
Abstract
Background:
Obesity is a major global health challenge with significant metabolic and cardiovascular consequences. Artificial intelligence (AI) offers novel opportunities for prediction, risk stratification, and management; however, the structural landscape of this research has not been comprehensively assessed.
Methods:
We conducted a bibliometric analysis of 5893 unique articles from 2015 to July 15th, 2025, indexed in Web of Science and Scopus. We used R (Bibliometrix and Biblioshiny) and VOSviewer to evaluate publication trends, citations, collaborations, and thematic clusters. Data integrity was verified by dual review of 5% of studies.
Results:
Scientific output rose steadily, with a marked acceleration after 2019. Citation activity peaked in 2020, reflecting increased focus on digital health during the Coronavirus Disease 2019 (COVID-19) pandemic. Thematic mapping identified four main clusters: (1) AI in surgical outcomes, including bariatric surgery and risk prediction; (2) digital health and remote care; (3) conversational technologies like natural language processing and chatbots; and (4) precision health, focusing on personalized medicine and predictive analytics. Collaboration networks were sparse, with few prolific authors.
Conclusions:
AI research in obesity is expanding rapidly across diverse themes but remains fragmented. Strengthening interdisciplinary collaboration will be critical to maximize impact on obesity care and outcomes.
Keywords
Introduction
Obesity is a multifactorial condition influenced by genetic, biochemical, cultural, and behavioral determinants and remains one of the most pressing global health challenges of the 21st century. 1 Its widespread implications span from adverse birthweight outcomes linked to maternal prepregnancy body mass index, 2 to the elevation of abnormal cardiac function in children, 3 and the increased risk of chronic metabolic disorders such as type 2 diabetes mellitus. 4 Moreover, obesity is associated with heightened susceptibility to several cancers, including colorectal cancer, and contributes substantially to all-cause mortality.5,6 In response to this escalating burden, therapeutic strategies such as bariatric surgery have become essential interventions for achieving sustained weight reduction and normalization of key biochemical markers, particularly in cases of morbid obesity. 1
Amid this escalating challenge, artificial intelligence (AI) has emerged as a transformative paradigm in health sciences, offering unprecedented capabilities in disease modeling, prediction, and decision support. The intersection of obesity and AI is compelling due to their shared multimodal nature: obesity manifests through diverse etiological pathways and clinical presentations, while AI offers a spectrum of computational methodologies for diagnosis, prevention, and personalized management.7–9 This intersection marks a critical shift in how complex health conditions are studied and addressed. Machine learning and related AI techniques have demonstrated promise in automating screening and diagnostic workflows, mitigating algorithmic bias, and enhancing prediction of obesity-related health outcomes. 10 Additionally, AI contributes to individualized risk stratification and tailored intervention strategies for comorbid conditions such as cardiovascular disease. 7 Studies also point to patient-facing and digital approaches. Asensio-Cuesta et al. 11 introduced a user-centered chatbot (Wakamola) to capture linked behavioral and environmental data for obesity research, and Koo et al. 12 reviewed emerging telehealth and AI-driven strategies for obesity management, highlighting remote monitoring and decision support. These examples illustrate diversification beyond prediction toward technology-assisted care pathways.
Recent syntheses highlight AI’s expanding roles across obesity prediction, phenotyping, perioperative risk modeling, and digital therapeutics; computer vision and Natural Language Processing (NLP) now complement tabular ML in both clinical and public-health contexts.7,9 Yet, existing reviews typically focus on clinical performance or single modalities and do not map how topics, methods, and collaborations coevolved across the field. Our contribution is field-level cartography: we integrate performance bibliometrics with thematic science mapping to reveal clusters, influential works, collaboration structure, and gaps that strategic funding and translational efforts can target.
This bibliometric analysis aims to chart the emerging and rapidly evolving landscape of AI research within the context of obesity. By examining the scientific literature, this study delineates the structural development, thematic trends, and interdisciplinary linkages that characterize this hybrid field. Moreover, it foregrounds essential considerations—such as model interpretability, transparency, and contextual adaptability—that are critical for the ethical and effective integration of AI into obesity-related health care research and practice. Bibliometric mapping allows scalable, reproducible synthesis across thousands of studies—particularly suited to multidisciplinary and rapidly evolving domains such as AI in obesity research. We address a knowledge-synthesis gap by moving beyond narrative reviews to provide a reproducible, data-driven map of AI-for-obesity.
Materials and Methods
Literature search strategy
This bibliometric analysis focused on publications between 2015 and 2025 related to AI applications in the context of obesity. A comprehensive query combining keywords related to both AI and obesity was used to search Web of Science (WoS) and Scopus databases. WoS and Scopus were queried on July 15, 2025; records dated up to this search date were included. The search was conducted within topic fields, and the same logic was adapted for each database’s syntax. WoS and Scopus were selected due to their comprehensive coverage of scientific literature across diverse disciplines, including health sciences, computer science, and engineering, which are highly relevant to the interdisciplinary nature of AI in obesity research. While other specialized databases exist, these two platforms offered the broadest interdisciplinary capture for a bibliometric overview. The core search string combined terms such as “artificial intelligence,” “machine learning,” “deep learning,” and “neural networks” with “obesity,” “bariatric surgery,” “weight management,” and “metabolic syndrome” using appropriate Boolean operators and wildcards to ensure broad yet focused retrieval. To ensure consistency and quality of included studies, the search was limited to publications in English and restricted to original articles and reviews. Details of the full search strategy are provided in Table 1.
Boolean Search Syntax for Each Database

Data collection and processing
The initial search retrieved 5454 articles from Scopus and 2966 articles from Web of Science, resulting in a total of 8420 records. Of these, 107 records were excluded as they were not published in English, and 628 records were removed because they did not meet the study type criteria (i.e., not original articles or reviews). To ensure methodological integrity and consistency in applying the exclusion criteria, two independent authors randomly evaluated 5% of the initial retrieved records. This assessment focused on confirming the accuracy of classification based on publication type and relevance to AI in obesity. Discrepancies were resolved through discussion to reach a consensus, ensuring a uniform application of criteria. While a formal interrater reliability statistic like Cohen’s Kappa was not calculated for this preliminary quality check, this consensus-based approach aimed to mitigate potential biases in the screening process. We did not compute kappa, as the intent was calibration rather than formal dual screening. Following this review, an additional 295 records were excluded for being unrelated to the context of AI in obesity. The remaining 7390 articles were screened for duplicates, and after removing 1497 duplicates, a final set of 5893 unique articles was included for analysis. The selection and screening process is summarized in a Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) flow diagram (Fig. 1). Bibliometric science-mapping is appropriate for synthesizing large, multidisciplinary corpora at scale. We therefore used standard performance and network analyses to objectively characterize nearly 6000 records without duplicating narrative review methods. We used a triangulated approach: (1) descriptive bibliometrics (production and citations), (2) science-mapping (coauthorship and keyword co-occurrence), and (3) brief thematic synthesis of clusters. This combination provides both structural and interpretive insight.
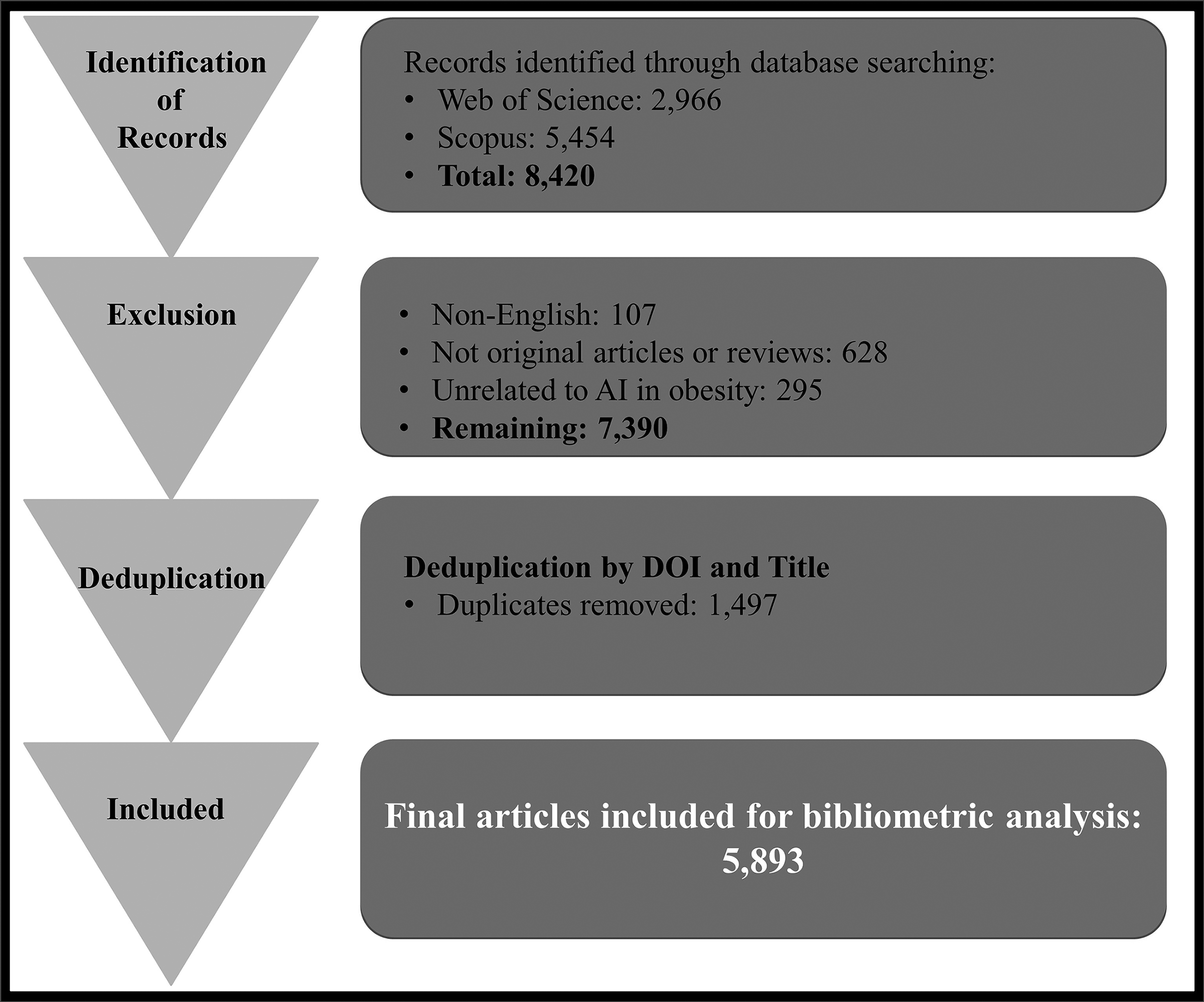
PRISMA flow diagram of study selection process.
Tools and analysis
All analyses were performed using R version 5.1. Bibliometric mapping and statistical summaries were generated using the following tools:
Bibliometrix (v5.0): used for performance analysis and science mapping. Biblioshiny (v5.0): used for visualization of publication and citation trends. VOSviewer: used for thematic keyword co-occurrence mapping.
Performance analysis and science mapping were conducted with bibliometrix/Biblioshiny (R) and VOSviewer, standard toolchains for bibliometric synthesis in health sciences. 13 Coauthorship and co-occurrence networks used fractional counting; layout followed LinLog/modularity optimization with default stabilization.
Author keywords were normalized and ranked by frequency. The rank–frequency curve exhibited a Zipfian heavy tail; therefore, to improve network readability and ensure stable co-occurrence estimates, we retained only head terms (≥50 occurrences) for keyword mapping. 14 Theme labels and summaries were reviewed by clinical coauthors with bariatric/obesity expertise to ensure field relevance.
The dataset was divided into three periods: 2015–2018, 2019–2021, and 2022–2025. Author and index keywords were lowercased, cleaned (punctuation and duplicates removed), and counted within each period, excluding generic or noninformative terms. Period-specific keyword frequencies were compared to identify dominant themes and highlight the emergence of representative concepts such as machine learning, deep learning, bariatric surgery, computer vision, and large language models.
Author productivity followed Lotka’s law (few authors contribute most output); to avoid sparse ego-networks and label overlap, we restricted the coauthorship map to authors with ≥5 publications. 15
Results
Annual scientific production and citations
A total of 5893 unique articles were identified from Web of Science and Scopus databases between 2015 and 2025, covering AI applications in obesity-related research. As shown in Figure 2, there was a consistent upward trend in the number of annual publications, with a marked acceleration beginning around 2019. Between 2018 and 2023, the number of publications more than tripled, indicating growing interest in the field.
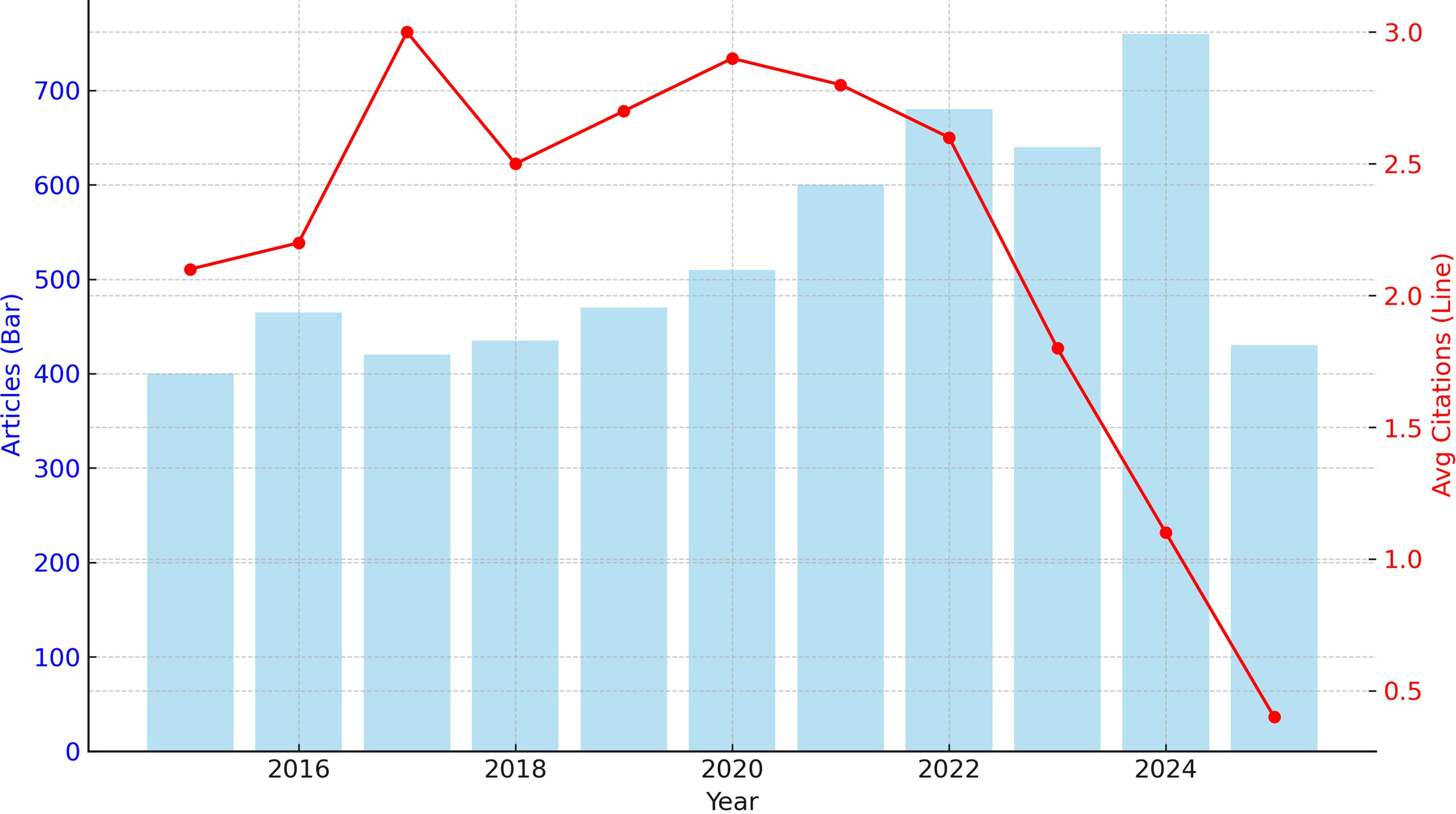
Annual scientific production and average citations per year (2015–2025). The bar plots represent the number of articles published each year on artificial intelligence applications in obesity research between 2015 and 2025. The line graph (right Y-axis) displays the average citations per article for that specific year. The observed decrease in average citations for recent years reflects the expected citation lag for newer publications.
Citation trends followed a similar pattern. Older studies accumulated more citations over time, consistent with the time lag inherent to citation dynamics. Notably, articles published in 2020 exhibited the highest average citation rate per article, an observation likely reflecting a surge in digital health and AI research during the early stages of the COVID-19 pandemic, which spurred rapid engagement with newly published work.
The mean number of citations per article was 14.3, with a median of 6, and 17.4% of articles had not been cited at the time of analysis. Only a small number of articles exceeded 400 citations, indicating a concentration of influence among a few key publications.
Author collaboration network
Across 34,033 authors, productivity followed Lotka’s law; we, therefore, mapped only authors with ≥5 publications (n = 66) to focus on stable collaboration structure (Fig. 3). Most authors were clustered in small, institutionally affiliated groups, although a few larger hubs emerged in domains such as bariatric surgery, machine learning, and surgical informatics.
Coauthorship network of prolific authors (≥5 publications). This network visualization displays the collaboration structure among authors with at least five publications in the field of artificial intelligence in obesity research. Node size reflects publication count, and edge thickness indicates the strength of coauthorship links. Color clusters represent distinct collaboration communities, helping highlight key research hubs and their interconnectivity.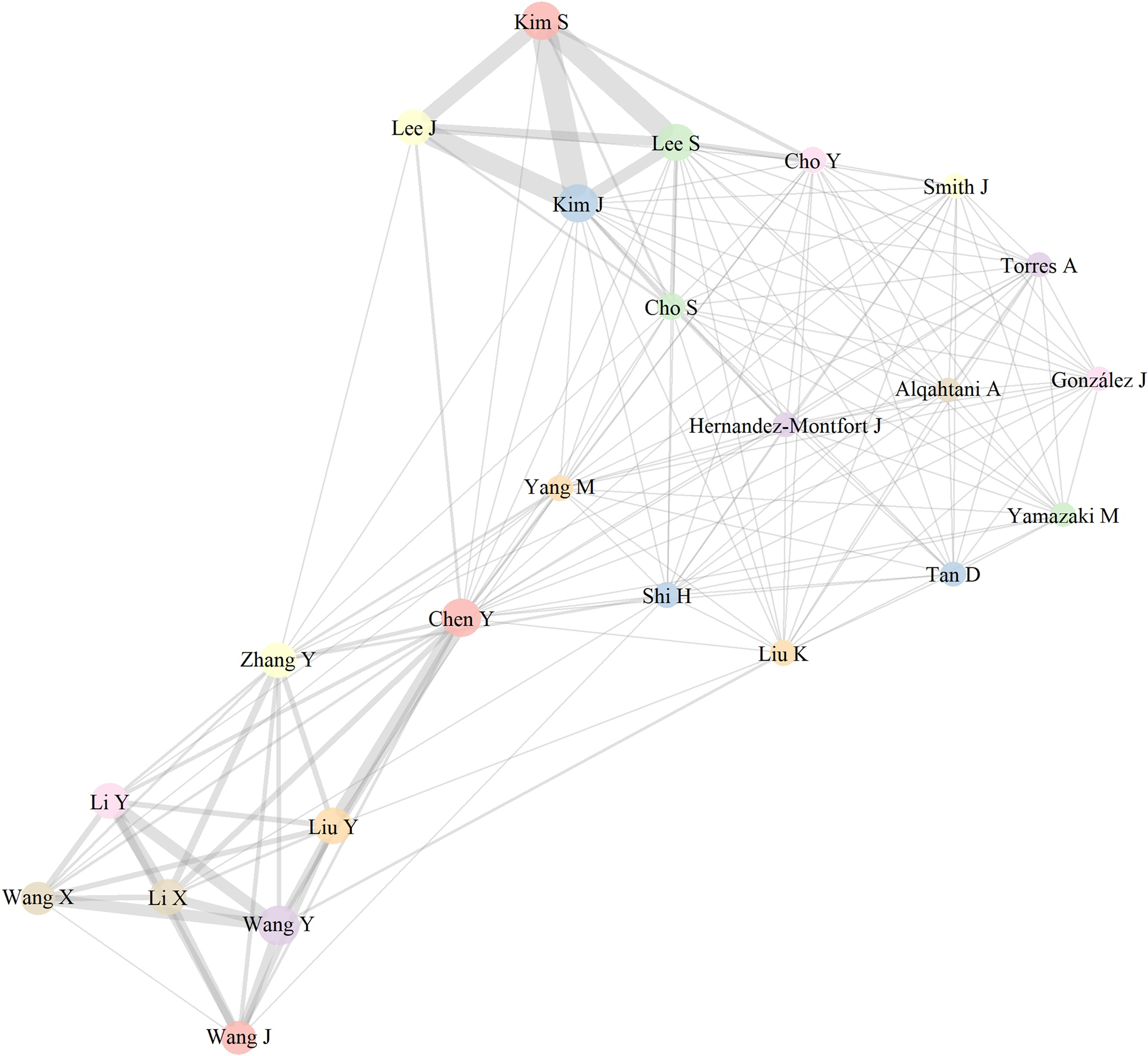
The most prolific authors identified in the dataset were as follows:
Mohan, Viswanathan, nine publications. Kwon, Young-Min, nine publications. Qu, Shen, eight publications. Kroh, Matthew, seven publications.
Author disambiguation using the AF field improved accuracy, especially for common surnames. While a few high-output authors were prominent, the overall network remained relatively sparse and decentralized, suggesting an emerging and still-fragmented field.
Thematic structure of keywords
Using VOSviewer, we identified 9868 keywords. In line with Zipf’s law, only the head terms (≥50 occurrences; n = 32) were included in the map to prune the Zipfian long tail. A co-occurrence map of keywords appearing in at least 50 publications revealed four major thematic clusters (Fig. 4):
Keyword co-occurrence network and thematic clusters. This network illustrates the co-occurrence of author keywords in AI-driven obesity research. Node size indicates keyword frequency, and edge thickness reflects co-occurrence strength. Four thematic clusters were identified: a red cluster focusing on surgical applications of AI, including bariatric surgery, risk prediction, and decision support; a green cluster centered on lifestyle and remote care through digital health, mobile apps, and wearables; a blue cluster highlighting conversational technologies such as chatbots, natural language processing, and large language models; and a yellow cluster representing precision health concepts like personalized medicine and predictive analytics. The network captures the multidimensional integration of AI into obesity and metabolic health research. AI, artificial intelligence.
Cluster 1 (Red): Bariatric surgery, machine learning, risk prediction, and clinical decision support—highlighting applied AI in surgical outcomes.
Cluster 2 (Green): Digital health, mobile apps, wearables, and eHealth—reflecting lifestyle interventions and remote monitoring.
Cluster 3 (Blue): Natural language processing, chatbots, and large language models—pointing to conversational agents and generative AI.
Cluster 4 (Yellow): Personalized medicine, metabolic syndrome, and predictive analytics—indicating the rise of precision health paradigms.
These clusters reflect the multidimensional growth of the field, spanning both technical development and clinical integration.
Temporal evolution of research themes
When grouped chronologically, keyword patterns revealed a distinct thematic progression within the literature. During 2015–2018, research primarily addressed metabolic and epidemiological aspects of obesity, with emphasis on risk factors, glucose metabolism, triacylglycerol levels, and cross-sectional analyses. Mentions of “machine learning” were limited and exploratory, while “deep learning” and “natural language processing” appeared only sporadically. Between 2019 and 2021, AI-related terms became more frequent, indicating a transition toward clinical and perioperative applications. The keywords “machine learning,” “deep learning,” and “bariatric surgery” gained prominence, suggesting the adoption of predictive modeling and early computer-vision efforts in surgical contexts. In 2022–2025, the field expanded rapidly, with “machine learning” and “deep learning” dominating the keyword landscape, alongside the emergence of “ChatGPT,” “large language model,” and “natural language processing,” reflecting the integration of conversational and generative AI tools into obesity-related research. Across all periods, the increasing frequency of bariatric surgery–related terms demonstrated a sustained and growing clinical interest.
Most influential articles
Top five most cited works are listed below with their first authors and verified citation counts. A systematic literature review on obesity: Understanding the causes and consequences and reviewing various machine learning approaches used to predict obesity (Safaei M.), cited 396 times.
16
Computer vision analysis of intraoperative video: Automated recognition of operative steps in laparoscopic sleeve gastrectomy (Hashimoto D.A.), cited 294 times.
17
A review of machine learning in obesity (DeGregory K.W.), cited 158 times.
18
Visualizing the knowledge structure and evolution of big data in obesity research in health care informatics (Gu D.), cited 150 times.
19
Machine learning techniques for prediction of early childhood obesity (Dugan T.M.), cited 135 times.
20
These publications span methodological overviews, bibliometric frameworks, and AI integration in both clinical and population health contexts.
Discussion
This bibliometric analysis provides a comprehensive overview of the research landscape at the intersection of AI and obesity, drawing insights exclusively from a rigorously curated dataset of 5893 unique articles extracted from Web of Science and Scopus databases. The findings underscore the escalating scientific interest and evolving research trends within this multidisciplinary field. This rise likely reflects broader access to usable datasets and analysis tools, making these methods more practical for clinical and public-health questions.
A striking observation is the consistent upward trajectory in the annual number of publications, with a particularly marked acceleration beginning around 2019. This growth signifies the increasing recognition of AI’s potential in addressing the complexities of obesity, a global health challenge. This aligns with the broader integration of advanced computational methods into biomedical research, as exemplified by studies focusing on machine learning’s application in health-related data analysis. 16 Even so, publication volume is not a surrogate for clinical benefit; meaningful translation depends on external validation, sound calibration, and evidence that model-guided decisions improve patient outcomes.
Chronologically, AI applications in obesity research have evolved from epidemiological observation to clinical implementation and intelligent automation. Early studies focused on identifying risk factors and metabolic markers using traditional data-driven approaches. The following phase broadened to predictive and image-based modeling, particularly within surgical and perioperative care. Most recently, the field has diversified into multimodal and language-based systems, aligning with the global shift toward explainable and conversational AI. This progression underscores a maturing research landscape that is increasingly clinically oriented.
The thematic clustering analysis further illuminates the diverse applications of AI in obesity research. The identified clusters—ranging from AI’s role in obesity prediction and management to its intersection with bariatric surgery and the broader implications for public health and policy—reflect the multifaceted nature of both obesity itself and the adaptable capabilities of AI technologies. For instance, research delves into using computer vision for analyzing surgical procedures, 17 and machine learning techniques for predicting childhood obesity, 11 demonstrating AI’s utility across various scales of intervention and prevention. The prevalence of systematic reviews within the top-cited articles, such as one on understanding the causes and consequences of obesity through machine learning, 18 highlights a foundational effort within the field to synthesize existing knowledge and identify promising avenues for future inquiry. Furthermore, the five most-cited articles identified in our Results (articles by Safaei et al., Hashimoto et al., DeGregory et al., Gu et al., and Dugan et al.) function as anchor points in our cocitation structure and illustrate the field’s methodological and translational priorities.
While the number of publications is rapidly expanding, the analysis of the author collaboration network reveals a relatively sparse and decentralized structure. This suggests that despite the growing volume of research, the field is still emerging and somewhat fragmented, with a lack of highly interconnected collaborative clusters. This pattern is typical of nascent interdisciplinary fields where researchers from different domains are beginning to converge, often working in smaller, independent groups before more robust collaborations are established.
The identification of highly influential articles provides insight into the foundational contributions shaping this domain. Works reviewing machine learning applications in obesity 19 or visualizing the knowledge structure of big data in health care informatics 20 serve as critical syntheses and conceptual frameworks. Similarly, articles exploring specific applications, such as computer vision in bariatric surgery 12 or machine learning for early childhood obesity prediction 11 represent key empirical contributions that demonstrate the practical utility of AI. These influential papers collectively highlight the field’s focus on methodological innovation and the development of predictive models, reflecting a strong emphasis on data-driven approaches to understand and combat obesity. Within our network, these papers also function as anchor points, shaping how subsequent work groups its methods and topics.
Equity and representativeness
Because obesity care spans diverse ages, sexes, and comorbidity profiles, models developed on narrow samples may not generalize well to important subgroups; routine subgroup reporting and basic bias checks are advisable. 21 For vision models, deliberate testing in challenging conditions (e.g., smoke, bleeding, and uncommon anatomy) is informative. 22
From prediction to care pathways
Models are most useful when tied to a clear next step—linking preoperative risk to optimization plans, using intraoperative prompts to support safety checks, or connecting discharge risk to structured follow-up; simple usability testing with clinical teams, followed by pragmatic evaluations, helps determine whether such tools change outcomes. 23
Interpretation and implications
Field map: A corpus-level view linking four applied areas—surgical/perioperative AI, digital/remote care, conversational/NLP tools, and precision/phenotyping—to their specific evidence needs.
Collaboration signal: Demonstrates fragmentation of coauthorship networks, motivating shared benchmarks and simple, reusable analysis pipelines.
Temporal perspective: Trend-topic slices show a shift from epidemiologic foundations (2015–2018) to clinical/perioperative ML/DL (2019–2021) and then to scaled use with early LLM-adjacent work (2022–2025).
Emerging directions
Combining data types (imaging, text, and sensor/device data), adapting foundation or vision-language models to surgical tasks, and explaining results in ways that support clinical decisions are promising; these advances benefit from straightforward governance: clear data permissions, audit trails for model updates, and transparent reporting of computing demands. 24
In conclusion, the bibliometric landscape of AI and obesity research is characterized by rapid growth and diverse thematic exploration. While the field is still maturing in terms of collaborative networks, the increasing volume of publications and the impact of highly cited articles underscore AI’s pivotal and expanding role in addressing the global obesity epidemic. Continued research, particularly fostering greater interdisciplinary collaboration, will be crucial in translating these advancements into impactful public health interventions.
Limitations
Despite its comprehensive scope, this bibliometric analysis has several inherent limitations as follows:
Searches were performed on July 15, 2025; work indexed after this date is not included, and very recent articles will have had less time to accrue citations. Thresholds were chosen to trim the long tail and produce interpretable figures; checks at lower cut-offs showed the same main clusters. While aiding clarity, these thresholds might exclude contributions from less prolific authors or highly specialized thematic areas. Its reliance solely on Web of Science and Scopus databases, coupled with a specific keyword-driven search strategy, means that relevant publications from other platforms, local journals, or those using alternative terminology may not have been captured. The primary indexing language of these databases is English, which introduces a language bias and may lead to an underrepresentation of significant research published in other languages. We did not analyze funding patterns because sponsor information was inconsistently indexed and not extracted in our workflow. Finally, as a quantitative bibliometric study, its scope is limited to describing publication trends and network structures and does not extend to evaluating the qualitative content, methodological rigor, or clinical impact of the individual research articles included in the analysis.
Authors’ Contributions
Conceptualization and writing—review and editing: O.E. and F.B. Data curation and methodology: A.A., T.C., and K.T. Formal analysis: O.E. Investigation: F.B. and A.A. Writing—original draft: O.E., A.A., T.C., and K.T.
Data Availability Statement
The data presented in this study are available on request from the corresponding author. The data are not publicly available due to ethical restrictions.
Ethical Approval
As this study is a bibliometric analysis of publicly available, aggregated data from published literature and does not involve human subjects, personal data, or confidential information, it was deemed exempt from formal ethical review by an Institutional Review Board or similar ethics committee. The study methodology is based on a systematic review and analysis of metadata and, therefore, does not require direct patient consent or ethical oversight typically associated with clinical research.
Disclosure
The authors declare that they have nothing to disclose.
Footnotes
Author Disclosure Statement
The authors have no conflicts of interest and have no affiliations or financial involvement with any commercial organization.
Funding Information
No funding was received for conducting this study.