
Abstract
The benefit of binaural summation (“summation”) is often measured in co-located steady-state noise; summation for competing speech is less understood. The goal of the present study was to evaluate how the target-masker acoustic properties and binaural listening mode affect summation for speech-in-speech recognition. Recognition of target speech in two-talker speech maskers was measured with each ear alone and with both ears in bilateral CI users (BiCI), CI users with asymmetric hearing loss (AHL), CI users who were single-sided deaf (SSD), and normal-hearing listeners (NH). Target and masker speech was co-located; the talker sex of the maskers was either the same as or different from the target. With same-sex maskers, significant binaural summation was observed only in the BiCI group. In contrast, with different-sex maskers, significant summation was observed only in the SSD and NH groups, where binaural summation was significantly greater with different-sex than with same-sex maskers. A significant but weak correlation between interaural performance asymmetry and binaural summation was observed in some within-group comparisons, but not in across-group comparisons. For the BiCI group, summation was significantly correlated with SRTs from the better-performing CI ear, but not with performance asymmetry. The findings can be partly accounted for by psychometric-function slope and performance asymmetry within a probability-summation model. However, the probability-summation model generally overestimated the observed summation, suggesting that the assumption of independent processing across ears may not hold for CI users, possibly due to the variability in binaural fusion across individuals.
Introduction
In cochlear implants (CIs), some degree of binaural hearing may be achieved with bilateral CIs (BiCIs) or with combined acoustic and electric hearing (AH in one ear and CI in the other ear). For masked speech recognition, the degree of binaural benefit over listening with one ear alone may depend on: 1) The degree of interaural performance asymmetry, 2) The degree of similarity in the stimulation patterns across ears, and/or 3) The listening demands (e.g., spatially separated vs. co-located target and maskers, steady noise vs. competing speech maskers, etc.). When target and maskers are presented from different spatial locations, binaural benefits may be due to head shadow and/or binaural squelch (Litovsky et al., 2009; Ramsden et al., 2005). When target and maskers are co-located, there also can be a binaural summation benefit (“summation”), defined as the advantage when listening with both ears over the better ear alone (e.g., Aronoff et al., 2011; Gifford & Dorman, 2019). These binaural benefits may differ according to the listening configuration in each ear: acoustic+acoustic, CI+CI, and acoustic+CI.
Although the spectral resolution and mode of hearing are quite different, stimulation patterns are generally symmetric across ears within individual BiCI users and normal-hearing (NH) listeners. Previous studies have reported a small but significant summation in NH listeners (e.g., Dieudonné & Francart, 2019; Heil, 2014; Rennies & Kidd, 2018; Yancey et al., 2021). For NH listeners, summation is likely driven by the redundancy of information in each ear when speech and maskers are presented from the same location. For BiCI users, while the speech information delivered to each ear may be qualitatively similar, the electrically evoked peripheral patterns may differ across ears due to differences in electrode placement, insertion depth, and/or the number of surviving ganglion cells across ears, possibly resulting in significantly different speech performance across ears (“interaural performance asymmetry”; Schleich et al., 2004; Ricketts et al., 2006; Tyler et al., 2007; Wackym et al., 2007; Buss et al., 2008; Dunn et al., 2008; Eapen et al., 2009; Litovsky et al., 2009). BiCI users with greater interaural performance asymmetry generally benefit less from listening with two ears, compared to the better ear alone (Litovsky et al., 2006; Mosnier et al., 2009; Polonenko et al., 2018; Yoon et al., 2011).
Different from NH listeners or BiCI users, the stimulation patterns in each ear are likely to be different for CI users with acoustic hearing in the non-implanted ear. Interaural performance asymmetry may be highly variable, depending on the amount of acoustic hearing in the non-implanted ear. Previous studies have shown significant summation for speech recognition in noise in bimodal CI users (e.g., Dorman et al., 2008; Gifford et al., 2007; Mok et al., 2006). However, summation observed in “bimodal” CI users (limited acoustic hearing in one ear, CI in the other ear) may be due to complementary information across ears, rather than the redundancy of information across ears observed in NH and BiCI users (e.g., van Hoesel, 2012). Similar to BiCI users (Litovsky et al., 2006; Mosnier et al., 2009; Polonenko et al., 2018; Yoon et al., 2011), summation in bimodal CI users has been significantly and negatively associated with the degree of interaural performance asymmetry (Yoon et al., 2015).
Different from bimodal CI users, CI users with greater amounts of acoustic hearing in the non-implanted ear typically better perform with the acoustic-hearing ear alone than with the CI ear alone. Due to the dominance of acoustic hearing, most previous studies show little-to-no summation when target speech and steady noise maskers are co-located (e.g., Arndt et al., 2011; Buss et al., 2018; Deep et al., 2021; Dillon et al., 2017; Döge et al., 2017; Dorbeau et al., 2018; Firszt et al., 2012; Galvin et al., 2019; Kitoh et al., 2016; Mertens et al., 2017; Távora-Vieira et al., 2015). However, some studies have shown that summation depends on the extent of acoustic hearing. Summation has been shown to be larger for CI users with asymmetric hearing loss (“AHL”; hearing loss > 25 dB HL at one or more audiometric frequencies between 250 and 8000 Hz in the acoustic-hearing ear) compared to CI users with NH in the acoustic-hearing ear (single-side deaf, or “SSD”; hearing thresholds ≤ 25 dB HL across 250 - 8000 Hz; Vermeire & Van de Heyning, 2009; Dorbeau et al., 2018). Since interaural performance asymmetry is likely to be larger in SSD CI users than in AHL CI users, this suggests a negative correlation between interaural performance asymmetry and summation, consistent with previous findings in bimodal CI users (Yoon et al., 2015).
Summation in BiCI users, CI users with residual acoustic hearing, and NH listeners has been examined primarily using speech masked by co-located steady noise, where the target and masker differ substantially in their temporal characteristics. Far fewer studies have assessed summation with dynamic maskers, particularly competing speech, which produces substantial informational masking in addition to energetic masking (e.g., Brungart, 2001; Brungart et al., 2001). Informational masking can arise from lexical interference (when both target and masker are intelligible) and from masker-talker characteristics such as talker sex. According to Shinn-Cunningham (2008), informational masking is strongly influenced by the acoustic similarity between target and masker (e.g., voice pitch, vocal tract length). Compared to NH listeners, CI users often struggle to segregate competing speech regardless of masker voice characteristics, largely due to degraded spectral resolution and the absence of TFS cues (e.g., Calandruccio et al., 2017; Chen et al., 2020; Cullington & Zeng, 2008). For bimodal CI users who have limited acoustic hearing, the CI ear likely provides the primary spectral cues for speech recognition, whereas the acoustic-hearing ear provides the TFS cues needed for speech segregation (complementary information). For AHL and SSD CI users, the more substantial acoustic hearing can provide both the primary spectral cues for recognition and the TFS cues for segregation, while the CI ear may add mostly redundant spectral information. The marked differences across ears in the ability to utilize talker-sex cues during speech-in-speech recognition may result in distinct patterns of interaural performance asymmetry across listener groups, compared with speech recognition in steady noise. Previous studies have demonstrated a significant negative correlation between performance asymmetry and binaural summation in steady-noise conditions (Yoon et al., 2011, 2015). However, it remains unclear how interaural performance asymmetry influences binaural summation for speech-in-speech recognition, particularly across different listener populations.
The goal of the present study was to understand how summation for speech-in-speech recognition is influenced by the acoustic similarity of target and masker speech and by the differing perceptual representations across ears. Four listener groups were tested that represented different perceptual representations across ears: 1) CI in each ear (“BiCI”), 2) CI + AHL (“AHL”), 3) CI + SSD (“SSD”), and 4) NH in both ears (“NH”). Speech recognition thresholds (SRTs), defined as the signal-to-noise ratio (SNR) that produced 50% correct recognition, were measured in the presence of two-talker speech maskers with either ear alone (monaural listening) or with both ears (binaural listening). The sex of the speech maskers were either same as or different from the of the target. Two-talker maskers were used because previous studies have shown that speech-in-speech recognition is more difficult with two-talker than with one-talker maskers, presumably due to increased informational masking (Calandruccio et al., 2017; Chen et al., 2020; Cullington & Zeng, 2008; Thomas et al., 2021) or more limited glimpsing opportunities (Buss et al., 2017; Chen et al., 2023). Summation was calculated as the difference in SRTs between binaural listening and monaural listening with the better-performing ear.
We hypothesized that binaural summation would be negatively correlated with interaural performance asymmetry for speech-in-speech recognition. Specifically, we expected summation to decrease as interaural asymmetry increased, consistent with previous findings for speech recognition in steady noise (Yoon et al., 2011, 2015). We predicted that performance asymmetry would increase substantially in AHL and SSD participants due to the availability of TFS cues in the acoustic-hearing ear, with much less asymmetry in BiCI users and NH listeners. Relatedly, we expected smaller binaural summation in the AHL and SSD groups, and larger summation on the BiCI and NH groups. To examine underlying mechanisms for summation, we applied a probability-summation model in which binaural summation arises solely from the increased likelihood of correct recognition when two independent input channels are available. The results provide important insight into the mechanisms underlying binaural summation for speech-in-speech recognition in different listener populations.
Methods
Participants
Nineteen BiCI users (13 females; mean age = 24.7 years, range: 14-49 years), 8 AHL CI users (4 females; mean age = 41.8 years, range: 32-52 years), 8 SSD CI users (5 females; mean age = 36.3 years, range: 25-42 years), and 21 NH listeners (11 females; mean age = 25.5 years, range: 20-33 years) participated in the present study. All participants were native Mandarin speakers, and all were recruited from Beijing Tongren Hospital. All CI users were post-lingually deaf or peri-lingually deaf (e.g., SEQ4 and SEQ5 received their first CI before 4 years old), all had a minimum of 3 months of CI experience, and all were implanted with the MED-EL Sonata Flex28 device. None of the AHL participants used a hearing aid before or after cochlear implantation. All CI users used the same speech processor (Opus 2, where no noise reduction techniques or microphone directionality are available) and speech processing strategy (FS4).
Demographic Information for the Bilateral CI (BiCI) Participants. Data for Sequentially Implanted BiCI Users (SEQ) is Shown at Top, Data for Simultaneously Implanted BiCI Users (SIM) is Shown in the Middle. Data Across all BiCI Users are Shown at Bottom. For the Simultaneously Implanted Group, the Age of CI and CI Experience Were the Same for Both Ears; Both Values Were Included With the Sequentially Implanted Group When Averaging Across all Bilateral CI Participants
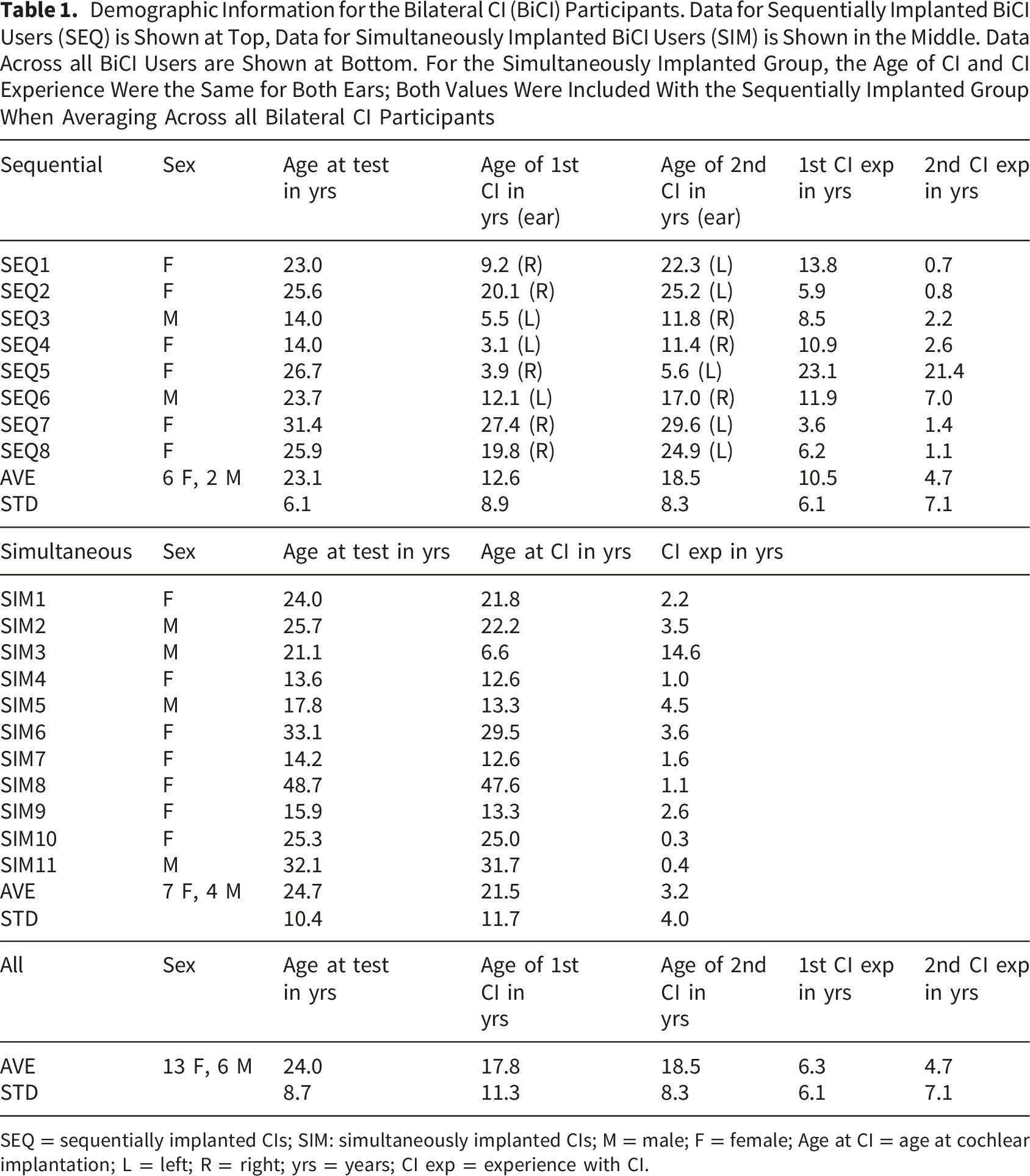
SEQ = sequentially implanted CIs; SIM: simultaneously implanted CIs; M = male; F = female; Age at CI = age at cochlear implantation; L = left; R = right; yrs = years; CI exp = experience with CI.
Demographic Information for CI Participants With Hearing Loss Greater Than 25 dB HL at One or More Audiometric Frequencies Between 250 and 8000 Hz in the Non-implanted Ear (AHL; Top) and With Normal Hearing (≤25 dB HL Across 250–8000 Hz) in the Non-implanted Ear (SSD; Middle); Mean Data Across AHL CI and SSD CI Participants are Shown at the Bottom
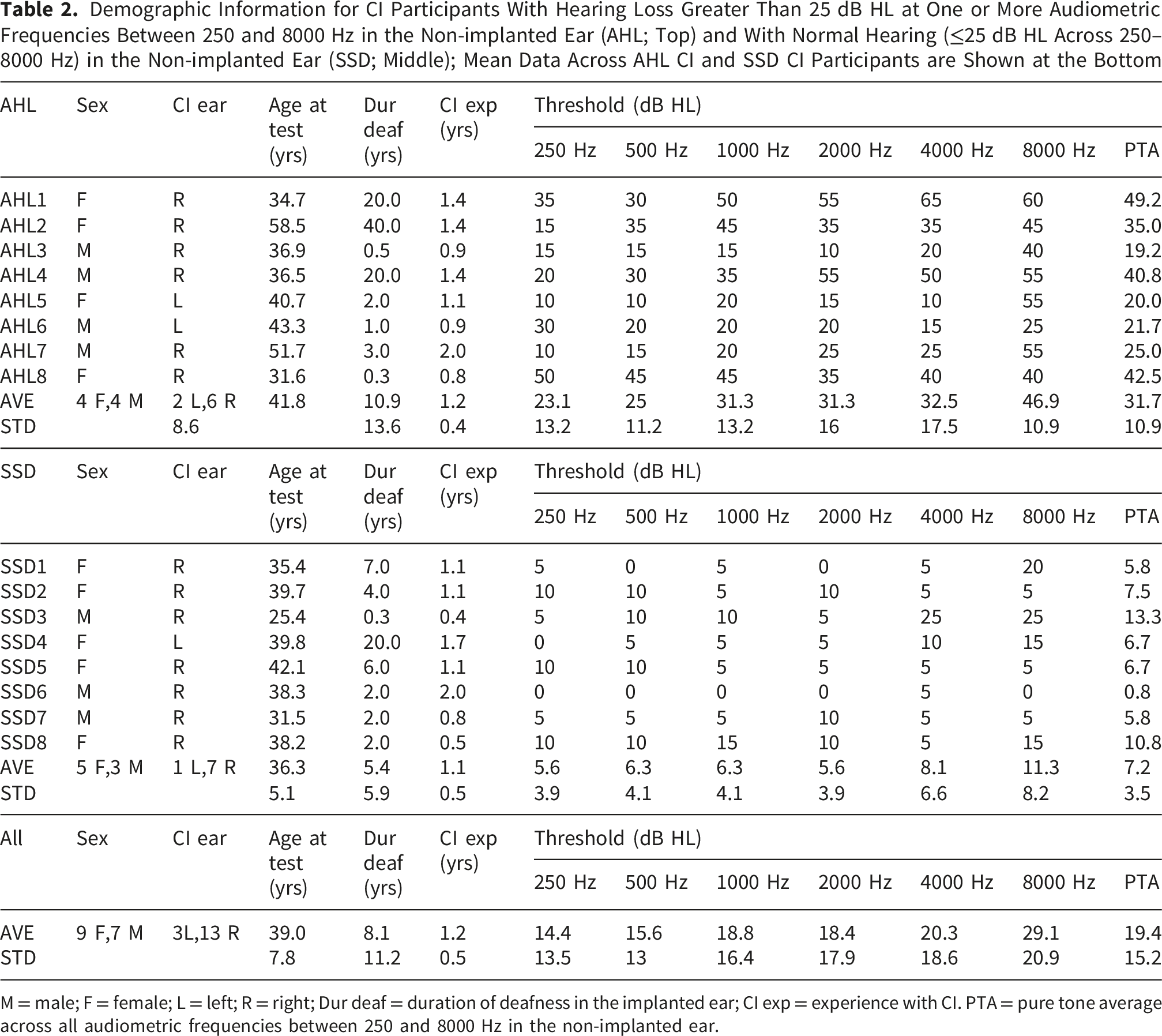
M = male; F = female; L = left; R = right; Dur deaf = duration of deafness in the implanted ear; CI exp = experience with CI. PTA = pure tone average across all audiometric frequencies between 250 and 8000 Hz in the non-implanted ear.
For NH participants, thresholds were <25 dB for all audiometric frequencies between 250 and 8000 Hz in each ear; the mean pure-tone average (PTA) threshold across all audiometric frequencies were 7.78 ± 2.61 dB HL and 7.90 ± 2.18 dB HL in the left and right ears, respectively. Paired t-tests showed no significant difference in PTAs across ears (p = 0.789). The mean asymmetry in PTA was 1.23 ± 1.57 dB HL. This study was approved by the Ethics Committee of the Beijing Tongren Hospital, Capital Medical University (TRECKY-2019-055-XZ-1) and this research was conducted in accordance with the principles of the Declaration of Helsinki and its later amendments. Written informed consent was obtained from all participants before proceeding with any of the study procedures. In cases where participants were younger than 18 years old, written consent was also obtained from their parents.
Test Materials and Procedures
Recognition of target speech in the presence of masker speech was measured using the matrix-style test materials from the Closed-Set Mandarin Speech corpus (Chen et al., 2020; Liu et al., 2019, 2020; Tao et al., 2017, 2018). The stimuli consisted of 5 categories (Name, Verb, Number, Color, and Object), each with 10 words. Target and masker sentences were randomly generated by choosing words from each category. Sentences were produced by native Mandarin-speaking talkers. The target sentence was produced by a native Mandarin-speaking male talker; the median F0 across all words was 124.0 Hz. The target sentence always began with the Name “Xiaowang”. The masker sentences began with any Name except “Xiaowang” and contained different words than those selected for the target sentence; sentences were also different across masker talkers. When the masker talkers were the same sex as the target, sentences were produced by two males that were different from the target talker (mean F0 = 128.5 and 156.3 Hz). When the masker talkers were a different sex from the target, sentences were produced by two females (mean F0 = 177.2 and 225.9 Hz). The estimated vocal-tract length was 17.0 cm for the male target talker, 16.8 cm and 17.1 cm for the two male masker talkers, and 14.7 cm and 14.6 cm for the two female masker talkers. Figure 1 shows the long-term average spectra (LTAS) for the target and the four masker talkers. The long-term average spectrum (LTAS) for the target and all maskers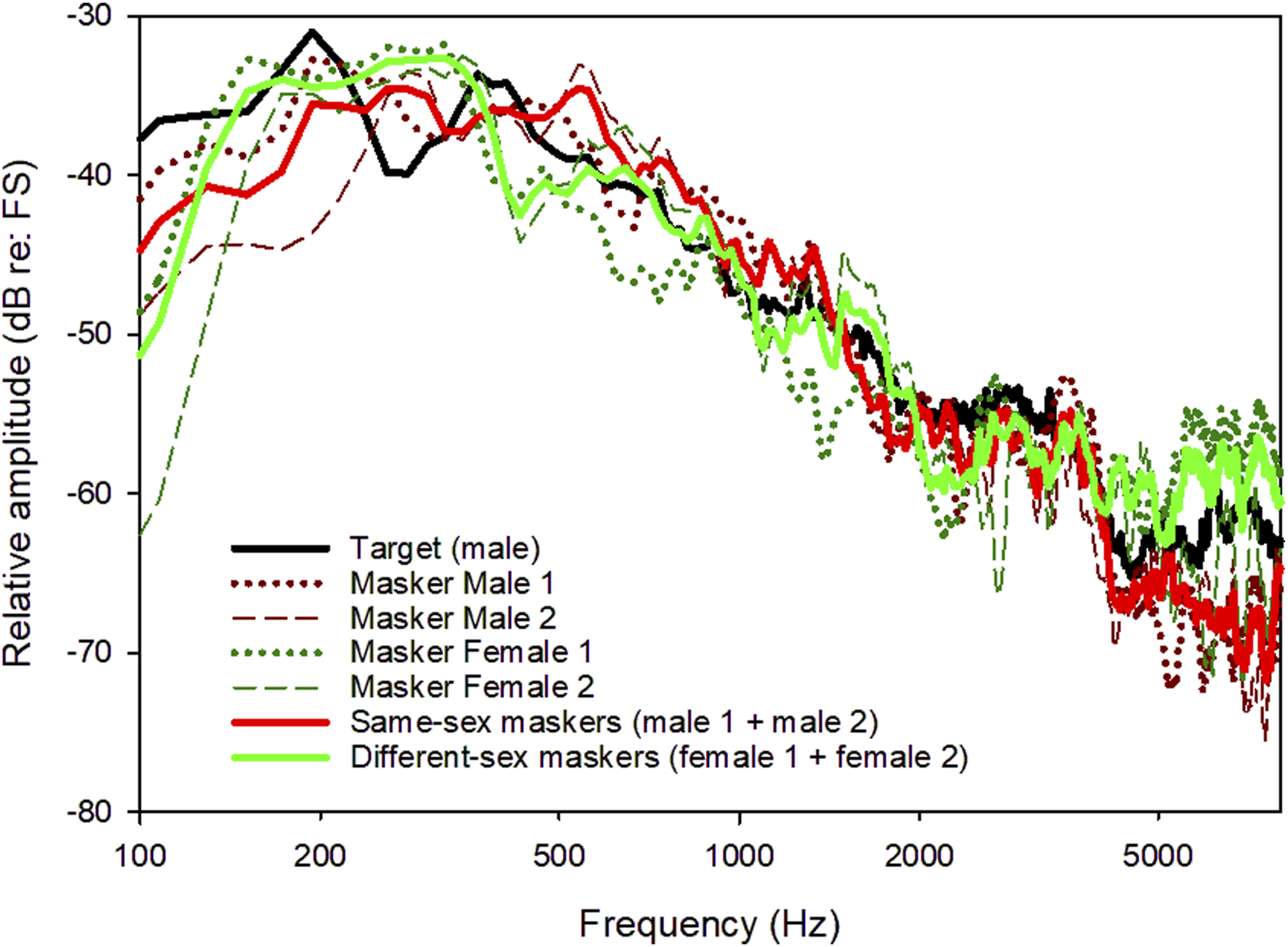
Stimuli were generated and delivered via audio interface (Edirol UA-25) connected to a mixer (Mackie 402). The stimuli were delivered via insert earphone(s) (Otometrics) to the acoustic-hearing ear(s) in the NH, SSD, and AHL groups, and delivered to the CI ear(s) via direct audio input (DAI) to the CI speech processor. Importantly, due to the expected wide range in SRTs, a fixed overall presentation level for the combined target and masker stimuli (i.e., conversational level; 65 dB A-weighted SPL) was used instead of a fixed target level to avoid loud presentation levels that would occur at highly negative SNRs. For the fixed overall presentation, after combining the target and masker sentences according to a specific SNR, the overall presentation level was further adjusted to have the long-term root-mean-square (RMS) level of 65 dB. For the AHL and SSD groups, stimuli were simultaneously presented to both ears and participants adjusted the volume level of the mixer output sent to the CI ear until the calibration stimulus was centralized and/or equally loud. For the BiCI and NH groups, stimuli were simultaneously presented to both ears and participants adjusted the volume level of the mixer output sent to the right ear until the calibration stimulus was centralized and/or equally loud. Note that for the AHL, SSD, and BiCI groups, the clinical settings for microphone sensitivity and amplitude mapping were not changed. The RMS level of the test stimulus (combined target and maskers) was equivalent to that of a calibrated stimulus that corresponded to 65 dBA in NH listeners. The actual presentation level in the CI ear may not have been exactly 65 dBA, especially for BiCI users who have no acoustic ear as the reference. Nevertheless, the presentation level was comfortably loud (according to CI users) and loudness balanced across ears. Once loudness-balancing across ears was complete, the overall stimulus presentation levels for each ear were not changed during testing.
SRTs were defined as the SNR that produced 50% correct recognition of both target keywords. A 1-up/1-down adaptive tracking rule was used, converging on 50% correct for two-keyword accuracy on the psychometric function (Levitt, 1971). During each test trial, listeners were asked to identify two key words (randomly selected from the Number and Color categories) in the target sentence; the other words on the response screen were greyed out and could not be selected during testing. The keywords were chosen to be comparable to those used in the coordinate response measure (CRM) task (Brungart, 2001). The target sentence was always cued by the Name “Xiaowang”. The initial SNR was 10 dB. If the listener identified both key words correctly, the SNR was reduced in the next trial; if the participant did not correctly identify both key words, the SNR was increased in the next trial.
The listener completed 20 trials for each test run. The initial step size was 4 dB (first two reversals) and the final step size was 2 dB. The SRT for each test run was calculated by averaging the last 6 reversals in SNR, and the test run was discarded if the number of reversals was less than 6. Two test runs were completed for each listening condition and SRTs were averaged across runs. The two test runs were completed independently. For all listeners, SRTs were measured with left ear alone, right ear alone, and both ears. The listening conditions (left, right, both), repetitions (test, retest), and maskers (same-sex, different-sex) were randomized within and across participants. The data collection was normally completed within an hour. Before formal testing, all participants were familiarized with the protocol and the speech materials. During formal testing, no feedback was provided.
Data Analysis
SRT, interaural performance asymmetry, and summation data were analyzed using linear mixed models (LMMs); LMMs allowed for statistical analysis when data were missing for some participants and conditions. A priori significance was set at p < 0.05. Bonferroni correction was applied to all post-hoc pairwise comparisons. For the LMM, a restricted maximum likelihood was used, with a maximum of 100 iterations, an absolute log-likelihood convergence value of 0, an absolute parameter convergence value of 0, and a Hessian absolute convergence value of 0, with a maximum scoring step value of 0 and a singularity tolerance of 0.00000000001. Participant was the only random effect and was modeled as the intercept. For each participant, the “poorer” and “better” ear for each masker condition was identified as having the higher or lower monaural SRT, respectively; interaural performance asymmetry was defined as the difference in SRT between the poorer and better ear. All analyses were performed using SPSS (Version 20.0; Armonk, NY). Note that data for the different-sex masker condition were available in only 11/19 BiCI participants due to time limitations at the end of the testing session.
Results
Figure 2 shows SRTs with the same-sex and different-sex maskers for the BiCI, AHL, SSD, and NH groups for the poorer ear, better ear, and both ears; mean SRTs are shown in Table 3. Mann-Whitney rank sum tests showed no significant difference between sequentially or simultaneously implanted BiCI users for any of the ear or masker conditions (p > 0.05 for all tests). Among BiCI and NH listeners, the poorer ear varied across the left and right ears; for AHL and SSD CI users, the poorer ear was always the CI ear. In general, SRTs were lower (better) with different-sex than with the same-sex maskers, and lower for the SSD and NH groups than for the BiCI and AHL groups. SRTs with the A) same-sex or B) different-sex maskers for the different listening groups and ear conditions. The horizontal dashes show mean values Top: Mean SRTs ± Standard Deviation With the Same-Sex and Different-Sex Maskers for the Different Ear Conditions and Listener Groups. Bottom: Results from linear mixed model (LMM) analysis on SRTs with the better-performing ear and both ears. Asterisked and italicized values indicate significant effects, and significant differences for pairwise comparisons are shown at right BiCI = bilaterally implanted CI users; AHL = unilaterally implanted CI users with hearing loss greater than 25 dB HL at one or more audiometric frequencies between 250 and 8000 Hz in the non-implanted ear; SSD = unilaterally implanted CI users with normal hearing (≤25 dB HL across 250–8000 Hz) in the non-implanted ear; NH = normal-hearing listeners; SRT = speech reception threshold; SS: same-sex maskers; DS: different-sex maskers. Better: listening with better-performing ear; Both: listening with both ears.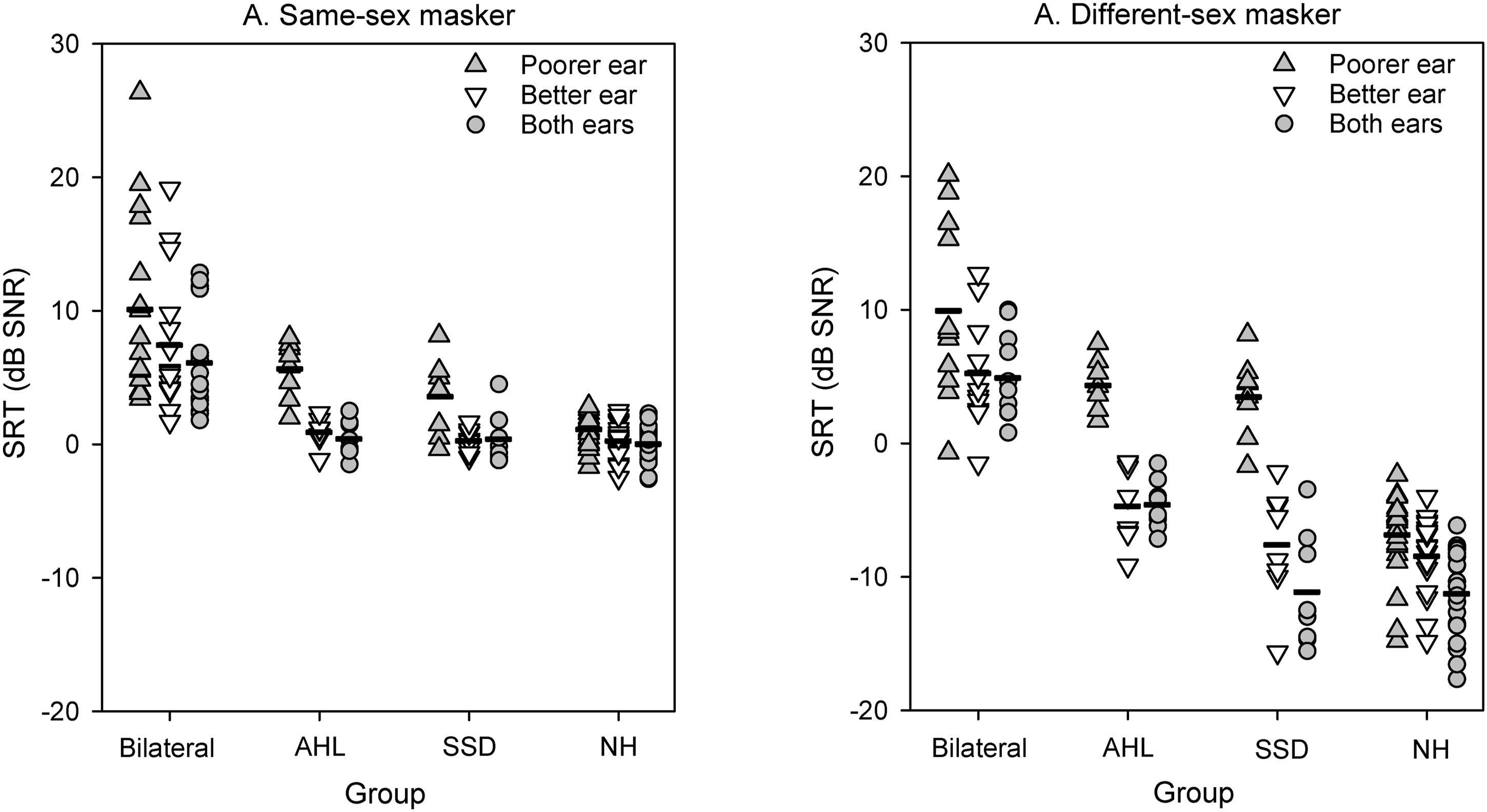
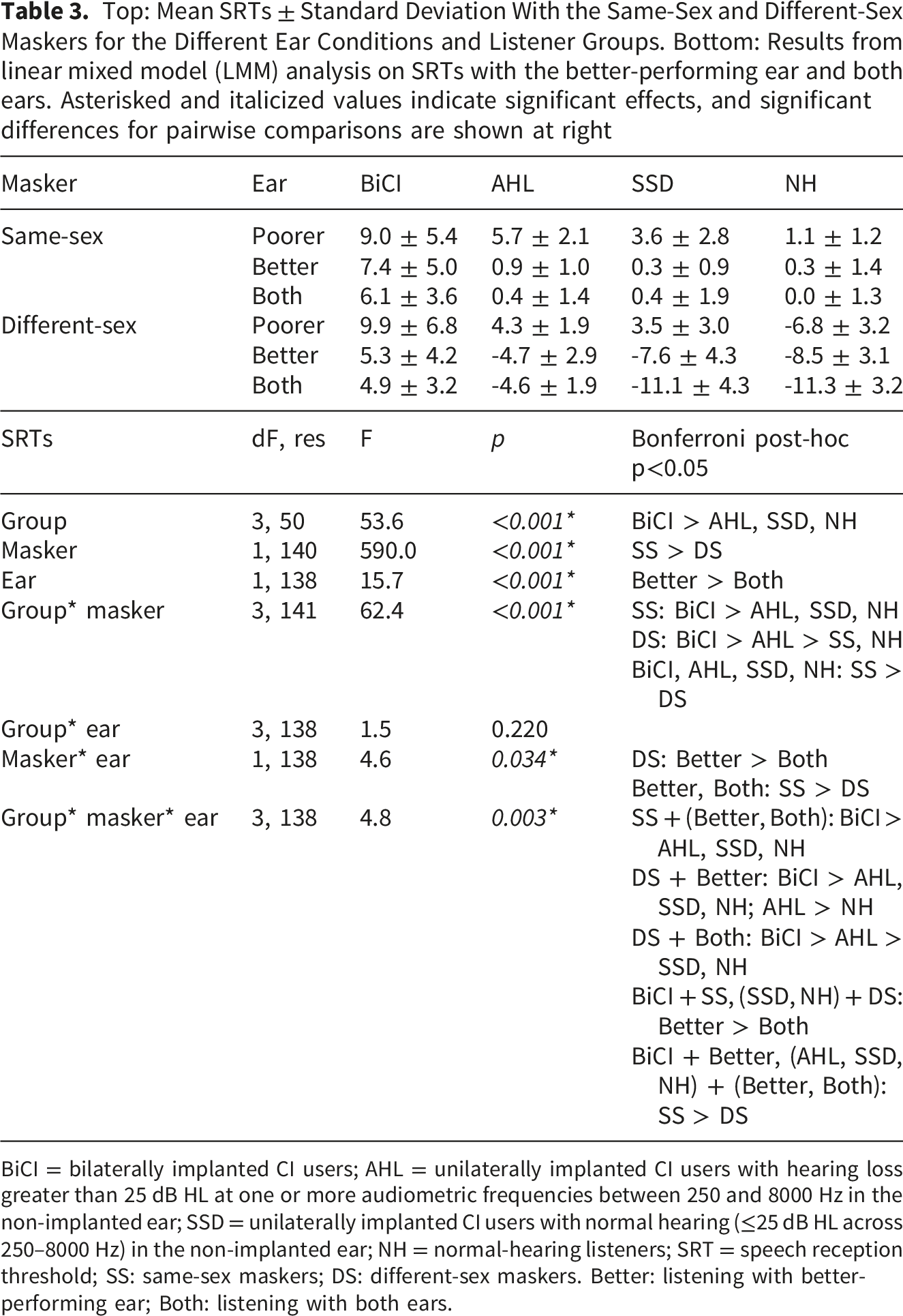
To determine whether there was a significant advantage when listening with both ears compared to the better ear alone, LMM analysis was performed on the SRT data, with group (BiCI, AHL, SSD, NH), ear (better, both), and masker (same-sex, different-sex) as fixed effects and participant as the random effect; complete results are shown in Table 3. Results showed significant effects for group [F(3, 50) = 53.7, p < 0.001], masker [F(1, 140) = 590.2, p < 0.001], and ear [F(1, 138) = 15.8, p < 0.001]. Significant interactions were observed between group and masker [F(3, 140) = 62.1, p < 0.001], between masker and ear [F(1, 138) = 4.5, p = 0.036], and among group, ear, and masker [F(3, 138) = 4.9, p = 0.003]. Post-hoc Bonferroni pairwise comparisons for the three-way interaction showed that for the BiCI group and the same-sex masker, SRTs were significantly higher (poorer) with the better ear than with both ears (p < 0.05), indicating significant summation. For the SSD and NH groups with the different-sex masker, SRTs were significantly higher with the better ear than with both ears (p < 0.05), again indicating significant summation. There was no significant summation for the AHL groups.
Figure 3 shows summation for the different groups and maskers; mean summation data are shown in Table 4. For the BiCI and AHL groups, mean summation was similar with the same-sex and different-sex maskers. For the SSD and NH groups, mean summation was larger with the different-sex than with the same-sex maskers. Summation for the different listening groups and masker conditions. The horizontal dashes show mean values Top: Mean Summation ± Standard Deviation With the Same-Sex and Different-Sex Maskers for the Different Listener Groups. Bottom: Results from LMM analysis on the binaural summation data. Asterisked and italicized values indicate significant effects, and significant differences for pairwise comparisons are shown at right BiCI = bilaterally implanted CI users; AHL = unilaterally implanted CI users with hearing loss greater than 25 dB HL at one or more audiometric frequencies between 250 and 8000 Hz in the non-implanted ear; SSD = unilaterally implanted CI users with normal hearing (≤25 dB HL across 250–8000 Hz) in the non-implanted ear; NH = normal-hearing listeners; SS: same-sex maskers; DS: different-sex maskers.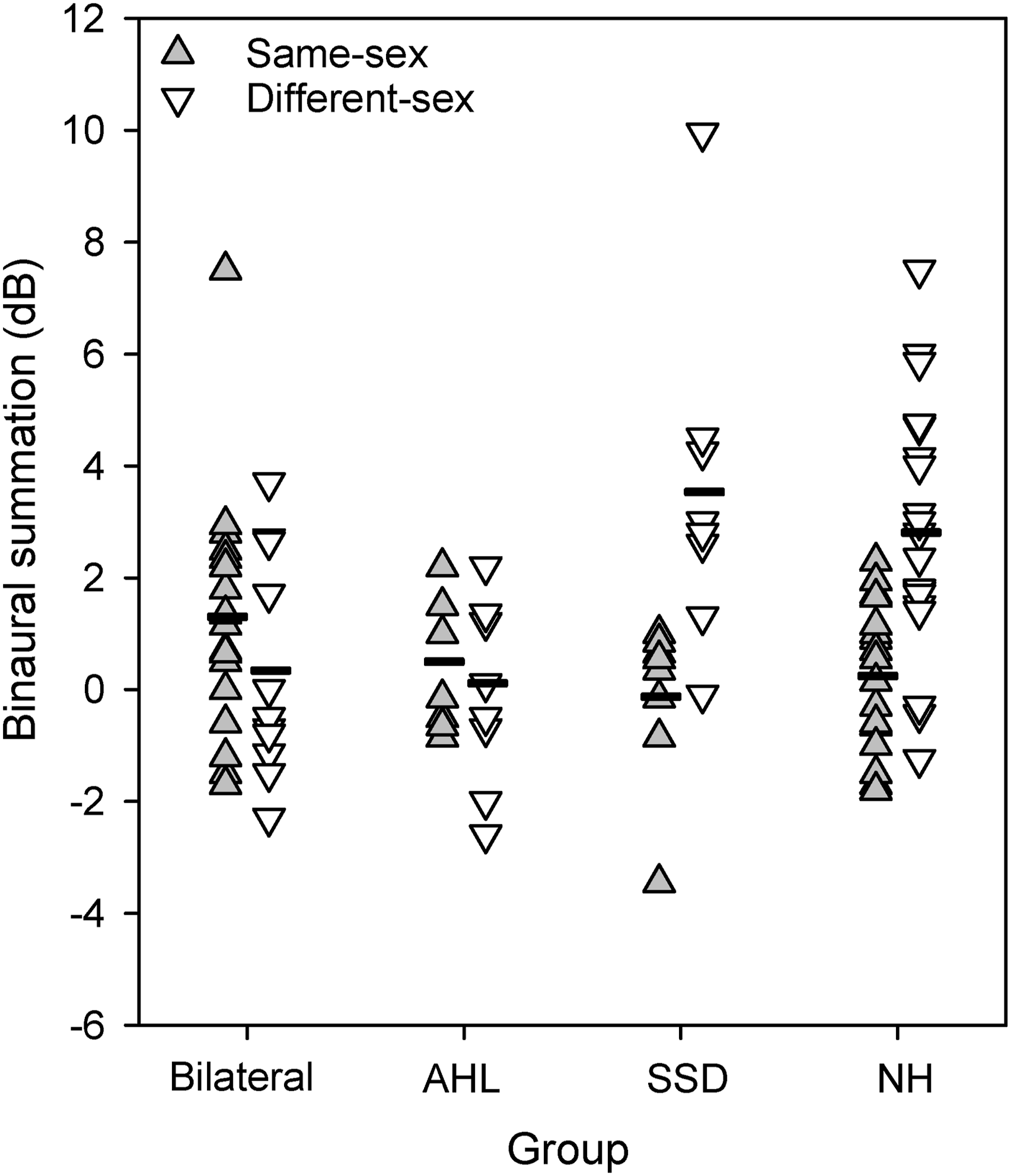
LMM analysis was performed on the summation data, with group (BiCI, AHL, SSD, NH) and masker (same-sex, different-sex) as fixed effects and participant as the random effect; complete results are shown in Table 4. Results showed a significant effect for masker [F(1, 44) = 10.9, p < 0.001], but not for group [F(3, 47) = 1.9, p = 0.136]; there was a significant interaction [F(3, 44) = 10.9, p < 0.001]. Post-hoc Bonferroni pairwise comparisons showed that for the SSD and NH groups, summation was significantly larger with the different-sex than with the same-sex maskers (p < 0.05). With the different-sex maskers, summation was significantly larger for the SSD and NH groups than for the BiCI and AHL groups (p < 0.05).
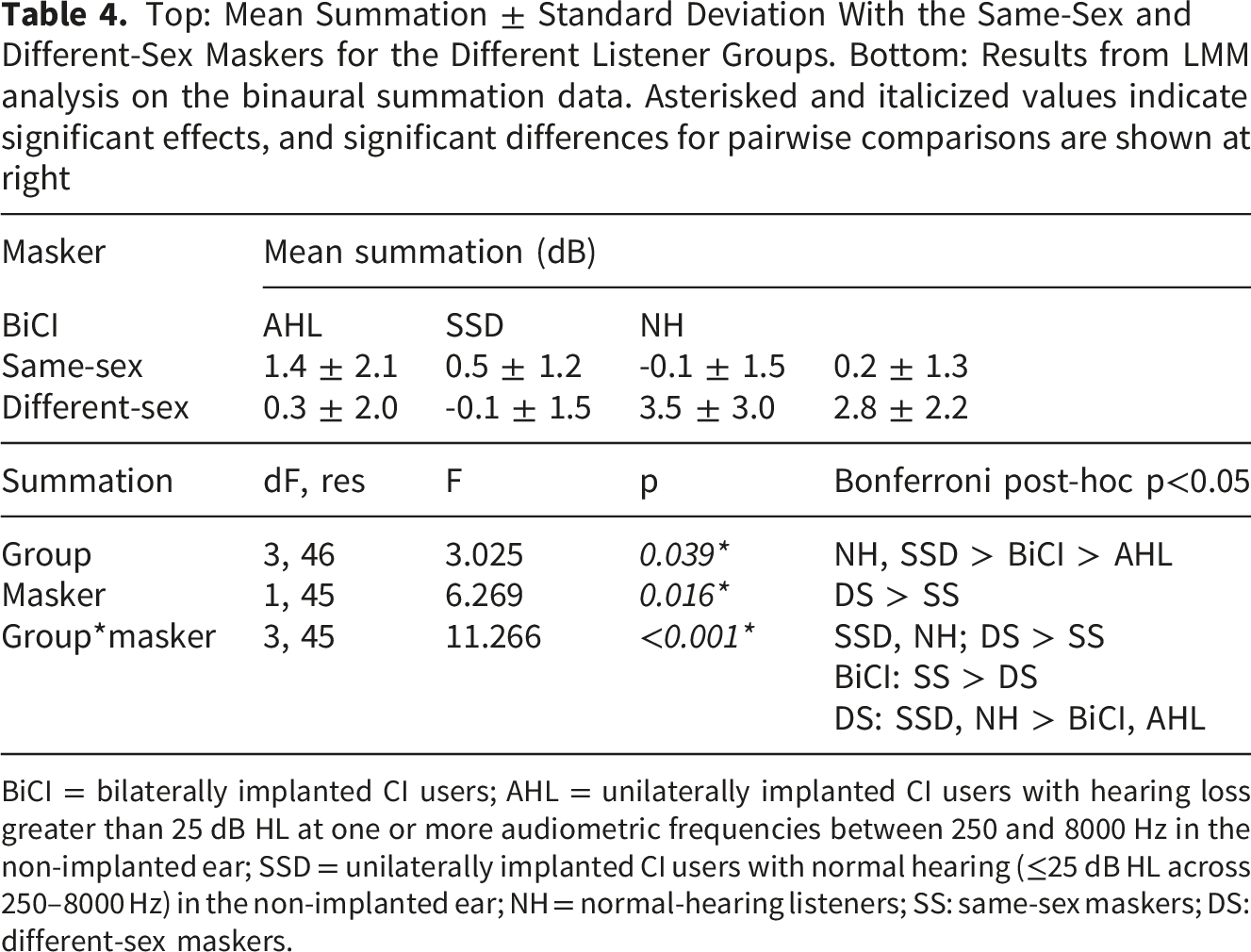
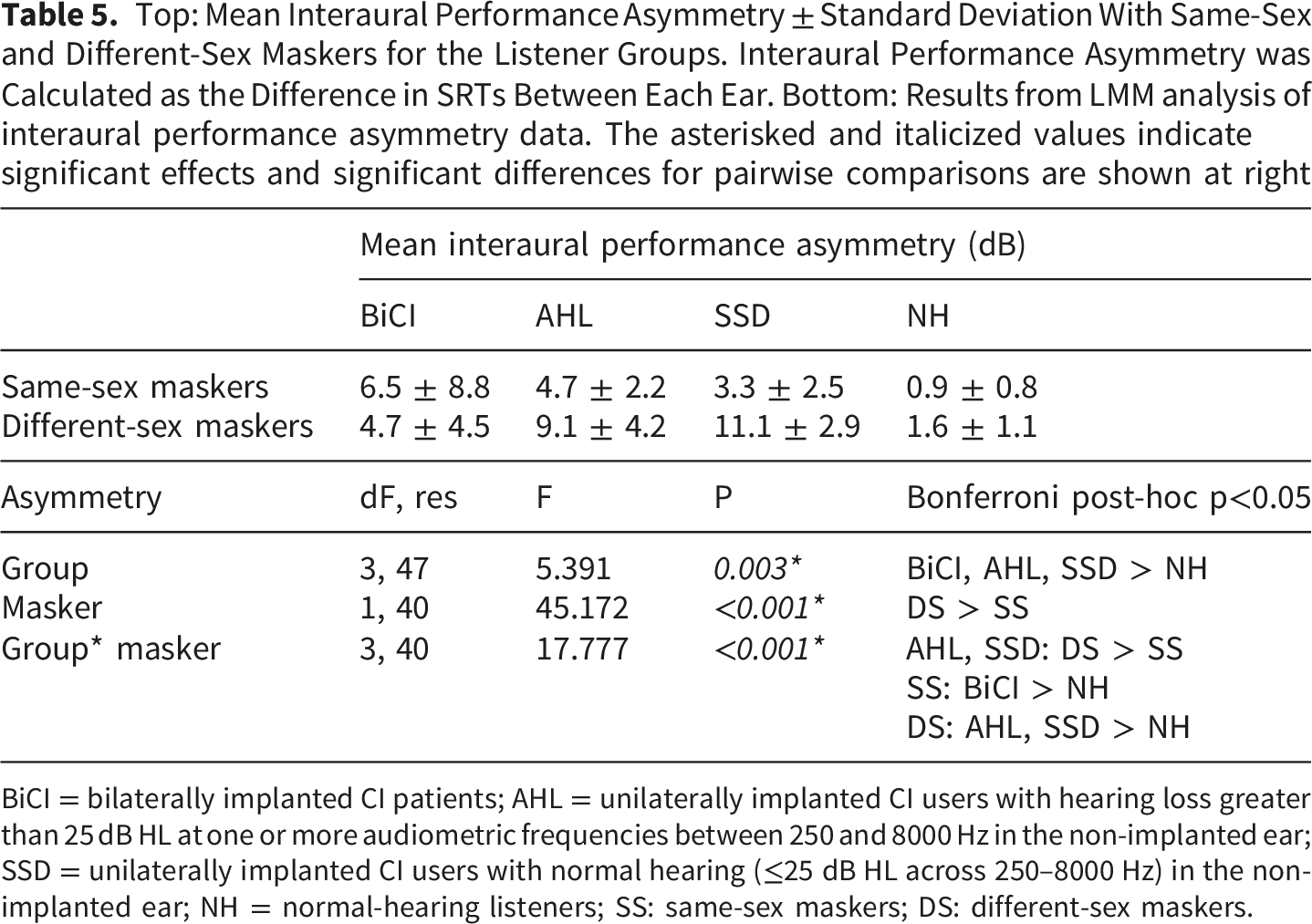
Figure 4 shows interaural performance asymmetry for the different groups and maskers; mean asymmetry data are shown in Table 5. Mean asymmetry was highest for the AHL and SSD groups, and lowest for the BiCI and NH groups. LMM analysis was performed on the interaural performance asymmetry data, with group (BiCI, AHL, SSD, NH) and masker (same-sex, different-sex) as fixed effects and participant as the random effect; complete results are shown in Table 5. Results showed significant effects for group [F(3, 34) = 21.1, p < 0.001] and masker [F(1, 32) = 70.2, p < 0.001]; there was a significant interaction [F(3, 32) = 15.0, p < 0.001]. Post-hoc Bonferroni pairwise comparisons showed that for the AHL and SSD groups, asymmetry was significantly larger with the different-sex than with the same-sex maskers (p < 0.05). With the same-sex maskers, asymmetry was significantly larger for the AHL than for the NH group (p < 0.05). With the different-sex maskers, asymmetry was significantly larger for the AHL and SSD groups than for the BiCI and NH groups, and significantly larger for the BiCI than for the NH group (p < 0.05). Interaural performance asymmetry for the different listening groups and masker conditions. The horizontal dashes show mean values Top: Mean Interaural Performance Asymmetry ± Standard Deviation With Same-Sex and Different-Sex Maskers for the Listener Groups. Interaural Performance Asymmetry was Calculated as the Difference in SRTs Between Each Ear. Bottom: Results from LMM analysis of interaural performance asymmetry data. The asterisked and italicized values indicate significant effects and significant differences for pairwise comparisons are shown at right BiCI = bilaterally implanted CI patients; AHL = unilaterally implanted CI users with hearing loss greater than 25 dB HL at one or more audiometric frequencies between 250 and 8000 Hz in the non-implanted ear; SSD = unilaterally implanted CI users with normal hearing (≤25 dB HL across 250–8000 Hz) in the non-implanted ear; NH = normal-hearing listeners; SS: same-sex maskers; DS: different-sex maskers.
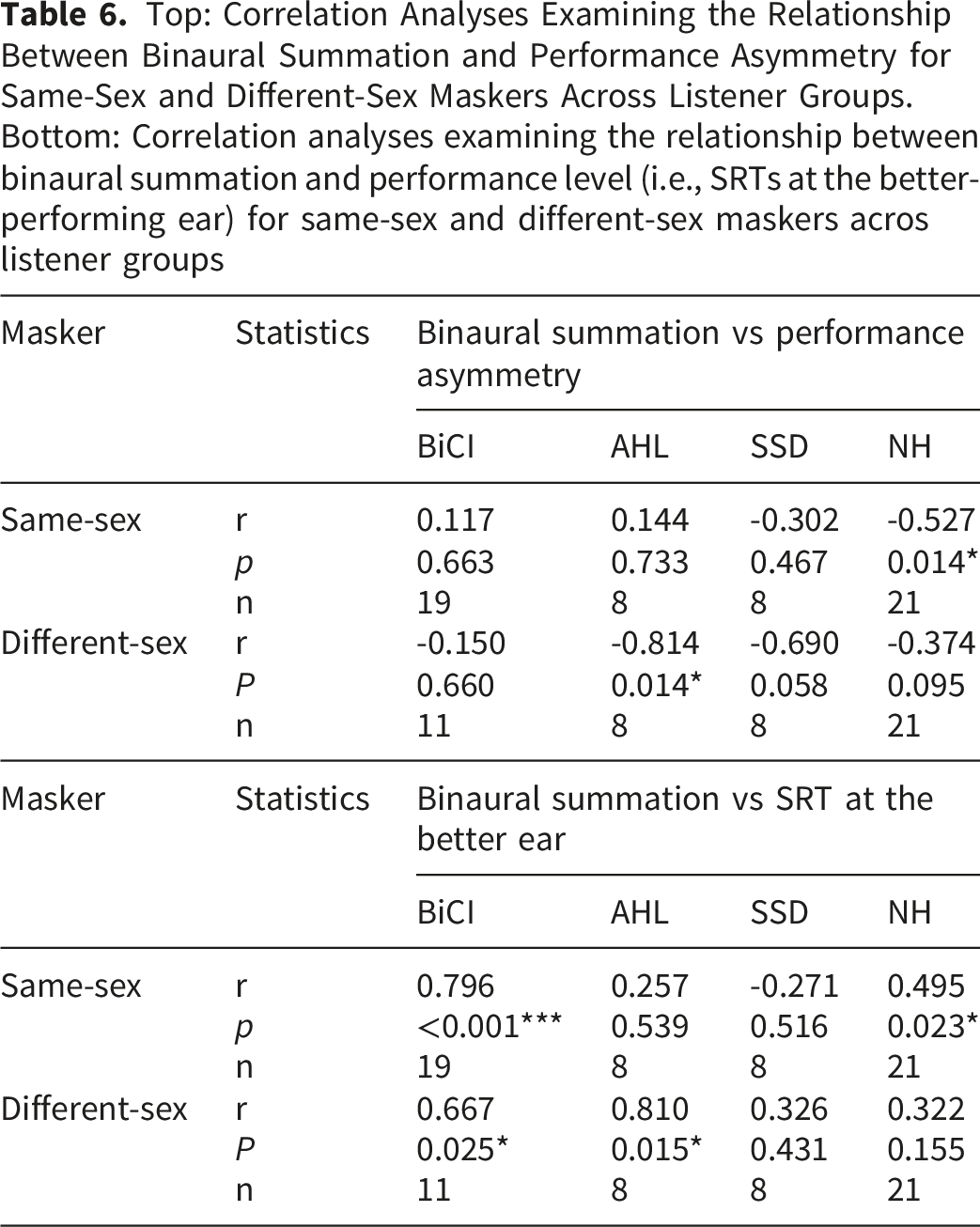
Top: Correlation Analyses Examining the Relationship Between Binaural Summation and Performance Asymmetry for Same-Sex and Different-Sex Maskers Across Listener Groups. Bottom: Correlation analyses examining the relationship between binaural summation and performance level (i.e., SRTs at the better-performing ear) for same-sex and different-sex maskers acros listener groups
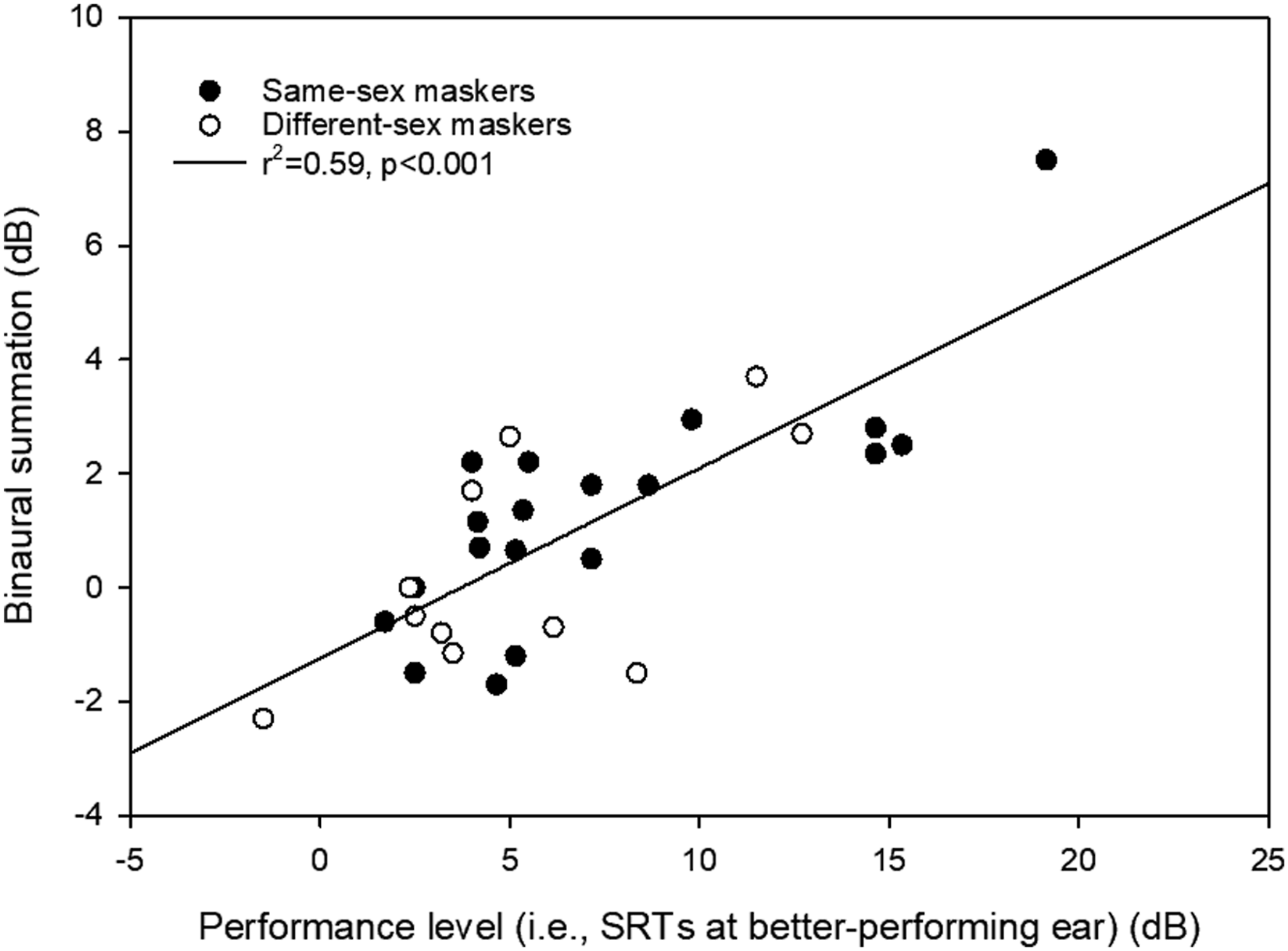
Binaural summation as a function of the SRT at the better-performing ear across all masker conditions
Discussion
The data indicate that binaural summation was highly variable for speech-in-speech recognition, consistent with prior findings obtained with steady-noise maskers in CI listeners (Yoon et al., 2011, 2015). The magnitude of summation (Table 4) and performance asymmetry (Table 5) for the different listening groups depended on masker sex. Performance asymmetry with the different-sex maskers increased substantially in the AHL and SSD groups, but much less so in the BiCI and NH groups. A significant but weak correlation between performance asymmetry and binaural summation was observed in some within-group comparisons, but not in across-group comparisons. This suggests a complex relationship between performance asymmetry and binaural summation that depends on the listening configuration (full acoustic+full acoustic, limited acoustic+electric, full acoustic+electric, electric+electric).
Association Between Interaural Performance Asymmetry and Binaural Summation
Previous studies have reported a significant negative correlation between interaural asymmetry and binaural summation in BiCI users (Litovsky et al., 2006; Mosnier et al., 2009; Polonenko et al., 2018; Yoon et al., 2011) and Bimodal CI users (Yoon et al., 2015), suggesting that asymmetry can at least partly account for the variability in summation benefits for speech recognition in steady noise. For the present speech-in-speech recognition, the magnitude of performance asymmetry varied significantly across listener groups and masker sex. With the same-sex maskers, the magnitude of asymmetry was significantly larger for the BiCI than for the NH group; with the different-sex maskers the magnitude of asymmetry was significantly larger for the AHL and SSD groups than for the NH group. For the AHL and SSD groups, the magnitude of asymmetry was significantly larger with the different-sex than with the same-sex maskers (Table 5). Thus, there appears to be an inter-dependence between listener group and the availability of voice segregation cues for interaural asymmetry.
Across listener groups, the relationship between interaural performance asymmetry and summation was not consistent. For example, the largest interaural asymmetry and the largest summation were observed in the SSD group with the different-sex maskers. This outcome is not consistent with previous findings that show a significantly negative correlation between interaural performance asymmetry and binaural summation in BiCI (Yoon et al., 2011) and bimodal CI users (Yoon et al., 2015). Conversely, the AHL group with the different-sex maskers exhibited poor summation but substantial interaural performance asymmetry. Further complicating the picture, interaural asymmetry was significantly (negatively) associated with summation in the NH group with the same-sex maskers and in the AHL group with the different-sex maskers.
While significant interaural performance asymmetry was observed in some groups under some masker conditions, it is worthwhile to consider the clinical relevance of such asymmetry. Litovsky et al. (2006) used a 3.1 dB threshold to indicate clinically relevant performance asymmetry, finding better summation in symmetric than in asymmetric BiCI users. Using this 3.1 dB metric to categorize asymmetry, for the present BiCI participants, 5/14 (36%) could be considered as “asymmetric” with the same-sex maskers, and 6/11 (55%) with the different-sex maskers. For the same-sex maskers, there was no significant difference in summation between asymmetric (mean = 1.2 ± 1.9 dB) and symmetric BiCI participants (mean = 0.7 ± 1.6 dB) [t(12) = -0.6, p = 0.573]. Similarly, for the different-sex maskers, there was no significant difference in summation between asymmetric (mean = 0.9 ± 2.3 dB) and symmetric BiCI participants (mean = -0.4 ± 1.4 dB) [t(12) = -0.6, p = 0.573]. Thus, in the present study, there was no significant difference in summation between the asymmetric and symmetric BiCI participants given the 3.1 dB threshold used by Litovsky et al. (2006). Note that steady noise was used as the masker in Litovsky et al. (2006), versus competing speech in the present study.
In summary, although previous studies have demonstrated a robust negative relationship between performance asymmetry and binaural summation in steady-noise conditions, the present data indicate that this relationship does not generalize straightforwardly to competing speech conditions. These present findings suggest that correlational analyses between performance asymmetry and binaural summation alone are insufficient to account for the observed summation patterns in complex listening environments involving competing speech.
Association Between Performance Level and Binaural Summation
Besides performance asymmetry, other metrics have also been proposed to predict binaural summation. For example, Mosnier et al. (2009) compared summation to both speech performance in the better ear and interaural asymmetry in BiCI users. According to word recognition scores in quiet in the better ear, participants were categorized as “poor performers” (<60% correct, n = 8) or “good performers” (≥60% correct, n = 19). Binaural summation was significantly larger in poor than in good performers. Using a similar approach, we divided BiCI participants into two groups according to the median SRT in the better ear. For the same-sex maskers, the median was 5.4 dB. Using this threshold, 10/19 (53%) BiCI participants were categorized as being “poorer” performers, and 9/19 (47%) as being “better” performers. Summation was significantly larger in the poorer performers (mean = 2.7 ± 1.9 dB) than in the better performers (mean = 0.0 ± 1.3 dB) [t(17) = -3.6, p = 0.003]. For the different-sex maskers, the median SRT in the better ear was 4.0 dB. Using this threshold, 6/11 (55%) BiCI participants were categorized as being “poorer” performers, and 5/11 (45%) as being “better” performers. Summation was significantly larger in the poorer performers (mean = 1.4 ± 2.1 dB) than in the better performers (mean = -1.0 ± 0.9 dB) [t(9) = -2.4, p = 0.041]. When the median SRT in the poorer ear was used (6.9 dB with the same-sex maskers, 8.4 dB with the different sex maskers), there was no significant difference in summation between the better (mean = 0.7 ± 1.4 dB) and poorer performers (mean = 1.2 ± 1.8 dB) with the same-sex maskers [t(13) = -0.6, p = 0.539]. Similarly, there was no significant difference in summation between the better (mean = -0.4 ± 1.3 dB) and poorer performers (mean = 1.3 ± 2.4 dB) with the different-sex maskers [t(9) = -1.1, p = 0.309].
The categorization of listeners into “good” and “poor” performers is inherently arbitrary and highly dependent on the selected criteria. To avoid such arbitrary classification, correlational analyses were used to examine the relationship between binaural summation and performance level. Specifically, SRTs at the better-performing ear were used as a continuous metric to reflect individual performance level. The results (see Table 6) showed significant positive correlations between binaural summation and SRTs in the better ear only for some listener groups and masker conditions (e.g., BiCI users with same- and different-sex maskers, and NH users with same-sex maskers). Overall, the present findings suggest that correlational analyses between performance level and binaural summation are insufficient to fully explain the observed summation patterns for speech-in-speech recognition.
Using a Probability-Summation Model to Predict Summation
While associations between binaural summation and behavioral metrics (e.g., interaural performance asymmetry, performance level in the better ear) are informative, they do not directly reflect the underlying mechanisms of binaural summation. Several models have been proposed to explain binaural summation. At the most basic level, binaural summation arises from neural convergence of inputs from both ears at the brainstem, where signals are combined or pooled, leading to increased neural firing reliability, improved detectability, and reduced internal noise variance (Green & Swets, 1966; Jeffress, 1948). However, such integration does not explain the differences in summation observed between same-sex and different-sex maskers in SSD and NH listeners, as there is no clear evidence that masker sex systematically affects neural firing reliability or internal noise.
Binaural summation can also be modeled as a probability-summation process, in which the two ears provide independent information channels and bilateral performance reflects the increased likelihood of correct recognition when both channels are available. This model assumes that bilateral performance can be explained simply as the combination of information from both ears. If the probability-summation model provides a good approximation of bilateral performance, this suggests that the two ears behave quasi-independently. Alternatively, if the model under- or over-predicts bilateral performance, this suggests that additional processes may contribute to binaural summation.
According to the probability-summation model, performance improves because the listener has two chances to correctly detect or recognize the signal. If 
The predicted summation 
A standard logistic psychometric function for percent-correct 
To investigate the relative contributions of psychometric-function slope and interaural performance asymmetry, the predicted binaural summation in SRTs was estimated using different psychometric-function slopes (β values) and different degrees of interaural performance asymmetry (i.e., differences in SRTs between ears). Figure 6A shows the predicted summation in SRTs as a function of interaural asymmetry for different values of β. For a given slope, predicted summation decreases monotonically with increasing interaural performance asymmetry, consistent with previous findings (Yoon et al., 2011, 2015) and with some listener group and masker conditions in the present study (e.g., NH listeners with same-sex maskers and AHL listeners with different-sex maskers). Figure 6B shows the predicted summation in SRTs as a function of the psychometric-function slope (β) for varying degrees of interaural performance asymmetry. For a given level of asymmetry, predicted summation increases monotonically with increasing β (i.e., shallower psychometric-function slope). Predicted summation for SRTs as a function of interaural performance asymmetry in SRTs at different exemplary slopes (A) and as a function of slope at different exemplary asymmetries (B)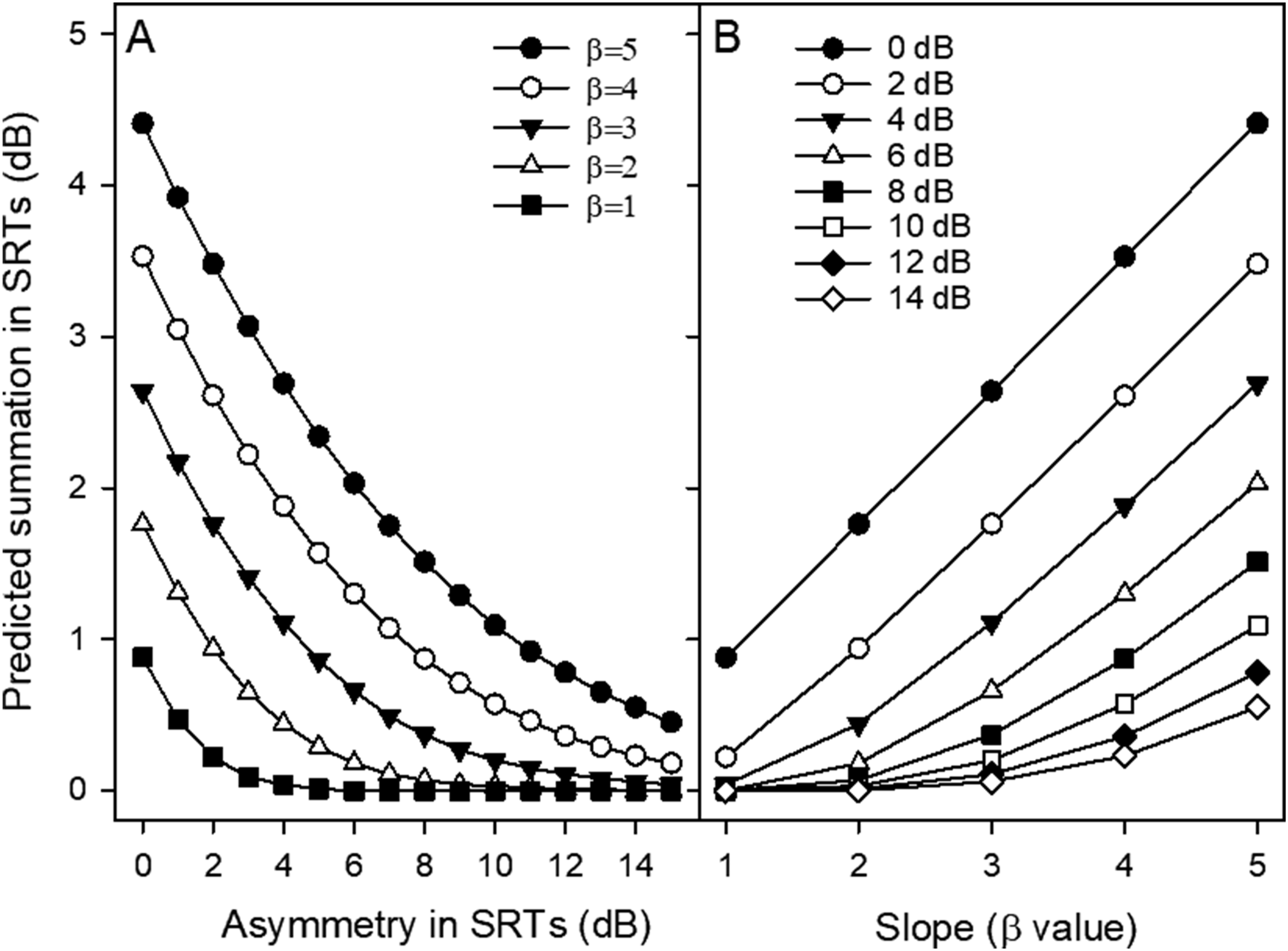
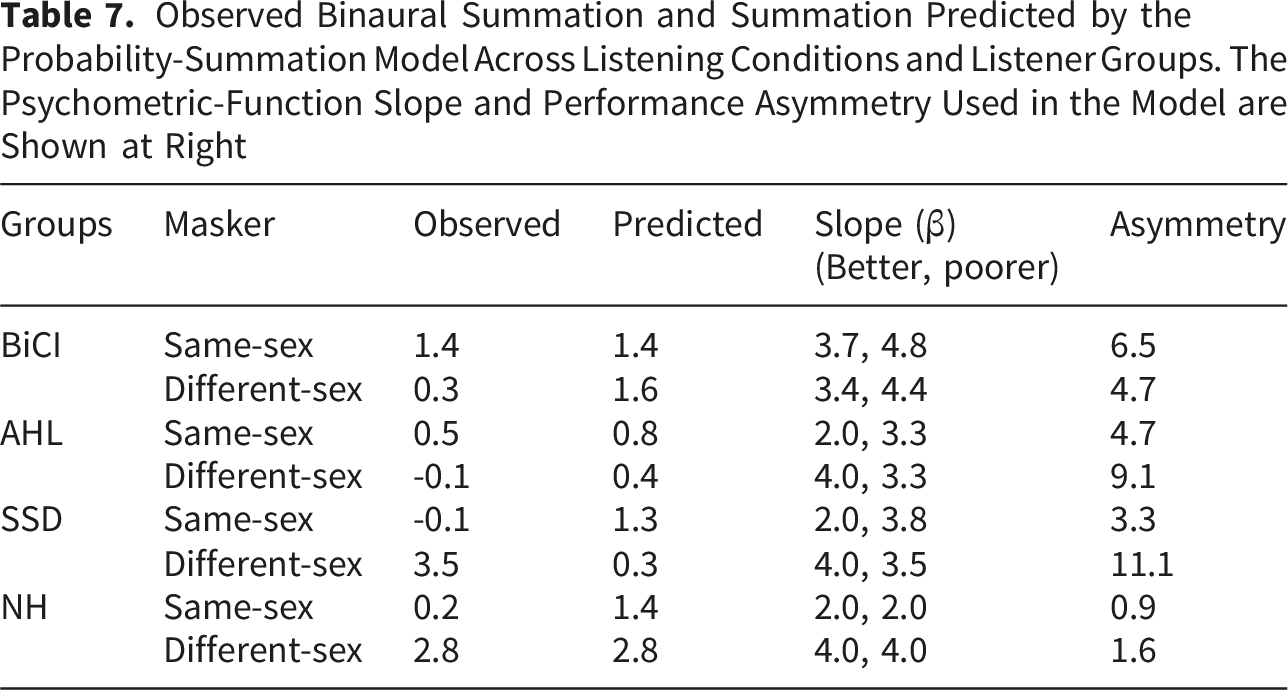
Observed Binaural Summation and Summation Predicted by the Probability-Summation Model Across Listening Conditions and Listener Groups. The Psychometric-Function Slope and Performance Asymmetry Used in the Model are Shown at Right
There are few, if any, published studies that report psychometric-function slopes for speech-in-speech recognition with two-talker maskers in CI users. We collected psychometric function data in an additional 10 BiCI users who did not participate in the present study, using the same test materials and methods as in the present study. Percent correct scores were obtained at various fixed SNRs. Figure 7 shows slope (β values) as a function of the SRT across all masker conditions. Slope (β values) as a function of the SRT across all masker conditions. The regression was performed across all data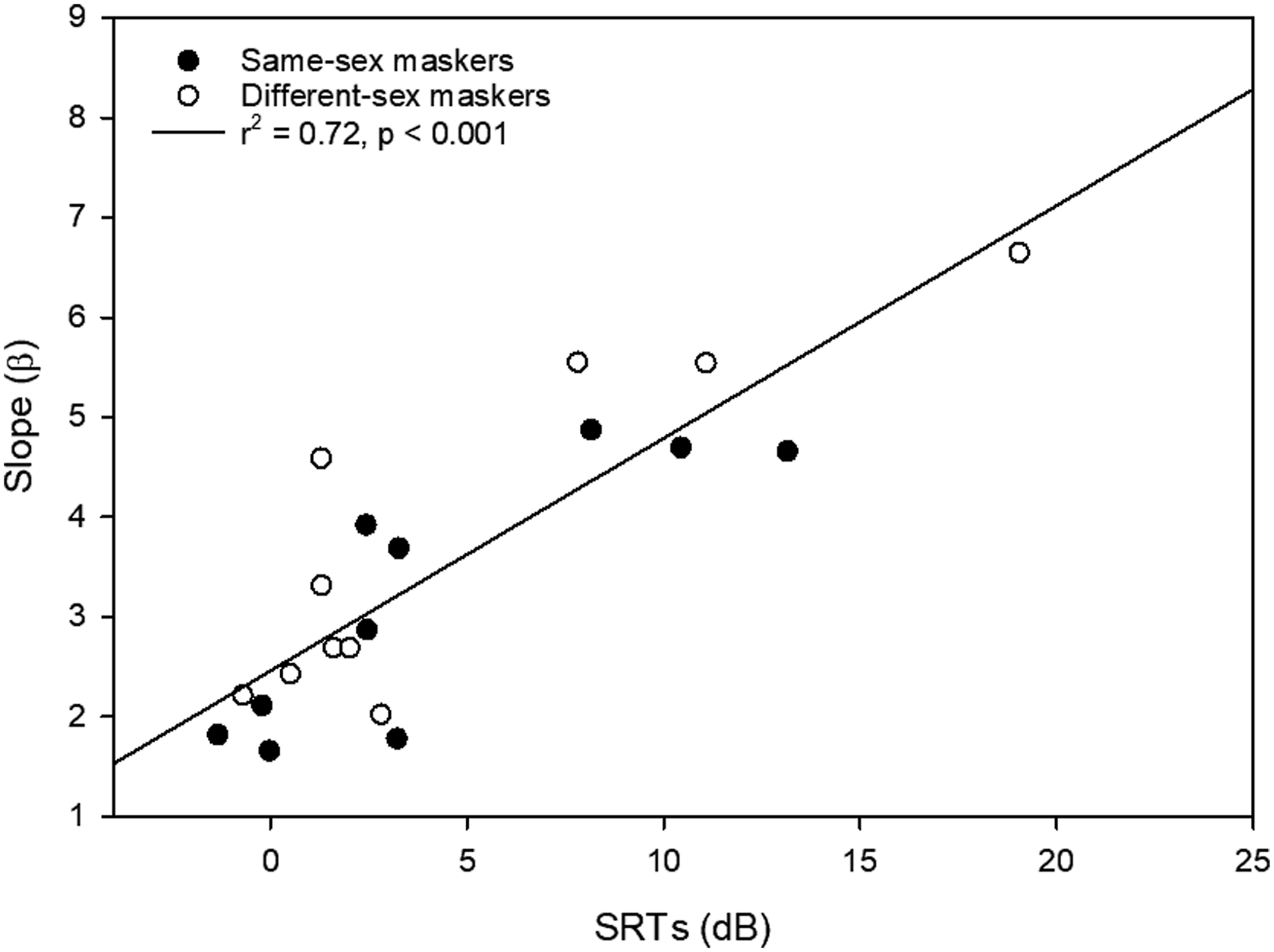
The psychometric function slope was well predicted by SRTs in these BiCI users across masker types [
The relationship between SRTs and psychometric-function slope, together with the probability-summation model, also provides a plausible account of the observed association between binaural summation and performance level (Figure 5). Poorer-performing CI users (i.e., higher SRTs in the better ear) tended to exhibit shallower psychometric functions (i.e., larger β values; Figure 7), which in turn are associated with greater summation as predicted by the probability-summation model (Figure 6B).
For SSD CI users, SRTs in the acoustic-hearing ear are generally comparable to those of NH listeners. Thus, it is reasonable to assume that the psychometric function slopes in the acoustic-hearing ear of SSD users are similar to those reported for NH listeners. The mean
Additional Factors Contributing to Variability in Binaural Summation
The probability-summation model described above may account for binaural summation on the basis of psychometric-function slope (β) and interaural performance asymmetry in some listener groups and masker conditions. As shown in Table 7, the model predicts mean group-level binaural summation reasonably well for the BiCI group with the same-sex maskers and for the NH group with the different-sex maskers. However, the model failed to fully account for the observed summation across many listening conditions. In most cases, it overestimated binaural summation, suggesting that processing across ears may not be fully independent. Instead, binaural summation in CI users may reflect the combined contributions of probability summation, binaural fusion, and binaural interference. Probability summation arises when the two ears provide partially independent information, increasing the likelihood of correct recognition through redundant cues. In contrast, binaural fusion involves the integration of inputs across ears into a unified percept. In CI users, such fusion may be imperfect due to interaural mismatches in frequency, spectral resolution, and/or temporal encoding, resulting in altered or degraded effective representations. Additionally, when the inputs from the two ears are inconsistent or provide conflicting speech information, particularly at low performance levels, interaural interference may occur, where the poorer ear disrupts processing in the better ear, leading to reduced or even negative summation. The relative contribution of these mechanisms likely varies across listener groups and listening conditions, depending on factors such as interaural asymmetry, the psychometric function slope, and the availability of perceptual segregation cues.
For the SSD group with different-sex maskers, the model underestimated the observed summation, indicating that additional mechanisms may contribute to the synergistic summation. For the different-sex maskers, SRTs when listening with both ears were low (mean = -11.1 ± 4.3 dB). Here, the stimulus presented to the CI ear may have largely been the masker, due to the limited dynamic range in the CI. This may have resulted in some degree of contralateral unmasking (e.g., Bernstein et al., 2016), where a “copy” of the masker in both ears allows for better perception of the target. Such contralateral unmasking may reduce informational masking at low SNRs, allowing for greater summation. For the same-sex maskers, SRTs were near zero when listening with both ears (mean = 0.4 ± 1.9 dB), suggesting that the CI signal consisted of the combined target and masker and thus may not have provided a contralateral unmasking benefit.
Limitations and Clinical Implications
One possible limitation to the present SRTs and the derived summation and asymmetry data may be measurement error. The inter-subject variability in SRTs (i.e., standard deviation of the mean) was substantially larger in the BiCI group than in the AHL, SSD, and NH groups, and substantially larger with the different-sex than with the same-sex maskers. Such variability would be handled by the post-hoc Bonferroni pairwise comparisons in the LMMs. However, intra-subject variability in SRTs across test runs may have also contributed to pattern of results. To test this, the standard error of the mean (SEM) was calculated for each BiCI participant for SRTs across the two test runs for each masker condition and for each listener condition. With the poorer ear, the mean SEM across BiCI participants was 1.0 ± 0.6 dB with the same-sex maskers and 1.0 ± 1.0 dB with the different-sex maskers. With the better ear, the mean SEM was 0.7 ± 0.5 dB with the same-sex maskers and 1.0 ± 0.8 dB with the different-sex maskers. With both ears, the mean SEM was 1.0 ± 1.0 dB with the same-sex maskers and 1.2 ± 0.7 dB with the different-sex maskers. Taken together, this analysis suggests that measurement error across test runs (intra-subject variability) most likely was not a limiting factor when comparing SRTs, summation, asymmetry, and masking release across the listener groups and masker conditions.
The summation patterns observed across listening groups and masker conditions in the present study may also be influenced by the use of a tonal language. There is currently no strong evidence that speakers of tonal versus non-tonal languages show systematic differences in binaural summation. Binaural summation, including loudness summation, threshold summation (typically 2–3 dB), and speech-in-noise summation (small redundancy benefits when target and masker are co-located), reflects peripheral and brainstem-level integration. These processes occur prior to cortical linguistic processing and therefore are not expected to differ as a direct consequence of language background. In this sense, tonal-language experience (e.g., Mandarin) would not be expected to affect the core mechanisms of binaural summation.
Although the probability-summation model accounted for binaural summation in some listener groups and masker conditions (e.g., BiCI users with same-sex maskers and NH listeners with different-sex maskers), it did not fully account for the observed summation in other listener groups and masker conditions. Also, the model simulations were intended only to capture group-average results across conditions and listener groups, rather than predict individual variability. Importantly, the model’s predictions depend strongly on interaural performance asymmetry and the psychometric function slope. While interaural asymmetry is expected to be broadly comparable between tonal and non-tonal language users across similar listening groups and masker conditions, the psychometric function slopes may differ due to the critical role of lexical tones in sentence recognition for tonal languages. Such differences could influence the slope vs. SRT relationship and, consequently, the predicted magnitude of summation. Direct measurement of psychometric function slopes across listening groups and masker conditions for both tonal and non-tonal languages would therefore provide valuable insight into the extent to which summation patterns may be language-specific.
Significant summation was observed for the BiCI group with the same-sex maskers and for the SSD group with the different-sex maskers (Table 4). This provides some evidence that adding a CI may allow for some summation in BiCI or SSD CI users, even if SRTs are poorer in that CI ear, at least under conditions of informational masking. For the present BiCI, AHL, and SSD groups, performance was never significantly poorer when listening with both ears than with better ear alone, suggesting that the CI in the poorer ear did not interfere with the better ear when listening with both ears. In the present study, performance was evaluated for each listener and masker condition with co-located speech and maskers. When spatial cues are available, adding a CI may provide head-shadow benefits to BiCI, bimodal CI, and SSD CI users, subject to target speech location and better-ear effects (e.g., Litovsky et al., 2009; Ramsden et al., 2005). Thus, it seems reasonable to suggest that adding a second CI may benefit bilaterally deaf CI users, and adding a CI may benefit unilaterally deaf individuals. For bimodal CI users, auditory training in the CI ear may increase summation benefits (e.g., Kerneis et al., 2023).
Conclusion
SRTs were measured in the presence of two-talker speech maskers with each ear alone or with both ears in BiCI, AHL, SSD, and NH listener groups. The two speech maskers were either the same sex as or different sex from the male target. Major findings include: 1. When the sex of the target and masker speakers was the same, there was little summation for any of the listening groups, except for the small but significant summation for the BiCI group. When the sex of the target and masker speakers was different, the SSD and NH groups experienced significant summation, while the BiCI and AHL groups did not. 2. Using interaural performance asymmetry with psychometric function slopes, a probability-summation model accounted for the variability in summation in some listener groups and masker conditions. 3. The probability-summation model generally overestimated the observed summation, suggesting that the assumption of independent processing across ears may not hold for CI users, possibly due in part to variability in binaural fusion across individuals.
Footnotes
Acknowledgments
We thank all participants for taking part in this study.
Ethical Considerations
This study was approved by the Ethics Committee of the Beijing Tongren Hospital, Capital Medical University (TRECKY-2019-055-XZ-1) and this research was conducted in accordance with the principles of the Declaration of Helsinki and its later amendments.
Consent to Participate
Written informed consent was obtained from all participants before proceeding with any of the study procedures. In cases where participants were younger than 18 years old, written consent was also obtained from their parents.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China [Grant number 82471161 and 81870716 (PI: Yongxin Li)], National Key R&D Program of China [Grant number 2022YFC2402705 (PI: Yongxin Li)], the Beijing Natural Science Foundation [Grant number 7212015 (PI: Yongxin Li)], the Capital Medical University Natural Science Foundation [Grant number PYZ23106 (PI: Jingyuan Chen)] and Beijing Tongren Hospital [Grant number 2021-YJJ-ZZL-038 (PI: Biao Chen) and 2022-YJJ-ZZL-035 (PI: Jingyuan Chen)].
Declaration Of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
De-identified raw data are available upon request.