
Abstract
Abstract
Foreign currency is bought and sold in the financial markets, every minute, every day, on trading days, like any commodity or stocks of companies. The players in this market are (a) people with underlying interest in foreign currency such as exporters and importers who are continuously hedging in futures or options markets, (b) speculators and (c) arbitrageurs. This paper focuses on this microeconomic flavour of foreign currency as a continuously tradable product and presents a granular framework for forecasting the exchange rate. We initially investigate year-wise inherent nature of movements of three exchange rates, namely Indian rupee/US dollar, Indian rupee/euro and Indian rupee/Japanese yen, during 2011–2016 through Mandelbrot’s single fractal model. Subsequently, maximal overlap discrete wavelet transformation (MODWT) is used to decompose the time series of the individual exchange rates. Random forest and bagging are applied on the decomposed components for predictive modelling.
Keywords
Introduction
Determination of the exchange rate has been a subject matter of much discussion in books and research papers in macroeconomics and international trade theory. Some of the well-known papers in this area are Mundell (1963), Fleming (1962), Balassa (1964) and Samuelson (1964). The often referred books are Meade (1951, 1955), Caves and Jones (1981), Dornbusch (1980) and Krueger (1983).
Foreign currency is also bought and sold in the financial markets, every minute, every day, on trading days, like any commodity or stocks of companies. The players in this market are (a) people with underlying interest in foreign currency such as exporters and importers who are continuously hedging in futures or options markets, (b) speculators and (c) arbitrageurs. The foreign currency market in India and other countries is online and system-driven. Each day, in India, the spot rate or reference rate is announced by the Reserve Bank of India (RBI). The market-driven competitive rates are available in the futures markets, the immediate month delivery futures being the most liquid one.
This paper focuses on this microeconomic flavour of foreign currency as a continuously tradable product and delves into exchange rate determination and forecasting. In a recent contribution, Chaudhuri and Ghosh (2016) have proposed a framework for prediction of the rupee–dollar exchange rate in a multivariate framework, using variables derived from the ‘covered interest arbitrage’ condition and also variables which represent market volatility. In this paper, from the trading point of view, we present a more granular framework for forecasting the exchange rate.
We initially investigate year-wise inherent nature of movements of three exchange rates, namely Indian rupee/US dollar, Indian rupee/euro and Indian rupee/Japanese yen, during 2011–2016 through Mandelbrot’s (1972) single fractal model. Subsequently, maximal overlap discrete wavelet transformation (MODWT) has been applied to decompose the time series of the individual exchange rates. Random forest (RF) and bagging are applied on the decomposed components for predictive modelling.
Plan of the remainder of the paper is as follows. The second section highlights the key research objectives in detail. Survey of related research has been presented in the third section. The fourth section elucidates the utilized research methodologies. Key descriptive statistics are computed to characterize the nature of exchange rates and summarized in the fifth section. The sixth section discusses the overall results and key inferences drawn. Finally, the paper is concluded in the seventh section.
Objective
Advances in computing techniques have led to greater understanding of patterns in time series data and both fractal and wavelet analyses have thrown significant light on the nature of movement of data over time. While fractal analysis enables us to determine whether the data shows strong persistent or anti-persistent characteristics, wavelet analysis enables us to break down the data into various components such as trend, random and periodic movements. In order to forecast from past time series data, it is important to first understand the inherent characteristics of the data. In this paper we take a granular approach to forecasting the exchange rate. We first apply fractal framework to understand the overall pattern of the series. Then we break down the data into various components through wavelet analysis and then forecast the exchange rate by forecasting each component, and then aggregating. In this way, each component of the series is given weightage/cognizance and also improves our understanding of the pattern. It also helps us in characterizing a series to be either trend-dominated, or periodic or purely random. Forecasting on the basis of the aggregate exchange rate robs us of our understanding of the finer details of the series. We use three exchange rates, namely the Indian rupee/US dollar rate, the Indian rupee/euro rate and the Indian rupee/Japanese yen rate to demonstrate our framework of analysis and determine its efficacy.
Related Work
Zhang and Berardi (2001) applied artificial neural networks (ANN) for forecasting the British pound/US dollar exchange rate in a univariate framework deploying lagged values of target as predictors.
Bellgard and Goldschmidt (1998) examined foreign exchange rate forecasting in terms of the random walk hypothesis (RWH). The various techniques used were random walks, exponential smoothing, auto-regressive integrated moving average (ARIMA) and ANN. The focus was on RWH and the data that was used was Australian–US dollar data. Their work was based on Bellgard (1998) where the basic objective was to explore whether ANN are superior to simple linear modelling techniques in forecasting foreign exchange rates, for different frequency data.
Shmilovici, Kahiri, Ben-Gal and Hauser (2009) used a universal variable-order Markov (VOM) model to test weak form of the efficient market hypothesis (EMH) with 12 pairs of international intra-day currency exchange rates for one year series of 1, 5, 10, 15, 20, 25 and 30 minutes. They found statistically significant compression and observed that although high-frequency series are predictable above random, the model could not generate a profitable trading strategy. They concluded that the forex market is efficient, at least most of the time.
Yu, Wang and Lai (2005) used adaptive smoothing neural networks in forecasting the exchange rate. In this model, adaptive smoothing techniques were used to adjust the neural network learning parameters automatically by tracking signals under dynamic varying environments. To verify the effectiveness of the proposed model, they used the British pound, euro and Japanese yen as the forecasting targets. Their results indicate that the model is an effective approach for foreign exchange rate forecasting.
Zhang (1994) applied ANN to search for non-linear relations in high-frequency foreign exchange time series. Three years’ (1985–1987) tick-by-tick bid prices for the Swiss franc to the US dollar exchange rate were used in this study as training data to specify predictive models for intra-day trading. The model was then tested on the same exchange rate time series in the following year (1988). In contrast to a linear model, the non-linear model used produced profit and thus prediction was relatively efficient.
Wong, Ip, Xe and Lui (2003) applied wavelets to model the movement of the US dollar against Deutsche Mark (DM) exchange rate data, and 10 steps ahead (two weeks) forecasting was compared with several other methods. In the paper, the time series was decomposed into sum of three separate components, namely trend, harmonic and irregular components. They found that under the average percentage of forecasting error (APE) criterion, the wavelet approach is the best one.
Septiarini, Abadi and Taufik (2016) considered application of wavelet fuzzy model to forecast the exchange rate between Indonesian IDR and US dollar. The wavelet fuzzy model is the combination of fuzzy Mamdani model and discrete wavelet transforms (DWT). In this paper, the data of exchange rate used was weekly exchange rate data from 1 January 2012 until 9 November 2014. The result of forecasting gave a level of accuracy of mean absolute percentage error (MAPE) of 3.45 per cent for training data and 1.74 per cent for testing the data.
Tao (2006) uses a hybrid model which integrates the wavelet neural network with genetic algorithm for predicting the exchange rate. Their model shows that the proposed model can predict exchange rate with the scale of one day, one week and other intervals. Some other papers in this area are Lebaron (1999), Baetaens, Van Den Berg and Vaudrey (1996) and Kaashoek and Van Dijk (2002).
Research Methodology
In this paper, to understand the dynamic pattern of exchange rate movements over time, initially rescaled range (R/S) analysis-based Hurst exponent (H) and fractal dimensional index (FDI) are calculated. Once the inherent patterns are identified, MODWT is applied to transform the respective exchange rate series into sub-series. Then machine learning algorithms are applied on each sub-series, and final forecast is made by aggregating the forecasted values obtained from each sub-series. For prediction, RF, an advanced ensemble machine learning tool, is employed. A brief overview of the techniques applied in this study is elucidated here.






The Hurst exponent (H) can take any value in the range [0, 1]. Theoretically, an estimated H value of 0.5 means that the series is ideally following an independent and identically distributed (iid) Gaussian random walk model. On the other hand, if the value of H is different from 0.5, then the series is said to exhibit characteristics of fractional Brownian motion or biased random walk. Persistent or long memory nature of a time series is established when the value of H is greater than 0.5. If the computed value of H is less than 0.5, then the series is said to be governed by anti-persistent pattern.

Since the range of H is 0 to 1, the values of D varies in the range of 1 to 2. For a given sequence, a D value of 1.5 signifies that the sequence follows random walk. Persistent and anti-persistent behaviour of a sequence correspond to
In the wavelet analysis, the original function


If rit denotes the value of time series i at time t, then the time series is approximated using the detail coefficients
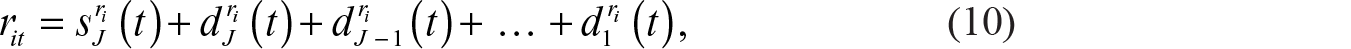




For j = 1, 2, …, J.
As discussed,

The inverse wavelet transform is defined as

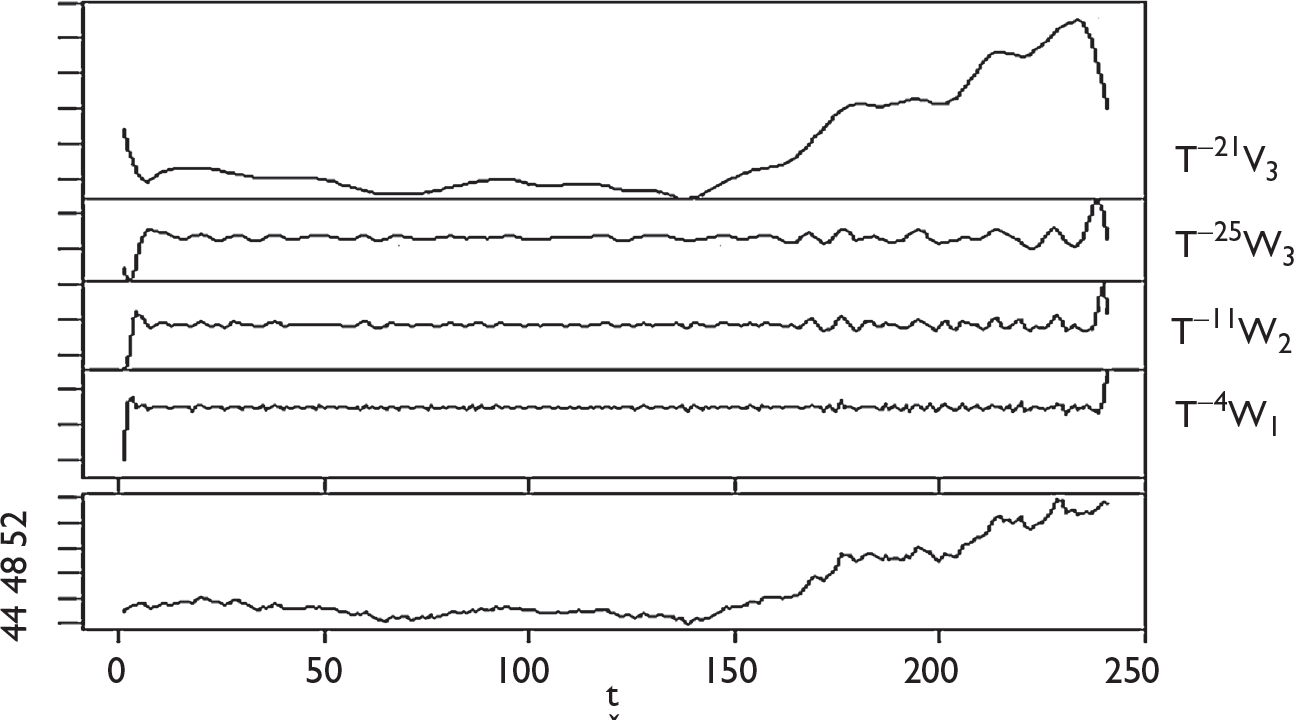
In general, traditional DWT method operates on the principle of convolution for decomposition. There are several advantages of MODWT over DWT for decomposition of time series. First of all, unlike DWT, MODWT does not require the dataset to be dyadic. It is also invariant to circular shift. Overall, MODWT is a robust and non-orthogonal transformation that keeps the down-sampled values at each level of decomposition.
The major difference between RF and bagging is that unlike RF, in bagging, decision trees are built considering all the features. They are not chosen randomly. For regression tasks, bagging reduces the variance of unstable learning methods leading to improved prediction. In general, the steps involved in learning process of bagging are as follows:
Like RF, bagging too has successfully been applied in discovering and comprehending complex patterns (Lemmens & Croux, 2006; Zheng, Caixin, Jian, Qing, & Weigen, 2011).
Analysis on Data
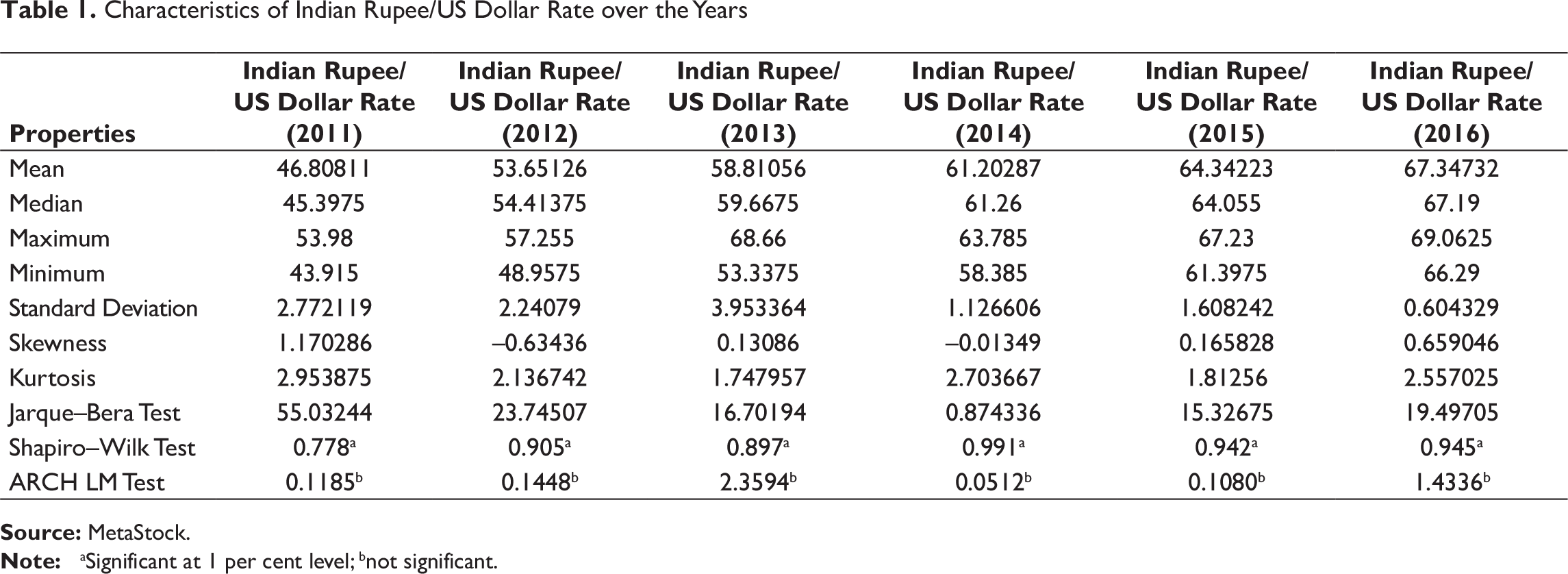
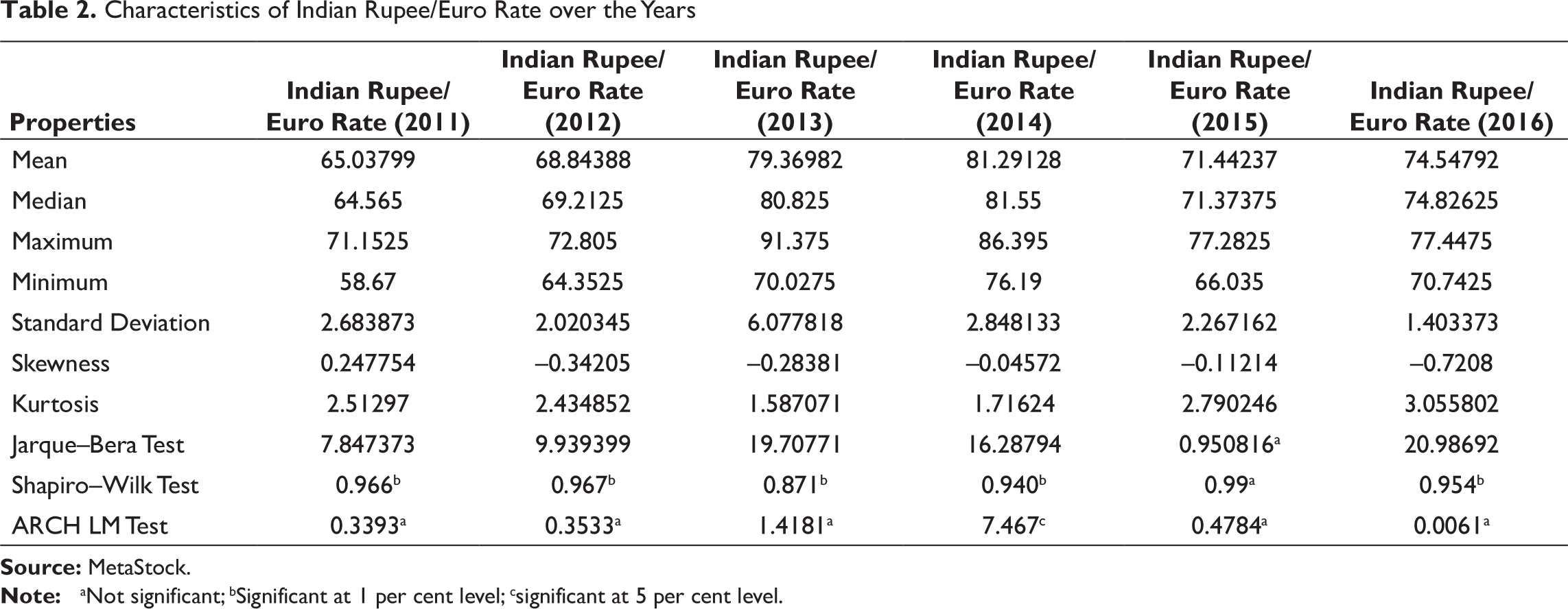
Data on exchange rates of Indian rupee/US dollar, Indian rupee/euro and Indian rupee/yen for the years 2011–2016 have been compiled from MetaStock, and the descriptive statistics are presented in Tables 1–3.
It is evident from both Jarque–Bera and Shapiro–Wilk tests that Indian rupee/US dollar rate did not follow normal distribution over the years. Auto-regressive conditional heteroscedasticity (ARCH) Lagrange multiplier (LM) test confirms that year wise, there was no effect of conditional heteroscedasticity in movements of Indian rupee/US dollar exchange rate.
Like Indian rupee/US dollar rate, normality assumption is rejected for year-wise Indian rupee/euro rates. No significant effects of conditional heteroscedasticity have been observed, except for year 2014.
For the Indian rupee/yen rate, Jarque–Bera and Shapiro–Wilk tests statistics show that Indian rupee/yen rates do not follow normal distribution. ARCH LM test reveals presence of conditional heteroscedasticity in year-wise movement.
Results and Analysis
Characteristics of Indian Rupee/US Dollar Rate over the Years
Characteristics of Indian Rupee/Euro Rate over the Years
Characteristics of Indian Rupee/Yen Rate over the Years


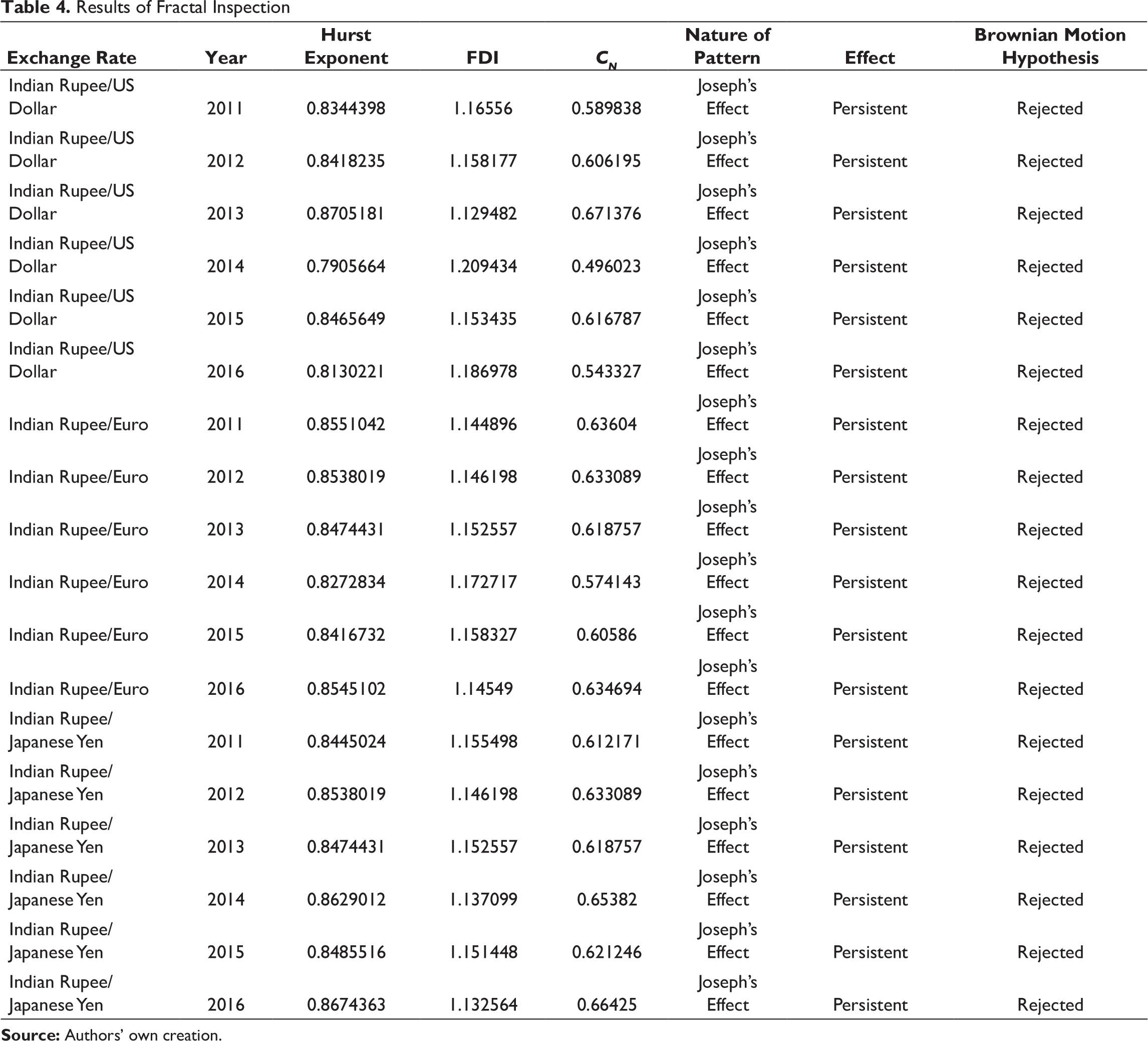
If a time series is found to be perfectly random (H = 0), value of CN is 0. For a persistent time series, CN is positive. An anti-persistent time series results in negative correlation. A CN value of 0.2 implies that 20 per cent of the entire data is influenced by past. Tables 4 and 5 narrate the results of fractal investigation of the respective exchange rates over the years.
Results, manifested through values of Hurst exponent and FDI clearly indicate that the yearly movements of three exchange rates exhibit strong presence of persistent pattern. Correlation between periods indicate that on an average, 60 per cent of the data on exchange rates are influenced by historical values. Presence of fractal structure and significant values of correlation between periods justifies the dominance of trend components in exchange rate dynamics and provides support for univariate predictive modelling framework based on lagged values for forecasting purpose.
Results of Fractal Inspection
Descriptive Statistics of Hurst Exponent, FDI and CN

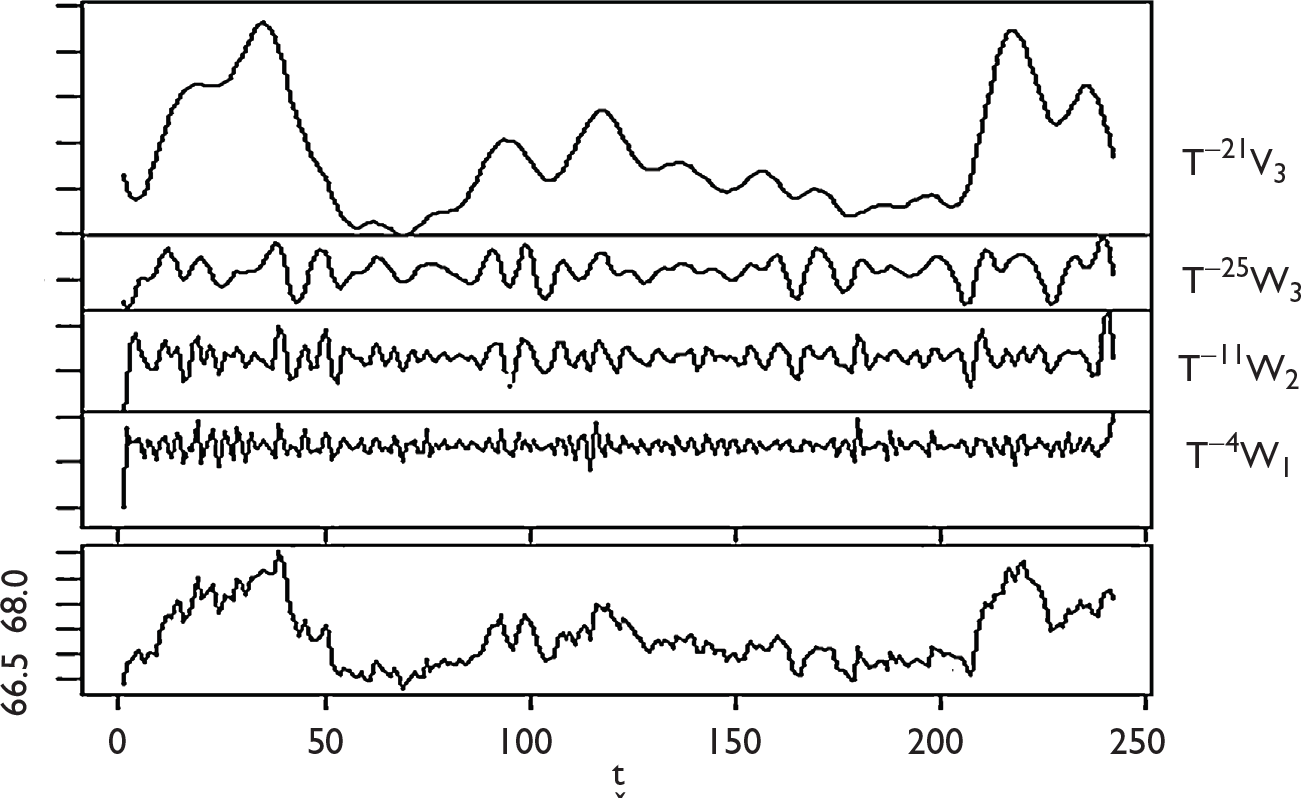

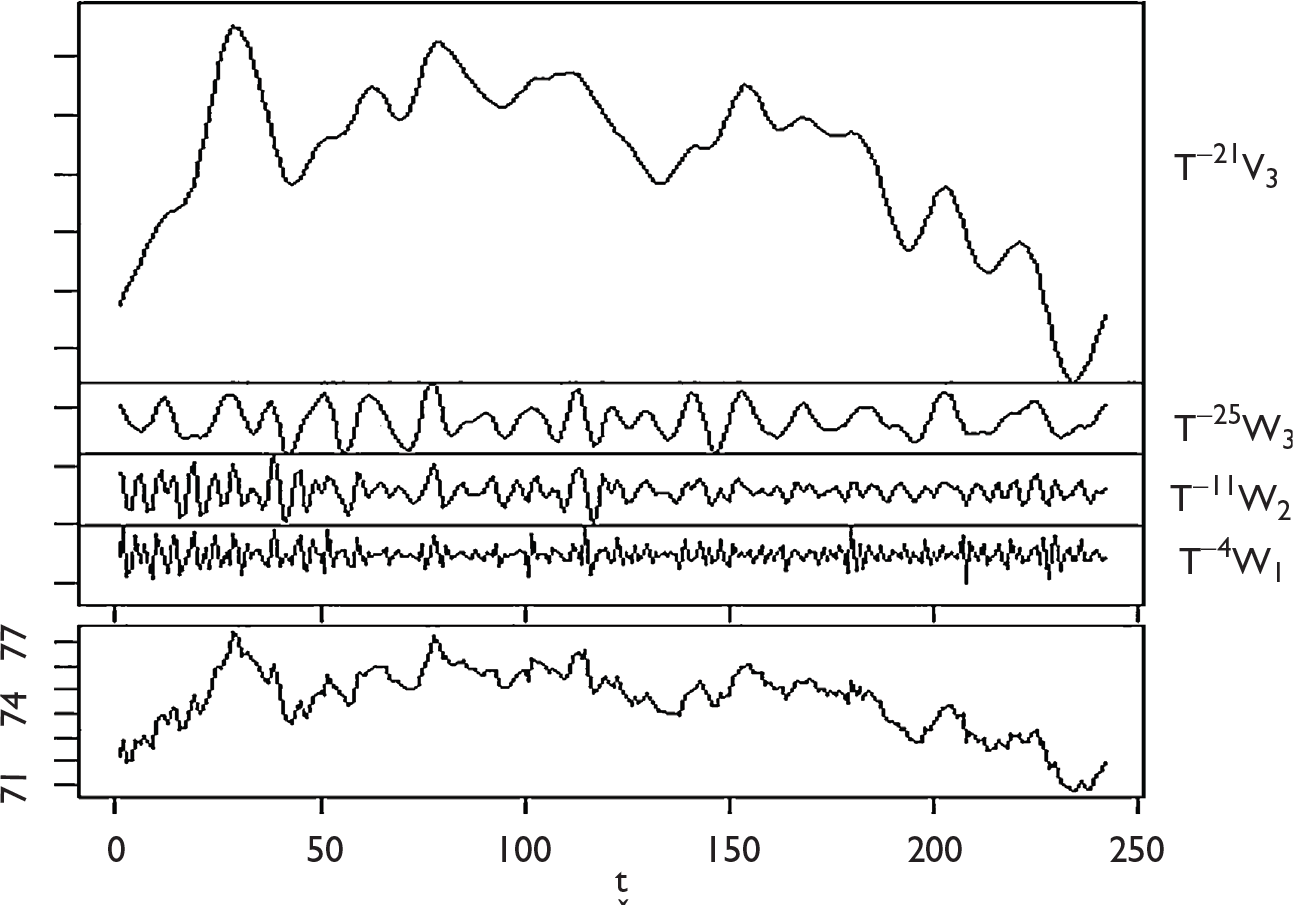

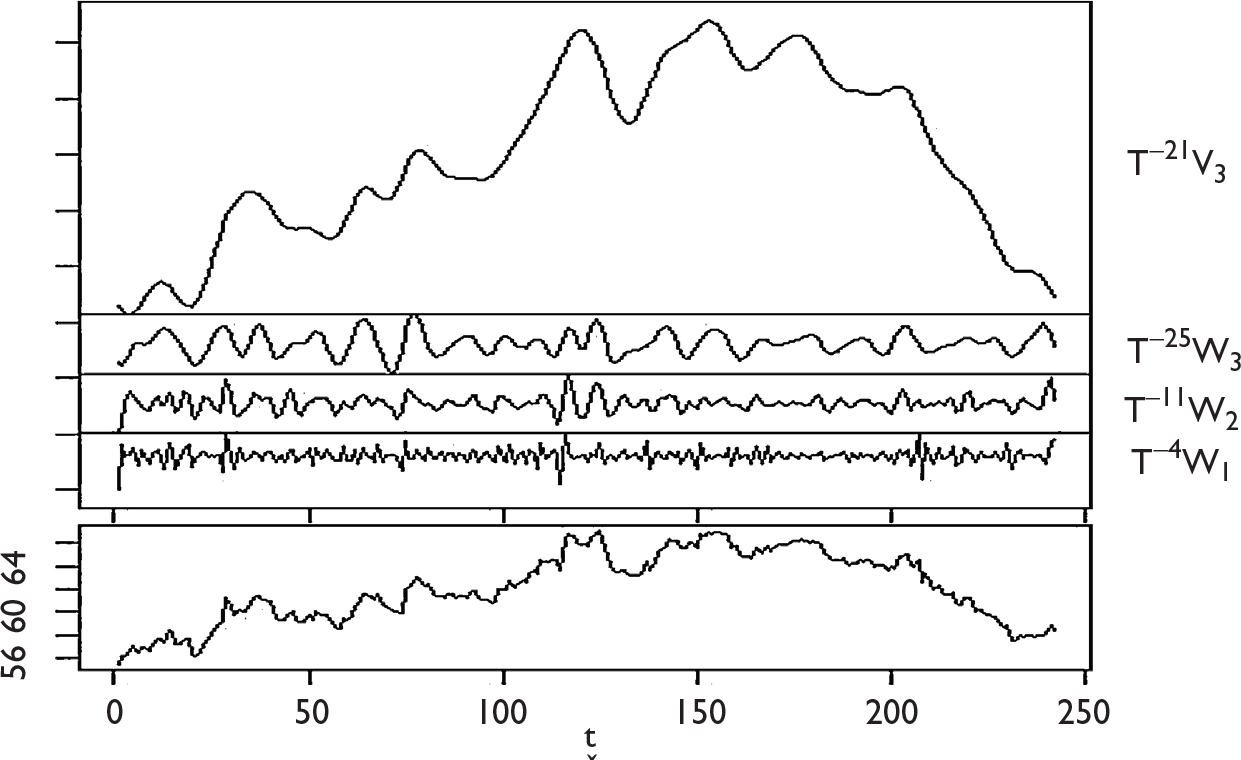
(Indian rupee/US dollar)Final_Forecast = (Indian rupee/US dollar_V3)RF_Forecast + (Indian rupee/US dollar_W1)RF_Forecast + (Indian rupee/US dollar_W2)RF_Forecast + (Indian rupee/US dollar_W3)RF_Forecast,
where (Indian rupee/US dollar_V3)RF_Forecast is the forecast by RF on scaling component and (Indian rupee/US dollar_W1)RF_Forecast, (Indian rupee/US dollar_W1)RF_Forecast and (Indian rupee/US dollar_W1)RF_Forecast are the forecasts generated by RF for respective wavelet components. In a similar manner, final prediction is made for Indian rupee/euro and Indian Rupee/yen rates.
In this paper, univariate predictive modelling is adopted considering one-day-lagged, two-days-lagged, three-days-lagged and four-days-lagged values as independent variables. RF has simply been used to map the functional relationships as given in the following equation.
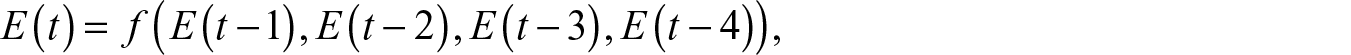
To implement the algorithms, ‘caTools’ (to generate training and test datasets), ‘randomForest’ (to simulate RF) and ‘ipred’ (to run bagging) packages of R have been used. The codes for implementing the respective predictive models are as follows:
Data<-read.csv (file.choose()) \\ To load dataset (year-wise exchange rate) in R require (caTools) \\ To load the package
set.seed (101) \\ For reuse purpose
sample = sample.split (Data$Target, SplitRatio = 0.85) \\ For splitting dataset
train = subset (Data, sample = TRUE) \\ Generating training data
test = subset (Data, sample = FALSE) \\ Generating test data
require (randomForest) \\ To load the requisite package for RF
fmodel_RF<-randomForest (train$Target~., data = train, ntree = 200, importance = T) \\ For building RF model with 200 trees
U<-predict (fmodel_RF, test) \\ To predict on test dataset with built RF model
Require (ipred) \\ To load the requisite package for bagging
fmodel_Bagging<-bagging (train$Target~., data = train, nbagg = 200) \\ For building bagging model with 200 base learners
U<-predict (fmodel_Bagging, test) \\ To predict on test dataset with constructed bagging model
To evaluate the performance of predictive modelling, four quantitative measures, namely mean squared error (MSE), Nash–Sutcliffe coefficients (NSC), index of agreement (IA) and Theil inequality (TI) are computed. These measures are defined as follows:

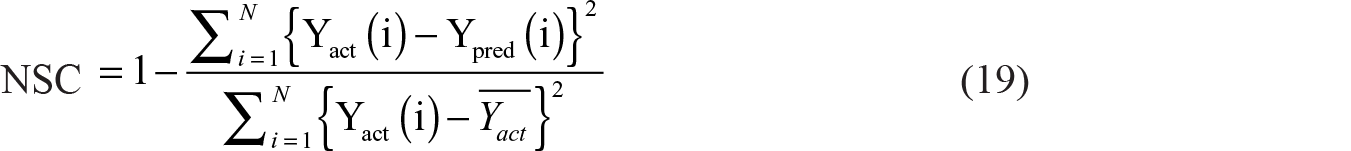
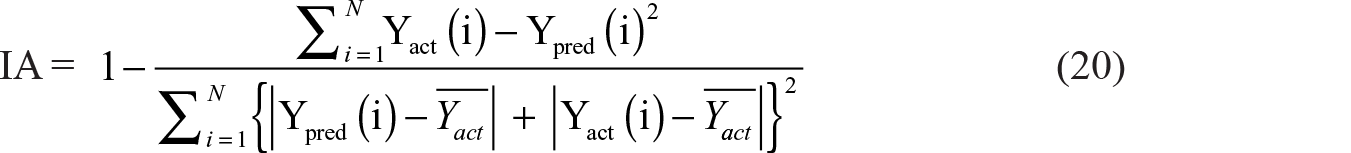
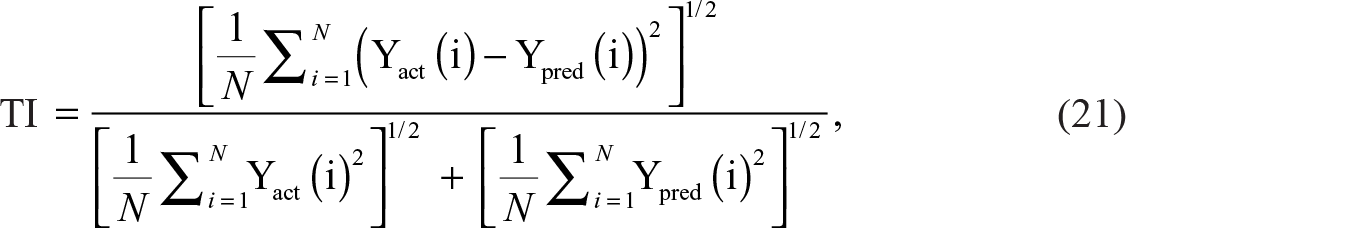
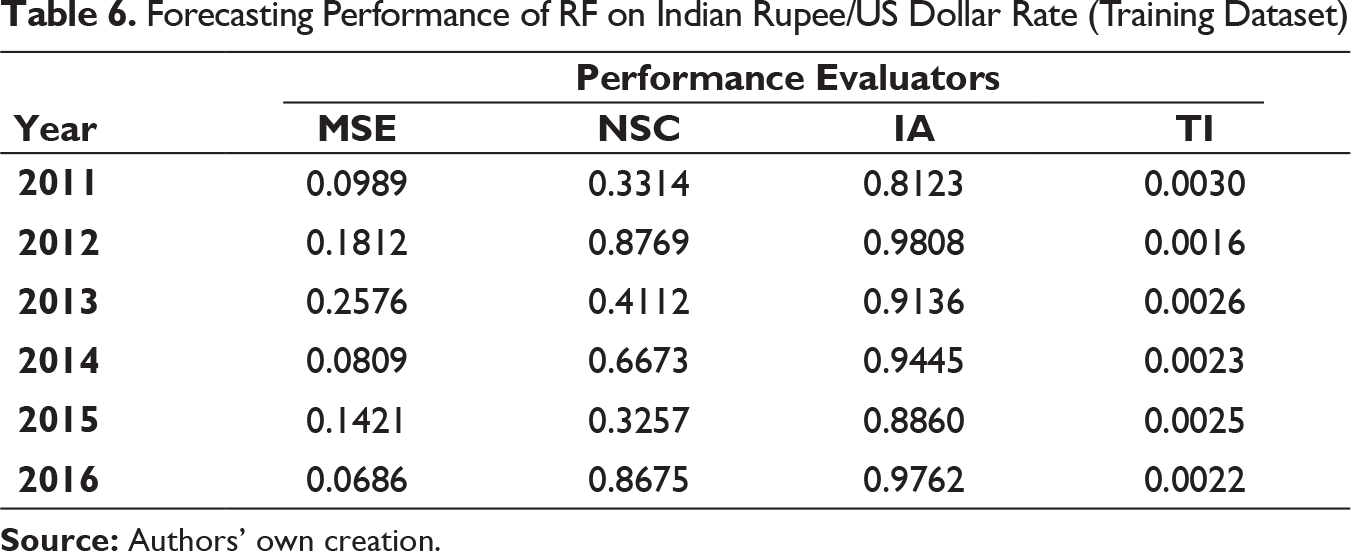
Forecasting Performance of RF on Indian Rupee/US Dollar Rate (Training Dataset)
Forecasting Performance of RF on Indian Rupee/US Dollar Rate (Test Dataset)

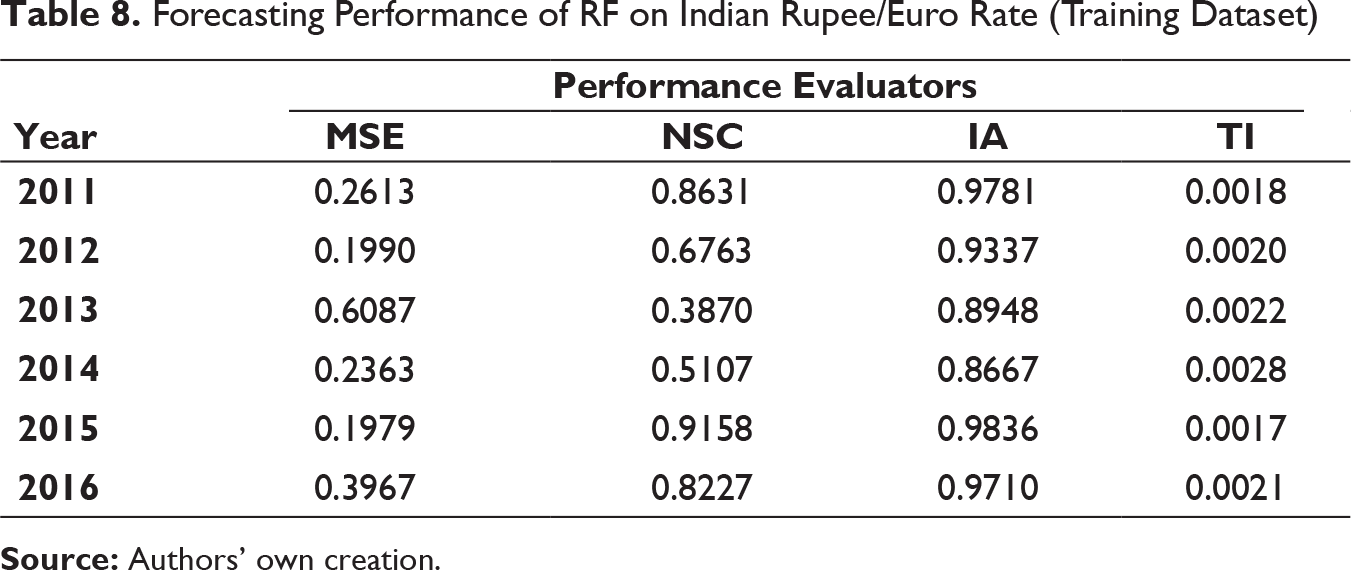
Forecasting Performance of RF on Indian Rupee/Euro Rate (Training Dataset)
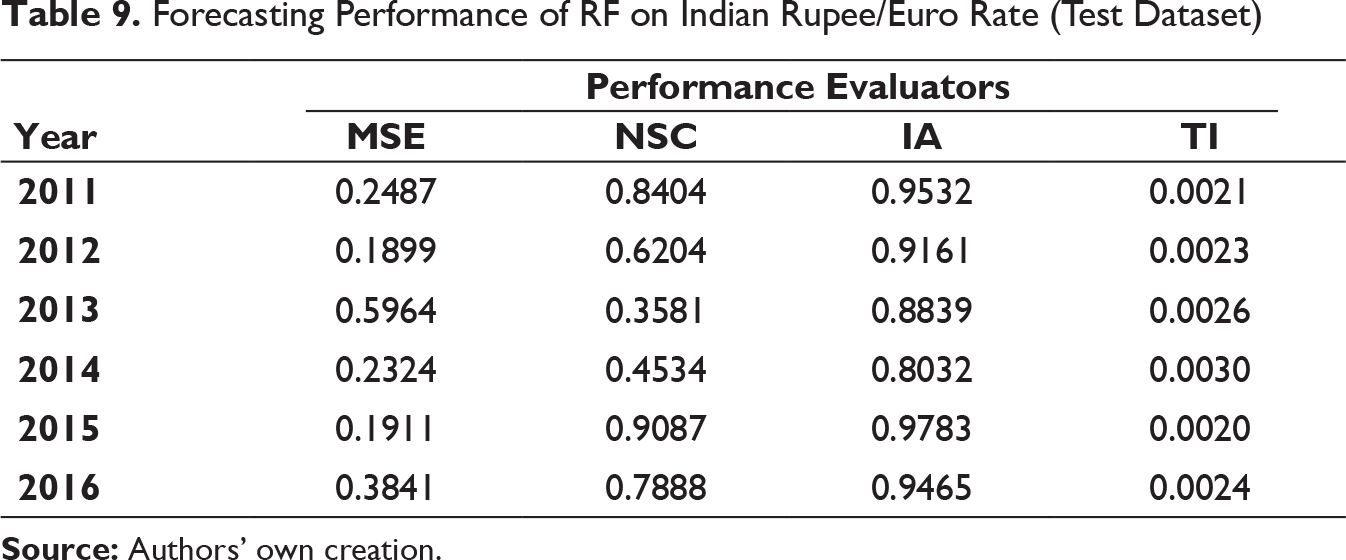
Forecasting Performance of RF on Indian Rupee/Euro Rate (Test Dataset)
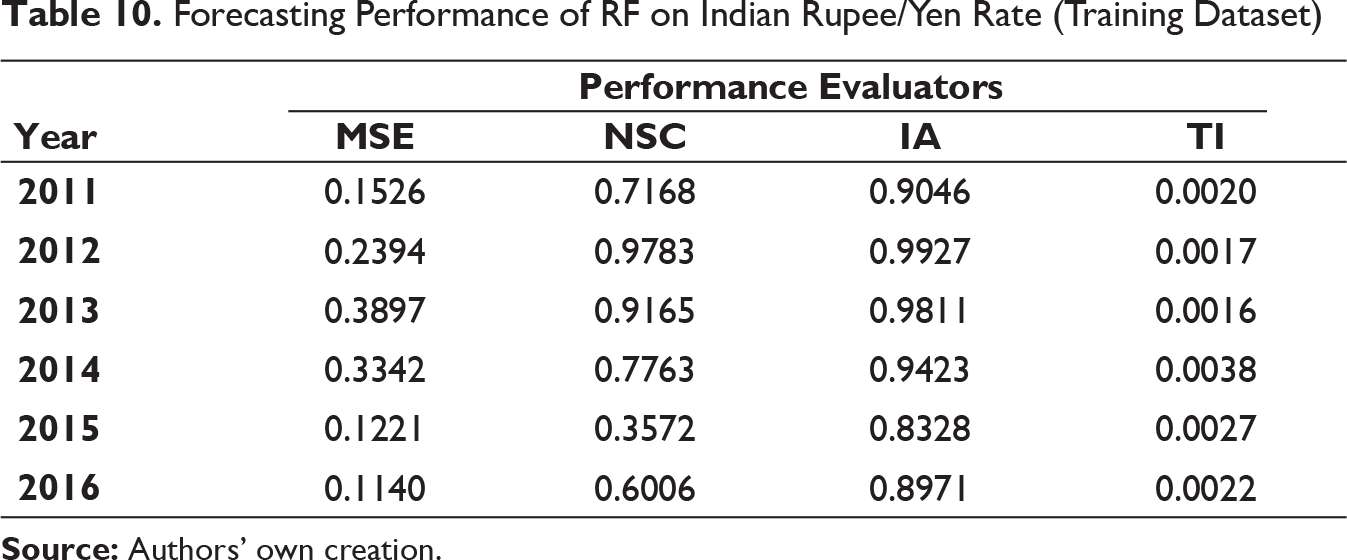
Forecasting Performance of RF on Indian Rupee/Yen Rate (Training Dataset)
Forecasting Performance of RF on Indian Rupee/Yen Rate (Test Dataset)
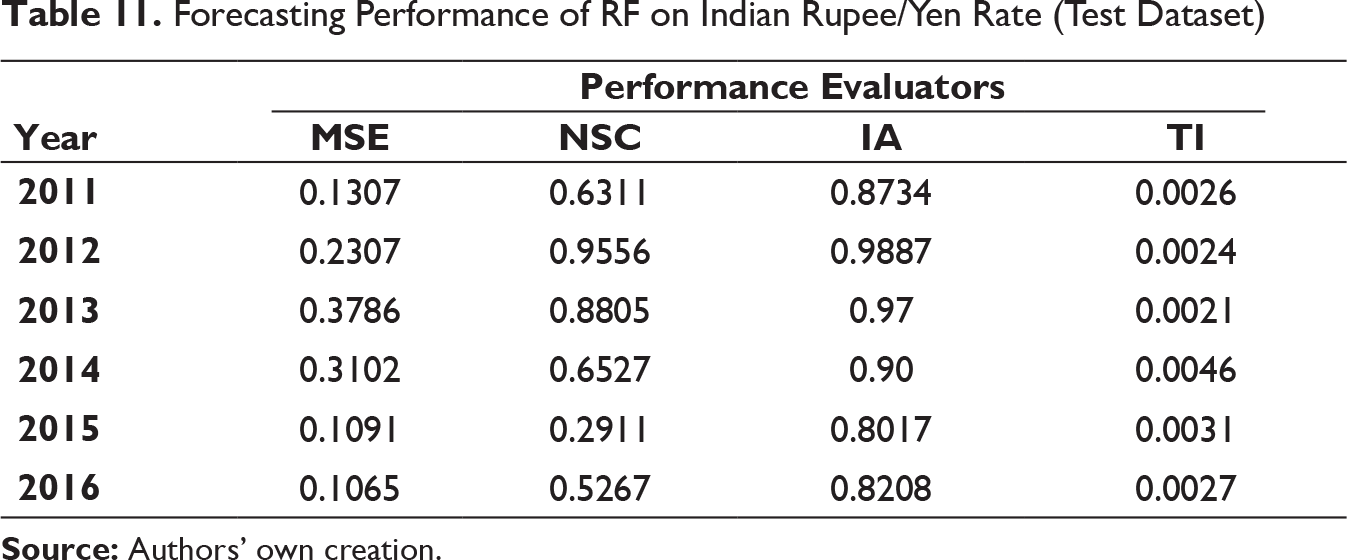
It can be clearly observed that the values of MSE and TI are substantially low for all three exchange rates on both training and test dataset for all six years. IA values are on higher side as well. On few occasions, it can be seen that the NSC values are not as high as compared to IA but not close to 0 also. It can thus be inferred that MODWT–RF-based framework can be effectively deployed for forecasting the respective exchange rates in the univariate framework used.
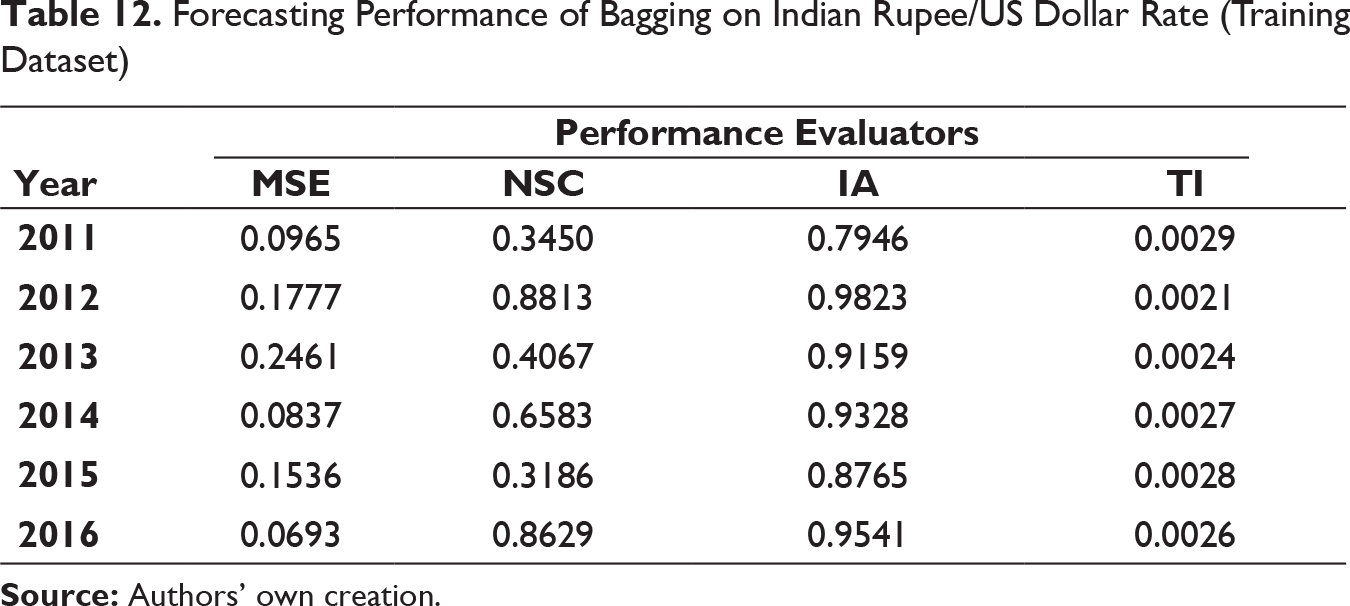
Forecasting Performance of Bagging on Indian Rupee/US Dollar Rate (Training Dataset)
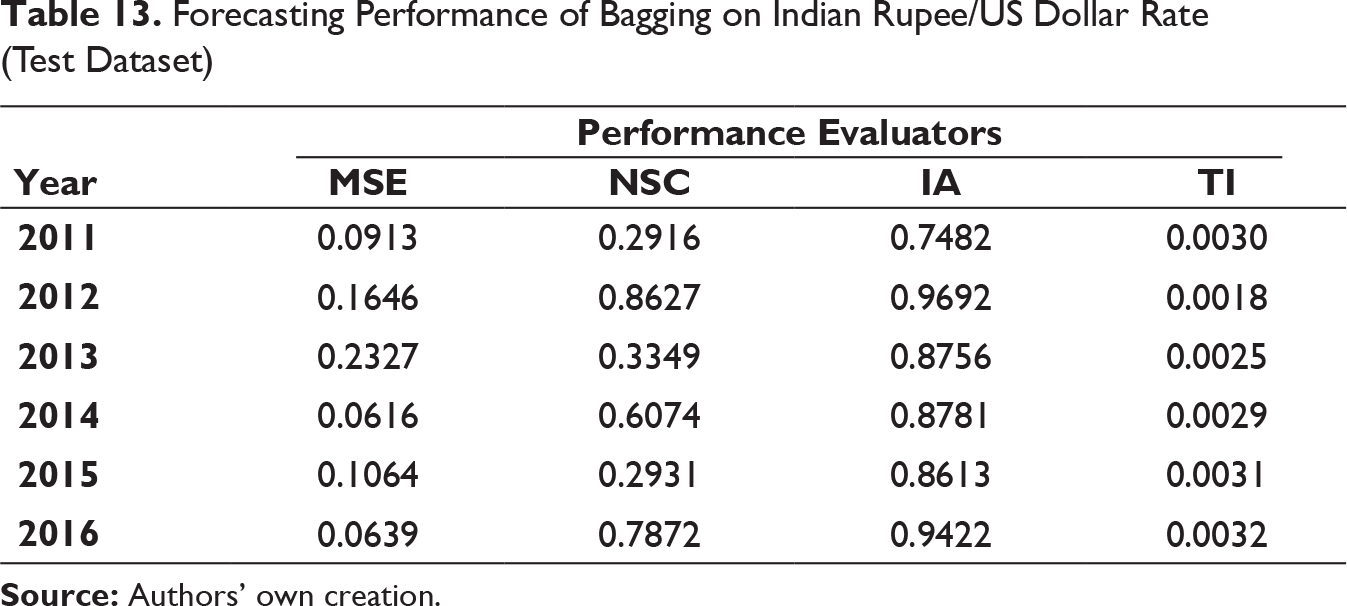
Forecasting Performance of Bagging on Indian Rupee/US Dollar Rate (Test Dataset)
Forecasting Performance of Bagging on Indian Rupee/Euro Rate (Training Dataset)

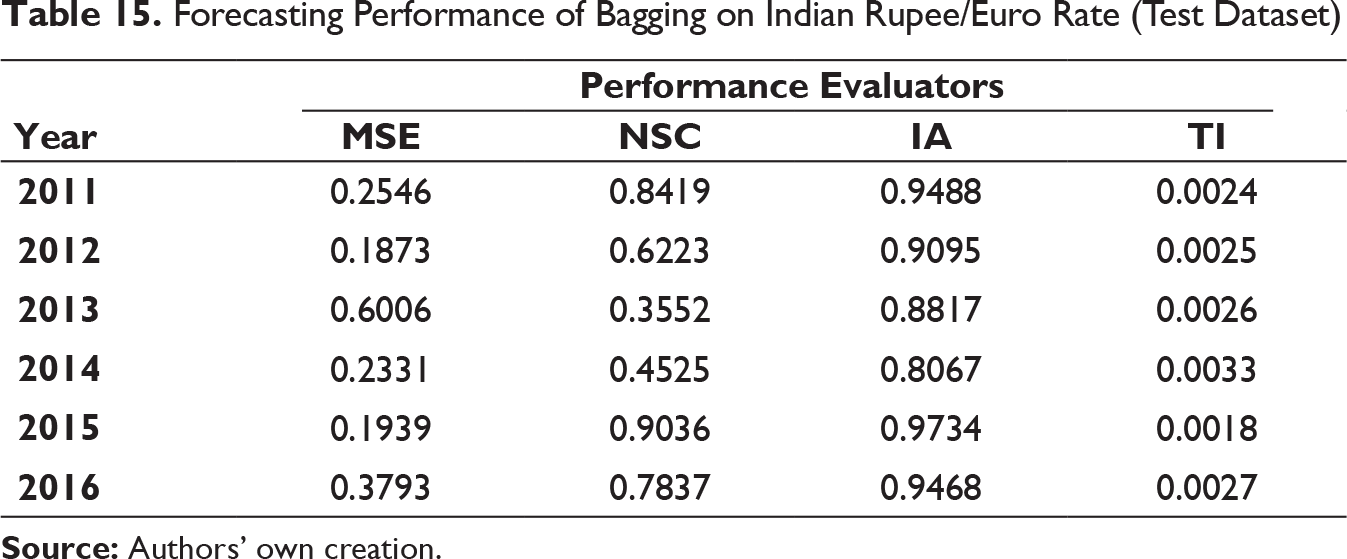
Forecasting Performance of Bagging on Indian Rupee/Euro Rate (Test Dataset)
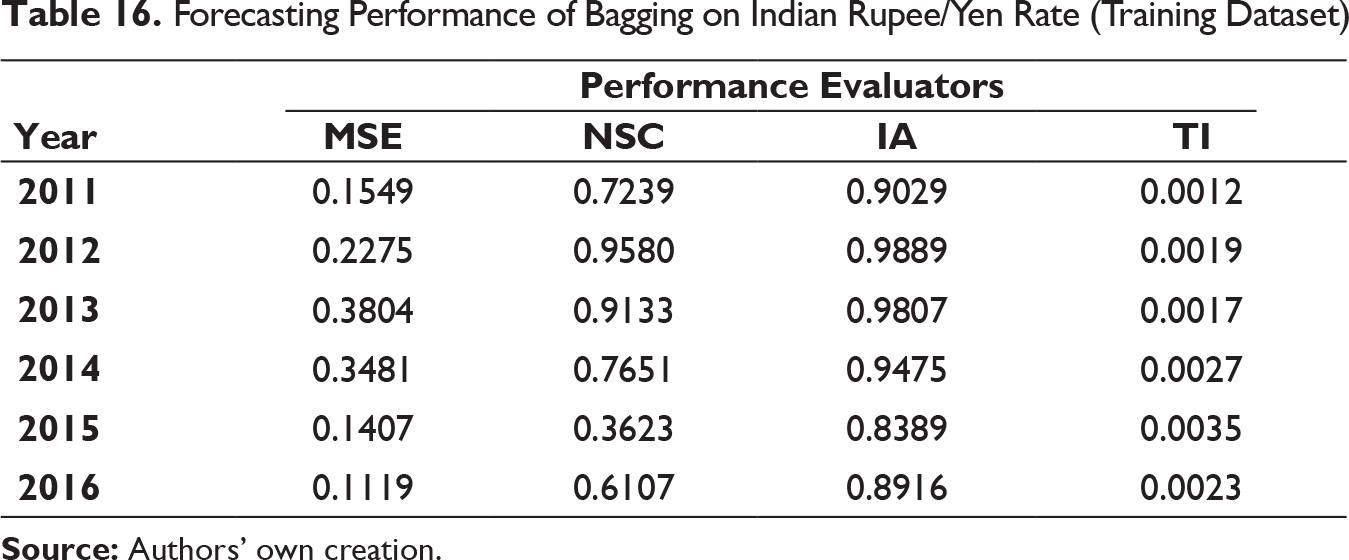
Forecasting Performance of Bagging on Indian Rupee/Yen Rate (Training Dataset)
Forecasting Performance of Bagging on Indian Rupee/Yen Rate (Test Dataset)
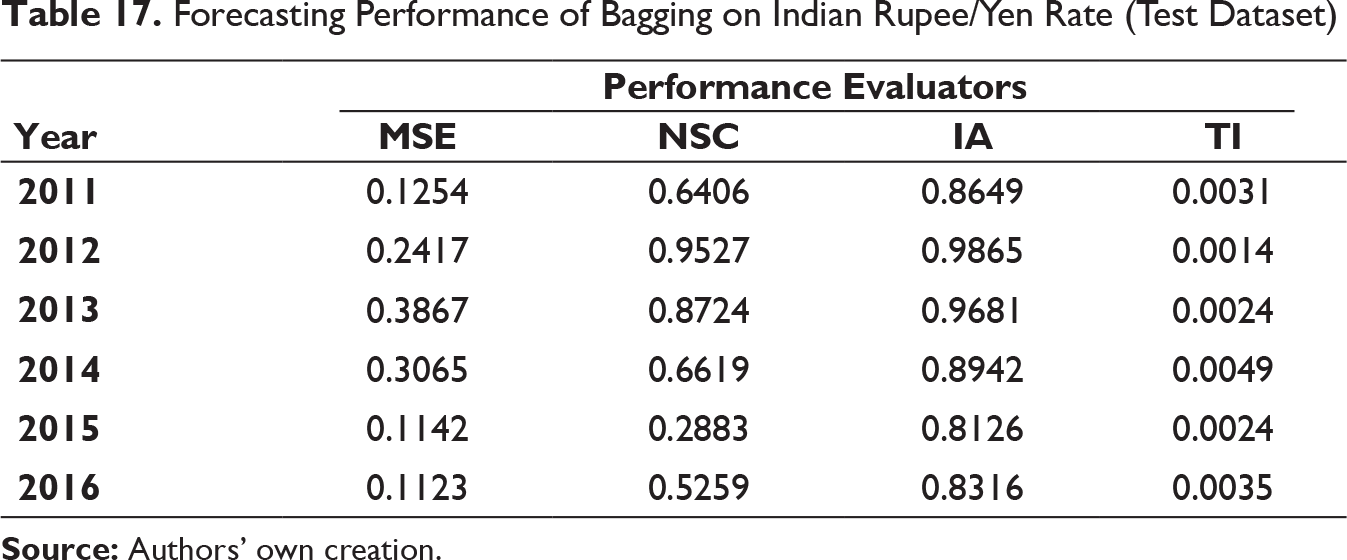
Similar to the previous model, that is, MODWT–RF, MSE and TI values have been found to be low and IA values are on higher side on all the occasions. The similar trend NSC values for MODWT–RF framework have been reflected in MODWT–bagging model too. Thus, MODWT–bagging forecasting model can also be used for effective prediction.
Results of Comparative Analysis
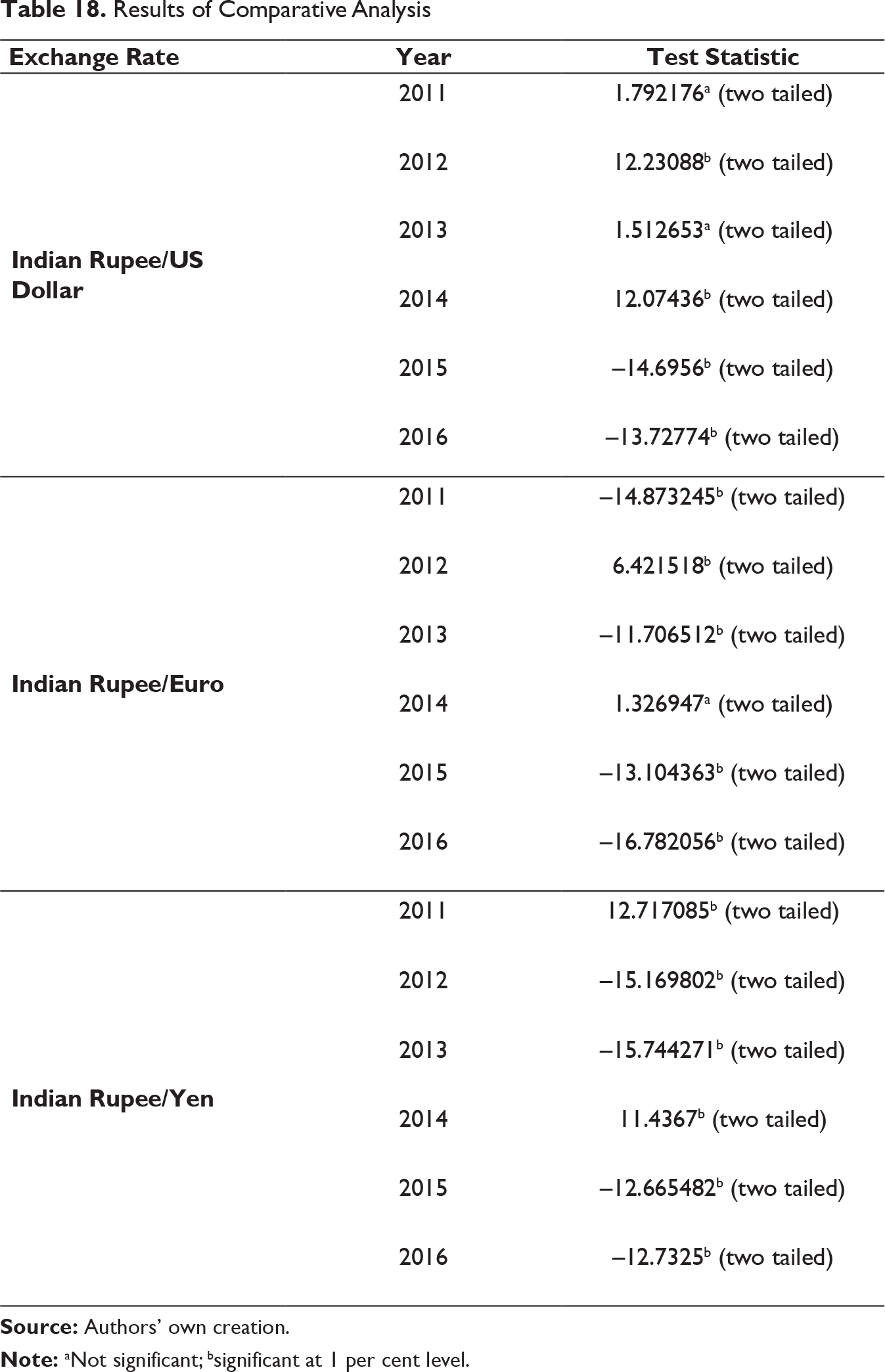
Although it is evident that both MODWT–RF and MODWT–bagging generate good predictions, it may be observed from Table 18 that there exists significant difference between their predictive performances. Total 18 experiments have been performed to assess the utility of both frameworks in predicting the respective exchange rates. In terms of MSE, MODWT–RF has yielded better forecasts as compared to MODWT–bagging on 10 occasions out of 18 cases (as indicated by negative significant test statistic). MODWT–bagging outperformed the former on five occasions. No significant difference in performance of two frameworks is observed in three instances (Indian rupee/US dollar in 2011 and 2013 and Indian rupee/euro in 2014).
Conclusion
This paper proposes a prediction framework of three different exchange rates, namely Indian rupee/US dollar, Indian rupee/euro and Indian rupee/Japanese yen during 2011–2016, by first decomposing each aggregate exchange rate series by MODWT using Haar wavelets and then aggregating the forecast of each sub-series to obtain the forecast values. For specifying the functional form between dependent and independent variables, an understanding of the time series data on exchange rates was undertaken through fractal investigation. Once the presence of persistence was observed in the time series, lagged values of the dependent variable were chosen as independent variables. The results indicate that both MODWT–RF and MODWT–bagging generated good predictions of the exchange rates.