
Abstract
Generative AI is set to transform the legal profession, though its most promising uses and ultimate effects are still unclear. While AI models like GPT-4 improve efficiency, they can also “hallucinate” and may undermine legal judgment, particularly in complex tasks typically handled by skilled lawyers. This article examines two emerging AI innovations that may mitigate these concerns: Retrieval Augmented Generation (RAG), which grounds AI-powered analysis in legal sources, and AI reasoning models, which structure complex reasoning before generating output. We conduct the first randomized controlled trial assessing these technologies, assigning upper-level law students to complete legal tasks using a RAG-powered legal AI tool (Vincent AI, 2024), an AI reasoning model (OpenAI’s o1-preview), or no AI. We find that both AI tools significantly enhance legal work quality, a marked contrast with previous research examining older large language models like GPT-4. Moreover, these newer models appear to maintain the efficiency benefits associated with older AI technologies. Our findings also show that these AI tools significantly boost productivity in five out of six tested legal tasks, with statistically significant gains of anywhere from 50% to 130%. They perform exceptionally well in complex tasks like drafting persuasive letters and analyzing complaints. Notably, o1-preview improves the analytical depth of work product and Vincent AI avoids introducing more hallucinations, suggesting that integrating domain-specific RAG capabilities with reasoning models could yield even larger improvements.
Keywords
1. Introduction
Generative AI is poised to transform the legal profession in the coming years. Yet the scope and nature of this transformation remain uncertain. Some legal technology enthusiasts foresee a fundamental restructuring of the industry, where AI automates countless legal tasks and even replaces certain types of lawyers entirely (Brescia, 2024; Susskind & Susskind, 2023). Skeptics, however, argue that while AI may streamline certain aspects of legal work, it is unlikely to alter the core nature of lawyering (Armour et al., 2022). In this article, we bring new empirical evidence to bear on these competing claims. Using data from the first randomized controlled trial to test how next-generation AI tools affect the way lawyers perform core legal tasks, we examine the impact of these systems on the quality, efficiency, and productivity of written legal work. Our findings offer one of the first systematic glimpses into how these emerging technologies are likely to shape the organization and substance of lawyering in practice.
The stakes of the debate about the implications of AI for legal practice are substantial and far-reaching. Billions of dollars are pouring into AI-driven legal startups, and industry giants like Westlaw and LexisNexis are racing to integrate AI into their existing platforms (LexisNexis, 2025; Thompson Reuters, 2025). Across the profession, lawyers—from Big Law partners to legal aid attorneys—are grappling with how best to incorporate AI into their work (Beioley & Criddle, 2023; Chien et al., 2025; Kim & Chien, 2025; Garg & Ma, 2025). Even judges are exploring ways AI may help them adjudicate cases and draft opinions (Arbel & Hoffman, 2024; Liu & Li, 2024; Re, 2024). Meanwhile, law schools face growing uncertainty about how to prepare students for the profession’s increasingly uncertain future (Bliss, 2024; Head & Willis, 2024).
As this conversation unfolds, empirical research has begun to investigate AI’s likely impact on legal practice. Most prior work, however, focuses on AI benchmarking, which evaluates how AI outputs compare both across models and to human outputs (Guha et al., 2023; Vals.AI, 2025). But for most lawyers, the more relevant question is how human lawyers with access to AI tools perform compared to human lawyers who do not have access to these tools. Although a handful of studies concentrate on this question, a salient shortcoming of this existing research has been its use of older AI models, such as ChatGPT-3.5 and GPT-4 (Choi et al., 2024; Choi & Schwarcz, 2025; Nielsen et al., 2024). Because these models have only a modest ability to break down analytically complex tasks or draw from the most relevant and accurate legal source materials, their usefulness to practicing lawyers engaged in sophisticated legal work may be limited.
By contrast, two emerging technologies have the potential to significantly enhance AI’s capacity to facilitate human legal work by improving reasoning capabilities and grounding outputs in authoritative legal materials. The first is Retrieval Augmented Generation (RAG), a technique that integrates generative AI with trustworthy, authentic legal source materials. Unlike traditional models that rely solely on their training data to answer prompts, legal AI systems with RAG capabilities can retrieve relevant legal texts—such as case law, statutes, and regulations—before generating output. Perhaps even more importantly, RAG makes it easier for humans to check an AI’s work product by consulting the underlying sources on which the software relies to generate an answer. The second major advance relevant to the legal profession is a new class of generative AI language models known as “reasoning models.” Developers explicitly design these models—unlike earlier AI chatbots—to draw on additional computational resources at the point of use, planning responses before generating them, much like a human taking longer to think and outline their thoughts before answering a complex question.
To better understand AI’s impact on the future of lawyering, and especially the potential of these two types of cutting-edge innovations, we conduct a randomized controlled trial to determine how RAG and reasoning models affect lawyering and legal work. Our study evaluates the performance of 137 law students from the University of Minnesota and the University of Michigan on various legal tasks with or without access to AI tools. We asked each participant to complete six realistic legal tasks developed in collaboration with practicing lawyers. For two tasks, participants received no AI assistance; for two, they had access to the mid-2024 version of Vincent AI, a leading tool that integrates RAG and automated prompting assistance; and for the remaining two, they worked with an early AI reasoning model (o1-preview). We randomized the assignment of AI tools and control conditions to ensure a balanced distribution across participants.
In our empirical work, we test the overarching hypothesis that giving participants access to these kinds of tools will enhance both the quality of legal work product and the efficiency of task completion. For Vincent AI, we expect quality gains to come primarily from improved accuracy and greater professionalism, reflecting the system’s ability to draw directly from relevant source materials. By contrast, we anticipate that o1-preview may strengthen the analytical rigor of lawyering, owing to the model’s superior capacity (relative to GPT-4) to structure, refine, and organize output.
Our results largely confirm these hypotheses. The findings reveal that access to both Vincent AI and o1-preview lead to substantial, statistically significant improvements in the speed of lawyering. Also, with respect to at least four of the six tasks, access to AI tools considerably improves the quality of legal work product. While the speed-related gains are comparable in magnitude to those observed in prior research examining the impact of GPT-4 on lawyering, the quality enhancements of AI-augmented legal work product mark a significant departure from the findings of earlier studies.
We also observe variation in how—and the extent to which—these two AI tools enhance the quality of legal work product. This variation largely, but not entirely, matches our hypotheses. For Vincent AI, quality improvements are primarily seen in the clarity, organization, and professionalism of the work. The tool’s impact on accuracy, however, is mixed. On the one hand, we find no evidence that overall accuracy scores—which depend on whether work product includes and properly characterizes the most relevant legal authorities and facts—significantly improve with access to Vincent AI, aside from a single task-specific gain with respect to analyzing a complaint. On the other hand, Vincent AI-supported work appears to contain fewer “hallucinated” citations to nonexistent source materials (3 total) than work produced using o1-preview (11 total). For o1-preview, we find stronger and more widespread improvements in the quality of legal work compared to Vincent AI. Most notably, in addition to enhancing clarity, organization, and professionalism, o1-preview produces substantial improvements in the strength of legal analysis—reflecting logical coherence and nuanced reasoning—especially in the two most analytically demanding tasks we test.
Our findings suggest that the value of access to AI tools may depend on the nature of the legal work. Improvements in quality from the two AI tools are concentrated in litigation-oriented tasks; these gains do not appear to extend to the one transactionally oriented task we evaluate, which involved drafting a short contract. We also document through post-experiment surveys that most participants feel their experience with the two AI tools in the study increases their likelihood of using similar tools in the future. Many also report gaining proficiency in using these tools over the course of the experiment. This positive subjective experience from using the two tools is particularly pronounced for Vincent AI relative to o1-preview.
The implications of our findings for Vincent AI and o1-preview are each independently significant. Considered together, however, they are even more noteworthy: these two AI technologies enhance legal work in distinct yet complementary ways. For Vincent AI, the primary such mechanism is RAG. Notably, however, Vincent AI 2024 uses an ensemble of non-reasoning OpenAI models—such as GPT-4 and GPT-4o—as its core foundation models. By contrast, o1-preview offers technological improvements to foundation models, which can be integrated into legal AI tools like Vincent AI. Moreover, o1-preview was the first reasoning model to be made publicly available. Many new generations have since improved on predecessors (Wiggers, 2025). These facts together suggest that AI models are already enhancing lawyering in ways that extend beyond the effects we report in this article.
2. Background
OpenAI’s public release of the Large Language Model (LLM) ChatGPT in late 2022 marked a pivotal moment in the development of AI and in expectations about its future impact. Although ChatGPT’s core design was not entirely novel—like earlier chatbots, it generated text by predicting the next token in a sequence—the technology reshaped the AI landscape with its remarkable ability to produce high-quality responses across diverse types of queries. ChatGPT’s performance stemmed from several key advances. First, the model’s size was much larger than prior LLMs, growing from 117 million parameters in early iterations to 175 billion in later versions (OpenAI, 2022). Second, ChatGPT’s training included Reinforcement Learning from Human Feedback, a fine-tuning method that uses human evaluations to align outputs with user intent (Choi et al., 2022).
After ChatGPT’s public release, commentators worldwide began speculating about whether the underlying technology could revolutionize legal practice (Susskind & Susskind, 2023). This excitement grew with reliable indications that early versions of ChatGPT could achieve passing—albeit low—grades on a range of law school exams simply by processing the exam text (Choi et al., 2022; Nay et al., 2023). Further research indicated that more advanced AI models could attain higher scores on law school exams and even pass the bar exam, heightening expectations that AI would significantly reshape the legal profession (Alimardini, 2024; Katz et al., 2024). 1
Although this early work highlights the capacity of AI-produced output to score well on legal exams, the more pressing set of empirical questions relate to how access to generative AI tools will affect legal practice by attorneys, especially in light of the broad consensus that ethical and practical considerations necessitate some human involvement in legal services (Browning, 2023; Pierce & Goutos, 2024; Wendel, 2019; Yamane, 2020). Throughout late 2023 and 2024, several studies began to explore this issue, finding preliminary evidence to suggest that tools like GPT-4 could significantly enhance lawyers’ speed for certain legal tasks, but limited evidence that these tools could consistently improve the quality of legal work (Choi et al., 2024; Choi & Schwarcz, 2025; Kim & Chien, 2025). Evidence also emerged that GPT-4 is vulnerable to producing hallucinations when used for legal research (Dahl et al., 2024). 2 By contrast, other contemporary research focusing on nonlegal writing tasks provided support for the idea that giving humans access to ChatGPT could enhance their performance (Noy & Zhang, 2023).
In short order, several key innovations in AI and legal technology sparked renewed enthusiasm about the technology’s potential to enhance the practice of law. First, several companies introduced specialized Retrieval Augmented Generation (RAG) AI systems for lawyering tasks. RAG systems integrate LLMs with legal search engines and document retrieval systems (Lewis et al., 2020), enabling these tools to respond to queries based on authoritative legal materials. Widely touted for its potential to minimize or even eliminate hallucinations (Ju, 2024; LexisNexis, 2024), RAG also enhances transparency, allowing users to verify LLM responses using underlying sources (Grupen & Pereyra, 2024). 3
To date, however, little empirical evidence exists on the impact of RAG-enabled legal technology on human lawyering. One study suggests that RAG-enabled legal AI tools can and do hallucinate (Magesh et al., 2024). 4 But the study assesses only the capabilities of legal research tools in isolation, without human involvement. Another recent study finds that many RAG-enabled legal tools outperform human lawyers at basic tasks, such as document extraction, summarization, and transcript analysis, but perform worse than human lawyers on more complex tasks (Vals.AI, 2025). But this study too compares AI-produced output with human output, not the work of humans with AI-tool access to the work of humans without access to AI tools.
The second major AI development relevant to lawyering is the rise in mid-2024 of a new class of “reasoning models,” designed specifically to handle complex logical and analytical tasks. OpenAI introduced the first such model with o1-preview; since then, both OpenAI and other AI developers, including Google and DeepSeek, have released more advanced reasoning models (Wiggers, 2025). Reasoning models mark a significant departure from earlier LLMs like ChatGPT-3.5 and GPT-4 by allocating more compute at the time of inference, allowing them to process prompts step-by-step in ways earlier models did not. By constructing an internal chain of reasoning, these models continuously reevaluate initial output to refine the answers they ultimately produce. A large-scale reinforcement learning algorithm implemented during training further enhances this ability, optimizing how the model evaluates and adjusts its reasoning. This shift is significant enough that, to highlight the distinction, OpenAI introduced an entirely new naming convention for its first reasoning model: “o1” (OpenAI, 2024).
Early evidence from other domains demonstrates that these reasoning models can outperform their predecessors in complex tasks across fields such as mathematics, coding, and medical diagnosis (Brodeur et al., 2024). 5 However, there is limited evidence regarding how giving attorneys access to tools relying on these models may affect human performance on legal tasks. We offer the first systematic test of that possibility.
3. Methodology
We use a randomized controlled trial to assess the potential impact of emerging AI reasoning models and specialized legal AI platforms on the future of lawyering. 6 We focus on the two leading generative AI models as of late 2024. The first, o1-preview, is a general-purpose AI reasoning model released by OpenAI in September 2024. The second, VLex’s Vincent AI, is a specialized AI tool for lawyers that uses RAG to facilitate the work of lawyers. At the time of the study, Vincent AI used an ensemble of non-reasoning models, including GPT-4 and 4o, as its underlying foundation models.
Baseline Balance Across Task–AI Assignment Groups

Notes. This table reports baseline participant characteristics for Groups A, B, and C. Groups differ only in how the six legal tasks are paired with AI conditions; all participants complete tasks under all three conditions (No AI, o1-preview, and Vincent AI). Reported means and proportions therefore reflect participant-level characteristics rather than differential exposure to AI conditions. Standard deviations are shown in parentheses for continuous variables. “Missing (%)” reports the share of participants within each group with missing data for the corresponding variable; first-year GPA is unavailable for LL.M. students, so missing GPA values reflect program enrollment rather than attrition or nonresponse. P-values are from F-tests of equality of means for continuous variables and chi-square tests of independence for categorical variables. N denotes the number of participants in each group.
Study participants completed the experiment remotely from October 1, 2024, to October 31, 2024, using a Canvas interface. The study began with all participants in the study completing three online training modules. 9 These modules included both general training on the use of AI models for legal work and training specifically tailored to Vincent AI. We then presented all participants with six lawyering tasks, each with task-specific instructions regarding the use of generative AI. For instance, for Task One, we prohibited participants in Group A from using any generative AI, required Group B participants to use only o1-preview, and required Group C participants to use only Vincent AI. These instructions varied systematically across groups and tasks, ensuring that each participant completed two tasks without AI, two tasks using o1-preview, and two tasks using Vincent AI.
To ensure that the six tasks reflected realistic scenarios typically assigned to first- or second-year law firm associates, we developed all of them in collaboration with one or more practicing attorneys. We set task time limits using guidance from practicing lawyers regarding the amount of time they expected a junior associate would typically need to complete each task. These tasks, along with their respective time limits, are as follows: • • • • • •
In designing our experiments, we sought to create tasks that meaningfully differed in the lawyering skills they required. Task One requires participants to explain a relatively straightforward set of legal precedents in plain language for a non-lawyer client. Task Two, by contrast, expects them to grapple with a complex contract-interpretation issue and to compare competing case law across jurisdictions. Task Three asks participants to identify key features of a longer document (a complaint), evaluate the elements of the claim, and consider both legal and non-legal factors in formulating a response strategy. Task Four, the most distinct, requires participants to complete a transactional task by adapting a template document to a new context. Task Five asks participants not only to develop an argument but also to present it in the form of a motion that would meet a court’s formal requirements. Finally, Task Six requires participants to draft a document akin to a legal opinion by evaluating the relative strengths of competing arguments. By structuring the tasks to test different facets of legal practice, we aim to assess whether particular types of AI tools are better suited to assisting with some types of legal work than others. Appendix B contains the text of all assigned tasks. 10 We instructed all participants to complete the six tasks in order and to report the amount of time they spent working on each task. 11
Three co-authors evaluated all work product, with each grader responsible for evaluating two tasks. 12 We used a blind grading process to ensure that graders were unaware of the experimental condition and participant identity and characteristics. All three graders have legal practice experience and were uninvolved in data collection or analysis. Before the experiment began, the three grading co-authors collaboratively developed standardized grading rubrics to ensure consistency of grading across tasks.
We measure five core attributes of quality legal work across all six tasks: Accuracy (the precision and usefulness of the research), Analysis (the depth and insightfulness of the reasoning), Organization (the structure of the work product), Clarity (the quality and persuasiveness of the writing), and Professionalism (the extent to which directions were followed). We use a standard 1–7 scale to assess performance on each attribute for each task. Each grader adapted this general rubric to create a version tailored for each of the two tasks they were assigned to grade. For example, the rubric for Accuracy in Task Two (Draft Legal Memo) lists the precise legal authorities that should be identified, their key holdings, the relevant insurance policy language to be highlighted, and the critical facts that should be incorporated into the analysis. Similar refinements for each rubric reflect the task’s distinctive doctrinal and practical demands. Each task rubric also includes a separate binary metric for whether any cited sources or assertions appear to be hallucinated, either because they do not exist or because their descriptions are entirely inaccurate. Appendix C contains the final grading rubrics for all tasks.
We use participants’ self-reported time spent on each assigned task, together with each task’s time limit, to construct measures of efficiency and task-level productivity that are comparable across heterogeneous forms of legal work. We define efficiency as the fraction of the task’s allotted time spent completing the task, so that lower values of this measure correspond to faster task completion. Combining this efficiency measure with participants’ quality attribute scores, we define task-level productivity as the sum of the five quality attribute scores divided by the fraction of allotted time spent. These outcome measures allow us to examine how access to AI tools affects the speed with which legal tasks are completed and how variation in time spent interacts with the quality of work product.
To evaluate treatment effects, we use an ordinary least squares (OLS) regression framework with two treatment indicator variables. Conceptually, we can write our baseline specification as follows: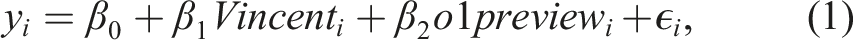

We measure the effects of access to AI tools for each type of task along each outcome dimension (e.g., an attribute like Accuracy) because there are reasons to believe that access to AI tools might affect the quality of lawyering across some but not all quality dimensions and for some but not all types of legal tasks. Following Equations (1) and (2), one straightforward way to proceed would be to produce treatment estimates for each task and attribute, with approximately 125 observations per test, treating each attribute outcome for each task separately and conducting the test by separate regressions for each task/attribute. By pooling the data, however, we can also estimate treatment effects for AI access overall (across tasks and outcomes) and across each task and each outcome, and at the same time, we can account for more potential confounders, such as fixed differences across participants.
For these reasons, we opt to employ a flexible pooled OLS regression framework, which allows us to account for the fact that tasks and attributes may have baseline differences and that participants contribute as many as 30 scores (6 tasks × 5 attributes) that may not be independent of each other. To analyze our experimental data, we estimate: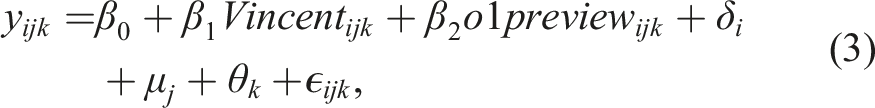
As a further robustness check, we also estimate a system of seemingly unrelated regressions (SUR). SUR is helpful in our setting because each participant-task generates five related quality scores—Accuracy, Analysis, Organization, Clarity, and Professionalism—that may have unexplained components that move together, for example, when a participant experiences a task-specific shock. For instance, a misread prompt or an unexpected interruption during a task can depress all five quality scores for that task simultaneously. A pooled OLS model with participant fixed effects cannot absorb this kind of within-task correlation because fixed effects only capture stable differences across participants (and other fixed effects control for fixed differences across tasks and attributes) but not shocks unique to a single participant–task combination. SUR can address this gap by estimating the five attribute equations jointly and allowing their residuals to be correlated for the same participant and task, thereby improving efficiency and testing whether our findings depend on assuming these errors are independent. In practice, our SUR estimates closely track the pooled OLS and fixed-effects results, suggesting that task-specific shocks that affect multiple quality dimensions do not materially influence our estimated treatment effects. We report full SUR results in Table A1 in Appendix A.
At the conclusion of the experiment, we also invited all participants to complete a post-experiment survey about their experiences with completing the tasks and using the AI tools to conduct legal work. We collected responses from 120 participants. At the time of the survey, participants had not yet received grades or feedback on their submitted work. We preregistered a rough outline of the experiment prior to analyzing our results; the pre-analysis plan is archived with the American Economic Association’s registry for randomized controlled trials. 13
4. Findings
In this Section, we present our empirical results, beginning with the core causal effects of access to reasoning models or RAG systems on the quality, efficiency, and productivity of legal work. We then supplement these findings with qualitative assessments of how AI shaped the substance and structure of participants’ work product, along with an exploration of heterogeneous treatment effects across participants and descriptive evidence from a brief post-experiment survey. Taken together, these results provide a comprehensive picture of how access to tools like o1-preview and Vincent AI alters multiple dimensions of lawyering performance.
4.1. Effects of AI Access on Work Quality
Treatment Effects on Overall Performance Pooled Across Tasks and Attributes
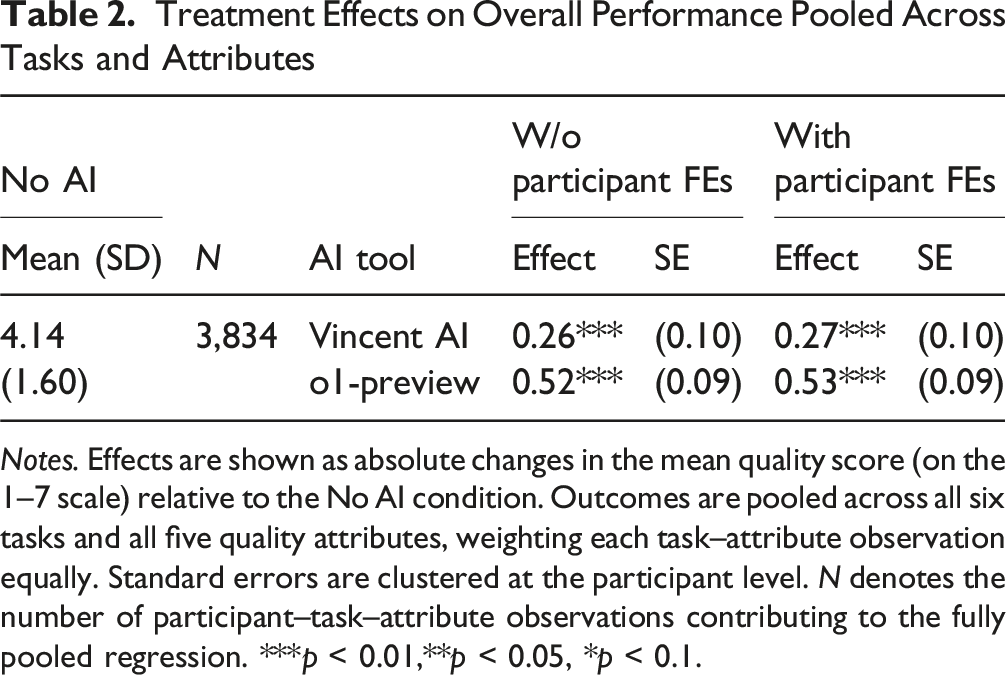
Notes. Effects are shown as absolute changes in the mean quality score (on the 1–7 scale) relative to the No AI condition. Outcomes are pooled across all six tasks and all five quality attributes, weighting each task–attribute observation equally. Standard errors are clustered at the participant level. N denotes the number of participant–task–attribute observations contributing to the fully pooled regression. ***p < 0.01,**p < 0.05, *p < 0.1.
Using the observed dispersion of the control-group scores in Table 2, we can directly standardize the treatment effects to assess the magnitudes of our findings. Relative to control-group standard deviations, access to Vincent AI improves quality by roughly 0.15 to 0.20 standard deviations, while o1-preview produces gains of approximately 0.30 to 0.35 standard deviations. Effects of this magnitude are readily observable to trained graders and are large by the standards of other intervention studies: improvements on the order of one quarter to one half of a standard deviation are typically regarded as meaningful in medical competency training (Veloski et al., 2006), active-learning reforms in higher education (Crouch & Mazur, 2001), and managerial communication interventions (DeRue et al., 2012).
Because standard deviations capture the typical spread in the quality of work product without access to AI tools (i.e., of the control group), expressing effects in standard-deviation units (SD) provides an intuitive sense of magnitude: a 0.30 to 0.35 SD improvement is roughly equivalent to moving a lawyer from the 50th percentile of writing quality to about the 62nd to 64th percentile, and a 0.20 SD improvement corresponds to a shift to roughly the 58th percentile. As we will see, when we examine specific attributes for individual tasks, standardized improvements become more pronounced, as we would expect given that effects are likely to be concentrated along particular dimensions of quality and for certain tasks, even though the estimates of these task-specific effects are naturally less precise because each estimate draws on fewer repeated observations for a single task–attribute combination. For example, in Table 9, we find evidence that o1-preview improves Professionalism on the analyzing a complaint task by nearly a full standard deviation (0.92 SD improvement), an effect size consistent with moving a lawyer from the 50th percentile to roughly the mid-80s to high-80s in terms of quality (a striking improvement in practical terms and entirely separate from accompanying speed gains). Relative to these benchmarks, the increases from AI access we observe here, especially the roughly half-point gain associated with o1-preview, represent substantial and practically significant improvements in the quality of written legal work.
Treatment Effects on Quality Attribute Performance Pooled Across Tasks
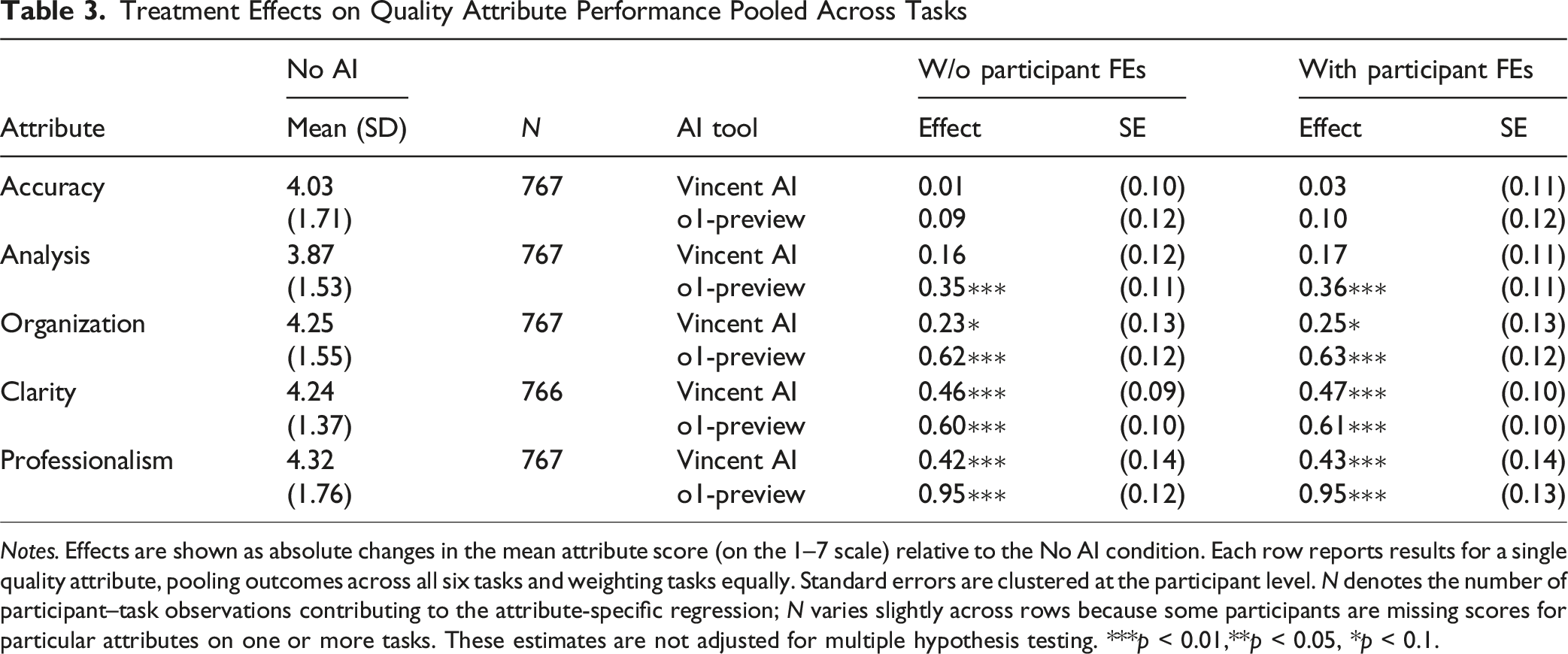
Notes. Effects are shown as absolute changes in the mean attribute score (on the 1–7 scale) relative to the No AI condition. Each row reports results for a single quality attribute, pooling outcomes across all six tasks and weighting tasks equally. Standard errors are clustered at the participant level. N denotes the number of participant–task observations contributing to the attribute-specific regression; N varies slightly across rows because some participants are missing scores for particular attributes on one or more tasks. These estimates are not adjusted for multiple hypothesis testing. ***p < 0.01,**p < 0.05, *p < 0.1.
Treatment Effects on Task Performance Pooled Across Attributes
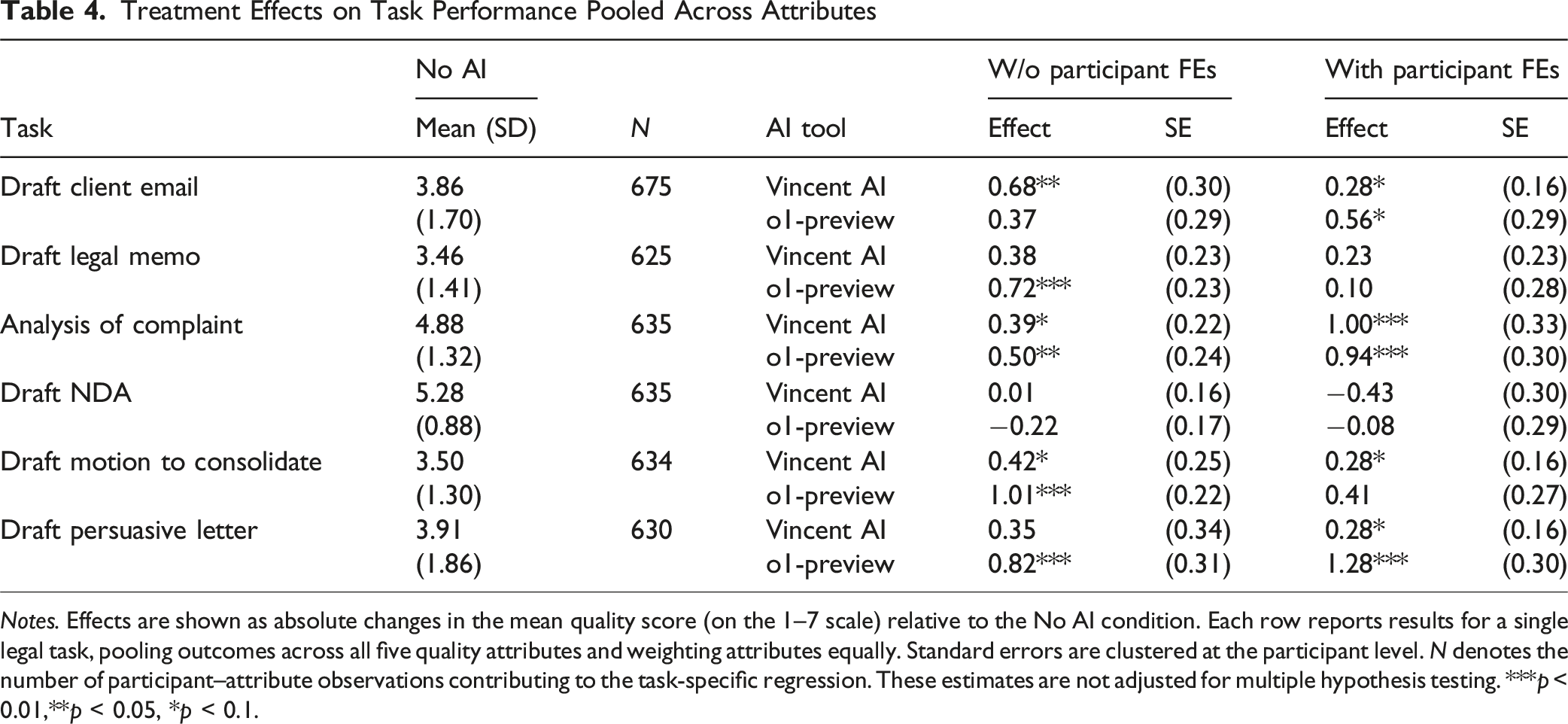
Notes. Effects are shown as absolute changes in the mean quality score (on the 1–7 scale) relative to the No AI condition. Each row reports results for a single legal task, pooling outcomes across all five quality attributes and weighting attributes equally. Standard errors are clustered at the participant level. N denotes the number of participant–attribute observations contributing to the task-specific regression. These estimates are not adjusted for multiple hypothesis testing. ***p < 0.01,**p < 0.05, *p < 0.1.
Table 3 shows clear, statistically significant improvements in Clarity, Organization, and Professionalism when participants have access to either AI tool. For Analysis, we observe a statistically significant improvement for o1-preview—a result consistent with the model’s more advanced reasoning capabilities. In contrast, we find no evidence that either tool improves Accuracy, including Vincent AI, the RAG system. Across all attributes, o1-preview generally appears to produce larger gains in quality than Vincent AI, although the difference between the two tools is clearly statistically significant only for Organization and Professionalism. Notably, in this specification, adjusting for participant fixed effects has virtually no impact on the magnitude or significance of the treatment effects.
In Table 4, we see that access to AI tools improves task performance, although the size of these improvements varies substantially across tasks. Focusing on our specification that includes participant fixed effects, we find that o1-preview produces large and statistically significant improvements on two tasks—Analysis of Complaint and Draft Persuasive Letter—and marginal improvements on Draft Client Email and Draft Motion to Consolidate. Vincent AI shows a similar pattern, with a large effect on Analysis of Complaint and marginal gains on Draft Client Email, Draft Persuasive Letter, and Draft Motion to Consolidate. Neither tool appears to improve performance on the NDA or legal memo tasks, although the point estimate for Vincent AI on Draft Legal Memo is positive and sizable. These results stand in contrast to the findings of a previous randomized controlled trial of GPT-4, which detects no statistically significant improvements in overall quality across the four tasks tested in that study (Choi et al., 2024).
The fact that the fixed-effects estimates differ more noticeably in Table 4 than in Table 3 reflects the different role participant-level heterogeneity plays when outcomes are aggregated across attributes within a task. In practical terms, some participants consistently write more clearly, reason more effectively, or follow instructions more closely across all five quality dimensions, and these stable differences can distort task-level treatment effects unless they are held constant. Once we control for each participant’s overall writing and analytic ability, the treatment effects more clearly reflect how AI assistance shapes performance on each specific task, independent of which student was assigned to complete it. Overall, these fixed-effects results reinforce the conclusion that o1-preview provides the most consistent gains, particularly on tasks requiring substantial reasoning and written advocacy.
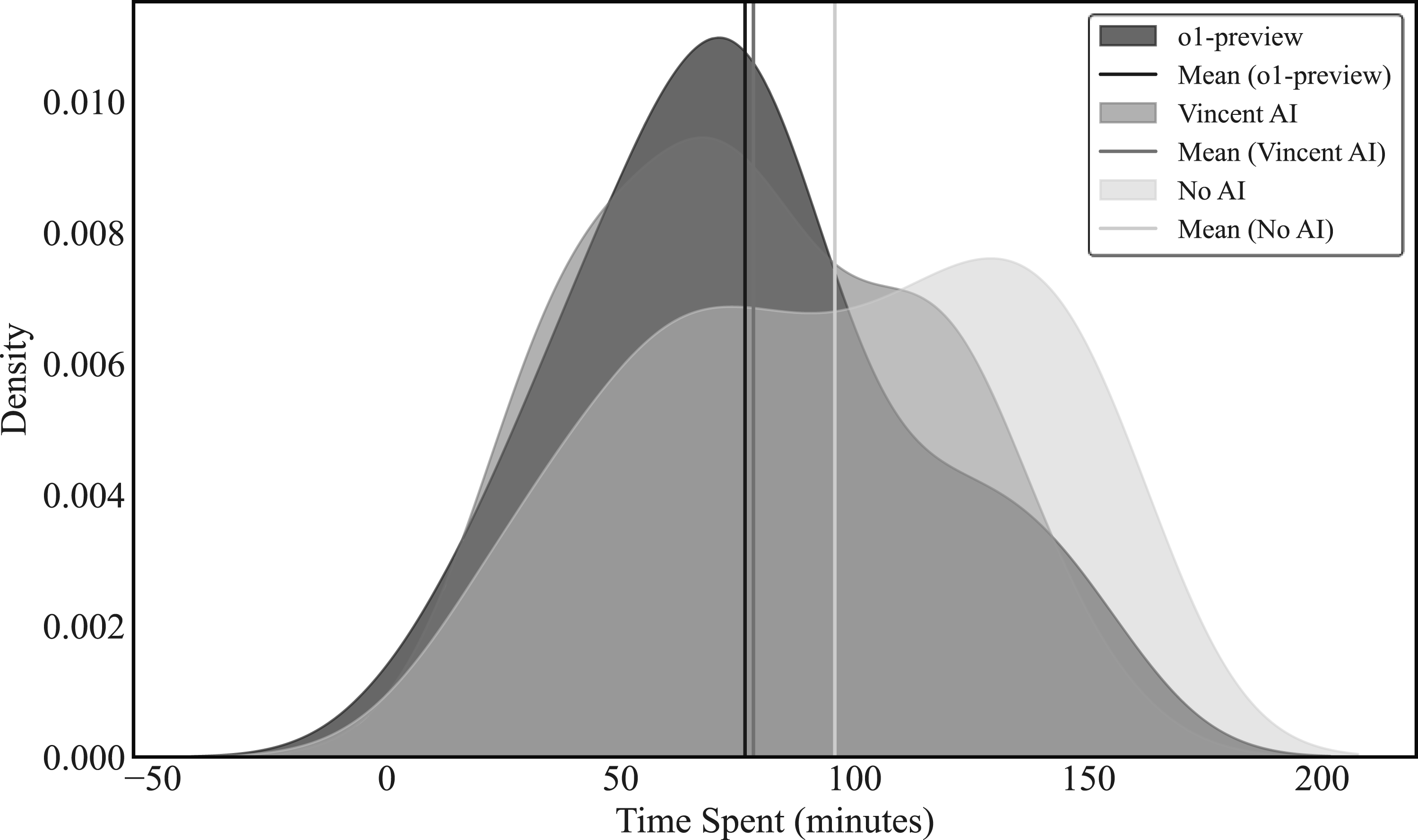
Figures 1 through 6 plot the raw distributions of aggregate quality scores for each task, separately for the control group, the Vincent AI group, and the o1-preview group. These figures are kernel density plots that show, for each group, the share of participants (y-axis) receiving each possible score (x-axis). They allow us to observe whether the improvements we report in Table 4 stem from broad rightward shifts in the full score distribution, reductions in low-scoring submissions, or changes concentrated near the upper tail. Consistent with the fixed-effects estimates, the distributions for o1-preview show clear rightward movements for Analysis of Complaint, Draft Motion to Consolidate, and Draft Persuasive Letter, with fewer low-scoring submissions and a greater concentration of high-quality work. By contrast, the distributions for Draft NDA and Draft Legal Memo overlap significantly, visually reinforcing the null treatment effects we identify in Table 4. Total Score Distributions, Draft Client Email. Notes: This figure displays kernel-smoothed distributions of total scores for the Draft Client Email task by AI condition. Total score is the sum of all five quality attributes for a given task. Because the distributions are kernel-smoothed, estimated densities extend beyond the task’s allowable score range (0–35); these boundary violations are a mechanical artifact of the smoothing procedure rather than observed scores. Total N = 135. Total Score Distributions, Draft Legal Memo. Notes: This figure displays kernel-smoothed distributions of total scores for the Draft Legal Memo task by AI condition. Total score is the sum of all five quality attributes for a given task. Because the distributions are kernel-smoothed, estimated densities extend beyond the task’s allowable score range (0–35); these boundary violations are a mechanical artifact of the smoothing procedure rather than observed scores. Total N = 125. Total Score Distributions, Analysis of Complaint. Notes: This figure displays kernel-smoothed distributions of total scores for the Analysis of Complaint task by AI condition. Total score is the sum of all five quality attributes for a given task. Because the distributions are kernel-smoothed, estimated densities extend beyond the task’s allowable score range (0–35); these boundary violations are a mechanical artifact of the smoothing procedure rather than observed scores. Total N = 127. Total Score Distributions, Draft NDA. Notes: This figure displays kernel-smoothed distributions of total scores for the Draft NDA task by AI condition. Total score is the sum of all five quality attributes for a given task. Because the distributions are kernel-smoothed, estimated densities extend beyond the task’s allowable score range (0–35); these boundary violations are a mechanical artifact of the smoothing procedure rather than observed scores. Total N = 127. Total Score Distributions, Draft Motion to Consolidate. Notes: This figure displays kernel-smoothed distributions of total scores for the Draft Motion to Consolidate task by AI condition. Total score is the sum of all five quality attributes for a given task. Because the distributions are kernel-smoothed, estimated densities extend beyond the task’s allowable score range (0–35); these boundary violations are a mechanical artifact of the smoothing procedure rather than observed scores. Total N = 127. Total Score Distributions, Draft Persuasive Letter. Notes: This figure displays kernel-smoothed distributions of total scores for the Draft Persuasive Letter task by AI condition. Total score is the sum of all five quality attributes for a given task. Because the distributions are kernel-smoothed, estimated densities extend beyond the task’s allowable score range (0–35); these boundary violations are a mechanical artifact of the smoothing procedure rather than observed scores. Total N = 126.





Across all tasks, we see only modest differences in the shape or spread of the distributions, with no strong evidence that AI access meaningfully narrows or widens the overall variance of scores. Some density plots appear “taller” for one treatment group than another, but this typically reflects a slightly tighter clustering of scores around the modal region rather than a systematic compression or expansion of the distribution. On tasks with clear average improvements—such as Analysis of Complaint and Draft Persuasive Letter—the uplift reflects broad rightward movement rather than polarization between stronger and weaker performers. Conversely, on tasks with no discernible average effect, such as Draft NDA, the distributions are nearly indistinguishable, indicating that the null results are not due to offsetting positive and negative effects at different points in the performance spectrum. Together, these distributional patterns show that the strongest quality improvements occur on tasks requiring sustained reasoning and written advocacy and reinforce the suggestion that these gains appear consistently across the distribution rather than being confined to a narrow subset of participants.
Treatment Effects on Task-Level Accuracy
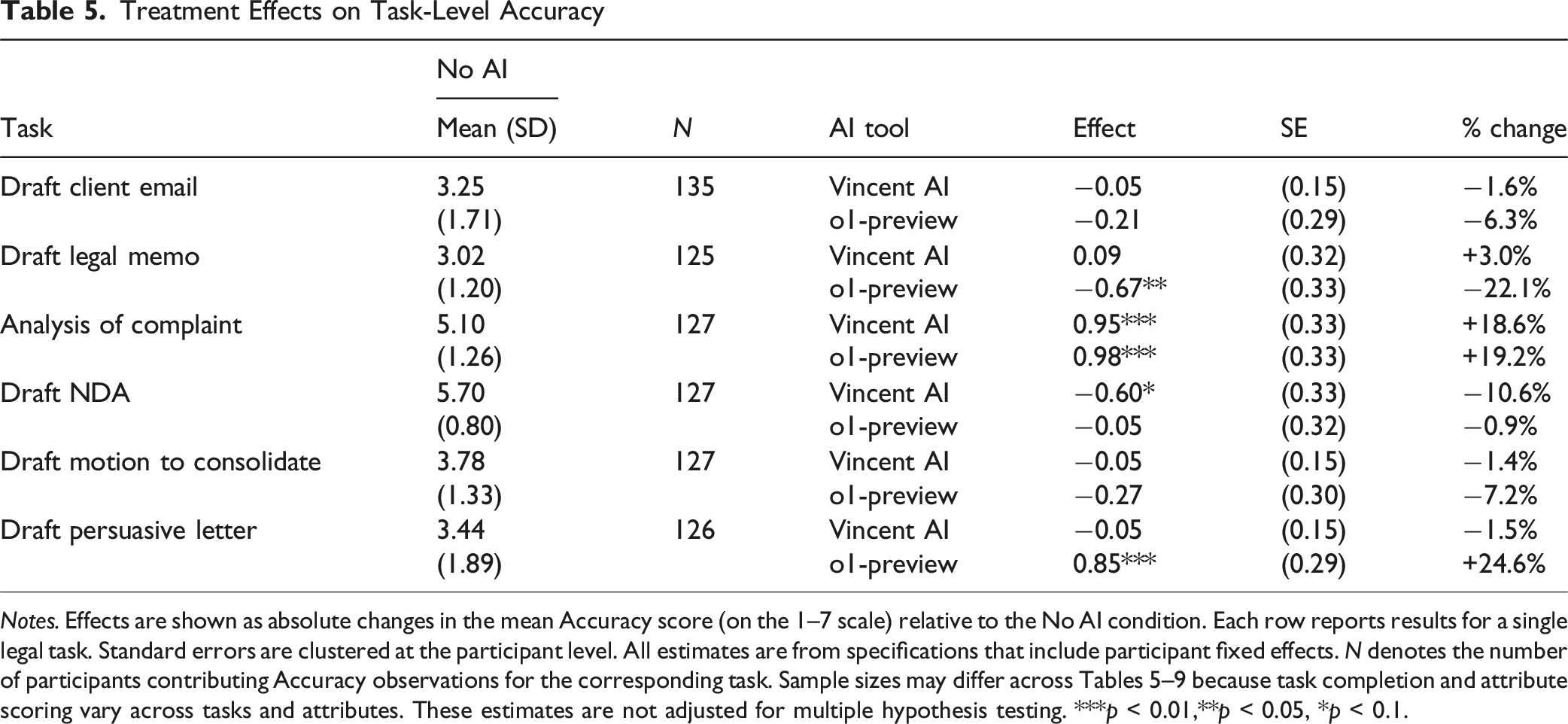
Notes. Effects are shown as absolute changes in the mean Accuracy score (on the 1–7 scale) relative to the No AI condition. Each row reports results for a single legal task. Standard errors are clustered at the participant level. All estimates are from specifications that include participant fixed effects. N denotes the number of participants contributing Accuracy observations for the corresponding task. Sample sizes may differ across Tables 5–9 because task completion and attribute scoring vary across tasks and attributes. These estimates are not adjusted for multiple hypothesis testing. ***p < 0.01,**p < 0.05, *p < 0.1.
Treatment Effects on Task-Level Analysis

Notes. Effects are shown as absolute changes in the mean Analysis score (on the 1–7 scale) relative to the No AI condition. Each row reports results for a single legal task. Standard errors are clustered at the participant level. All estimates are from specifications that include participant fixed effects. N denotes the number of participants contributing Analysis observations for the corresponding task. Sample sizes may differ across Tables 5–9 because task completion and attribute scoring vary across tasks and attributes. These estimates are not adjusted for multiple hypothesis testing. ***p < 0.01,**p < 0.05, *p < 0.1.
Treatment Effects on Task-Level Organization
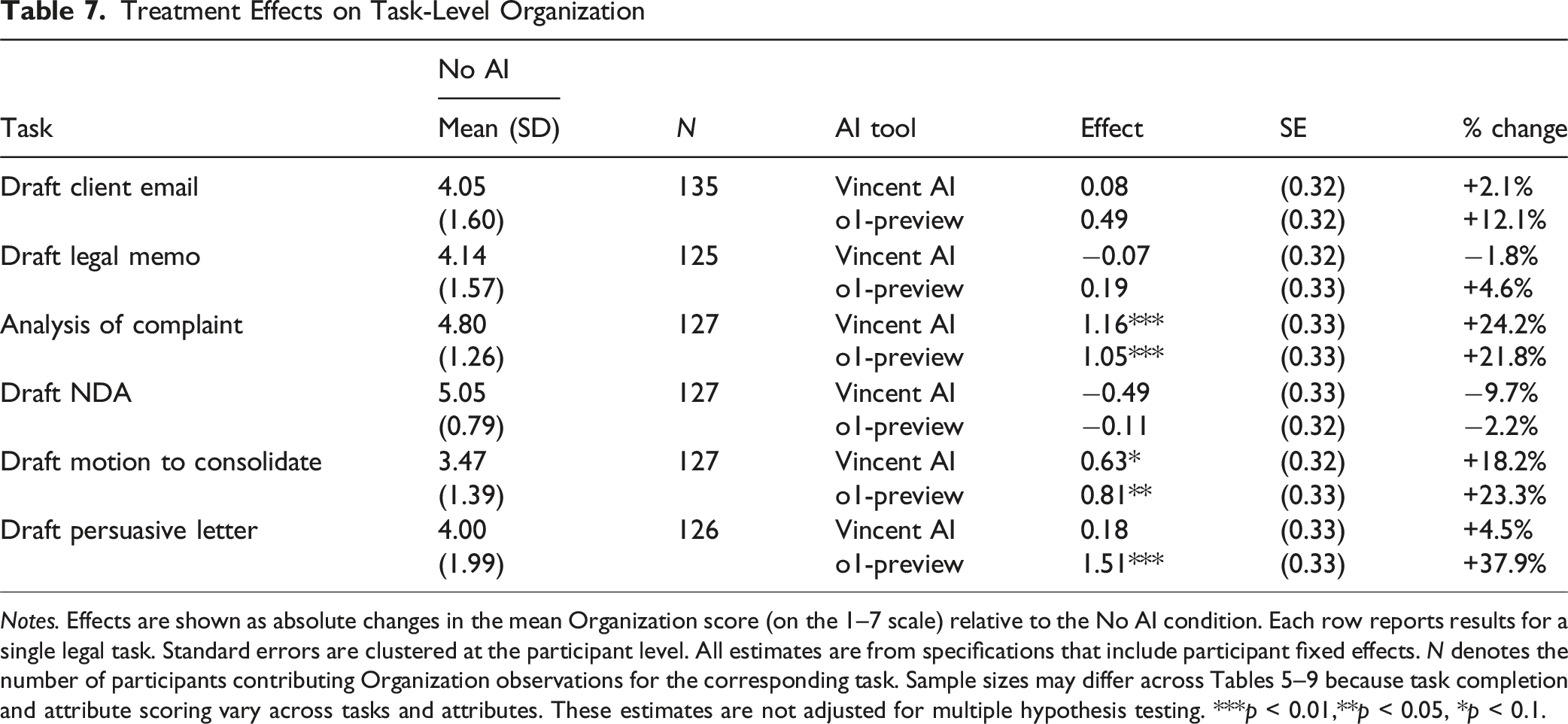
Notes. Effects are shown as absolute changes in the mean Organization score (on the 1–7 scale) relative to the No AI condition. Each row reports results for a single legal task. Standard errors are clustered at the participant level. All estimates are from specifications that include participant fixed effects. N denotes the number of participants contributing Organization observations for the corresponding task. Sample sizes may differ across Tables 5–9 because task completion and attribute scoring vary across tasks and attributes. These estimates are not adjusted for multiple hypothesis testing. ***p < 0.01,**p < 0.05, *p < 0.1.
Treatment Effects on Task-Level Clarity

Notes. Effects are shown as absolute changes in the mean Clarity score (on the 1–7 scale) relative to the No AI condition. Each row reports results for a single legal task. Standard errors are clustered at the participant level. All estimates are from specifications that include participant fixed effects. N denotes the number of participants contributing Clarity observations for the corresponding task. Sample sizes may differ across Tables 5–9 because task completion and attribute scoring vary across tasks and attributes. These estimates are not adjusted for multiple hypothesis testing. ***p < 0.01,**p < 0.05, *p < 0.1.
Treatment Effects on Task-Level Professionalism

Notes. Effects are shown as absolute changes in the mean Professionalism score (on the 1–7 scale) relative to the No AI condition. Each row reports results for a single legal task. Standard errors are clustered at the participant level. All estimates are from specifications that include participant fixed effects. N denotes the number of participants contributing Professionalism observations for the corresponding task. Sample sizes may differ across Tables 5–9 because task completion and attribute scoring vary across tasks and attributes. These estimates are not adjusted for multiple hypothesis testing. ***p < 0.01,**p < 0.05, *p < 0.1.
Across the task–attribute results, a consistent pattern emerges: AI assistance improves several dimensions of legal work quality, but the strength and scope of these improvements vary meaningfully across both tasks and attributes. The most frequent and robust gains appear in Clarity, Organization, and Professionalism, where both tools—but especially o1-preview—deliver large improvements across multiple forms of legal writing (i.e., often close to one standard deviation in the control mean). Improvements in Analysis are more selective, concentrated in tasks that require substantial legal reasoning and structured explanation (e.g., Draft Persuasive Letter).
Within this broader pattern, our estimates of the effects of access to AI tools on Analysis of Complaint stand out. On this task, o1-preview produces large, statistically significant improvements across all five quality attributes—including the only meaningful gain in Accuracy we observe in the study—while Vincent AI also appears to yield substantial, though more modest, benefits. These unusually strong gains help drive the aggregate improvements we report in Table 3, particularly in Analysis, Organization, Clarity, and Professionalism. The complaint analysis task—requiring issue identification, synthesis of factual allegations, and articulation of a reasoned legal argument—aligns closely with the strengths of a reasoning-oriented model like o1-preview and may help to explain why the RAG-based Vincent AI model, although helpful, produces smaller improvements.
At the other end of the spectrum, we find no evidence that access to either AI tool helps to improve performance on the NDA task. For this form of transactional drafting, neither o1-preview nor Vincent AI produces significant gains on any quality attribute, and the distributions of raw scores overlap almost completely across treatment conditions. Several factors may explain these null results, though each remains speculative. One possibility is that transactional drafting receives less emphasis in typical law school training, giving participants a weaker foundation for using AI effectively on this task, which would leave open the possibility that experienced lawyers might benefit more from access to AI tools. Another is that these tools, especially the RAG-based Vincent AI model, may be better suited to litigation-oriented reasoning than to transactional drafting. Because we supplied a template for the NDA task, the use of which is a common feature of transactional practice, participants had less discretion in drafting, which likely limited the scope for AI-driven quality improvement. Finally, the design of the task required only modest factual customization, leaving limited room for quality gains regardless of whether AI tools were available. In any event, the estimates from the NDA task contribute little to the aggregate results in Tables 2–4, and the precise reasons why tasks requiring structured reasoning, legal analysis, or written advocacy exhibit the largest gains remains an open question for future research.
These task–attribute patterns also help clarify why the fixed-effects results in Tables 5 through 9 differ from the pooled OLS estimates that we report in Appendix A. Because the fixed-effects specification adjusts for each participant’s overall writing and analytic ability, it removes baseline differences that can inflate or attenuate the pooled estimates—particularly on tasks where stronger or weaker writers are unevenly distributed across treatment groups. For instance, the pooled OLS results suggest that o1-preview improves Analysis on Draft Legal Memo and Draft Motion to Consolidate, but these effects weaken or disappear once we include participant fixed effects, whereas the large improvements on Analysis of Complaint and Draft Persuasive Letter remain robust. This contrast underscores the idea that the fixed-effects model more cleanly captures how AI assistance alters the quality of different types of legal work, independent of who performs that work. Taken together, the task–attribute results show that AI tools deliver the greatest quality improvements on legal work that demands reasoning, narrative synthesis, and persuasive writing, while highly structured or template-driven tasks—most notably Draft NDA—benefit far less.
In addition to evaluating legal work using our five quality-related metrics, we separately tracked instances of hallucinations, which we define as citations to entirely fabricated sources or to real sources cited based on a fundamentally inaccurate understanding of their content. The results, presented in Figure 7, indicate that while hallucinations are rare with these tools, they do occur. Although the small number of reported hallucinations limits our ability to draw definitive conclusions about their comparative likelihood, the data tentatively suggest that RAG-based systems like Vincent AI may reduce hallucinations. Indeed, we identified fewer hallucinations in tasks completed with Vincent AI (3 total) than in those completed without any AI assistance at all (4 total).
14
By contrast, tasks completed with o1-preview exhibit a substantially higher absolute number of hallucinations (11 total). Hallucinations. Notes: This figure reports the number of submissions by task and AI condition in which at least one hallucination was identified. Hallucinations are defined as citations to entirely fabricated sources or to real sources cited based on a fundamentally inaccurate understanding of their content. Because hallucinations are rare events in the sample, the figure is intended to be descriptive rather than to support formal statistical inference.
4.2. Effects of AI Access on Time Use
We next examine how access to AI tools affects efficiency in completing legal work. Prior work provides strong evidence that AI assistance meaningfully accelerates legal analysis: Choi et al. (2024) report that access to GPT-4 reduces the time needed to complete realistic lawyering tasks by 12 to 32%. Our study enables us to evaluate whether similar efficiency gains arise when participants use either a reasoning-oriented model (o1-preview) or a RAG-based legal tool (Vincent AI). Because the six tasks in our experiment vary substantially in their allocated time—from 60 minutes for Draft Client Email to 240 minutes for Draft Legal Memo—we measure time spent as the percentage of the allotted time participants devote to each task. This standardized metric enables direct comparison across heterogeneous forms of legal work, although using absolute minutes yields the same substantive conclusions. As with our quality analysis, we rely on the participant fixed-effects specification to isolate the causal effect of AI assistance on speed.
Treatment Effects on Task Time Spent (Share of Allotted Time)

Notes. Effects are shown as absolute changes in the fraction of the task’s allotted time that the participant spent relative to the No AI condition. Each row reports results for a single legal task. Standard errors are clustered at the participant level. All estimates are from specifications that include participant fixed effects. N denotes the number of participants contributing time-spent observations for the corresponding task. These estimates are not adjusted for multiple hypothesis testing. ***p < 0.01,**p < 0.05, *p < 0.1.
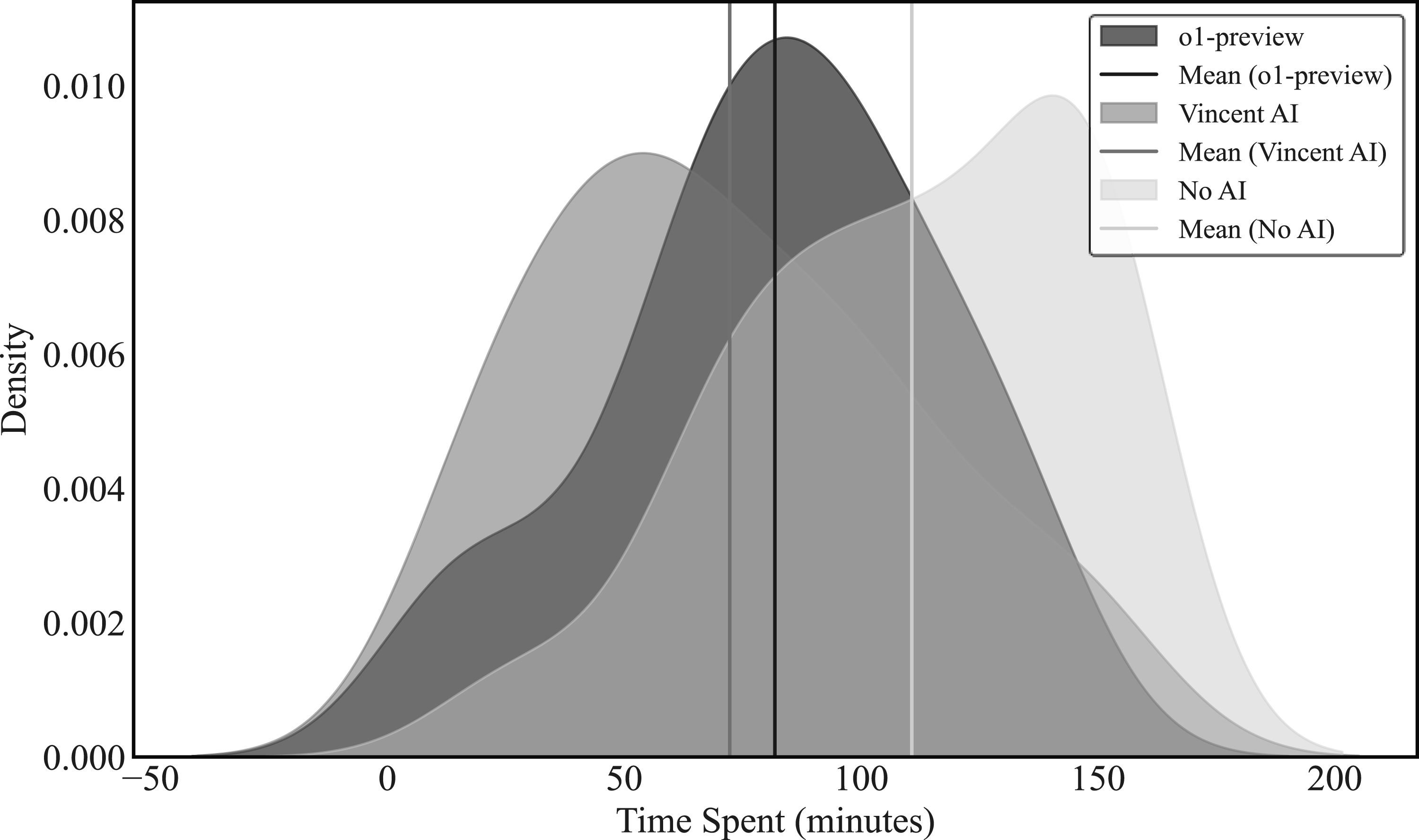
Figures 8 through 13 provide additional insight into how AI affects the distribution of time spent across the six forms of legal work. These density plots show, for each treatment group, the distribution of the number of minutes participants used to complete each task. For tasks such as Draft Client Email, Analysis of Complaint, Draft Motion to Consolidate, and Draft Persuasive Letter, the Vincent AI and o1-preview curves shift noticeably to the left, indicating broad-based reductions in time spent rather than changes concentrated among only a few participants. By contrast, the curves for Draft NDA overlap almost exactly across groups, visually reinforcing the notion that drafting a nondisclosure agreement is the one task where neither tool produces meaningful speed gains or quality improvements, perhaps because of the task’s template-driven, transactional structure or its limited opportunities for substantive modification. Time Spent Distributions, Draft Client Email. Notes: This figure displays kernel-smoothed distributions of time spent on the Draft Client Email task by AI condition. Time spent is measured in minutes and is bounded by the task’s time limit (0–60 minutes). Because the distributions are kernel-smoothed, estimated densities extend beyond the task’s time limit; these boundary violations are a mechanical artifact of the smoothing procedure rather than observed behavior. Total N = 134. Time Spent Distributions, Draft Legal Memo. Notes: This figure displays kernel-smoothed distributions of time spent on the Draft Legal Memo task by AI condition. Time spent is measured in minutes and is bounded by the task’s time limit (0–240 minutes). Because the distributions are kernel-smoothed, estimated densities extend beyond the task’s time limit; these boundary violations are a mechanical artifact of the smoothing procedure rather than observed behavior. Total N = 124. Time Spent Distributions, Analysis of Complaint. Notes: This figure displays kernel-smoothed distributions of time spent on the Analysis of Complaint task by AI condition. Time spent is measured in minutes and is bounded by the task’s time limit (0–120 minutes). Because the distributions are kernel-smoothed, estimated densities extend beyond the task’s time limit; these boundary violations are a mechanical artifact of the smoothing procedure rather than observed behavior. Total N = 126. Time Spent Distributions, Draft NDA. Notes: This figure displays kernel-smoothed distributions of time spent on the Draft NDA task by AI condition. Time spent is measured in minutes and is bounded by the task’s time limit (0–180 minutes). Because the distributions are kernel-smoothed, estimated densities extend beyond the task’s time limit; these boundary violations are a mechanical artifact of the smoothing procedure rather than observed behavior. Total N = 127. Time Spent Distributions, Draft Motion to Consolidate. Notes: This figure displays kernel-smoothed distributions of time spent on the Draft Motion to Consolidate task by AI condition. Time spent is measured in minutes and is bounded by the task’s time limit (0–150 minutes). Because the distributions are kernel-smoothed, estimated densities extend beyond the task’s time limit; these boundary violations are a mechanical artifact of the smoothing procedure rather than observed behavior. Total N = 127. Time Spent Distributions, Draft Persuasive Letter. Notes: This figure displays kernel-smoothed distributions of time spent on the Draft Persuasive Letter task by AI condition. Time spent is measured in minutes and is bounded by the task’s time limit (0–150 minutes). Because the distributions are kernel-smoothed, estimated densities extend beyond the task’s time limit; these boundary violations are a mechanical artifact of the smoothing procedure rather than observed behavior. Total N = 126.


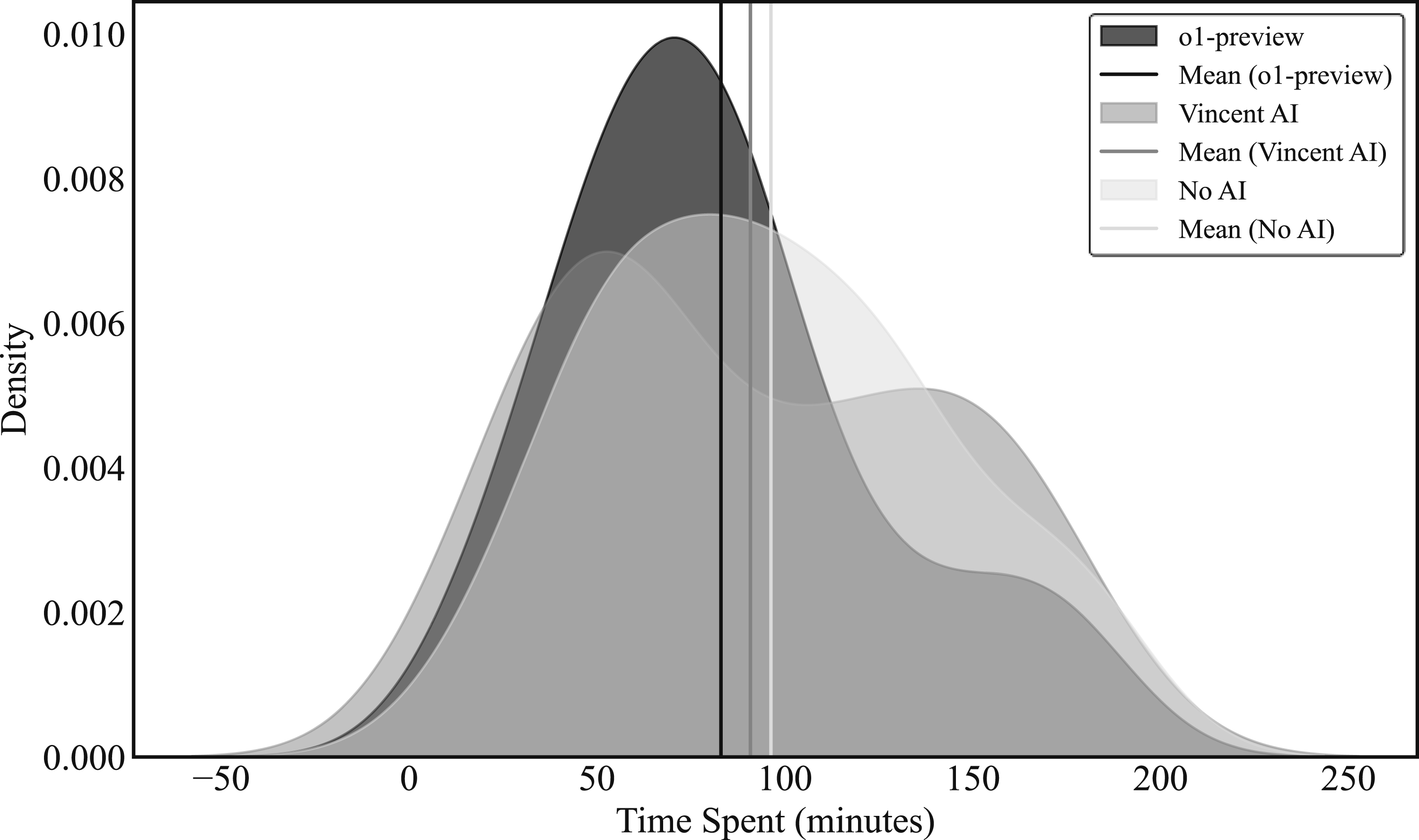
Average Time Spent Completing Tasks With and Without GPT-4 (Choi et al., 2024)

Notes. This table reproduces results reported in Choi et al. (2024) showing the average time their participants spent completing several legal tasks (in minutes) with and without access to GPT-4. See Choi et al. (2024) for details on the experimental design and estimation strategy.
4.3. Effects of AI Access on Productivity
Treatment Effects on Task-Level Productivity
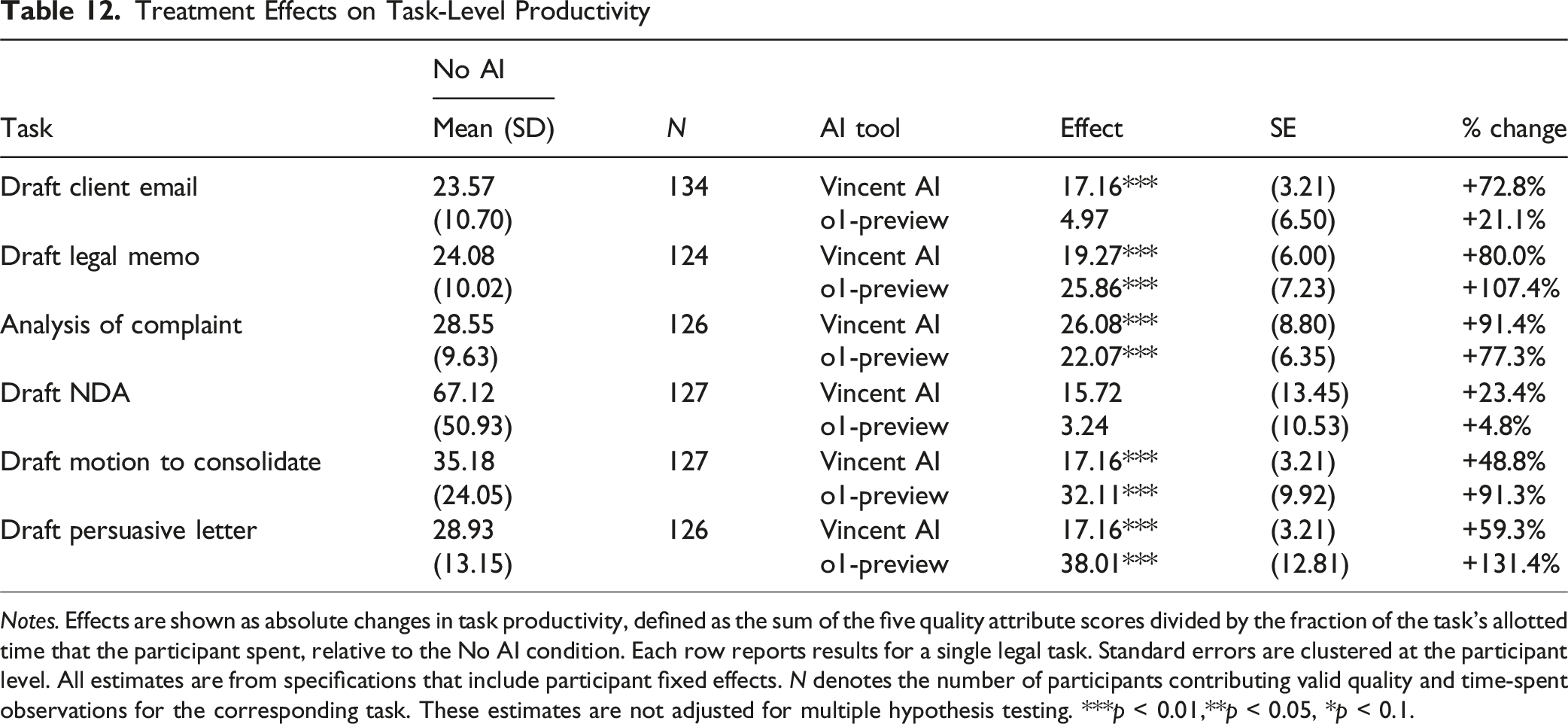
Notes. Effects are shown as absolute changes in task productivity, defined as the sum of the five quality attribute scores divided by the fraction of the task’s allotted time that the participant spent, relative to the No AI condition. Each row reports results for a single legal task. Standard errors are clustered at the participant level. All estimates are from specifications that include participant fixed effects. N denotes the number of participants contributing valid quality and time-spent observations for the corresponding task. These estimates are not adjusted for multiple hypothesis testing. ***p < 0.01,**p < 0.05, *p < 0.1.
The productivity gains associated with the availability of AI assistance are striking. Access to Vincent AI generates substantial improvements on five of the six tasks, ranging from roughly +50% to +110%. Access to o1-preview produces comparably large and, on several tasks, even larger gains, improving productivity on four tasks with increases of about +75% to +130%. The largest effects appear on tasks requiring structured reasoning and written advocacy, especially Analysis of Complaint, Draft Legal Memo, and Draft Persuasive Letter. Participants complete these tasks far faster while maintaining or improving quality. To put these magnitudes in perspective, a 130% increase in productivity means that lawyers using o1-preview produce more than twice as much quality-adjusted work after accounting for the fraction of the task’s allotted time spent (for example, by completing a task in less than half the allotted time without sacrificing quality or by delivering substantially higher-quality work in the same amount of time). These impressive gains reflect modest improvements in quality coupled with large, consistent reductions in the amount of time spent on the task. The same qualitative pattern appears in pooled OLS specifications that omit participant fixed effects, reported in Appendix A (Table A8). The sole exception to this pattern of productivity improvements is the NDA task, where we find no evidence in our experiment that either tool affects performance, mirroring the null effects on both quality and time for this form of transactional drafting.
4.4. Qualitative Assessment of AI-Assisted Work
To gain deeper insight into how access to AI tools affects the quality of legal work, our three grading co-authors conducted a post-analysis qualitative review of the task submissions they evaluated, this time with knowledge of whether the participant in question had access to o1-preview, Vincent AI, or neither AI tool. Their observations provide a complementary perspective on the quantitative patterns we document above and highlight the kind of legal writing and analysis that AI access tends to generate.
A consistent theme emerges from the qualitative review: legal professionals who have access to AI tools produce writing that is clearer, more polished, and easier to read than work produced without access to AI tools. Their sentences are more concise, their paragraphs flow more smoothly, and the overall structure presents information in a more coherent and user-friendly manner. Their submissions also contain far fewer surface-level errors—such as typos, comma splices, and other distracting mistakes—which AI support helps eliminate. These stylistic improvements align closely with the quantitative gains we observe in Clarity, Organization, and Professionalism, and any differences between the work product of people using Vincent AI and those using o1-preview appear modest along these dimensions. By contrast, the quality of writing varies widely when people performing legal work do not have access to AI tools. As one grading co-author, using a bowling analogy, put it: it is as if people with access to AI tools are not only playing with bumpers built into the gutters—to prevent huge mistakes—but also are told which ball to use, which shoes to use, and where to aim.
Importantly, the stabilizing, “raise-the-floor” effect of AI access appears to be less pronounced in Analysis and Accuracy. Still, in several tasks, AI assistance seems to help legal writers focus more effectively on the central legal questions. For example, practitioners with AI access are less likely to veer off on tangents and more likely to concentrate on key material issues. AI tools also appear to reduce the amount of time people spend floundering during the research stage in a way that might otherwise leave too little time to write. These patterns suggest a connection between AI’s speed and its quality-related benefits: by streamlining early-stage research and issue-spotting, access to AI tools may effectively free lawyers to invest more time in analysis and refinement of their work product.
Yet the positive effects of AI support on Analysis and Accuracy are inconsistent at best, especially for Vincent AI. AI assistance, and access to Vincent AI in particular, tends to be more beneficial when the legal task involves a narrow, well-defined issue with a clearly articulated deliverable. Conversely, its advantages diminish on broader tasks that require identifying the key issues. Vincent AI users were more likely to struggle with task identification on such broad tasks. AI users are more prone to respond to a far broader set of issues than they should and frequently include fewer relevant citations. In some cases, they provide case names without citations or rely on non-binding administrative or secondary sources. Additionally, AI access seems to lead participants to oversimplify legal questions or, in the case of o1-preview, to omit legal authorities altogether.
Our qualitative review bears out our expectation that access to o1-preview might generate a disproportionate number of hallucinated sources in legal work. Although the overall number of hallucinated citations was very small (18 across all treatment groups on a total of 768 tasks), the pattern of inaccuracies was clear. For example, o1-preview users occasionally cited cases that were entirely fabricated—meaning they did not exist under the names or citations that participants provided. A more subtle issue relates to the types of sources that AI users might use to establish or defend their claims. Vincent AI users appeared to be more likely to include obscure and often unnecessary sources, setting them apart from other participants.
4.5. Effects of AI Access Across Baseline Skill Levels
In addition to assessing how access to o1-preview and Vincent AI can affect the performance of legal work on average, we also explore how outcomes vary with participants’ baseline skill levels. Prior research suggests that when GPT-4 does affect the quality of legal work, it does so unevenly, benefiting those with lower initial skill levels by more than those with higher baseline proficiency (Choi et al., 2024; Choi & Schwarcz, 2025). To assess whether similar patterns appear in our data, Figure 14 through 17 plot two outcomes—productivity and quality—averaged across the two tasks each participant completed under each experimental condition against participants’ first-year GPAs. Figures 14 and 16 report the relationship between GPA and average task-level productivity, while Figures 15 and 17 present the corresponding relationship for average task-level quality scores, where each task-level score is computed as the mean of the five quality attribute scores. In each figure, outcomes are shown separately for participants with and without access to an AI tool. Productivity and First-Year Law School GPA, o1-preview. Notes: This figure plots participant-level productivity against first-year law school GPA. Productivity is defined as total score divided by the fraction of the task’s allotted time that the participant spent on the task. For each condition, productivity is averaged across the two tasks completed under that condition. Each participant therefore contributes two observations, one from tasks completed without AI assistance and one from tasks completed with access to o1-preview. Fitted lines summarize the conditional relationship between GPA and productivity and are intended to be illustrative. Total N = 122 participants. Total Score and First-Year Law School GPA, o1-preview. Notes: This figure plots participant-level total score against first-year law school GPA. Total score is defined as the sum of the five quality attributes for a given task and is averaged across the two tasks completed under each condition. Each participant therefore contributes two observations, one from tasks completed without AI assistance and one from tasks completed with access to o1-preview. Fitted lines summarize the conditional relationship between GPA and total score and are intended to be illustrative. Total N = 122 participants. Productivity and First-Year Law School GPA, Vincent AI. Notes: This figure plots participant-level productivity against first-year law school GPA. Productivity is defined as total score divided by the fraction of the task’s allotted time that the participant spent on the task. For each condition, productivity is averaged across the two tasks completed under that condition. Each participant therefore contributes two observations, one from tasks completed without AI assistance and one from tasks completed with access to Vincent AI. Fitted lines summarize the conditional relationship between GPA and productivity and are intended to be illustrative. Total N = 122 participants. Total Score and First-Year Law School GPA, Vincent AI. Notes: This figure plots participant-level total score against first-year law school GPA. Total score is defined as the sum of the five quality attributes for a given task and is averaged across the two tasks completed under each condition. Each participant therefore contributes two observations, one from tasks completed without AI assistance and one from tasks completed with access to Vincent AI. Fitted lines summarize the conditional relationship between GPA and total score and are intended to be illustrative. Total N = 122 participants.
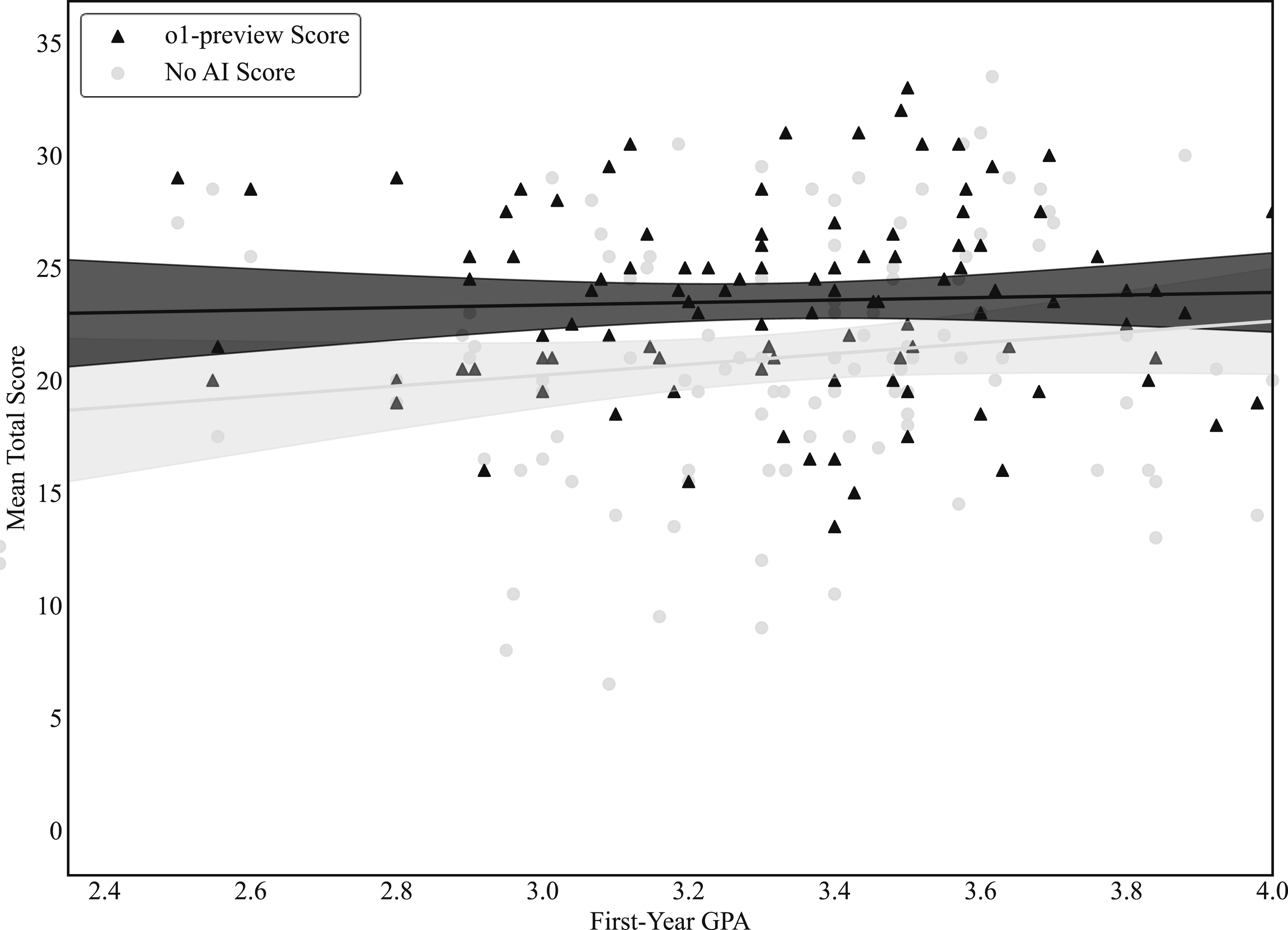

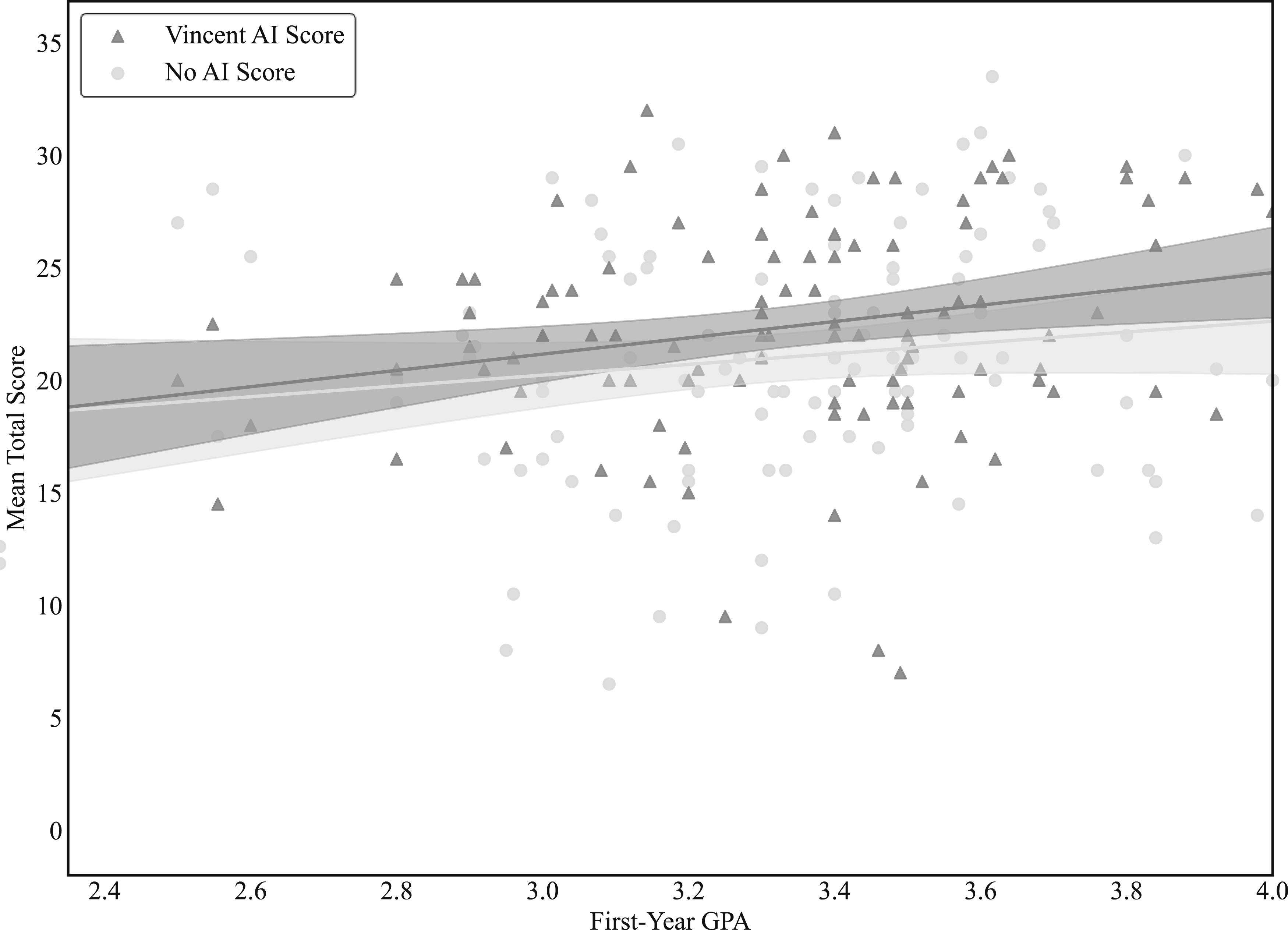
If o1-preview disproportionately benefits lower-GPA participants, we would expect a wider gap between the two lines on the left side of each graph where baseline skill may be lower, with the o1-preview line lying noticeably above the no-AI line. Although Figure 14 shows some evidence of convergence as first-year GPAs increase, the pattern does not indicate pronounced heterogeneous effects, suggesting that the productivity gains from o1-preview access are relatively constant across participant skill levels. By contrast, Figure 15 suggests that the differential effect of o1-preview access by ability—as measured by first-year GPA—is more pronounced when we focus on task scores. Specifically, the near convergence in Figure 15 of the two lines as GPAs increase implies that access to o1-preview provides a greater boost in quality for potential users with lower baseline skill levels as compared to potential users with higher baseline skills (as measured by first-year GPA, which we acknowledge is limited in important respects). Even among the highest skill levels, however, we detect no evidence to indicate that access to o1-preview reduces the overall quality of work.
Figures 16 and 17 repeat this same analysis for Vincent AI. Interestingly, these figures reveal a pattern opposite to the one we observe for o1-preview. In terms of productivity, a differential effect across baseline skill level (measured by first-year GPA) is evident from the convergence of lines in Figure 16. By contrast, Vincent AI’s effect on overall scores appears relatively uniform across baseline skill levels, as shown in Figure 17. Taken together, these results suggest that Vincent AI’s heterogeneous productivity effects arise chiefly from differential time savings: lower-skill participants speed up more with access to Vincent AI, whereas quality scores remain relatively uniform across the skill distribution. This pattern is somewhat at odds with the one for o1-preview, where heterogeneity arises primarily through differences in quality gains rather than differences in time savings.
Another way to assess the relative impact of AI access across participants with different baseline skill levels is to measure baseline skill not by first-year GPA but by participants’ scores on tasks completed without AI assistance. Figures 18 and 19 illustrate this approach for o1-preview and Vincent AI, respectively. In these figures, the outcome on the y-axis is each participant’s average change in task score (standardized within task, based on No-AI scores) when using the AI tool relative to their own performance on tasks completed without AI. Because baseline skill in this setting is measured using participants’ own task scores rather than an external proxy such as GPA, these figures are more susceptible to mechanical regression-to-the-mean effects and should therefore be interpreted descriptively and with caution. This score-based approach reveals even more pronounced differences in how the two tools affect the quality of legal work product across the skill distribution. Importantly, although values below zero are consistent with the possibility that AI reduces performance for high-skill participants, we cannot interpret them in this way. Such negative differences can arise mechanically from both regression to the mean and the assignment of participants to different tasks with varying baseline difficulty and treatment intensity: specifically, if a participant’s AI-assisted tasks are ones with lower baseline scores or smaller AI effects, the resulting difference may be negative even when AI improves performance on those tasks. Consistent with this interpretation, unreported regression analyses that interact AI access with baseline performance measures yield qualitatively similar patterns, suggesting that the heterogeneity observed in Figures 18 and 19 is not driven solely by regression to the mean, even though task-level composition may continue to contribute to variation in individual-level differences. Change in Standardized Performance Relative to No-AI Benchmark, o1-preview. Notes: This figure plots each participant’s average standardized performance on tasks completed without AI assistance (x-axis) against the participant’s average change in standardized performance when using o1-preview (y-axis). For each task, the score is standardized using the mean and standard deviation of scores among participants who completed that task without AI assistance. For each participant, the x-axis value is the average standardized score across the two tasks completed without AI assistance. The y-axis value equals the participant’s average standardized score across the two tasks completed with o1-preview minus the participant’s baseline average standardized score. Values on the x-axis therefore reflect relative standing when working without AI assistance. Fitted lines summarize the conditional relationship between baseline performance and AI-related changes and are intended to be illustrative. Total N = 122 participants. Change in Standardized Performance Relative to No-AI Benchmark, Vincent AI. Notes: This figure plots each participant’s average standardized performance on tasks completed without AI assistance (x-axis) against the participant’s average change in standardized performance when using Vincent AI (y-axis). For each task, the score is standardized using the mean and standard deviation of scores among participants who completed that task without AI assistance. For each participant, the x-axis value is the average standardized score across the two tasks completed without AI assistance. The y-axis value equals the participant’s average standardized score across the two tasks completed with Vincent AI minus the participant’s baseline average standardized score. Values on the x-axis therefore reflect relative standing when working without AI assistance. Fitted lines summarize the conditional relationship between baseline performance and AI-related changes and are intended to be illustrative. Total N = 122 participants.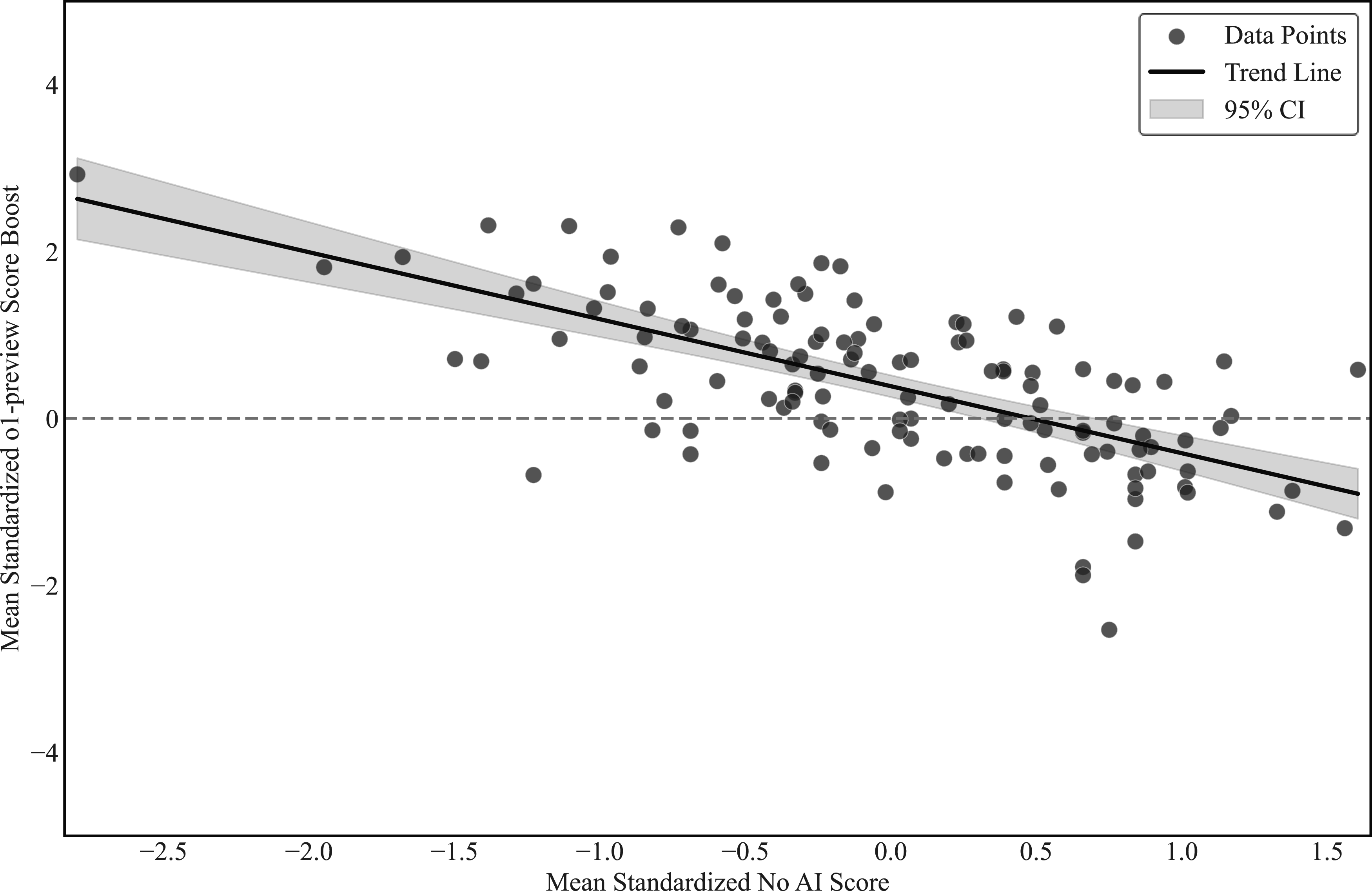
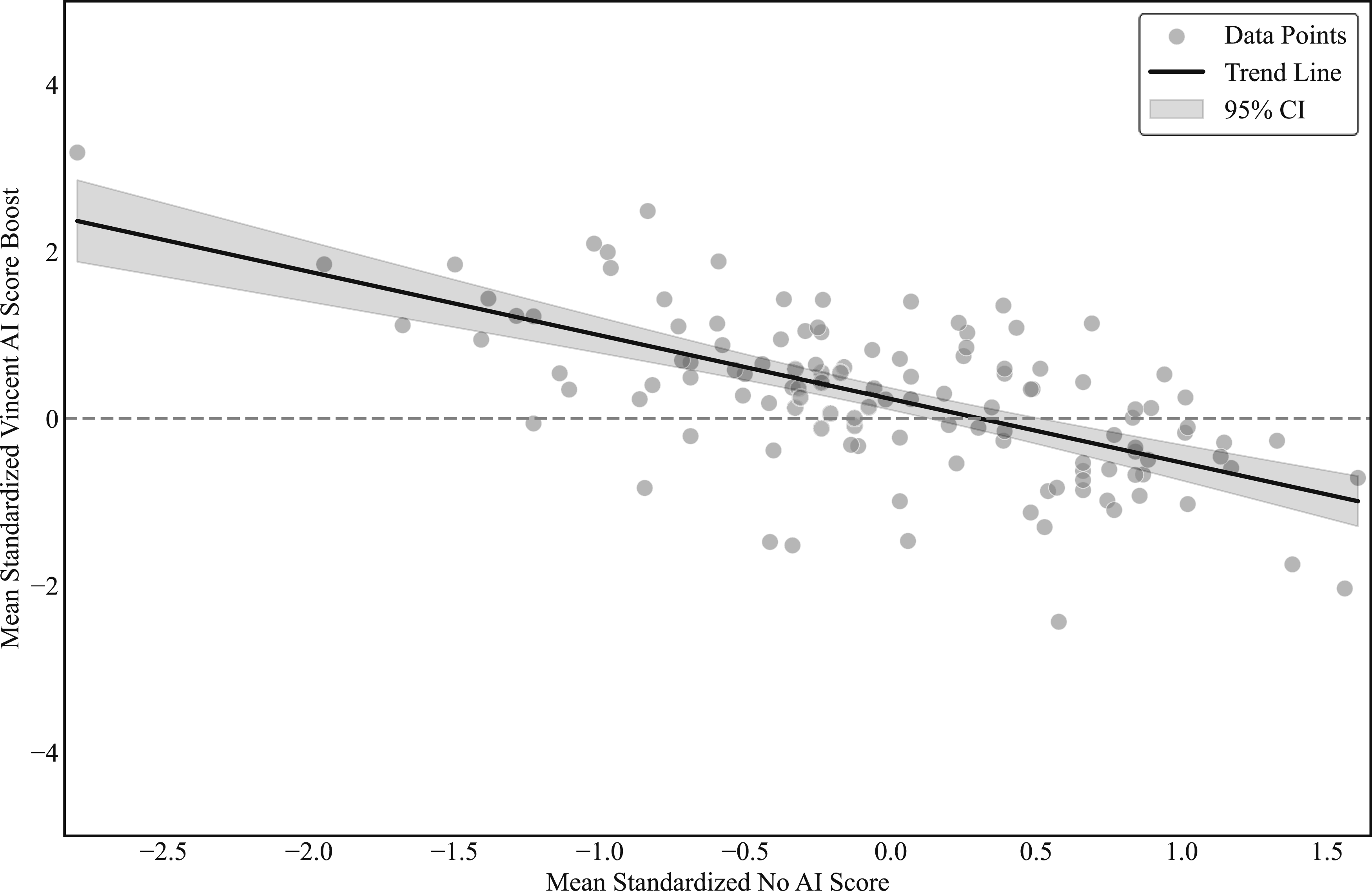
Taken together, our findings reinforce a pattern documented in earlier GPT-4 studies (e.g., Choi & Schwarcz, 2025): AI tools appear to provide the largest gains for participants with lower baseline skill, while offering smaller—and in some cases slightly negative—estimated effects for those with the strongest baseline performance. These negative estimates are concentrated in settings where measurement and task-composition issues complicate interpretation and may not imply systematically worse performance. Accordingly, we find no reliable support for the idea that AI access meaningfully harms the quality of work for higher-skilled participants. Instead, the results suggest that access to cutting-edge AI systems primarily “raise the floor,” narrowing performance gaps rather than uniformly shifting the entire distribution upward. These heterogeneous effects underline that the value of access to AI assistance depends not only on the specific AI tool and the legal task, but also on the user, with important implications for how legal organizations and educators integrate AI into training and practice.
4.6. Post-Experiment Survey Results
Our post-experiment survey results are generally consistent with our quantitative findings on quality, efficiency, and productivity, though our analysis surfaces a few discrepancies. Figure 20 displays the average responses to several survey questions, each of which we designed to elicit a distinct dimension of participants’ experiences with the two AI tools: participants’ intended future use of AI tools, their perceived improvement in proficiency with the AI tools over the course of the experiment, the extent to which the AI tools enhanced their overall satisfaction as they completed their tasks, their perceptions of how the tools affected the quality of their work, and their perceptions of how the tools affected their speed of completion. Self-Reported Experiences with o1-preview and Vincent AI. Notes: This figure reports mean participant ratings on post-experiment survey questions assessing perceived quality impact, perceived speed impact, self-reported satisfaction, self-assessed improvement, intended future use, and perceived helpfulness of the two AI tools. Ratings are measured on a 1–5 scale. Perceived helpfulness scores are averaged across all six tasks. Error bars represent standard errors of the mean. Total N ranges from 113 to 114 participants, depending on the survey item.
These data indicate that participants generally believed that both AI tools enhanced the quality of their work and increased their speed in completing their legal tasks. Interestingly, participants perceived o1-preview as more effective for boosting speed and Vincent AI as more helpful for enhancing quality. These subjective impressions diverge in important respects from the actual results of our experiment: in practice, the two tools produce similar gains in speed, while o1-preview delivers broader and more substantial improvements in quality across tasks and attributes. Even so, the survey responses in Figure 20 reveal that participants had a largely positive experience using both tools, with markedly strong approval expressed for Vincent AI.
Figure 21 displays the average overall helpfulness ratings of the two AI tools, computed for each task using the ratings provided by participants who completed that task under the relevant AI condition. These results reveal that participants also have somewhat unreliable intuitions about where the tools were most and least helpful. In particular, their perceptions do not fully align with the actual performance data, which do not provide any reliable evidence that o1-preview or Vincent AI enhance speed or quality in the NDA drafting task as compared to the other five tasks. Yet participants registered only small to moderate reductions in perceived helpfulness for the NDA task, despite the quantitative data showing that both systems—especially o1-preview—delivered substantially stronger gains on most other tasks. Perceived Helpfulness by Task and AI Tool. Notes: This figure reports mean participant ratings of the perceived helpfulness of o1-preview and Vincent AI for each of the six assigned tasks. Ratings are measured on a 1–5 scale and are reported only for tasks on which participants used the corresponding AI tool. Error bars represent standard errors of the mean. Total N varies by task–AI condition pair, ranging from 35 to 41 participants.
5. Limitations
Although our experiment provides valuable evidence about the impact of giving lawyers access to AI reasoning models and RAG-based AI systems as of 2024, our findings are subject to several important limitations involving both our study population and the design of the experiment.
To begin with, our participants were not fully licensed lawyers but upper-level law students. This raises a significant question about how well the results generalize to licensed practitioners engaging in real legal practice. We chose this structure because hiring a sufficiently large sample of practicing lawyers to complete a wide range of tasks would have been prohibitively expensive and hard to administer in a manner that ensured compliance with our experimental protocols. Plus, we believe that upper-level students at the two highly selective law schools in our study serve as a reasonably good proxy for junior associates at typical law firms, especially because many third-year students have already worked as summer associates at large law firms. Even so, the extent to which this generalization holds true remains uncertain and costly to test. Also uncertain is the extent to which our results would generalize to upper-level law students at less selective law schools.
A further related limitation is the possibility of a demand effect: although graders were blind to treatment status, participants knew when they were permitted to use an AI tool, which could have influenced how much effort they invested and thereby raised or lowered performance for reasons that are independent of access to the tool itself (a concern mitigated somewhat by the fact that most participants finished with time to spare).
We also cannot know whether our results extend to more experienced lawyers. On one hand, it is plausible that senior lawyers would exhibit smaller gains in efficiency and quality from access to AI tools because they tend to be more expert at their craft and more knowledgeable about the law. Such a pattern would mirror findings from other contexts where AI often enables less experienced workers to perform at the level of more experienced ones, while offering limited returns for those who are already highly skilled (Brynjolfsson et al., 2025). On the other hand, senior lawyers might benefit even more than young lawyers, particularly in avoiding the consequences of AI failures, since their greater expertise could better equip them to critically evaluate and refine AI-generated output (Schwarcz & Choi, 2023).
Another limitation concerns the scope of the legal tasks we asked participants to perform. Because we believe our subjects most closely resemble junior lawyers, we designed tasks that would be appropriate for individuals in that role. None of the six tasks, however, were ones that senior lawyers or law firm partners would typically perform. Moreover, since law students generally receive more training in litigation than in transactional work, our tasks are predominantly litigation-oriented, with only our NDA task squarely transactional. Additionally, while we designed the tasks to test a broad variety of legal reasoning skills that might be required of young lawyers working in litigation-oriented settings, we cannot be sure how well we achieved this objective. For these reasons, the somewhat specific features of our chosen tasks might constrain the generalizability of our findings.
Moreover, the only law-specific tool we test—Vincent AI—was designed primarily to support litigation-related tasks, though at the time of testing, the version we used did include some features aimed at transactional work. This litigation-oriented design may help explain why we do not observe statistically significant effects on the transactional NDA task. We did not evaluate tools specifically built for that type of task. More generally, performance improvement, both actual and perceived, may be in part a function of how users experience the software entirely separately from its raw ability to generate high quality outputs. Better user experience may improve or reduce user performance even when underlying AI models are identical.
Other potential limitations involve how AI use may change over time. For example, our study cannot provide a longitudinal perspective on how lawyers’ use of AI might change in the future as they become more familiar with the tools or have regular access to other AI systems and technology. In addition, we did not counterbalance the tasks by varying the order in which participants completed them. It is therefore possible that participants improved in their ability to use the AI tools over the course of the experiment or that they relied on the tools differently in earlier versus later tasks. Given our results (which do not show performance improving monotonically) and the fact that tasks differ meaningfully in content, we doubt these possible confounders significantly bias our results. Still, we cannot discount these concerns.
A final potential limitation concerns the grading process. We conducted all evaluations blindly, without knowledge of whether task submissions had been produced with AI assistance. Nonetheless, it is possible that we could intuit which tasks were more likely to have been supported by AI and unconsciously graded those tasks more favorably (or more harshly). We sought to mitigate this risk by strictly separating graders from those who managed the data, instructing graders not to speculate about AI involvement, and using pre-specified rubrics to constrain discretion. Even so, these safeguards were surely not perfect, as illustrated by the inherent subjectivity in applying many elements of the rubrics to individual task submissions.
6. Discussion
Our findings demonstrate that Vincent AI and o1-preview each independently improve the quality of certain types of legal work and increase the productivity of the people who produce it. Each AI system appears to do so through distinct and independent technological innovations, which can be and already are being combined with one another in updated legal technology tools. It stands to reason that the combined effects of these technologies on legal practice are likely to be greater than our results suggest.
Consider the primary mechanism through which Vincent AI is likely to affect legal work beyond facilitating access to a foundation model: Retrieval Augmented Generation (RAG). Perhaps the most significant limitation of RAG-based AI systems is their inability to reliably identify and leverage the most relevant sources among the millions of potentially relevant cases, statutes, regulations, and secondary materials. This challenge is particularly acute in legal analysis, where one of the key difficulties facing lawyers is determining which materials are most pertinent and how best to use them in constructing an argument. This difficulty may help explain why access to Vincent AI does not appear to improve Accuracy or Analysis across any of the six tasks, even though it yields fewer hallucinations than o1-preview access and even than working without any AI support. Legal accuracy and analytical quality depend not only on correctly summarizing legal sources but also on strategically selecting and persuasively leveraging the most compelling authorities to support an argument. Our results suggest that reasoning models like o1-preview have the potential to excel in precisely these areas relative to older AI models such as GPT-4.
Just as o1-preview and increasingly advanced reasoning models can enhance RAG-based tools by addressing their primary weakness, the reverse is also true. When combined with extensive legal databases, RAG technology can mitigate a key shortcoming of general-purpose foundation models in legal analysis: their lack of direct access to authoritative legal source materials. This limitation is evident in our results, which show a higher hallucination rate when participants used o1-preview than when they used Vincent AI or when they had no access to AI at all. Additionally, this limitation is underscored by the lack of statistically significant improvement in Accuracy across the six tasks—except for Analysis of Complaint, where we directly provided the key source material (the complaint) to all participants.
A further reason that our results are likely to understate the potential impact of AI on lawyering is more familiar: AI technology is continuing to improve at a blistering pace. Even the specific technology we test in this experiment is already out of date at the time of this writing. But this point has special salience in the context of our study, because the reasoning model we test (o1-preview) and find to improve the quality of human legal reasoning in ways that differ from any other previously tested model was the very first reasoning model to be made publicly available. The pace of innovation in AI, or any other field, is typically greatest when the first version of a new approach initially appears. Indeed, since OpenAI publicly released o1-preview—an event that immediately preceded the start of our experiment in October 2024—the company has released several new generations of reasoning models. Not surprisingly, the company’s more recent reasoning models, such as o3, substantially outperform the previous o1 model on numerous objective benchmarks (Wiggers, 2025).
As AI continues to improve, the legal community must thoughtfully consider how best to integrate these tools. Legal institutions will need to develop systematic, empirical methods for evaluating AI’s capabilities on a broad range of legal tasks (Schwarcz et al., 2025). Some law firms and commentators have attempted to address this gap by developing legal benchmarks to objectively evaluate AI tools (Fei et al., 2023; Grupen & Pereyra, 2024; ValsAI, 2025). But these benchmarks are becoming increasingly inadequate for measuring AI’s legal capabilities. First, many are saturated. AI models have already achieved near-maximum—or even superhuman—performance, leaving little room for meaningful improvement. Second, because valuable lawyering tasks cannot be easily measured formulaically, the real-world relevance of AI performance on these tests is often unclear. Third, such benchmarking studies do not seek to evaluate how access to AI impacts the practice of human lawyers.
Our approach to studying legal AI—randomized controlled trials focused on realistic lawyering tasks—offers key evidence for better understanding the role AI will play in legal practice. Unlike benchmarks, RCTs allow researchers to evaluate AI’s impact on humans’ ability to do what lawyers do in the real world. Given the transformative potential of AI on the profession, we believe it is important and timely for clients, law firms, and law schools to start embedding such trials into their operations and adapt accordingly.
7. Conclusion
This article presents the first rigorous empirical evidence that access to Retrieval Augmented Generation (RAG) and reasoning models can significantly enhance the quality of legal work in realistic lawyering tasks, while preserving the efficiency gains observed with earlier generations of generative AI. Our findings demonstrate that access to early reasoning models improves not only the clarity, organization, and professionalism of legal work but also the depth and rigor of legal analysis itself. Additionally, we provide suggestive evidence that access to late 2024 versions of RAG-enabled legal AI tools may be able to reduce hallucinations in human legal work to levels comparable to those found in work completed without AI assistance. The distinct yet complementary strengths of these technologies indicate that their integration could yield even greater benefits, a development already taking shape in emerging legal tech. The rapid advancement of reasoning models also indicates that the improvements observed in this study may only be the beginning of AI’s transformative potential for legal practice.
Supplemental Material
Supplemental Material - AI-Powered Lawyering: AI Reasoning Models, Retrieval Augmented Generation, and the Future of Legal Practice
Supplemental Material for AI-Powered Lawyering: AI Reasoning Models, Retrieval Augmented Generation, and the Future of Legal Practice by Daniel Schwarcz, Sam Manning, J.J. Prescott, Patrick Barry, David R. Cleveland and Beverly Rich in Journal of Law & Empirical Analysis
Supplemental Material
Supplemental Material - AI-Powered Lawyering: AI Reasoning Models, Retrieval Augmented Generation, and the Future of Legal Practice
Supplemental Material for AI-Powered Lawyering: AI Reasoning Models, Retrieval Augmented Generation, and the Future of Legal Practice by Daniel Schwarcz, Sam Manning, J.J. Prescott, Patrick Barry, David R. Cleveland and Beverly Rich in Journal of Law & Empirical Analysis
Footnotes
Acknowledgements
For helpful comments and guidance, we thank Pablo Arredondo, Victor Bennett, Jonathan Choi, Christoph Engel, Miryam Gorelashvili, Dan Ho, Christina Lee, Eric Martinez, Bryan Mechell, Amy Monahan, Daniel Rock, Kyle Rozema, Alan Rozenshtein, James Snelson, Tim Sullivan and Peter Wills, the editor, and two anonymous reviewers. Tomás Aguirre and Jared Sloan provided excellent research assistance. The anonymized data and code for the experiment and analysis are available online and upon request.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: For generous financial support of this project, we thank Fredrikson & Byron PA, Robins Kaplan LLC, University of Minnesota Law School, and University of Michigan Law School. Neither OpenAI nor VLex (the company that owns Vincent AI) provided financial support for this project, but they both did make their AI platforms freely available to study participants.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.