
Abstract
There has been recent interest in the use of network analysis to quantify bike network features and their impact on biking levels and safety. However, limited bike network indicators have been evaluated. This study introduces a list of network indicators to quantify the bike network and study its effect on bike kilometers traveled and bike–vehicle crashes. Data from the city of Vancouver, Canada, are used as a case study. Full Bayesian modeling incorporating spatial effects is employed to develop Bike Kilometers Travelled (BKT) and bike–vehicle crash models. The developed BKT models show that the bike network centrality, assortativity, and weighted slope have negative associations with BKT, while the bike network directness, length, complexity and development, and connectivity have positive associations with BKT. The developed crash models show that the bike network length, centrality, assortativity, and continuity have negative associations with bike–vehicle crashes. On the other hand, the bike network complexity and development, connectivity, and linearity have positive associations with bike–vehicle crashes. The models provide insights that can be useful for planning bike networks to increase bike traffic and improve bike safety. The models also show that some changes to a bike network to increase bike traffic should be accompanied by crash risk-mitigating measures. As well, the models can be used to identify zones within a city that require safety improvements.
Keywords
Introduction
Many road authorities worldwide are promoting biking to create sustainable and livable communities and to improve public health. However, cyclists are vulnerable road users that have an elevated injury/fatality risk, which may deter road users from biking. Therefore, understanding the underlying factors that affect biking levels and bike safety is essential for promoting biking.
Previous studies showed associations between biking levels and network features (Buehler and Pucher, 2012; Dill and Carr, 2003; Marshall and Garrick, 2010; Nelson and Allen, 1997; Osama et al., 2017; Schoner and Levinson, 2014). As well, several previous studies have identified associations between bike–vehicle crashes and network indicators (Chen, 2015; Chen et al., 2012; Cho et al., 2009; Harris et al., 2011; Kaplan and Prato, 2015; Osama and Sayed, 2016; Saha et al., 2018; Siddiqui et al., 2012; Wei and Lovegrove, 2013; Yasmin and Eluru, 2016). Bike network (on-street and off-street bike lane) indicators are developed using network theory where they were found to be significantly associated with both biking levels and bike–vehicle crashes. These network indicators included connectivity, directness, and linearity. However, many other network indicators can be employed to evaluate bike networks, such as network centrality (network inter-connectivity and accessibility), assortativity (the propensity of similar nodes to be linked), complexity (network development), and robustness (the network ability to maintain its connectivity after the deletion of a node). Network indicators are useful tools for network planners, as they can be used to identify deficiencies in the network to improve safety. This is especially important when some network indicators may have contradictory associations with promoting biking and reducing bike crashes.
This paper provides a review of various bike network indicators and investigates their relationship with biking levels and safety. Full Bayesian (FB) models incorporating spatial effects are developed to assess the effect of bike network indicators (e.g. centrality, assortativity, complexity, and robustness) on Bike Kilometers Travelled (BKT) and bike–vehicle crashes. The models are developed by employing data for 134 traffic analysis zones (TAZs) in the city of Vancouver, Canada.
Previous work
Effect of bike network indicators on biking levels
Many studies have explored the relationship between bike network features and biking levels. Previous studies explored the impact of bike network length on the number of bike commuters (Buehler and Pucher, 2012; Dill and Carr, 2003; Nelson and Allen, 1997). These studies found that the higher the bike network length is, then the higher the bike commuting. Other studies found a negative association between network slope and biking levels (Dill and Carr, 2003; Hood et al., 2011; Osama et al., 2017; Winters et al., 2016).
Several studies showed the importance of bike network connectivity on affecting biking levels (Berrigan et al., 2010; Handy and Xing, 2011; Marshall and Garrick, 2010; Mekuria et al., 2012; Osama et al., 2017; Schoner and Levinson, 2014; Winters et al., 2016). Berrigan et al. (2010) analyzed spatial data from the 2001 California Health Interview Survey from two Californian counties and showed that network connectivity has a positive correlation with walking and biking levels. Schoner and Levinson (2014) used several network indicators to measure network connectivity, size, density, and directness for 74 cities in the United States. They found that network connectivity, directness, and density were positively associated with bike commuting. A summary of the various network indicators investigated and their effect on biking levels is presented in Table S1 in the online Supplementary Material.
Bike network indicators associated with bike safety
Several studies investigated the impact of network size on bike safety. On the macro level, Wei and Lovegrove (2013) showed that an increase in the bike lane length, intersection density, traffic signals, and bus stops is associated with an increase in bike–vehicle crashes. Yasmin and Eluru (2016) studied crash frequency across TAZs. After controlling for exposure measures, sociodemographic characteristics, socioeconomic characteristics, and the built environment, they found bike network length and highway length are positively correlated with bike–vehicle crashes.
Many studies have investigated the association between network connectivity and bike safety (Cho et al., 2009; Osama and Sayed, 2016; Zhang et al., 2012). At the TAZ level, Zhang et al. (2012) employed a geographically weighted regression model to explore the association between network connectivity and pedestrians’ and bike safety. They found that the increase in network connectivity is associated with an increase in pedestrian–vehicle and bike–vehicle crashes. In contrast, Siddiqui et al. (2012), Strauss et al. (2013), and Wei and Lovegrove (2013) found that density, a network connectivity metric, is positively associated with bike–vehicle crashes. Osama and Sayed (2016) found that an increase in network connectivity is associated with an increase in bike–vehicle crashes. In addition, they found that the longer the links without hindrances or discontinuities, the safer it is to cycle.
Zhang et al. (2015) investigated the effect of bike network indicators in the form of network centrality, clustering, and the average geodesic distance on non-motorists’ safety for TAZs in 321 census tracts in Alameda County, California, USA. They suggested that a highly centered network is associated with fewer non-motorist crashes, and higher clustering road networks are also associated with fewer non-motorist crashes. A summary of the various network indicators investigated and their effect on bike–vehicle crashes is presented in Table S1 in the online Supplementary Material.
Network analysis
Kansky (1963) and Rodrigue et al. (2013) introduced indices that characterized transportation network connectivity, complexity, development, and accessibility. Centrality measurements are common in urban network analysis. Previous studies showed that centrality has a strong association with vehicle movements (Jayasinghe et al., 2015; Jiang, 2009). At the TAZ level, Zhang et al. (2011) applied three centrality measures on a road network to explore the association between network quantification and street network patterns. Similarly, In Barcelona, Spain, Porta et al. (2012) employed a kernel density estimation method to examine three street centrality measures and their relationship with economic activities. De Montis et al. (2007) introduced the assortativity and rich-club coefficients to analyze interurban network characteristics using weighted network analysis. Jiang et al. (2014) calculated the assortativity and rich-club coefficients to assess the degree of correlation in urban street networks. For an air transportation network, Ponton et al. (2013) measured the network robustness by employing the average clustering coefficient. Similarly, Yao et al. (2018) employed the average clustering coefficient to evaluate the impact of street network robustness on resident commuting efficiency and the traffic flow. Many important network indicators have been employed to investigate urban streets, air transportation, or maritime networks. For bike networks, researchers investigated the effect of indicators such as connectivity, continuity, and density. However, other indicators such as network centrality, assortativity, complexity, and robustness have not been employed in bike network analysis.
Data collection
The models developed in this study are based on 134 TAZs in the city of Vancouver, Canada. Three years (2009–2013) of bike crash data have been employed. The Metro Vancouver transportation authority provided the 2013 bike network, road network, and TAZ boundaries. The Vancouver Cycling Data Model (VCDM) provides estimates of the Annual Average Daily Bike traffic. Lastly, the city of Vancouver’s open data catalog provided the contour map.
The same data set was used previously to demonstrate the importance of accounting for mediation in safety models and to develop a comprehensive zone-based index to represent both biking attractiveness and bike crash risk (Kamel et al., 2019, 2020), modeling Bike Kilometers Traveled as a function of network characteristics (Osama et al., 2017), and accounting for measurement error in traffic exposure variables (e.g. BKT) in bike–vehicle crash modeling (Kamel and Sayed, 2020). For more details on data sources, please refer to the Data sources section of the online Supplementary Material.
Variables in the analysis
Definitions of the variables that are used in the analysis and their summary statistics are presented in Table S2 in the online Supplementary Material. The variables are divided into three main categories: crashes, exposure, and bike network indicators. To calculate bike network indicators, the bike network is characterized as a set of links and nodes. The links represent the bike lanes (on-street and off-street bike lanes), while the nodes represent the intersections between network links. For this study, the network indicators are divided into seven main categories: centrality, assortativity, complexity, robustness, connectivity, directness, and topography.
Crashes and exposures
Bike–vehicle crashes are accumulated according to their locations for each TAZ. Vehicle Kilometers Travelled (VKT) and BKT are employed as traffic exposure measures. Recently, Osama and Sayed (2016) used genuine bike exposure and BKT to develop bike–vehicle crash models. BKT is developed by multiplying each segment length by the number of trips conducted on this link and then aggregating it for each TAZ. The number of trips conducted on each link was extracted from the VCDM provided by Acuere (El Esawey et al., 2015).
Centrality
Centrality recognizes the supreme nodes within a graph (Freeman, 1978). Network centrality represents network inter-connectivity and accessibility. As the “supreme” can lead to different definitions, there are different definitions for centrality. Centrality measures include degree, betweenness, closeness, and straightness centrality that could quantify how central or important each node is inside a network.
Degree centrality
The degree centrality measures to what extent a node is connected directly by other nodes (Freeman, 1978). Influential nodes have a high degree of centrality. Previous studies have employed the degree of centrality in urban network analysis (Jiang, 2009; Porta et al., 2006; Zhang et al., 2011). The degree of centrality is calculated using equation (1), where

Betweenness centrality
The betweenness centrality is large if the node is traversed by many of the shortest paths connecting each two nodes (Freeman, 1978), in other words, if a node is positioned between several other nodes. Several studies have used betweenness centrality in urban network analysis (Crucitti et al., 2006; Jiang, 2009; Porta et al., 2006; Zhang et al., 2011, 2015). Betweenness centrality is calculated using equation (2), where
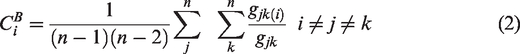
Closeness centrality
The closeness centrality is based on the notion that a node is central if a node is near to all the other nodes along the shortest paths (Freeman, 1978). It captures the travel cost of overcoming the geographic separation between nodes. Previous studies have employed closeness centrality to analyze an urban network (Crucitti et al., 2006; Jiang, 2009; Porta et al., 2006; Zhang et al., 2011). Closeness centrality is calculated using equation (3), where
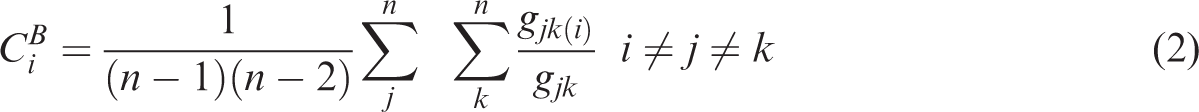
Straightness centrality
The straightness centrality is based on the notion that a node is central if the paths connecting node
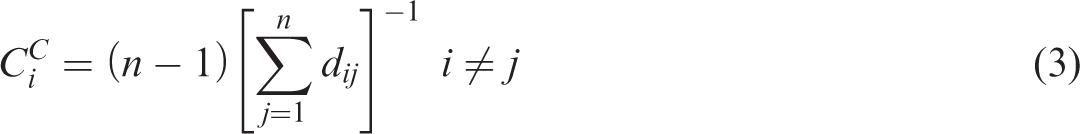
Graph centrality
Graph centrality

The bike network with heat maps for betweenness, straightness, closeness, and degree graph centralities for different TAZs are shown in Figure S1 in the online Supplementary Material.
Network assortativity
Assortativity is defined as the propensity of similar nodes to be linked (Newman, 2002). In this study, two metrics are proposed to quantify the network assortativity: assortativity and rich-club coefficients.
Newman (2002, 2003) suggested a concept like the Pearson correlation coefficient to quantify the assortativity coefficient. The assortativity coefficient is calculated using equation (6), where
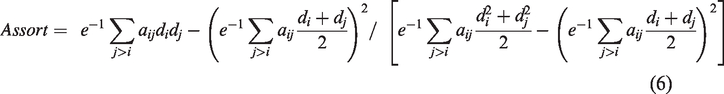
The rich-club coefficient is a specific representation of the degree correlations in a network. It focuses on the higher connectivity nodes (rich nodes). The rich-club coefficient is the proportion of the links connecting the higher connectivity nodes (rich nodes) to the possible links for the rich nodes to produce a complete graph (Jiang et al., 2014; Zhou and Mondragon, 2004). The rich-club coefficient is calculated using equation (7), where
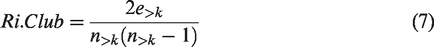
The bike network along with heat maps for assortativity and rich-club coefficients for different TAZs are shown in Figure S2 in the online Supplementary Material.
Network complexity
Rodrigue et al. (2013) introduced two network metrics to quantify network development and complexity: the Pi index and the number of cycles. The Pi index is the ratio between the network diameter and the length of the network. Rodrigue et al. (2013) defined the network diameter as “the length of the shortest path between the most distanced nodes of a network.” The number of cycles is the number of independent cycles, and it is calculated using equation (8), where

A low Pi index or the number of cycles indicates a low level of network complexity and development. The bike network along with heat maps for the Pi index and the number of cycles for different TAZs are shown in Figure S3 in the online Supplementary Material.
Network robustness
The average clustering coefficient is extensively implemented to assess the robustness of the network (Barthélemy, 2011; Ponton et al., 2013; Yao et al., 2018). In other words, it measures the network’s ability to withstand the deletion of its nodes. The average clustering coefficient is calculated using equation (9), where
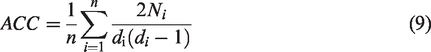
Network connectivity
Network connectivity has been extensively investigated in previous studies, where several measurements have been introduced (e.g. intersection density, network density, and network coverage). Two measures of connectivity are used in this study to quantify network connectivity: network density and intersection density. Network density is calculated as the proportion of the aggregated length of the bike links in a TAZ to the corresponding TAZ area. This measure was employed in previous studies for measuring network connectivity (Berrigan et al., 2010; Osama and Sayed, 2016; Saha et al., 2018; Schoner and Levinson, 2014; Zhang et al., 2012). Intersection density is the number of nodes (intersections) in a TAZ divided by the area of the corresponding TAZ. Previous research has introduced intersection density as a network connectivity metric (Cervero and Kockelman, 1997; Osama and Sayed, 2016; Zhang et al., 2012).
Network directness
Two measures are used to assess network directness: linearity and the average edge length. To measure linearity, theoretical links are created that characterize the length of the bike network in the case where all the links are straight while maintaining the nodes’ location. The aggregated length of the theoretical straight links is called modified bike network length. Linearity is then defined as the modified bike network length divided by the actual length of the bike network, for each TAZ. The average edge length is the total length of the bike network divided by the number of links in each TAZ (Kansky, 1963).
Topography
The total length of the bike network is estimated by summing up all the bike network link lengths while ignoring their types, i.e. separated, on-street, etc., within each TAZ. The average weighted slope of the bike network is the aggregated length weighted slope divided by the length of the bike network in each TAZ (Osama and Sayed, 2016).
Method
Model development
The FB approach has two main advantages in comparison to the traditional frequentist approach. First, it has the benefit of accounting for uncertainty and a more flexible framework that can be adjusted in compliance with the modeling process (El-Basyouny and Sayed, 2009). Second, because of its capability of dealing with complex correlations, the FB method is more appropriate for spatial modeling (Aguero-Valverde and Jovanis, 2008).
The FB model for BKT was created with a random error lognormally distributed. In this way, the error term,


The Poisson lognormal model is employed for the bike–vehicle crash models. Then spatial effects are employed to account for structured heterogeneities. The FB model procedure emulates the practice presented in El-Basyouny and Sayed (2009).

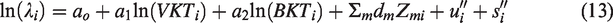

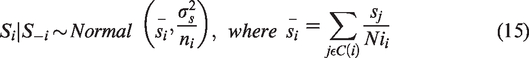
The spatial variation is assessed according to equation (16) (Aguero-Valverde and Jovanis, 2008)

The FB model estimation follows El-Basyouny and Sayed (2009); for more details, please refer to the FB model estimation section of the online Supplementary Material. The model development process followed is like that of the BKT model development process.
Bayesian mediation analysis is employed to assess the mediated effects that bike network indicators may have on crashes through their effects on BKT by recognizing BKT as a mediator. Kamel et al. (2019) defined mediation analysis as follows: Mediation analysis is used to estimate how a variable transmits its effects to another variable through a certain mediator. These effects could be direct only, indirect only (through a certain mediator), or both direct and indirect. Fully mediated variables are variables with indirect effect only.

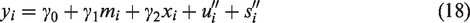

Results and discussion
Bike Kilometers Traveled models
Table 1 presents the developed BKT FB models A–G. All the variables are statistically credible at the 5% or 10% level. Degree, betweenness, closeness, and straightness graph centralities have negative associations with the BKT. This is logical as high network centrality indicates low inter-connectivity and accessibility (Zhang et al., 2015). Furthermore, Marshall and Garrick (2010) found that gridded street networks (low centrality networks) were associated with higher walking and biking.
Full Bayes Bike Kilometers Traveled models (A–G).
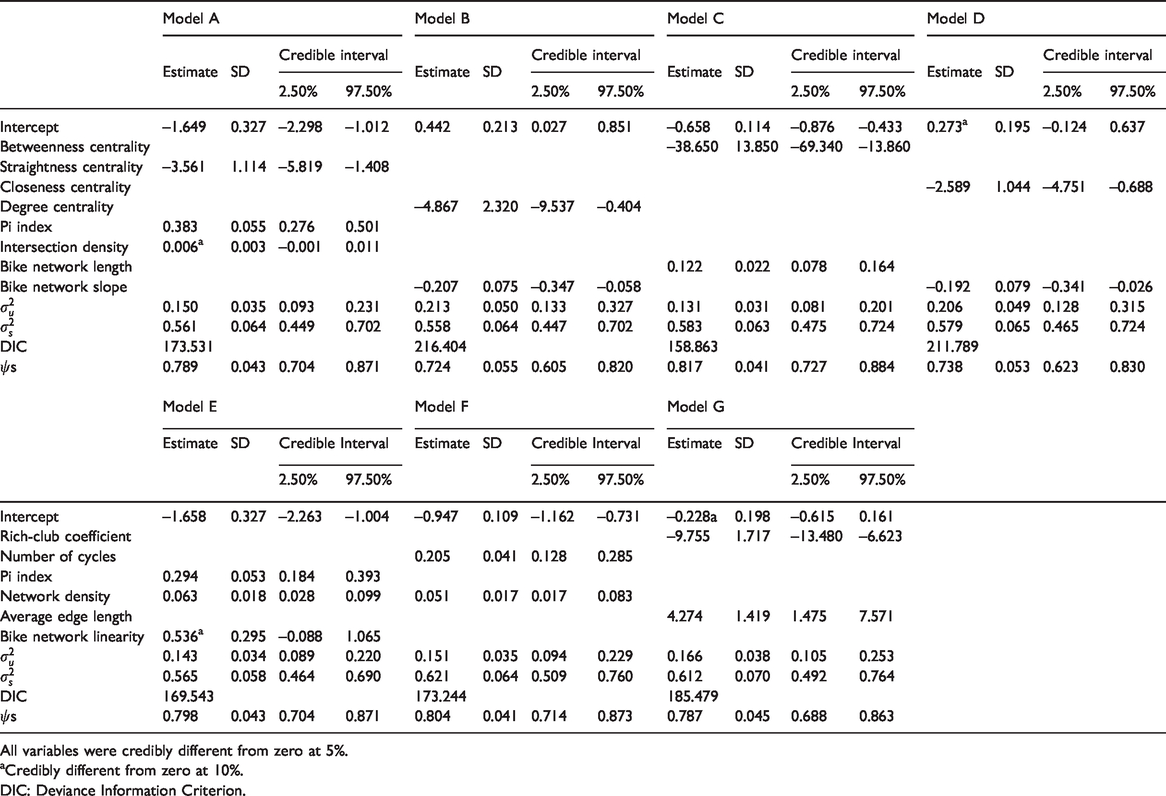
All variables were credibly different from zero at 5%.
aCredibly different from zero at 10%.
DIC: Deviance Information Criterion.
The rich-club coefficient is negatively associated with BKT. In other words, networks where highly connected nodes are connected (“The rich get richer”) have low bike traffic. When systemically connected nodes are getting more connections, the network forces cyclists through traffic dense intersections (highly connected nodes). This situation may deter bikes, as it lengthens their trips. Also, cyclists may perceive it as a less safe network as it forces bikes toward intersections with many conflict points with road users.
The Pi index and the number of network cycles are positively associated with BKT. This is logical as developed networks encourage road users to cycle, which is consistent with previous findings (Buehler and Pucher, 2012; Dill and Carr, 2003; Nelson and Allen, 1997; Winters et al., 2016).
Intersection density and network density are positively associated with BKT, which is in line with previous studies (Berrigan et al., 2010; Marshall and Garrick, 2010; Osama et al., 2017; Schoner and Levinson, 2014) in which they showed that connectivity and density are positively associated with biking levels. Linearity and average edge length are positively associated with BKT. This is consistent with Schoner and Levinson (2014) and Osama et al. (2017), where they showed that a continuous network with fewer hindrances is positively associated with biking levels. The bike network length is positively associated with BKT, which is intuitive, as more bike infrastructure usually yields more bike trips (Buehler and Pucher, 2012; Dill and Carr, 2003; Nelson and Allen, 1997 ; Osama et al., 2017; Winters et al., 2016). The average weighted slope is negatively associated with BKT; this is also intuitive and consistent with previous studies (Hood et al., 2011; Osama et al., 2017; Winters et al., 2016), as steeper slopes work as a deterrent for bikes.
The assortativity coefficient and the average clustering coefficient have non-credible negative and positive associations with the BKT, respectively. The DIC of Model C is credibly lower than the other models as the difference between Model C and the second-best model (Model E) is 10.680. This indicates that Model C has the best performance compared to the other models developed here. Future studies should investigate the best-fitted model after including other relevant variables such as land use, demographics, and the street network. The variation associated with the spatial term
Correlated variables were restricted from being included in the same model to avoid multicollinearity, which may lead to biased and insignificant estimates. Multicollinearity makes it difficult to determine which variables (out of the correlated variables) are causal and which are the result of illusory correlation (Washington et al., 2010).
Bike–vehicle crash models
Table 2 presents the FB crash models 1–4. All the variables are statistically credible at the 5% or 10% levels. Vehicle kilometers traveled and BKT are found to be positively associated with bike–vehicle crashes. This is expected and consistent with previous research (Hamann and Peek-Asa, 2013; Kaplan and Prato, 2015; Miranda-Moreno et al., 2011; Strauss et al., 2013).
Full Bayes bike–vehicle crash models 1–4.
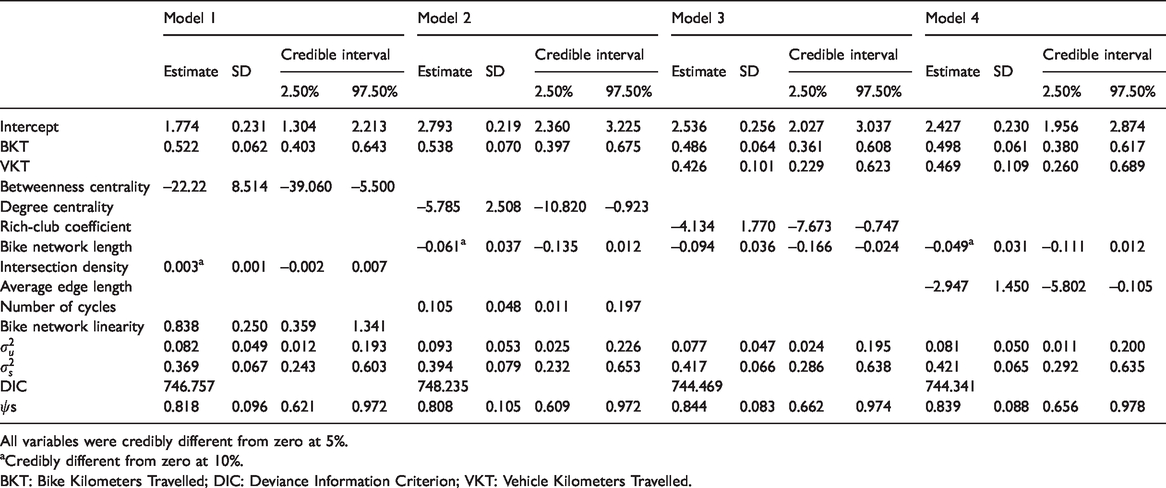
All variables were credibly different from zero at 5%.
aCredibly different from zero at 10%.
BKT: Bike Kilometers Travelled; DIC: Deviance Information Criterion; VKT: Vehicle Kilometers Travelled.
The betweenness and degree centralities have a negative association with bike–vehicle crashes. This is consistent with previous research (Zhang et al., 2015) and largely intuitive. A network with low centrality indicates high inter-connectivity and accessibility. High connectivity promotes vehicle accessibility that encourages intra-zonal trips, which take place through collectors and local roads instead of arterial roads. Since collectors and local roads are usually designed for low volume and low-speed traffic, therefore, combining this traffic with local bike traffic has been shown to impact road safety negatively (Lovegrove and Sayed, 2006).
The rich-club coefficient has negative associations with bike–vehicle crashes. One possible explanation is that cyclists are forced onto major links and nodes where usually risk mitigation measures are applied. However, such results need to be further investigated with out-of-sample or longitudinal data.
The number of cycles has a positive association with bike–vehicle crashes. These results indicate that network complexity decreases bike safety. This may be attributed to complex and developed networks creating more conflict points between vehicles and bikes.
The intersection density has positive associations with bike–vehicle crashes. This is expected and consistent with previous research (Siddiqui et al., 2012; Strauss et al., 2013; Wei and Lovegrove, 2013; Osama and Sayed, 2016; Chen et al., 2018). The positive association of intersection density with bike–vehicle crashes may be attributed to the fact that bike–vehicle interactions are high at the intersections, which would lead to increased crash risk. The average edge length has a negative association with bike–vehicle crashes. The results imply that elongated paths have links with fewer intersections and are safer for bikes. This agrees with the previous study conducted by Quintero et al. (2013) in which they explore the Metro Vancouver transit network. Moreover, the increase in linearity is correlated with an increase in bike–vehicle crashes, which may be accredited to the propensity of vehicles and bikes to increase their speed on straight links, which would increase bike–vehicle crash risk. The bike network length has a negative association with bike–vehicle crashes. This is consistent with previous studies’ findings, where it is concluded that more bike infrastructure would increase bike safety (Kaplan et al., 2014; Prato et al., 2016; Rome et al., 2014).
The straightness and closeness centralities as well as the assortativity coefficient have non-credible negative associations with bike–vehicle crashes. The Pi index, average clustering coefficient, network density, and weighted slope have non-credible positive associations with bike–vehicle crashes. Comparing the DIC values for the developed models indicates that there is no significant difference in model performance between the developed models. Like the BKT model,
Several bike network indicators (centrality, complexity, connectivity, directness, and topography) are credibly associated with BKT, and BKT is credibly associated with bike–vehicle crashes. BKT works as a mediator (mediating an impact of bike network indicators on bike–vehicle crashes) while the bike network indicators have mediated effects (indirect effects) on bike–vehicle crashes. To compare bike network indicators’ direct effects on bike–vehicle crashes and total effects (the aggregation of the direct and indirect effects), the indirect effect of bike network indicators on bike–vehicle crashes was evaluated. Mediation analysis shows that some bike network indicators have different direct and indirect effects on bike–vehicle crashes while other indicators have a consistent effect on bike–vehicle crashes, as shown in Table S3 in the online Supplementary Material. However, bike network indicators’ direct and total effects have the same impact direction (estimates’ sign) on bike–vehicle crashes.
Conclusion and summary
The study developed zone-level BKT models and bike–vehicle crash models using FB techniques incorporating spatial effects. A set of network theory indicators were introduced to quantify bike network features. The bike network indicators were divided into seven categories: centrality, assortativity, complexity, robustness, connectivity, directness, and topography.
The developed BKT models showed that bike network centrality, assortativity, and weighted slope have a negative association with BKT, while bike network directness, length, complexity and development, and connectivity have a positive association with BKT. The developed crash models show that the bike network length, centrality, assortativity, and continuity have negative associations with bike–vehicle crashes. On the other hand, bike network complexity and development, connectivity, and linearity have positive associations with bike–vehicle crashes.
The results indicate that increases in bike network length and network continuity are expected to increase BKT and decrease bike–vehicle crashes. On the other hand, while enhancing zone attractiveness to bikes by adjusting bike network centrality, assortativity, complexity, connectivity, and linearity, network planners should be careful as these indicators have a contradictory effect on bike safety. Therefore, adjusting these network indicators should be accompanied by risk mitigation measures.
This study comes with some limitations. The network theory indicators investigated in this study describe the bike network’s infrastructure, but they do not account for the built environment context surrounding the bicycle network, such as land use, socioeconomic factors, and road facilities. Osama et al. (2017) have studied the impact of land use, socioeconomic factors, and road facility variables on bike–vehicle crashes using the same data set. In other words, this study is limited to quantification of bike lanes (on-street and off-street bike lanes), without consideration of the surrounding facilities (e.g. bike racks, shoulder location and other characteristics, on-street car parking, etc.). This study treated off-street and on-street bike lanes interchangeably as they provide a designated space for bikes. However, cyclists may value (or treat) these facility types differently. This study considered only bike–vehicle crashes due to data limitations. Investigating other types of crashes such as bike–bike or bike–pedestrian crashes would be beneficial. The data used in the study are from a medium–low bike-use community. Therefore, studies are needed from cities and regions with complete bikeway networks and higher bike-use communities, most probably in European countries, to further investigate the impact of bike network infrastructure on biking activity level and safety. Future research should investigate the association of the presented network indicators with motorists’ safety and ridership, as well as pedestrians’ safety and walkability.
Supplemental Material
sj-pdf-1-epb-10.1177_2399808320964469 - Supplemental material for The impact of bike network indicators on bike kilometers traveled and bike safety: A network theory approach
Supplemental material, sj-pdf-1-epb-10.1177_2399808320964469 for The impact of bike network indicators on bike kilometers traveled and bike safety: A network theory approach by Mohamed Bayoumi Kamel and Tarek Sayed in Environment and Planning B: Urban Analytics and City Science
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.