent variable loading sequences and used particle filtering to estimate the parameters of the crack propagation model. The findings validated the capability of this approach in accurately estimating crack propagation and fatigue lifespan.
Nevertheless, physics-based approaches have notable limitations in practice. They rely on an in-depth understanding of degradation mechanisms and precise mathematical formulations, which are often difficult to establish under nonlinear, multicondition, or noisy sensor environments. Moreover, the high cost of acquiring complete parameters and boundary conditions further restricts their applicability. Consequently, attention has increasingly shifted toward data-driven approaches. 7 By directly extracting features and learning degradation patterns from historical monitoring data, data-driven methods avoid the need for explicit physical modeling and offer greater flexibility in capturing nonlinear dynamics and multidimensional characteristics. This methodological transition not only addresses the shortcomings of physics-based models but also lays the groundwork for introducing advanced deep-learning techniques.
Data-driven prognostic methods leverage statistical and machine learning algorithms to directly extract relevant features and patterns from monitoring data, thereby avoiding the limitations inherent in physics-based models. 8 Owing to their flexibility, these methods can accommodate various forms of data and effectively uncover subtle features that conventional rule-based systems are often unable to detect. Statistical and AI techniques 9 represent the two main branches of data-driven prognostics. Classical statistical models, such as the Wiener and gamma processes, 10 can effectively model the degradation as a stochastic process but face challenges in feature extraction for complex equipment components. Wang et al. 11 proposed a nonlinear Wiener process-based model to address the nonlinear characteristics and triple-source uncertainties commonly observed during the performance degradation of aircraft engines. Liu et al. 12 evaluates the reliability of wind turbine blades based on a nonlinear Wiener degradation process, taking into account the influence of stochastic failure thresholds across different degradation stages.
In the field of machine learning, methods such as support vector machines, relevance vector machines, and neural networks have been widely used for RUL prediction. Among these, recurrent neural networks (RNNs) and convolutional neural networks (CNNs) 13 are two representative algorithmic paradigms. Jiahao et al. 14 proposed a variant of the RNN, to mitigate the limitation of dependency on long-term relationships, effectively uncovering latent patterns within sensor data for more accurate RUL prediction of aircraft engines. Ren et al. 15 introduced a multiscale dense gated recurrent unit (GRU) model composed of a feature layer, multiscale layer, GRU skip connections, and dense layers, in which the feature layer was initialized using a pretrained restricted Boltzmann machine. Experimental validation based on real-world bearing datasets demonstrated the model’s effectiveness in RUL prediction. As a representative deep learning architecture, CNN is a feedforward neural network comprising convolutional layers, pooling layers, and fully connected (FC) layers. Li et al. 16 proposed a novel deep CNN-based approach that processes data along the temporal dimension for RUL prediction.
In practical applications, the temporal evolution of various feature parameters exhibits diverse patterns, which poses challenges for achieving high prediction accuracy through a single approach. Therefore, hybrid methods that integrate physics-informed models and data-driven models have emerged, combining the high precision of model-based methods with the strong robustness of data-driven techniques to enhance both prediction accuracy and reliability. Remadna et al. 17 proposed a hybrid model combining CNNs and bidirectional long short-term memory (BiLSTM) to capture spatial and temporal features, respectively, for predicting engine RUL. Liu et al. 18 applied attention mechanisms (AM) to condition monitoring data to evaluate the relevance of input features, followed by bidirectional GRU (BGRU) and CNN for encoding critical information, and ultimately used an FC network for decoding and RUL estimation.
With the rapid advancement of machine learning and sensor technologies, machine learning-based hybrid approaches have demonstrated significant advantages and promising research prospects in the field of RUL prediction. 19 Although machine learning has exhibited outstanding performance in time-series data modeling, most existing methods tend to overlook the quantification of uncertainty. Quantification of uncertainty in RUL prediction aims to characterize the distribution of predicted RUL by accounting for multiple sources of uncertainty inherent in the prediction process, thereby enabling interval estimation. Confidence intervals for RUL predictions can offer insight into the reliability of the forecast results and are of critical importance for optimal maintenance decision-making. Currently, the main approaches to uncertainty quantification in RUL prediction include stochastic processes, 20 filtering algorithms, 21 and Bayesian neural networks. 22
Beyond aero-engine prognostics, deep learning has advanced a wide spectrum of predictive tasks across domains. For example, education analytics leverages CNN-derived multimedia features fused with ensemble learners to predict academic success, achieving state-of-the-art performance on LMS data. 23 In medical imaging, multistage pipelines built upon high-capacity CNN backbones (e.g., NASNet) have reported consistent gains for lesion detection under limited supervision and noisy acquisition settings. 24
In industrial and engineering domains, deep learning frameworks have been widely used for fault diagnosis and health monitoring of rotating machinery, 25 as well as for RUL prediction of aero-engines using transformer-based architectures and multisensor fusion. 26 Recent studies also explore multiscale attention networks for time series prognostics in manufacturing systems, achieving improved feature representation and robustness under covariate shifts. 27 These trends are aligned with our design choices—bidirectional temporal encoding (BiLSTM), efficient long-range modeling (GRU), and data-dependent weighting (self-attention)—which together yield stronger RUL estimates under single-condition subsets.
Based on the investigation and application of the aforementioned methods, this research proposes a new network architecture that combines BiLSTM, GRU, and AM, along with dropout-based uncertainty quantification, for the prediction of aircraft engine RUL. This study improves RUL prediction by separating the model into three steps: learning local patterns in both the time directions (BiLSTM), capturing longer term trends (GRU), and weighting the most informative signals (attention). Unlike single models or hybrids that blend these steps, our BiLSTM–GRU–Attention design keeps their roles distinct, trains more stably, and makes it easier to see which inputs matter.
Materials and Methods
LSTM model and BiLSTM model
LSTM 28 is a special type of RNN, 29 specifically designed to address the long-term dependency problem in time series data. 30 By introducing gating mechanisms, LSTM effectively overcomes the gradient vanishing and exploding issues commonly encountered by traditional RNNs when processing long sequences. 31 The structural diagram of the LSTM model is illustrated in Figure 1.
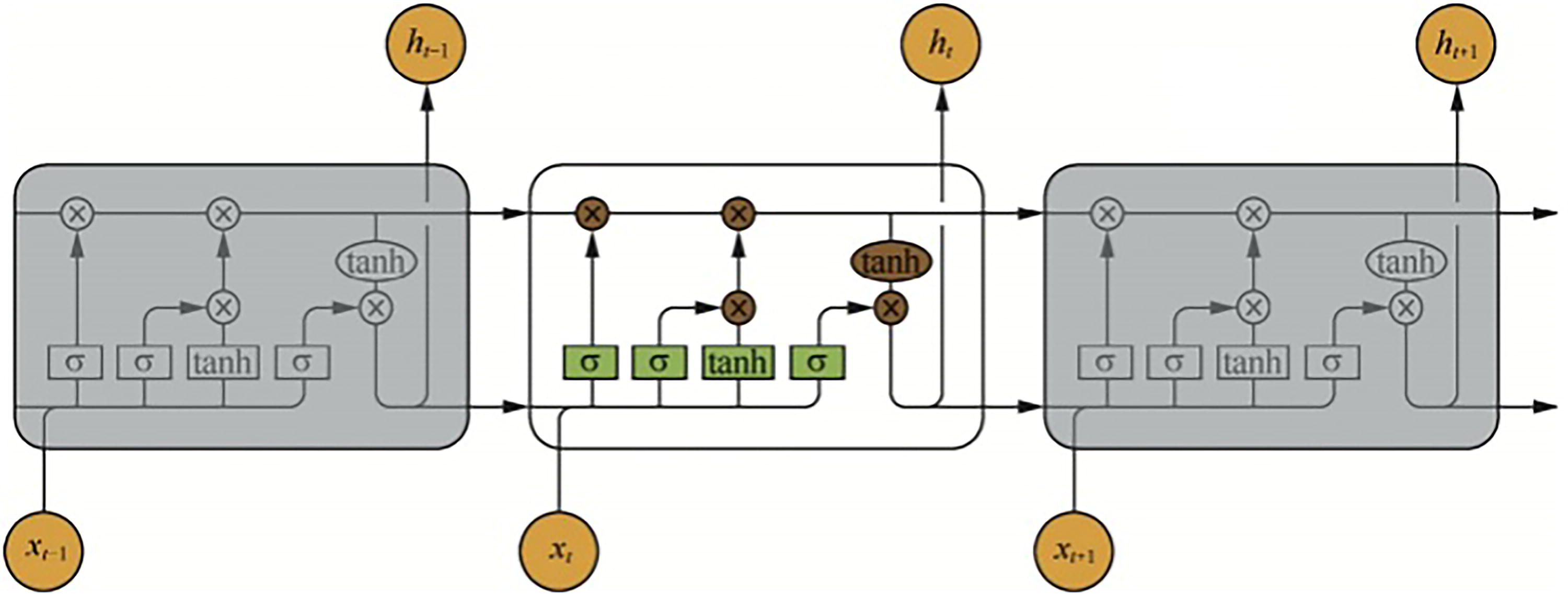
The fundamental unit of an LSTM network is referred to as an “LSTM cell.” Each LSTM cell consists of four primary components: the forget gate, input gate, candidate memory-cell update, and output gate. 32 These gating mechanisms are realized via specialized neural network layers and nonlinear activation functions, allowing the model to selectively preserve, modify, and release information across temporal sequences.
Forget Gate
The forget gate regulates the degree to which the previous cell state is preserved at the current time step.
33
It receives the current input 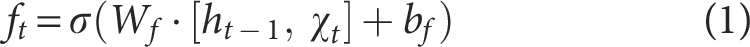
The symbol
Input Gate
The input gate determines the extent to which current input data impact the memory cell state. It comprises two components: the input gate itself and the candidate memory state. The input gate controls the admission of new information into the memory cell, whereas the candidate memory state produces potential memory content. The relationship is quantitatively described by the following equation:
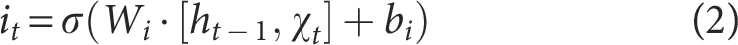
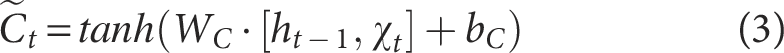
Where
Cell State Update
The cell state is modified according to the outputs of the forget and input gates. The forget gate specifies the portion of the prior cell state to preserve, while the input gate dictates how much of the new candidate memory should be added. The update rule is defined as follows:
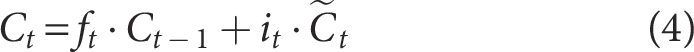
Among them,
Output Gate
The output gate controls the influence of the memory cell state on the hidden state at the current time step. It integrates the current input with the updated cell state to generate the new hidden state. The computation is given by the following:
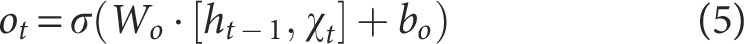

BiLSTM 34 represents an evolution of the RNN, integrating information from both the past and future contexts, enabling the model to process information in two directions. However, traditional LSTM can only process sequential data in one direction (typically from past to future), 35 which limits its performance in many practical applications. The BiLSTM architecture captures contextual dependencies from both past and future time steps by incorporating hidden layers that process the sequence in forward and backward directions simultaneously. These hidden layers jointly extract key information from both directions at each time step, 36 thereby further enhancing the capability to model time series data. The architecture of the BiLSTM model is illustrated in Figure 2.
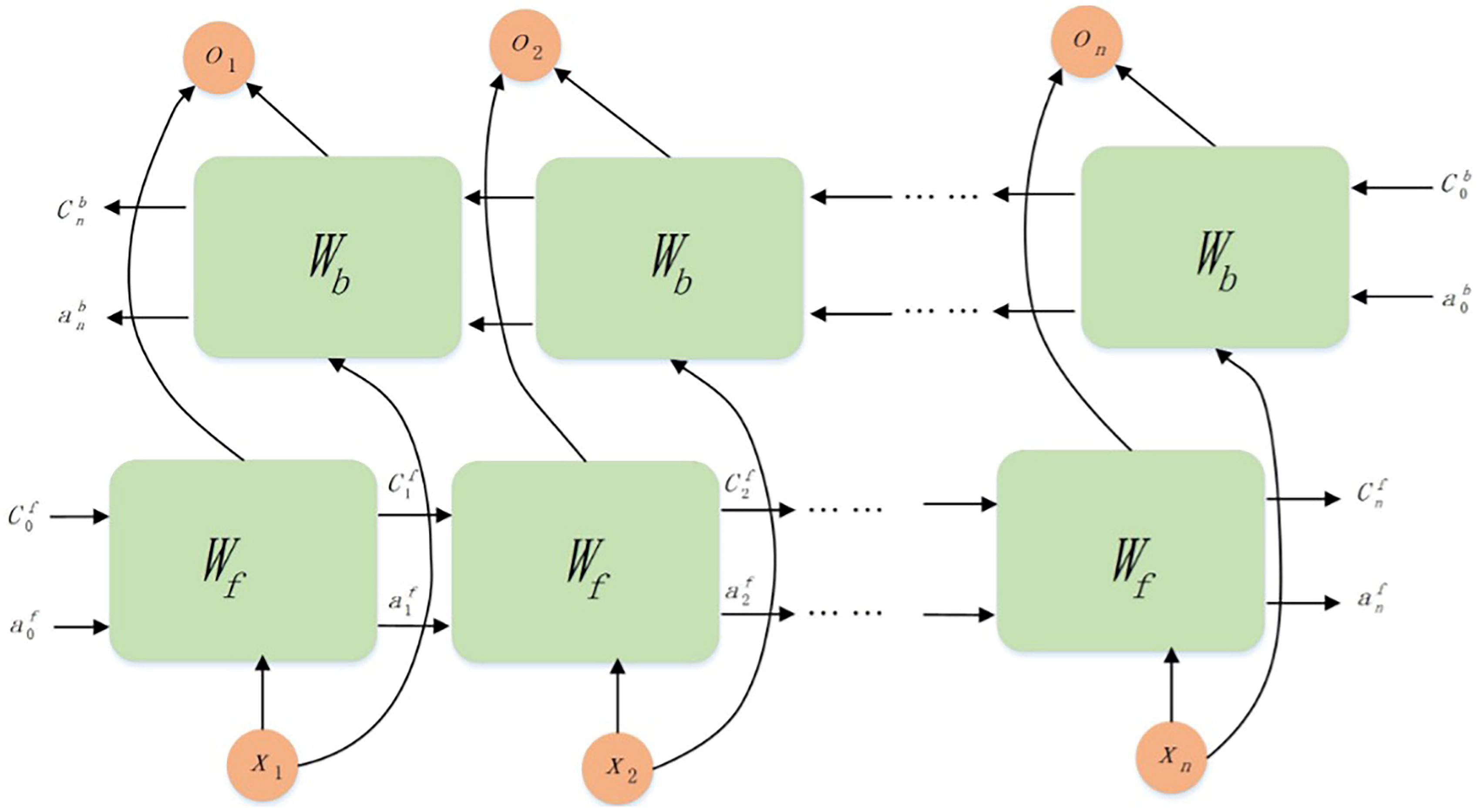
In a BiLSTM network, one LSTM layer captures information from past to future, while the other traverses the sequence in reverse.
37
Each LSTM layer generates an output sequence of the same length as the input. The final representation at each time step is obtained by concatenating the outputs from both directions, thereby capturing contextual information from both the past and the future.
38
Specifically, for a given input sequence 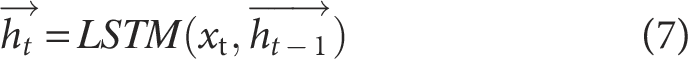
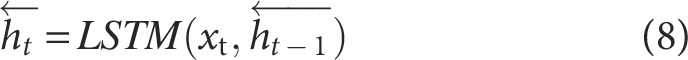
At time step 
GRU network model
GRU is an improved variant of RNNs. Compared with LSTM networks, GRU introduces two main modifications: First, it merges the forget gate and input gate into a single gate called the update gate, alongside another gate termed the reset gate; second, it does not introduce an additional internal cell state
The fundamental building block of the GRU network is referred to as the “GRU cell.” Each GRU cell comprises two primary gating mechanisms: the reset gate and the update gate. These gates regulate the flow of information and are implemented through distinct neural network layers and nonlinear activation functions. The architectural structure of the GRU model is illustrated in Figure 3.

Gated recurrent unit (GRU) model structure diagram (adapted from refs.39,40).
Reset Gate
The reset gate regulates how much the previous hidden state influences the candidate activation at the current time step.
39
It receives the current input vector 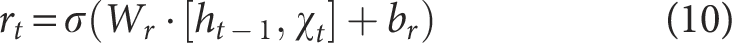
Here,
Update Gate
The update gate determines the proportion by which the current hidden state 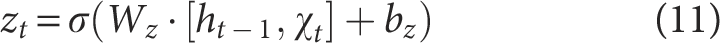
Candidate Hidden State Update
The candidate hidden state 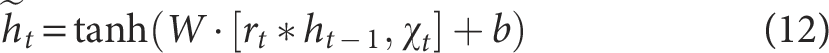
Where
Hidden State Update
The updated hidden state 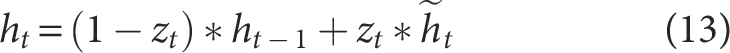
Attention mechanism
The AM is a widely used technique in deep learning models, originally introduced in machine translation. It has since been extensively applied to various time series processing tasks and has become a crucial component for enhancing model performance. The core idea of attention lies in allowing the model to dynamically adjust attention weights for each input by evaluating the importance of different segments of the input sequence. This enables the model to more effectively capture long-range dependencies and salient features. 41
Several forms of attention have been developed, including additive, multiplicative, and self-attention.
42
This study uses the self-attention mechanism,
43
a variant that establishes dependencies among different positions within a single sequence. The core principle involves computing the pairwise correlations among all positions within the input sequence for the purpose of allocating importance weights to each position. When processing sequential data, self-attention can capture dependencies between any two positions in the sequence, thereby improving the model’s representation capability and predictive performance. The specific formulation of the self-attention mechanism is as follows:

Uncertainty quantification
In engineering practice, data collection processes often encounter issues such as missing data or measurement errors, which exacerbate the uncertainty in model predictions. 44 The raw signals acquired by monitoring systems are typically accompanied by noise interference, causing point estimates in each prediction to vary. Both data-driven and model-driven prognostic methods inevitably face two types of uncertainties: epistemic uncertainty and aleatory uncertainty. Epistemic uncertainty reflects the limitations in understanding the model’s inherent properties, whereas aleatory uncertainty arises from noise and disturbances during data acquisition and transmission. 45
Assuming the model is expressed as

Sources of uncertainty (adapted from refs. 46 ).
Building on the above modeling components and uncertainty handling, the next section presents the overall architecture and information flow of the proposed BiLSTM–GRU–Attention model.
Remaining Life Prediction Model Based on BiLSTM-GRU-Attention
BiLSTM–GRU–attention network architecture
This study proposes a hybrid network architecture combining BiLSTM and GRU enhanced by an AM, as depicted in Figure 5. The architecture is composed of four sequential layers, beginning with a BiLSTM layer aimed at extracting bidirectional temporal dependencies; the second layer uses a GRU to enhance the learning of sequential patterns while reducing computational complexity; the third layer introduces an AM that dynamically allocates weights to significant temporal features, while the final layer serves as an FC layer responsible for generating the output prediction. Guided by this rationale, the layered design proceeds from bidirectional within-window encoding to cross-scale temporal integration and data-dependent weighting, culminating in a robust regression of RUL.

Bidirectional long short-term memory (BiLSTM)-gated recurrent unit (GRU)-attention prediction model flowchart.
Initially, in the context of multivariate time series prediction, continuous sequences are generated by setting a specific cycle interval. A sliding window approach is then applied to produce multiple groups of multivariate time series, thereby constructing a time series training set for various devices. After normalization and sample construction, the BiLSTM aggregates forward and backward information at each time step to extract more complete degradation features, alleviating gradient-related issues in long-sequence modeling.
Subsequently, the outputs from the BiLSTM layer are input into the GRU layer to further extract complex temporal features. The GRU layer, through its update and reset gates, effectively captures long-term dependencies within the sequence and alleviates the gradient vanishing problem that may occur in LSTM, thereby enhancing the model’s feature representation capability.
Following this, the attention layer performs weighted processing on the outputs of both the BiLSTM and GRU layers. By computing importance weights for each time step, the AM enables the model to emphasize the most relevant features and create a feature representation that accentuates key information, leading to improved prediction accuracy. 47 Finally, the features processed by the AM are fed into an FC layer for further dimensionality reduction. Through two successive linear transformations, the feature dimension is progressively reduced while retaining essential information, enabling accurate multivariate time series forecasting.
Evaluation metrics for RUL prediction models
To compare the RUL prediction performance among different models, two commonly used evaluation metrics in regression tasks,
48
namely root mean squared error (RMSE) and the score function,
49
are adopted as rating indicators. The RMSE is commonly utilized to evaluate the extent of deviation between estimated and actual values, and is computed using the following formulation:
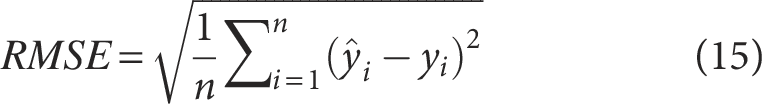
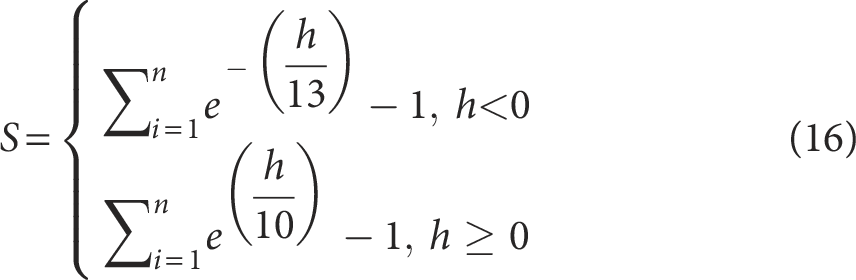
Results and Discussion
Dataset
Due to the confidentiality requirements and high acquisition costs associated with the aerospace industry, this study uses the publicly available C-MAPSS turbofan engine degradation simulation dataset released by NASA. 51 Owing to its practical relevance and variability in testing environments, the dataset—made available in 2008—has become a benchmark resource widely adopted in RUL-related studies across the global academic community. Experts and scholars have utilized the dataset—which records critical condition monitoring data and the corresponding operational parameters of turbofan engines throughout their operational cycles until failure—for research on RUL prediction, 52 performance degradation analysis, and fault diagnosis, thereby validating the effectiveness of proposed models or algorithm. 53
All four subsets within the C-MAPSS dataset (FD001–FD004) share a consistent set of parameters, and the corresponding raw data are made available in standardized plain text (.txt) files. Each subset is organized as an
Column parameter names
As illustrated in Figure 6, os_1–3 denote the three operational conditions, while sm_1–21 represent the 21 sensor measurements. It was observed that the readings from sensors 1, 5, 6, 10, 16, 18, and 19 remain constant throughout the engine’s operational life cycle and exhibit no correlation with the degradation process. Therefore, these seven sensor signals were excluded from the analysis. The remaining 14 sensor measurements, in conjunction with the three operational condition parameters, were selected as input features for subsequent model evaluation and training.
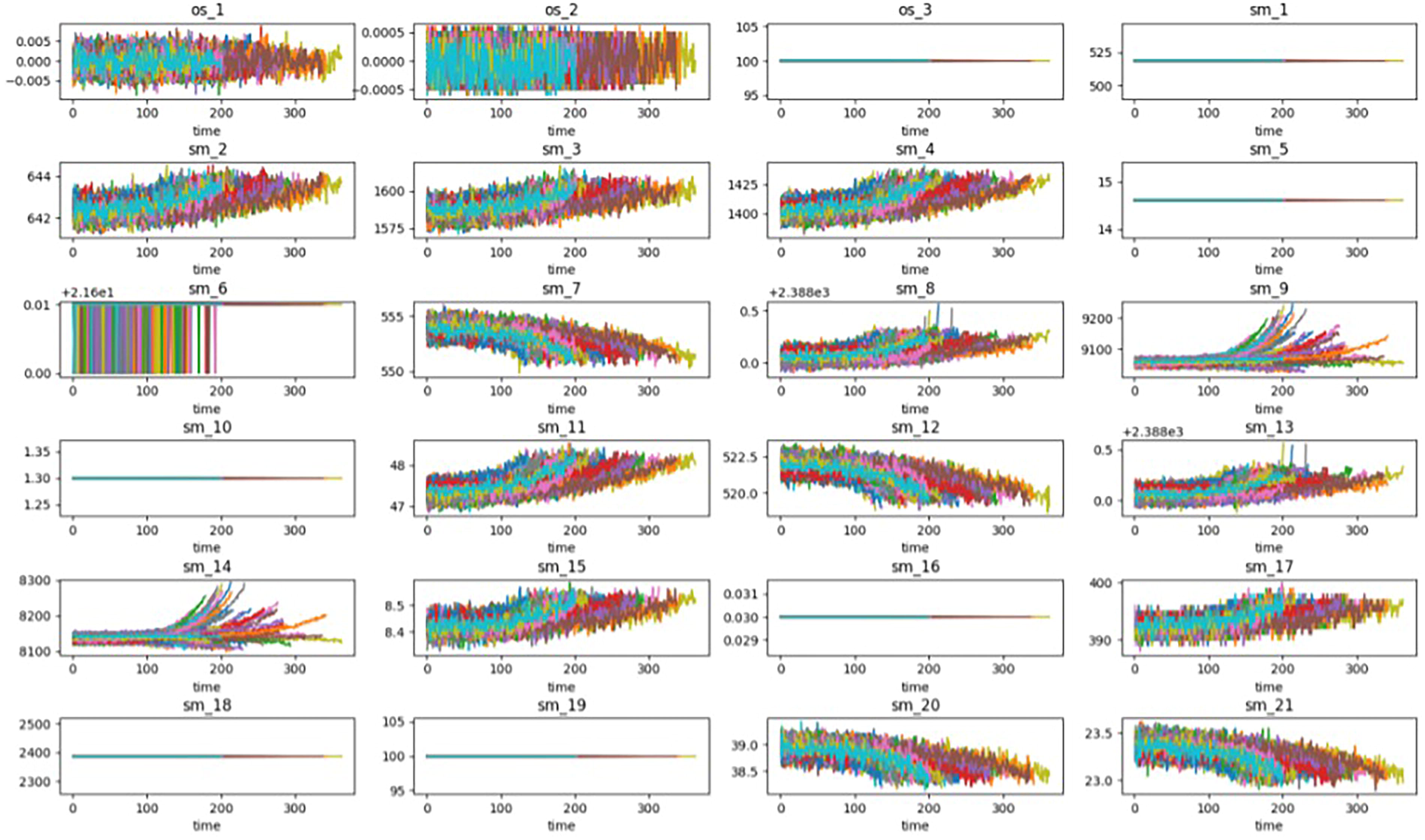
Sensor data.
Data preprocessing
Differences in units and scales can cause large-magnitude features to dominate training and mask others. To remove dimensional/scale effects and improve stability and convergence, we apply min–max normalization to [0,1] for all features.
54
The corresponding normalization procedure is mathematically defined by Equation (17) in this article:
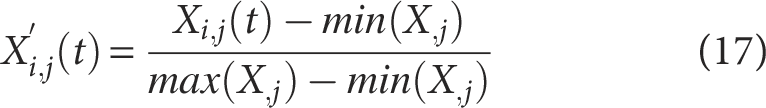
To preclude information leakage, all splits were conducted strictly at the engine ID level. We used the official C-MAPSS train/test partition and did not reassign engines across sets; thus, no engine appears in more than one set. Within the training set, a validation set was created by randomly selecting a fixed proportion of engines (engine-level split; fixed random seed) and reserving the remaining engines for training. Sliding-window sequences were then generated independently within each engine, ensuring that windows do not cross engine boundaries. Feature normalization (min–max scaling) was fit on the training set only and subsequently applied to the validation and test sets using the same parameters. This protocol eliminates cross-set contamination arising from windowing or scaling and yields a credible evaluation of generalization performance.
Model parameter settings
After normalization, the input data derived from the C-MAPSS dataset are scaled to the range of [0,1]. The normalized data are subsequently processed using a sliding time window to generate the input sequences for the network. During model training, to mitigate the risk of overfitting, the dropout technique is used. Specifically, dropout randomly deactivates a subset of neurons during each training iteration, thereby compelling the network to learn more robust and generalizable feature representations. This approach reduces the model’s dependency on specific training data and effectively enhances both its generalization capability and robustness.
To ensure the reliability of the experimental results, the model was trained and validated multiple times, and the final hyperparameter configuration is summarized in Table 3. The learning rate was set to 0.01, which provided a balance between convergence speed and stability, avoiding both slow convergence at lower rates and instability at higher ones. The dropout rate was fixed at 0.2 to mitigate overfitting while preserving model capacity for complex feature learning. A batch size of 100 was used to balance computational efficiency and generalization. The number of training epochs was set to 32 for FD001 and 64 for FD003, determined by observed convergence behavior to ensure sufficient training without overfitting. The sliding window length was set to 30 cycles, enabling the capture of key temporal dependencies while reducing noise. These settings were validated through repeated experiments, confirming stable and robust performance of the proposed framework.
Model parameter settings
Complexity comparison
To demonstrate the advantages of the proposed BiLSTM-GRU-Attention prediction model over the LSTM, BiLSTM, and GRU models, the complexity of these four models was compared. The comparison results of a number of model parameters are presented in Table 4. As shown in Table 4, the BiLSTM-GRU-Attention prediction model has a greater number of parameters than the LSTM, BiLSTM, and GRU models.
Parameter comparison across different models

BiLSTM, bidirectional long short-term memory; GRU, gated recurrent unit; LSTM, long short-term memory.
Analysis of prediction results
To thoroughly evaluate the proposed model’s performance, ablation studies were conducted on the BiLSTM-GRU-Attention framework used. Specifically, BiLSTM, BiLSTM-Attention, and BiLSTM-GRU models were individually trained and their prediction performance was compared. The FD001 and FD003 datasets, characterized by single operating conditions from the C-MAPSS dataset, were chosen for conducting several experimental trials. One representative set of RUL prediction results is presented in Figure 7 and Table 5. In Figure 7, the x-axis represents sequential sample indices, and the y-axis represents normalized RUL values after regularization. Due to the high sampling density, some tick labels on the x-axis may overlap. All curves are plotted using the original data, and slight smoothing is applied only for visual clarity.

Ablation experiment prediction results.
Ablation Experiment
The final results demonstrate that the proposed BiLSTM-GRU-Attention-based RUL prediction method outperforms the BiLSTM, BiLSTM-Attention, and BiLSTM-GRU models in terms of both RMSE and score metrics. As shown in Table 5, for the FD001 and FD003 datasets, the predicted values generated by the proposed method are the closest to the actual values, yielding the lowest mean absolute error and maximum absolute error among the four models. Specifically, for the FD001 dataset, the BiLSTM-GRU-Attention model reduces the RMSE by 30.60% compared with the BiLSTM model, and by 8.81% and 10.24% compared with the BiLSTM-Attention and BiLSTM-GRU models, respectively. For the FD003 dataset, the RMSE is reduced by 37.96% relative to the BiLSTM model, and by 7.48% and 13.64% relative to the BiLSTM-Attention and BiLSTM-GRU models, respectively.
Root mean squared error and score results of ablation experiments on a single-condition dataset

RMSE, root mean squared error.
To visually illustrate the comparative results of the ablation experiments, a bar chart is presented in Figure 8. As observed, the BiLSTM-GRU-Attention model consistently yields lower RMSE and score values compared with the other three models, demonstrating a substantial enhancement in predictive accuracy. The practical efficacy and robustness of the proposed approach are further substantiated from multiple perspectives.

Comparative histogram of ablation experiments.
Uncertainty Quantification
Predictive uncertainty is estimated via the Monte Carlo dropout; the mean of stochastic passes serves as the point estimate, and the 95% interval quantifies confidence. Tighter intervals on FD001 indicate higher model certainty.
As illustrated in Figure 9, the uncertainty in the FD001 dataset gradually decreases, indicating that the model’s comprehension of the data improves with an increasing number of samples. The narrowing of the confidence interval suggests more stable and reliable predictions over time. In contrast, the FD003 dataset exhibits pronounced fluctuations in predictive uncertainty, with considerable instability persisting even at higher sample indices. This behavior may be attributed to higher levels of noise, greater environmental variability, or increased heterogeneity in the data characteristics. These complexities hinder the model’s ability to accurately learn the underlying patterns, resulting in less consistent and more volatile predictions.

Uncertainty quantification results.
Comparative Experiment
To rigorously evaluate the feasibility of the proposed prediction approach, a comprehensive comparative analysis was conducted among the proposed BiLSTM-GRU-Attention model, conventional architectures such as BiLSTM and GRU, and several state-of-the-art methods reported in the literature. All models were trained and tested on the same single-operating-condition subsets FD001 and FD003 from the C-MAPSS dataset, obtaining RMSE and score of different methods for comparative analysis.
As shown in Table 6, the proposed BiLSTM-GRU-Attention model achieves lower values in both the score function and RMSE compared with the BiLSTM and GRU models on the FD001 and FD003 subsets. Furthermore, in comparison with other approaches reported in existing literature, the BiLSTM-GRU-Attention model also outperforms in terms of both the evaluation metrics across the same subsets. These results demonstrate that the proposed multilayer architecture, with enhanced feature extraction capability, achieves superior predictive performance compared with the conventional GRU and BiLSTM models.
Evaluation of experimental outcomes across various methods
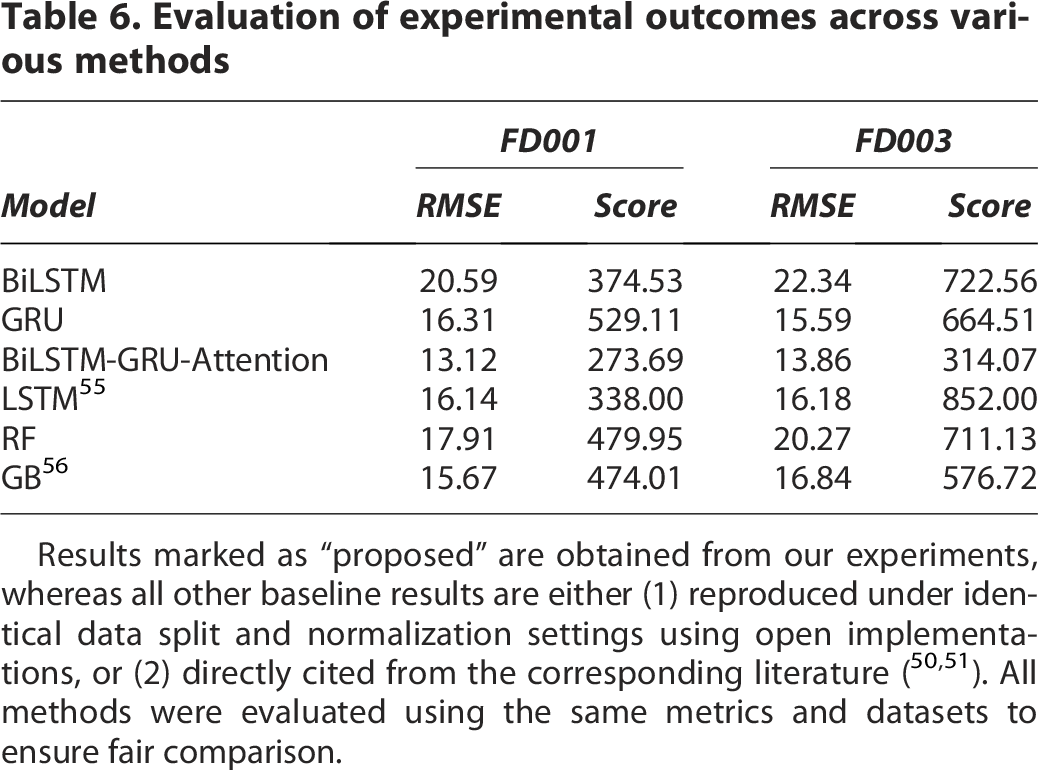
Results marked as “proposed” are obtained from our experiments, whereas all other baseline results are either (1) reproduced under identical data split and normalization settings using open implementations, or (2) directly cited from the corresponding literature (50,51). All methods were evaluated using the same metrics and datasets to ensure fair comparison.
Conclusions
This study investigates and resolves key shortcomings in conventional RUL prediction approaches for aircraft engines, focusing on enhancing feature extraction, improving long-sequence data modeling, and increasing model interpretability. To address these issues, an optimized hybrid model, integrating BiLSTM and GRU with an AM, was proposed to improve the accuracy of RUL prediction. The study draws the following three conclusions:
The BiLSTM-GRU-Attention hybrid model integrates BiLSTM’s bidirectional feature extraction capability, the AM’s capability to select critical features, and GRU’s efficient handling of long-term dependencies. This integration facilitates the extraction and combination of diverse feature representations across different network layers, thereby constructing a richer and more comprehensive feature space. Furthermore, the model reduces computational complexity and memory requirements, which improves both training and inference efficiency; it also exhibits enhanced generalization ability and adaptability. By integrating the AM, the proposed model dynamically emphasizes the most critical features, thereby further improving prediction accuracy. Results from ablation studies indicate that models incorporating attention consistently achieve lower RMSE and score metrics compared with their counterparts without attention. This demonstrates that attention-enabled models effectively identify and prioritize features exerting the greatest influence on prediction outcomes, enhancing sensitivity to salient information while mitigating the impact of irrelevant or secondary features, ultimately leading to improved predictive performance. It is shown through experimental results that the proposed BiLSTM-GRU-Attention model attains enhanced prediction accuracy by significantly mitigating errors in the RUL estimation for aircraft engines. Compared with BiLSTM, BiLSTM–Attention, and BiLSTM–GRU models, the BiLSTM–GRU–Attention model achieves superior performance on the RMSE and score metrics, indicating improved accuracy in RUL prediction.
Although the proposed BiLSTM–GRU–Attention framework demonstrates significant progress in feature extraction, long-sequence modeling, and prediction accuracy, certain limitations remain. The experiments were conducted solely on the C-MAPSS dataset, which may not fully capture the complexity and diversity of real-world operating conditions. Moreover, the uncertainty analysis is primarily qualitative and has not yet systematically incorporated quantitative reliability metrics. Future research will focus on extending the framework to more representative and diverse datasets, integrating more rigorous quantitative uncertainty evaluation methods, and further refining the theoretical foundations of the hybrid architecture, with the aim of enhancing the robustness and practical applicability of RUL prediction models.
Authors’ Contributions
Q.H. wrote the first draft of the article, contributed to the conception of the study, and worked on the coding of tables and figures. X.G. contributed to the design of the study and helped perform the analysis with constructive discussions. All the authors read the article and approved the final version of the article.
Footnotes
Author Disclosure Statement
The authors have no relevant financial or nonfinancial interests to disclose.
Funding Information
This article was supported by the Beijing Municipal Education Commission Research Plan General Project (grant number: KM202411232007).
Data Sharing Agreement
The datasets used and analyzed during the current study are available from the corresponding author on reasonable request.