
Abstract
Knowledge graphs (KGs) are published across diverse repositories using heterogeneous metadata models that vary in their descriptive elements, level of detail, vocabularies, and support for semantic interoperability, in part due to the absence of a standardized specification. This lack of consistency in metadata practices hinders effective discovery and reuse of KGs. To address this gap, we present a KG metadata specification and validation framework designed to foster structured, FAIR-aligned KG descriptions. Developed through a community-driven process, the specification defines 33 metadata elements formalized using the Shapes Constraint Language (SHACL) to enable automated validation. We applied the framework to metadata from 1,573 datasets in the Linked Open Data Cloud by mapping its 17 metadata fields to those in our specification. This mapping demonstrated the specification’s compatibility with the largest Linked Data repository and validation process revealed common issues and areas for improvement in metadata quality. Furthermore, we demonstrated how metadata can be published in a way that enhances its visibility for end users and its discoverability by search engines, achieving full compliance with FAIR-Checker evaluations through the publication of specification-conformant metadata for the Food Health Claims KG. The framework provides a foundation for KG publishers, repository managers, and researchers, promoting uniform, high-quality metadata practices and advancing FAIR principles within the KG community.
Introduction
Knowledge graphs (KGs) are data structures that represent real-world concepts or objects as nodes and their relationships as edges. They are useful for integrating and analyzing heterogeneous data (Hogan et al., 2021). KGs are becoming widely used across diverse domains such as education (Abu-Salih & Alotaibi, 2024; Fettach et al., 2022), healthcare (Cui et al., 2023), and artificial intelligence (Lecue, 2020; Peng et al., 2023), supporting systems such as recommender engines (Guo et al., 2020), question answering (Saxena et al., 2021), and information retrieval (Dietz et al., 2018; Reinanda et al., 2020). Their ability to represent rich, interconnected, and semantically diverse data makes KGs a powerful tool for data integration and analytics (Mohamed et al., 2025). However, this structural complexity also introduces challenges in understanding, navigating, and reusing their content effectively (Jayaram et al., 2015). Addressing such complexity requires high-quality metadata that can guide users and systems in understanding the content of a KG.
In practice, KGs are published across a wide range of repositories, such as the Linked Open Data (LOD) Cloud 1 and the KGHub KG Registry, 2 using heterogeneous metadata models. These models differ in their descriptive elements, level of detail, choice of vocabularies, and support for semantic interoperability. Several studies report that KG metadata are often incomplete or contain errors (Assaf et al., 2015; Debattista et al., 2018; Mohammadi et al., 2022). Such limitations hinder KG discovery, comparison, and reuse, and ultimately restrict alignment with the FAIR principles (Wilkinson et al., 2016). Despite the growing importance of KGs, the lack of consistent and high-quality metadata remains an open challenge.
To support dataset and resource description, several established metadata vocabularies are commonly used. The Data Catalog Vocabulary (DCAT; W3C, 2014) and Dublin Core Metadata Terms (DCTerms; Dublin Core Metadata Initiative, 2012) provide generic metadata for datasets and resources. The Vocabulary of Interlinked Datasets (VoID; W3C, 2011) focuses on Resource Description Framework (RDF) dataset statistics and interlinking, while Schema.org (Schema.org, 2024) enables dataset-level descriptions optimized for web discoverability. Provenance information can be expressed using the Provenance Ontology (PROV; W3C, 2013). In addition, the Metadata for Ontology Description and Publication (MOD) vocabulary (Dutta et al., 2015) supports ontology reuse by providing structured metadata tailored to ontology users. Beyond vocabularies and profiles, tooling such as rdf-config (rdf-config) demonstrates how KG metadata can be generated according to a particular specification, including the provision of example SPARQL queries.
Although these vocabularies address important aspects of dataset description, interlinking, statistics, and provenance, they were designed with distinct scopes and assumptions. When applied independently or without explicit constraints, they do not provide a complete or coherent solution for the diverse and practical requirements of KG metadata. In particular, they do not provide a KG-specific specification that defines a community-agreed set of required metadata elements together with enforceable validation constraints. As a result, KG metadata descriptions remain highly variable in quality and coverage.
Recognizing that no single vocabulary is sufficient to comprehensively describe RDF datasets, the W3C Healthcare and Life Sciences (HCLS) Community Group proposed a dataset description profile (Dumontier et al., 2016) that integrates multiple RDF vocabularies. This profile provides a strong foundation for RDF dataset description and promotes best practices through vocabulary reuse. However, the HCLS profile does not explicitly address several KG-specific features that are highly valuable in practice. These include, for example, metadata describing sample SPARQL queries, which provide concrete entry points for exploring a KG’s structure and content, as well as metadata describing REST API endpoints, which facilitate programmatic access and integration with applications. In addition, the HCLS profile is based on earlier versions of DCAT, whereas newer versions enable more fine-grained role attribution and richer metadata modeling. These limitations motivate the need for a more expressive and comprehensive approach to KG metadata specification.
In this work, we present a KG metadata specification and validation framework that builds upon the HCLS profile and extends it with additional elements and vocabularies tailored to KG-specific functionalities. Following established Semantic Web best practices, we deliberately reuse and combine well-adopted vocabularies rather than introducing a new one, as vocabulary reuse has been shown to improve interoperability and foster community adoption (Dumontier et al., 2016; Wilkinson et al., 2016). Where applicable, vocabulary terms are mapped to their Schema.org equivalents to enable indexing and discovery by services such as Google Dataset Search, thereby enhancing dataset findability. The specification was developed through a community-driven process using a collaborative spreadsheet, and its elements and constraints are formalized using the Shapes Constraint Language (SHACL) to support automated validation. We compare and map the proposed specification to the LOD Cloud metadata schema and apply SHACL validation to the metadata records of LOD Cloud datasets to identify common quality issues. Finally, we demonstrate the applicability of the framework by publishing and validating the metadata of a real-world KG from the Food Health Claims project (Celebi et al., 2024). The framework is useful for enhancing the quality of KG metadata, improving the discovery and aggregation of metadata, and ultimately fostering the reuse of KGs.
The remainder of this paper is organized as follows: Section 2 describes the method. Section 3 presents the specification and LOD Cloud metadata evaluation. Section 4 demonstrates the publication of Food Health Claims KG metadata in a FAIR-compliant manner. Section 5 compares the specification to existing models, interprets the results, and discusses limitations and future work. Finally, Section 6 summarizes the main contributions and findings.
Method
The metadata specification was collaboratively developed during a three-day workshop 3 organized as part of the COST Action 4 on Distributed KGs. Thirteen Experts in KG development, metadata curation, and semantic technologies contributed to defining the essential elements needed to thoroughly describe KGs. The initial version was captured in a collaborative spreadsheet and later refined and formalized into SHACL (W3C, 2017) during the FedQuery Workshop 5 in 2024. The following describes the workflow that led to the final KG metadata specification and its associated validation shapes.
KG Metadata Specification
The aim was to define a set of metadata elements that provide a complete description of KGs while remaining aligned with existing schemas to maximize interoperability and adoption. The development process followed an iterative, consensus-based workflow: Brainstorming KG-Specific Metadata Elements: Experts collaboratively discussed the scope of information needed to comprehensively describe KGs for both human and machine use, focusing on aspects such as discoverability, interoperability, accessibility, and reusability in line with the FAIR principles. As part of this process, participants reviewed existing KG repositories and metadata models (e.g., HCLS, DCAT, VoID, MOD, Schema.org, and the LOD cloud) to identify common best practices and areas where KG-specific requirements were missing. This step revealed several gaps that were not well supported by existing models, including the need for metadata elements such as example SPARQL queries, REST API endpoints, visual representations of the KG schema, and fine-grained provenance roles. Selecting Vocabularies and Data Types: For each metadata element, we assigned an appropriate vocabulary IRI or data structure, reusing RDF terms from the reviewed schemas and vocabularies. Where a Schema.org equivalent was available, it was included alongside the primary RDF term to support broader adoption and enable indexing by services such as Google Dataset Search. Consensus and Minimum Set Definition: Proposed elements were iteratively discussed and refined until consensus was reached. For each element, the purpose, data type, and cardinality were defined. In addition, we classified elements as mandatory or optional based on their relevance to core metadata functions such as identification, access, licensing, provenance, and interoperability, which are key aspects of the FAIR principles. The set of mandatory elements establishes the minimum requirements for a high-quality KG description. Specification Illustration: To test the utility and validity of the specification, we created metadata for Wikidata (Vrandečić & Krötzsch, 2014). We chose Wikidata because it is widely used, openly accessible, and familiar to the community.
KG Metadata Validation
To enable automated validation of KG metadata, each element in the proposed specification was formalized using SHACL (W3C, 2017). These SHACL shapes define constraints such as cardinality and data types, establishing clear validation rules. To validate the SHACL shapes, we performed a manual test using a representative metadata instance based on Wikidata. We iteratively modified individual values and reran the validation to check whether constraint violations occurred as expected, and valid data passed successfully.
LOD Metadata Validation
To assess the specification’s compatibility with established metadata practices, we map it to the LOD Cloud metadata model.
6
Out of 17 fields in LOD Cloud metadata model, 13 had direct semantic matches: title, description, website, owner, contact_point, triples, license, namespace, DOI, image URL, keywords, domain, and SPARQL. The remaining four: example, links, full_download, and other_download required closer inspection and examination of their values. This mapping process was implemented in a Python script, which parsed the original JSON metadata and transformed it into a Turtle file containing RDF vocabularies. The resulting RDF metadata was then validated against our SHACL-based constraints using the PySHACL library (Sommer, 2019), allowing us to assess its conformance with the proposed specification.
Results
KG Metadata Specification
The proposed KG Metadata Specification defines 33 core elements, reusing terms from 13 well-established vocabularies (Table 1). Each element is described by a set of attributes: whether it is mandatory, its cardinality, the associated RDF property, any mapping to Schema.org, the expected value type, its purpose, and an illustrative value drawn from Wikidata.
Vocabularies Reused in the Metadata Specification.

Vocabularies Reused in the Metadata Specification.
The complete specification is maintained in a collaborative spreadsheet. For clarity, Table 2 presents a streamlined version containing the most essential columns, while Figure 1 shows a fully detailed entry for the element dct:title. In this example, the cardinality constraint specifies that the title must appear at least once but may have multiple values (e.g., alternative or multilingual titles). The allowed data types are either a language-tagged string ( rdf:LangString ) or a simple string (xsd:string), and the purpose is to provide the formal name of the KG.

An example element from the specification spreadsheet.
Overview of all 33 Metadata Elements Defined in the Proposed KG Metadata Specification, With Their Descriptions, Corresponding Properties, and Schema.org Vocabularies.

Note. Bold fields are mandatory elements. KG = knowledge graph; VoID = vocabulary of interlinked datasets.
Of the 33 elements, 14 are designated as mandatory (shown in bold in Table 2): rdf:type , dct:title , dct:identifier , dct:description , foaf:page , prov:qualifiedAttribution , dct:issued , void:vocabulary , dcat:distribution , dcat:version , dct:license , dcat:keyword , dct:language , and dct:accessRights . These elements were chosen for their essential role in supporting key aspects of the FAIR principles. For instance, dct:title and dct:description are fundamental to identifying the dataset, while dcat:distribution ensures users can access it. Provenance and licensing elements, such as prov:qualifiedAttribution , dct:license , and dct:issued , are critical for enabling responsible reuse and ensuring legal clarity. Other elements, such as void:vocabulary , dcat:keyword , and dct:language , support dataset contextualization, filtering, and interoperability, and are therefore mandatory for FAIR-aligned KG descriptions.
Figure 2 illustrates the structural relationships among the components of the specification. At its core is the dcat:Dataset entity, which incorporates all 33 metadata elements proposed for describing KGs. Many of these elements are represented as IRIs or literals (e.g., strings or other datatypes), while others reference structured entities that allow more detailed descriptions. For example, dcat:servesDataset links to the dcat:DataService entity, which captures programmatic access points through properties such as dcat:endpointURL and dcat:endpointDescription . Likewise, the dcat:distribution element connects to the dcat:Distribution class, where additional details about downloadable files are specified, including their title, description, media type, download URL, and access URL.
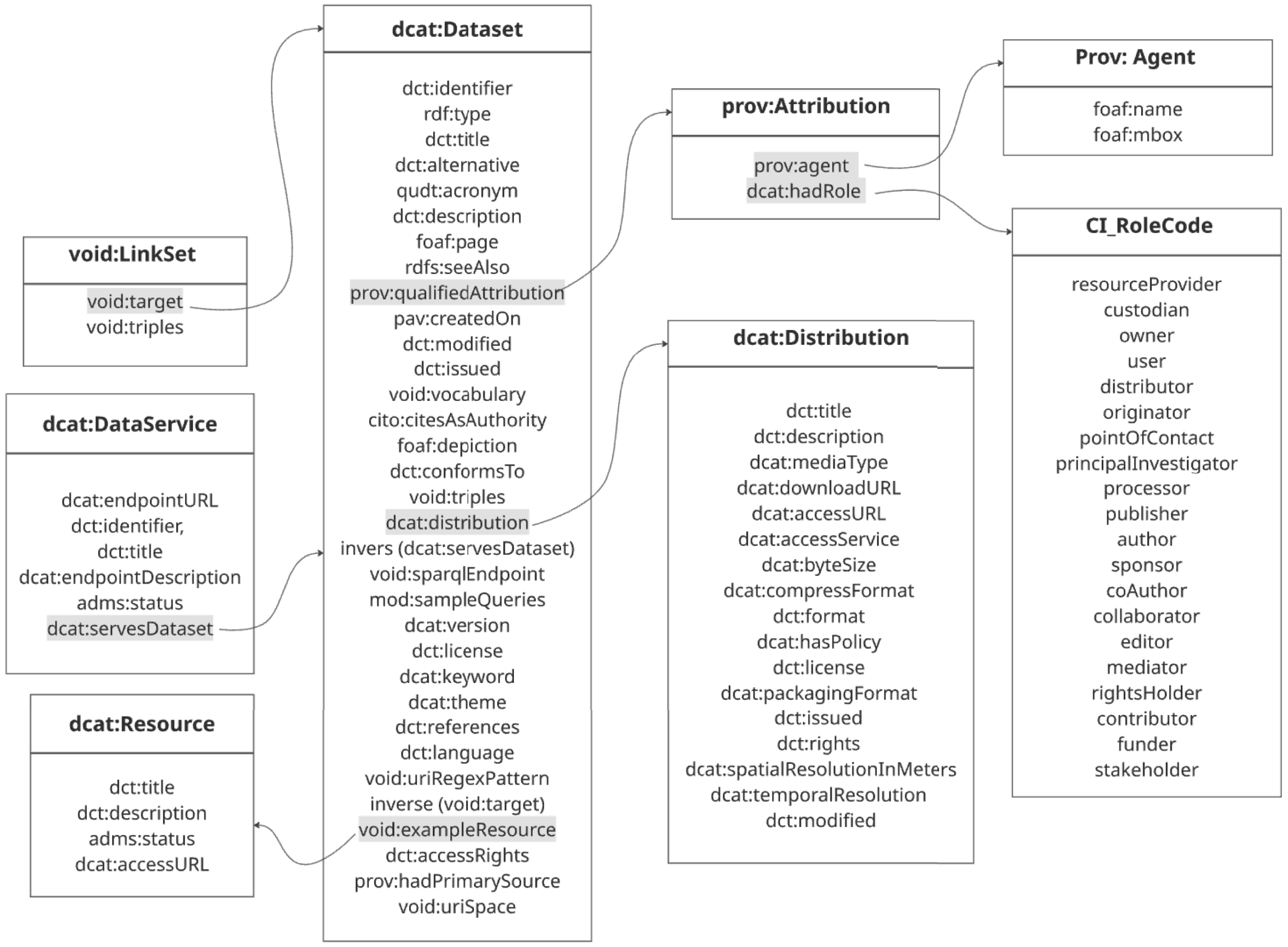
Structural relationships between components of specification.
A key design feature is the adoption of the flexible prov:qualifiedAttribution model. In contrast to simpler provenance fields that record only a dataset’s creator, this model enables detailed attribution of multiple agents (e.g., owners, funders, authors, and publishers) together with their specific roles, making use of the CI_RoleCode vocabulary. 8 This approach supports more precise credit assignment, increases transparency, and facilitates complex provenance tracking in KG publishing workflows.
Finally, void:Linkset provides a mechanism for explicitly linking datasets by specifying the target dataset along with the number of triples involved. A complete example of specification-conformant metadata for Wikidata is presented in Listing 2?>Listing 2 in Appendix A.
To enable automated validation of metadata elements and their relationships, all 33 elements in the specification were formalized using SHACL. For each shape, SHACL constraints define the property path (sh:path), expected datatype (sh:datatype), RDF node kind (sh:nodeKind), and cardinality (sh:minCount, sh:maxCount), as well as a human-readable description of the property and an example value to support implementers (sh:description, skos:example). Listing 1?>Listing 1 illustrates an example using the dct:title property, which must appear at least once (sh:minCount 1) and must have a value that is either a plain string (xsd:string) or a language-tagged string (rdf:langString).
As shown in Figure 2, several metadata elements (e.g., dcat:distribution , void:sparqlEndpoint , and prov:qualifiedAttribution ) reference structured entities. These were modeled as separate SHACL shapes to capture their internal properties and constraints. The complete SHACL implementation 9 defines four shapes: DCATDatasetShape, which covers the full set of 33 metadata elements describing a KG; AgentShape, which captures roles and responsibilities via prov:qualifiedAttribution ; DCATDataService, which describes programmatic access points such as SPARQL endpoints; and LinksetShape, which specifies dataset-to-dataset links. Each shape constrains the properties relevant to its corresponding entity. For example, AgentShape validates attributes such as foaf:name and foaf:mbox ; DCATDataService includes dcat:endpointURL and dcat:endpointDescription ; and LinksetShape requires void:target and void:triples.

LOD Metadata Validation
To demonstrate the utility of SHACL-based validation in detecting violations against defined constraints, we validate LOD Cloud metadata against the proposed SHACL-based metadata specification. The 2025 LOD cloud contains 1,573 datasets and includes 17 metadata fields in its catalog. As described in Section 2.2.1, we map elements of the LOD metadata schema to the vocabularies defined in our specification and generate a Turtle file compatible with the validation framework.
Table 3 summarizes the mapping between LOD metadata fields and the proposed specification. For each element, it also provides the total number of instances, the number of datasets in which it appears at least once, and the corresponding number of validation violations. The validation identified a total of 22,349 violations. The majority of these, 16,507 cases, were due to missing mandatory values (“less than 1 values”). For example, the dct:license element was present in 835 datasets but missing from 738, resulting in 738 validation errors. Other frequently missing mandatory elements included foaf:page , dcat:keyword , foaf:name , and foaf:mbox (for owner and contact point roles), as well as distribution-related fields such as dcat:downloadURL , dcat:accessURL , dcat:mediaType , and descriptive fields such as dct:title , dct:description , dcat:version , dct:language , dcat:distribution , dct:issued , and void:vocabulary .
Mapping of Linked Open Data (LOD) Metadata Elements to Specification Fields.
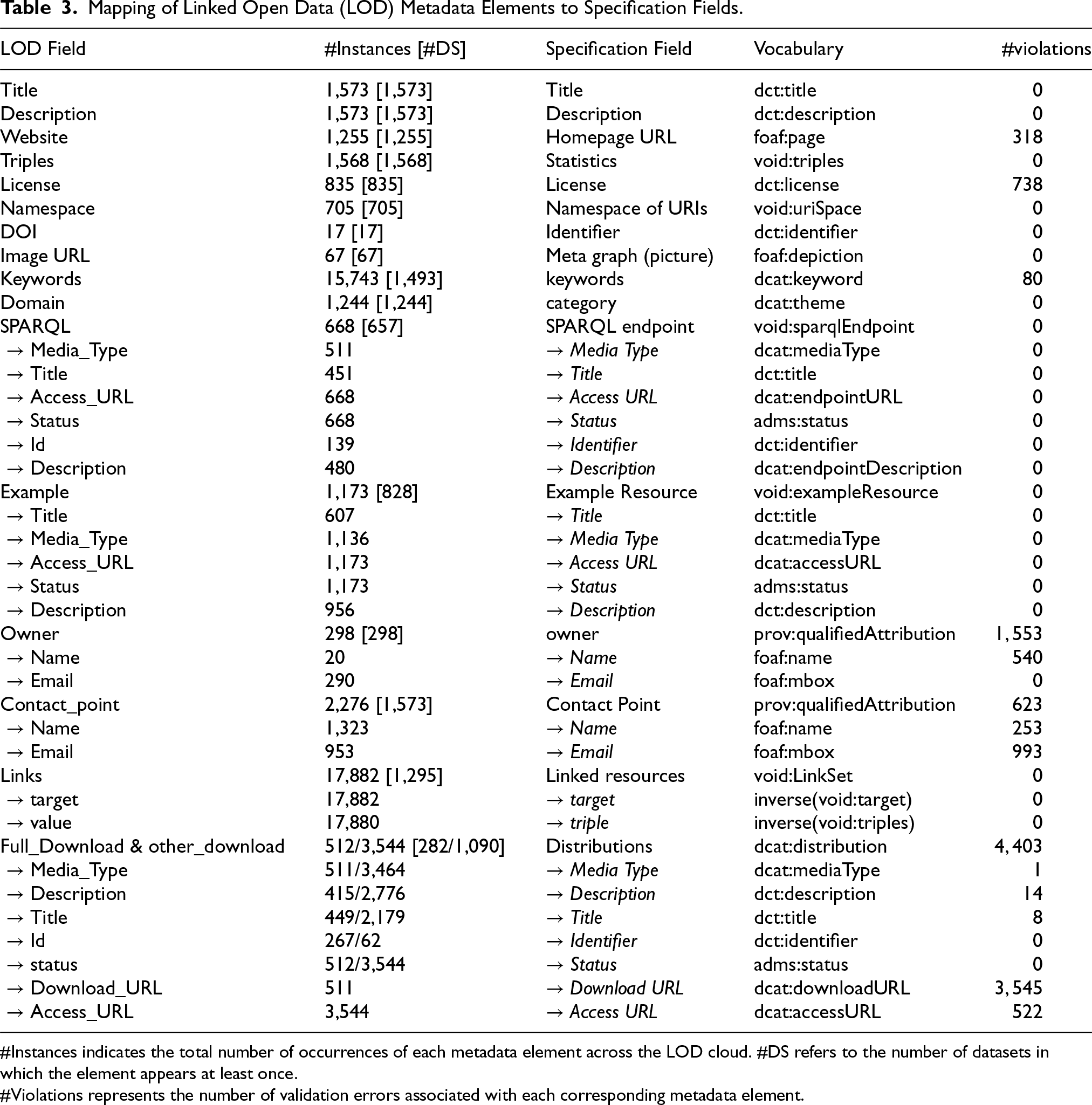
Mapping of Linked Open Data (LOD) Metadata Elements to Specification Fields.
#Instances indicates the total number of occurrences of each metadata element across the LOD cloud. #DS refers to the number of datasets in which the element appears at least once.
#Violations represents the number of validation errors associated with each corresponding metadata element.
Some missing elements can be partially explained by the design of the LOD Cloud metadata schema. For instance, elements such as dcat:keyword are optional in the 2025 LOD Cloud metadata form, 10 which helps explain their frequent absence across datasets. However, similar explanations do not apply to other missing elements, such as license and distribution-related fields, which are defined as mandatory in the schema yet are frequently absent in practice. The available metadata does not provide sufficient evidence to determine whether these missing values result from historical changes in the schema, incomplete enforcement at submission time, or limitations in the tooling used to create and validate metadata.
The remaining 5,842 violations were caused by structural mismatches (“Value does not conform to Shape”). These occurred in composite elements where nested structures did not match the specified constraints. The most frequent sources of violations were Distribution, Owner, and Contact Point entities, which lacked required internal properties. All conformance errors were linked to missing mandatory sub-elements, and in such cases SHACL reported violations both at the sub-element and at the parent shape level. No datatype-related violations were observed, because during the conversion from JSON to Turtle, malformed URIs, incorrect data types, and other syntax errors were corrected, while missing values were not imputed.
Publication of KG Metadata
Creating and validating high-quality metadata is an essential step toward improving the FAIRness of a KG. To further enhance FAIRness, metadata should be made accessible through channels that support both human-readable presentation and machine-readable indexing. In this section, we apply the proposed Metadata Specification and Validation Framework to the Food Health Claims KG 11 (Celebi et al., 2024) and describe how the resulting metadata was published to enhance its visibility for end users and its discoverability by search engines. This KG, developed by one of the authors, captures structured representations of 260 authorized health claims, based on scientific assessments of food ingredients and their health effects.
The metadata for the Food Health Claims KG was created and validated using the proposed specification. We primarily used terms from the schema.org vocabulary to maximize visibility through web-based indexing services, and supplemented these with additional RDF vocabularies to fully represent all 33 metadata elements defined in our framework. The resulting metadata was expressed in JSON-LD format and embedded in an HTML page that also provides a human-readable overview of the KG. This page was deployed using GitHub Pages under a publicly accessible URL 12 . As recommended by the FAIR principles, and specifically sub-principle F1 (Wilkinson et al., 2016), the metadata includes a globally unique and persistent identifier. To implement this, a dedicated w3id.org namespace 13 was registered. This persistent URI redirects to the metadata page, allowing the value used in the schema:identifier field to remain stable over time, even if the hosting location changes. We then validated the generated metadata using SHACL 14 to ensure conformance with the specification. The complete script containing specification-conforming metadata for Food Health Claims KG is provided in the listing 3 in Appendix B.
To verify whether search engines can correctly interpret the embedded structured data, the metadata page was tested using Google’s Rich Results Test. 15 After successful validation, the site was registered in Google Search Console 16 to confirm site ownership and request indexing. Within a few days, the Food Health Claims KG metadata appeared among the top results in Google Dataset Search, 17 significantly improving its discoverability. The scripts and deployment instructions are available in the project’s GitHub repository.
KG Metadata FAIRness Assessment
In addition to enhancing web-based discoverability, the published metadata was evaluated using the FAIR-Checker service 18 (Gaignard et al., 2023; Rosnet et al., 2021), which automatically assesses metadata against FAIR principles (Wilkinson et al., 2016): Findable (F), Accessible (A), Interoperable (I), and Reusable (R). Each principle is divided into numbered sub-principles, such as F1 or F2, that define specific requirements including the use of persistent identifiers or the inclusion of structured metadata. FAIR-Checker further divides these into individual machine-checkable tests, identified by adding a letter suffix (e.g., F1A or F1B), where each letter corresponds to a distinct criterion under the same sub-principle.
The Food Health Claims KG metadata achieved a score of 100% (12 out of 12), with all tested criteria satisfied. The criteria covered all four FAIR principles: for findability, unique identifiers (F1A), persistent identifiers (F1B), structured metadata (F2A), and use of shared vocabularies (F2B); for accessibility, open resolution protocols (A1.1) and authorization or access statements (A1.2); for interoperability, machine-readable formats (I1), shared ontologies (I2), and external links (I3); and for reusability, a licence (R1.1), provenance information (R1.2), and compliance with community standards (R1.3) were provided. These tool-generated metrics confirm that the proposed specification and publication approach satisfies the FAIR principles.
Discussion
This study introduced a metadata specification for KGs, consisting of 33 elements formalized using SHACL to enable automated validation. The design process was community-driven, involving experts in KG development to establish best practices informed by the FAIR principles (Wilkinson et al., 2016) and the analysis of existing metadata practices and Schemas. The demonstration with the Food Health Claims KG illustrated that the specification can be readily implemented by KG publishers and that it produces metadata which achieves full compliance with FAIR principles according to FAIR-Checker evaluations, as shown in Section 4.2.
The FAIR-Checker evaluation showed that the metadata produced with our specification satisfies all machine-checkable FAIR criteria. However, FAIR-Checker currently applies a predefined set of generic tests and does not consider KG-specific validation rules. Our SHACL shapes help to address this gap by enabling more detailed checks on the structure and content of metadata. In this way, FAIR-Checker and SHACL are complementary: the former verifies compliance with high-level FAIR principles, while the latter ensures conformance with a community-agreed schema. Looking ahead, integrating SHACL-based validation into FAIR assessment services such as FAIR-Checker could offer a more comprehensive approach that combines general FAIR criteria with domain-specific requirements.
In the broader metadata quality landscape, initiatives such as the EU Metadata Quality Assurance framework of the European Data Portal provide automated checks for metadata completeness and consistency in open data catalogs. Our work complements these efforts by improving metadata quality earlier in the process, through a KG-specific specification and SHACL-based validation that makes requirements explicit and machine-checkable at publication time.
Compared to existing metadata schemas, our specification offers broader descriptive coverage while maintaining compatibility with established models. Validation against LOD Cloud metadata highlights three key aspects: (i) the specification fully accommodates all 17 metadata fields defined in the LOD Cloud schema, (ii) the associated SHACL schema is effective in detecting omissions and errors in LOD descriptions, and (iii) the specification introduces 16 additional metadata elements that extend beyond LOD Cloud’s coverage. These additions include fields such as Type, Alternative Title, Acronym, Other Pages, a more expressive attribution model for roles (e.g., creator, owner, and publisher), and temporal metadata such as Created, Modified, and Published dates. Further additions include Reference Article, KG Schema, REST API, Version, Language, IRI Template, Access Statement, and Source Datasets.
Compared to the HCLS profile, which provides a solid foundation for RDF dataset metadata and supports validation through ShEx, our specification extends coverage by introducing several practical elements that HCLS does not include. These elements are example SPARQL queries, REST API endpoints, visual representations of the KG, dataset acronyms, and fine-grained provenance roles. By incorporating these features, the specification enables richer metadata descriptions, improves programmatic access, and enhances transparency in attribution, while maintaining interoperability with existing standards. In practical terms, adoption of the proposed specification offers a standards-based template for both new KGs and the enhancement of existing ones. Its compatibility with established schemas lowers adoption barriers while its extended coverage enables more effective resource discovery and reuse.
The proposed specification provides a general and comprehensive set of metadata elements; however, certain use cases may still fall outside its scope. For instance, more technical information related to the methods used to create a KG, such as specific tools, workflows, or pipelines, is not explicitly captured. In addition, the specification does not currently include an element to indicate the underlying data model of a KG (e.g., property graph or RDF). This reflects a decision to prioritize the reuse of existing vocabularies rather than creating new ones. Another limitation is the continued reliance on manual metadata creation and publication, which may hinder the adaptability, accuracy, and consistency of the specification. Moreover, while the specification is currently formalized using SHACL, alternative shape languages such as ShEx could also be explored to improve readability and accessibility for different tooling ecosystems.
Future work will address these challenges by developing an automated pipeline for metadata creation, validation, and publication, enabling decentralized KG metadata that can be harvested into KG registries. In addition, we plan to investigate the use of large language models (LLMs) and retrieval-augmented generation (RAG) for automated metadata generation. In this work, the specification is applied to the Food Health Claims KG as a proof of concept; applying it to a wider range of KGs beyond a single case study is a direction for future work. Future work will also focus on broader community adoption and formal standardization of the specification. In particular, seeking endorsement through the W3C community and working groups would strengthen its status as a recognized standard for KG metadata. This endorsement would promote interoperability, encourage widespread adoption, and facilitate integration with existing web and linked data best practices.
Conclusion
In this paper, we introduced a Metadata Specification and Validation Framework designed to establish a robust foundation for standardized KG metadata practices and publication. Developed through a community-driven process, the framework defines 33 metadata elements and encodes them, along with their constraints, using SHACL shapes to enable automated metadata validation.
To evaluate its applicability, we mapped the LOD Cloud metadata to the proposed specification, validated it with SHACL, and analyzed the resulting violations. This assessment revealed gaps in existing LOD Cloud metadata, underscoring the need for richer and more consistent descriptions of KGs. As a case study, we applied the framework to the Food Health Claims KG, demonstrating how publishers can implement the specification to generate metadata that is indexable by Google and thereby improve discoverability. Evaluation with FAIR-Checker confirmed that metadata produced in this way achieves full compliance with the FAIR principles.
This work advances the state of practice in KG metadata by offering a specification that is interoperable with established models, extends their descriptive coverage, and provides verifiable FAIR compliance. As future work, we plan to develop an intuitive user interface for the specification, investigate the use of LLMs and RAG for automated metadata generation, and seek community and W3C endorsement to formalize the specification as a recognized standard. Through these efforts, we aim to foster the broader adoption of high-quality, FAIR-aligned metadata across the KG ecosystem.
Footnotes
Acknowledgments
We gratefully thank the participants of the workshop who contributed to the development of the metadata specification through their feedback and discussion: Manuel Paneque, Matthijs Sloep, Ilan Kernerman, Jinzhou Yang, Maxime Lefrançois, Katja Hose, Flavio De Paoli, Remzi Celebi, Erkan Yasar, and María del Mar Roldán. In particular, we are thankful to Maxime Lefrançois for his valuable and insightful comments, which significantly improved the quality and clarity of this work.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project has received funding from COST Action. Funding for M. Mohammadi is provided by the European Union’s Horizon 2020 research and innovation program under the Marie Skłodowska-Curie grant agreement no. 860801, as well as support from COST Action.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data and Code Availability
Notes
Appendix A. Wikidata Metadata
The following listings provide complete metadata examples, one in RDF/Turtle and one in HTML/Schema.org, demonstrating compliance with the proposed specification
Appendix B. Full HTML Script