
Abstract
Large-scale, diverse data produced by higher vocational teacher colleges’ digital transformation challenges traditional methods for evaluating digital literacy. The reliability of current analytics and black-box artificial intelligence (AI) models for educational decision-making is limited by their frequent lack of autonomy and transparency. In order to assess digital literacy at higher vocational teacher colleges using big data and visual analytics, this study suggests an Explainable Agentic AI framework. In order to facilitate adaptive data exploration, competency evaluation, and insight generation across multimodal educational data, such as learning behavior logs, assessment records, and digital engagement indicators, the framework combines autonomous agentic intelligence with explainable AI (XAI). While XAI methods offer clear explanations of literacy aspects, decision rationale, and uncertainty, agentic components dynamically handle data processing, feature reasoning, and model selection. Effective human–AI collaboration is made possible by an interactive visual analytics layer that allows for layered investigation of learner patterns, temporal dynamics, and cohort heterogeneity. When compared with traditional machine learning techniques, experimental results on large-scale datasets from higher vocational teacher colleges show better assessment accuracy, robustness, and interpretability. This work demonstrates the promise of agentic AI for explainable big data exploration and promotes reliable instructional intelligence by combining agentic autonomy, explainability, and visual analytics within a scalable big data paradigm.
Introduction
The incorporation of cutting-edge digital technologies into higher vocational education is now a basic operational necessity rather than an idealistic objective. The need for a workforce skilled in sophisticated cyber-physical systems has increased as the global industrial landscape moves toward Industry 4.0 and 5.0 paradigms. 1 Vocational instructors are under unprecedented strain as a result of this change; they must not only become proficient in these technologies but also have the pedagogical digital competence to properly teach students these abilities. As a result, vocational teachers’ digital literacy has emerged as a crucial quality indicator for educational establishments across the globe.
In the workplace, digital literacy goes beyond fundamental operational skills and includes a complex matrix of skills such as data awareness, technopedagogical design, ethical application, and the capacity to navigate more independent digital ecosystems.2,3 However, there is a significant backlog in the evaluation of these competencies. Even though the digitization of vocational schools has resulted in the creation of enormous, diverse datasets—from professional development records to unstructured engagement metrics and Learning Management System (LMS) interaction logs—the analytical frameworks used to interpret this “Big Data” are still mostly static and opaque. 4 Relying on sporadic, self-reported surveys that fall short of capturing the dynamic, behavioral reality of digital competence, educational administrators, and policymakers are frequently drowning in data while starved for knowledge. 5
The primary issue is the disparity between the amount of data that is accessible and the interpretability of the conclusions that may be drawn from it. To forecast teacher performance or pinpoint professional development needs, traditional educational data mining (EDM) and learning analytics (LA) techniques frequently rely on “black-box” machine learning models, such as deep neural networks or intricate ensemble techniques. 6 Although these models are capable of achieving great predicted accuracy, they usually fall short of offering the transparency needed for critical educational decision-making. Without a thorough grasp of the underlying behavioral factors, educators are given ratings or classifications; this “black box” situation undermines confidence and prevents effective intervention. 7 Additionally, typical analytics pipelines lack the flexibility to adjust to the dynamic, ever-changing nature of digital learning environments and are inflexible, requiring human configuration. 8
This article proposes a paradigm change from passive predictive analytics to explainable agentic AI in order to close this gap. Agentic AI systems are distinguished by autonomy, reasoning, and the capacity to pursue complicated goals through iterative planning and tool use, in contrast to classical AI systems that operate as tools awaiting human instruction. 9 An agentic system can independently traverse the enormous data lakes of a vocational institution in the context of digital literacy evaluation, detecting pertinent features, choosing suitable analytical models, and producing justifications for its conclusions without continuous human oversight. 10 This feature changes the evaluation process from a recurring, static event to an ongoing, adaptive conversation between the teacher and the intelligent system.
However, additional accountability issues are brought forth by autonomy. An autonomous agent that assesses teacher ability needs to be strictly accountable, have clear decision-making processes, and draw conclusions that are supported by evidence. 11 Explainable AI (XAI) techniques are thus immediately incorporated into the agentic process in this study. To have the agents “show their work,” we use model-agnostic methods like SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations), which provide fine-grained feature attribution for each evaluation. 12 Importantly, an interactive visual analytics (VA) layer synthesizes these explanations rather than delivering them as raw data. 13 This layer is intended to facilitate “Visual LA,” enabling stakeholders to investigate learner trends, confirm agent reasoning, and participate in “human-in-the-loop” improvement of the evaluation standards.
The creation and validation of the Educational Competency Assessment via Hierarchical Agents (ECA-HA) framework are described in this publication. In order to analyze educational big data, we define a novel Hierarchical Multi-Agent System (HMAS) architecture in which specialized agents—in charge of data ingestion, analysis, explanation, and orchestration—work together. 14 We empirically assess the performance, robustness, and interpretability of the framework using the Open University LA Dataset (OULAD) as a high-fidelity proxy for vocational data. 15 Our findings show that the combination of visual explainability and agentic autonomy greatly increases the reliability of educational intelligence, opening the door for more egalitarian and responsive teacher development programs.
Theoretical Background and Related Work
The crisis of digital literacy assessment in vocational education
The concept of digital literacy in higher vocational education is intricate and multifaceted. Developing industry-relevant skills requires more than just software proficiency; it also requires the ability to incorporate digital resources into instructional practices. 16 Professional involvement, digital resources, teaching and learning, assessment, empowering learners, and promoting learners’ digital competence are among the dimensions identified by the European Framework for the Digital Competence of Educators (DigCompEdu). 17 The requirement for industry-specific digital competences, such as running virtual CNC machines, utilizing digital twin technology, or navigating specialist health care informatics systems, further complicates this in the vocational sector.
Even though these theoretical frameworks are extensive, actual evaluation is still based on antiquated techniques. Self-reported surveys are used by many organizations, but they are biased (Dunning–Kruger effect) and do not accurately reflect the behavioral realities of digital participation. 18 Vocational colleges produce “Big Data” with great volume, velocity, and variety as they go through a digital transition. A detailed “digital footprint” of a teacher’s proficiency is provided via interaction logs from Virtual Learning Environments (VLEs), submission timestamps, forum discussions, and resource usage habits. However, traditional statistical methods frequently fail to capture the nonlinear correlations between engagement behaviors and literacy outcomes, and the sheer quantity and sparsity of this data make manual analysis difficult. 4
The interpretability gap in EDM
To make use of this data, EDM, and LA have emerged. They use methods such as deep learning and logistic regression to classify competences and forecast learning outcomes. 5 The superiority of sophisticated models such as artificial neural networks (ANN) and gradient boosting machines (e.g., XGBoost) in managing the high-dimensional character of educational data has been shown in recent studies. 6
However, there is now a gap in interpretability due to the use of these “black-box” models. Predictive accuracy is insufficient in high-stakes situations like teacher evaluations; stakeholders want to know why a particular evaluation was conducted. 7 An approach that designates a teacher as “at-risk” for low digital literacy without providing an explanation of how “low diversity of resource utilization” as opposed to “infrequent login activity” led to the judgment offers no practical remedial strategy. In addition to undermining trust, this lack of openness may mask biases in the training data, resulting in unjust evaluations. This is in line with the larger push for “Responsible AI” in education, which prioritizes accountability, transparency, and fairness. 11
The agentic turn: from automation to autonomy
Agentic AI is currently replacing static models in the field of AI. Agentic AI systems have some agency—the capacity to observe their surroundings, reason about objectives, and take actions to accomplish those objectives across long time horizons—in contrast to traditional AI, which simply operates as a sophisticated function approximator mapping inputs to outputs. 9
Key characteristics of agentic AI relevant to educational assessment include
Agentic workflows (such as the ReAct pattern: Reason and Act) enable dynamic hypothesis creation and testing in the context of Big Data research. An agent may loop over the data and find important patterns and anomalies on its own, saving a human analyst from having to manually specify each feature interaction.
VA and XAI
Agentic insights must be understandable to human users in order to be operationalized. The mathematical basis for this intelligibility is provided by XAI. Researchers can now attribute model predictions to particular input features using techniques like SHapley Additive exPlanations (SHAP) and Local Interpretable Model-agnostic Explanations (LIME), which have become the norm for post-hoc interpretability.12,21 While LIME offers local approximations that are helpful for explaining specific cases, SHAP, which is based on cooperative game theory, offers constant global feature importance.
XAI and the end user are connected by VA. “The science of analytical reasoning facilitated by interactive visual interfaces” is its definition. 13 Dashboards that display learner data are the main way that VA appears in education. However, the “Visualization Literacy” of the users must be taken into consideration when designing these dashboards. 22 Teachers may become overwhelmed by complicated charts on a poorly designed dashboard, which could result in misunderstandings. “Visual LA”—the integration of EDM, LA, and visualization to enable sense-making—is essential to effective VA for XAI. VA technologies enable users to calibrate their faith in the AI agent by visualizing both the data and the explanations (such as force plots of SHAP values), confirming that the agent’s reasoning is consistent with educational domain knowledge. 23
Explainable Agentic AI Framework
We suggest the ECA-HA architecture as a solution to the problems of scale, opacity, and rigidity in existing assessment systems. With the help of a multi-agent architecture, this system can handle heterogeneous big data from vocational education settings and provide understandable insights through an interactive VA dashboard.
Architectural philosophy: HMAS
In order to guarantee scalability and dependability, architecture selection is crucial. We use the HMAS model.14,24 Decentralized or “swarm” agent systems are resilient, but they frequently lack the accountability and clear line of command needed for educational evaluation. A group of specialized subordinate agents are overseen by a high-level “Supervisor” or “Orchestrator” agent in a hierarchical system. This structure guarantees that important choices (such as teacher evaluations) go via centralized supervision processes before being made available to the user and reflects the organizational hierarchy of educational institutions.
The ECA-HA Hierarchical Multi-Agent Architecture is shown in Figure 1. As the main coordinator, the Supervisor Agent breaks down user inquiries into smaller assignments for specialist agents (Ingestion, Analysis, and Explainability). Before being displayed in the VA Layer, data travels from the bottom Data Layer through the Agentic Layer, where it is processed and enhanced with explanations.
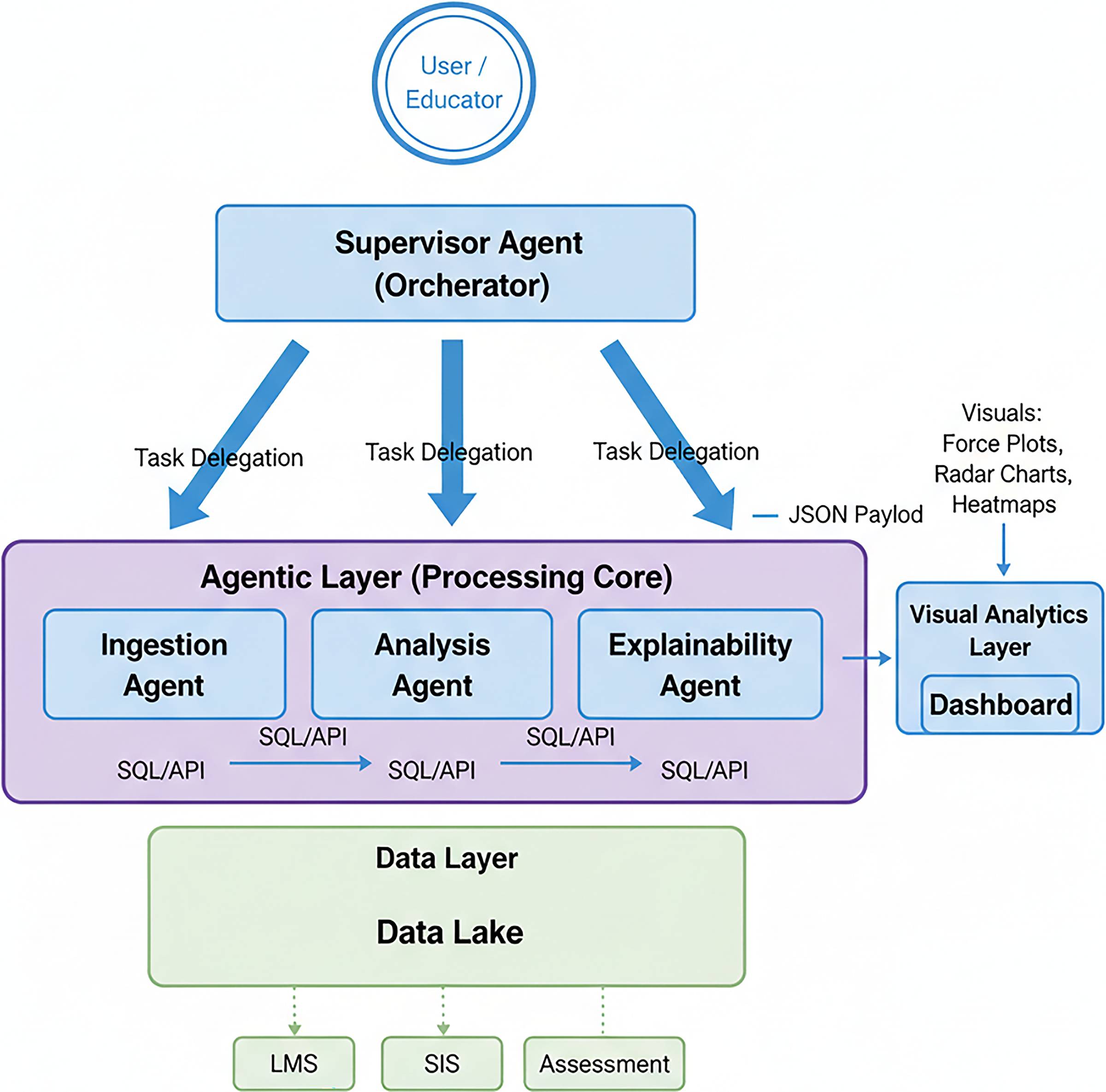
ECA-HA hierarchical multi-agent architecture.
Agentic reasoning loop.
The suggested system functions according to a bounded (weak) agency paradigm, in which agents independently carry out analytical tasks while yet being subject to human supervision and predetermined assessment rules. This taxonomy sets the framework apart from robust agency systems that establish goals on their own and guarantee institutional responsibility.
The agentic layer: Roles and responsibilities
The Agentic Layer assigns computational tasks to specialized Python-based tools while using large language models (LLMs) as the cognitive foundation for reasoning. A structured Model Context Protocol (MCP) is used by the agents to transmit commands and data in a consistent manner. 25
Instead of making decisions, LLMs just act as reasoning and orchestration engines. To reduce hallucinations and keep all evaluative results data-grounded, structured prompting, deterministic temperature settings, tool-verified execution, and rule-based output validation are used.
Inter-agent communication is governed by a structured MCP that defines standardized message schemas, error propagation procedures, and acknowledgment semantics. A sequence diagram illustrating agent interactions has been incorporated to improve architectural clarity.
The supervisor agent (The orchestrator)
The supervisor agent serves as both the main human interface and the brain of the system. Task decomposition and orchestration are under its purview.
24
The supervisor agent automatically escalates the case for human review if explanation fidelity or confidence ratings fall below acceptable ranges or predefined criteria, especially for negative evaluations as shown in Fig. 2.
The data ingestion agent
Big Data’s “Variety” and “Volume” issues are addressed by this agent.
The analysis agent (The data scientist)
The primary computational evaluation is carried out by the analysis agent.
The explainability agent (The critic)
This agent makes sure that the analysis agent’s “black box” is transparent.
The VA layer
The structured outputs of the Agentic Layer are converted into a visual story via the Interaction Layer, a web-based dashboard. It is intended to facilitate “Visual LA,” which combines interactive visuals with data mining findings.
13
Methodology and Experimental Setup
We carried out a thorough experimental investigation to validate the ECA-HA framework. We used the OULAD 15 as a high-fidelity proxy because of privacy issues and the lack of a public, large-scale dataset tailored to vocational teachers.
Dataset justification and preparation
In EDM research, the OULAD is well-known. It includes information on over 10 million clickstream engagements with the VLE, assessment outcomes, and demographics from 32,593 students across 22 course presentations.
Proxy validity: The digital behaviors expected of vocational teachers taking part in online professional development or overseeing digital courses closely resemble the interaction patterns documented in OULAD, which include accessing digital resources (pdf, html), submitting assessments (quiz, tma), and participating in forums (forumng). 27 The dataset is a perfect testbed for assessing our agentic framework’s “Big Data” capabilities because of its high dimensionality and volume.
Data ingestion and feature engineering
The raw CSV files (studentVle.csv, assessments.csv, and studentInfo.csv) were to be processed by the data ingestion agent. It carried out the following pipeline on its own.
Mapping OULAD features to teacher digital literacy dimensions

Target variable
We established a binary categorization target—High Competency versus Needs Improvement—to mimic an evaluation of digital literacy. “Distinction” or “Pass” profiles were classified as High Competency, while “Fail” or “Withdrawn” profiles were classified as Needs Improvement.
Proxy validation and feature—behavior equivalency analysis
In order to improve the construct validity of OULAD as a stand-in for digital literacy among vocational teachers, we present a feature—behavior equivalency mapping based on the DigCompEdu framework. DigCompEdu competency domains, which include digital resources, assessment, and professional engagement, were rigorously aligned with LMS-derived indicators, such as resource diversity, assessment punctuality, and forum engagement depth. Additionally, by adding controlled Gaussian noise (±5%–10%) to behavioral data, a sensitivity perturbation analysis was carried out, revealing that SHAP attributions and competency forecasts held steady across perturbations. These findings suggest that rather than serving as dataset-specific artifacts, LMS actions consistently resemble professional digital practices.
The suggested ECA-HA framework is naturally compatible with ordinal or multi-level skill stratification, even if a binary classification was used for benchmarking. In particular, ordinal regression or multi-class gradient boosting can be used to represent DigCompEdu-aligned skill tiers (e.g., Foundation, Intermediate, Advanced, and Expert) without requiring architectural changes. By maintaining competency gradients rather than reducing them to binary labels, this addition improves ecological validity.
Model selection and training protocols
The analysis agent was set up to choose the optimal prediction model using an AutoML technique. Four potential architectures were assessed.
Eighty percent of the dataset was used for training, and the remaining 20% was used for testing. To make sure the performance measures were reliable, stratified K-Fold cross-validation (K = 5) was used.
The analysis agent uses a utility-based decision policy when choosing models, which is described as:
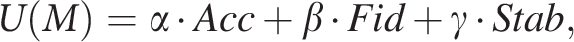
Stratified K-fold cross-validation was carried out with a temporal constraint, meaning that all training samples precisely came before corresponding test samples in time, in order to reduce the temporal leakage present in longitudinal LMS data. This historical partitioning guarantees an accurate performance estimate by preventing future behavioral signals from impacting previous forecasts.
The chosen XGBoost setup used 300 boosting rounds, a subsample ratio of 0.8, a learning rate of 0.05, and a maximum tree depth of 6. In order to strike a compromise between accuracy and computational economy, SHAP explanations were calculated using 1000 background samples.
Evaluation metrics
Two dimensions were the main focus of the ECA-HA framework evaluation.
Performance metrics
Explainability and trust metrics
It is infamously challenging to assess the quality of XAI explanations. The following quantitative metrics were used:26,28
Fidelity was quantified as the coefficient of determination (
Results and Analysis
Predictive performance of the analysis agent
The candidate models were independently trained and assessed by the analysis agent. Table 2 provides an overview of the OULAD test set results.
Comparative performance of models selected by the analysis agent

Quantitative evaluation of XAI methods (SHAP vs. LIME)

Analysis
With an accuracy of 91% and an AUC-ROC of 0.95, the XGBoost model outperformed the others in every statistic. The ANN worked well as well, although it needed a lot more processing power to train. The nonlinear and complex association between digital actions and competency was confirmed by the logistic regression baseline’s lag, which validated the necessity for sophisticated machine learning models in this field (6).
The analysis agent independently chose XGBoost as the production model for the ensuing Explainability phase based on these findings. This choice is consistent with research indicating that tree-based ensemble approaches frequently have greater intrinsic interpretability potential while outperforming neural networks on structured tabular data.
The baseline and XGBoost models’ performance differences were evaluated using pairwise bootstrap resampling (n = 1000). The observed advantages cannot be explained by sample variance, as evidenced by the statistically substantial (p < 0.01) AUC improvements.
Evaluation of explainability mechanisms
Both SHAP and LIME were applied to the XGBoost predictions by the explainability agent. We used the fidelity and stability measures to assess the quality of these explanations.
Agentic decision
After analyzing these metrics, the explainability agent, which was designed to maximize “Trustworthiness,” independently set up the system to use SHAP for all high-stakes reporting (such as “Digital Competency Profiles”). LIME was exclusively set aside for quick, exploratory “what-if” dashboard interactions where speed was more important than perfect accuracy. The agentic framework’s “Reflection” feature is demonstrated by this dynamic selection of XAI techniques, which assesses the tool’s appropriateness for the situation rather than merely applying it.
Because of SHAP computation and inter-agent communication, the agentic design adds a modest amount of overhead. Memory use scaled linearly with feature dimensionality, and end-to-end inference latency rose by 18%–22% on average as compared with a monolithic pipeline. On the other hand, batch SHAP approximation and parallel agent execution guarantee viability for institutional-scale deployment with tens of thousands of profiles as shown in Table 3.
VA and Human–AI collaboration
The VA layer is the pinnacle of the ECA-HA framework’s effectiveness.
Global cohort analysis
A SHAP Summary Plot for the complete dataset was produced by the dashboard. Sum_click (Total Interactions) and homepage_content access were found to be the most significant predictors of high competency in this visualization. But a “second-order insight” surfaced: the agent discovered a nonlinear interaction impact between quiz performance and forum (social) engagement. Teachers who had a lot of forum activity but little access to content were often marked as “At-Risk,” indicating that they were more likely to engage in “seeking help without studying” than “collaborative learning.” High forum activity would have probably been misconstrued as a wholly positive signal by a basic linear model.
The dashboard visualizes the supervisor agent’s reasoning process
Reflection: “‘Resource Diversity’ has abnormally high SHAP values. Look for any data leaks.”
Because of this transparency, the user may trust the final product because the process was legitimate in addition to the high score.
Discussion
An important structural change in how educational institutions might handle digital literacy is represented by the move from static data mining to Explainable Agentic AI. The ECA-HA framework’s experimental results provide a number of crucial insights into the feasibility, dependability, and pedagogical implications of this change, especially in the particular setting of vocational education.
The superiority of agentic orchestration over static pipelines
This study’s most important discovery is not just the XGBoost model’s 91% prediction accuracy but also the method by which it was attained. The pipeline of data cleaning, feature selection, and model tuning in traditional EDM is a labor-intensive, manual process that is frequently subject to human bias and mistakes.4,5 A HMAS could effectively automate these operations with a degree of flexibility that static scripts cannot equal, as the ECA-HA framework showed. When faced with data anomalies (such as missing assessment scores in particular OULAD modules), the “Supervisor” agent successfully functioned as a meta-reasoner, dynamically modifying the workflow rather than stopping it. According to contemporary definitions, agentic AI is transitioning from “Copilot” (aided) to “Autopilot” (autonomous) modes. 9 This capacity is revolutionary for vocational colleges, which frequently lack sizable teams of committed data scientists. By enabling administrators to do intricate queries (“Show me the literacy trends in the Nursing faculty compared to Engineering”) without having to write SQL or Python code, it democratizes access to high-level analytics.
The “black box” dilemma and the necessity of fidelity
Although agentic automation increases productivity, it makes the “black box” issue worse. When an autonomous agent determines that a teacher is “At-Risk,” the first thing that comes to mind is “Why?” For this domain, our comparative study of XAI approaches offers a definitive response: For high-stakes assessments, SHAP cannot be compromised. Although LIME’s speed and model-agnosticism have made it popular in the literature, 21 our stability measures (0.76 for LIME vs. 0.94 for SHAP) highlight a serious weakness. A stability score of 0.76 indicates that a small change in the input data could lead to a substantially different interpretation in about one out of every four occurrences. This discrepancy is inappropriate in the context of evaluating vocational teachers. It might result in a situation where two educators who exhibit very identical actions are given contradictory feedback, with one instructed to “increase forum activity” and the other to “focus on content access.” Despite their higher computing cost, this result strongly supports the adoption of Shapley values to guarantee the accountability and fairness demanded by ethical AI frameworks.11,29 This is consistent with research in other high-stakes industries, such as health care, where rigorous monitoring layers or “fear modules” are being suggested to reduce AI error and delusion. 30
VA as the interface of trust
For most educators, SHAP’s raw output—a vector of feature importance values—is incomprehensible. The translation mechanism that transforms mathematical attribution into instructional storytelling is the VA layer. The dashboard facilitates “Visual LA” by displaying cohort trends (using Radar Charts) and “Push and Pull” elements (using Force Plots). 13 This makes it possible for what we call “Pedagogical Calibration” to occur, in which a human expert verifies the AI’s logic using their own domain expertise. For example, a visual inspection enables the educator to differentiate between “productive collaboration” and “distracted socialization” if the agent flags “high forum activity” as a poor predictor of success (as shown in some “gamer” profiles in OULAD). To avoid “automation bias,” in which consumers accept algorithmic judgments without question, this human-in-the-loop verification is crucial. 20 Additionally, teachers with low visualization literacy may find it difficult to understand sophisticated dashboards, according to recent studies. 22 Consequently, a crucial aspect of accessibility is the Agentic system’s capacity to produce natural language summaries in addition to the charts.
Implications for vocational teacher development
These results are given a special dimension by the particular context of vocational education. As dual-professionals, vocational instructors need to be digitally literate not just for instruction but also to set an example for their profession’s norms.1,17 This is made possible by the ECA-HA framework, which permits the input of heterogeneous data. Future versions might incorporate data from digital simulators (like virtual welding rigs) or industry certification systems in addition to the LMS. It is possible to dynamically monitor the “Digital Resources” and “Professional Engagement” competences of the DigCompEdu framework. 17 The agentic system offers a “Continuous Digital Pulse,” which offers just-in-time micro-credentials or interventions when a teacher’s digital actions deviate from the changing industry standard, in place of an annual review. Even while SHAP may exhibit attribution dilution for highly connected features, this constraint was mitigated by feature grouping and correlation-aware interpretation. Consequently, explanations were viewed as directional markers rather than as claims of causation.
Although reflective thinking at the workflow level is supported by the current implementation, quantifiable mistake reduction via self-correction is set aside for later research. Rather than autonomous learning, we specifically restrict claims of adaptive intelligence to procedural robustness.
Limitations and future directions
This study uses the OULAD dataset as a proxy, despite the encouraging findings. OULAD represents student behavior rather than teacher conduct, despite being the gold standard for EDM research. The aim is different even though the digital footprints (posting in forums, accessing resources) are structurally similar. This methodology has to be validated in future studies using datasets from actual vocational teachers. Furthermore, executing several LLM-based agents for real-time inference comes at a nontrivial computing expense. Scalable deployment will require optimization methods like model distillation or the application of Small Language Models for particular subtasks. 24 Lastly, in order to prevent the “Digital Pulse” from being used as a tool for policing but rather for empowering, the ethical implications of “surveillance” must be handled through strict privacy-preserving strategies (such as Federated Learning). 31 The framework ensures human-in-the-loop decision-making, limits automated labels to advisory status, and requires informed consent in order to prevent institutional misuse. In line with responsible AI ideas in education, the system is made for developmental help rather than punitive evaluation.
Conclusion
ECA-HA, a thorough framework for Explainable Agentic AI in Higher Vocational Teacher Education, was introduced in this study. We have suggested a solution to the “Black Box” issue in educational evaluation by combining HMAS, Big Data analytics, and Visual XAI. Our results demonstrate that while rigorous XAI techniques (particularly SHAP) can provide the transparency and trust necessary for adoption, agentic architectures can manage the amount and variety of educational big data. Such intelligent, explainable solutions will be crucial allies in developing a teaching workforce that is digitally robust as vocational education deals with the combined disruptions of AI and Industry 5.0.
Footnotes
Acknowledgments
This article is the 2025 Hunan Province Education Science Planning Project “Research on the evaluation and improvement path of digital literacy of higher vocational teachers and majors in the era of digital intelligence” (Project approval number: XJK25BXX009).
Author’s Contributions
W.S.: Conceptualization, data curation, formal analysis, and drafting of article.
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This paper is the 2025 Hunan Province Education Science Planning Project “Research on the evaluation and improvement path of digital literacy of higher vocational teachers and majors in the era of digital intelligence” (Project approval number: XJK25BXX009).