
Abstract
Multidimensional scaling (MDS) is a widely used technique for mapping data from a high-dimensional to a lower-dimensional space and for visualizing data. Recently, a new method, known as Geometric MDS, has been developed to minimize the MDS stress function by an iterative procedure, where coordinates of a particular point of the projected space are moved to the new position defined analytically. Such a change in position is easily interpreted geometrically. Moreover, the coordinates of points of the projected space may be recalculated simultaneously, i.e. in parallel, independently of each other. This paper has several objectives. Two implementations of Geometric MDS are suggested and analysed experimentally. The parallel implementation of Geometric MDS is developed for multithreaded multi-core processors. The sequential implementation is optimized for computational speed, enabling it to solve large data problems. It is compared with the SMACOF version of MDS. Python codes for both Geometric MDS and SMACOF are presented to highlight the differences between the two implementations. The comparison was carried out on several aspects: the comparative performance of Geometric MDS and SMACOF depending on the projection dimension, data size and computation time. Geometric MDS usually finds lower stress when the dimensionality of the projected space is smaller.
Keywords
Introduction
Every day we receive an enormous amount of data, information, and knowledge. Data becomes information when it is contextualised and related to a specific problem or solution. Data mining is an important part of knowledge discovery processes in various fields and sectors, such as medicine, economics, finance, telecommunications. Data mining helps uncover hidden information from vast amounts of data, which is valuable for recognising important facts, relationships, trends, and patterns. As data sets become increasingly large, more efficient ways of visualizing, analysing and interpreting the information they contain are needed. Comprehension of data is challenging, especially when the data relates to a complex object, a phenomenon that is described by many parameters, attributes, or features. Such data are called multidimensional, and the main goal is to make some visual insight into the data set being analysed. Visual information can be perceived much faster than textual information. For human perception, the multidimensional data must be represented in a low-dimensional space, usually two or three dimensions.
The main task in dimensionality reduction is to represent objects with a smaller set of more “compressed” features. Another reason for reducing the dimensionality or visualization of the data is to reduce the computational load for further data processing. Dimensionality reduction techniques enable the extraction of meaningful information hidden in the data. In addition, one of the most important purposes of data visualization is to get an idea of how close or far away certain points of the analysed multidimensional data are from each other.
Consider the multidimensional data set as an array
Dimensionality reduction or data visualization techniques play an important role in machine learning (Murphy, 2022; Zhou, 2021; Ray et al., 2021; Dzemyda et al., 2013; Dos Santos and Brodlie, 2004; Buja et al., 2008). Such visualization is useful, especially in exploratory analysis: they provide insights into similarity relationships in high-dimensional data that would be unlikely to be obtained without visualization (Lee and Verleysen, 2007; Van Der Maaten et al., 2009; Markeviciute et al., 2022; Xu et al., 2019; Bernatavičienė et al., 2007; Kurasova and Molyte, 2011; Borg and Groenen, 2005; Dzemyda and Kurasova, 2006; Dzemyda et al., 2013; Jolliffe, 2002; Karbauskaitė and Dzemyda, 2015, 2016; Groenen et al., 1995). The classical dimensionality reduction methods for data visualization include linear principal component analysis (PCA) (Jolliffe, 2002; Jackson, 1991) and multidimensional scaling (MDS) (Torgerson, 1958; Borg and Groenen, 2005; Borg et al., 2018). PCA seeks to reduce the dimensionality of the data by finding orthogonal linear combinations (principal components) of the original variables with the highest variance (Jackson, 1991; Medvedev et al., 2011). The interpretation of principal components can sometimes be complex. PCA cannot cover non-linear structures consisting of arbitrarily shaped clusters or manifolds because it describes the data in terms of a linear subspace. Since global methods such as PCA and MDS cannot represent the local non-linear structure, there have been developed methods that preserve the raw local distances, i.e. the values of distances between nearest neighbours. Isomap, Local Linear Embedding (LLE), Hessian Local Linear Embedding and Laplacian Eigenmaps are traditional methods that attempt to preserve local Euclidean distances from the original space (Wang et al., 2021; Espadoto et al., 2021). More recent methods that focus on local structure preservation are t-Distributed Stochastic Neighbour Embedding (t-SNE) (Van der Maaten and Hinton, 2008) and UMAP (McInnes et al., 2018). A comprehensive review of dimensionality reduction methods is presented in Murphy (2022), Espadoto et al. (2021), Wang et al. (2021), Vachharajani and Pandya (2022), Dzemyda et al. (2013), Lee and Verleysen (2007), Van Der Maaten et al. (2009), Xu et al. (2019).
Artificial neural networks can also be applied to reduce dimensionality and visualize data (Dzemyda et al., 2007). A feedforward neural network is used for a topographic, structure-preserving, dimension-reducing transformation of data, with the additional ability to incorporate various degrees of related subjective information. There is also a neural network architecture developed specifically for topographic mapping, known as a Self-Organizing Map (SOM) (Kohonen, 2001; Stefanovic and Kurasova, 2011), which uses implicit lateral connections in the output layer of neurons. SOM is a technique used for both clustering and data dimensionality reduction (Dzemyda et al., 2007, 2013). In addition, there is a special learning rule, similar to backpropagation, which allows an ordinary feedforward artificial neural network to learn the Sammon mapping, which is a special case of metric MDS, in an unsupervised way. The learning rule for this type of neural network is known as SAMANN (Mao and Jain, 1995; Ivanikovas et al., 2007; Medvedev et al., 2011; Dzemyda et al., 2007).
An alternative view of dimensionality reduction is offered by multidimensional scaling (Borg and Groenen, 2005). Multidimensional scaling (MDS) is a classical non-linear approach that maps an original high-dimensional data set onto a lower-dimensional data set, but does so in an attempt to preserve the proximities between the corresponding data points. It is one of the most popular methods for multidimensional data visualization (Murphy, 2022; Borg et al., 2018; Dzemyda et al., 2013). Despite the fact that MDS demonstrates great versatility, it is computationally demanding. This can be challenging when the data amount increases. Traditional MDS approaches are limited when analysing very large data sets, as they require long computational time and large amounts of memory. Until now, there have been various studies aimed at creating a new solution or modifying the MDS to analyse large amounts of data and speed up the visualization process (Orts et al., 2019; Qiu and Bae, 2012; Pawliczek et al., 2014; Ingram et al., 2008; Medvedev et al., 2011; Ivanikovas et al., 2007).
The input data for MDS is a symmetric
One of the most popular algorithms for MDS is SMACOF (De Leeuw, 1977; De Leeuw and Mair, 2009). The algorithm is based on the majorization approach (Groenen et al., 1995), which iteratively replaces the original objective function with an auxiliary majorization function that is much easier to optimize. Majorization is not just an algorithm, it is more of a prescription for constructing optimization algorithms. The principle of majorization consists in constructing a auxiliary function that majorizes a certain objective function (De Leeuw and Mair, 2009). Experimental studies have shown that SMACOF is the most accurate algorithm compared to others (Orts et al., 2019; Ingram et al., 2008). There are a number of popular software implementations of SMACOF (De Leeuw and Mair, 2009; Pedregosa et al., 2011; Orts et al., 2019; MATLAB, 2012).
An alternative to SMACOF the Geometric MDS proposed in Dzemyda and Sabaliauskas (2020) and Dzemyda and Sabaliauskas (2021a), and developed in Sabaliauskas and Dzemyda (2021), Dzemyda and Sabaliauskas (2021b, 2021c), Dzemyda et al. (2022), Dzemyda and Sabaliauskas (2022). This will be discussed in more detail further in the paper. Figure 1 illustrates the visualization using Geometric MDS of 10, 50, and 100-dimensional datasets generated with Gaussian and Ellipsoidal cluster generators (Handl and Knowles, 2005). The dimensionality of the multidimensional data has been reduced to 2 (
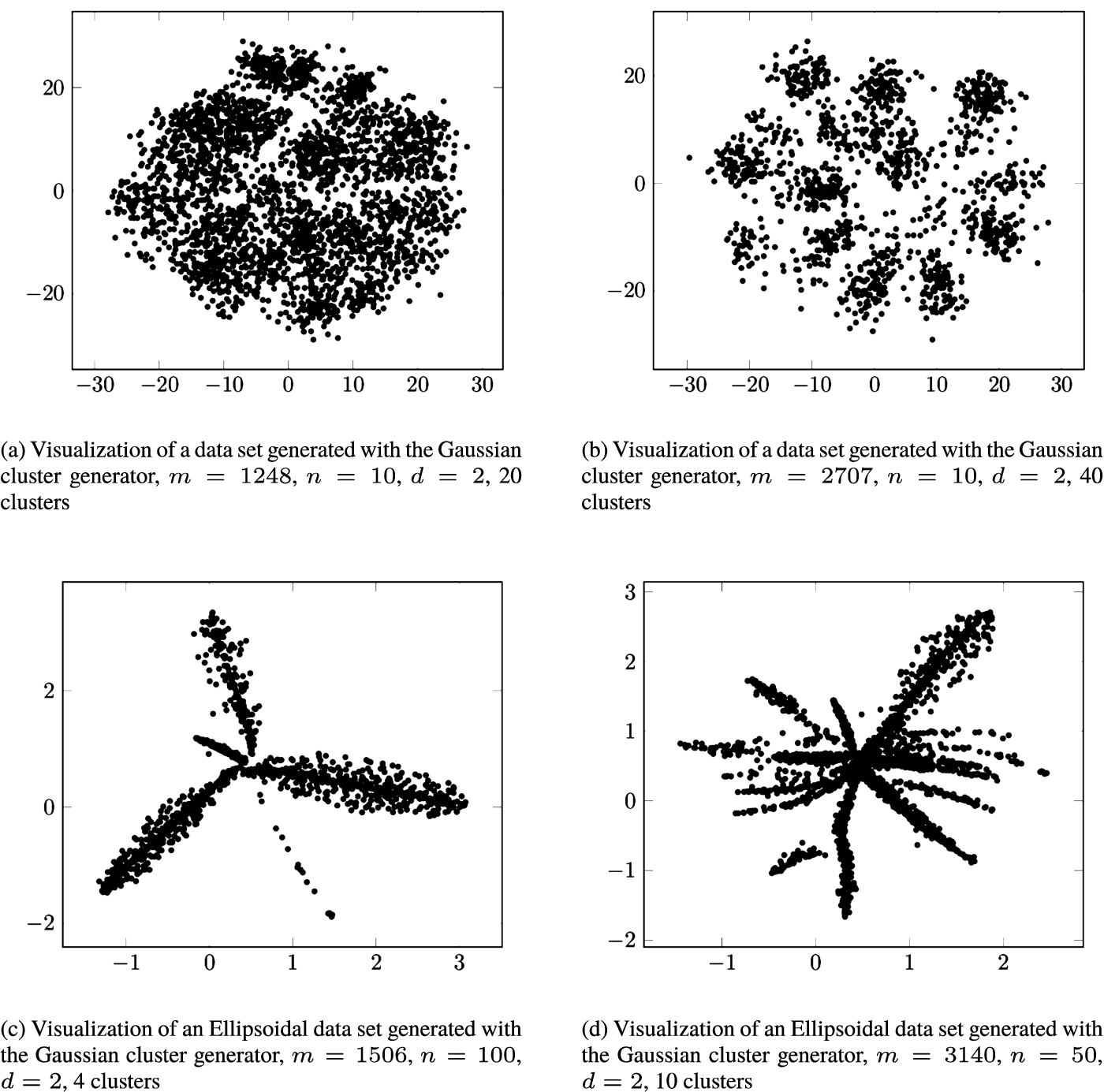
Examples of dimensionality reduction results obtained using Geometric MDS.
The novelty of this paper consists in the experimental investigation of parallelization of recently developed Geometric Multidimensional Scaling. The process of parallelization can lead to faster dimensionality reduction and data visualization process and to the possibility to process a large-scale multidimensional data. Theoretically proved properties of Geometric MDS are applied in parallelization. In addition, Geometric MDS is also experimentally compared with SMACOF, which is one of the most popular implementations of MDS. It was found that Geometric MDS is superior to the SMACOF in most cases.
MDS looks for coordinates of points
A Geometric MDS has the advantage that it can use the simplest stress function, and there is no need to normalize it based on the number of data points and the scale of proximities. In Dzemyda and Sabaliauskas (2021a) it is shown that Geometric MDS does not depend on the scale of proximities and can therefore use a simple stress function, such as a raw stress function:
The optimization problem is to find the minimum of the function
Let there be some initial configuration of points
The core formula of Geometric MDS, when defining the transition from
Let’s consider a generalized way to update the entire set of points
The GMDSm version of the Geometric MDS updates all points

A parallel Geometric MDS algorithm for simultaneous calculation of new points
The purpose of the experiment is to compare the time required to compute new points
Average dependence of the computation time of new coordinates (not considering the complete visualization process) on the data size when using different numbers of CPU threads for parallel processing,

Average dependence of the computation time of new coordinates (not taking into account the complete visualization process) on the size of the data, when using different numbers of CPU threads for parallel processing,
The results obtained (see Table 1 and Fig. 2) demonstrate that even using two CPU threads for parallel processing, it is possible to achieve significant process speedup (on average up to 2 times) compared to sequential computing. The results obtained conclude that when using more than two processor threads for parallel computing, it is possible to increase the speed of the process of calculating new coordinates in the projected space on average up to 6 times. It is also worth noting that the difference in time increases with increasing the size of the analysed data, that is, the larger the size of the data used for visualization, the more efficient the process of parallel computing (see Fig. 2). It should be noted that these data were obtained as a result of initial experiments, using the computational power of a personal computer. Consider also that the CPU used for the experiments had 6 cores and 12 threads, so, as can be seen from the results, the efficiency of calculations using more than 6 threads is not high. The results are promising, which indicates the feasibility of using Geometric MDS to visualize large-scale multidimensional data using the computing power of a supercomputer or cluster for parallel computing.
Although MDS demonstrates great versatility, it is computationally expensive and not scalable, and requires handling the entire data distance or other proximity matrix. This can be challenging when we deal with large-scale data. In this section, we propose the optimized Python implementation of GMDSm for sequential computations.
MDS-type algorithms require to update a matrix of
However, as noted in Albanie (2019), the Euclidean distance matrix can be computed in another way, which is equivalent to (2):
This method defined by (6) of calculating the Euclidean distance matrix has been implemented and used in Geometric MDS Python programming implementation. Applying (6) allows to speed up the visualization significantly because of much simpler calculations, and also allows to extend the dimensionality reduction for relatively large-scale data. Python function code for calculating distance matrix from a given

Python function code for calculating distance matrix.

Python function code for calculating new points

Python function code for calculating new points
The algorithm in Listing 1 returns
The Geometric MDS and SMACOF programming implementation code for Python has been optimized for computational speed. The Geometric MDS stress minimization method as well as the SMACOF implementation are featured by the fact that all points in low-dimensional space change their coordinates simultaneously and independently of each other during one iteration of stress minimization. We provide a function code implemented to calculate new coordinates of points in d-dimensional space in one iteration using Geometric MDS and SMACOF (see Listings 2 and 3), as well as the code of a fully working Python program that implements the sequential Geometric MDS algorithm (see Listing 4), where the stopping condition for stress (1) minimization is either the iteration number or the accuracy. In one iteration (see Listings 2 and 3), the coordinates of all points in the projected space are recalculated once. Listing 3 presents the function code for calculating new coordinates using SMACOF, adapted from the scikit-learn library (Pedregosa et al., 2011) and updated to improve computation speed (this implementation is denoted as SMACOF-Fast). In this implementation, the stress majorization, which is also known as the Guttman transform, guarantees monotonic stress convergence and is more powerful than traditional methods such as gradient descent.

Main program of Geometric MDS.
Geometric MDS becomes the main competitor of SMACOF. We would like to highlight the main differences between the two algorithms. More detailed theoretical comparison of them is provided in Dzemyda and Sabaliauskas (2022).
At first, we define a Geometric MDS step from point
Geometric MDS can be expressed in matrix form as well:
The dimensionality reduction performance was compared using SMACOF (from the scikit-learn library, Pedregosa et al., 2011), SMACOF-Fast (Listing 3) and Geometric MDS algorithms (Listing 2). Experiments were carried out using:
randomly generated sets of 10-dimensional data points
random proximity matrices with elements uniformly distributed in the interval
Average dependency of time required to compute new coordinates and Stress function values per iteration on data size when
Average dependence of the time required to compute new coordinates and Stress function values per iteration on the data size on random proximity matrices whose element takes uniformly distributed values in the interval (0, 1), using SMACOF-Fast, SMACOF and Geometric MDS.
The dimensionality was reduced to
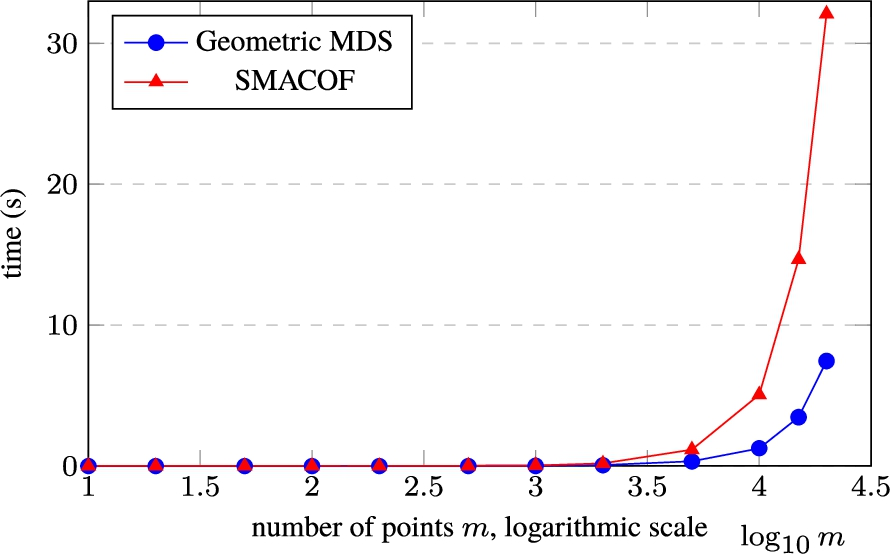
Dependence of computation time on the number of points when reducing the dimensionality of 10-dimensional data
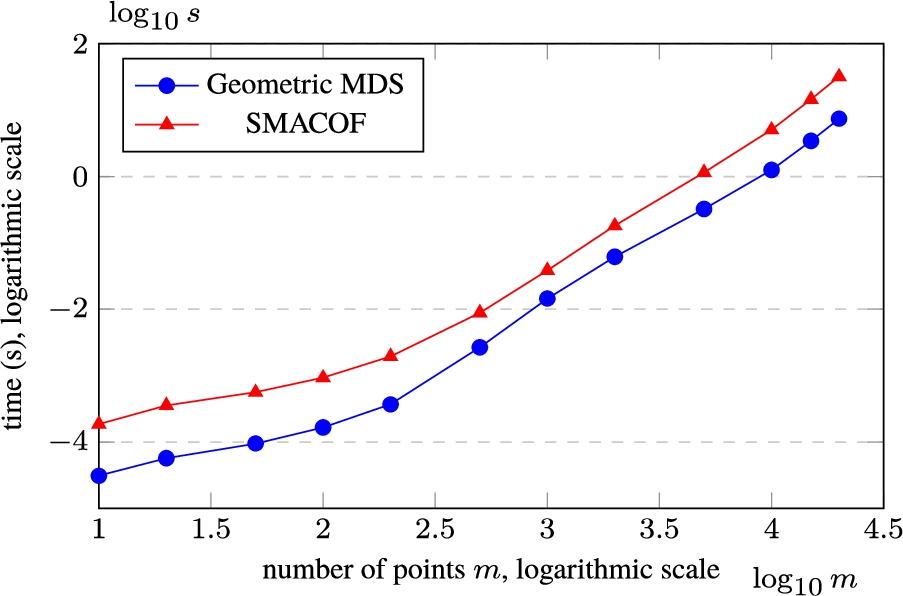
Dependence of computation time on the number of points when reducing the dimensionality of 10-dimensional data
The dependency of the calculation time on a number of points using Geometric MDS (see Listing 2) and SMACOF (Pedregosa et al., 2011) is shown in Fig. 3. The number m of points (
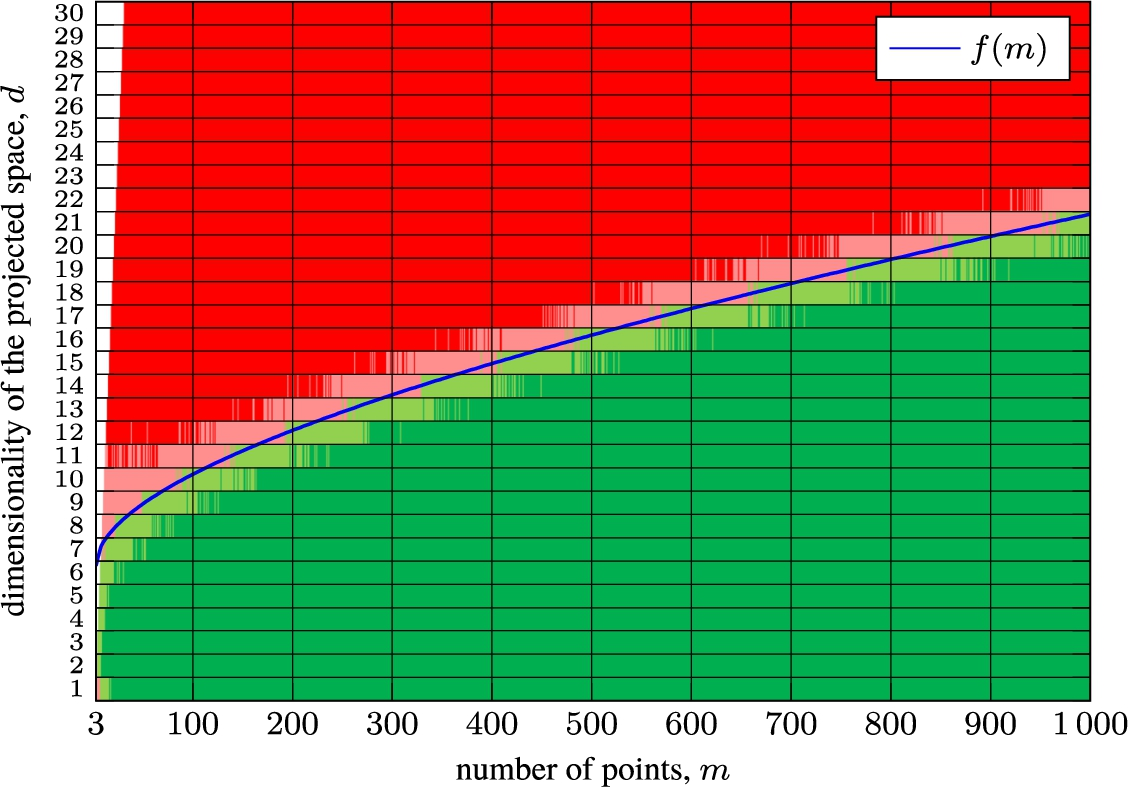
Stress comparison between Geometric MDS and SMACOF depending on the number of points m and and the dimensionality of the projected space d.
To compare which method, Geometric MDS or SMACOF, better reduces the MDS stress
Figure 5 discloses a very interesting and essential difference between the performance of Geometric MDS and SMACOF. Geometric MDS finds smaller stress when the dimensionality of projected space is lower. This is particularly important for the multidimensional data visualization task.
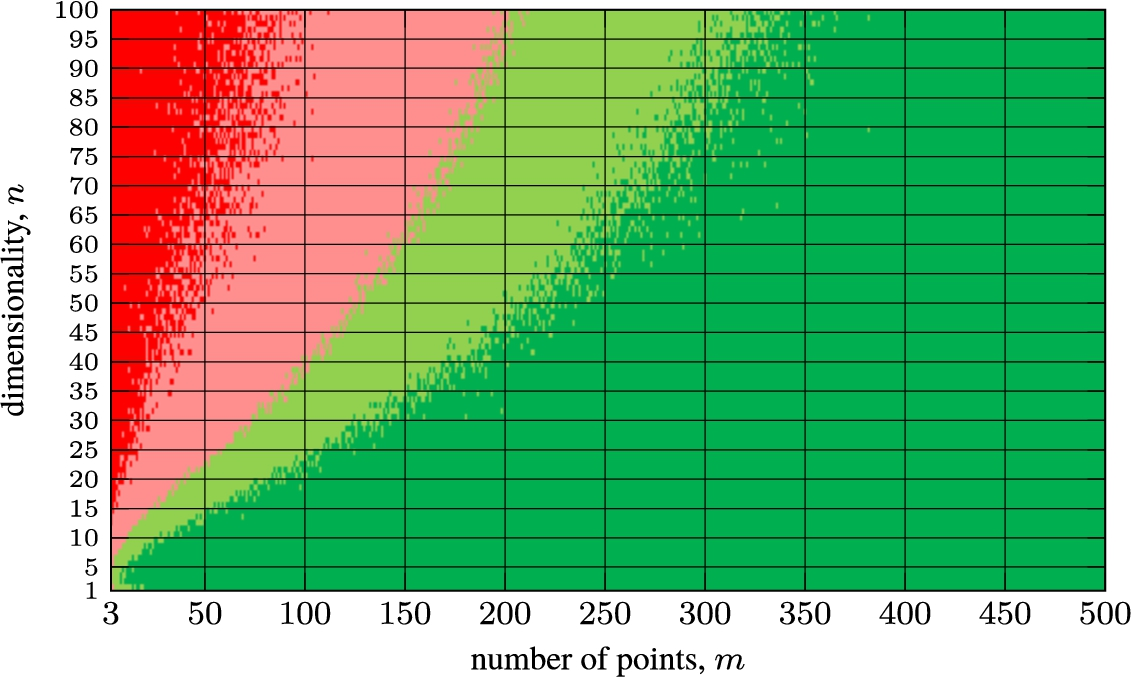
Stress comparison between Geometric MDS and SMACOF depending on the number of points m and the dimensionality n, when reducing the dimensionality to
In Fig. 5, we present a curve that would allow us to choose either Geometric MDS or SMACOF in order to get a better stress after their first step and assuming that the values of the elements of the symmetric distance matrix are uniformly distributed in the interval
Particular case is
A new Geometric MDS method with the low computational complexity has been proposed in Dzemyda and Sabaliauskas (2021a, 2022). Geometric MDS provides an iterative procedure to minimize MDS stress where coordinates of a particular point of the projected space are moved to a new position defined analytically. Such a change in position is easily interpreted geometrically. Moreover, the coordinates of points of the projected space may be recalculated simultaneously, i.e. in parallel, independently of each other during one iteration of stress minimization. Two implementations of Geometric MDS are suggested and analysed experimentally: parallel and sequential.
A parallel implementation of Geometric MDS is developed for dimensionality reduction using multithreaded multi-core processors. Based on the results obtained, we can claim that Geometric MDS allows to implement parallel computing using multithreaded multi-core processors, as a result, the time to calculate new coordinates of points in the low-dimensional space may be reduced by 6 times on average, depending on the data size.
The sequential implementation given in this paper is optimized for computational speed, enabling it to solve large data problems. It is compared with the SMACOF version of MDS. Python codes for both Geometric MDS and SMACOF are presented to highlight the differences between the two implementations. These codes were optimized for computational speed. The comparison was carried out on several aspects: the comparative performance of Geometric MDS and SMACOF depending on the projection dimension, data size and computation time. Geometric MDS usually finds lower stress when the dimensionality of the projected space is smaller.
SMACOF is an iterative procedure that calculates the Guttman transform. We discovered that the procedure of updating lower-dimensional points by Geometric MDS is a generalization of the Guttman transform. If we apply