
Abstract
Regionalization, under various guises and descriptions, is a longstanding and pervasive interest of urban studies. With an increasingly large number of studies on urban place detection in language, behavior, pricing, and demography, recent critiques of longstanding regional science perspectives on place detection have focused on the arbitrariness and non-geographical nature of measures of best fit. In this paper, we develop new explicitly geographical measures of cluster fit. These hybrid spatial–social measures, called geosilhouettes, are demonstrated to capture the “core” of geographical clusters in racial data on census blocks in Brooklyn neighborhoods. These new geosilhouettes are also useful in a variety of boundary analysis and outlier detection problems. In this paper, the thinking behind geosilhouettes is presented, their mathematical form is defined, they are demonstrated, and new directions of research are discussed.
Introduction
Analysis of spatial community dynamics is a longstanding domain of regional science and urban geography, and a burgeoning concern for spatial data science. One common kind of geography, the “ecologically meaningful” municipal neighborhood (Drukker et al., 2003) is a prime geography used in urban data science. Neighborhoods are often analyzed for their impacts on health (O’Campo et al., 1997; Roberts, 1997; Santos et al., 2010; Spielman et al., 2013), crime (Hipp and Boessen, 2013; Sampson et al., 1997), and life outcomes (Duncan et al., 1994). However, since these neighborhoods are often defined by government or administrative bureaucracies for convenience’s sake, these neighborhood impacts measure the effect of this pre-existing geography, not the geography that might emerge latent in the data (Shelton and Poorthuis, 2019).
A different and longstanding mode of analysis focuses on estimating or “bounding” the neighborhood according to some specific objective or known phenomenon under study (Isard, 1956). One domain focuses on latent geographies in demographic data—the study of geodemographics (Harris et al., 2005; Singleton and Longley, 2009; Singleton and Spielman, 2014). Geodemographic analysis produces a demographic “typology,” or collection of interpretable demographic categories, which are mapped and examined to provide a sense of the social tapestry of a (typically) urban space. In contrast to this, detecting latent ecologically meaningful communities directly from data is growing more popular in spatial data science. While serious work “bounding” the neighborhood is not new (Galster, 2001; Spielman and Folch, 2015; Spielman and Logan, 2013), the advent of high-quality spatiotemporal data has made this pursuit more feasible (Anselin and Williams, 2016; Arribas-Bel and Bakens, 2018; Gibbons et al., 2018; Poorthuis, 2018; Wachsmuth and Weisler, 2018). In both geodemographic and latent-neighborhood approaches, these places can be defined consistently in terms of a coherent demographic profile, containing a consistent “bundle” of attributes, behaviors, interactions, marketing, or social ties.
Latent neighborhoods may be used in a similar context as prescriptive administrative ones, but can also be used themselves as indicators of spatial social structure (Mikelbank, 2011; Morenoff et al., 2001) or to study the perceptions or experiences of these boundaries (Duncan et al., 2014; Hipp et al., 2012). Further, some latent neighborhood methods provide data-dependent geographic frames for the analysis of urban dynamics, volatility, and social change (Duque et al., 2012; Rey et al., 2011). Regardless, latent spatial neighborhood analyses provide data-driven regions for secondary models or for analysis in their own right.
For this spatial clustering problem, it is often necessary to characterize how “cohesive” a candidate neighborhood is. Traditional measures of cluster cohesion, or “goodness of fit,” do not take into consideration the geography of the data being clustered. Although the analysis of urban “boundaries” arose early in geography (Womble, 1951) and has seen consistent application in epidemiology (Jacquez, 1995; Jacquez et al., 2000, 2008; Lu and Carlin, 2005) and ecology (Fitzpatrick et al., 2010; Fortin et al., 1996), fundamental work in the area continues (Dean et al., 2018; Dong et al., 2019). In these contexts, goodness of fit is used to measure whether some members, houses, families, or blocks are distinct from a neighborhood’s general spatial–social profile; but, the way that this goodness of fit is measured or operationalized is often entirely non-geographic, and has no knowledge of spatial proximity, boundaries, or adjacency (Shelton and Poorthuis, 2019). Thus, we develop a new boundary strength measure inspired by ecological and epidemiological methods, but one which is appropriate for urban data science applications like geodemographics and neighborhood-bounding.
In the following work, we explore the trade-offs involved between demographic coherence and spatial integrity in the analysis of urban structure through common geodemographic or neighborhood-bounding methods. Then, inspired by the logic of parametric statistical boundary detection (Womble, 1951), we suggest a geographic innovation on Rousseeuw (1987) called the geosilhouette. We demonstrate the usefulness of these new measures in both an empirical–descriptive example, assessing the strength and direction of racial boundaries between Zillow neighborhoods over Brooklyn Census blocks, and in latent neighborhood/place learning, where they can be used to characterize the joint spatial–social goodness of fit. Together, these new measures provide novel insight into the structure of spatial partitions and enable new analyses of the power of boundaries in quantitative human geography.
Conceptualizing “goodness” of fit
In general, geodemographic and neighborhood-bounding exercises use goodness of fit statistics to characterize the homogeneity or consistency of a given neighborhood or demographic partitioning. Further, measures of segregation are used in a similar fashion for empirical analyses of how thoroughly mixed (or not) urban spaces are when split by race, class, or other demographic traits. These ancillary measures of neighborhood homogeneity or cluster fit are usually not leveraged directly in theory-driven analyses, but are instead a part of the barely visible constellation of descriptive statistics used in the heuristic analysis of geographical clusters. To support the wide variety of cluster analyses, there is a similarly wide set of goodness of fit measures.
Silhouette scores, as suggested by Rousseeuw (1987), are one particularly useful measure. The silhouette score expresses the relationship between an observation, the other observations in the same cluster, and a counterfactual “next-best-fit” cluster (NBFC) for that observation. In the original presentation of the silhouette score, Rousseeuw (1987) offers an intelligible conceptual motivation for this next-best-fit cluster: [The next-best-fit cluster] is like the second-best choice for object i: if it could not be accommodated into [its current] cluster A, which cluster B would be the closest competitor? (p. 55)
The silhouette’s motivating concepts are clear—“tightness” of each cluster and “separation” between clusters. Each concept has a distinct term in the formal statement of the silhouette score for observation i

Silhouette values range between –1 and 1, with values close to 1 indicating i is “well classified” into c. Conceptually, this occurs when
Data: Neighborhoods and endogenous racial clusters
In part due to their simplicity, silhouettes have long been used to detect observations that are not well grouped with their cluster. However, for geographic analysis, next-best-fit scores can be made more informative. As it stands, the NBFC represents a group to which observation i can be most plausibly reassigned—the “second-best choice.” What “best” means is more complex in geographical analysis, though.
To examine various kinds of geographic “second-best choice” cluster assignments, we examine self-reported race in the 2010 Census blocks across neighborhoods in Brooklyn, NY, using the neighborhood boundaries provided by Zillow. 1 One view of this data is provided by Figure 1, which demonstrates the populated census blocks and neighborhood boundaries and provides an indication of the racial composition across Brooklyn blocks. To contrast with these exogenous neighborhoods, we will also analyze detected clusters in the racial composition of census blocks in the 2010 US Census using an aspatial k-means approach common in geodemographics (Harris et al., 2005) and a spatial-hierarchical agglomerative clustering heuristic based on Ward’s method (Ward, 1963). 2

Zillow neighborhoods (left), with 2010 Census blocks with nonzero population under-laid for Brooklyn, NY. Blocks with low populations are shown in black on the left figure, and omitted entirely from the remainder of the analysis. The single most-predominant race for blocks in the study area is also shown (right). Throughout, basemaps are provided by Stamen Design.
Fragmentation in urban regions
Fundamentally, the idea of cluster quality in spatial cluster analysis implicates two distinct concepts: attribute coherence, that an observation’s characteristics are similar to its cluster, and spatial coherence, that the cluster itself demarcates or delineates a geographically coherent “zone” or region of the overall problem frame. 3 To varying degrees, “real” neighborhoods generally exhibit both demographic coherence and spatial coherence: they are a “bundle of spatially-based attributes associated with [a] cluster of residences” (Galster, 2001: 2112). Both the “bundle of attributes” and the “spatial cluster” are needed to characterize a classification’s fitness in a geographical process.
However, most goodness of fit measures (including silhouettes) only measure attribute coherence. This is fine for non-spatial clustering applications, but is difficult to justify in geographical applications. Indeed, for the contiguous regions used in the neighborhood dynamics and neighborhood effects literature, nearly all of the “second-best choices” constructed for silhouette scores are actually infeasible choices: i might be nowhere near
Acknowledging this, we can leverage observations’ spatial contexts (in addition to their group memberships) to extract more meaningful information about neighborhoods or spatial clusters themselves. Observations on the boundary of a spatial cluster are the only ones that could be connected to their next-best-fit spatial cluster if they were reassigned. All other interior observations require more than one block to be reassigned in order to be a feasible, internally connected cluster. As clusters become less geographically coherent, the size of their interior decreases. Visually, the clustering solutions shown in Figure 2 illustrate this: as the number of clusters increases, the spatial fragmentation of clusters increases quickly.
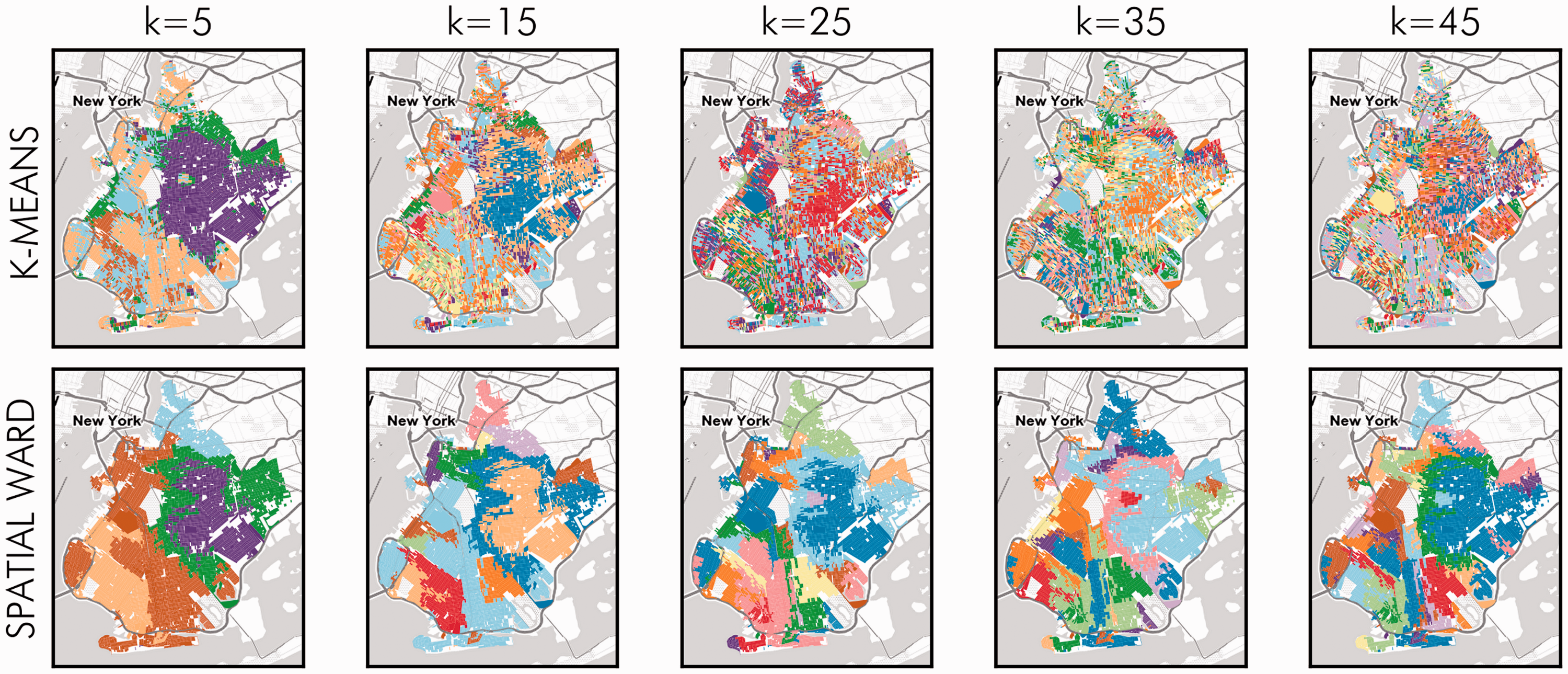
Demographic clusters in Brooklyn, NY, for k-means and spatially constrained ward agglomerative clustering. Fragmentation increases dramatically as the number of demographic clusters increases.
Another view of this fragmentation is provided by Figure 3. In this composition plot, the share of all blocks that are interior to the cluster—those that only touch other blocks in the same cluster—is represented by the gray area. The blue fraction shows blocks that are touching their NBFC. These are blocks where the “second-best choice” assignment is feasible, since the block could be re-classified to its second-best choice and not affect the spatial fragmentation in the map. Finally, the red area denotes the share of blocks that are on the boundary of their own cluster, but are not near any member of their NBFC. These are the blocks where a “second-best choice” assignment would affect territorial integrity. In addition to the shares from latent/discovered neighborhoods, we show “empirical” fractions of the same quantities: census blocks in Zillow neighborhoods that touch a neighborhood that is next-most demographically similar to the block itself, or that are on the boundary of a neighborhood but do not touch a neighborhood that is next-most demographically similar. These are shown by the horizontal dashes crossing the right vertical axis of each facet in Figure 3.

Interpreting Figure 3, we can understand a few things. First, as is mathematically necessary, the share of interior blocks declines as the number of clusters increases. Second, despite this increasing fragmentation, the number of blocks that touch their NBFC is relatively stable as the number of clusters increases. This occurs quickly for the spatial agglomerative clusters, but both are remarkably stable at around k = 20. Third, we see that groups defined without spatial information (k-means) tend to be much more fragmented than either the empirical neighborhoods or the clusters discovered using the explicit spatial clustering technique. The fraction of blocks that is interior to a cluster is consistently smaller in the aspatial k-means map, and clusters are much more dramatically interspersed. The most spatially coherent solution seen in the k-means clustering solutions (that with the smallest k) is still more fragmented than the most fragmented spatial agglomerative clustering solution (that with the largest k). Finally, the empirically observed breakdowns are quite low; given that only 7% of the 7729 blocks with non-zero population sit on the boundary between two Zillow neighborhoods, only 11% of these boundary blocks (approximately 0.08% overall) are themselves near their NBFCs. Thus, the level of spatial cohesion in the Zillow neighborhoods is much higher than even those detected using the spatially explicit clustering method.
Silhouette scores are not spatial
Focusing on the empirical case, the interplay between these NBFCs and the silhouette scores is shown in Figure 4. Note that the preponderance of silhouette scores is negative for real-world neighborhoods. This means that, in terms of their racial composition, census blocks are nearly always more similar to a different neighborhood than they are to the neighborhood in which they reside. Together, this suggests that silhouette scores will always favor more socially homogeneous neighborhoods, without regard for spatial feasibility or geographical plausibility. Neighborhoods (empirical or embedded within the data) are more diverse than these optimal socially homogeneous partitions that the silhouette refers to. Indeed, any realistic urban place geography will be considered less “well-fit” by the silhouette score, since attribute coherence and geographic coherence are usually opposing objectives. By the same logic, any spatially informed clustering method must also be less “well-fit.” Any non-geographical measure of cluster fit exhibits this same property, as noted by Shelton and Poorthuis (2019).

Silhouettes and next-best-fit clusters for US Census blocks within Zillow neighborhoods in Brooklyn, NY.
Indeed, neighborhood social homogeneity should not be regarded as a necessarily intrinsically desirable normative objective when conducting place detection. Social scientists have long argued that diverse and socially integrated neighborhoods provide benefits to residents when they are able to foster meaningful social exchanges (Chaskin and Joseph, 2013; Joseph et al., 2007; Talen and Koschinsky, 2014; Tolsma and van der Meer, 2018). Further, there is evidence that neighborhood diversity in the USA is increasing, carrying important benefits for residents: methods that distill neighborhoods according to maximum demographic homogeneity may be overlooking important aspects of the ways that neighborhoods are experienced by their residents (Logan, 2013). As trends towards diversification continue, there is also recent evidence that neighborhood boundaries are perceived differently among residents from different social backgrounds (Hwang, 2016), too. Together, this suggests that neighborhood definitions are tenuous, occasionally contested, and may be defined by attribute homogeneity, resident perception, or physical demarcation—and each of these definitions has unique value in different research contexts.
Geosilhouettes: Measures of spatial cluster similarity
While silhouette scores are particularly useful for identifying spatial configurations of attribute homogeneity (such as racial and ethnic enclaves), the point we raise here is that other definitions are important and useful for other research questions; building explicitly geographic measures of fit is necessary to improve the validity of geographical work on urban regions. Therefore, contra Shelton and Poorthuis (2019), it is not the designation of a goodness of fit criterion itself that harms the construct validity of detected places; it is the inflexibility, simplicity, and arbitrariness of these criteria that makes detected regions uninteresting or unhelpful. For more interesting and helpful computational geographies, it is necessary to improve, develop, and strengthen the conceptualization and operationalization of these measures of best fit.
In short, we need better geographical measures of cluster fit. They should characterize the local attribute coherence in a way that respects or controls for spatial coherence. While others may examine Figure 2 and observe simple or straightforward fragmentation in shape (e.g. McGarigal et al., 2002), we instead take inspiration from Jacquez et al. (2008): geographical cluster fit is determined by boundaries and the social similarity of nearby observations. Fortunately, the silhouette score provides a conceptually elegant structure for this. Below, we derive two geosilhouette specifications. One, the so-called path silhouette, focuses on joint attribute-spatial affinity through the use of so-called dissimilarity paths. The other, the boundary silhouette, restricts the set of each observation’s NBFCs to only those clusters that are nearby. That is, the boundary silhouette constrains the NBFC to be a feasible cluster reassignment (Duque et al., 2011). These two methods will be derived and discussed for the three styles of clustering analyses of neighborhoods and Brooklyn census blocks. 4
Path silhouettes
One way to make the silhouette score geographically aware is to account for the fact that objects that are closer should be rated as more similar to one another in a joint geographical–social silhouette score. Thus, let us use a dissimilarity path to model the dissimilarity between two observations, i and j, as a function of the total social dissimilarity between observations along the path connecting them. This recognizes that for i and j to be in the same geographically contiguous cluster c, they must be connected by a set of observations also in c. Thus, a “path” silhouette is a silhouette score computed using the length of dissimilarity paths from i to j as the distance metric.
From Rousseeuw (1987)’s silhouette, let us consider the N × N matrix,
Bringing

The path silhouette is then computed using the same formula as in equation (1), using cij instead of d. Since an observation’s NBFC (
An example of this approach to analyzing cluster quality can be seen in Figure 5. In this color ramp, the darker purple areas are those where an observation is classed as not well fit to its cluster (since the silhouette is negative), and lighter yellow are areas where the observation is well fit. This is in the same style as Figure 4, but shows the path silhouette versions: the NBFC becomes the “next-best-connected” cluster, and the silhouettes shown are the path silhouette variant.
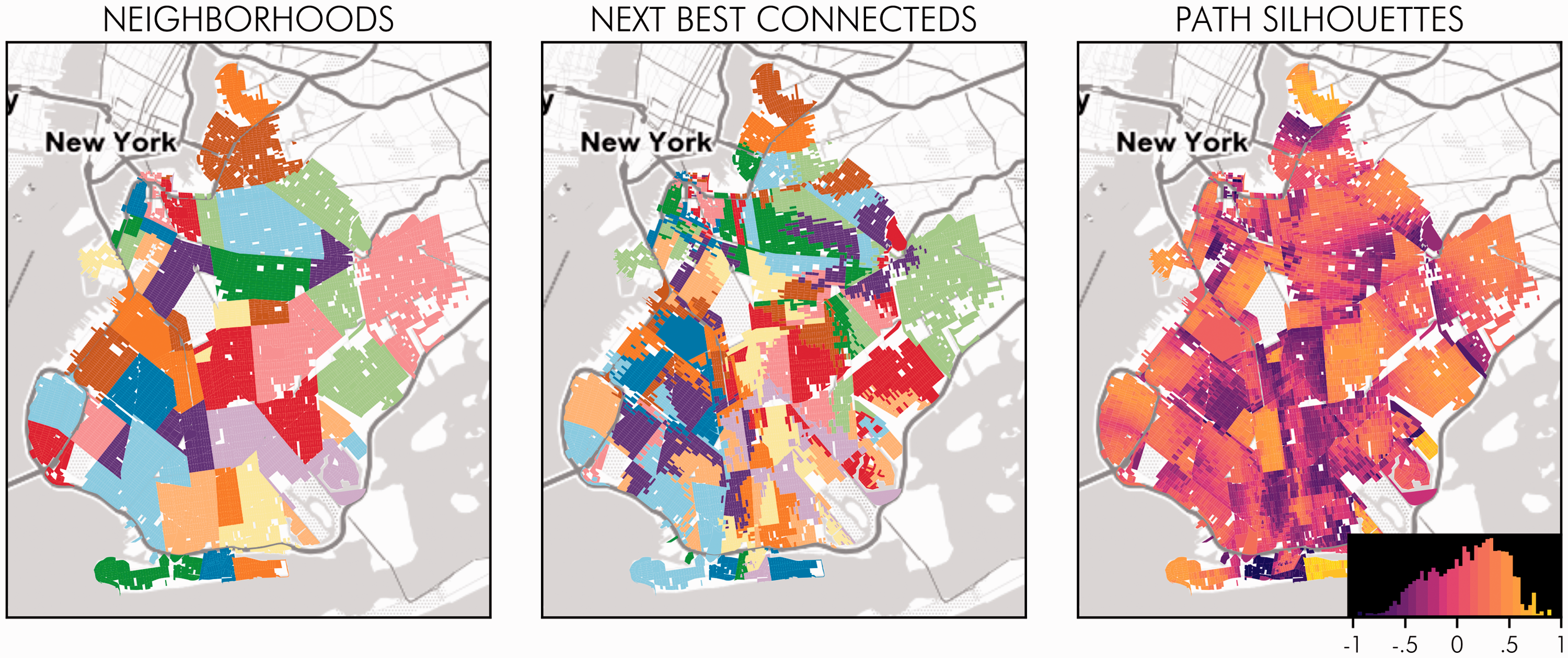
Neighborhoods and next-best-fit clusters using the path dissimilarity metric. This is the path silhouette analogue of Figure 4.
These maps show a few things. First, the geographically remote neighborhoods in the far north, west, and south of Brooklyn exhibit strong joint spatial–social cohesion due to their joint social coherence and geographical remoteness. Second (and more critically), the empirical neighborhoods with path silhouettes closer to 1 in Figure 5 tend to remain together in the spatially informed clusterings in Figure 6, even when they are in more central areas of the city. Since the path silhouette measures joint spatial–social similarity, it is reasonable that the spatial agglomerative clustering picks up on this. However, there is no constraint forcing this to occur, so this reinforces the utility of the path silhouette as an exploratory measure of the local spatial–social coherence for urban regions.

Assignments to 15 clusters, silhouettes, and path silhouettes for aspatial k-means and spatial ward agglomerative clustering.
To illustrate, central Brooklyn has many neighborhoods with majority-African American populations, as shown in Figure 1. The aspatial silhouettes shown in Figure 4 show one quite clearly: East Flatbush. Recalling its atypically high silhouette scores in Figure 4 and path silhouettes in Figure 5, this area in the deep center of Brooklyn is spatially and socially distinctive. This distinctiveness is recognized regardless of cluster heuristic. In this area, both the silhouettes and the path silhouettes are high, showing this is an area with significant demographic homogeneity (a bundle of similar attributes) that is also spatially coherent (this bundle clusters geographically).
Notably, though, high path silhouettes still betray spatial–social similarity in demographically more-complex neighborhoods, such as Bushwick, along the northeast Queens–Brooklyn border. This area is not as strongly self-similar (it is not predominately mono-racial in the Census), but its profile is still distinct from other nearby neighborhoods. Path silhouettes pick up on this weaker form of spatial–social similarity, too. However, this sociogeographic distinctiveness is missed by aspatial silhouettes, regardless of the clustering heuristic. The “core” of Bushwick is assigned its own cluster in the spatial Ward clustering, and shares the same high path silhouette values as the empirical neighborhoods. Thus, geographical measures of cluster fit like the path silhouette can identify geographical exemplars: the components of a geographical cluster that are spatially and socially distinctive for that cluster.
Boundary silhouettes
While path silhouettes are a novel useful measure of joint social–spatial similarity, it too suggests a somewhat unrealistic “second-best choice” counterfactual: when computing the NBFC, the cost of moving i from c to k is modeled by the average length of paths from i to
Consider that for each i, the NBFC
In light of this, a boundary silhouette is defined as a restriction of the standard silhouette score. Reprising the original silhouette statement from equation (1)

the boundary silhouette must restrict
Using this idea, the boundary silhouette is the silhouette-style score between i, c, and

Second, the set of clusters around site i can also be defined in a similar fashion

Together, these definitions are sufficient to define the boundary silhouette. The “best local alternative,” the boundary silhouette’s version of the NBFC, is the cluster in

This score has the same interpretation as Rousseeuw (1987)’s silhouette, but measures the cost of “flipping” i over the border of c and
Practically speaking, when both sides of the boundary have a positive median boundary silhouette, it means that the parts of the clusters immediately adjacent to one another are strongly distinct. When both are negative, it suggests that the neighborhoods may be misaligned from the true underlying demographic difference in that locality. When one is positive and one is negative, the cluster on the positive side of the boundary blocks could merge with the blocks on the other side of the boundary and improve the local structure of fit without adjusting the spatial coherence of the two clusters. Thus, the boundary silhouette assesses the local goodness of fit for a cluster. It relates the similarity of the observation to its current cluster versus the cluster across the boundary.
The boundary silhouette exhibits an interesting property: it can be asymmetric for any boundary. For cluster k and cluster c, the median boundary silhouette score for observations in k bordering c may not necessarily be equal to the score for observations in c bordering k. This would imply that observations in c that are near k are more similar to observations in k, but observations in k that are near c are still closer to their own cluster, k. Put another way, assume that c has a large positive boundary silhouette and k has a large negative boundary silhouette. Then, observations in k that are geographically near c are also more demographically similar to c than they are to their currently assigned cluster, k. In reverse, observations in c that are geographically near k are more similar to their currently assigned cluster than to the i nearby alternative.
For an example, we provide an empirical illustration of the boundary silhouettes in downtown and north-central Brooklyn in Figures 7 and 8. In addition to the figures, the median boundary silhouette values for each adjacent neighborhood pair is provided in Tables 1 and 2. On the left of each plot, the neighborhoods are labeled. On the right, the boundary silhouettes are shown.
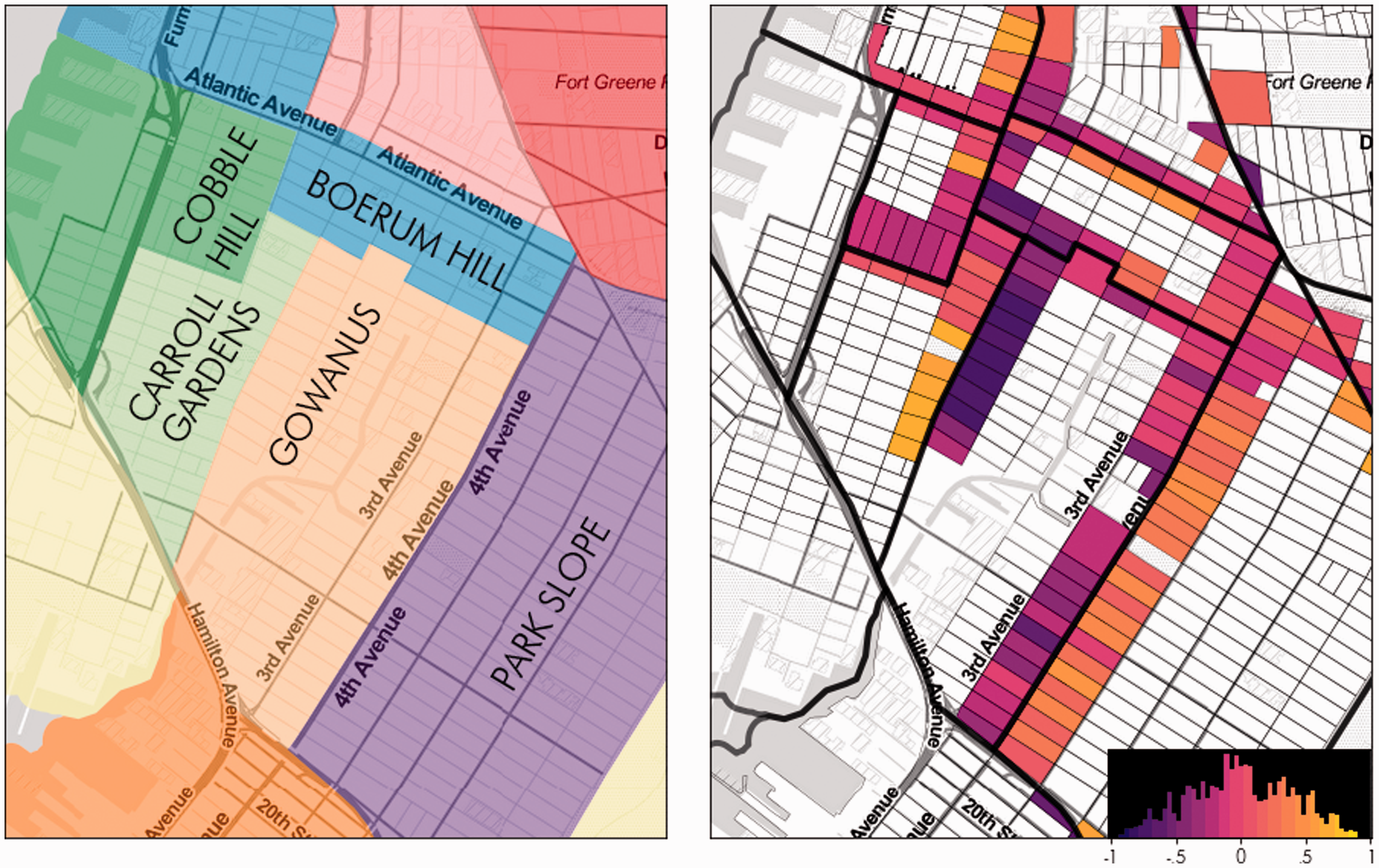
Detail of downtown Zillow neighborhoods in Brooklyn, with boundary silhouettes overlaid. The legend on the bottom right demonstrates the distribution of boundary silhouettes.

Detail of north-central Zillow neighborhoods in Brooklyn, with boundary silhouettes overlaid. The legend on the bottom right demonstrates the distribution of boundary silhouettes.
Median boundary silhouette values for blocks abutting each cluster in downtown Brooklyn neighborhoods.

The rows record blocks in the “focal” cluster that touch the “neighbor” cluster.
Median boundary silhouette values for blocks abutting each cluster in north-central Brooklyn neighborhoods.

The rows record blocks in the “focal” cluster that touch the “neighbor” cluster.
A few strongly asymmetric boundaries are apparent. Looking at the strongest asymmetry, blocks in Gowanus near Carroll Gardens are more similar to Carroll Gardens than the rest of Gowanus, while the blocks in Carroll Gardens bordering Gowanus are much more similar to Carroll Gardens. Thus, the demographic profile of Carroll Gardens is a better demographic fit for those boundary blocks in Gowanus, so the similarity is directional, and the two neighborhoods may appear to change gradually in demographic composition when moving from Gowanus into Carroll Gardens. This contrasts with a socially undirected boundary, such as the one between Bedford-Stuyvesant and Bushwick in Figure 8. For boundaries with positive scores on both sides, social characteristics change remarkably between the boundary and its adjacent cluster. Blocks in Bushwick immediately north of Broadway Boulevard, simply could not easily be demographically passed off as a typical Bedford-Stuyvesant block.
In addition, some neighborhoods may be quite internally heterogeneous and still have positive boundary silhouettes. Plainly, a neighborhood may be an arbitrarily bounded “bundle” of inchoate and dissimilar attributes, and yet be distinct from every other bundle nearby. Some neighborhoods may even have positive and negative boundaries of nearly equal magnitude. For instance, the boundaries for Cobble Hill are positive when abutting two neighborhoods (Boerum Hill and Gowanus) but not a third (Carroll Gardens). Indeed, an even stronger example of this is in the north-central detail shown in Figure 8 with medians in Table 2. The border area between Bedford-Stuyvesant and Williamsburg is directed towards Williamsburg, but Williamsburg overall is more heterogeneous than Bedford-Stuyvesant according to their aspatial silhouette values. Further, Williamsburg blocks on the Bushwick boundary are about equally split in their demographic similarity to Williamsburg or Bushwick. This is despite the fact that Bushwick is much more demographically cohesive than Williamsburg as a whole, measured by its median aspatial silhouette score.
Discussion
Thus, between the path and boundary silhouettes, these methods introduce spatial structure into the canon of (aspatial) methods common in spatial data science. Formally, each statistic does this using a slightly different spatial structure. Both, however, introduce a formal, direct notion of geographical proximity or distance directly into the computation of social distance used to assess the coherence of a given neighborhood or the goodness of fit for an urban cluster.
The path silhouette, by mixing together attribute similarity and spatial proximity, provides a useful mechanism to measure and assess the joint spatial–social similarity in a dataset. This strategy shows increasing promise at the methodological frontiers of urban data science (Chodrow, 2017; Wolf, 2019), providing a comprehensive way to introduce an explicit model of geographical similarity into the analysis of urban clusters. The “cores” identified by path silhouettes are clustered in spatial, aspatial, and exogenously determined boundaries This shows the joint spatial–social similarity measure is useful both in empirical description and in unsupervised learning.
The boundary silhouette similarly introduces spatial thinking into a classic data science measure, but does so with a different focus in mind. Instead of specifying an explicit model for joint spatial–social similarity, this measure aims to quantify how strongly (and in which direction) does each side of a boundary align? It provides a novel, explicitly spatial method to examine how demographic differences coincide (or fail to) in the areas where regions meet. While this is a post-hoc diagnostic (rather than a boundary detection method), it can easily be incorporated into the myriad heuristics that guide cluster design, too.
It is important to note that the directional structure inherent in boundary silhouettes is not simply caused by some neighborhoods being more internally cohesive than others. These boundary silhouettes are not functions of the absolute goodness of fit of a given observation; they indicate the relative goodness of fit comparing an observation’s home cluster to its local alternatives. The aspatial silhouette also does not take into account the proximity of the next-best-fit choice; again, only 16% of blocks have their next-best-fit neighborhood as their best local alternative neighborhood. Since it is often the case that local urban structure can be quite distinct from global urban patterning (Harris, 2017; Jones et al., 2015; Leckie et al., 2012), this distinction between the relative goodness of local fit and the global best alternative considered by the classic silhouette is novel and insightful.
Conclusion
Geosilhouettes, both path and boundary variants, are immensely useful in their own right for detecting the latent social–spatial “core” of geographical regions, identifying the strength and direction of spatial boundaries, and for understanding the local socio-geographical structure of cluster fit. There is a large variety of possible refinements available for these methods, as well as possible extensions or applications. Moving forward, a classic statistical perspective could be used to identify the formal distributional properties of silhouette statistics in conditions common in urban data science (e.g. Anselin and Rey, 1991; Rey et al., 2018). Second, the strongly scale-driven reasoning embedded in the boundary silhouette could be used to generalize the analysis of boundaries between multiple levels, allowing for “local” alternatives at a micro (i.e. primitive units such as census blocks/tracks), meso (individual clusters), or macro (citywide) scale (e.g. Harris, 2017). Third, these measures could be extended to spatiotemporal clustering, applying the conceptual logic of the “second-best choice” to alternatives in time and space, or considering the trajectories of demographic classifications using a spatiotemporal distance metric (e.g. Delmelle, 2016; Delmelle et al., 2013). Fourth, a common use case of silhouettes is for graphical heuristics to identify the “optimal” number of clusters in an aspatial context; the path silhouette should provide a similar method for geographical clustering problems, and this should be further studied in future work.
At a more conceptual level, the silhouette provides a useful formal method to introduce spatial thinking because Rousseeuw (1987) is so explicit in the operationalization of their intent. Future work should be similarly explicit in intent. However, our choice to use silhouettes as the basic structure onto which geographical thinking can be grafted does not limit the scope of “spatializing” data science methods. Where possible, enhanced methods for spatial data science should make the intent of the statistic explicit and then accommodate geographical relationships directly in the statistic, rather than in post hoc geographical analysis of aspatial data science.
In our execution of this research program, we develop two new ways of measuring the local “goodness of fit” for urban clusters. Assessing the local structure of “neighborhoods,” either detected lying latent within a dataset or exogenously determined using government or colloquially defined boundaries, is a ubiquitous problem in urban data science. For the path silhouette, demographic similarity and geographical similarity are combined, providing a single measure of how cohesive neighborhoods are, both spatially and socially. For the boundary silhouette, local thinking is introduced into how observations’ are assessed for similarity. This provides an indication of how quickly or dramatically social characteristics change between two adjacent urban clusters, and speaks to the inherently multi-scale structure of urban geography.
Generally speaking, this effort participates in the broader project of developing new methods for urban spatial data science. Sometimes, is not enough to conceptualize fundamentally geographical problems in aspatial structures; instead, we suggest that introducing spatial thinking directly into the way a statistic operationalizes its core measurement is necessary to provide new insights, as we have done. Further, it is through these better concepts and operationalizations that better, more meaningful, and more useful results on the structure of urban society will be obtained.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by NSF-SES 1733705: Neighborhoods in Space-Time Contexts.