
Abstract
We have developed a method for extracting the number of trial participants from abstracts describing randomized controlled trials (RCTs); the number of trial participants may be an indication of the reliability of the trial. The method depends on statistical natural language processing. The number of interest was determined by a binary supervised classification based on a support vector machine algorithm. The method was trialled on 223 abstracts in which the number of trial participants was identified manually to act as a gold standard. Automatic extraction resulted in 2 false-positive and 19 false-negative classifications. The algorithm was capable of extracting the number of trial participants with an accuracy of 97% and an F-measure of 0.84. The algorithm may improve the selection of relevant articles in regard to question-answering, and hence may assist in decision-making.
Introduction
The quantity of information available in the clinical literature is doubling every five years. 1 Physicians need to seek the newest and most relevant information to provide the best possible patient care. 2 This information is found predominantly in the research literature in the form of free text. 3 Usually, physicians locate information via keyword-based searches such as PubMed. 2,4 Studies show that these searches can help to answer questions, 5–7 but the large volume of published information is now causing overload, 4 making searching and question-answering increasingly unmanageable. 3 Automated information extraction methods may help physicians to locate the answers to clinical questions 8 and reduce the time spent on information search. 3
Randomized controlled trials (RCTs) are often used as primary sources of evidence because they provide the most reliable evidence about interventions for any given condition. 9 In evidence-based medicine (EBM), a specialized framework called PICO is used to facilitate the literature search. PICO is short for Patient/Problem, Intervention, Comparison and Outcome. 10 Physicians who practise EBM can formulate questions in a PICO format in order to help them match the relevant answers in the research literature. 11 Other researchers have furthered this by developing automated text mining methods to extract PICO elements from the literature using computer programs. 4,12 However, the PICO framework only provides a model for question-answering and not a method of extracting the information. 4
Automated information extraction can be performed by using natural language processing (NLP) techniques 8 which perform a deeper analysis of the text than simple keyword-based searches. NLP depends on linguistic knowledge, e.g. part of speech (POS), syntax, semantics and text structure. 13
We have developed a method for extracting the number of trial participants from abstracts describing RCTs. The number of trial participants may be an indication of the reliability of the trial. 4 The extraction is performed on abstracts of RCTs and not on full text articles, as the abstracts are freely available.
Related work
Extracting and classifying information regarding the participants in medical abstracts has been attempted in two recent studies. 4,12 The approach developed by Demner-Fushman and Lin 12 extracted the number of trial participants based on manually crafted pattern-matching rules. The rules used biomedical concepts and relations labelled by MetaMap 14 and SemRep, 15 both based on understanding of the domain codified in the Unified Medical Language System (UMLS). 16 The extraction of the number of trial participants obtained an accuracy of 80%. The authors pointed out that some of the errors were due to POS-tagging and chunking. As performance of the Demner-Fushman and Lin algorithm (F-measure) was not reported, their algorithm was applied to the data-set of the present study, where the F-measure was calculated to be 0.85.
The most recent approach was developed by Xu et al. where both the number of trial participants and other subject descriptors such as diseases and symptoms were extracted. The method was based on text classification augmented with a hidden Markov model on POS-tagged sentences to identify sentences containing information about the participants. Subsequently, these sentences were parsed using NLP techniques to extract relevant information, which resulted in an accuracy of 93%. The errors were primarily a result of POS-tagging and chunking errors as in the Demner-Fushman and Lin approach, as the applied parser was not trained in the medical field.
Methods
Because the number of participants usually falls during the progress of the study, an abstract may contain several different numbers. A typical scenario is shown in Figure 1. A group of participants is enrolled in the study and then some are excluded or rendered ineligible through specific criteria. The participants are allocated to one or more arms of the study in which they are treated with one or more interventions. In many cases the number of participants that are evaluable at the end of the study will be a subset of those who were allocated. 17
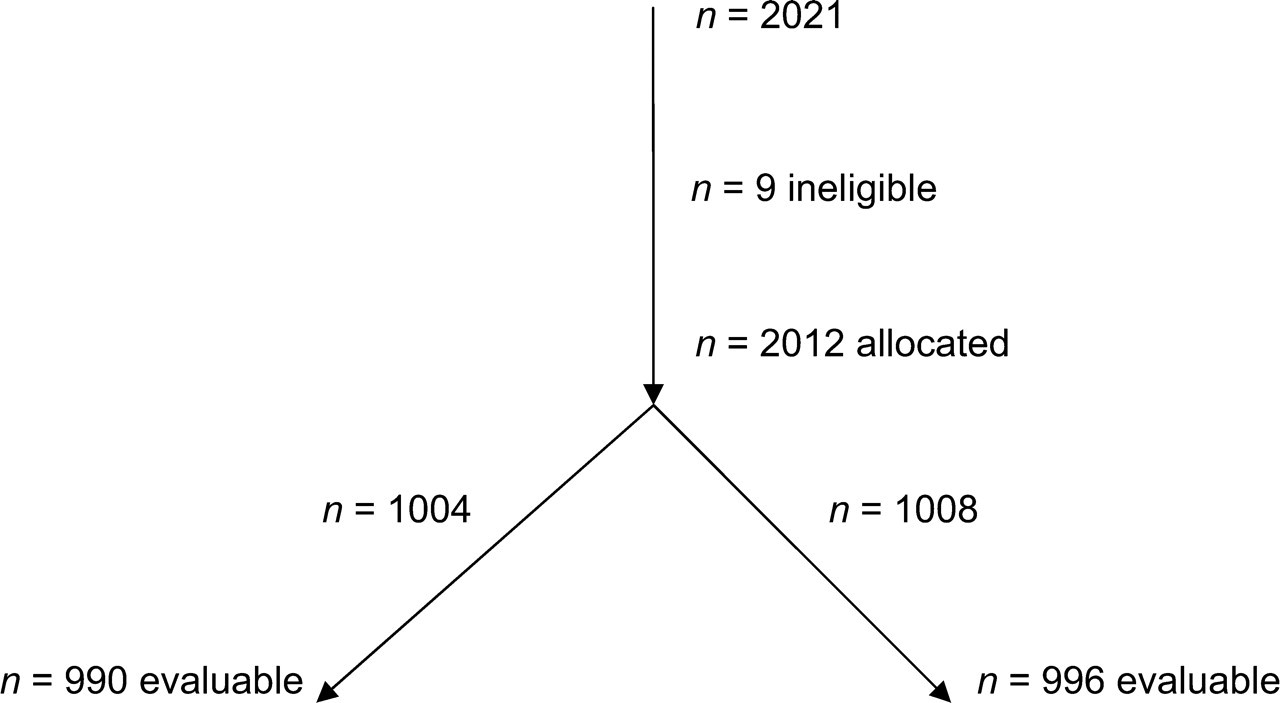
Participant flow diagram in a typical study, where n = 2021 equals the number of trial participants
Our approach focused on extracting the total number of trial participants, defined as the original number of participants in the study before any exclusions or allocations to different arms. Thus only one number can describe the number of trial participants in each abstract. According to this definition, the number to be extracted corresponds to the value 2021 in Figure 1.
We determined the number of trial participants from abstracts of RCTs using a binary classifier to assign an integer to one of two classes; the positive class for the numbers of trial participants or the negative class representing all other candidate numbers.
Data
Abstracts were obtained from a previous study 9 in which a search in PubMed was conducted using the keywords asthma, diabetes, breast cancer, prostate cancer, erectile dysfunction, heart failure, cardiovascular and angina. This resulted in over 7300 abstracts from which 455 were randomly selected. Non-RCT studies were manually discarded and the RCT subset containing only pharmaceutical interventions was used, leaving a total of 223 abstracts. For each abstract, the number of trial participants was identified manually. This acted as the reference or gold standard.
The sample of 223 abstracts was randomly divided into a training set with 148 abstracts and a test set with 75 abstracts.
The method for automatic extraction of the number of trial participants can be divided into four steps: (1) pre-processing; (2) feature selection/extraction; (3) classification; (4) post-processing (Figure 2).

An overview of the method for extracting the number of trial participants divided into four steps: (1) pre-processing; (2) feature selection and extraction; (3) classification; and (4) post-processing
Pre-processing
The first step prepared the raw abstracts for the feature extraction. This included labelling each sentence with a reference to a topic or discourse label based on the subheading given in the abstract if it was structured. There were 142 structured abstracts and 81 unstructured abstracts in the data-set. If the abstract was structured, sentences were manually labelled to one of the following: Aim, Participants, Method, Results and Conclusion. Otherwise, if it was unstructured, sentences were labelled as Unlabeled.
All alphanumeric numbers were converted into numeric numbers, as a consistent representation of all numbers made the comparison easier. To ease unnecessary processing, sentences not containing an integer were disregarded for further processing. To extract POS information, we used a shallow parser optimized for biomedical data (Genia Tagger 18 ).
Feature selection and extraction
After the pre-processing the modified abstracts were transformed into data that could be used for classification. This was done by selecting features followed by the extraction of the feature vectors. The features were chosen based on an analysis of how the numbers of trial participants appeared in abstracts of RCTs. This resulted in a set of 14 different types of features which can be seen in Table 1. Altogether there were 94 features.
Feature templates used for classification and their representation. The centre of attention is either the integer Ii or the word Wi. The • symbol indicates features that formed the basis for evaluation of the additional applied features
A feature was only extracted if the number was an integer, and not followed by a unit defined in a closed set of words. There was one feature vector per candidate number. The features ‘patientGroup’, ‘patientWindow’, and ‘verbInSentence’ all involved use of a predefined closed set of words. To identify participant-related words, a list was created containing words such as: patient, participants, woman and man. In addition, a closed set of verbs was created, which included verbs that often appear in sentences containing the number of trial participants, such as: allocate, enrol and assign.
After transforming the data into feature vectors, the information was reduced to sparse data for the purpose of saving memory, where the non-zero entries in the feature vector were stored instead of storing all entries.
Classification
The choice of supervised classifier was based on an evaluation of three different algorithms: linear support vector machine (SVM), Naive Bayes and K-nearest Neighbour. The evaluation conducted on the features indicated with a • symbol in Table 1, resulted in the linear SVM being chosen as it outperformed both the Naive Bayes and the K-nearest Neighbour algorithm. SVMs have been used successfully in other text classification tasks. 19–21 Linear kernels have outperformed non-linear ones in the past. 22 We used Weka 23 for our experiments.
The input to the SVM algorithm was based on a set of feature vectors. Fifty-six (marked with a • in Table 1) out of 94 features formed the basis for evaluating additional features. Thirty-eight more features were added to the feature set after being tested on the training data. Only features which contributed to an increased F-measure were applied to the algorithm. The algorithm was trained using the ground truth reference with manually identified numbers of trial participants. Afterwards this model was applied to the training set to classify the candidate numbers into one of the two classes.
Post-processing
To reduce the number of false-positive predictions, we selected only one number per abstract to be labelled. This number was chosen as the one with the maximum value among all the numbers tagged in an abstract.
Performance
The performance of the classifier was evaluated using the following metrics: precision, recall, F-measure. These measures were given by:
The accuracy of the extraction was determined. The accuracy was defined as the percentage of correctly classified candidate numbers.
For comparison a simple rule-based baseline extractor was created, which returned the largest integer in the abstract that met the following criteria:
larger than 10; not followed by a unit, where the units were defined in a closed set of words; followed by a participants-related noun with the pattern: [Integer] [Adjective]* [Participants Noun], where the participants-related nouns were defined in a closed set of words.
Results
The SVM algorithm outperformed the baseline system in terms of accuracy as well as F-measure (Table 2).
Evaluation of the extracted number of trial participants compared to the baseline system
The results of evaluating the number of trial participants in regards to the actual class and the predicted class are shown in Table 3. The extraction resulted in two false-positive and 19 false-negative classifications.
Results of the extraction in regard to the actual and predicted value. Class 1 is the number of trial participants and Class 2 is all other candidate numbers
Discussion
We have proposed a method for extracting the number of trial participants in abstracts describing RCTs. The selection of articles was based on keyword search, publication type and topic. There were no further restrictions to the data, such as publication date or the fact that there should be a number of trial participants present in the abstract. If the extraction included the entire PICO framework, an abstract could still be relevant even though the number of trial participants was missing.
The training set and test set both concerned pharmaceutical interventions. It could be argued that the data-set should have been extended to include topics other than pharmaceutical interventions to make the data less similar.
Algorithm
The SVM algorithm was chosen as supervised classifier. It has been well argued in the literature that the SVM is capable of handling unbalanced classes. 21 This was a major advantage in our approach as the class with numbers of trial participants was considerably smaller than the remaining candidate numbers. The algorithm discarded integers which were followed by a unit (e.g. ‘200 mg’), but it did not account for a series of integers appearing in coordination (e.g. ‘50, 100, and 200 mg’).
The patientGroup feature did not capture more complex noun phrases such as ‘42 Type 2 diabetic patients’, as ‘Type 2’ is not an adjective in the grammatical sense, but in the medical field disorder-related words are often used as adjectives. To identify such numbers of trial participants properly, these disorder-related words would need to be clarified and involved in the feature set.
Performance
The performance of the algorithm was compared to a simple rule-based baseline system. This showed that the SVM algorithm outperformed the baseline system. The major drawback of the baseline system was the number of times it missed the number of trial participants, because no candidate number in the abstract met the three criteria it employed.
A test of the algorithm showed that 21 candidate numbers were misclassified: two false positives and 19 false negatives. The false positives occurred when abstracts did not have the number of trial participants present, resulting in a participant number in one of the arms being chosen instead. This does not represent a serious problem.
Our chosen task was to label only those population numbers that refer to the total number, and all others were considered as part of the negative class. This gave rise to a number of errors particularly when there was some variation in the study design. Often the total population number was confusable with the population number for each arm, or if multiple population numbers were mentioned for subgroups analysed in an RCT or parallel groups used in a study. On three occasions the instance ‘n = [number]’ led to confusability because it sometimes referred to the participants in each arm of the study, and sometimes to the number of trial participants. False-negative classification errors occurred when two actual numbers of trial participants were present in the same abstract, but because of the post-processing only the largest candidate number was predicted as the number of trial participants, even though the predictions were correct before the post-processing.
Some errors were introduced by chunking errors made in the Genia Tagger. The accuracy of the Genia Tagger is reported as 97%. 18 After analysing the classification errors in the test data, some of the chunking errors were rectified by rule-based text pre-processing prior to processing via the Genia Tagger resulting in a better performance of the algorithm. The accuracy and F-measure were 97.0% and 0.84, respectively, before the correction, and improved to 97.5% and 0.86 afterwards.
The algorithm presented by Demner-Fushman and Lin 12 was run on our data-set and resulted in a similar F-measure of 0.85.
Future work
The P in the PICO framework includes both the problem and the participants. Extracting the problem would require other methods, for example including the UMLS, which utilize access to different semantic types such as [disorder], [symptom], [gender] and [age]. By extracting the entire P, it would be possible to select the abstracts relevant to the characteristics of the participants specified in the question asked by the physician. Meanwhile, the number of trial participants is not unambiguous. As mentioned earlier an RCT can include several numbers of trial participants. If it was possible to classify all the numbers in a trial, a multi-classification should be performed instead. However, the number of trial participants is a good indicator of the reliability of the article, where classification of the remaining participants will only contribute to a more specific description.
Conclusion
An algorithm for extracting the number of trial participants was developed using an SVM classifier. The preliminary results obtained with the algorithm were promising. A high performance was obtained, where candidate numbers in RCT abstracts were correctly classified in 97.5% of the cases into either the positive class containing the number of trial participants, or the class with all other numbers. Evaluation of the results showed that the algorithm outperformed a baseline algorithm in F-measure. This suggests that the algorithm may be used to improve the selection of relevant articles in regard to question-answering, and hence may assist in decision-making.
Footnotes
Acknowledgements
We thank Dina Demner-Fushman for running their algorithm on our data.