
Abstract
Background:
This study aim to identify key determinants of high fertility and enhance model interpretability for both population-level and individual-level predictions.
Methods:
This cross-sectional analytic study utilized data from the 2024 Nigeria Demographic and Health Survey, focusing on 7370 women aged 40–49 years across Nigeria’s six geopolitical zones, of whom 4089 (55.5%) were classified as high fertility (parity ≥5) and 3281 (44.5%) as low fertility (parity 0–4). Multiple machine learning algorithms, including logistic regression, stochastic gradient descent (SGD), random forest, gradient boosting, and XGBoost, were evaluated for predictive performance using metrics such as accuracy, precision, recall, F1-score, and area under the receiver operating characteristic curve (ROC–AUC). A decision threshold of 0.45 was applied to optimize sensitivity for high fertility classification. An explainable artificial intelligence framework incorporating SHapley Additive explanations (SHAP) and Local Interpretable Model-agnostic Explanations (LIME) was used to elucidate feature contributions and ensure transparency.
Results:
Gradient boosting achieved the highest accuracy (76.9%) and recall for high fertility (0.845) under the optimized threshold, while SGD excelled in sensitivity (recall: 0.857). All models demonstrated strong discriminatory ability (ROC–AUC: 0.827–0.840). SHAP and LIME analyses identified ideal family size, ethnicity, education, contraceptive use, and region as principal predictors of high fertility. Women with no formal education (adjusted odds ratio [AOR]: 2.31; 95% confidence interval [CI]: 1.79–2.98) and those in the Northwest (AOR: 2.20; 95% CI: 1.67–2.91) faced significantly higher odds of high parity, while urban residence (AOR: 0.83; 95% CI: 0.72–0.95) and internet use (AOR: 0.69; 95% CI: 0.58–0.82) were protective.
Conclusions:
These findings underscore the critical role of sociocultural and economic factors in driving high fertility in Nigeria, offering evidence for targeted reproductive health interventions. Policymakers can prioritize education and digital access initiatives, particularly in high-risk regions like the Northwest and Northeast, to reduce fertility-related health risks.
Introduction
High fertility rates is a pressing public health and demographic challenge, particularly in low- and middle-income countries where they contribute to maternal and child health risks, economic strain, and population growth pressures. 1 Elevated parity is associated with increased risks of maternal mortality, obstetric complications, and child undernutrition, while also straining health care systems and hindering sustainable development goals related to gender equality and family planning. 2 In sub-Saharan Africa, where fertility rates remain among the highest globally, understanding the determinants of high parity is essential for designing effective interventions to improve reproductive health outcomes and empower women through informed reproductive choices. 3
Globally, the total fertility rate (TFR) has declined to an average of 2.4 children per woman as of 2020, yet significant regional disparities persist. 4 In sub-Saharan Africa, the TFR stands at approximately 4.6 children per woman, driven by cultural norms favoring large families, limited access to contraception, and low educational attainment among women. 5 Nigeria, the most populous country in Africa, exemplifies these challenges with a TFR of 5.4 children per woman according to recent estimates, positioning it among the highest in the region. 6 This high fertility rate contributes to rapid population growth, with projections suggesting Nigeria’s population could reach 400 million by 2050, exacerbating pressures on health, education, and economic systems. 7
Previous research on fertility determinants in sub-Saharan Africa has identified sociodemographic, economic, and behavioral factors.8–14 Studies have consistently shown that low educational attainment, rural residence, and limited access to family planning services are strongly associated with higher parity.15,16 Cultural factors, such as preferences for large family sizes and early marriage, further exacerbate fertility rates, particularly in regions with strong patriarchal norms. 17 In addition, economic constraints and lack of media exposure have been linked to reduced awareness of contraceptive methods, perpetuating high fertility. 18 While these studies provide valuable insights, many rely on traditional statistical methods that may fail to capture nonlinear interactions and complex patterns in large, heterogeneous datasets, highlighting the need for innovative analytical approaches. 19
In Nigeria, high fertility is particularly pronounced in northern regions, where cultural and religious norms often prioritize large families, and access to education and health care remains limited.20–24 Regional disparities, combined with low contraceptive prevalence (23% among women aged 40–49 as per the 2024 Nigeria Demographic and Health Survey [NDHS]), underscore the urgency of tailored interventions. This study uses a supervised machine learning (ML) approach, complemented by an explainable artificial intelligence (XAI) framework, to analyze data from the 2024 NDHS. By modeling fertility as a binary outcome (low parity: 0–4 live births; high parity: ≥5 live births) and using algorithms such as gradient boosting and random forest alongside interpretability tools like such as SHapley Additive explanations (SHAP) and Local Interpretable Model-agnostic Explanations (LIME), we aim to uncover nuanced predictors of high fertility with enhanced transparency.
This study address critical gaps in the literature by providing up-to-date, comprehensive estimates of high fertility predictors among Nigerian women aged 40–49, a group nearing the end of their reproductive lifespan. Unlike prior research limited by traditional statistical models, our use of ML enables the detection of complex, nonlinear relationships, while the XAI framework ensures model transparency for public health application. By identifying key determinants such as ideal family size, education, and regional disparities, this research offers actionable insights for policymakers to design targeted interventions, ultimately reducing fertility-related health risks and supporting Nigeria’s progress toward sustainable development goals related to maternal health and gender equity.
Methods
Study design
This study used a cross-sectional analytic design to examine predictors of high total fertility among women in Nigeria using a supervised ML approach. Fertility status was modeled as a binary outcome, distinguishing low parity (0–4 live births) from high parity (≥5 live births), in line with established demographic thresholds. An XAI framework was applied to support transparent interpretation of model predictions, enabling both population-level and individual-level insights into fertility patterns (Fig. 1).

Methodical pipeline. LIME, Local Interpretable Model-agnostic Explanations; NDHS, Nigeria Demographic and Health Survey; PR, precision–recall; ROC–AUC, area under the receiver operating characteristic curve; SGD, stochastic gradient descent; SHAP, SHapley Additive explanations.
Data source and outcome definition
This study drew on the 2024 secondary survey data collected from women of reproductive age in Nigeria, containing detailed information on fertility history alongside key sociodemographic, economic, and behavioral characteristics. Only records with complete parity information were included in the analysis to ensure accurate outcome classification. Total fertility was measured as the lifetime number of live births reported by each woman.
Description of the dataset and study population
The data for this study were sourced from the 2024 NDHS, a nationally representative cross-sectional survey conducted to provide comprehensive information on demographic, health, and nutritional indicators in Nigeria. The NDHS is implemented by the National Population Commission in collaboration with international partners, using a stratified two-stage cluster sampling design to ensure representativeness across Nigeria’s six geopolitical zones and 36 states, including the Federal Capital Territory. The survey collects data on a wide range of topics, including fertility, family planning, maternal and child health, and socioeconomic characteristics, through structured interviews with women of reproductive age (15–49 years) and other household members.
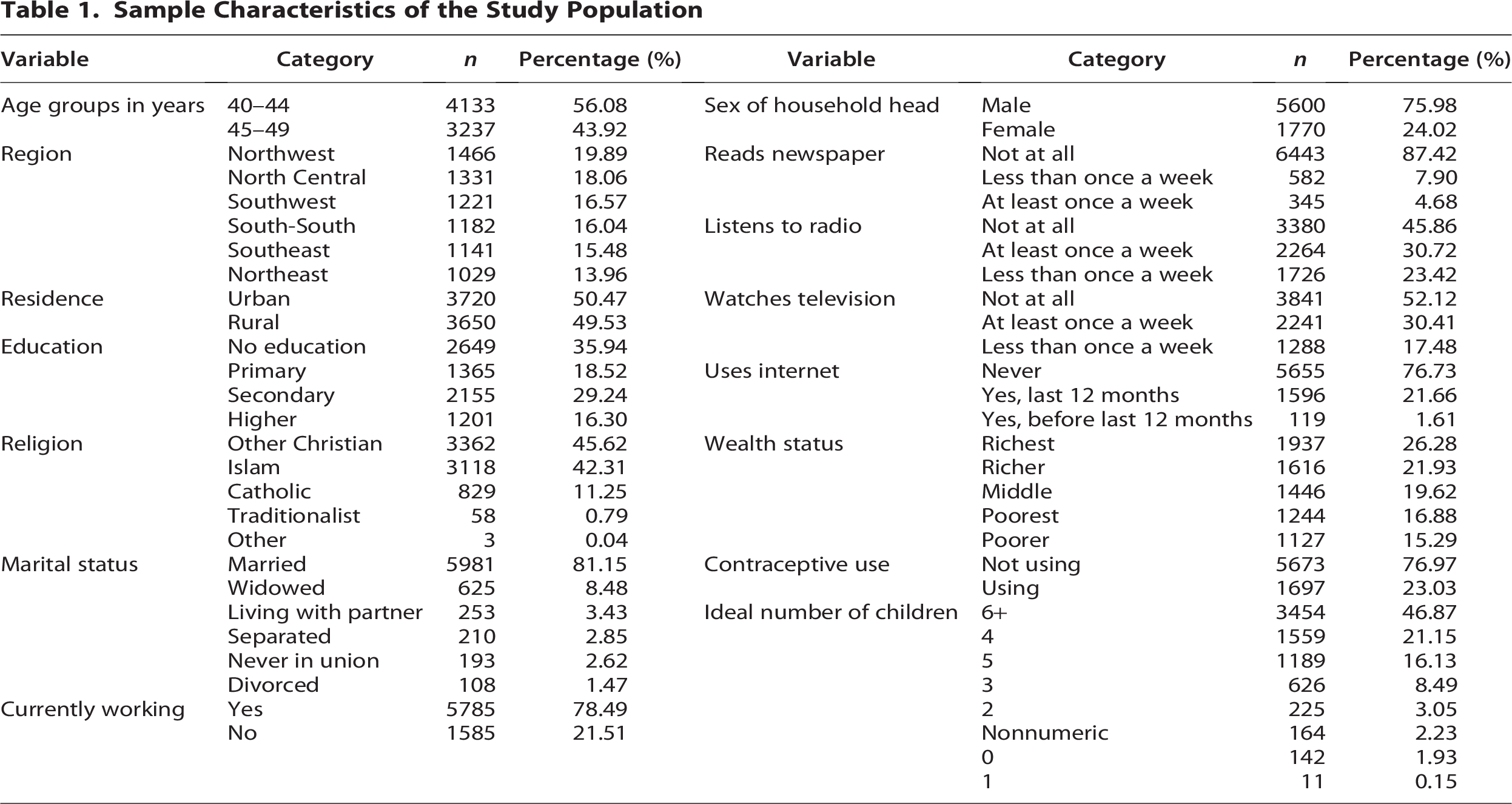
For this study, the analysis focused on a subset of 7370 women aged 40–49 years, representing those nearing the end of their reproductive lifespan. This age group was selected to capture lifetime fertility patterns and associated risk factors. The study population exhibited diverse sociodemographic characteristics: 56.1% were aged 40–44 years, while 43.9% were aged 45–49 years. Geographically, the highest proportions of respondents resided in the Northwest (19.9%) and North Central (18.1%) regions, with an almost equal distribution between urban (50.5%) and rural (49.5%) areas. Educational attainment was notably low, with 35.9% of women reporting no formal education, and only 16.3% having higher education. The majority were married (81.2%) and lived in male-headed households (76.0%). Socioeconomic disparities were evident, with 26.3% in the richest wealth quintile and 16.9% in the poorest. Exposure to mass media and digital platforms was limited, with 87.4% not reading newspapers and 76.7% never using the internet. Contraceptive use was low (23.0%), and fertility preferences leaned toward larger families, with 46.9% of women reporting an ideal family size of six or more children.
Inclusion and exclusion criteria
To ensure the validity and relevance of the study findings, specific inclusion and exclusion criteria were applied to the 2024 NDHS dataset. Inclusion criteria encompassed women aged 40–49 years who participated in the survey and provided complete information on parity (total number of live births). This age range was selected to focus on women likely to have completed or nearly completed their reproductive years, thereby providing a comprehensive view of lifetime fertility patterns. Only records with none missing data on the primary outcome variable (parity) were retained to ensure accurate classification into low-fertility (0–4 live births) and high-fertility (≥5 live births) categories.
Exclusion criteria included women outside the 40–49 age range, as their fertility trajectories might still be ongoing or less representative of completed family size. These criteria resulted in a final analytical sample of 7370 women, providing a robust dataset for examining predictors of high fertility using both statistical and ML approaches.
Data preprocessing and encoding
Outcome construction
The outcome, variable parity, was recoded to represent fertility risk status. Women reporting 0–4 live births were classified as low fertility, while those with five or more live births were classified as high fertility. This threshold is consistent with established demographic conventions widely applied in sub-Saharan African fertility research, where high parity is operationalized at ≥5 live births to capture women who have exceeded the regional average TFR and face progressively elevated reproductive health risks, including obstetric complications, maternal mortality, and child undernutrition.2,8 In the Nigerian context, where the national TFR stands at approximately 5.4 children per woman, this threshold is epidemiologically meaningful and ensures that a clinically and demographically significant segment of at-risk women is captured in the high-fertility category. By contrast, the grand multiparity threshold (≥6 births), while clinically recognized, would have excluded women with exactly five births, a group that already faces substantially elevated reproductive risks, thereby reducing both the sensitivity and the statistical power of the analysis. Furthermore, the ≥5 threshold ensures direct comparability with prior studies examining completed fertility among women aged 40–49 in Nigeria and comparable sub-Saharan African settings,13,14 providing a robust and contextually justified basis for the outcome classification adopted in this study.
Feature preprocessing and encoding
Predictor variables were examined for completeness and consistency before model development. Numerical variables with missing values were imputed using the median to reduce sensitivity to extreme observations, while categorical variables were imputed using the most frequent category to preserve empirical distributions. Categorical features were subsequently transformed using a two-tier encoding strategy to preserve the mathematical integrity of the feature space. For variables with a natural ordinal structure including education level (no education < primary < secondary < higher), wealth quintile (poorest < poorer < middle < richer < richest), and media exposure frequency (not at all < less than once a week < at least once a week), ordinal encoding was applied, whereby categories were mapped to rank-ordered integer representations that preserved the inherent hierarchy. For purely nominal categorical variables including region, ethnicity, religion, and marital status, one-hot encoding (dummy encoding) was applied, generating binary indicator variables for each category. This approach explicitly avoided imposing any false mathematical hierarchy on nominal features, ensuring that no spurious ordinal relationships were introduced into the model inputs for variables such as region or ethnicity, where categories carry no inherent rank order. The combined encoding strategy produced a unified numerical feature space suitable for all ML algorithms evaluated in this study.
Rationale for model selection
To ensure a comprehensive assessment of fertility prediction, multiple ML algorithms with differing learning characteristics were evaluated. The selected models span linear, ensemble, and boosting-based approaches, allowing comparison between interpretable baseline methods and more complex nonlinear learners. This strategy supports both predictive benchmarking and robust explainability analysis.
Logistic regression
Logistic regression was included as a baseline classifier due to its widespread use in demographic and public health research. Its probabilistic formulation provides a transparent reference model against which the performance of more complex algorithms can be compared. Inclusion of logistic regression enables evaluation of whether nonlinear ML methods offer meaningful performance gains beyond traditional statistical approaches.
Stochastic gradient descent classifier
The stochastic gradient descent (SGD) classifier was used as an efficient linear learning algorithm capable of optimizing large-scale datasets through iterative updates. Its inclusion allows assessment of linear decision boundaries under regularized optimization, providing insight into the extent to which fertility patterns can be captured through linear relationships alone.
Random forest
Random forest was selected to model complex nonlinear interactions among fertility determinants through an ensemble of decision trees. By aggregating multiple trees trained on bootstrapped samples, the algorithm reduces variance and improves generalization. Its ability to capture feature interactions makes it particularly suitable for modeling heterogeneous socioeconomic and demographic effects.
Gradient boosting classifier
Gradient boosting was incorporated due to its strong performance in structured tabular data and its capacity to sequentially refine prediction errors. The algorithm learns additive decision rules that effectively capture subtle nonlinear patterns, making it well suited for fertility modeling where interactions between education, wealth, residence, and behavioral factors are often nonadditive.
Threshold tuning
Model predictions were generated as probabilities of high fertility rather than as fixed class labels. Instead of applying the conventional 0.50 classification threshold, the decision threshold was systematically evaluated across a range of candidate values (0.40–0.55, in increments of 0.05) to identify the optimal operating point for high-fertility classification. Threshold selection was guided by the Youden’s J statistic (J = Sensitivity + Specificity − 1), which identifies the threshold that maximizes the combined discriminatory performance of the classifier. Across all models evaluated, the threshold of 0.45 consistently yielded the highest Youden’s J values, outperforming both the conventional 0.50 threshold and alternative candidate values in terms of the sensitivity–specificity balance for the high-fertility class. This selection was further validated through a public health cost–benefit rationale: In the context of fertility risk identification, a false negative failing to identify a woman with high fertility carries a substantially greater programmatic cost than a false positive, as missed cases represent missed opportunities for targeted family planning counseling, reproductive health support, and preventive intervention. The 0.45 threshold therefore reflects both a statistically principled decision grounded in the Youden’s J criterion and a contextually justified public health prioritization of sensitivity, reducing the likelihood of under-identifying women at elevated fertility risk while maintaining overall model stability and interpretability.
Model evaluation and performance metrics
Model performance was assessed using a comprehensive set of classification metrics computed on the hold-out test dataset. These included accuracy, precision, recall, and F1-score, reported for both low- and high-fertility classes to capture class-specific predictive behavior. In addition, model discrimination was evaluated using the area under the receiver operating characteristic curve (ROC–AUC), which quantifies the ability of each model to distinguish between fertility classes across varying decision thresholds. Precision–recall (PR) analysis was also conducted to provide complementary insight into model performance under class imbalance conditions. All metrics were derived from predicted probability outputs and evaluated using a consistent classification threshold, enabling standardized comparison across modeling approaches.
XAI framework
To enhance transparency and interpretability of the ML models, an XAI framework was incorporated into the analytical pipeline. This framework was designed to enable understanding of both population-level patterns and individual-level predictions, addressing the inherent opacity of ensemble-based learning algorithms. Two complementary post hoc explanation methods were used: SHAP and LIME. SHAP was used to quantify the contribution of each predictor to model outputs through additive feature attributions, supporting both global importance assessment and local explanation of individual predictions. LIME was applied to generate instance-specific explanations by approximating the complex model locally with an interpretable surrogate. Together, these methods provided a multilevel interpretability framework that supported transparent examination of fertility risk predictions while maintaining model-agnostic applicability.
Results
Sample characteristics
The analysis included 7370 women aged 40–49 years, of whom 56.1% were aged 40–44 years and 43.9% were aged 45–49 years. Respondents were drawn from all geopolitical regions, with the highest proportions residing in the Northwest (19.9%) and North Central (18.1%), and an almost equal distribution between urban (50.5%) and rural (49.5%) areas. Educational attainment was generally low, as 35.9% of women reported no formal education, while 18.5%, 29.2%, and 16.3% had primary, secondary, and higher education, respectively. The majority of participants were married (81.2%) and lived in male-headed households (76.0%). Overall exposure to mass media and digital platforms was limited, with 87.4% reporting no newspaper readership, 45.9% no radio exposure, 52.1% no television viewing, and 76.7% having never used the internet. Socioeconomic status varied across the sample, with 26.3% of women classified within the richest wealth quintile, followed by 21.9% in the richer and 19.6% in the middle quintiles. Contraceptive uptake was low, as 77.0% of respondents were not using any contraceptive method at the time of the survey. Fertility preferences remained high, with nearly half of the women (46.9%) reporting an ideal family size of six or more children, reflecting persistent normative preferences for large family sizes among women approaching the end of their reproductive lifespan (Table 1). With respect to the outcome variable, 4089 women (55.5%) were classified as high fertility (parity ≥5 live births) and 3281 women (44.5%) as low fertility (parity 0–4 live births), yielding a near-balanced class distribution (approximately 55:45 ratio) that supports the interpretability of the reported classification metrics without necessitating aggressive resampling techniques. The modest class imbalance nonetheless justified the inclusion of PR analysis as a complementary evaluation framework.
Sample Characteristics of the Study Population
Adjusted odds ratio results
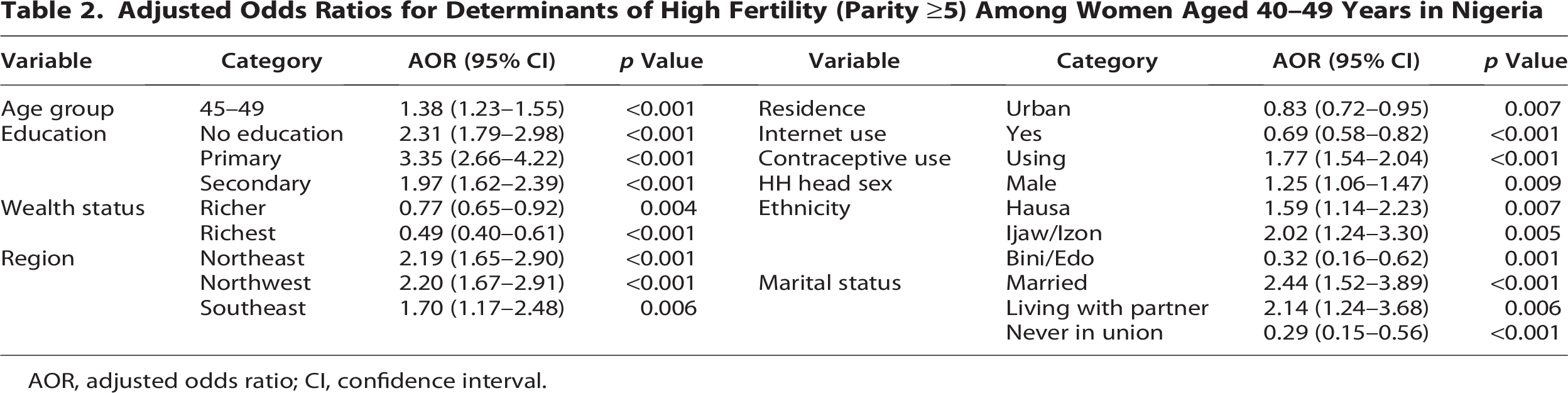
The multivariable logistic regression analysis demonstrated significant associations between high fertility (parity ≥5) and several sociodemographic and contextual factors (Table 2). Older women aged 45–49 years exhibited higher odds of high fertility compared with those aged 40–44 years (adjusted odds ratio [AOR] = 1.38; 95% confidence interval [CI]: 1.23–1.55). Markedly elevated odds were observed among women with no formal education (AOR = 2.31) and primary education (AOR = 3.35), whereas women in the richest wealth quintile had substantially lower odds (AOR = 0.49). Pronounced regional disparities persisted, with women residing in the Northeast (AOR = 2.19) and Northwest (AOR = 2.20) experiencing higher fertility risks. Urban residence (AOR = 0.83) and recent internet use (AOR = 0.69) were associated with reduced odds of high fertility, while current contraceptive use showed a positive association (AOR = 1.77), likely reflecting reverse causality (Table 2).
Adjusted Odds Ratios for Determinants of High Fertility (Parity ≥5) Among Women Aged 40–49 Years in Nigeria
AOR, adjusted odds ratio; CI, confidence interval.
Baseline ML results
The baseline ML models demonstrated comparable performance in classifying fertility status (Table 3), with overall accuracy ranging from 75.4% to 76.7%. The SGD classifier achieved the highest predictive performance, with an accuracy of 76.7% and the strongest recall (0.834) and F1-score (0.805) for the high-fertility class, indicating improved sensitivity in identifying women with parity ≥5. The gradient boosting model also performed competitively (accuracy = 76.3%), exhibiting balanced precision and recall across both fertility classes. Logistic regression, used as a baseline interpretable model, achieved an accuracy of 75.4% with stable discrimination between low- and high-fertility groups. Tree-based models, including random forest and XGBoost, showed similar performance levels (accuracy ≈75.6%), with slightly higher precision for the high-fertility class but modestly lower recall for low-fertility women. Overall, the relatively consistent performance across models suggests moderate separability between fertility classes and provides a robust baseline for subsequent model optimization and explainability analyses.
Baseline Machine Learning Model Performance for Fertility Classification
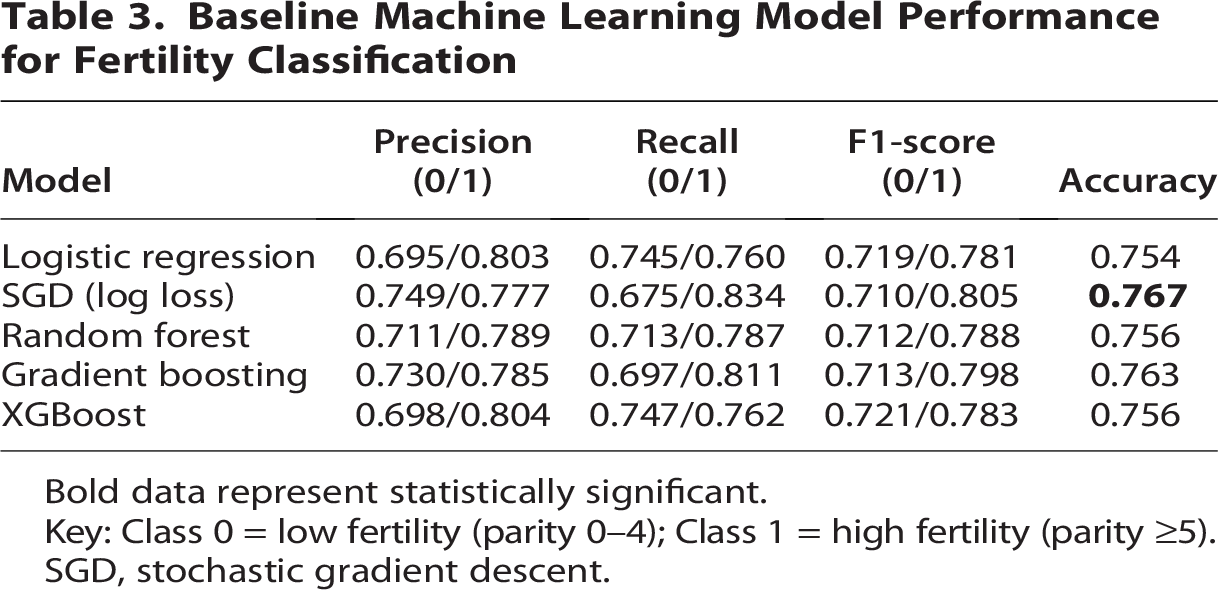
Bold data represent statistically significant.
Key: Class 0 = low fertility (parity 0–4); Class 1 = high fertility (parity ≥5).
SGD, stochastic gradient descent.
Threshold-optimized model performance (τ = 0.45)
Applying a calibrated decision threshold of 0.45 resulted in improved sensitivity toward high-fertility classification across models (Table 4). Under the optimized threshold, gradient boosting achieved the strongest overall performance, with the highest accuracy (76.9%) and a high-fertility recall of 0.845, indicating improved identification of women with parity ≥5. The SGD classifier similarly demonstrated enhanced sensitivity for the high-fertility class (recall = 0.857; F1-score = 0.809), although with reduced recall for the low-fertility group. Logistic regression exhibited more balanced performance between classes, yielding comparable precision and recall for both low- and high-fertility outcomes (accuracy = 75.9%). Tree-based models, including random forest and XGBoost, showed moderate gains in high-fertility recall (≥0.83) but at the expense of lower discrimination for the low-fertility class.
Threshold-Optimized Machine Learning Model Performance (
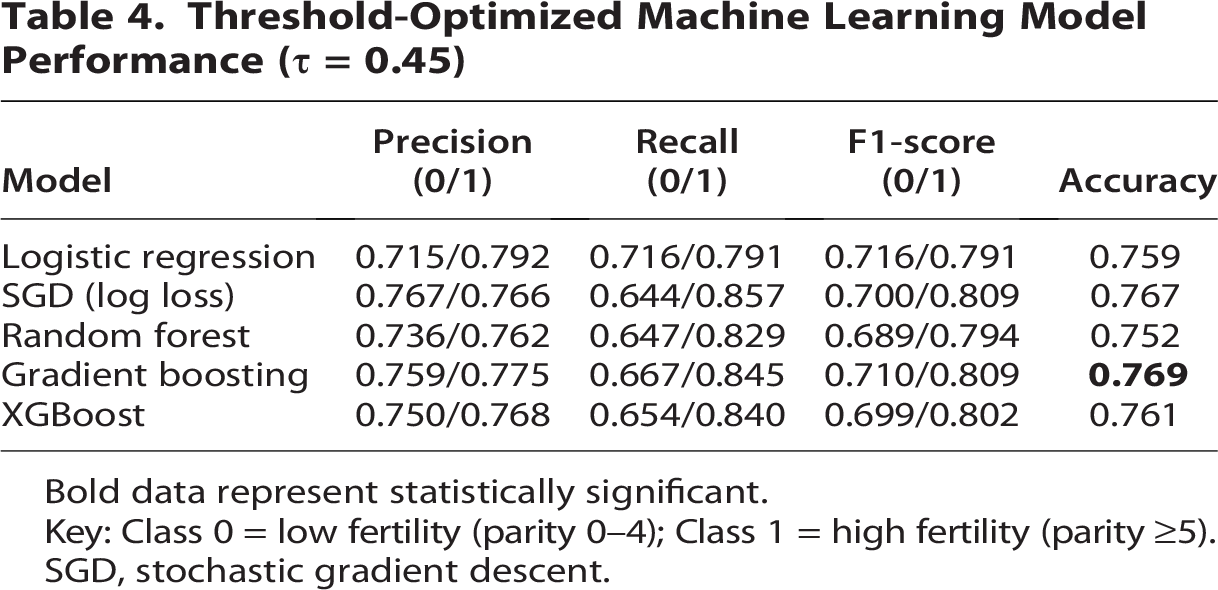
Bold data represent statistically significant.
Key: Class 0 = low fertility (parity 0–4); Class 1 = high fertility (parity ≥5).
SGD, stochastic gradient descent.
Discrimination performance using ROC and PR curves
The discrimination performance of the threshold-optimized models (τ = 0.45) is illustrated in Figure 2 using ROC and PR curves. All models demonstrated good discriminatory ability, with ROC–AUC values ranging from 0.827 to 0.840, indicating consistent separation between low- and high-fertility classes. Logistic regression and XGBoost achieved the highest ROC–AUC values (both 0.840), followed closely by SGD (0.839) and gradient boosting (0.833), while random forest showed slightly lower discrimination (AUC = 0.827). PR analysis yielded similarly strong performance, with average precision (AP) scores between 0.848 and 0.864, reflecting robust predictive capacity under class imbalance. The highest AP was observed for XGBoost (AP = 0.864) and logistic regression (AP = 0.861), indicating superior reliability in identifying women with high fertility (parity ≥5).

ROC and precision–recall curves for threshold-optimised machine learning models (τ = 0.45) predicting high fertility (parity ≥ 5).
LIME and SHAP explainability results
LIME interpretation of high-fertility predictions
LIME was used to generate instance-level explanations of model predictions for high fertility (parity ≥5). Six representative cases were examined, including both high-confidence and borderline predictions (Fig. 3). For each instance, LIME decomposed the predicted probability into positive and negative feature contributions, enabling transparent interpretation of model decision pathways.

LIME-based explanations for six representative predictions, illustrating feature contributions to low fertility (Class 0) and high fertility (Class 1) outcomes.
In high-confidence predictions for high fertility (predicted probability >0.90), dominant positive contributions consistently arose from the ideal number of children, ethnicity, and contraceptive use. In several cases, the ideal number of children contributed approximately 0.29–0.30 toward the final prediction, with reinforcing effects from ethnicity (≈0.11–0.15) and contraceptive use (≈0.07–0.08). These features jointly outweighed weaker opposing effects, producing stable classifications.
Conversely, predictions strongly favoring low fertility (predicted probability ≥0.97) were characterized by negative contributions from lower ideal family size, higher educational attainment, and favorable socioeconomic characteristics. In such instances, the cumulative negative influence of education and fertility preference substantially reduced the likelihood of high fertility. Media exposure variables and employment status generally contributed minimally across cases.
For borderline predictions near the classification threshold (probability range 0.45–0.55), LIME plots revealed competing feature effects, with moderate positive contributions from fertility preferences offset by negative influences from education, residence, or wealth status. These balanced contributions explain model uncertainty in marginal cases and highlight the contextual nature of fertility behavior.
SHAP explainability analysis
SHAP was applied to complement LIME by providing globally consistent and locally additive explanations. The global SHAP feature importance plot (Fig. 4A) identified the ideal number of children as the most influential predictor, followed by ethnicity, contraceptive use, education, and region, underscoring the dominant role of fertility preferences and sociocultural context.
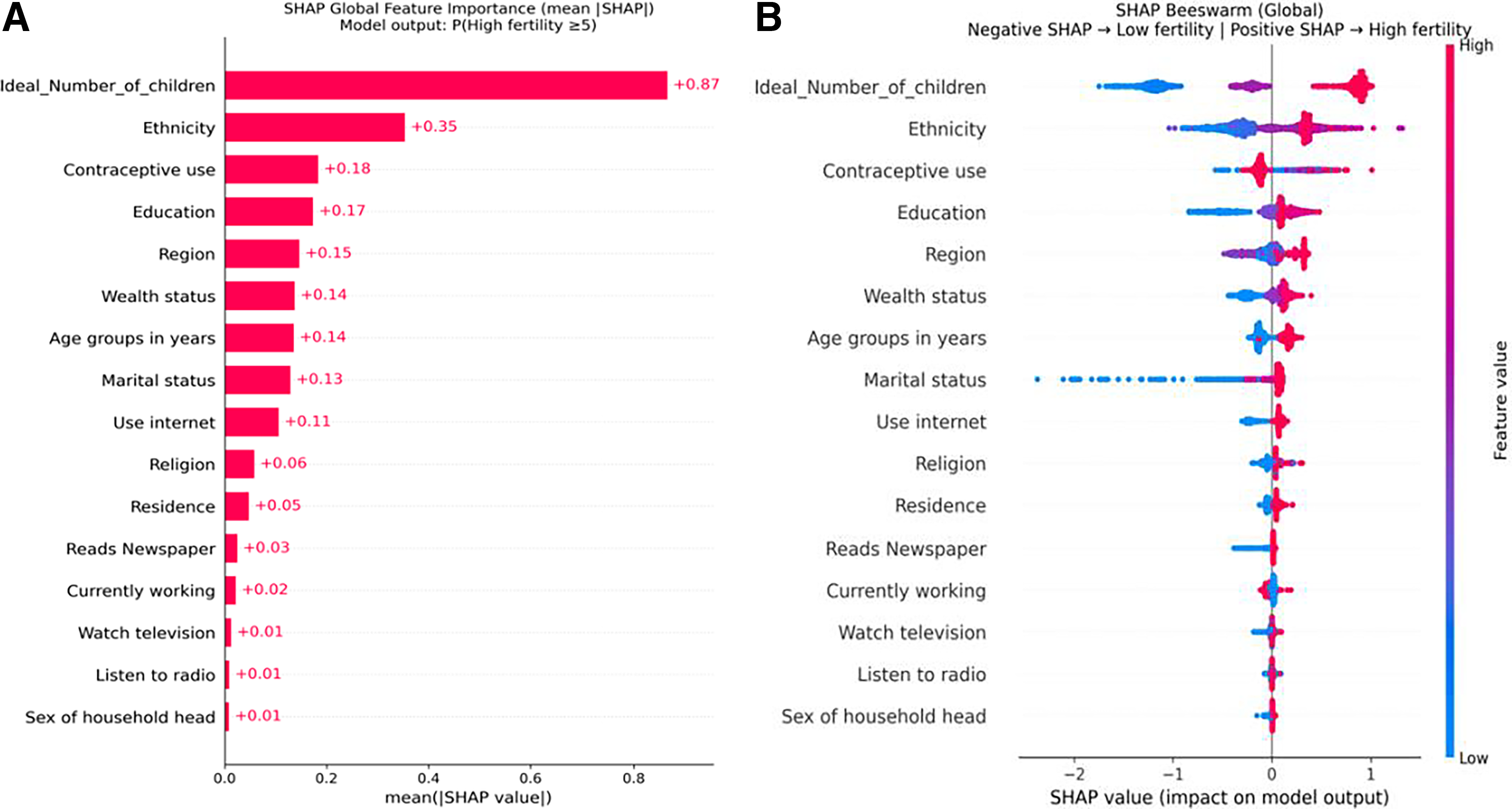
The SHAP beeswarm plot (Fig. 4B) demonstrated clear directionality of effects across the population. Higher values of ideal family size generated strongly positive SHAP values, markedly increasing the probability of high fertility, whereas lower values exerted substantial negative effects. Lower educational attainment and certain ethnic and regional categories were associated with positive SHAP contributions, while higher wealth status and information access variables exhibited predominantly negative effects.
Instance-level SHAP waterfall plots (Fig. 5) further clarified individual predictions. High-risk cases (p ≥ 0.93) showed aligned positive contributions from fertility preferences, ethnicity, and contraceptive use, whereas low-risk cases (p ≤ 0.02) were driven by strong negative contributions from education and lower ideal family size. Borderline cases exhibited near-equal opposing SHAP forces, explaining prediction instability around the decision threshold.
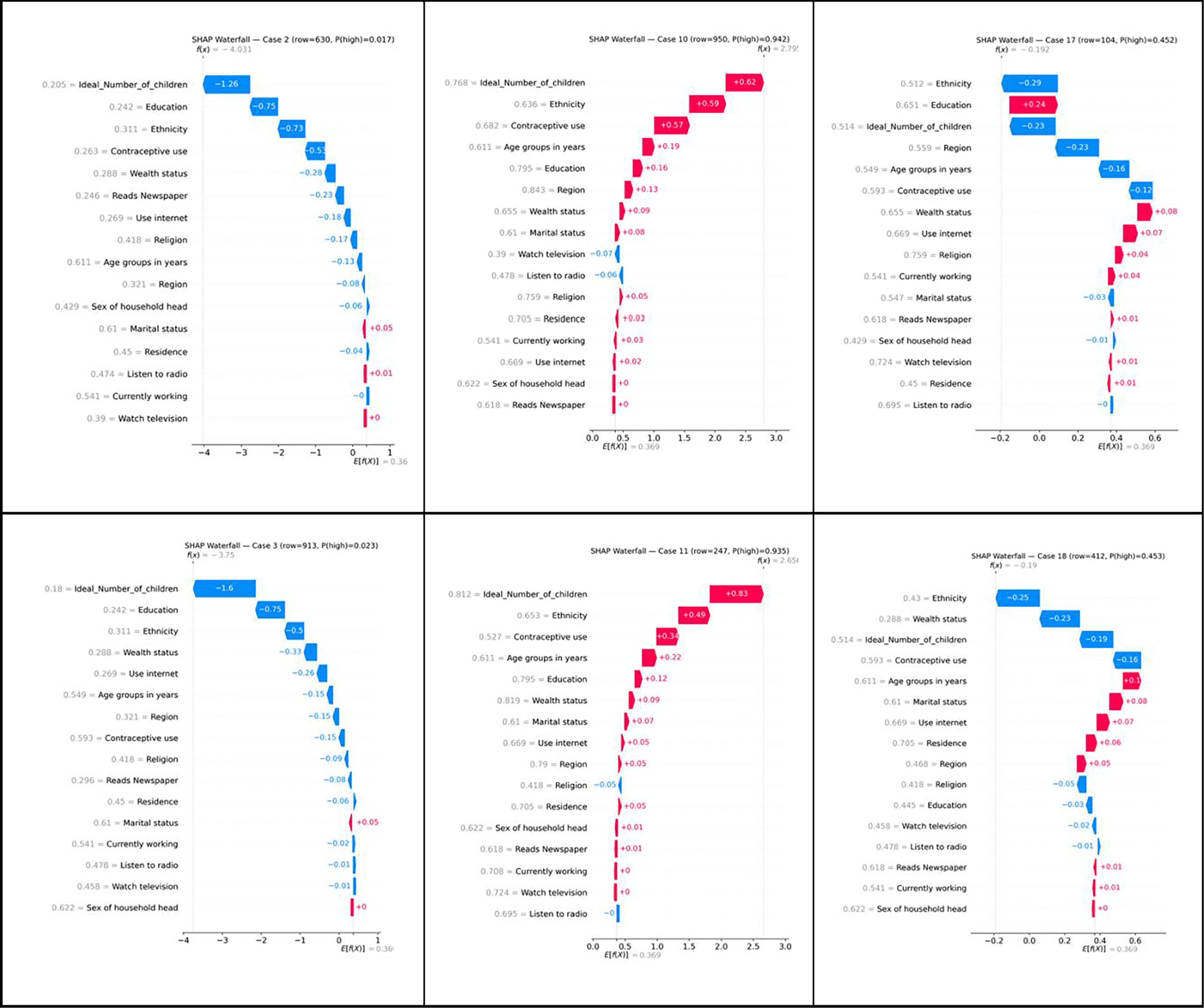
Aggregated SHAP explanations illustrating global and local feature contributions.
LIME and SHAP produced convergent interpretability findings, consistently identifying fertility preference, ethnicity, education, and contraceptive use as principal determinants of high fertility. While LIME offered intuitive, instance-specific explanations, SHAP provided a rigorous probabilistic decomposition of predictions. Their combined application enhances model transparency and supports the interpretability of ML-based fertility risk assessment.
Discussion
This study provides novel insights into the predictors of high fertility (parity ≥5) among 7370 Nigerian women aged 40–49, leveraging data from the 2024 NDHS and using a supervised ML approach with an XAI framework for transparent interpretation. Our findings reveal that gradient boosting achieved the highest predictive accuracy (76.9%) and recall for high fertility (0.845) under an optimized threshold of 0.45, with SGD demonstrating marginally superior sensitivity (recall: 0.857). However, this apparent advantage of SGD must be interpreted in the context of its PR trade-off. While SGD’s higher recall reduces false negatives, ensuring fewer high-fertility women are missed, it does so at the cost of reduced precision for the high-fertility class (0.766 vs. 0.775 for gradient boosting) and notably lower recall for the low-fertility class (0.644 vs. 0.667). In practical terms, this means SGD would incorrectly flag a greater proportion of low-fertility women as high risk, potentially straining the limited family planning counseling and reproductive health resources in already resource-constrained Nigerian health systems. Gradient boosting’s superior balance across both fertility classes, combined with its higher overall accuracy and a comparable ROC–AUC (0.833 vs. 0.839 for SGD), therefore makes it the more operationally viable model for population-level fertility risk screening. This distinction is critical for policymakers and program implementers who must weigh the costs of missed cases against the costs of unnecessary intervention, a balance that gradient boosting navigates more effectively than SGD in the present analytical context. Key determinants identified through SHAP and LIME include ideal family size, ethnicity, education, contraceptive use, and regional disparities. Women with no formal education faced significantly higher odds of high parity (AOR: 2.31; 95% CI: 1.79–2.98), as did those in the Northwest (AOR: 2.20; 95% CI: 1.67–2.91) and Northeast (AOR: 2.19; 95% CI: 1.65–2.90) regions. Conversely, urban residence (AOR: 0.83; 95% CI: 0.72–0.95) and recent internet use (AOR: 0.69; 95% CI: 0.58–0.82) were protective. These results underscore the sociocultural, economic, and geographic factors driving fertility outcomes in Nigeria.
The dominant influence of ideal family size on high-fertility predictions, as evidenced by SHAP analyses, reflects deep-rooted cultural norms favoring large families in Nigeria, particularly among women nearing the end of their reproductive years. This preference, reported by 46.9% of participants as six or more children, aligns with theories of fertility transition that emphasize the role of normative values in sustaining high parity in pretransition societies. 3 The significant contribution of ethnicity, with groups such as Hausa (AOR: 1.59; 95% CI: 1.14–2.23) and Ijaw/Izon (AOR: 2.02; 95% CI: 1.24–3.30) showing elevated odds, suggests that cultural identities shape reproductive behaviors through mechanisms like early marriage and limited female autonomy. 17 Low educational attainment emerged as a critical risk factor, likely due to its association with reduced access to reproductive health information and empowerment, which delays fertility decline. 16 The protective effect of urban residence and internet use highlights the role of modernization and information access in shifting fertility preferences, consistent with the demographic transition theory. 5 The protective effect of internet use (AOR: 0.69; 95% CI: 0.58–0.82) is among the most policy-relevant findings of this study, suggesting that digital information access functions as an independent pathway through which women acquire reproductive health knowledge and shift fertility preferences, a mechanism that partially parallels, and in some contexts may complement or compete with, the influence of formal education. This is particularly notable given that 76.7% of the study sample reported never using the internet, indicating substantial untapped potential for digital health interventions. The effect size observed here is stronger than previously reported in comparable studies, 25 which may reflect the accelerated expansion of mobile internet infrastructure in Nigeria by 2024. Critically, internet use may operate through distinct pathways from formal education including exposure to digital family planning content, peer health networks, online health communities, and social media campaigns promoting contraceptive awareness, suggesting that digital literacy initiatives could serve as a cost-effective complement to structural education investments. This is especially relevant in regions where formal schooling access remains constrained by geographic, economic, or cultural barriers, and where digital connectivity may represent a more rapidly scalable channel for reproductive health communication. The convergence of internet access and education as dual protective pathways underscores the importance of a multichannel approach to fertility transition in Nigeria, in which digital infrastructure investments are pursued alongside rather than as a substitute for long-term educational development. Surprisingly, current contraceptive use was associated with higher fertility odds (AOR: 1.77; 95% CI: 1.54–2.04), a finding likely attributable to reverse causality, where women with higher parity adopt contraception later to limit further births rather than prevent them initially. These interpretations underscore the need for context-specific interventions that address both structural and cultural drivers of fertility in Nigeria.
Our findings resonate with prior research in sub-Saharan Africa, which consistently identifies low education, rural residence, and cultural norms as key drivers of high fertility.26–28 For instance, a study using the 2018 NDHS reported similar regional disparities, with northern Nigerian women exhibiting higher parity due to limited access to education and family planning services.29,30 However, our study extends beyond traditional logistic regression by using ML algorithms that capture nonlinear interactions, achieving higher sensitivity for high-fertility classification (recall up to 0.857 with SGD) compared with earlier studies relying on conventional methods.21,31–33 The protective role of internet use aligns with emerging evidence on the impact of digital media in promoting contraceptive awareness, although our effect size (AOR: 0.69) is stronger than previously reported, possibly due to increased digital penetration by 2024. 25 Unlike some studies that found no significant association between ethnicity and fertility after controlling for socioeconomic factors,34,35 our SHAP and LIME analyses highlight ethnicity as a persistent predictor, suggesting that cultural identities exert independent effects not fully mediated by wealth or education. These differences may reflect the enhanced granularity of ML approaches in detecting subtle patterns, underscoring the value of integrating advanced analytics with demographic research.
The persistence of significantly elevated fertility odds in the Northwest (AOR: 2.20) and Northeast (AOR: 2.19) after controlling for individual-level education, wealth, residence, internet use, and other covariates is a particularly important finding, as it signals the operation of structural and community-level drivers that transcend individual socioeconomic characteristics. Several mechanisms may account for this residual regional effect. First, the Northwest and Northeast are characterized by deeply entrenched patriarchal norms and religious frameworks that institutionally prioritize large family sizes and circumscribe female reproductive autonomy, including near-universal early marriage practices, low female household decision-making power, and strong community-level opposition to contraception.17,31 These normative environments sustain pronatalist preferences independently of individual educational attainment or wealth, explaining why the regional effect persists after covariate adjustment. Second, contraceptive prevalence in these regions remains critically low even relative to the national average of 23%, reflecting compounding supply-side barriers including sparse health care infrastructure, inadequate distribution networks for family planning commodities, and a severe shortage of trained reproductive health workers alongside demand-side barriers rooted in community-level opposition. 29 Third, community educational norms, where low female schooling is generationally reinforced as a social expectation rather than an individual circumstance, may sustain high-fertility preferences at a level that individual-level education variables fail to fully capture. Fourth, the geographic concentration of ethnic groups with culturally embedded pronatalist values, particularly the Hausa-Fulani communities in these northern zones, likely contributes to the residual regional effect, as cultural identity exerts an independent influence on reproductive behavior beyond what individual ethnicity variables alone can account for. These findings collectively underscore the need for geographically targeted, multilevel interventions in Nigeria’s northern geopolitical zones that simultaneously address individual-level barriers, community-level normative environments, and structural supply-side constraints in reproductive health service delivery.
Implications
The implications of this study are multifaceted, spanning clinical, public health, and policy domains in Nigeria and across sub-Saharan Africa. At the clinical level, the high recall of our models (up to 0.857 for high fertility) suggests potential for ML-based tools to identify women at elevated reproductive risk, enabling targeted counseling and family planning services in resource-constrained settings. From a public health perspective, the pronounced regional disparities particularly in the Northwest and Northeast call for geographically tailored interventions, such as mobile health units to deliver contraceptives and education campaigns to shift cultural norms around family size. The protective effect of education and internet use supports policy investments in female literacy and digital infrastructure as long-term strategies to reduce fertility-related health burdens, aligning with sustainable development goals on gender equality and health. Globally, the application of XAI frameworks like SHAP and LIME offers a blueprint for integrating complex ML models into public health decision-making, enhancing trust and interpretability in contexts where algorithmic opacity has hindered adoption. In Nigeria specifically, policymakers should prioritize multisectoral approaches that address structural barriers (e.g., education access) alongside cultural factors (e.g., family size norms), ensuring that interventions are both evidence-based and contextually relevant. Building directly on the demographic segments identified through the SHAP and LIME analyses, specifically women with no formal education, those residing in the Northwest and Northeast, women from the Hausa and Ijaw/Izon ethnic groups, and rural women with low contraceptive uptake, we propose the adoption of a targeted Digital Family Planning (DFP) framework as a concrete, ML-informed policy instrument for Nigeria. This framework would encompass three operationally distinct but complementary components. First, mobile-based family planning messaging delivered via SMS and low-bandwidth applications targeting women with limited internet access but mobile phone ownership, with content tailored to local languages (particularly Hausa) and culturally sensitive communication strategies that address pronatalist norms directly rather than circumventing them. Second, community digital health hubs in high-risk regions, where trained community health workers use tablet-based decision-support tools informed by the ML risk models developed in this study to identify and counsel women at elevated fertility risk during routine community outreach visits, enabling real-time, data-driven triage of reproductive health needs. Third, social media and influencer-based campaigns targeting women in transitional fertility stages, leveraging the strong protective internet effect identified in this study (AOR: 0.69) to promote contraceptive awareness, normalize smaller family size preferences, and amplify the voices of community health advocates within digital spaces. This DFP framework directly operationalizes the ML model outputs, ensuring that digital health investments are strategically allocated to the demographic segments where they are most likely to reduce high-fertility risk, thereby maximizing programmatic efficiency and health impact in resource-constrained Nigerian settings.
Strengths and limitations
This study benefits from several methodological strengths that enhance the robustness of its findings. The use of a large, nationally representative sample (7370 women) from the 2024 NDHS ensures generalizability across Nigeria’s diverse geopolitical zones. The application of multiple ML algorithms, benchmarked against traditional logistic regression, provides a comprehensive assessment of predictive performance, while the XAI framework addresses the “black box” challenge of complex models, offering transparent insights at both population and individual levels. The optimized decision threshold (0.45) prioritizes sensitivity for high fertility, reflecting the public health imperative to minimize under-identification of at-risk women.
Nevertheless, several limitations must be acknowledged. The cross-sectional design of the NDHS precludes causal inference, limiting the ability to determine whether identified predictors (e.g., education) directly influence fertility or are confounded by unmeasured factors. Data on certain variables, such as historical contraceptive access or spousal attitudes, were not available, potentially omitting key contextual influences. While imputation techniques addressed missing data, they may introduce bias, particularly for categorical variables imputed with the mode. The focus on women aged 40–49, while appropriate for assessing completed fertility, may not capture the dynamics among younger cohorts experiencing ongoing reproductive transitions. Finally, the generalizability of ML models to other sub-Saharan African contexts remains uncertain, as cultural and structural factors vary widely across the region. These limitations suggest caution in over-interpreting the findings and highlight areas for methodological refinement in future research.
Future directions
Several avenues for future research emerge from this study. Longitudinal studies tracking fertility behaviors over time could elucidate causal pathways, addressing the temporality constraints of cross-sectional data. Incorporating additional predictors, such as partner dynamics and community-level norms, could enhance model comprehensiveness, particularly in culturally diverse settings like Nigeria. The application of ML and XAI to other reproductive health outcomes, such as maternal mortality or unmet contraceptive need, warrants exploration, potentially broadening the utility of these tools in public health. Comparative analyses across sub-Saharan African countries could assess the transferability of our findings, identifying common and context-specific fertility drivers. Finally, intervention studies evaluating the impact of education and digital access initiatives on fertility outcomes would provide actionable evidence for scaling effective strategies, ensuring alignment with local priorities and resources. In particular, randomized or quasi-experimental evaluations of DFP interventions designed to target the high-risk demographic segments identified by the ML models in this study would generate the causal evidence needed to validate and refine the DFP framework proposed here, establishing a rigorous evidence base for national-scale digital reproductive health programming in Nigeria and comparable sub-Saharan African contexts.
Conclusions
This study advances the understanding of high-fertility predictors among Nigerian women aged 40–49, highlighting the critical roles of ideal family size, education, ethnicity, and regional disparities through a novel integration of ML and XAI. By achieving high predictive performance and transparent interpretation, our findings offer a robust foundation for targeted reproductive health interventions in Nigeria, with potential relevance across sub-Saharan Africa. Addressing structural barriers like education access and leveraging digital tools to shift cultural norms emerge as priority areas for policy action. As global health systems increasingly adopt data-driven approaches, this research underscores the transformative potential of combining advanced analytics with interpretability to tackle complex demographic challenges, paving the way for a healthier, more equitable future.
Authors’ Contributions
A.O. contributed to the study design and conceptualization. K.U. and A.O. performed the analysis. A.O., D.B.O., K.M.B., F.M., B.O., U.S., and K.U. developed the initial draft. All the authors critically reviewed the article for its intellectual content. All authors read and amended drafts of the article and approved the final version. U.S. had the final responsibility of submitting it for publication.
Ethics Approval and Consent to Participate
Ethical clearance was not sought for the study because the secondary dataset is freely available in the public domain.
Availability of Data and Materials
The data used for this study are freely available at https://dhsprogram.com/data/dataset/Nigeria_Standard-DHS_2024.cfm?flag=1.
Footnotes
Acknowledgment
The authors thank the MEASURE DHS Program for support and for making the dataset freely accessible.
Author Disclosure Statement
No competing financial interests exist.
Funding Information
The study received no funding.