
Abstract
When automation takes over many functions and is highly reliable, humans often insufficiently monitor the correct system functioning. We investigated this phenomenon by introducing automation at the action implementation stage in two conditions: Participants working with monitored automation could veto the automation, whereas participants working with consensual automation had to agree with the automation. Based on neuropsychological research on cognitive dissonance, we expected that participants would devote more resources to checking the monitored automation compared to participants working with consensual automation, because the justification of a potential disagreement (veto) should be based on sufficient information. Additionally, we examined effects of risk on trust attitude and behavior when participants worked in virtual reality at either 0.5- or 70-meters altitude. We found a decrease in dissonance discomfort and an increase in self-reported trust across experimental blocks. At high risk, participants monitored automation significantly more. However, no main effects of automation were found.
Trust in automation is described as an attitude (e.g., Lee & See, 2004; Hoff & Bashir, 2015) that translates into corresponding behavior when interacting with automated systems (e.g., Mayer et al., 1995; Hancock et al., 2011). However, trust attitude and trust behavior do not necessarily match (Lee & See, 2004). Divergent trust values are likely, for example, because of a lack of consequences for automation failures or misuse of automation (Chancey, 2016). In such cases, one might not trust the automation (attitude), but still rely on it (behavior) because the situation does not involve relevant consequences for the individual. Therefore, not only is the distinction between attitudinal and behavioral trust essential for understanding the implications for human-automation interaction (Lee & See, 2004; Hoff & Bashir, 2015), but it is also necessary to consider the context of the interaction as this may determine whether trust attitude and trust behavior match or diverge.
An important variable on which trust depends is the allocation of functions between automation and human (Lee & See, 2004; Hoff & Bashir, 2015). With higher degrees of automation, more functions are automated which also increases the potential for mistrust in automation (Manzey et al., 2012; Onnasch et al., 2014). Most empirical evidence for this relationship comes from studies that have focused on trust behavior in terms of automation misuse (e.g., Avril et al., 2021; Endsley & Kaber, 1999). Neither trust attitude nor the relationship between attitude and behavior have received comparable attention in relation to function allocation yet. Furthermore, empirical research mostly compares different stages of automation (i.e., information acquisition, information analysis, decision support, action implementation; Parasuraman et al., 2000) but not levels of automation within a single stage.
The question therefore remains whether the phenomenon of higher automation being associated with more misuse can also be observed for trust attitude and even for different levels of automation within the same stage. With respect to the latter, it is particularly interesting to compare two successive levels within the stage of action implementation automation (AIA, Parasuraman et al., 2000). In consensual AIA, automation selects actions which the human has to approve (Endsley & Kiris, 1995). In monitored AIA, the human is informed by the system and has sufficient time to disagree with the proposed action (Endsley & Kiris, 1995). This seems to be a minor difference in terms of overall function allocation. However, it is reasonable to assume that misuse might be greater with consensual than with monitored AIA, as these levels are closely related to findings regarding cognitive dissonance. In neuropsychological research, cognitive dissonance is described as a state of heightened mental distress and discomfort when peoples’ perception is inconsistent. Moreover, cognitive dissonance is a key psychological mechanism behind some people’s difficulty in disagreeing with others (Domínguez et al., 2016). In relation to monitored AIA, a veto is an active decision against something and has a greater potential for cognitive dissonance compared to conforming to a given decision, i.e., when working with consensual AIA. Because individuals seek to avoid cognitive dissonance (Frey, 1982), consensual decisions should be preferred to veto decisions. Consistent with this assumption, Guenzler and Manzey (2013) found that people would rather make a mistake by following an alarm than by disagreeing with it (i.e., ignoring an alarm). As disagreement is a deviant decision, this decision should be based on sufficient information. In line with that, Guenzler and Manzey (2013) report that "people seem to accept low amounts of uncertainty when complying with an alarm cue, but not when contradicting it" (p. 1362).
Translating this to the interaction with monitored AIA and the implications for behavioral trust, participants should seek information and verify an automated diagnosis to a greater extent than with consensual AIA. Consistent with this, the body of automation research reveals some interesting findings, although studies have not directly compared consensual and monitored AIA in terms of trust attitude and trust behavior. While some studies have shown less behavioral trust in the form of more active monitoring when interacting with monitored AIA compared to lower stages of automation (e.g., Calhoun et al., 2009), others have shown high behavioral trust, indicated by monitoring behavior when working with consensual AIA compared to lower stages of automation (Manzey et al., 2012). Thus, based on the research presented, the question remains whether cognitive dissonance mechanisms might be key in interacting with selected levels of automation, specifically in relation to trust attitude and behavior.
Another point of criticism regarding the presented studies is the insufficient consideration of contextual factors of the operators’ work environment. One of these contextual factors is risk, which has frequently been postulated as an important factor for the effect of the degree of automation on variables like trust and joint human-machine performance (Chancey, 2016). For example, Hoesterey & Onnasch (2022a) showed that the effects of different stages of automation on trust behavior were considerably lower in the high-risk compared to the low-risk situation.
Accordingly, it can be assumed that reduced (i.e., inadequate) verification with consensual AIA is most evident in low-risk situations. In this case, participants’ trust attitude would be reflected in their trust behavior (i.e., high trust for consensual AIA under low risk with reliable automation). In contrast, with monitored AIA, participants should be more likely to verify the automation because of the assumed cognitive dissonance they experience when they disagree, regardless of the risk. Thus, even though their trust attitude is assumed to be high when the automation is reliable and transparent (Lee & See, 2004), their trust behavior would be lower.
At high risk, trust behavior should still be low for monitored AIA, both, because of the increased risk and the urge to reduce cognitive dissonance. On the other hand, trust attitude should not be affected by higher risk if the automation is still reliable and could therefore deviate from trust behavior. Similarly, also when working with consensual AIA under high risk, trust attitude might be high but trust behavior rather low due to the fear of negative consequences associated with mistakes. Differences between consensual and monitored AIA might therefore only be found at low risk.
In summary, based on the state of research on cognitive dissonance, we hypothesized that participants working with monitored AIA should report higher dissonance discomfort than participants working with consensual AIA (H1), but that this effect should decrease over time due to positive experience when verifying the reliable automation (H2). Regarding trust, we hypothesized that trust attitude and behavior should increase after positive interaction experience with the automation (i.e., across experimental blocks; H3). Based on previous results regarding cognitive dissonance, we expected that participants in the monitored AIA condition show less behavioral trust (i.e., greater verification) compared to participants working with consensual AIA (H4). Because trust attitude in consensual and monitored AIA has not yet been assessed comparatively, this aspect was analyzed exploratively. With respect to situational risk, we expected to find the described effects of automation on trust behavior at low situational risk. At high risk, however, the differences in trust behavior should level off (H5).
Method
Participants
A sample size of N = 62 was defined based on an a priori power analysis using GPower (Faul et al., 2007). A total of 77 subjects came to participate in the study of which 11 had to be excluded prior to either data collection or analysis. Participants were excluded either because they failed the training (N = 2), because they did not show any verification behavior and did not follow instructions (N = 4), because their post-test statements indicated that they did not understand the task (N = 2), because of technical problems (N = 2) or because of missing data (N = 1). Thus, a total of 66 participants were included in the current study, mostly students, with German as their native language or equal language skills (36 females, 28 males, 2 non-binary, M = 23.38 years, SD = 4.61 years). Participants signed a consent form at the beginning of the experiment. As compensation, participants could choose between course credits or € 15.
Apparatus and Task
The experiment was conducted in the virtual reality (VR) multi-task environment ViRTRAS (Virtual Reality Testbed for Risk and Automation Studies; Hoesterey & Onnasch, 2022b). Participants were exposed to ViRTRAS using a head-mounted display (HTC Vive Pro, HTC, Taiwan, ROC).
The virtual environment was set at a fictional technical site, and participants slipped into the role of an operator performing maintenance. The main goal in each trial was to perform a simple repair task at different altitudes of the technical site. They were transported to these locations in a small capsule the size of an elevator, from which they could extend a ramp (214 cm long and 110 cm wide) to walk on (Figure 1A). Before they could safely cross the ramp and perform the repair, they first had to diagnose the current environmental condition outside of the capsule. This could be done by performing a test procedure on a panel inside the capsule where up to four different parameters could be assessed for a conclusive diagnosis (Figure 1B). A total of seven environmental conditions were possible, six of which were harmful. For each of these harmful conditions, participants had to apply a specific protection to the ramp to ensure safe passage. If there was a harmful environmental state and participants applied no or the wrong protection, the ramp began to crack as soon as they stepped on it. If they did not return to the capsule quickly enough, the ramp would crack, and the participant would virtually fall. The environment turned white before they reached the virtual ground.

Screenshots of the VR environment. A) View from inside the capsule towards the extended ramp and the place to be repaired (oval shaped structure). B) The panel inside used for diagnosis.
In summary, the primary task on each trial consisted of three phases: 1) diagnosing of the current environmental condition by measuring and evaluating various parameters, 2) deciding on the correct protection and applying it (if necessary), 3) crossing the ramp and performing the manual repair.
Design
A 2 (automation, between) × 2 (risk, within) × 4 (block, within) mixed design was used. Participants worked with either consensual or monitored AIA. Both systems provided participants with an automated diagnosis of the atmospheric condition (phase 1) and were 100% reliable. The automation further implemented the action, i.e., mixed and applied the protection to the ramp (phase 2) if confirmed (consensual AIA) or not vetoed (monitored AIA). Action implementation was therefore initiated either by pressing a ‘confirm’ button (consensual AIA) or by refraining from pressing a ‘veto’ button (monitored AIA). The participants could also manually verify the automated diagnosis by accessing the system parameters at any time. To ensure comparability between both automation conditions, the time to confirm or veto the automation was held constant.
The study consisted of eight experimental blocks for each participant in total. In four blocks, participants had to perform maintenance tasks at 0.5 m above ground level (low risk), and in the other four blocks they had to perform their task at 70 m above ground level (high risk). The order of the risk conditions was alternating. Whether participants started their first block in the low-risk or high-risk condition was counterbalanced within both groups.
Dependent Measures
Dissonance discomfort was measured using four items by Ask et al. (2011). Participants were asked how they felt regarding these four items on a 7-point Likert scale (1 = fully disagree, 7 = fully agree) as they re-imagined their situation before deciding to (not) verify the automation. The items were (a) uncomfortable, (b) uneasy, (c) bothered, and (d) unsettled. Participants reported their dissonance discomfort twice per risk condition (a total of four times): after the second and last (i.e., fourth) block in each risk condition.
Trust attitude was assessed after the first block of each risk condition using the Trust in Automated Systems Scale from Jian et al. (2000; German adaptation by Pöhler et al., 2016) on a 7-point Likert scale ranging from fully disagree (1) to fully agree (7). Additionally, we presented a single item that asked participants how much they trusted the automation. Responses could be given on a scale ranging from 0-100. This single item was presented after the first and last block of each risk condition.
Trust behavior was operationalized as participants’ information sampling behavior, i.e., the number of parameters checked in relation to the number of parameters needed to conclusively verify the automated diagnosis (values between 0 and 1). For example, in a trial with an anomaly, two specific parameters had to be checked in order to verify the automated diagnosis of the atmospheric condition. If a participant only checked one parameter and skipped the other, the value of the parameters checked in that trial was 0.5. The number of required parameters varied between two and four parameters per atmospheric condition.
Procedure
Participants were informed about the virtual exposure to extreme altitudes and the possibility of virtually falling in the invitation to the study and when they arrived. After giving written consent they completed a sociodemographic survey. In addition, they completed a questionnaire to check for acrophobia (vHISS; Huppert et al., 2017). If participants were not diagnosed with acrophobia, they were instructed in the task and asked to put on the head-mounted display before being given the controllers. Participants then received a tutorial within ViRTRAS, which explained the task. In addition, they completed three manual and three automation supported training trials of the task in a completely white environment with very limited altitude cues. The experiment consisted of eight blocks of trials. Each block consisted of four trials. The experiment lasted one and a half to two hours in total.
Results
Dissonance discomfort
The dissonance discomfort sum score was analyzed using a 2 (automation) x 2 (risk) x 2 (block) mixed ANOVA. The analysis revealed main effects for block (F(1,64) = 24.20, p < .001, partial η2 = .274) and risk (F(1,64) = 16.28, p < .001, partial η2 = .203), both with large effect sizes. The main effect of block indicated that dissonance discomfort decreased over time. The main effect of risk indicated that participants experienced more dissonance discomfort under high risk (Figure 2).
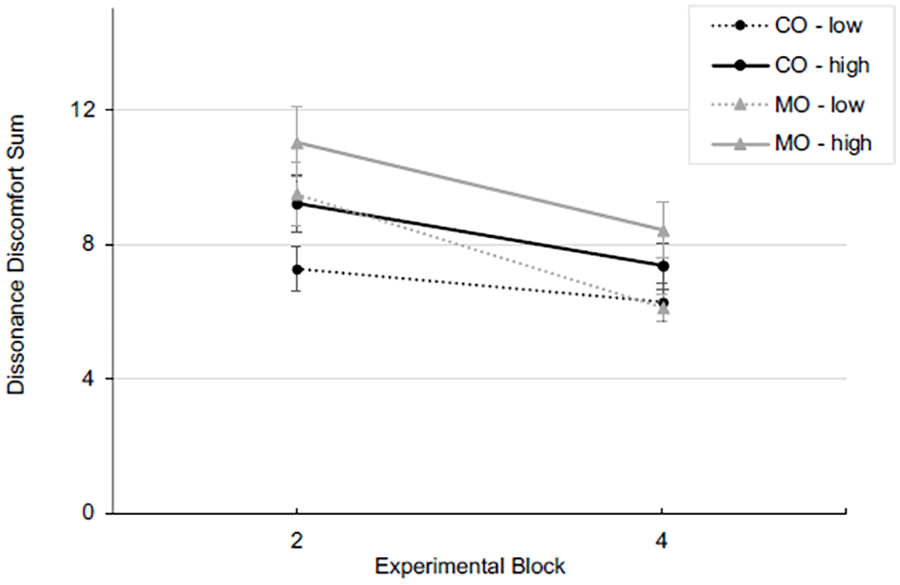
Dissonance discomfort sum score and SE in blocks two and four, for consensual (CO) and monitored (MO) automation and risk (low, high) conditions.
We did not find a main effect of automation (F(1,64) = 2.27, p = .137, partial η2 = .034), an interaction effect of automation x risk (F < 1), automation x block, (F(1,64) = 3.03, p = .086, partial η2 = .045), risk x block (F <1), or a three-way interaction (F(1,64) = 1.24, p = .270, partial η2 = .019).
Trust attitude
We conducted a 2 (automation) x 2 (risk) mixed ANOVA on Jian et al. (2000) trust scale, but no significant differences were found between the conditions.
The single trust item was administered in the first and last block of each risk condition (i.e., blocks one and four). It was analyzed using a 2 (automation) x 2 (risk) x 2 (block) mixed ANOVA. The results showed significant main effects of block (F(1,64) = 31.73, p < .001, partial η2 = .331) and risk (F(1,64) = 13.05, p < .001, partial η2 =.169), both with large effect sizes. We found no main effect of automation on trust attitude (F(1,64) = 0.22, p = .638, partial η2 = .003) nor any interaction effect (all p > .1). Figure 3 illustrates the main effects. The block effect is visible in the increase in trust attitude over time. At the same time, for the main effect of risk, we found lower attitudinal trust measured by the single item for both automation groups under high risk.
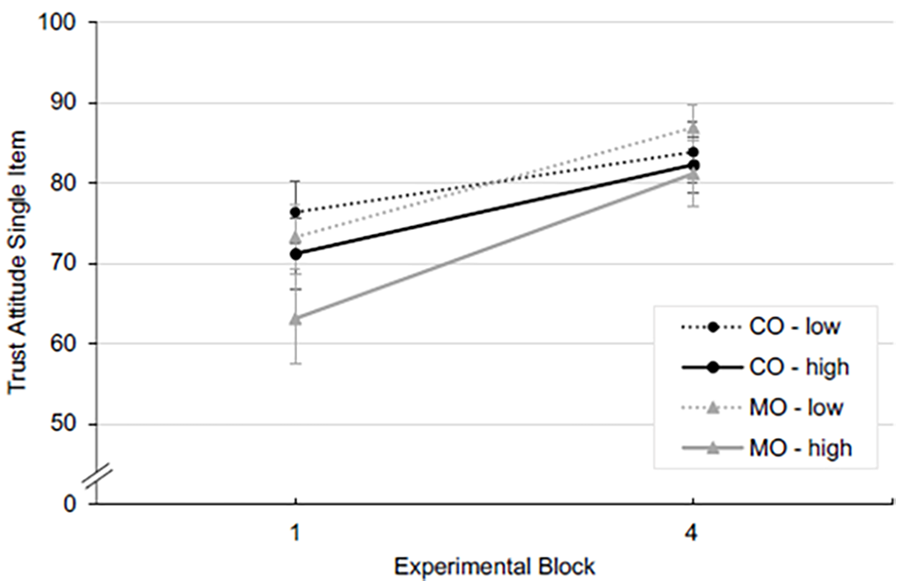
Trust single item values and SE in blocks one and four, differentiated for automation and risk conditions.
Trust behavior
Participants’ information sampling was analyzed using a 2 (automation) x 2 (risk) x 4 (block) ANOVA which revealed significant main effects of block (F(1.61,103.00) = 23.03, p < .001, partial η2 = .265) and risk (F(1,64) = 16.21, p < .001, partial η2 = .202) with large effect sizes. The main effect of block showed that as time on task increased, participants in both automation groups checked fewer parameters (see Figure 4). At the same time, Figure 4 also shows that risk had a main effect, with participants checking more required parameters under high risk. No main effect of automation was found (F(1,64) = 0.32, p = .570, partial η2 = .005), nor was an automation x risk interaction found (F(1,64) = 0.00, p = .96, partial η2 = .000). However, the risk x block (F(2.82,180.24) = 2.55, p = .061, partial η2 = .038) and the three-way interaction of automation x risk x block just missed the conventional level of significance (F(2.82,180.24) = 2.62; p = .056, partial η2 = .039). At start, participants’ information sampling was relatively similar in the low-risk and high-risk conditions. Over time, it decreased, most considerably in the low-risk condition. Both automation groups showed a similar decrease in information sampling across blocks under low risk. Under high risk, especially participants working with monitored AIA reduced their information sampling whereas it was more stable for participants working with consensual AIA.
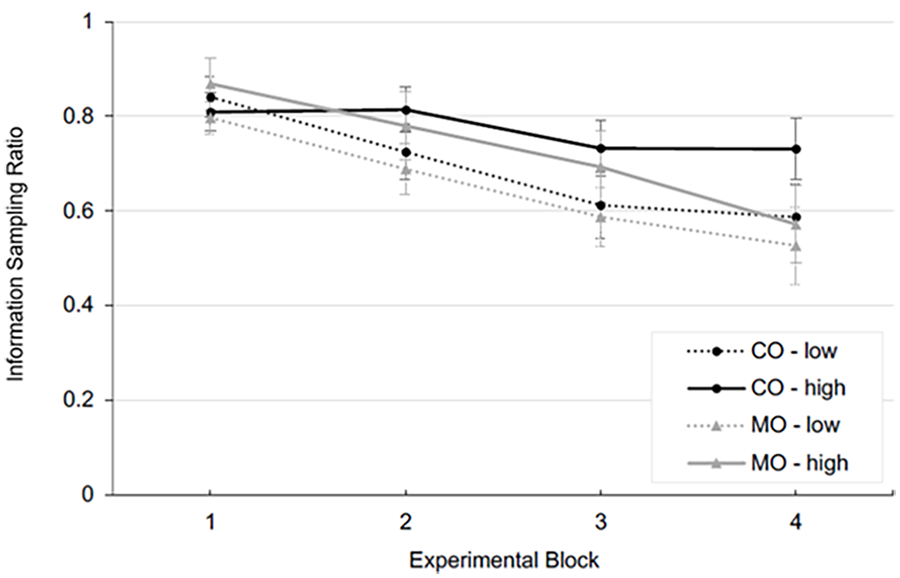
Trust behavior in terms of information sampling (means and SE) for each experimental block, differentiated by automation and risk conditions.
Discussion
The current study examined dissonance discomfort and trust in two different levels of automation while simultaneously manipulating risk in a VR environment. One group worked with consensual AIA, which provided an automated diagnosis that participants could agree to. The other group was supported by monitored AIA. In this case, the automation implemented the action if participants did not veto the automated diagnosis.
With regard to cognitive dissonance, we expected a higher dissonance discomfort when working with monitored AIA due to its disagreement character (H1). However, we did not find this main effect of automation. Descriptively, participants working with monitored AIA had a higher dissonance discomfort on the first measurement compared to consensual AIA. This trend was consistent with the assumption that participants would experience greater discomfort with monitored AIA because of the potential need to disagree. Because the automation was always reliable, it is possible that this continuous positive experience overshadowed the hypothesized effect of automation on dissonance discomfort, as participants learned that disagreement would (most likely) not be necessary.
Consistent with our second hypothesis, we found that dissonance discomfort decreased as interaction experience increased. Interestingly, dissonance discomfort decreased particularly for participants working with monitored AIA, especially under low risk. For consensual AIA, under low risk, participants’ dissonance discomfort remained at a similar level throughout the whole experiment. Their dissonance discomfort would mainly arise from a high-risk situation, as generally indicated by the main effect of risk, which was not hypothesized. It should be noted, however, that the interaction effect of automation and risk was not significant, although close. In summary, for all participants, a positive interaction experience with the reliable automation reduced dissonance discomfort.
Hypothesis 3 postulated that trust attitude and behavior should increase across blocks as participants had positive interaction experiences. This hypothesis was based on Parasuraman and Manzey’s (2010) model of complacency and automation bias, specifically their positive feedback loop. We found full support for this hypothesis for both trust attitude and trust behavior: Working with a reliable system increased trust over time. Thus, we were able to replicate existing findings for trust attitude and behavior (e.g., Bailey & Scerbo, 2007; Sharp et al., 2023).
The fourth hypothesis stated that participants in the monitored AIA condition should show less behavioral trust (i.e., greater verification) compared to participants working with consensual AIA. However, this effect should be levelled off by high-risk situations (H5). We did not find support for either of these hypotheses, but a three-way interaction of automation x risk x block just missed the conventional level of significance and is therefore discussed in more detail. Participants working with monitored AIA verified quite a few parameters at high risk in the beginning of the experiment. This changed with continued interaction experience, as the verification behavior decreased over time for monitored AIA, while the verification decrease was not as strong for consensual AIA under high risk.
A possible explanation for this surprising result could be related to the participants’ perception of their role in interacting with the automation. In the consensual AIA group, participants may have perceived their role as a supervisor confirming the correct functioning of the automation. Their role was active as they always had to confirm the automated diagnosis. In the monitored AIA, however, the participants’ role was to monitor the automation and possibly disagree. As the automation was always working reliably, this was never necessary. Their role was therefore rather passive as they took supervisory control without interfering with the 100% reliable automated diagnoses. Even after cross-checking the diagnoses, they could only let the automation continue: their contribution was therefore not visible. In contrast, in the consensual AIA, the action was implemented only when the human operator confirmed it, so their confirmation had visible and immediate consequences. This post-hoc explanation finds support in research on social loafing, which is also most likely to occur when an individual effort is not visible in the overall outcome (Cymek, 2018; Karau & Williams, 1993). In this line of thinking, participants in the monitored AIA condition may have started loafing because they may have perceived their contribution as useless and not visible. However, as this is a post-hoc explanation, future research is needed to see if such social effects are transferable to human-automation interaction.
In conclusion, the results provide interesting insights into the dynamics of agreement and disagreement. These should be further investigated, especially when implementing an automation that does not always work reliably.