
Abstract
Sports spectatorship is fundamentally affective, and the rise of fan-generated data has enabled large-scale computational analysis of fan sentiment and emotion. This paper synthesises 64 studies (2000–2025) that infer fan affect from (i) digital text and online discourse, (ii) broadcast-linked second-screen interaction, and (iii) in-venue or non-textual signals such as crowd audio, video, and wearable sensing. We organise the literature into three modality-based categories: text-centric discourse analytics, second-screen/social-TV behaviour, and in-venue or multimodal sensing. Across studies, a consistent empirical pattern is event-driven synchrony: aggregate affective signals shift rapidly around salient match events and controversy. However, three structural limitations constrain behavioural inference and generalisability: strong platform dependence (especially Twitter/X), overreliance on coarse polarity sentiment, and conceptual slippage between affective expression and behaviour. Research on harmful expressions (e.g., toxicity, hate speech) is expanding and behaviourally relevant, but introduces methodological and ethical challenges. Overall, the literature is effective at detecting affective expression but weaker in linking affect to explicit behavioural outcomes or integrating evidence across modalities. We highlight directions for behaviour-centred, multimodal fan analytics, including improved construct validity, clearer outcome definitions, cross-modality integration, and stronger cross-platform and ethical considerations.
Keywords
Introduction
Sport spectatorship is inherently affective, with fans experiencing anticipation, excitement, frustration, anger, and joy before, during, and after sporting events. These emotional states are not only internal experiences but are also expressed through observable behaviours such as cheering, booing, chanting, online posting, commenting, and engagement with media content. The increasing digitisation of sports consumption has substantially amplified the visibility of these expressions, particularly through social media platforms, online fan communities, and second-screen interactions linked to live broadcasts. As a result, sentiment analysis has emerged as a prominent methodological approach for studying sports fans at scale.
Early studies in this area demonstrated that fan-generated content on social media reacts rapidly to in-game events. Analyses of Twitter data during major competitions such as the FIFA World Cup and the Super Bowl showed that aggregate sentiment closely tracks goals, penalties, controversial referee decisions, and match outcomes (Chang, 2019; Yu and Wang, 2015). These findings positioned social media as a real-time sensor of collective fan reactions and motivated the widespread adoption of sentiment analysis techniques in sports research. Related work subsequently formalised this “social sensing” perspective in sports settings (Zhao et al., 2011). Later studies extended this approach to league-level competitions and a wider range of sports, including football, basketball, and American football, further confirming the sensitivity of online sentiment to match dynamics (Schumaker et al., 2016).
Alongside event-driven analyses, a substantial body of research has investigated whether fan sentiment can be leveraged for predictive purposes. Studies have examined relationships between pre-match or in-play sentiment and outcomes such as match results, goal occurrences, or betting spreads. However, reported findings are mixed and appear to be highly dependent on contextual factors, sport-specific dynamics, and modelling choices (Schumaker et al., 2016; Sinha et al., 2013).
Beyond immediate live-event reactions, researchers have increasingly focused on post-match discourse and sustained fan interaction within online communities. Analyses of online discussions surrounding sporting events reveal longer-term affective patterns, including blame attribution following losses, reinforcement of in-group and out-group identities, rivalry escalation, and the persistence of negative sentiment beyond the immediate match window (Blaszka et al., 2012; Mazhar et al., 2025; Wang and Lu, 2023). These studies highlight that fan affect is not limited to short-lived reactions but is embedded within ongoing social and cultural practices.
Another important strand of research examines second-screen behaviour, in which fans simultaneously consume live broadcasts and engage on social media. Studies in this area show that broadcast peak moments such as goals, replays, and controversial decisions trigger synchronised bursts of online activity and sentiment shifts. These findings reinforce the close coupling between mediated sport consumption and digital fan expression (Chang, 2019; Zhao et al., 2011).
More recently, research on fan affect has begun to move beyond text-based data sources. A smaller but growing body of work investigates non-textual and in-venue signals such as crowd noise, chanting, facial expressions, movement patterns, and physiological measurements to infer collective affect. Research on crowd noise and refereeing decisions demonstrates that auditory expressions of fan emotion can influence on-field behaviour and outcomes, suggesting that such signals are behaviourally consequential rather than merely expressive (Dohmen, 2008; Nevill et al., 2002). In parallel, other studies explore multimodal and deep-learning approaches for analysing large-scale sport-event discussions and audience affect (Bandyopadhyay and Karmakar, 2024; Poria et al., 2017).
Despite the breadth of this literature, several systematic limitations are evident. First, there is a strong bias on the platform towards Twitter/X and other easily collectable data sources, which can distort representativeness and threaten external validity (Tufekci, 2014). A practical consequence of Twitter/X dominance is that many sport-sentiment findings are most defensible for the platform population and the language slice that is actually analysed. In practice, large-scale studies often restrict data to English (explicitly or implicitly through lexicons and standard models), which can overrepresent English-speaking majority groups and underrepresent multilingual, diasporic or locally located fan publics. Even when multilingual tweets are collected, modelling and evaluation are frequently conducted in English-centric pipelines, weakening external validity and cross-cultural generalisability. More broadly, social media traces are not neutral samples of fans: platform demographics, participation inequalities, API constraints, and visibility dynamics systematically shape what is observable and thus what can be inferred (Olteanu et al., 2019; Sloan et al., 2015; Tufekci, 2014).
Accordingly, throughout this review we interpret Twitter/X-based sentiment primarily as an indicator of expressed affect on a specific platform rather than as a direct estimate of population-level fan behaviour.
Second, sentiment is most often operationalised using coarse polarity measures, even though sports fandom involves complex emotional states that are poorly captured by simple positive and negative distinctions (Wunderlich and Memmert, 2020). Third, sentiment is frequently treated as behaviour itself rather than as an affective signal related to behaviour. Many studies report sentiment trends, often aligned with match events or broadcast cues, without explicitly linking these trends to concrete behavioural outcomes such as sustained engagement, escalation or abuse, or disengagement. As a result, behavioural claims are often largely inferential (Chang, 2019; Kolbinger and Knopp, 2020; Patel and Passi, 2020; Sapiña et al., 2024; Wunderlich and Memmert, 2020; Yu and Wang, 2015; Zhao et al., 2011).
In addition, the literature remains fragmented across media and modalities. Text-based sentiment analysis, second-screen studies, and in-venue affect sensing have largely evolved in parallel, with limited cross-referencing or methodological integration (Nevill et al., 2002; Zhao et al., 2011). Consequently, it remains unclear how fan affect propagates across digital and physical spaces, how different modalities reinforce or attenuate one another, and how sentiment signals expressed online relate to behaviour expressed in stadiums or other offline settings.
Taken together, these observations point to several unresolved gaps. There is a lack of conceptual clarity in distinguishing sentiment, emotion, affect, and behaviour in sports fandom research. Behavioural grounding is often weak, with limited attention paid to explicit outcomes beyond platform activity. Multimodal integration remains rare, and cross-context synthesis across sports, cultures, and platforms is limited (Mazhar et al., 2025). Finally, despite the large number of empirical studies, there remains a shortage of comprehensive review papers that organise this literature in a coherent and behaviour-centred manner across modalities.
To address these gaps, the goal of the present study is to systematically synthesise research on sentiment analysis of sports fans’ behaviour across digital and non-digital media, with particular emphasis on how sentiment has been operationalised, interpreted, and linked to behaviour. This paper surveys 64 studies spanning text-based social media analysis, online fan communities, second-screen interactions, and in-venue affective sensing. By organising this work into a unified framework and critically examining its conceptual and methodological foundations, the review aims to clarify the current state of the art, identify persistent limitations, and provide guidance for future research toward more behaviourally meaningful and multimodal analyses of sports fandom. From a sports analytics perspective, this synthesis positions fan-affect signals as measurable covariates and outcomes that can complement traditional performance, broadcast, and venue analytics.
Conceptual foundations
Sentiment, emotion, and affect
In the sports analytics literature, the terms sentiment, emotion, and affect are frequently used interchangeably, despite referring to analytically distinct constructs. Sentiment is most commonly operationalised as coarse polarity (positive, negative, neutral), particularly in large-scale social media studies due to its computational simplicity and compatibility with lexicon-based or shallow machine learning approaches (Pang and Lee, 2008; Wunderlich and Memmert, 2020). Recent work has also explored causal and debiasing approaches to improve the robustness and fairness of sentiment models across domains, highlighting the importance of mitigating spurious correlations in affect classification tasks (Zhu et al., 2025). While polarity measures enable efficient aggregation and temporal alignment with match events, they collapse qualitatively distinct emotional states such as anger, disappointment, anxiety, pride, and joy into a single valence dimension, obscuring differences in their behavioural implications.
An additional source of conceptual ambiguity is that sentiment and emotion inference can operate at multiple analytical levels. In document-level inference, a single polarity or emotion label is assigned to an entire post, comment thread, or document. Sentence-level approaches narrow the unit of analysis to individual sentences, enabling more fine-grained modelling of mixed evaluations within longer texts. Target- or aspect-level sentiment analysis (often referred to as aspect-based sentiment analysis, ABSA) goes further by explicitly linking evaluative language to a specific object or attribute (e.g., the referee, a star player, officiating decisions, ticket prices, or stadium services) (Pontiki et al., 2016). Finally, token-level or span-based methods identify the exact linguistic segments that express evaluative content.
These distinctions matter because the behavioural interpretation of sentiment depends strongly on the level of analysis being performed. For example, document-level polarity may summarise the overall tone of a discussion thread, whereas aspect-level inference can reveal simultaneous but contrasting evaluations of different elements of the sport experience. Consequently, sentiment should not be treated as a single technique but rather as a family of operationalisations whose analytical resolution determines what claims can be made about fan perception and behaviour.
A smaller body of work adopts discrete emotion frameworks, classifying fan expressions into categories such as anger, joy, sadness, or fear. These approaches better reflect the emotional richness of sports fandom but require stronger modelling assumptions, higher-quality annotations, and domain-specific validation, which limits their adoption at scale (Calvo and D’Mello, 2010). Related work draws on dimensional affect models, most commonly valence and arousal representations, which capture intensity and activation alongside positivity or negativity. Although such models are theoretically well grounded, they remain underutilised in sports sentiment research, particularly in text-centric studies (Poria et al., 2017).
While richer emotion taxonomies can in principle capture nuances beyond simple polarity, they do not automatically improve behavioural interpretation. In sports discourse, fans frequently perform exaggerated emotion, employ sarcasm, or engage in rivalry banter that appears negative on the surface but functions socially as affiliation or identity signalling. Even when models reliably distinguish categories such as anger and sadness, the downstream behavioural meaning may remain ambiguous: expressions labelled as anger may correspond to disengagement, intensified engagement, collective identity reinforcement, or ritualised complaining within fan communities. Accordingly, expanding the number of emotion categories does not necessarily reduce interpretive uncertainty and may widen the gap between computational labels and theoretically meaningful constructs.
More recently, sentiment-related analysis in sports contexts has expanded to include constructs such as toxicity, aggression, and hate speech, especially in studies examining online abuse directed at players, referees, or rival fan groups. In general NLP (Natural Language Processing) toxicity/hate detection has been operationalised with widely used supervised benchmarks and feature sets (Davidson et al., 2017; Waseem and Hovy, 2016). These operationalisations shift the analytical focus from general affective tone to norm-violating or harmful expressions, implicitly embedding behavioural judgments within the sentiment construct itself. A key technical and validity challenge is domain mismatch: widely used toxicity/hate benchmarks are typically annotated without sports-specific pragmatic context (e.g., rivalry banter, ironic praise, reclaimed slurs, or sarcasm), and models trained on them may therefore inflate false positives when applied to sports talk. In addition, annotation practices can encode socio-linguistic bias (e.g., dialect being over-flagged as abusive), which becomes especially consequential if outputs are used to justify moderation, policing, or stadium security interventions (Bender et al., 2021; Fortuna and Nunes, 2018; Gillespie, 2018; Hovy and Spruit, 2016; Sap et al., 2019).
Across these operationalisations, a persistent issue is the tendency to equate sentiment measures with emotional experience or behavioural intent. In practice, sentiment scores capture properties of observed signals (most often text) rather than underlying affective states. As a result, sentiment should be understood as an inferred indicator of affective expression, not a direct measurement of emotion or motivation (Calvo and D’Mello, 2010; Pang and Lee, 2008). Failure to maintain this distinction has led to overinterpretation of sentiment outputs and weak behavioural claims in parts of the literature.
Defining fan behaviour
Fan behaviour refers to observable actions and interaction patterns through which sports spectators express affiliation, evaluation, and engagement. In digital contexts, this includes posting frequency, reply and retweet behaviour, commenting dynamics, emoji use, and participation in hashtagged or community-specific discourse (Billings, 2018; Blaszka et al., 2012). Beyond individual actions, behavioural patterns also encompass collective dynamics such as blame attribution after losses, polarisation between rival fan groups, escalation of abusive language, and persistence of engagement beyond live match windows (Mazhar et al., 2025; Rowe, 2014; Wang and Lu, 2023). Media narratives surrounding international sporting events can also shape fan discourse and collective identity formation, influencing how fans interpret performances, controversies, and national representation in sport (Ziaee et al., 2021, 2024).
In mediated viewing environments, fan behaviour extends to second-screen practices, including live-tweeting, synchronised reactions to broadcast events, and coordinated audience responses during peak moments such as goals or controversial referee decisions (Zhao et al., 2011). These behaviours are temporally coupled to media consumption and reflect how affect is expressed through platform-specific affordances rather than through language alone. In physical settings, fan behaviour includes chanting, booing, applause, coordinated visual displays, and other embodied or environmental signals that shape the in-venue atmosphere and, in some cases, influence on-field decisions (Dohmen, 2008; Nevill et al., 2002).
A recurring conceptual problem in the literature is the treatment of sentiment itself as behaviour. Many studies implicitly equate changes in sentiment polarity with behavioural change, despite sentiment representing an inferred affective signal rather than an action. To avoid this conceptual slippage, sentiment should be treated as an intermediate signal situated between internal affective states and observable behaviour. Behavioural interpretation requires explicit linkage between sentiment measures and concrete outcomes, such as sustained engagement, discourse escalation, attendance-related proxies, or collective action (Billings, 2018; Rowe, 2014). Without such linkage, sentiment analytics remain primarily descriptive, limiting their explanatory and predictive value in the study of sports fandom.
Although sentiment and emotion detection are among the most visible NLP applications in sports analytics, they represent only one subset of computational text analysis methods.Other families of NLP approaches examine the thematic structure, semantic organisation, and identity dynamics of fan discourse.Topic modelling and related unsupervised techniques identify recurring themes within large corpora, enabling researchers to map what fans are discussing and how these topics evolve over time (Blei et al., 2003). Beyond affect detection, topic modelling approaches have been used to identify latent themes in sport consumer discourse and to map how customer experience constructs emerge from large-scale textual feedback (Mao et al., 2024). Embedding-based methods represent words, phrases, or posts in continuous semantic spaces, and recent contextual language models further improve semantic representation learning (Devlin et al., 2019; Mikolov et al., 2013).
These approaches complement sentiment analysis by revealing the content and structure of fan conversations rather than only their evaluative tone. For example, topic models can identify the themes that co-occur with spikes in emotional expression, while embedding methods can capture slang, irony, and community-specific language patterns that lexicon-based sentiment tools often miss. Taken together, these broader NLP techniques enable richer analyses of fan discourse dynamics and provide additional pathways for linking language patterns to behavioural and cultural processes in sports fandom.
Method
This study adopts a structured narrative review with systematic elements to synthesize research on sentiment, emotion, and affect analysis of sports fan behavior across digital, mediated, and in-venue contexts. This methodological choice follows guidance from recent meta-research on review design, which emphasises selecting review structures appropriate to the maturity and heterogeneity of the research domain (Burggren, 2024).
In fields where empirical studies span multiple data modalities, analytical traditions, and disciplinary contexts, as is the case for sports sentiment and fan-affect research, structured narrative synthesis is often recommended over strict meta-analysis because effect sizes and outcome definitions are rarely comparable across studies. Taxonomies of review types similarly distinguish structured narrative and scoping-style reviews from statistical meta-analyses when the goal is conceptual integration and methodological mapping rather than quantitative aggregation (Grant and Booth, 2009).
Structured narrative reviews are particularly appropriate when a research domain is characterised by conceptual plurality, heterogeneous data modalities, and diverse analytical traditions, rendering statistical meta-analysis inappropriate or potentially misleading (Green et al., 2011; Paré et al., 2015). In the present case, the reviewed literature spans multiple signal types, including text, audio, video, and physiological data, and employs a wide range of analytical approaches, from lexicon-based sentiment analysis to machine learning, deep learning, and multimodal affect recognition (Calvo and D’Mello, 2010; Pang and Lee, 2008; Poria et al., 2017). Accordingly, the review prioritises transparent identification, screening, coding, and qualitative synthesis over quantitative aggregation, with the aim of enabling conceptual integration and behavioural interpretation across otherwise fragmented research streams.
The review covers publications from January 2000 to January 2026. This time window was selected to capture both foundational research on crowd effects and social influence in sports settings, which predates the widespread adoption of online social networks (Dohmen, 2008; Nevill et al., 2002), and the subsequent expansion of computational sentiment analysis applied to sports fandom following the rise of large-scale social media platforms after 2010 (Wunderlich and Memmert, 2020; Yu and Wang, 2015; Zhao et al., 2011).
Literature searches were conducted iteratively between 1 December 2025 and 21 January 2026 using multiple bibliographic databases to ensure broad disciplinary coverage. Google Scholar served as the primary discovery tool due to its extensive cross-disciplinary indexing, supplemented by targeted searches in Scopus, the Web of Science Core Collection, the ACM Digital Library, IEEE Xplore, and major publisher platforms including Elsevier’s ScienceDirect, SpringerLink, and Wiley Online Library. This multi-database strategy reflects the dispersed nature of relevant work across sports science, communication studies, human–computer interaction, natural language processing, and signal processing.
Search queries were constructed using Boolean combinations of key terms related to affective constructs, fandom, sport domains, and media or settings. To minimise the risk of excluding relevant studies due to narrow terminology, the search strategy incorporated a broad set of synonyms related to sentiment, emotion, affect, engagement, reactions, and spectatorship (Kozinets, 2015). Queries combined affect-related terms (e.g., sentiment, emotion, valence, arousal, toxicity), actor-related terms (e.g., fan, spectator, supporter, fandom), sport-related terms (e.g., football, basketball, cricket, Olympics, World Cup), and media or setting terms (e.g., Twitter/X, Reddit, YouTube, social media, social TV, second screen, broadcast, stadium, crowd noise, sensors, video). Backward and forward snowballing from highly cited seed papers was also employed to identify additional relevant studies that may not have been retrieved through database queries alone (Webster and Watson, 2002).
Prior to screening, explicit inclusion criteria were defined to ensure consistency and transparency in study selection. Eligible studies were required to focus on sports fans or spectators and to analyse sentiment, emotion, or affect using computational, analytical, or sensing-based approaches. Studies focusing exclusively on athletes or teams, marketing or brand sentiment without behavioural interpretation, non-empirical contributions, and non-English publications were excluded.
The primary search yielded approximately 267 records after aggregating results across databases and removing duplicates. Titles and abstracts were screened for relevance using the predefined inclusion criteria, resulting in 211 records. Full-text evaluation further excluded studies with insufficient focus on fan affect or behaviour, unclear or incomplete methodological reporting, or redundancy with more complete versions of the same work. The final corpus comprised 64 studies, reflecting conceptual saturation with respect to data modality, affect operationalisation, and behavioural interpretation. The study identification, screening, and inclusion process is illustrated in Figure 1. These studies form the basis of the synthesis and are reported in the bucketed literature tables.
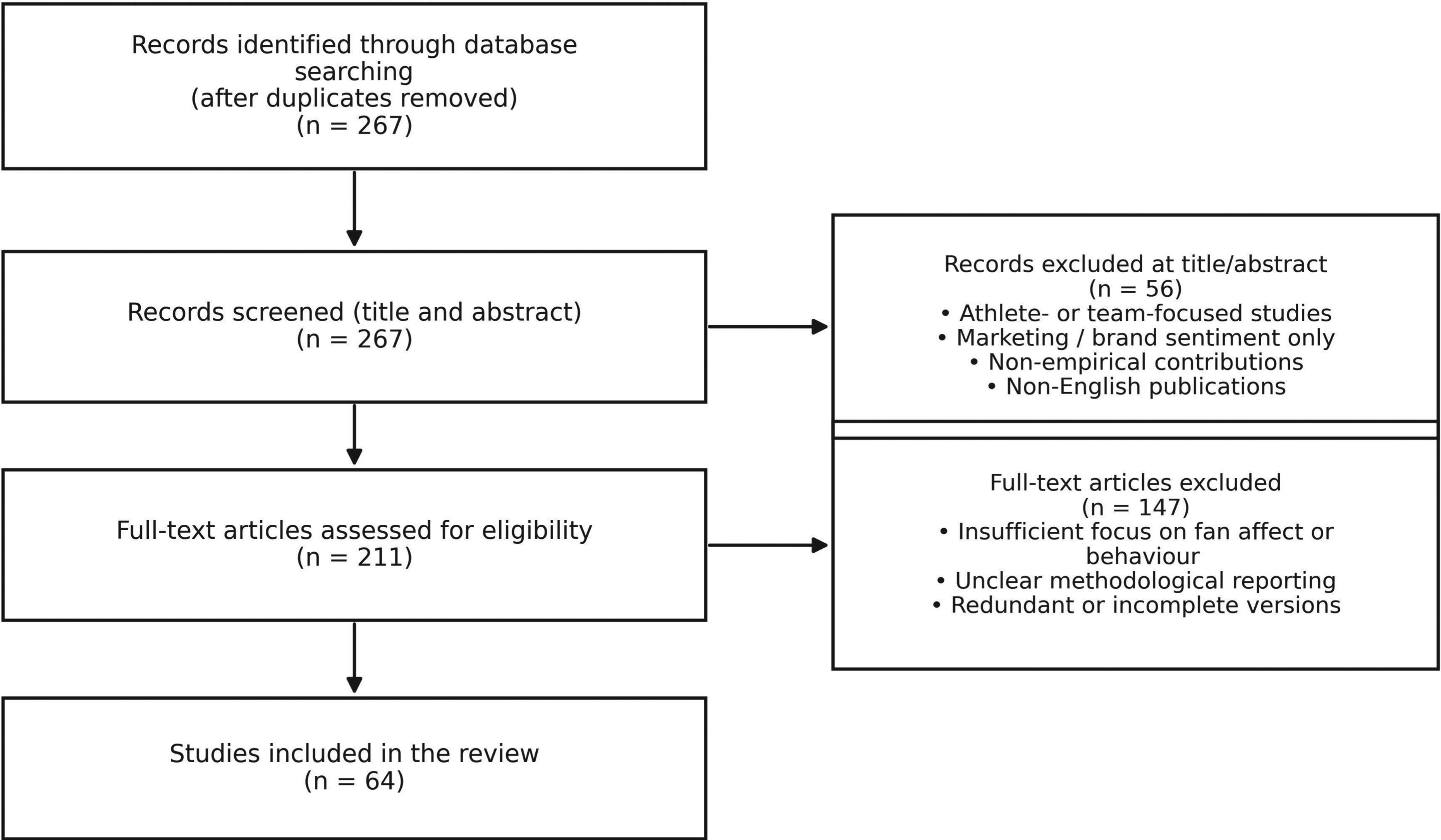
Study identification, screening, and inclusion process.
Development of the coding and evaluation scheme
To support systematic comparison and synthesis, a structured coding and evaluation template was developed. The template captured bibliographic information, sport and event context, data source and modality, affect operationalization, analytical approach, and the manner in which affective signals were interpreted in relation to fan behavior. Particular emphasis was placed on distinguishing descriptive affect detection from studies that explicitly linked affective signals to behavioural outcomes.
The initial version of the coding scheme was developed by the two authors in alignment with the objectives of the review and refined through pilot application to a subset of studies. Face and content validity were assessed collaboratively by the authors and subsequently reviewed by five domain experts in sport management and behavioural sciences. Feedback from this expert review informed minor modifications to category definitions and coding instructions.
Coding procedure and inter-coder reliability
The two authors independently coded all included studies using the finalised coding scheme. Prior to full coding, a pilot coding phase was conducted to align interpretation of coding categories and resolve ambiguities. Inter-coder reliability was assessed on the pilot subset using Cohen’s

Synthesis and quality appraisal
Following coding, studies were synthesised using a bucket-based approach, grouping them according to their primary modality and proximity to observable fan behaviour: (A) digital text and online discourse, (B) second-screen and broadcast-linked behaviour, and (C) in-venue or non-textual affective signals. This structure enables systematic comparison across modalities while preserving methodological diversity and differences in behavioural proximity.
Study quality was appraised using pragmatic criteria addressing construct validity of affect measures, transparency of data collection, appropriateness of analytical methods, clarity of behavioural claims, and ethical considerations. Because the reviewed literature relies heavily on computational inference, the credibility of NLP findings depends strongly on how models are evaluated.
In supervised learning settings, this typically requires explicit separation of training, validation, and test data, comparison with appropriate baselines, and transparent reporting of performance metrics matched to the task and class balance. Typical evaluation metrics include precision, recall, and F1 scores, often accompanied by confusion matrices that reveal systematic error patterns across classes (Sokolova and Lapalme, 2009).
Recent research also emphasises the importance of fairness-aware evaluation in sentiment classification, particularly when models are deployed across heterogeneous domains where biases in training data can affect interpretability and downstream conclusions (Naranbat et al., 2025). For multi-class emotion or stance detection tasks, macro-averaged metrics and per-class performance are particularly important because theoretically salient minority categories often represent the empirical weak point.
Reliability and construct validity also depend on annotation consistency and clearly defined label schemas. Beyond technical performance, behaviour-oriented research should ideally evaluate whether inferred affective signals correspond to observable outcomes. Where possible, this may involve validating sentiment or emotion measures against behavioural traces such as engagement trajectories, viewing duration, purchasing behaviour, churn, or attendance patterns.
Even when direct behavioural linkage is unavailable, convergent validity checks using surveys, event annotations, or known match moments can strengthen confidence in model outputs. Quality appraisal informed interpretation during synthesis rather than serving as a strict exclusion criterion (Kitchenham, 2007). For each included study, information was extracted using the structured coding scheme, with particular attention paid to whether sentiment or emotion was treated as a descriptive signal or explicitly linked to behavioural outcomes such as engagement dynamics, discourse escalation, attendance-related proxies, or collective in-venue responses (Billings, 2018; Rowe, 2014).
This review, however, has limitations. Reliance on link-based discovery may surface preprints or non-peer-reviewed material, and restriction to English-language publications introduces language bias. In addition, data accessibility constraints bias the literature toward easily collectable platforms, particularly Twitter/X, a limitation widely recognised in social media research (Tufekci, 2014). Table 1 presents the text-based studies examining sports fans’ sentiment, emotion, and online discourse across social media and digital platforms. Table 2 summarises studies investigating second-screen behaviour and broadcast-linked fan engagement during live sports consumption. And finally, Table 3 presents studies analysing in-venue and multimodal affective signals, including crowd noise, physiological responses, and non-textual fan behaviour indicators.
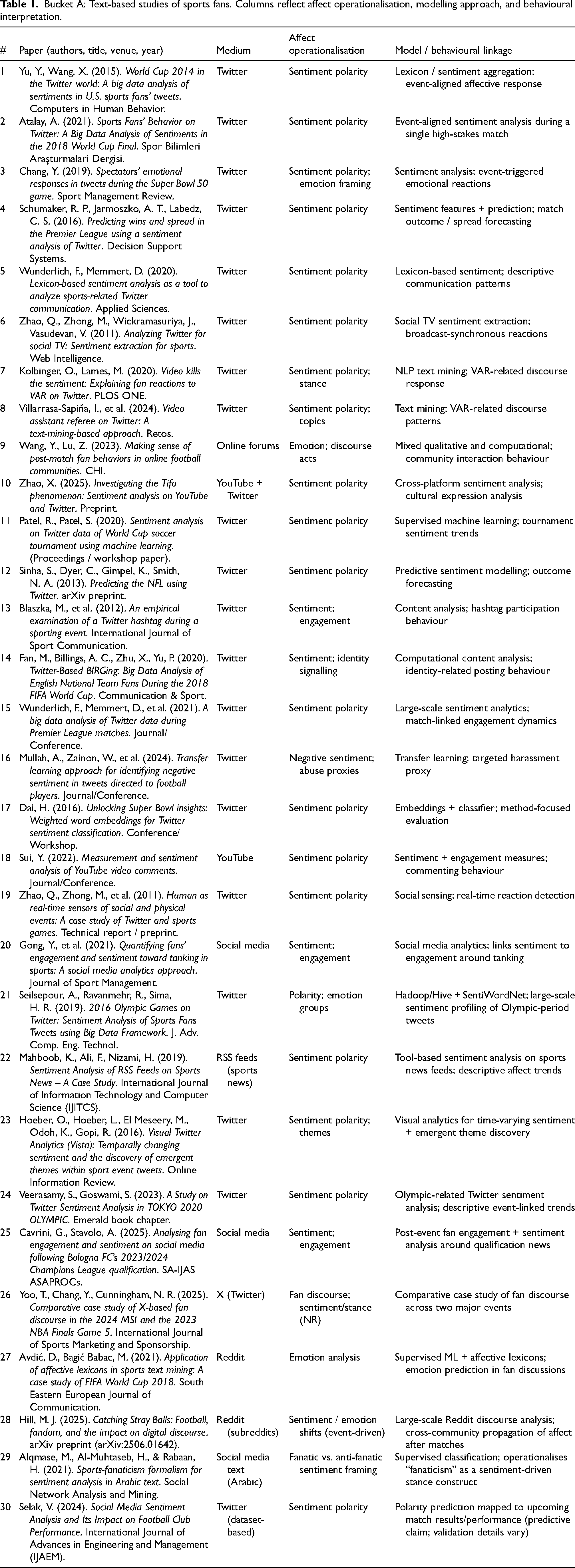
Bucket A: Digital text and online discourse (Twitter/X, Reddit, YouTube comments, forums)
Bucket A: Text-based studies of sports fans. Columns reflect affect operationalisation, modelling approach, and behavioural interpretation.
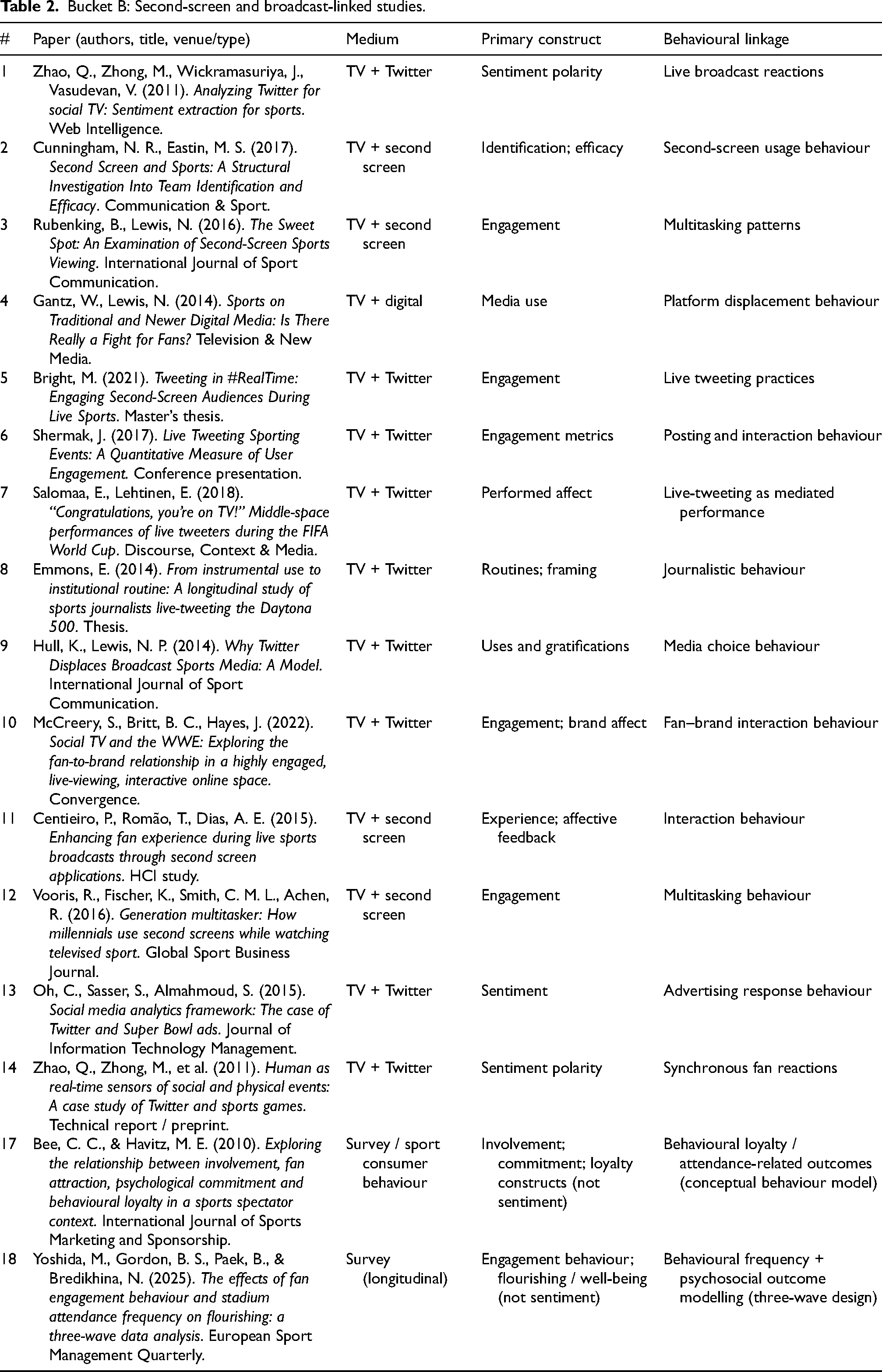
Bucket B: Second-screen and broadcast-linked fan behaviour (Social TV, live-tweeting, second-screen use)
Bucket B: Second-screen and broadcast-linked studies.
Bucket C: In-venue and non-textual fan affect as sentiment signals (crowd noise, video, sensors)
Bucket C: In-venue and non-textual affect studies.

Discussion
This review synthesised 64 studies (2000–2025) examining sentiment, emotion, and affect-related signals in sports fandom across digital discourse, broadcast-linked interaction, and in-venue modalities. The bucketed tables indicate an uneven empirical landscape: most studies are text-centric and rely on platform-native discourse (especially Twitter/X), fewer examine second-screen viewing as a behavioural context, and an even smaller set uses non-textual in-venue signals (audio, video, wearables) where affect is closer to embodied behaviour. This distribution matters because it largely determines what can be claimed. Text-first studies measure affective expression and often infer behaviour indirectly, whereas in-venue and broadcast-synchronised work provides more defensible links between affect and observable action.
Across Bucket A, a robust and repeated empirical pattern is that aggregate sentiment traces are temporally aligned with salient match events and controversy (goals, penalties, officiating decisions, VAR), particularly in tournament and marquee-event contexts (Chang, 2019; Hoeber et al., 2016; Kolbinger and Knopp, 2020; Sapiña et al., 2024; Yu and Wang, 2015). Computational analysis of fan responses on social media platforms also illustrates how digital discourse can reflect broader dynamics of athlete branding, fan identity, and parasocial engagement within sport communities (Li et al., 2026). These studies provide strong evidence that sports discourse behaves as a high-frequency “reaction stream” around event triggers, consistent with the social-sensing framing introduced in early social-TV and real-time sensing work (Zhao et al., 2011, 2011?). However, the same table evidence also shows a recurring limitation: sentiment is most commonly operationalised as coarse polarity (positive, negative, neutral), particularly in large-scale social media studies due to its computational simplicity and compatibility with lexicon-based or shallow machine learning approaches (Liu, 2012; Pang and Lee, 2008; Wunderlich and Memmert, 2020). Polarity enables scale and temporal alignment, but it collapses distinct emotional states that plausibly have different behavioural consequences (e.g., anger versus anxiety versus pride). When the dominant dependent variable is polarity, many studies can reliably answer when fans react, but struggle to answer what the reaction implies for behaviour.
A second empirical stream in the tables uses sentiment features for forecasting or performance-related claims. Predictive work exists across multiple sports and settings, including outcome/spread prediction and performance proxies (Schumaker et al., 2016; Selak, 2024; Sinha et al., 2013). The main conclusion from this stream is not that sentiment is a universally reliable predictor; rather, predictive performance is context-sensitive and often unstable across competitions, seasons, and sampling designs. More importantly, much of this literature treats sentiment as an input feature without specifying the behavioural mechanism that would justify generalisation. As a result, prediction becomes method-driven rather than explanation-driven: models can correlate sentiment with outcomes, but the field frequently fails to articulate how expressed affect is generated, amplified, and translated into behaviour or decision-making under different platform and viewing conditions.
A third pattern, visible in both Bucket A and the surrounding literature, is the expansion from generic sentiment toward harmful-expression constructs such as targeted negativity, toxicity, and hate speech, especially in studies analysing abusive content directed at players or groups (Davidson et al., 2017; Mullah et al., 2024; Waseem and Hovy, 2016). This shift is substantive, not cosmetic. Unlike polarity, toxicity and hate speech are closer to behaviourally consequential outcomes because they correspond to norm-violating acts with identifiable targets and potential real-world harms. Empirically, this stream forces the field to confront annotation validity, thresholding, and cultural context, and it exposes a methodological risk: applying generic NLP benchmarks to sports rivalry talk, sarcasm, and in-group banter can inflate false positives and distort conclusions.
In this context, “benchmarks” can refer to several distinct elements that are often conflated in interdisciplinary research. First, benchmark datasets provide labelled corpora used to train or evaluate models. Second, benchmarks may refer to evaluation protocols or metrics used to compare models. Third, the term is sometimes used to describe pretrained models trained on large generic datasets and later applied to new domains. When models trained or evaluated on general-domain resources are transferred to sports discourse without adaptation, their performance can degrade because rivalry language, sarcasm, and community-specific slang differ substantially from everyday conversational text.
Accordingly, several practical remedies are recommended: domain adaptation using sport-specific corpora, annotation guidelines tailored to rivalry discourse, evaluation on sport-specific held-out test sets, and error analyses focusing on sarcasm, irony, and in-group banter. Robustness checks across teams, leagues, and platforms can further test whether models generalise beyond a single fan community.
Despite the strong event-alignment regularity, the central weakness across the corpus is behavioural inference. A large proportion of studies implicitly treat sentiment as behaviour or as sufficient evidence of behavioural change, while behavioural outcomes are reduced to posting volume, likes, or short-window engagement counts (Hoeber et al., 2016; Patel and Passi, 2020; Wunderlich and Memmert, 2020). This is a category error. Behaviour requires an observable action or consequence, such as sustained engagement trajectories, escalation into abuse, community polarisation, attendance-related proxies, collective mobilisation, or in-venue responses. Without explicit outcome definitions and linkage strategies, sentiment analytics remains largely descriptive regardless of modelling sophistication.
The bucket comparison also suggests where stronger behavioural grounding is achievable. Second-screen and broadcast-linked studies anchor fan expression in a known consumption context, and they show that reaction dynamics are synchronised not only to sport events but also to mediated narrative timing, commentary, and replay structure (Chang, 2019; Salomaa and Lehtinen, 2018; Zhao et al., 2011). This implies that sentiment traces are partially a function of broadcast production, not only match events, which weakens naïve behavioural interpretations and strengthens the case for modelling media context explicitly.
In-venue and non-textual work provides the most behaviourally consequential evidence in the corpus. Studies on crowd noise and social pressure show measurable effects on officiating decisions and performance-related outcomes (Dohmen, 2008; Nevill et al., 2002). This evidence is stronger than correlations between tweet polarity and goals because it connects affective expression to consequential decision behaviour. In parallel, multimodal affect recognition research indicates that arousal and engagement can be inferred from audio/visual and physiological cues, offering more direct proxies for embodied fan states than text alone (McDuff and colleagues, 2016; Poria et al., 2017; Zhang and colleagues, 2019; Zhou and colleagues, 2018). The major limitation is integration: the tables show these modalities are rarely combined with text streams in aligned designs, leaving cross-space propagation of affect (online
However, because most studies observe only one modality at a time, the literature does not yet support strong claims about propagation (how affect moves between digital and physical spaces) or interaction (whether one modality amplifies or dampens another).
To move from co-occurrence to mechanism, future work requires time-aligned designs that observe at least two modalities concurrently.
Two minimal design patterns are especially actionable:
Together, the empirical record implies that the bottleneck in the field is not primarily technical accuracy but conceptual alignment. The literature has successfully demonstrated scalable detection of event-driven affective expression, but it has not consistently established what those signals mean for behaviour.
One promising direction for improving behavioural interpretability is the use of target-aware sentiment analysis, particularly aspect-based sentiment analysis (ABSA) (Pontiki et al., 2016). Rather than assigning a single emotion or polarity label to an entire post, ABSA explicitly links evaluative expressions to specific entities or attributes. In sports discourse, this enables simultaneous modelling of distinct evaluations within the same discussion stream, such as criticism of refereeing decisions, praise for team performance, concern about injuries, or dissatisfaction with ticket pricing. Recent work applying large language models and transformer architectures to stadium review data further demonstrates the potential of aspect-based sentiment analysis for capturing nuanced fan evaluations of venue attributes and service experiences (Qian et al., 2025).
This target-level mapping aligns naturally with constructs widely used in sport consumer research, including perceived service quality, fairness perceptions, team identification, satisfaction with the core product, and brand associations. By preserving the relationship between evaluative language and its referent, aspect-level inference provides a clearer conceptual bridge between computational text analysis and established behavioural theories in sport management (Darko et al., 2023).
Finally, the review evidence suggests several pragmatic remedies that can be implemented without waiting for entirely new data infrastructures: domain adaptation for sports corpora, error analyses on sarcasm-heavy subsets, subgroup robustness evaluation, and bias audits for high-stakes applications such as moderation or security interventions (Bender et al., 2021; Fortuna and Nunes, 2018; Gillespie, 2018; Hovy and Spruit, 2016; Sap et al., 2019). These steps move the field toward behaviour-centred fan analytics where sentiment outputs are interpreted as intermediate indicators within broader social, cultural, and behavioural processes.
Conclusion
This review synthesised 64 studies published between 2000 and 2025 on sentiment, emotion, and affect analysis in sports fandom across three interconnected domains: digital text and online discourse, second-screen and broadcast-linked interaction, and in-venue or non-textual affective sensing. Across these domains, the clearest and most consistent empirical pattern is that fan affective expression is strongly event-driven, shifting rapidly in response to salient match moments, controversy, and mediated peak events. At the same time, the review shows that the literature remains uneven in its ability to move from detecting affective expression to explaining sports fans’ behaviour in a conceptually rigorous and behaviourally grounded way.
The review was guided by the central proposition that sentiment analysis can make a meaningful contribution to understanding sports fans’ behaviour only when affective signals are interpreted as intermediate indicators of expression rather than as behaviour itself, and when they are linked explicitly to observable behavioural outcomes across contexts and modalities. The evidence collected in this review largely supports this proposition. Existing studies are effective at identifying real-time emotional responses and shifts in collective mood, especially in social media environments, but they are substantially weaker when claims extend to behavioural explanation, prediction, or generalisation. In particular, much of the literature relies on platform-specific traces, especially Twitter/X, uses coarse polarity sentiment as its dominant operationalisation, and often blurs the distinction between sentiment, emotion, affect, and behaviour. As a result, many findings are descriptively useful but theoretically and behaviourally limited.
The overall contribution of this study is fourfold. First, it organises a fragmented body of work into a unified multimodal framework that brings together research streams that have largely developed in parallel. Second, it provides a conceptually clearer account of how sentiment, emotion, affect, and behaviour should be distinguished in sports fandom research, thereby reducing interpretive ambiguity in future studies. Third, it demonstrates that the strongest evidence for behaviourally consequential fan affect currently comes from research that is closer to observable action, particularly second-screen interaction studies and in-venue work on crowd noise, arousal, and collective response. Fourth, it identifies the main structural limitations of the field, platform dependence, overreliance on polarity measures, weak behavioural validation, limited cross-platform and multilingual evidence, and insufficient multimodal integration, while outlining a practical agenda for improvement.
Taken together, the findings suggest that the main bottleneck in this field is not simply methodological sophistication, but conceptual alignment and behavioural validity. Future progress will depend on research designs that define behavioural outcomes more explicitly, validate affective measures more rigorously, integrate signals across digital and physical settings, and apply stronger ethical safeguards when sentiment- and toxicity-based systems are used in moderation, governance, or security contexts. If these advances are achieved, sentiment analysis will be better positioned not merely to track what fans feel or express, but to explain how those affective expressions connect to engagement, interaction, escalation, and other meaningful forms of sports fan behaviour across the broader media and venue ecosystem.
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of interest statement
The authors declared no potential conflicts of interest with respect to the research, authorship, and publication of this article.