
Abstract
We have undertaken a series of simulations to assess the effectiveness of commercially available sets of STR loci, including the loci recommended for inclusion in the expanded European Standard Set, for the purpose of human identification. A total of 9200 genotype simulations were performed using DNA · VIEW. The software was used to calculate likelihood ratios (LRs) for 23 groups of relatives, and to determine the probability of identification given scenarios that ranged between 10 and 250,000 victims. The additional loci included in the recommended expanded European Standard Set, when used in conjunction with the Identifiler® kit, significantly improved the typical LRs for tested scenarios and the likely success of providing correct identifications.
Introduction
With the availability of commercial STR kits that allow the typing of multiple loci, the use of DNA analysis has become a powerful tool for the identification of victims of natural disasters, man-made disasters and conflict. 1–4 Currently, kinship testing laboratories typically use two commercially available kits, Promega's PowerPlex® 16 5 (Promega, Madison, WI, USA) and Applied Biosystems’ (Applied Biosystems, Carlsbad, CA, USA) AmpFℓSTR® Identifiler®, 6 both of which amplify 15 STR loci.
Fifteen STR loci comprise a powerful battery both for parentage testing and for the identification of human remains. 7–11 However, there are circumstances when it is desirable to type more loci, such as standard parentage testing when there has been a mutation, kinship tests where direct relatives (i.e. parents/children) are not available for testing and in victim identification cases where in addition to the need to test complex relationships there is a large number of victim-relative comparisons to be made. 7,9,12,13
The identification of human remains becomes more complex as the number of victims increases, in particular from open systems such as natural disasters and conflicts. In order to limit the possibility of false identifications it is necessary to apply thresholds to ensure that the strength of the evidence is sufficient. This can be done by applying appropriate prior probabilities, which are normally directly related to the number of victims, so if there are 100 victims the prior probability of a given body being a specified victim is 1/100 or 0.01. As the number of victims increases the posterior probability of obtaining a correct identification decreases unless higher likelihood ratios (LRs) can be obtained. Moreover, in large-scale identification programmes it is desirable to set a threshold for the identification programme as a whole, 9,11 for example, with the identification of victims of the World Trade Center, a target LR for each identification was set at 10 billion, which provided a 99% chance of making no errors in 10,000 identifications. 12
In order to meet the challenges presented by testing for complex relationships, laboratories are now able to increase their battery of tests by, for example: using both the PowerPlex® 16 and Identifiler®, which provide a total of 17 loci; by using the FFFL kit (Promega) that types an additional four loci (LPL, F13A1, FESFPS, F13B); by using other commercial kits that incorporate additional loci, such as the AmpFℓSTR® SEfiler™ (Applied Biosystems) and PowerPlex ES system (Promega), which both incorporate the highly polymorphic SE33 locus; and by using their own primer sets for individual loci or multiplexes. 14
In 2008, the European Network of Forensic Science Institutes recommended expanding the current European Standard Set of STR (ESS) loci to include D10S1248, D22S1045, D2S441, D1S1656 and D12S391 15 (from here on referred to as e-ESS) – these have now become available in several commercial kits. While these loci were selected to improve the effectiveness of data sharing between national DNA databases in Europe, they also make a welcome addition to the STR loci that are readily available for kinship testing.
In this paper, using DNA · VIEW's simulation function, 16,17 we describe the effectiveness of the Identifiler® loci with and without the addition of the additional e-ESS loci and the FFFL loci, to provide sufficiently powerful matches for the identification of human remains. Identifiler® was also compared with PowerPlex® 16. In total, 23 different sets of relatives have been tested, including those recommended by the International Society for Forensic Genetics. 11
Materials and methods
Population databases
An allele reference database was constructed based on US Caucasian data. The database included frequency data for all loci in the Identifiler® loci 18 ; Penta D and Penta E 19 ; the e-ESS for D12S391, D1S1656, D10S1248, D22S1045, D2S441 20 ; and FFFL (data for LPL, F13A1, FESFPS, F13B). 19 The database was imported to DNA · VIEW as described in the user's manual. 17
LR calculations
LR calculations were performed in DNA · VIEW version 29.13 using the Automatic Kinship feature of DNA · VIEW, as described in the DNA · VIEW manual.
16,17
The relationship scenario to be tested was entered as a series of statements defining relationships. Individuals for whom genotypes were available were represented by a single-letter ‘role code’. All un-typed individuals were represented by a name. The LR was calculated by entering a primary and alternative hypothesis; e.g. victim V is the child of M and F, versus another unidentified person is the child of M and F. This would be entered into DNA · VIEW as: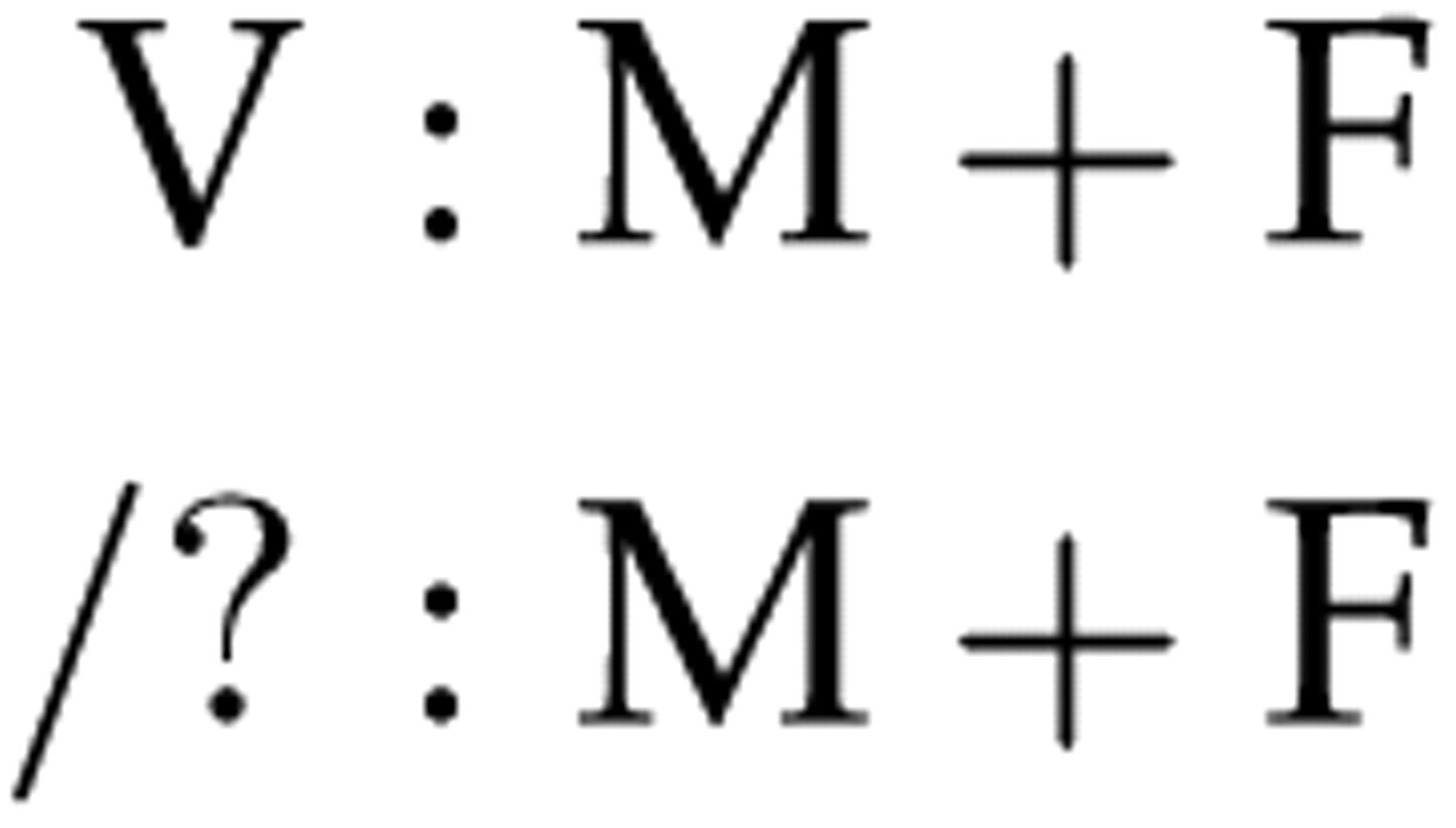
A total of 9200 simulations were carried out for 23 relationship scenarios, using four different STR panels: PowerPlex® 16, Identifiler®, Identifiler® + FFFL and Identifiler® + e-ESS loci. DNA · VIEW was set to perform 100 simulations per scenario. The programme simulated genotypes for any individuals who were defined by a one-letter role code. The LR was then automatically calculated. A ‘Typical LR’ was reported, based on the results of 100 simulations. Individual LR data for each simulation were accessed by returning to the basic menu, selecting ‘Freeze the current simulated types and exit simulation’ and ‘Show (log) report’. The DNA · VIEW report displayed individual LRs within a string of text; a basic Excel tool was created to extract LRs from the reports. Analysis of these data provided a list of the 100 individual LRs for each simulation exercise.
Calculating posterior probabilities
The posterior probability of identification was calculated from raw LR data, using the following formula:
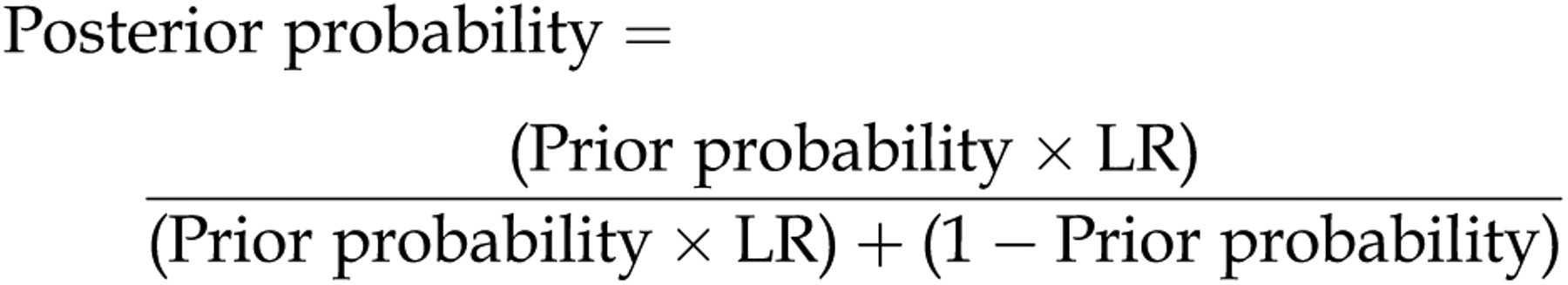
Calculating minimum LRs
The minimum LR required to achieve a target posterior probability for all the identifications being correct was calculated using the following formula (adapted from Brenner and Weir [2003]
9
):

Calculation of typical LRs for macro-generated data
Typical LRs were calculated for each scenario by taking the mean of the log values of individual LRs. The antilog of the mean was the ‘typical LR’.
Statistical analysis in R
All statistical analyses were performed using the freely available package ‘R’ version 2.11.1. 21 All data frames were generated in Microsoft® Excel.
Results
The simulation feature of DNA · VIEW was used to assess the usefulness of testing different relatives, or sets of relatives, for victim identification. 16,17 This was achieved by comparing typical LRs for each scenario. Genotypes were simulated using four different panels of STRs to assess the effect of which and how many loci were tested.
DNA · VIEW simulations
Typical likelihood ratios (LRs) for 23 relationship sets using different STRs
Usefulness of testing different relatives
The results, as expected, show that in general the more relatives that are tested, the higher the LR that can be obtained. Naturally, close relatives such as a parent or child give a higher LR than more distant relatives such as a sibling or grandparent. It was noted that the order of ‘usefulness’ of each set of relatives was different for each STR panel tested. Some of the results are also anomalous, e.g. Identifiler® data gave a higher typical LR for a spouse and two children than for a parent, spouse and two children. These anomalies illustrate that 100 simulations are not sufficient to give an accurate prediction of the typical LR in all simulations. The individual LR data tend to be distributed over a large range, as shown in Figure 1, and results at the extreme end may skew the data. However, the data provide a very useful overview regarding which relatives are most beneficial to test and the range of values that would be expected.
Boxplot comparing the typical likelihood ratios (LRs) of 23 relationship scenarios. The groups of relatives labelled A–W in the box plot are ordered as in Table 1. The plot is based on the data from (a) Identifiler® simulations; (b) Identifiler® plus e-ESS loci simulations. The groups of relatives recommended by International Society for Forensic Genetics are circled. These are: one parent and sibling (J); children and spouse (I = 1 child, U = 2 children); one parent, spouse and children (Q = 1 child, W = 2 children); and two parents (V)
Significance of using different STR systems
The effect of using different sets of STR loci on individual sets of relatives was assessed using raw LR data. Six relationship scenarios were selected that typically gave particularly low LRs (1 sibling, 3 grandparents, 1 child and 1 parent) or high LRs (1 parent and 2 children and 2 parents). The analysis was carried out to test whether the expected LRs may be improved by using one combination of loci in preference to another; the results for each scenario are shown in Figure 2. Analysis of variance followed by a Tukey's Honestly significant differences test for all six tested scenarios showed that there were significant differences between the STR loci tested (P < 0.00138) (Table 2).
Effect of using different STR systems on LR for selected relationship scenarios. The plots are based on individual LR results from 100 DNA · VIEW simulations for each test Pairwise comparison of STR multiplexes for six relationship scenarios The asterisks indicate pairs of STR multiplexes that produced significantly different LR (P < 0.00138). Log LR data from 100 DNA · VIEW simulations were used for each relationship scenario
Effectiveness of different STR systems to achieve target posterior probabilities
The LRs shown in Figure 1 and Table 1 provide an indication of the strength of evidence likely with different combinations of relatives. However, prior probabilities have to be considered when dealing with multiple victims. In order to assess the impact of multiple victims, in this study we have assessed five different scenarios with a range of between 10 and 250,000 victims. The prior probability has been calculated by assuming that each set of human remains was equally as likely to be any given one of the victims, therefore the prior probabilities are: 0.1 (10 victims); 0.004 (250 victims); 0.0004 (2500 victims); 0.00001 (100,000 victims); and 0.000004 (250,000 victims).
Minimum LRs required to achieve a set statistical threshold
The statistical threshold is the minimum posterior probability of correct identification of all the victims
Percentage of simulated cases resulting in identification using (a) Identifiler® genotypes and (b) Identifiler® + recommended expanded-ESS
The success rates are based on the percentage of DNA · VIEW simulations that, with different prior probabilities, met the required LR to obtain a posterior probability of 99.9%
Discussion/conclusions
Under ideal circumstances comparisons would be made between human remains and direct reference samples, which provide extremely high LRs. However, this approach is often hampered by the lack of antemortem DNA records (or cellular material that can be used to generate a DNA profile) and the only option is to use the DNA profiles of relatives for comparison. The simulation exercise has provided a typical LR for 23 combinations of relatives and, equally importantly, provided a range of values that would be expected to be encountered in casework. The data presented are based on Caucasian data, and the values presented would change with different allele reference databases. The only data available for comparison are based on Identifiler® loci with a Hispanic database; the values for comparable relationships are all very similar (values are within 0.1% of each other).
The different STR systems performed as expected in relation to each other. PowerPlex® 16, in most cases, outperformed Identifiler®. This is also seen when comparing typical paternity indices, and can be attributed to the Penta D and Penta E loci being more polymorphic than D2S1338 and D19S433 that are found in the Identifiler®. The FFFL loci did improve the LRs, but the e-ESS loci had a greater impact, partially because it comprised an extra five loci, as compared with the four loci in the FFFL, but also because the loci are more polymorphic. 14,19 In real casework the e-ESS loci will be a significant improvement over the FFFL loci as they have been selected in part to work with small PCR amplicons, and therefore are predicted to have a higher success rate with degraded DNA; this has already been demonstrated in multilab trials with DNA recovered from crime scenes. 15
The simulation function in DNA · VIEW provides a valuable tool to estimate the usefulness of different sets of relatives, and has already been used to provide guidelines to the forensic community. 8,11 In reality, when carrying out casework involving the identification of mass fatalities there may well be several confounding factors that are experienced that are not seen in computer-based simulations, for example: complications over which allele frequency database to use when there are victims of different geographical origins among the dead 7,13 ; ascertaining the correct biological relationship of individuals who are providing reference samples, the obvious example being samples from fathers who are not the actual biological father; the presence of multiple relatives among the victims, the likelihoods provided are based on the alternate hypothesis being that they are unrelated; and the profiles in the simulation are all complete, whereas in casework the degradation of DNA is a problem, with partial profiles often resulting, which will impact on the potential LR that can be obtained. Notwithstanding, the data presented provides a useful reference for organizations that are executing or planning identification programmes with a DNA component, illustrating what can potentially be achieved using different combinations of reference profiles in different scenarios. The simulations shown here illustrate the value of using the recommended expanded ESS loci, in addition to STR markers that are already in routine use.