
Abstract
The U.S. Navy has a sophisticated manpower planning process for recruiting, selecting, training, and placing thousands of enlisted Sailors into hundreds of specific jobs every year. Given the large number of “moving parts” in this manpower planning process, some inefficiencies are unavoidable. For example, there may be a non-trivial time gap between when some Sailors complete their job-specific training course and when they arrive at their duty station. During this time, their knowledge and skills will invariably decay due to lack of use. Electronic job aids, such as Interactive Electronic Technical Manuals (IETMs) and Decision Support Systems (DSS), are important to mission success because they help to reduce the need for Sailors to memorize rarely used factual details. However, IETMs and DSSs are job aids, not training tools. In this paper, we describe how we repurposed an existing digital twin-based DSS to create a ubiquitous, online training tool. We did so by leveraging the learning science principles of human performance measurement, adaptive learning with scaffolding, performance feedback, and training data analytics. We conclude with a series of best practices and lessons learned that other practitioners could follow when attempting to repurpose electronic job aids that were not originally designed for training.
Keywords
Introduction
Every year, the U.S. Navy recruits, selects, trains, and places thousands of enlisted Sailors into hundreds of different jobs. After completing their basic training, enlisted Sailors complete 16 weeks of Class “A” technical school in their area of technical specialty. For example, vehicle mechanics-in-training learn: generalizable processes for fault diagnosis, isolation, and verification; the proper way to use a variety of mechanical and electronic tools; specialized procedures for planned and emergency vehicle maintenance; methods and systems for documenting their maintenance-related activities, and; detailed technical specifications for the types of vehicles that they will be responsible for maintaining at their duty station.
Given the large number of “moving parts” in this manpower planning process, some inefficiencies are inevitable. For example, there may be a 2-3 month gap between graduating from “A School” and arriving at their duty station. During this time, the Sailor will likely be performing other duties as required and may have limited (or no) opportunities to practice their newly learned knowledge and skills, thereby resulting in decay. Similarly, the training tools and simulators in the schoolhouse may be outdated vis-à-vis the actual hardware which is being used at the duty station. This is an unfortunate but all-too-common occurrence, because training schoolhouses are often last in the “pecking order” to receive new equipment. As a result, recent schoolhouse graduates quickly need to figure out which knowledges and skills do – versus do not – generalize from the old equipment to the new equipment.
Digital Twins
Given the complexities of modern military equipment – which have complex interdependencies among their electrical, hydraulic, mechanical, and ventilation systems – paper manuals are now being replaced with Interactive Electronic Training Manuals (IETMs) that provide text searching functionality and some multimedia instruction. Despite their improvement over paper manuals, IETMs are poorly suited to express complex failure cause-and-effect dependencies. By comparison, digital-twin based Decision Support Systems (DSS) can present first-order cause-effect dependencies by modeling the system faults with their resulting physical manifestations and diagnostic test results. Moreover, higher-order dependencies can be inferred from patterns of first-order dependencies over time. This multi-signal modeling methodology (Deb et al., 1995) can be conceptualized as a dependency graph where the structural components are modeled as nodes, and the directional links denote dependencies based on structural adjacency.
In practice, digital twin-based DSSs are typically deployed on ruggedized tablets that provide maintenance technicians with Just-In-Time (JIT) troubleshooting support. This approach obviates the need to memorize large volumes of infrequently accessed information. In addition, digital twin-based DSSs can recommend the most efficient troubleshooting pathway based on certain factors such as minimizing overall repair times or repair costs. Finally, digital twin-based DSSs are extremely flexible and scalable. As older versions of the physical hardware systems are upgraded, the digital twins can be modified to include those differences from the previous version.
Learning Sciences Principles
Despite their advantages over paper manuals and IETMs, digital-twin based DSSs are job aids that are designed to maximize task performance (the quality, probability, rate, or latency of a particular response at a particular point in time) rather than to support learning (a relatively permanent change in knowledge or skills which are demonstrated across tasks, time, or environments) (Bjork & Bjork, 2011). However, with some modifications, DSSs can be transformed into ubiquitous training tools, thereby supporting both task performance and learning. In the following sections, we describe some of the modifications that we made to our digital twin-based DSS, along with our justification for doing so.
Human Performance Measurement
Training and performance assessment are “two sides of the same coin” (National Research Council, 1996, p.5). Performance assessments operationally define the standards that are expected from learners at the completion of training. Without systematic performance assessment, there is no way to determine the extent to which the training was successful at improving relevant outcomes such as mastery of the training content, behavioral transfer to the post-training environment, or improvements in organizational outcomes.
When used as the engine that powers a real-time DSS, digital twins provide a “single source of truth” with regard to fault diagnosis, isolation, and verification. For example, our DSS asks the Sailor which specific symptoms or error codes/messages are being displayed. Upon entering their response, the Sailor is then presented with a list of all possible diagnoses, along with the exact mathematical probability of each one being correct. Similarly, the DSS can also provide the Sailor with a list of candidate test procedures, again with the exact mathematical probability of each one correctly isolating the fault.
When repurposing a digital twin for training purposes, the user experience requires a few minor changes. Specifically, the instructor first needs to select a specific system fault (unbeknownst to the learner) based on the desired learning objectives. The digital twin then leverages the dependency diagrams to generate a list of potential symptoms or error codes/messages for that specific fault. From there, the Sailor makes an initial fault diagnosis decision from a list of potential faults. The Sailor then attempts to isolate the fault by performing one or more test procedures to verify that the initial diagnosis was correct. After correctly identifying the fault, the learner then selects the appropriate remediation activity and verification procedure to determine if the repair was successful or not. At each point in the process, the mathematical probability of correctness can be used to measure the Sailor’s mental model.
Each maintenance task or diagnostic test has an associated cost. For example, each test requires taking the system offline for a certain period of time. In addition, each test may require pulling one or more assets from the inventory. If the diagnosis is incorrect, the asset must be bench tested before it can be returned back to inventory. All of these time delays and costs can be factored into the Sailor’s total score. This way, each Sailor can be simultaneously graded on 3 separate dimensions: decision accuracy, total repair time, and (unnecessary) repair costs. Moreover, depending on the instructor’s goals, these grading dimensions can be differentially weighted, as appropriate. For example, novices may be graded based on the accuracy of their responses. By comparison, there will likely be little variance among the decision accuracy scores of experts. Therefore, grading may focus on minimizing unnecessary downtime and repair costs.
Adaptive Learning with Scaffolding
Based on their numerical profile of accuracy, repair cost, and repair time scores, learners are categorized into one of four experience groups: novices, intermediate learners, experienced learners, and experts. The experience grouping is then used to adapt the instructional approach. Specifically, scaffolding (Wood et al., 1976) is an instructional technique that provides learners with support that is directly tied to their level of task proficiency. For our specific training application, we chose to adapt the training process by tailoring the types of hints that learners receive. Specifically, as the learners become more expert-like, they receive more indirect hints (e.g., teaching or metacognitive hints) and fewer direct hints (e.g., bottom-out or pointing hints).
Metacognitive hints (Fiorella et al., 2012) help the learners to critically examine their own decision processes, for example by clarifying or prioritizing their goals. In practice, we do this by reminding the learner of the broad types of diagnostic tests that they have already performed, as well as the results of those tests. This is done to help the learner better plan out their strategy moving forward. Metacognitive hints are provided only to expert learners.
Teaching hints (Vanlehn, 2006) describe the implications of the test results, but don’t explicitly reveal the correct answer. In practice, we do this by restating the system’s theory of operations and explaining why certain types of tests cost more (in terms of repair time or repair costs) than others. This is done to help the learner understand “the big picture,” rather than becoming focused on specific details. Teaching hints are provided only to experienced learners.
Pointing hints (Vanlehn, 2006) direct the learners to where they can find the correct answer, but do not explicitly tell them what the answer is. In practice, we direct the learners to relevant instructional multimedia or system documentation that can help them to resolve the problem. Pointing hints are provided only to intermediate and novice learners.
Finally, bottom-out hints tell the learners the correct answer. In practice, learners are allowed to leverage the bottom-out hints if they are unable to benefit from the pointing hints, or if they make several mistakes in a row. However, every time that the learner uses a bottom-out hint, their overall task performance score is docked. This is done to prevent them from becoming too dependent on these hints. Pointing hints are provided only to novice learners. Selected examples of the different types of hints are depicted in Figure 1.
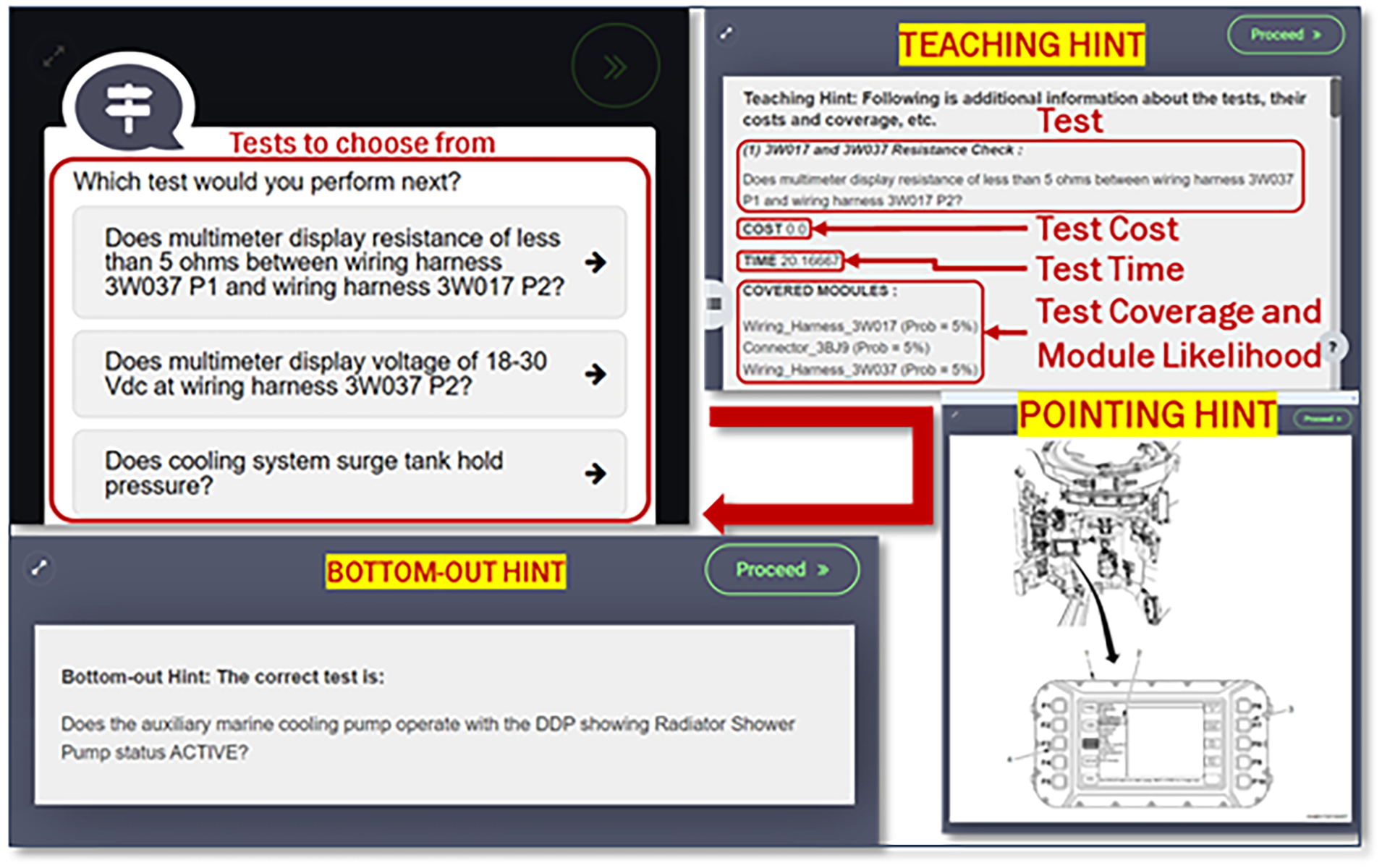
Examples of how certain hints have been incorporated into the training application.
Learner Performance Feedback
It is a common misperception that “practice makes perfect.” In reality, frequent practice only makes a behavior more habitual. When coupled with process-based performance feedback, practice makes perfect (Lefroy et al., 2015). Compared to outcome-based feedback, which only indicates whether the learner’s action was correct or not, process-based feedback conveys some critical information that can improve the learners’ decision processes.
For our specific training application, the performance feedback includes: the user’s decision choice (as a reminder in case they forgot); the correct choice (based on the digital twin’s intelligent reasoner); the mathematical probability of success for each choice; the actual cost and time for each test choice; and a detailed explanation as to why the correct answer was the best of all possible options. Example performance feedback is depicted in Figure 2.
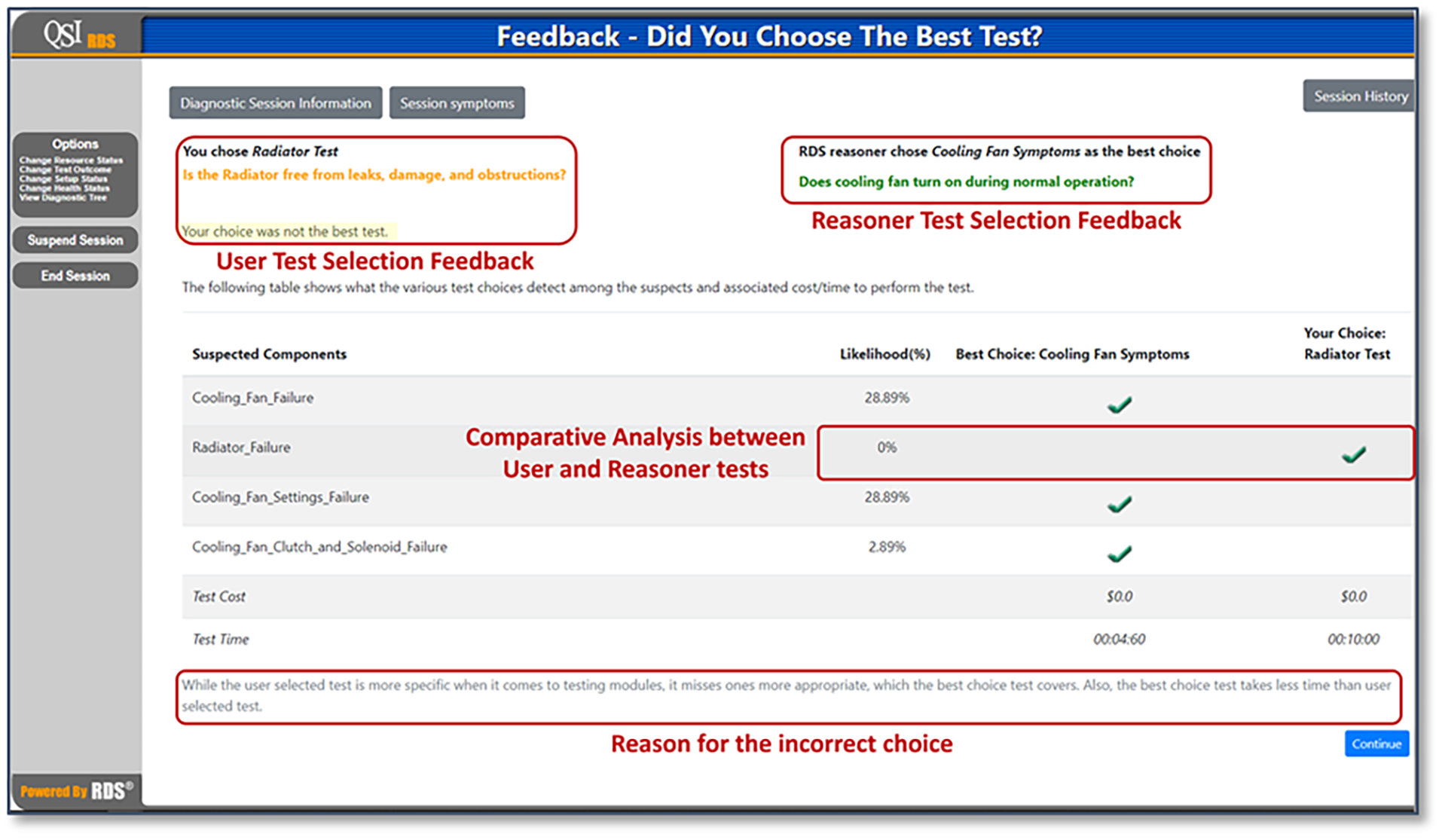
Example feedback screen depicting the user-selected answer, the correct answer, and process-based feedback for improving the learner’s subsequent performance.
Training Data Analytics
The days of self-contained training tools have long since passed. Increasingly, Department of Defense (DoD) organizations are looking to track learner proficiency across time, tasks, and situations/environments. We do this by integrating our Teams RDS training tool within a larger milieu that includes the open-source Moodle Learning Management System (LMS) and Learning Locker Learner Record Systems (LRS) tools, both of which are increasingly being used within the DoD.
The Moodle LMS is used to organize, sequence, and launch lessons that are part of a larger “course” of instruction. By comparison, the Learning Locker LRS is used to maintain a persistent log of the learner’s task proficiency across time, tasks, and training scenarios/environments. Multiple LRS systems can be networked together, thereby allowing the aggregation of learner records across schoolhouses and/or across the Sailors’ Navy career. Learning Locker is also used to analyze broad trends, both within and across learners, so that instructors can identify problems, such as which learners are significantly above or below the group mean, or which training exercises confound a large number of learners.
The “glue” that holds these systems – Moodle, Teams RDS, and Learning Locker – together is the Experience Application Program Interface (xAPI). xAPI uses JavaScript Object Notation for Linked Data (JSON-LD) to generate human-readable records of human performance in the “actor-verb-object-qualifier-context” format (Poeppelman et al., 2013). An example xAPI learner record might indicate: “John Smith (actor) diagnosed (verb) the faulty switch (object) correctly (qualifier) in less than 120 seconds (context).”
xAPI is an evolving DoD standard for documenting human performance across a wide range of learning media from e-book readers, interactive multimedia instruction, and even high physical fidelity simulators. One advantage of using xAPI is that it makes it easier to network multiple LMS and LRS systems together within a larger system-of-systems. Also, when coupled with a Common Access Card (CAC) reader, it becomes possible to definitively link the learner’s identity with their training scores throughout their Navy career (Miller & Voloshin, 2019).
Best Practices and Lessons Learned
In this paper, we repurposed an existing, digital twin based DSS for use as a training application. Many of our training-centric design choices – such as how we chose to measure the learner’s performance, how we chose to provide them with performance feedback, and how we chose to adapt the training experience based on their prior performance – were selected because they were well-suited to the existing DSS system, and therefore did not require wholesale revision of the software. That being said, a number of other (equally effective) design choices could have been incorporated instead. Therefore, we offer the reader no specific recommendations about how to convert their own job performance aids into training tools.
Instead, we summarize what we consider to be the “top five” lessons that we have learned during the course of our multi-year research and development effort. We believe that these lessons are sufficiently generic such that other training professionals can benefit from them as they attempt to repurpose their existing IETMs, DSS systems, and other real-time performance support tools for use as training tools.
Lesson #1
Network multiple training systems using xAPI and CAC to track learner proficiency across time, tasks, and environments. As a general rule, DoD organizations are moving away from stand-alone training tools. Even if the training produces impressive learning gains, it will be met with resistance if learner records cannot be easily extracted from the system and integrated with other data to provide a holistic picture of each learners’ strengths and weaknesses. The xAPI communications protocol solves this problem, and CACs provide definitive identity management across multiple Learner Record Stores.
Lesson #2
Collect consistent data during both training and operations to ensure that the training accurately reflects what is occurring in the actual workplace. The DSS works in two different “modes”: as a real-time job aid, and as a training tool. By collecting xAPI learner records in both modes, we believe that it will be possible to identify specific gaps where the training has failed to prepare learners for real world challenges. This information can then be used to modify the program of instruction accordingly.
Lesson #3
Whenever possible, adapt the training experience to the learner’s level of task proficiency to maintain their level of motivation. In the current instantiation, the learners’ performance is scored in terms of decision accuracy, total repair time, and total repair costs. As the learners’ performance improves over time, we provide them with increasingly fewer direct (bottom-out and pointing) hints and more indirect (teaching and metacognitive) hints.
Lesson #4
Differentially weight the task-performance scores based on what outcomes are most important to the organization. Task performance is not unidimensional. As noted previously, we have developed measures of decision accuracy, repair time, and repair costs. For novice and intermediate learners, the primary focus is on just improving the accuracy of their decision skills. By comparison, as learners become more expert-like, they should begin to choose more judicious courses of action that balance other criteria such as repair time and costs, as dictated by scenario constraints.
Lesson #5
Mine the aggregate data across multiple learners who have completed the same events for continuous organizational improvement. Training is not a “one and done” event, such that after the post-training debriefing has been completed, nothing else can be learned from the exercise. Nothing could be further from the truth. Consider what could be learned if an organization systematically archived the human performance data – in a Learner Record Store – from every maintenance technician across multiple exercises. Given that corpus of data, it would be possible to determine how many training trials are required to achieve initial mastery; the optimal retraining interval to maintain proficiency, and; the extent to which performance varies as a function scenario content. Currently, these types of decisions are made by eliciting domain Subject Matter Expert (SME) opinions. While domain experts have a critical insight into how the task should be performed in situ, their understanding of training schedules and instructional methods may be less informed. By aggregating all learner records in a centralized LRS, it will be possible to design training events based on empirical data, rather than on SME opinions.