
Abstract
This study uses natural language processing and machine learning to classify financial fraud based on the SEC Accounting and Auditing Enforcement Releases disclosures. It introduces a hybrid framework combining Latent Dirichlet Allocation topic modeling and supervised learning to identify five fraud categories: financial misstatements, bribery, tax fraud, investment fraud, and related-party transactions. These are mapped to industry sectors to reveal contextual vulnerabilities. Logistic regression delivers stable, interpretable results, while deep learning models capture procedural fraud patterns. Chi-square tests and clustering confirm significant industry–fraud links, highlighting the need for sector-specific detection. By aligning outcomes with criminological theories, the study contributes to fraud analytics and regulatory enforcement. The findings support forensic accountants and analysts in building targeted, industry-aware fraud detection systems.
Introduction
Fraud encompasses diverse forms of financial misconduct, including bribery, financial misstatements, tax violations, related-party transactions, and investment fraud. Despite these differences in mechanisms, actors, and severity, most fraud detection research and regulatory tools treat fraud as a single, undifferentiated category (Bao et al., 2020; Cecchini et al., 2010; M. Lokanan & Sharma, 2024). Such generalization obscures industry-specific risk patterns and limits the ability to understand how distinct forms of misconduct emerge across organizational and regulatory contexts.
The core problem addressed in this study is the lack of industry-aware and theory-informed fraud classification. Existing approaches rarely distinguish fraud types or examine how misconduct varies across sectors, despite clear differences in opportunity structures, governance mechanisms, and regulatory oversight. As a result, research to date has mostly focused on applying machine learning to fraud prediction, with comparatively limited engagement with criminological theory. The present study draws on Routine Activity Theory (RAT), which suggests that fraud should vary systematically across industries due to differences in motivated actors, suitable targets, and guardianship conditions. Empirical approaches capable of capturing these patterns, however, remain underdeveloped.
Against this backdrop, the present study examines whether fraud typologies exhibit systematic variation across industry sectors and whether such patterns can be identified through natural language processing (NLP) applied to regulatory disclosures. Specifically, the study asks: Do distinct fraud typologies exhibit systematic associations with specific industry sectors, and can these relationships be identified using NLP applied to regulatory disclosures? To address this question, an NLP-based framework is developed using textual disclosures from the U.S. Securities and Exchange Commission’s (SEC) Accounting and Auditing Enforcement Releases (AAERs). Latent Dirichlet Allocation (LDA) and supervised classification are used to identify fraud types, while statistical testing and clustering techniques examine their distribution across industries. Analytical emphasis is placed on interpretability, ensuring that identified patterns can be linked to underlying opportunity structures rather than treated as outputs of a “black box” model.
The study contributes to the white-collar crime scholarship in three ways. First, the classification of fraud by type and industry enables more targeted identification of sector-specific risks, supporting improved regulatory and enforcement strategies. Second, the integration of RAT with NLP-based analysis advances a theory-driven approach to fraud detection, linking observed patterns to variations in opportunity and guardianship across industries. Third, mapping fraud typologies directly to industry contexts extends existing research by moving beyond binary fraud detection toward a structured understanding of how different forms of misconduct cluster within sectors.
The paper is organized into seven sections. The literature review outlines prior research on fraud detection in accounting and white-collar criminology, highlighting gaps in applying machine learning and NLP to financial misconduct. The theoretical framework introduces RAT and CSA as lenses for understanding structural and procedural aspects of fraud. The methods section details data collection, preprocessing, and model development using topic modelling, supervised learning, and deep learning. Results present model performance and sectoral patterns identified through chi-square tests and network analysis. The discussion interprets these findings within criminological and institutional contexts, and the conclusion summarizes key contributions and directions for future research.
Related Literature
Conceptualizing Fraud: Disciplinary Definitions and Contextual Boundaries
Fraud is a relative and discipline-specific concept, defined differently across criminology and accounting and finance. In criminology, fraud—often framed within the broader category of white-collar crime—is understood as a non-violent act of deception committed for financial or personal gain through the abuse of trust, manipulation, or concealment (Shapiro, 1990, pp. 347–348; Sutherland, 1949, p. 9). Accounting research, by contrast, defines fraud as the intentional misrepresentation or omission of financial information designed to mislead stakeholders and distort financial outcomes (Cooper et al., 2013, pp. 440–441; M. E. Lokanan, 2015, p. 203; Matthews, 2005, p. 520). While both disciplines converge on the central role of deceit and financial advantage, criminology emphasizes systemic violations of trust and the social mechanisms enabling deception, whereas accounting focuses on fraudulent reporting practices within organizational and regulatory contexts.
Understanding fraud as an abuse of trust rather than a fixed behavioral trait allows for its classification into more specific types—such as bribery, investment fraud, related-party transactions, misrepresentation, and tax fraud—each shaped by distinct motivations, actors, and industry vulnerabilities (Shapiro, 1990; Sutherland, 1949). Treating these forms as interchangeable under a single definition obscures key operational distinction and reduces the precision of detection models. The lack of differentiation among fraud types across industries represents a fundamental shortcoming in both academic research and applied detection frameworks. Machine learning systems trained on uniform definitions of fraud risk oversimplify its structural and contextual diversity, leading to lower detection accuracy and limited cross-sector adaptability. Integrating industry context into fraud detection frameworks is therefore both theoretically essential and operationally necessary to build more targeted, risk-sensitive, and context-aware detection systems. Criminological perspectives further suggest that such variation is not random but shaped by differences in opportunity structures across industries. Identifying these patterns requires approaches capable of capturing context-dependent signals within unstructured disclosures, motivating the integration of RAT with interpretable analytical methods.
Machine Learning in Fraud Detection
Advances in artificial intelligence and machine learning have reshaped fraud detection research in accounting and finance. Most studies rely on predictive models using structured data such as financial statements, stock prices, and firm characteristics (Bao et al., 2020; Bertomeu et al., 2021; Cecchini et al., 2010). Supervised algorithms—including linear, probabilistic, ensemble, and neural network models—demonstrate strong predictive accuracy, particularly in capturing non-linear relationships in financial data (Bao et al., 2020; Wu et al., 2025). Despite these advances, fraud is typically treated as a binary construct—fraudulent or not—without accounting for variation in type or industry context (Bao et al., 2020; M. Lokanan & Sharma, 2024). Such approaches overlook distinctions among financial misstatements, bribery, tax evasion, and related-party transactions, each shaped by different actors, incentives, and concealment strategies (Coleman, 1987). Collapsing these forms into a single category reduces analytical precision and limits the practical value of detection systems (Davis & Pesch, 2013; Power, 2013).
Interpretability remains a central limitation. Many models operate as black-box systems, restricting their usefulness for auditors and regulators who require transparent, explainable outputs linked to observable behaviors. As a result, improved fraud detection depends not only on predictive performance but also on models that are interpretable and sensitive to contextual variation. Recent developments in NLP extend fraud detection to unstructured textual data, including corporate disclosures and regulatory filings (Bochkay et al., 2023; Feuerriegel & Pröllochs, 2021). Topic modelling, particularly LDA, has been used to identify latent themes related to managerial tone and disclosure patterns. However, applications remain limited in scope and rarely differentiate fraud types or examine how misconduct varies across industries (Cheng & Cai, 2023; Wang & Xu, 2018). The prevailing focus on generalized indicators of deception therefore overlooks the structural and sectoral dimensions of fraud.
Existing approaches therefore lack a framework for explaining why different forms of fraud emerge across industries and organizational contexts. Criminological theories, particularly RAT, suggest that such variation is driven by differences in opportunity structures, including the configuration of actors, targets, and guardianship. However, empirical methods capable of systematically identifying these patterns from unstructured disclosures remain limited. Addressing this gap requires approaches that can extract interpretable, context-sensitive signals from textual data, motivating the use of NLP techniques in the present study.
Theoretical Foundations: Routine Activity Theory
Very few studies have applied machine learning to fraud detection have engaged explicitly with theory to explain the contextual factors—such as industry structure, regulatory oversight, and sector-specific risks—that shape how misconduct emerges (M. Lokanan & Sharma, 2024; Wu et al., 2025). Most research focuses on refining model performance or algorithmic accuracy without accounting for how distinct forms of fraud arise under different organizational and institutional conditions (Bao et al., 2020; Cecchini et al., 2010; Perols, 2011). Conceptual distinctions among fraud types remain underdeveloped, forcing detection systems into reductive frameworks that treat all misconduct as uniform. The present study integrates criminological theory—specifically RAT —to ground AI-based models in explanations that link fraud typologies to their industry contexts.
RAT provides a structural framework for analyzing conditions that enable corporate fraud. Crime occurs when a motivated offender, a suitable target, and the absence of capable guardianship converge in time and space (Cohen & Felson, 2015; Pratt et al., 2010). Originally developed to explain conventional crimes, RAT has since been applied to white-collar and cyber offenses (Leukfeldt & Yar, 2016; Natarajan, 2016). RAT emphasis on opportunity structures—shaped by organizational and environmental conditions—offers insight into why certain fraud types cluster within specific industries (Kleemans et al., 2012; Paternoster & Simpson, 1993; Williams et al., 2019). In corporate contexts, suitable targets include financial reporting systems or large transactions, while guardianship may take the form of internal controls, auditing, or regulatory oversight.
RAT conceptualizes fraud as an outcome of situational opportunities rather than individual deviance (Cohen & Felson, 2015; Schaefer, 2021). Industry sectors with weak regulation, opaque transactions, or high managerial discretion create conditions of low guardianship and elevated fraud risk. Although the framework prioritizes external structures and may overlook cultural or relational dynamics within firms (Kleemans et al., 2012; Schaefer, 2021; Steinmetz, 2025), it remains valuable for identifying environmental asymmetries that shape sector-specific vulnerabilities. Understanding how opportunity structures differ across industries enhances the interpretability of NLP-based classification models. High-risk sectors such as finance or mining may face increased exposure to tax fraud, while bribery often concentrates in construction or energy industries due to procurement vulnerabilities. These theoretical elements are operationalized in the empirical analysis through the identification of linguistic indicators of actors, transactions, and control conditions within AAER disclosures, allowing fraud patterns to be interpreted as variations in opportunity structures across industries.
Methodological Framework
The methodological design prioritizes transparency and interpretability to ensure that the analytical process remains explainable and aligned with criminological inquiry, rather than operating as a “black box” predictive system. The approach supports theory-driven analysis, with techniques selected to uncover structured, industry-specific patterns of fraud consistent with RAT. Emphasis is placed on linking model outputs to meaningful sectoral dynamics, reinforcing the integration of computational methods with criminological explanations.
Dataset: SEC AAER-Based Corporate Fraud Disclosures
The dataset is drawn from the SEC’s AAERs, a widely used source in financial fraud research. It includes 4,278 disclosures issued between May 17, 1982, and December 31, 2023, capturing 1,816 firm-level fraud events across approximately 1,364 unique firms. Each observation consists of a narrative disclosure detailing the misconduct, implicated actors, affected accounts, and procedural elements of fraud. These disclosures provide a rich, unstructured textual foundation for analysis, allowing fraud to be examined as a context-dependent and socially embedded phenomenon rather than a purely technical anomaly. RAT informs the use of these narratives by framing fraud in terms of motivated offenders, suitable targets, and the absence of capable guardianship. Narrative detail within AAERs enables these elements to be identified and systematically analyzed across industries. Consequently, the dataset supports a theory-driven approach in which linguistic patterns reflect underlying opportunity structures rather than serving as inputs to a purely predictive “black box” model.
Data Source
The structured AAER dataset was obtained from the University of Southern California, where it has been compiled for academic use. Each entry includes structured identifiers (e.g., firm name, AAER number, year) alongside detailed narrative disclosures that explain the nature and context of enforcement actions. Narrative content is particularly suited to operationalizing RAT within the analytical framework. Disclosures consistently contain: • • •
Together, these elements provide interpretable, theory-relevant indicators that allow fraud typologies to be linked to industry contexts. The analytical focus, therefore, extends beyond classification to identifying structured patterns of opportunity and control consistent with criminological theory.
NLP Workflow
Text Preprocessing and Feature Engineering
AAER narrative disclosures were processed using a streamlined NLP pipeline to standardize text while preserving semantically meaningful cues relevant to fraud classification. Preprocessing focused on reducing noise and ensuring consistency across disclosures so that linguistic patterns reflecting fraud mechanisms and industry context could be identified in a transparent and interpretable manner (Chang et al., 2022; Khurana et al., 2023). The pipeline included lowercasing, removal of punctuation and non-alphanumeric characters, tokenization, and stopword removal to eliminate syntactic noise. Stemming (Porter Stemmer) and lemmatization (WordNet Lemmatizer) were applied to unify word forms and improve the interpretability of key terms. These steps ensure that language linked to actors, transactions, and control environments—central to RAT—is retained, allowing subsequent analysis to capture structured indicators of opportunity and guardianship across industries. The resulting normalized text provides a consistent and interpretable input for TF-IDF vectorization, topic modeling, and classification. Below is a breakdown of the preprocessing steps: • • • • • •
Text to Numerical Conversion
Cleaned disclosures were transformed into numerical features using Term Frequency–Inverse Document Frequency (TF-IDF). TF-IDF was selected because it emphasizes terms that are both frequent within a document and distinctive across the corpus, allowing fraud-related language to be identified in a transparent and interpretable manner. Such weighting supports the identification of terms associated with specific fraud typologies and industry contexts, aligning feature construction with the study’s focus on explainable, theory-informed analysis rather than opaque representations. The TF-IDF weight for a term t in document d from corpus D is given by:
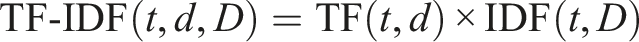
Where:
• •
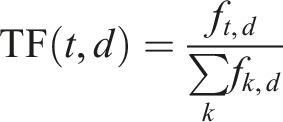
The Term Frequency measures how often term t appears in document d relative to its length.
• N: Total number of documents in the corpus • • The “+1” in the denominator prevents division by zero
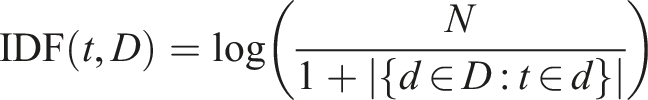
The IDF measures how unique or rare the term t is across the entire corpus.
Latent Dirichlet Allocation
Latent Dirichlet Allocation (LDA) was applied to identify latent thematic structures within AAER disclosures, allowing fraud typologies to emerge from recurring linguistic patterns. Using TF-IDF and CountVectorizer representations, LDA grouped co-occurring terms into interpretable clusters reflecting procedural elements of fraud, including patterns such as “round-tripping,” “sham transactions,” and “undisclosed related parties.” These patterns provide structured indicators of fraud mechanisms that extend beyond predefined categories. LDA models each document as a mixture of topics and each topic as a distribution over words. The probability of observing a word w in a document d is given by:
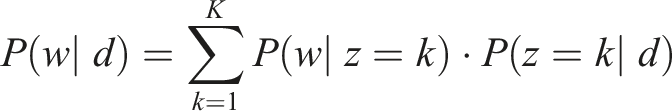
Independent and Dependent Variables
Fraud Types

aSchemes includes fraudulent stock operations.
Modeling Performance
Performance Measures

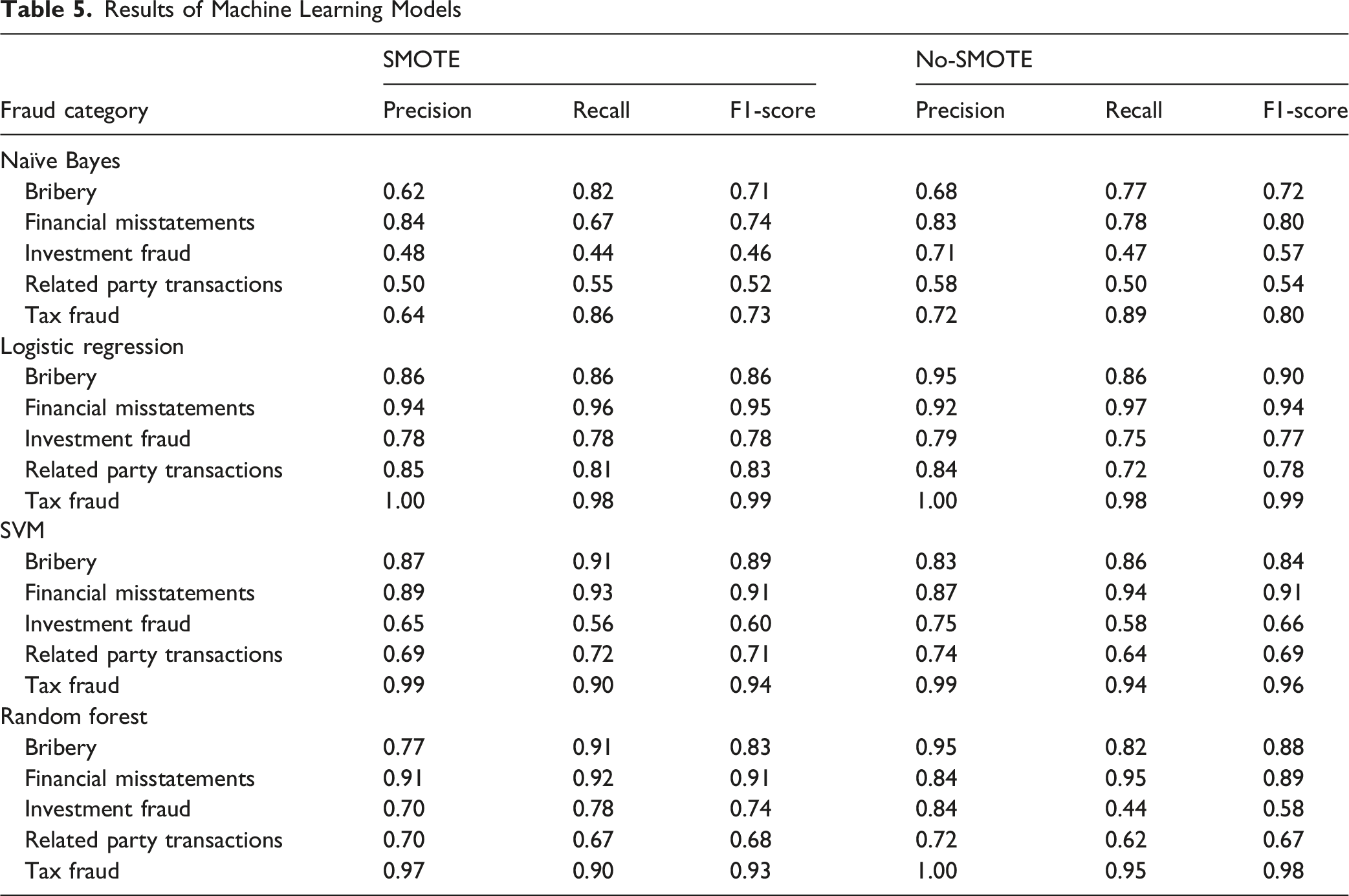
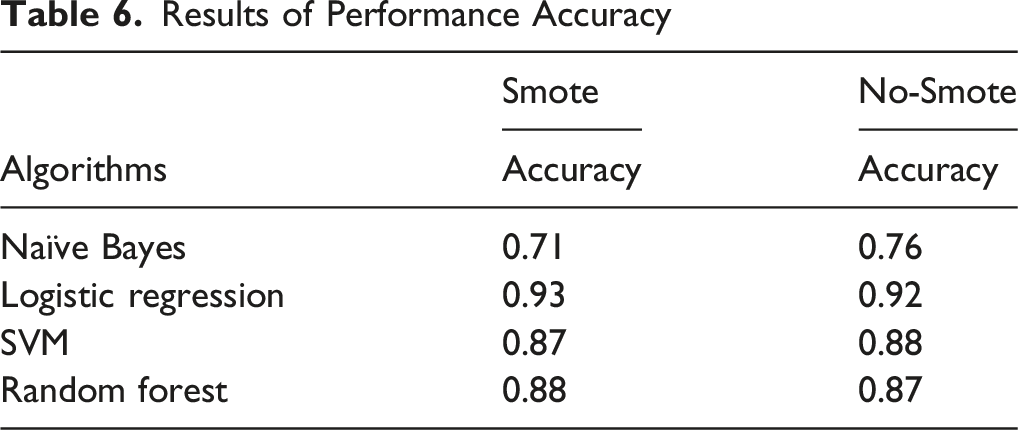
Experiment: SMOTE vs. No-SMOTE Evaluation With Machine Learning Classifiers
To thoroughly assess model performance and better understand fraud patterns across industries, two experimental setups were used: one with Synthetic Minority Oversampling Technique (SMOTE) resampling and one without. The dataset exhibited significant class imbalance, with fraud types like Financial Misstatements (n = 891) and Tax Fraud (n = 413) greatly outnumbering less frequent categories such as Loan and Related-Party Transactions (n = 218), Investment Fraud (n = 119), and Bribery (n = 64). To account for this imbalance, models were trained under two conditions: (1) using the original imbalanced dataset and (2) applying SMOTE, which generates new instances for minority classes by interpolating between nearest neighbors (Chawla et al., 2002; Elreedy & Atiya, 2019), resulting in a balanced dataset of 624 samples per class. Comparing SMOTE and non-SMOTE conditions clarified how class imbalance, synthetic augmentation, and industry-specific data distributions affect model sensitivity, classification accuracy, and detection of rare fraud types.
Algorithms Employed
Algorithms Employed

Findings and Analysis
Exploratory Data Analysis
Figure 1 presents a word cloud illustrating the most frequent terms in the fraud dataset. Prominent words such as asset, revenue, expense, sale, and overstated reflect recurring patterns of financial misrepresentation, including inflated revenues, misstated expenses, and improper asset reporting across industries. The frequent appearance of failed suggests widespread regulatory noncompliance, while terms such as income, inventory, cost, and recorded point to manipulation of core accounting metrics. Procedural terms including bribe, scheme, and transaction highlight mechanisms through which fraud is enacted. Together, these patterns provide an initial indication of how fraud manifests in narrative disclosures and suggest industry-specific operational and regulatory vulnerabilities. Word cloud of frequent words
Figure 2 shows the distribution of fraud types across industry sectors, highlighting sector-specific vulnerabilities. Financial misstatements dominate in Mining (82.14%), Business Services (71.43%), and Software (70.59%), indicating that complex reporting environments heighten manipulation risk. Investment fraud is most prevalent in the investment sector (36.36%) and appears frequently in Pharmaceuticals and Information Technology, reflecting valuation uncertainty. Bribery is concentrated in Pharmaceuticals (28.95%), consistent with regulatory and procurement exposure. Tax fraud is more dispersed but prominent in Construction (45.45%), Retail (30.26%), and Real Estate (30.95%), sectors characterized by flexible revenue recognition and deductions. Fraud type frequency by industry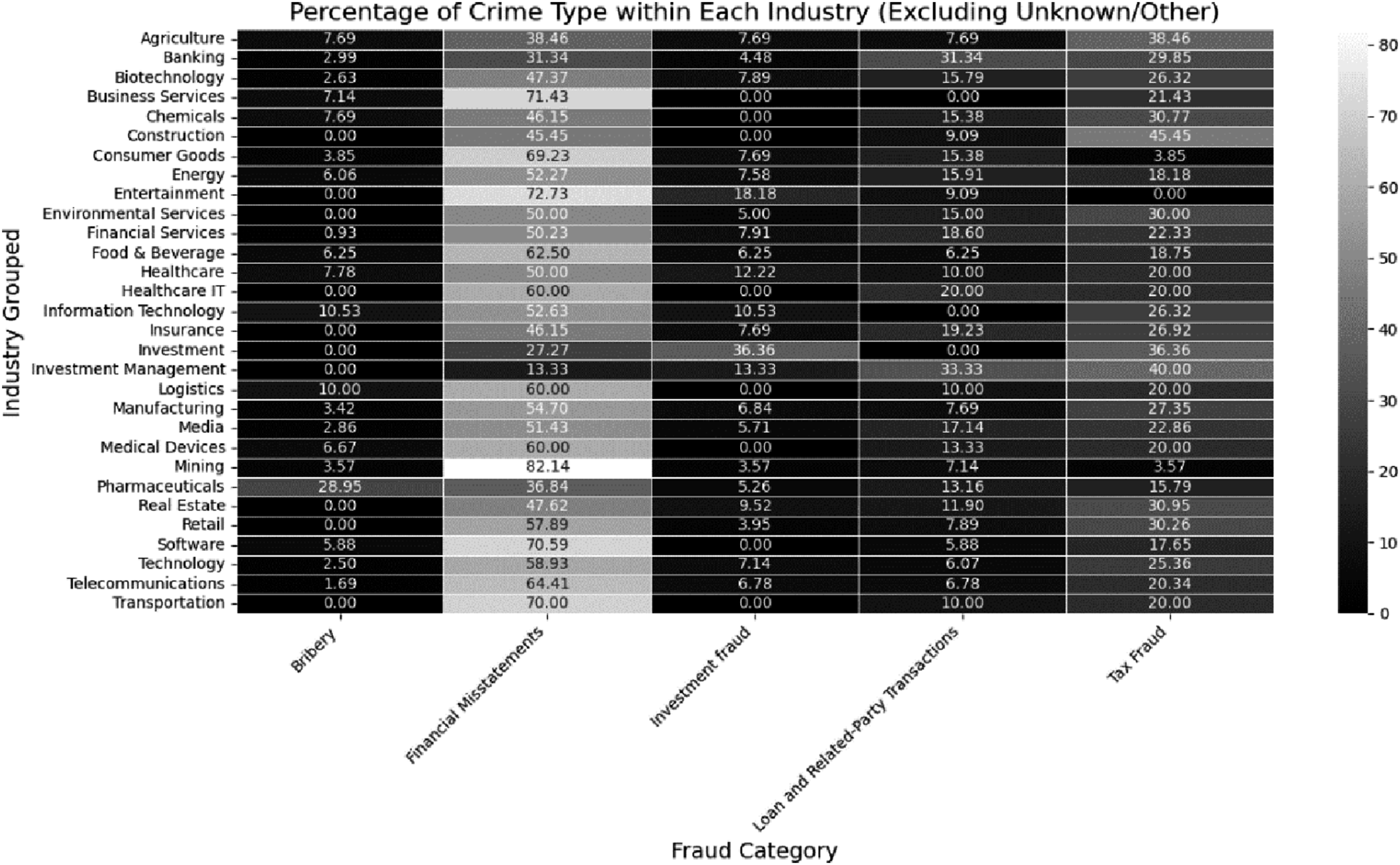
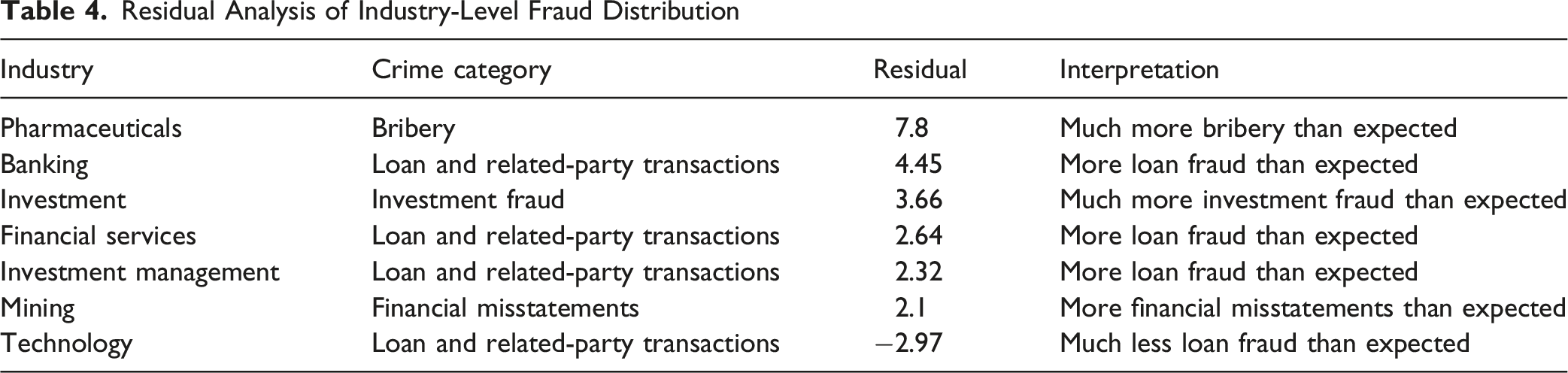
Chi-Square Test of Independence
Residual Analysis of Industry-Level Fraud Distribution
HDBSCAN Clustering Techniques
Figure 3 shows HDBSCAN clustering applied to UMAP-reduced industry fraud risk profiles. HDBSCAN was selected for its ability to identify density-based clusters without predefining cluster numbers. The results reveal distinct industry groupings with similar fraud risk characteristics, including a cluster linking Telecommunications, Software, and Food & Beverage, and another aggregating Banking, Insurance, Real Estate, and Construction—sectors associated with complex, institutional forms of misconduct. A silhouette score of 0.48 indicates moderate cluster separation, suggesting meaningful but overlapping fraud typologies across industries. These clusters support the development of industry-specific fraud detection and mitigation strategies. Hdbscan clustering of industry fraud risk group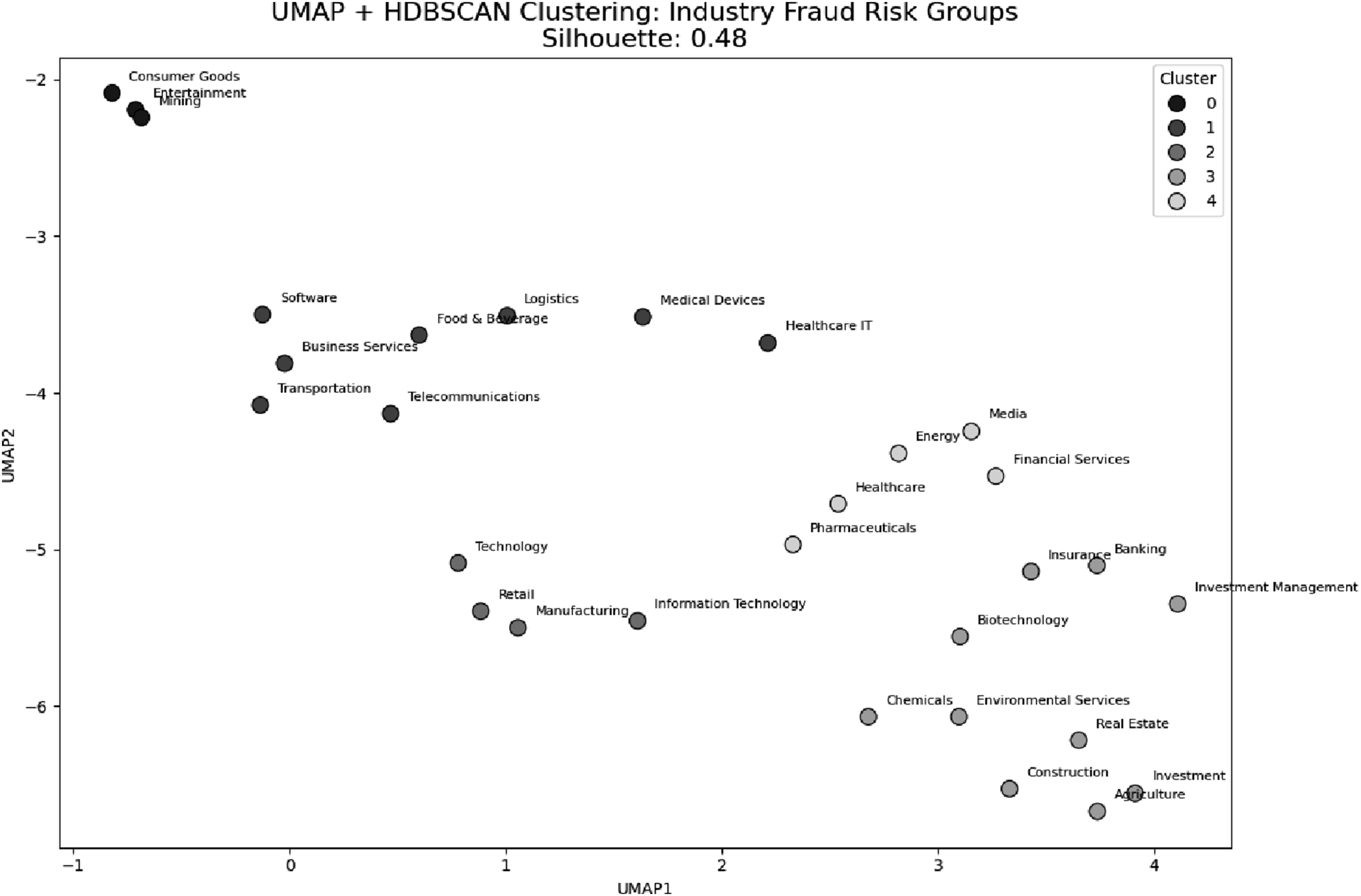
Machine Learning Model Results
Results of Machine Learning Models
Results of Performance Accuracy
In the context of imbalanced datasets, overall accuracy is insufficient, as it may mask underperformance on minority fraud categories often tied to specific industries. ROC analysis offers a more robust evaluation by measuring the trade-off between true positive and false positive rates across thresholds. As illustrated in Figure 4, micro-averaged ROC curves confirm that Logistic Regression, SVM, and Random Forest are among the top-performing models in detecting fraud across industry sectors. Random Forest yielded the highest micro-average AUC (0.99), indicating superior discriminatory power, followed closely by Logistic Regression and SVM (0.98). Naïve Bayes performed notably worse, with an AUC of 0.92, aligning with its weaker classification metrics. These findings underscore that while Logistic Regression maintains balanced performance across fraud types and industries, Random Forest offers marginally better overall ranking capability in identifying industry-specific fraud risks. Machine learning model ROC curves results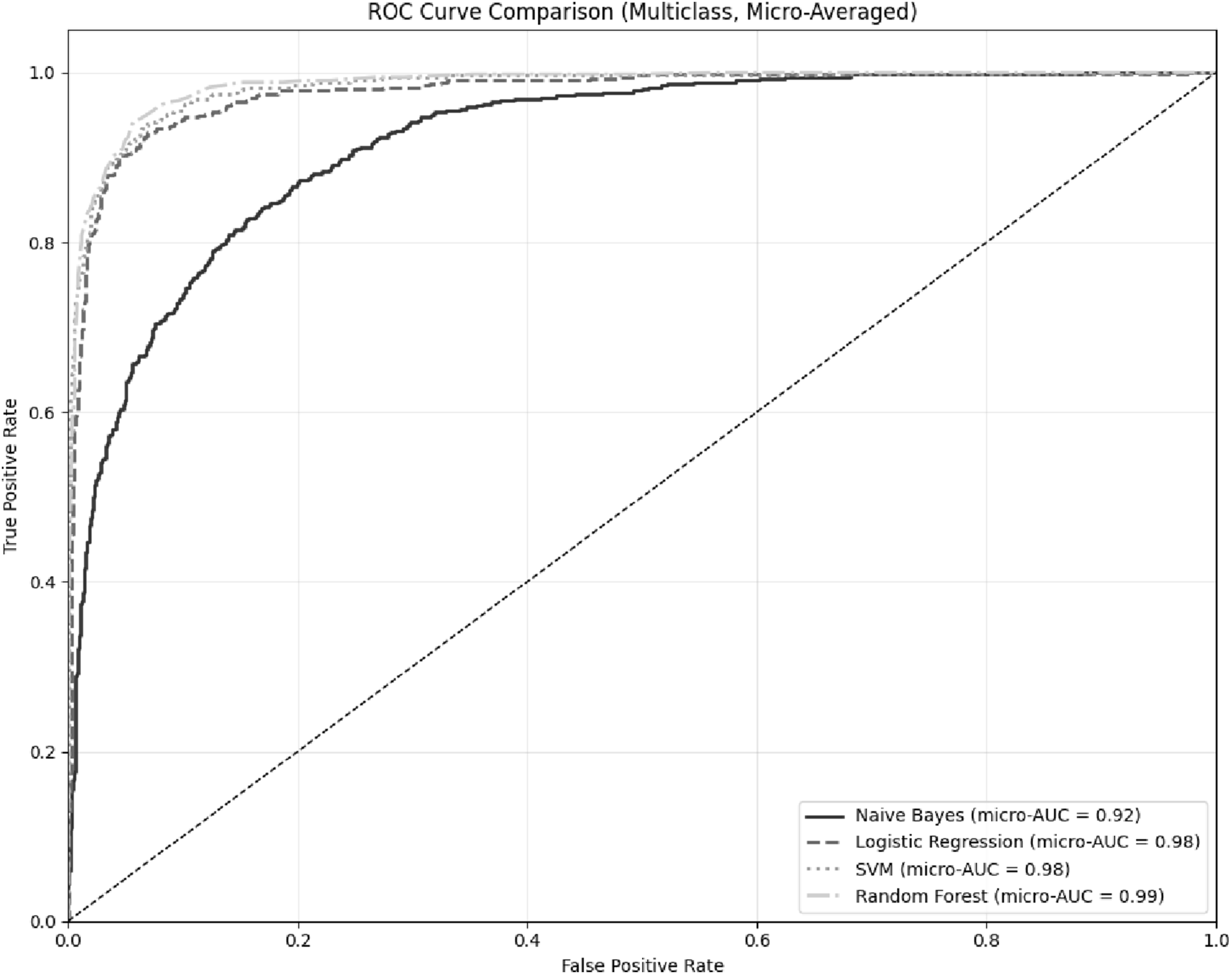
Deep Learning Models
Deep Learning Results
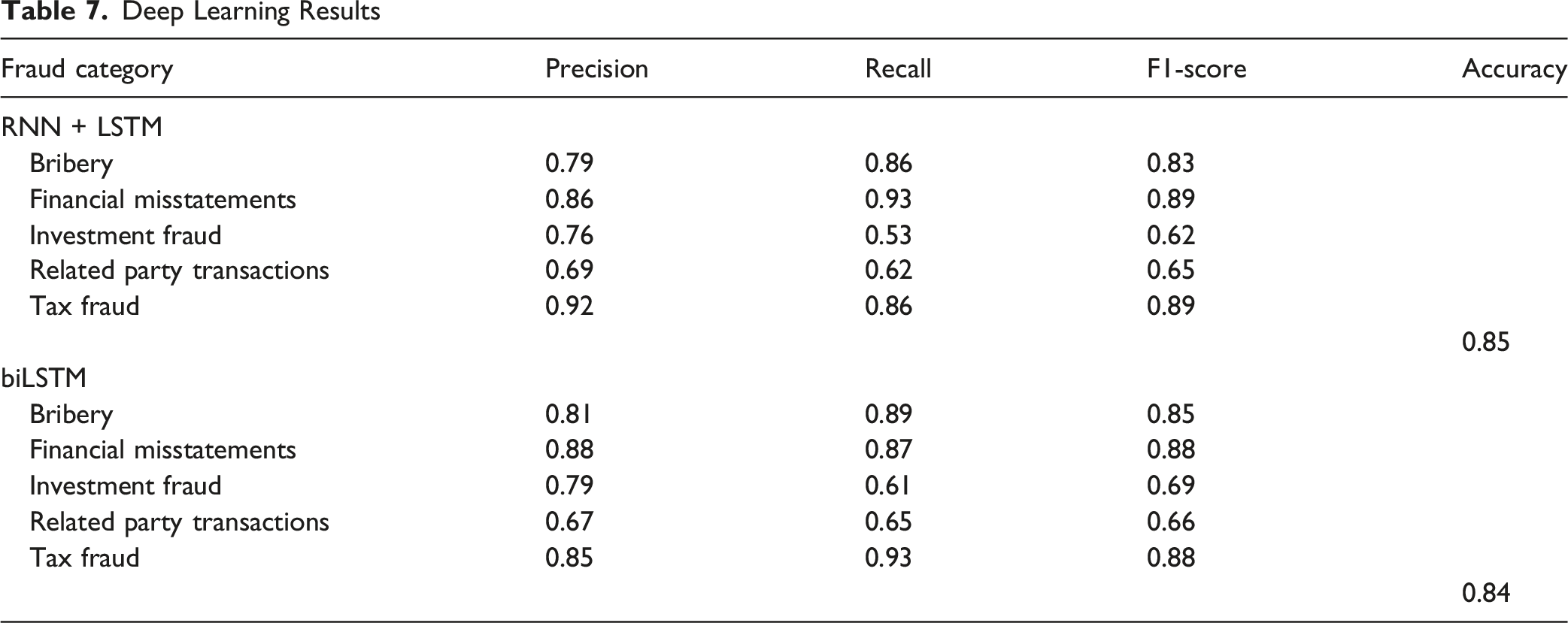
Figure 5 presents the macro-averaged ROC curves for the RNN + LSTM and biLSTM models, comparing their discriminative performance across all fraud categories. Both models achieved high AUC values—0.96 for RNN + LSTM and 0.94 for biLSTM—indicating a strong capability in distinguishing between multiple fraud types across sectors. RNN + LSTM showed a slightly better trade-off, particularly at lower false positive thresholds, consistent with its higher overall accuracy and balance in precision and recall. While biLSTM’s bidirectional architecture offers theoretical advantages in capturing context, RNN + LSTM demonstrated superior macro-level discrimination. These findings suggest that, for industry-specific fraud classification, RNN + LSTM provides a more effective deep learning solution for handling complex narrative disclosures. Deep learning model ROC curves results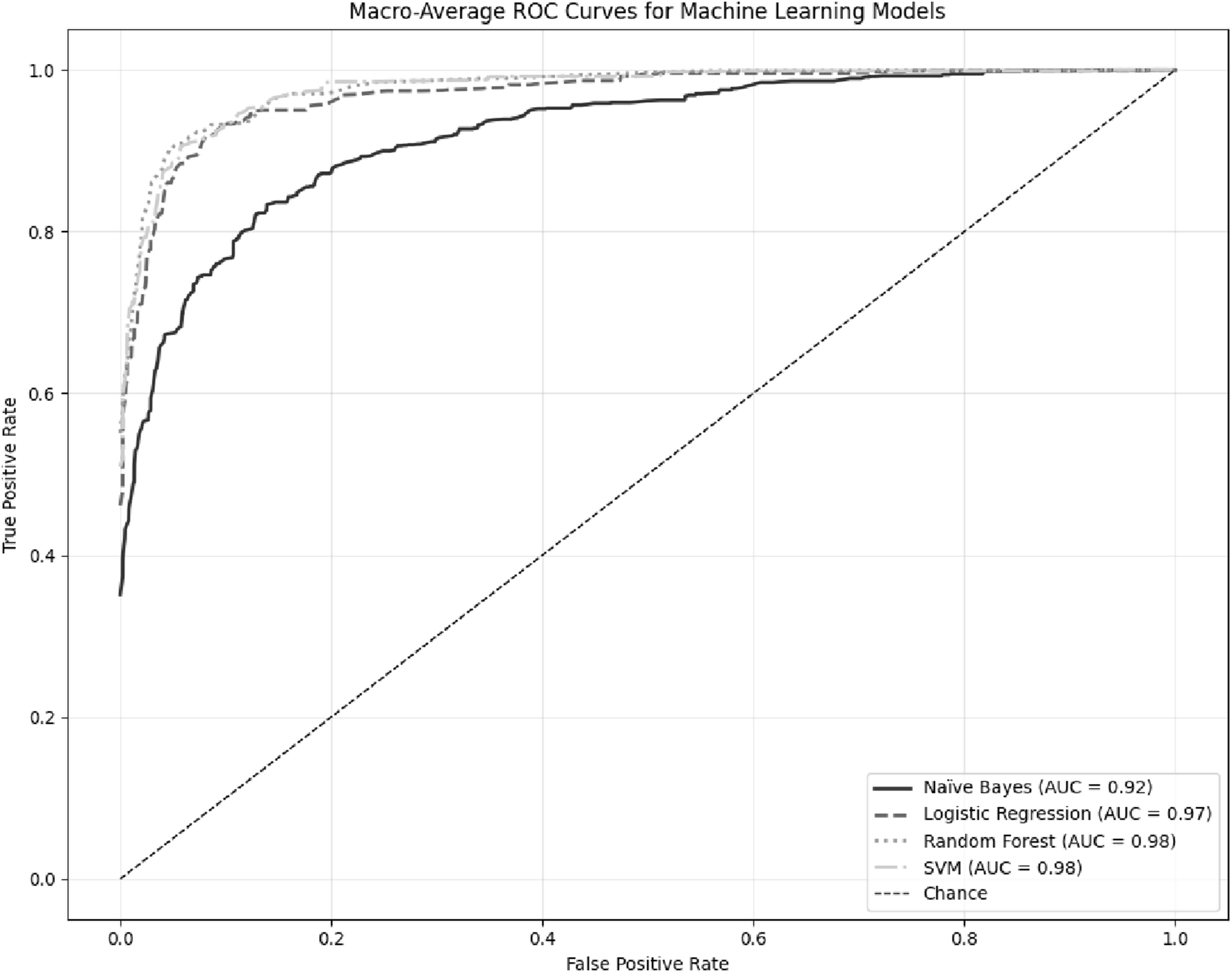
Discussion
Traditional fraud detection approaches often overlook the diverse nature of financial misconduct, failing to distinguish which industries are most associated with specific types of fraud (Bao et al., 2020; Bertomeu et al., 2021; Perols, 2011). Such generalizations limit regulatory and audit effectiveness, producing policies that may target the wrong behaviors. Addressing this limitation, the study applies NLP techniques—specifically supervised classification and topic modelling—to classify distinct fraud typologies and uncover their industry-specific patterns. Rather than treating fraud as uniform, the analysis highlights its heterogeneity across sectors, namely bribery, tax fraud, investment fraud, related-party transactions, and financial misstatements. The strong performance of logistic regression, supported by high F1 scores and ROC-AUC values, reinforces the interpretability of linear models (Cecchini et al., 2010; Perols, 2011), while deep learning adds nuance to classification. Together, these methods yield a more granular understanding of fraud and its sectoral contours, laying the groundwork for targeted and effective detection and enforcement strategies.
The application of SMOTE revealed that oversampling can improve recall for underrepresented fraud types—such as investment fraud and related-party transactions—but its benefits depend on model architecture and industry risk patterns. Logistic regression and random forest benefited most, achieving stronger balance between precision and recall in sectors where these frauds are prevalent. In contrast, Naïve Bayes and SVM showed signs of overfitting or degraded precision, particularly in industries with complex or heterogeneous disclosures. The findings challenge assumptions of universal efficacy in imbalanced classification (Chawla et al., 2002; Elreedy & Atiya, 2019) emphasizing the need to align resampling strategies with both model biases and sectoral dynamics.
Topic modelling results further support the view that fraud typologies are not randomly distributed but exhibit thematic and structural coherence within industry sectors. Successful mapping of latent patterns—identified through LDA and aligned with industry classifications—demonstrates that fraud emerges from patterned opportunity structures and procedural routines embedded within specific organizational contexts. Industries such as pharmaceuticals, banking, and investment management, which show elevated bribery and investment fraud risks, reflect RAT’s structural predicates: motivated offenders, suitable targets, and weak guardianship (Cohen & Felson, 2015; Leukfeldt & Yar, 2016). These environments often feature weakened internal controls, normalized complexity, and diffuse oversight, reinforcing RAT’s ecological logic (Kleemans et al., 2012; Pratt et al., 2010; Yar, 2005).
CSA complements RAT by illuminating the stages and methods underlying distinct fraud types. Deep learning models—RNN + LSTM and biLSTM—captured sequential narrative elements such as preparation (fictitious contracts), execution (asset inflation), and concealment (complex accounting entries). These phases mirror CSA’s conceptualization of fraud as a routinized process. Analysis of disclosures revealed sectoral differences in procedural cues, particularly concealment methods. The stronger performance of the biLSTM model on investment and tax fraud underscores that such misconduct is articulated through temporally ordered language.
Chi-square and clustering analyses revealed a differentiated fraud landscape shaped by sectoral dynamics: procurement practices in pharmaceuticals align with bribery, and opaque financial structures in banking with related-party transactions. These results provide empirical support for the claim that institutional environments shape both opportunity structures and procedural modalities of fraud (Gabbioneta et al., 2013; M. Lokanan, 2018; Morales et al., 2014). Clustering from HDBSCAN and UMAP showed that industries with similar fraud profiles coalesce into coherent communities—revealing fraud not as isolated organizational failure but as an outcome of shared structural logics across sectors.
The integrated theoretical framing grounded in RAT and CSA departs from actor-centered models by situating misconduct within broader structural and procedural contexts (Pratt et al., 2010; Schaefer, 2021). RAT outlines ecological conditions of opportunity, while CSA exposes the procedural choreography of fraud. Industries with high regulatory complexity and low guardianship—such as mining or financial services—illustrate RAT’s opportunity structures, and CSA explains how these are operationalized through repeatable behavioral patterns. Together, the theories present fraud as both structurally situated and procedurally enacted, supporting the need for context-sensitive models that move beyond binary classification toward richer understandings of organizational misconduct (Coleman, 1987; M. Lokanan, 2018; Shapiro, 1990). The theoretical grounding enhances the interpretability of model outputs, helping auditors, regulators, and compliance officers derive actionable insights that extend beyond anomaly detection toward sector-aware evaluations of financial misconduct (Perols, 2011).
Conclusion
At first glance, the present study may appear to depart from conventional fraud research, with its emphasis on algorithmic modeling and textual classification rather than on the proximate causes of financial wrongdoing. Yet, from a broader vantage point, what emerges is a significant contribution to the accounting literature: a reframing of fraud not simply as an individual or organizational transgression but as a patterned and discursively embedded phenomenon. By integrating NLP techniques with criminological theories, the study reveals a more granular and context-sensitive understanding of fraud typologies—one that bridges predictive analytics with the structural and procedural logics through which financial misconduct unfolds. Rather than limiting inquiry to the binary detection of fraud, the analysis situates financial misconduct within a broader epistemic field—one that traces the patterned emergence of fraud typologies through latent discursive structures and sectoral regularities. The integration of topic modeling, supervised classification, chi-square analysis, and graph-based clustering reveals a differentiated architecture of fraud wherein acts such as bribery, tax evasion, and related-party transactions are not random deviations but manifestations of deeper institutional logics. These findings suggest that the legibility of fraud is governed not merely by statistical anomalies but by historically sedimented industry norms, oversight structures, and procedural routines that together delimit what is seen, how it is interpreted, and by whom it is rendered actionable.
A key insight to emerge from this analysis lies in the necessity of stepping beyond narrow, ontological accounts of fraud that reduce misconduct to individual pathology or isolated regulatory failure. Viewed through the structural prism of RAT, the research maps how weakened internal controls, complex transactional environments, and diffuse regulatory oversight create patterned opportunity structures that accommodate semantically porous and context-dependent fraud typologies. In parallel, CSA advances this line of inquiry by exposing the sequential logic through which fraudulent practices are enacted—revealing a procedural architecture encoded in the language of narrative disclosures. Together, these frameworks reveal fraud to be both contextually contingent and procedurally routinized, offering an integrated theoretical anchor for interpreting model outputs and guiding regulatory or investigative action.
Limitations and Future Research
The study focuses on fraud case narratives and industry classifications primarily within a specific regulatory or institutional context. As such, the structural patterns and linguistic cues used to classify fraud types may not generalize across jurisdictions with different regulatory environments, legal definitions of fraud, or disclosure norms. Aligned with the broader discursive turn in critical accounting fraud scholarship, future research should move beyond a narrowly realist stance by applying the NLP-based techniques across jurisdictions and temporal spans, thereby acknowledging the contextual and symbolic dimensions that shape fraud classification. Extending the analysis to multilingual corpora and varied regulatory environments would enable a deeper interrogation of how legal, cultural, and institutional discourses mediate the construction and detection of fraud—yielding a more nuanced and globally attuned understanding of financial misconduct, including its veiled, subterranean, and symbolically coded manifestations.
Although deep learning models such as biLSTM demonstrate strong performance in identifying fraud typologies, the opacity of their internal decision-making processes limits their practical utility in high-stakes regulatory or auditing environments, where explainability is critical. Integrating model-agnostic interpretability tools such as SHAP (SHapley Additive exPlanations) or LIME (Local Interpretable Model-agnostic Explanations) could help unpack the model’s decisions. Additionally, combining interpretable models like logistic regression with deep learning outputs in a hybrid framework may provide a balance between predictive power and explanatory value.
Footnotes
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.