
Abstract
Wearable displays may enhance information access, but potential interference between device use and the primary operational task may result. Multiple Resource Theory (2002) helps predict which information modalities will interfere, but in the case of head mounted displays (HMDs), the importance of competition for focal attention versus central processing resources in determining dual-task interference remains unclear. We investigated the interference between manual tracking and a word memory task, where words were presented on a HMD, the same display as the tracking task, or audibly. Compared to single-task tracking, performance was impaired by both audio and HMD word presentation, but not by words presented on the same visual plane. This suggests some interference is due to demands on vison itself, not just central resources, and that bottom-up shifts in information seeking may also impair performance. Future research into the best methods of utilizing wearable aids and directing user attention is needed.
Dual-task or multi-task interference is of particular concern given the proliferation of ubiquitous computing and wearable displays (Wickens et al., 2021). For example, a heavy equipment operator may soon be wearing a head-mounted display (HMD) and a 3-D spatial bone conductive headset. While these display devices may expand the equipment operators’ information access, the downside is the potential interference these devices may cause to handling the heavy equipment itself. For the heavy equipment operator, the difference between a slow and quick response to an event in the world may be the difference between flipping their machine, losing a valuable load, or perhaps injuring or killing someone on the ground. The heavy equipment operator is a singular example, but this challenge faces many workers who have to operate in complex and dangerous environments (Epling et al., 2018; Ward et al., 2019).
Ward and Helton (2022) investigated how a word recall task presented on a HMD (Google Glass) impacted simultaneous compensatory tracking task performance. In their experiment, participants performed five tasks: (1) a compensatory tracking task performed alone, (2) a word memory task performed alone, (3) a tracking and word memory dual-task, (4) a word memory task with words preceded by audial signals, and (5) a tracking and word memory dual-task with words preceded by audial signals. Their dual-task tracking task was designed so that half of word presentations on the HMD were paired with directions changes (drag force changes) in the tracking task. This enabled them to explore the impact of immediate perceptual interference on the participants’ time to regain control of the tracking task (re-centering). They found that there were significant dual-task costs for both mean tracking error and later word recall of the words presented. More interestingly, participants were significantly slower to respond to motion changes paired with word presentations than motion changes not paired with word presentations, indicating real-time perceptual interference.
Ward and Helton (2022) found that when drag force changes in the tracking task were paired with word presentations on the HMD, response times increased by ~15%. This amount of additional time is similar to that found with handheld and hands-free mobile devices in other experiments (Caird et al., 2008); other studies such as Sawyer et al. (2014) have also found greater increases in HMD presentations on response time.
To clarify the source of the increased delay, we conducted an experiment similar to Ward and Helton (2022). However, we have included additional conditions. In one condition, the word was displayed on the same screen as the tracking task (i.e., the same focal place or display depth). Human actors are able to perform multiple discrimination tasks when the features to be discriminated share a surface (Wickens et al., 2021), and by removing the displacement in depth between the word memory task and the tracking task there should be no requirement for participants to make an attention shift in this condition. Without an attention shift, any present delay caused by cognitive cost of processing and adding a new word to the phonological loop should be isolated. To ensure that the participant is not making a shift of visual attention, another condition will present the words aurally. If the delay in responding to the tracking task is solely caused by the attention shifts required to attend to information displayed on the Glass, then there will be no difference in response times for tracking task events when they are paired or unpaired with a word presentation.
Method
Participants
Participants were five men and seven women recruited on the University of Canterbury campus and via a local participant recruitment website. They were compensated $10NZ for their participation. One participant refused to complete all five trials; they found wearing the glasses uncomfortable. A second participant did not respond consistently enough to direction changes in the tracking task to give an accurate representation of their response time. The remaining 10 participants (five men, five women) had a mean age of 24.8 years (SD = 1.69).
Word Memory Task
The word memory task was presented visually either on a Google Glass HMD or on the same screen as the tracking task, or it was presented audibly via the Glass speakers. Lists of 20 words (see Appendix A) were created using the online Paivio et al. Word List Generator (Paivio et al., 1968). The words were presented to the participants during the tracking task (see below), as well as in a single-task condition. The participants at the end of each experimental condition responded with as many of the 20 words as they could recall. This task has been used extensively in dual-task studies (Darling & Helton, 2014; Epling, Blakely, et al., 2016; Epling, Russell, et al., 2016; Epling et al., 2017; Green et al., 2014; Green & Helton, 2011; Jackson et al., 2022; 2023; Stets et al., 2020; Woodham et al., 2016).
Tracking Task
The same compensatory tracking task used in Ward and Helton (2022) was used in this study. In the task, a target comprised of five red concentric circles was presented on top of a light grey background on a computer display terminal. The tracking object was a white circle which the participant attempted to keep in the center of the red concentric circles. The task with the addition of word presentation is displayed in Figure 1. Participants responded to the tracking task with joystick movements (tilt). See Ward and Helton (2022) for specific details about this tracking task.

The tracking task with a Glass presented word layered on top.
Procedure
When participants arrived for their scheduled study time, researchers explained the experiment, its purpose, and the approximate amount of time required, after which participants gave informed consent for their participation. For the word recall tasks, participants were told they would have to recall the words at the end of the task. For the tracking task, participants were told to maintain the position of the white cursor in the middle of the concentric circles. The participant was then given an opportunity to adjust the Google Glass for comfort, and to get familiar with its use. All participants were then given a two-minute period to practice the tracking task (previous research had demonstrated the task is quickly learned; Ward & Helton, 2022).
Each participant was expected to complete all five experimental conditions: (1) tracking alone, (2) tracking with the visual word memory condition presented on the Glass, (3) tracking with the visual word memory condition presented on the same computer screen, (4) tracking with the word memory condition presented aurally via the Google Glass speaker, and (5) the word memory task alone presented on the computer screen. The order of conditions was counterbalanced using a Latin Square Design.
Before each task, instructions were repeated both verbally and on the computer screen while the desktop and Glass synchronized. In condition without the tracking task, the computer screen showed only the background neutral grey color with no cursor or target. Each condition ran for 4.5 minutes, and a minute rest period was given between conditions (this was the same as from Ward and Helton, 2022). In total, the experiment took roughly 52 minutes to complete.
In the word recall task conditions, word presentations were displayed either in the center of the Glass’ prism, on the same screen as the tracking task, or audibly. Word text was white on a transparent background. The task began after a 15 second pause in all conditions. Participants were instructed to read the words aloud, or in the case of the audio presentation condition, to repeat them. This was recorded and used as a check to determine if the participants were really attending to the words.
In each condition, the presentation of each word had a 50% chance of triggering a drag force change in the tracking task. The minimum duration of drag force changes was six seconds, but otherwise shared all the same properties as a regular drag motion drag force change during the task. The tracking task alone condition simulated these drag force changes using the same hidden background timer for consistency across conditions. There were approximately 10 paired drag force changes and 16.7 unpaired drag force changes (not paired with word presentations) in each tracking task. The paired and unpaired drag force changes enabled the researcher to calculate a response time to the drag force changes (see Ward and Helton, 2022). This affords the determination of what impact, if any, simultaneous word presentation has on response time to changes in the tracking task (i.e., how long it takes the participant to correct back to center).
Results
Table 1 shows a summary of each participant’s performance across the five conditions of the experiment. We conducted an omnibus repeated measures ANOVA for words remembered, overall root mean square tracking error (RMSE mm), unpaired event response times (ms), and paired event response times (ms). There was no significant difference in the number of words remembered between conditions, F(3,27) = 0.86, p = .481, ω2 = 0.00. There was a significant difference in overall RMSE tracking error (mm), F(3,27) = 4.85, p = .008, ω2 = 0.045.
Averaged memory and tracking results.
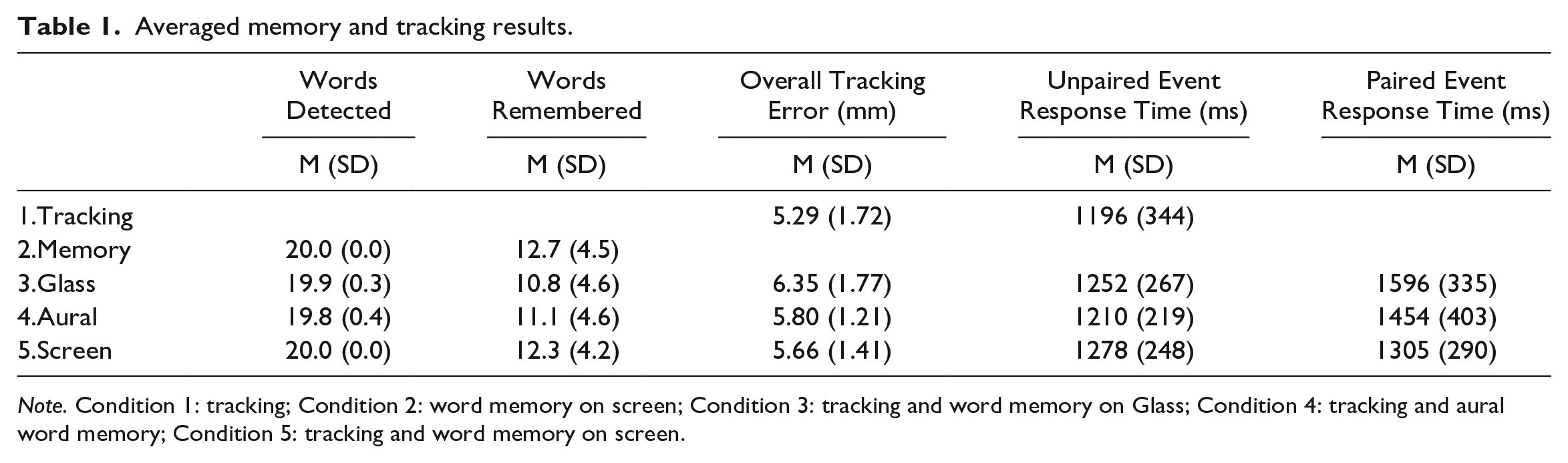
Note. Condition 1: tracking; Condition 2: word memory on screen; Condition 3: tracking and word memory on Glass; Condition 4: tracking and aural word memory; Condition 5: tracking and word memory on screen.
We followed this up with a planned comparison between the single-task tracking and the combined dual-task tracking, and this comparison was statistically significant, t(9) = 3.13, p = .012, d = .99. The dual-tasks were not significantly different from each other for overall tracking error, p > .05. There was no significant difference in response times to unpaired tracking task events between conditions, F(3,27) = 0.67, p =.577, ω2 = 0.00, but there was a statistically significant difference in response times to paired tracking task events between conditions, F(2,18) = 8.92, p =.002, ω2 = 0.119. For the paired tracking tasks, we compared the paired and unpaired event reaction times. For the Aural word presentation, there was a significant difference, t(9) = 2.59, p = .029, d = .82. There was also a significant difference for Glass word presentation, t(9) = 5.97, p = .001, d = 1.89. For Screen presentation, however, there was no significant difference, t(9) = .48, p = .65, d = .15.
Discussion
In this experiment, researchers sought to explore whether the delay in responding to paired events between the compensatory tracking and word memory tasks in Ward and Helton (2022) was due to competition for focal visual attention, versus competition for central cognitive processing resources. To test this, the word memory task was presented on the Glass and also through two methods which were expected to remove the need for a shift of focal visual attention. One method was to have the presentation of the words and the tracking task share the same perceptual surface. Previous research into dividing attention between superimposed surfaces show that participants have the ability to process multiple features of the same surface simultaneously, even when detecting the same number and type of features across separate surfaces imposes a performance cost (Wickens et al., 2021).
A similar pattern was found here; when the need to shift the depth of focal attention was removed, participants were not significantly slower to respond to momentum changes in the tracking task when a word was presented simultaneously, compared to when the tracking task event was unpaired. Other performance indicators of dual-task interference were also minimal in the same depth screen presentation condition. This could be because the ability to process both tasks in parallel removed the need for the participant to make higher-level performance evaluation decisions regarding the division of attention, reducing the overall cognitive load of the task.
The second method of removing the need for a perceptual attention shift in focal depth was to deliver the word memory task aurally. In contradiction to the hypothesis of this experiment, the Aural condition did not remove the delay in responding for participants. The reason for this delay is unclear, since under the Wickens’ Multiple Resource Model, this pair of tasks should have had the least overlap in required mental resources (Wickens, 2002). One explanation could be that some participants were compelled to visually search for the sound source upon hearing a word read to them. This shift in orientation may be unconscious or bottom-up, as there are strong cross-modal links in the orientation of spatial attention (Driver & Spence, 1998). This would explain the relatively large variability in paired response times for the aural presentation trials compared to the other dual-task conditions, as the auditory presentation may disorient visual attention.
This study did, however, have a relatively low sample size and future research with larger samples would need to be conducted to explore these finding further. There may be subtle central resource interference in the screen presentation task which could be detected statistically with a larger sample. Nevertheless, this interference in the present case appears less than the interference detected in the Aural and Glass (different visual plane) conditions. This suggests some of the dual-task interference detected in other studies using a HMD display may also be due to demands on vison itself, not just central resources (see for example Woodham et al., 2016). Switching visual attention to and from HMD devices imposes a perceptual cost separate from the cognitive demands of the tasks involved, which will constantly vary from task to task. This may make apps which deliver warnings to a user about their environment counterproductive, as a highly salient warning signal may draw the user’s attention inwards in depth and the delay in returning it to the environment may slow, rather than improve, the user’s response to the hazard. Future research into the best methods of directing a user’s attention already centered on the device back to the environment would be of value to developers of apps which include components to monitor the user’s environment or equipment.
Footnotes
APPENDIX A: Word Lists
“slipper”, “glacier”, “pepper”, “settler”, “odor”,
“dreamer”, “cigar”, “captive”, “banner”, “poster”, “arrow”, “piston”, “pencil”, “hardwood”, “beggar”, “invoice”, “robber”, “elbow”, “butcher”, “salute"
“costume”, “saloon”, “kerchief”, “python”, “fiord”, “bullet”, “mammal”, “salad”, “lemon”, “twilight”, “abode”, “jelly”, “singer”, “goblet”, “painter”, “wigwam”, “typhoon”, “basement”, sulfur”, “juggler"