
Abstract
In the paper, we consider a modification of the Recursive Bayesian Estimation technique and incorporate the Fast Sweeping Method to extend recent work in search applications with an algorithm capable of calculating optimal trajectories in the context of multiple targets and searchers. In addition to providing a computational overview of the algorithm, we demonstrate how incorporating knowledge, deception, and belief biases into the algorithm alters the optimal trajectories of the searchers. Finally, we present Monte-Carlo simulations of how these psychological factors influence the mean probability that the searchers detect the target. We will discuss the implications of the findings, current limitations and future extensions of the model, and potential applications to decision support.
Keywords
Introduction
The U.S. Coast Guard, U.S. Navy, and U.S. federal law enforcement agencies contribute to the multi-national detection, monitoring, and interdiction of transnational criminal organizations exploiting transshipment routes for moving black market goods (e.g., narcotics or weapons). Finding and stopping these vessels involves a great deal of aerial and maritime monitoring and international cooperation.
As depicted in Figure 1, the interdiction task is a complex search and detection task where a target platform (e.g., drug smuggler boat or semi-submersible) is transitioning between locations while attempting to avoid detection by searcher platforms (e.g., Coast Guard Cutter or helicopter). Each platform might have varying levels of mobility, detectability, and endurance.
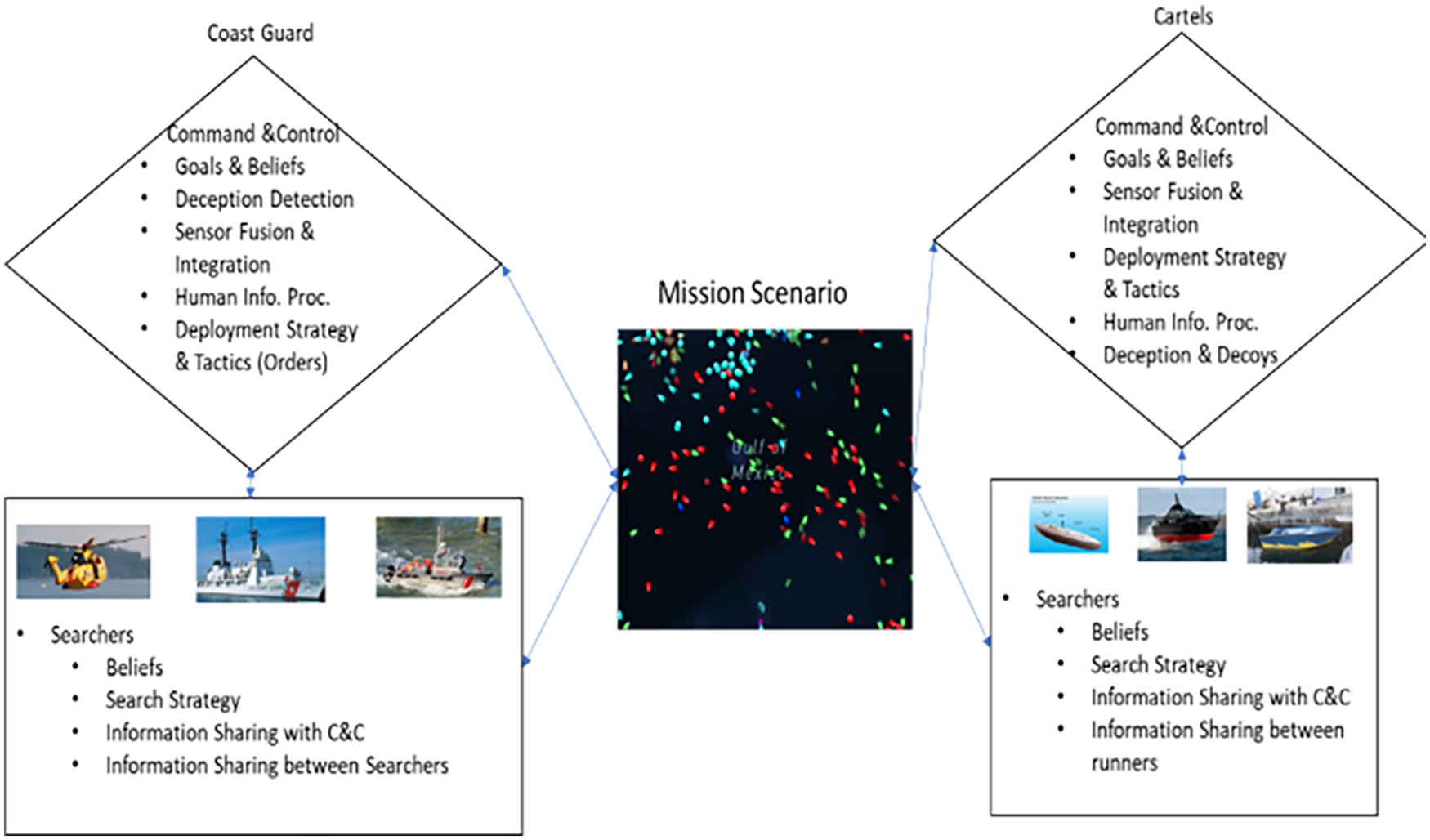
Overview of the USCG search and interdiction task.
The search and detection task can be highly complex given the scenario’s geometry. Multiple searchers and targets can operate simultaneously anywhere within the game plane. Stationary and dynamic obstacles (e.g., weather hazards or maritime traffic) can hinder straight-path transits between originating and destination locations. For any given scenario, geometry, physics, and mathematics can be applied to ascertain realistic, optimal waypoints and paths for both platforms.
In addition to the complexity imposed by the environment on the search and interdiction mission, we must account for the human aspects of the operators, including their knowledge, decision-making, and coordination. For example, the target platform may have preferred originating and/or destination locations. A searcher platform may prioritize the protection/monitoring of one location over another location. One platform may bias its activities based on historical knowledge of another platform’s activities or demonstrated Pattern of Life (PoL). Intelligence and deception can further bias and influence the operators’ beliefs. These factors could also be layered; a search platform might favor mobility choices that improve/maintain its endurance over ensuring frequent coverage of areas in which the target platforms may transit. Further, either platform might have entrenched strategies driving repeated processes or patterns or could be feigning the establishment of those entrenched strategies (engaging in deception). These competing criteria drive the paths that can be taken by each platform and therefore increase the complexity of the models that can be developed to demonstrate the probabilities of likely outcomes.
Given the complexity of maritime operations, artificial intelligence (AI) applications have begun to emerge in which an AI agent acts as an advisor to support operator decision-making. For example, the Tool for Multi-Objective Planning and Asset Routing (TMPLAR) aids navigation for Naval and commercial shipping, providing recommended paths optimized based on several objectives or decision attributes (e.g., travel time, fuel efficiency, navigator-specified deadlines, etc. (Avvari et al., 2018). Other Naval tasks that implement decision and navigational aids include counter-smuggling operations (Courses of Action Simulated Tool - COAST), dynamic autonomous aerial systems’ operations under uncertainty (Supervisory Control Operations User Testbed - SCOUT), and pirate interdiction (Pirate Attack Risk Surface - PARS (Esher, Regnier, et al., 2010)).
Previous research has developed methods to address the search and detection problem, but many applications have been limited to scenarios with only a single searcher and a single target (Eagle, 1984, Kress et al., 2010). In the current project, we consider a single target with multiple searchers. Further, in our model we implement the Recursive Bayesian Estimation (RBE) technique of Bourgault et al. (2004) together with the Fast Sweeping Method (FSM) by Zhao (2005) to compute the optimal trajectory of the searchers for interdiction.
We provide a computational overview of the model in the following section, as well as demonstrate how knowledge, deception, and belief biases alter the optimal trajectories of the searchers. Next, we present Monte-Carlo simulations of how psychological factors influence the mean probability and latency that the searchers detect the target. Finally we discuss the implications of the findings, current limitations and future extensions of the model, and potential applications to decision support.
Model Background and Overview
At time

with
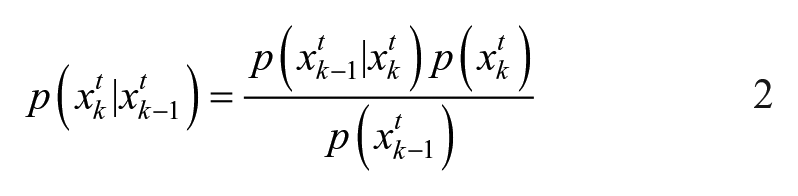
Each of the terms used in Eq 2 can be computed from

where
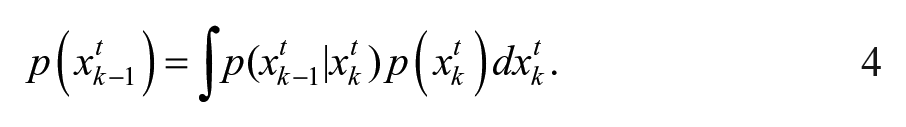
Noting that
Given
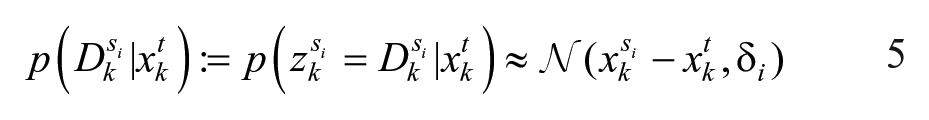
where
The probability that searcher
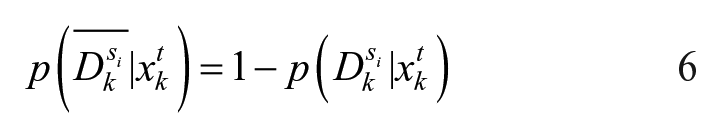
and the probability that none of the searchers have detected the target by time k to be
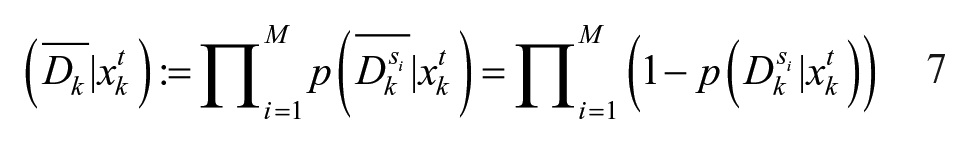
In this paper, we consider a modified version of the RBE approach by updating the searchers’ state a single step at a time with the anticipated knowledge of where the target’s PDF is within the next
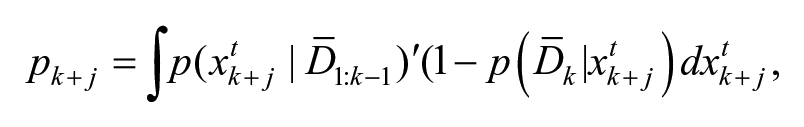
where
Suppose
Prediction step: Compute
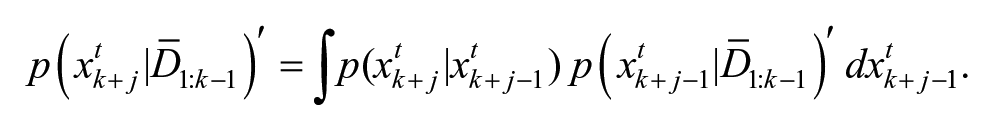
Update step:
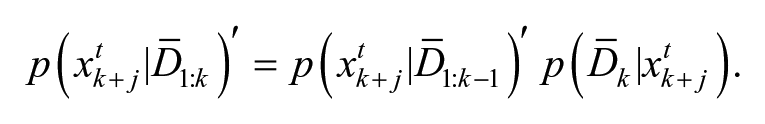
Define the detection rate of the searchers’ states
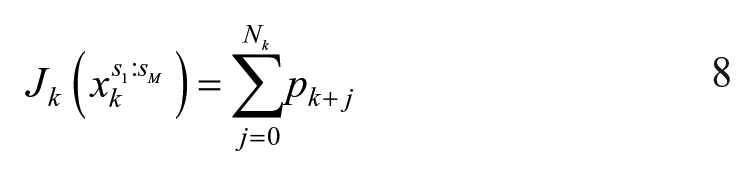
and the associated cost by
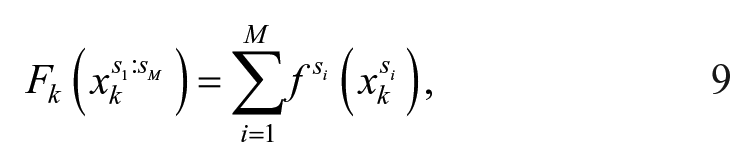
where
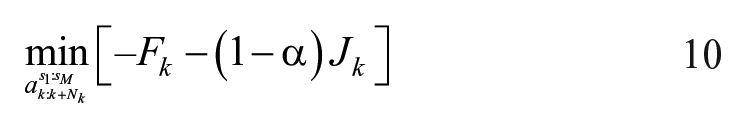
where
Of course, the searchers' knowledge about the target's PDF and conditional probability can be imperfect, affecting the detection rate. We will go over different scenarios where this knowledge and beliefs range from perfect to imperfect calibration and how knowledge/belief calibration affects the success of the searchers detecting the target.
Model Demonstrations
The demonstration scenario entails targets from a single source traveling to three possible destinations under constraints and beliefs. The single target has no knowledge of the searchers. The objective of the target is to travel from the origination location to the destinations optimally while minimizing costs, and where the target has constraints and biases—preferences for destinations and minimizing navigational costs. The searchers know the target's origination point and the target's possible movements assuming optimality under constraints and beliefs. The objective of each searcher is to follow the trajectory that it believes to be optimal (maximizing the probability of target detection while minimizing its costs). Thus, the searchers' strategies to find the target can assume different constraints and beliefs from the target's true beliefs and constraints. For instance, the searchers may base their beliefs about the target's trajectory and destination on their PoL or historical knowledge about the target. In contrast, the target's current beliefs (i.e., goal) can strategically deviate from their PoL.
Demonstration 1: Searcher Beliefs Based on Pattern of Life
Figure 2 demonstrates how the target's PoL is incorporated into the searchers' beliefs and behavior using a simplified example with only two destination ports, located at the top and bottom right corners. The rectangle in the middle of the frames represent an impassible barrier, e.g., an island, that agents must travel around. The white clouds in the left panels illustrate the searcher beliefs for the target position, based on the historical PoL. The right panels show the behavior (routes) of the target and the searchers, which start traveling from the left and right edges of the frame, respectively. The top-right panel illustrates a situation where the searchers head in opposite directions around the center barrier since the target is equally likely to take either route based on the PoL. The lower-right panel illustrates a situation where both searchers take the same route around the center barrier, as that is the route with the highest probability of detection based on their proximity. This demonstrates the impact that the target’s PoL have on the behavior of the searchers and targets.
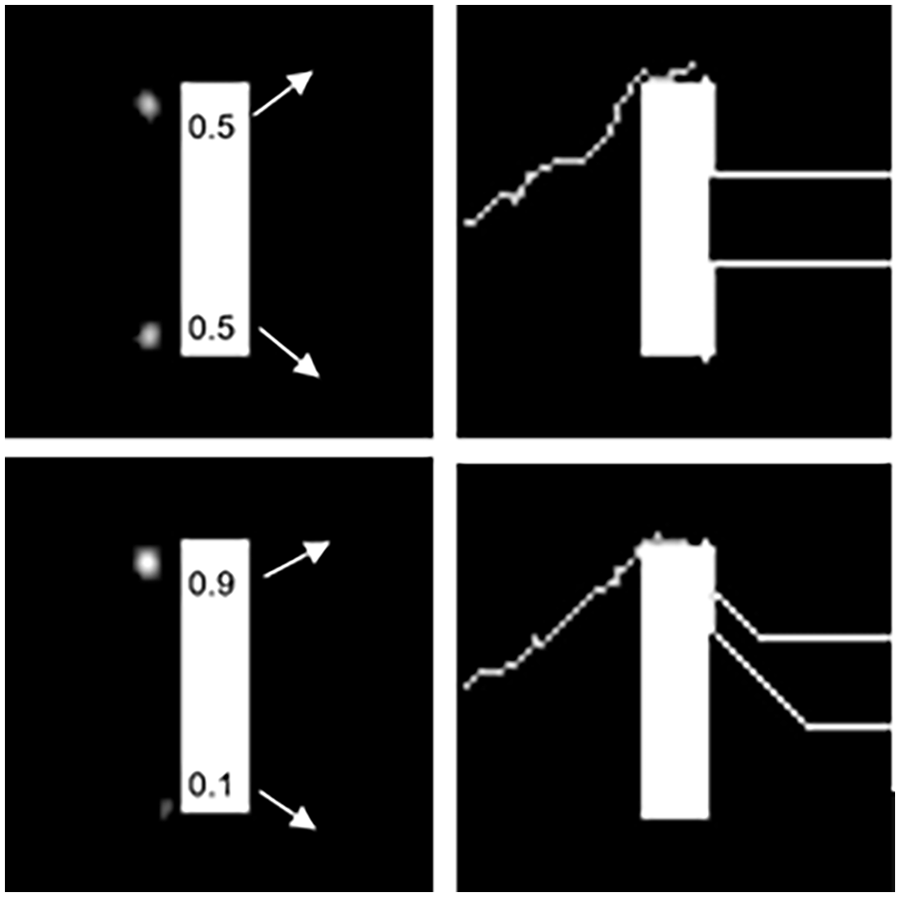
Left: Two different target PoL PDFs. Searchers travel in the direction with highest probability of detection based on their proximity and beliefs about the target’s intentions (PoLs).
Demonstration 2: Target Deviates from Searcher Knowledge of Target PoL
We provide a demonstration of how beliefs and biases change the behavior of the searchers and the probability that they successfully detect the target.
Figure 3 illustrates two examples where the searchers base their movement on a known PoL, but the target’s novel behavior deviates from that PoL. In each example, the dots represent the current location of the agents, red for the searchers and white for the target, while the gray cloud represents the searchers' beliefs of the target's PoL based on historical data. In both examples, the target is moving more slowly than expected from the PoL. Note in the right panel of Figure 3, that the searchers are actively searching the areas that they believe the target is most likely to be, but these beliefs are inaccurate. These examples illustrate how deviations from PoL compromise detection.

The searchers’ movement is based on the historical PoL for the target. By deviating from its historical PoL, the target avoids detection.
Demonstration 3: Effects of Look Ahead Steps
Figure 4 illustrates the influence of the searchers’ ability to look ahead steps in the future, where

Searcher's Paths as a Function of Increasing the Number of Look-Ahead Steps (
In theory,
Monte-Carlo Simulations
In the following simulations two searchers are assigned to originate from one of three target destination ports. One searcher is always assigned to the first port, and a second searcher is assigned to the second port with a 2/3 probability or to the third port with a 1/3 probability. Additionally, the first searcher only considers the PoL PDF that terminates at the first port, while the second searcher considers the other two PoL PDFs, terminating at ports two and three. Estimates of mean detection probability are based on at least 500 Monte-Carlo runs for each simulated scenario.
Simulation 1: Biased Beliefs Based on Intelligence can Affect Detect Probability & Latency
The belief matrix that drives Simulation 1 is provided in Table 1. The columns show the port preference for the target and the port preference beliefs the searchers have for the target. In the No Bias condition, the target's behavior and the searchers' beliefs exhibit maximum uncertainty for which port the target will prefer. In the Good Intelligence condition, the target is biased to port one, .94, and the searcher's beliefs are perfectly calibrated to the target's bias. In the Bad Intelligence condition, the target is biased to port two, .94, but the searcher's beliefs about the target are highly biased to port three.
Sim 1: Target Bias and Searcher Beliefs.
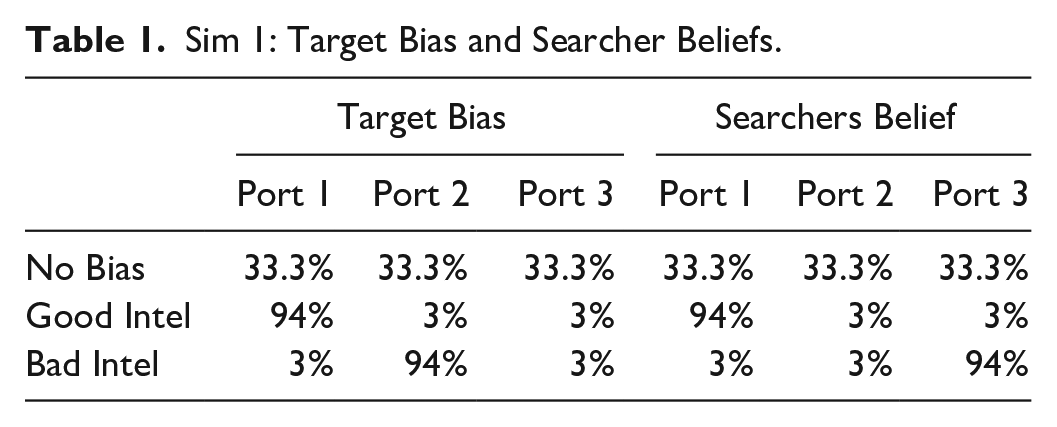
Figure 5 plots the mean probability of detection by the level of bias imposed on the searchers’ beliefs. As illustrated, the mean detection probability increases for Good Intelligence relative to No Bias and decreases for Bad Intelligence relative to No Bias.

Mean Detect Probability by Searcher Belief Bias.
Thus, Figure 5 illustrates that the mismatch between the searchers’ beliefs and the target’s intent can significantly compromise mean detect probability and latency.
Simulation 2: Calibration of Searcher Beliefs on Detection
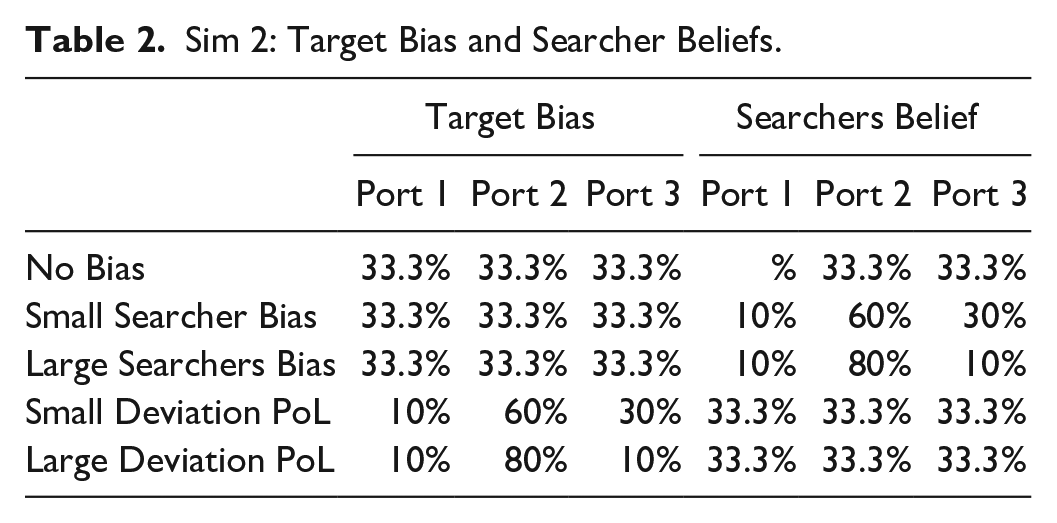
Simulation 2 further explores how the level of calibration of searcher beliefs to the target’s preferences affects mean detect probability. Table 2 is the belief matrix, where the columns show the port preference for the target and the port preference beliefs the searchers hold for the target across the different scenarios (rows). The first three rows illustrate a situation where the target’s behavior exhibits equal preference for the three ports or destinations. The searchers’ beliefs match the target’s preference in the No Bias scenario, show a relatively small deviation (bias for port two) in the Small Searcher Bias scenario, and show a relatively large deviation in the Large Bias scenario (significant bias for port two). The bottom two rows (scenarios) represented in Table 2 are situations where the searchers’ beliefs are calibrated to the target’s PoL, but the target purposefully deviates from its PoL, exhibiting a slight or strong preference for port two.
Sim 2: Target Bias and Searcher Beliefs.
As illustrated in Figure 6, the mean detection is substantially compromised when there are small and large deviations from PoL. Surprisingly, the small and large searcher bias does not compromise mean detect probability compared to the calibrated condition. Searcher bias is mitigated by scenario-specific characteristics, primarily because the PoL exhibits maximum uncertainty. Also, the target bias was always for port two, where the searcher was only assigned to start from 67% of the time and its search behavior was based on the combination of PoL PDFs terminating at both ports two and three.

Mean Detect Probability by Scenario.
Discussion & Implications
The goal of this paper was to extend recent work in search with an optimal algorithm capable of incorporating multiple targets and searchers. In addition, we provided several demonstrations and simulations where the optimal search algorithm incorporated psychology and human behavior via belief biases. Our simulations show that belief biases mirroring the effects of good intelligence and bad intelligence, or deception, significantly affected the ability of searchers to detect targets. Although, generally, our demonstrations and simulations show that good calibration between searcher and target beliefs supports detection, scenario-specific details did moderate this effect. The fact that scenario-specific characteristics can interact with belief biases in often counter-intuitive ways further supports the need to incorporate psychological beliefs into models and optimizations to support search in mission-realistic scenarios. In other words, knowing what is optimal depends on understanding how less-than-rational searchers and targets behave in different contexts. Thus, our model could support a tool that provides USCG-recommended paths to support interdiction.
A critical aspect of the model is the incorporation of the searcher's beliefs of the target's POL coded via the conditional probability equation
Limitations & Future Directions
There are several limitations and exciting future directions for the current work. First, we intend to extend the simulation environment. Our targets did not know about the searchers’ behavior, and we plan to incorporate such knowledge of the searchers in future extensions.
Modeling tradeoffs between detect probability and utility—the searchers may unequally value detections in different locations—could be fruitful. The searchers may value specific locations over others and want to protect them. Moreover, once we incorporate utility functions, we can model the influence of psychological parameters like loss and risk aversion on the searcher, target behavior, and detection probability.
We also plan to incorporate Command & Control (C2) nodes into the model. C2 will allow the searchers and targets to share information vicariously via a higher level (shared operating picture). C2 decision and deployment strategies, including those that are less than optimal, could be interesting to model.
Finally, we would like to incorporate dynamic maximization criteria. For instance, looking back at Figure 3 (right panel), we suspect that searchers will shift their criteria when they cannot find a target in a location they believe it should have been detected with near certainty after a certain amount of time.
Ultimately, we hope our model can generate, represent, display, and manipulate mixed-initiative, agile courses of action under uncertainty, competing goals, and dynamic threats while accounting for human beliefs and constraints in the solutions. As the system continuously updates the mission-transition state beliefs based on information concerning the adversary (sensor updates, intelligence reports, etc.), the system will also update the strategic level of analysis at the command-node level to generate alerts and update COA. Moreover, incorporating What-If capability and intuitive visualizations could be helpful to operators, particularly presentations of the rationale for the anticipated location of a target in terms of current and prior beliefs.