
Abstract
Retrieval-augmented generation (RAG) is rapidly emerging as a transformative paradigm for large language models (LLMs), especially in high-stakes domains like oncology that demand precision, factual grounding, and up-to-date knowledge. By pairing LLMs with external knowledge repositories, RAG systems explicitly ground model outputs in relevant retrieved documents, helping to reduce hallucinations and ensure responses reflect current evidence. In oncology, where clinical knowledge evolves continually with new research and drug approvals, RAG offers a way to integrate the latest data (e.g., trial results, guidelines, genomic databases) into decision-making. This review synthesizes the technical foundations of RAG, including its architecture and key components, and examines current applications in oncology such as clinical decision support, patient education, radiology reporting, pathology analysis, and genomics-driven precision medicine. We highlight recent studies that demonstrate RAG’s potential—for instance, improving treatment recommendations by incorporating genetic profiles and literature, and enhancing diagnostic accuracy by integrating guidelines. We also discuss emerging developments like multimodal RAG (combining text with imaging or other data), ensemble model approaches, and new explainability tools that trace model outputs to sources. Finally, we critically analyze the limitations and challenges of deploying RAG in healthcare, including computational costs, retrieval errors, noise or conflicts in retrieved information, and ethical and regulatory considerations. While RAG-based systems show promise in augmenting oncologists’ expertise with timely knowledge, careful implementation, high-quality curation of knowledge bases, and human oversight will be crucial for safe and effective adoption in clinical practice.
Keywords
Introduction
Large language models (LLMs) such as OpenAI ChatGPT, Claude, and LLaMA have demonstrated impressive capabilities in text generation and reasoning. However, in high-stakes domains like oncology, their tendency to hallucinate (fabricate information), lack up-to-date domain-specific knowledge, and inability to provide source traceability limit their clinical utility. 1,2 These shortcomings pose risks in clinical settings, as confident but incorrect outputs could misguide care decisions (e.g., suggesting a non-existent treatment). LLMs have increasing abilities to cite sources or provide evidence for their answers, though clinicians’ trust in the results continues to develop. 3,4
Retrieval-augmented generation (RAG) has emerged as a promising paradigm to address these issues by pairing LLMs with up-to-date, external knowledge sources. 5 In a RAG pipeline, the model’s outputs are explicitly grounded in retrieved documents (e.g., scientific literature, guidelines, or databases), which helps reduce hallucinations and ensures responses reflect current evidence. This approach is especially relevant in oncology, where new research findings, drug approvals, and guidelines continually evolve and must be incorporated into decision-making.
Copy-pasting chart text into a general GPT provides a one-off summary with no control over which sources is used, no guarantee of up-to-date evidence, and limited traceability. A RAG system makes the source selection explicit: it searches approved knowledge (e.g., guidelines, literature, local policies, curated electronic health record [EHR] fields), returns the passages it actually used, and cites them, thereby allowing for inspection of missed facts (e.g., overlooked positive nodes), adjusting the retriever or corpus, and re-iterating.
For example, if an LLM is prompted in a RAG pipeline: “What is the recommended therapy for ALK-positive lung cancer after progression on crizotinib?” It first retrieves relevant documents such as journal articles, clinical guidelines, or trial databases, and then conditions the LLM’s answer on that retrieved evidence. 6 By grounding responses in up-to-date information, RAG can both reduce outdated or incorrect answers and provide traceability for facts via source citations. 5
Early applications of RAG in healthcare suggest substantial benefits. By integrating real-time data, RAG can produce more accurate, context-aware outputs than standalone LLMs. For example, in oncology domains, RAG has shown promise in improving treatment recommendations by incorporating patients’ genomic profiles and recent trials, thereby personalizing therapy choices. 5 Other examples of RAG in oncology include automatic in-basket message response 7 and cancer patient education with promising results. 8,9 These advances suggest RAG’s potential to augment oncologists’ expertise with timely knowledge at the point-of-care. At the same time, initial studies also highlight pitfalls and the impact of biased or incomplete source data that can yield misleading answers. This review provides a comprehensive overview of the RAG paradigm and its technical foundations, surveys its current and potential applications in oncology, compares RAG to alternative LLM approaches (zero-shot and cache-augmented generation), and discusses the limitations, future directions, and ethical/regulatory considerations for deploying RAG-based tools in clinical oncology.
Technical Foundations of RAG in Medicine
Traditional LLM workflows begin with a clinical query that is fed into a pre-trained LLM, which then creates an output (Fig. 1). RAG refers to a class of architectures where an LLM is coupled with a retrieval module that supplies relevant external information to guide text generation 5,6 (Fig. 2). Implementing a RAG system involves several key technical components: (1) an index of knowledge sources split into manageable “chunks” and encoded for fast search, (2) a retriever that finds the most relevant chunks in response to a query, and (3) a generator (the LLM) that produces the final answer conditioned on both the query and retrieved evidence.
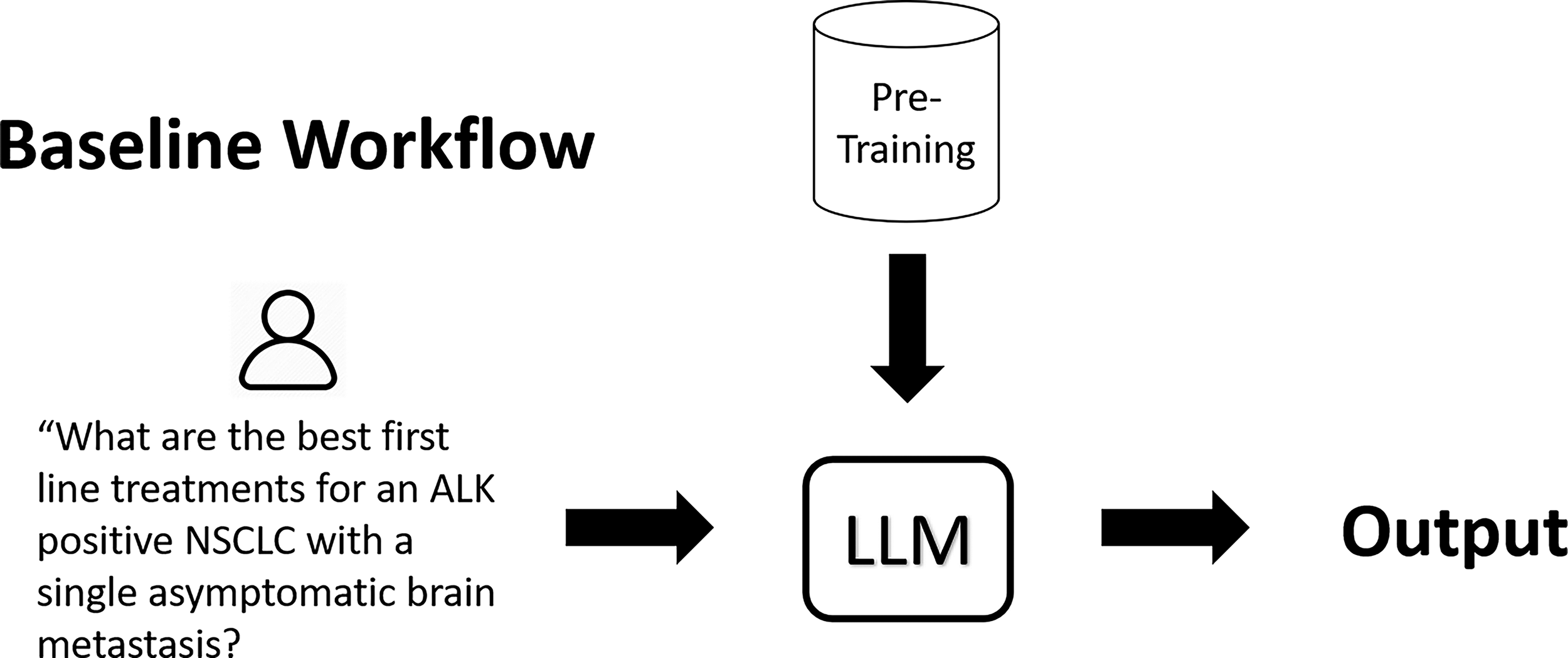
In this conventional large language model (LLM) setup, a clinical query is processed by a pre-trained large language model without access to updated or external references. The model generates an output based solely on information embedded during pretraining, limiting factual currency and source traceability.
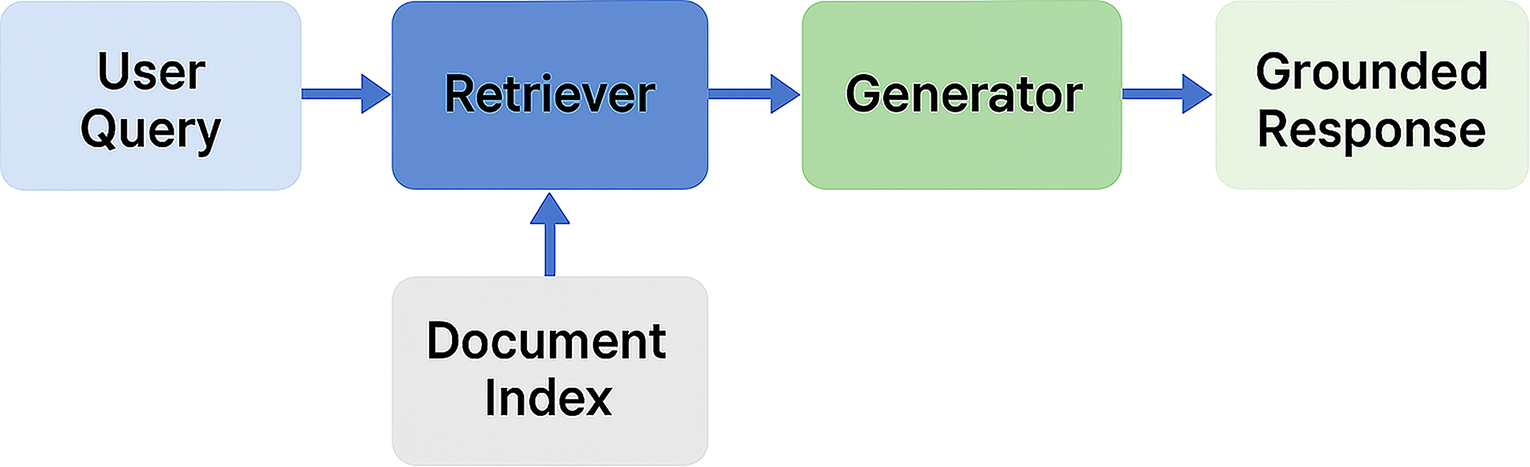
Core architecture of a retrieval-augmented generation (RAG) system. A user query is first processed by a retriever that searches a document index for relevant content. The retrieved passages are then passed to a generator, which produces a grounded response that is both contextually relevant and source-aware—enhancing factual accuracy and enabling traceability compared with baseline LLM approaches.
Figure 3 conceptually illustrates this pipeline in oncology: in the indexing stage, large documents (textbooks, guidelines, research articles, EHR notes) are broken into chunks and converted into high-dimensional vectors (embeddings) stored in a vector database. In the retrieval stage, a user’s query is also embedded into a vector, and a similarity search retrieves the top-matching chunks from the database. Modern RAG systems typically rely on dense vector retrieval (using transformer-based embedding models) rather than simple keyword matching, enabling semantic search that can capture medical synonyms and concepts. 10,11 Crucially, the model’s output is thus explicitly conditioned on the content of the retrieved documents, which helps anchor the response in factual information. Compared to fine-tuning an LLM on a static dataset, this retrieve-then-read approach is generally more computationally efficient for knowledge-intensive tasks and allows more flexibility in updating the knowledge source without retraining the model.
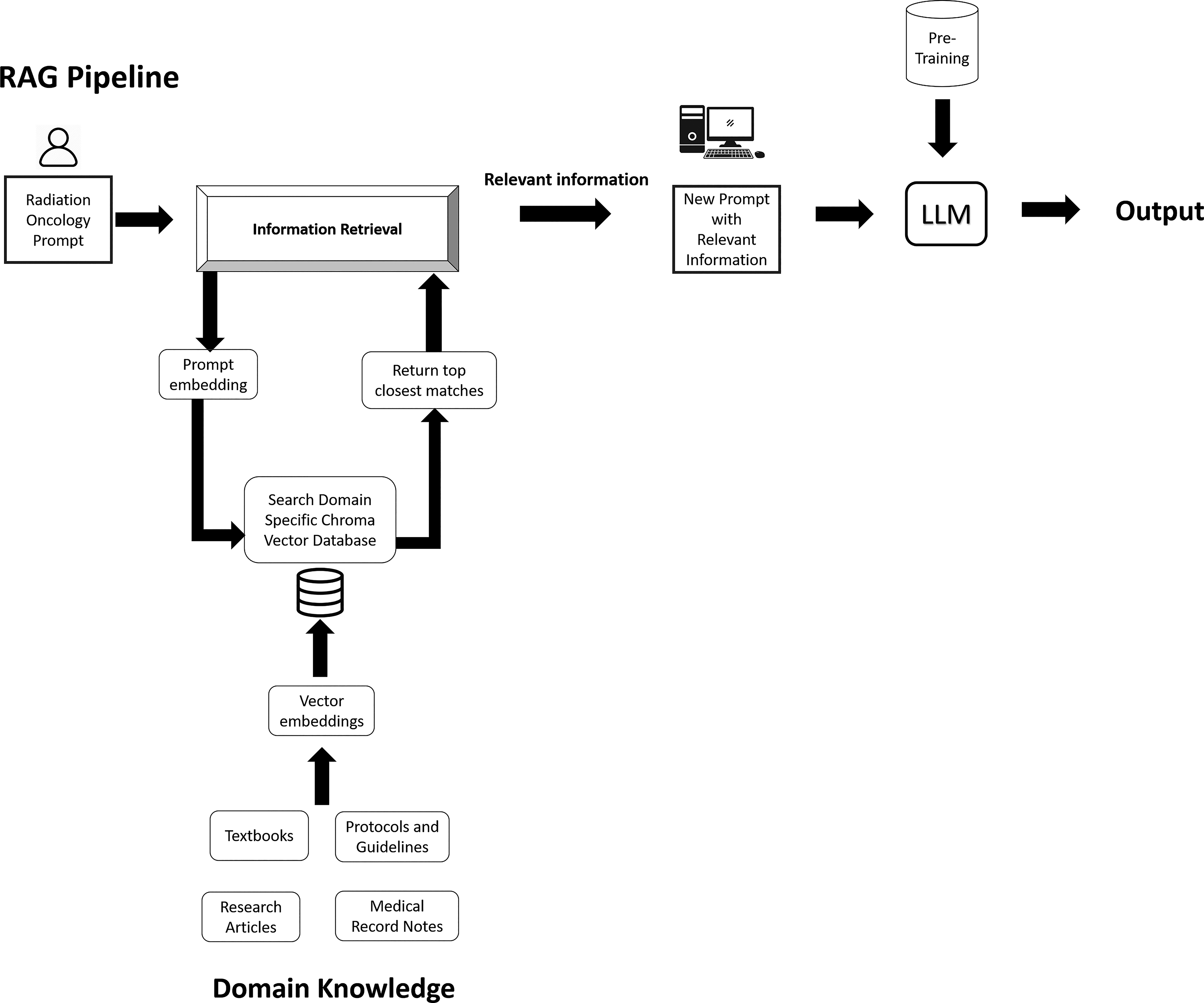
Domain-adapted RAG workflow. A user prompt (e.g., a clinical query) is embedded and matched against a vector database built from domain-specific content such as textbooks, research articles, clinical protocols, and medical records. The retriever returns the most relevant matches, which is used to augment the original query. The enriched prompt is then processed by a pre-trained LLM, resulting in an output that is both contextually grounded and traceable to oncology-specific evidence sources.
Retriever mechanisms and vector databases
Central to RAG is a retrieval system that can search a knowledge repository for information relevant to the user’s query. 12 Modern RAG implementations typically rely on dense vector retrievers, which convert text into high-dimensional numeric embeddings and use similarity search to find semantically relevant documents. 13 In practice, textual sources (e.g., journal articles, guidelines, EHR notes) are pre-processed into embedding vectors and indexed in a vector database. When a user inputs a query (such as a clinical question), the query is similarly embedded, and the closest matching text chunks are retrieved as context for the LLM. This embedding-based retrieval allows RAG to go beyond keyword matching, capturing clinical synonyms and concepts (e.g., “immunotherapy for Epidermal Growth Factor Receptor-mutant NSCLC” can retrieve articles on osimertinib even if the query doesn’t mention the drug by name). In some cases, lexical retrievers (like the classic keyword ranking method BM25 or keyword search) may be used or combined with dense retrievers for efficiency or precision, but the core idea is to supply relevant knowledge snippets to the model to augment the context surrounding the query.
Furthermore, RAG doesn’t require a private vector database; it can also query trusted web endpoints (e.g., PubMed, PMC, NCCN sites) with allow-lists and logging. Many deployments run hybrid retrieval: local curated corpora for reliability plus PubMed/PMC for freshness, with the validator agent checking that the final answer cites real, relevant articles. So RAG can be current without being a free-for-all web scrape.
Notably, the quality of the embedding model is crucial—domain-specific embeddings (trained on biomedical text) can improve retrieval of oncology literature and guidelines, whereas a general embedding model might miss subtleties of medical terminology. For instance, a traditional search engine or BM25 could be used to narrow the retrieved body of knowledge and then to apply vector search on that subset. There is also active research into advanced retrieval techniques for RAG: one approach is re-ranking, where an initial set of retrieved documents is re-sorted by a second-stage model (or by heuristic scores) to improve relevance. 6 Another approach is entity-based or knowledge graph–augmented retrieval, which ensures that results contain specific clinical entities of interest (like a patient’s mutation and cancer type. 14
Hybrid retrieval with knowledge graphs
In practice, the best results come from mixing two strengths: (1) semantic search (finding passages that “mean” the same thing, even if the wording is different) and (2) graph lookups (following real relationships like guideline → section → cited study → Fig.). One popular pattern is “vector → graph”: start with a quick semantic search to get a few promising snippets, then use the graph to pull in closely connected evidence (e.g., cited guidelines, co-mentioned drugs/genes, or the table/figure that the paragraph refers to). Microsoft’s GraphRAG shows how this kind of structure helps surface globally relevant context with clearer evidence trails than vector-only RAG. 15
A complementary pattern is “graph → vector”: begin with a small, targeted graph query (for example, “HER2 after trastuzumab” within breast cancer guidelines, or the latest trials after a certain date), then re-rank those candidates by semantic similarity to the question. Recent work like ArchRAG reports better answers with fewer tokens by using community/grouping in the graph before doing any heavy text retrieval, and Text2Cypher tools make the natural-language → graph-query step practical in Neo4j. 16 In short, hybrid retrieval uses graphs to keep context precise and explainable, and vectors to keep it flexible and language-robust.
Chunking strategies for knowledge indexing
Medical documents such as oncology guidelines, manuscripts, or textbooks can have large word (or token) counts. Feeding entire documents into an LLM is infeasible due to context length limits and would dilute relevance. Furthermore, medical literature is not written in an easily digestible way for LLMs, given the complexity, density, and specialized terminology of medical texts, as well as the need for background knowledge and context, which make them difficult for LLMs to process effectively. 17,18
Instead, RAG pipelines split documents into smaller units (chunks) before encoding and indexing. Each chunk might be a section, paragraph, or sentence, chosen to be small enough for the LLM to handle but large enough to contain a self-contained idea or fact. Simple approaches use a sliding window or sentence/paragraph boundaries to create chunks, sometimes with overlaps to avoid cutting important facts in half. More sophisticated strategies align chunks with semantic or topical sections (e.g., splitting at section headers or clinical headings) so that each chunk is self-contained.
There isn’t a single best chunk size, and the optimal size depends on document type and question. A practical default is 200–400 tokens for text paragraphs with 10%–20% overlap, one atomic chunk per table, and figure + caption as a single unit. In practice, many systems adapt chunk size: shorter for definition-style questions, but longer for rationale questions. A/B tests on a specific corpus of information are the most ideal way to select a chunk size. There is a trade-off in choosing chunk size: smaller chunks (e.g., a single sentence) increase the chances that one chunk exactly matches the query intent, but too-small chunks might lack context and lead the model to misinterpret information. Larger chunks (multiple paragraphs) provide more context but risk including tangential content that could confuse retrieval ranking. 19,20 Previous work suggests using 500 words as a starting point for NLP applications. 21,22 In one precision oncology study, researchers chunked content from a cancer knowledge base (OncoKB) and scientific publications into passages of a few hundred words, then used those for RAG-driven Q&A; the system was able to reproduce over 80% of known treatment relationships for clinical scenarios without any task-specific fine-tuning of the LLM. 23 As RAG systems evolve, chunking may become adaptive—for example, tailoring chunk size or overlap based on the type of document (guideline vs. research article) or the specific query needs.
Beyond text splitting, biomedical PDFs often use multi-column layouts, long tables, and figures with informative captions—structures that naïve chunkers flatten or scramble. A better approach is to first parse the page layout (columns, headings, regions), then extract tables as structured rows/columns and pair figures with their captions, and only then create chunks by element type: short paragraphs as text chunks, each table as an atomic chunk (plus a brief textual summary), and each figure + caption as a single unit. 24 Keeping reading order, section headers, page numbers, and coordinates as metadata preserves provenance and lets retrieval pull the right neighbor (e.g., the paragraph that describes a table) rather than unrelated text.
Integration with LLMs
The final stage of a RAG pipeline is the generator (Fig. 2), where the LLM integrates the retrieved evidence with the user’s query to produce a response. In current implementations, this is often done by prepending the retrieved text chunks to the model’s prompt:
Context: [retrieved passages] + Question: [user query]
Answer:
The LLM then generates an answer that ideally uses the context to ground its statements. Some systems also inject special tokens or formatting to delineate the sources, or prompt the model to explicitly cite the documents. Notably, RAG does not involve updating the internal weights of the LLM; the model remains pre-trained (and possibly instruction-tuned) on general text, and the retrieval acts as an external memory that supplements the model’s knowledge. This means that improvements in the knowledge base (e.g., adding new articles or removing outdated info) immediately reflect in the model’s outputs without retraining. 6 However, some retrieved passages could be irrelevant or even conflicting, which could lead to an incoherent or wrong answer. Some advanced RAG setups use multiple retrieval + generation rounds or an agentic approach where the LLM can iteratively refine its query or verify answers by querying again. 25 For instance, an agent might break a complex clinical question into sub-questions, retrieve answers for each, and then synthesize a final answer, thereby reducing the chance of missing needed information. Such chaining of retrieval and reasoning is an area of active exploration in making LLM responses more accurate.
Multimodal Extensions
Multimodal RAG extends the retrieval concept to other data types like images, genomics, or audio (Fig. 4). 26 In oncology, this system would not only fetch text literature but also retrieve relevant medical images (e.g., similar radiology scans or pathology slides) or genomics data (mutation profiles, gene expression plots) to inform an LLM’s answer. Such a workflow requires encoding non-text data into a form that the model can use—for example, using a convolutional neural network (CNN) or vision transformer to embed an image into a vector in the same space as text embeddings, or using a sequence encoder for genomic data. A CNN is a neural architecture that excels at images and grids (e.g., radiology, pathology, or even spectrograms), commonly used to turn images into features that LLMs can reason over.
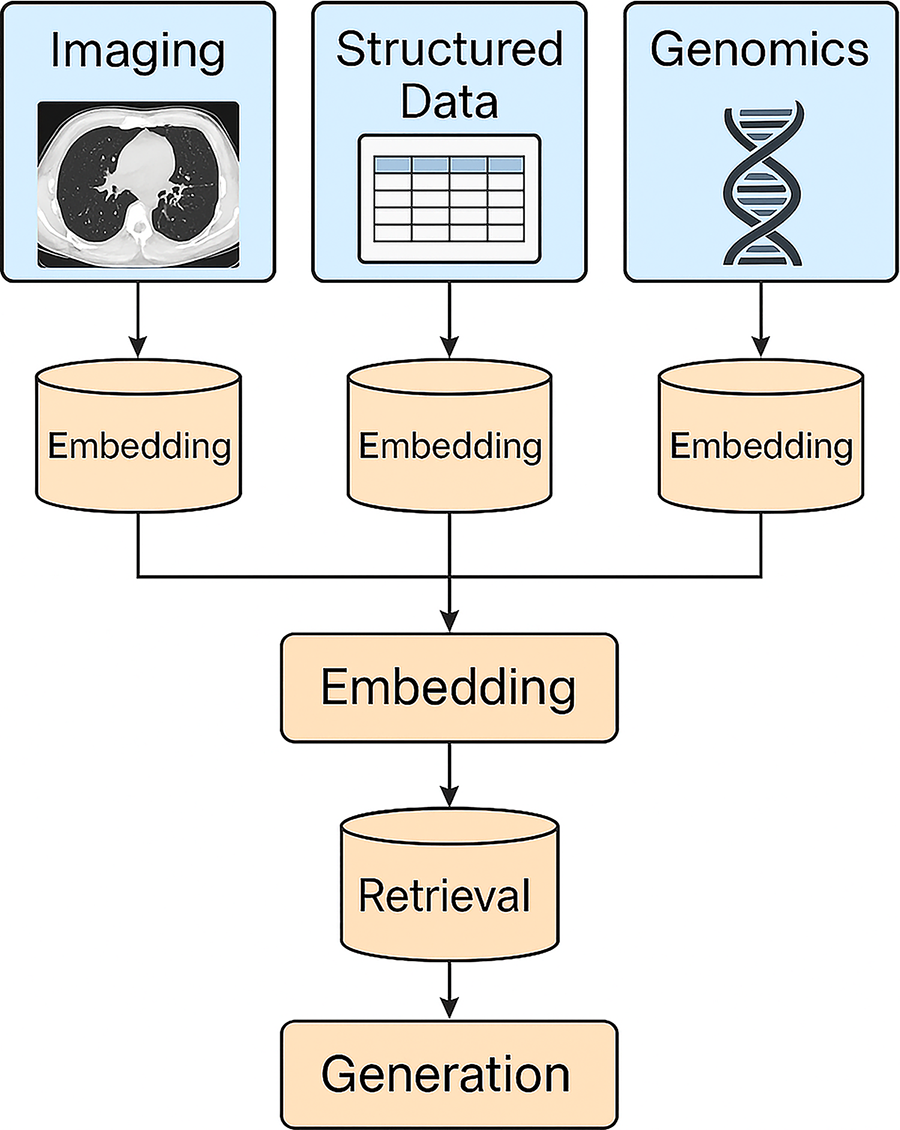
Multimodal RAG framework that integrates diverse clinical data types—including imaging (e.g., radiology or pathology), structured electronic health record (EHR) data, and genomic profiles. Each modality is embedded into a vector space independently and unified through a joint embedding layer. These embeddings are then queried using a retriever to identify the most relevant information across modalities, which is subsequently passed to a generator to produce a contextually rich and clinically grounded output.
Emerging evidence suggests that multimodal RAG can handle more modalities in addition to text, including images, audio, or video, which may further enhance RAG performance. Numerous current sources, including textbooks and pictorial guidelines, utilize images to display vital information, and future hybrid RAG models may allow for enhancements in multi-modal LLM performance. 27 In principle, a cancer chatbot could retrieve relevant radiology images from a database based on a patient’s imaging scan, to enhance diagnostic accuracy or link the radiological exam to other modalities of information including genomic sequencing. These capabilities remain experimental, but small-scale studies suggest that incorporating multi-modal data can enhance the model’s performance on certain tasks. For staging tasks, RAG can retrieve the staging criteria text while a vision model summarizes key findings from radiology or pathology images. The system then cross-checks the rules (e.g., nodal size/number) against extracted findings and drafts the stage with inline rule citations, leaving the clinician to confirm or adjust.
Early Applications of RAG in Oncology
In oncology, RAG-enabled LLMs have shown significant promise in various clinical applications. Key use cases include clinical decision support, patient communication and education, radiology and pathology report augmentation, and precision oncology for personalized treatment. Below, we summarize current systems and studies for each use case, highlighting their clinical impact and outcomes.
Clinical decision support
RAG-based systems can act as intelligent assistants to support clinical decision-making by retrieving and synthesizing relevant evidence on demand. 28 Early applications have focused on labeling patient outcomes, protocol-aware plan evaluation in radiotherapy, matching patients to appropriate clinical trials, and providing guideline-concordant recommendations.
Holmes et al. introduced a GPT-4o-based autonomous LLM agent, RadOnc-GPT, designed to automate and audit radiation oncology outcomes labeling across structured and unstructured clinical data. 29 Using a two-tier evaluation framework, the system first demonstrated 100% accuracy in structured demographic retrieval and 99.4% accuracy in treatment plan extraction (QA tier). It then generalized to complex outcomes labeling, identifying osteoradionecrosis (ORN) and cancer recurrence across prostate and head-and-neck cohorts (n = 895). After expert adjudication, accuracy improved to 95%–96%, with most discrepancies traced to errors in institutional registries rather than the model itself (63% ground-truth errors vs. 27% model errors). RadOnc-GPT autonomously executed function calls to retrieve EHR data, synthesize evidence, and output structured JSON summaries within 10–30 s per patient, enabling scalable, real-time registry curation. Its design—modular, transparent, and self-retrieving without traditional RAG—reduces hallucination and enhances auditability. The study concludes that LLM agents like RadOnc-GPT can serve as continuous, trustworthy clinical auditors, improving data integrity and operational efficiency in radiation oncology research and practice. Cui et al. introduces a transparent and modular RAG framework for automated, protocol-aware radiotherapy plan evaluation. 30 Built on the LLaMA-4 109B model, the system integrates structured dose-volume data, population-based percentile scoring, and a clinical constraint-checking tool. Using a curated dataset of 614 treatment plans across four disease sites, it employs a retrieval engine optimized through Gaussian Process tuning and a constraint module referencing protocol-defined dose limits. The best-performing configuration (all-MiniLM-L6-v2 backbone) achieved perfect nearest-neighbor accuracy within ± 5 percentile points and <2 MAE. End-to-end tests confirmed 100% agreement between LLM-generated summaries and independent module outputs, demonstrating both precision and reliability. By separating retrieval, constraint logic, and generation, this RAG-driven design minimizes hallucination, maintains traceability, and produces interpretable plan assessments. The work exemplifies how LLM-guided, tool-augmented reasoning can enhance scalability, safety, and explainability in radiation therapy plan evaluation.
Hung et al. developed a RAG-enhanced GPT-4 system for recommending head and neck cancer clinical trials based on patient cases. 31 In a prospective study of 178 cases, the RAG-augmented model achieved 100% recall in identifying the trial chosen by tumor board physicians, with a precision of 63% (versus 0% for GPT-4 without retrieval). This translated to narrowing ∼56 available trials down to a few relevant options per patient. While some irrelevant trials were suggested (lower precision), the system never missed an actual eligible trial (high recall), demonstrating RAG’s ability to keep LLM outputs up-to-date with real-time trial databases. Other work has similarly shown that RAG can enable LLMs to incorporate current clinical knowledge. For instance, Weinert and Rauschecker found that augmenting an LLM with a database of radiology literature significantly improved its score on radiology board-style questions (from 75.5% to 81.2% on GPT-4, p = 0.04) and allowed it to cite relevant journal articles in its answers. 32 Although that study was in radiology, it underscores how RAG can improve decision support accuracy in medical Q&A tasks by providing citable, evidence-based outputs.
RAG-based decision aids have been prototyped to retrieve oncology guidelines or publications in response to clinician queries. For example, Ozmen and Mathur discuss a “knowledge-enhanced” clinical decision support workflow where a surgeon’s query about an unusual cancer case triggers retrieval of relevant surgical guidelines and recent case reports, which the LLM then uses to formulate suggestions. 28 By querying curated databases (e.g., NCCN guidelines or PubMed), RAG models ensure that recommendations are evidence-based and transparently referenced, addressing key limitations of vanilla LLMs (which often give generic or hallucinated answers). Indeed, the integration of RAG was necessary to make general models like ChatGPT adhere to oncology expert recommendations; without retrieval, standard LLMs tend to deviate from guidelines or rely on outdated training data. 31
Clinical trial matching is as a high-leverage use case for RAG. Matching patients to trials is high-impact but labor-intensive. RAG can pull inclusion/exclusion snippets straight from protocols and compare them to structured chart fields (stage, biomarkers, prior therapy). Even when recall is prioritized (to avoid missing an eligible trial), transparent citations allow clinical trial coordinators to quickly dismiss false positives and focus on enrollment logistics.
Patient communication and education
RAG also shows promise in improving how complex oncologic information is communicated to patients. Oncology involves highly technical terminology that can be overwhelming for patients. RAG-powered LLMs can bridge the gap by retrieving authoritative definitions and explanations, then phrasing them in lay-friendly language. One illustrative prototype is the “Decoding Oncology Terminology” system by Wang et al., which fine-tuned an Large Language Model Meta AI, 7 billion parameters model to translate hematology/oncology terms into plain language. 33 When this model receives a medical term, it retrieves the official National Cancer Institute (NCI) Dictionary definition and relevant patient-oriented explanations (e.g., from NCCN patient guidelines), and then generates a simplified summary. In evaluations on a test set of cancer terms, the RAG-augmented model produced explanations with significantly improved readability (measured by standard readability scores) compared with baseline. Specifically, the patient-focused outputs were about 5% clearer by Flesch Reading Ease and had a modest reduction in required reading level (Dale-Chall score) – both improvements were statistically significant (p < 0.01). Qualitatively, the model could successfully translate dense medical paragraphs into patient-friendly language, a task that general models struggled with prior to RAG integration. Such a tool has obvious clinical impact: it can generate on-demand explanations of diagnoses, pathology reports, or treatment plans for patients, potentially improving understanding and easing anxiety. By grounding responses in trusted sources (NCI, NCCN), the system ensures accuracy while simplifying content.
Hao et al. evaluated RadOnc-GPT, a GPT-4o-based RAG system designed to generate responses to in-basket messages from prostate cancer patients. 7 Integrated with Epic and Aria electronic health record systems, RadOnc-GPT was tested on 158 in-basket message pairs from 90 patients treated at Mayo Clinic (2022–2024). Responses were assessed using NLP metrics and multi-clinician, single-blinded grading on completeness, correctness, clarity, and empathy. The model achieved comparable performance to clinicians in most domains and slightly surpassed them in empathy, while reducing average nurse and clinician response time by 5.2 and 2.4 min per message, respectively. Limitations included occasional lack of clinical context, domain-specific inaccuracies, hallucinations, and inability to perform meta-tasks like updating records. Overall, the study demonstrates that domain-adapted RAG frameworks can effectively augment oncology communication workflows, offering significant efficiency gains and maintaining human-level response quality when used with clinician oversight.
Additionally, RAG-enabled chatbots are being explored to answer patients’ questions with high factual accuracy. Because general LLMs sometimes confidently provide incorrect medical advice, researchers have tried coupling them with medical knowledge bases for safer patient-facing use. For instance, early studies in urologic oncology found that a GPT-based chatbot, when enhanced with retrieval of relevant patient education materials, could answer common patient questions with moderate to high quality and consistency across multiple cancer scenarios. 34,35 Furthermore, Hao et al presented MedEduChat, a closed-domain LLM agent integrated with Mayo Clinic’s EHR systems (Epic and Aria) to enhance prostate cancer patient education. 8 Using a retrieval-function-based approach rather than traditional RAG, MedEduChat accesses patient-specific clinical data—including treatment history, notes, and diagnostics—to generate context-aware, layperson-friendly explanations aligned with NCCN guidelines. In a mixed-method usability study involving 15 non-metastatic prostate cancer patients and three clinicians, MedEduChat achieved a high usability score (UMUX = 83.7/100) and significantly improved patients’ Health Confidence Scores (mean + 4.0, p < 0.05). Clinician evaluations rated its responses as highly correct (2.9/3), complete (2.7/3), safe (2.7/3), and moderately personalized (2.3/3). Qualitative findings highlighted patient “unlearning and relearning” of misconceptions and strong acceptance of MedEduChat as an educational companion, though challenges remained with incomplete EHR data, emotional sensitivity, and off-scope inquiries. The study demonstrates that EHR-integrated LLM agents can effectively augment patient education and engagement in oncology, bridging informational gaps while reducing clinician workload when deployed with safety oversight and human-in-the-loop validation.
RAG can also assist in creating informed consent documents and treatment summaries for patients. By pulling in details from clinical trial protocols or drug prescribing information, a RAG model could draft patient-specific consent forms that explain the trial’s purpose, risks, and benefits in simpler terms. 28,36 Though this application remains under development, rigorous evaluation of these tools with patient users (measuring understanding, trust, and health outcomes) will be critical.
Because RAG can retrieve clinical trial-specific language and patient-specific facts, it’s feasible to draft consent summaries tailored to a patient’s diagnosis, prior therapies, and likely procedures—while still embedding the Institutional Review Board-approved core text. Human review remains essential, but the heavy lift (finding and assembling the right clauses) can be automated.
Radiology and imaging augmentation
In oncologic imaging, RAG is being leveraged to help radiologists interpret images and generate reports with greater confidence and evidence. Radiology decisions (e.g., staging, differential diagnosis) often depend on integrating imaging findings with prior cases and reference criteria. RAG systems can retrieve similar prior cases, relevant journal articles, or clinical guidelines based on the content of a new radiology case, thereby augmenting the radiologist’s decision-making with instantly accessible knowledge.
A notable application is cancer staging from imaging. Tozuka et al. evaluated NotebookLM (a RAG-LLM) for lung cancer staging using CT cases. 37 These investigators provided the model with the official lung cancer staging guidelines (as the reference knowledge) and had it determine stage for 100 fictional cases. NotebookLM with RAG achieved 86% accuracy in staging the cases, dramatically outperforming a standard GPT-4 model, which managed only 25% accuracy without retrieval (and 39% even when given the same text within the prompt). The RAG model could pinpoint where in the guideline its answer came from, correctly identifying the reference section 95% of the time. This indicates that a RAG approach can not only improve accuracy in image-based decisions but also provide traceable justifications (e.g., citing the guideline criteria used), which is crucial in clinical practice.
Choi et al. implemented a custom RAG chatbot for Positron Emission Tomography/Computed Tomography imaging reports, backed by a database of more than 10 years of archived PET scan reports. 38 Given a new PET scan, the system can pull the closest matching prior cases and use them to suggest diagnoses or next steps. In a pilot study, experienced nuclear medicine physicians found that in 84.1% of PET cases, the system retrieved at least one relevant similar case that all reviewers agreed was useful. More importantly, when the RAG system’s suggested diagnosis was compared with one generated by the LLM without retrieval, the RAG version scored significantly higher for appropriateness as rated by physicians. The chatbot could also offer plausible differential diagnoses by leveraging the large case library, sometimes surfacing rare possibilities that a human might not recall immediately. RAG augmentation in radiology can improve diagnostic accuracy, provide decision support (staging, differential diagnosis) with just-in-time knowledge, and increase the transparency of AI-driven interpretations. Challenges remain (ensuring retrieved cases truly match the current patient, avoiding information overload, etc.), but these prototypes highlight a future where radiologists work hand-in-hand with RAG systems to leverage vast troves of imaging data and literature, ultimately improving diagnostic confidence and patient care.
Pathology and laboratory augmentation
Pathology, particularly in the subfield of digital pathology, is another domain where RAG is providing useful. Pathologists increasingly work with high-resolution digital slides and advanced image analysis tools, which produce a deluge of data. RAG-augmented LLMs can assist by answering pathology-specific questions, aiding in using computational tools, and summarizing pathology findings with reference to the literature.
A groundbreaking example comes from a collaboration between Dana-Farber Cancer Institute and Weill Cornell, where researchers customized ChatGPT for digital pathology questions using RAG. They created a secure instance called “GPT-4DFCI” and augmented it with a curated database of ∼650 recent digital pathology publications (∼10,000 pages). 39 In testing, GPT4DFCI was able to answer complex pathology queries (for example, about novel image analysis techniques or biomarkers in tissue samples) with greater detail and accuracy than the generic ChatGPT-4, and it provided source citations to the literature for every answer. This demonstrates that with well-curated knowledge, RAG can dramatically improve the reliability of LLM responses in specialized medical domains.
The same group developed a RAG-powered assistant for a pathology image analysis library (PathML). By integrating PathML’s documentation into an LLM via RAG, the assistant can answer “how-to” questions (e.g., “How do I segment tumor regions using PathML?”) and provide step-by-step coding guidance in plain English, effectively lowering the barrier for pathologists to utilize AI and image analysis in their workflow.
Precision oncology and molecular tumor boards
Precision oncology refers to tailoring treatment based on a patient’s molecular and genomic profile. Oncologists on molecular tumor boards (MTBs) must sift through vast literature on targeted therapies, genomic biomarkers, and clinical trials to identify personalized treatment options. RAG-augmented LLMs have emerged as promising aids to streamline this process, by automatically retrieving and integrating evidence for a given patient’s tumor mutations or biomarkers. Several systems have been developed including therapy recommendation engines, biomarker and indication database, and molecular tumor board assistance.
Lammert et al. introduced an LLM-based system called MEREDITH to support treatment recommendations for precision oncology. 40 Built on Google’s Gemini Pro LLM, MEREDITH uses RAG and chain-of-thought prompting to incorporate knowledge from oncology literature, clinical trials, drug approvals, and guidelines. In an evaluation on 10 fictional cases reviewed by a German MTB, MEREDITH (with RAG) suggested a broader range of therapy options than the experts alone (median of 4 options per case vs 2 from the MTB), notably identifying additional possibilities such as combination treatments or therapies supported by preclinical data. The MTB experts found these AI-suggested options relevant—there was 94.7% concordance between MEREDITH’s suggestions and the experts’ own recommendations for the refined system. The system’s ability to mimic the expert reasoning process (e.g., prioritizing contextually relevant targets) was attributed to incorporating the same evidence the experts would consult (clinical studies, guidelines, etc.).
Jun et al. developed a RAG-LLM pipeline that integrates the Molecular Oncology Almanac (MOAlmanac)—an expert-curated knowledge base of genomic biomarkers and U.S. Food and Drug Administration (FDA)-approved drug indications. 41 Their system takes a patient’s genomic profile (mutations, disease type, treatment history) and retrieves pertinent entries from MOAlmanac (both structured data and free-text) to inform the LLM. In an evaluation across 234 biomarker–therapy pairs spanning 37 cancer types, the RAG-augmented model achieved 94.0% accuracy in recommending the correct FDA-approved therapy, compared with only 65.8% accuracy by the base LLM without retrieval. Even using unstructured text (like FDA drug labels) for RAG yielded an improvement to ∼73% accuracy. This accuracy gain came without a runtime penalty—the best RAG model ran as fast as the baseline, illustrating that improved accuracy did not compromise efficiency. These results underscore that access to a structured precision oncology database via RAG dramatically boosts an LLM’s performance, closing the gap on known biomarker–drug indications.
Berman et al. evaluated a RAG-enhanced LLM for suggesting treatments in a real MTB setting. 14 Their system retrieved from PubMed literature in responding to MTB cases and was asked to provide treatment options with citations. The MTB clinicians then rated the AI outputs. The study found that 25% of the AI’s treatment recommendations were considered equivalent to the experts’ own recommendations, and an additional 37.5% were deemed plausible alternatives (though not the first choice). 75% of the references cited by the AI were confirmed to be valid (real PubMed articles correctly supporting the content), although 17% of references were hallucinated (fabricated) and others were mis-cited, highlighting a need for further improvement.
Limitations and Future Directions
Despite its potential, there are significant barriers to deploying RAG systems in real-world oncology practice. Many of these challenges stem from the complexity of both the AI technology and the clinical environment, including computational and operational burden, retrieval quality and errors, hallucinations and synthesis errors, knowledge-based limitations, integration and validation hurdles.
Implementing RAG at scale requires maintaining large, up-to-date knowledge corpora and fast retrieval pipelines. Vector databases must store thousands of documents (e.g., guidelines, publications) and enable real-time similarity search. This infrastructure can be computationally intensive and may introduce latency. Ensuring that retrieval remains efficient as knowledge bases grow is non-trivial, especially in a busy clinical setting where responses must be quick. Additionally, integrating RAG into existing clinical IT systems (EMRs, PACS for imaging, etc.) poses challenges of compatibility and performance. On-premises deployments (often needed for privacy) might lack the computational power of cloud-based systems, requiring careful optimization. On the model side, handling long contexts (e.g., multiple retrieved documents) can strain the LLM’s input limitations. Solutions like chunking and summarization help but add complexity. 42
Additionally, the cost of RAG workflows may be higher than zero-shot workflows, due to the increased cost of vector embeddings (and associated data retrieval and indexing) and tokenization. These costs will also scale linearly with modest increases in demand, such as computing 1000 queries rather than 300 queries. As workloads increase substantially (e.g., 1 million pages of data processed through a RAG system in a large healthcare system), additional factors like data retrieval latency, infrastructure limits, and computational bottlenecks can introduce nonlinear cost increases due to inefficiencies in resource utilization, such as infrastructure costs and parallel processing needs.
As the amount of information contained in vector databases increases for a given topic, it is possible that there can be misalignment or noise in the retrieved context that is used for prompt augmentation, potentially leading to a reduction in performance. 43 In larger datasets, there may be increased ambiguity in the retrieval of diverse but semantically similar database entries. The relevance scoring created by state-of-the-art vector search algorithms may prioritize content that ultimately is not directly relevant to the prompt. Retrieved information could also be conflicting. Filtering the retrieved data, prioritizing relevance to the question over the quantity of searches returned, or employing multiple strategies with an agentic AI approach could help ensure that context-augmentation enhances rather than hinders performance. As an example, retrieved chunks could be filtered using a predefined threshold on their similarity with the user query to determine when insufficient relevant information was retrieved. 44 Future search algorithms may benefit from combining vector distances with relevant concepts derived from the prompt.
While RAG significantly reduces unguided hallucinations, it does not eliminate them. RAG performance is tightly coupled to the quality of the underlying knowledge sources. 5 If minority populations or rare cancers are underrepresented in the literature corpus, the RAG system might consistently fail to retrieve relevant insights for those scenarios. The LLM might still fabricate connections between the retrieved facts or draw erroneous conclusions. If the retrieved documents contain conflicting information (e.g., two studies with differing conclusions), the LLM might produce a conflated or incorrect summary. Unlike structured question answering, RAG systems often operate in a generative mode that can introduce mistakes, such as incorrectly merging patient data with literature data. Common failure modes include (1) near-miss retrieval (snippets that look relevant but aren’t), (2) conflicting sources, and (3) fabricated or mis-matched citations when the generator over-generalizes. Mitigations that help in practice: strict citation checking (URLs/PMIDs must exist and support the claim), smaller, higher-quality corpora over high quantity, and agentic re-querying when evidence is thin. Rigorous evaluation is needed to catch such errors, and currently, many RAG prototypes have only been tested on limited case sets. 31 In addition, a fact-checking agent can be integrated within the RAG pipeline to verify outputs against structured sources, ensuring accuracy, truthfulness, and reproducibility. Another challenge is the presence of missing values in clinical variables, which can compromise downstream inference. To mitigate this, a deep denoising autoencoder (DAE)–based imputation framework has been proposed. 45 DAEs can learn low-dimensional latent representations of data and reconstruct clean samples from noisy or incomplete inputs, thereby improving data integrity and robustness of clinical factor extraction. Together, these safeguards will minimize error propagation, strengthen data reliability, and ensure that the RAG systems remain clinically trustworthy and suitable for integration into clinical workflows.
For clinical use, any AI (including RAG systems) must undergo thorough validation to ensure safety and efficacy. There is a gap in prospective clinical trials or real-world studies demonstrating improved patient outcomes or workflow efficiency. Without such evidence, adoption will be slow. Additionally, regulatory bodies (like the FDA) will likely treat a RAG clinical decision support tool as a medical device requiring approval if it provides treatment recommendations. Meeting regulatory requirements for transparency, risk assessment, and quality control is a challenge. RAG’s complexity (two models—retriever and generator—plus a dynamic database) makes it harder to validate than a static algorithm. Furthermore, ongoing clinical use of a RAG application may require a commitment to periodic evidence updates to keep pace with new research.
Even a highly accurate RAG tool could fail if it doesn’t mesh with clinical workflows. Oncologists and multidisciplinary teams have limited time; a RAG system must deliver value with minimal disruption. If the interface is cumbersome (e.g., requiring manual entry of patient data into a separate application) or if results are presented in an overwhelming or non-intuitive way (e.g., a dump of documents rather than a concise summary), clinicians may not adopt it. Designing the system to integrate seamlessly, perhaps summarizing findings within the electronic health record interface or tumor board software, will be important. Moreover, heavy reliance on such systems could potentially deskill trainees over time (if they always default to the AI for literature search), which is a subtle but real concern in the community.
Finally, RAG approaches represent just one step in a broader series of innovations needed to enhance performance in healthcare. For example, they may become a crucial component of agentic AI workflows that operate with greater autonomy and potentially split and redirect inputs and RAG contexts to specialist models. As we continue to explore the possibilities of RAG and similar methodologies, we anticipate further breakthroughs that will solidify the role of AI in advancing medical science.
Ethical and Regulatory Considerations
Implementing RAG-based solutions in medical environments requires stringent safeguards to meet privacy regulations (e.g., Health Insurance Portability and Accountability Act, General Data Protection Regulation) and to ensure patient data are adequately protected. 46 A practical mitigation is to confine all patient data and retrieval operations to secure on-premises servers under hospital control, which avoids transmitting protected health information to external platforms, which would help meet privacy obligations and maintain patient confidentiality. 18 Equally important is transparency about the system’s limitations. Clear communication of a model’s uncertainties and potential errors (e.g., hallucinations or incomplete literature retrieval) is crucial so that clinicians and patients remain aware of its fallibility. To further enhance trust, future oncology RAG deployments are envisioned to provide not only answers but also evidence-backed explanations with source citations, allowing users to trace the rationale behind recommendations. Providing interpretable reasoning and references meets emerging transparency requirements and bolsters end-user confidence in the AI’s outputs. Lastly, robust algorithmic accountability frameworks are needed. In high-stakes domains such as cancer care, it must be clear who is responsible if an AI-generated suggestion contributes to an adverse outcome.
Footnotes
Author Disclosure Statement
No competing financial interests exist.
Funding Information
W.L. was partially supported by NIH/NIBIB R01EB293388, by NIH/NCI R01CA280134, by the Eric & Wendy Schmidt Fund for AI Research & Innovation, and by the Kemper Marley Foundation.