
Abstract
Background:
Many researchers seek to measure people’s knowledge of and attitudes toward neurodiversity concepts and advocacy. In this systematic literature review, we characterize measures of neurodiversity knowledge and attitudes and summarize studies that have used such measures.
Methods:
This study was funded by a Boston College Ignite grant aandwas preregistered on Prospero, ID# CRD420251013298. We searched ERIC, Education Source, PsycINFO, Scopus, Web of Science, and Sociological Abstracts databases on March 11, 2025. We hand searched the journal Neurodiversity on June 11, 2025. Inclusion criteria were that studies were peer-reviewed, published in English, and included a neurodiversity knowledge or attitudes measure. For formal validation studies, we follow the COnsensus-based Standards for the selection of health Measurement INstruments (COSMIN) guidelines for describing and evaluating measurement properties and study quality. Procedures include the COSMIN Risk of Bias checklist, the COSMIN Good Measurement Properties to rate study results, and the Grading of Recommendations Assessment, Development, and Evaluation (GRADE) system for synthesis and presentation. For studies in which a neurodiversity knowledge and/or attitude measure was used but not formally validated, we used an abbreviated coding scheme to assess their basic characteristics and whether they were incidentally validated on any of the nine measurement properties.
Results:
We located 13 studies: four validation studies of four neurodiversity attitudes measures, and nine studies using a neurodiversity knowledge and/or attitudes measure. All four measures received “very low” GRADE ratings for all aspects of content validity, and no measure received more than two “high” ratings across all measurement properties. Only one measure received a high GRADE rating corresponding with positive evidence, and this was for internal consistency of the Autism and Neurodiversity Attitudes Scale.
Conclusions:
We cannot recommend any of the measures we examined for use in research, but our findings suggest that continued efforts at validating these measures could be promising.
Community Brief
Why is this an important issue?
Neurodiversity refers to a set of concepts and movements led by autistic and other neurodivergent people. There are different ways of describing neurodiversity, but many neurodiversity advocates agree that neurodivergence is natural and not a sign of disease, neurodivergent people need support and not cures, neurodivergent people should have rights, and neurodivergent people are disabled when society does not value or accommodate neurodivergence. Some researchers use assessments to determine how much people know and what they feel about neurodiversity concepts and advocacy. These assessments are important because they help researchers determine things such as whether people know enough about these concepts to be ready to do work to include neurodivergent people, or whether knowledge and attitudes have improved after intervention.
What is the purpose of the review?
Our purpose was to evaluate measures of neurodiversity knowledge and attitudes. We wanted to know how frequently researchers use measures such as these, and how good the measures are at determining what people know and feel about neurodiversity. If measures were not designed well, research results can be misleading.
What did the authors do to review the literature?
We used software to find and sort through research that has been published using neurodiversity attitudes and knowledge measures. We then used guidelines for evaluating studies designed to develop neurodiversity measures, called the COnsensus-based Standards for the selection of health Measurement Instruments (COSMIN) guidelines. These guidelines help researchers determine how well the measures work for nine different measurement properties. For studies that used a neurodiversity measure but were not designed to develop the measure, we used a simpler version of these guidelines.
What studies did the authors find?
We found 13 studies; four studies that were designed to develop and test the properties of neurodiversity attitudes measures, and nine studies that used a neurodiversity attitudes or knowledge measure, but were not designed to test its properties. One study belonged to both these groups.
In summary, what did those studies show?
We found some positive aspects of the measures, which are that they are easy to administer and free for researchers to use. We also found that the four studies designed to develop and test the properties of neurodiversity knowledge and attitudes measures received “very low” grades for most measurement properties. There were some properties that looked good for some measures, but none of the measures had good supporting evidence for more than one property.
What are the remaining gaps in the literature?
Researchers will need to do more work to develop measures that we can be sure assess the neurodiversity-related concepts and attitudes we intend to assess, produce consistent results, and are sensitive to changes in people’s knowledge and attitudes that may occur over time or as a result of participating in an intervention.
Based on this review, what do the authors recommend?
We cannot yet recommend that researchers use the neurodiversity knowledge and attitudes measures that have been developed so far. Instead, we encourage researchers to continue to work on improving these measures.
Introduction
Neurodiversity frameworks
The concept of neurodiversity was developed by autistic advocates in the early 1990s to describe their experiences of marginalization, and to guide emerging efforts to improve the social, political, and material conditions of neurodivergent people.1,2 Many scholars and movement leaders credit Jim Sinclair’s classical essay Don’t Mourn for Us as the first major publication to express ideas now central to neurodiversity frameworks. 3 Sinclair framed his essay as a letter challenging parents of autistic children to celebrate their children as they are, rather than grieve over imagined non-autistic children. This sentiment has evolved into a core principle that neurodivergence should be accepted as a way of experiencing the world, and not construed as a tragedy to be cured or eradicated.
The term neurodiversity can be applied in at least three ways 4 : (a) to describe human interactional, cognitive, and sensory differences thought to correspond with purported variations in neural organization (e.g., “neurotypes” 5 ); (b) to characterize frameworks for understanding neurodevelopmental disabilities (e.g., autism, attention-deficit/hyperactivity disorder, learning disability, and Tourette’s syndrome) that heavily borrow from social models of disability; and (c) to describe political advocacy movements aimed at securing rights and inclusion for neurodivergent people. However, many neurodiversity scholars recognize that these three applications are not easily separable. 6 While the major ideas behind neurodiversity scholarship and praxis originated largely from nonacademic neurodivergent people, researchers who focus on neurodivergent populations (including both neurodivergent and non-neurodivergent researchers) have begun to incorporate these ideas into their work. Especially over the last 5 years, many academics are now developing these frameworks alongside neurodivergent nonacademics.7,8
The proliferation of neurodiversity scholarship has substantially transformed research relevant to neurocognitive disabilities, including, for example, the introduction of a neurodiversity-focused, peer-reviewed academic journal. 9 Given that this work has been taken up across different constituencies (e.g., academics, self-advocates, allies, professionals), the central concepts and organizing principles have transformed and branched over time. Indeed, there are now several different versions of neurodiversity frameworks with substantively different definitions and commitments.7,10,11 For example, some neurodiversity scholars a advocate for securing inclusion and rights for neurodivergent people under current political systems. 12 In contrast, other scholars purport that neurodivergent people’s inclusion and rights are unlikely to be fully realized unless capitalist and imperialist political systems that prioritize productivity over human flourishing are radically transformed. 13 Scholars also disagree on the extent to which the “neuro” in neurodiversity should be emphasized as a central principle. Some assert that the brain basis of these disabilities is crucial for understanding the immutability of neurodivergence and for organizing coalitions of similarly disabled people under the neurodiversity umbrella,2,7,14 while others warn against neuroessentialism, in which differences are construed as inevitable manifestations of neurology despite the facts that social pressures act on behavioral presentation and not purported neurology, and neuroscientific evidence backing distinct neurologies is weak and rarely incorporated into neurodiversity scholarship.4,15,16 Finally, there is disagreement over how wide a net the neurodiversity umbrella should be cast, with some scholars arguing that the net should be as wide as possible to include acquired disabilities such as aphasia and traumatic brain injury, and mental health disabilities such as bipolar and schizophrenia,17,18 while others caution that a too-wide application could mean that communities who do not agree with basic neurodiversity principles are included. 6
Despite these differences, neurodiversity scholars and advocates tend to agree that: (a) neurodivergence should be regarded as natural forms of human variation that contribute to a sense of identity, rather than as diseases; (b) neurodivergent people need support and not cures (although neurodivergent people do sometimes seek cures for commonly co-occurring conditions such as epilepsy or gastrointestinal ailments); (c) neurodivergent people should be included in society and granted full human rights; and (d) disablement is not an inevitable outcome for many aspects of neurodivergence; it occurs when neurodivergence is not accounted for, accommodated, and/or valued in social contexts and/or the built environment (e.g., noisy classrooms, social norms that prioritize spoken language and other behavior associated with neurotypicality 2 ).
Measuring neurodiversity knowledge and attitudes
In addition to scholarly interest in neurodiversity frameworks, other professionals and lay people are now also aware of these concepts and may rely on them to better understand neurocognitive disabilities. They may further leverage neurodiversity frameworks to better include neurodivergent people into society and support their well-being. 19 Assessing people’s knowledge of, and alignment with, neurodiversity frameworks may give insight into social progress in contexts such as schools, work environments, clinics, and other areas of daily life.20,21 In addition, assessments could help researchers determine how neurodiversity knowledge and attitudes correlate with other variables (e.g., contact with disabled people, political beliefs, psychological distress,22,23 how they vary across contexts and groups (e.g., across genders or ethnicity), how they change across time (e.g., longitudinal analyses), and the extent to which they are malleable following neurodiversity-focused interventions. 24
To appropriately assess knowledge and attitudes, including about neurodiversity, researchers need to develop instruments that are valid, reliable, and responsive to change. 25 Validity has to do with the extent to which the measure assesses the construct it was designed to assess. Reliability has to do with the extent to which the measure consistently produces similar scores when used with similar people in similar contexts, with minimized measurement error (e.g., variation due to factors other than the “true” score on the measure). Responsiveness to change has to do with the ability of the measure to detect small changes that naturally occur over time, or that occur as a result of participation in an intervention. Producing sufficiently valid, reliable, and responsive instruments [see materials on the Open Science Framework (OSF) for a schematic describing these properties] requires formal research efforts aimed at developing, piloting, testing, and adjusting the measure as needed. Without these formalized efforts, researchers may disseminate misleading, uninterpretable, or unreplicable evidence regarding people’s knowledge and attitudes about neurodiversity.
Current study
The purpose of this systematic review is to characterize measures of neurodiversity knowledge and attitudes. For measures in which there are formal validation studies b available, we determine the following: their basic characteristics; the feasibility in using them; the populations in which they have been studied; and the quality of studies, reported findings, and an overall evaluation of confidence for each of the nine measurement properties (content validity, structural validity, internal consistency, cross-cultural validity/measurement invariance, hypothesis testing for construct validity, criterion validity, reliability, measurement error, and responsivity). To guide our description and evaluation of these measurement properties, we use tools created by the COnsensus-based Standards for the selection of health Measurement Instruments (COSMIN). COSMIN is an initiative that provides a comprehensive set of resources for researchers to evaluate and select direct-report measurement instruments.
For studies in which a neurodiversity knowledge and/or attitude measure was used but not formally validated, we will report on their basic characteristics, and whether they were incidentally validated on any of the nine measurement properties.
Methods
Transparency and openness
Study aims and procedures were preregistered on Prospero, where they can be accessed via ID# CRD420251013298. After the initial protocol was approved, we made three changes: (a) we clarified the research questions to offer more detail and greater alignment with our coding procedures (our overall goals remained the same); (b) we changed the inclusion criteria to specify that we would not include studies that only used single-item neurodiversity knowledge/attitudes measures, as we do not believe they are appropriate for the complexity of these constructs 26 ; and (c) we added a hand search of the journal Neurodiversity. All screening instruments, coding manuals, coding spreadsheets, supplementary files, and an item bank of all included measures c are publicly available on the OSF platform (https://osf.io/c8tem/?view_only=a3cfc1399ea049b4a647deff395a4d20). We also completed the PRISMA-COSMIN checklist for outcome measurement instruments, and this is included with our OSF files.
Search and screening
The aim of our search and screening process was to locate studies in which a neurodiversity knowledge and/or attitudes measure was validated and/or used. To retrieve relevant literature across disciplines, we conducted a systematic search of the databases ERIC, Education Source, PsycINFO, Scopus, Web of Science (Core Collection), and Sociological Abstracts using the following combination of search terms: neurodiver* AND (knowledge OR attitude OR perception OR perceiv* OR belief OR believ* OR aware* OR understand*) AND (measur* OR scale OR assess* OR test* OR instrument OR survey OR questionnaire). We did not apply any additional filters or restrictions to the searches, which were carried out on March 11, 2025. In addition, we also screened all published articles in the journal Neurodiversity as of June 11, 2025. We included a hand search of this journal because it was not indexed in our selected databases given the newness of the journal, and we suspected that it may have relevant articles given the focus on neurodiversity.
All screening and selection were conducted with Covidence, a web-based platform designed to aid in the conduct of systematic reviews. We screened studies in two stages; titles and abstracts were scanned in the first stage using a hierarchical screening tool (see OSF files), and full-texts that had not been screened out in the first stage were reviewed in the second stage. All screening and selection procedures were piloted and refined before implementation. Two coders independently screened files in both stages. The average agreement between pairs of coders was 90% for title and abstract screening, and 89% for full-text screening. All disagreements were resolved through consensus with a third coder adjudicating as necessary.
Inclusion and exclusion criteria
We included studies that were (a) peer-reviewed d ; (b) published in English; and (c) included quantitative analysis of a neurodiversity knowledge measure (what a person understands or knows about the neurodiversity concept, neurodivergent people, neurodiversity paradigm, or neurodiversity movement) or neurodiversity attitudes measure (what a person feels about the neurodiversity concept, neurodivergent people, neurodiversity paradigm, or neurodiversity movement). We also included attitude and knowledge measures of specific disabilities (e.g., attitudes about autism) if the measure used neurodiversity as a key concept. We excluded studies (a) in which participants were not exposed to a neurodiversity knowledge/attitudes measure; (b) that use or validate measures that determine whether or not a person is neurodivergent; (c) that only used qualitative methods to investigate participants’ perceptions/attitudes; and (d) in which the neurodiversity/knowledge measure consisted of only a single item. See Figure 1 for the PRISMA diagram illustrating the flow of studies through the screening process.
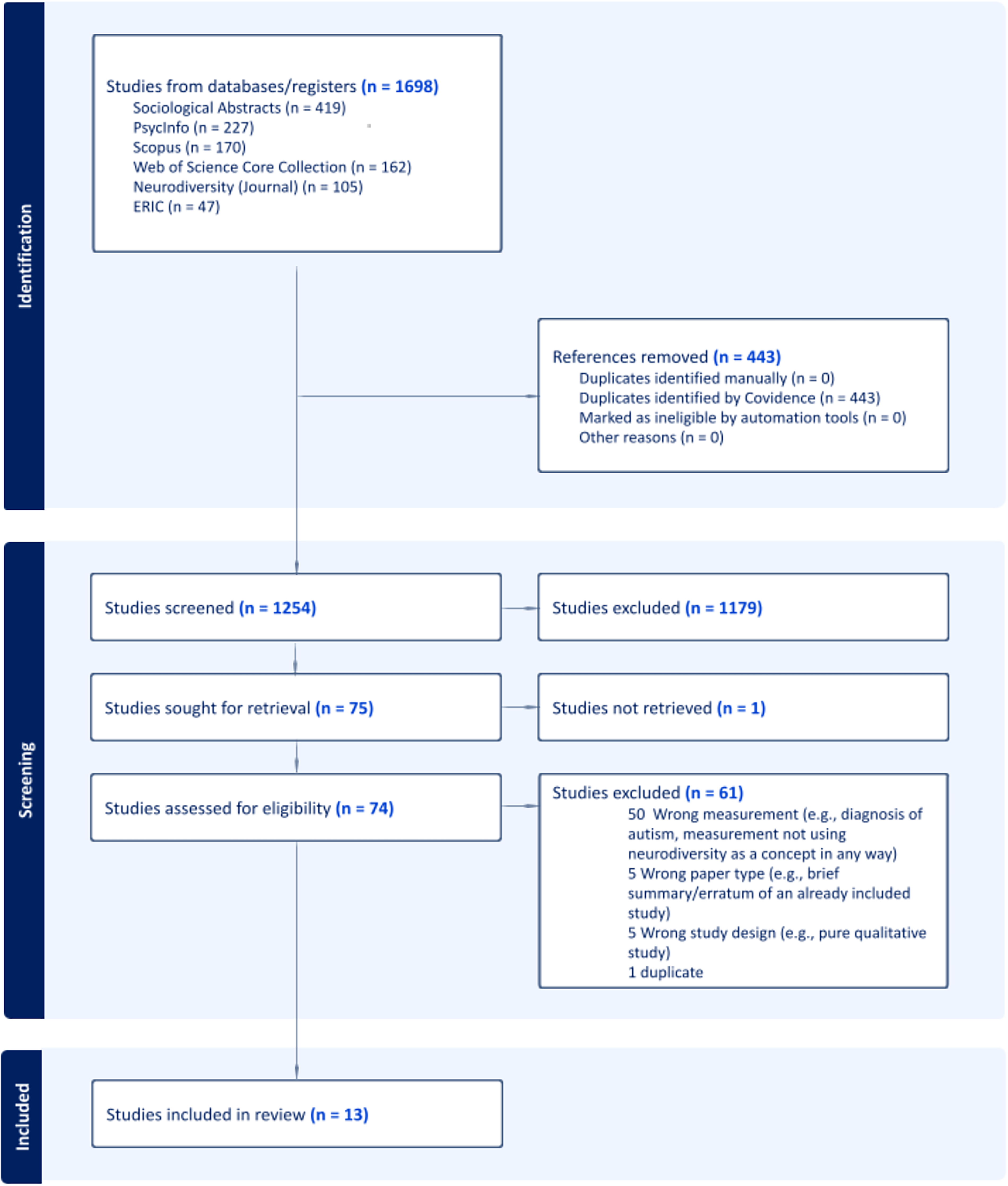
Preferred Reporting Items for Systematic Review and Meta-Analysis (PRISMA) diagram illustrating flow of records through screening process.
COSMIN data extraction for validation studies
All coding was completed by the first and second authors. First, all studies that met our inclusion criteria were coded for whether or not the study was designed to validate a measure, use and validate a measure, or only use a measure (agreement was 100%). The studies that were coded as formal validation studies were subject to the COSMIN evaluation methodology, version 2.0. 25 We chose this set of tools because of the extensive, manualized, and freely accessible resources available to guide researchers in their use. Furthermore, although the COSMIN evaluation methodology was developed for patient-reported health outcomes, we felt that they were a good fit for the instruments in our study with only very minor adaptations. Namely, references to “patients” (who are the measurement completers for patient-reported health outcomes) were changed to “completers” to better reflect the measures, and we did not examine content validation related to the intended context of use, as these instruments are not designed for clinical purposes.
The evaluation tools we used include the COSMIN Risk of Bias Checklist version 3.0 for assessing study quality, the COSMIN Criteria for Good Measurement Properties version 2.0 for evaluating measurement properties, and the Grading of Recommendations Assessment, Development, and Evaluation (GRADE) system for categorizing levels of confidence in study findings. All data were recorded on a copy of the COSMIN Review Management file, an Excel spreadsheet formatted to align with COSMIN evaluation procedures. We followed COSMIN manual recommendations regarding coding; the first author coded all the items, and the second author reviewed the first author’s coding and indicated areas of discrepancy. These discrepancies were then discussed among coders until consensus was reached.
Preliminary coding
Before evaluating the measurement properties, studies were coded for basic measurement characteristics, including language, the scope of the measure (including the construct of interest, origin of the construct, target population, and intended context of use), and the structure of the measure (including subscale names and number of items, response options, possible range of scores, and scoring algorithm). Studies were also coded for feasibility, including time to administer, practical aspects of obtaining the measure (e.g., whether a full copy is publicly available, licensing information and cost, and the availability of translations); and interpretability, including information on how to interpret single scores and change scores.
Study quality
The COSMIN Risk of Bias checklist includes assessment of the study design in 10 areas (with 112 total items); the development of the measure, plus nine measurement properties, including content validity (consisting of relevance, comprehensiveness, and understandability), structural validity, internal consistency, cross-cultural validity/measurement invariance, reliability, measurement error, criterion validity, hypothesis testing for construct validity, and responsiveness. The COSMIN taxonomy and definitions for each of these measurement properties are available on OSF. The checklist provides response options for each aspect of each quality area, which include very good, adequate, doubtful, inadequate, and not applicable (in some cases, not all response options apply). COSMIN guidelines indicate that the lowest score for any area should correspond to the overall rating for that area.
Evaluation of measurement properties
Findings from each study were then recorded and assessed for each measurement property, using the COSMIN Criteria for Good Measurement Properties. This manual provides benchmarks for assessing study results in each area, which could be categorized as sufficient, insufficient, or indeterminate. For example, for findings on internal consistency to receive a rating of sufficient, Cronbach’s alpha must be ≥0.70, and the authors must provide at least some evidence of unidimensionality of the scale (i.e., whether the scale measures a single overall construct). For content validity, coders rated the findings reported in the studies, but then also examined the measurement instructions, items, and response options to provide their own ratings of the relevance, comprehensiveness, and comprehensibility (i.e., extent to which it is understandable to informants) of the measure.
Categorizing overall quality of evidence
The GRADE approach allows researchers to summarize their confidence in the final rating of each measurement property per measure. Quality levels include high, moderate, low, and very low. Four factors are taken into account to assign categories, including risks of bias captured in study quality ratings, inconsistency in results within and across studies, imprecision (e.g., small sample sizes), and indirectness (e.g., findings from populations that are not the population of interest). We followed COSMIN guidelines for making recommendations based on these findings; if there is high-quality evidence that all measurement properties are sufficient, the measure can be recommended for use. If there is high-quality evidence that one or more measurement properties are insufficient, we recommend against the measures for use. In all other cases, we draw no conclusion about the measure as more quality research is needed.
Abbreviated data extraction for incidental validation studies
For studies in which it was not stated that a purpose of the study was to validate an instrument, we applied a simplified version of the COSMIN coding scheme to determine whether any “incidental” validation was conducted on the study population. We developed this simplified version because we expected that these studies would provide much less information than formal validation studies, and therefore, the very labor-intensive COSMIN procedures were not warranted. Given the relatively small number of incidental validation studies that met our inclusion criteria, we did not compute intercoder reliability statistics, as there would have been too few studies to independently code after a subset was used to train on the coding manual. Instead, we used procedures analogous to full COSMIN coding—two coders independently coded all studies, and discrepancies were resolved by consensus. All abbreviated coding was conducted in Covidence.
Results
Included studies
A total of 13 studies met our inclusion criteria. Four studies were formal validation studies of four different neurodiversity attitudes measures that we subjected to COSMIN coding,27–30 and nine studies used a measure but were not designed as validation studies and were therefore subjected to our abbreviated coding procedures. One study validated a measure and also used a different measure that met our inclusion criteria, 28 and was therefore subject to both types of coding. Across all studies, 24 different neurodiversity knowledge and/or attitudes measures were implemented. Three of these measures were used in more than one study. See Supplementary Table S1 for general characteristics of each study.
COSMIN coding results
Measurement characteristics
All four COSMIN-coded measures were developed in English; three were developed in the United States, and one was developed in Australia. The scope of the four measures is described in Table 1, along with our clarity ratings for descriptions of the construct, the origin of the construct, and the population of interest. All four measures assessed neurodiversity-related attitudes and not knowledge. Of these four instruments, only the Neurodiversity Attitudes Questionnaire (NAQ) 29 was designed to assess neurodiversity attitudes beyond autism. Kim’s Autism Attitude Acceptance Scale (AAAS) 27 was rated as having a clear construct description, but the other three instruments did not adequately describe some aspects of the measurement construct. The NAQ and VanDaalen and colleagues’ Autism and Neurodiversity Attitudes Scale (ANAS) 30 were rated as clearly specifying the origins (theoretical or empirical) underlying their constructs of interest, while the other two measures were rated as unclear. The NAQ, the ANAS, and the AAAS were rated as clearly describing the population of interest, while Lee et al.’s Parental Acceptance and Understanding of Autistic Children Scale (PAUACS) 28 was rated as unclear because the authors did not describe parents of which age range of children for whom the measure would be appropriate. None of the measures described the context of use for the measures, but this feature may be unimportant for measures that have no clear clinical or diagnostic use. See Supplementary Table S2 for information on the structure of each measure. We note that only the PAUACS study provided a scoring algorithm (e.g., whether scores should be summed or averaged), and there were no details on how response options should be scored for the NAQ, so we were unable to infer the possible range of scores.
Scope of Measures from Validation Studies

AAAS, Autism Attitude Acceptance Scale; ANAS, Autism and Neurodiversity Awareness Scale; Neurodiversity Attitudes Questionnaire; NAQ, Neurodiversity Attitudes Questionnaire; PAUACS, Parental Acceptance and Understanding of Autistic Children Scale.
Feasibility and interpretability
None of the study authors reported the average response time to complete the measure; however, the number of items for each measure ranged between 17 and 30, so the burden for participants is likely low. All measures had publicly available copies and none was licensed or included a cost for users. None was translated to languages other than English. None of the four studies provided information about the interpretability of either single scores or change scores, including percentage of respondents with the lowest and highest scores (for assessing the probability of ceiling or floor effects), number of missing items, or reference/cutoff scores to classify responses (e.g., “low acceptance of neurodiversity”).
Study populations
For all four measures, development studies consisted of literature reviews and so did not have human participants. Three of the four studies conducted pilot tests before the main validation study, with sample sizes of n = 190 (22 of whom identify as either disabled or having ADHD), 29 n = 5 (a mix of autistic adults, autistic parents or autistic children, and non-autistic parents of autistic children), 28 and n = 3 (two of whom were autistic). 27 All four studies conducted content validation studies, with sample sizes of n = 6 (three of whom were neurodivergent) 29 ; n = 4 professionals (three of whom were autistic) and an unclear number of autistic adult nonprofessionals 30 ; n = 5 (two parents of autistic children and three professionals) 28 ; and n = 9 (one of whom was autistic). 27 For all other validation procedures (e.g., internal consistency, factor analysis), all four studies used larger sample sizes ranging from n = 122 to n = 351 (mean n = 223). All sample populations were adult participants (mean age = 33 years). More detailed information about the study populations for item development, pilot testing, and the nine measurement properties is available on OSF.
Quality of studies for each measurement property
Study quality ratings for content validity, structural validity, reliability, measurement error, and construct validity are presented in Supplementary Table S3. Study quality ratings for criterion validity, cross-cultural validity/measurement invariance, and responsiveness are not included in this table because none of the studies was designed to assess these measurement properties. All aspects of content validation, including the assessment of the relevance, comprehensiveness, and comprehensibility of the instructions, items, and response options in both end users of the survey/nonacademic informants and experts, were rated as either doubtful or inadequate across all four studies. The remaining five measurement properties received at least one rating of “adequate” or “very good” in at least one study e .
Study findings and GRADE evaluations
Table 2 shows the results from each study, along with a rating (whether it offers support for or against the validity of the measure) and a GRADE evaluation indicating the overall quality of the evidence. We do not summarize findings for cross-cultural validity/measurement invariance, measurement error, criterion validity, and responsiveness because none of the studies assessed these properties.
Study Results, Evidence Rating, and Grade Rating per Measurement Property per Measure
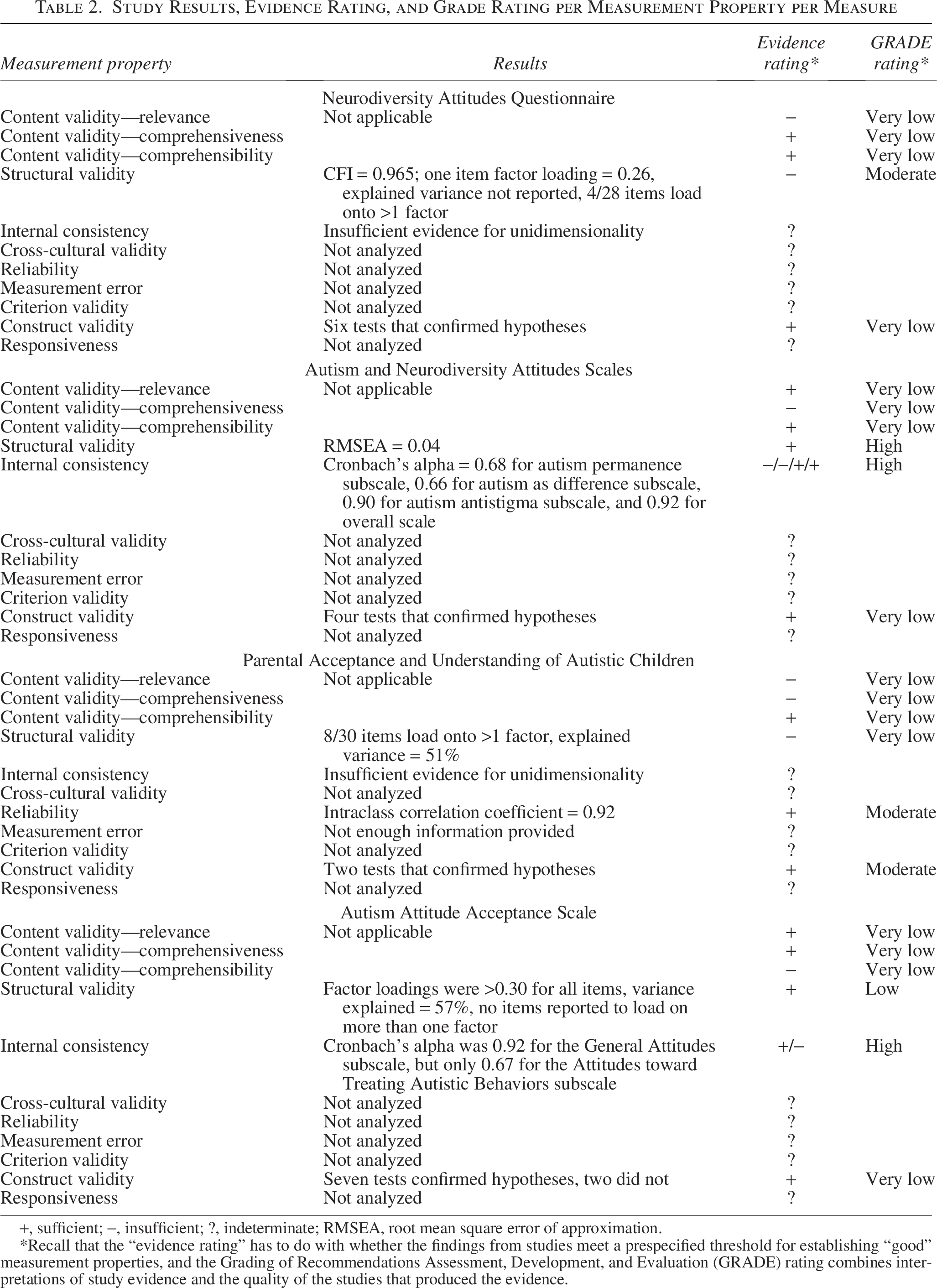
+, sufficient; −, insufficient; ?, indeterminate; RMSEA, root mean square error of approximation.
*Recall that the “evidence rating” has to do with whether the findings from studies meet a prespecified threshold for establishing “good” measurement properties, and the Grading of Recommendations Assessment, Development, and Evaluation (GRADE) rating combines interpretations of study evidence and the quality of the studies that produced the evidence.
Content validity
As mentioned above, study quality for content validation procedures was poor, which meant that the evidence ratings we report reflect our own assessment of the relevance, comprehensiveness, and comprehensibility of the measure instructions, items, and response options, as directed in the COSMIN coding manual. None of the four measures received positive ratings across all three content validity areas, but the NAQ, ANAS, and AAAS received at least two positive ratings. However, the GRADE evaluation of the evidence supporting this finding is “very low” confidence across the board, mainly due to “doubtful” quality ratings of the development and content validity studies.
Structural validity
The ANAS reported findings that met the criteria for sufficient evidence of structural validity, and received a confidence rating of “high.” The remaining three instruments did not report findings that met the threshold of evidence and/or received “low” or “very low” confidence ratings.
Internal consistency
The NAQ and the PAUACS provided insufficient evidence of unidimensionality of the measure, which prevented us from evaluating internal consistency findings. The ANAS reported sufficient evidence of internal consistency for one subscale and the overall subscale, but not for the two remaining subscales; this evidence received a “high” confidence rating. One of the two subscales of the AAAS findings met the criteria for sufficient evidence of structural validity, but the other did not; no findings were reported for the overall scale, and confidence ratings were “high.”
Reliability
Only the PAUACS reported reliability, and the findings met the threshold criteria to consider the instrument to have test–retest reliability, with “moderate” confidence.
Hypothesis testing for construct validity
All four studies received positive ratings for hypothesis tests for construct validity, including convergent validity (all four studies) and known-groups validity.27,30 However, three of the four measures received “very low” confidence ratings for this property, because the instruments selected for convergent validity were not well-validated themselves, in many cases, the instruments had not been subject to any formal validation (see OSF for summaries of validation work for these instruments). Hypothesis testing for construct validity evidence for the PAUACS was rated as “moderate” because measures selected for convergent validity had undergone some validation, although it was not clear that the studies were validated on similar subject populations (as this was a measure of caregiver attitudes toward their children, it was not clear that the selected measures were validated on populations of caregivers with similar aged children).
Recommendations
We recommend against using the Autism Permanence subscale and the Autism as Difference subscale of the ANAS, and the Attitudes toward Treating Autistic Behaviors subscale of the AAAS as stand-alone scales, as there is high-quality evidence of insufficient internal consistency (we note that the low Cronbach’s alpha values can be due to too few items in these subscales as well as insufficient intercorrelations between items). We draw no conclusions about the four full-scale measures and all other subscales, as there is not enough high-quality evidence to make a recommendation.
Nonvalidation study results
For the set of studies in which a measure was used but not formally validated, the United States was the most represented country (five studies), followed by Australia (three studies) and Poland (three studies). Twelve studies were conducted with adult participants, one study was conducted with upperelementary-aged children, and one study was conducted with adolescents and adults. Sample sizes ranged from 54 to 508 participants, with a mean of 250 participants. All studies were conducted between 2021 and 2025. Refer back to Supplementary Table S1 for these characteristics broken down by study.
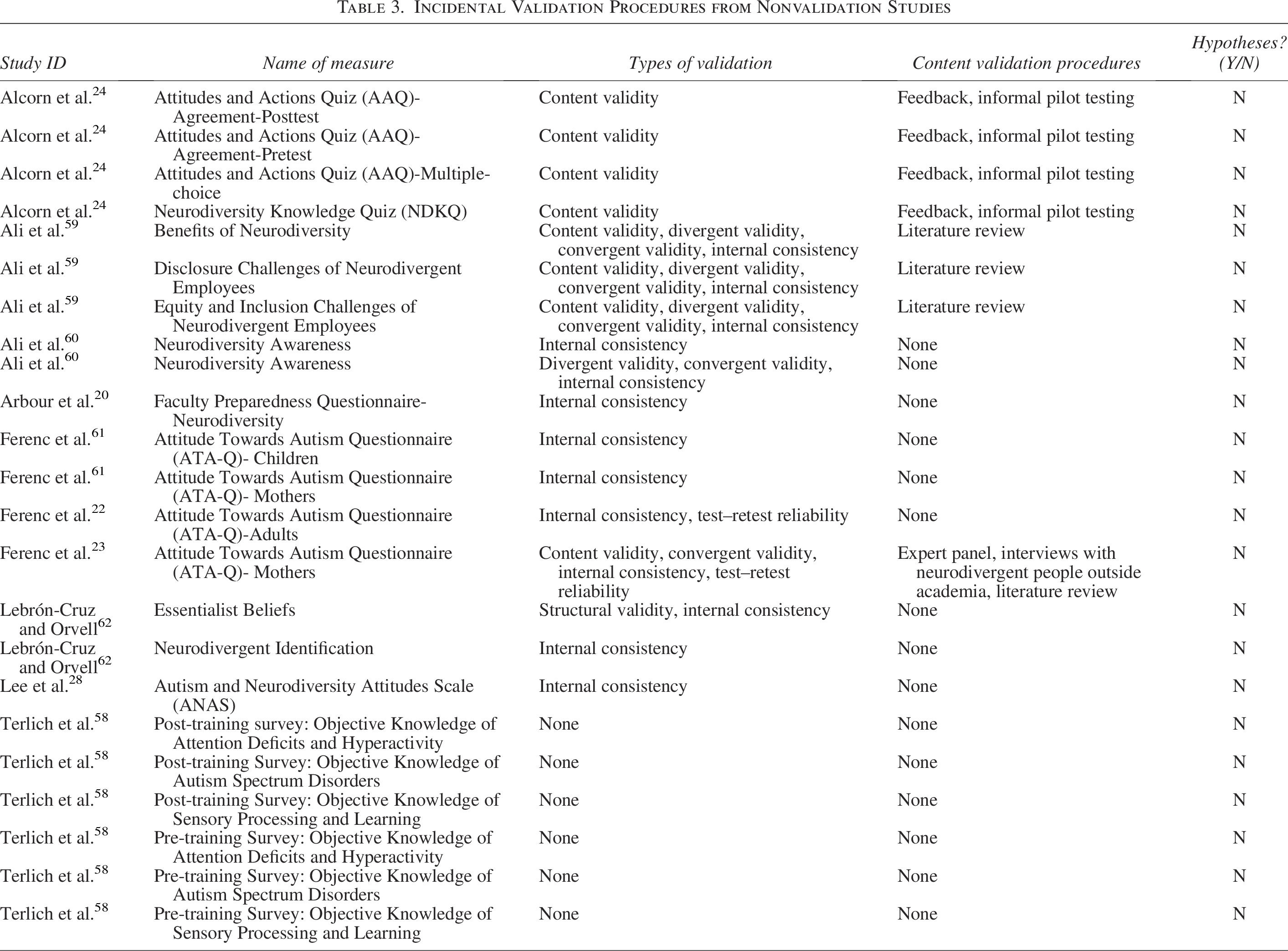
In the nonvalidation studies, 21 different measures were used (see Supplementary Table S4). Five measures were adapted from previously developed measures, 15 were bespoke measures created by the study authors, and one was a measure that had undergone some formal validation (the NAS was used to establish convergent validity for the PAUACS). Six measures had not undergone any validation (all from Terlich 58 ). Internal consistency was the most common form of validation, and was reported for 11 measures (conducted in two separate studies for one measure). Content validity was only reported to have been performed for eight of the measures. Five measures were reported to have been subject to convergent and/or divergent validation, although we note that the study authors did not report formal hypotheses (e.g., the proposed degree of alignment with the measure of interest or expected magnitude of the correlation) that guided these procedures. Two measures were examined for test–retest reliability, and one measure was examined for structural validity. See Table 3 for this information reported by study.
Incidental Validation Procedures from Nonvalidation Studies
Discussion
Currently, there are no measures of neurodiversity knowledge or attitudes with high-quality evidence showing sufficient validity, reliability, and responsiveness to warrant a recommendation that they be used in research. We recommend against the use of the Autism Permanence subscale and the Autism as Difference subscale of the ANAS, and the Attitudes toward Treating Autistic Behaviors subscale of the AAAS. Despite this assessment, there is a critical mass of researcher effort and interest in this area that holds promise for continued development of these measures in the future. It is important to recognize that the development of the measures we evaluated is in its very early stages. The first validation study was published only 5 years before the date of our search, and only one study was conducted for each of the four measures represented in the four formal validation studies. Measurement validation work is incremental, ongoing, and context-dependent.63,64 We also note that the COSMIN bar for categorizing evidence as being of sufficient quality is high. It is therefore unreasonable to expect that all measurement properties for any given measure would be thoroughly explored and meet all thresholds of evidence to recommend its use in just one study. However, we assert that a formal review and evaluation of these measures at this early stage are helpful to encourage ongoing validation work, provide necessary guidance on the measurement properties that require most attention, and ensure that the use of as-yet insufficiently validated instruments does not become entrenched before the completion of this work. We also note that issues related to instrument validation are common in psychology more generally, and in other areas of autism research.64–67
Formal validation efforts
Four measures were extensively evaluated according to COSMIN procedures: the NAQ, ANAS, PAUACS, and the AAAS. The strengths of these measures are that they are publicly available and easy to obtain without cost, and can likely be administered with minimal burden to participants, and all four have undergone at least some construct validation and two or three other types of validation. Additional work remains for adequately developing these instruments, however.
While the instruments appear feasible to administer, there are no benchmarks to guide the interpretation of single or change scores. As such, these instruments are not yet informative for a variety of uses for which researchers or lay people may wish to administer them; for example, to determine if a given group of people (e.g., employees in a school, professionals in a clinical practice) are sufficiently aware of or hold positive attitudes about neurodiversity such that neurodivergent people would feel welcome and included among them. In addition, researchers would have difficulty interpreting the magnitude of change on these measures due to the intervention, and what the change might mean for the participants.
Perhaps most pressing are issues relating to the articulation of the constructs these measures assess and establishing their content validity. Insufficient content validation can negatively influence all other measurement properties, for example, by lowering statistical indices of a given property so that they fall below benchmarks of acceptability, or by rendering such indices uninterpretable even if they are above benchmarks. 68 None of the measures was rated as “clear” for describing all three aspects of construct scope (defining the construct of interest, articulating the origin of the construct, and specifying the target population). Given the complexity of neurodiversity scholarship and advocacy, the clarity of construct scope is important. We anticipate that researchers will benefit from having several different measures with differently, but clearly, defined scopes available to them, so that they can select the measures that most closely align with their conceptualization of neurodiversity (e.g., whether it entails the pursuit of radical social change or incremental change under existing sociopolitical systems, the degree of emphasis placed on the brain basis of neurodivergence, the included disability categories, etc.) and their population of interest. Notably, none of the measures was developed for use with children, and none was exclusively devoted to neurodivergence beyond autism (we note, however, that the NAQ contained items that were related to other types of neurodivergence).
In addition, the quality of development studies (including concept elicitation and pilot studies) and content validation studies was rated as “doubtful” for all four measures, corresponding with a “very low” confidence rating in study findings regarding content validity. In most cases, this was due to a lack of specificity in how these studies were conducted. Study authors tended to provide little detail about the procedures used to extract themes from the literature to inform item development, and most did not describe formal qualitative analysis procedures for eliciting (e.g., interview guides) or analyzing (e.g., content analysis of transcribed interview recordings) pilot and content validation data. The authors did not specifically report that content validity studies involved questioning experts or lay people about all three aspects of content (relevance, comprehensiveness, and comprehensibility) for all three aspects of the measures (instructions, test items, and response options), and the authors did not describe specific procedures for analyzing feedback, or evaluating the extent to which subjects in their content validity studies approved of the final version of the measures. In many cases, it was not clear that participants in content validation studies were shown the final measure at all. One study 29 used response process evaluation in a pilot test, an appropriate set of procedures. However, the study quality was still rated as “doubtful” because the sample of participants did not represent the population for whom the study was designed, it was not clear that participants were asked about the comprehensibility of the measure, and the procedures for analyzing qualitative responses were vaguely described. In our assessment of the measures’ instructions, items, and response options, there were many instances where the directions were not entirely clear, and/or the items did not clearly correspond to the stated scope of the measure.
Quantitatively assessed measurement properties, including structural validity and internal consistency, were the relative strengths of our studies, with at least two studies reporting sufficiently high thresholds of evidence for measurement properties alongside high confidence ratings in the findings, for at least one subscale. One exception was hypothesis tests for construct validation, which were performed in all four studies. The authors reported positive findings, but these findings were rated with “very low” confidence because, in a majority of instances, researchers selected instruments for convergent validity that have been subject to little or no validation themselves.
Cross-cultural reliability/measurement invariance, criterion validity, measurement error, and responsiveness were not examined for any of the four measures and should be covered in future work. Cross-cultural validity is especially important to explore, given the recent discussions of how neurodiversity concepts are construed differently across cultures, geographies, and languages.69–71
Incidental validation in studies that used neurodiversity attitudes/knowledge measures
Researchers appear to have growing interest in incorporating assessments of neurodiversity knowledge and attitudes into their work, and a lack of available measures has meant that many create their own and conduct only cursory (or no) validation in the course of their research. While ongoing or “incidental” validation is important when using quantitative assessments, relying exclusively on these informal validation efforts means that the reliability, validity, and responsiveness of these measures are largely unknown. The study results for the group of studies that used neurodiversity attitudes and knowledge measures (but were not formal validation studies) are therefore difficult to interpret. For example, three of these studies were designed to determine how participants’ neurodiversity knowledge or attitudes changed as a result of intervention. However, none of the measures used by the study authors had previously been examined for their responsiveness to change. It is therefore possible that participants changed in such a way that was not detectable by the measures created by the authors.
Recommendations for continuing validation work
Based on our findings, we have several recommendations for continuing to develop these and additional measures assessing neurodiversity attitudes and knowledge. Before listing our recommendations, we emphasize that this work must necessarily be considered ongoing, as neurodiversity concepts and advocacy will continue to evolve. First, researchers should conduct stand-alone content validation studies with robust qualitative procedures for developing the measure and establishing content validity. These studies should include formal literature reviews with clear procedures for extracting themes, formal interview or focus group data collection efforts, and rigorous and transparently reported procedures for data analysis (e.g., content analysis). Researchers should be sure to conduct both content validation and pilot studies, describe how measures are adjusted based on participant feedback, and provide quantitative and qualitative results summarizing participants’ assessment of the final version of the measure. Stand-alone studies will ensure researchers have adequate word-space to adequately describe the rigorous procedures involved in this work. Second, researchers should conduct rigorous assessments of the eight quantitative measurement properties, especially those that have not received any attention (cross-cultural validity, measurement error, and responsiveness) or have received little attention (reliability) in current validation work. Once this work has been completed, there will be sufficiently validated measures with which to assess criterion validity. In selecting measures for convergent validity, researchers should select measures that have been rigorously validated, and then specify the level of alignment they expect between the instruments selected for construct validation and the measure being validated, alongside empirically supported rationales for their hypotheses. To implement our first and second suggestions, researchers could conduct instrument development manuals aligned with COSMIN benchmarks for rigor. 72 Third, researchers should establish benchmarks for interpreting single and change scores. Fourth, measures should be developed that can be administered to children. This is an area of need, given the interest in developing and assessing neurodiversity curricula in schools. Fifth, researchers should develop measures that explicitly assess attitudes/knowledge of neurodivergence other than autism, such as ADHD, learning disabilities, and Tourette’s syndrome. Finally, for these recommendations to become a reality, systemic efforts are also needed. Namely, public and private funding bodies should devote funds toward instrument development research, especially those aligned with neurodiversity frameworks, as rigorous development of these instruments is costly and time-consuming.
Limitations
There are some limitations to this review that should be considered when interpreting our findings. First, there were a relatively low number of available studies that met our inclusion criteria, and their insufficient quality to allow for stronger conclusions. Future high-quality studies should be conducted to allow for confident recommendations regarding these instruments. Second, the COSMIN evaluation system has been critiqued by others in the field, most notably because it was developed through expert consensus and not through other kinds of validation. 73 Third, the COSMIN evaluation system does not capture many aspects of instrument development that are important to research related to neurodiversity, such as engagement with neurodivergent communities.
Conclusion
In this systematic review, we provide a rigorous evaluation of four neurodiversity attitude measures, and give summaries of studies that have neurodiversity knowledge and/or attitude measures but were not formal validation studies. The efforts represented in studies that have attempted to develop and explore the measurement properties of these measures show promise for developing robust measures for future use that have clearly described scopes, are feasible to implement, and are sufficiently valid, reliable, and responsive. However, much work remains to be done to achieve these aims; our hope is that this review at the early stages of research will provide actionable guidance for doing so.
Footnotes
Author Disclosure Statement
K.B.-B. has previously received fees for consulting with school districts on intervention practices for autistic children and teaches courses on autism interventions in her role as a professor of special education. She has also accepted speaker fees to discuss her work on research quality, adverse events, and researcher conflicts of interest as they pertain to autism intervention research, and on topics related to neurodiversity. She also receives royalties for a coedited book titled Clinical Guide to Early Interventions for Children with Autism, published by Springer. A more detailed log of conflicts of interest can be found here ![]() R.G. declares no conflicts of interest with respect to the publication of this article. J.H.-W. reports no conflicts of interest. Y.S. previously completed a master’s program in Applied Behavior Analysis and has received compensation for work as a behavioral interventionist in several inclusion classrooms, working with autistic individuals from early childhood through adulthood across different school settings. C.B. has previously accepted speaker fees to present on topics related to neurodiversity. She is also a speech language pathologist and has received compensation for providing speech, language, and feeding services to children and adults in multiple settings.
R.G. declares no conflicts of interest with respect to the publication of this article. J.H.-W. reports no conflicts of interest. Y.S. previously completed a master’s program in Applied Behavior Analysis and has received compensation for work as a behavioral interventionist in several inclusion classrooms, working with autistic individuals from early childhood through adulthood across different school settings. C.B. has previously accepted speaker fees to present on topics related to neurodiversity. She is also a speech language pathologist and has received compensation for providing speech, language, and feeding services to children and adults in multiple settings.
Funding Information
This study was funded by an Ignite grant to the first author, which is administered by Boston College. The funders had no role in the conduct or dissemination of this review.
Authorship Confirmation Statement
K.B.-B.: Acquired funding for the project; conceptualized the study aims and design; assisted in the search and screening process; led data extraction, data analysis, and interpretation; and wrote the article draft. R.G.: Assisted in the search and screening process; participated in coding, data analysis, and interpretation; and edited the article. J.H.-W.: Led the search and screening process, created the PRISMA diagram, and edited the article draft. Y.S.: Participated in search and screening and edited the article draft. C.B.: Participated in search and screening and edited the article draft. This article has been given solely to this journal and is not published, in press, or submitted elsewhere.