
Abstract
Generative large language models (LLMs) entered scientific writing at scale after the public release of ChatGPT in November 2022, but their adoption in sociological research remains largely unmapped. This visualization estimates the share of LLM-modified sentences in 1.49 million abstracts from sociology papers indexed in OpenAlex between January 2018 and December 2025, using the distributional alpha estimator developed by Liang and colleagues. By tracing change over time, across substantive subfields, and across author groups, it provides a field-level view of how rapidly LLM-assisted writing has diffused through sociology. The visualization highlights three patterns. First, estimated LLM modification rose from near zero before late 2022 to 24.3 percent of abstract sentences in July–December 2025. Second, adoption varies substantially and persistently across subfields: empirical and applied areas show the highest estimated uptake, while theory-oriented subfields remain lowest. Third, data from the post-ChatGPT era show that LLM-assisted writing is also more prevalent among younger scholars, authors from less prestigious institutions, and publications in less prestigious outlets. Together, these patterns show that LLM use in sociology has become widespread but remains unevenly distributed across scholarly communities.
Introduction
The release of ChatGPT in November 2022 made fluent generative writing freely available to scientists, and a growing body of work has since documented the rapid penetration of large language model (LLM) text into scientific abstracts (Kusumegi et al. 2025; Liang et al. 2025). The large-scale evidence, however, has been assembled almost entirely from natural science fields (Kobak et al. 2025; Liang et al. 2025). In addition to survey- and interview-based evidence, sociology has rarely been examined as a field with its own internal organization of LLM diffusion. As a result, we know little about whether LLM-assisted writing has spread evenly through sociology or whether it follows patterns observed elsewhere.
In this report, I address this gap using open abstracts in sociology from OpenAlex, one of the largest bibliometric data sets of scientific publications. Starting with a candidate pool of 110 OpenAlex topics drawn from eight sociology-related areas, I curate the set substantively, embed the topic descriptions using text-embedding-3-small vectors, and cluster them with UMAP and HDBSCAN into 19 stable and coherent sociological subfields (see Appendix A for methodological details). For each sociological subfield and each half-year window from 2018H1 to 2025H2, I estimate the share of LLM-modified sentences using the maximum-likelihood distributional estimator developed by Liang et al. (2024, 2025; Appendix B). Following the established method, I use gpt-3.5-turbo-0125 as the main reference model, so the estimates are directly comparable to the benchmarks for scientific writing reported there. I also reestimate the alpha coefficient under three additional reference models in Appendix C (GPT-4o-mini, Gemini 2.0–flash, and Qwen 2.5-7B), with the descriptive patterns broadly preserved across model settings. These estimates are then aggregated to the subfield and group levels, allowing me to map how LLM-assisted science is distributed across sociology’s communities.
The main figure reveals three patterns. Figure 1, Panel A traces the trajectory of each subfield across 16 half-year windows. The curves are flat and indistinguishable through period 10 (July–December 2022), fan out almost monotonically beginning in the first full post-ChatGPT window (first half of 2023, i.e., 2023H1), and continue through the second half of 2025 (2025H2). Aggregate sociology rises from a noise-floor baseline to around 25 percent in the most recent period. Figure 1, Panel B ranks subfields in the final period: Cultural Sociology leads at 34.2 percent, followed by Development and Governance (29.3 percent) and Media and Digital Sociology (29.1 percent), while Social Psychology and Identity (13.5 percent) and Global Sociology and Colonialism (17.6 percent) sit roughly 20 points below the leading fields. In Figure 1, Panel C, I further compared average LLM adoption across groups after ChatGPT’s release (2023H1–2025H2), distinguishing publication channels, first-author career stage, and first-author institutions. Details for variable construction are documented in Appendix D. The results indicate that LLM-assisted writing is disproportionately adopted by younger scholars, somewhat more often by scholars from less prestigious institutions, and much more often in publications appearing in less prestigious outlets. This pattern suggests that LLMs are not socially neutral tools but can be intertwined with scholars’ identities and positions within the broader academic and institutional contexts.
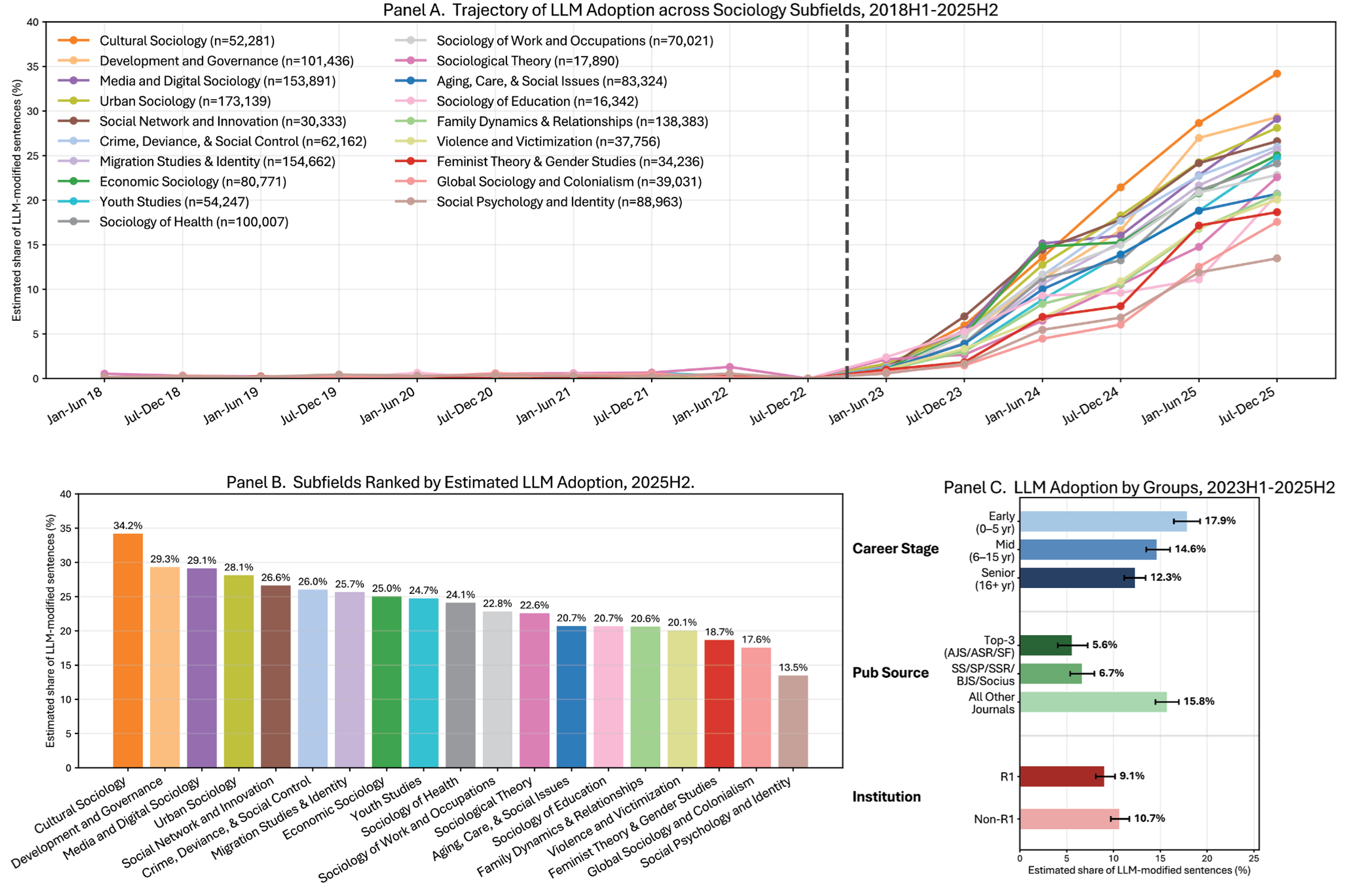
Large language model (LLM) adoption in sociology, 2018–2025. Estimated share of sentences in published abstracts whose word distribution is consistent with LLM modification, expressed as a percentage. The estimate is the maximum-likelihood α from Liang et al.’s (2024, 2025) distributional estimator; intuitively, α captures the share of sentences whose vocabulary patterns more closely match an LLM reference distribution than a pre-ChatGPT human-writing distribution. Estimates are adjusted relative to each topic’s July–December 2022 baseline to account for estimation noise. Panel A shows adoption trajectories across sociology subfields; Panel B ranks subfields by estimated adoption in July–December 2025; Panel C compares adoption across social groups during the six post-ChatGPT periods (2023H1–2025H2). Estimates aggregate 1,491,873 abstracts across 19 sociology subfields and 16 half-year windows, with subfield-specific abstract counts (n) reported in Panel A. In Panel C, error bars indicate 95 percent confidence intervals by bootstrap.
Two interpretations are suggested by Figure 1. First, LLM-assisted writing appears to have diffused most quickly in empirical and applied subfields, especially those in which authors are more likely to rely on quantitative evidence or to address policy, organizational, or industry audiences. By contrast, uptake is lower in core-theoretical areas, where prose is more tightly bound to conceptual argument and theoretical positioning. Read this way, the subfield gradient suggests that sociology is not a unified epistemic community with a single writing style but rather a stratified ensemble of subfields with distinct prose conventions, audience expectations, and tolerances for the kind of “generic” academic English that LLMs are posttrained to produce. The behavioral signal in Figure 1 thus indexes a systematic divide in how sociologists write, a longer-standing phenomenon that may be amplified in the era of generative artificial intelligence. This emerging pattern deserves close scholarly attention because how communities respond to this technological shock will shape the politics of discourse and academic voice in the near future. Second, this work also complements existing studies of LLM use in sociology. Alvero et al. (2026) survey sociologists’ self-reported use of and attitudes toward generative AI, while Ladegaard (2025) documents how editors and gatekeepers in three academic disciplines interpret “AI-aided writing.” While this work confirms some patterns identified in prior research (e.g., roughly 20 percent to 30 percent of sociology researchers used AI to assist writing in mid- to late 2025), our approach enables large-scale inference from publication corpora rather than smaller-scale survey data and from there reveals patterns that prior work could not observe. The early evidence in Figure 1, Panel C is one example. In this sense, I regard the present article as complementary to and a form of triangulation for existing survey-based and interview-based evidence on generative AI in social science, extending the generalizability and broader applicability of small-sample approaches.
Supplemental Material
sj-pdf-1-srd-10.1177_23780231261460657 – Supplemental material for Visualizing the Adoption of Large Language Models across Sociology Subfields
Supplemental material, sj-pdf-1-srd-10.1177_23780231261460657 for Visualizing the Adoption of Large Language Models across Sociology Subfields by Likun Cao in Socius
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: We are grateful for support from Purdue CLA EXCEL grant.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Author Biography
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.