
Abstract
Racial inequality persists despite major advances in formal, legal equality. Scholars and policymakers argue that individual biases (both explicit and implicit) combine with subjective organizational decision-making practices to perpetuate racial inequality. The standardization of decision making offers a potential solution, promising to eliminate the subjectivity that biases consequential decisions. We ask, under what conditions may standardization reduce racial inequality? Drawing on research in science studies and law and society, we argue that standardization must be understood as a heterogeneous practice capable of producing very different outcomes depending on the details of the standard and the organizational infrastructure surrounding its use. We compare selection devices—simple quantified tools for making allocation decisions—in undergraduate admissions and child welfare to highlight the complex relationships between race and standardization. Child welfare agencies adopted a colorblind actuarial device that attempted to predict which children were most at risk and then make decisions based on those predictions. In contrast, the University of Michigan’s points system explicitly considered and valued race, with the goal of increasing minority student enrollments in the context of promoting student body diversity. Comparing these cases demonstrates how actuarial standardization practices, including those adopted with the intention of reducing racial inequality, tend to reinforce an unequal status quo by ideologically reconfiguring mutable social structures into immutable individual risk factors. In contrast, nonactuarial practices that explicitly promote racial equality are vulnerable to political challenges as they violate norms of colorblindness and cannot be defended in terms of their predictive validity.
The Civil Rights revolution of the mid–twentieth century produced major legal reforms, including federal bans on racial discrimination in employment, education, housing, and credit. Despite gains in formal equality, racial inequality persists in each of those same domains—employment (Pager, Western, and Bonikowski 2009), education (Lewis and Diamond 2015), housing (Rugh and Massey 2014), credit (Hwang, Hankinson, and Brown 2015), and others, including child welfare (Putnam-Hornstein et al. 2013; Roberts 2003) and criminal justice (Pettit and Western 2004).
Many scholars, policymakers, and activists have pointed to standardization as a technique for combating persistent racial inequality. By standardization, we refer to attempts to formalize organizational practices to reduce the variability of decision making. Advocates of standardization argue that one mechanism for persistent racial inequality is racially biased decisions resulting from either explicit prejudice, understood as on the decline (Manning et al. 2015), or implicit bias, understood as pervasive (Quillian 2006). When individuals are provided with little formalized means for making decisions, racially biased determinations will insert themselves. In contrast, the more standardized a system, the less it should matter who makes a particular decision. Reskin (2012:31) puts the argument cleanly: “Because discretionary decisions are necessarily subjective, they open the door to cognitive (as well as intentional) bias.” Removing discretion and replacing it with standardization thus promises to ameliorate racial inequality by limiting the potential for bias to infiltrate decision making. This article examines the promise and limitation of the standardization of decision making as a means for reducing biased decisions and unequal outcomes.
While advocates of standardization typically identify racially disproportionate outcomes as resulting from some combination of explicit prejudice and implicit bias, sociologists of race have long argued that both historical and contemporary racial inequality must be understood as structural and systemic (Bonilla-Silva 1997; Golash-Boza 2016). Sociologists of race and organizations have also demonstrated how organizational practices, even those that are seemingly race-neutral, may produce and reproduce racial inequality independently of the biases of individual actors (Ray 2019; Wooten and Couloute 2017).
Understanding racism as a structural phenomenon, we ask: How and under what conditions can standardization reduce racial inequality? What are the limits on the promises of standardization to transform unequal outcomes? We examine the tension between the promise of standardization to solve issues of subjectivity that generate unequal outcomes and the potential to encode structural inequality in the context of a relatively streamlined form of standardized decision making: selection devices. Selection devices are simple standardization tools designed for making categorical decisions about individuals. Hailed as an antidote to implicit bias, selection devices have also been denounced as another mechanism for reproducing categorical inequality in the United States. In contrast, the sociology of standardization reveals how the social processes embedded within attempts to create uniform outcomes may instead produce new kinds of variability. In other words, standards are not themselves standardized.
In this article, we compare across two selection devices in order to better understand the relationship between race and various forms of standardized decision making. Our cases examine selection devices in child welfare and college admissions, which themselves exemplify the two distinct diagnoses of mechanisms for racial inequality (psychological vs. structural). In both cases, the introduction of standardization was intended to reduce racial inequality. In the first case, Child Protective Service (CPS) agencies adopted a colorblind device designed to improve consistency in decision making and eliminate implicit racial bias in decision making to reduce racial disproportionality. In the second case, admissions officers at the University of Michigan turned to a race-conscious device to help create a more racially diverse class in light of the systemic disadvantages faced by minority applicants. We draw on insights from the sociology of race, law and society, and science studies to make sense of these devices and the controversies in which they became embroiled. Our analysis yields three main findings about the limits of standardization to transform social hierarchies.
First, there is no single relationship between standardization and race. Standardization and objectivity are often conflated concepts in discussions about the need for more mechanical forms of decision making, and both are often conflated with quantification. Quantification seems to provide a rational, objective tool for standardizing decisions (Porter 1995), but there is more than one way to use numbers to make a given decision, numbers are not value free, and not all numbers carry the same air of objectivity and rationality (Hirschman, Berrey, and Rose-Greenland 2016). Racism is itself easy to standardize. Even avowedly antiracist standardization initiatives approach the task very differently. As the examples of affirmative action and child welfare show, similar intentions can lead to very different solutions, which in turn yield different outcomes.
Second, we assert that actuarialism, the most prominent and lauded form of standardization in many domains, is in tension with decision making intended to reduce racial disparities. Actuarial methods create a simple, quantitative system for making decisions previously entrusted to expert judgment. This method involves predicting future outcomes based on past experiences. By redefining fairness in terms of riskiness—being fair to someone means treating them according to the prediction of their risk—actuarial techniques tend to reinforce structural disadvantage (Simon 1988). Actuarialism transforms risk into an immutable characteristic of an individual instead of a potentially mutable characteristic of that individual’s social context (Starr 2014). In a context of extreme racial inequality, actuarialism identifies and then builds on structural disadvantages that cannot be solved through interventions aimed at decisionmakers alone. Child welfare agencies adopted actuarial devices, but in this context, actuarial standardization may fail to reduce racial disproportionality in outcomes because this disproportionality likely does not result primarily from individual-level bias but rather from structural inequalities, including racialized disparities in poverty.
Third, nonactuarial standardization may produce decision-making practices that successfully reduce racial disparities but may also lose the appearance of objectivity that insulates controversial decisions from challenges. Affirmative action in undergraduate admissions offers one example where selection devices were not developed solely as a more accurate classification system; instead, those devices directly valued equalizing racial outcomes in the service of promoting racial diversity. These devices proved politically weak, however, as successful legal challenges forced their abandonment. If actuarial techniques are strong because they scramble politically salient social identities and justify themselves based on the quality of their accuracy, then nonactuarial forms of quantification may be weak if they fail to scramble those identities and fail to justify themselves in terms of predictive validity.
The remainder of this article proceeds as follows. First, we synthesize existing conversations on race, standards, and decision making to establish a framework for understanding our cases. Second, we describe our methods and data. We then turn to the cases proper. For each case, we explore the motivations behind standardizing decision making, the actual selection devices used for making decisions, the success or failure of the device in reducing racial inequality, and the challenges that emerged to the device’s implementation.
Theorizing Race, Theorizing Standards
In this section, we first synthesize key arguments from the sociology of race before turning to research on standards and quantification. We then combine these arguments to assess existing claims about the role of standardized organizational practices in reducing racial inequality.
The Changing Structures of Racism
Drawing on the contemporary sociology of race and racism (Golash-Boza 2016), we situate our research within the following premises. First, race and racism must be understood as structural, systemic phenomena not reducible to individual psychology. Second, organizations in particular must be understood as racialized. Third, colorblind racism and diversity have replaced explicit racism as key ideological supports for the persistence of racial inequality in organizations.
During the twentieth century, structural understandings of racism gave way to psychological understandings in public and political discourse (Gordon 2015). Sociologists of race, in contrast, have long advocated a structural understanding of race and racism (Golash-Boza 2016). Bonilla-Silva (1997) argues that American society should be understood through the lens of racialized social systems and that race and racism are “normal,” constitutive parts of American economic, political, and social institutions rather than unusual features of individual ideology. Racism in this perspective is “the organizational map that guides actions of racial actors in society. It becomes as real as the racial relations it organizes” (Bonilla-Silva 2001:44).
While much of the sociology of race has focused on micro- and macro-level practices, a recent strand of research has emphasized the importance of meso-level practices situated inside formal organizations (Ray 2019; Wooten and Coulette 2017). Wooten and Coulette (2017) identify how organizations themselves may have racialized identities and reputations and how those identities reflect the unequal distribution of resources. Ray (2019) demonstrates how organizations empower or disempower individuals and legitimate racialized inequalities. Taken together, this work highlights how much of the production and reproduction of racial inequality happens at the interface between individuals and organizations.
The persistence of racial inequality alongside gains in formal equality has spurred the creation of new explanatory ideologies. At the individual level, theories of implicit bias or unconscious racism are most prominent (Quillian 2006). At the organizational level, diversity came to be the language through which organizations could talk about race as one of many benign differences (Berrey 2015).
These discourses of unconscious racism and diversity have strongly shaped organizational responses to persistent racial inequality. Two of the most common reactions to allegations of racism are implicit bias trainings and diversity trainings. Beyond these trainings, a psychological understanding of racism has led to a call for organizational solutions that focus on removing implicitly (and explicitly) racist subjectivities from consequential decision-making practices. Scholars argue that eliminating discretion in contexts like mortgage lending and prosecutorial decisions has reduced racial discrepancies and suggest that such processes could work in other institutional domains (Reskin 2012). Similarly, researchers studying child welfare have proposed standardizing investigator decisions as a means to ameliorate persistent racial disproportionality (see Bosk 2015 for a review).
In contrast, sociologists of race have identified both implicit bias and diversity as pillars of colorblind racism (Bonilla-Silva 2017; Kahn 2017) and argued that implicit bias and diversity trainings are ineffective for the larger project of reducing racial inequality (Kalev, Dobbin, and Kelly 2006; Russell-Brown 2018). Thus far, sociologists have attended less to the consequences of standardizing decision making for racial inequality. In the following section, we situate these proposed organizational decision-making practices within conversations about the role of standards, quantification, and actuarial practices.
Standardization, Quantification, Actuarialism
Timmermans and Epstein (2010:71) define standardization as “a process of constructing uniformities across time and space, through the generation of agreed-upon rules.” The rules, or standards, generated by these processes knit together distant actors and create coherence that makes possible large-scale, complex organizations. Actors pursue standardization projects for diverse reasons, including efficiency, effectiveness, regulatory compliance, and equality. We focus here on attempts to standardize decision making, specifically, categorical decisions about individual cases, and pay special attention to how standards negotiate tensions surrounding racial inequality.
Organizations may employ qualitative or quantitative standards to equalize outcomes. Campaigns to “ban the box” asking applicants for employment about their criminal record are qualitative efforts to standardize the flow of information in the hiring process and increase the employment of ex-offenders. Tragically, ban the box campaigns may have had the unintended effect of increasing racial discrimination as employers increased their use of race as a proxy for criminality, exemplifying the potential unintended consequences of standardized decision making for inequality (Agan and Starr 2018).
Organizations view quantification as one way to avoid such undesired outcomes. Quantification refers to “the production and communication of numbers” (Espeland and Stevens 2008:402). Quantified decision making relies on numbers to inform or make decisions. Organizations often turn to numbers to bolster the objectivity of their decisions (Porter 1995). In particular, quantification purports to provide “mechanical objectivity,” a guarantee that decisions are free from individual biases and thus defensible against outside challenges. Porter (1995) argues that quantification is a weapon of the weak, used by experts who have lost authority. Yet scholarship has paid much less attention to the conditions under which quantification provides that authority (Hirschman et al. 2016), particularly when related to such controversial subjects such as race and equality.
To produce effective, defensible choices, many organizations turn to actuarial practices to quantify their decision making. We define actuarial practices as decision-making systems that first use statistical techniques to predict what factors lead to a successful outcome for an individual case (as defined by the organization) and then use those predictions to make decisions about individual cases (choosing cases to maximize the likelihood of success or minimize the risk of failure). Inspired by the success of insurance pricing by actuaries, actuarial techniques are now widespread. Generally, these techniques use data on the actual outcomes of previous cases to determine what characteristics predict negative (or positive) outcomes. These characteristics are then transformed into a scoring system for classifying the likelihood of future outcomes, which in turn provides the basis for decisions.
Actuarialism, the ideological justification for actuarial techniques, brings with it a particular conception of fairness that equates fair treatment with outcomes determined by your predicted level of risk (Stone 1993). In principle, actuarial fairness could lead to the allocation of rewards to the most disadvantaged (as in a system that identifies high-risk patients to be the first to receive a vaccine). 1 In practice, actuarial fairness is an anti-redistributive logic used to justify individuals bearing more of their own risks (Stone 1993). In credit scoring, actuarial fairness means that individuals at higher risk of default should either be denied credit or charged higher rates. In criminal justice, actuarial fairness implies that convicted criminals with a higher risk of reoffending should serve longer sentences.
The push for actuarial techniques as a replacement for individual judgment began as early as the first half of the twentieth century, especially in the context of sentencing and parole (Harcourt 2006). The movement began to gain ground in other domains with a line of papers beginning with Meehl ([1954] 2015) and extending through Grove et al’s (2000) meta-analysis of 136 studies of actuarial prediction techniques, which determined that “on average, mechanical prediction techniques were about 10 percent more accurate than clinical predictions” (Grove et al. 2000:19). Notably, this broad push for actuarial decision making was initially motivated in terms of the inconsistency (or low “reliability”) and weak predictive power of expert decisions, not around issues of racial bias. More recent efforts, however, have framed these techniques as tools for reducing racial disparities (Bosk 2018, forthcoming). In the following section, we bring together critical insights on standardization and quantification with findings from the sociology of race to theorize the complex relationship between standardization and racial inequality and, more specifically, some of the pitfall of actuarial techniques.
Theorizing Standardization and Racial Inequality
We return now to our initial question: Under what conditions can standardization reduce racial inequality? What are the conditions under which actuarial and nonactuarial forms of quantified decision making succeed or fail in reducing racial inequality? Here, we connect our discussions of the complexities of standardization to the discussion of different diagnoses of persistent racial inequality.
Individualistic theories, like implicit bias, tend to explain persistent racial inequality as a function of decisions made by (intendedly) nonracist actors in the context of formally equal, race-neutral practices. In contrast, structural racism perspectives, including the racialized organizations approach, assert that racial inequality persists (in part) because formally equally and colorblind policies are racist in practice and effect.
The implicit bias perspective implies that standardization will be highly effective at reducing racial inequality as long as it succeeds at removing discretion from decision makers. For example, Reskin (2012) cites research showing how discretionary decisions by real estate agents, mortgage lenders, prosecutors, and public assistance workers all lead to discriminatory outcomes but that the automation of mortgage lending has “reduced the racial gap” (Reskin 2012:31) by removing discretion from the system.
The example of mortgage lending is a useful one for thinking through the promises and perils of standardization. As Reskin (2012) notes, automated mortgage lending based on credit scores has expanded access to mortgages, but those same actuarial technologies made possible the emergence of the subprime mortgage market and eventual housing crash (Poon 2009). Despite the seemingly automated, race-neutral character of the lending process, researchers have determined that racial minority borrowers were disproportionately tracked into subprime mortgages, even controlling for their credit scores (Hwang et al. 2015; Rugh and Massey 2010). In a prescient 2005 article, Williams, Nesiba, and McConnell (2005) noted that changes in the mortgage industry had not eliminated racial inequality as much as reshaped it.
That standardized decision making would lead to a transformation of inequality in mortgage lending rather than its elimination is unsurprising in light of scholarship on the complex and often contradictory consequences of standardization and the scholarship on racialized organizations. When brought into conversation, these perspectives suggest that seemingly race-neutral, objective standards may re-embed racial inequalities in new logics and justifications while simultaneously immunizing organizations from claims of explicit racial bias.
More broadly, scholarship on race and standardization suggests three problems that confront attempts to use actuarial techniques to address racial inequality: implementation, diagnosis, and ideology. First, scholars in science studies and organizational sociology have argued that standards never work as advertised and that organizational processes are hard to standardize (Timmermans and Epstein 2010). That is, the actual implementation of an actuarial technique may differ markedly from its design. In principle, at least, quantified decision making completely removes subjectivity from the process of deciding about individual cases. In practice, judgment is (at best) moved up one level to the construction of the system. 2 In turn, the relevant potential biases transform from the individual decision maker to the system as a whole—what kind of data it considers, what factors are seen as relevant, how they are combined, and what goals the designers of the system choose to emphasize. Second, because racial inequalities are best diagnosed as reflecting structural racism (Bonilla-Silva 1997), not (just) individual bias, efforts to reduce racial inequality through standardizing gatekeeping decision making may have little effect. Third, law and society scholars have argued that actuarial decision making may actually make discriminatory decisions harder to challenge (Simon 1988). Actuarialism tends to bake inequality into the decision-making process, transmuting social disadvantages into seemingly objective measures of individual riskiness (Fourcade and Healy 2013; Krippner 2017).
In contrast, nonactuarial standards do not rely primarily on predictions of future outcomes to generate decisions and thus may be more useful in combating racial inequality. In particular, nonactuarial systems present the opportunity to account for structural forms of inequality and directly value equalizing outcomes based on race. But for the same reason that actuarial standards are difficult to challenge, nonactuarial standards may be politically vulnerable. Without the justification of statistically superior decision making according to a mechanically objective metric, nonactuarial standards may be easier to challenge and more difficult to defend—especially when they explicitly challenge racially unequal outcomes. Our two cases exemplify these contrasting relationships between standardization and racial inequality: a politically defensible but largely ineffective actuarial standard in child welfare compared to a politically vulnerable but promising standard in undergraduate admissions.
Cases and Methods
In the remainder of our analysis, we examine these tensions of standardization and racial inequality in the contexts of child welfare and undergraduate admissions to understand the potential and limitations of standardization to transform social hierarchies. These two cases share several important features, including the explicit goal of reducing racial inequality and the form of quantified decision making employed by the relevant organizations. Borrowing a term from Duncan et al. (1953:573), we identify this form as a selection device: “an apparatus consisting of a selection instrument (e.g., a test) which, independently of the judgment of the administrator, assigns a score to each applicant; and a rule for deciding which applicants shall be accepted and which ones rejected, solely on the basis of their assigned scores.” 3 In child welfare, a nonprofit organization designed a selection device to determine how a case should be approached by state child welfare agencies after a substantiated charge of neglect or abuse, including whether a child should remain at home. In undergraduate admissions, the University of Michigan developed a selection device to determine whether to admit applicants to its undergraduate program.
The cases differ in key respects as well, including most notably their respective diagnoses of the cause of racial inequality and in their use of actuarial techniques. Child welfare agencies adopted a formally race-neutral selection device statistically designed to classify cases according to the likelihood of future abuse and neglect with the theory that this device would improve decision making and reduce racial inequality by constraining the subjectivity of decision makers. In contrast, the selection device developed at the University of Michigan was not designed to classify which students would be the most likely to succeed; rather, the device balanced several competing concerns, including the need to create a racially diverse student body, and did so by explicitly considering race.
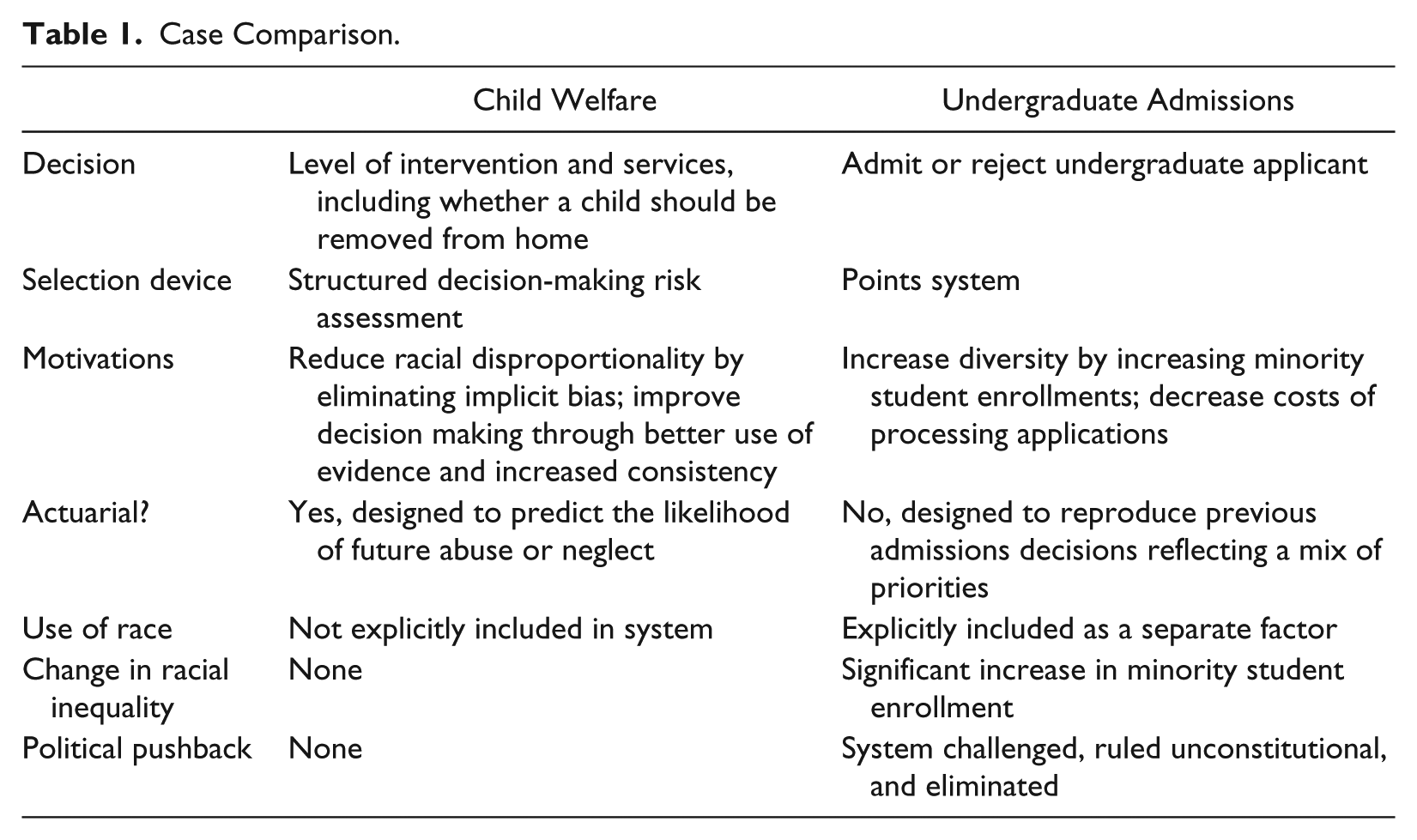
Our data come from primary and secondary research. The second author conducted extensive primary data collection on child welfare decision making in two states, including 80 interviews with child welfare workers and agency administrators. The first author, as part of a collaborative research project, conducted primary historical research on college admissions, including analyzing internal admissions documents from University of Michigan’s archives along with court documents and media coverage (see Bosk 2018, forthcoming; Hirschman et al. 2016 for details). For each case, we analyze the development of the selection device, intentions of the developers and implementers, functioning of the device itself, challenges raised against the new quantified decision-making system, and the system’s overall performance in terms of reducing racial inequality. We summarize our analysis in Table 1.
Case Comparison.
Diverse Standards
In the following sections, we describe the development of selection devices in child welfare and undergraduate admissions. We begin with child welfare to showcase how actuarial standardization succeeds at achieving mechanical objectivity but fails to address racial disproportionality. We then turn to undergraduate admissions at the University of Michigan to showcase how nonactuarial quantified decision making that makes explicit use of race as a variable can succeed in promoting racial equality at the risk of provoking successful political backlash.
Structuring Child Welfare Decisions
Child welfare decisions are among the weightiest a state can make and are also associated with significant racial and ethnic disproportionality at every point in the process (from who is reported for child maltreatment to the number of children in foster care). While decisions about child protection are rooted in child safety mandates, sociological research makes clear that racialized and classed narratives about families, motherhood, and appropriate caregiving shape this process in ways that can punish minority families (Reich 2005; Roberts 2003).
The move to standardized, actuarial decision making in child welfare is a relatively recent phenomenon. 4 From the turn of the twentieth century until the mid-1980s, clinical and bureaucratic decision-making models were the only available tools used to frame decisions regarding child welfare substantiations and placements (e.g., whether the allegation of maltreatment is found to be true and whether a child is safe to remain at home). Prior to the 1980s, debates about decision making centered around the best ways to make clinical decisions, the impact of race and gender on the decision-making process and its outcomes, and the extent to which bureaucratic policies should influence clinical decisions.
In the mid-1980s, the Children’s Research Center (CRC), a part of the National Council on Crime and Delinquency (NCCD), became the first organization to develop actuarial-based risk assessments for child welfare. Figure 1 is an example of the risk assessment designed by the CRC for the State of Michigan in 1998 to predict the risk of future maltreatment. This model is a relatively simple tool that classifies cases according to the likelihood of future instances of abuse or neglect using variables associated with reentry into the child welfare system in past cases.

Selection device for making child welfare decisions.
The Risk Assessment (RA) contains two sets of inventories, one for neglect and one for abuse. Factors associated with abuse and neglect, such as parental history of abuse, history or presence of domestic violence, number of children in the house, age of caregiver, and previous involvement with CPS, make up the scales. Points are assigned to each item that the caseworker endorses. For example, if a worker agreed with the statement that the “parent has a mental health problem,” one point would be assigned.
Point values for each statement are weighted to reflect distinct levels of severity as determined by statistical regression models. The total points from the neglect inventory and the abuse inventory are calculated separately. The highest number from either inventory then sorts a family into intensive, high, moderate, or low risk for the recurrence of maltreatment. The goal of the RA is to accurately classify which children are most at risk for re-abuse and direct appropriate intensive services to those at highest risk. The developers assert that the RA objectively classifies cases based on the likelihood that a caregiver will maltreat their child(ren) in the future. In promotional materials, the National Council on Crime and Delinquency states: “It is important that if given the same information, all workers, despite the personal biases they may have, consistently evaluate families in an objective way.” 5
In the late 1990s, the NCCD funded validation studies conducted on early adopter states, which concluded that actuarial prediction was the most valid and reliable method for child welfare decision making (Baird and Wagner 2000). Although other forms of quantified decision-making tools were being tested and used at this time, these validation studies and other comparative research made a strong case for the adoption of actuarial-based tools (Baird and Wagner 2000; Baird, Wagner, and Johnson 1999). Building on this research, NCCD expanded the use of actuarial assessments to other decision points in the child welfare decision-making process such as reunification (CRC 2008). Bringing a series of actuarial and other clinically structured standardized tools under the umbrella of one, easy to use, step by step procedure, the Structured Decision Making Model (SDM) provided a process for case decision making that mixed mechanical with clinical judgment. The RA represents the most prominent component of the SDM and is the focus of evaluations of this model. By the end of the 1990s, 10 states adopted the SDM for guiding child welfare decision making, and today over 33 states use the SDM.
As the SDM was being adopted, the field of psychology began to emphasize the superiority of actuarial prediction over clinical assessment more generally. As noted previously, Dawes, Faust, and Meehl’s (1989) meta-analysis argued that actuarial-based methods were more accurate than clinical predictions. Although Dawes et al. (1989) acknowledged that actuarial-based models were not superior in all cases, their study was framed by the NCCD as settling the issue over what method to use to approach cases. In promotional material, the NCCD (1999) prominently quoted Dawes, stating: In the last 50 years or so, the question of whether a statistical or clinical approach is superior has been the subject of extensive empirical investigation; statistical vs. clinical methods of predicting important human outcomes have been compared with each other, in what might be described as a “contest.” The results have been uniform. Even fairly simple statistical models outperform clinical judgment.
Currently, the NCCD asserts on its website that SDM is much more accurate than any other form of decision making, noting: “The SDM model offers an elegant and comprehensive way to incorporate research and consistency into key child welfare decisions. To date, no set of CPS assessments has demonstrated the degree of reliability and validity, nor the improved outcomes of the SDM Model.” 6
The shift toward actuarial-based risk assessment in child welfare emerged at the intersection of three interrelated concerns: the low reliability of clinical decision making, the emergence of the evidence-based medicine movement, and the need to address the disproportionality of ethnic and racial minorities in the child welfare system. These are discussed in order.
Reliability issues with clinical decision making became especially salient following research conducted in the late 1980s and 1990s that suggested that case decisions were highly dependent on which worker a family received and the larger institutional context in which the case was processed and less dependent on the seemingly objective facts of the case (Lindsey 1992; Rossi, Schuerman, and Budde 1999; Stein and Rzepnicki 1983). Further, research demonstrated little connection between the criteria CPS workers used to make a judgment and established risk factors related to re-abuse (Baird and Wagner 2000; Gambrill and Shlonsky 2001). Compounding these issues in decision-making were the difficult conditions under which CPS workers made judgments, namely with limited information, under time pressure, and in conditions of high uncertainty (Gambrill and Shlonsky 2001). Since decision-making errors can lead to the death or the unnecessary separation of a child from their family, improving reliability in child welfare decision making was understood to be essential.
Moves toward evidence-based medicine in both health care and psychology in the late 1990s and early 2000s also heavily influenced the expansion of the SDM into state child welfare policy. Concerned with improving the effectiveness of social work, resolving continued gaps between research and practice, and aligning professional standards with those in medicine, social work researchers and practitioners have advocated for the necessity of evidence-based practice (EBP) as a means to ensure the scientific legitimacy of the field and provide interventions that “work,” leading EBP to become the guiding model for theory and practice in the field (Okpych and Yu 2014).
The emergence of the EBP movement coincided with the introduction of new federal policies such as the Government Performance and Results Act of 1993, which mandated the collection of data both on performance targets and outcomes for major federal programs (Hatry 1997; Okypych and Yu 2014). In child welfare, between 2000 and 2004, all states were required to conduct Child and Family Service Reviews (CFSR), which included new substantiations after the close of an investigation as a variable for state performance. This criterion further generated interest in “simple risk assessment procedures with known predictive attributes” regarding the risk of future maltreatment (Shlonsky and Wagner 2005:412).
In response, the NCCD framed the SDM not only as the most accurate form of decision making in child welfare but also a model that facilitates compliance with the new guidelines. Use of the SDM expanded to over 30 states by 2010, and the NCCD began exporting their model internationally. According to the NCCD, the SDM is “now the most widely used case management model in the United States” (CRC 2008). Research in child welfare considers actuarial-based risk assessment to be the “gold standard” for case decision making (Schwalbe 2009:205).
Finally, and most important to our larger argument, the significant overrepresentation of ethnic and racial minorities at every point in the child welfare system, including reports, placement in foster care, time in foster care, and family reunification (Sedlak and Broadhurst 1996), also influenced the development and expansion of actuarial based methods for decision making in child welfare. While disproportionality in the child welfare system is currently understood to be a complex issue with multiple causes (Font and Maguire-Jack 2015; Pelton 2015; Putnam-Hornstein et al. 2013), child welfare research in the 1990s framed the persistent overrepresentation of racial and ethnic minorities as partly a result of decision-maker bias in which “race, rather than risk, was the relevant factor” (Putnam-Hornstein et al. 2013:34). Decreasing cognitive errors in decision making that rested on the heuristic errors and implicit biases of the child welfare worker therefore represented an important policy corrective to race-based differential treatment (Gambrill and Shlonsky 2000).
The NCCD promoted the RA as a tool to advance this goal (CRC 1999, 2008). On an earlier version of their website, the NCCD listed equity alongside reliability, validity, and utility as forming the basis on which the value of the SDM rests. Describing equity, the page noted: “SDM assessments ensure that critical case characteristics, risk factors, and domains of functioning are assessed for every client, every time, regardless of social differences. Detailed definitions for assessment items increase the likelihood that workers assess all clients using a common framework.” 7 Through the formulation of standard criteria for evaluation and their systematic application, the NCCD offered a mechanism to reduce racial disproportionality.
In their promotional materials from the 2000s, the NCCD continued to assert that actuarial-based decision making could equalize racial outcomes in child welfare decision making: In all CRC studies to date, the developed risk systems also promote equity in decision making [italics added]. Because equity is a major principle of the development process, the proportion of various races and ethnic groups assigned to each risk level is virtually identical in all jurisdictions. These results suggest that well-structured assessment tools and decision making systems can help overcome some of the racial disparities resulting from traditional practices. (italics added; CRC 2008:12)
Disentangling race and ethnicity from the decision-making process was thus one explicit goal of the developers of the SDM. The list of variables collected does not include race or ethnicity. By explicitly leaving race out of the model, focusing on individual behaviors and family circumstances, and standardizing the content CPS workers use to make decisions, the SDM understands itself to be removing race from the decision-making process.
Despite these intentions, proxies for disadvantage slip in through questions on the neglect inventory about residential status (whether a family has a home), employment, and number of children. And much as in the case of parole predictions (Harcourt 2015), the SDM includes past complaints and offenses, a variable that is far from race-neutral. Research on racial disparities in child welfare highlights that racial minorities are overrepresented in allegations of maltreatment to CPS for all groups of reporters (Krase 2013). By including criteria associated with disproportionality such as past complaints, the SDM (to at least some extent) reintroduces the problem it was designed to correct.
Further, new research on racial disproportionality in the child welfare system highlights the role that socioeconomic status (SES) plays in driving disproportionate outcomes (Drake et al. 2011; Font, Berger, and Slack 2012; Pelton 2015; Putnam-Hornstein et al. 2013). This line of work suggests that when economic disadvantage is taken into account, race-based differences in maltreatment rates are either reduced, eliminated, or reversed. Racial disproportionality in the child welfare system therefore may not be mostly driven by bias in the decisions of CPS workers but instead may reflect structurally situated socioeconomic risk factors. Proxies for race in the RA such as residential status and employment are also proxies for SES, continuing to confound attempts to reduce race-based differential results.
Beyond problematic proxy variables, the SDM also includes many variables that require substantial judgment on the part of social workers to code and thus reintroduces the possibility for cognitive racial prejudices to influence decisions. As Bosk (2018) shows, even a question as straightforward as “Primary caretaker currently has a substance abuse problem” requires interpretive acts on the part of caseworkers—how should one score a parent with a history of alcoholism but who is currently sober and regularly attends AA? Examining how child welfare makes meaning of and utilizes actuarial-based risk assessments in practice, Bosk demonstrates workers’ wide range of responses and approaches to them. While a minority of workers understand the RA to be an important tool to eliminate bias and disparate assessments of similar cases, the majority of child welfare workers viewed the RA as one more way to encode subjectivity into the decision-making process (Bosk 2018). Workers’ critiques focus on their belief that the RA penalizes caregivers for being victims of circumstance, situating risk in factors that are not changeable or overtly related to abusive behaviors such as the number of children in the home, the age of the child, and whether the caregiver has a history of experiencing intimate partner violence. Workers’ lack of confidence in the RA to objectively or fairly assess risk can lead them to ignore it in their decision making (Bosk 2018, forthcoming).
We could locate only two specific independent evaluations of racial disparities after the introduction of the SDM. These analyses found that while the introduction of the SDM was more successful in accurately classifying low, moderate, and high-risk cases, it did not reduce racial disproportionality (Miller 2011; Osterling, D’andrade, and Austin 2008). Further, at a national level, racial and ethnic disproportionality at all points in the child welfare system remains a persistent and major cause for concern (Font 2013; Putnam-Hornstein et al. 2013), suggesting that the widespread take-up of the SDM has had little impact on overall racial disparities. These results are consistent with newer studies that find that racial disproportionalities in child welfare largely reflect structural inequalities, particularly those related to economic inequality, and thus that even when implicit bias strongly shapes child welfare decisions, standardization efforts like the RA will have limited effects in reducing racial disproportionality.
Affirmative Action in College Admissions
College admissions have been a site of controversy since the early twentieth century (Karabel 2005). Access to selective colleges has been understood as a key path to upward class mobility or upper-class reproduction. For colleges, admissions practices have served multiple functions, including legitimacy, prestige, and financial stability (Killgore 2009). In the first half of the twentieth century, selective colleges turned toward quantified assessments of academic merit to identify promising (white) students from less affluent backgrounds (Lemann 1999). Inspired by the civil rights movements of the early 1960s, some selective colleges also began to engage in programs of affirmative action to increase the enrollment of nonwhite students (Stulberg and Chen 2014). These practices spread such that by the mid-1990s, approximately 60 percent of selective colleges claimed to consider race in admissions (Hirschman and Berrey 2017).
Our research here focuses on a single case within higher education, the University of Michigan. In 2003, the Supreme Court ruled unconstitutional Michigan’s use of a particular selection device, the famous “points system,” because it mechanically awarded 20 points to underrepresented minority applicants (out of 100 needed for admission) while simultaneously upholding the constitutionality of more holistic modes of affirmative action. We review the history of affirmative action at Michigan prior to these decisions and use debates over the points system to showcase how the university arrived at a nonactuarial selection device that successfully streamlined and standardized the admissions processes while increasing minority enrollments but failed to survive political challenges.
Like some peer institutions, Michigan began pursuing a policy of intentionally recruiting minority (especially Black) students in the mid-1960s (Stulberg and Chen 2014). At the time, Black students represented just .1 percent of the student body. Initial efforts to increase minority recruitment centered on an alternative path to admissions for minority students identified as promising. These efforts were justified in terms of a logic of redistribution and creating opportunities for previously marginalized groups (Berrey 2015). In the 1960s and 1970s, Michigan expanded its affirmative action programs and moved away from a model based on admissions officers’ personal connections to streamline the process and further increase minority enrollments. These efforts were undertaken in part in response to the Black Action Movement, which in 1969 demanded that Michigan increase minority student enrollment to 10 percent (at the time, it was 3.4 percent) (Brune 1994).
In 1978, the legal context for affirmative action changed when the Supreme Court ruled that quotas were unconstitutional violations of equal protection. The somewhat opaque ruling left open the possibility that some forms of affirmative action could be justified. According to Justice Powell’s decision, universities might have a constitutionally protected interest in promoting diversity that justified affirmative action even as the Court rejected arguments based on reducing societal inequalities (Berrey 2015).
The University of Michigan revamped its admissions practices with this ruling in mind. But while many selective universities turned to individualized review, Michigan created a system of quantified admissions. Faced with increased application volume and tight budgets, Michigan sought to enroll a diverse student body as efficiently as possible (Hirschman et al. 2016). The system they created aimed to standardize race-conscious admissions without an explicit quota. In the 1980s and early 1990s, Michigan employed multiple “grids,” which mapped a student’s GPA and standardized test scores to an admission decision. Minority students were mapped onto separate grids, with lower thresholds for admission (Hirschman et al. 2016). These grids were made public following a 1995 Freedom of Information Act request by an anti–affirmative action activist, who considered them “smoking gun” evidence of unconstitutional discrimination (Hirschman et al. 2016:284). Conservative legal advocates agreed and chose Michigan for the lawsuits that became Gratz v. Bollinger and Grutter v. Bollinger in part because of the clarity of its quantified system of affirmative action.
In 1997, Michigan revised its grid system into a single page selection device known colloquially as the points system. Figure 2 shows the points system as it was used from 1998 to 2003. It was this system that the Supreme Court would evaluate and eventually rule unconstitutional in Gratz.

A selection device for undergraduate admissions at the University of Michigan.
This system differs in two important respects from the child welfare Risk Assessment. First, the points system was not developed to classify students based on past successful outcomes. That is, statisticians did not define some outcome (i.e., graduation) and then see what variables best predicted that outcome. Instead, statisticians built a system that incorporated heterogeneous organizational imperatives: to build a diverse class along racial and gender lines (e.g., 5 points for men in nursing), promote alumni relationships (4 points for legacies), and serve residents of the state (10 points for Michigan residents). 8
Second, and most controversially, the points system explicitly considered the race of applicants. Underrepresented minority students (defined as Black, Hispanic, or Native American) received 20 points. Making race explicit also separated race from other variables that may have a racialized component—the SAT may have a racial bias, underrepresented minority students may attend less well-resourced schools, but race here is treated as an isolated variable.
This system (along with other efforts to recruit a diverse student body) yielded a significant increase in racial diversity. By 2002, Michigan had almost 10 percent Black students in its entering class.
In 2003, the Supreme Court scrutinized the points system in Gratz v. Bollinger. In oral arguments, the justices debated whether 20 points for minority applicants was appropriate—was the equivalent of a full point of GPA too much? Was it fair that students from economically disadvantaged backgrounds received at most the same number of points as underrepresented minority students? The nonactuarially derived “20 points” was mentioned 19 times in oral arguments. For example, Breyer noted that a White male athlete from a poor family would receive the same points as an African American from a rich family, and so the athlete “just can’t overcome that 20 points—the best he can do is tie.” 9
These questions played into the eventual five to four decision ruling that the points system was not “narrowly tailored” to achieve the constitutionally protected interest of promoting diversity. The points system was not treated as a mechanically objective tool for making decisions (Porter 1995) but an ad hoc system that too coarsely advantaged minority students without clearly linking that advantage to the nebulous goal of promoting diversity. The Gratz majority opinion stated the “automatic distribution of 20 points has the effect of making ‘the factor of race . . . decisive’ for virtually every minimally qualified underrepresented minority applicant.” 10 The points system, with its explicit and legible quantification of race, violated the compact binding together colorblindness and diversity (Moore and Bell 2011).
Guided by these two rulings, Michigan abandoned the points system and replaced it with a version of holistic assessment. This new system required a 60 percent increase in admissions staff (Hirschman et al. 2016). At the same time, minority enrollments plummeted; Black enrollment in 2004 was just 6 percent, down from almost 10 percent under the points system (New York Times 2013). The new system was both more expensive and less effective at yielding a racially diverse student body.
Discussion and Conclusion
Our empirical cases examined two intendedly antiracist selection devices to identify how actuarial and nonactuarial forms of standardization offer different affordances and constraints in the service of redressing racial inequality. Child welfare organizations identified individual, psychological sources of racial disproportionality and sought to address them with an actuarial tool designed to improve decision making and increase objectivity. Its rollout had minimal effects on racial disproportionality in child welfare cases but faced virtually no political pushback. In contrast, at the University of Michigan, admissions staff produced a nonactuarial tool designed to facilitate efficient decision making. The points system recognized structural inequalities and directly valued increased racial minority enrollment to achieve its aims. This system was effective at increasing the enrollments of Black students to a level almost equal to the historical demands of Black student groups. But this system was also transparent, and transparently race-conscious, making it subject to significant challenge and as a violation of the paradoxical colorblind logic of diversity, which resulted in its elimination.
The contrasts between these two cases suggests three findings. First, there is no single relationship between standardization and race. The SDM and the points system reflected different diagnoses of the causes of racial inequality and offered different solutions. Both were forms of standardization intended to reduce racial inequality, but their construction and effects were quite different.
Second, actuarial techniques exist in tension with efforts to reduce racial inequality. The SDM and its Risk Assessment tool likely failed to reduce disproportionality, in part, because it is based on actuarial techniques. Despite not including race as an explicit variable, the RA likely detected extreme structural racial inequalities and transmuted them into risk classifications. These classifications in turn became seemingly race-neutral justifications for child welfare decisions. But nothing in this process could correct the disadvantages detected. Standards that rely on actuarial techniques are unlikely to succeed in promoting racial equality because of the way actuarial techniques tend to recast structural inequalities in terms of individual merit. 11 Even if the Risk Assessment detects risk accurately, it cannot resolve how these risks are disproportionately distributed.
Third, while actuarial standards may be limited in their ability to reduce racial inequality, nonactuarial standards may be vulnerable to challenges of bias precisely because they are not justified on a logic of prediction. The points system succeeded at helping the University of Michigan enroll more minority students but failed to survive sustained political challenge. The university could not argue that the points system was statistically derived to identify the “best” students according to their likelihood of graduation or GPA or any other criteria. The system was not designed to classify the likelihood of success; it was designed to enroll a diverse class. Nonactuarial techniques that transparently address racist structures are vulnerable to political and legal challenges as they violate norms of colorblindness and the jurisprudence of diversity.
Together, these cases suggest a frustrating contradiction. To construct an effective antiracist standard requires explicitly recognizing structural racial inequality. Yet constructing a politically defensible standard may require enacting a colorblind standard justified around individual understandings of racism. Unless and until political actors recognize structural racism, efforts to promote racial inequality through standardization are likely to fail.
Footnotes
Acknowledgements
We thank Ellen Berrey, Megan Feely, Kelley Fong, Greta Krippner, Kathryn Maguire-Jack, Melissa Wooten, and audiences at SKAT 25, the Center for the Study of Race and Ethnicity in the Americas at Brown University, the Annual Meetings of the Eastern Sociological Society, and the Annual Meetings of the American Sociological Association for helpful comments on previous versions of this paper.
Funding
Emily Bosk gratefully acknowledges funding from the following sources in support of the research related to standardized decision making in child welfare: National Science Foundation Dissertation Research Improvement Grant No. 1323916, Doris Duke Fellowship in the Prevention of Child Maltreatment and the Promotion of Child Wellbeing, and the Fahs-Beck Fund for Research and Experimentation.