
Abstract
Patent text segmentation is a fundamental task in patent data mining, enabling applications such as patent analysis and search. The objective is to decompose structurally complex, lengthy sentences into grammatically complete, semantically equivalent short sentences to facilitate downstream processing. Traditional approaches rely on manually defined rules or feature-based machine learning methods, which are labor-intensive, domain-specific, and exhibit limited generalizability. To overcome these limitations, this study proposes a Deep Segmentation Model for Patent Text (DS2PT), a two-stage fine-grained segmentation framework based on ALBERT. The first stage employs a conditional random field model to perform coarse segmentation of patent paragraphs into shorter clauses based on structural cues. The second stage utilizes the ALBERT model to perform deep, context-aware segmentation of complex clauses into syntactically independent and semantically complete sentences. Compared to conventional methods, DS2PT effectively captures hierarchical contextual information across two stages, significantly improving segmentation accuracy without semantic loss. Furthermore, this research draws inspiration from advancements in cross-lingual speech-to-text systems with low-latency neural networks for real-time applications. While the domains differ, the core technical challenges are analogous: both require models to process sequential, information-dense input (audio streams or long sentences) into structured, meaningful units (transcribed text or segmented clauses) with high accuracy and efficiency. The principles of low-latency neural networks—such as efficient context modeling, parallelizable architectures, and real-time incremental processing—inform the design of our segmentation pipeline to enhance its scalability and potential for integration into real-time patent analysis systems. Similarly, the cross-lingual capability highlights the importance of model generalization, which aligns with our goal of developing a domain-adaptive segmentation tool for diverse patent corpora.
Keywords
Introduction
Patent text segmentation is an important prerequisite for patent analysis and mining activities. Its task is to segment and simplify complex patent text, so that the segmented patent text is easy to be further analyzed and processed by computer-aided patent analysis tools. As for the domain of cross-lingual speech-to-text systems with low-latency neural networks for real-time applications, the task of patent text segmentation has the analogous core technical challenges: both require models to process sequential, information-dense input (audio streams or long sentences) into structured, meaningful units (transcribed text or segmented clauses) with high accuracy and efficiency.1,2 Patent text segmentation is relatively complex, which is reflected in the structural complexity on the one hand and the interdisciplinary nature on the other hand, which makes the task of segmentation challenging and difficult.3,4 Current patent-oriented text segmentation research is mainly divided into three categories: rule-based method,5–10 machine learning-based method,11–15 and shallow artificial neural method. 16 Early research work either required expert experience or complex feature template engineering. In recent years, some researchers have introduced the artificial neural network model into the research of patent text segmentation, by fusing the word vector into the sentence feature representation, and then building a special and shallow artificial neural network to achieve patent paragraph segmentation.
To solve the problem of poor readability of patent text due to long sentences and the complex structure of patent text paragraphs, a two-stage progressive Deep Segmentation Model for Patent Text (DS2PT) is proposed to transform the text segmentation problem into a sequential labeling problem. First, considering the structural characteristics of patent text, the patent text paragraphs are segmented into short and different sentences based on conditional random field (CRF). Then, it is further segmented into syntactically and structurally independent short sentences based on the ALBERT-CRF model. The experimental results show that compared with the traditional machine learning text segmentation method, the DS2PT model can effectively obtain the context information of patent documents and has better overall segmentation performance.
The subsequent work of this work is listed as follows: The second part introduces the related research work of patent text segmentation. The third part introduces the patent deep segmentation model and two basic models, CRF and ALBERT. The fourth part illustrates the superiority of the proposed model by comparing several basic text segmentation models. The fifth part summarizes the work of this study.
Related Work
The task of patent text segmentation is to segment and simplify complex patent text, so that the segmented patent text is easy to be further analyzed and processed by computer-aided patent analysis tools, which is a highly challenging task. On the one hand, the structure of patent text is too complicated; on the other hand, patent text has interdisciplinary characteristics, involving linguistics, computer science, biology, mechanics, and so on, which makes the current patent text segmentation challenging and difficult.
Patent text segmentation is a subfield of text segmentation, which also follows the development route of text segmentation technology. Current patent-oriented text segmentation research is mainly divided into three categories: rule-based approach,5–10 machine learning-based approach,11–15 and artificial neural approach. 16
Early patent text segmentation relied on human-defined rules. Fujii and Takaki 5 and Takaki et al. 6 divided Japanese patent claims with punctuation symbols as separators and used the sentence similarity after segmentation to measure the similarity of the whole sentence. Shinmori and Sheremetyeva7,8 divided patent claims into several short sentences and claim terms according to the rules of English patent organizational structure, such as various punctuation marks, lists, and symbols at the beginning of paragraphs, and visualized the relationship between patent structure and terms. Kim and Agatonovic9,10 set up a grammatical rule set based on patterns and prompt words. This information, which separates the patent documents of the United States Patent and Trademark Office (USPTO) and the European Patent Office (EPO), belongs to the category of rule-based information extraction methods.
Most of the research work is still based on feature engineering and machine learning methods. Gabriela et al. 11 proposed a text segmentation algorithm to improve the readability of patent claims. The segmentation method consists of two steps: First, the claims are divided into preamble, transitional phrase, and body by rules. Second, a machine learning model called CRFs is used to segment sentences into small clauses. Ding and Sofean12–14 proposed an automatic segmentation method for patent big data, and the cut substructure can be used for information retrieval and information extraction. The approach first specifies guidelines for splitting paragraphs in the patent description section and then combines ontology rules, machine learning techniques, and heuristic discovery methods to identify individual subsections. Zhang 15 proposed an English long and short sentence recognition and segmentation method based on machine translation. Based on the NTCIR-9 patent dataset, the method combined rule matching and data-driven approaches and achieved better performance than Baidu’s online translation platform on the test dataset.
However, there are few researches of patent text segmentation on neural network models. Danilo et al. 16 proposed a patent text segmentation method with word order probability based on structural artificial neural networks. In paragraph and sentence-level segmentation, this method fuses word vectors into sentence feature representation and uses them as sequence classification features to determine sentence boundaries. By analyzing the structure of patent text, deep neural network model and natural language processing (NLP) processing technology are used to fully excavate and segment the segmented phrase blocks. However, all previous related work has been based on shallow neural network models to complete patent segmentation tasks. In this article, we propose a high-level hybrid neural network model to elevate the patent segmentation task to a higher level.
DS2PT Model
This study proposes a two-stage and progressive DS2PT, which converts the text segmentation problem into a sequence annotation problem, and comprehensively utilizes machine learning and deep learning techniques to gradually complete the fine-grained segmentation of patent text. The DS2PT model consists of two modules: coarse segmentation and fine segmentation. Coarse segmentation refers to the syntactic segmentation of long patent sentences; fine segmentation involves dividing long sentences into shorter ones; the output of the former’s processing results serves as the input for the latter’s model.
The corresponding model is shown in Figure 1.

Frame diagram of the patent text depth segmentation method. CRF, conditional random field.
According to the characteristics of patent text structure, the former uses CRF to divide the paragraphs of patent claims into short sentences. The latter uses a neural network model to further segment the patented long sentences into syntactically and structurally independent, complete short sentences. After rough segmentation pre-processing (such as word segmentation and labeling), the claims are input to the CRF-based rough segmentation module. The claims are processed by CRF’s rough segmentation module to obtain a number of sentences of varying lengths, and then the sentences whose length exceeds a certain threshold are further segmented, while the sentences whose length is less than the threshold are directly used as the output of the patent text deep segmentation method. The long sentences output by the coarse segmentation module are input to the fine segmentation module, which is based on the deep learning framework after the fine segmentation pre-processing (such as word segmentation, annotation, and word embedding). Finally, according to the sufficient hardware resources, different deep learning frameworks are selected to complete the semantic segmentation of long sentences in the fine segmentation module.
Coarse segmentation module
Coarse segmentation formulation
The coarse segmentation refers to the syntactic segmentation of long patent sentences. The coarse segmentation module divides the entire patent claim into multiple sentences of varying lengths. The output of the coarse segmentation module’s processing results serves as the input for the fine segmentation module’s model. Figure 2 is a schematic diagram of a typical patent claim before and after rough segmentation. The text of the claim is derived from IPC: A46B5/00 of the patent document USPTO.
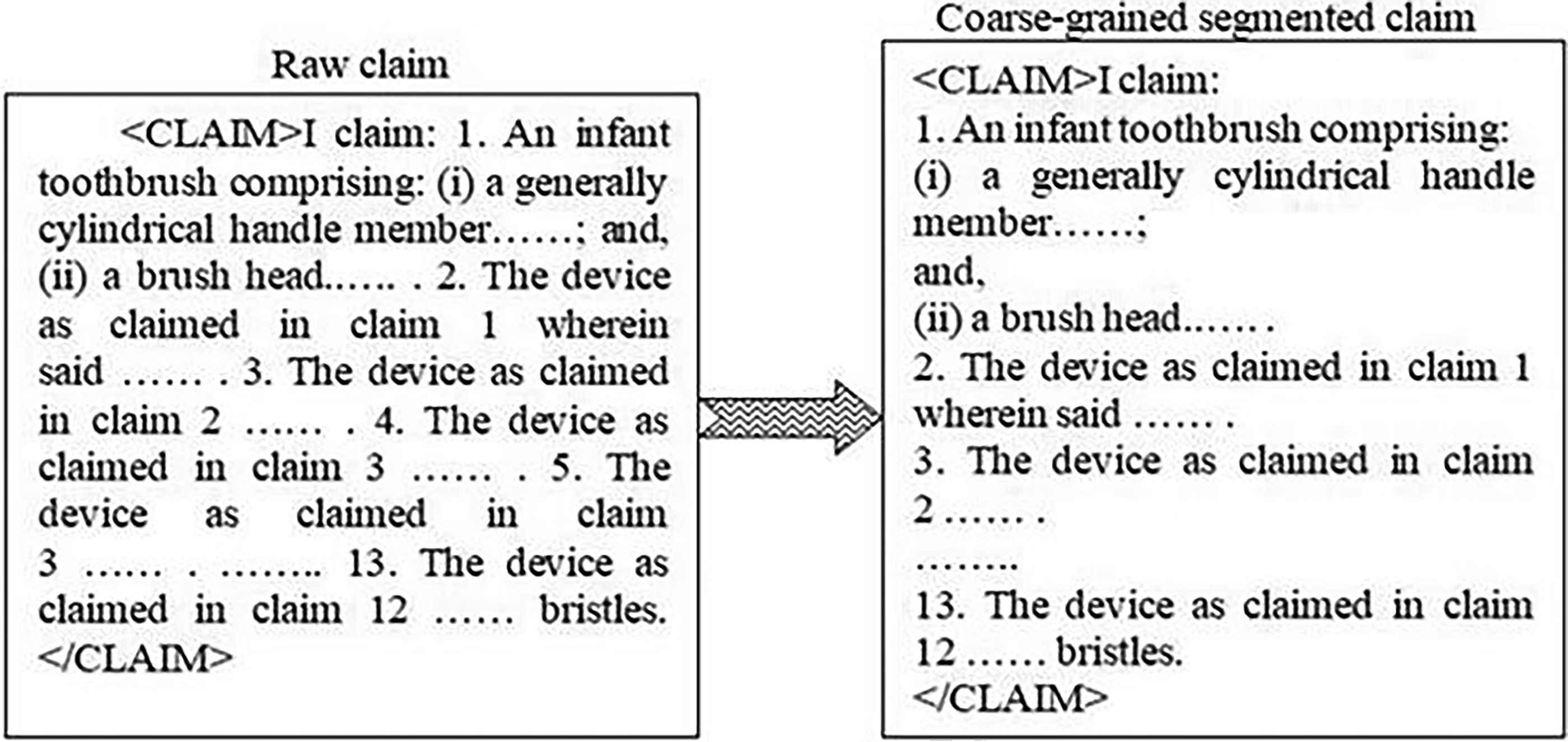
Example of coarse segmentation of claims.
The input to the coarse partition module is a complete claim, which is formalized as:
From the above formal description, the rough segmentation can be converted into a sequence labeling task, and the words, numbers, and punctuation marks in the whole paragraph of the claim are input into the CRF model. The CRF model learns the sequence context features by pre-setting the feature template, makes label prediction, and divides the entire claim into several sentences of varying lengths by using the splitter.
The annotation mechanism, feature extraction, and CRF model theory involved in the coarse segmentation module are described in the following sections.
“SO” annotation mechanism
A patent claim contains a main claim and several dependent claims. The main claim description is the core of the patent claims and even the whole patent text, and the other subsidiary claim description is the detailed explanation and supplement to the main claim description.
There are various types of separators between the main claim and several subsidiary claims, such as punctuation “:,” “.,” “,” and so on, a list of options “(a),” “a),” “(1),” “1),” “(I),” such as a specific word “o,” “comprising,” “containing,” and so on. These punctuation marks, option lists, and specific words can be used as proprietary coarse-split character sets.
In view of the organizational characteristics of claims and patent texts, this study focuses on designing an “SO” labeling mechanism, 17 where “S” represents delimiter and “O” represents non-delimiter. In the implementation of the rough segmentation module, by training and predicting the text sequence of patent claims with “SO” label, the characters separating the preceding and following paragraphs or sentences in the text sequence of patent claims are identified and used as prediction separators to achieve rough segmentation. Therefore, we can transform the rough segmentation into the problem of character binary classification in the sequence labeling model.
The patent claims are segmented by NLP tool and then marked based on the “SO” marking mechanism, and the marking sequence with “SO” is obtained. In the labeled sequence, the word or symbol marked with “S” is the segmentation point of the sequence, and the word or symbol marked with “O” represents the non-segmentation point.
A typical example of a patent claim is shown in Figure 3.

Example of “SO” marking in patent claims.
Therefore, the rough segmentation module is divided into two stages: training and segmentation, and the corresponding process framework of the two stages is shown in Figure 4.

CRF training and segmentation diagram of rough segmentation.
As shown in Figure 4, in the training stage, the claims are pre-processed by a series of texts and combined with the patent rough segmentation feature template to obtain a CRF model with well-trained parameters. In the segmentation stage, the trained CRF model is used to predict the label corresponding to the claim sequence, and the above sequence is divided into several sentences of different lengths by the label as the separator of the prediction, so as to complete the rough segmentation of the patent text.
Fine segmentation module
The fine segmentation involves dividing long sentences into shorter ones, whose input is from the output of the former’s processing results. Although several sentences of varying lengths can be obtained through the rough segmentation module, there are still some sentences with relatively complex sentence structure due to excessive segmentation granularity. These sentences with complex structure are difficult to be directly processed by NLP tools, which affects the performance of a series of related subtasks such as patent analysis, mining, and retrieval to some extent. Therefore, we still need further fine-grained segmentation of patent long sentences that exceed a certain length threshold.
In the rough segmentation module, CRF focuses on identifying the single separator between paragraphs and sentences, and the corresponding context features are simple, obvious, and easy to capture, so the rough segmentation effect is better. In the fine segmentation module, a complex long sentence is formed by connecting several short sentences through one or more segmentation blocks, and these segmentation blocks are often multiple consecutive words with complex and obscure context features, which are not easy to characterize and capture. Therefore, the traditional CRF model is relatively poor when applied to the fine segmentation task.
Since the features of deep learning models are self-learning, it is not necessary to design feature templates like those required by traditional machine learning CRF, so that complex and obscure features of text context can be captured. Therefore, this module proposes a hybrid neural network model based on deep learning for patent text segmentation.
Fine segmentation formulation
In the fine segmentation module, the deep learning model can self-learn the complex features of the segmentation phrase block context in long sentences without designing complicated feature templates. The input of the fine segmentation module is a long sentence with complex sentence structure, which is formalized as:
From the above formal description, the fine segmentation can also be converted into a sequence annotation task, and the sequence words of long sentences are input into the deep learning neural network model after word embedding. The neural network model learns the context features by means of its own structure. Therefore, CRF is introduced to constrain the label prediction of adjacent words, in order to achieve the optimal prediction of the whole sentence sequence label. Then the prediction label sequence is post-processed, and the sequences predicted as segmented phrase blocks are segmented. At this point, a long, complex sentence is divided into several short sentences with complete grammatical structure.
This section continues with several important parts related to the segmentation task, including the segmentation of the phrase block, the IOBES-based labeling mechanism, and the neural network framework.
Segmentation of phrase blocks
Long sentences in patent claims contain a lot of connective words that connect different sentence components, and these connective words can connect parallel structures, such as “and,” “but,” “as well as,” “while,” “thereby,” and so on. Adverbial structures can be connected, such as “so as to,” “so that,” “in order to,” “when,” “wherein,” “for,” “to,” “in,” “upon,” and so on. Attributive clause structures can be connected, such as “that,” “which,” “whose,” and so on. Some connectives are unique to patent documents, including “is,” “say,” “form,” “characterize,” “have,” “consist of,” and “contain.” Some sentences in patent claims are more than 200 characters in length due to the use of the above connectives, which is not convenient for patent analysis and patent mining and other downstream tasks. Through the statistics and analysis of patent text, we find that these connectives only satisfy the writing style of patent text in terms of syntactic structure, but have no actual intrinsic meaning.
In this study, the conjunctions inside these long sentences is used as phrase blocks to simplify the patent text structure without semantic loss by identifying and deleting these phrase blocks. Different from the work of Gabriela et al., 11 which only identified single segmentation words, this study considers both common connective words and patent-specific connective words to segment long sentences in the claims in a fine-grained way.
“IOBES” annotation mechanism
Different from the binary classification mechanism of the coarse segmentation module, the segmented phrase block used by the fine segmentation module may contain multiple words. Considering that IOBES possessing stronger rule-based constraint capabilities has a stronger degree of differentiation than other labeling mechanisms, 18 we adopted IOBES labeling mechanism. A phrase segment starts with B tag and ends with E tag. The middle character of the statement block is marked with consecutive I, which is a common tagging method in part-of-speech (PoS) tagging, NER, and other sequential tagging tasks. Figure 5 is a schematic illustration of an example of IOBES labeling used in a fine segmentation module for long sentences of patent claims.

Schematic diagram of IOBES annotation in the fine segmentation module.
In Figure 5, the red “O” represents the non-segmented statement block, “through which” is the attributive clause connecting phrase, “through” is marked as the beginning character “B” of the segmented phrase block, and “which” is marked as the end character “E” of the segmented phrase block. By identifying the segmented phrase block, the long sentence is divided into two short sentences that are grammatically and structurally independent, which is convenient for further processing by the next subtask.
ALBERT-CRF model
Our “DS2PT” model proposed in this study comprises two core parts: BERT 19 and CRF. BERT is a deep bidirectional link of several underlying transformer structures. Since BERT was released in 2018, several deep learning models combined with BERT have appeared at home and abroad, and corresponding research results have been achieved.20–22 Due to the excellent performance of BERT model in many NLP tasks since its release, this study continues to try to propose a BERT-CRF-based neural network architecture in the fine segmentation stage. The framework introduces the BERT model in the word embedding stage for dynamic word embedding. Since BERT is a multi-semantic large-scale language model based on multi-corpus environment learning, it can bidirectionally learn multi-semantic features of context through the multi-layer superimposed transformer structure when the dynamic words of patent long sentences are embedded. The CRF layer accepts multiple semantic features of BERT as input and outputs the entity label sequence with maximum probability through the label constraint relationship. Finally, the segmented phrase blocks in the sequence are identified by a post-processing program to achieve semantic segmentation of long sentences.
The segmentation framework based on BERT-CRF is shown in Figure 6.
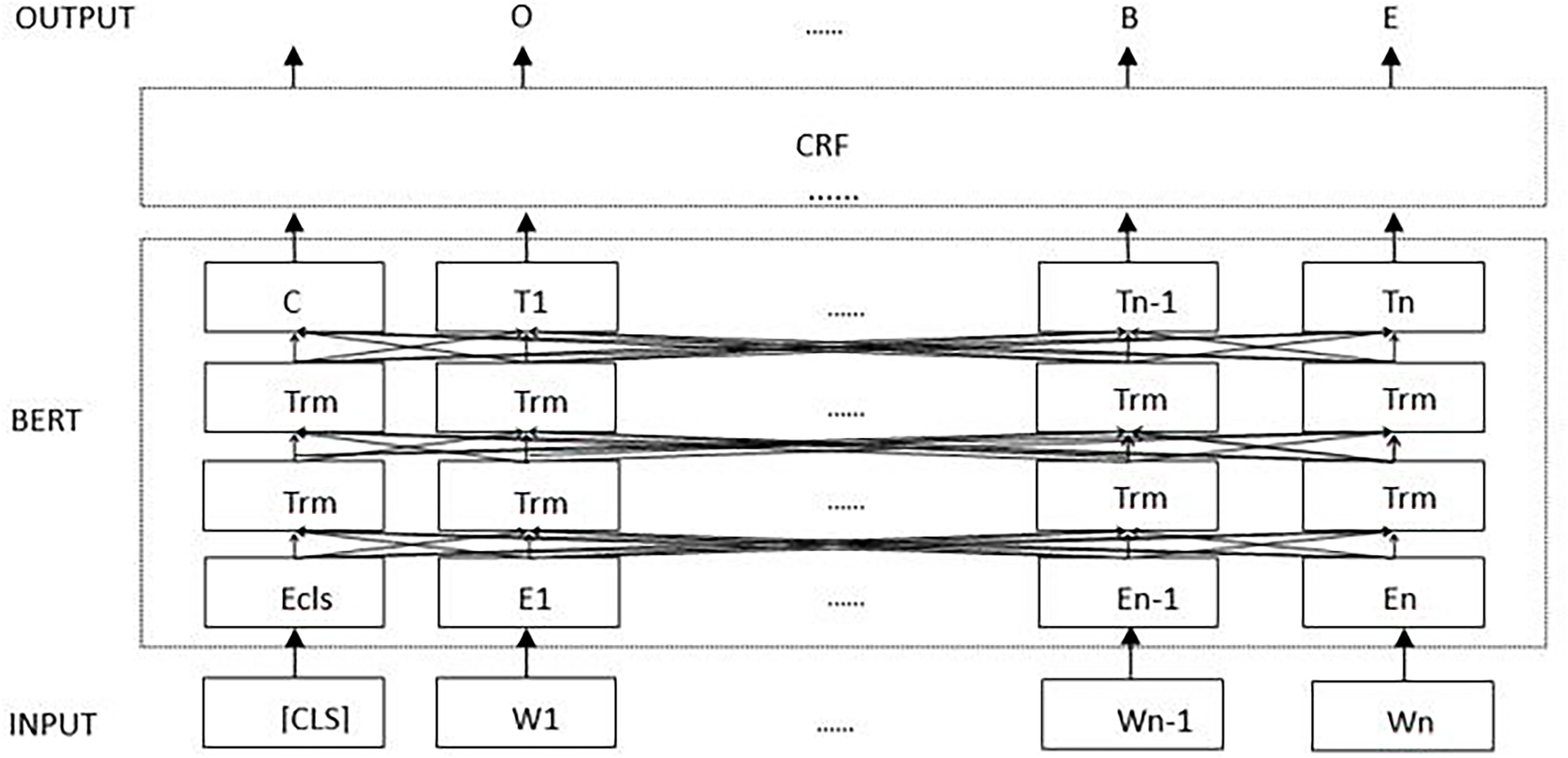
Schematic diagram of the patent text segmentation model based on BERT-CRF.
As shown in Figure 6, the CRF layer takes the sequence
In Figure 6, when the BERT model is used for tasks such as sequence annotation and sentence classification, the “CLS” identifier needs to be added at the beginning of the sentence. Long sentences in patent claims are pre-processed by NLP toolkit as inputs to the ALBERT-CRF framework, and their input sequences can be represented as
Experimental Results and Analysis
Coarse segmentation experiment
Coarse segmentation experiment setup
At present, there are relatively few researches on patent-oriented text segmentation. As a result, datasets for the study of patent text segmentation are extremely scarce. This section constructs datasets for patent rough segmentation. The specific method is to download the patent dataset NTCIR 2002 from the official website of USPTO for researchers to use for research. A random sample of 1100 patent claims in text format that were granted prior to 2016. According to the rough segmentation sequence labeling rules, the above patent data are segmented and labeled, and the NLP tool is used for word segmentation and PoS labeling, and the dataset of rough segmentation experiment is finally obtained. In the rough segmentation stage, the datasets of the above 1100 labeled claims are divided into training sets, verification sets, and test sets with a ratio of 6:2:2, and then the CRF model is used for training and testing.
The hardware platform implemented by all programs in this section is based on Dell’s NVIDIA Quadro P2000 small workstation, and its multi-core graphics card is suitable for high-speed parallel computing on a deep learning platform. The fine segmentation module uses the deep learning platform toolkit TensorFlow 1.4.0 developed by Google, and the coarse segmentation module uses the classifier Sklearn-crfsuite, which is a lightweight stochastic conditional field development library based on crf_suite, being open source by Naoaki Okazaki, University of Tokyo, Japan. The NLP word segmentation toolkit is the NLTK 3.0 version of Gensim, the development language is Python 3.5, and the tool management platform is Anaconda 5.2 installed under Windows 10.
In the coarse segmentation module, several hyperparameters corresponding to the CRF model are shown in Table 1.
Conditional random field parameters of coarse segmentation model

In Table 1, algorithm is set to “lbfgs,” indicating that the CRF model is trained using the quasi-Newton gradient descent algorithm, which is less affected by storage space conditions. L1 and L2 are regularization coefficients used to prevent overfitting during model training, and their values are both set to 0.1. Max_iterations represents the maximum number of iterations for model training, set to 100. All_possible_translations indicates whether all transition state probabilities are calculated for a given input state, and its value is set to true.
The two modules designed in this study are both implemented through sequence labeling-based classification problems, and the evaluation indicators can be precision (P), recall (R), and F1 score (F1), which are important evaluation indicators for information retrieval models and statistical classification models.
Experimental results and analysis
This study addresses the problem of patent text coarse segmentation and word sequence annotation using the CRF model. To achieve this, some common sequence annotation methods are used as benchmark models, such as rule-based methods, 14 Bayes, 23 HMM, 24 and support vector machine (SVM). 25 By comparing with several benchmark models in experiments, the effectiveness of the coarse segmentation model is verified.
The experimental results of the CRF 26 model used in the coarse segmentation module and several other benchmark comparison models on the test dataset are shown in Table 2.
Experimental results of rough segmentation

CRF, conditional random field; F1, F1 score; P, precision; R, recall; SVM, support vector machine.
According to Table 3, CRF was used for rough segmentation of patent text in this section, and compared with other benchmark models, CRF had the best average performance. Compared to the SVM model with an F1 value of 0.984 and the CRF model with an F1 value of 1.000, this performance metric has improved by 1.63%. The precision and recall performance of the CRF model are also good, with both performance values approaching the optimal value of 1.0 for other models. The three performance evaluation indicators indicate that CRF can effectively identify the segmentation point features of the claims sequence in the coarse segmentation module, thereby efficiently achieving the coarse segmentation task. Exploring its reasons may be that compared to other benchmark models, the CRF model is a set of random variables that come from the training sample space and have certain dependencies on the time series. After introducing the transition models of observation sequence and state sequence with accompanying variables, the dependency and constraint relationship between states can be better reflected, which can maximize the conditional probability of the predicted values of the entire sequence.
Patent text segmentation BERT parameters

For rule-based methods, the overall performance is the worst. Setting rules requires manual involvement, and rule-based methods have limited segmentation effectiveness when patent writing styles change or when patent research fields are altered. Bayes and HMM exhibit excellent performance in precision values, but perform slightly worse in recall and F1 values.
SVM performs second only to CRF in various evaluation metrics, which may be related to the model characteristics of SVM itself. SVM uses an inner product kernel function to non-linearly map to high-dimensional space, selecting some boundary support vectors from several support vector sets to minimize the vertical distance in the hyperplane, making it particularly suitable for small sample statistical learning classification; SVM does not involve probability measures and avoids the inductive reasoning process in machine learning, fundamentally simplifying classification and regression problems. Therefore, SVM has certain robustness on small sample test datasets.
Fine segmentation experiment
Dataset and experimental setup
Coarse segmentation focuses on paragraph and sentence segmentation and lacks segmentation processing within complex and long sentences; some of the output sentence lengths are still relatively long, which affects the progress of related subtasks such as patent text mining and retrieval in the future. Therefore, in this section, 12,845 patent long sentences with lengths greater than the preset threshold were selected from several sentences with different lengths output by the coarse segmentation module. Then, the NLTK toolkit was used for word segmentation and PoS tagging. Based on the IOBES tagging mechanism, manual tagging was performed on the long patent sentences mentioned above. The annotated data obtained were used as the experimental dataset for the fine segmentation module in this section. Similarly, this dataset is divided into a training set, a validation set, and a testing set with a ratio of 6:2:2 for the training, validation, and testing of various models. The evaluation indicators will continue to use precision, recall, and F1 values.
The experiment was conducted on Dell’s NVIDIA Quadro P2000 small workstation, using Python 3.6 programming language and PyTorch 1.3.0 deep learning framework. The basic BERT model was “BERT-base truncated,” and Adam was selected as the optimization model. The learning rate was set to 0.00005, the batch size was set to 20, and the maximum sequence length was set to 100. CRF calls pytorch-crf version 0.7.2, with a learning rate set to 0.001. The BERT parameters used for the fine segmentation of patent text are shown in Table 3.
Experimental results and analysis
In the patent text segmentation module, long sentence segmentation is essentially a sequence labeling classification problem. Therefore, we have chosen some commonly used sequence annotation methods as benchmark models, such as HMM, 24 CRF, 26 BiLSTM-CRF, and ALBERT-CRF. The experimental results comparing the fine segmentation stage with the benchmark model are shown in Table 4.
Comparative experimental results of fine segmentation stages
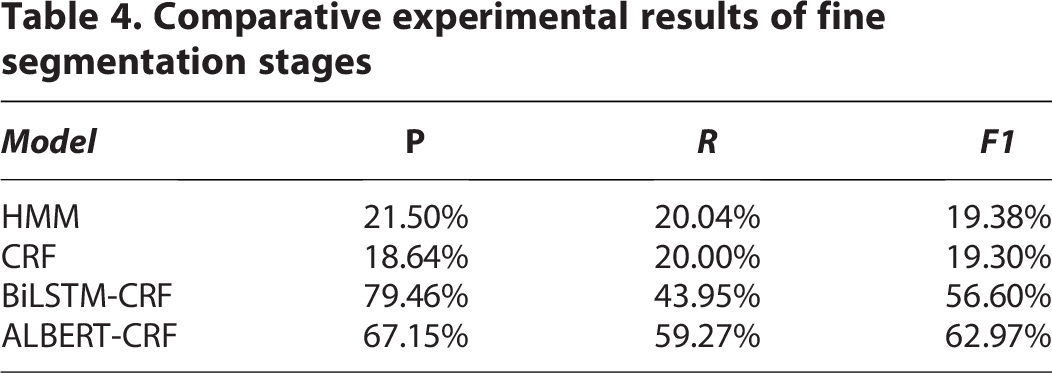
According to Table 4, the ALBERT-CRF model performs the best in recall, reaching 59.27%. Compared to the BiLSTM-CRF model, which achieved 43.95%, it improved by 34.86%. In addition, the ALBERT-CRF model achieved the best performance of 62.97% in terms of F1 score, which is an improvement of 11.25% compared to the BiLSTM-CRF model with 56.60%. In terms of precision, BiLSTM performed the best, reaching 79.46%. Compared to the ALBERT-CRF model, the performance has increased by 18.33%. When two traditional machine learning models, CRF and HMM are used for patent long sentence segmentation tasks, their performance in various indicators is poor.
From the above analysis, it can be seen that deep learning models are significantly superior to traditional machine learning algorithms in the task of fine segmentation of long sentences in patent texts. Compared to traditional machine learning models, the deep learning model proposed in this section has two advantages: first, it can self-learn contextual features based on semantic word vectors; second, the ALBERT neural network can capture the contextual information of segmented phrase blocks in long patent sentences in both directions.
When both deep learning frameworks are used for fine segmentation tasks, BiLSTM-CRF and ALBERT-CRF have their own performance advantages and disadvantages. The former is significantly better than the latter in precision, while the latter is significantly better than the former in recall and F1 values. By analyzing the structure of the neural network model, it can be seen that compared to BERT-CRF, the BiLSTM-CRF model has smaller training parameters and shorter training time. Therefore, in cases where segmentation performance requirements are not particularly high, it is recommended to use the lightweight BiLSTM-CRF framework for patent text segmentation. When high segmentation accuracy is required, and hardware resources are abundant, it is recommended to use the BERT-CRF framework. Although it occupies more space and the architecture is relatively complex, this architecture extracts finer features and performs better in subsequent segmentation tasks.
Due to the different neural network structures of these two models, the hardware resource overhead required for model training and operation also differs significantly. Therefore, the above two models have different application scenarios.
The impact of BERT model selection
The four BERT models used in this section are BERT model, 19 ALBERT model, 27 DistilBERT model, 28 and RoBERTa model. 29 The first model is the basic BERT model, and the last three are improved versions of the basic BERT model, as shown in Table 5.
Super-parameter values of four BERT models

The BERT model is composed of multiple transformers stacked and combined, resulting in a large number of training parameters and limited training scale due to GPU or TPU capacity, thus having certain drawbacks. Subsequently, many research works have emerged to reduce the parameters of BERT models, such as DistilBERT, RoBERTa, and ALBERT. The DistilBERT model is an improved distillation version that uses a student model to learn the output of the teacher model, thereby achieving parameter scale compression and reduced computational complexity. On the one hand, the ALBERT model reduces parameter dimensions through word embedding parameter factorization, and on the other hand, by sharing parameters across layers and achieving paragraph continuity tasks, the improved model has smaller parameters, faster speed, and better performance. The RoBERTa model does not fundamentally improve the model structure but only increases the volume of training corpus, giving the corresponding version of the BERT model stronger learning ability.
This study analyzes the impact of different BERT models on patent segmentation experiments, and the experimental results are shown in Table 6.
Experimental results of BERT-CRF-based model

According to Table 6, the ALBERT-CRF model has the best average performance, reaching 59.27% and 62.97% in F1 score and recall, respectively, but poor in precision. The suboptimal DISTILBERT-CRF model has F1 and recall values of 56.92% and 47.14%, respectively, but performs the best in precision value, reaching 71.82%. The basic version of the BERT-CRF fine segmentation model performs the worst, with precision, recall, and F1 values of 62.25%, 45.04%, and 52.26%, respectively.
In the fine segmentation module, the ALBERT pre-trained model is used to achieve the best average performance. The reason for this may be that the model uses matrix decomposition and parameter sharing during training, which reduces the size and training time of the model while also improving performance. The RoBERTa model only expands the training scale and does not substantially improve the basic BERT model. Compared to the other two improved versions of the BERT model, the RoBERTa model showed limited performance improvements in three evaluation metrics, with 12.27%, 2.20%, and 6.20%, which are close to theoretical expectations. The DistilBERT model based on distillation technology is a student model guided by the teacher model for a specific subtask. Although its overall performance has been improved, compared to the ALBERT model, its performance is not optimal.
Conclusion and Summarization
Our model of DS2PT proposes a two-stage, progressive patent text deep segmentation method, aiming to process sequential, information-dense input (long sentences) into structured, meaningful units (segmented clauses) with high accuracy and efficiency. Similar to the domain of cross-lingual speech-to-text systems with low-latency neural networks for real-time applications, the task of patent text segmentation has analogous core technical challenges. Our DS2PT model consists of two modules: coarse segmentation and fine segmentation. The coarse segmentation module uses CRF to segment the entire patent claims into several sentences of varying lengths, taking into account the structural characteristics of the patent claims. The fine segmentation module uses the ALBERT-CRF neural network framework to identify segmented phrase blocks in long sentences and perform semantic segmentation on the roughly segmented patent long sentences. Based on this, several grammatically complete and syntactic independent short sentences are obtained. The neural network framework in the fine segmentation module can deeply and adaptively learn the contextual semantic features of segmented phrase blocks for connecting short sentences before and after long patent sentences. Compared with the traditional machine learning methods for text segmentation, our DS2PT model can effectively obtain the context information of patent documents and has better overall segmentation performance. Therefore, our DS2PT model can achieve relatively good performance on self-built patent segmentation datasets, although it may require the consumption of certain resources.
Authors’ Contributions
B.G.: Conceptualization, methodology, validation, investigation, resources, data curation, and writing—original draft preparation. H.W.: Software and validation. P.Z.: Validation. J.X.: Conceptualization, writing—review and editing, supervision, and project administration. All authors reviewed the results and approved the final version of the article.
Availability of Data and Materials
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.
Footnotes
Author Disclosure Statement
The authors declare no conflicts of interest to report regarding the present study.
Funding Information
The authors received no specific funding for this study.